Downloaded 40 times


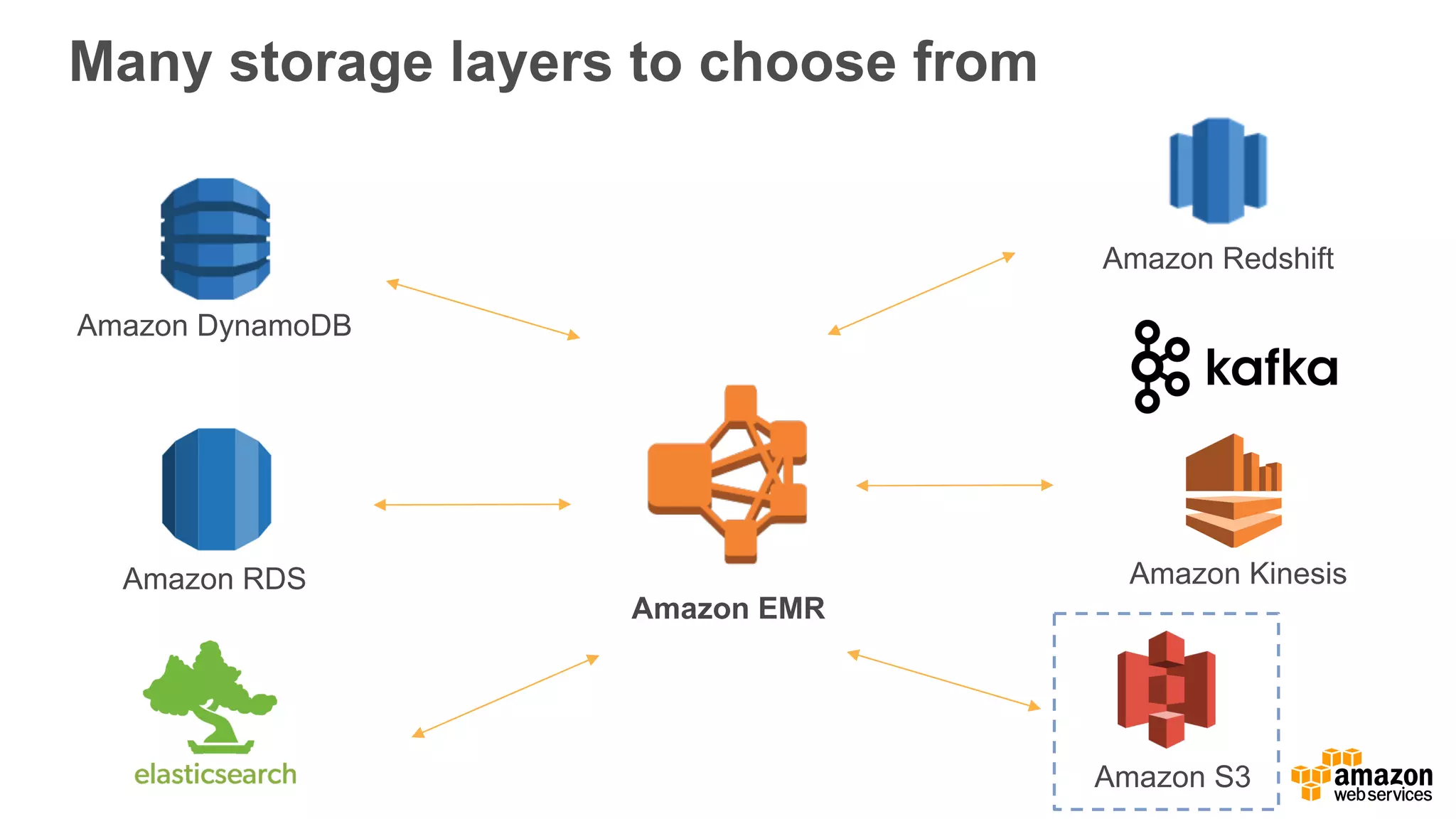
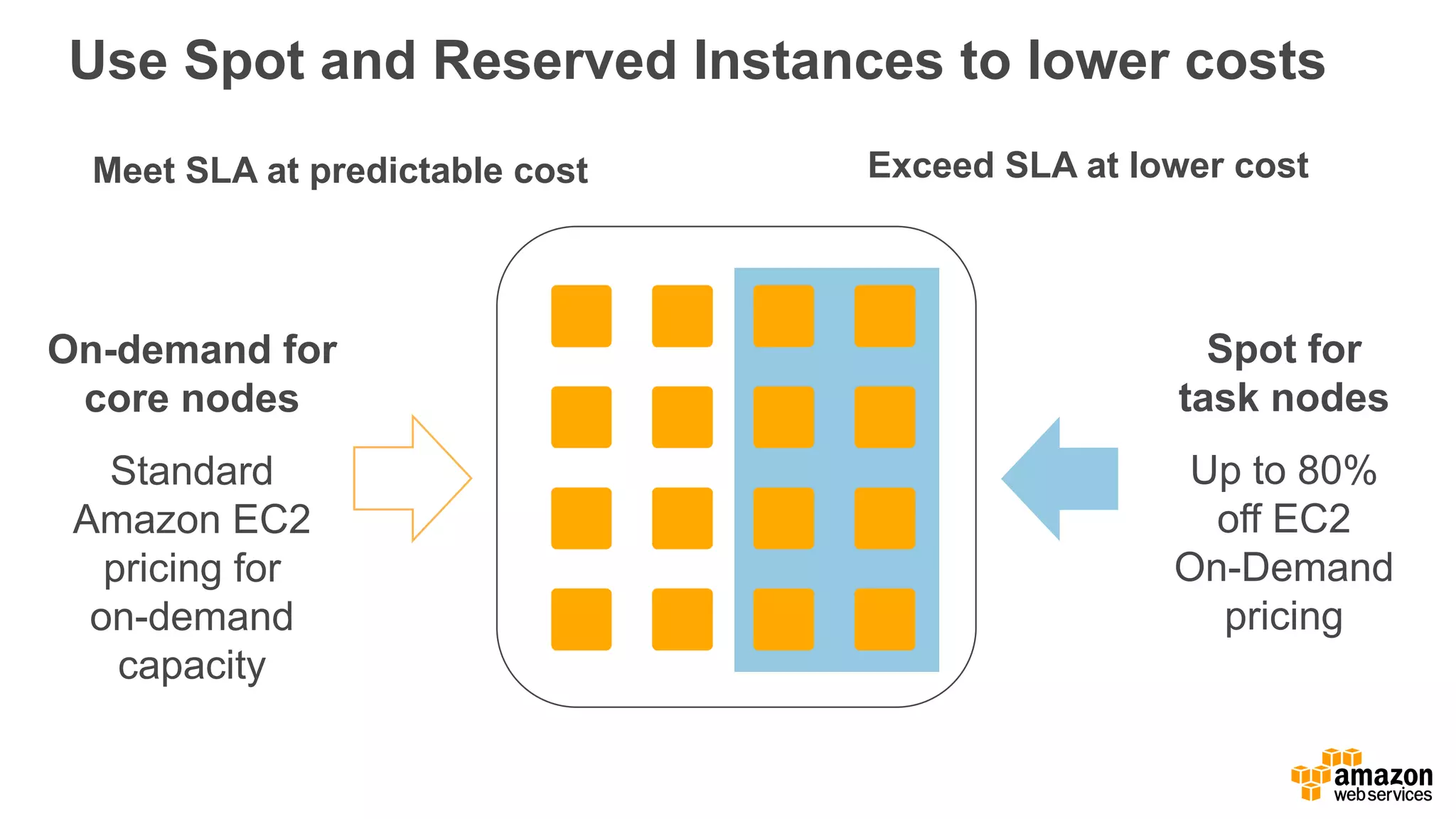
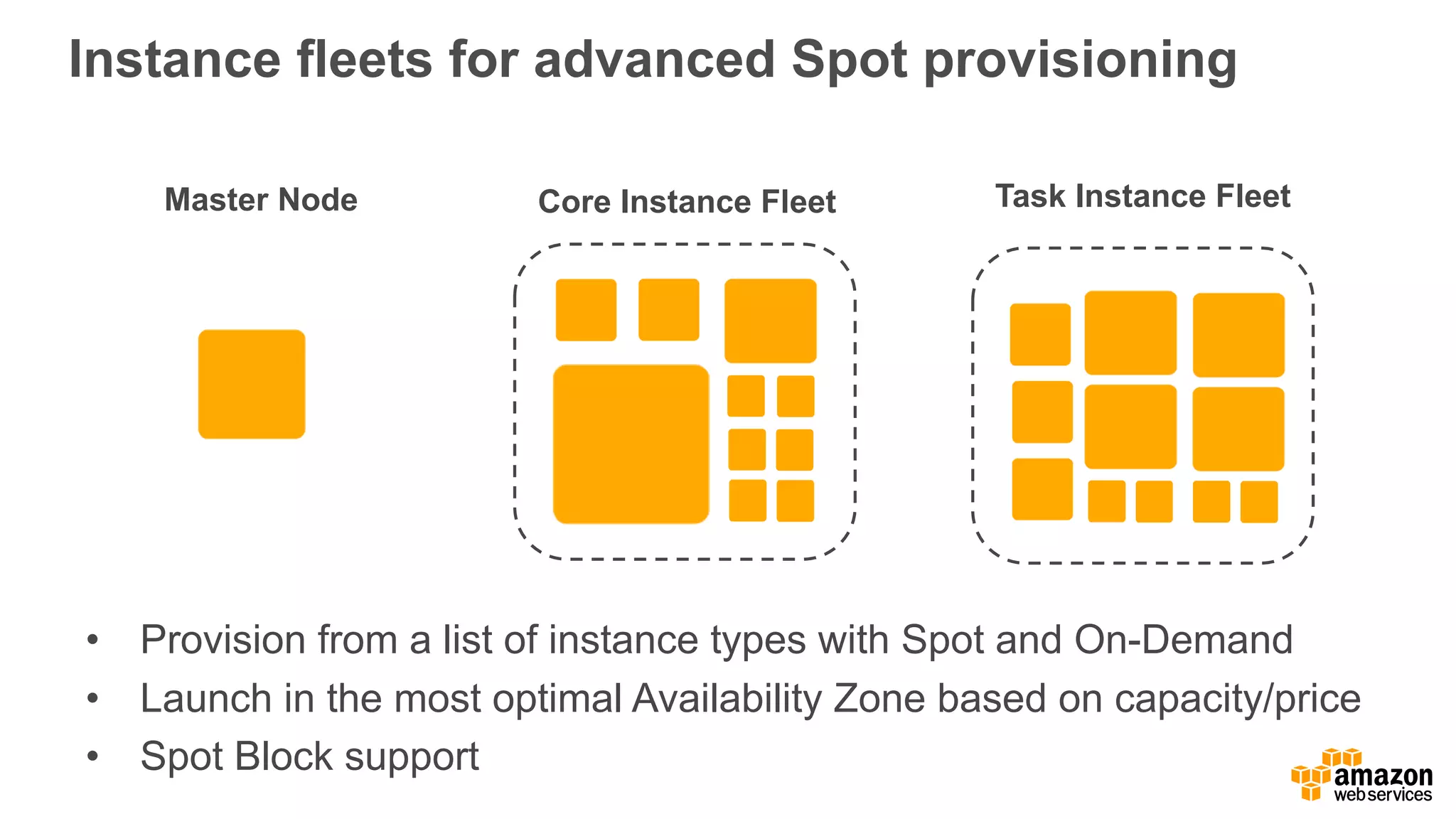
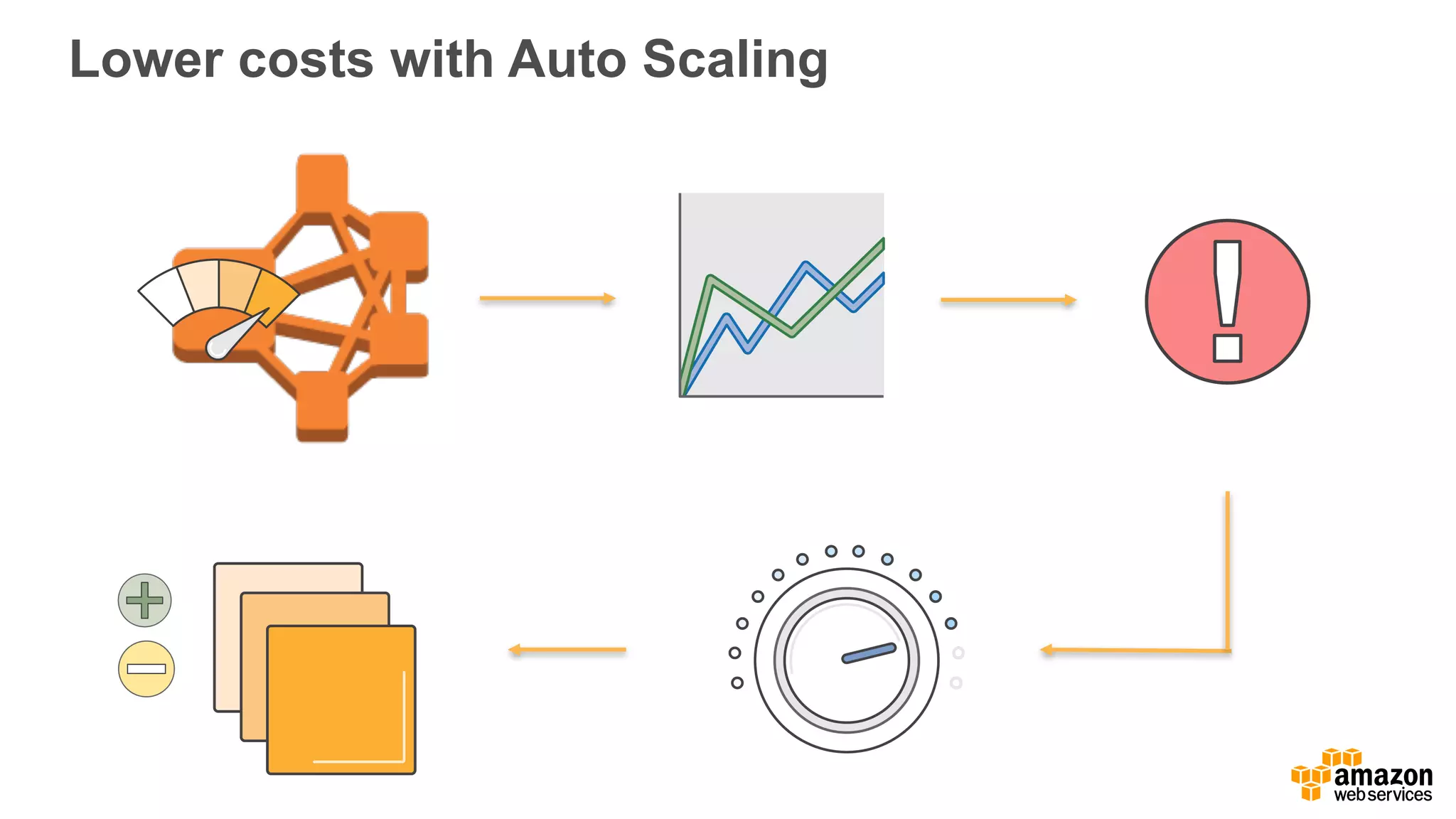
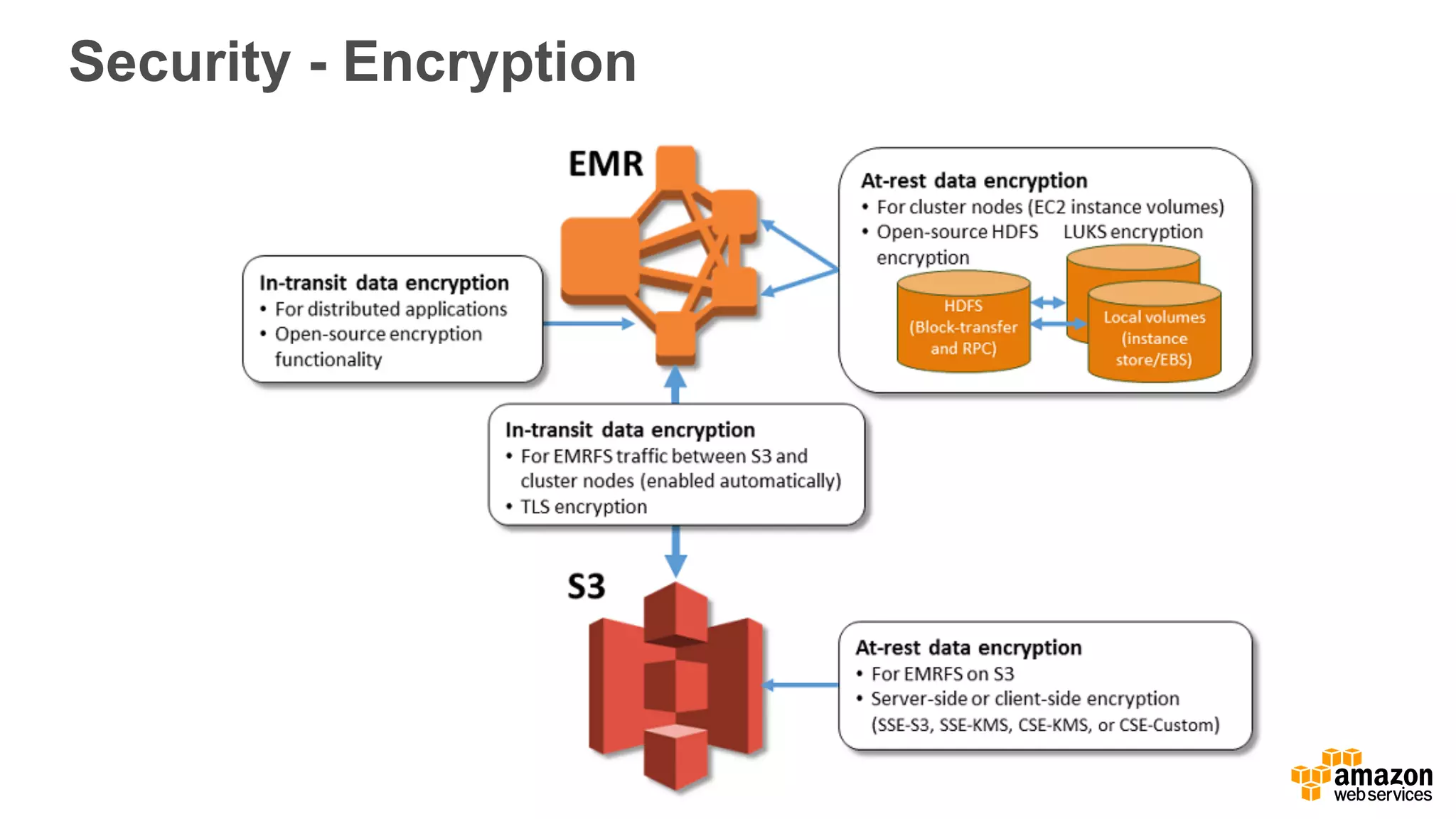
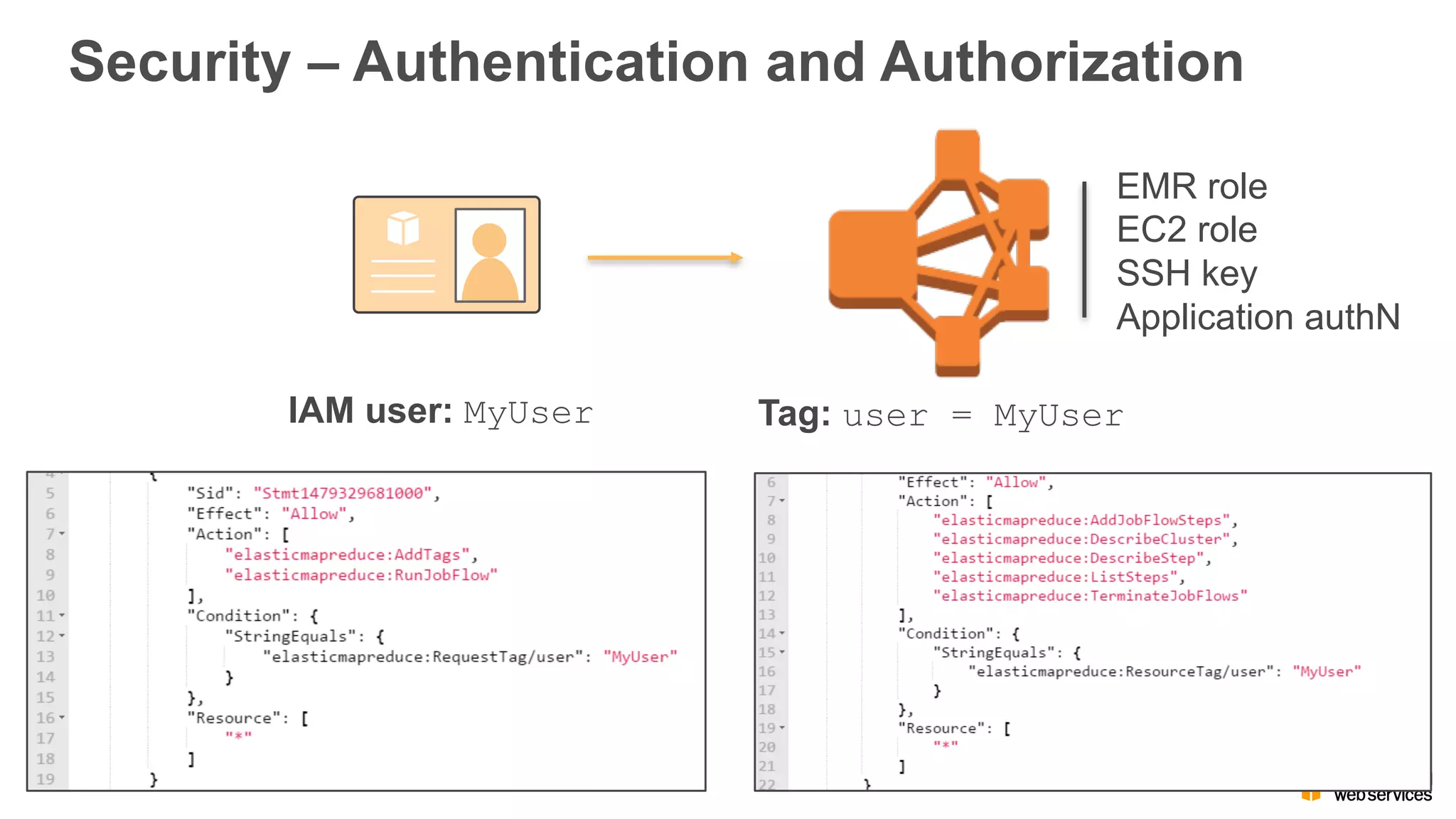
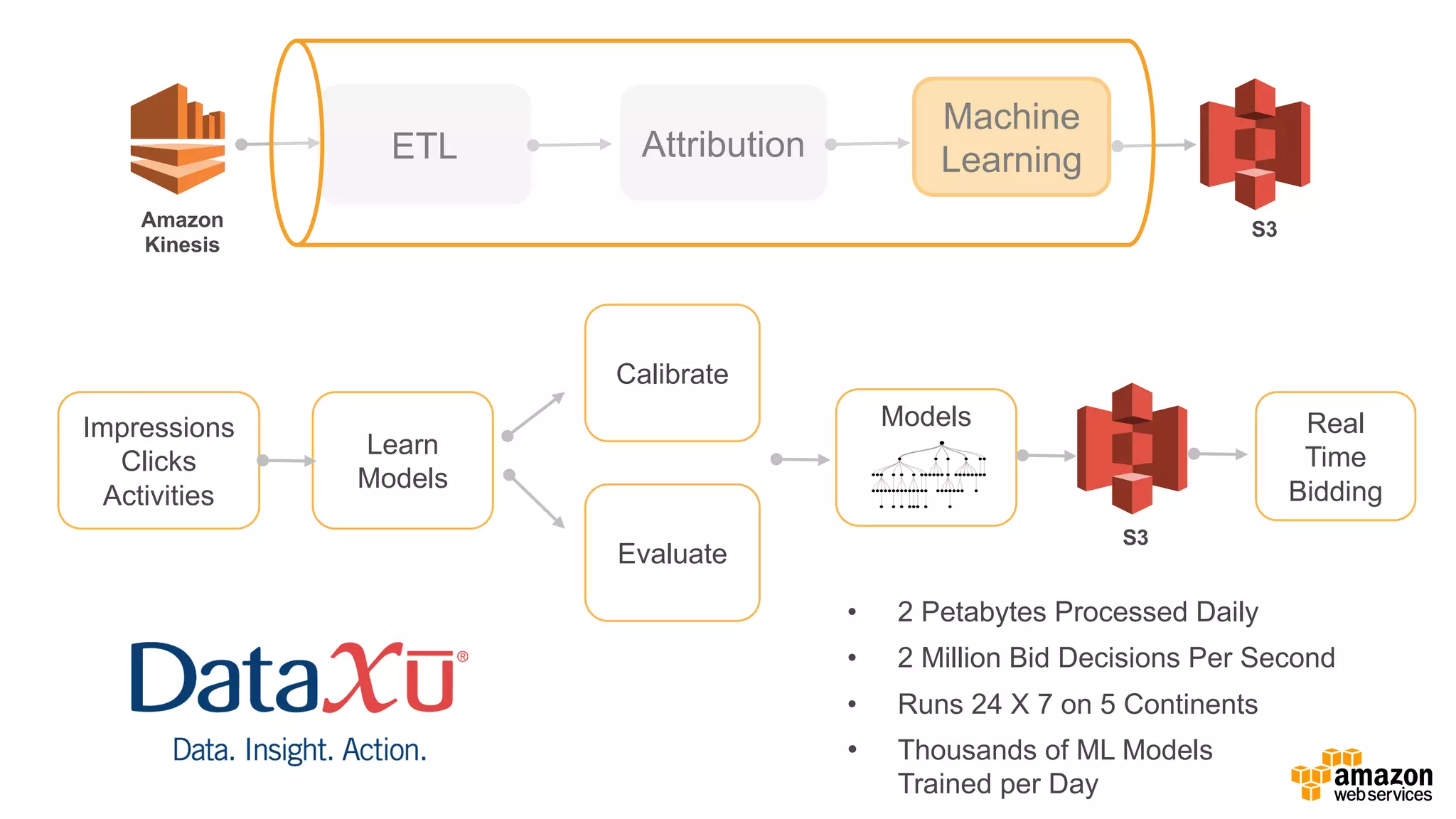
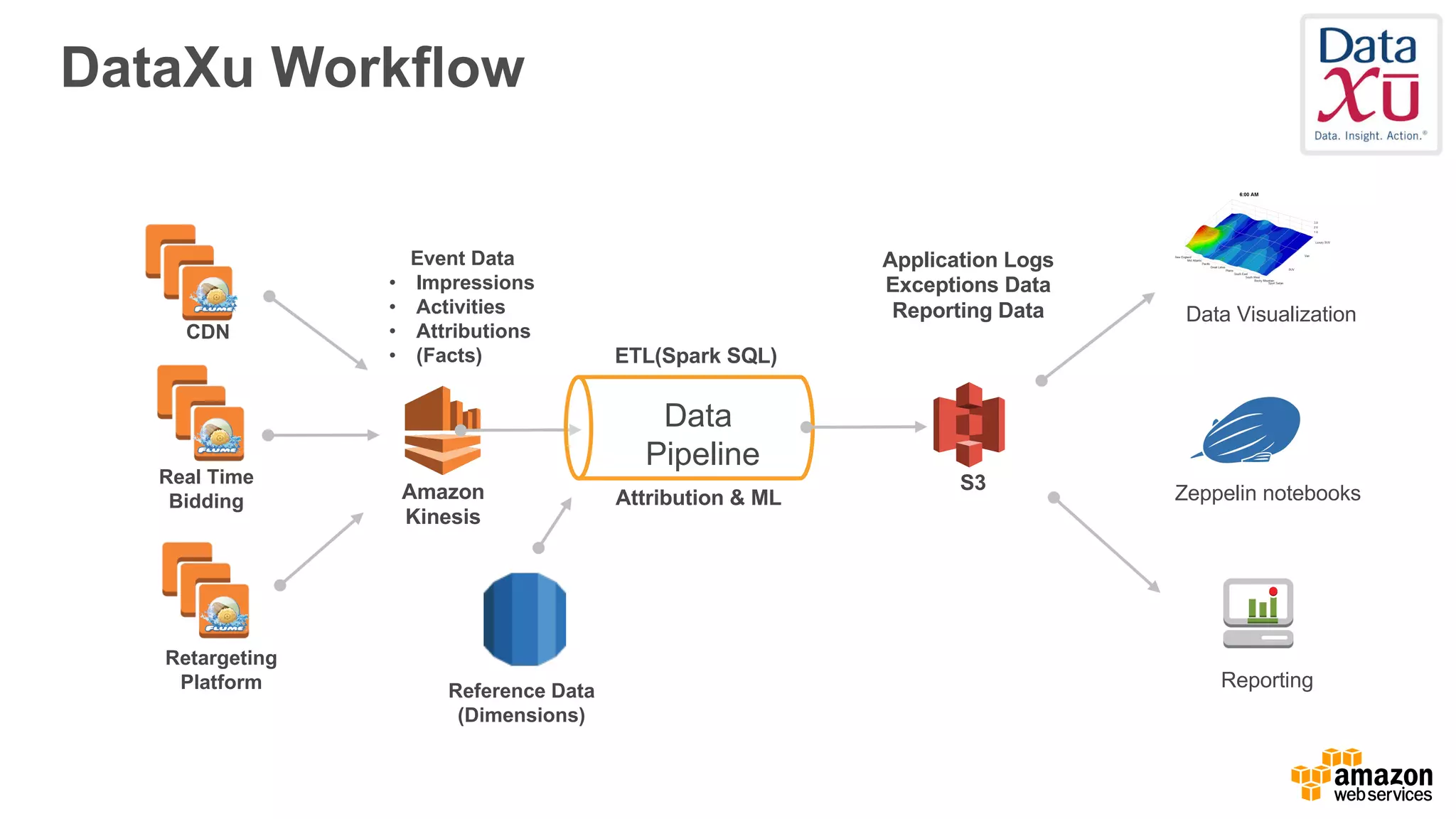
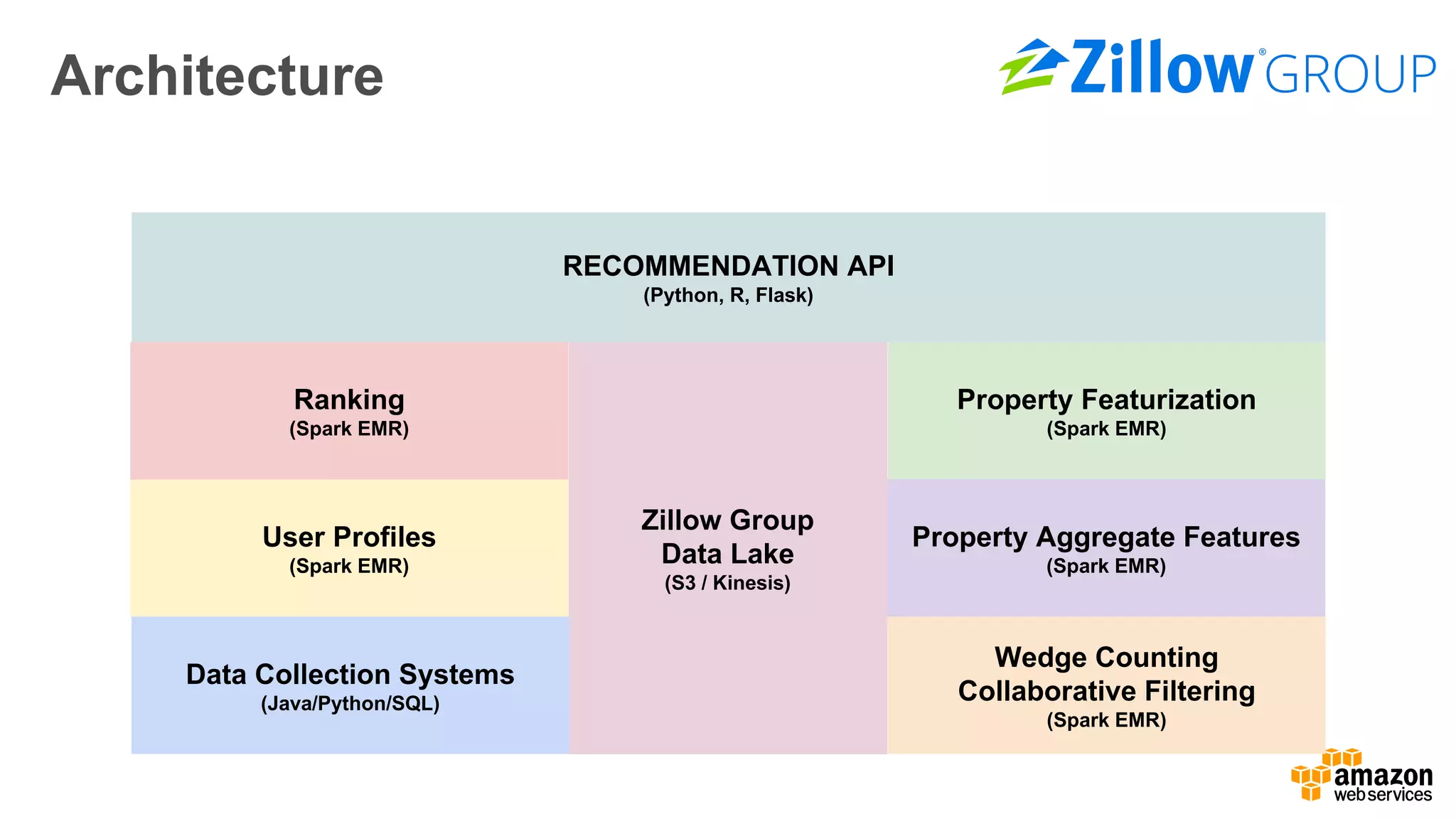
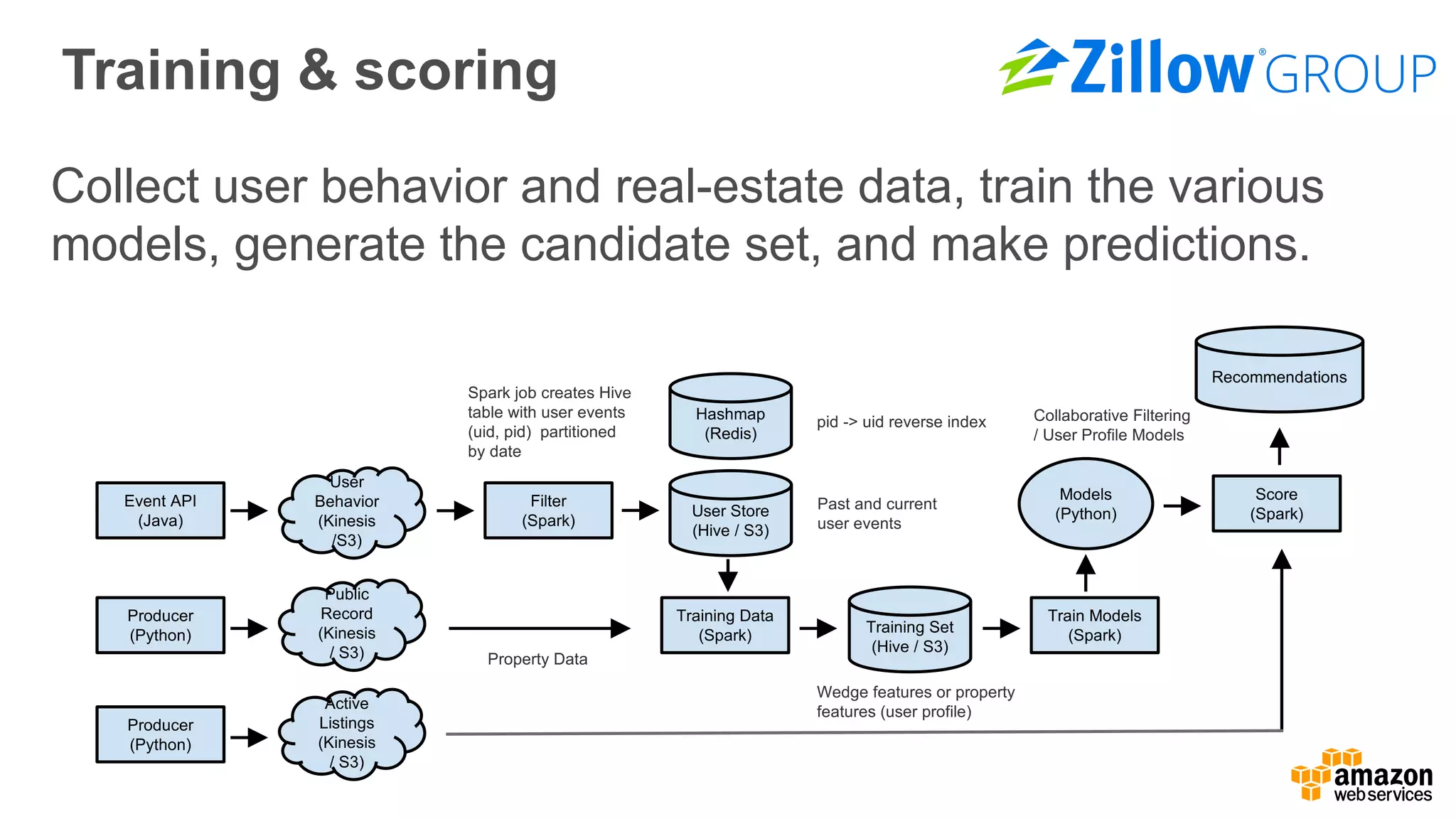
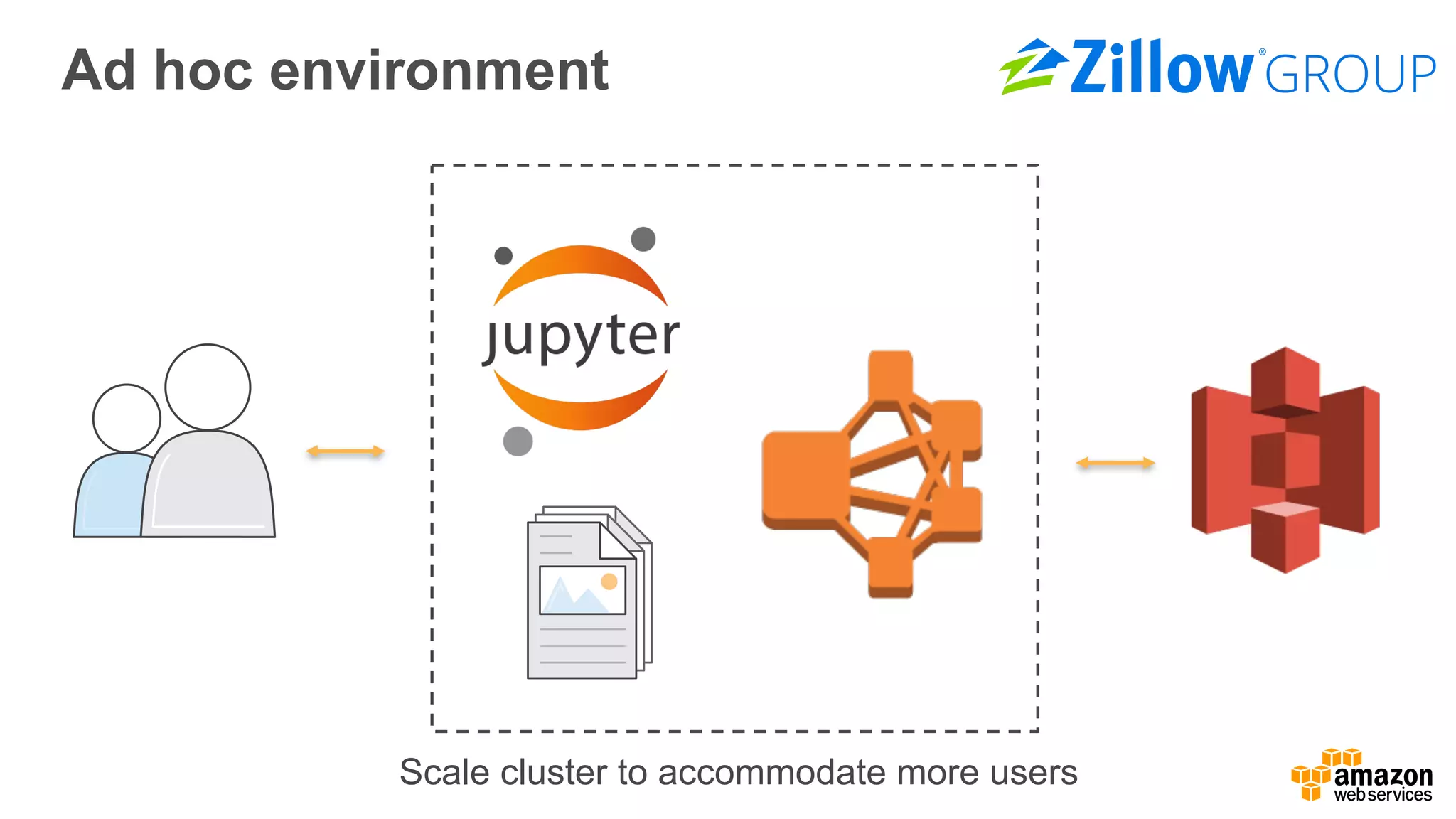
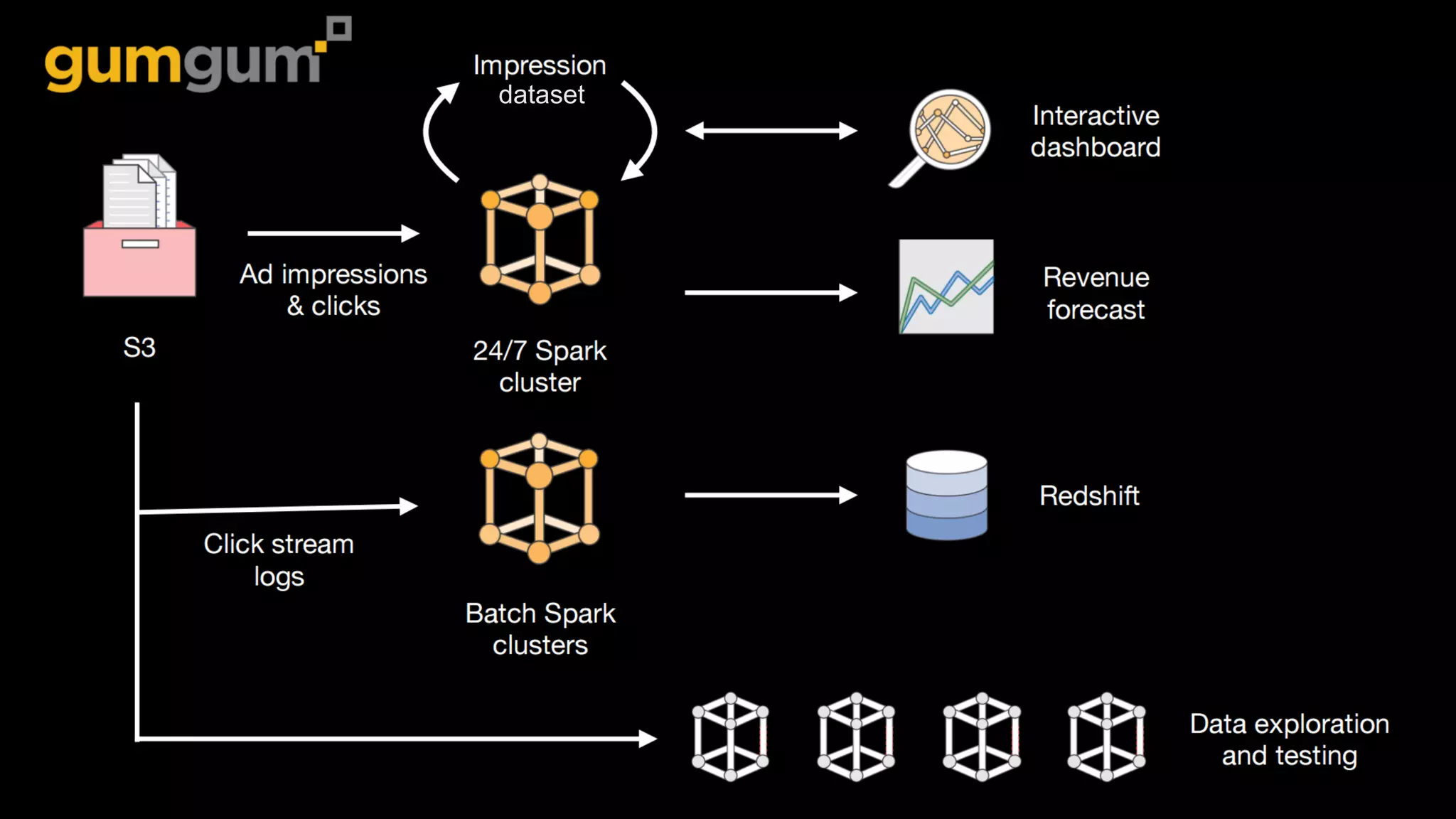



















The document outlines Amazon EMR's capabilities for utilizing Apache Spark on AWS, highlighting its integration with other AWS services, cost-effectiveness through EC2 spot instances, and various security features. It also discusses customer applications, such as real-time bidding and machine learning, showing how organizations process large datasets efficiently. Additionally, it mentions the ease of launching and managing clusters, enabling rapid data processing and analysis.























































































