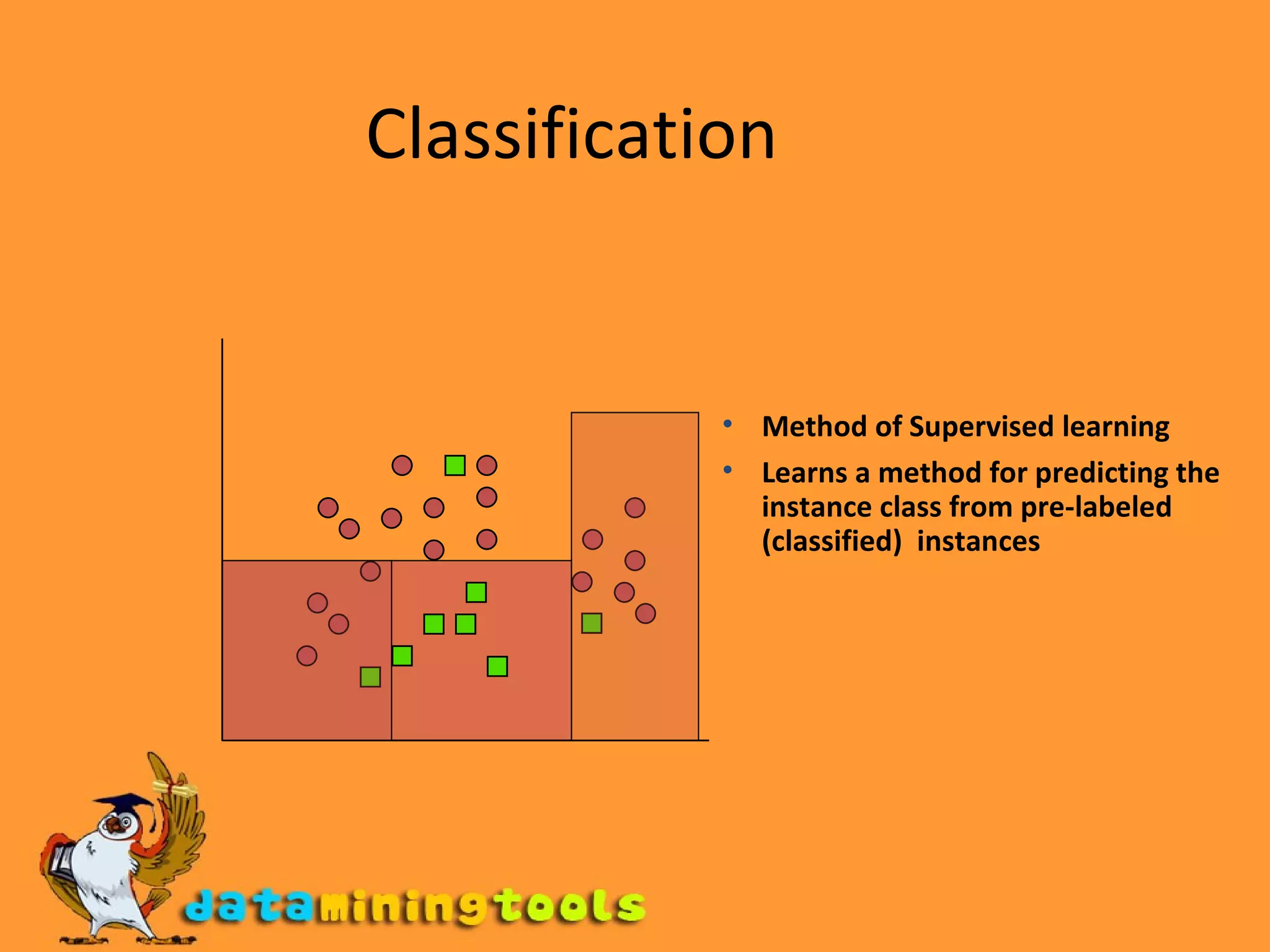
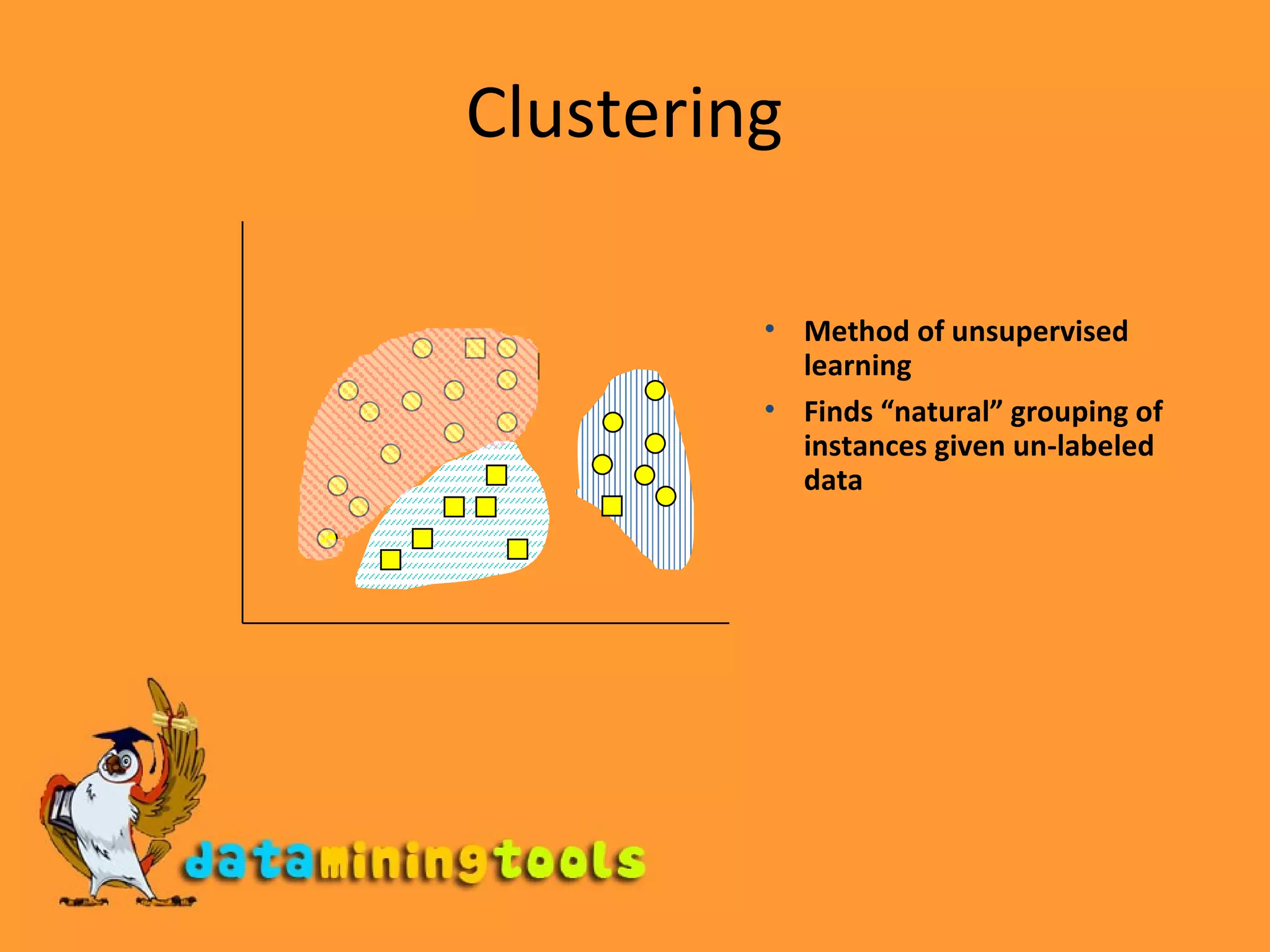
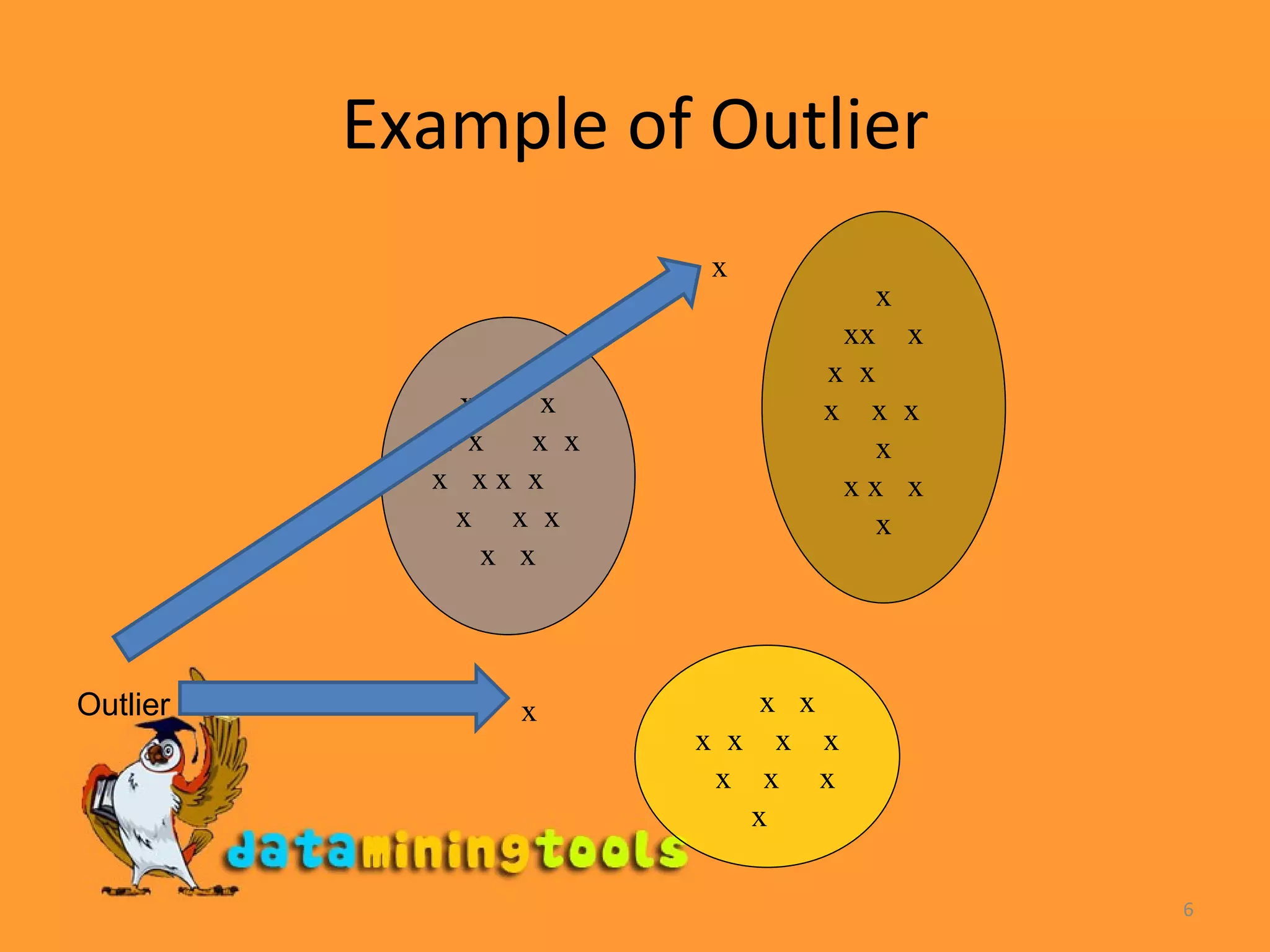
Clustering algorithms are a type of unsupervised learning that groups unlabeled data points together based on similarities. There are many different clustering methods that can group data either hierarchically or into flat clusters, and either exclusively or with overlap. K-means clustering is a simple algorithm that assigns data points to clusters based on proximity to randomly assigned cluster centroids, and is useful despite limitations around sensitivity to outliers and requiring pre-specification of the number of clusters. Clustering has applications across many domains including marketing, astronomy, seismology, and genomics.




















































































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)











![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)



![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)





























![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)










