Downloaded 16 times




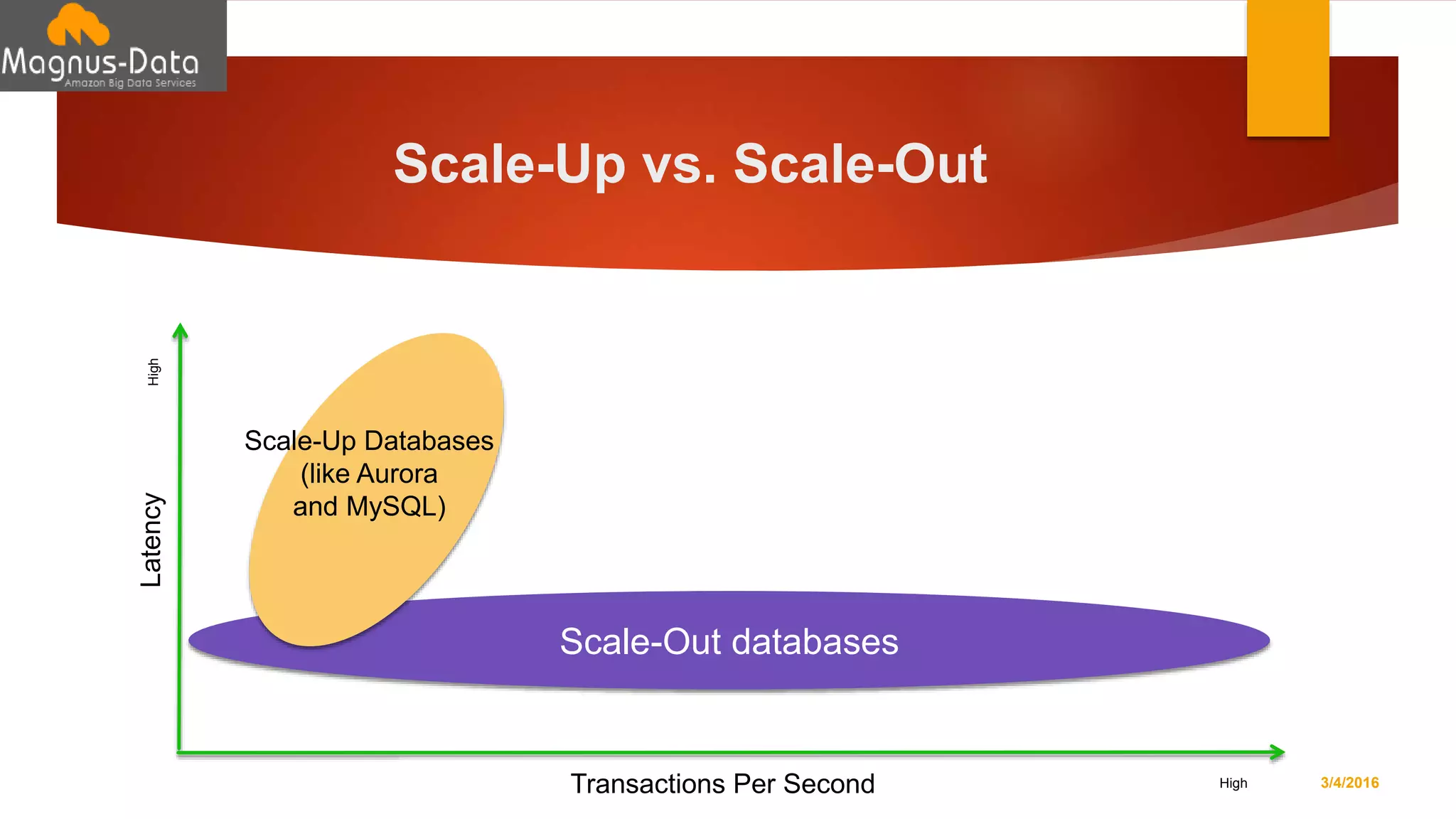

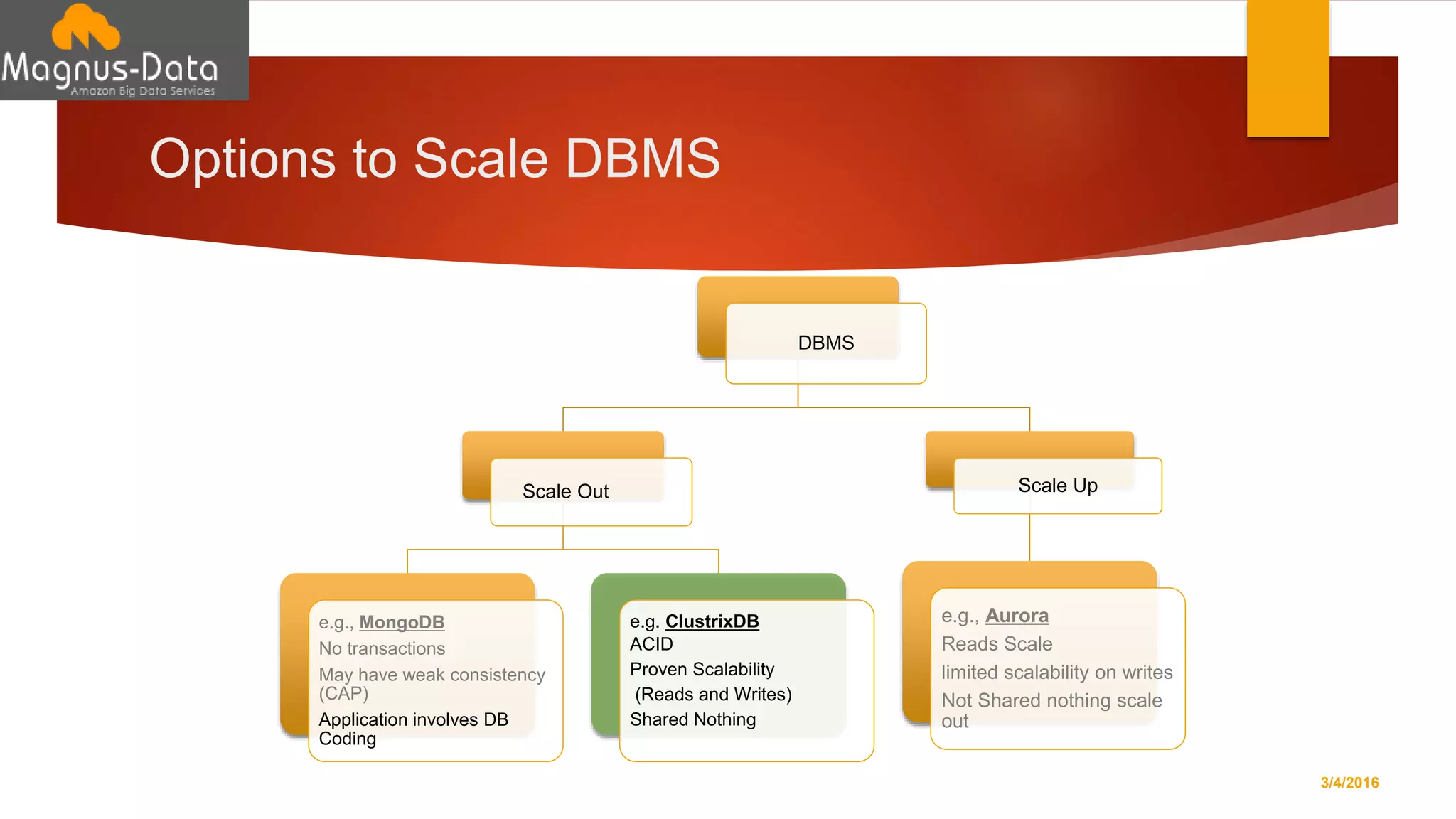






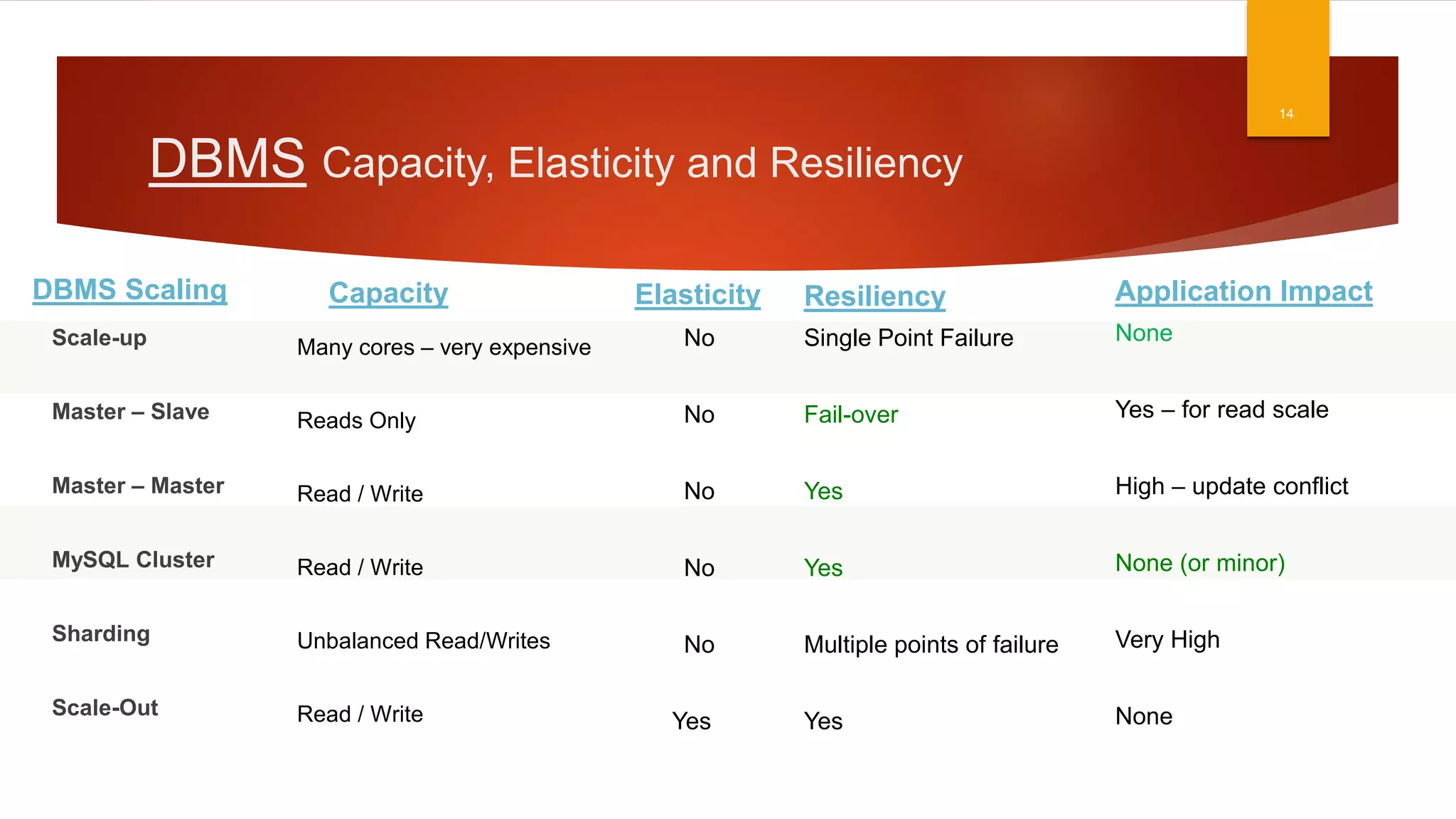

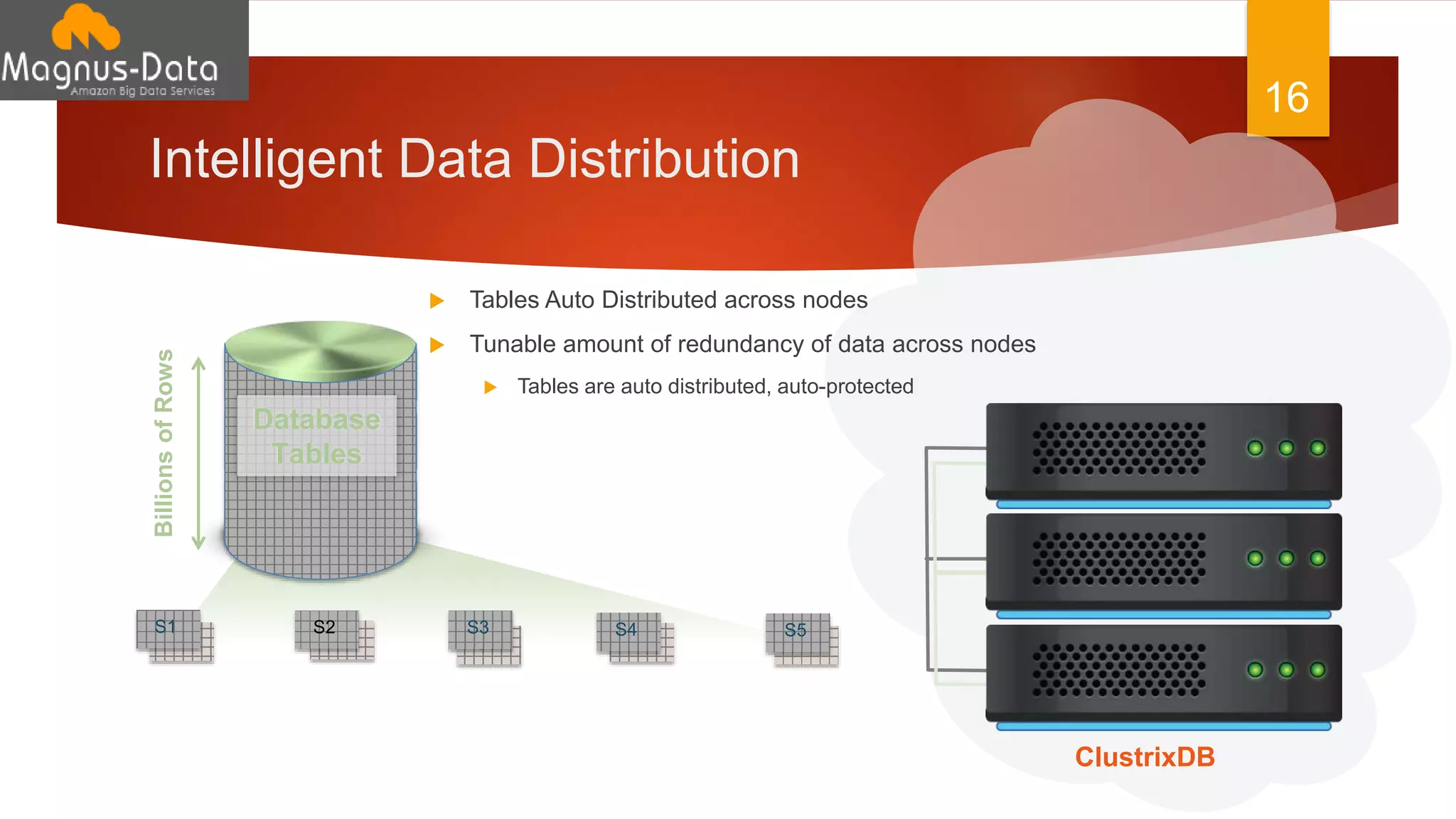
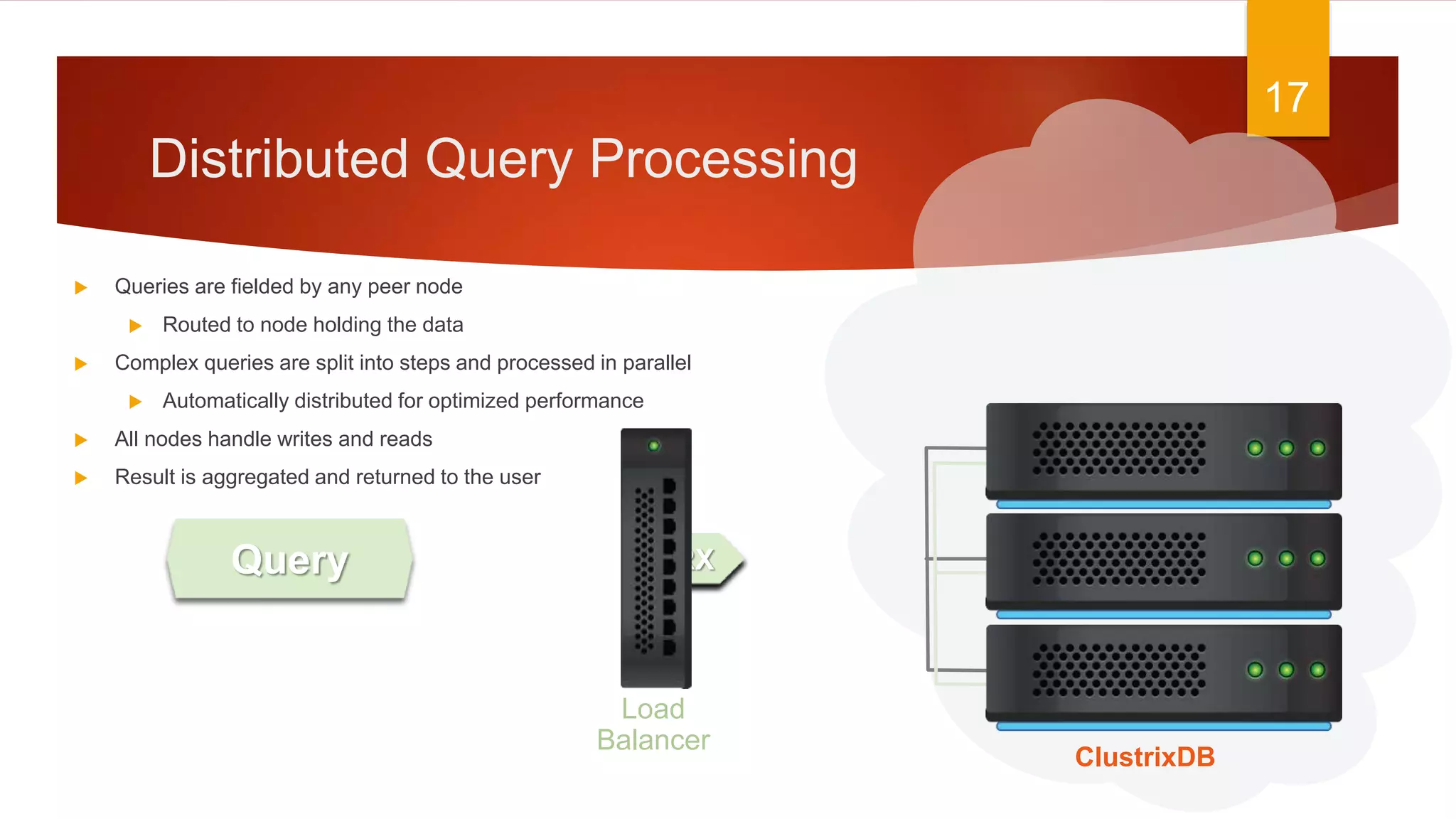
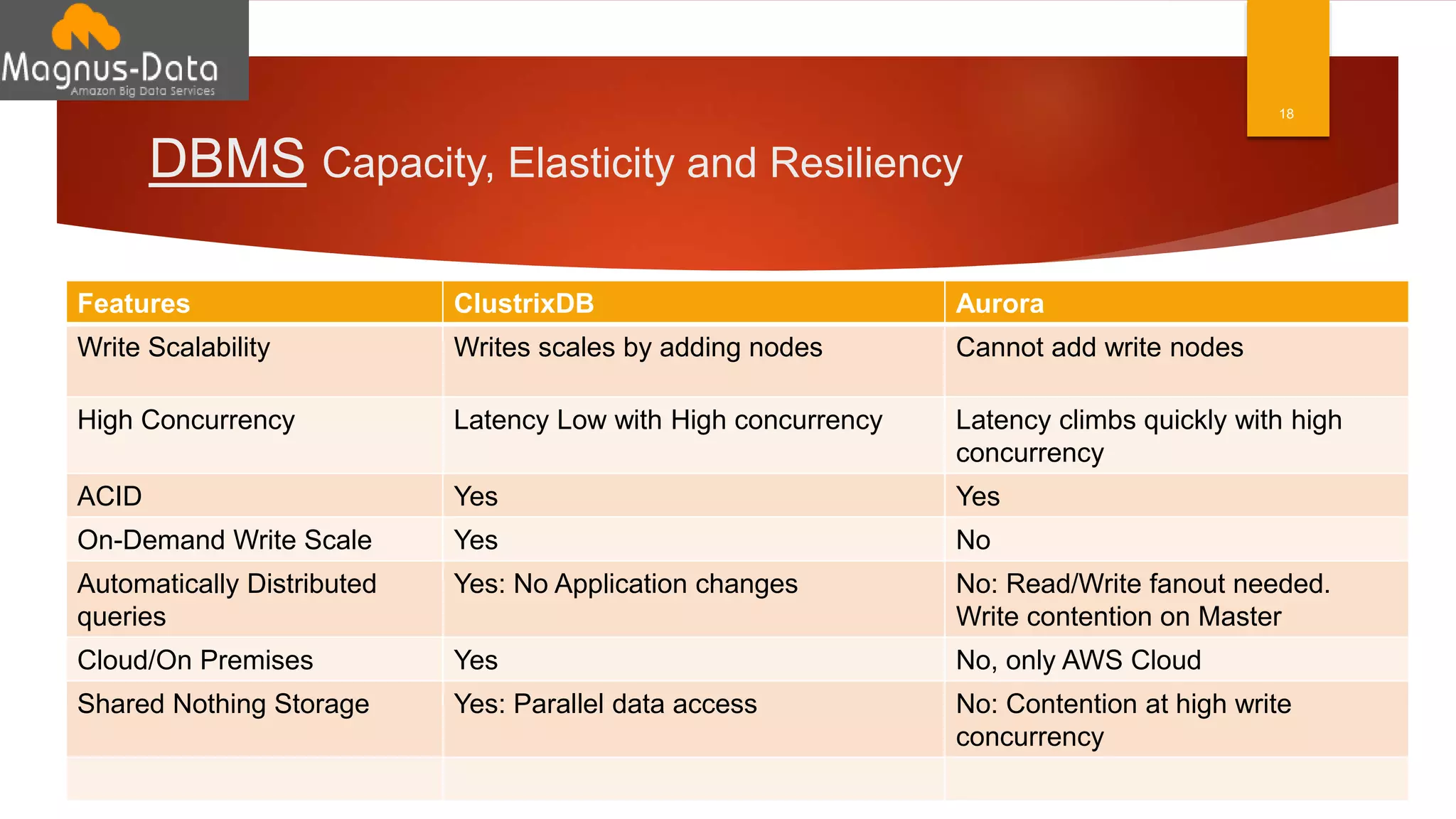
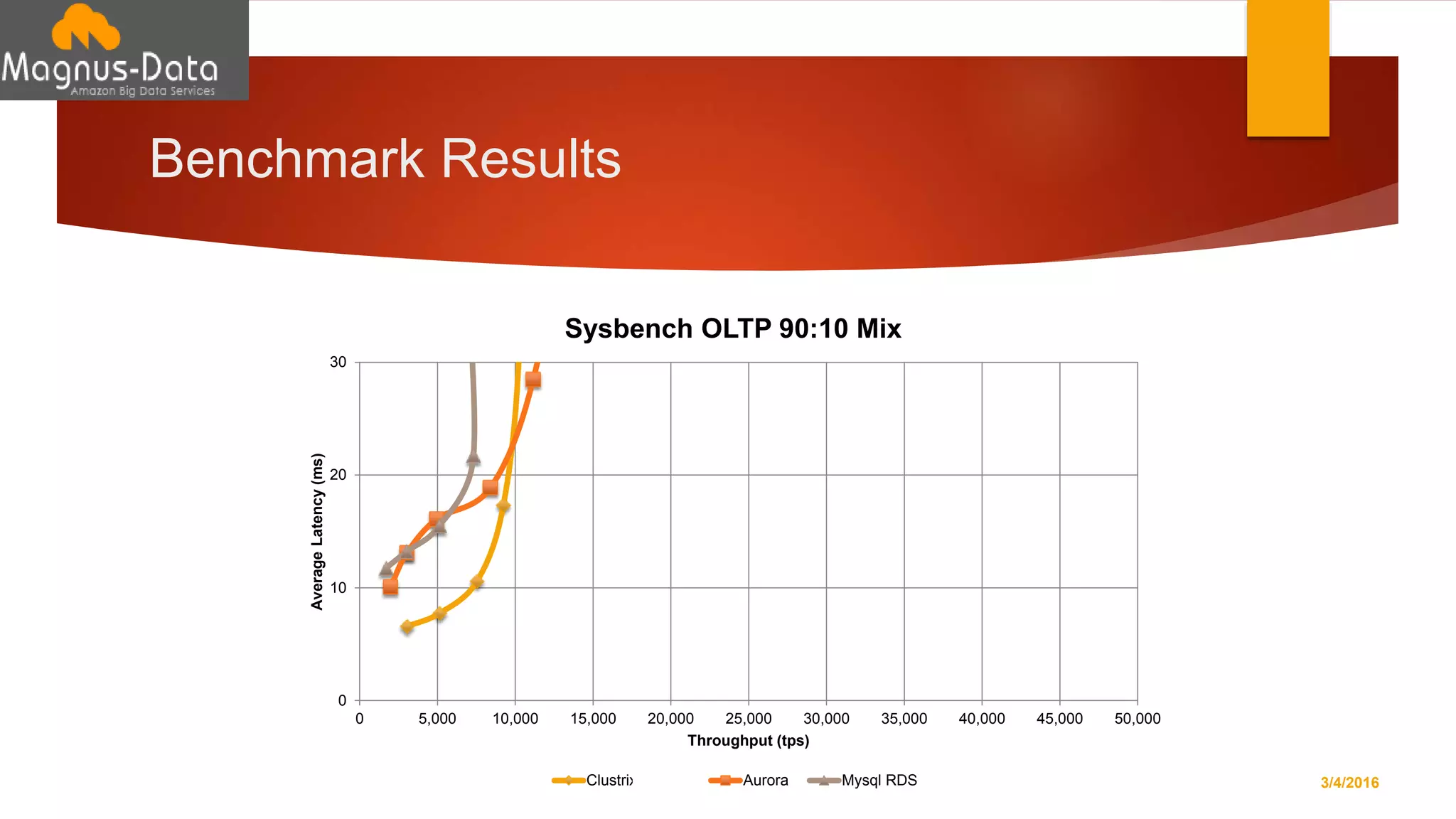
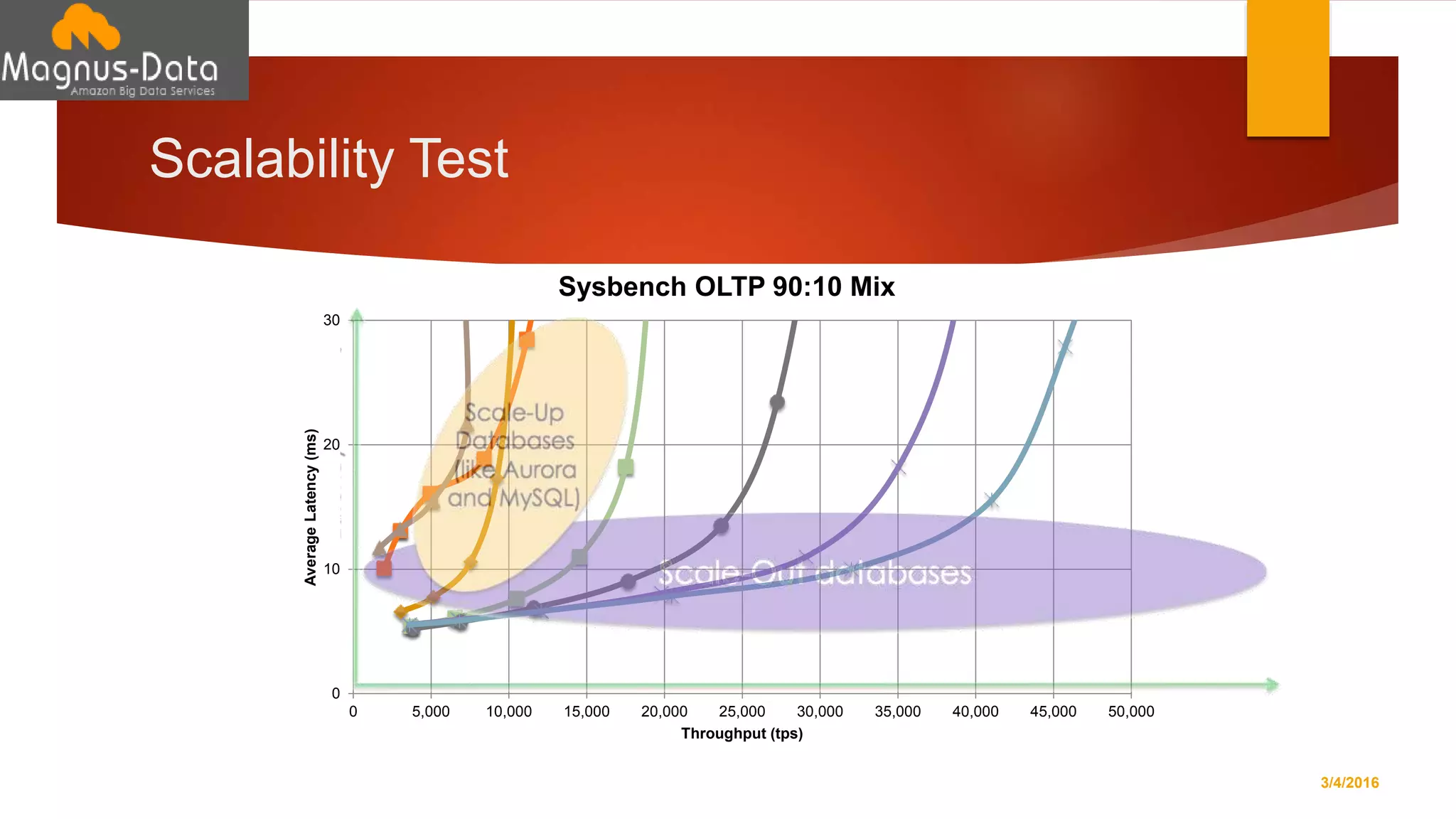























The document discusses the landscape of database management systems (DBMS), focusing on scaling options such as scale-up and scale-out architectures. It compares various solutions for high-transaction relational databases, including traditional databases, NoSQL, and specialized clustering technologies. Key features such as concurrency, latency, and scalability are highlighted, with an emphasis on ClustrixDB's capabilities in handling high concurrency and write scalability.

































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)









