Download as PDF, PPTX




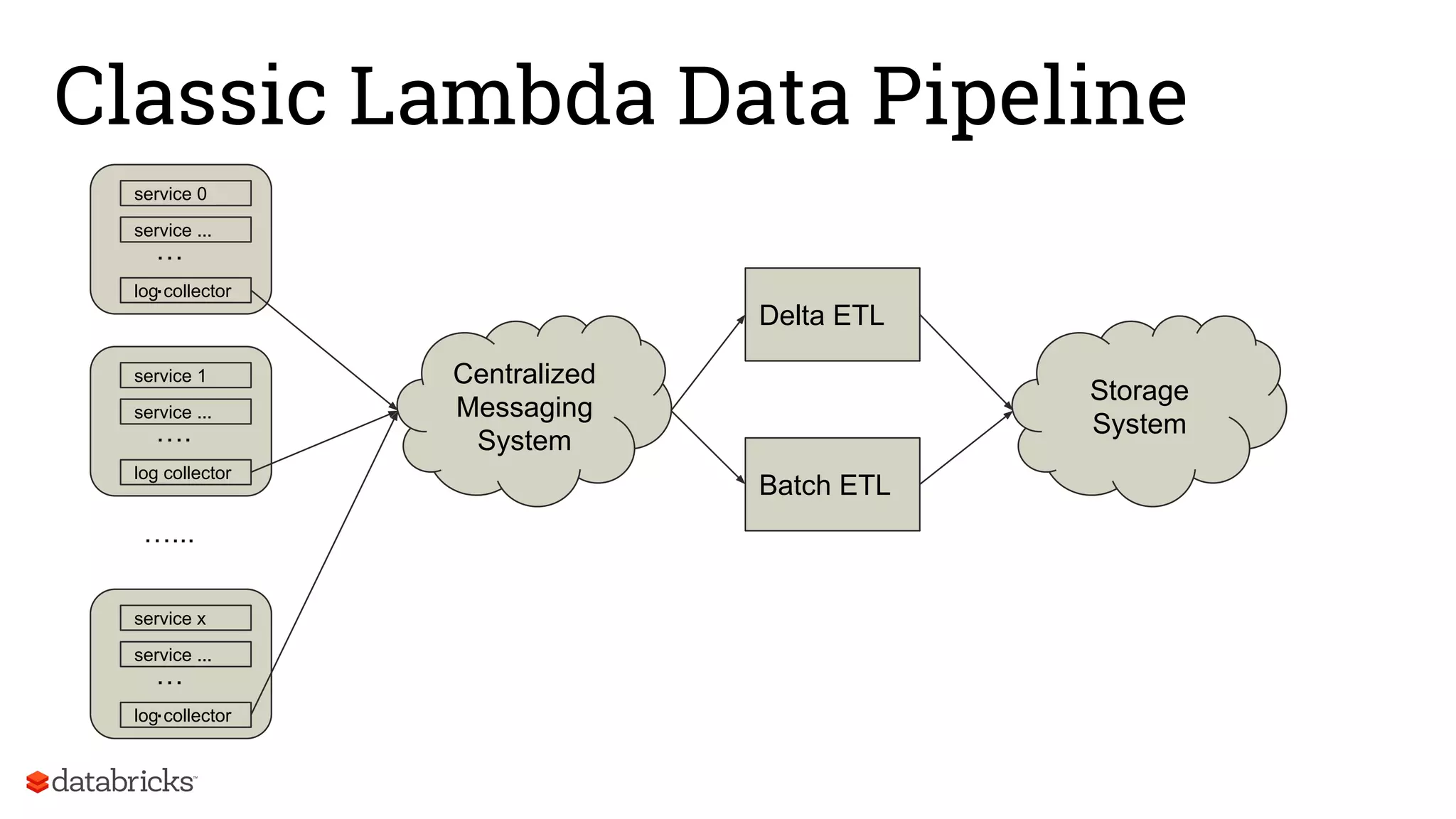
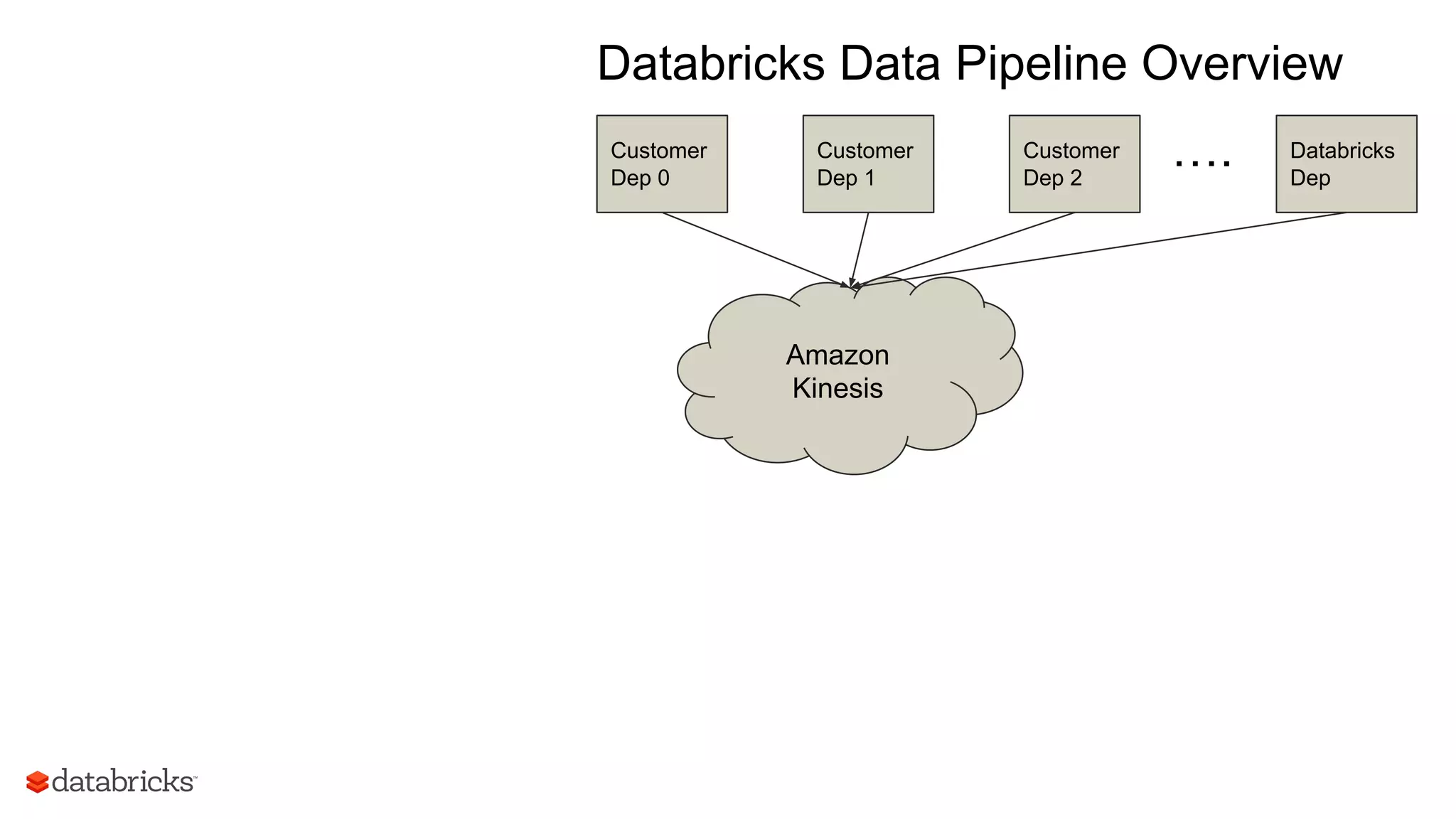
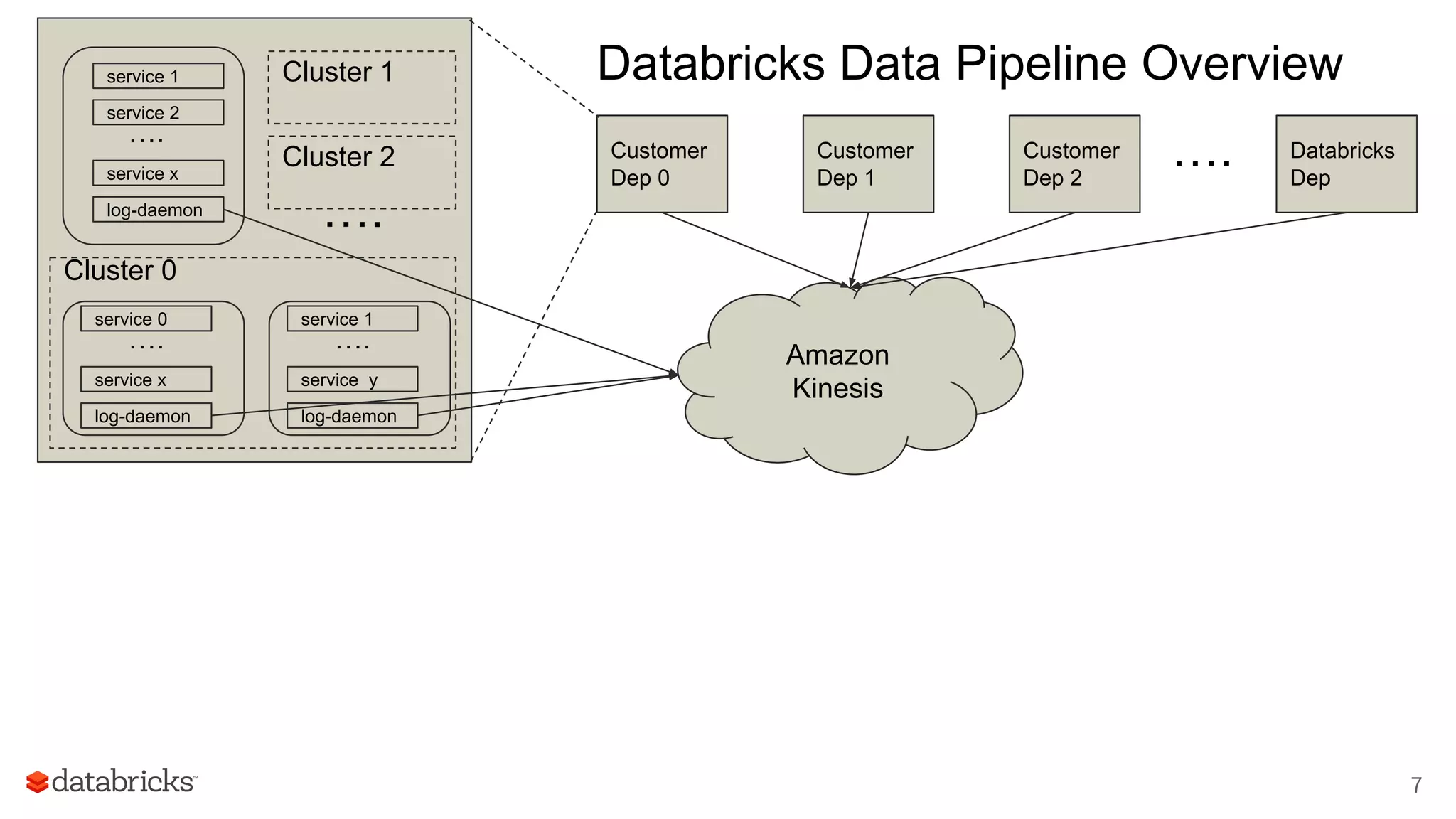
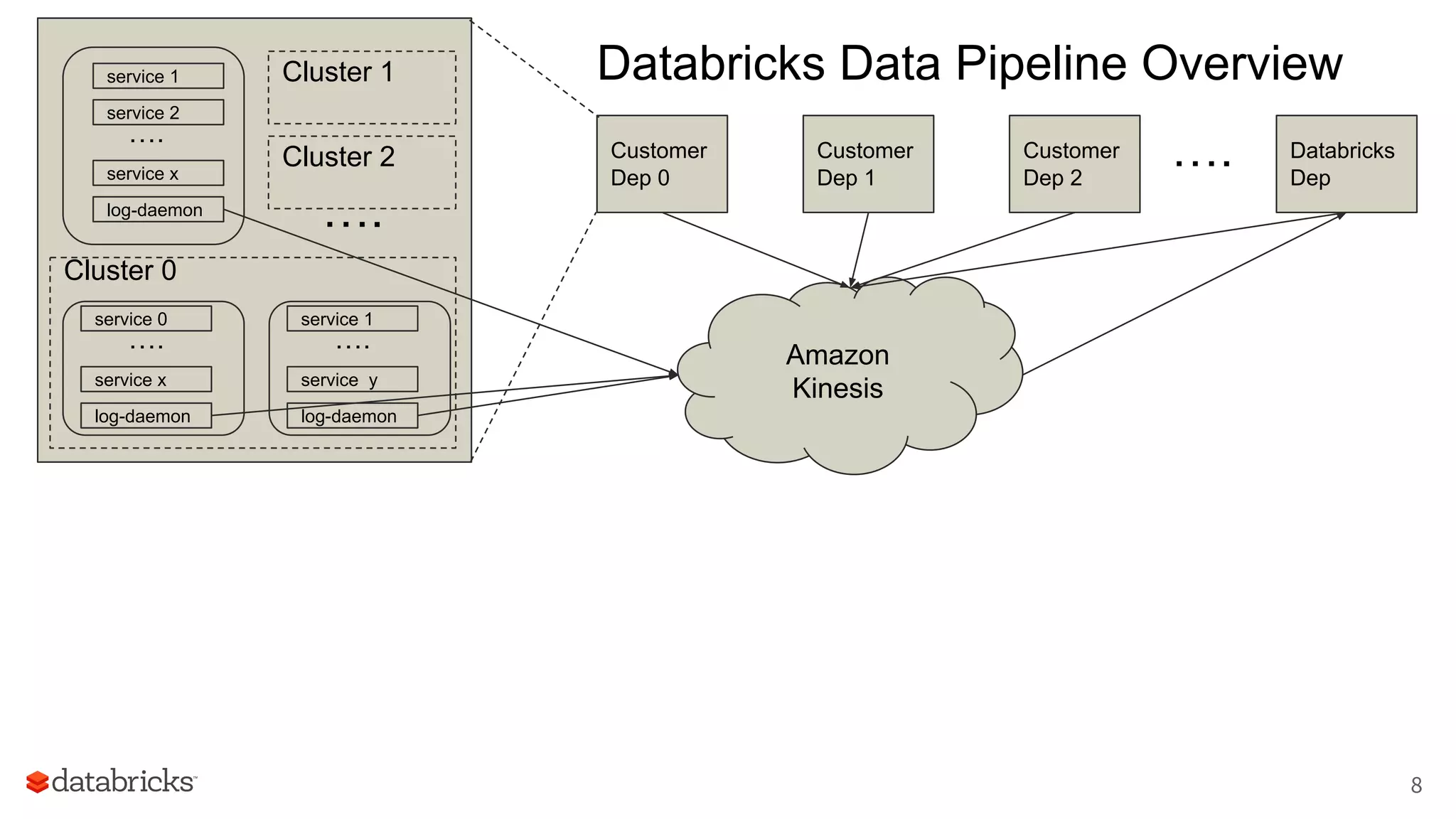
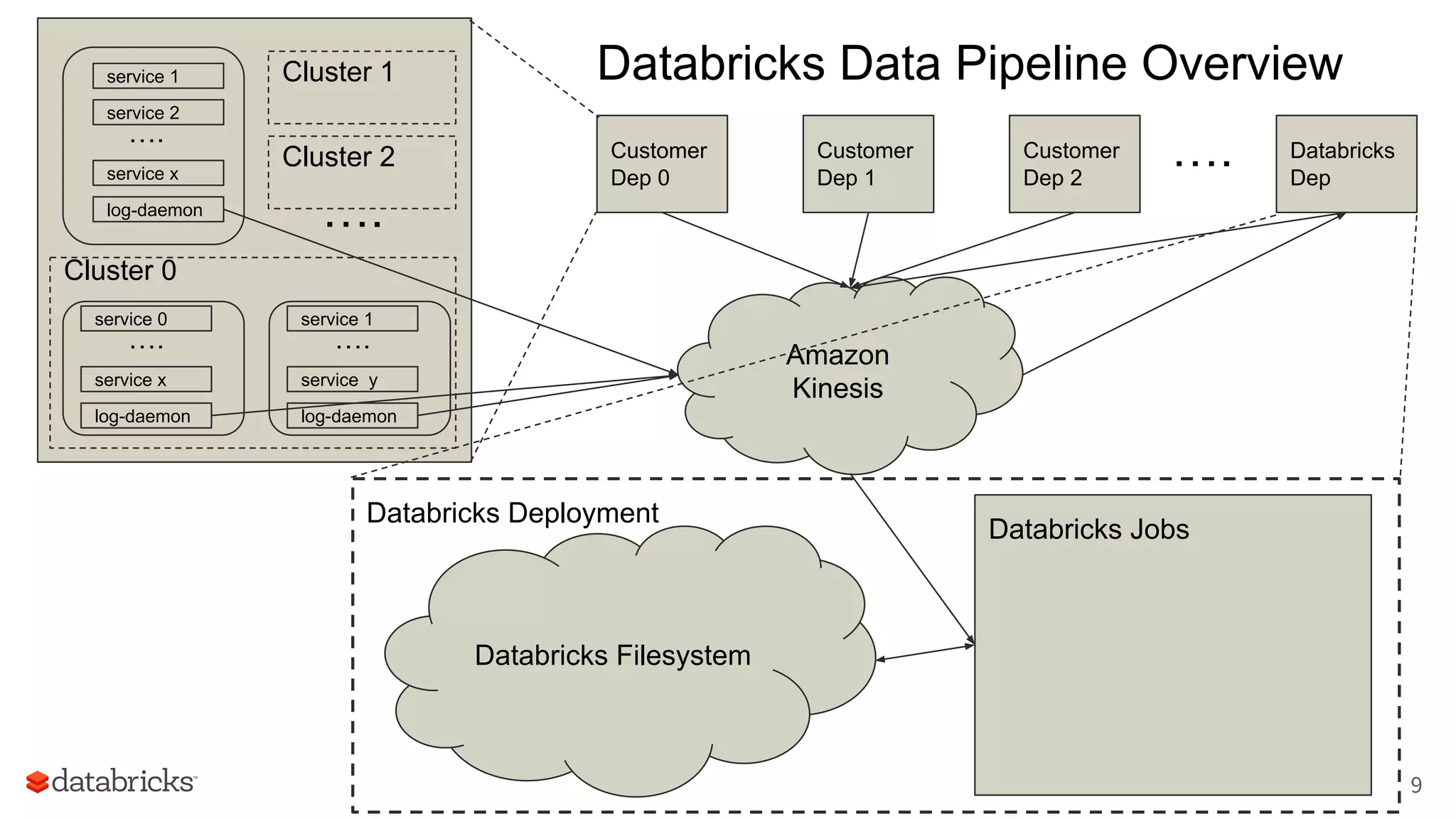
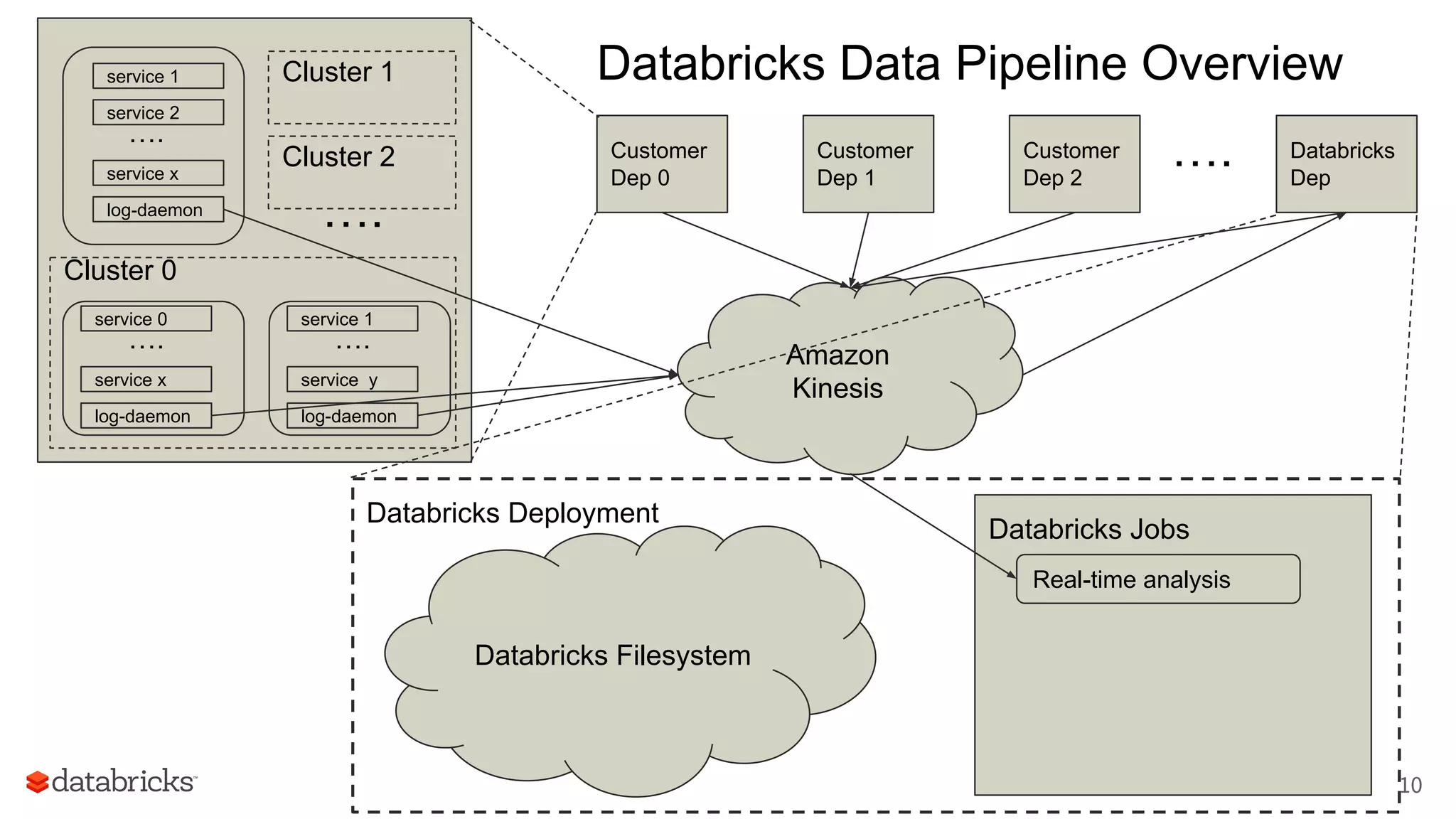
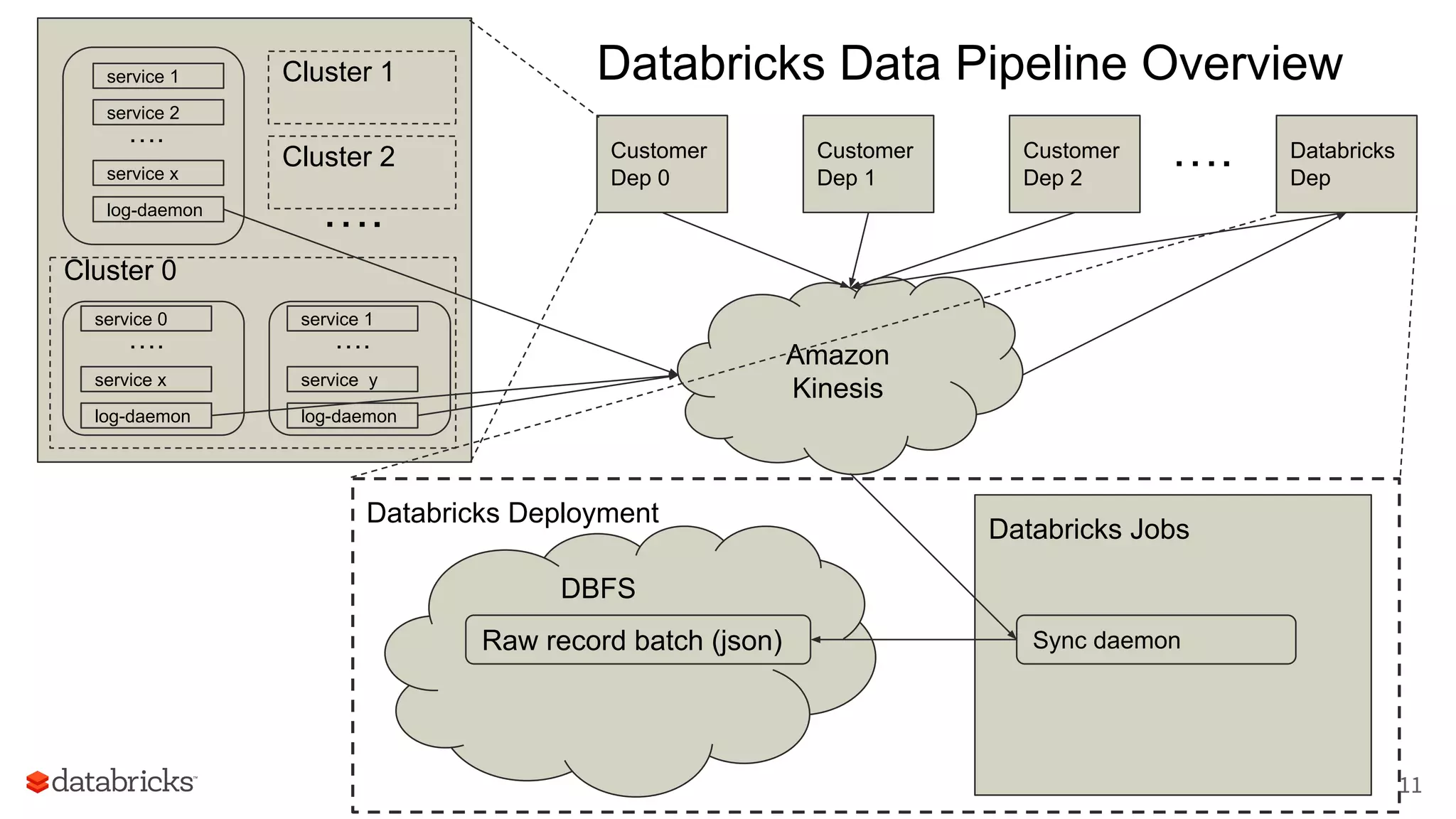
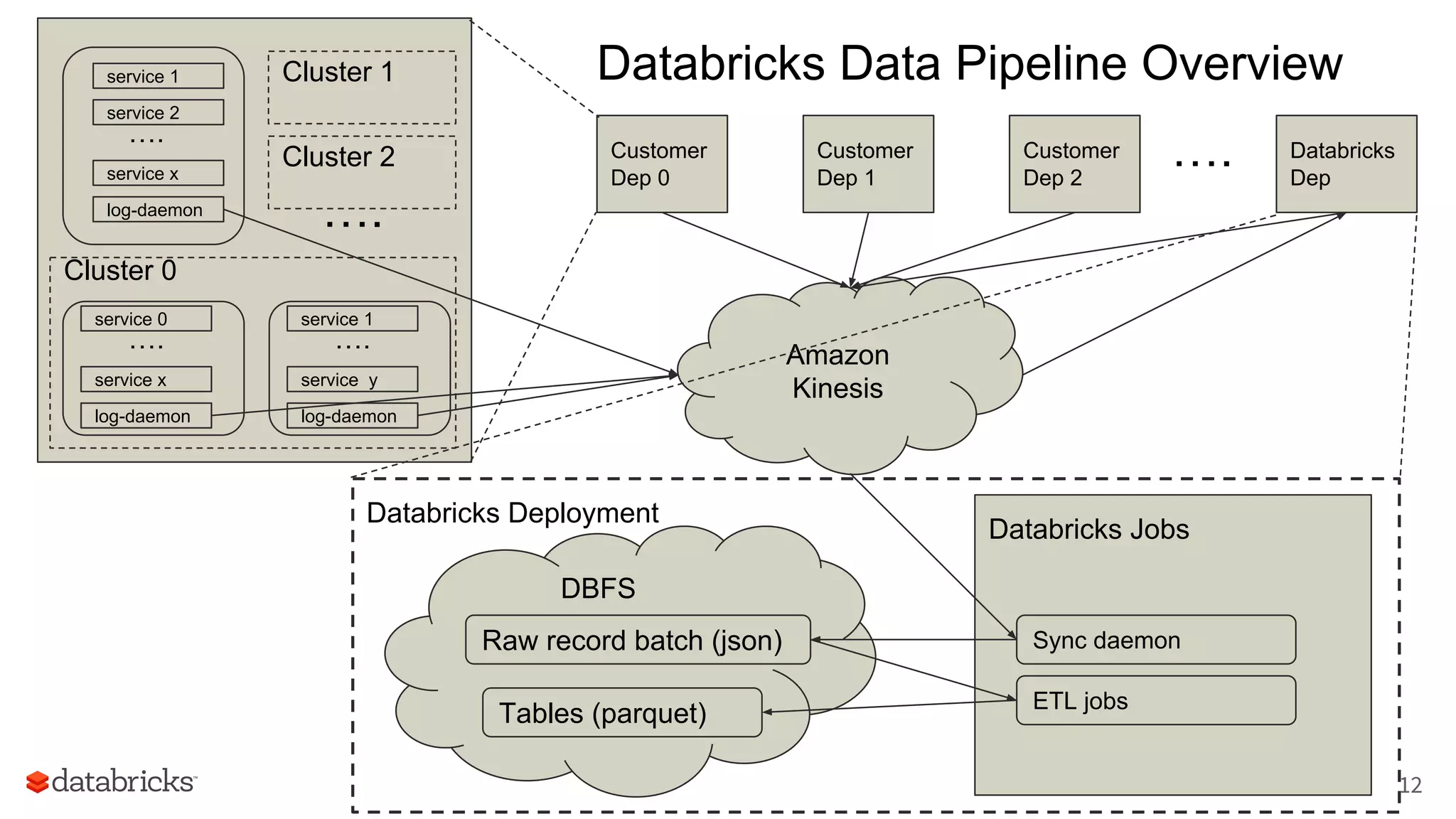
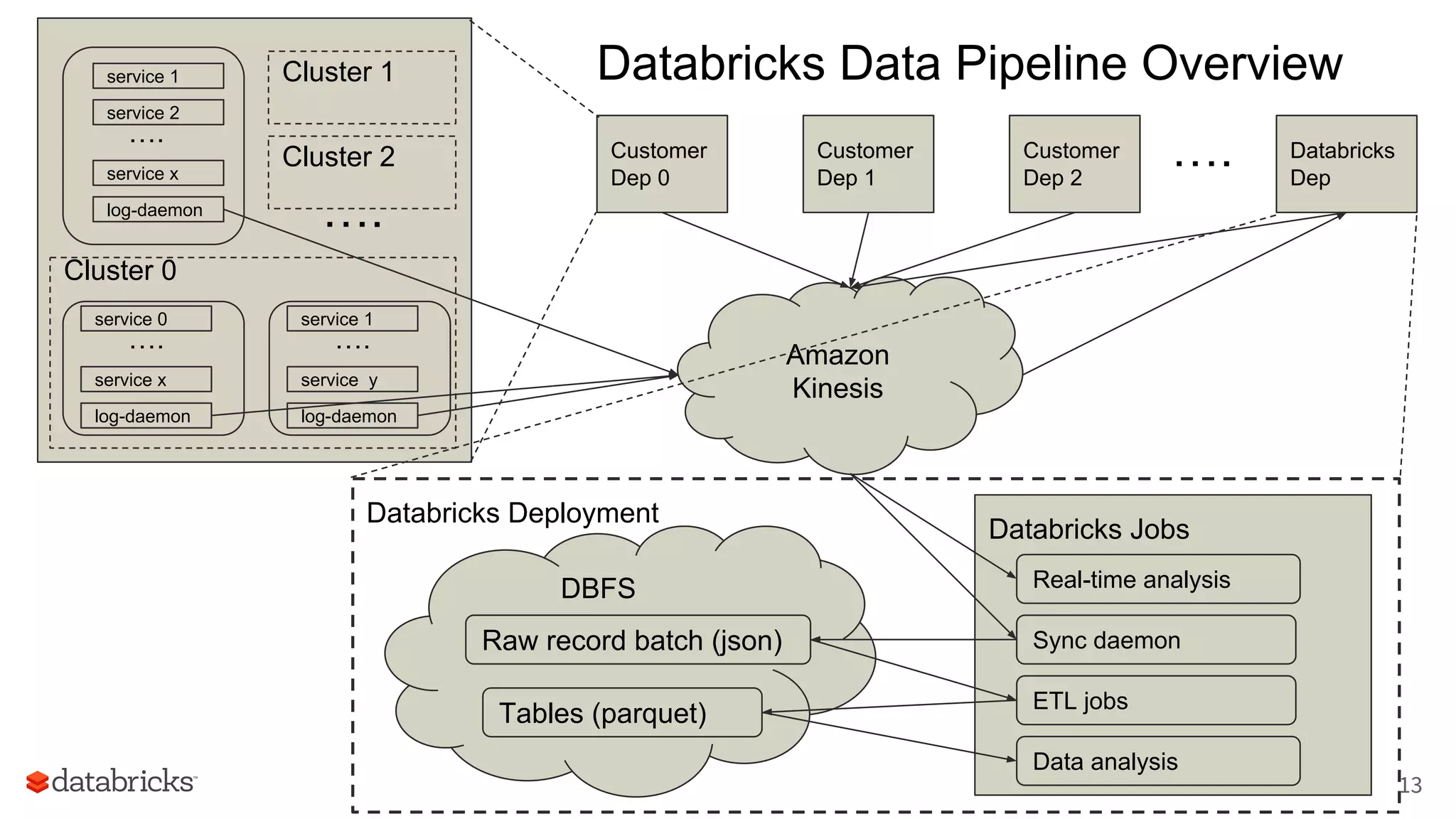

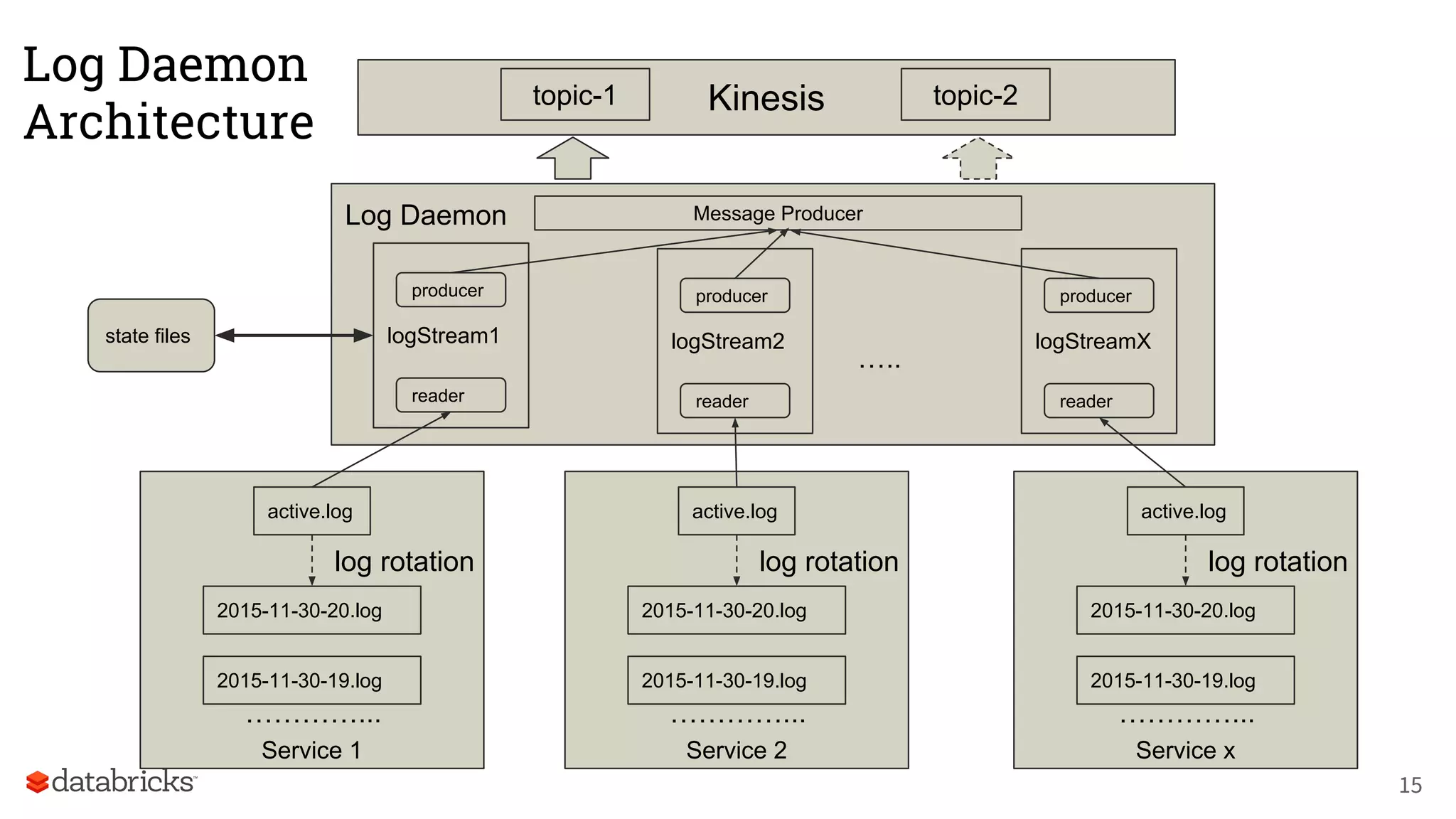

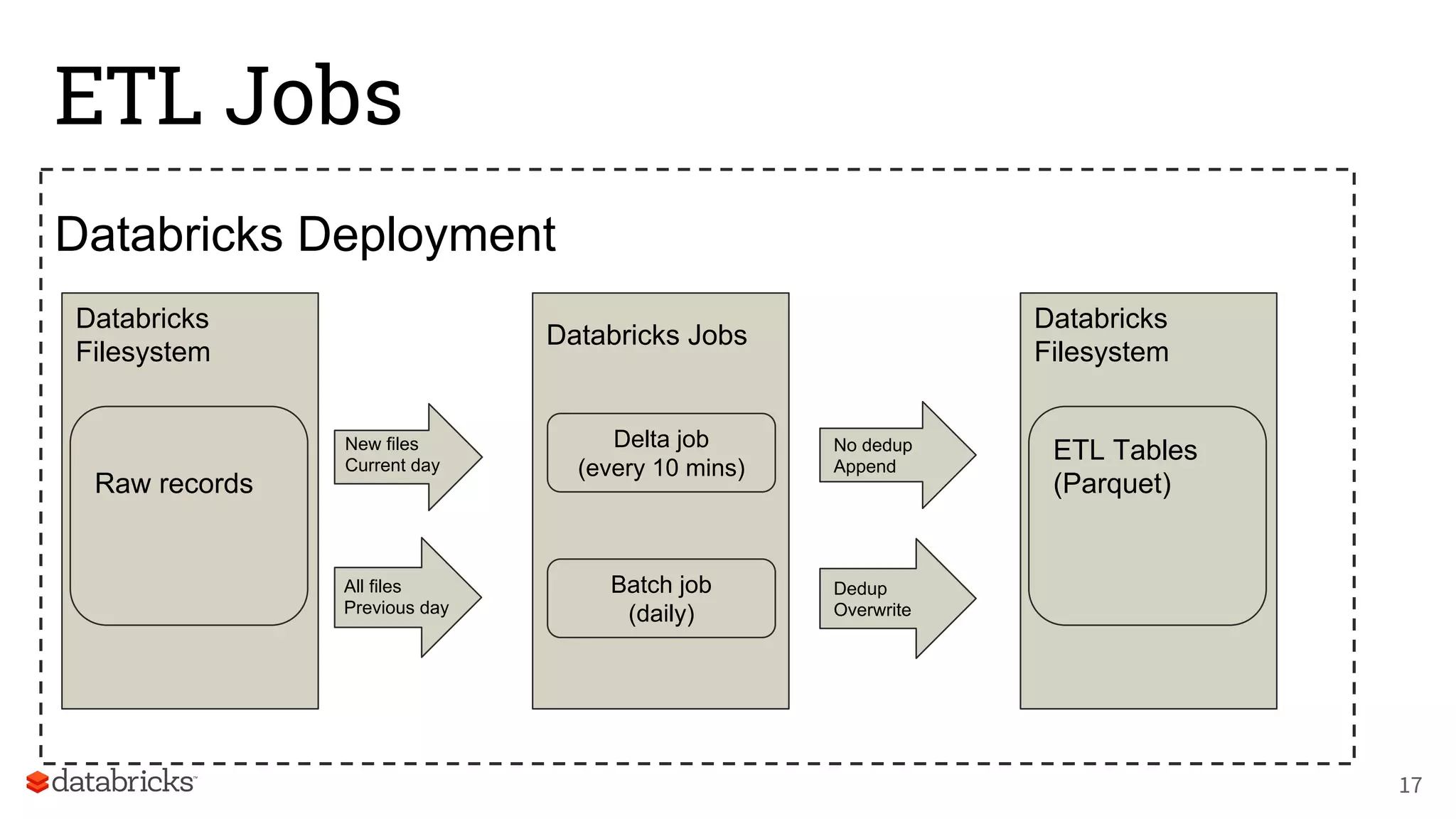


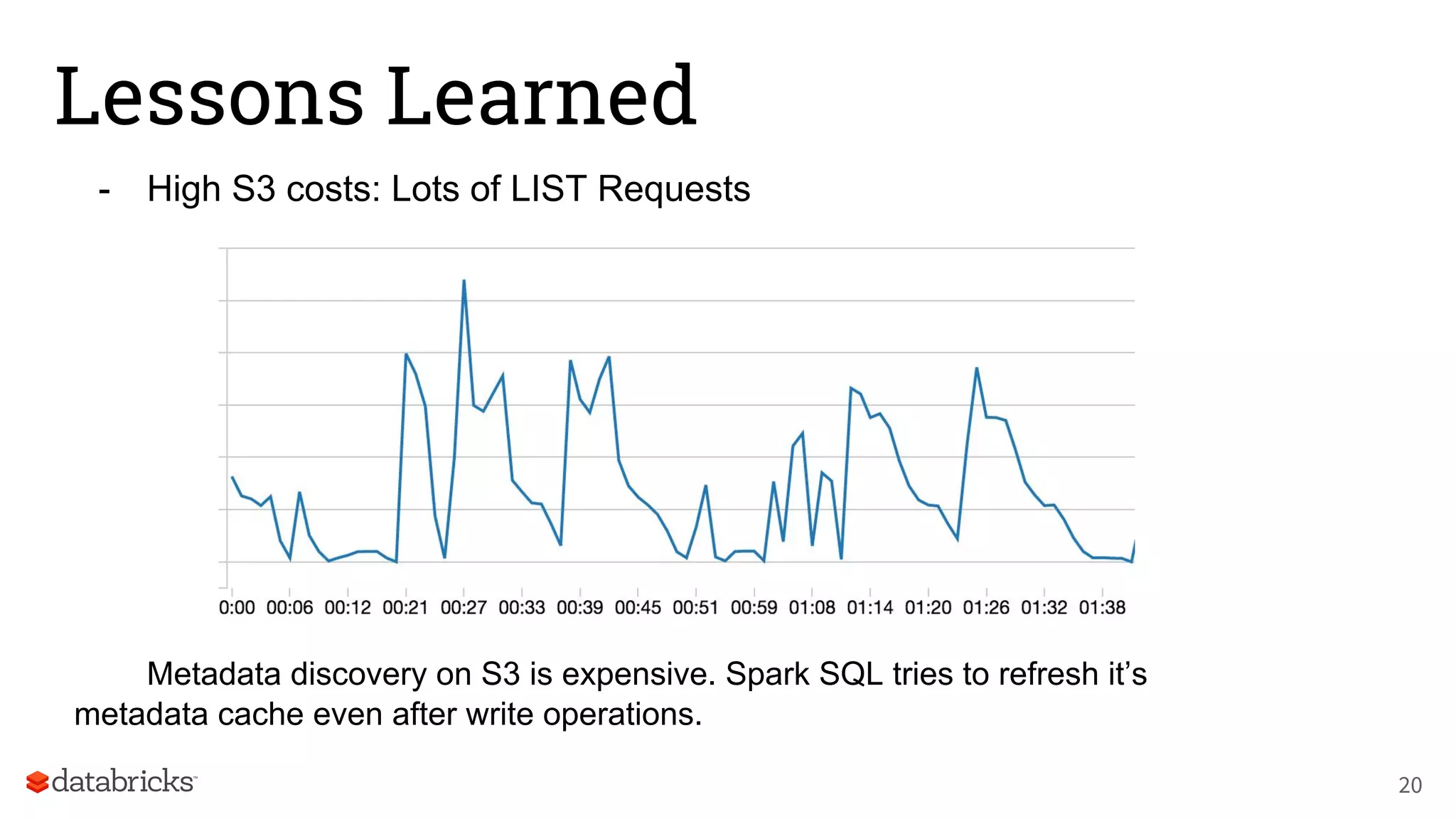
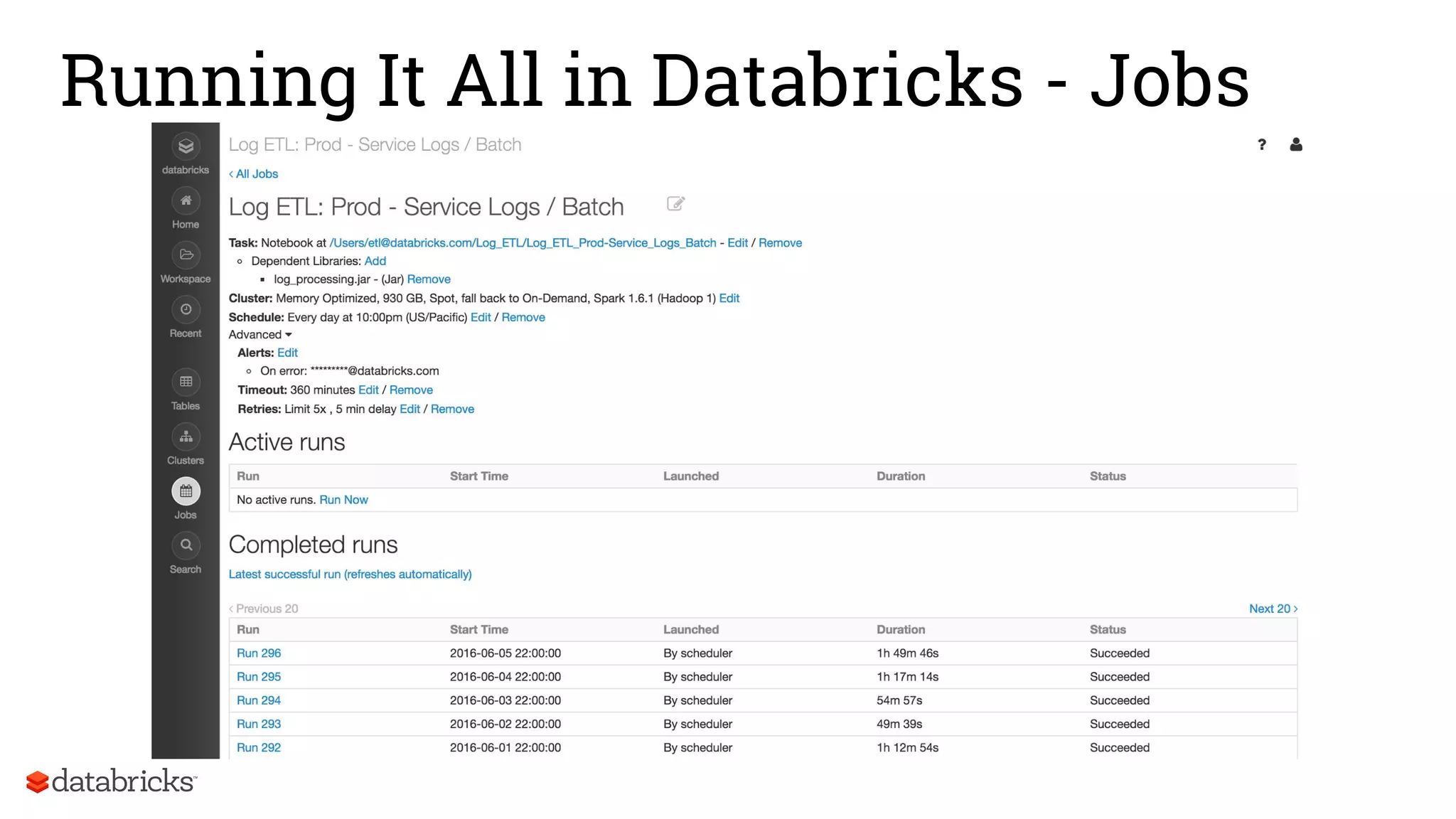
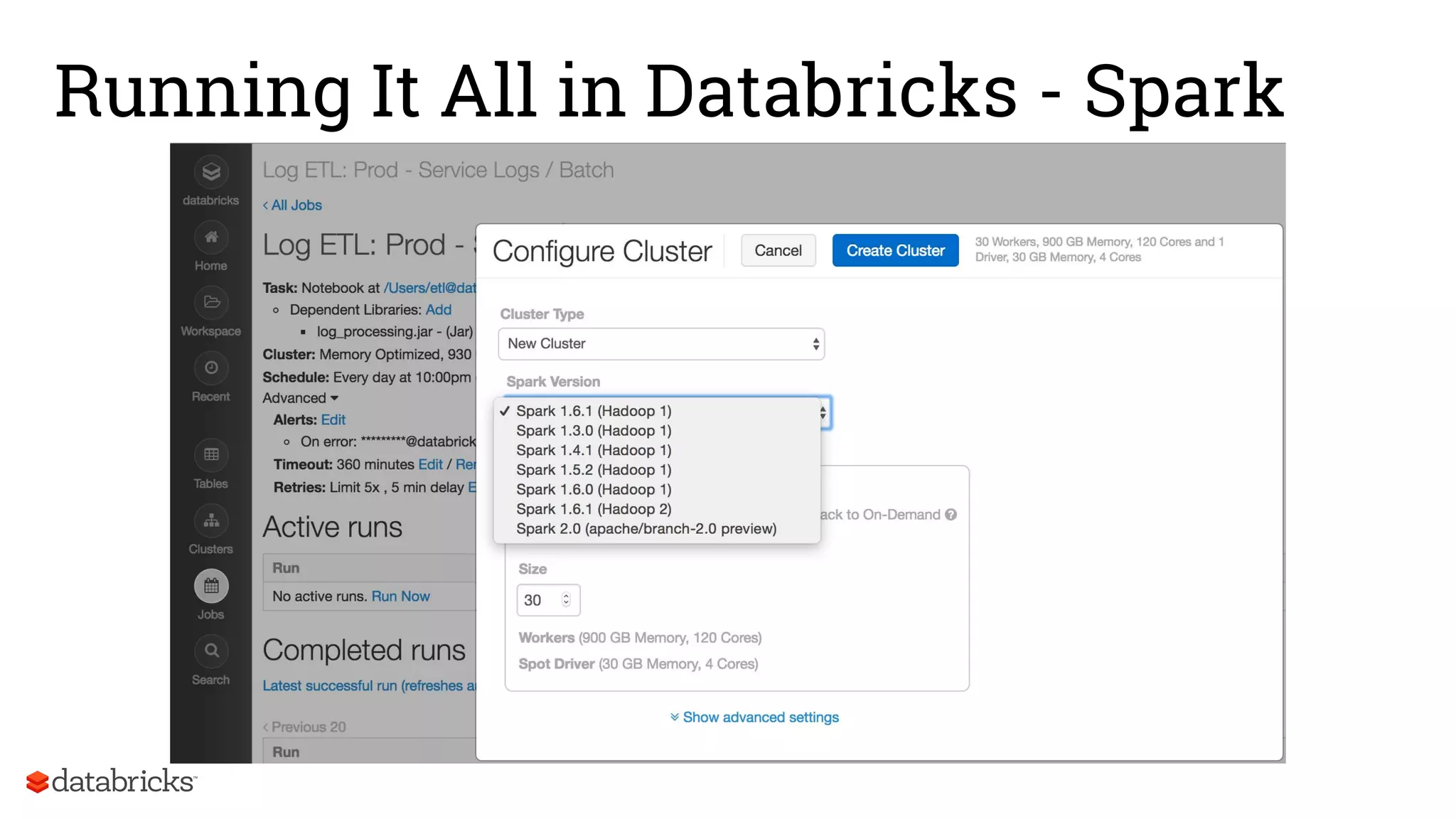

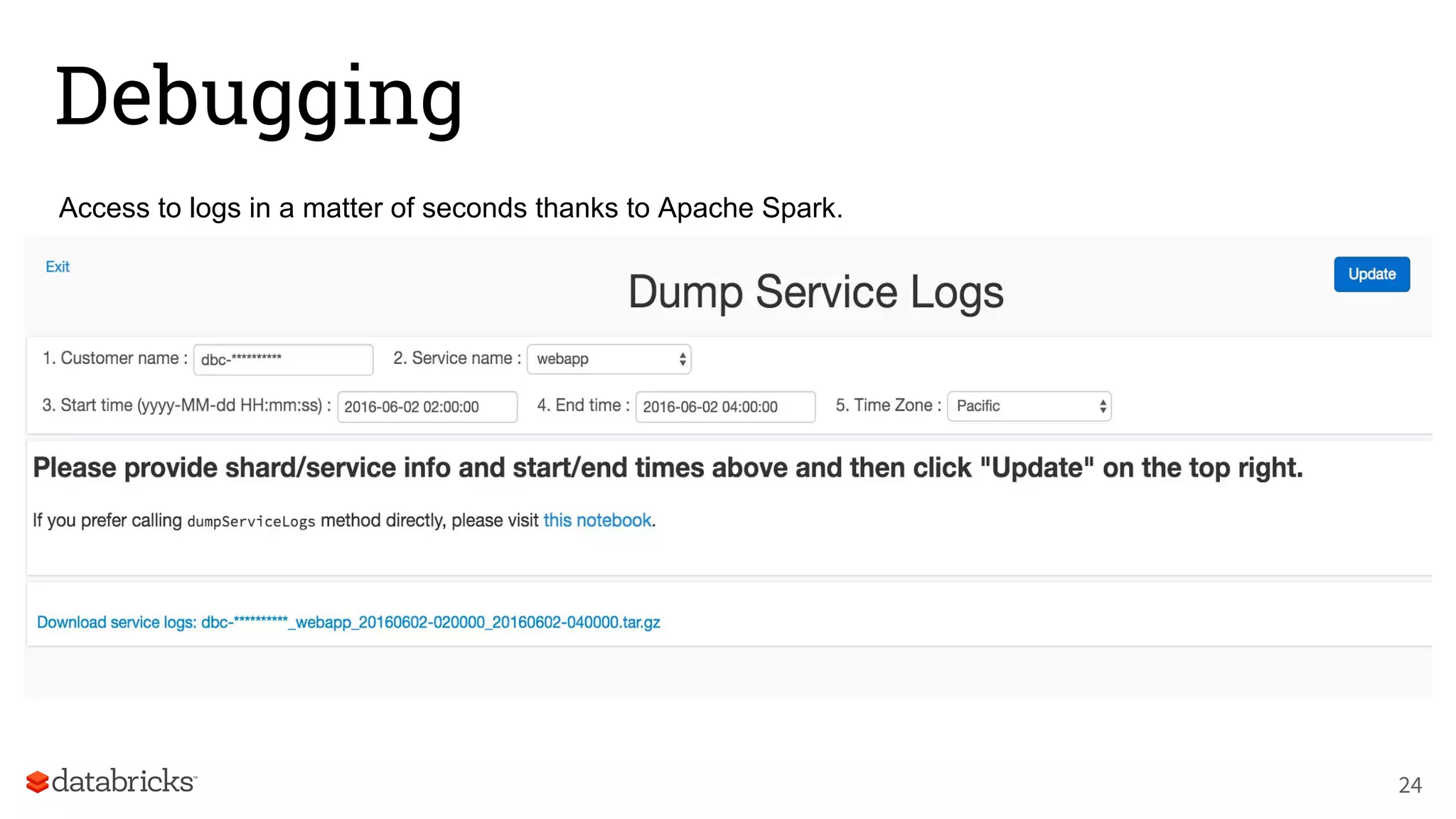
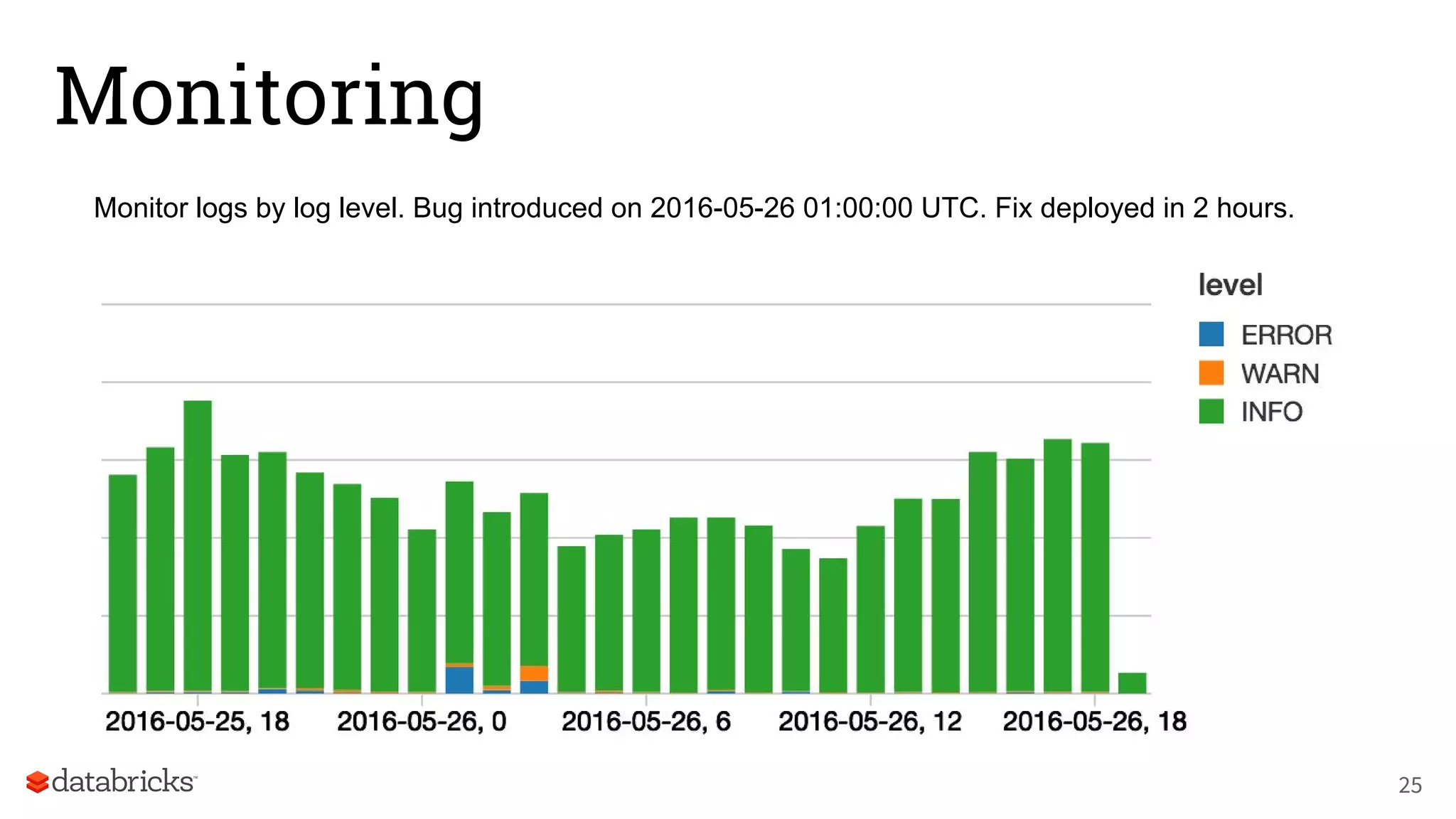
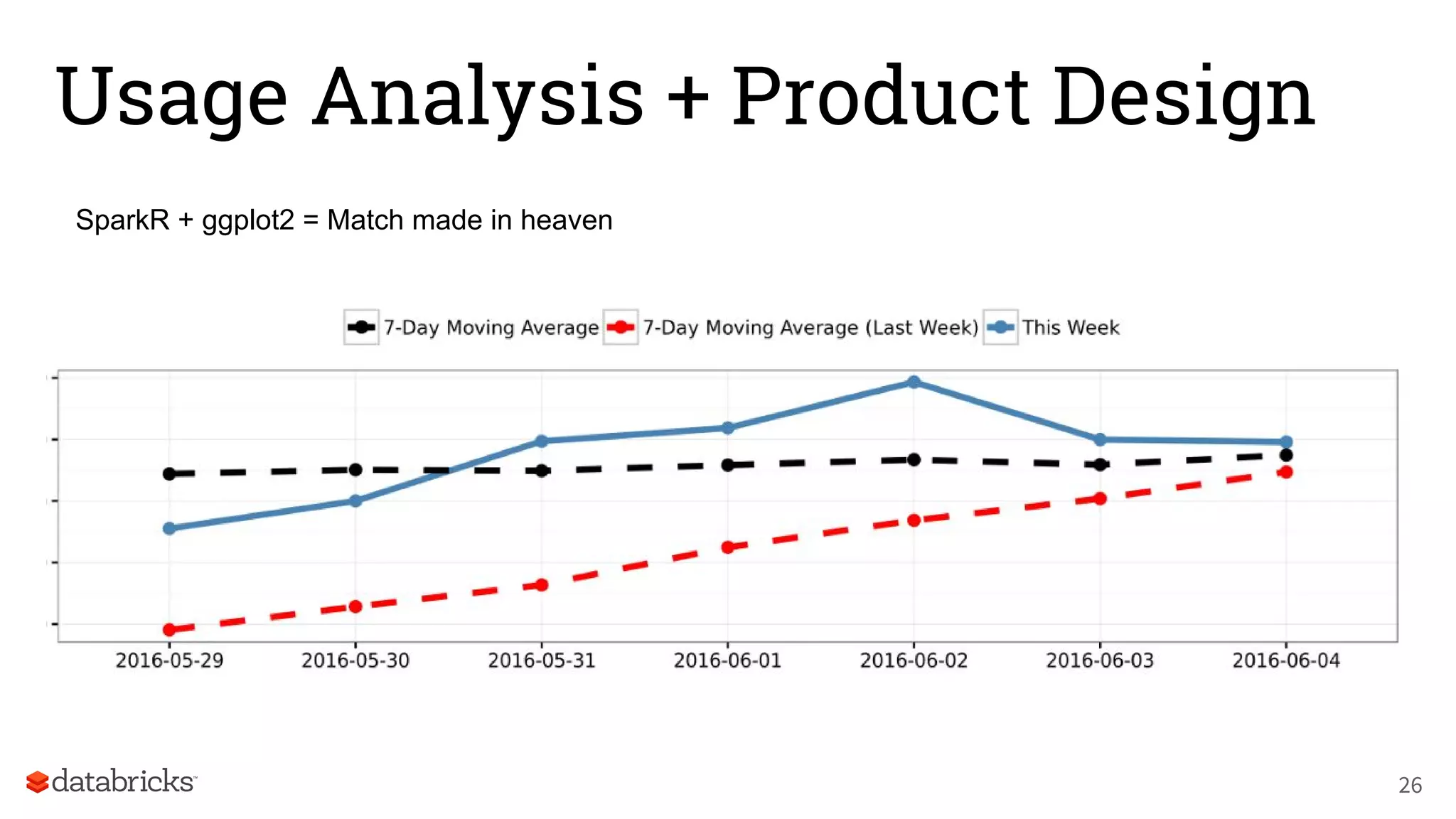



































The document discusses Databricks' development of a next-generation data pipeline utilizing Apache Spark, highlighting challenges like fault tolerance and scalability. It outlines the architecture of their data pipeline, including real-time and batch processing capabilities, and shares lessons learned regarding efficiency and cost management. The conclusion emphasizes the benefits of Databricks and Apache Spark as a unified platform for ETL, data warehousing, and analytics.