





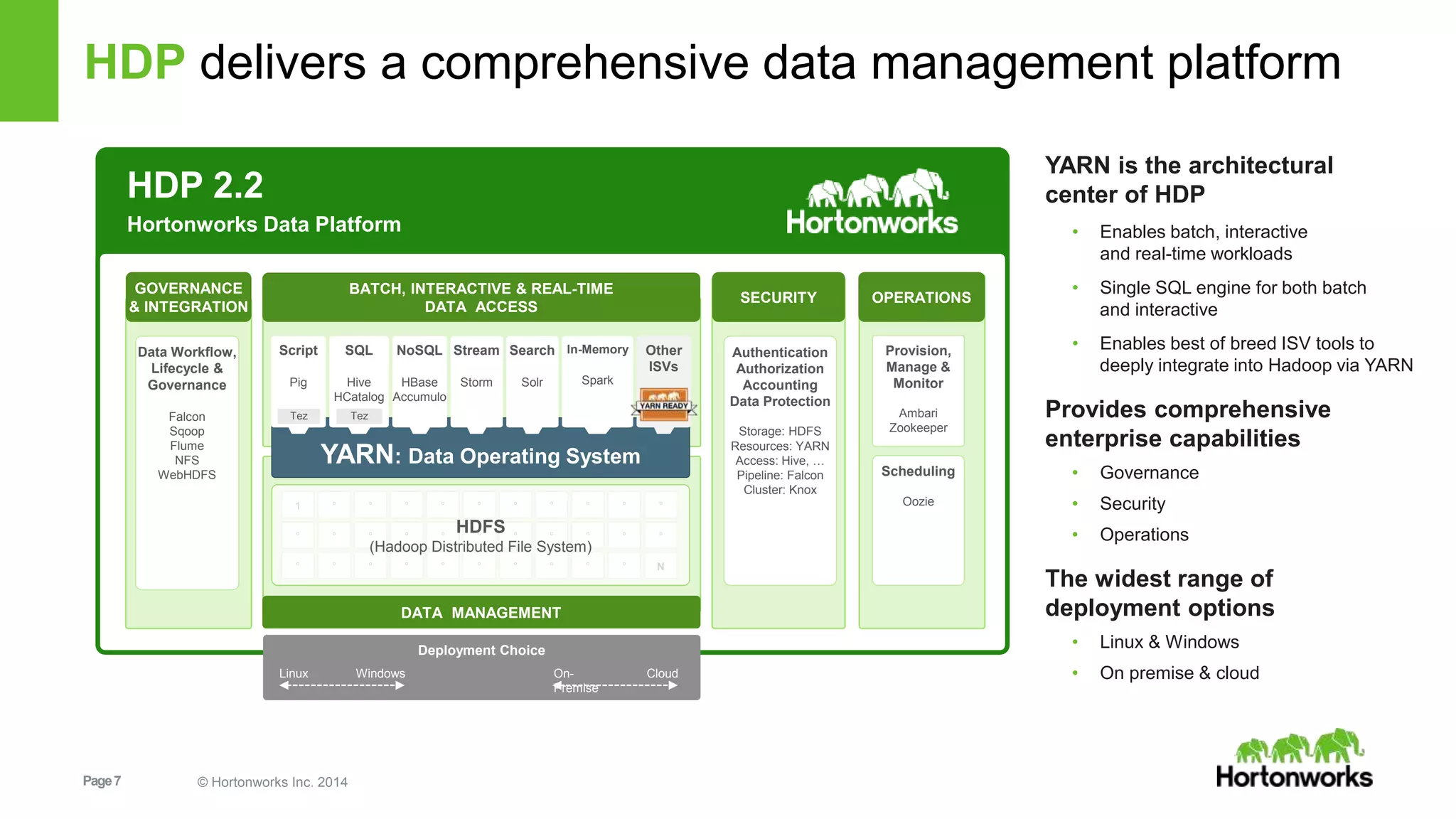
![Page9 © Hortonworks Inc. 2014
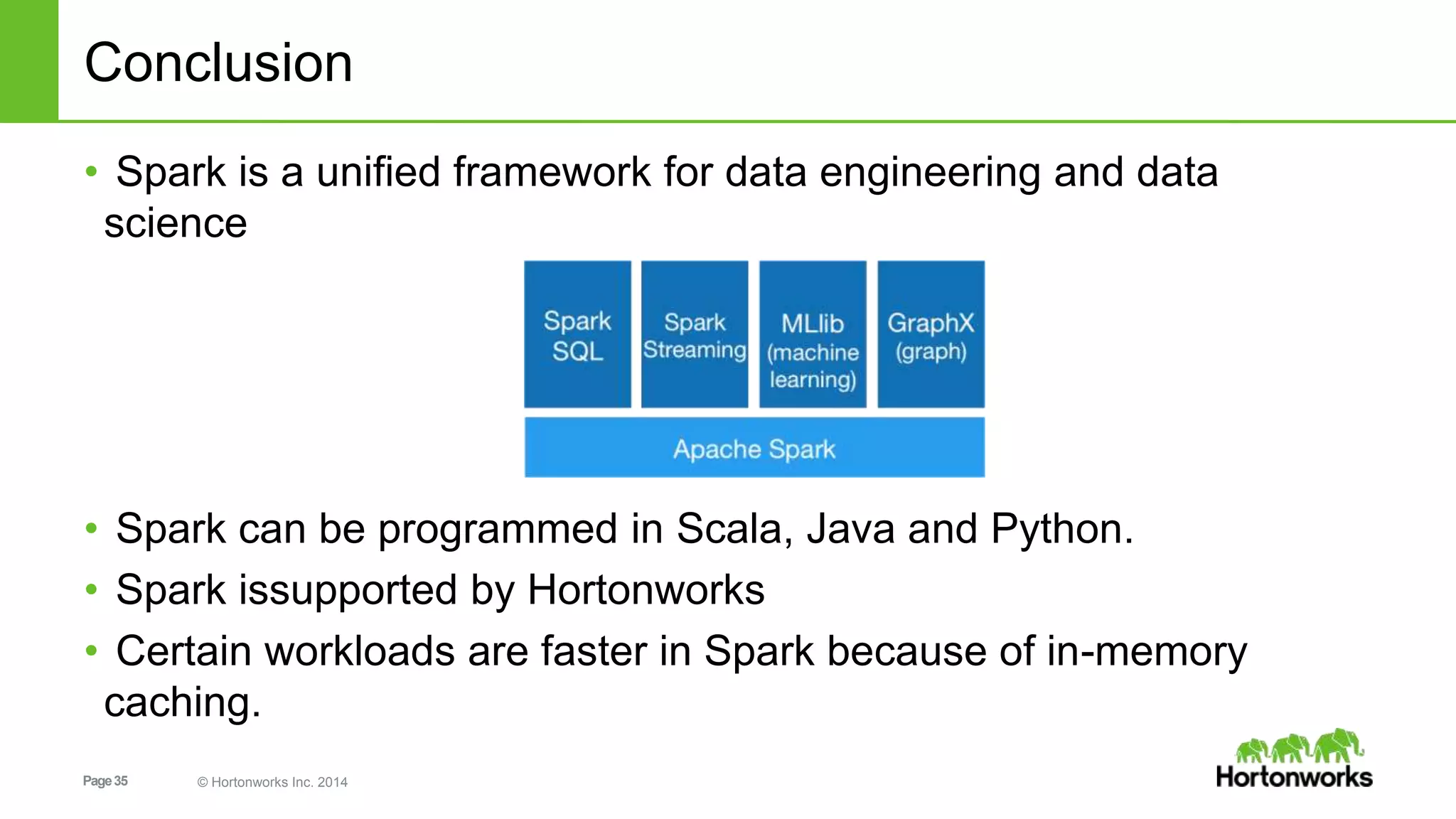
What is Spark?
• Spark is
– an open-source software solution that performs rapid calculations
on in-memory datasets
- Open Source [Apache hosted & licensed]
• Free to download and use in production
• Developed by a community of developers
- In-memory datasets
• RDD (Resilient Distributed Data) is the basis for what Spark enables
• Resilient – the models can be recreated on the fly from known state
• Distributed – the dataset is often partitioned across multiple nodes for
increased scalability and parallelism](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-9-2048.jpg)







![Page21 © Hortonworks Inc. 2014
1. Resilient Distributed Dataset [RDD] Graph
val v = sc.textFile("hdfs://…some-hdfs-data")
mapmap reduceByKey collecttextFile
v.flatMap(line=>line.split(" "))
.map(word=>(word, 1)))
.reduceByKey(_ + _, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
Array[(String, Int)]
RDD[(String, Int)]](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-21-2048.jpg)

![Page23 © Hortonworks Inc. 2014
Looking at the State in the Machine
//run debug command to inspect RDD:
scala> fltr.toDebugString
//simplified output:
res1: String =
FilteredRDD[2] at filter at <console>:14
MappedRDD[1] at textFile at <console>:12
HadoopRDD[0] at textFile at <console>:12
23](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-23-2048.jpg)


![Page26 © Hortonworks Inc. 2014
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the function
Argument to the function)](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-26-2048.jpg)


![Page31 © Hortonworks Inc. 2014
What About Integration With Hive?
scala> val hiveCTX = new org.apache.spark.sql.hive.HiveContext(sc)
scala> hiveCTX.hql("SHOW TABLES").collect().foreach(println)
…
[omniture]
[omniturelogs]
[orc_table]
[raw_products]
[raw_users]
…
31](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-31-2048.jpg)
![Page32 © Hortonworks Inc. 2014
More Integration With Hive:
scala> hCTX.hql("DESCRIBE raw_users").collect().foreach(println)
[swid,string,null]
[birth_date,string,null]
[gender_cd,string,null]
scala> hCTX.hql("SELECT * FROM raw_users WHERE gender_cd='F' LIMIT
5").collect().foreach(println)
[0001BDD9-EABF-4D0D-81BD-D9EABFCD0D7D,8-Apr-84,F]
[00071AA7-86D2-4EB9-871A-A786D27EB9BA,7-Feb-88,F]
[00071B7D-31AF-4D85-871B-7D31AFFD852E,22-Oct-64,F]
[000F36E5-9891-4098-9B69-CEE78483B653,24-Mar-85,F]
[00102F3F-061C-4212-9F91-1254F9D6E39F,1-Nov-91,F]
32](https://image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-32-2048.jpg)











![Page9 © Hortonworks Inc. 2014
What is Spark?
• Spark is
– an open-source software solution that performs rapid calculations
on in-memory datasets
- Open Source [Apache hosted & licensed]
• Free to download and use in production
• Developed by a community of developers
- In-memory datasets
• RDD (Resilient Distributed Data) is the basis for what Spark enables
• Resilient – the models can be recreated on the fly from known state
• Distributed – the dataset is often partitioned across multiple nodes for
increased scalability and parallelism](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-9-2048.jpg)











![Page21 © Hortonworks Inc. 2014
1. Resilient Distributed Dataset [RDD] Graph
val v = sc.textFile("hdfs://…some-hdfs-data")
mapmap reduceByKey collecttextFile
v.flatMap(line=>line.split(" "))
.map(word=>(word, 1)))
.reduceByKey(_ + _, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
Array[(String, Int)]
RDD[(String, Int)]](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-21-2048.jpg)

![Page23 © Hortonworks Inc. 2014
Looking at the State in the Machine
//run debug command to inspect RDD:
scala> fltr.toDebugString
//simplified output:
res1: String =
FilteredRDD[2] at filter at <console>:14
MappedRDD[1] at textFile at <console>:12
HadoopRDD[0] at textFile at <console>:12
23](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-23-2048.jpg)


![Page26 © Hortonworks Inc. 2014
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the function
Argument to the function)](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-26-2048.jpg)




![Page31 © Hortonworks Inc. 2014
What About Integration With Hive?
scala> val hiveCTX = new org.apache.spark.sql.hive.HiveContext(sc)
scala> hiveCTX.hql("SHOW TABLES").collect().foreach(println)
…
[omniture]
[omniturelogs]
[orc_table]
[raw_products]
[raw_users]
…
31](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-31-2048.jpg)
![Page32 © Hortonworks Inc. 2014
More Integration With Hive:
scala> hCTX.hql("DESCRIBE raw_users").collect().foreach(println)
[swid,string,null]
[birth_date,string,null]
[gender_cd,string,null]
scala> hCTX.hql("SELECT * FROM raw_users WHERE gender_cd='F' LIMIT
5").collect().foreach(println)
[0001BDD9-EABF-4D0D-81BD-D9EABFCD0D7D,8-Apr-84,F]
[00071AA7-86D2-4EB9-871A-A786D27EB9BA,7-Feb-88,F]
[00071B7D-31AF-4D85-871B-7D31AFFD852E,22-Oct-64,F]
[000F36E5-9891-4098-9B69-CEE78483B653,24-Mar-85,F]
[00102F3F-061C-4212-9F91-1254F9D6E39F,1-Nov-91,F]
32](https://crownmelresort.com/image.slidesharecdn.com/spark-crashcourseworkshop-final-150713215345-lva1-app6891/75/Spark-crash-course-workshop-at-Hadoop-Summit-32-2048.jpg)





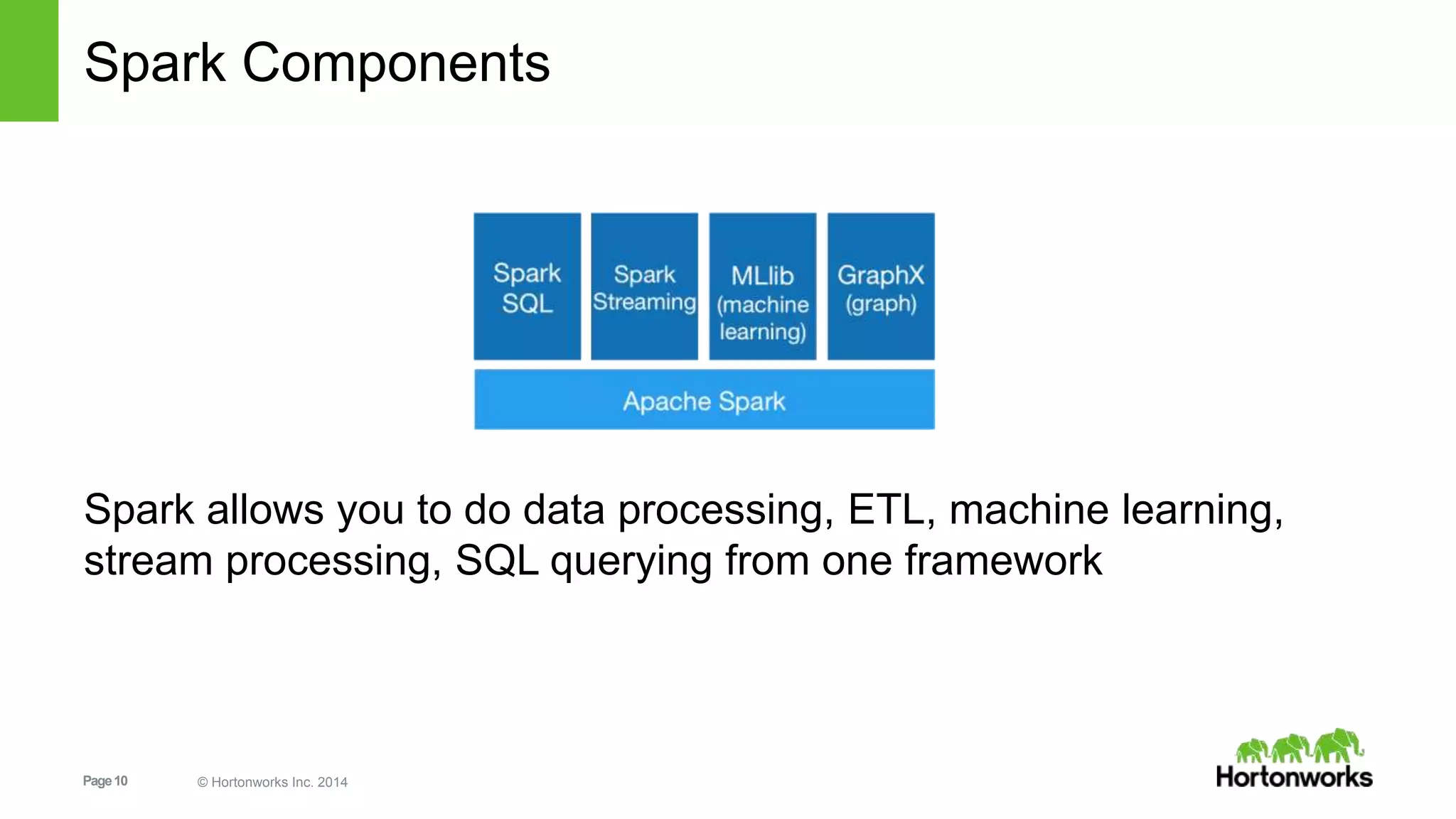
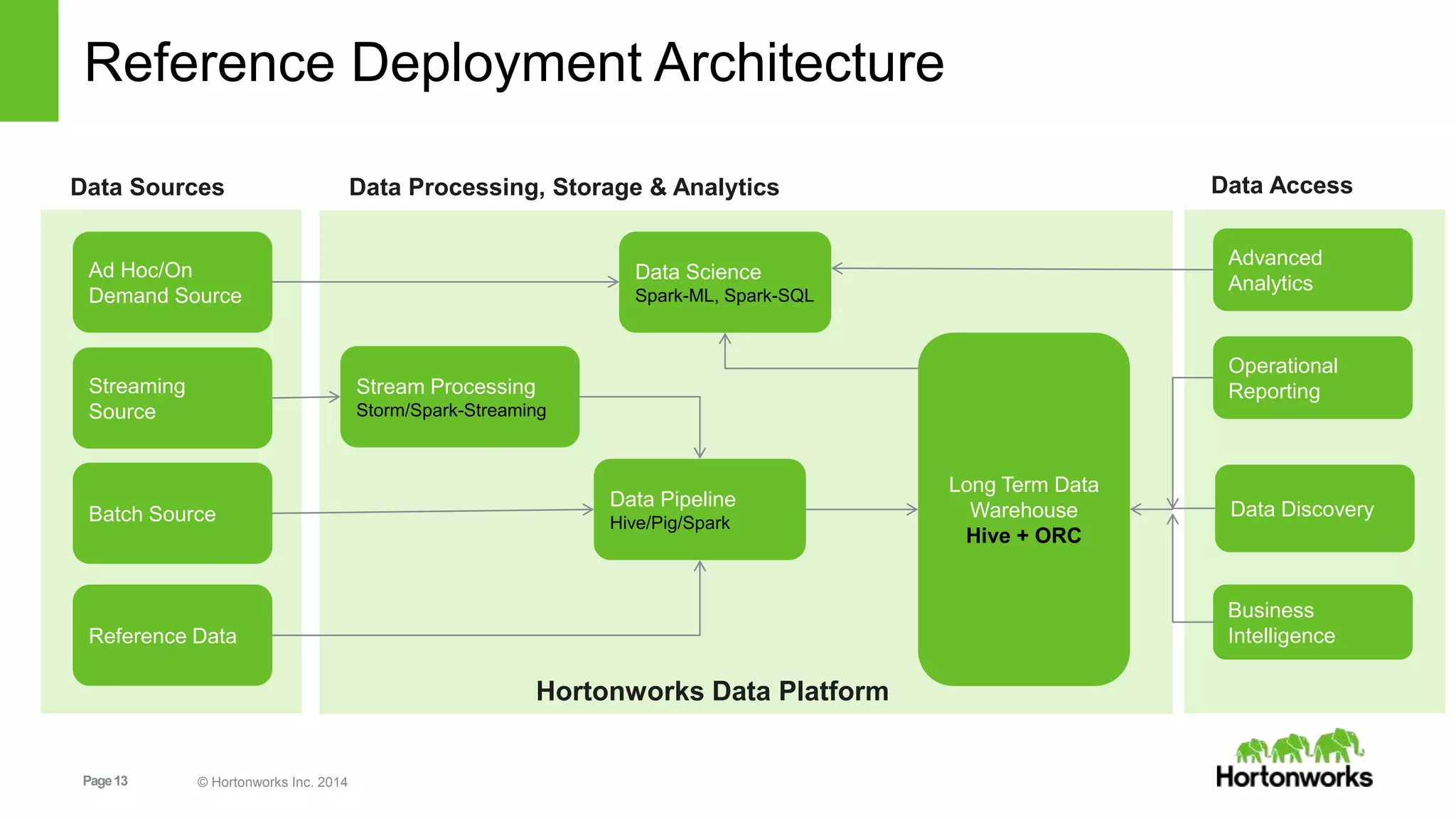
This document provides an overview of installing and programming with Apache Spark on Hortonworks Data Platform (HDP). It introduces Spark and its components, benefits over other frameworks, and Hortonworks' commitment to Spark. The document outlines an example Spark programming workflow using Resilient Distributed Datasets (RDDs) in Scala, and covers common RDD transformations, actions, and persistence methods. It also discusses Spark deployment modes like standalone and on YARN, and reference HDP architectures using Spark.










































































































