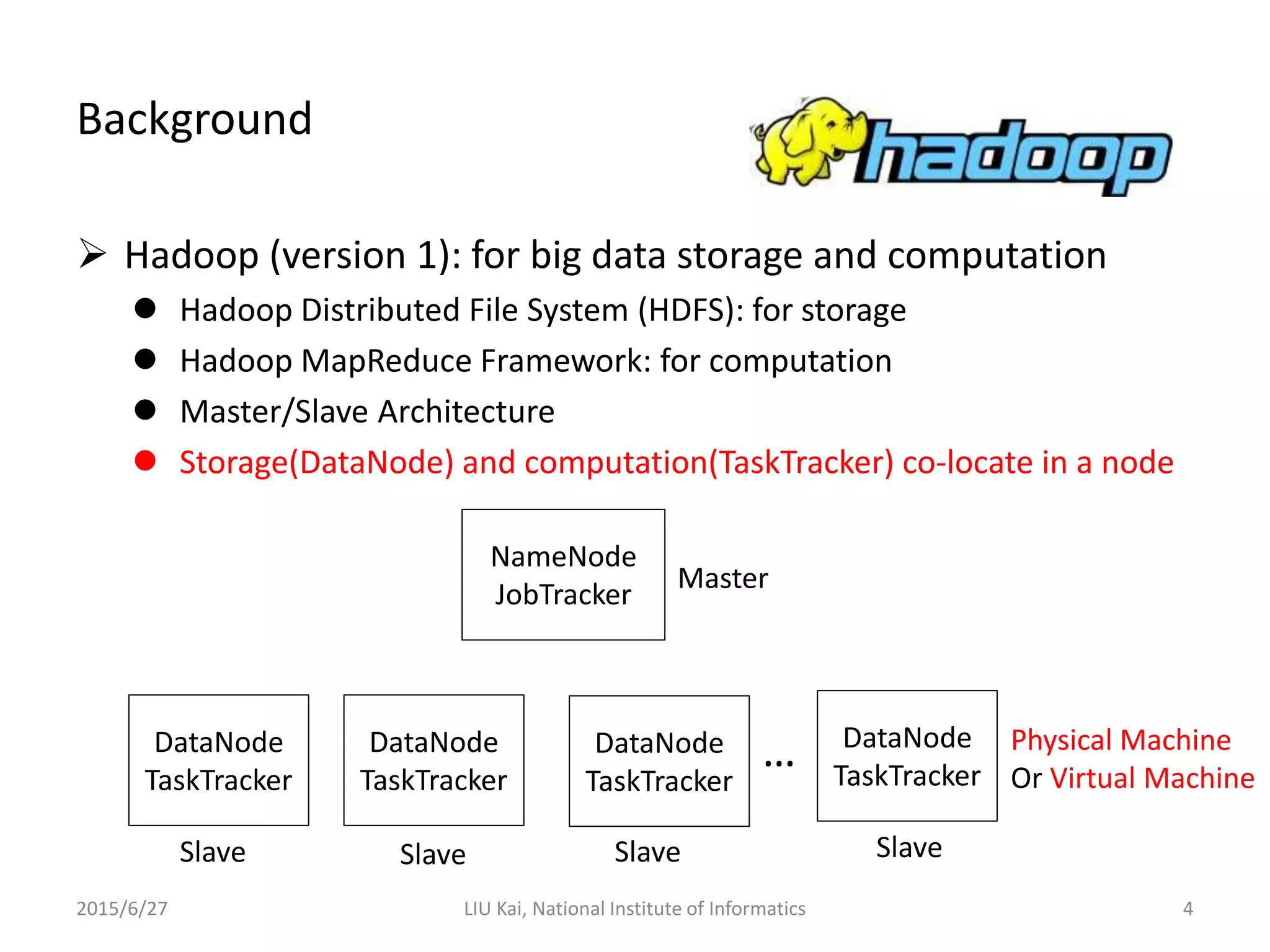
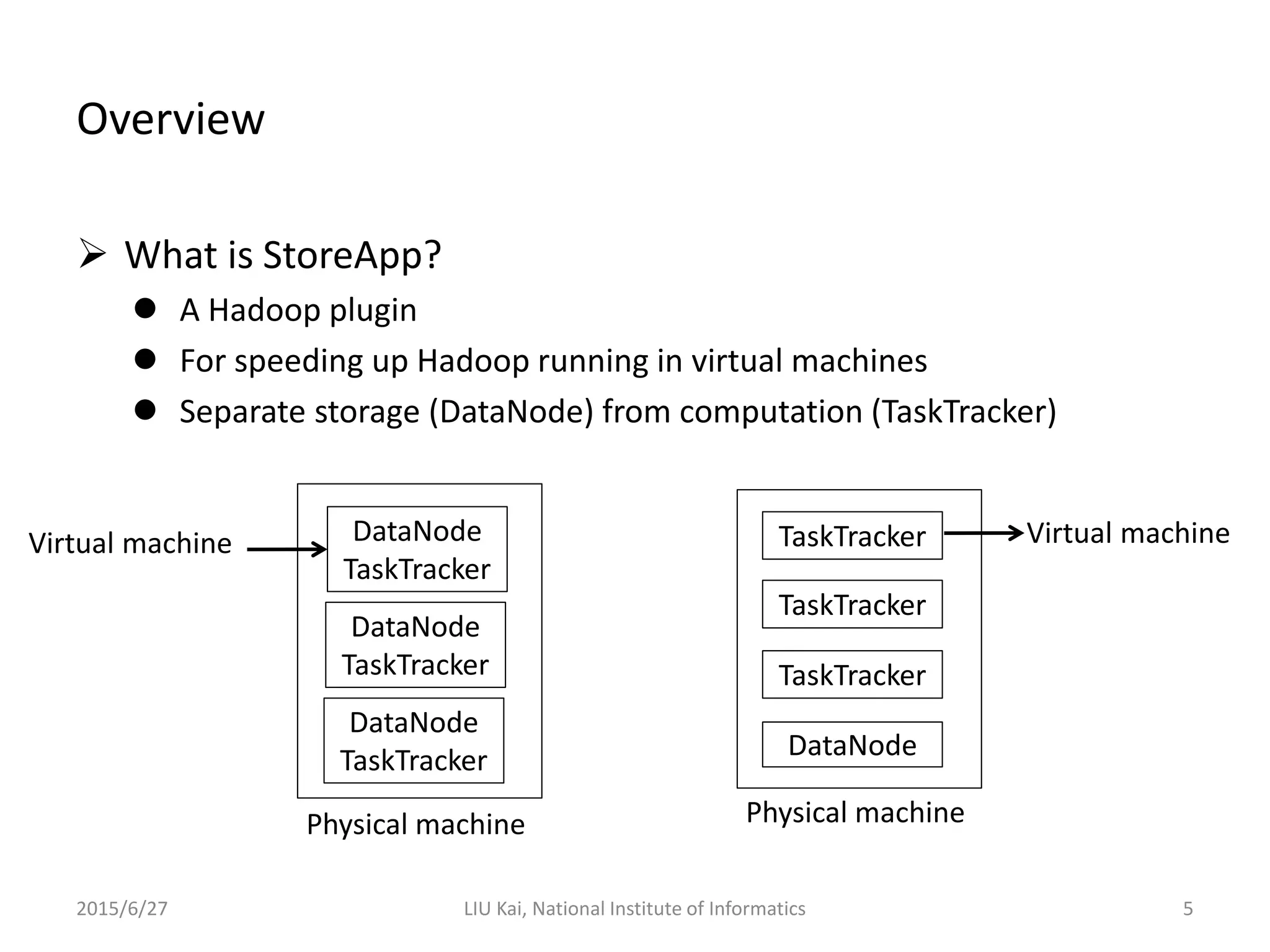
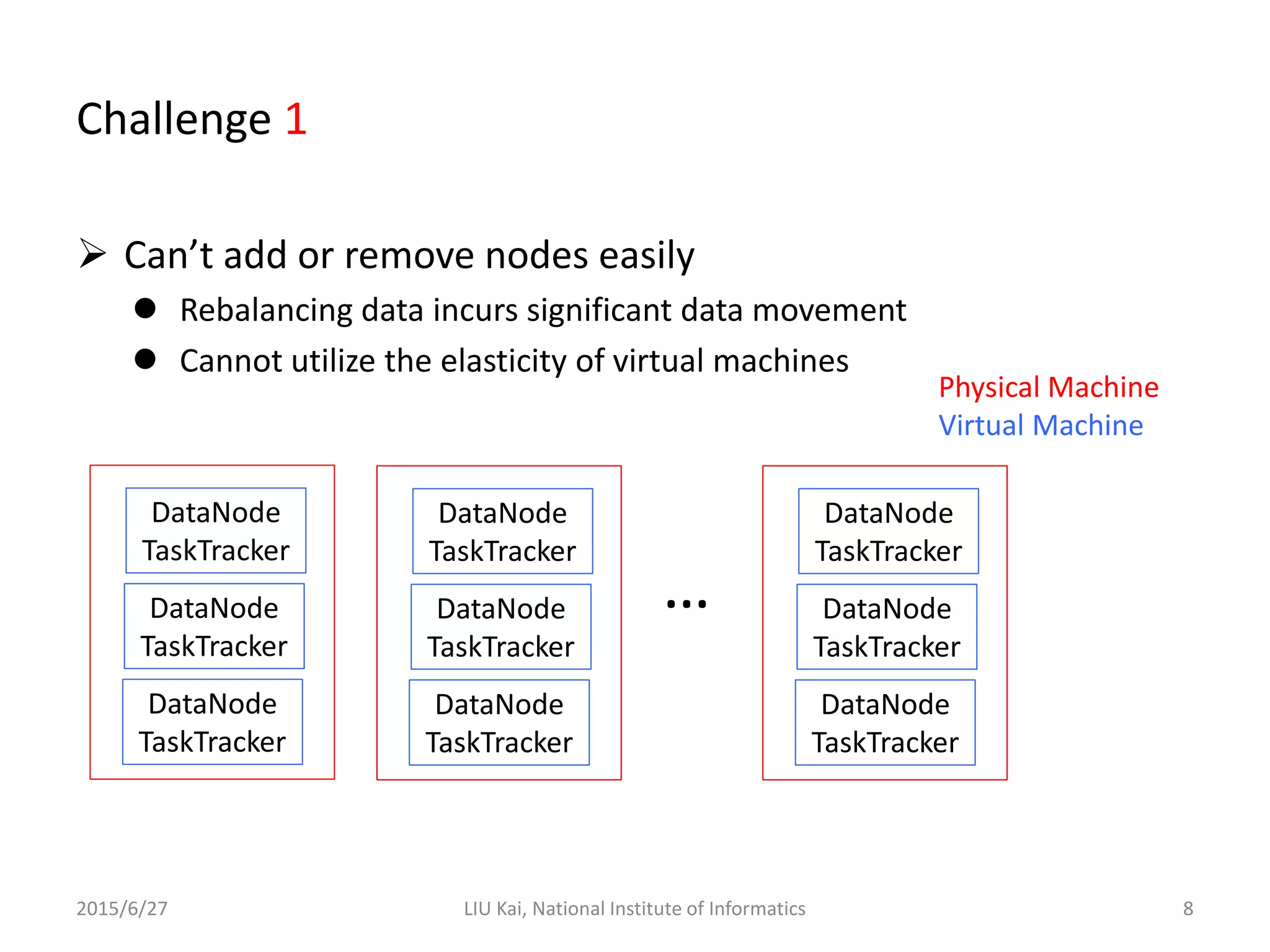
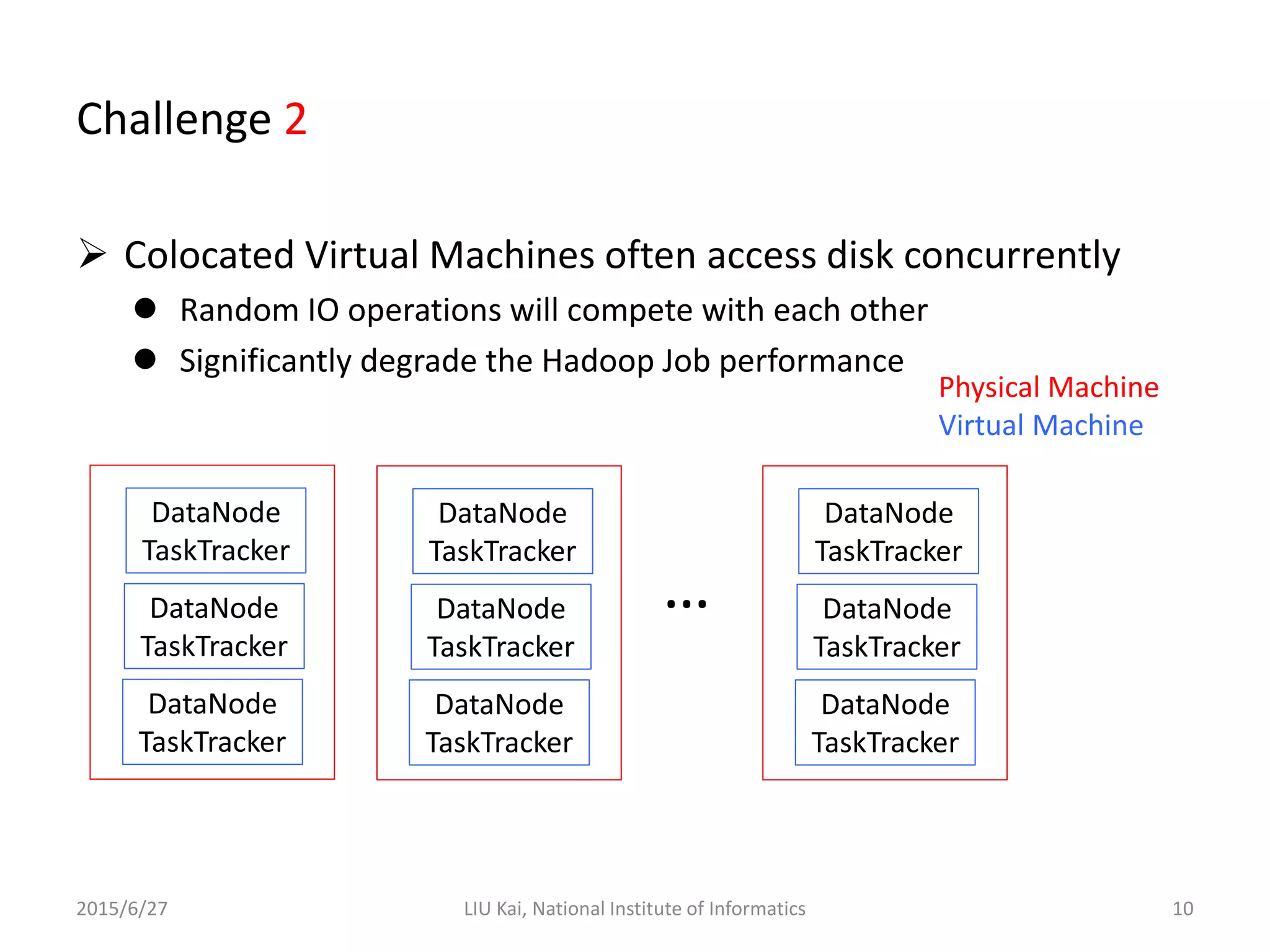
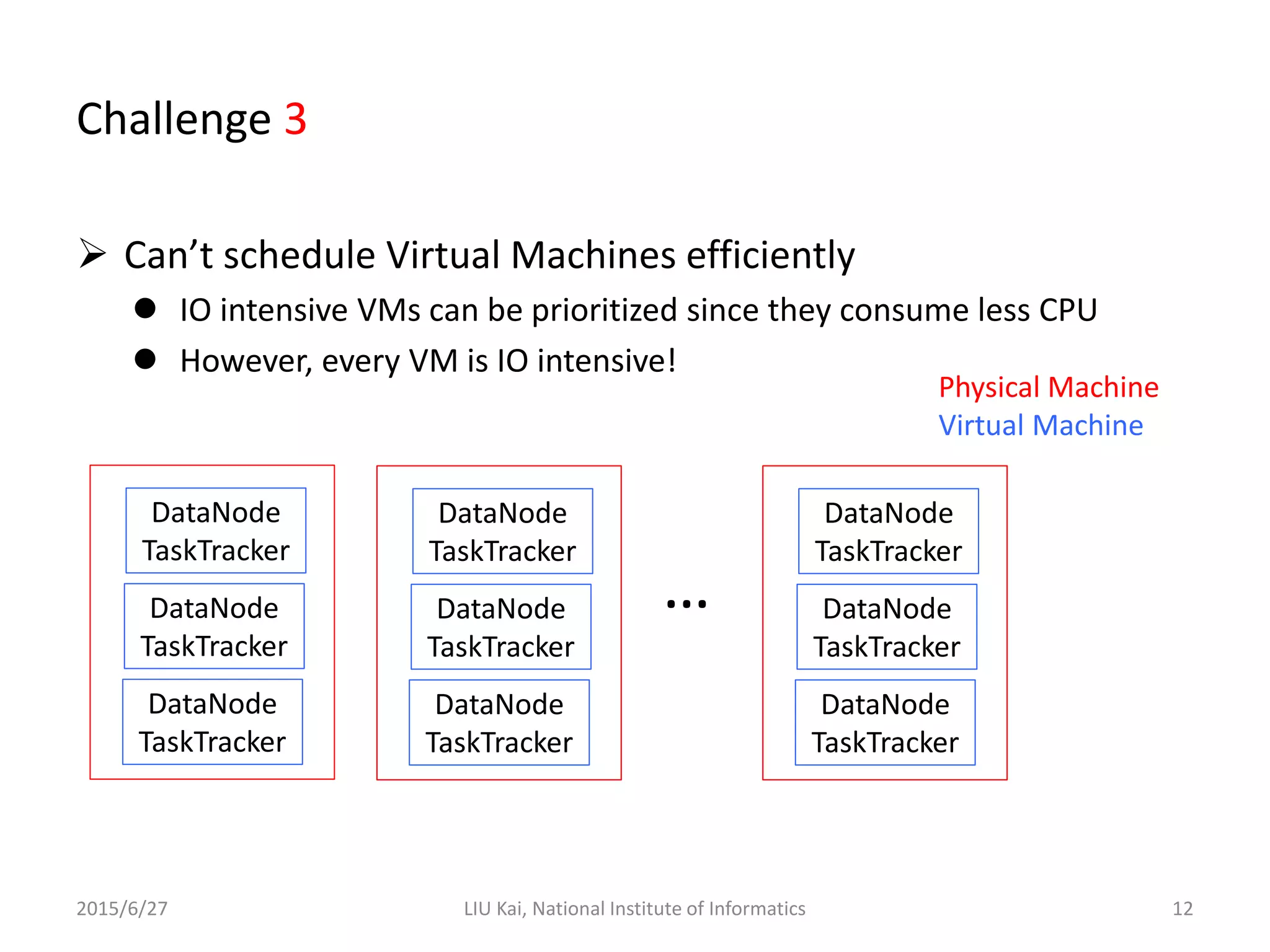
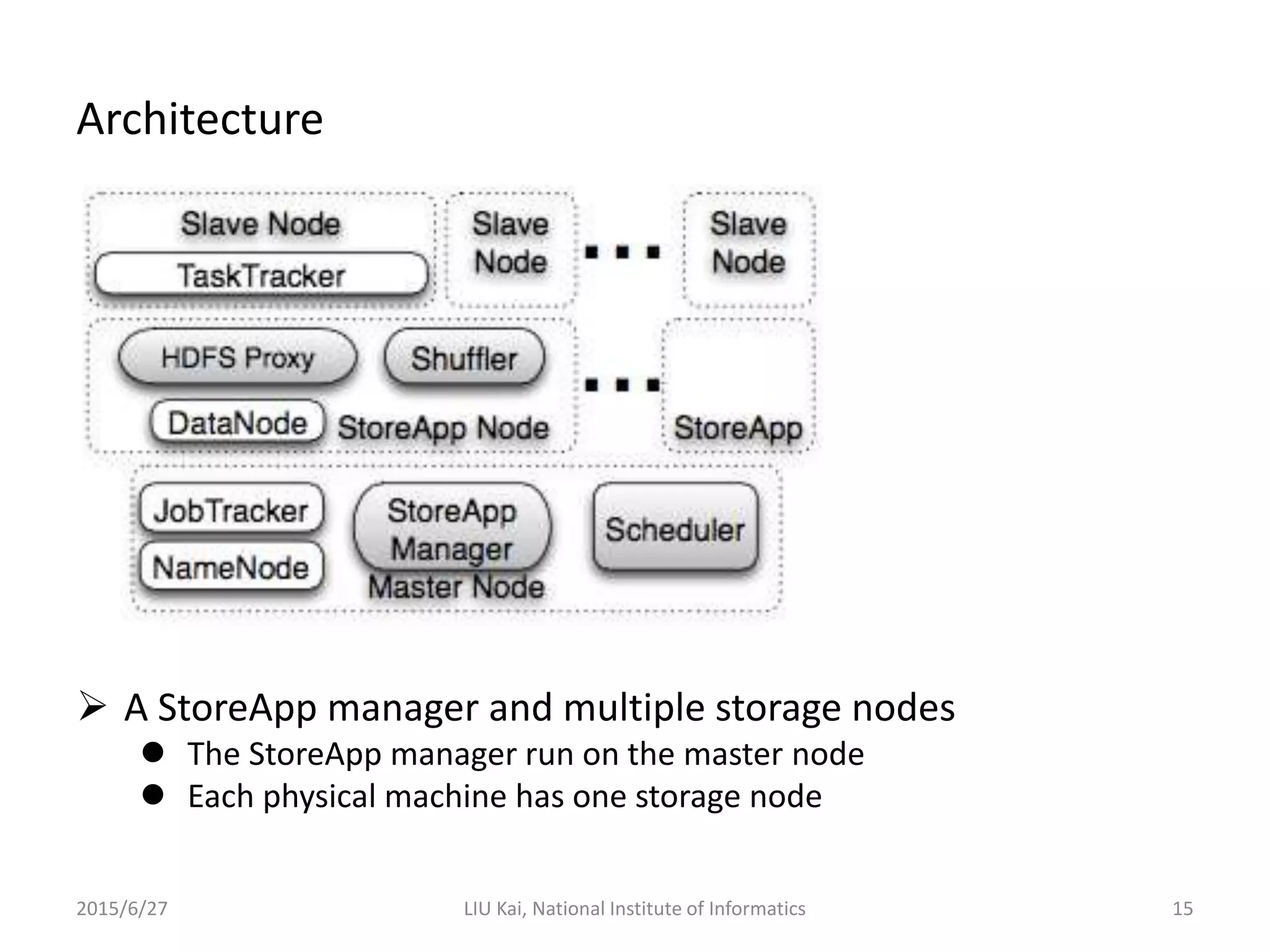
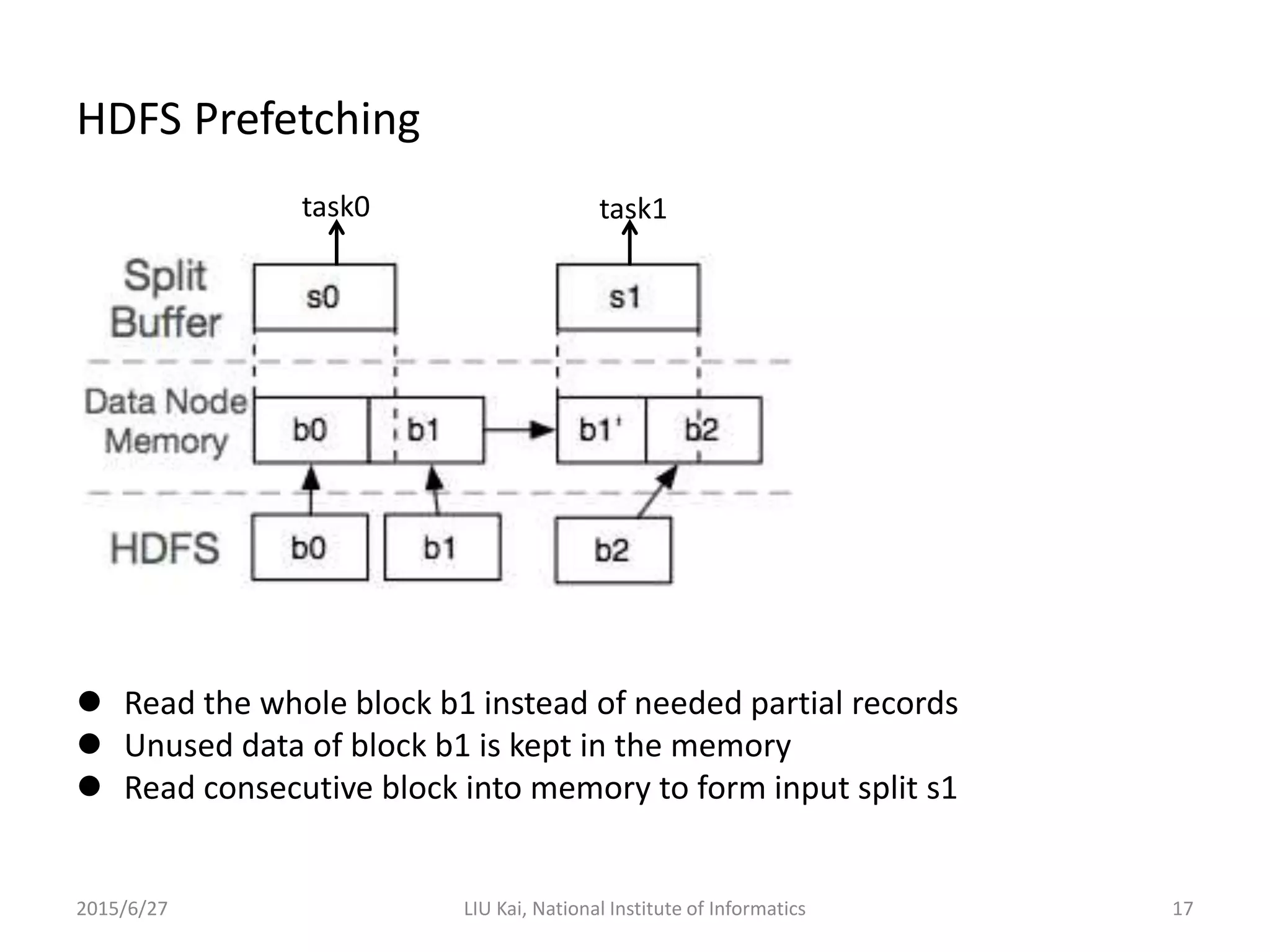
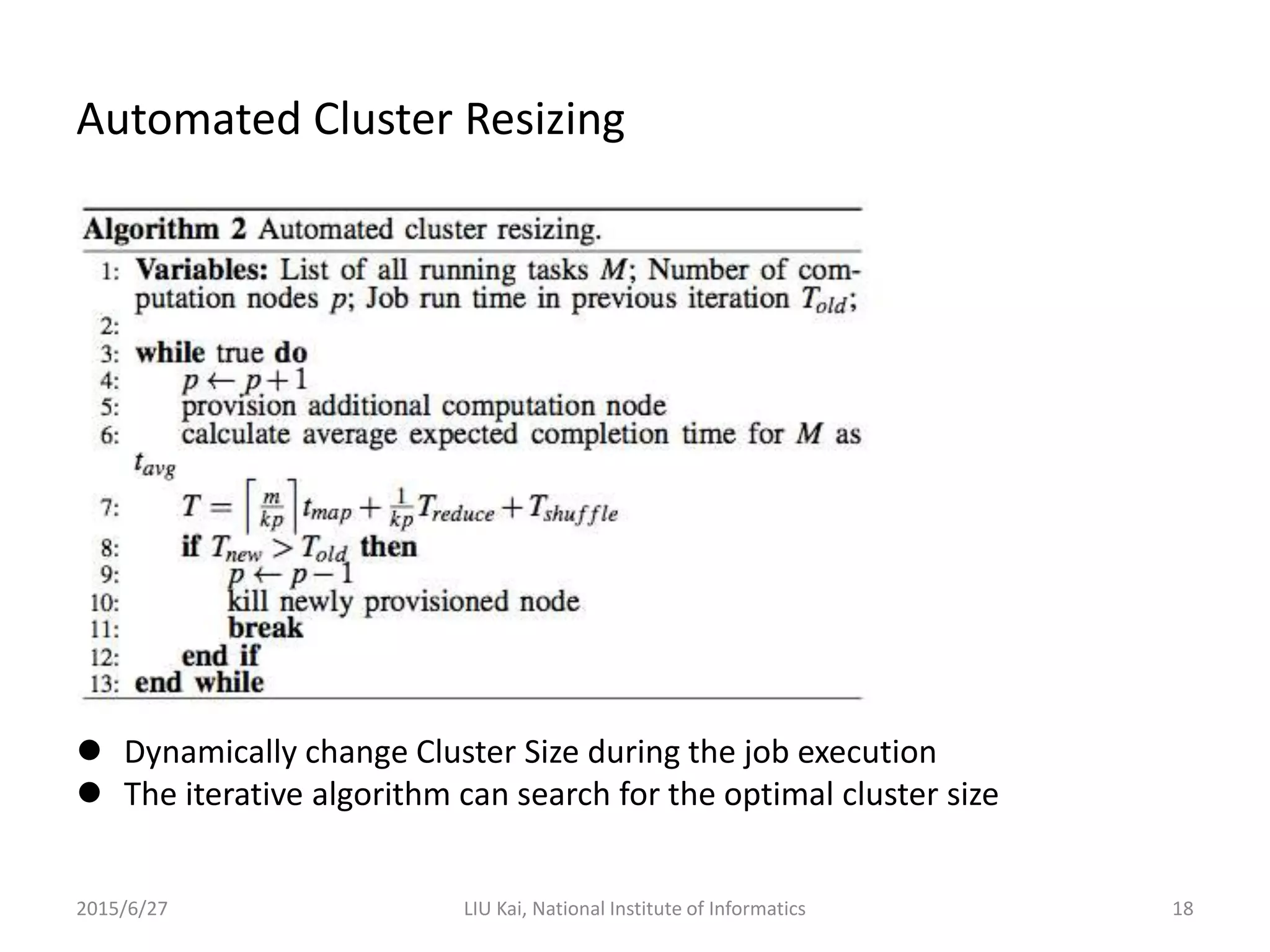
StoreApp is a Hadoop plugin that separates storage (DataNodes) from computation (TaskTrackers) in virtualized Hadoop clusters. This improves HDFS throughput by 78% and reduces job completion times by 61% by addressing challenges like inefficient scaling, disk I/O contention between colocated VMs, and suboptimal VM scheduling. StoreApp introduces a manager and storage nodes to coordinate separated DataNodes, uses a scheduler aware of data locations, and allows HDFS prefetching and automated cluster resizing. Future work could focus on adapting StoreApp for Hadoop 2 and using containers instead of VMs.






















































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
