Download as PDF, PPTX







![SELECT sum(requests) as total
FROM [fh-bigquery:wikipedia.pagecounts_20150511_05]
Wikipedia hits over 1 hour](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-10-2048.jpg)
![SELECT sum(requests) as total
FROM [fh-bigquery:wikipedia.pagecounts_201505]
Wikipedia hits over 1 month](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-11-2048.jpg)
![Several years of Wikipedia data
SELECT sum(requests) as total
FROM
[fh-bigquery:wikipedia.pagecounts_201105],
[fh-bigquery:wikipedia.pagecounts_201106],
[fh-bigquery:wikipedia.pagecounts_201107],
...](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-12-2048.jpg)
![SELECT
SUM(requests) AS total
FROM
TABLE_QUERY(
[fh-bigquery:wikipedia],
'REGEXP_MATCH(
table_id,
r"pagecounts_2015[0-9]{2}$")')
Several years of Wikipedia data](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-13-2048.jpg)
![How about a RegExp
SELECT
SUM(requests) AS total
FROM
TABLE_QUERY(
[fh-bigquery:wikipedia],
'REGEXP_MATCH(
table_id,
r"pagecounts_2015[0-9]{2}$")')
WHERE
(REGEXP_MATCH(title, '.*[dD]inosaur.*'))](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-14-2048.jpg)




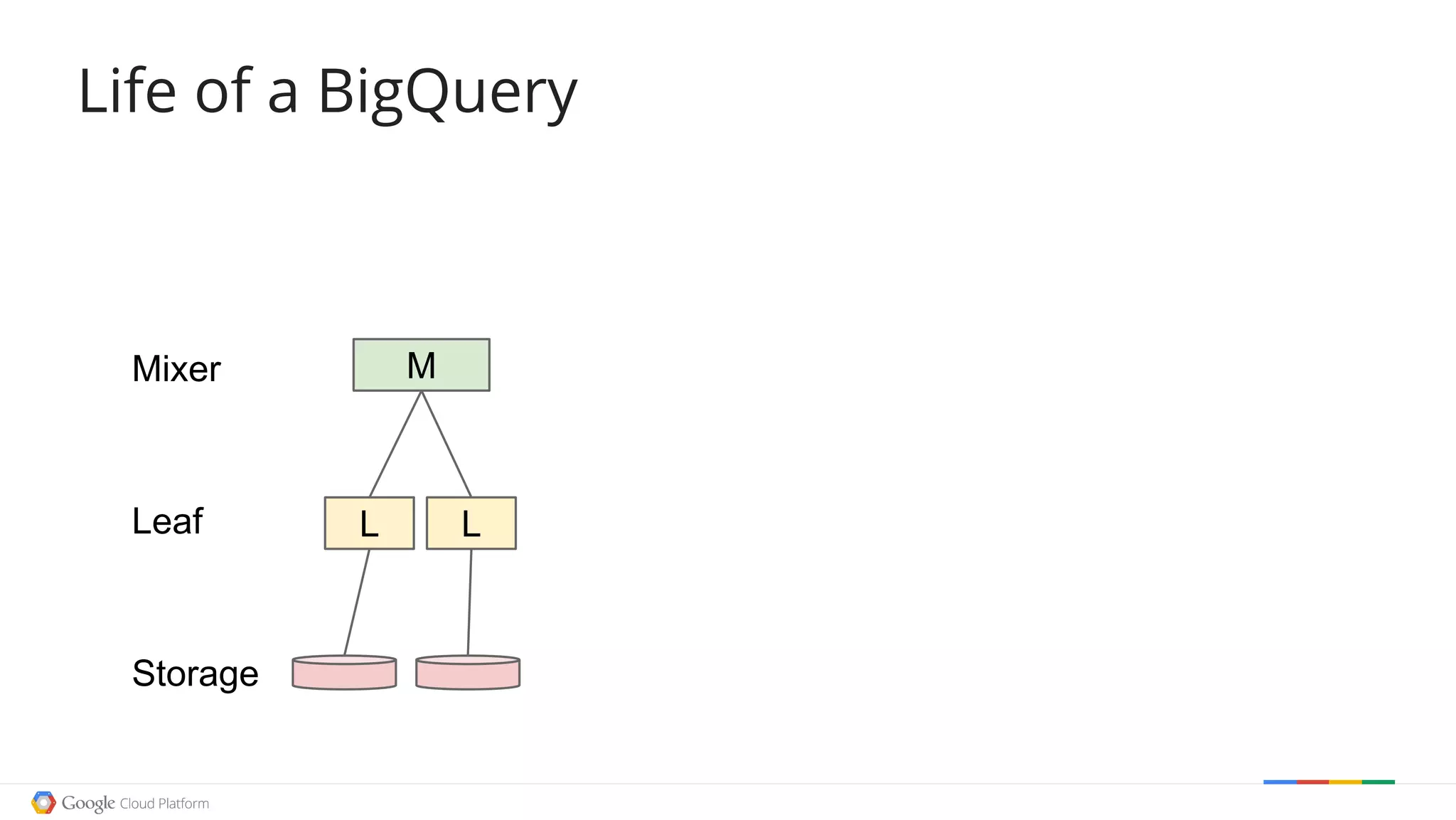
![Reading data: Life of a BigQuery
SELECT sum(requests) as sum
FROM (
SELECT requests, title
FROM [fh-bigquery:wikipedia.
pagecounts_201501]
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
)](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-23-2048.jpg)
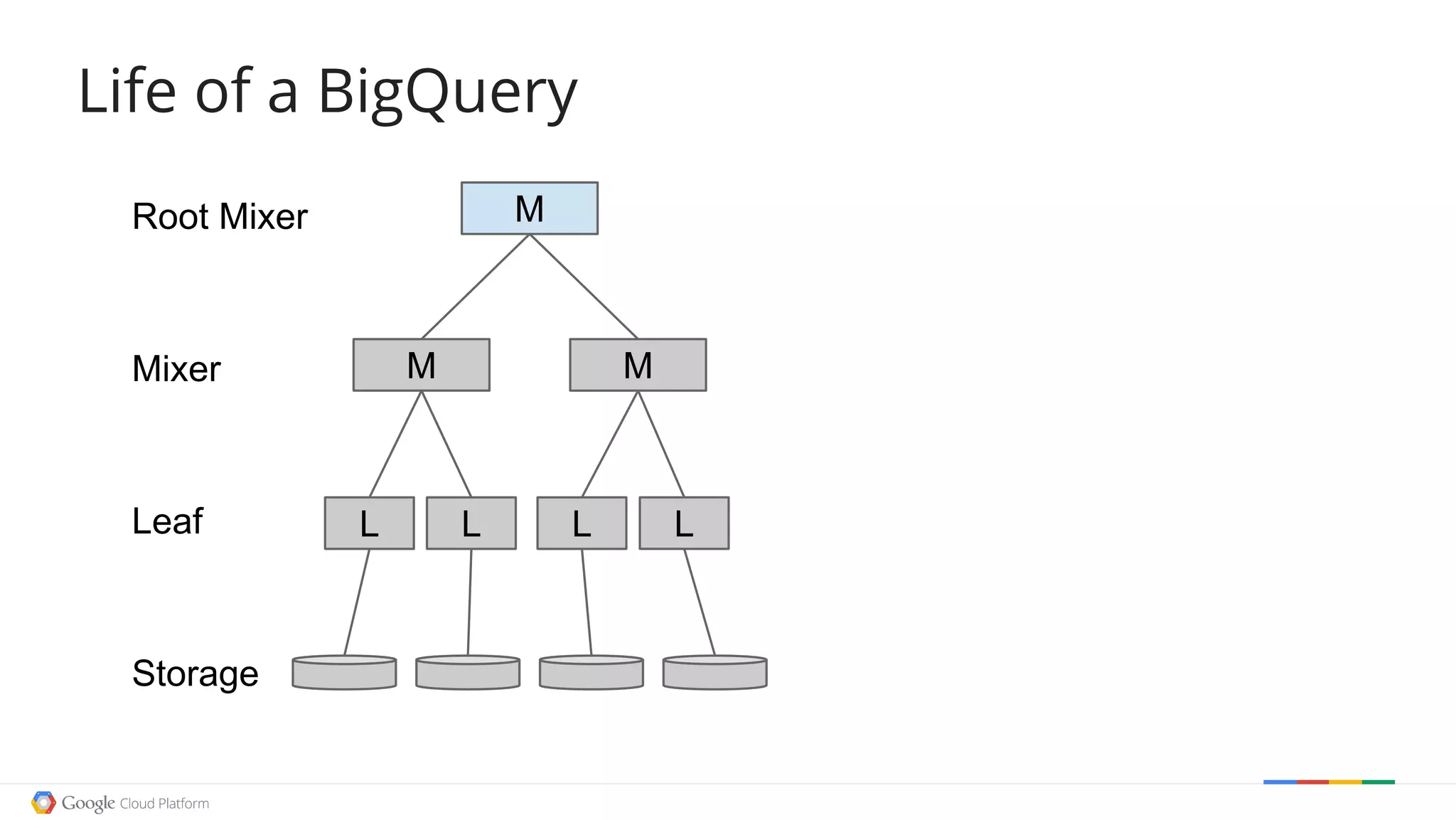
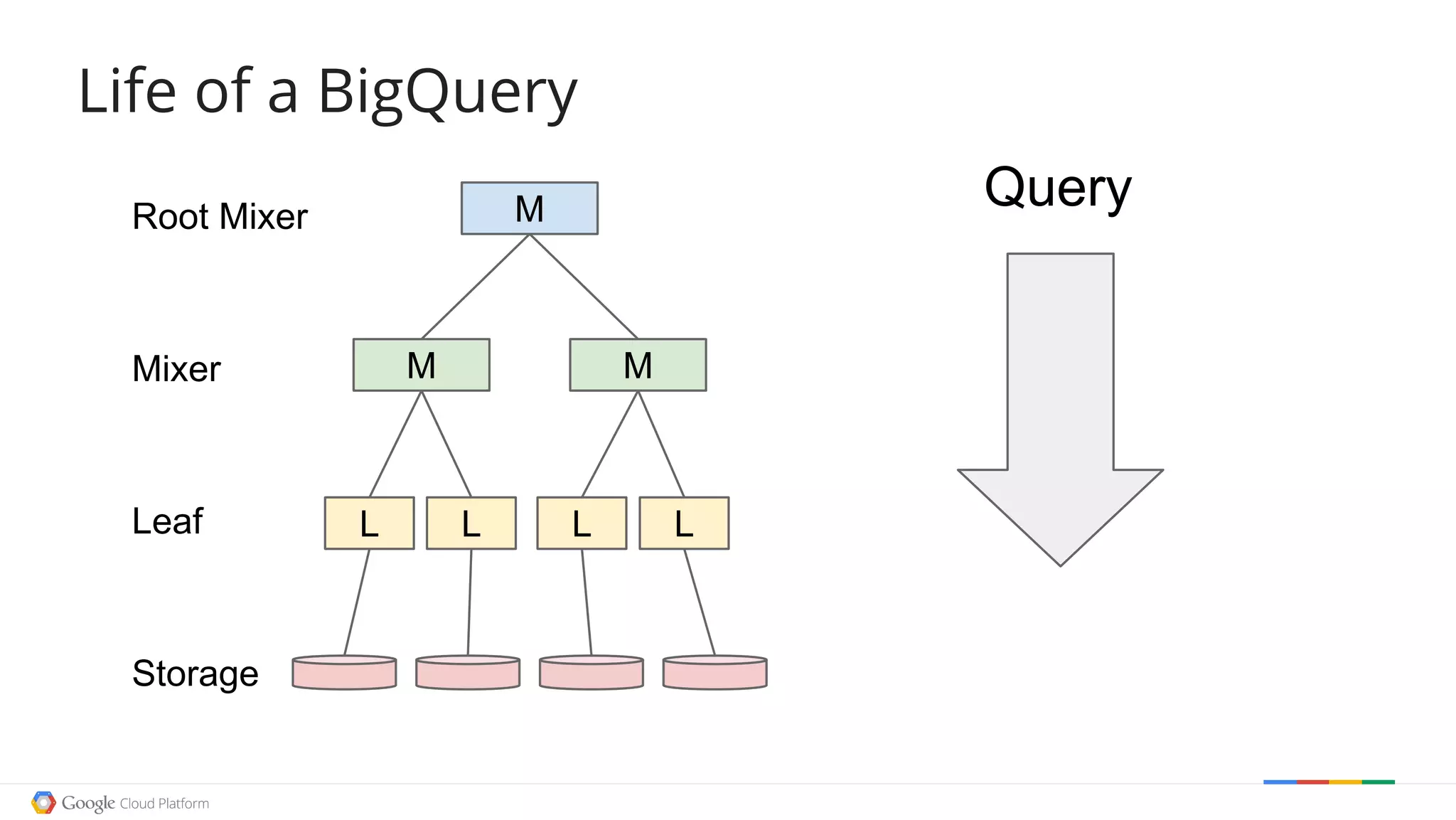
![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT requests, title
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-28-2048.jpg)
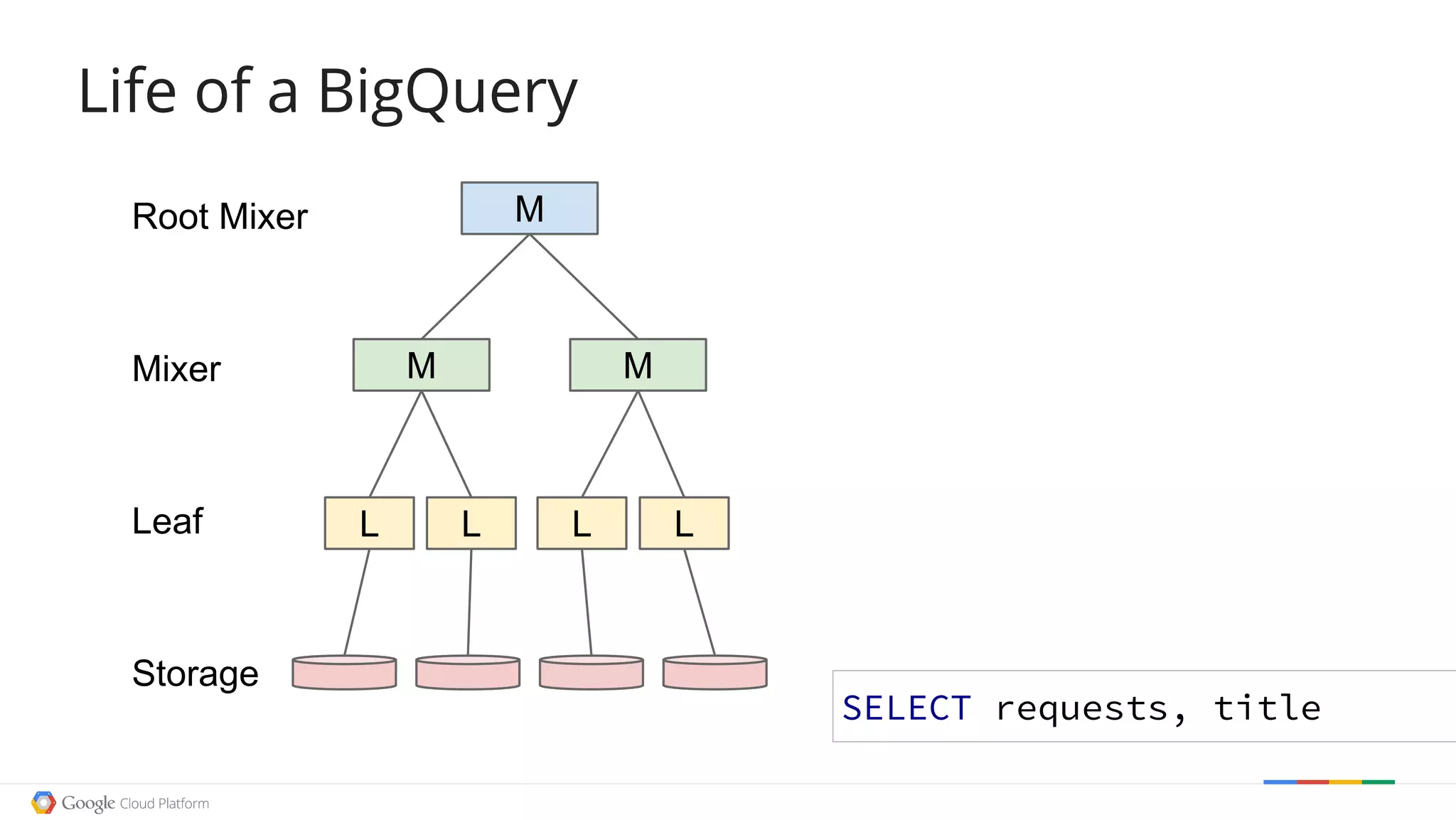
![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT sum(requests)
5.8 Mil
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
SELECT requests, title](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-29-2048.jpg)
![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT sum(requests)
5.8 Mil
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
SELECT requests, title
SELECT sum(requests)](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-30-2048.jpg)


![Weather in Half Moon Bay
SELECT DATE(year+mo+da) day, min, max
FROM [fh-bigquery:weather_gsod.gsod2013]
WHERE stn IN (
SELECT usaf FROM [fh-bigquery:weather_gsod.stations]
WHERE name = 'HALF MOON BAY AIRPOR')
AND max < 200
ORDER BY day;](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-36-2048.jpg)
![Weather in Half Moon Bay
SELECT DATE(year+mo+da) day, min, max
FROM [fh-bigquery:weather_gsod.gsod2013]
WHERE stn IN (
SELECT usaf FROM [fh-bigquery:weather_gsod.stations]
WHERE name = 'HALF MOON BAY AIRPOR')
AND max < 200
ORDER BY day;](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-37-2048.jpg)
![Global high temperatures
SELECT year, max(max) as max
FROM
TABLE_QUERY(
[fh-bigquery:weather_gsod],
'table_id CONTAINS "gsod"')
where max < 200
group by year order by year asc](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-38-2048.jpg)
![Stories per month - Massachusetts
SELECT DATE(STRING(MonthYear) + '01') month,
SUM(ActionGeo_ADM1Code='USMA') US
FROM [gdelt-bq:full.events]
WHERE MonthYear > 0
GROUP BY 1 ORDER BY 1](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-40-2048.jpg)
![SELECT DATE(STRING(MonthYear) + '01') month,
SUM(ActionGeo_ADM1Code='USMA') / COUNT(*) newsyness
FROM [gdelt-bq:full.events]
WHERE MonthYear > 0
GROUP BY 1 ORDER BY 1
Stories per month, normalized](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-41-2048.jpg)


![Genomics
SELECT Sample, SUM(single), SUM(double),
FROM (
SELECT call.call_set_name AS Sample,
SOME(call.genotype > 0) AND NOT EVERY(call.
genotype > 0) WITHIN call AS single,
EVERY(call.genotype > 0) WITHIN call AS double,
FROM[genomics-public-data:1000_genomes.variants]
OMIT RECORD IF reference_name IN ("X","Y","MT"))
GROUP BY Sample ORDER BY Sample](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-44-2048.jpg)
![Genomics
SELECT Sample, SUM(single), SUM(double),
FROM (
SELECT call.call_set_name AS Sample,
SOME(call.genotype > 0) AND NOT EVERY(call.
genotype > 0) WITHIN call AS single,
EVERY(call.genotype > 0) WITHIN call AS double,
FROM[genomics-public-data:1000_genomes.variants]
OMIT RECORD IF reference_name IN ("X","Y","MT"))
GROUP BY Sample ORDER BY Sample](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-45-2048.jpg)

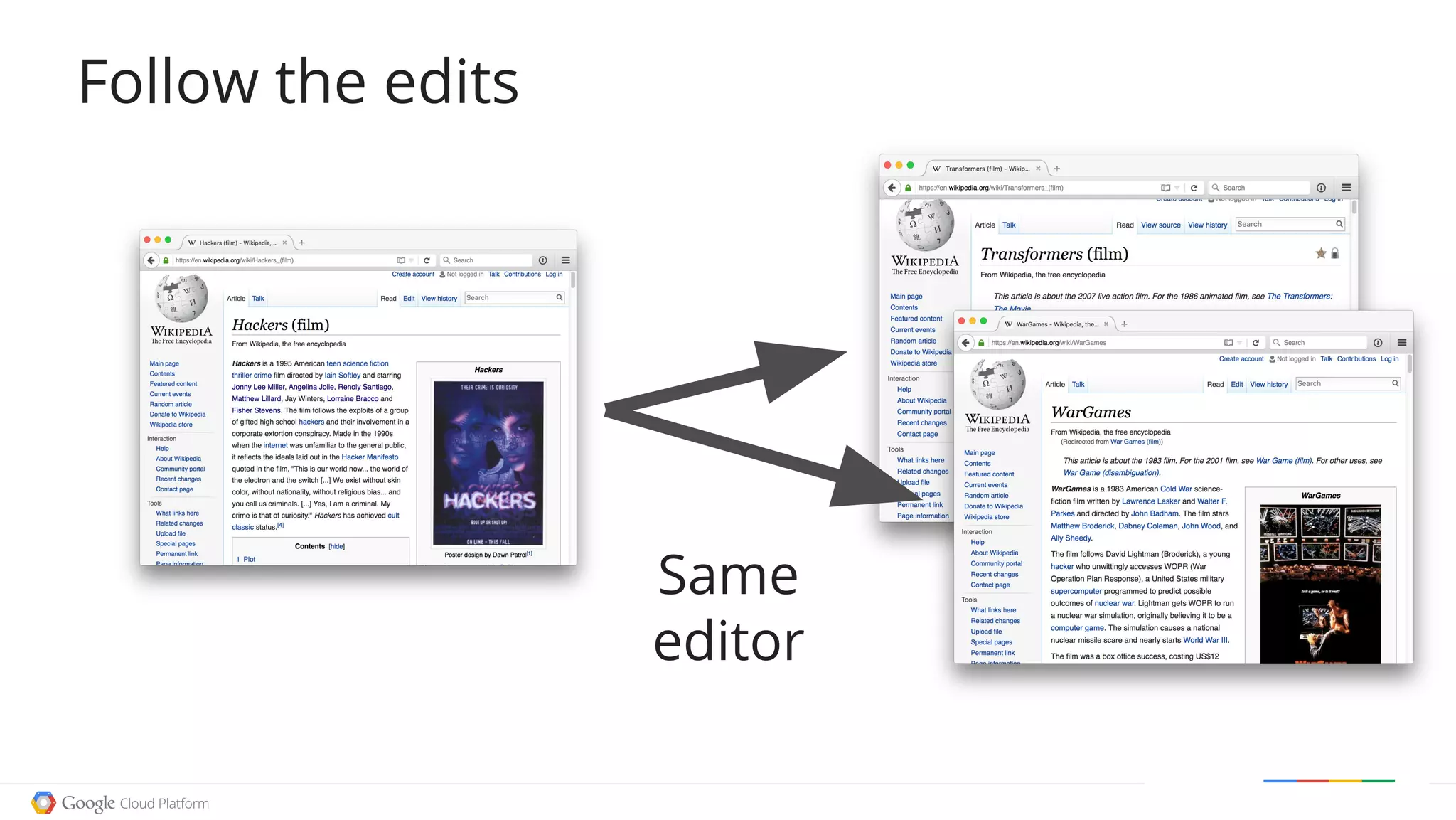
![select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where
title contains 'Hackers'
and title contains '(film)'
and wp_namespace = 0
group by title, id
order by edits
limit 10
Pick a great movie](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-49-2048.jpg)
![select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where contributor_id in (
select contributor_id
from [publicdata:samples.wikipedia]
where
id=264176
and contributor_id is not null
and is_bot is null
and wp_namespace = 0
and title CONTAINS '(film)'
group by contributor_id)
and wp_namespace = 0
and id != 264176
and title CONTAINS '(film)'
group each by title, id
order by edits desc
limit 100
Find edits in common](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-50-2048.jpg)
![Discover the most broadly popular films
select id from (
select id, count(id) as edits
from [publicdata:samples.wikipedia]
where
wp_namespace = 0
and title CONTAINS '(film)'
group each by id
order by edits desc
limit 20)](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-51-2048.jpg)
![Edits in common, minus broadly popular
select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where contributor_id in (
select contributor_id
from [publicdata:samples.wikipedia]
where
id=264176
and contributor_id is not null
and is_bot is null
and wp_namespace = 0
and title CONTAINS '(film)'
group by contributor_id)
and wp_namespace = 0
and id != 264176
and title CONTAINS '(film)'
and id not in (
select id from (
select id, count(id) as edits
from [publicdata:samples.
wikipedia]
where
wp_namespace = 0
and title CONTAINS '(film)'
group each by id
order by edits desc
limit 20
)
)
group each by title, id
order by edits desc
limit 100](https://image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-52-2048.jpg)












![SELECT sum(requests) as total
FROM [fh-bigquery:wikipedia.pagecounts_20150511_05]
Wikipedia hits over 1 hour](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-10-2048.jpg)
![SELECT sum(requests) as total
FROM [fh-bigquery:wikipedia.pagecounts_201505]
Wikipedia hits over 1 month](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-11-2048.jpg)
![Several years of Wikipedia data
SELECT sum(requests) as total
FROM
[fh-bigquery:wikipedia.pagecounts_201105],
[fh-bigquery:wikipedia.pagecounts_201106],
[fh-bigquery:wikipedia.pagecounts_201107],
...](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-12-2048.jpg)
![SELECT
SUM(requests) AS total
FROM
TABLE_QUERY(
[fh-bigquery:wikipedia],
'REGEXP_MATCH(
table_id,
r"pagecounts_2015[0-9]{2}$")')
Several years of Wikipedia data](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-13-2048.jpg)
![How about a RegExp
SELECT
SUM(requests) AS total
FROM
TABLE_QUERY(
[fh-bigquery:wikipedia],
'REGEXP_MATCH(
table_id,
r"pagecounts_2015[0-9]{2}$")')
WHERE
(REGEXP_MATCH(title, '.*[dD]inosaur.*'))](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-14-2048.jpg)








![Reading data: Life of a BigQuery
SELECT sum(requests) as sum
FROM (
SELECT requests, title
FROM [fh-bigquery:wikipedia.
pagecounts_201501]
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
)](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-23-2048.jpg)




![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT requests, title
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-28-2048.jpg)
![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT sum(requests)
5.8 Mil
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
SELECT requests, title](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-29-2048.jpg)
![Life of a BigQueryLife of a BigQuery
L L L L
M M
MRoot Mixer
Mixer
Leaf
Storage
5.4 Bil
SELECT sum(requests)
5.8 Mil
WHERE
(REGEXP_MATCH(title, '[Jj]en.+'))
SELECT requests, title
SELECT sum(requests)](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-30-2048.jpg)





![Weather in Half Moon Bay
SELECT DATE(year+mo+da) day, min, max
FROM [fh-bigquery:weather_gsod.gsod2013]
WHERE stn IN (
SELECT usaf FROM [fh-bigquery:weather_gsod.stations]
WHERE name = 'HALF MOON BAY AIRPOR')
AND max < 200
ORDER BY day;](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-36-2048.jpg)
![Weather in Half Moon Bay
SELECT DATE(year+mo+da) day, min, max
FROM [fh-bigquery:weather_gsod.gsod2013]
WHERE stn IN (
SELECT usaf FROM [fh-bigquery:weather_gsod.stations]
WHERE name = 'HALF MOON BAY AIRPOR')
AND max < 200
ORDER BY day;](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-37-2048.jpg)
![Global high temperatures
SELECT year, max(max) as max
FROM
TABLE_QUERY(
[fh-bigquery:weather_gsod],
'table_id CONTAINS "gsod"')
where max < 200
group by year order by year asc](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-38-2048.jpg)

![Stories per month - Massachusetts
SELECT DATE(STRING(MonthYear) + '01') month,
SUM(ActionGeo_ADM1Code='USMA') US
FROM [gdelt-bq:full.events]
WHERE MonthYear > 0
GROUP BY 1 ORDER BY 1](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-40-2048.jpg)
![SELECT DATE(STRING(MonthYear) + '01') month,
SUM(ActionGeo_ADM1Code='USMA') / COUNT(*) newsyness
FROM [gdelt-bq:full.events]
WHERE MonthYear > 0
GROUP BY 1 ORDER BY 1
Stories per month, normalized](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-41-2048.jpg)


![Genomics
SELECT Sample, SUM(single), SUM(double),
FROM (
SELECT call.call_set_name AS Sample,
SOME(call.genotype > 0) AND NOT EVERY(call.
genotype > 0) WITHIN call AS single,
EVERY(call.genotype > 0) WITHIN call AS double,
FROM[genomics-public-data:1000_genomes.variants]
OMIT RECORD IF reference_name IN ("X","Y","MT"))
GROUP BY Sample ORDER BY Sample](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-44-2048.jpg)
![Genomics
SELECT Sample, SUM(single), SUM(double),
FROM (
SELECT call.call_set_name AS Sample,
SOME(call.genotype > 0) AND NOT EVERY(call.
genotype > 0) WITHIN call AS single,
EVERY(call.genotype > 0) WITHIN call AS double,
FROM[genomics-public-data:1000_genomes.variants]
OMIT RECORD IF reference_name IN ("X","Y","MT"))
GROUP BY Sample ORDER BY Sample](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-45-2048.jpg)



![select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where
title contains 'Hackers'
and title contains '(film)'
and wp_namespace = 0
group by title, id
order by edits
limit 10
Pick a great movie](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-49-2048.jpg)
![select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where contributor_id in (
select contributor_id
from [publicdata:samples.wikipedia]
where
id=264176
and contributor_id is not null
and is_bot is null
and wp_namespace = 0
and title CONTAINS '(film)'
group by contributor_id)
and wp_namespace = 0
and id != 264176
and title CONTAINS '(film)'
group each by title, id
order by edits desc
limit 100
Find edits in common](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-50-2048.jpg)
![Discover the most broadly popular films
select id from (
select id, count(id) as edits
from [publicdata:samples.wikipedia]
where
wp_namespace = 0
and title CONTAINS '(film)'
group each by id
order by edits desc
limit 20)](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-51-2048.jpg)
![Edits in common, minus broadly popular
select title, id, count(id) as edits
from [publicdata:samples.wikipedia]
where contributor_id in (
select contributor_id
from [publicdata:samples.wikipedia]
where
id=264176
and contributor_id is not null
and is_bot is null
and wp_namespace = 0
and title CONTAINS '(film)'
group by contributor_id)
and wp_namespace = 0
and id != 264176
and title CONTAINS '(film)'
and id not in (
select id from (
select id, count(id) as edits
from [publicdata:samples.
wikipedia]
where
wp_namespace = 0
and title CONTAINS '(film)'
group each by id
order by edits desc
limit 20
)
)
group each by title, id
order by edits desc
limit 100](https://crownmelresort.com/image.slidesharecdn.com/fowa-jtong-slides-151125103930-lva1-app6892/75/Exploring-Open-Date-with-BigQuery-Jenny-Tong-52-2048.jpg)




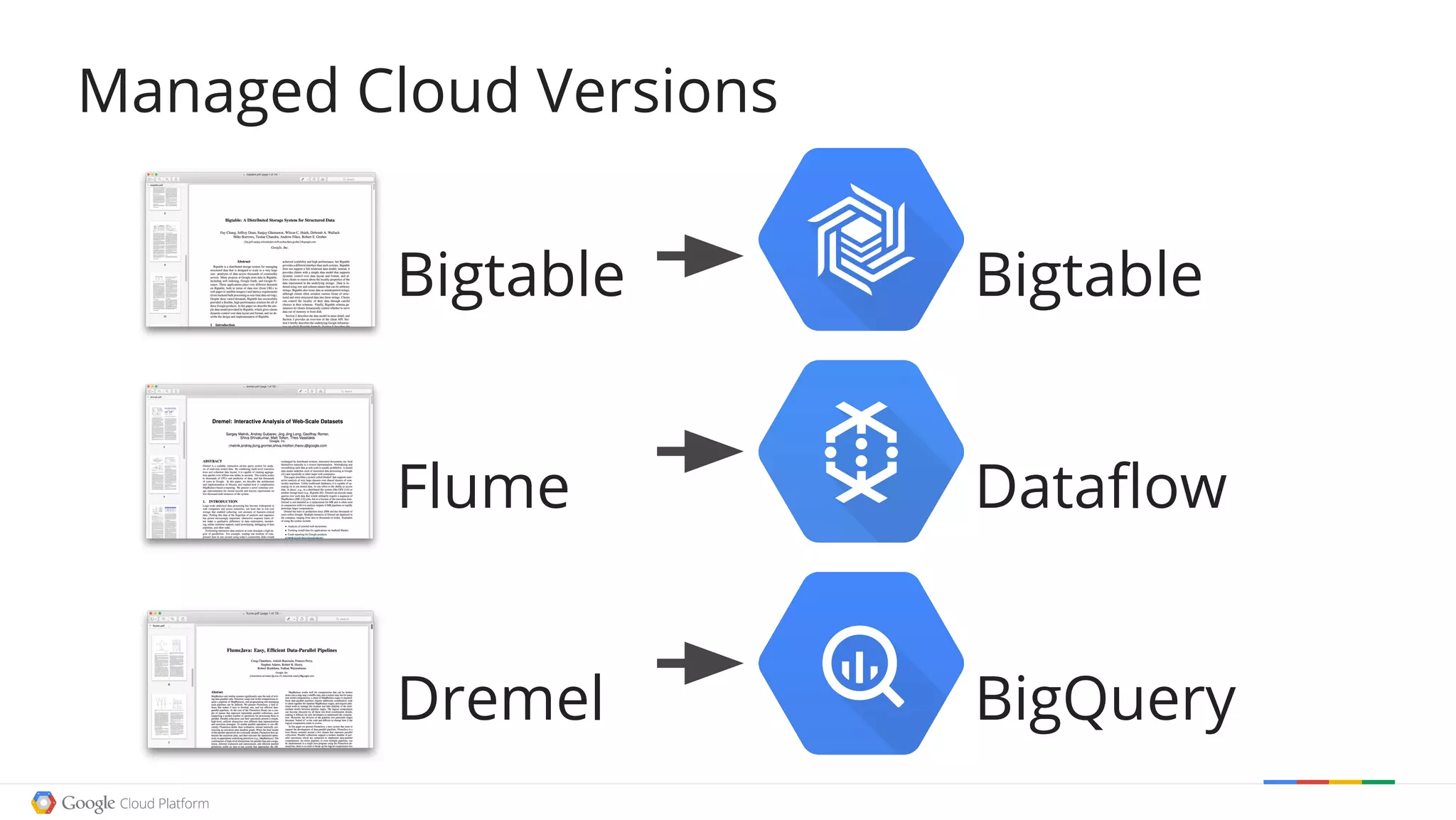
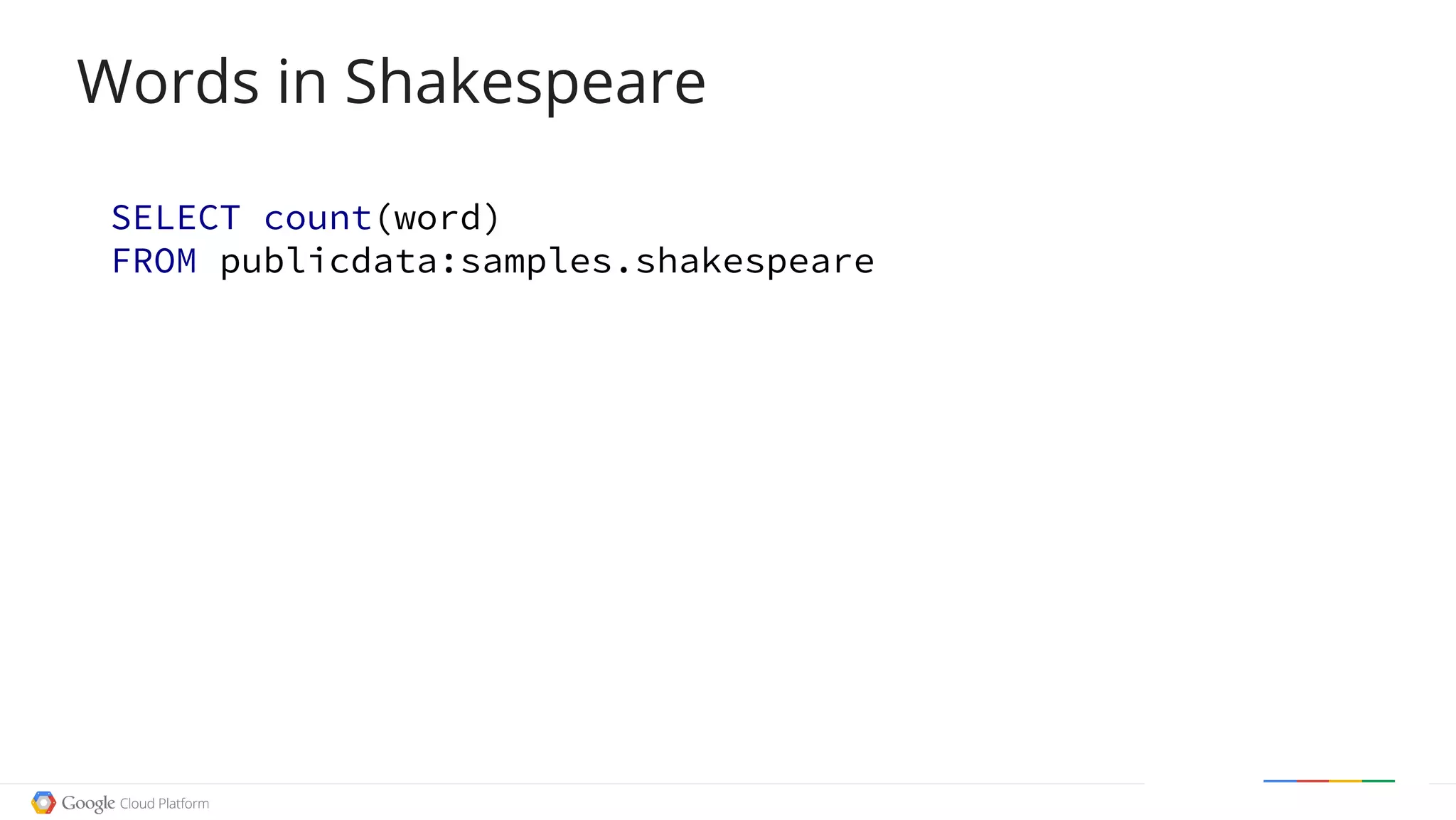
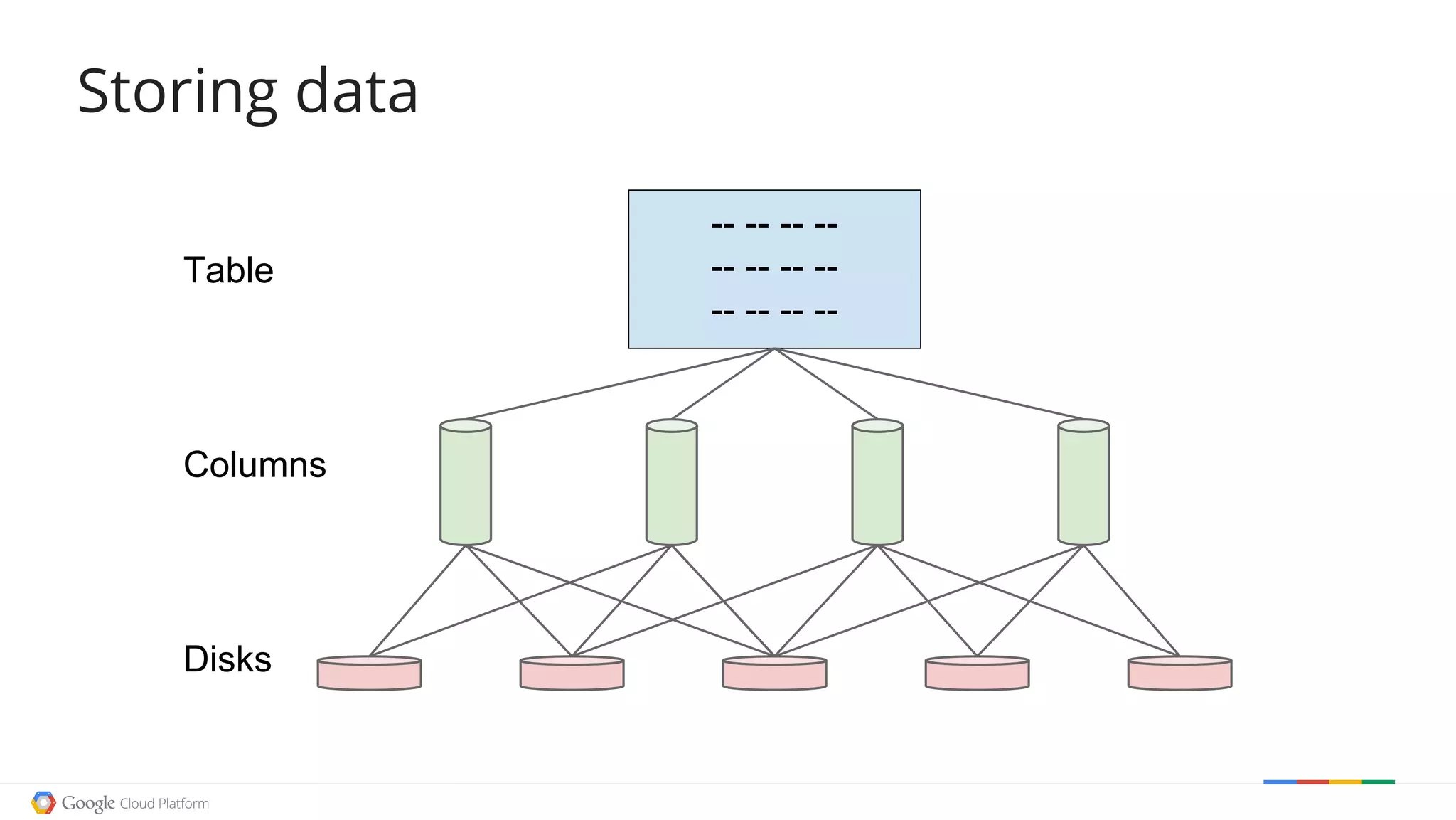
The document discusses exploring open data using Google BigQuery. It begins with an agenda that includes an origin story, counting data, how BigQuery works, examples of cool open data sources, and doing something useful with the data. It then demonstrates counting words in Shakespeare, Wikipedia page views over time, and filtering Wikipedia data using regular expressions. The document explains how BigQuery queries are executed and processed in parallel. It provides several examples of exploring open weather, event, and genetic data. Finally, it walks through a example of using Wikipedia edit data to recommend a movie.



























































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)















