Downloaded 13 times










![● Origin from Probabilistic Information Retrieval
● Default Similarity from Lucene 6.0 [1]
● 25th iteration in improving TF-IDF
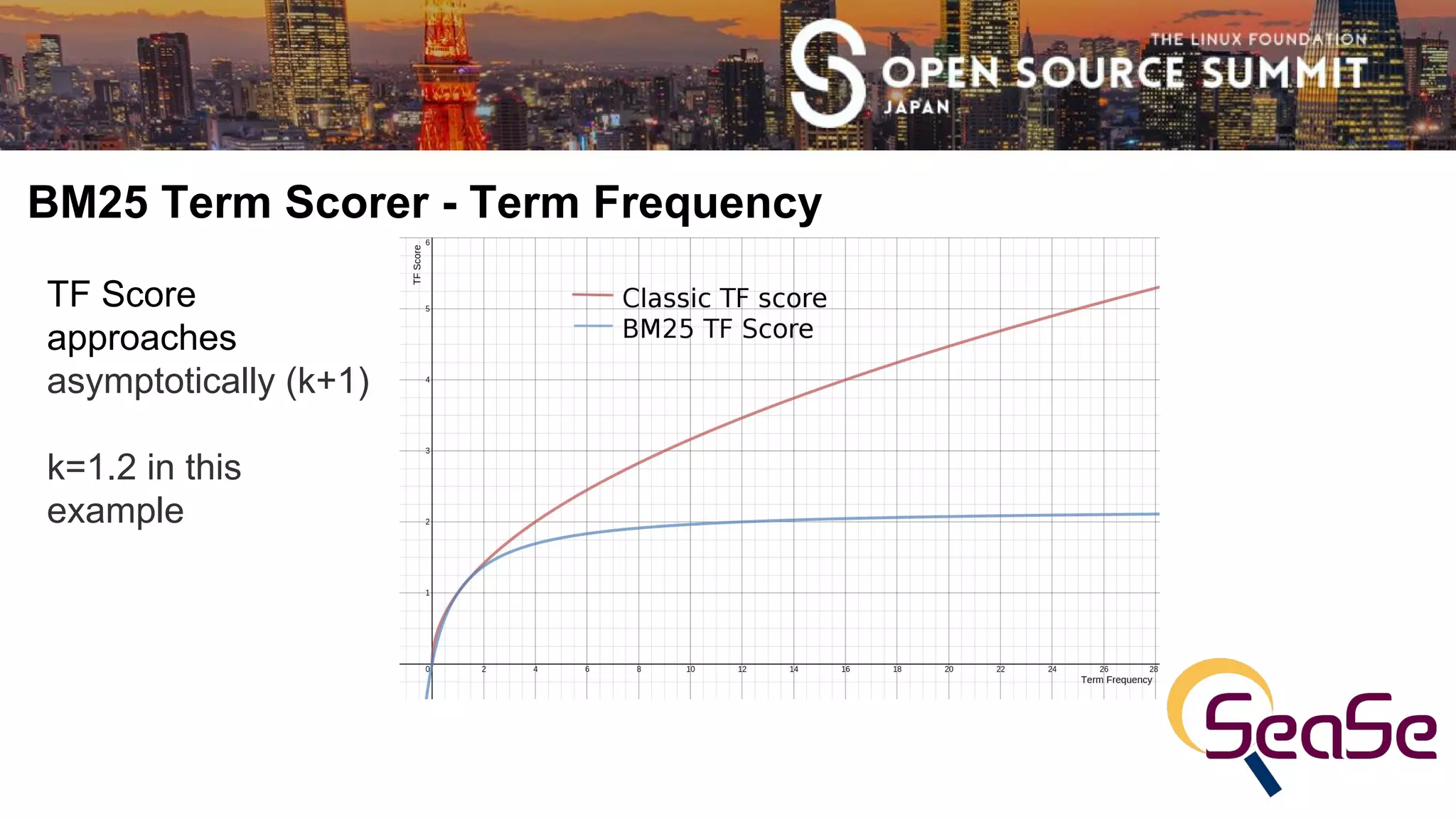
● TF
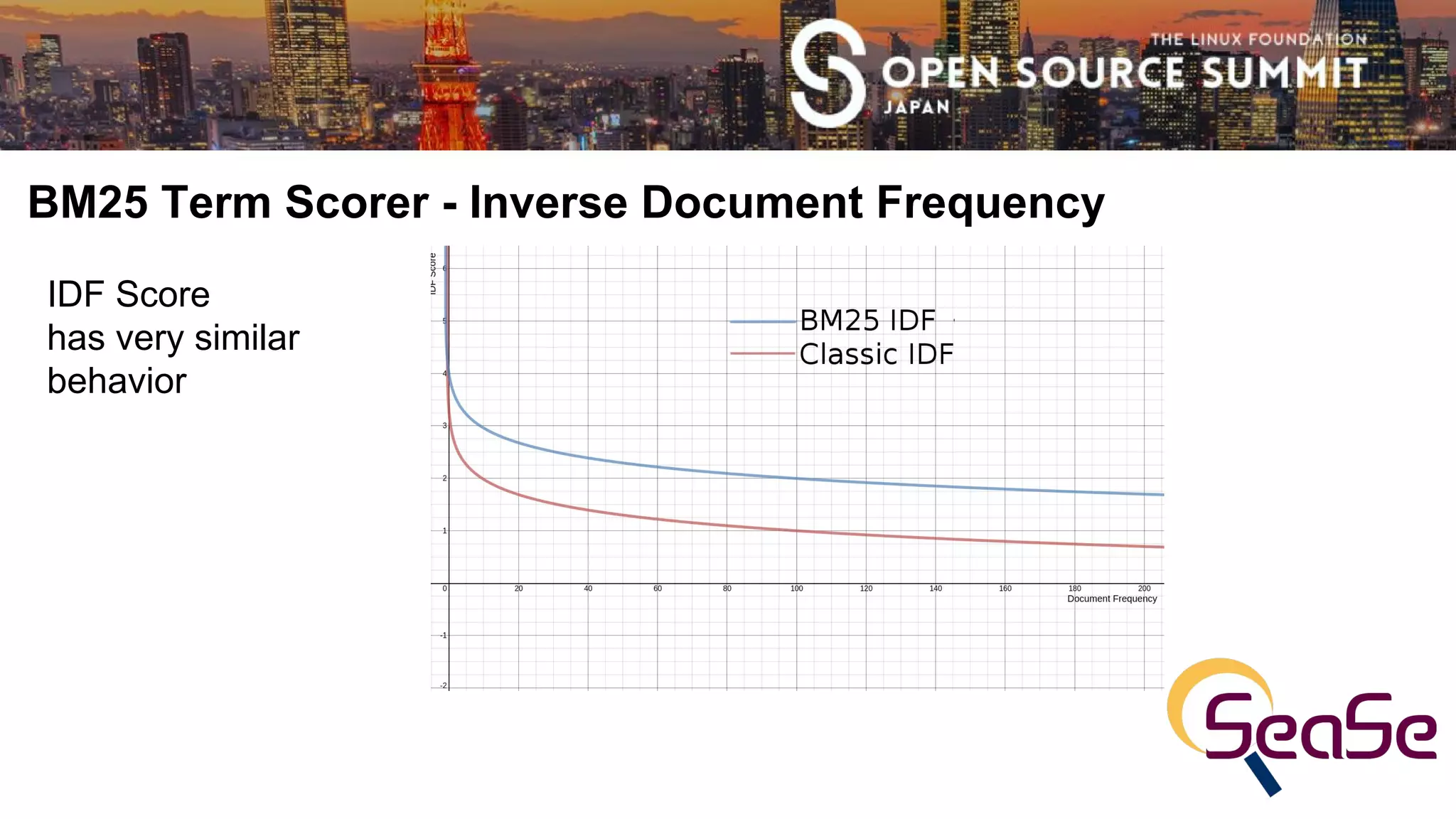
● IDF
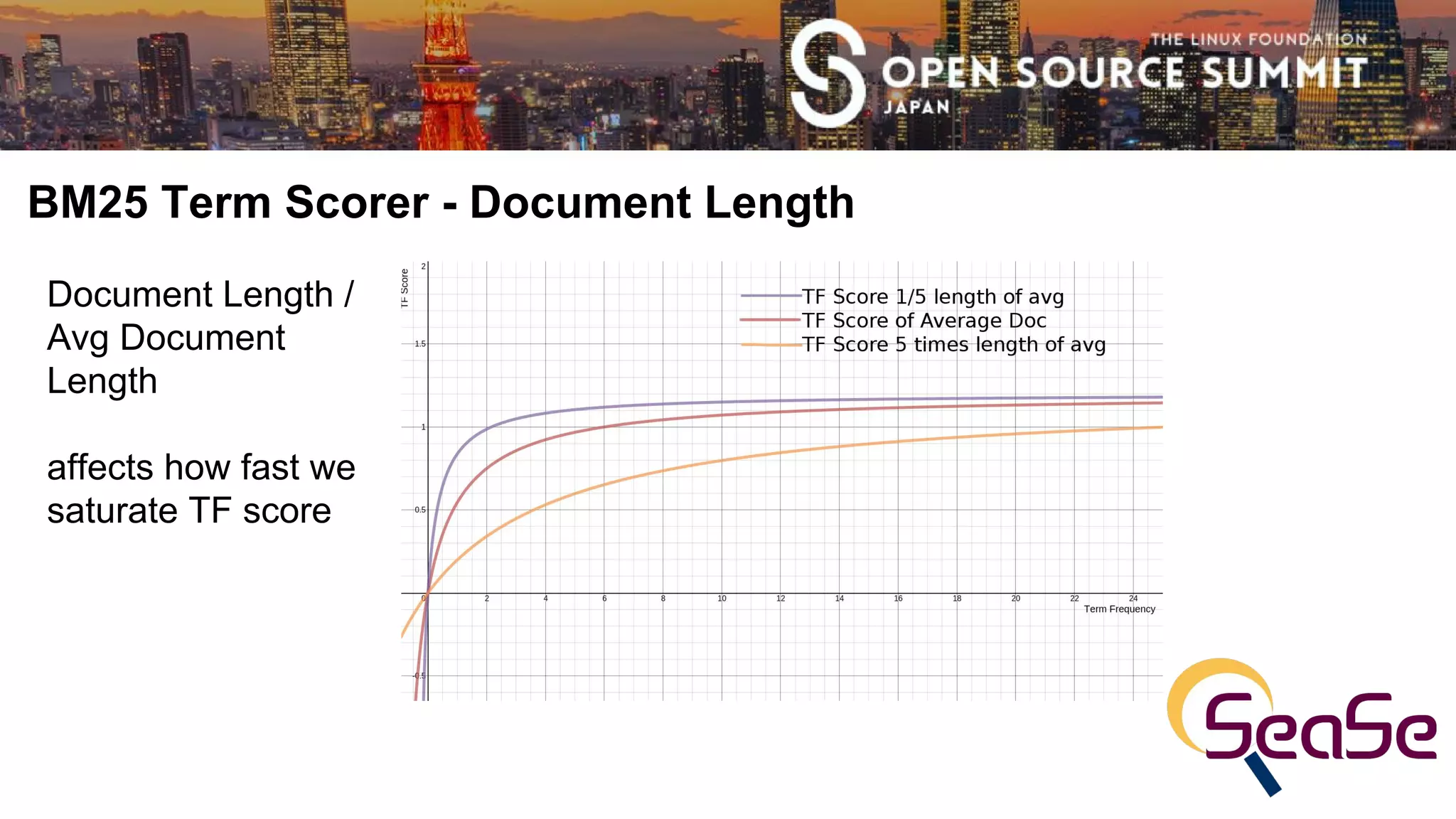
● Document Length
[1] LUCENE-6789
BM25 Term Scorer](https://image.slidesharecdn.com/opensourcesummitjapanalessandro-170614082941/75/Advanced-Document-Similarity-With-Apache-Lucene-15-2048.jpg)

























![● Origin from Probabilistic Information Retrieval
● Default Similarity from Lucene 6.0 [1]
● 25th iteration in improving TF-IDF
● TF
● IDF
● Document Length
[1] LUCENE-6789
BM25 Term Scorer](https://crownmelresort.com/image.slidesharecdn.com/opensourcesummitjapanalessandro-170614082941/75/Advanced-Document-Similarity-With-Apache-Lucene-15-2048.jpg)
















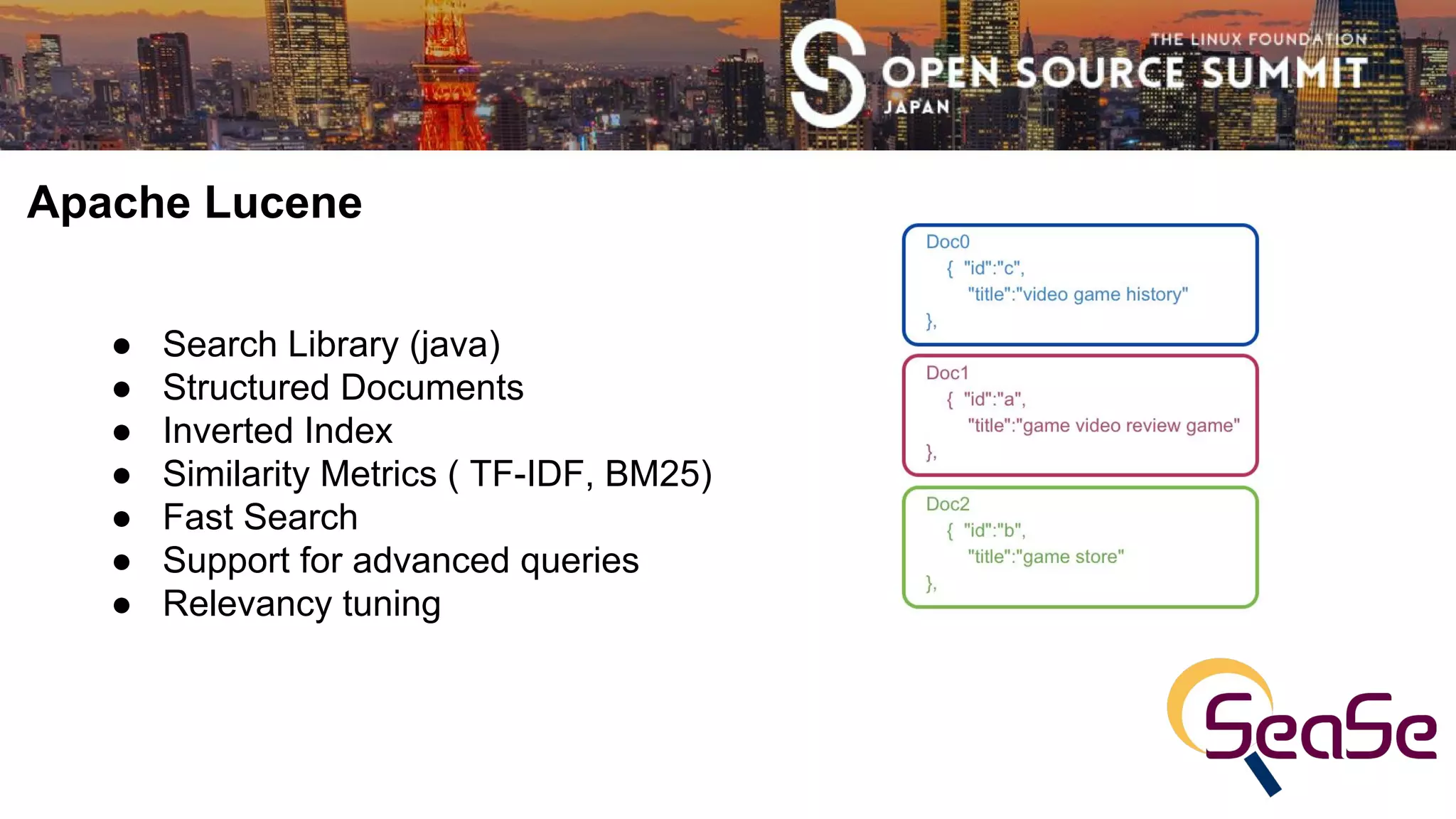
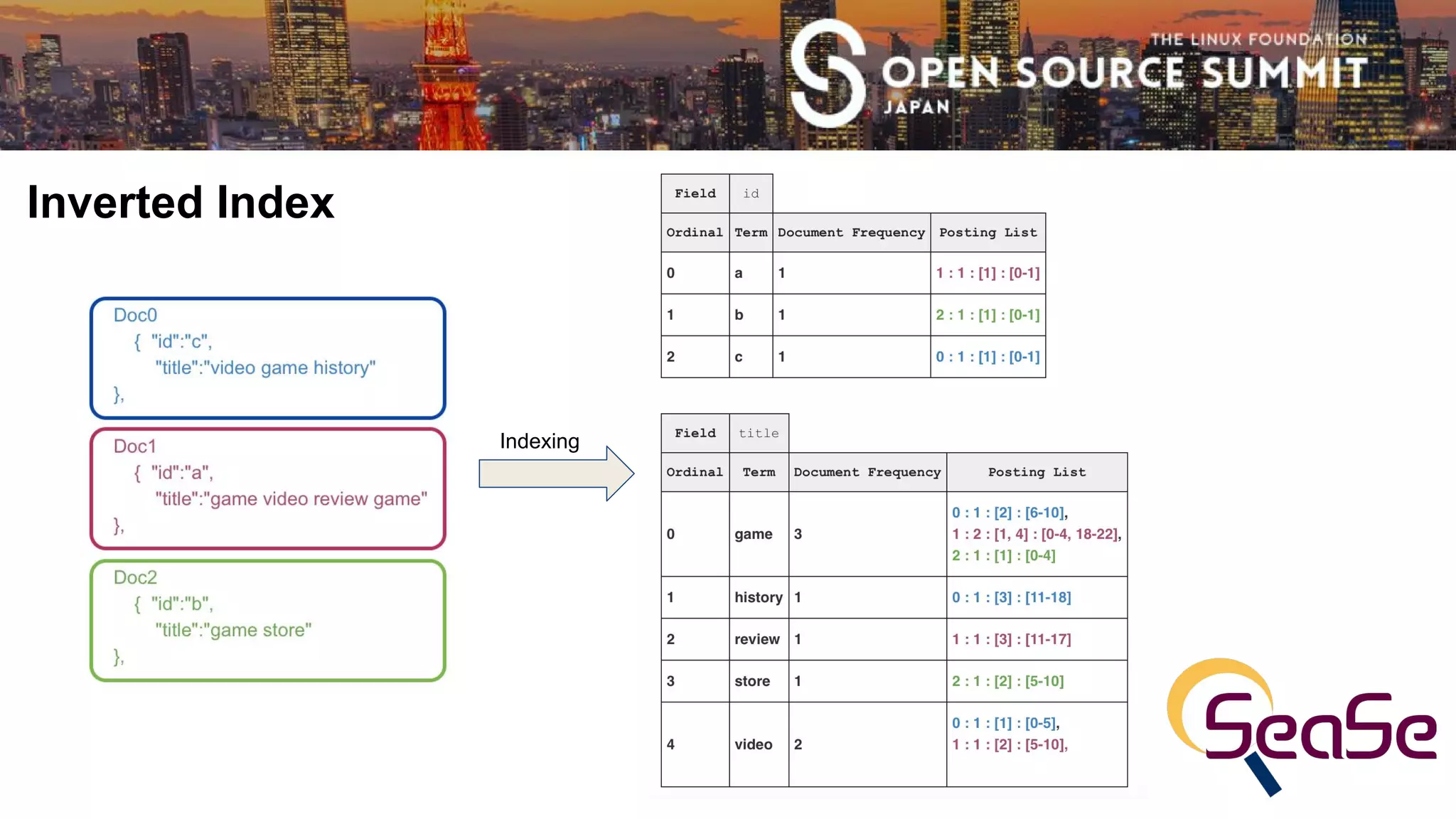
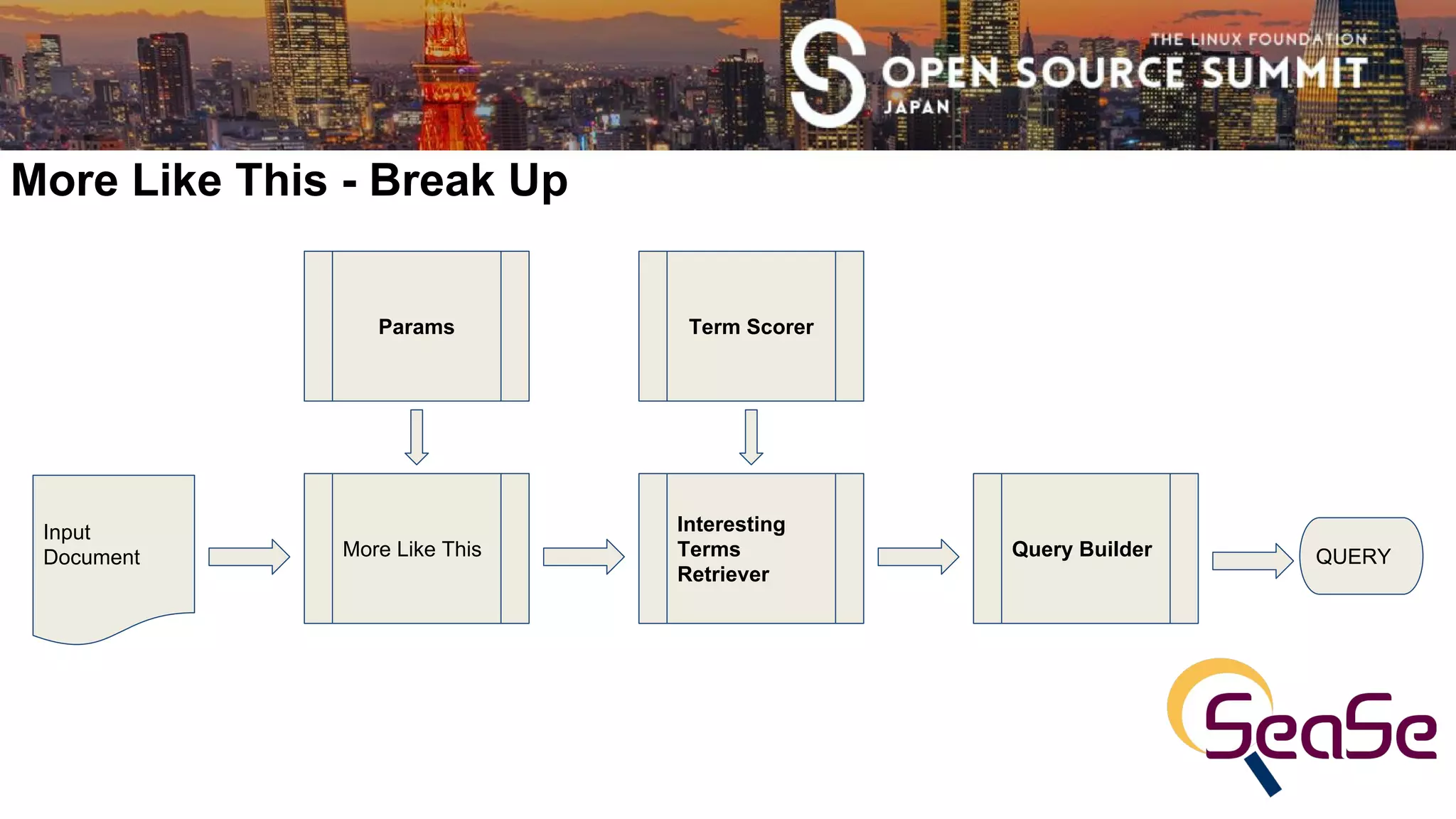
This document provides an overview of using Apache Lucene to perform document similarity searches. It discusses how Lucene indexes documents and calculates term scores using techniques like TF-IDF and BM25. The document demonstrates Lucene's More Like This module, which finds similar documents by building a query from weighted interesting terms in the input document. It also proposes future work, such as leveraging term positions and fields across multiple input documents to improve similarity searches.































































