Download as PDF, PPTX


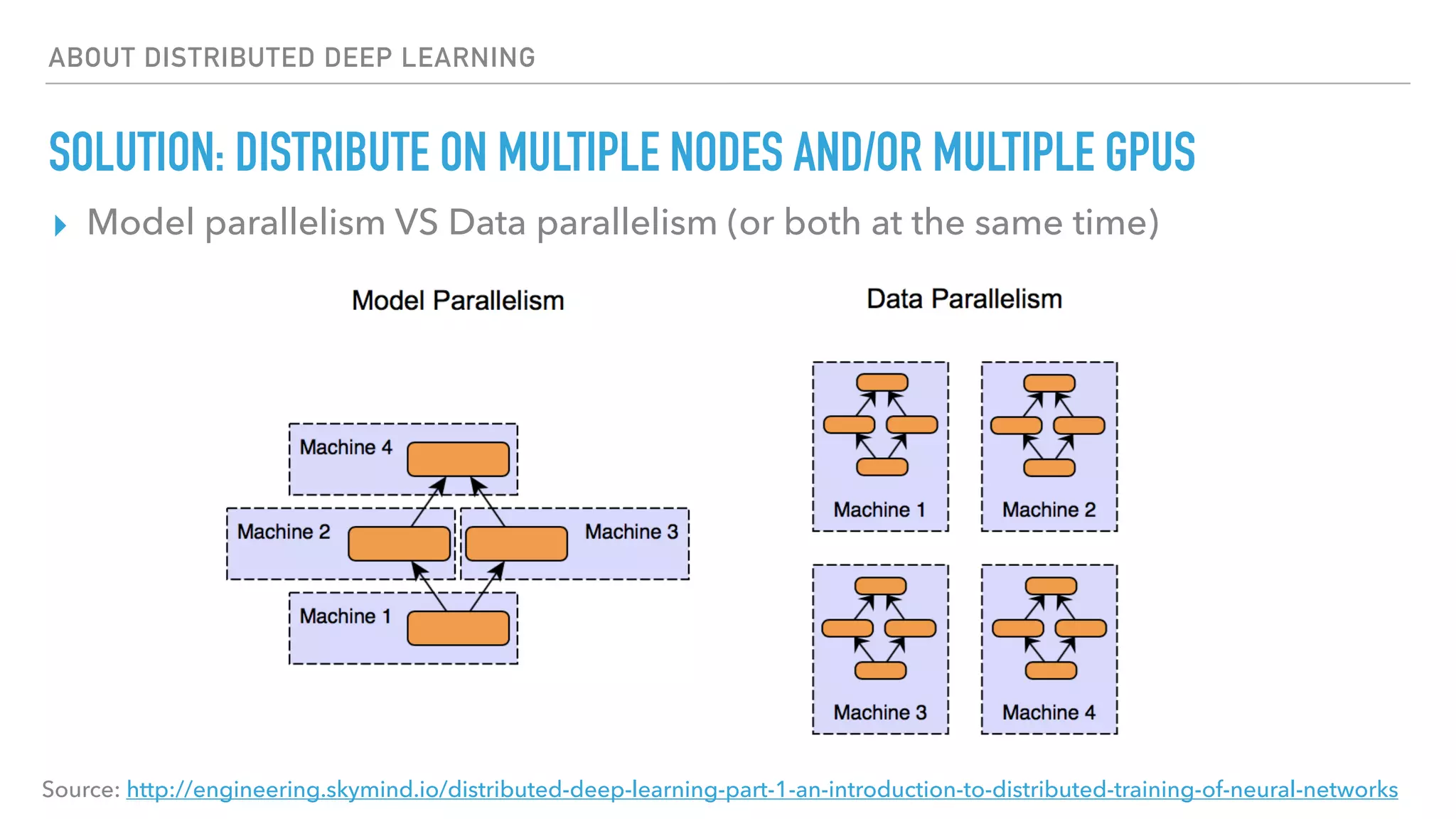

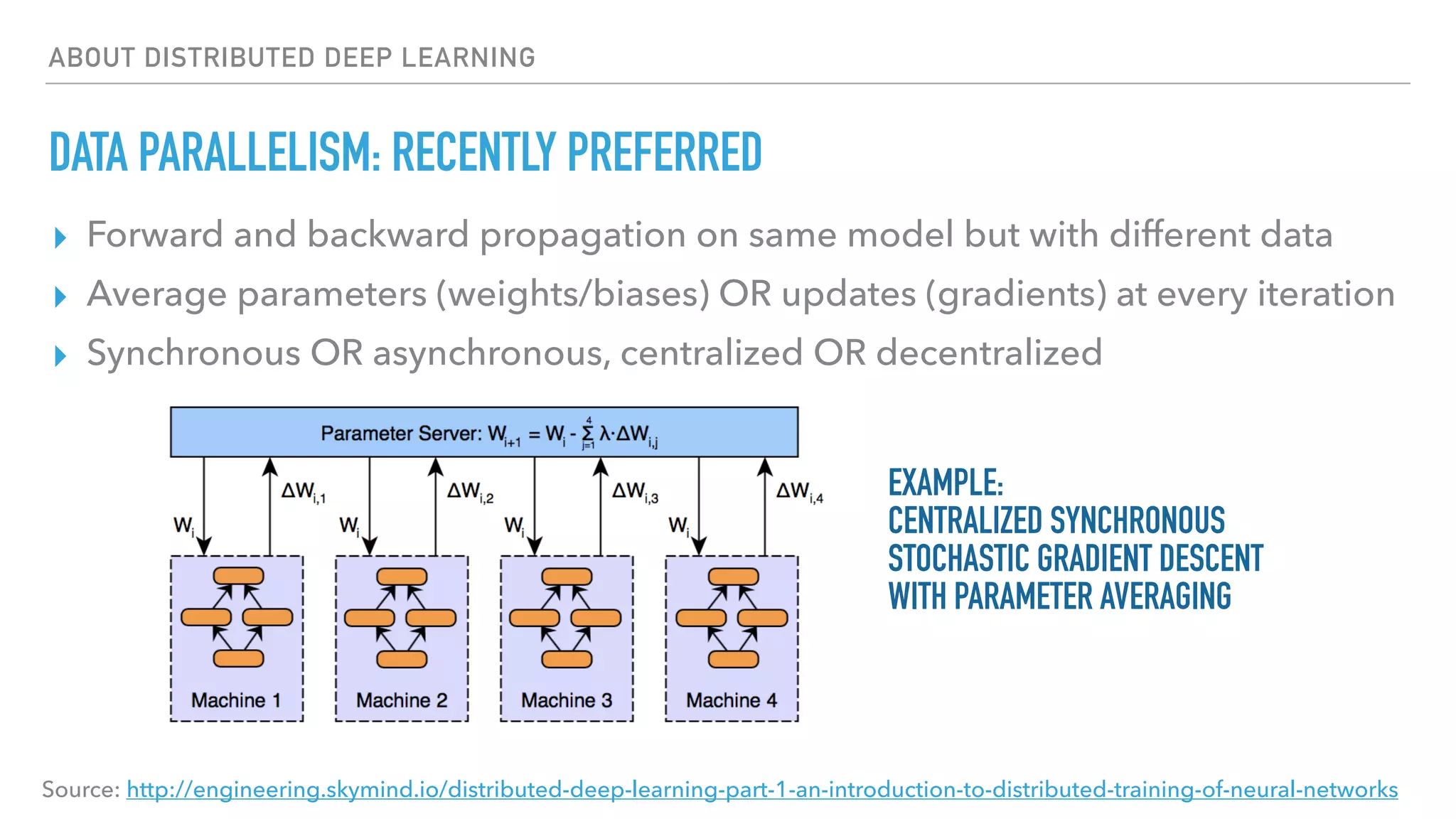
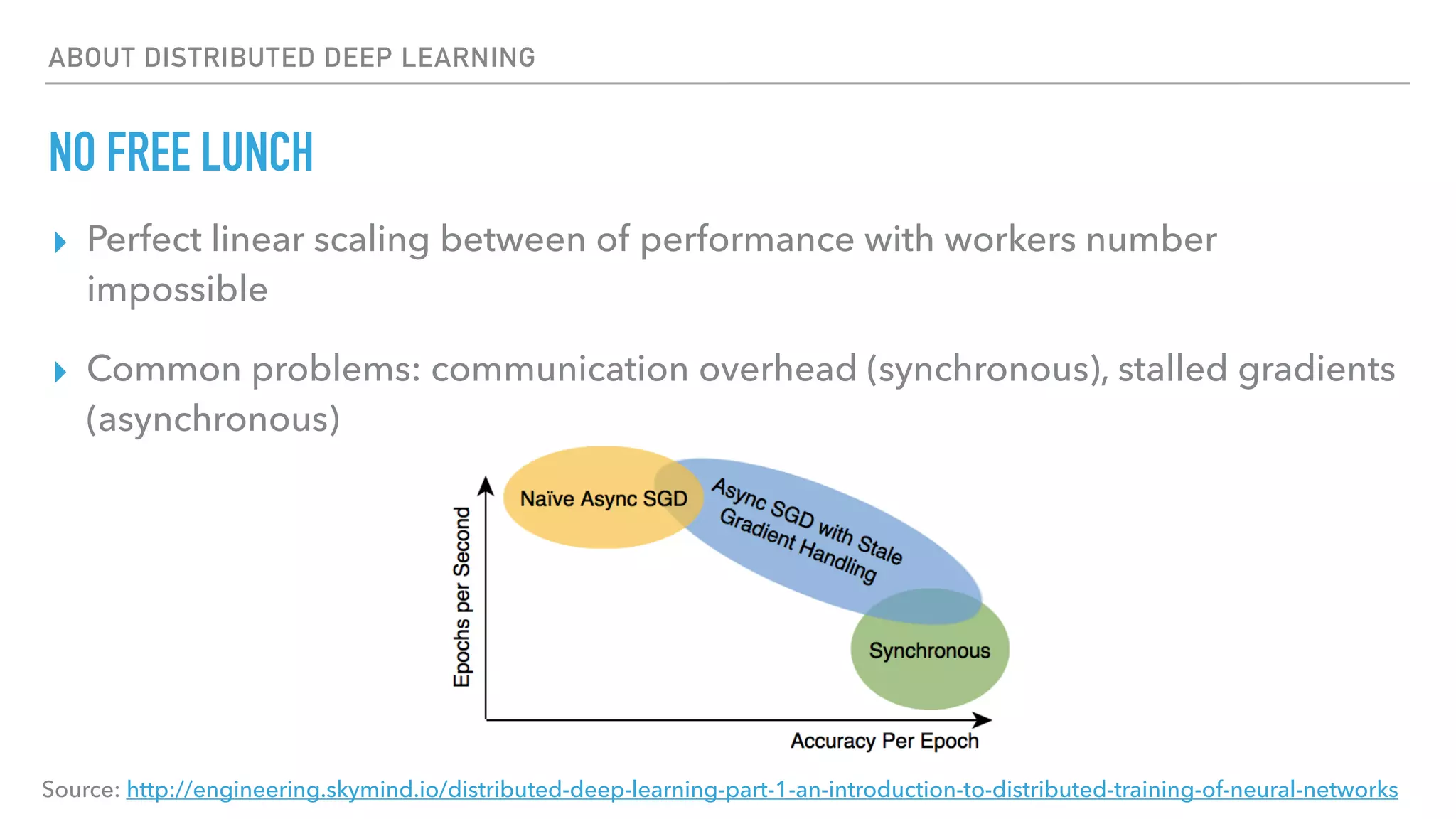









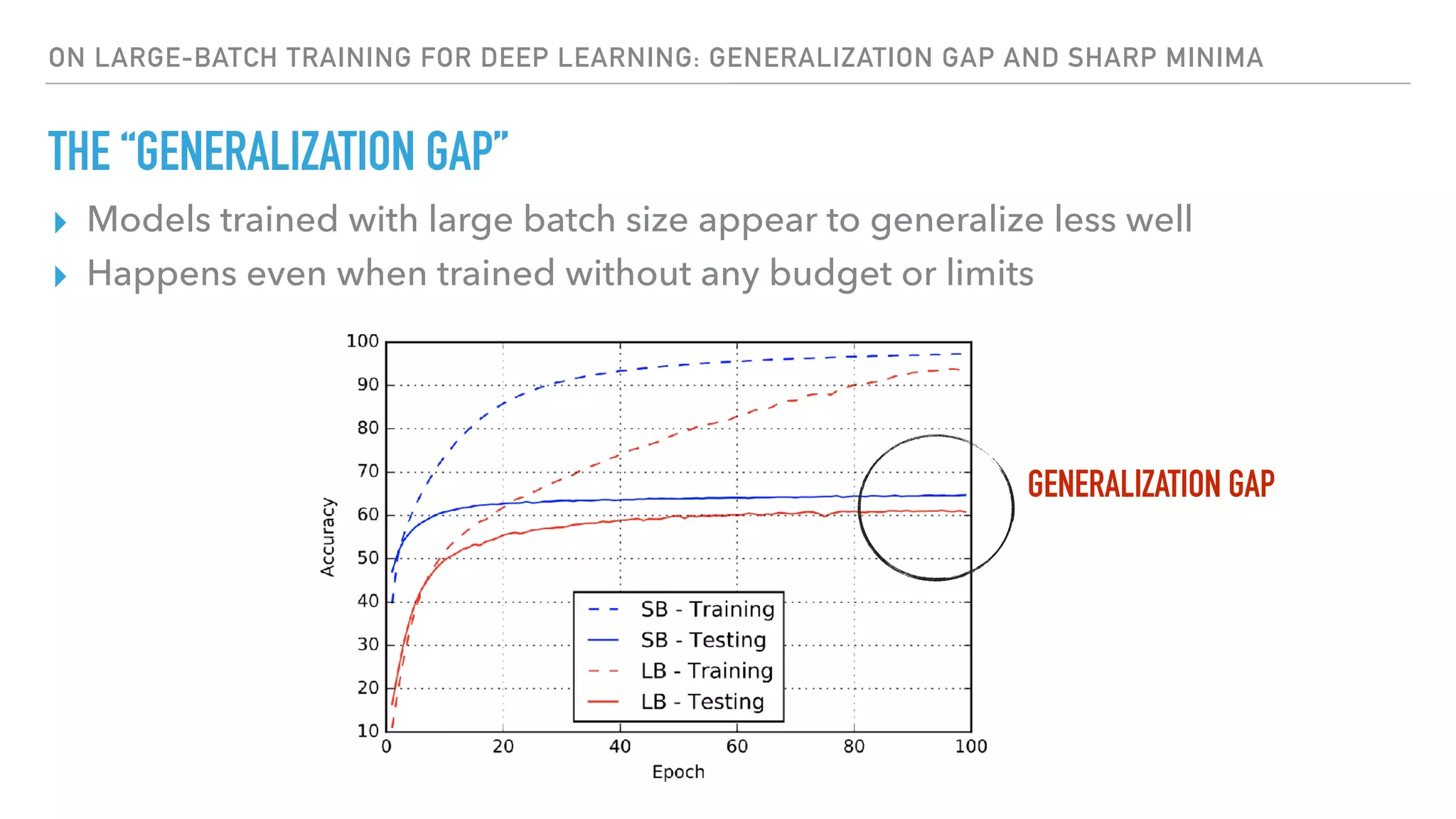
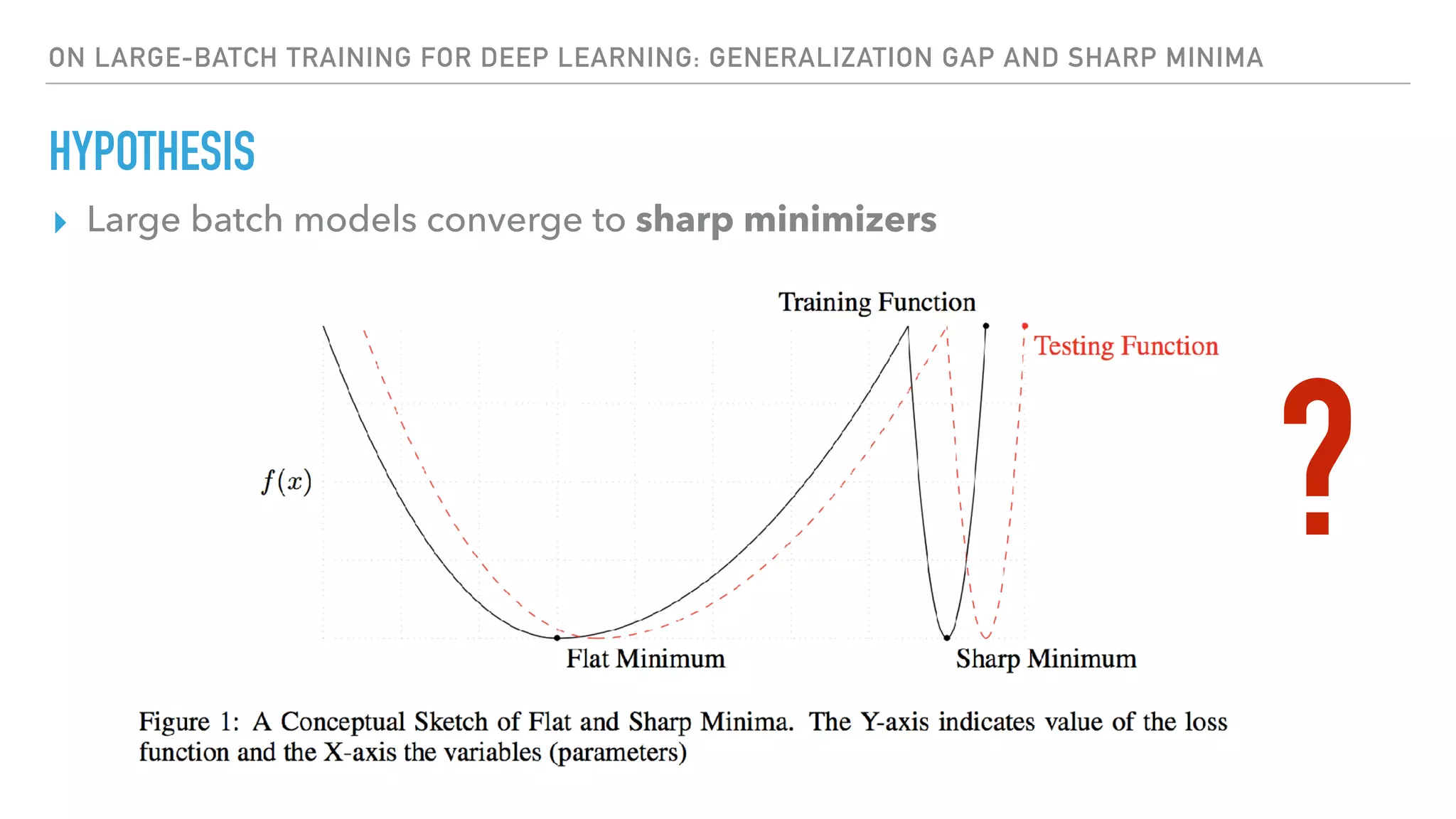


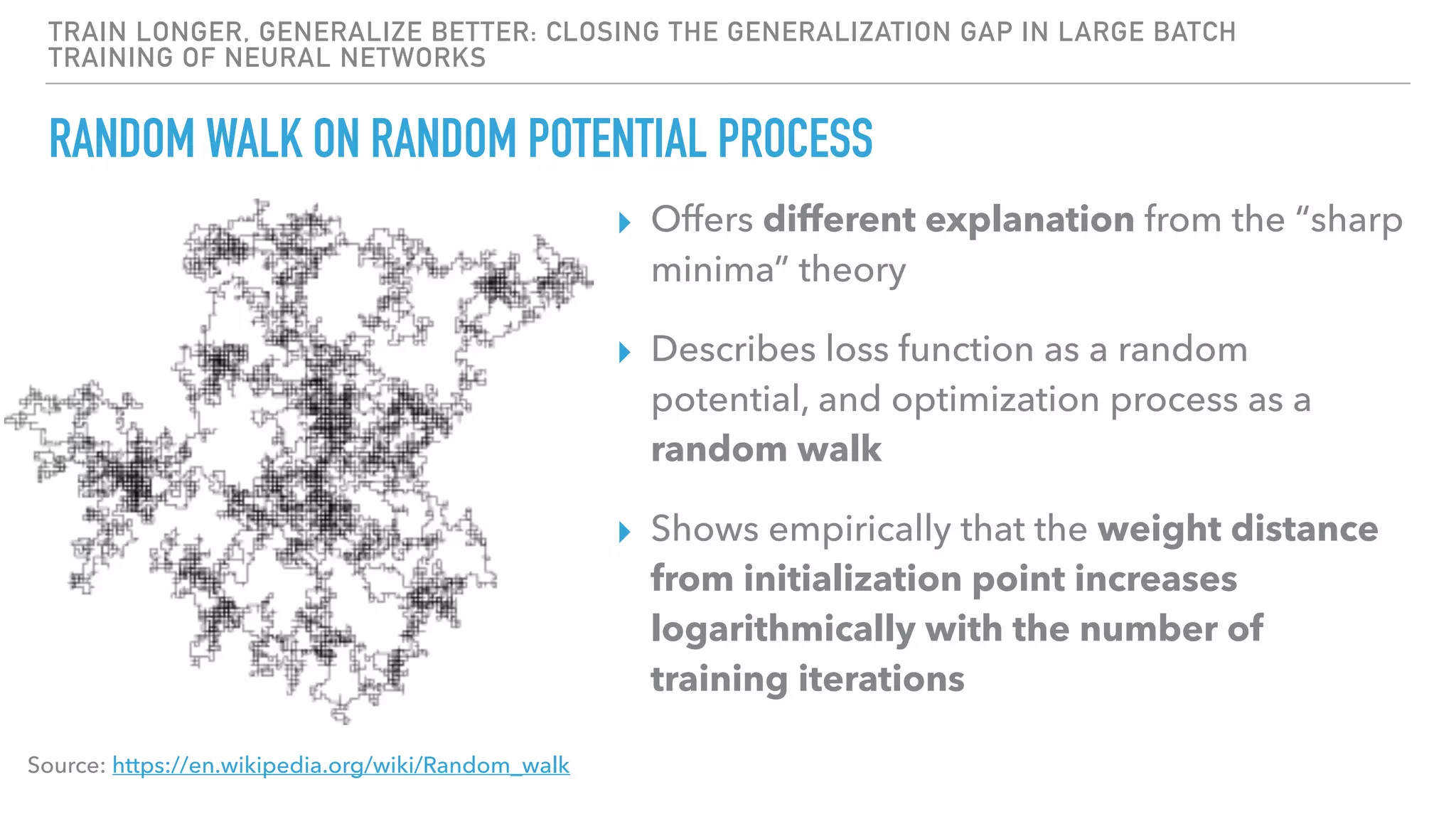

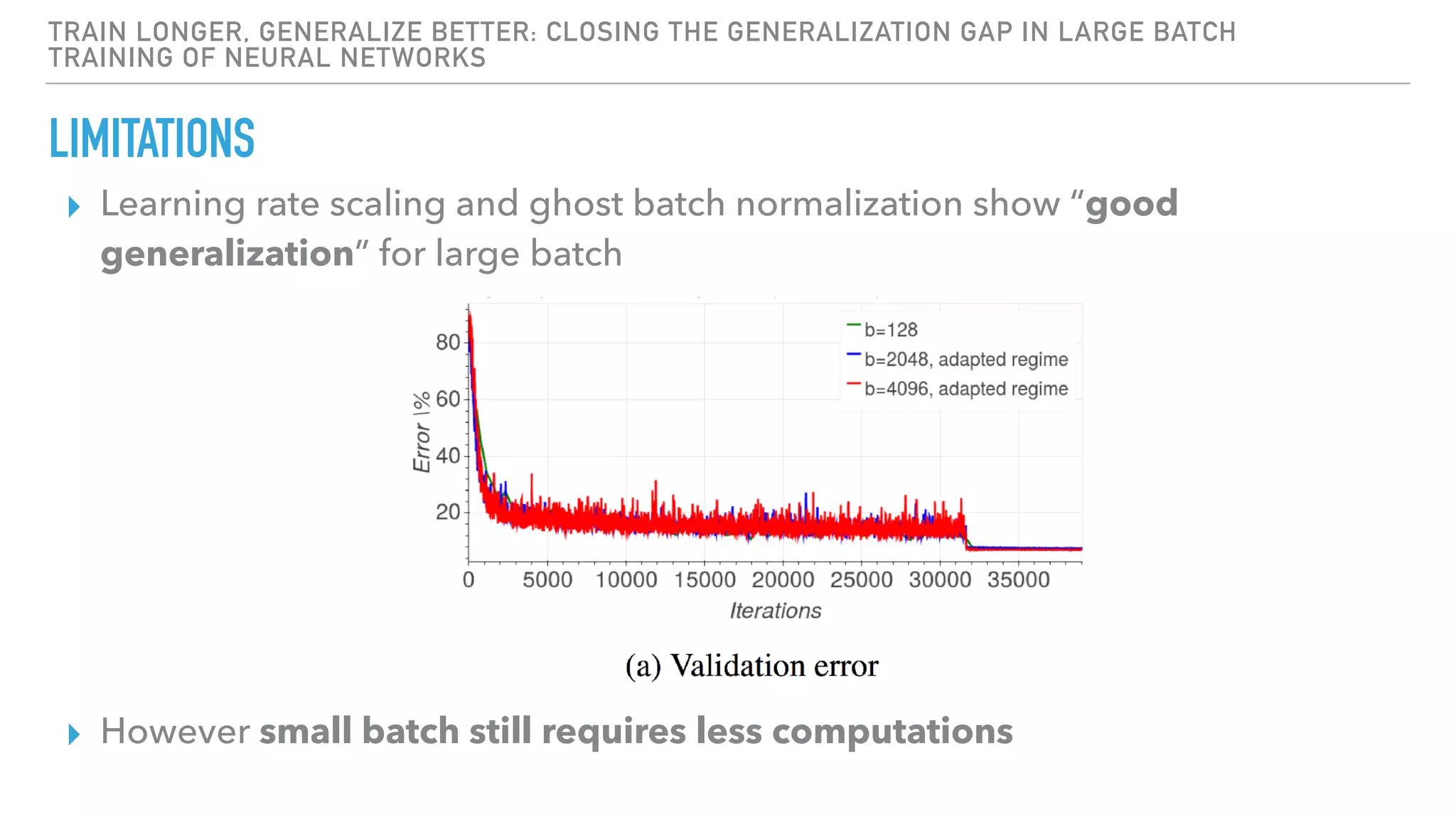




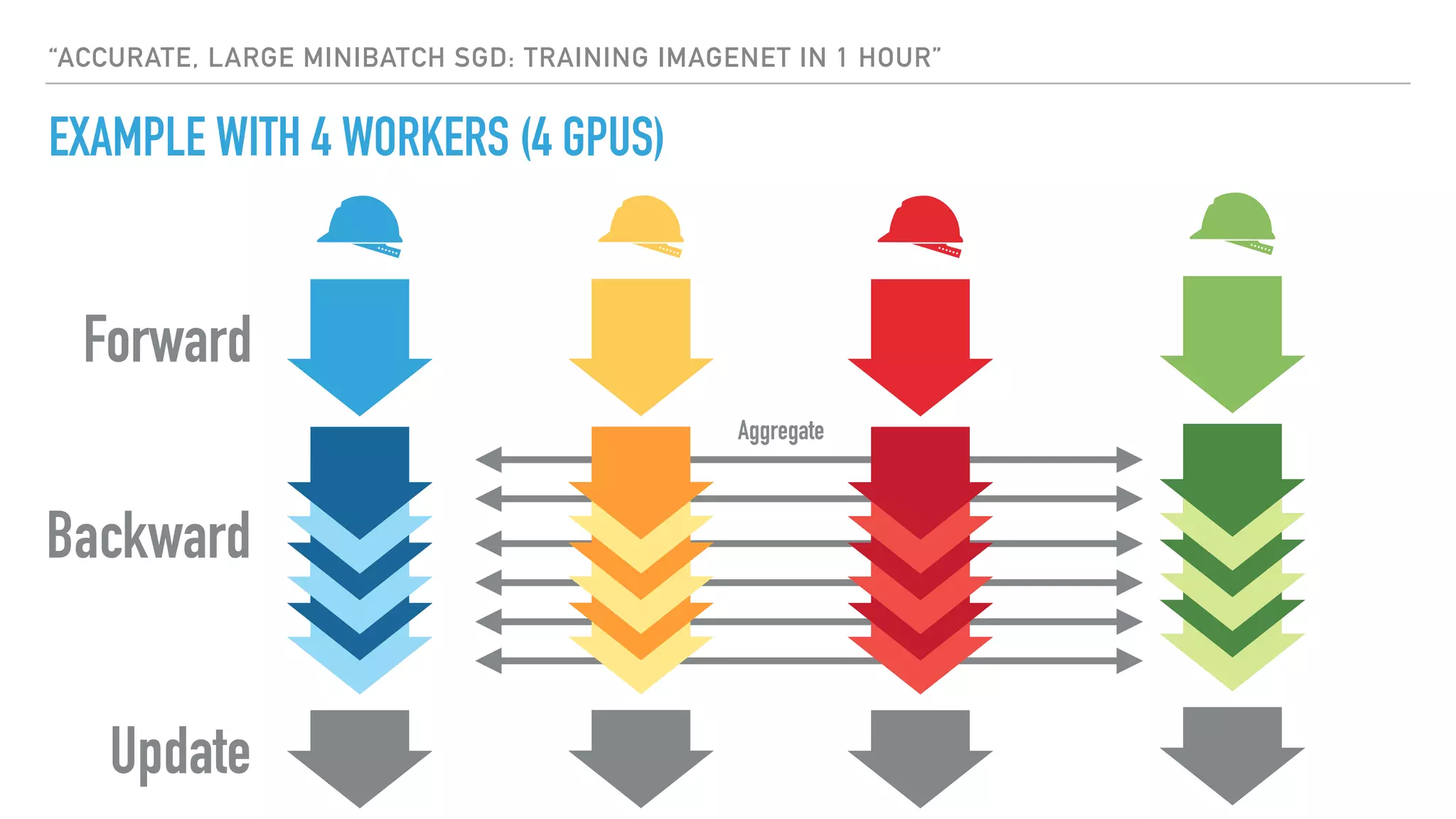
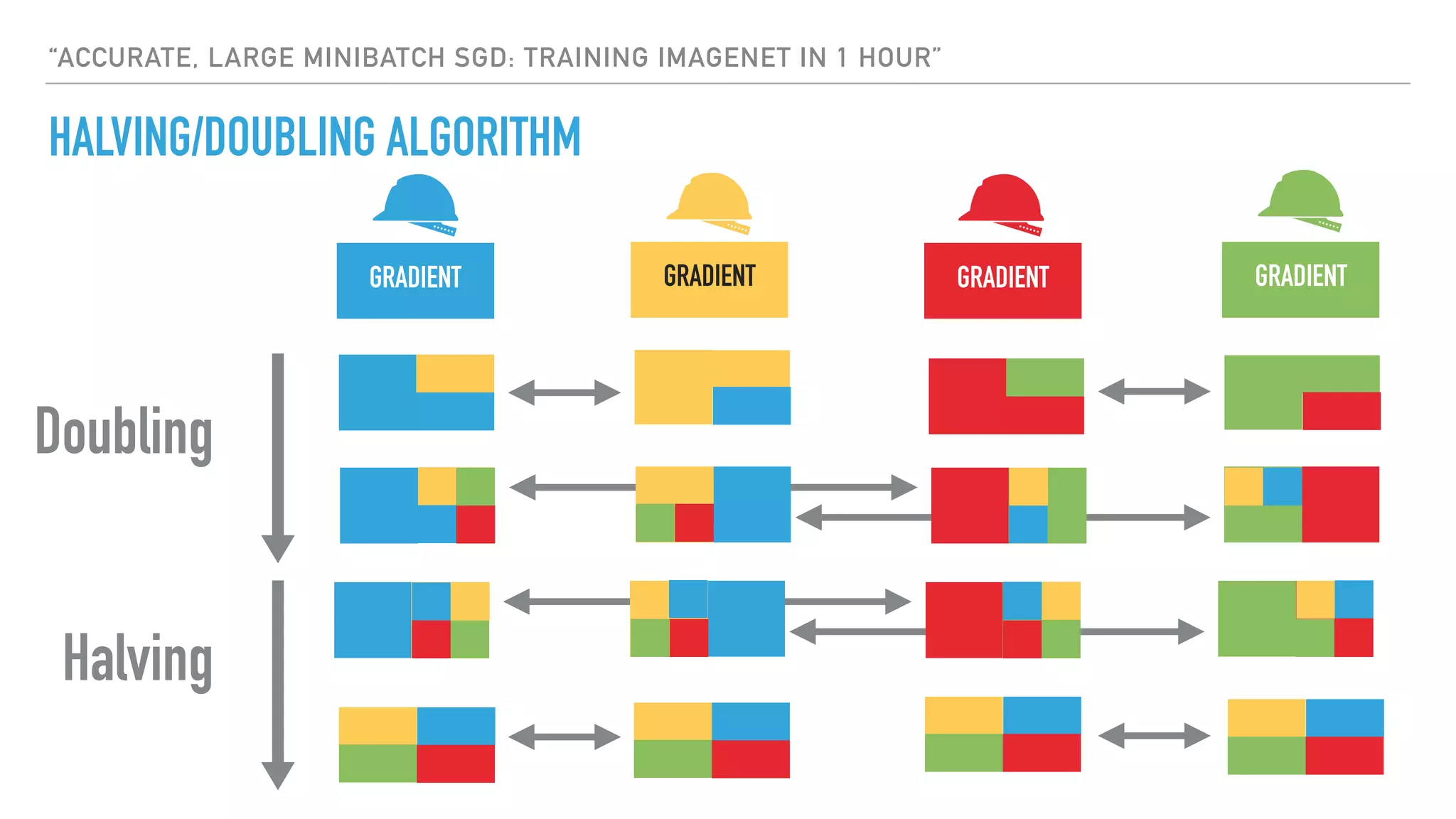

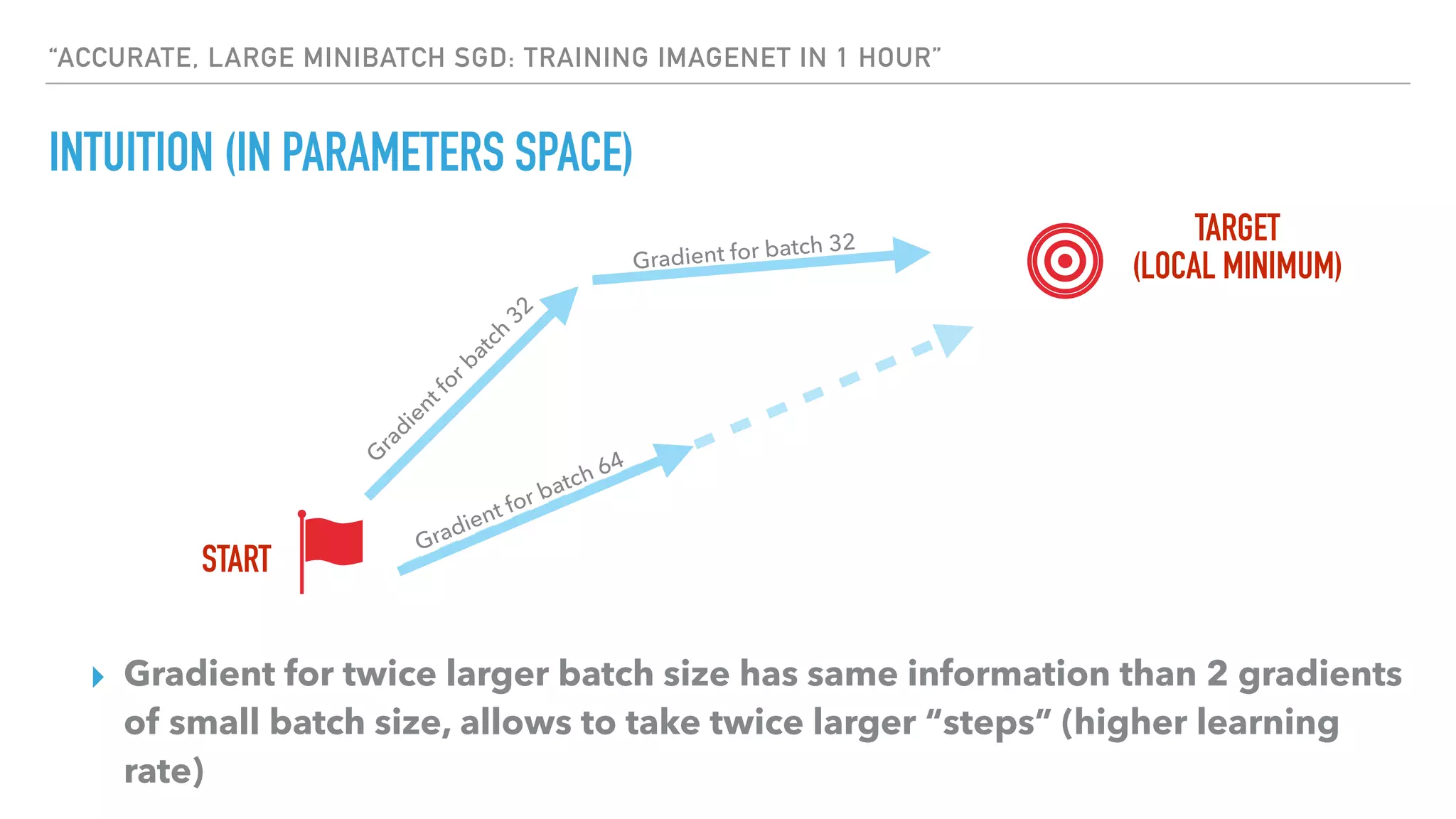

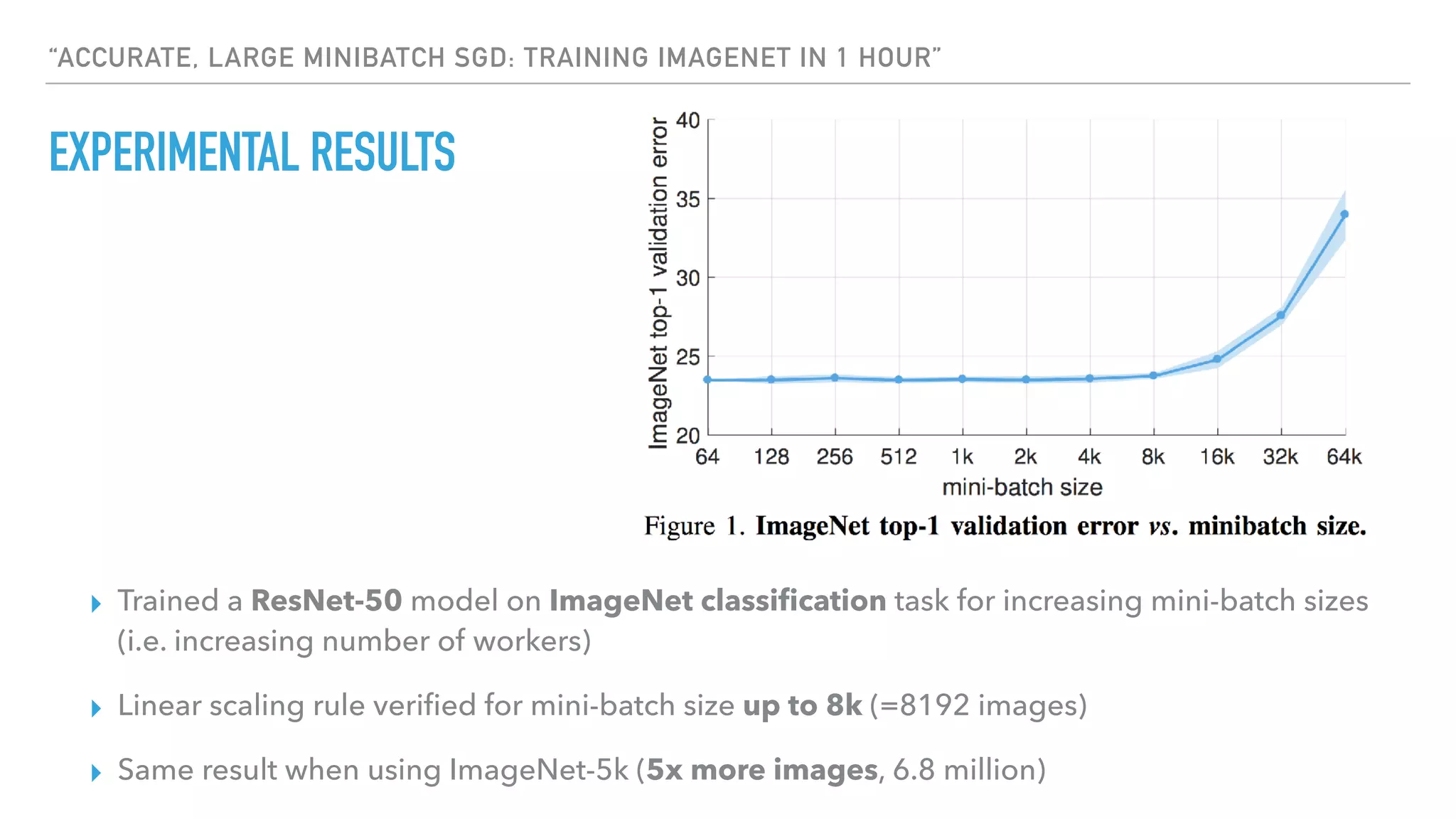
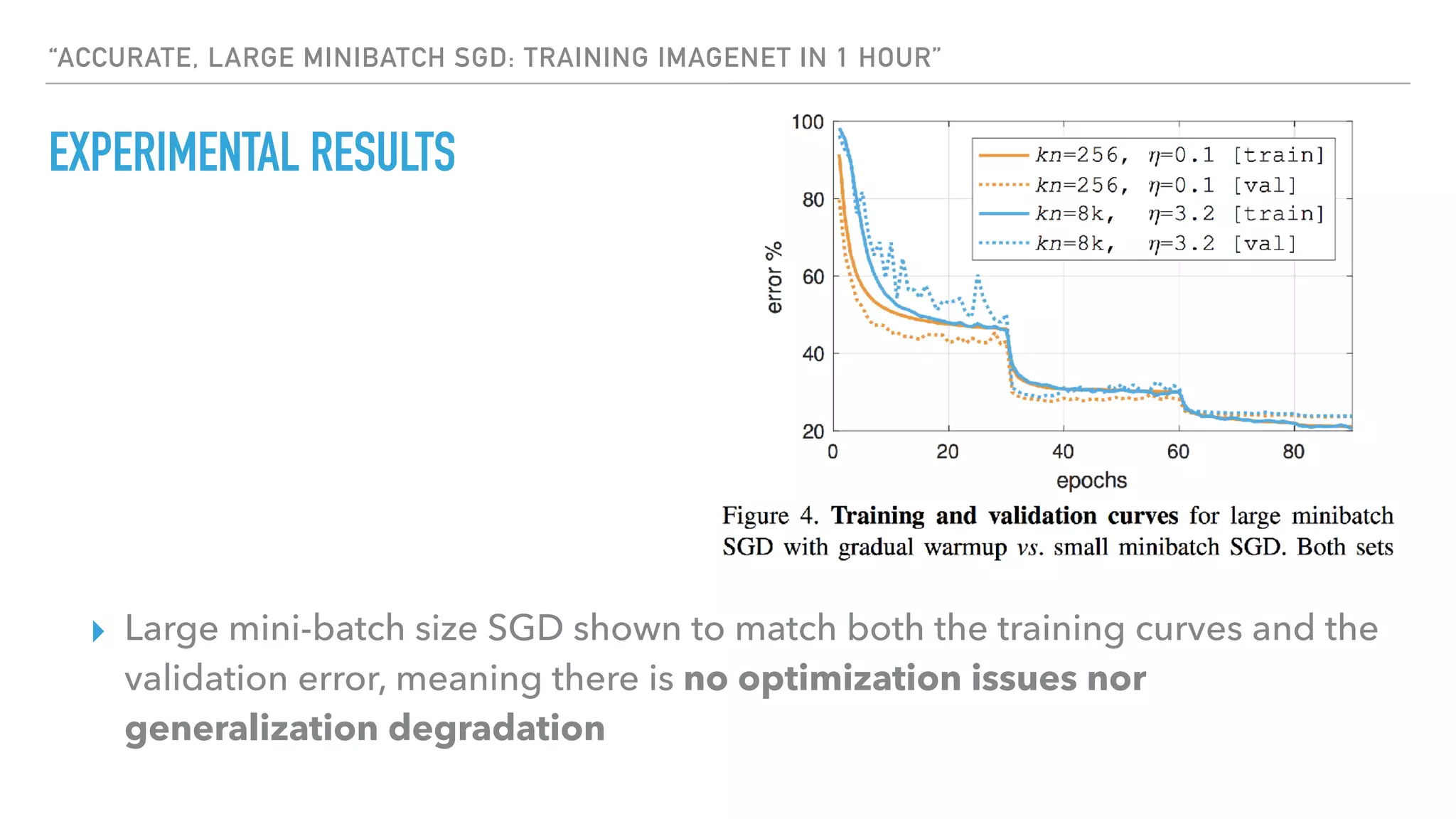
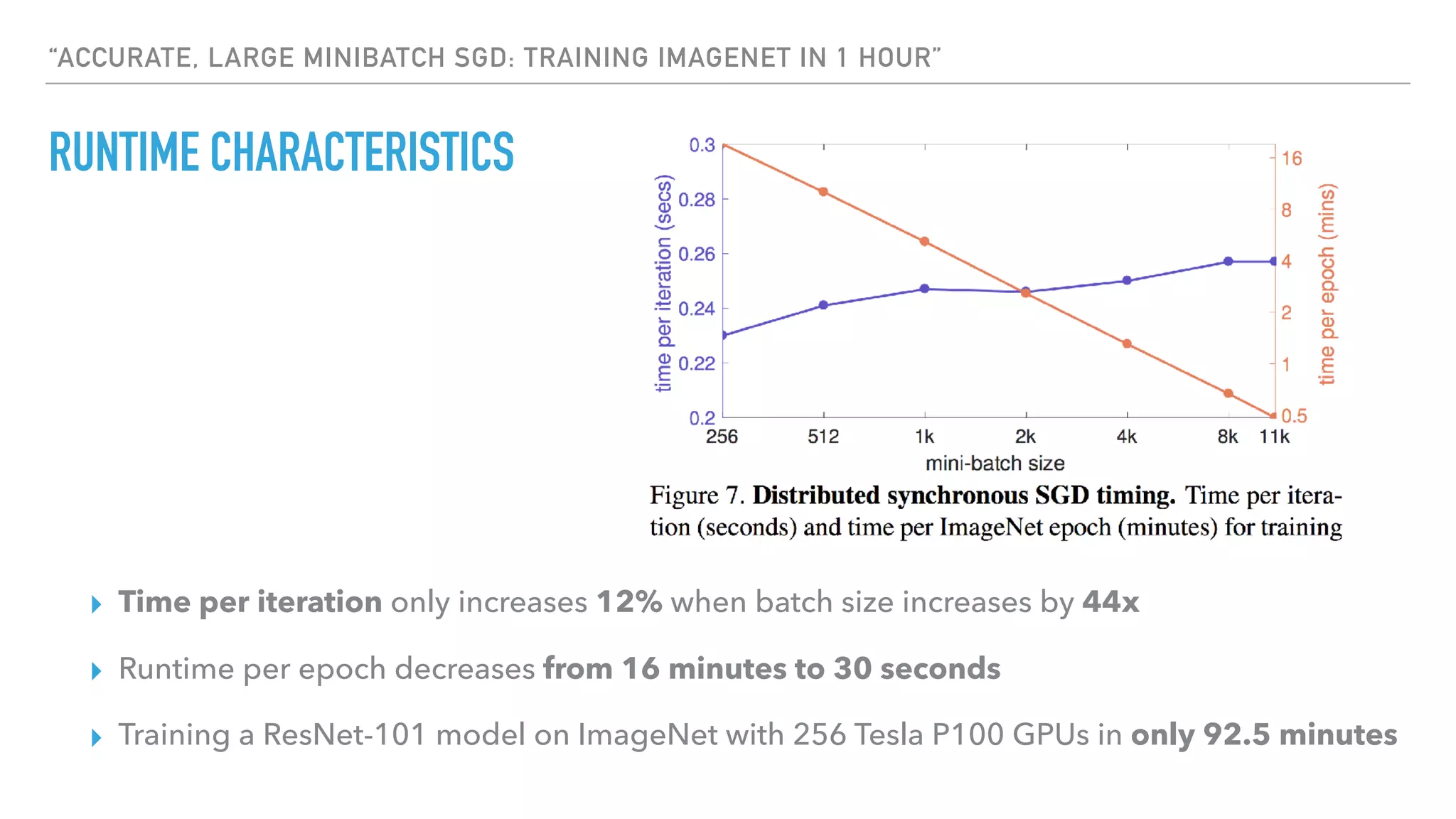
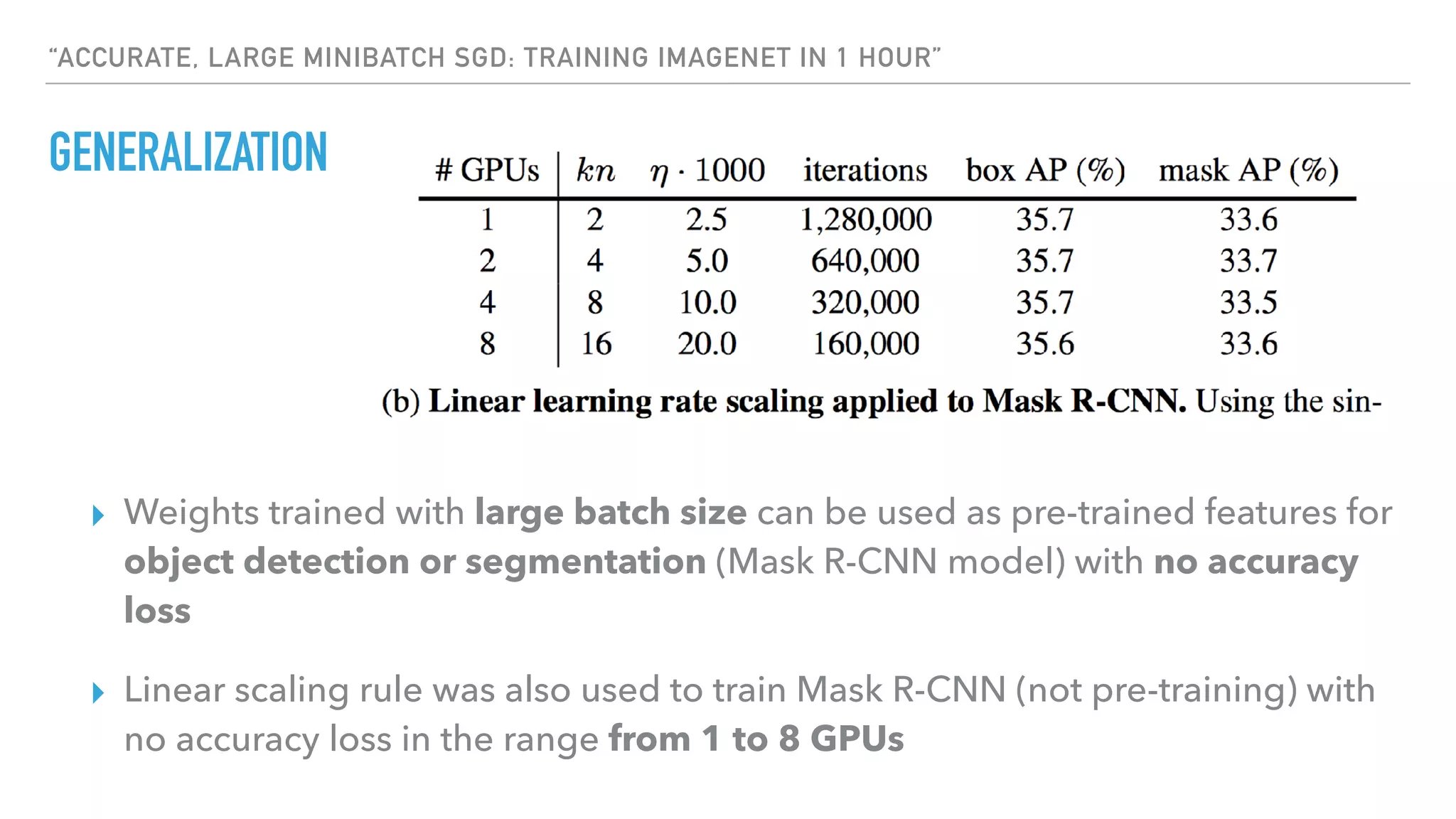









































The document discusses large-scale distributed deep learning, emphasizing the need for distributing computations across multiple nodes and GPUs for efficiency. It covers various parallelism techniques, such as model and data parallelism, and highlights frameworks like TensorFlow, PyTorch, and Caffe2, each offering different implementations for managing distributed training. Additionally, it examines challenges like the generalization gap in large-batch training and proposes strategies to optimize training duration and generalization performance.



































































