Download as PDF, PPTX




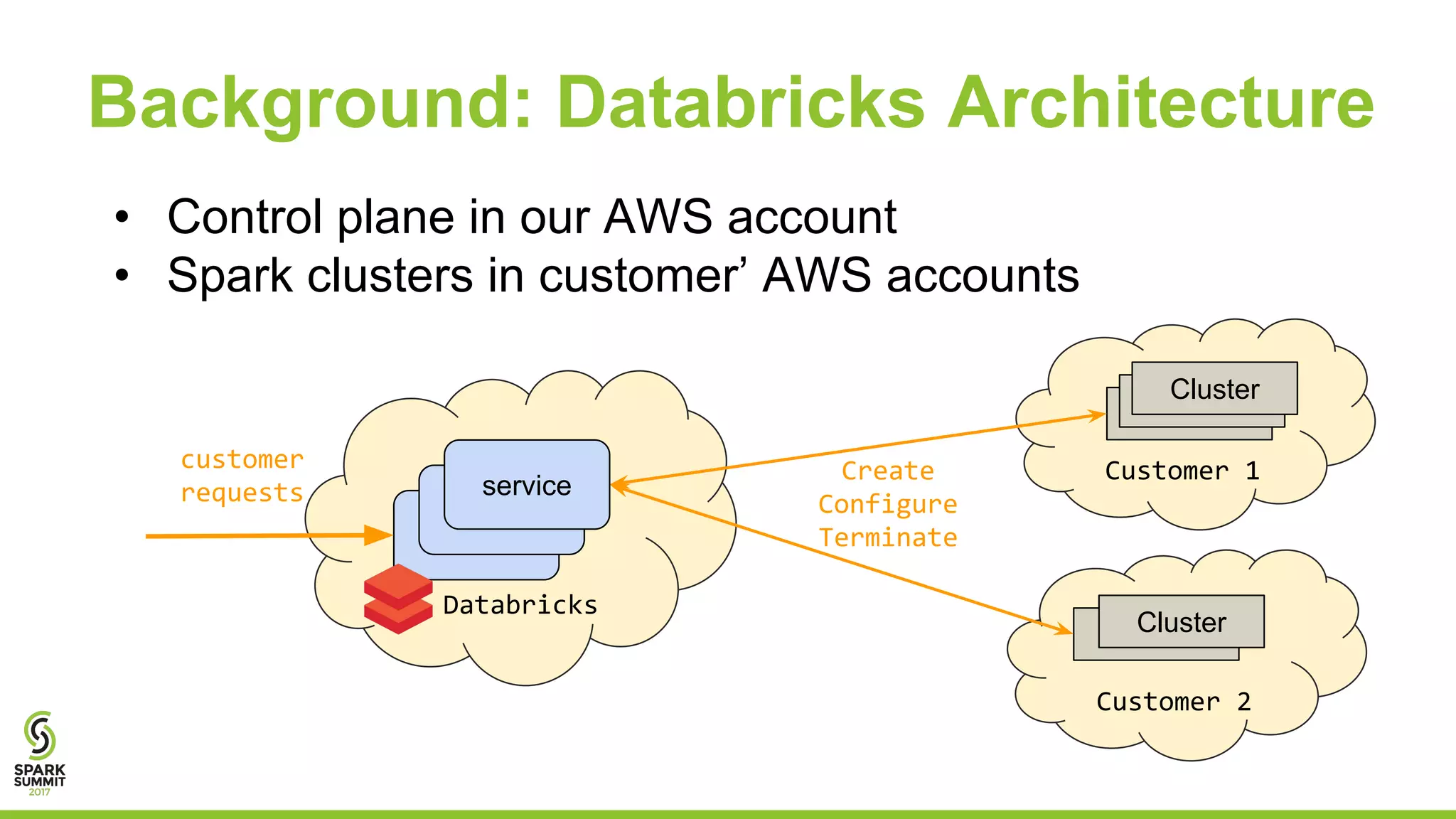
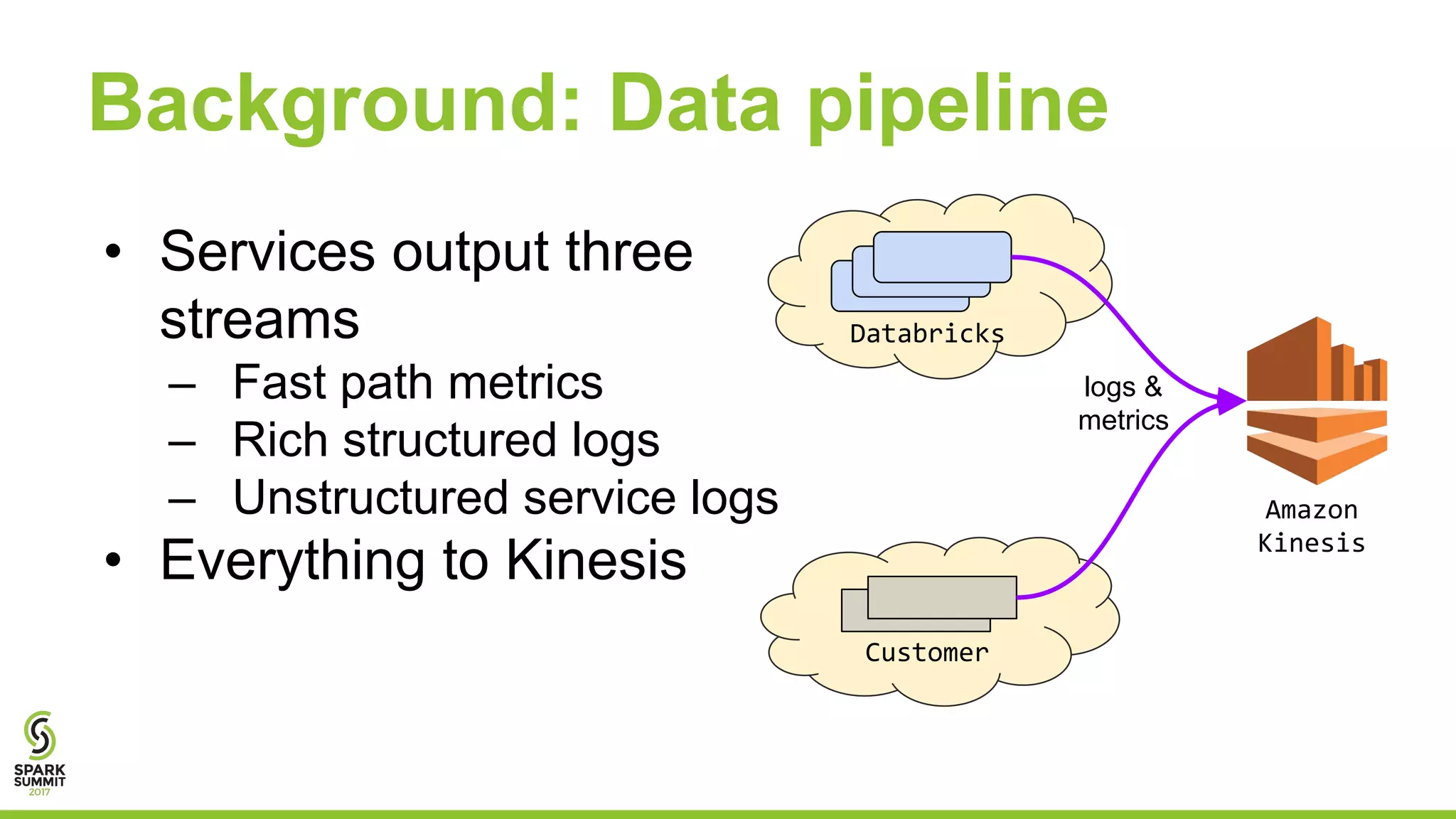
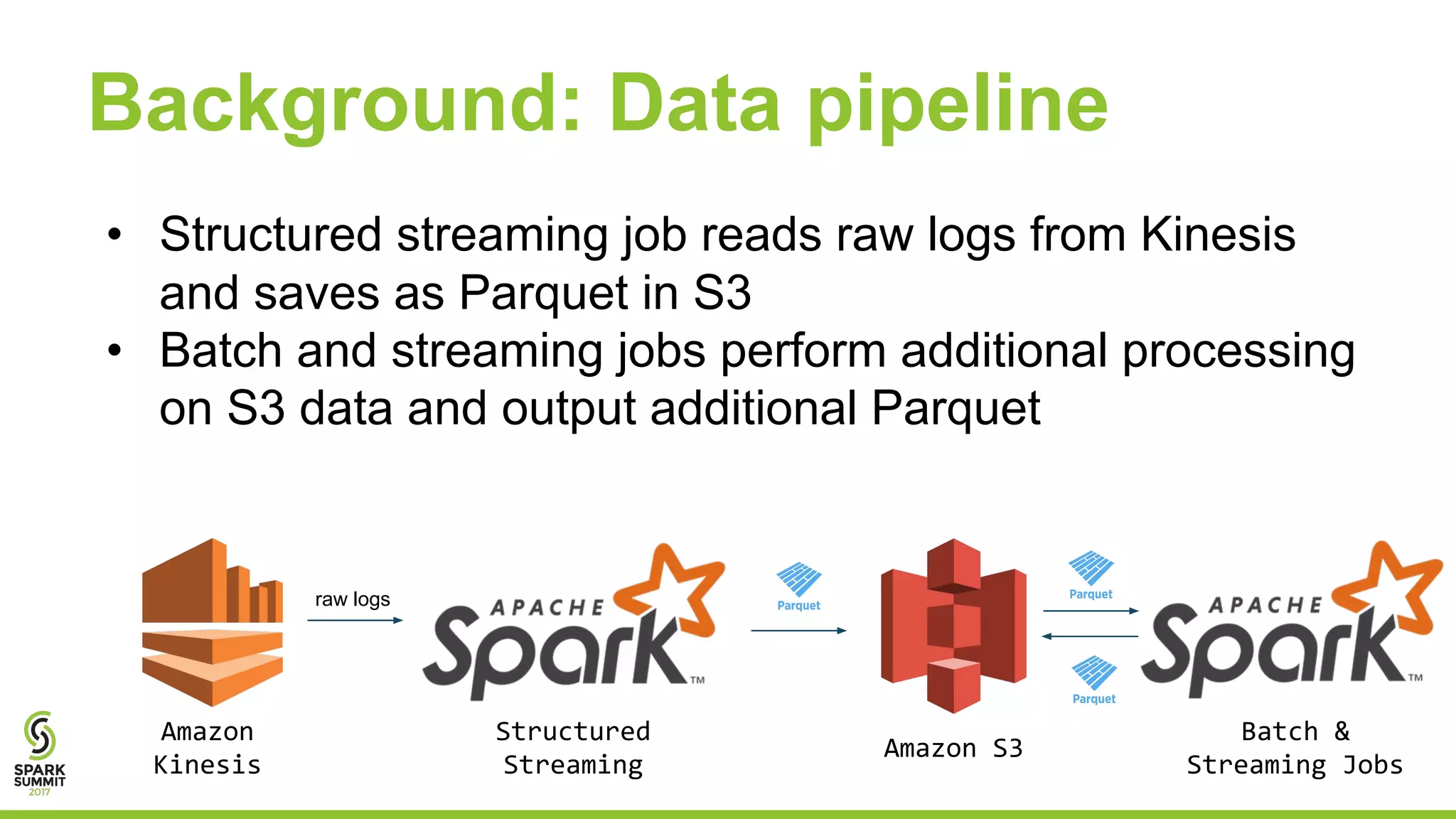




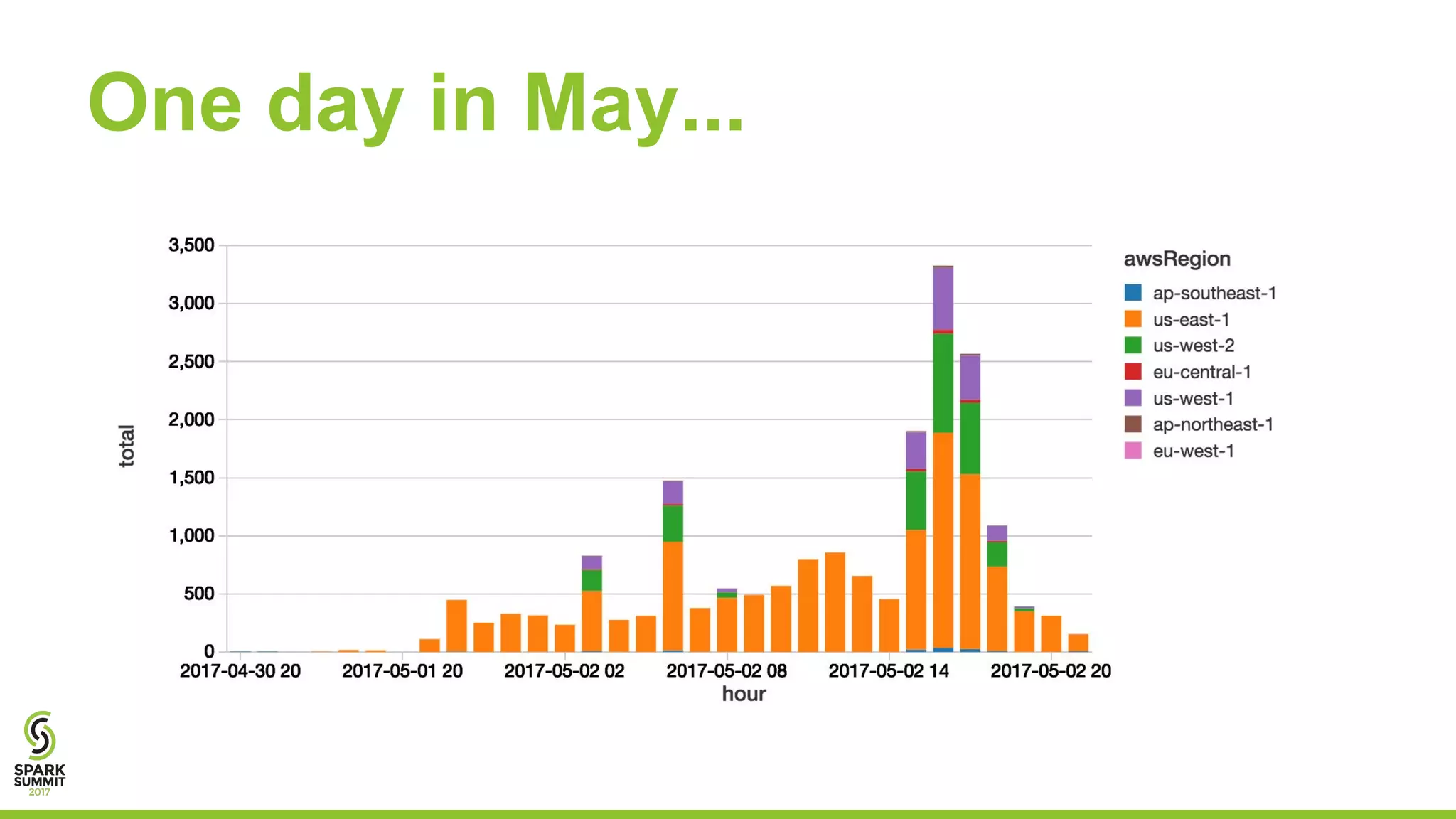





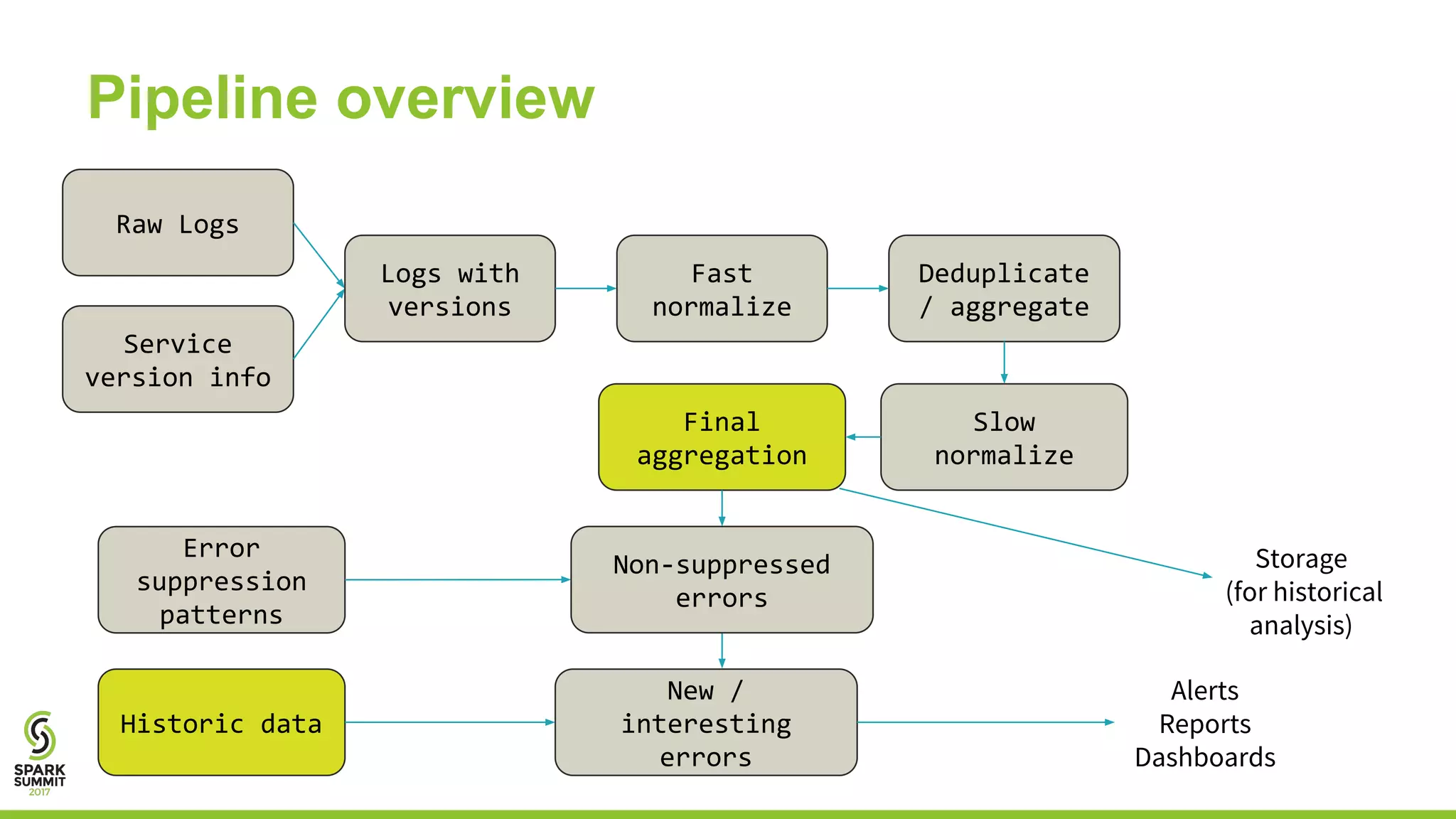































Josh Rosen and Henry Davidge share insights from managing thousands of Apache Spark clusters at Databricks, highlighting the complexities of monitoring metrics and logs in a cloud-based environment. They discuss strategies for tracking AWS anomalies and discovering bugs through structured and unstructured logs, emphasizing the importance of normalizing and filtering data to reduce false positives. Key lessons include the benefits of proactive structure in logging and multi-level alerting to effectively manage system health.