Download as PDF, PPTX

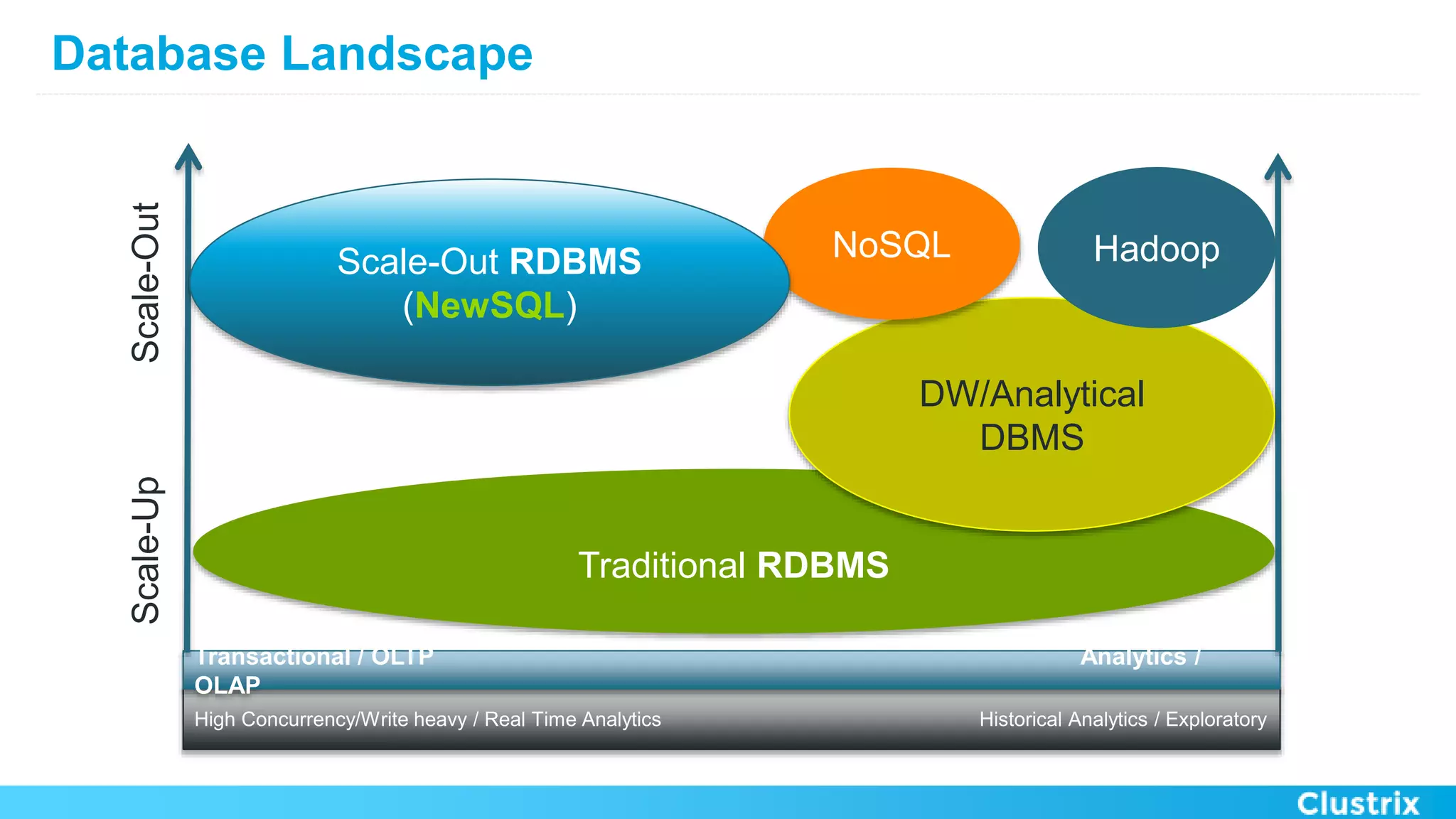
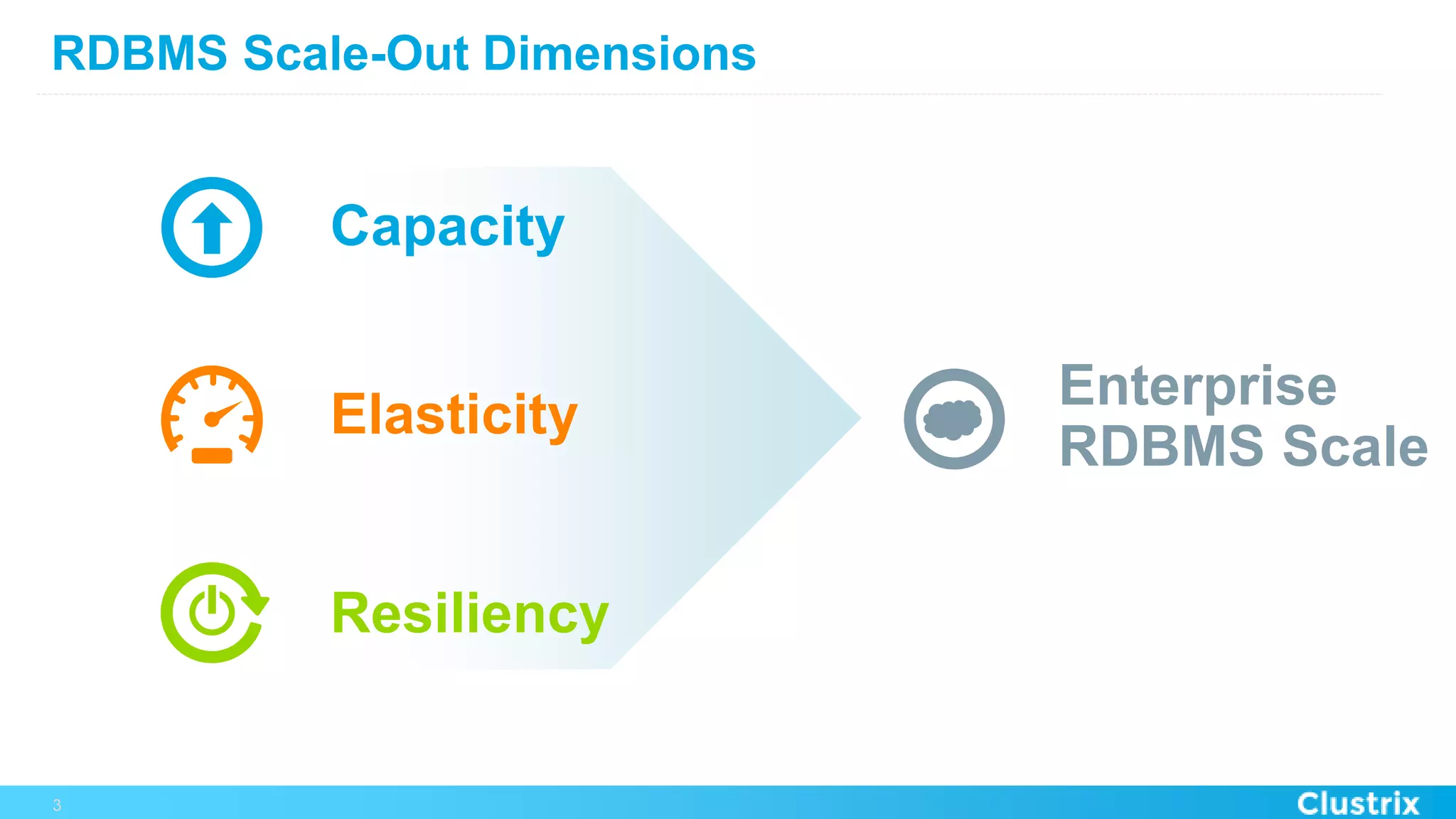

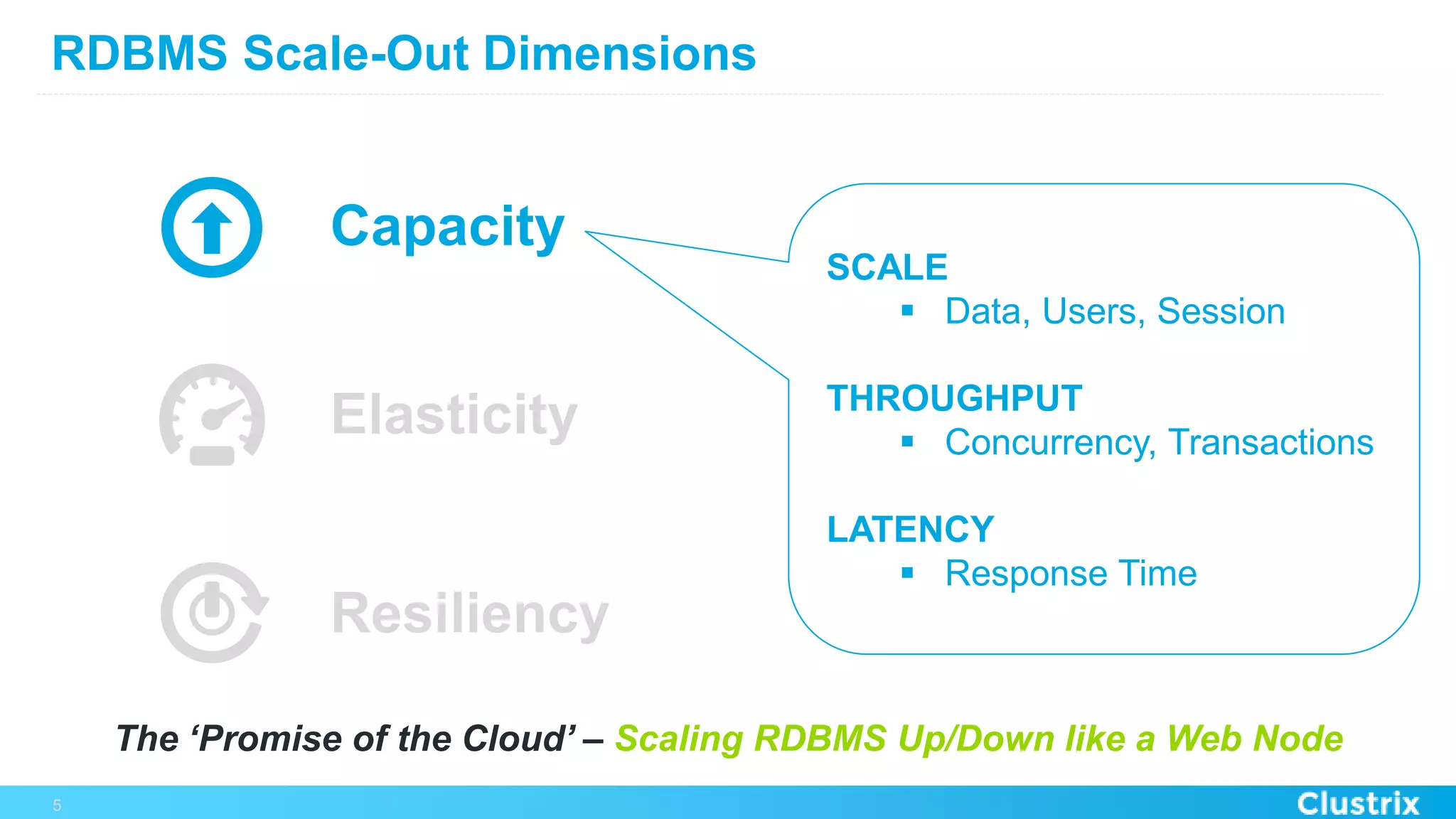










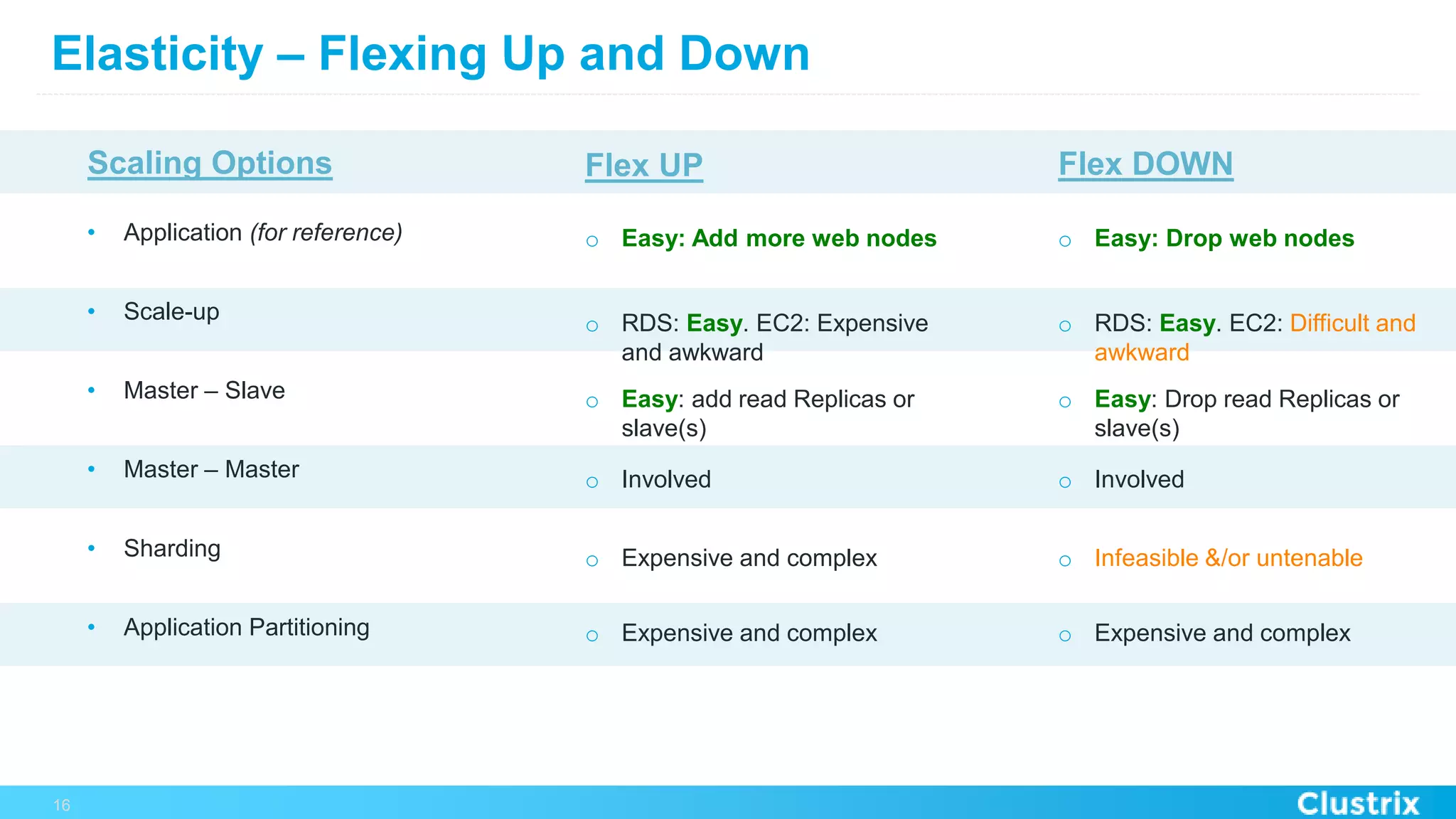
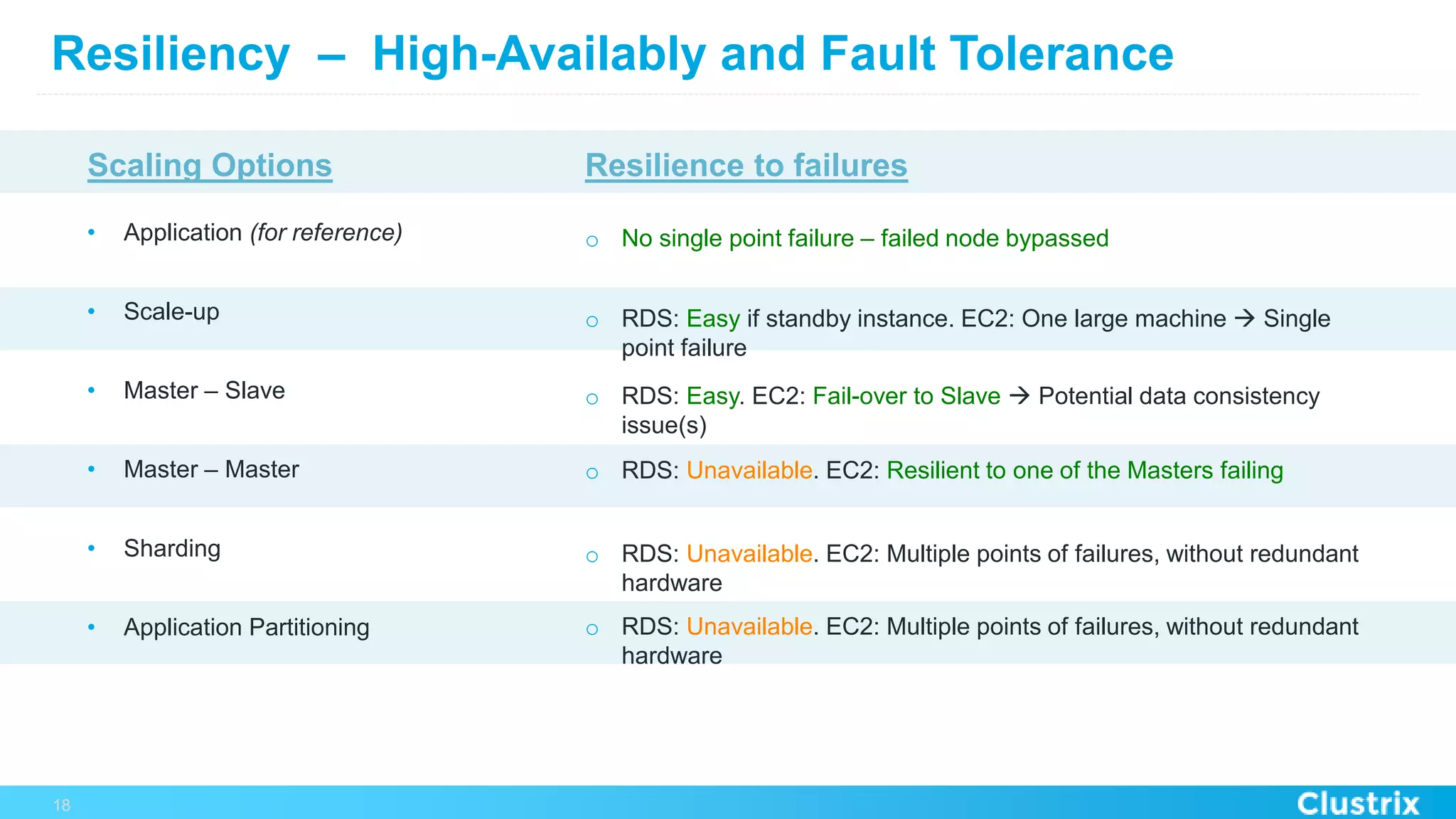


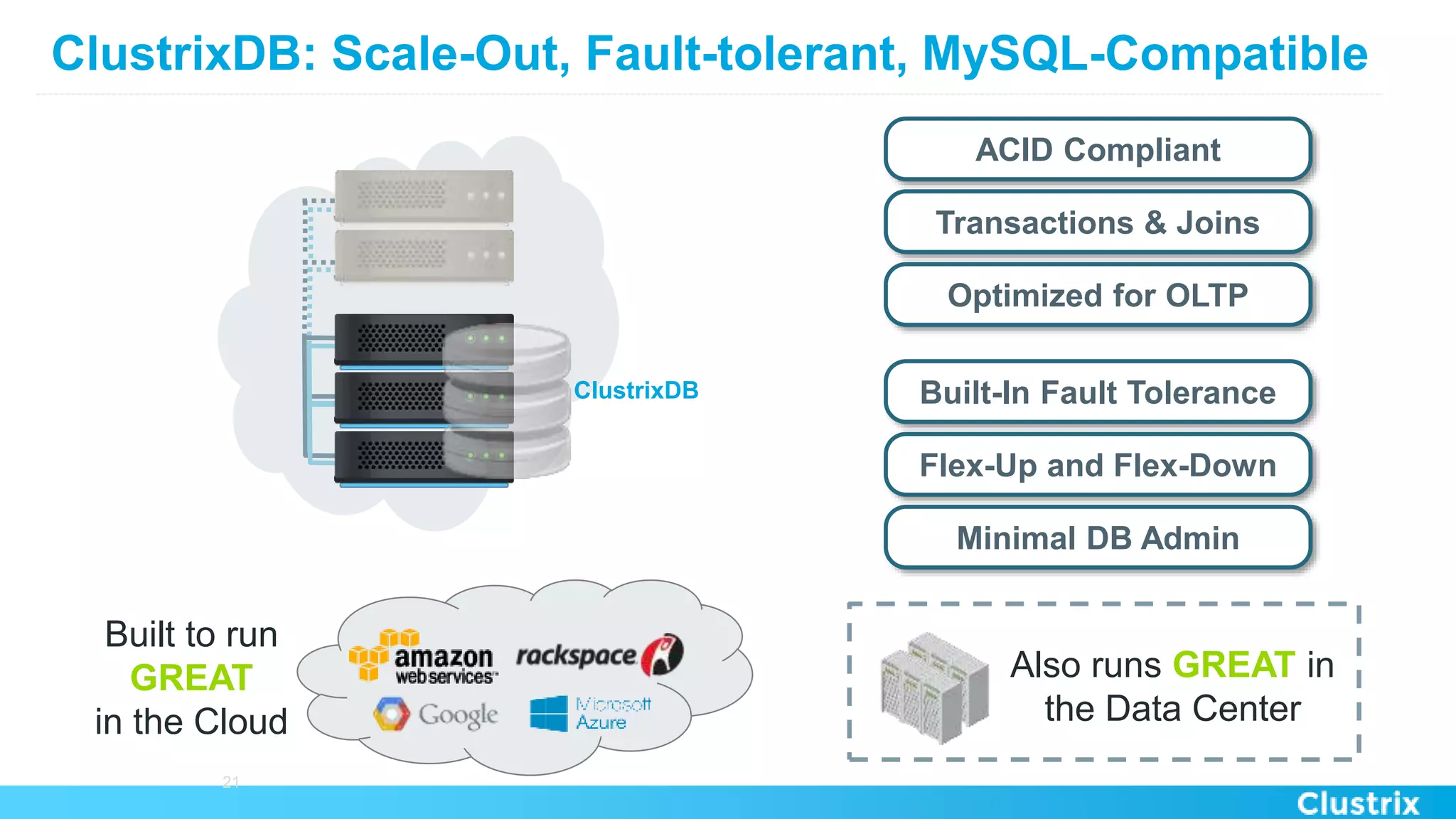
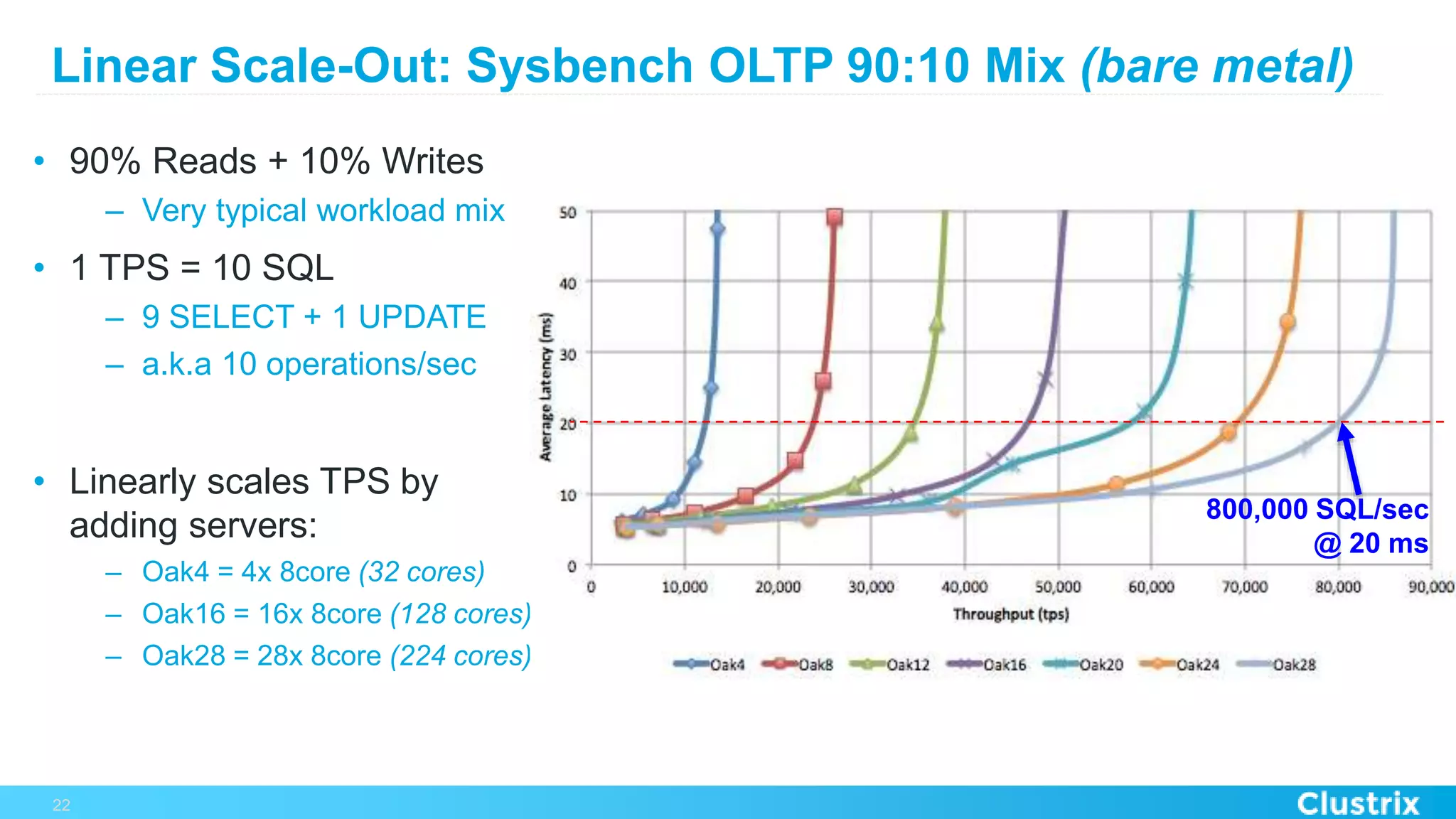
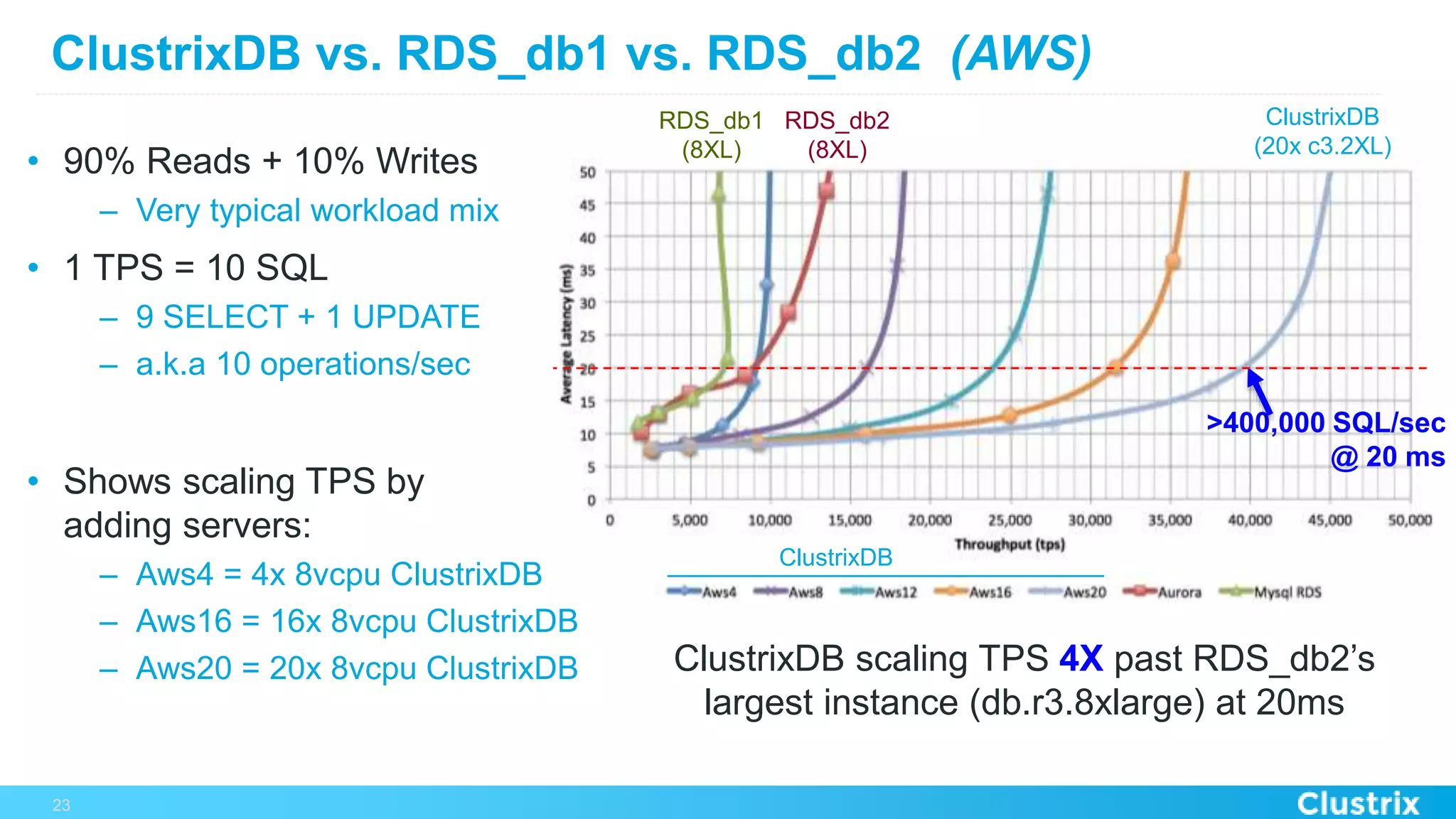

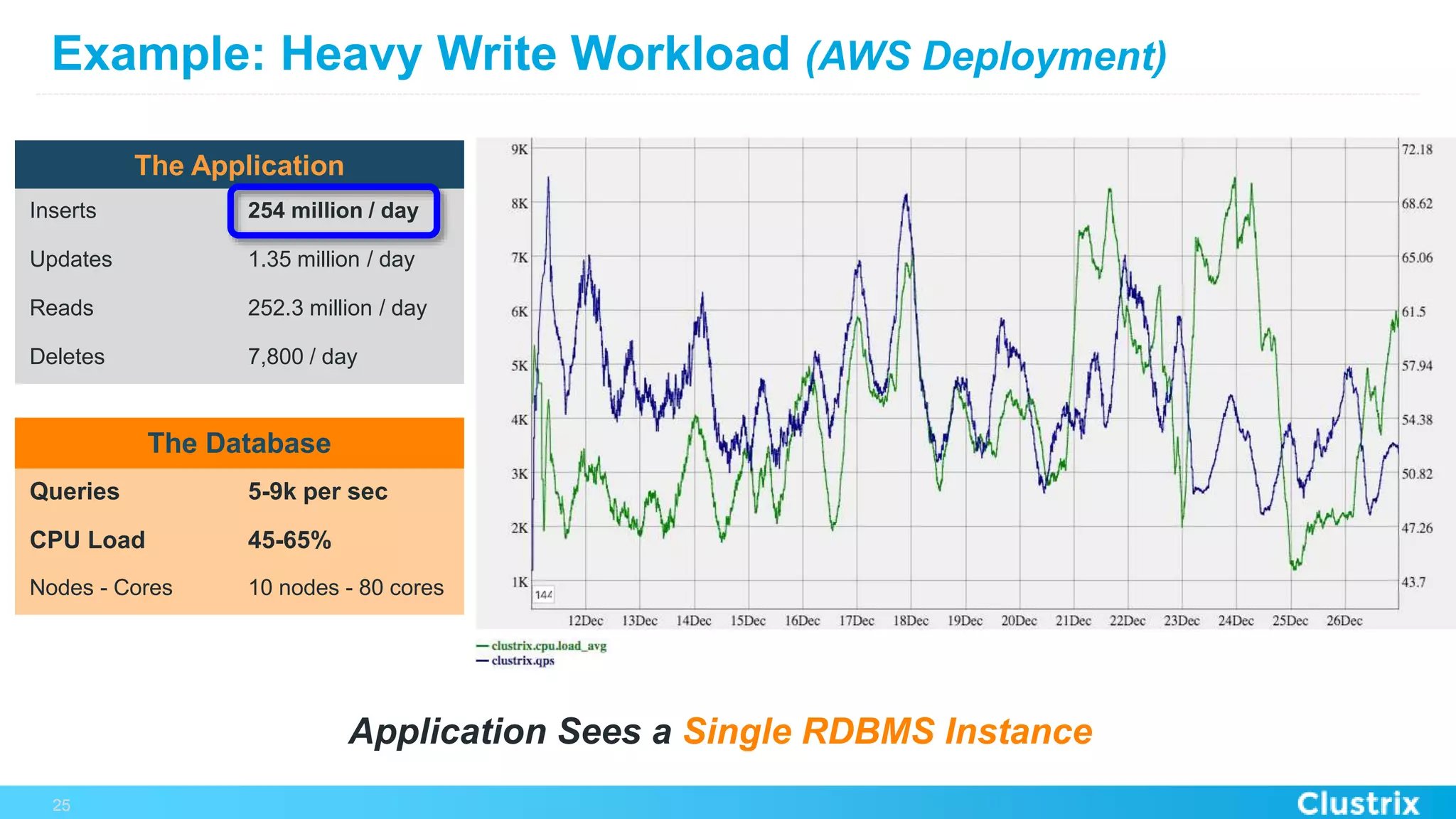
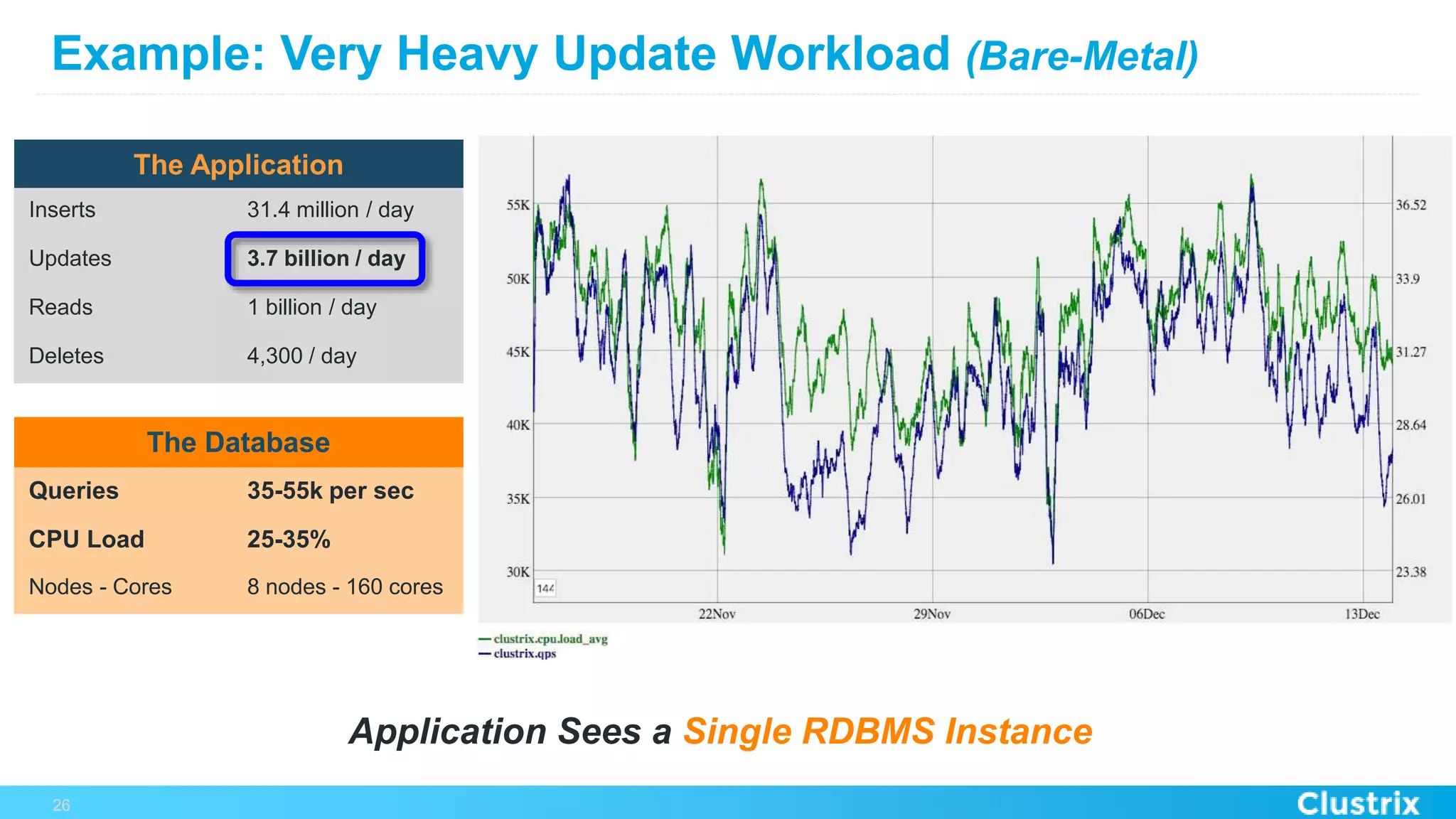

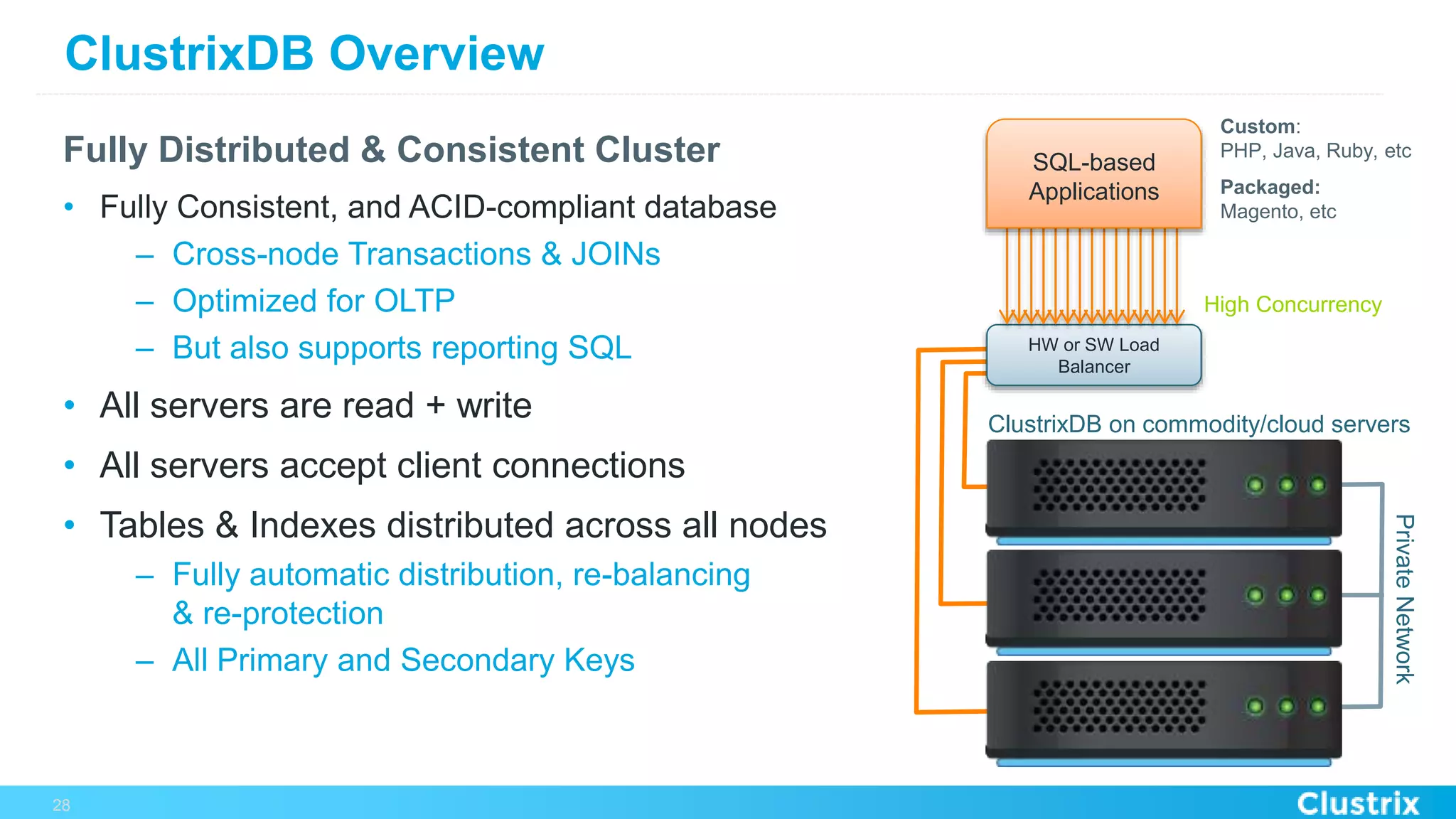
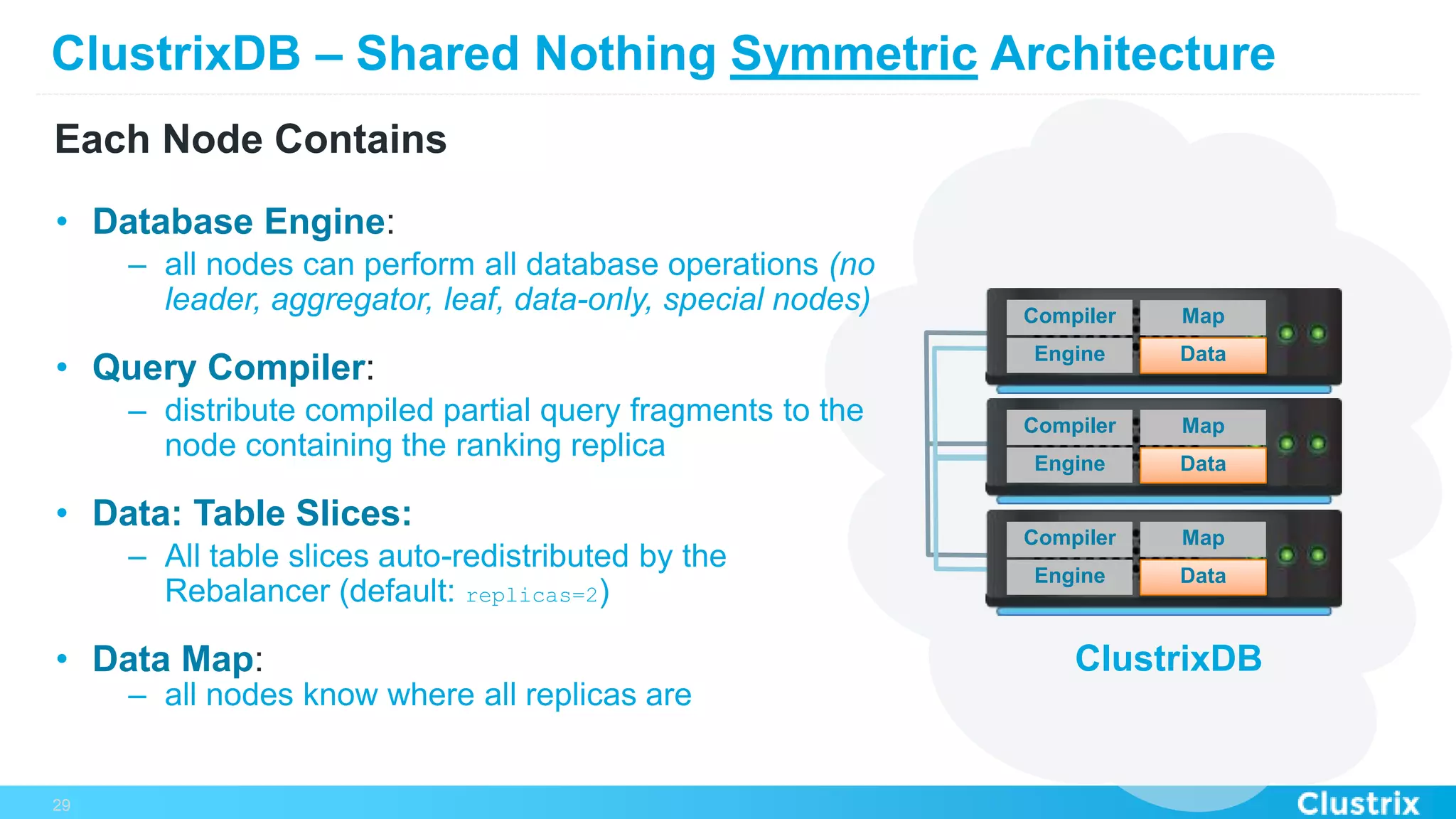
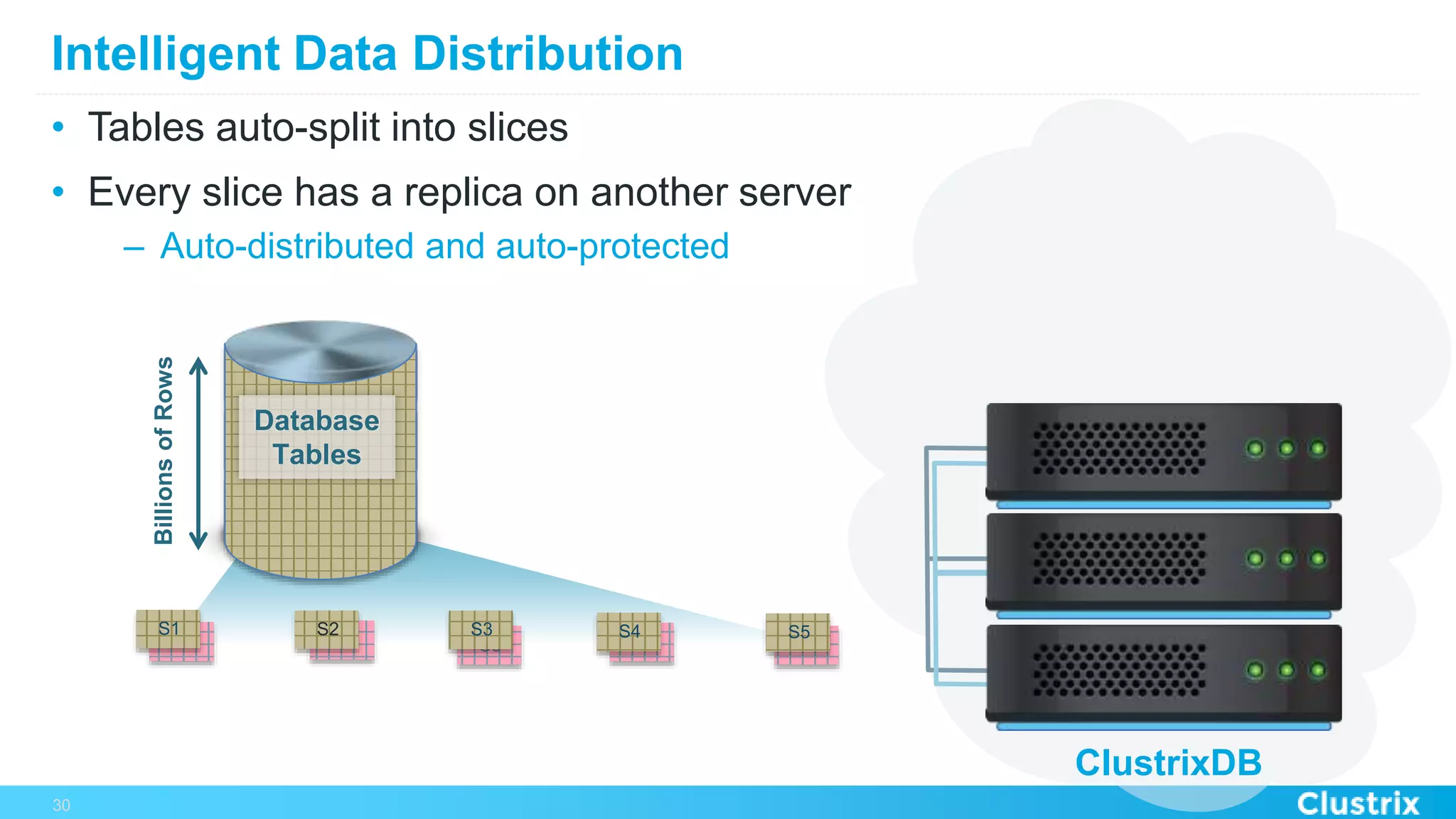
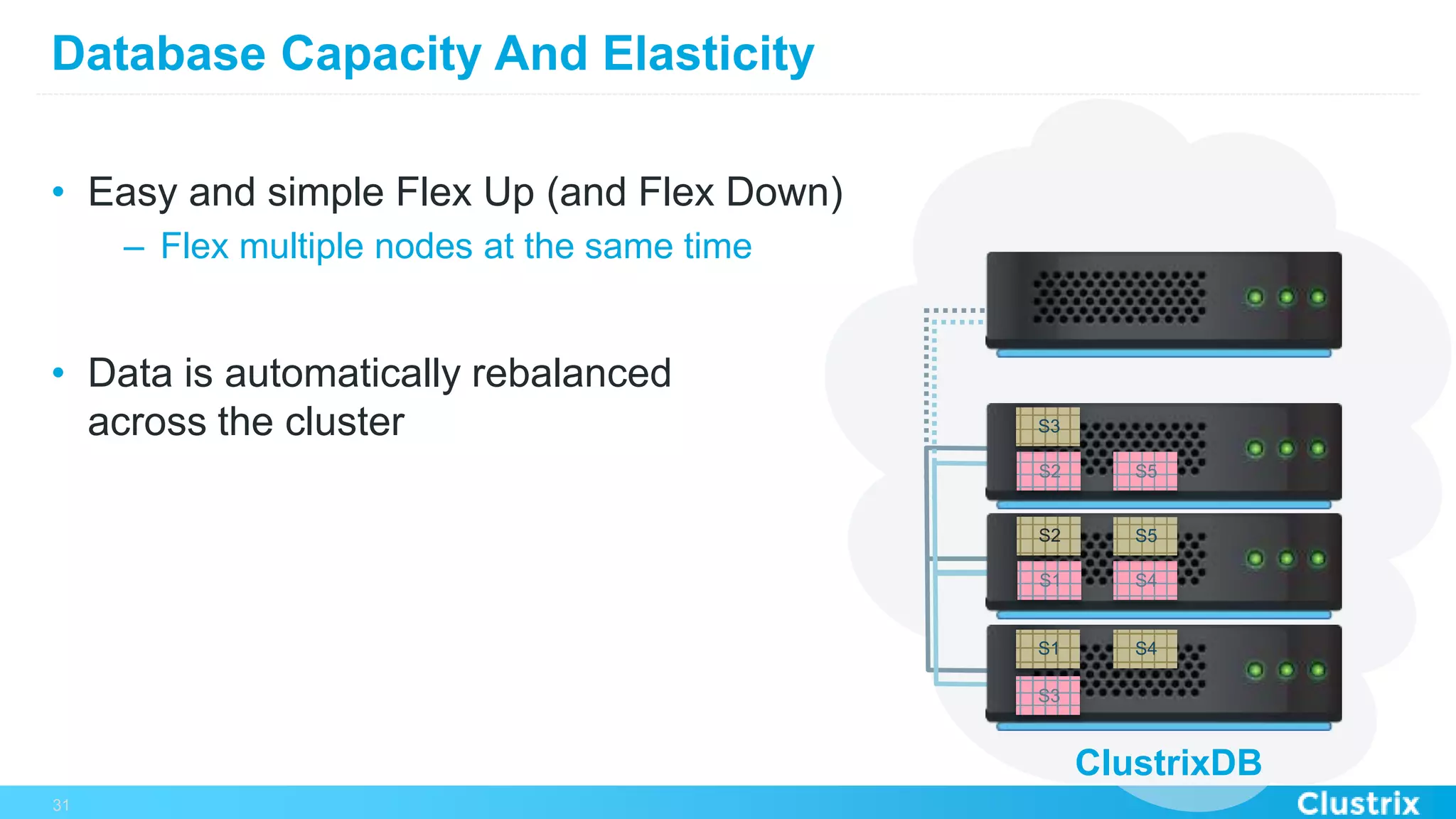
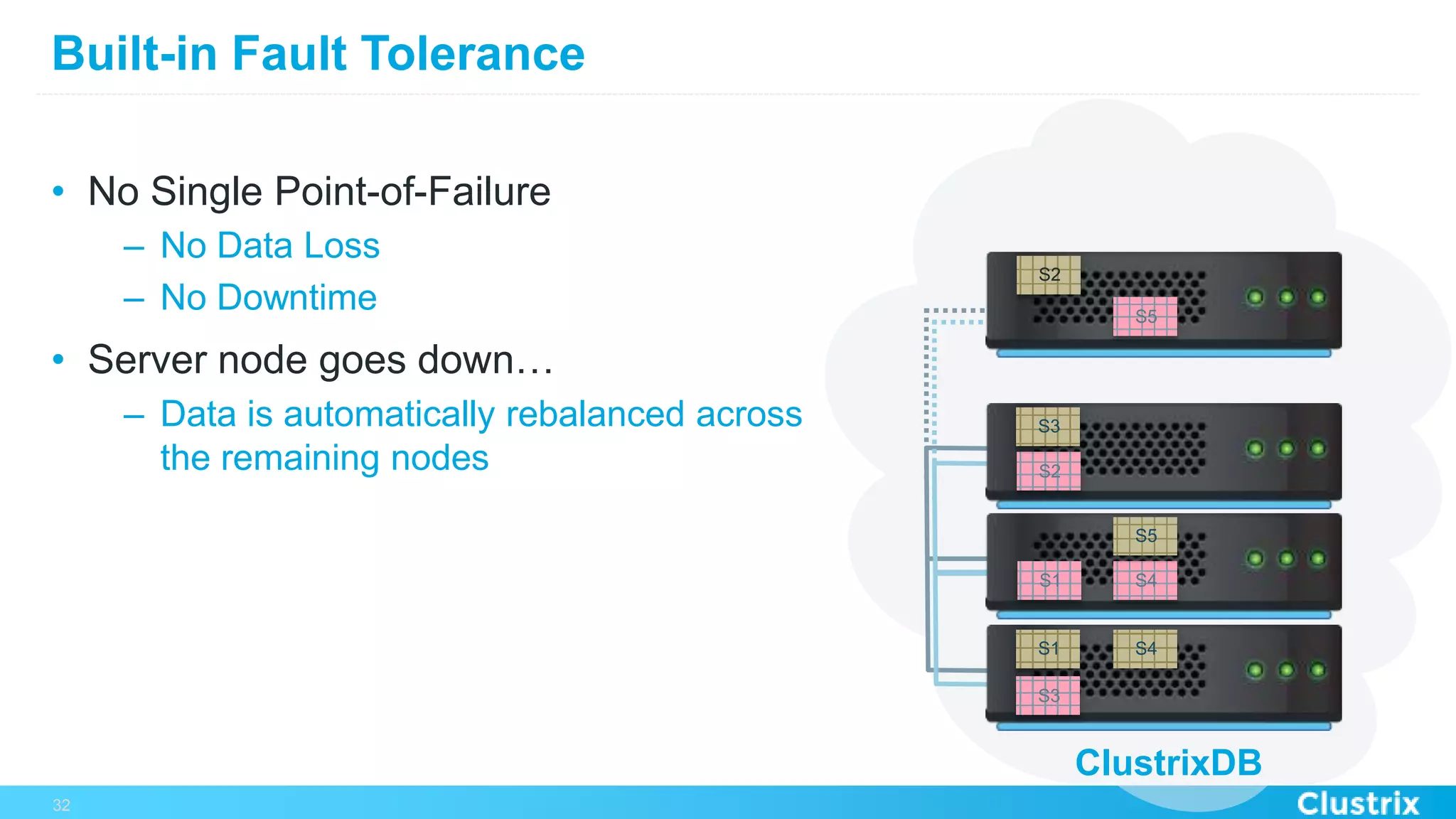
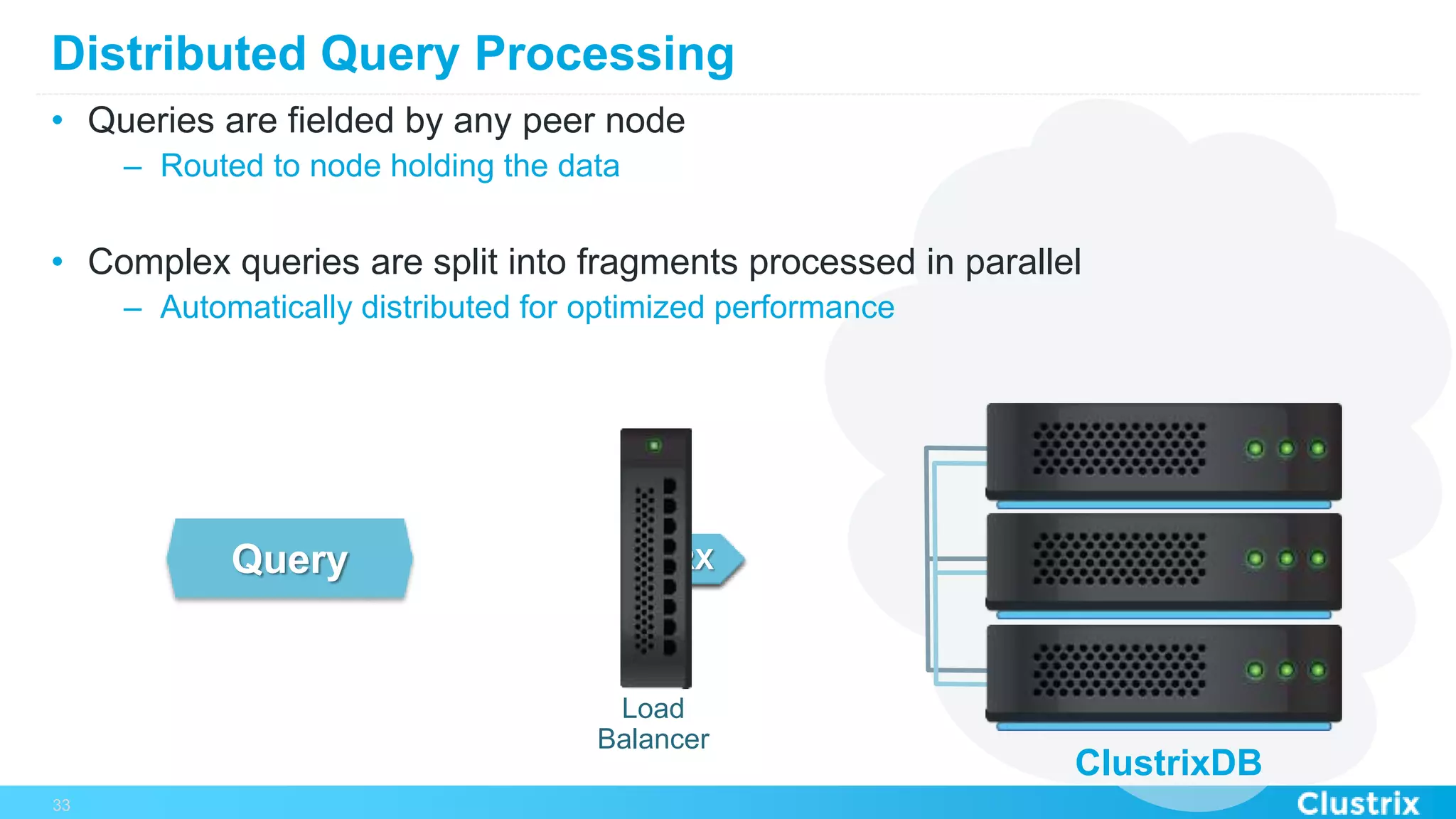

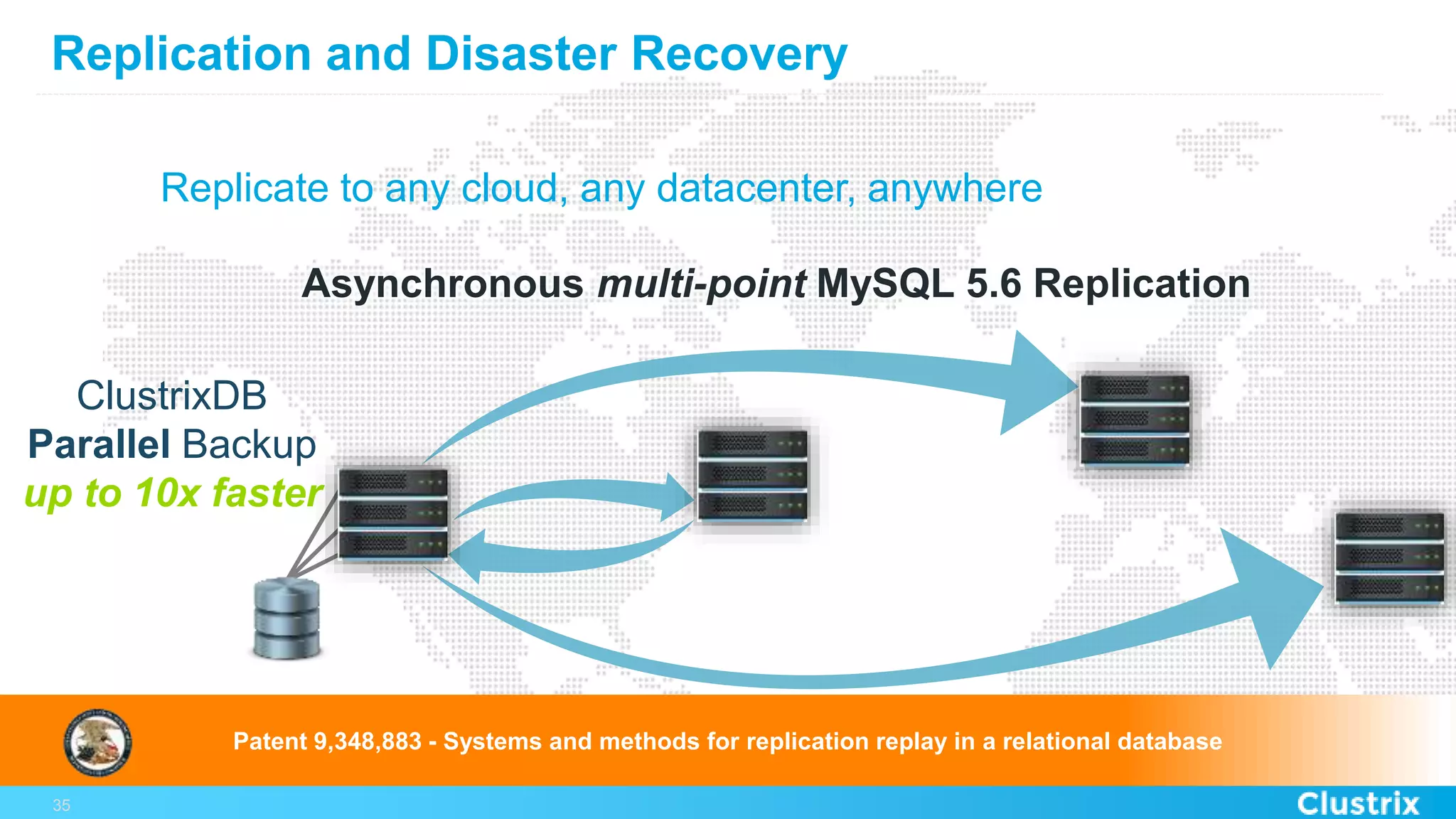





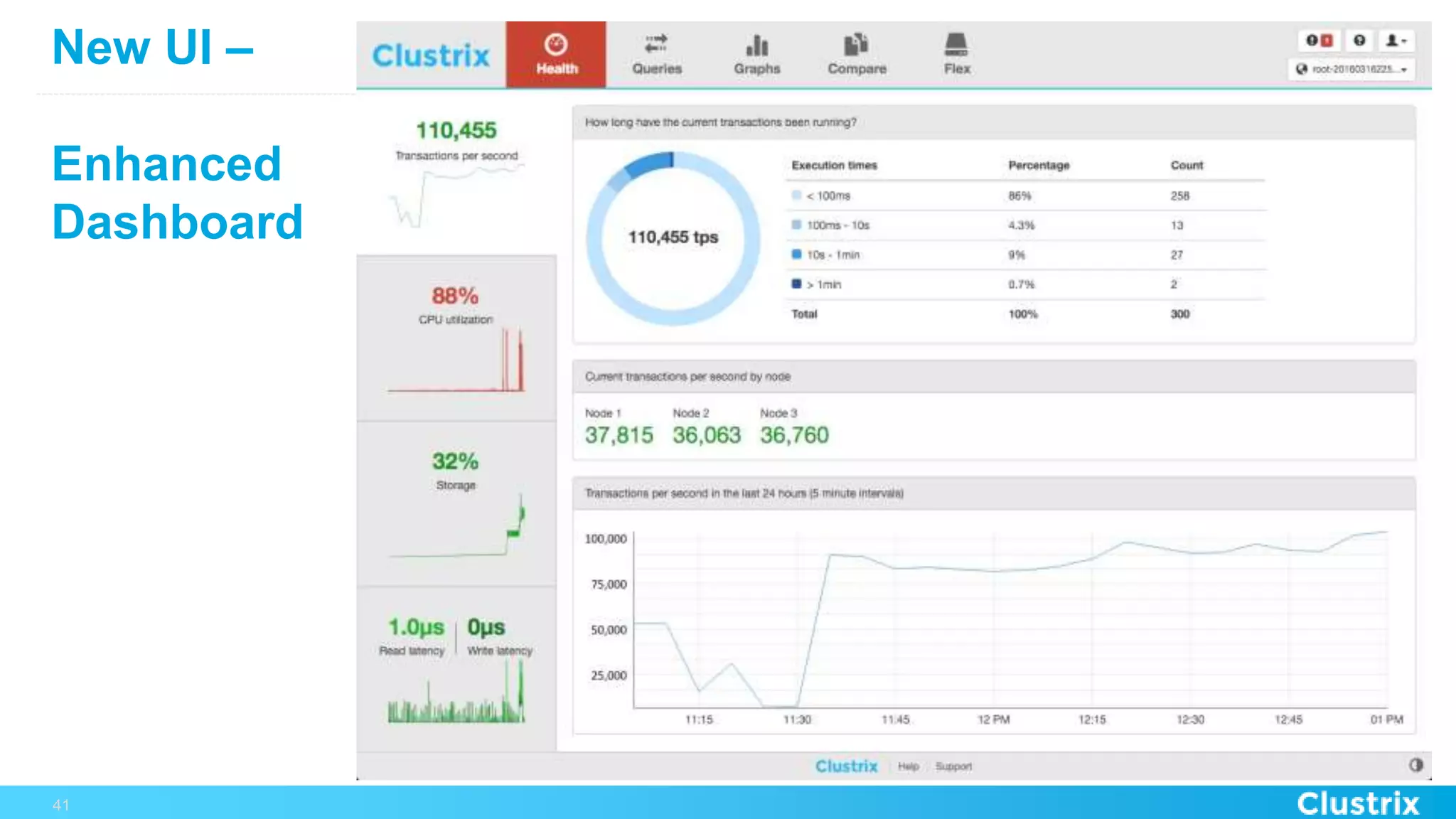
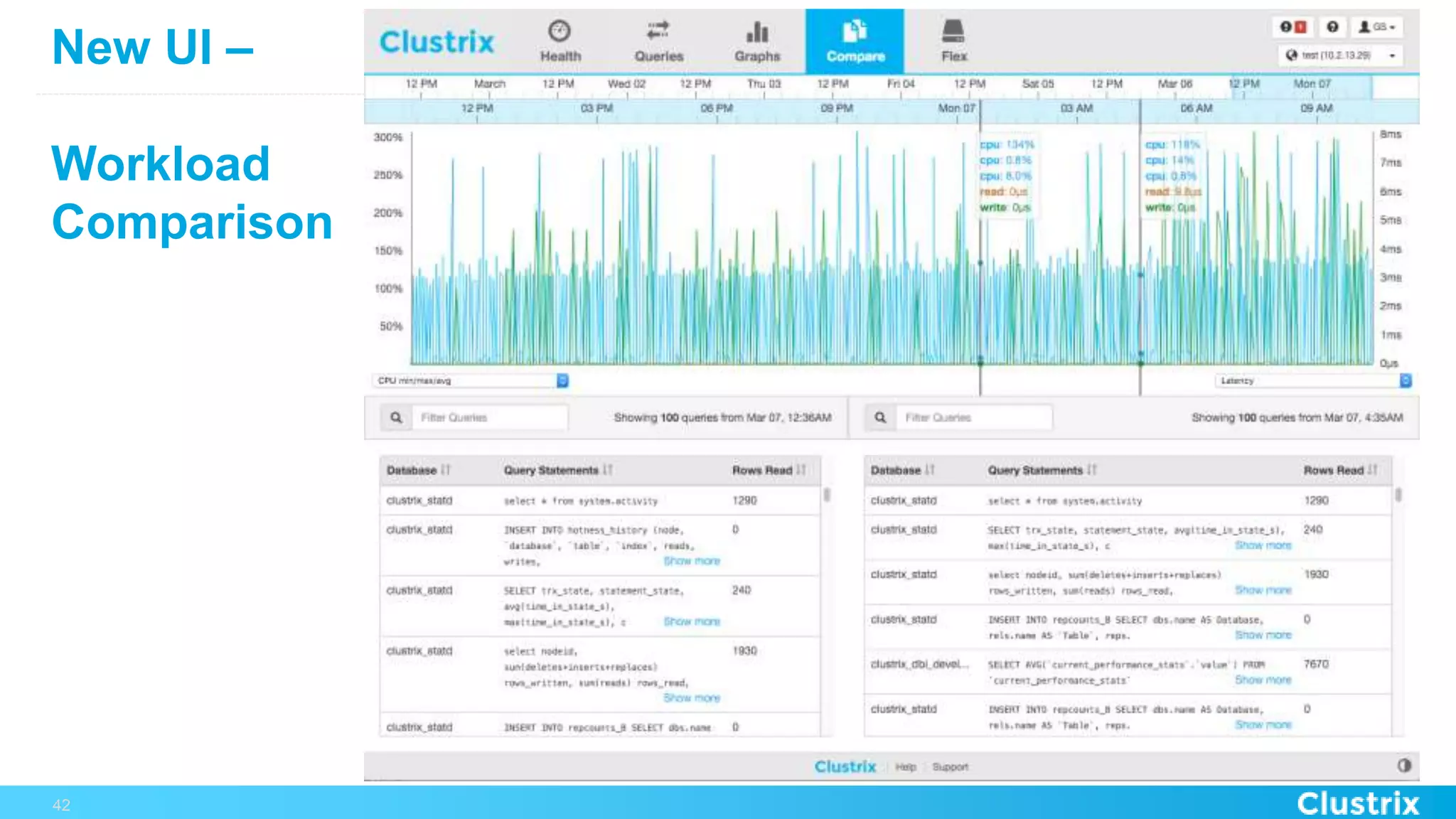

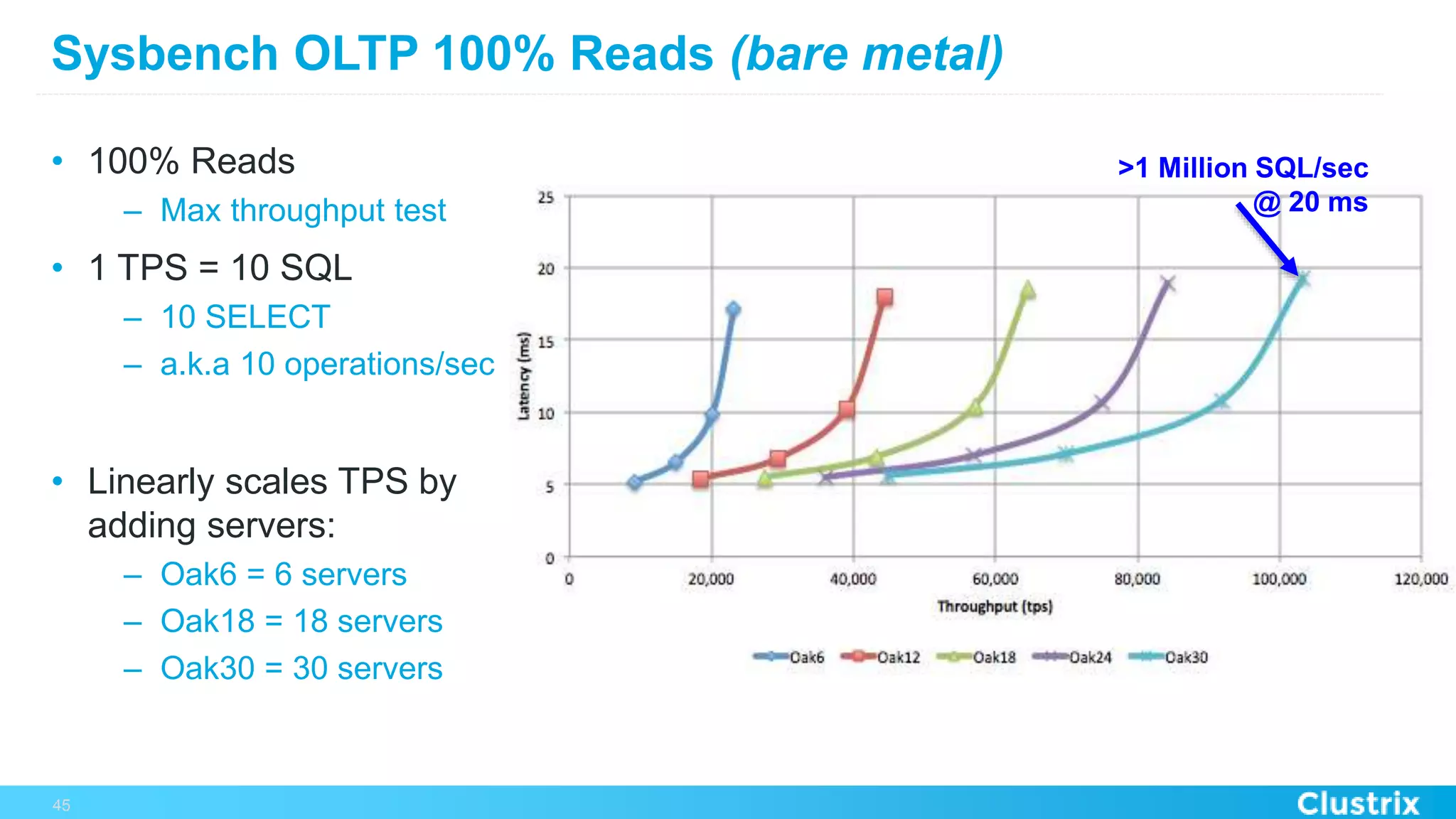
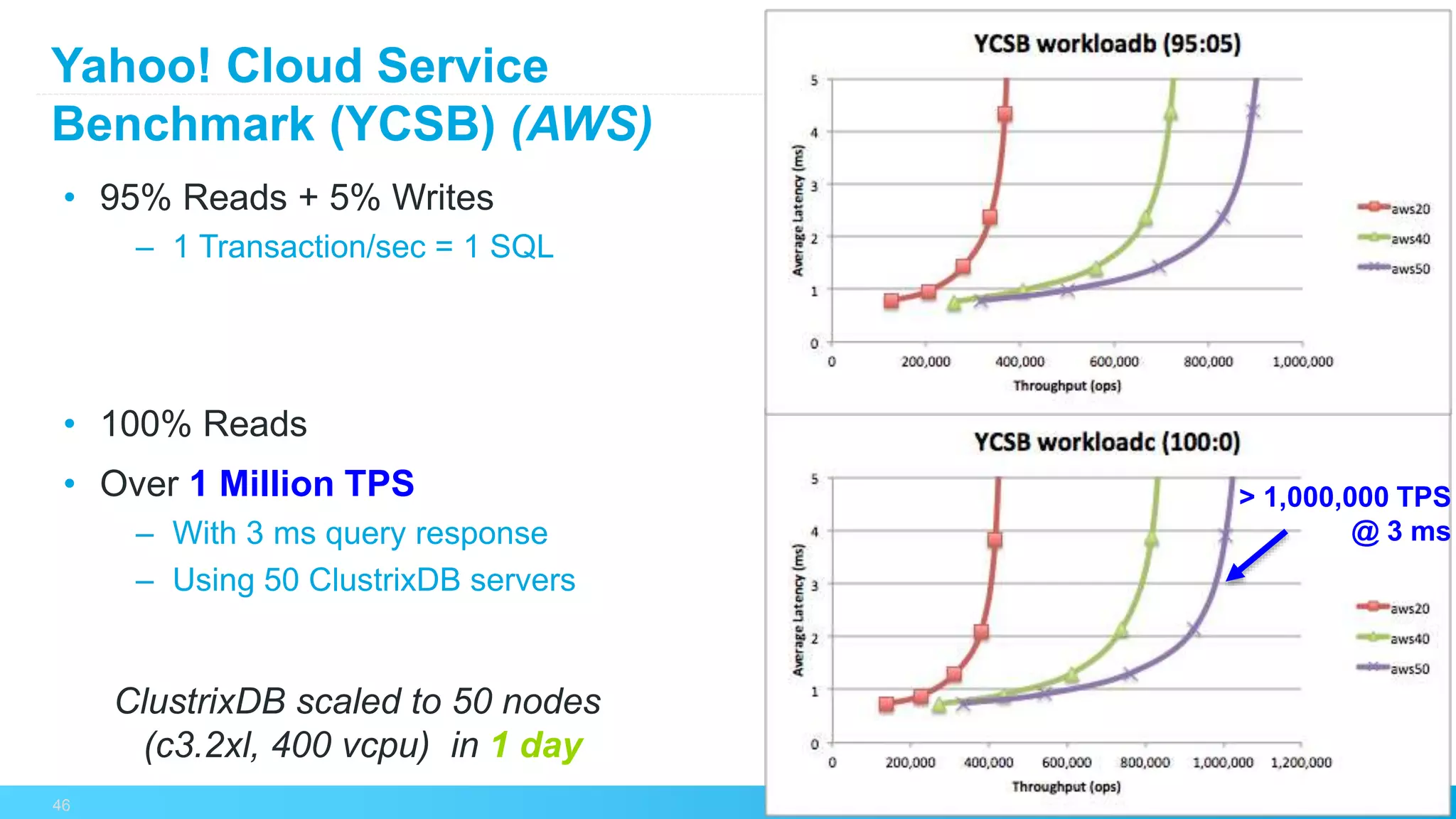





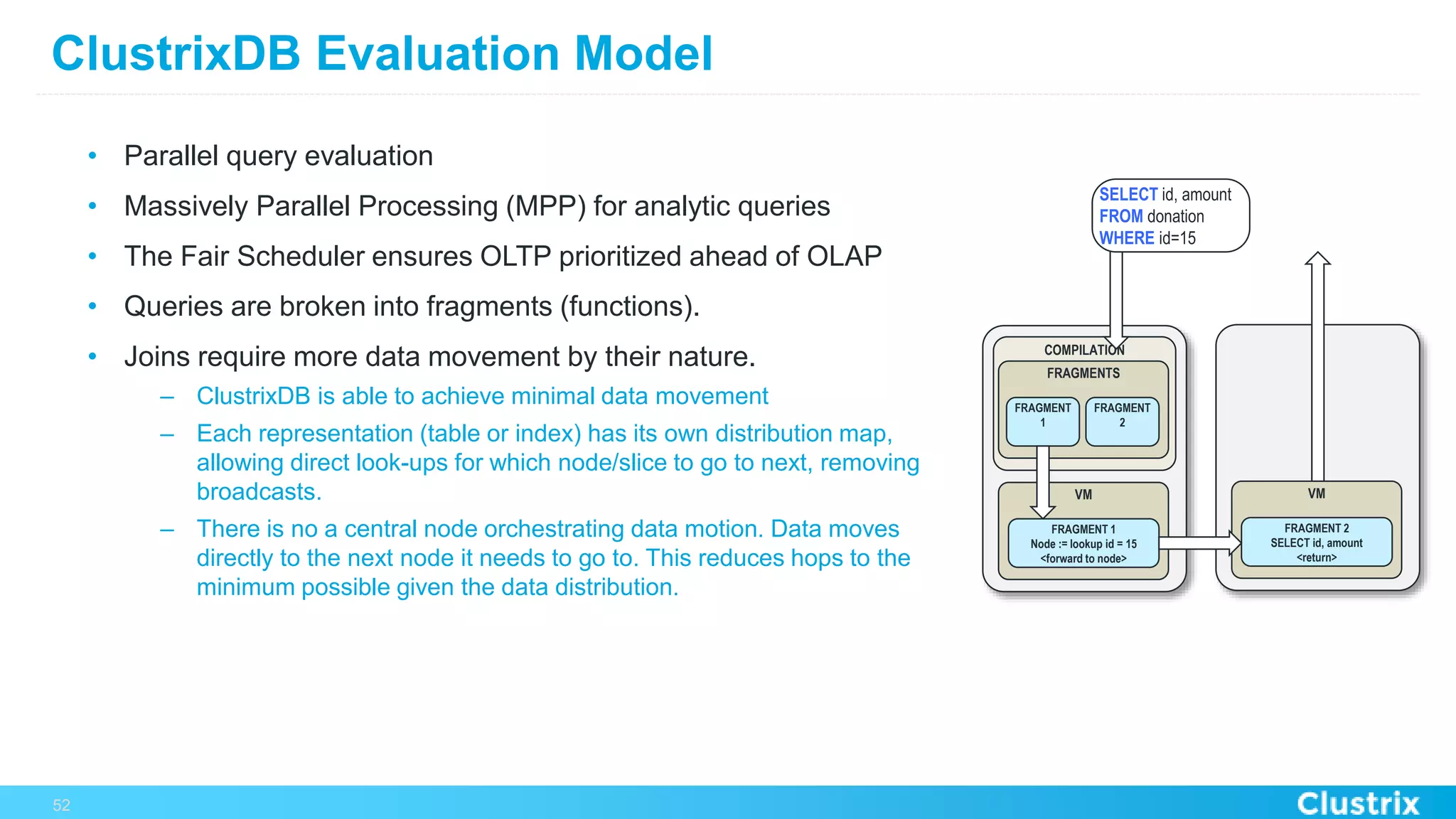
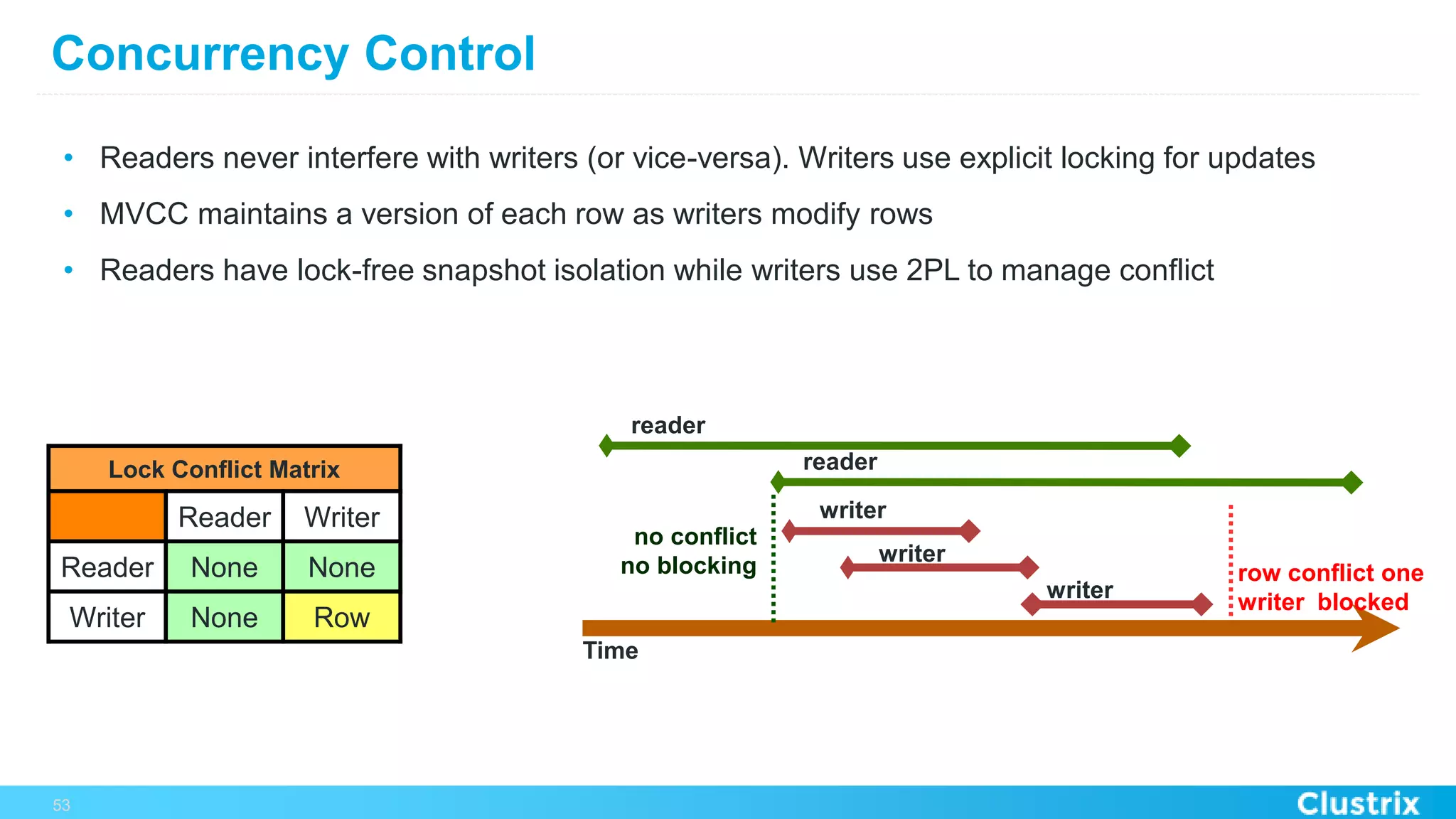
























































The document discusses the challenges and strategies for scaling relational database management systems (RDBMS) in cloud environments, particularly focusing on ClustrixDB as a solution. It outlines various scaling techniques such as scaling up, master/slave configurations, master/master setups, and different forms of sharding, each with their respective pros and cons. ClustrixDB is presented as a MySQL-compatible, fault-tolerant system designed for high transaction workloads with linear scalability, targeting both capacity and elasticity in cloud deployments.















































