Downloaded 15 times




![Page8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(‘t’)[2])
messages.cache()
messages.filter(lambda s: “foo” in s).count()
messages.filter(lambda s: “bar” in s).count()
. . .
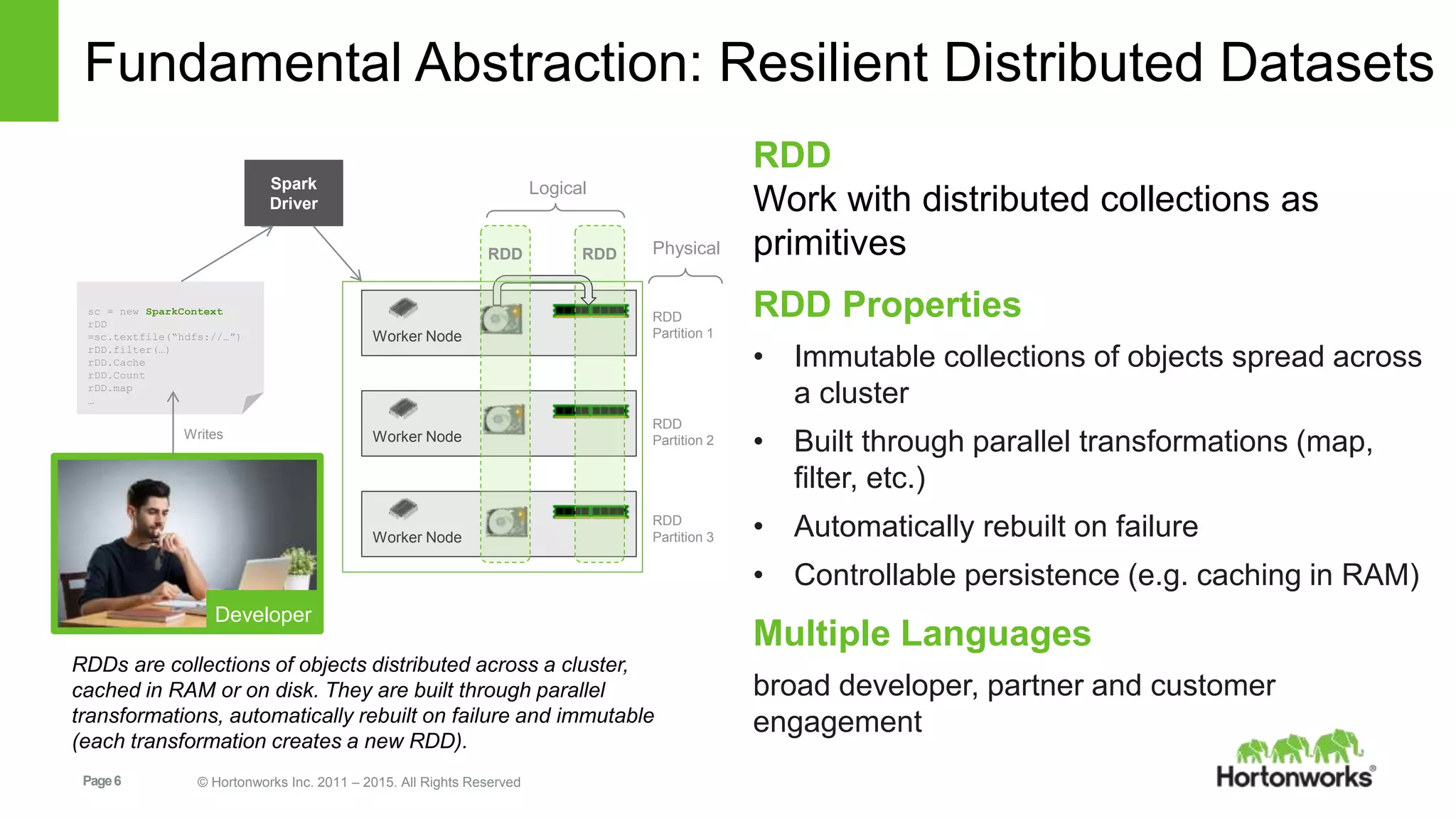
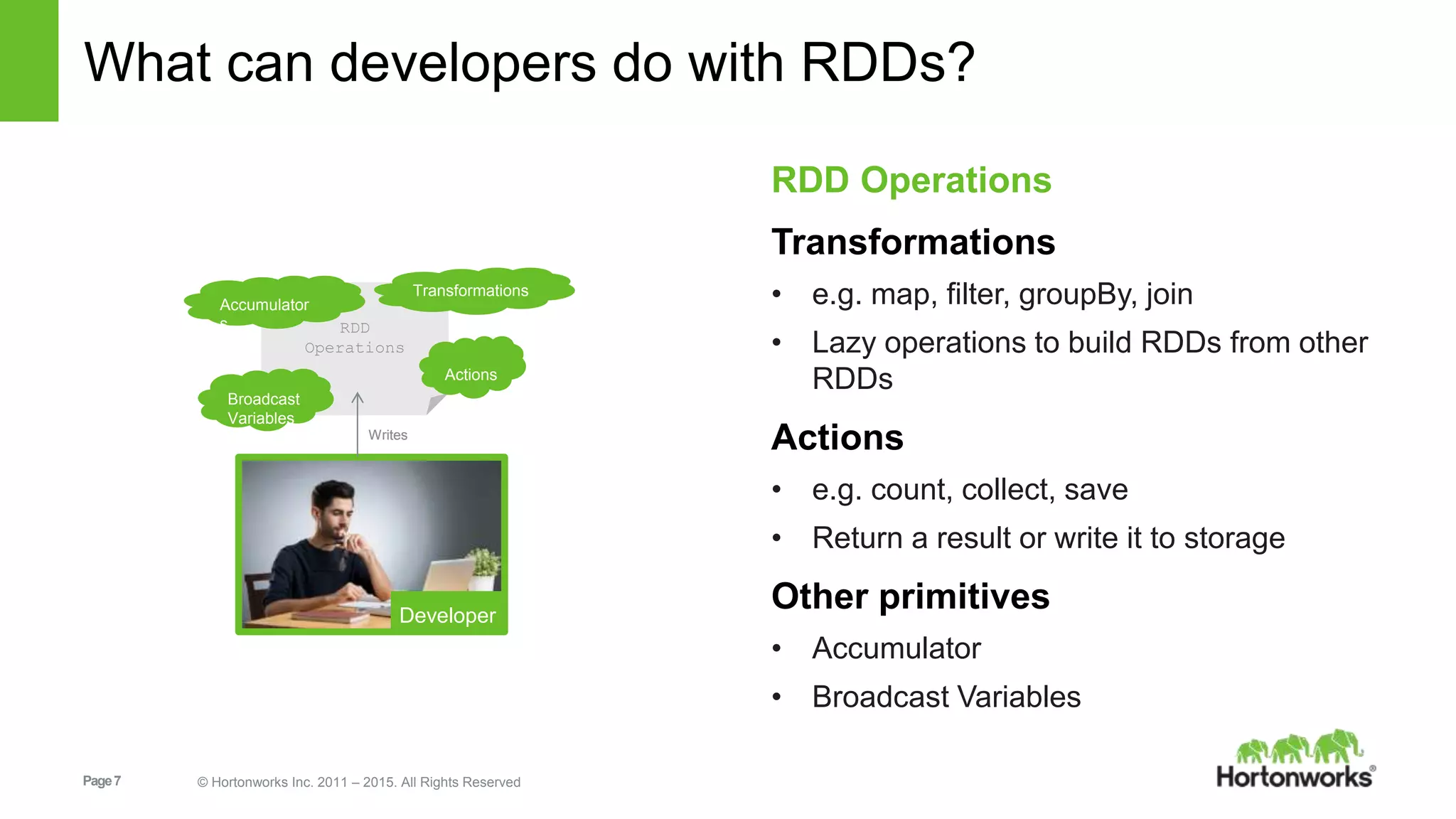
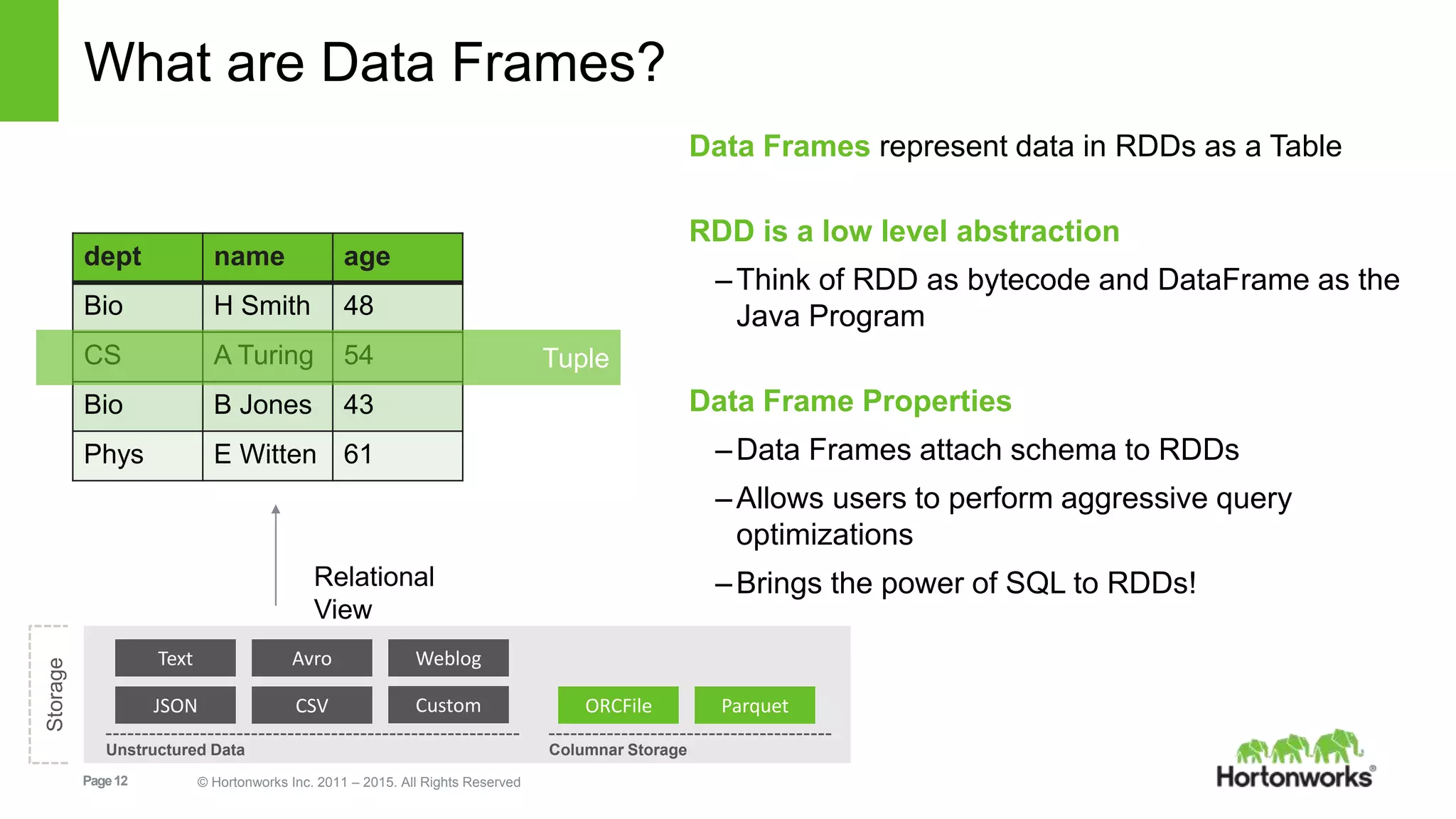
Base RDD
Transformed RDD
Action
Result: full-text search of Wikipedia in <1 sec
(vs 20 sec for on-disk data)
Result: scaled to 1 TB data in 5-7 sec
(vs 170 sec for on-disk data)
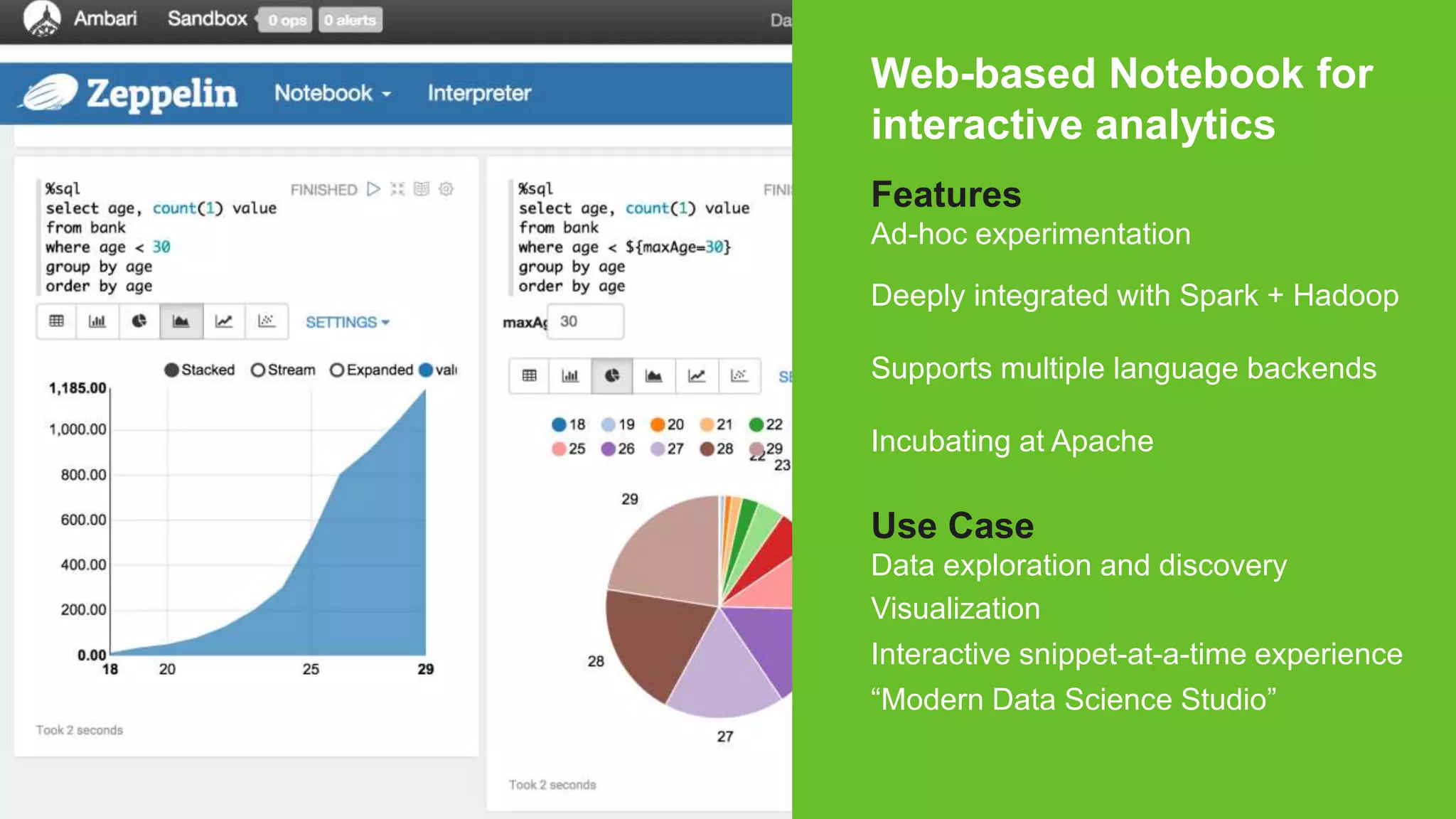
Example: Mining Console Logs
Load error messages from a log into memory, then
interactively search for patterns](https://image.slidesharecdn.com/sparkato-151120140438-lva1-app6892/75/Apache-Spark-Lightning-Fast-Cluster-Computing-8-2048.jpg)





















![Page8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(‘t’)[2])
messages.cache()
messages.filter(lambda s: “foo” in s).count()
messages.filter(lambda s: “bar” in s).count()
. . .
Base RDD
Transformed RDD
Action
Result: full-text search of Wikipedia in <1 sec
(vs 20 sec for on-disk data)
Result: scaled to 1 TB data in 5-7 sec
(vs 170 sec for on-disk data)
Example: Mining Console Logs
Load error messages from a log into memory, then
interactively search for patterns](https://crownmelresort.com/image.slidesharecdn.com/sparkato-151120140438-lva1-app6892/75/Apache-Spark-Lightning-Fast-Cluster-Computing-8-2048.jpg)




















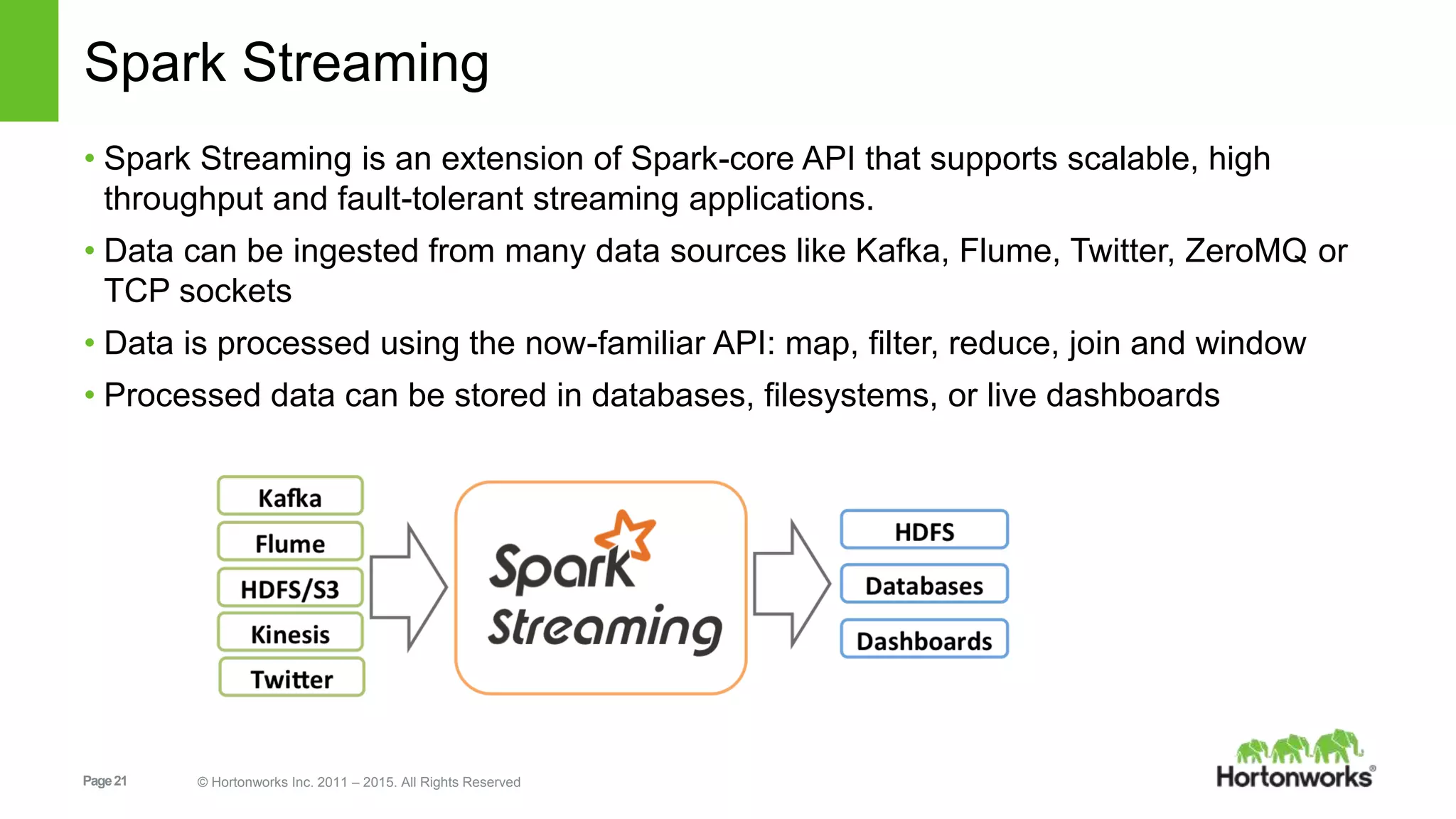
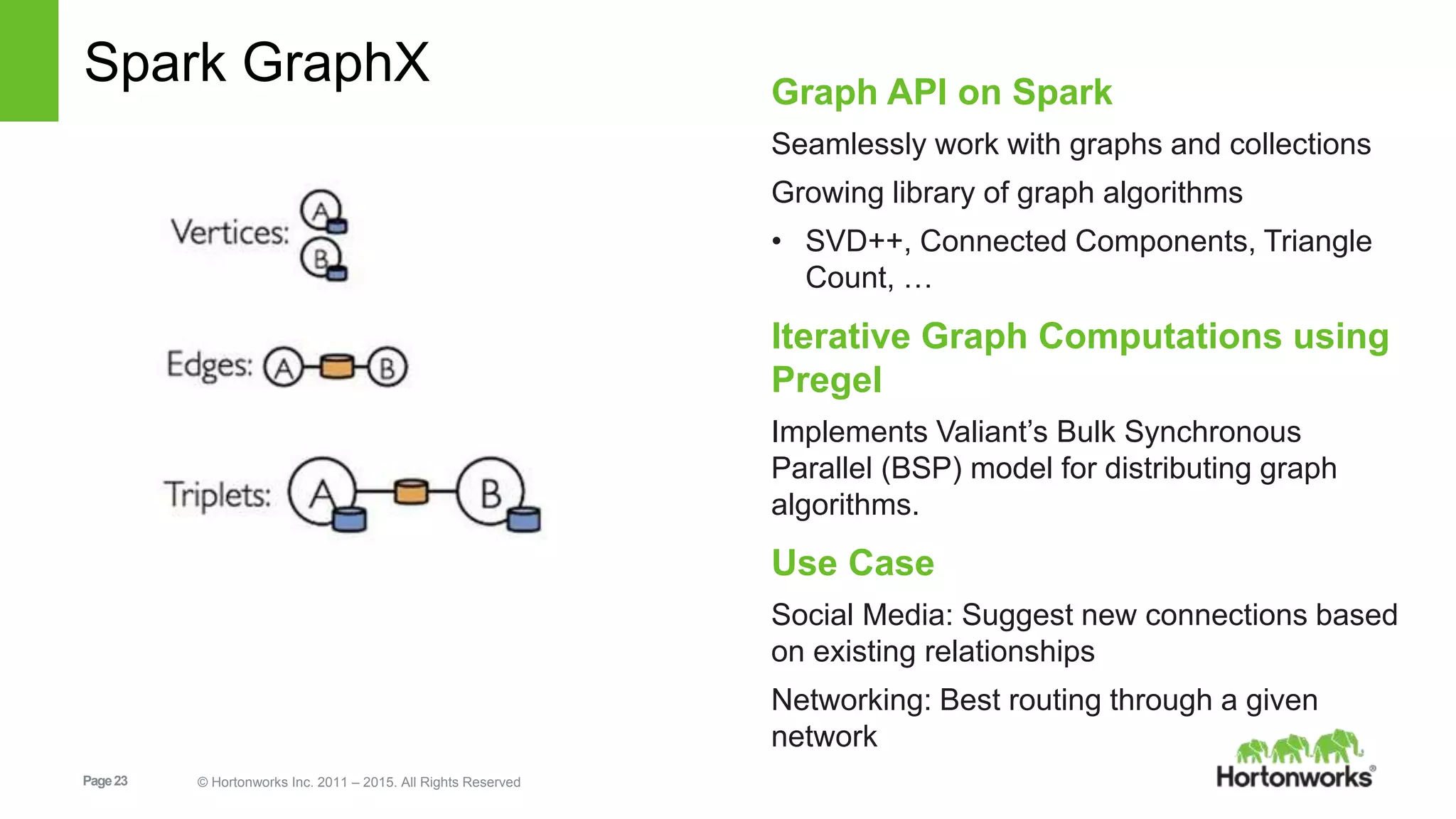
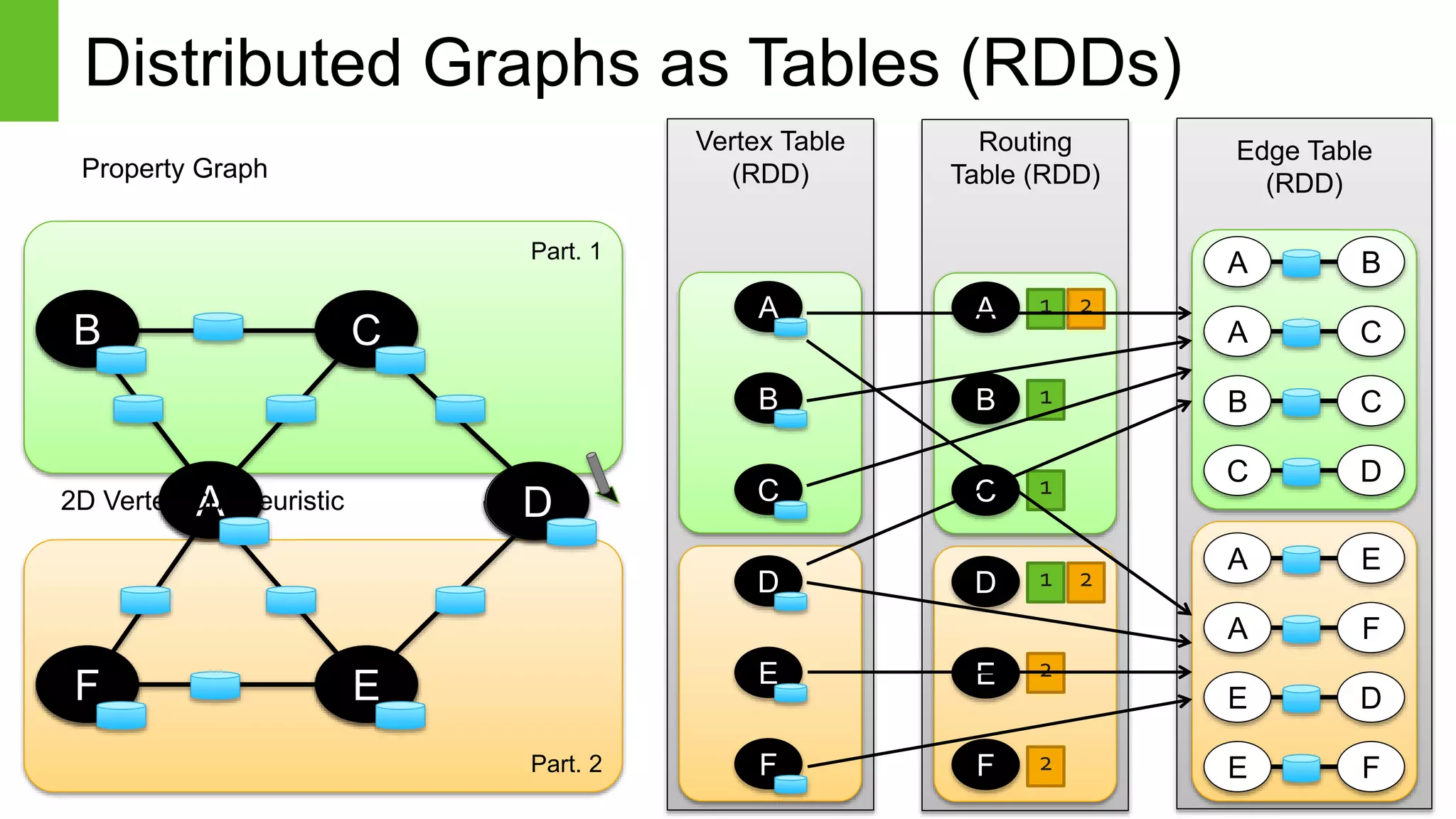
Apache Spark is an open-source cluster computing framework for fast and large-scale data processing. It uses an in-memory data abstraction called resilient distributed datasets (RDDs) that allow parallel operations on large datasets across a cluster. Spark also provides APIs in Java, Scala, Python and R for interactive data analysis through its core engine as well as high-level libraries for SQL, streaming, machine learning and graph processing.











































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)