Download to read offline










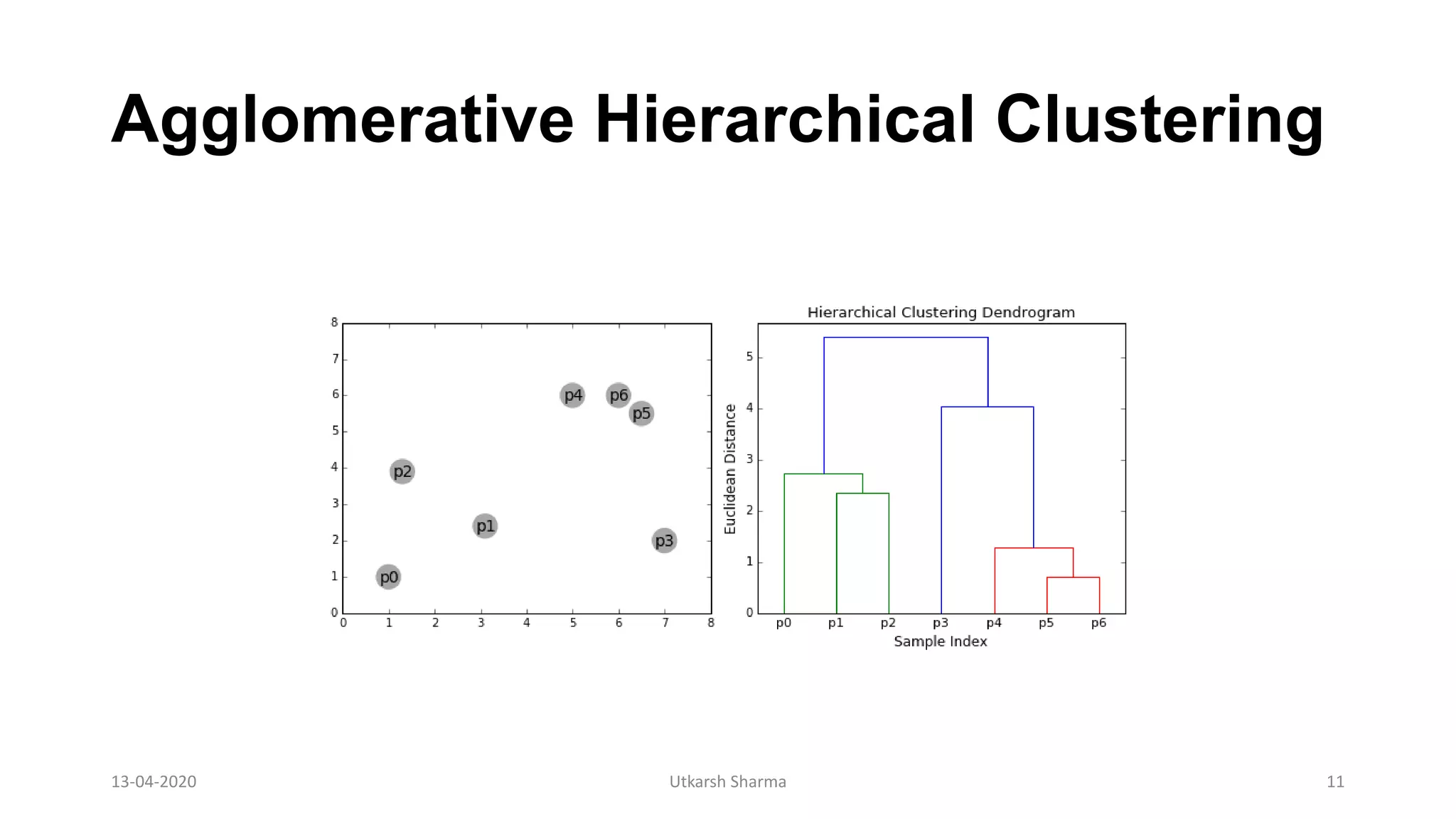
















The document discusses several clustering algorithms: Mean shift clustering works by iteratively shifting a sliding window to areas of higher point density until convergence; DBSCAN begins with a starting point and identifies neighboring points within a distance epsilon, forming clusters if sufficient neighbors are found and labeling outliers; Agglomerative hierarchical clustering treats each data point as an initial cluster and successively merges the closest pairs of clusters using a distance metric like average linkage until all points are in one cluster.













































































