Downloaded 27 times



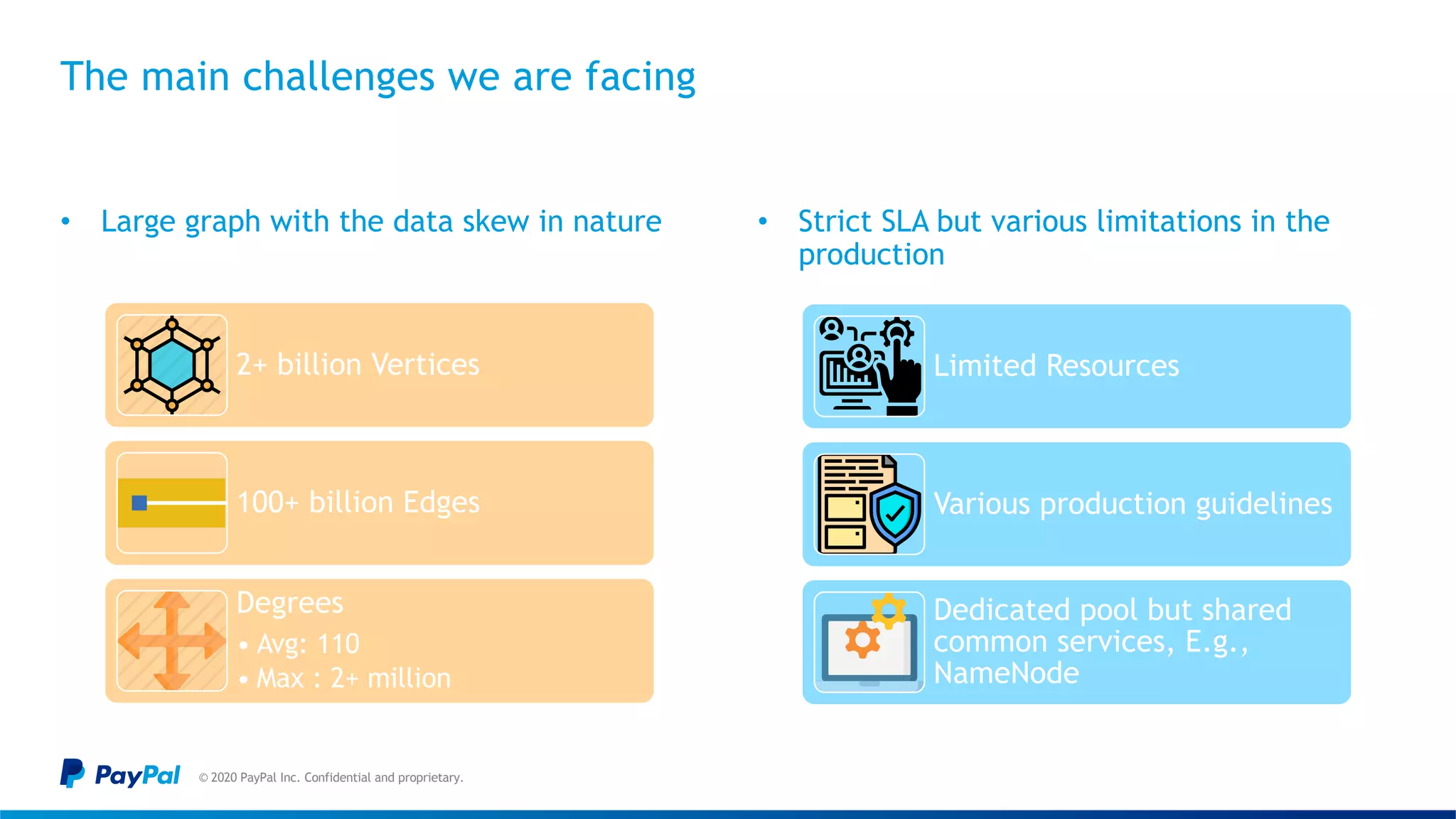

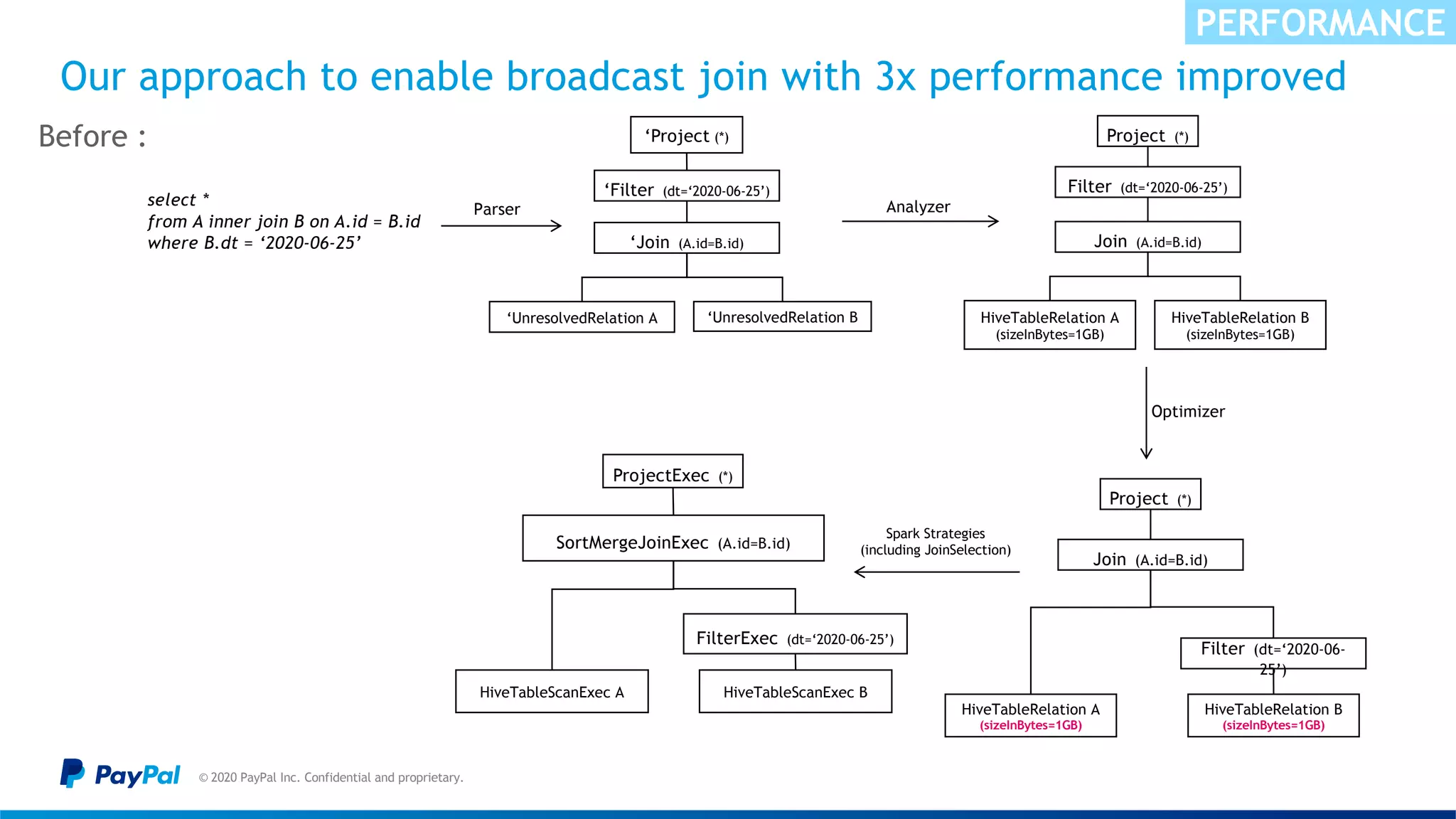
![The data skew in nature caused “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
Sample illustration
SCALABILITY
(6,1)
(6,1)
(6,2)
…
(5,2)
(4,2 )
(3,2)
Group by
starting
node
1. Find smallest node
in each group
2. Generate new
pairs by linking
node to smallest
node in each
group
(1,6)
(2,6)
(2,5)
(2,4)
(2,3)
(6,1)
(6,2)
(5,2)
(4,2)
(3,2)
(1,6)
(2,3)
(2,4)
(2,5)
(2,6)
Make it
directed
( 1, [6,2] )
( 2, [1,3,4,5,6]
)
( 3, [2] )
( 4, [2] )
( 5, [2] )
( 6, [1,2] )
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
Group by
starting
node
1. Find smallest
node in each
group
2. Generate new
pairs by linking
node to smallest
node in each
group
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
(1,6)
(2,6)
(1,2)
(2,3)
(2,4)
(2,5)
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
Make it
directed
Iteration#1
Iteration#2
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
Identify unique
representative vertex within
the community
Find connected components
in Reducer
(1, [6])
(6, [1,2])
(2,
[3,4,5,6])
(5, [2])
(4, [2])
(3, [2])
Iteration#1
1
5
4
6
3
2
Intermediate graph -
1
Iteration#2
1
5
4
6
3
2
Intermediate graph - 2
Dedup
(6,1)
(2,1)
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
…
Dedup](https://image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-7-2048.jpg)
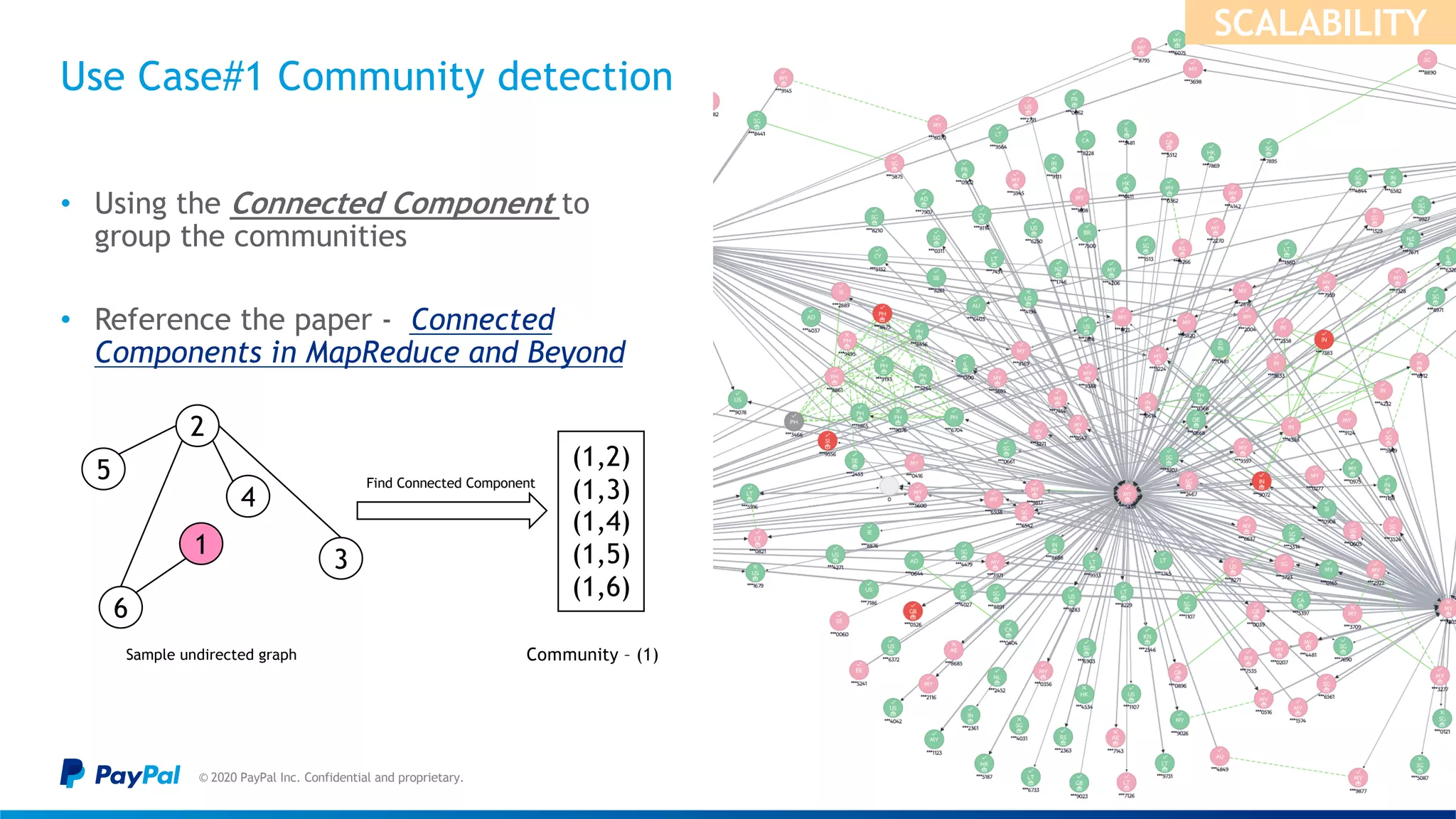
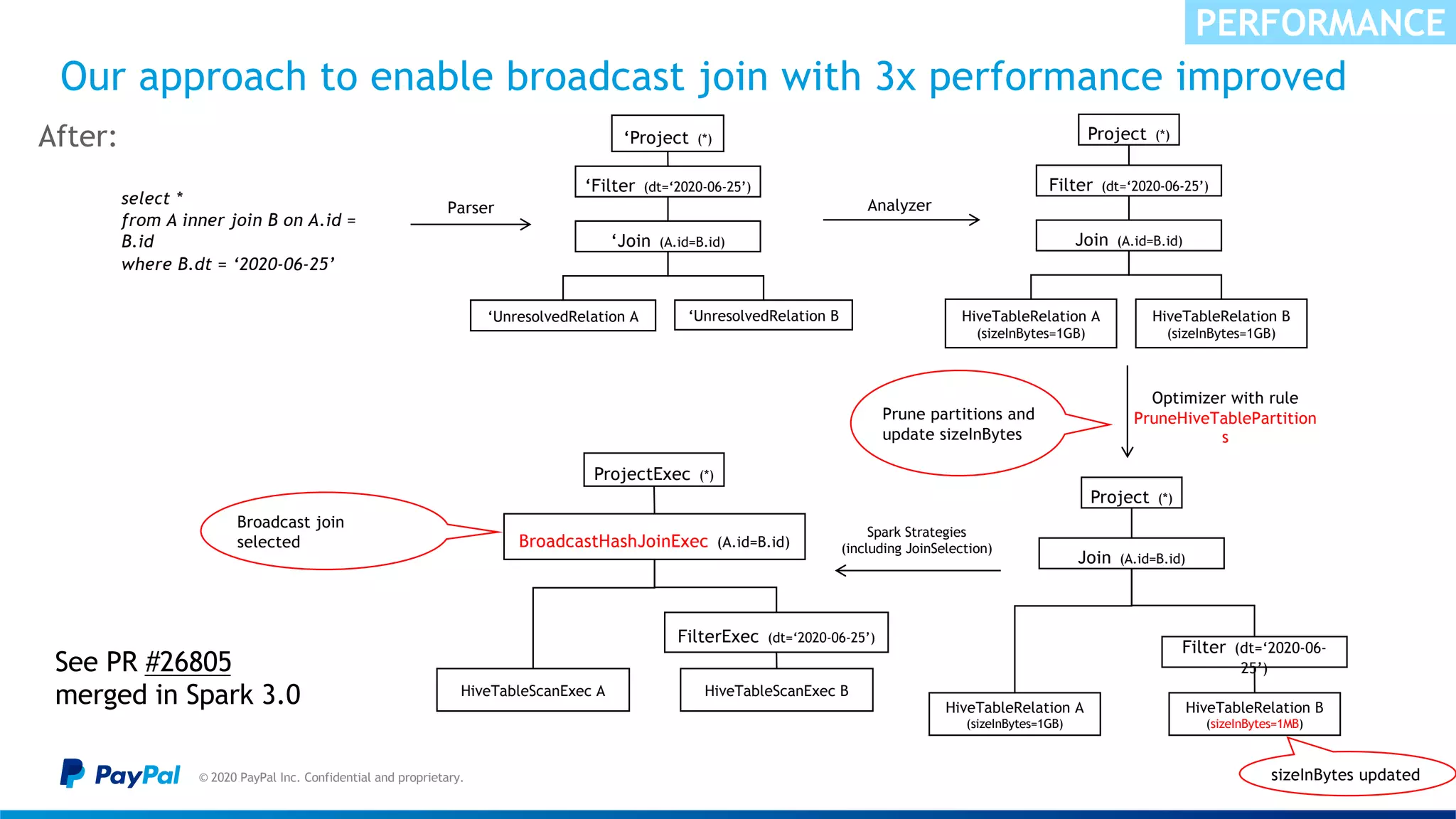
![The data skew in nature caused “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
Sample illustration – Cont.
( 1, [2,3,4,5,6] )
( 2, [1,3,4,5] )
( 3, [1,2] )
( 4, [1,2] )
( 5, [1,2] )
( 6, [1] )
Group by
starting
node
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
(1,6)
(1,2)
(1,3)
(1,4)
(1,5)
(2,3)
(2,4)
(2,5)
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
Make it
directed
SCALABILITY
Find connected components
in Reducer
(6,1)
(5,1)
(4,1)
(3,1)
(2,1)
Identify unique
representative vertex within
the community
• The size of connected components increases significantly in each iteration.
• It caused “bucket effect” (Slow Reduce tasks)
• Keeping the connected components in memory caused OOM in some Reducer
For example:
• 50,000,000+ nodes connected
Iteration#3
1
5 4
6
3
2
Found one connected component,
id is 1, members are [1,2,3,4,5,6]
Iteration#3
( 6,1 )
( 5,1 )
( 4,1 )
…
( 5,1 )
( 5,2 )
( 6,1)
1. Find smallest
node in each
group
2. Generate new
pairs by linking
node to smallest
node in each
group
Dedup](https://image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-8-2048.jpg)
![Our approach to resolve “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
SCALABILITY
Separate huge and
normal keys
(2,1)
(3,1)
(3,2)
(4,1)
(4,2)
(5,1)
(5,2)
(6,1)
(1,2)
(1,3)
(1,4)
(1,5)
(1,6)
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
(1,6)
(1,2)
(1,3)
(1,4)
(1,5)
(2,3)
(2,4)
(2,5)
1. Find min for
each huge key
2. Divide the key
by adding
random
number as
prefix
(01,6)
(01,2)
(11,3)
(11,4)
(11,5)
Processed as introduced :
1. Group by starting node
2. Find smallest node in each group
3. explode the map to rows
4. Dedup
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
1. Group by key
2. Spill to mmap file if list
length of single key
exceed threshold
3. Keep remaining list in
memory
4. Keep min value of original
key in each group (11, ([file1],
[5],1))
(01, ([file2],[],1))
• Spilled [3,4] into file1
• Spilled [2,6] into file2
• Min value of original key is
1
Read list of files and in-
memory list, then
generate new pairs
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
Merge &
Dedup
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
1.
Separate
keys
2. Splitting
huge keys
3. Spill to
disk](https://image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-9-2048.jpg)


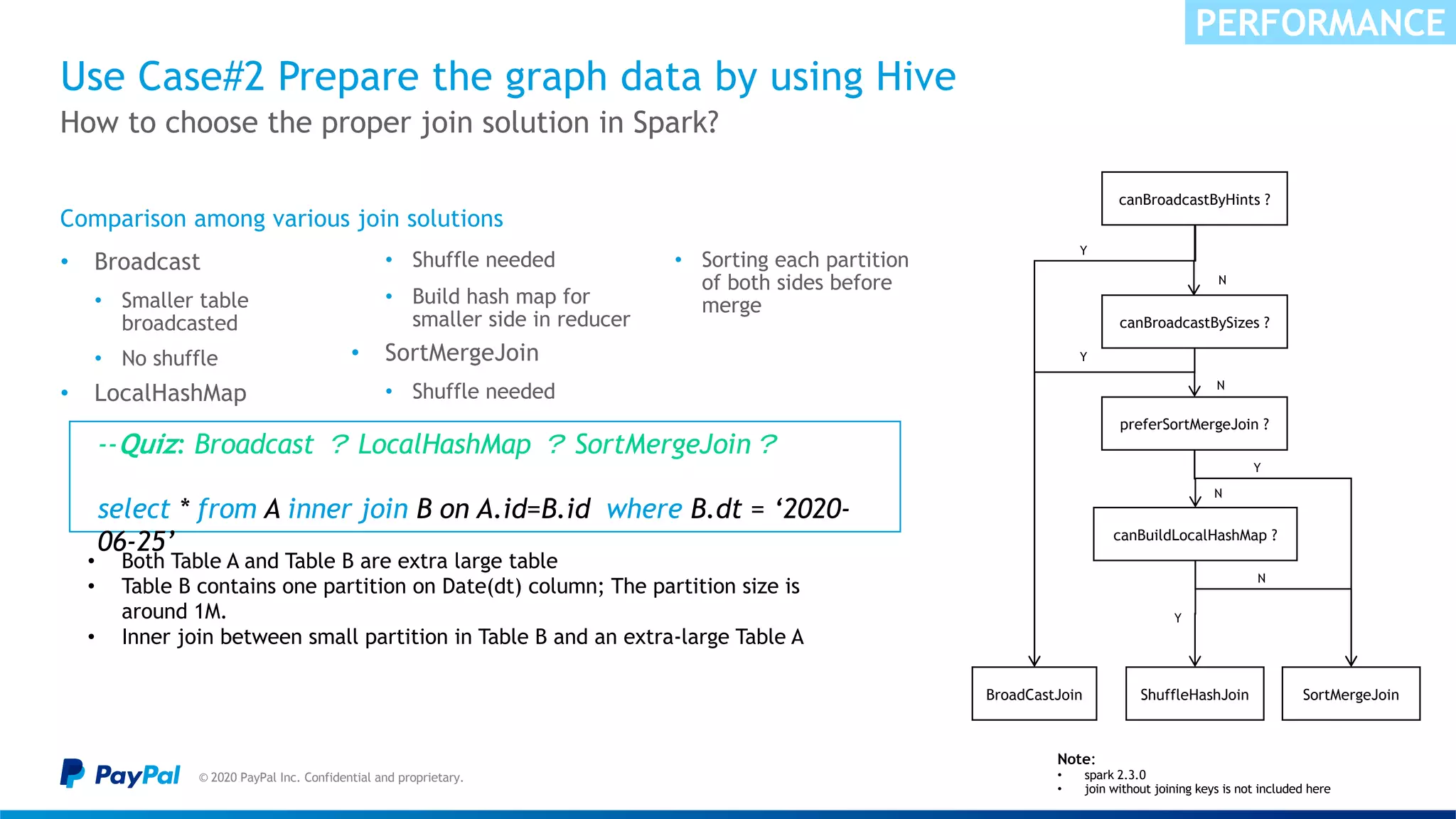












![The data skew in nature caused “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
Sample illustration
SCALABILITY
(6,1)
(6,1)
(6,2)
…
(5,2)
(4,2 )
(3,2)
Group by
starting
node
1. Find smallest node
in each group
2. Generate new
pairs by linking
node to smallest
node in each
group
(1,6)
(2,6)
(2,5)
(2,4)
(2,3)
(6,1)
(6,2)
(5,2)
(4,2)
(3,2)
(1,6)
(2,3)
(2,4)
(2,5)
(2,6)
Make it
directed
( 1, [6,2] )
( 2, [1,3,4,5,6]
)
( 3, [2] )
( 4, [2] )
( 5, [2] )
( 6, [1,2] )
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
Group by
starting
node
1. Find smallest
node in each
group
2. Generate new
pairs by linking
node to smallest
node in each
group
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
(1,6)
(2,6)
(1,2)
(2,3)
(2,4)
(2,5)
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
Make it
directed
Iteration#1
Iteration#2
(6,1)
(6,2)
(2,1)
(3,2)
(4,2)
(5,2)
Identify unique
representative vertex within
the community
Find connected components
in Reducer
(1, [6])
(6, [1,2])
(2,
[3,4,5,6])
(5, [2])
(4, [2])
(3, [2])
Iteration#1
1
5
4
6
3
2
Intermediate graph -
1
Iteration#2
1
5
4
6
3
2
Intermediate graph - 2
Dedup
(6,1)
(2,1)
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
…
Dedup](https://crownmelresort.com/image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-7-2048.jpg)
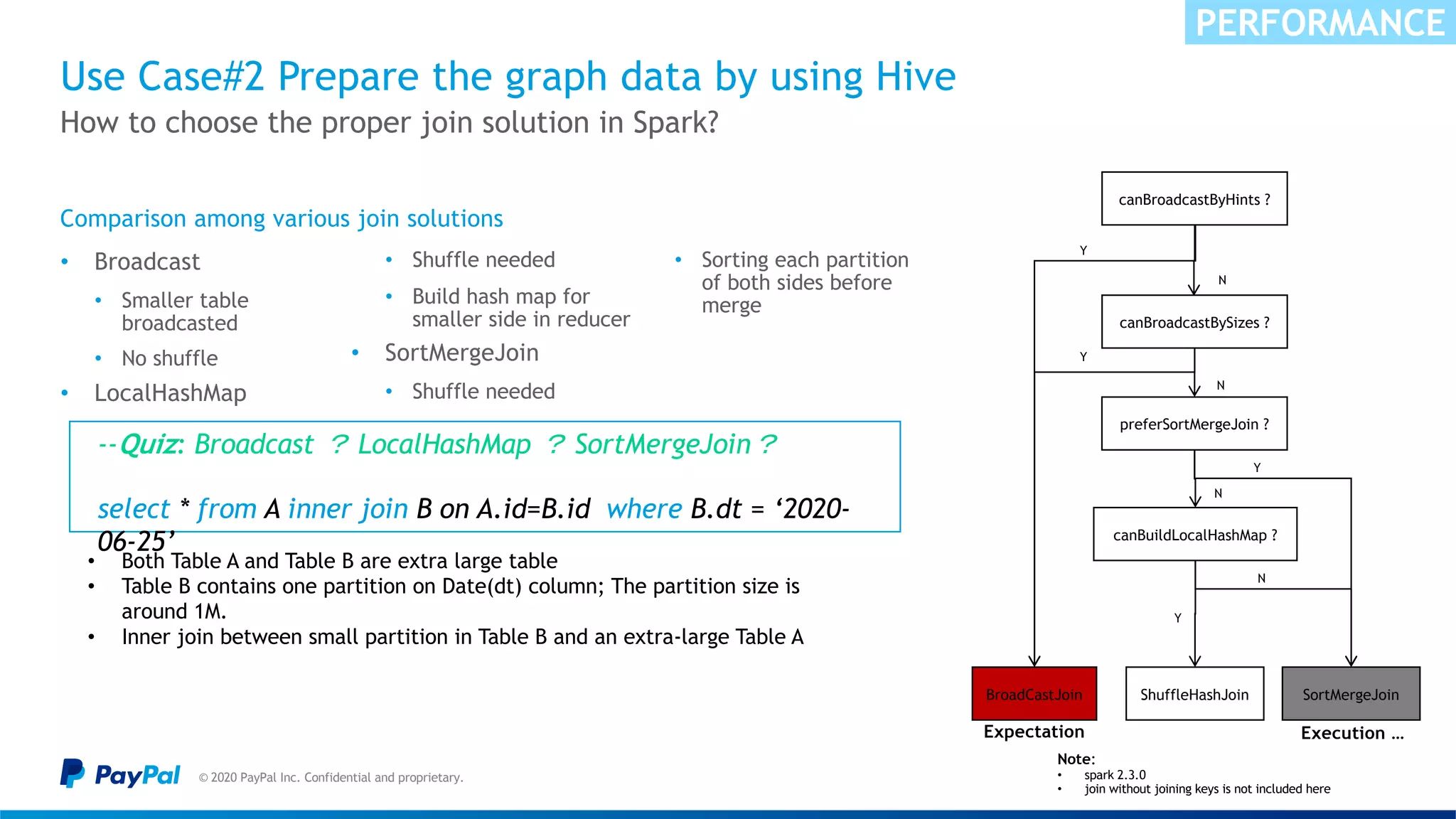
![The data skew in nature caused “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
Sample illustration – Cont.
( 1, [2,3,4,5,6] )
( 2, [1,3,4,5] )
( 3, [1,2] )
( 4, [1,2] )
( 5, [1,2] )
( 6, [1] )
Group by
starting
node
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
(1,6)
(1,2)
(1,3)
(1,4)
(1,5)
(2,3)
(2,4)
(2,5)
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
Make it
directed
SCALABILITY
Find connected components
in Reducer
(6,1)
(5,1)
(4,1)
(3,1)
(2,1)
Identify unique
representative vertex within
the community
• The size of connected components increases significantly in each iteration.
• It caused “bucket effect” (Slow Reduce tasks)
• Keeping the connected components in memory caused OOM in some Reducer
For example:
• 50,000,000+ nodes connected
Iteration#3
1
5 4
6
3
2
Found one connected component,
id is 1, members are [1,2,3,4,5,6]
Iteration#3
( 6,1 )
( 5,1 )
( 4,1 )
…
( 5,1 )
( 5,2 )
( 6,1)
1. Find smallest
node in each
group
2. Generate new
pairs by linking
node to smallest
node in each
group
Dedup](https://crownmelresort.com/image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-8-2048.jpg)
![Our approach to resolve “Buckets effect” & OOM
© 2020 PayPal Inc. Confidential and proprietary.
SCALABILITY
Separate huge and
normal keys
(2,1)
(3,1)
(3,2)
(4,1)
(4,2)
(5,1)
(5,2)
(6,1)
(1,2)
(1,3)
(1,4)
(1,5)
(1,6)
(6,1)
(2,1)
(3,1)
(4,1)
(5,1)
(3,2)
(4,2)
(5,2)
(1,6)
(1,2)
(1,3)
(1,4)
(1,5)
(2,3)
(2,4)
(2,5)
1. Find min for
each huge key
2. Divide the key
by adding
random
number as
prefix
(01,6)
(01,2)
(11,3)
(11,4)
(11,5)
Processed as introduced :
1. Group by starting node
2. Find smallest node in each group
3. explode the map to rows
4. Dedup
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
1. Group by key
2. Spill to mmap file if list
length of single key
exceed threshold
3. Keep remaining list in
memory
4. Keep min value of original
key in each group (11, ([file1],
[5],1))
(01, ([file2],[],1))
• Spilled [3,4] into file1
• Spilled [2,6] into file2
• Min value of original key is
1
Read list of files and in-
memory list, then
generate new pairs
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
Merge &
Dedup
(2,1)
(3,1)
(4,1)
(5,1)
(6,1)
1.
Separate
keys
2. Splitting
huge keys
3. Spill to
disk](https://crownmelresort.com/image.slidesharecdn.com/505fuwanghugracehuang-200707213625/75/Optimize-the-Large-Scale-Graph-Applications-by-using-Apache-Spark-with-4-5x-Performance-Improvements-9-2048.jpg)













This document discusses optimizing large graph applications using Apache Spark with 4-5x performance improvements. It describes challenges working with large graphs containing billions of vertices and edges with data skew. Techniques used to address "buckets effect" and out of memory errors included separating huge and normal keys, splitting huge keys, and spilling data to disk. Lessons learned emphasized optimizing memory usage, understanding Spark internals, and avoiding misusage. Performance was improved from 2 days to around 10 hours by enabling broadcast joins and refining data interfaces.








































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)














