Downloaded 366 times






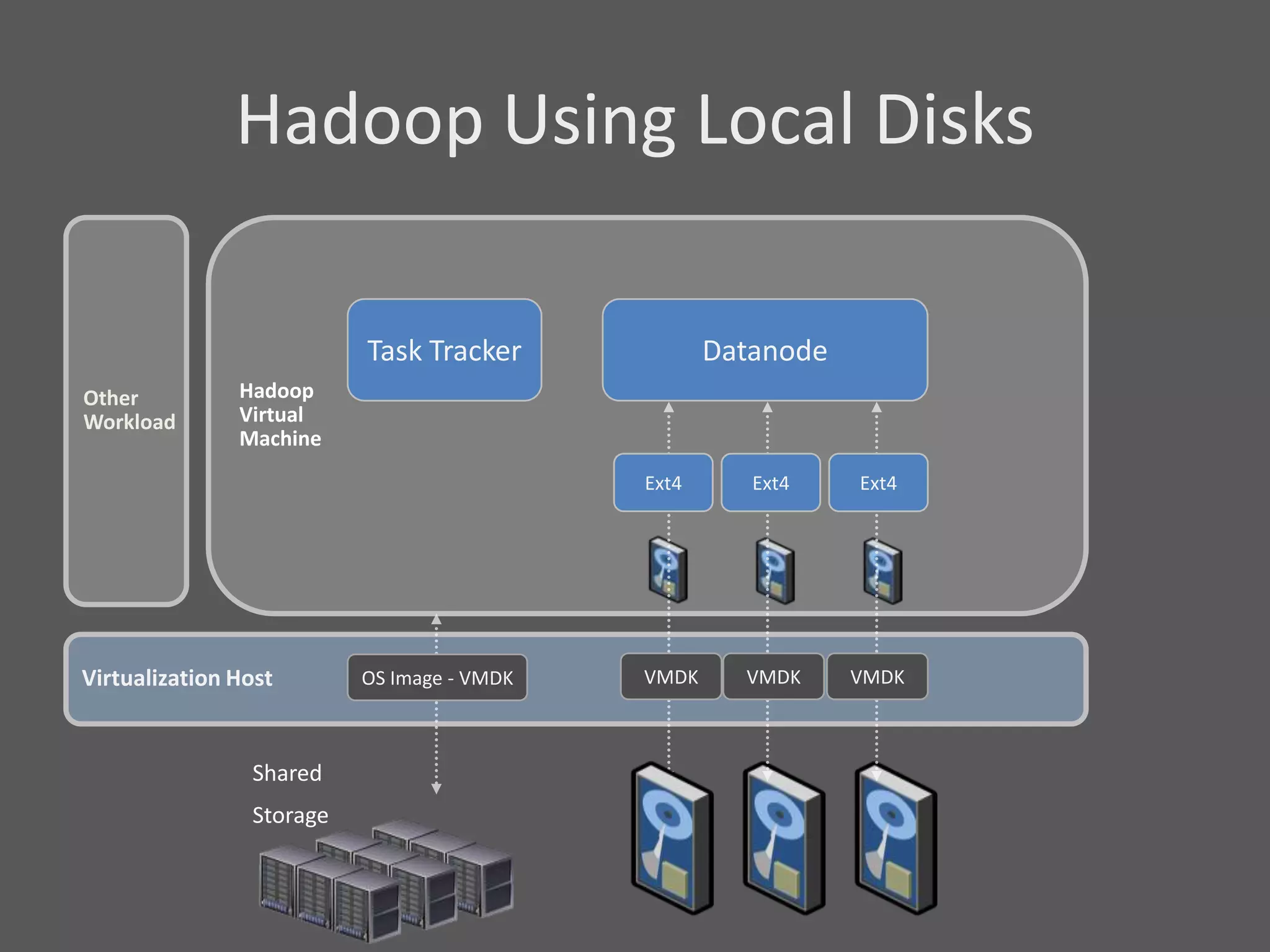
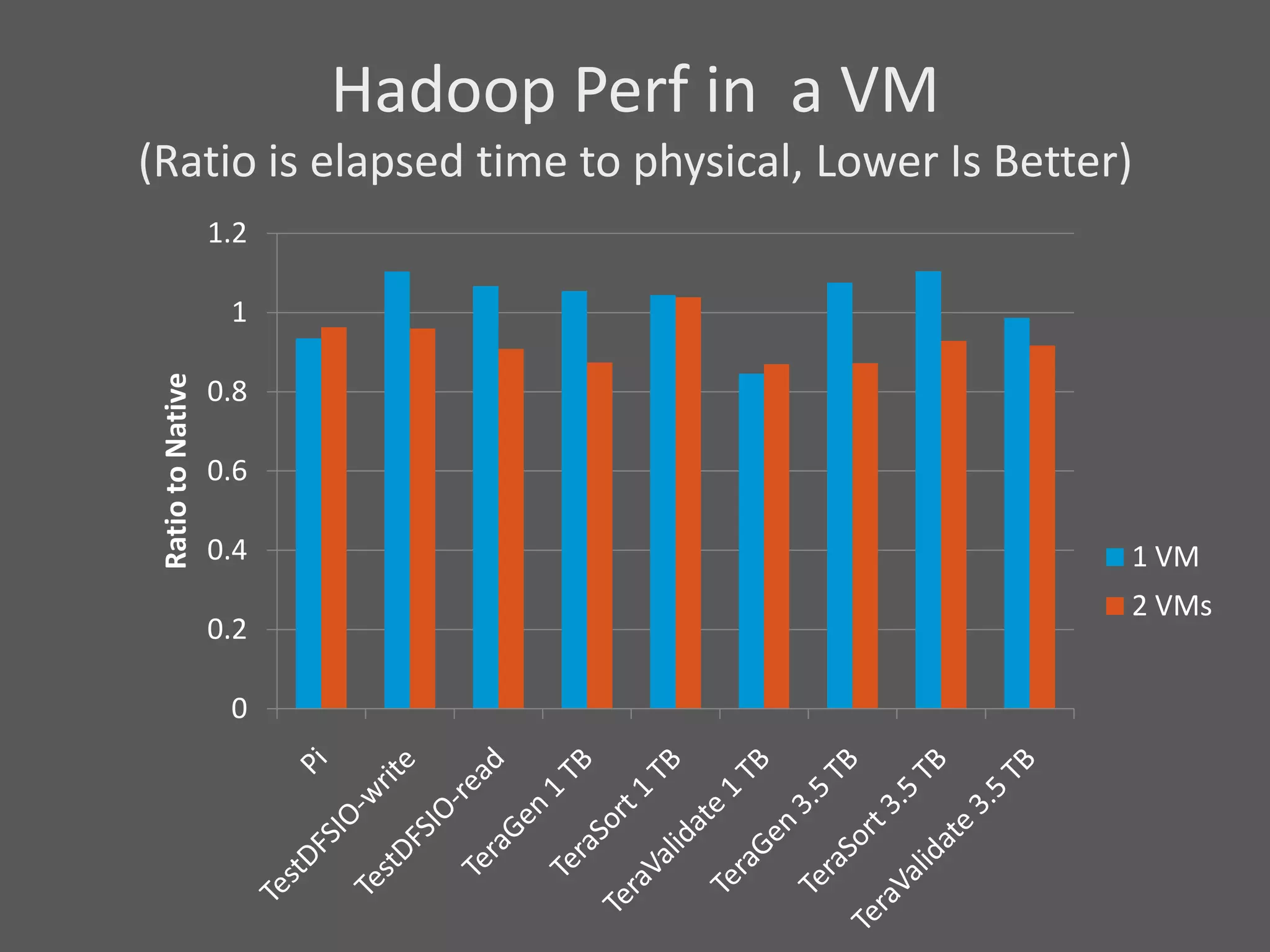
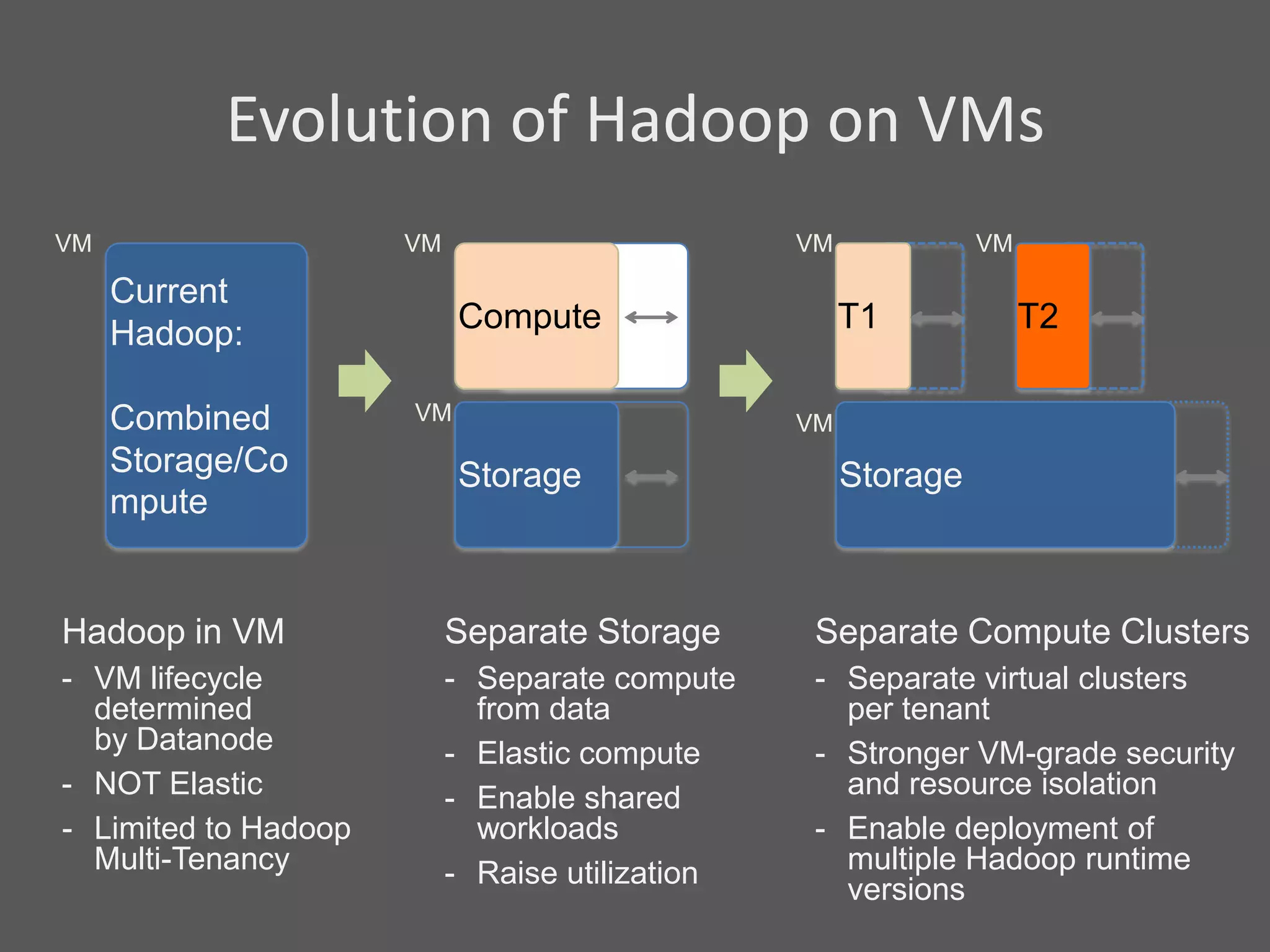
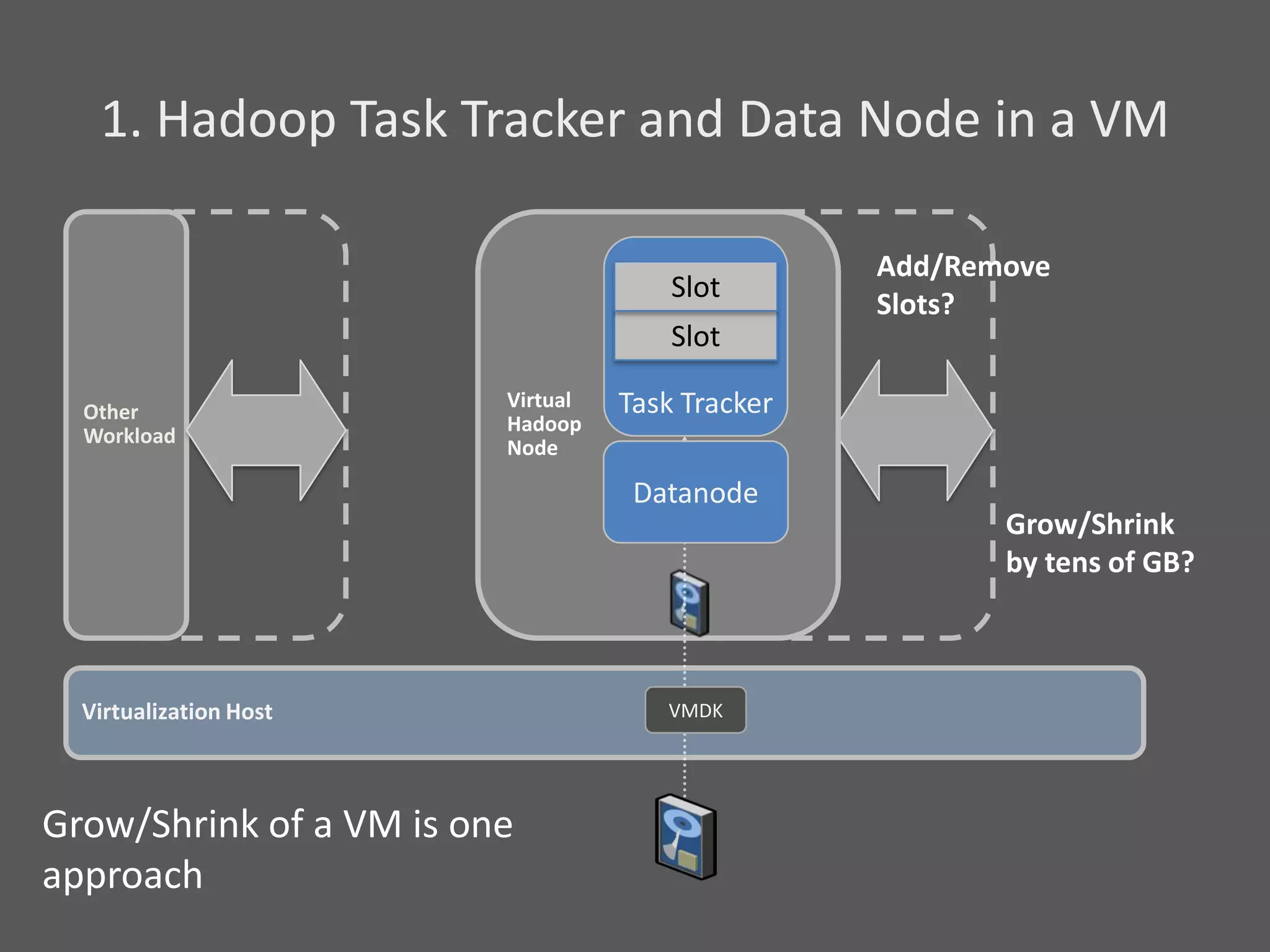
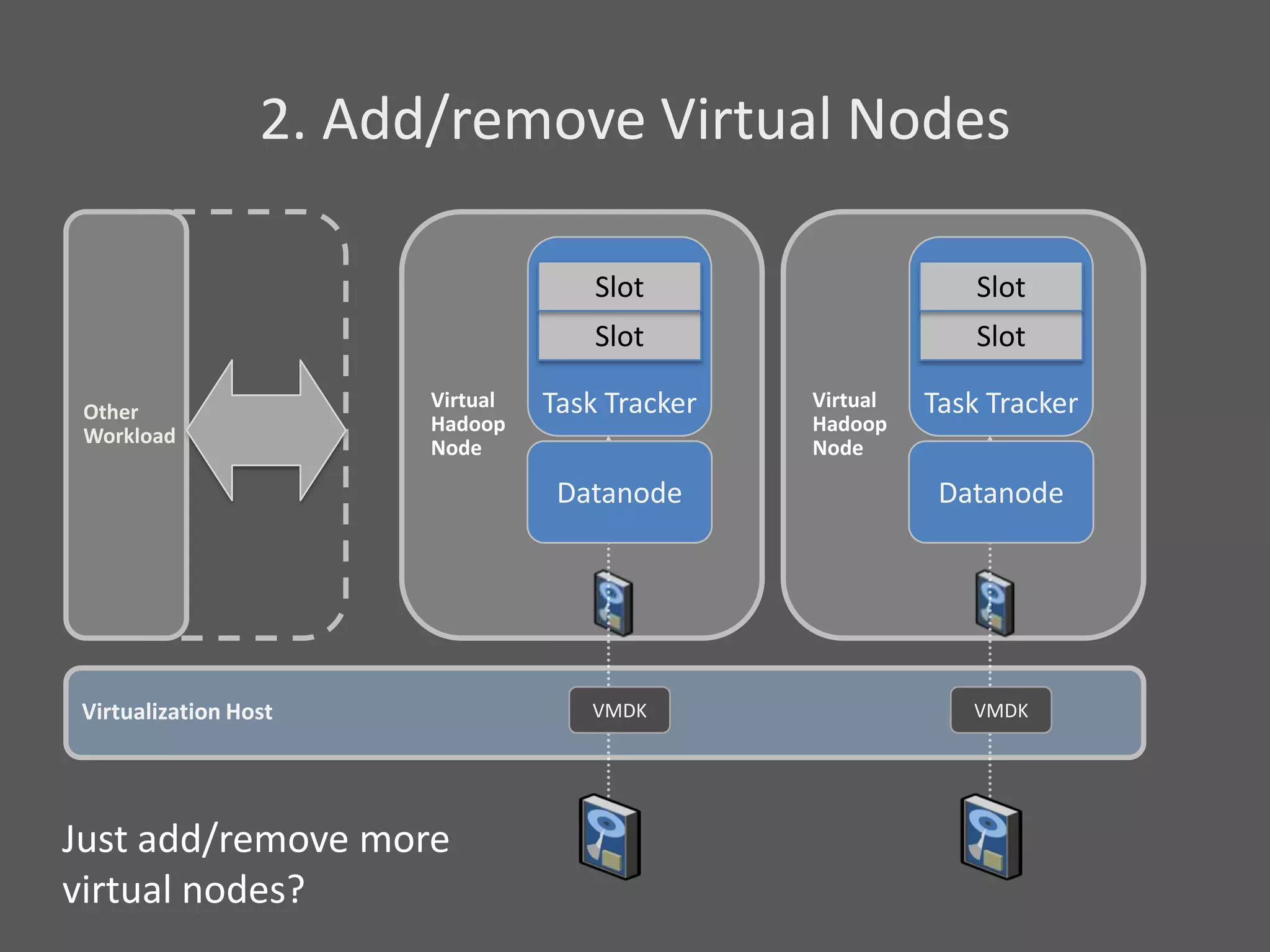
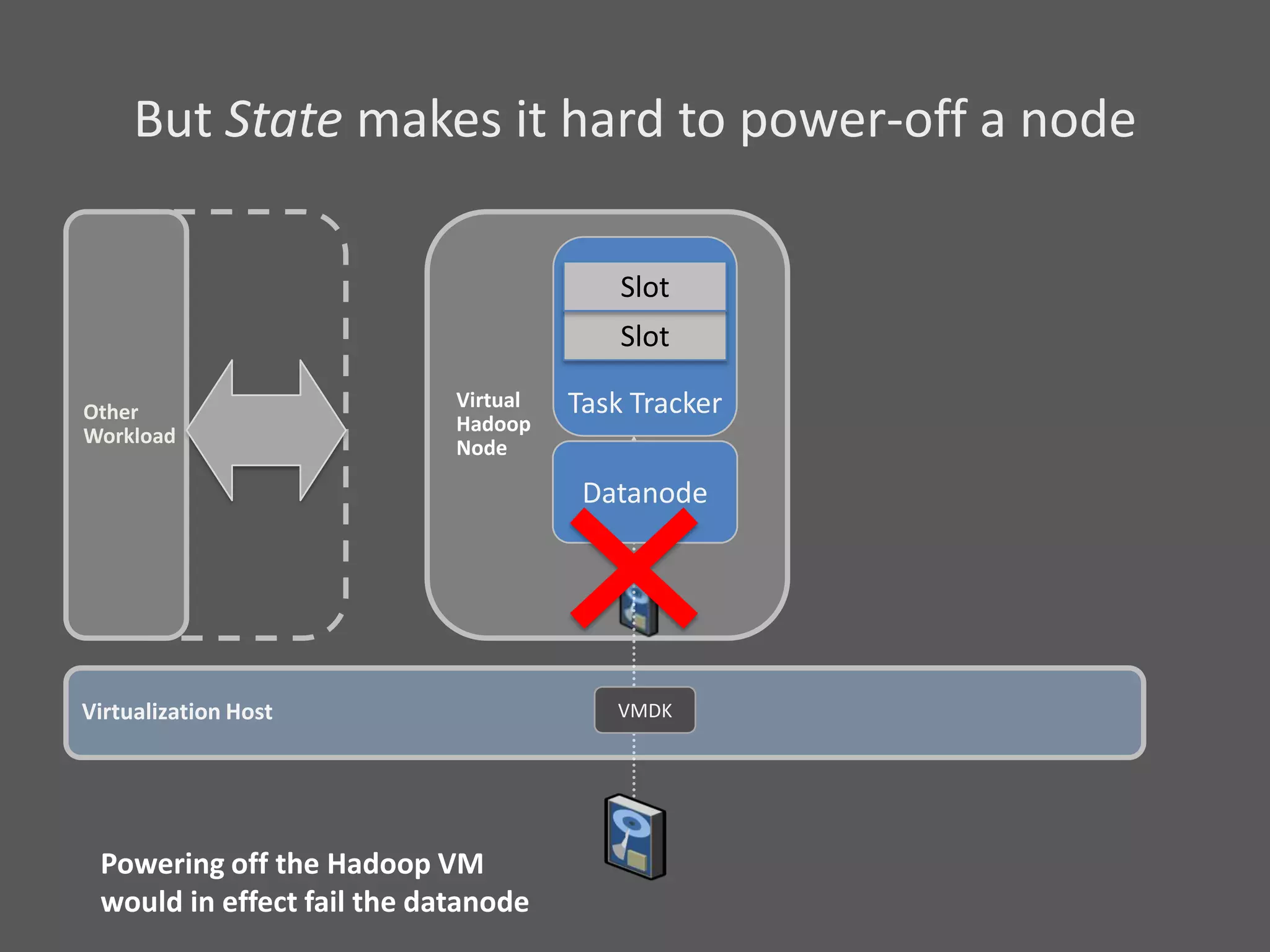
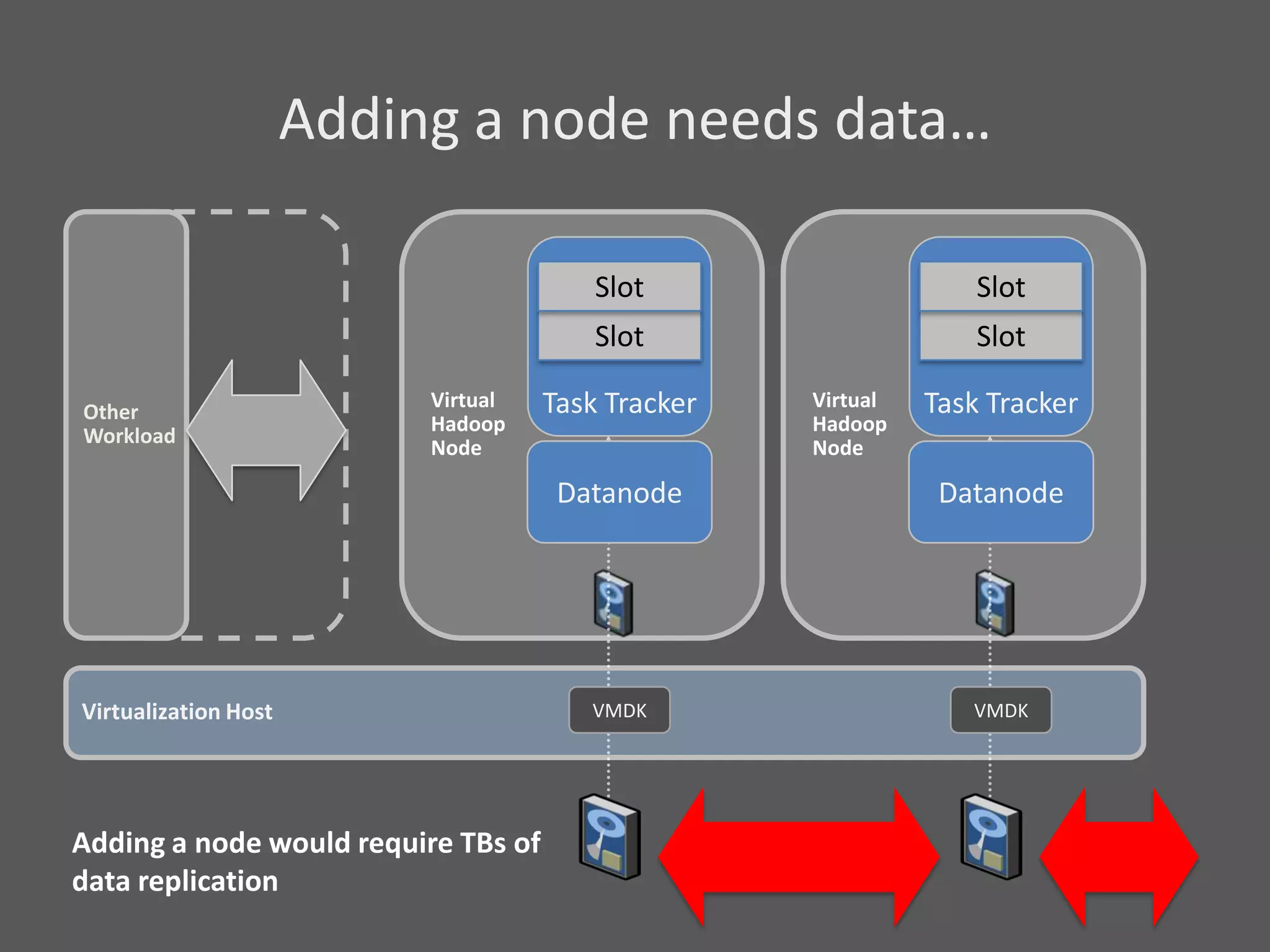
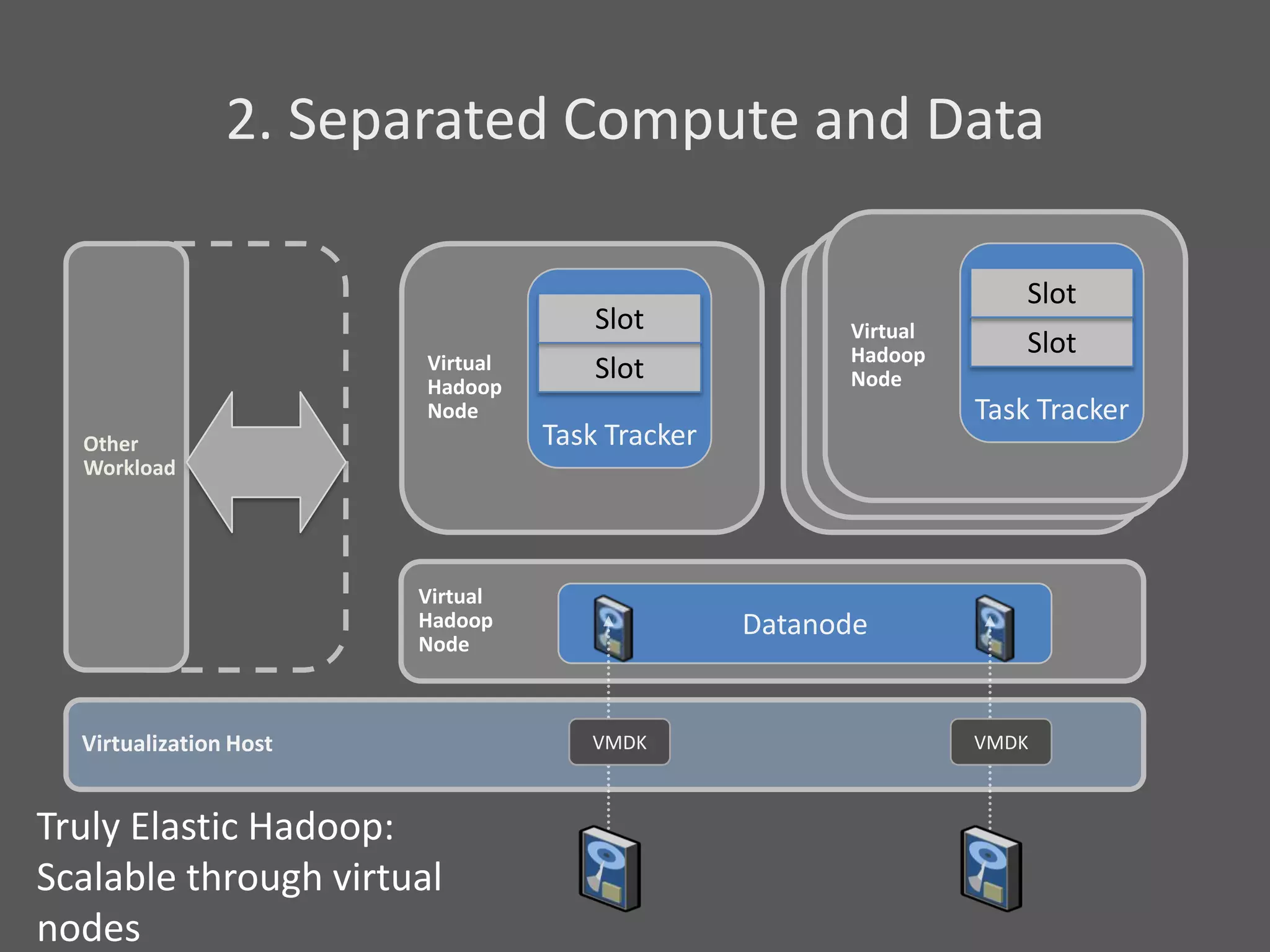
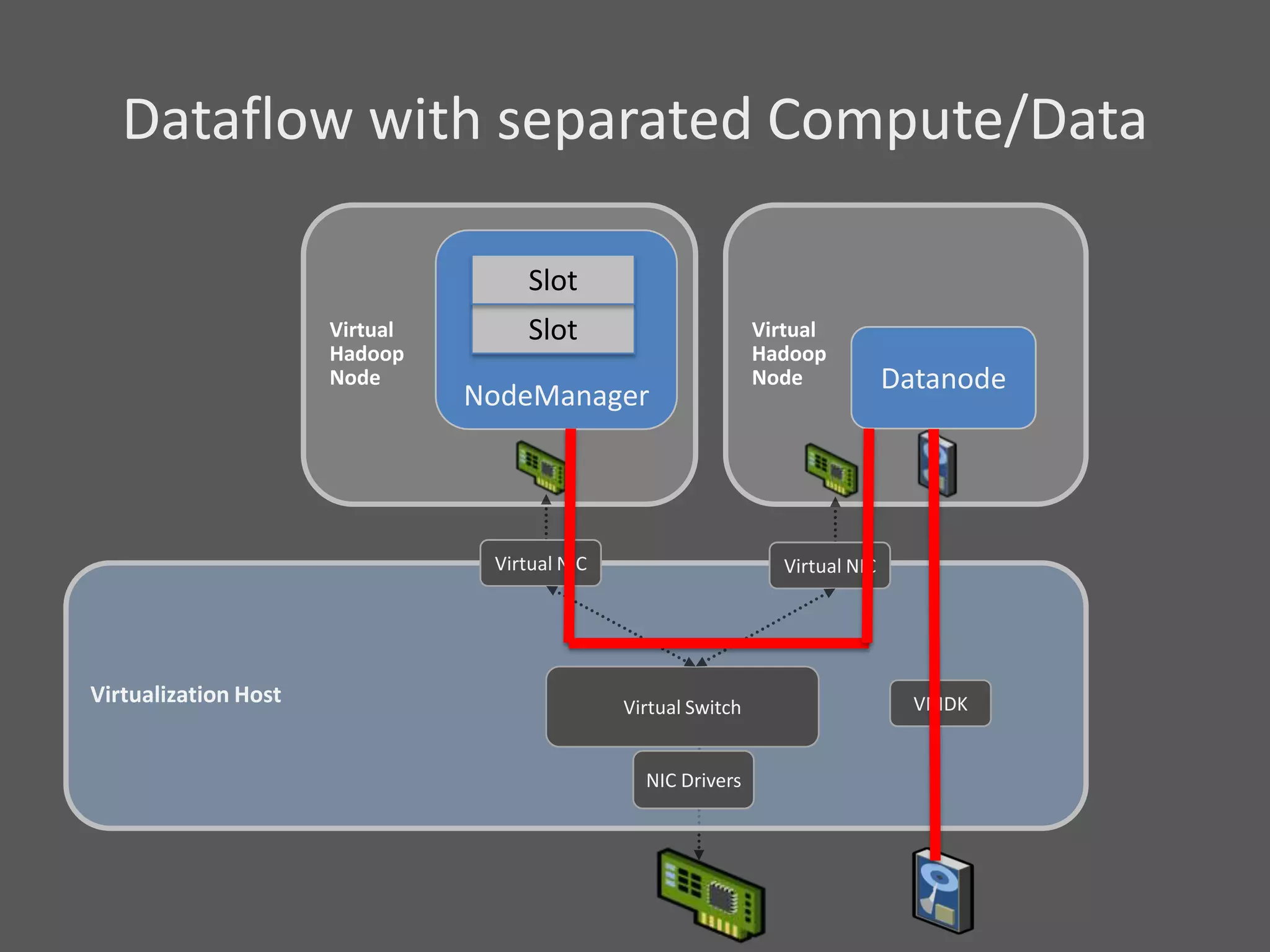

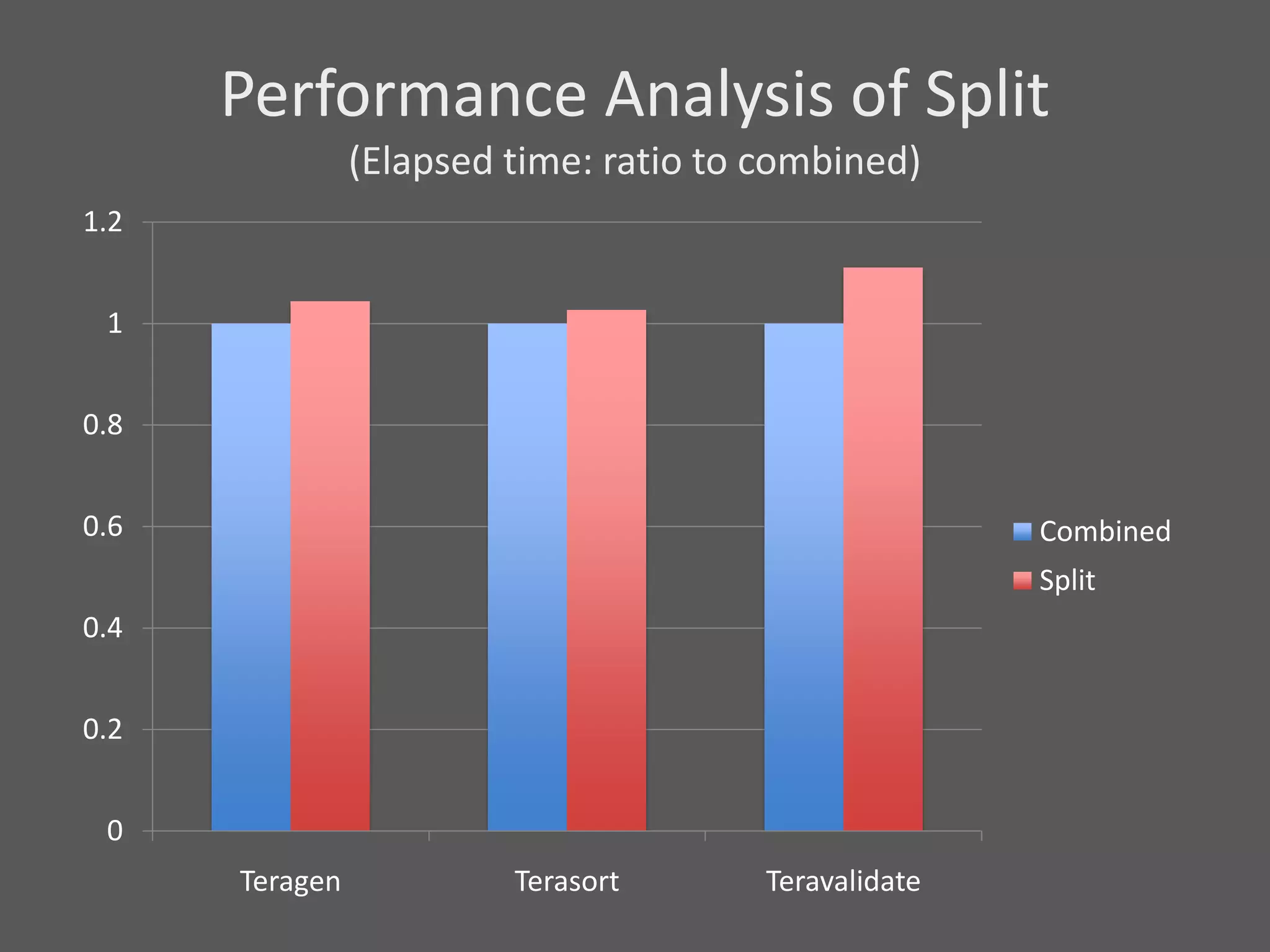
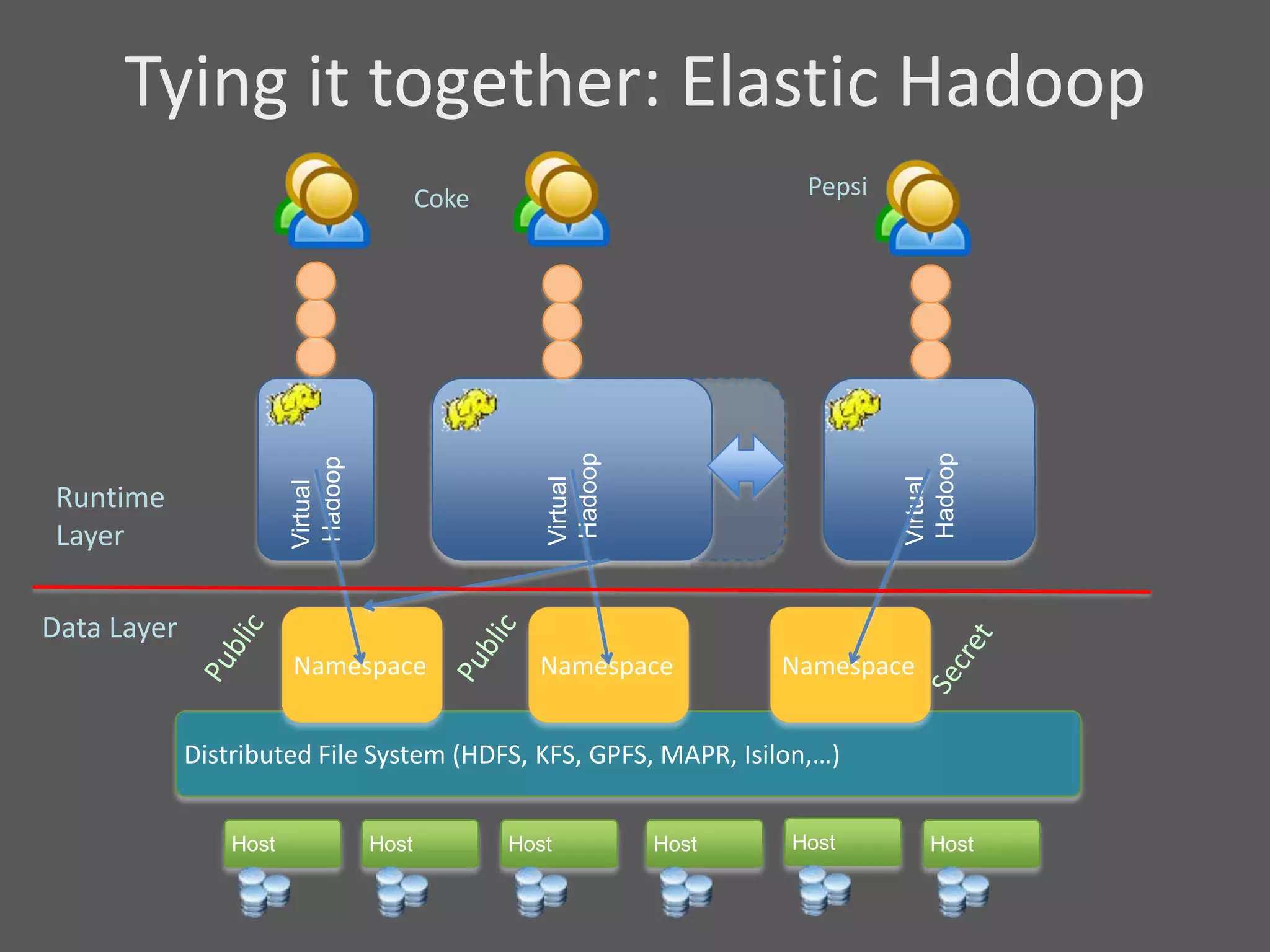
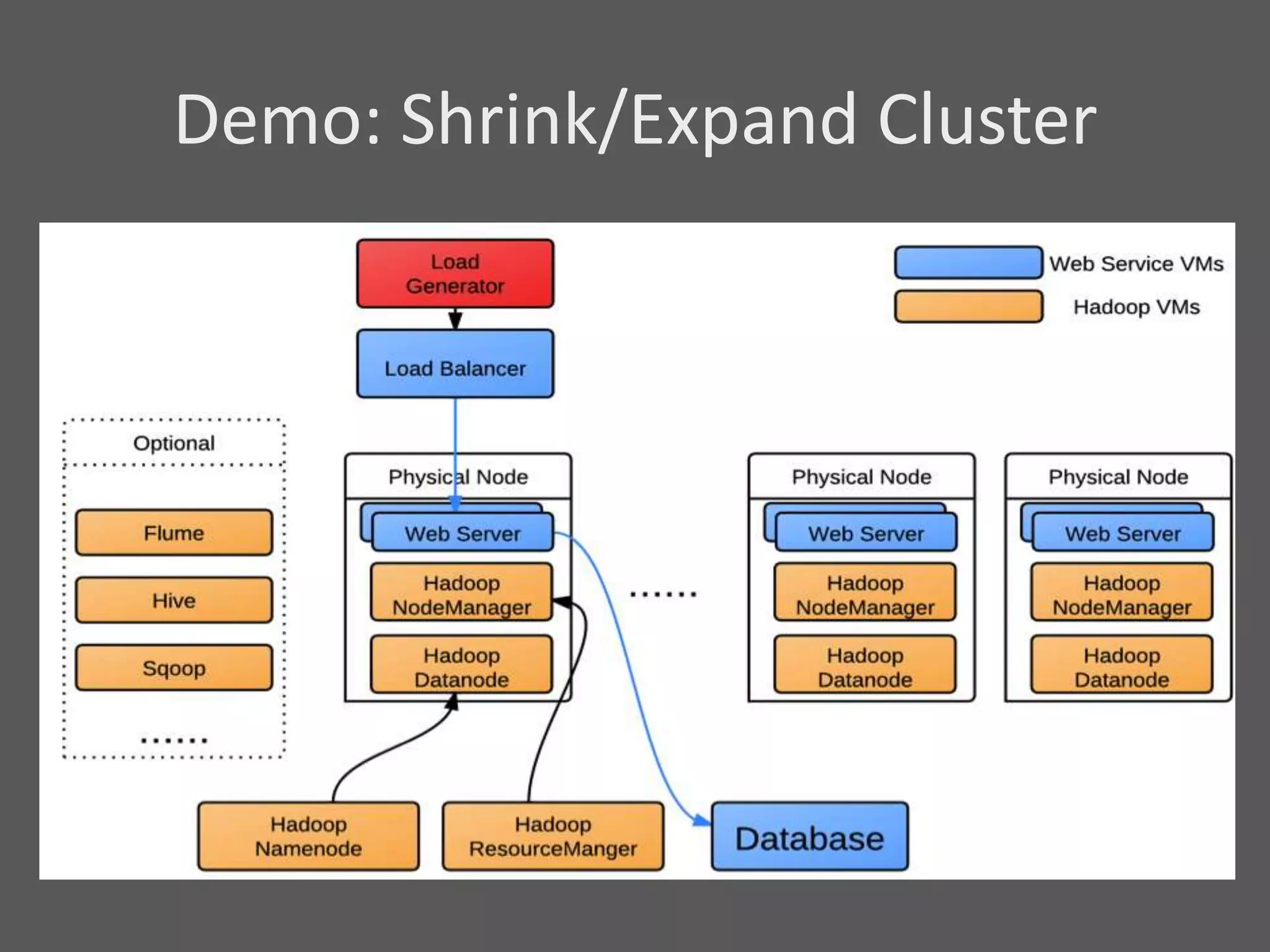
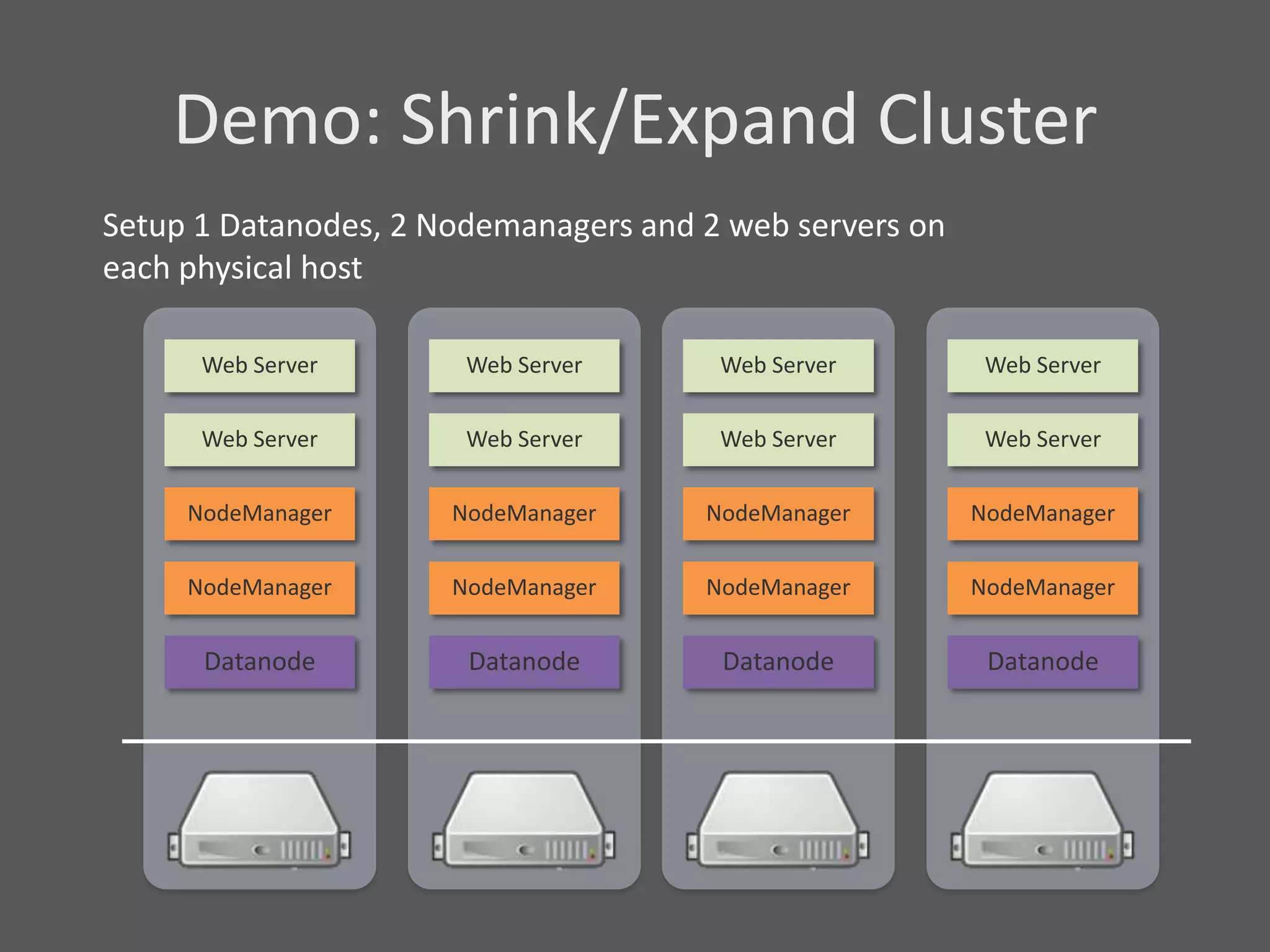
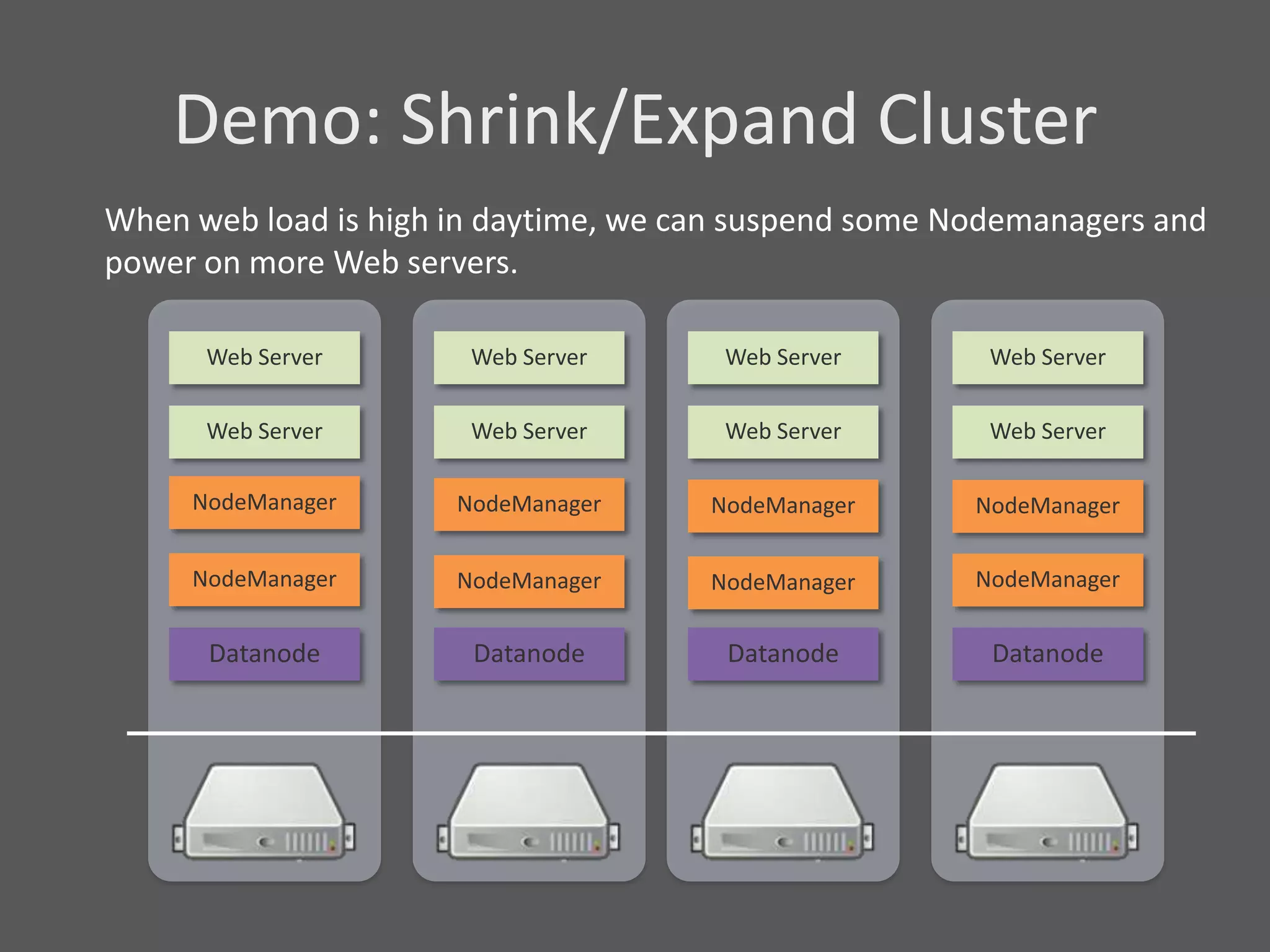




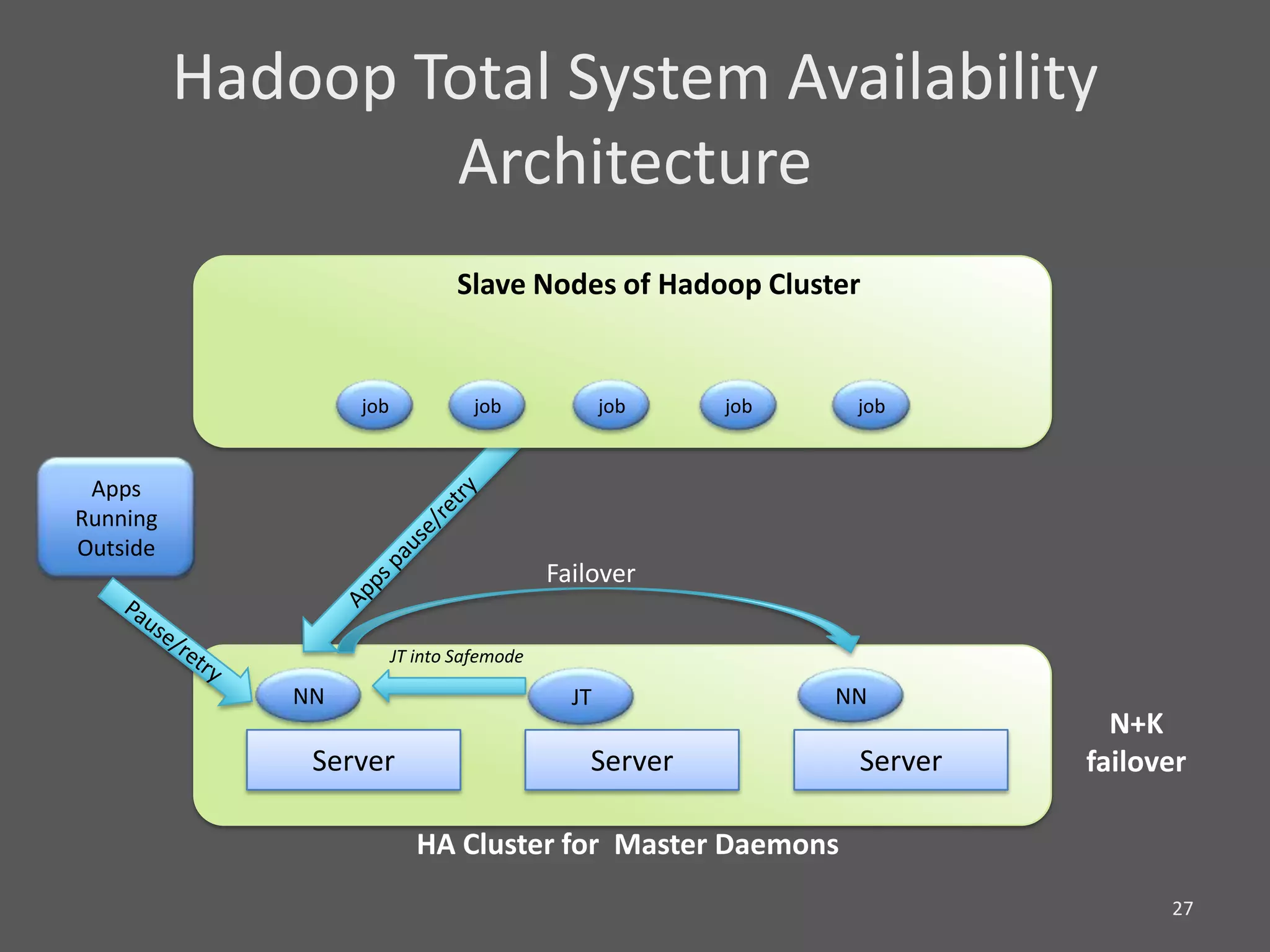


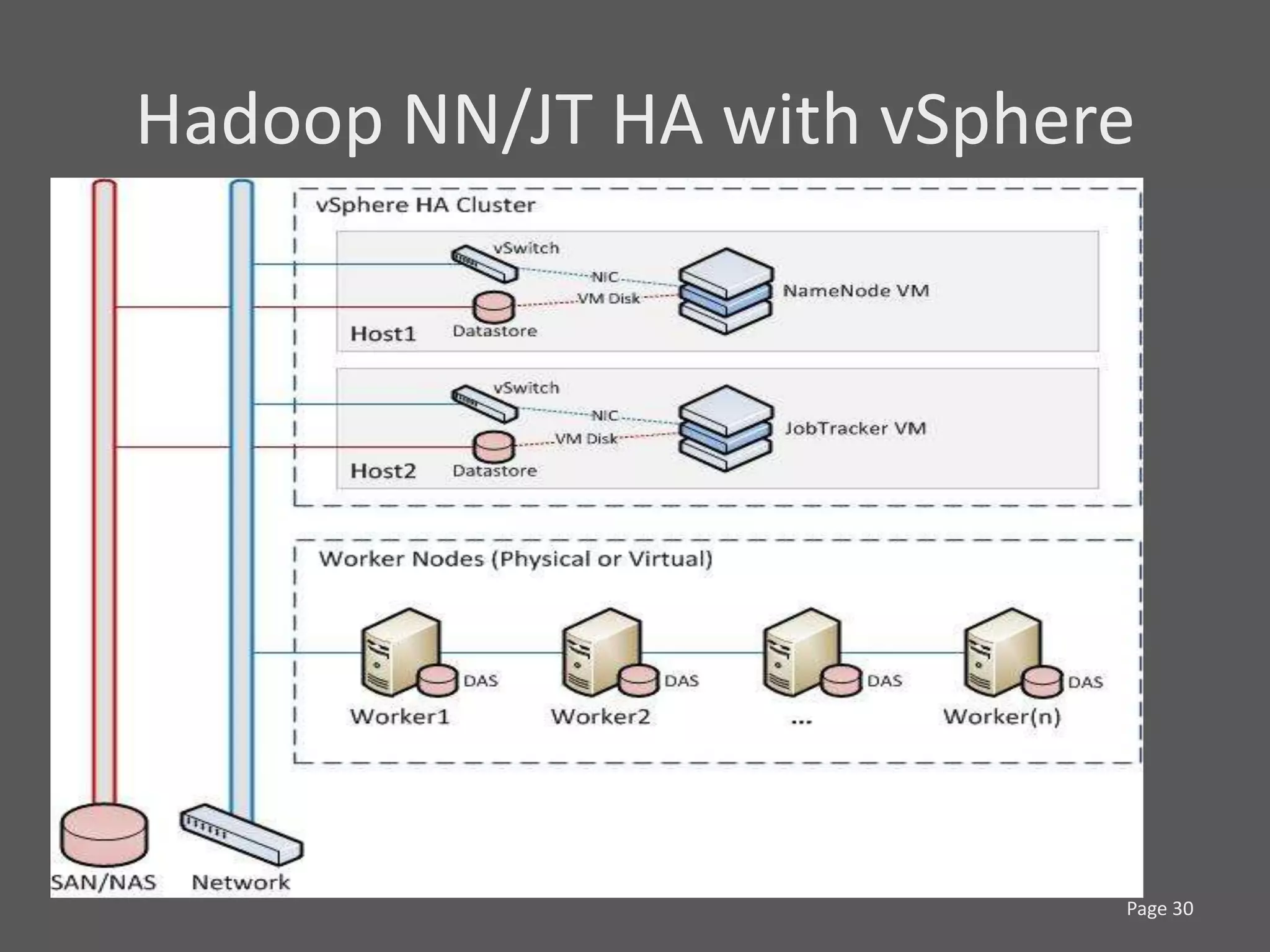




































1) Running Hadoop on VMs provides advantages like easier cluster management, ability to consolidate clusters on spare resources, and more elastic scaling of clusters. 2) Separating Hadoop compute and data nodes into different VMs allows truly elastic scaling of clusters. 3) Hortonworks is working with VMware to provide first class support for running Hadoop on VMs, including high availability features and optimizations for performance.




















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


