Download to read offline

































![Sample Code
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO emp VALUES(?,?,?,?,?)");
for (int i = 0; i < 10; i++) {
pstmt.setInt(1, 300 + i);
pstmt.setString(2, "Something" + i);
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setInt(4, i);
pstmt.setLong(5, i);
pstmt.addBatch();
}
int[] result = pstmt.executeBatch();
• Is split key dynamic or static?
• Each command is added to the correct DB,
execution is on all relevant DBs
• No Code Change](https://image.slidesharecdn.com/dataslainthecloud-100921143705-phpapp02/75/Scaling-data-on-public-clouds-41-2048.jpg)















































![Sample Code
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO emp VALUES(?,?,?,?,?)");
for (int i = 0; i < 10; i++) {
pstmt.setInt(1, 300 + i);
pstmt.setString(2, "Something" + i);
pstmt.setDate(3, new Date(System.currentTimeMillis()));
pstmt.setInt(4, i);
pstmt.setLong(5, i);
pstmt.addBatch();
}
int[] result = pstmt.executeBatch();
• Is split key dynamic or static?
• Each command is added to the correct DB,
execution is on all relevant DBs
• No Code Change](https://crownmelresort.com/image.slidesharecdn.com/dataslainthecloud-100921143705-phpapp02/75/Scaling-data-on-public-clouds-41-2048.jpg)








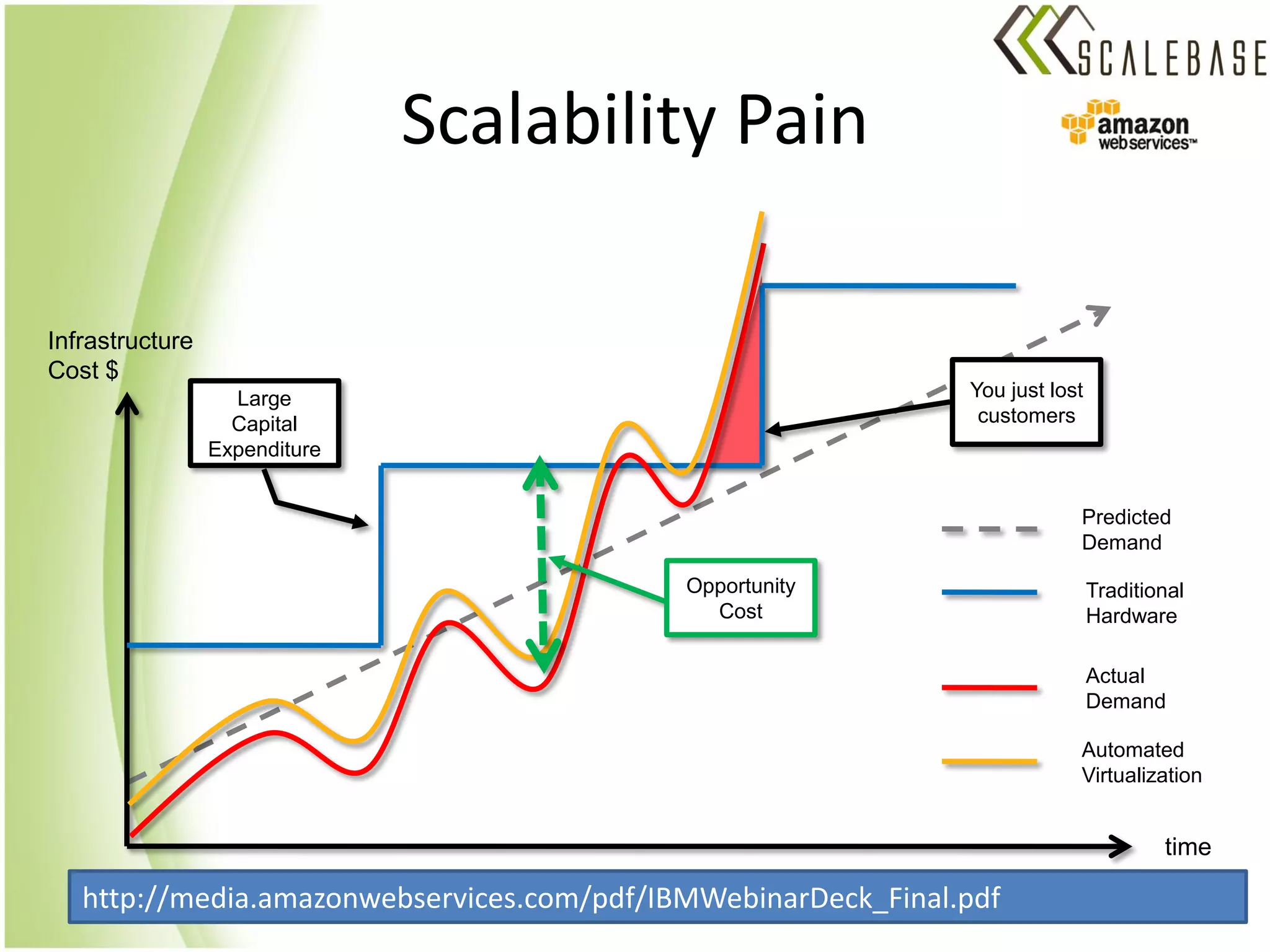
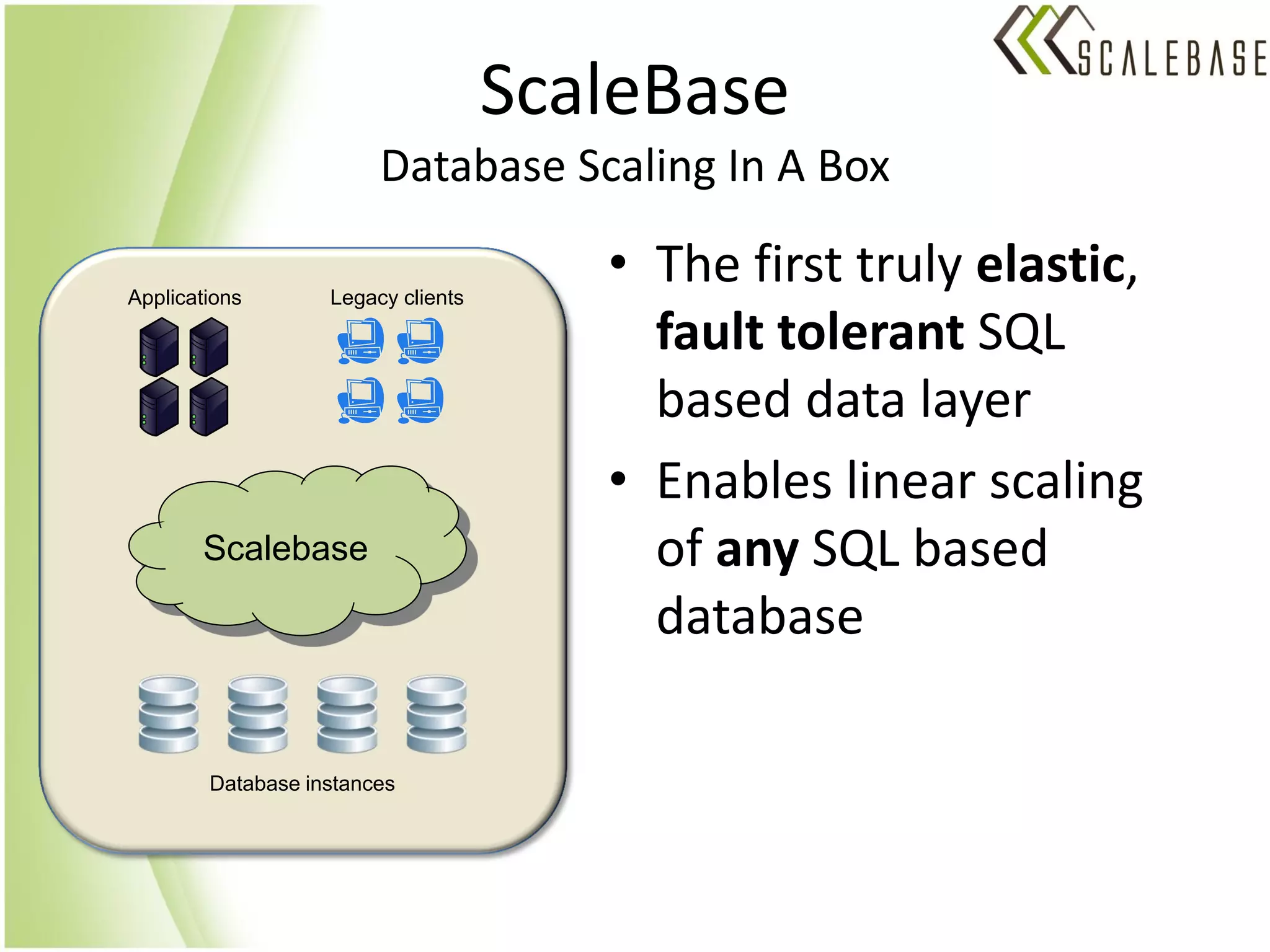
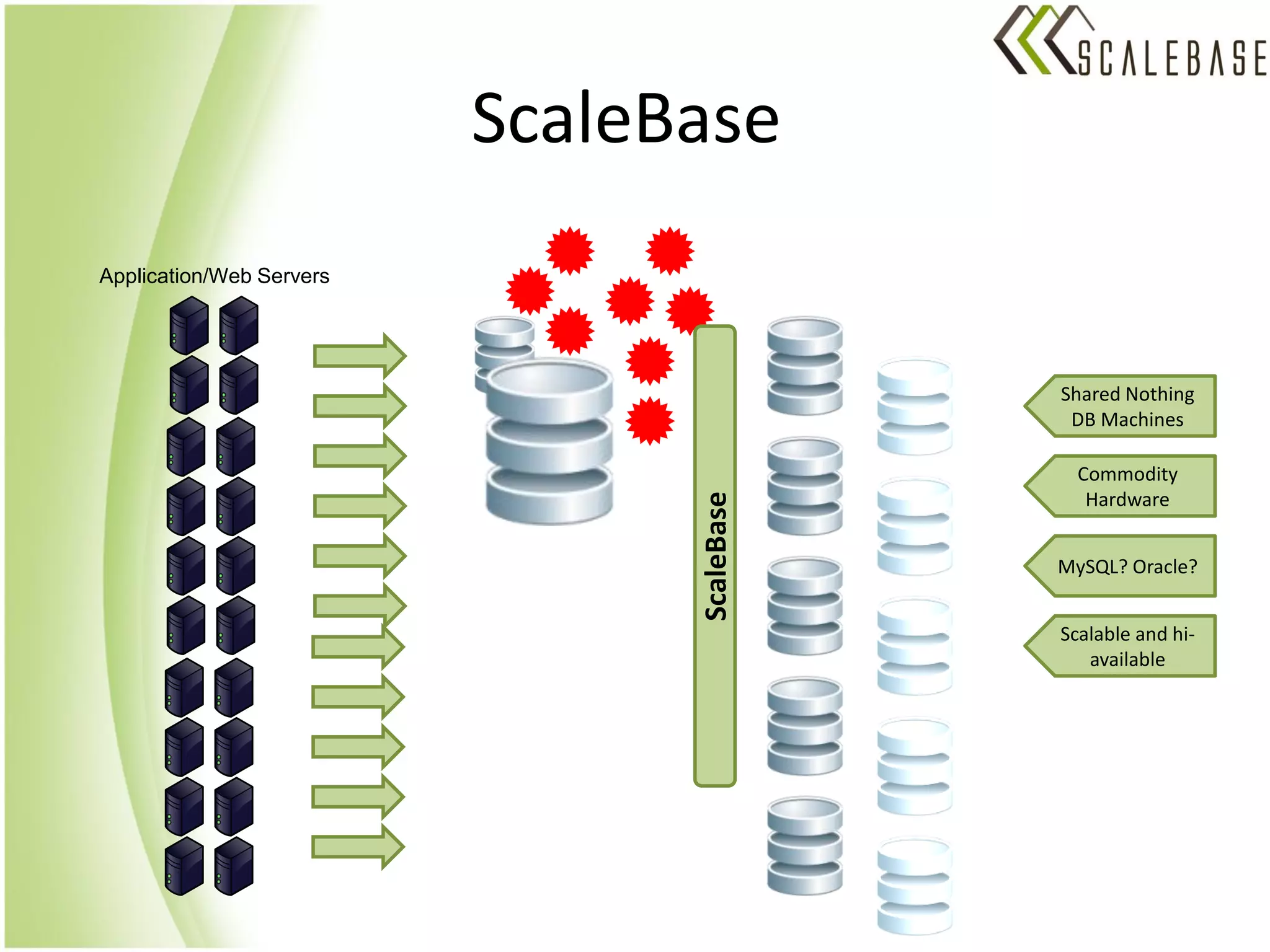
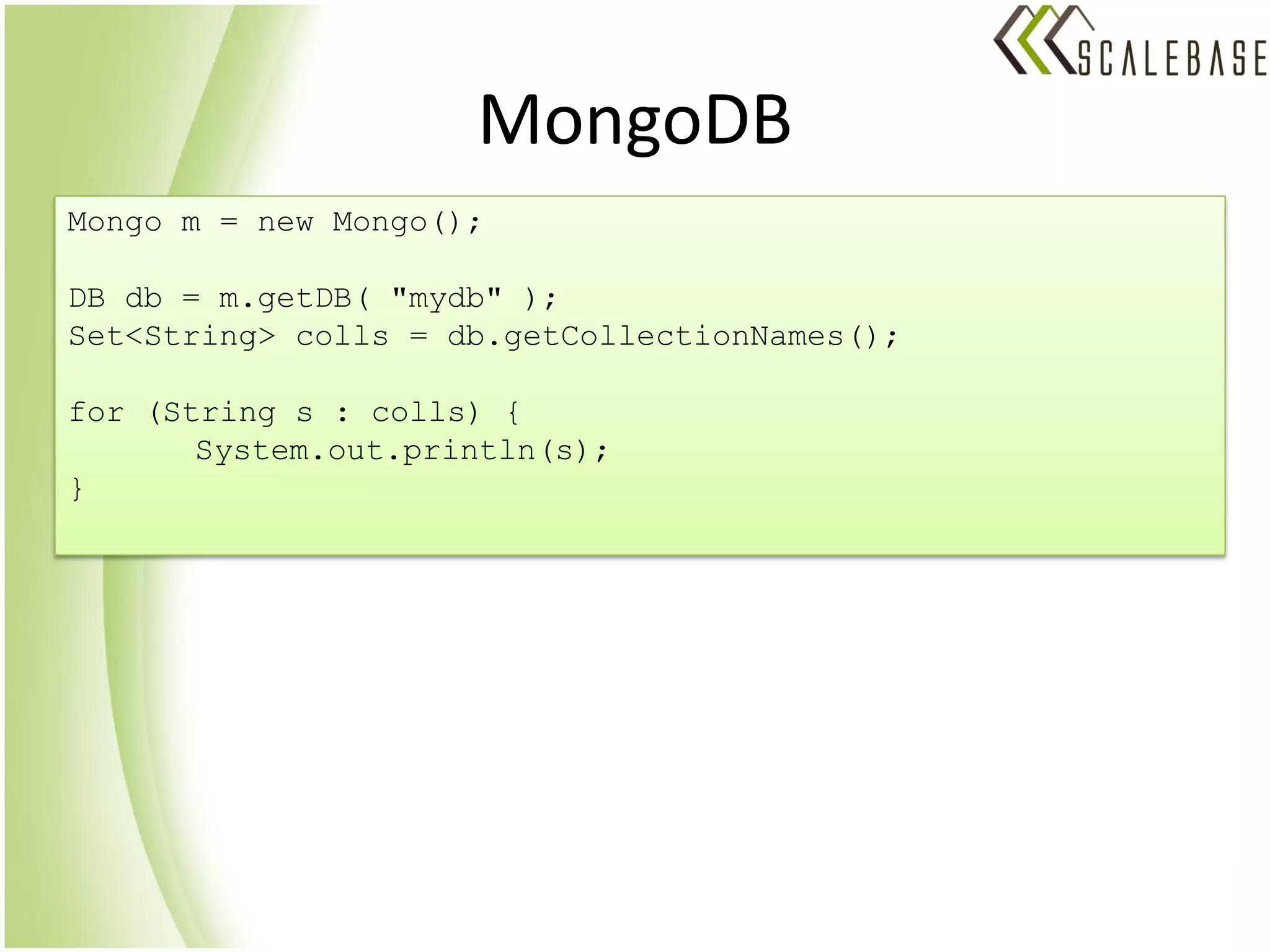
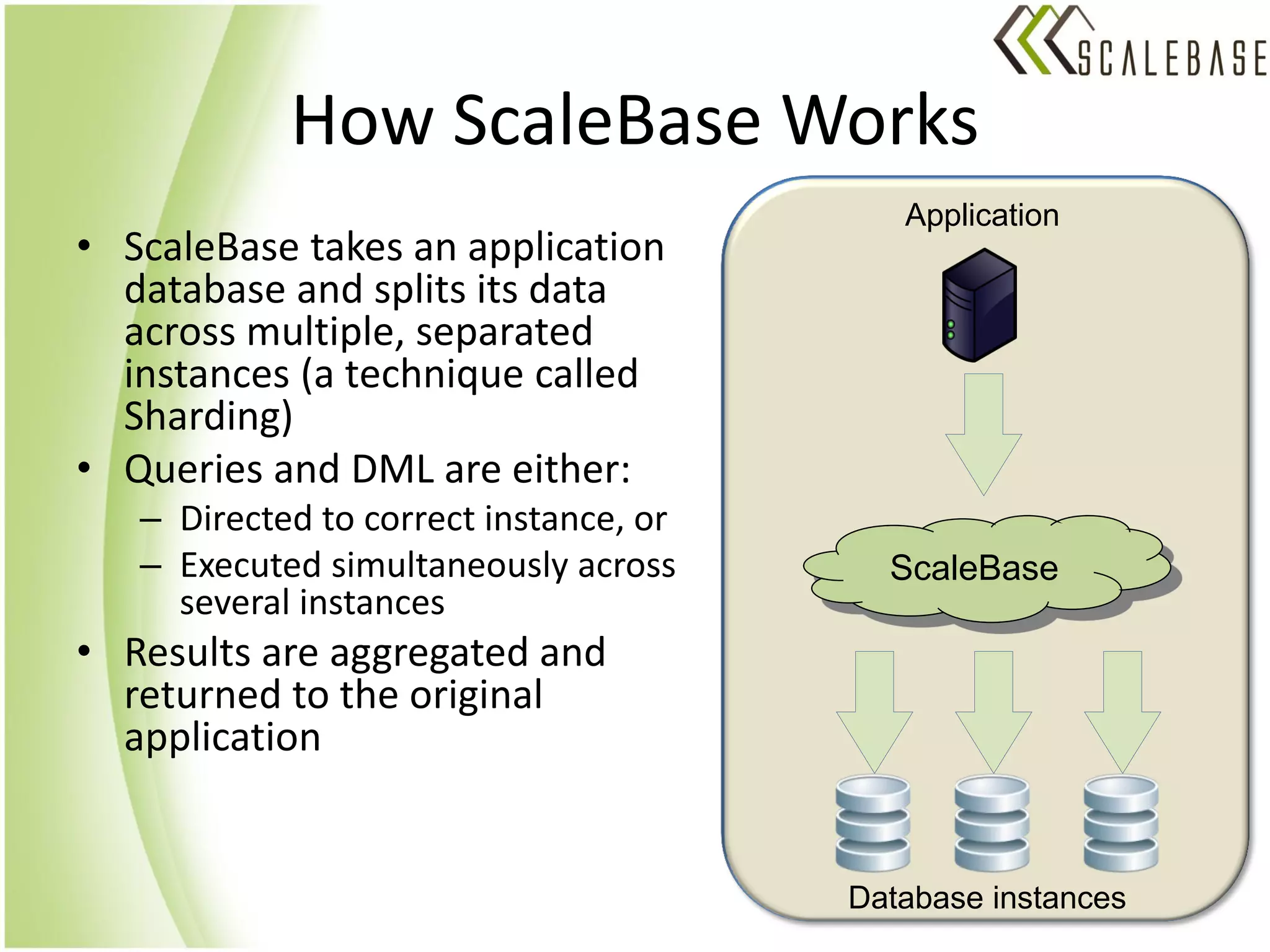
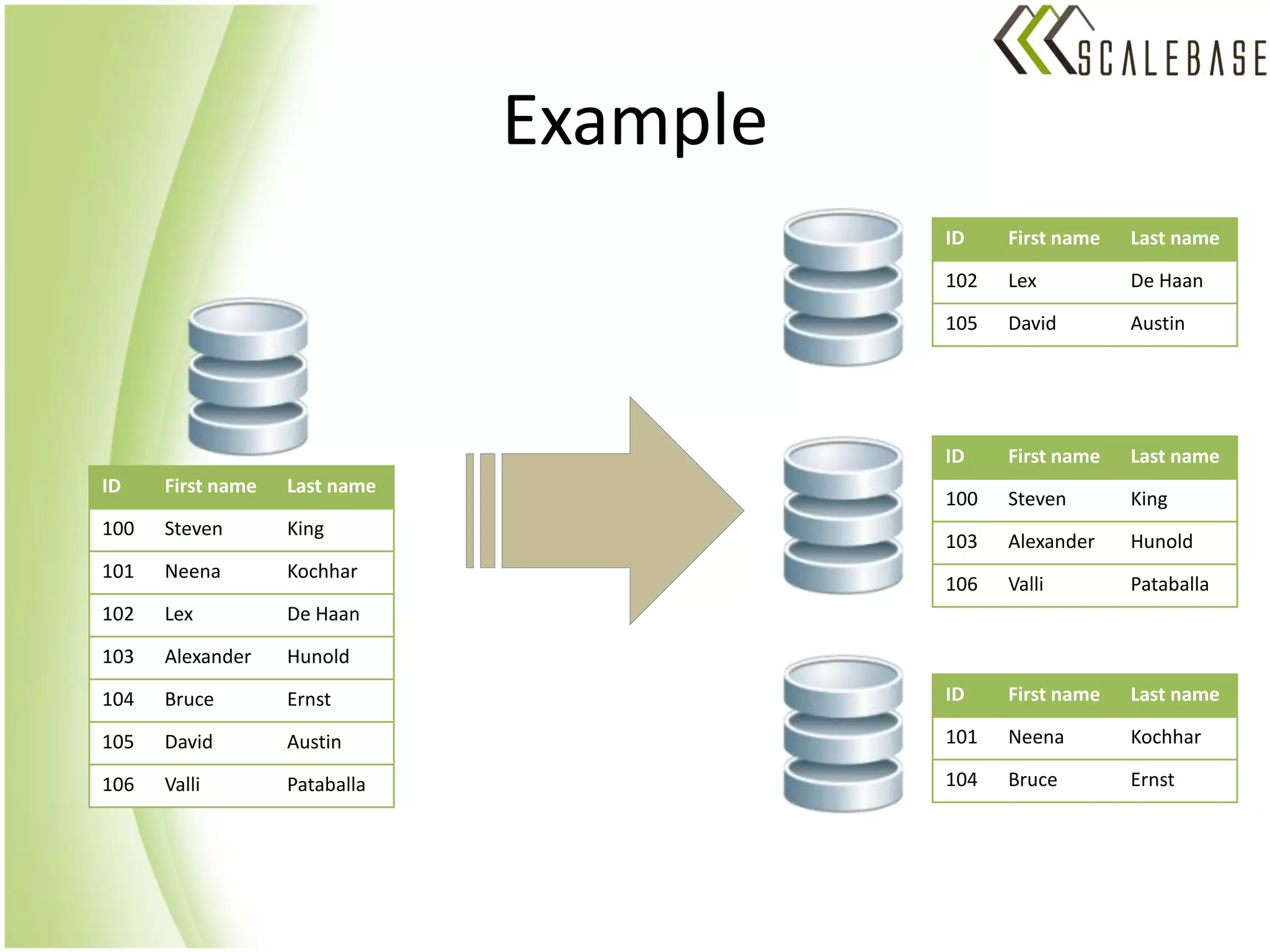
ScaleBase is a startup offering a database-as-a-service that provides unlimited database scalability and availability. It uses a Database Load Balancer to elastically scale any SQL database across multiple database instances in a shared-nothing architecture. This allows linear scaling of the database to meet increasing user demands and volumes of data while maintaining high availability.



































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)






