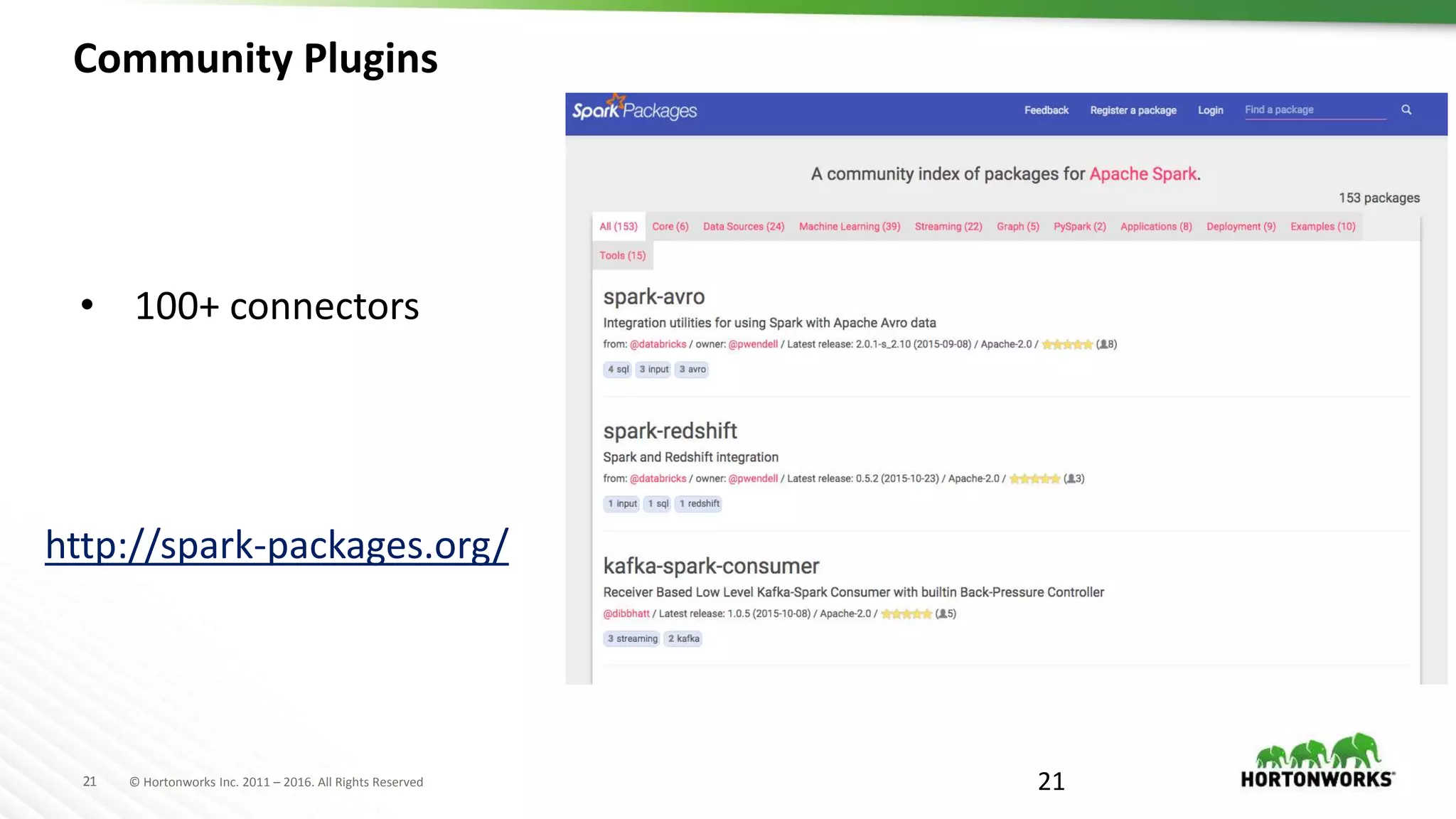
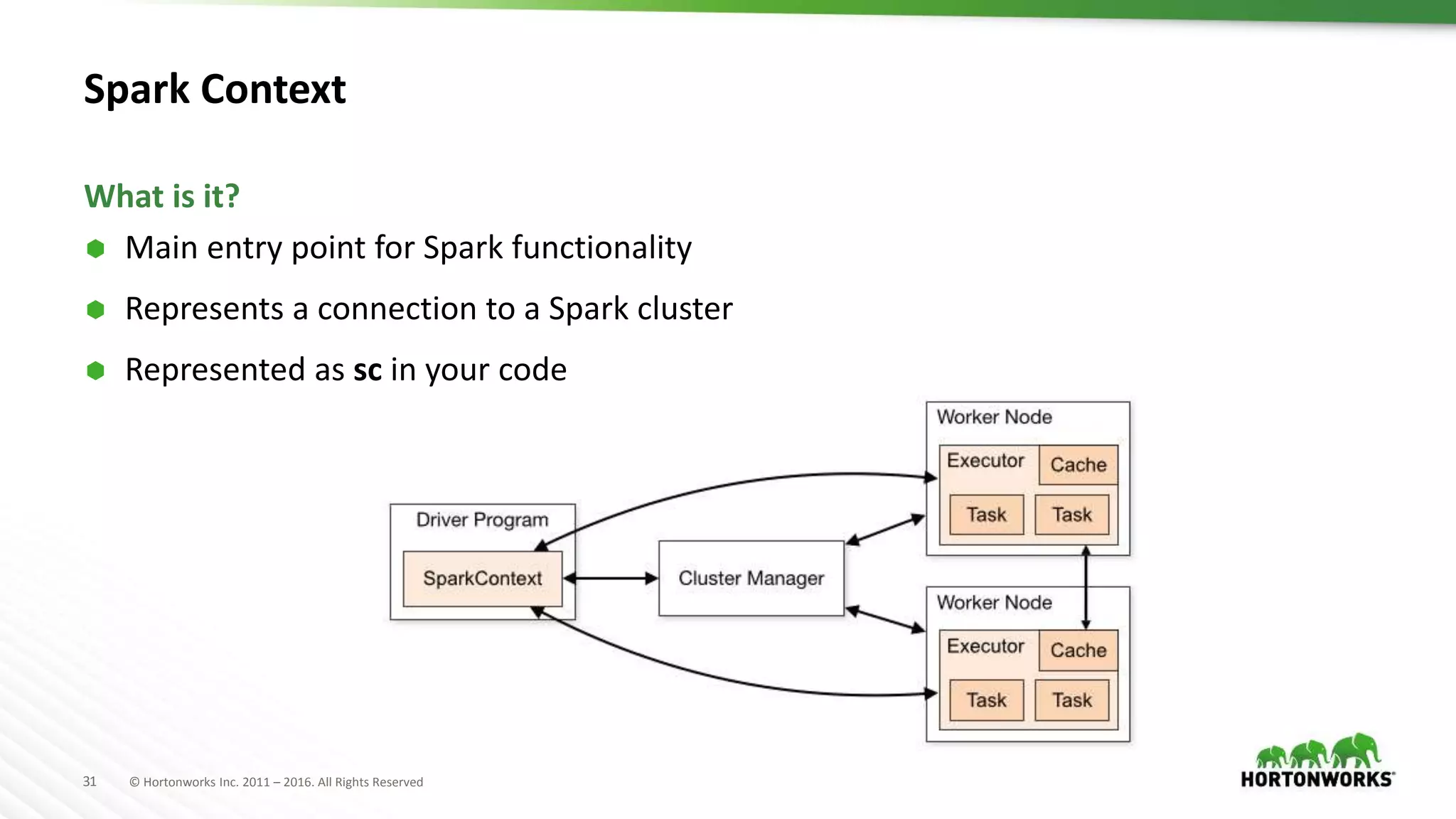
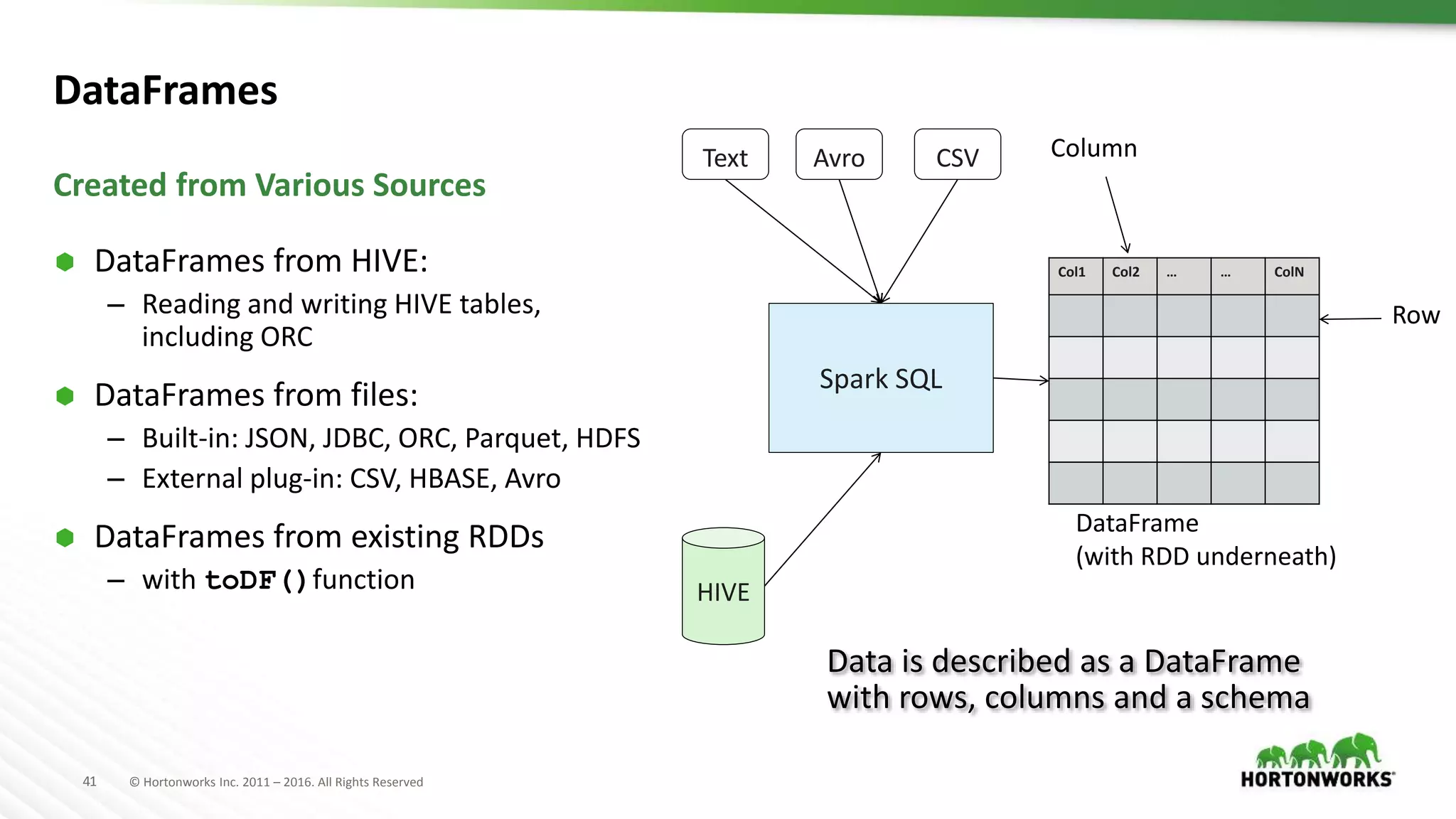
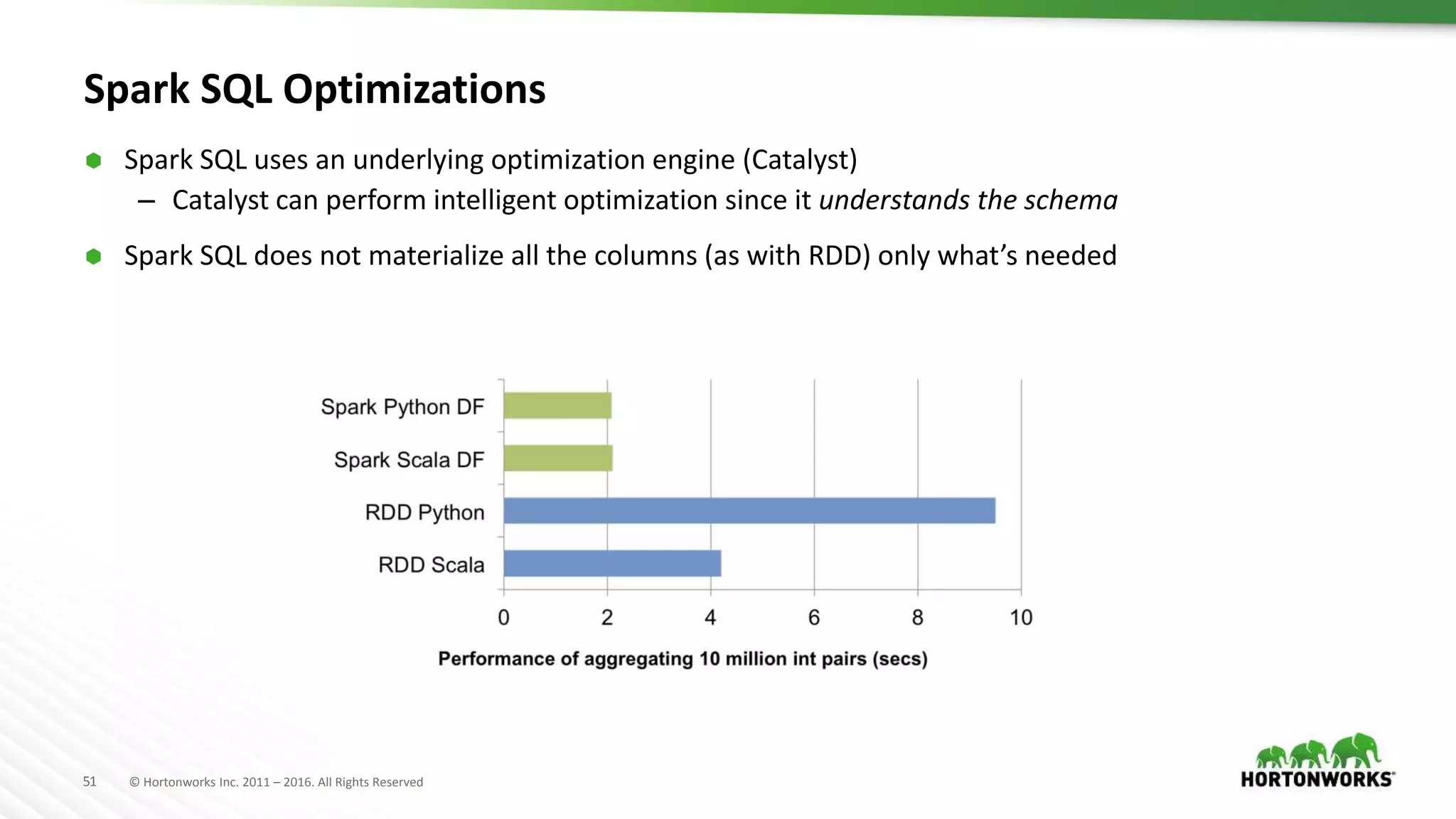
Downloaded 113 times
























![30 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
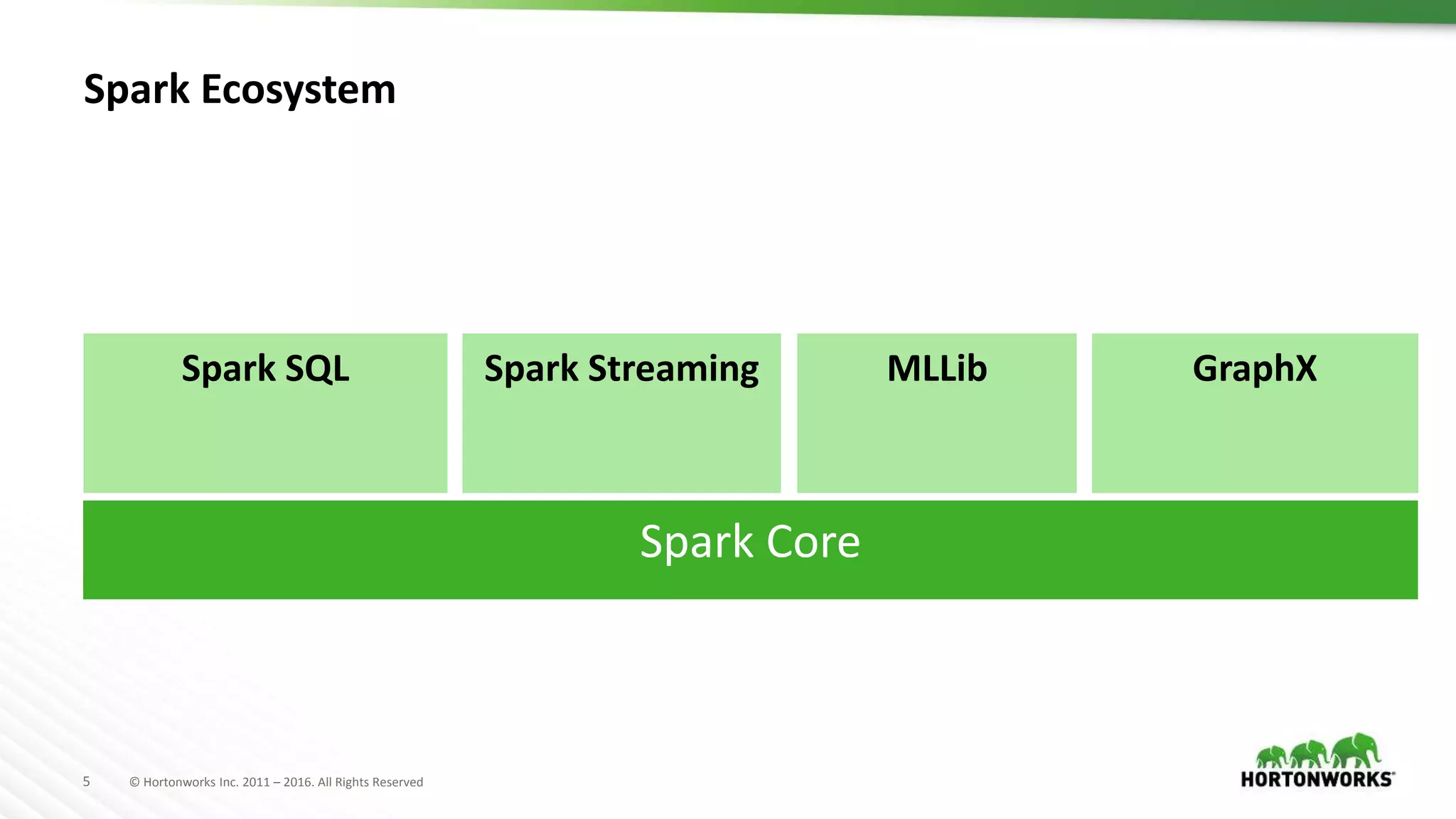
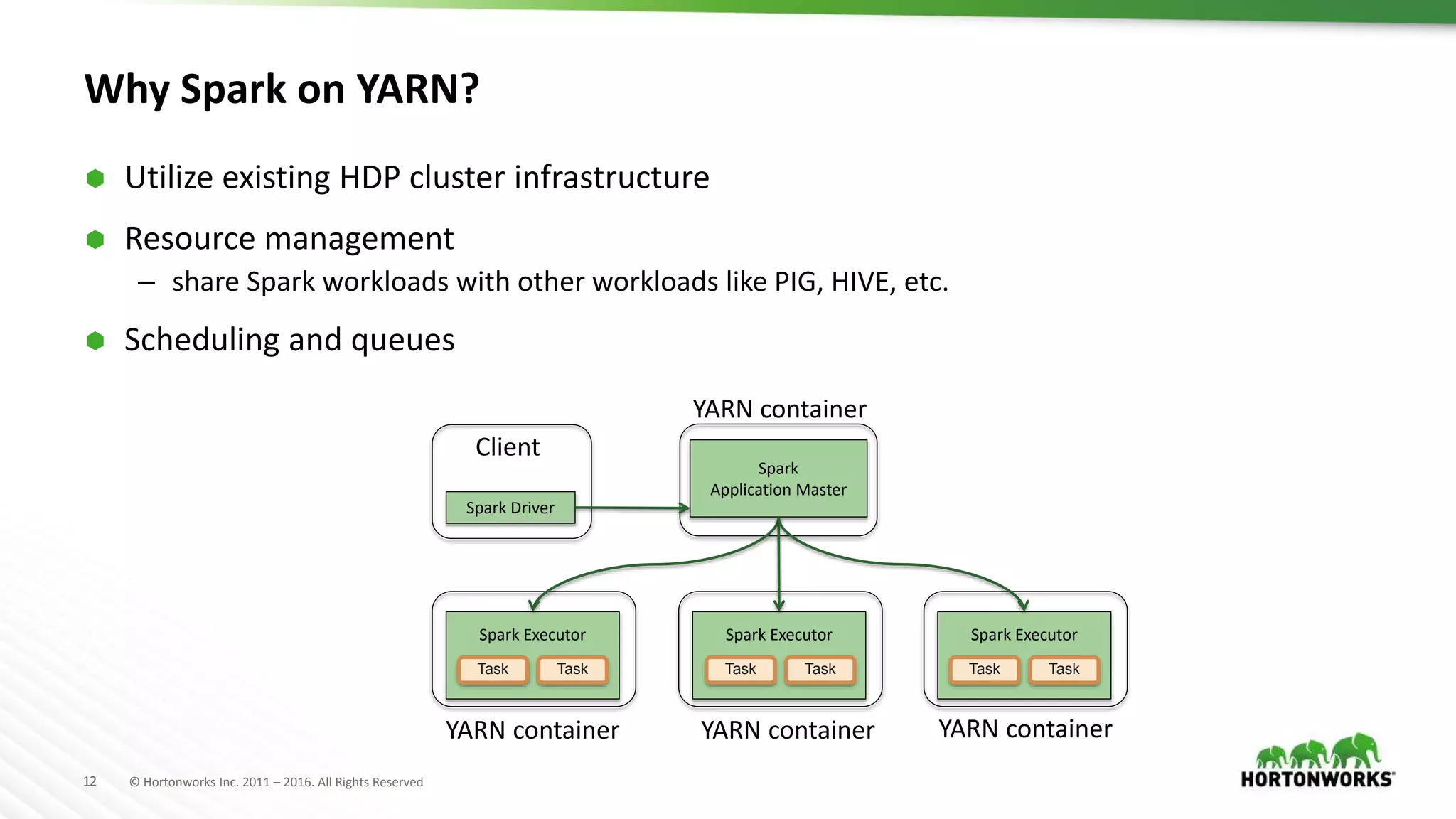
Spark Applications
Are a definition in code of
• RDD creation
• Actions
• Persistence
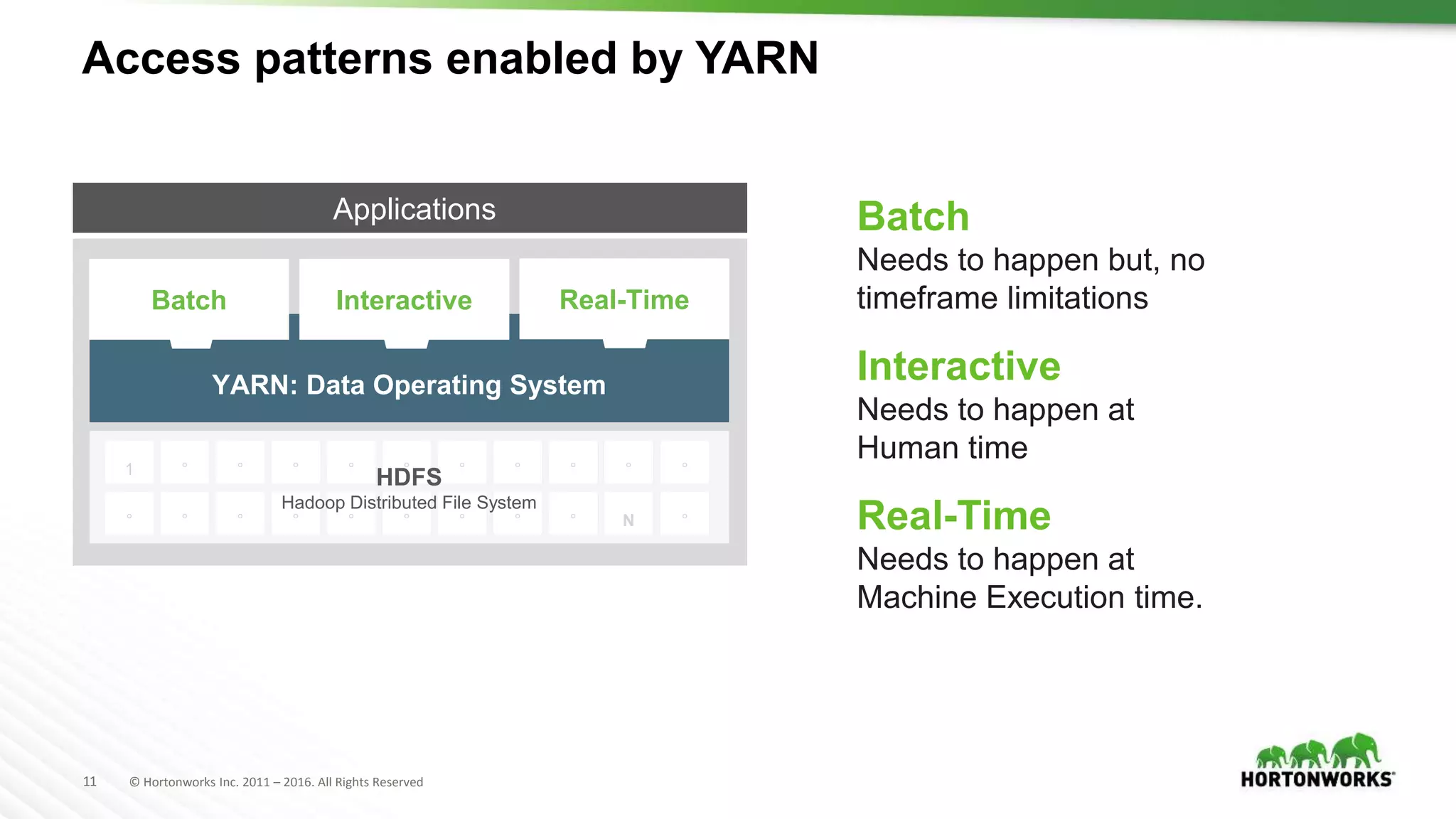
Results in the creation of a DAG (Directed Acyclic Graph) [workflow]
• Each DAG is compiled into stages
• Each Stage is executed as a series of Tasks
• Each Task operates in parallel on assigned partitions](https://image.slidesharecdn.com/introtosparkwithzeppelin-160505145550/75/Intro-to-Big-Data-Analytics-using-Apache-Spark-and-Apache-Zeppelin-30-2048.jpg)




![36 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the
function
Argument to the
function)](https://image.slidesharecdn.com/introtosparkwithzeppelin-160505145550/75/Intro-to-Big-Data-Analytics-using-Apache-Spark-and-Apache-Zeppelin-36-2048.jpg)














































![30 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Spark Applications
Are a definition in code of
• RDD creation
• Actions
• Persistence
Results in the creation of a DAG (Directed Acyclic Graph) [workflow]
• Each DAG is compiled into stages
• Each Stage is executed as a series of Tasks
• Each Task operates in parallel on assigned partitions](https://crownmelresort.com/image.slidesharecdn.com/introtosparkwithzeppelin-160505145550/75/Intro-to-Big-Data-Analytics-using-Apache-Spark-and-Apache-Zeppelin-30-2048.jpg)





![36 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the
function
Argument to the
function)](https://crownmelresort.com/image.slidesharecdn.com/introtosparkwithzeppelin-160505145550/75/Intro-to-Big-Data-Analytics-using-Apache-Spark-and-Apache-Zeppelin-36-2048.jpg)






















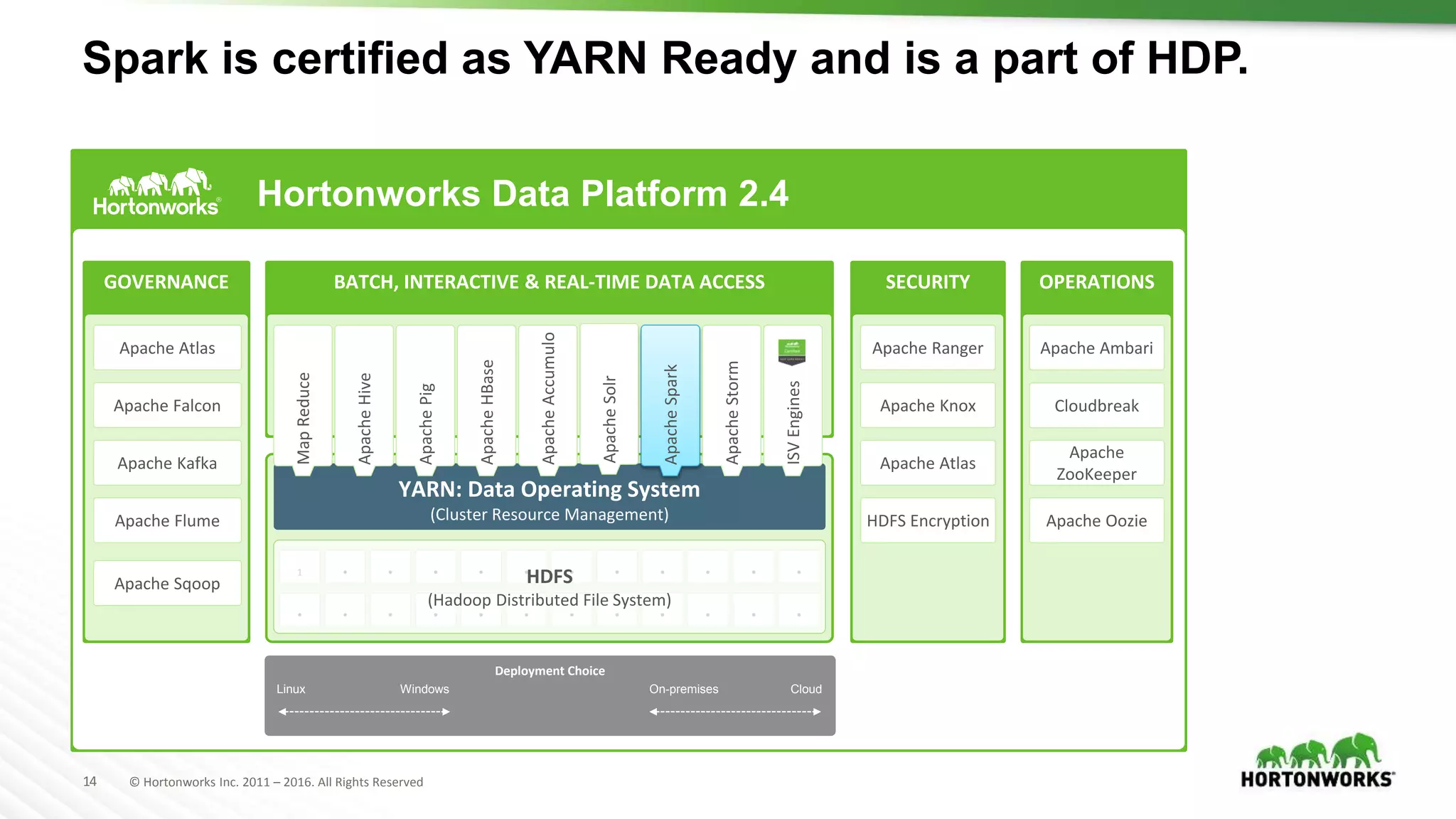
The document is a comprehensive workshop presentation introducing Apache Spark and its components, including SparkSQL, MLlib, and Spark Streaming. It highlights Spark's capabilities in big data analytics, programming interfaces, and integration with Hadoop and Zeppelin for interactive data processing. In addition, it covers the architecture, benefits, and typical use cases of Apache Spark in handling large datasets efficiently.





























































