Downloaded 28 times
















![Seminars
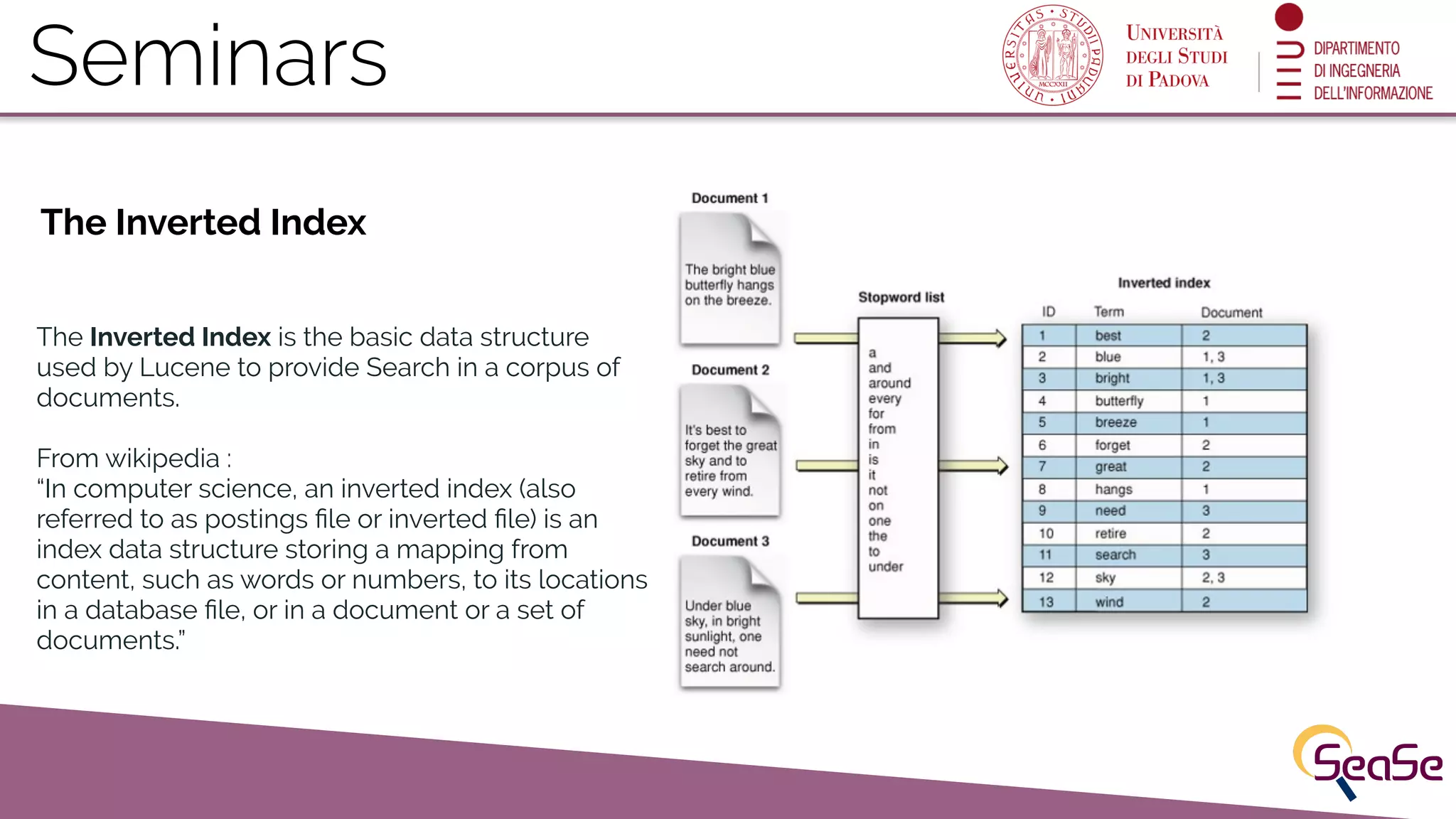
The Lucene Inverted Index
• Lucene directory (in memory, on disk, memory mapped)
• Collection of immutable segments (fully working)
• Each segment is composed by a set of binary files[1]
[1] Lucene File Format Documentation
Indexes evolve by:
1. Creating new segments for newly added documents.
2. Merging existing segments.](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-19-2048.jpg)




![Seminars
Tokenizers
Tokenizers are responsible for breaking field data into lexical units, or tokens.[1]
[1] https://lucene.apache.org/solr/guide/8_3/tokenizers.html](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-25-2048.jpg)
![Seminars
Token Filters
Filters[1] examine a stream of tokens and keep them, transform them or discard them,
depending on the filter type being used.
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-26-2048.jpg)
![Seminars
Word Delimiters Filter
• Improve recall
• Dedicated Filters:
solr.WordDelimiterGraphFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#word-delimiter-graph-filter
Example:
Default behavior. The whitespace tokenizer is used here to preserve non-alphanumeric characters.
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory"/>
</analyzer>
In: "hot-spot RoboBlaster/9000 100XL"
Tokenizer to Filter: "hot-spot", "RoboBlaster/9000", "100XL"
Out: "hot", "spot", "Robo", "Blaster", "9000", "100", "XL"](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-27-2048.jpg)
![Seminars
Stopword Filters
• Reduce index size
• Can improve precision (removing terms with low semantic value)
• Can improve recall
• Dedicated Filters: solr.StopFilterFactory, solr.ManagedStopFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#stop-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
In: "To be or what?"
Tokenizer to Filter: "To"(1), "be"(2), "or"(3), "what"(4)
Out: "what"(4)](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-28-2048.jpg)
![Seminars
Stemmers
• Improve Recall
• Reduce index size
• Dedicated Filters: solr.EnglishMinimalStemFilterFactory, solr.HunspellStemFilterFactory, solr.KStemFilterFactory,
solr.PorterStemFilterFactory, solr.SnowballPorterFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#porter-stem-filter
Example:
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
</analyzer>
In: "dogs cats"
Tokenizer to Filter: "dogs", "cats"
Out: "dog", "cat"](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-29-2048.jpg)
![Seminars
Synonym Filters[1/2]
• Improve Recall
• Dedicated Filters: solr.SynonymGraphFilterFactory
• Index Time -> affect terms distributions, needs re-indexing
• Query Time -> more flexible
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#synonym-graph-filter
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-30-2048.jpg)
![Seminars
Synonym Filters[2/2]
• Improve Recall
• Dedicated Filters:
solr.SynonymGraphFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#synonym-graph-filter
Example:
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
<filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
In: "teh small couch"
Tokenizer to Filter: "teh"(1), "small"(2), "couch"(3)
Out: "the"(1), "tiny"(2), "teeny"(2), "weeny"(2), "couch"(3), "sofa"(3), "divan"(3)](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-31-2048.jpg)
![Seminars
Keep Word Filter
• Help in Entity tagging
• Dedicated Filters: solr.KeepWordFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#keep-word-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true"/>
</analyzer>
In: "Happy, sad or funny"
Tokenizer to Filter: "Happy", "sad", "or", "funny"
Out: "Happy", "funny"](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-32-2048.jpg)
![Seminars
N-Gram Filtering
• Improve Recall
• Ideal for autocompletion
• Dedicated Filters: solr.EdgeNGramFilterFactory, solr.NGramFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#edge-n-gram-filter
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="4"/>
</analyzer>](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-33-2048.jpg)
![Seminars
Phonetic Matching
• Improve Recall
• Dedicated Filters: solr.BeiderMorseFilterFactory, solr.DaitchMokotoffSoundexFilterFactory,
solr.DoubleMetaphoneFilterFactory, solr.PhoneticFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/phonetic-matching.html
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.BeiderMorseFilterFactory" nameType="GENERIC" ruleType="APPROX" concat="true"
languageSet="auto">
</filter>
</analyzer>](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-34-2048.jpg)
![Seminars
Common Grams Filter
• Improve Precision
• Useful for phrase queries
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#common-grams-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.CommonGramsFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
In: "the Cat"
Tokenizer to Filter: "the", "Cat"
Out: "the_cat"](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-35-2048.jpg)





![Seminars
! Origin from Probabilistic Information Retrieval
! Default Similarity from Lucene 6.0 [1]
! 25th iteration in improving TF-IDF
! TF
! IDF
! Document(Field) Length
! Configuration parameters
[1] LUCENE-6789
BM25 Term Scorer](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-42-2048.jpg)




![Seminars
Standard Query Parser
• Phrase Search
q=title:”a tale of two cities”
• Wildcard Search
q=title:c?ti*
• Fuzzy Search
q=title:cties~1
• Proximity Search
q=title:"tale cities"~2
• Range Search
downloads:[1000 TO 2000], author:{Ada TO Carmen}
• Boosted Search
q=tale of two cities^100 bunny
• Constant Score Search
AND subjects:(war stories)^=4
• Boolean Search
(field1:term1) AND (field2:term1)](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-50-2048.jpg)
![Seminars
Date Queries
Queries against fields using the TrieDateField type (typically range queries) should use the appropriate date syntax [1]:
• timestamp:[* TO NOW]
• createdate:[1976-03-06T23:59:59.999Z TO *]
• createdate:[1995-12-31T23:59:59.999Z TO 2007-03-06T00:00:00Z]
• pubdate:[NOW-1YEAR/DAY TO NOW/DAY+1DAY]
• createdate:[1976-03-06T23:59:59.999Z TO 1976-03-06T23:59:59.999Z+1YEAR]
• createdate:[1976-03-06T23:59:59.999Z/YEAR TO 1976-03-06T23:59:59.999Z]
[1] https://en.wikipedia.org/wiki/ISO_8601
Timezone
By default, all date math expressions are evaluated relative to the UTC TimeZone, but the TZ parameter can be
specified to override this behaviour
N.B. Independently of the locale Solr is executed, only ISO-8601 dates are supported in requests](https://image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-51-2048.jpg)






















![Seminars
The Lucene Inverted Index
• Lucene directory (in memory, on disk, memory mapped)
• Collection of immutable segments (fully working)
• Each segment is composed by a set of binary files[1]
[1] Lucene File Format Documentation
Indexes evolve by:
1. Creating new segments for newly added documents.
2. Merging existing segments.](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-19-2048.jpg)





![Seminars
Tokenizers
Tokenizers are responsible for breaking field data into lexical units, or tokens.[1]
[1] https://lucene.apache.org/solr/guide/8_3/tokenizers.html](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-25-2048.jpg)
![Seminars
Token Filters
Filters[1] examine a stream of tokens and keep them, transform them or discard them,
depending on the filter type being used.
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-26-2048.jpg)
![Seminars
Word Delimiters Filter
• Improve recall
• Dedicated Filters:
solr.WordDelimiterGraphFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#word-delimiter-graph-filter
Example:
Default behavior. The whitespace tokenizer is used here to preserve non-alphanumeric characters.
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory"/>
</analyzer>
In: "hot-spot RoboBlaster/9000 100XL"
Tokenizer to Filter: "hot-spot", "RoboBlaster/9000", "100XL"
Out: "hot", "spot", "Robo", "Blaster", "9000", "100", "XL"](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-27-2048.jpg)
![Seminars
Stopword Filters
• Reduce index size
• Can improve precision (removing terms with low semantic value)
• Can improve recall
• Dedicated Filters: solr.StopFilterFactory, solr.ManagedStopFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#stop-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
In: "To be or what?"
Tokenizer to Filter: "To"(1), "be"(2), "or"(3), "what"(4)
Out: "what"(4)](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-28-2048.jpg)
![Seminars
Stemmers
• Improve Recall
• Reduce index size
• Dedicated Filters: solr.EnglishMinimalStemFilterFactory, solr.HunspellStemFilterFactory, solr.KStemFilterFactory,
solr.PorterStemFilterFactory, solr.SnowballPorterFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#porter-stem-filter
Example:
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
</analyzer>
In: "dogs cats"
Tokenizer to Filter: "dogs", "cats"
Out: "dog", "cat"](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-29-2048.jpg)
![Seminars
Synonym Filters[1/2]
• Improve Recall
• Dedicated Filters: solr.SynonymGraphFilterFactory
• Index Time -> affect terms distributions, needs re-indexing
• Query Time -> more flexible
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#synonym-graph-filter
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-30-2048.jpg)
![Seminars
Synonym Filters[2/2]
• Improve Recall
• Dedicated Filters:
solr.SynonymGraphFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#synonym-graph-filter
Example:
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
<filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters -->
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
In: "teh small couch"
Tokenizer to Filter: "teh"(1), "small"(2), "couch"(3)
Out: "the"(1), "tiny"(2), "teeny"(2), "weeny"(2), "couch"(3), "sofa"(3), "divan"(3)](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-31-2048.jpg)
![Seminars
Keep Word Filter
• Help in Entity tagging
• Dedicated Filters: solr.KeepWordFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#keep-word-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true"/>
</analyzer>
In: "Happy, sad or funny"
Tokenizer to Filter: "Happy", "sad", "or", "funny"
Out: "Happy", "funny"](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-32-2048.jpg)
![Seminars
N-Gram Filtering
• Improve Recall
• Ideal for autocompletion
• Dedicated Filters: solr.EdgeNGramFilterFactory, solr.NGramFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#edge-n-gram-filter
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="4"/>
</analyzer>](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-33-2048.jpg)
![Seminars
Phonetic Matching
• Improve Recall
• Dedicated Filters: solr.BeiderMorseFilterFactory, solr.DaitchMokotoffSoundexFilterFactory,
solr.DoubleMetaphoneFilterFactory, solr.PhoneticFilterFactory
[1] https://lucene.apache.org/solr/guide/8_3/phonetic-matching.html
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.BeiderMorseFilterFactory" nameType="GENERIC" ruleType="APPROX" concat="true"
languageSet="auto">
</filter>
</analyzer>](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-34-2048.jpg)
![Seminars
Common Grams Filter
• Improve Precision
• Useful for phrase queries
[1] https://lucene.apache.org/solr/guide/8_3/filter-descriptions.html#common-grams-filter
Example:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.CommonGramsFilterFactory" words="stopwords.txt" ignoreCase="true"/>
</analyzer>
In: "the Cat"
Tokenizer to Filter: "the", "Cat"
Out: "the_cat"](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-35-2048.jpg)






![Seminars
! Origin from Probabilistic Information Retrieval
! Default Similarity from Lucene 6.0 [1]
! 25th iteration in improving TF-IDF
! TF
! IDF
! Document(Field) Length
! Configuration parameters
[1] LUCENE-6789
BM25 Term Scorer](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-42-2048.jpg)







![Seminars
Standard Query Parser
• Phrase Search
q=title:”a tale of two cities”
• Wildcard Search
q=title:c?ti*
• Fuzzy Search
q=title:cties~1
• Proximity Search
q=title:"tale cities"~2
• Range Search
downloads:[1000 TO 2000], author:{Ada TO Carmen}
• Boosted Search
q=tale of two cities^100 bunny
• Constant Score Search
AND subjects:(war stories)^=4
• Boolean Search
(field1:term1) AND (field2:term1)](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-50-2048.jpg)
![Seminars
Date Queries
Queries against fields using the TrieDateField type (typically range queries) should use the appropriate date syntax [1]:
• timestamp:[* TO NOW]
• createdate:[1976-03-06T23:59:59.999Z TO *]
• createdate:[1995-12-31T23:59:59.999Z TO 2007-03-06T00:00:00Z]
• pubdate:[NOW-1YEAR/DAY TO NOW/DAY+1DAY]
• createdate:[1976-03-06T23:59:59.999Z TO 1976-03-06T23:59:59.999Z+1YEAR]
• createdate:[1976-03-06T23:59:59.999Z/YEAR TO 1976-03-06T23:59:59.999Z]
[1] https://en.wikipedia.org/wiki/ISO_8601
Timezone
By default, all date math expressions are evaluated relative to the UTC TimeZone, but the TZ parameter can be
specified to override this behaviour
N.B. Independently of the locale Solr is executed, only ISO-8601 dates are supported in requests](https://crownmelresort.com/image.slidesharecdn.com/sease-seminar1-191202114645/75/Let-s-Build-an-Inverted-Index-Introduction-to-Apache-Lucene-Solr-51-2048.jpg)





The document is a seminar presentation about building an inverted index with Apache Lucene and Solr, covering the importance of open-source software in information retrieval. It outlines the roles of various data structures, the workings of Apache Lucene and Solr, and key concepts such as indexing, text analysis, and query operations. Additionally, it discusses the contributions to and benefits of open-source projects, as well as advanced filtering techniques in search functionalities.
Presentation on Apache Lucene/Solr by Alessandro Benedetti and Andrea Gazzarini, highlighting their expertise in software engineering and information retrieval.
Overview of the Search Services team, their open-source culture, and expertise in Apache Lucene/Solr technologies.
Advantages of using open-source software include state-of-the-art technology, community support, and accessibility.
Services offered include training and consulting in open-source information retrieval technologies like Lucene/Solr.
Definition and scope of Information Retrieval (IR), emphasizing its processes related to searching documents and metadata.
Lucene is described as a high-performance library for scalable information retrieval, enabling search in applications.
Solr is a scalable search server based on Lucene, known for its reliability and extensive features for enterprise applications.
The Inverted Index is crucial for documents' search capabilities, as it maps content to its location in databases.
Documents in Lucene consist of indexed fields, with details on the structure and immutability of index segments.
Schema configurations dictate how an inverted index is constructed, defining fields and their attributes.
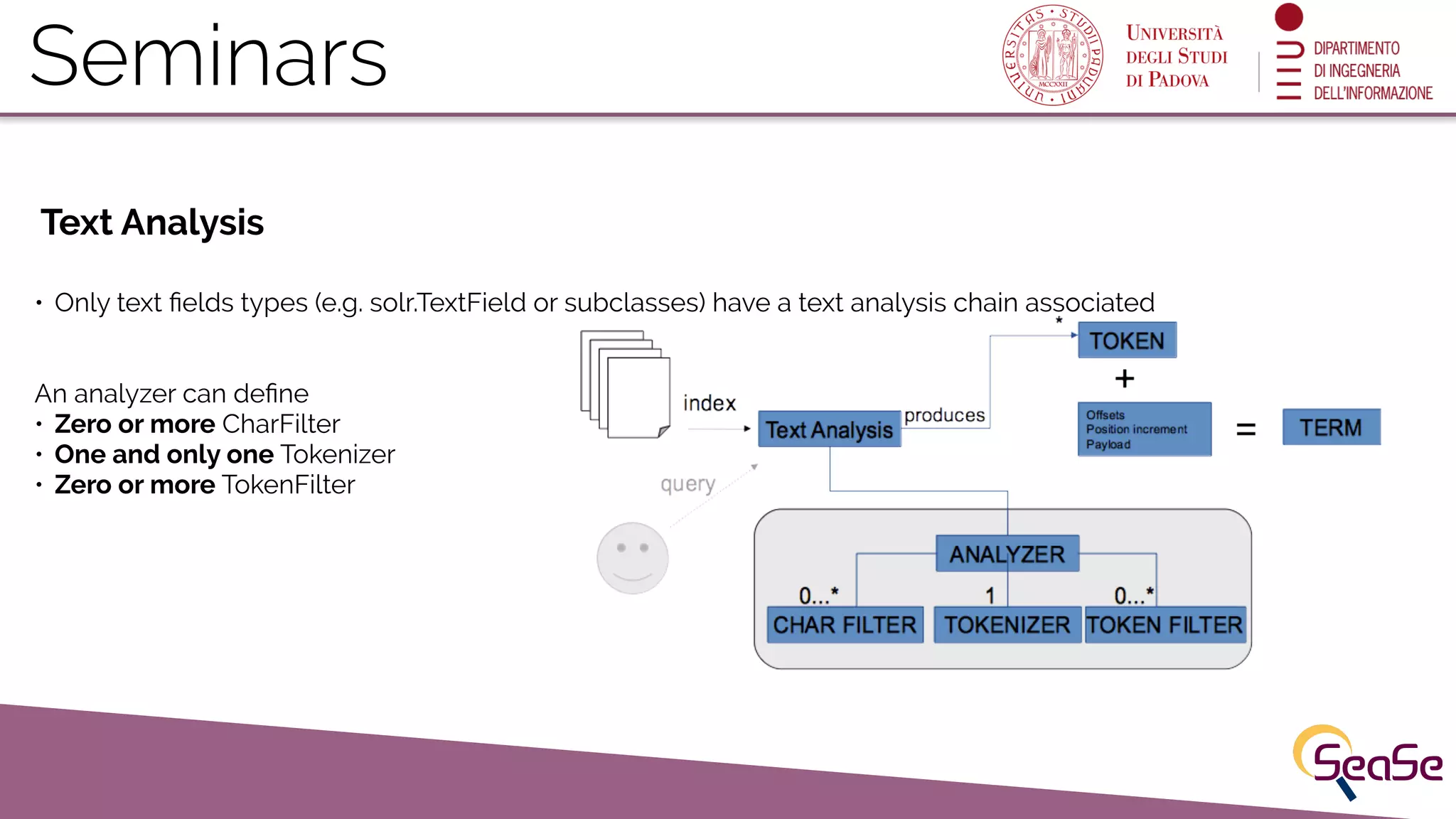
Field Types determine term generation within the index, and text analysis involves various processing elements like tokenizers.
Token filters, including word delimiters, stopword filters, and stemmers, improve search accuracy and index efficiency.
Synonym filters enhance recall in search results, allowing accurate retrieval of similar terms and phrases.
Introduction of Keep Word, N-Gram, and Phonetic Matching filters to improve search recall and precision.
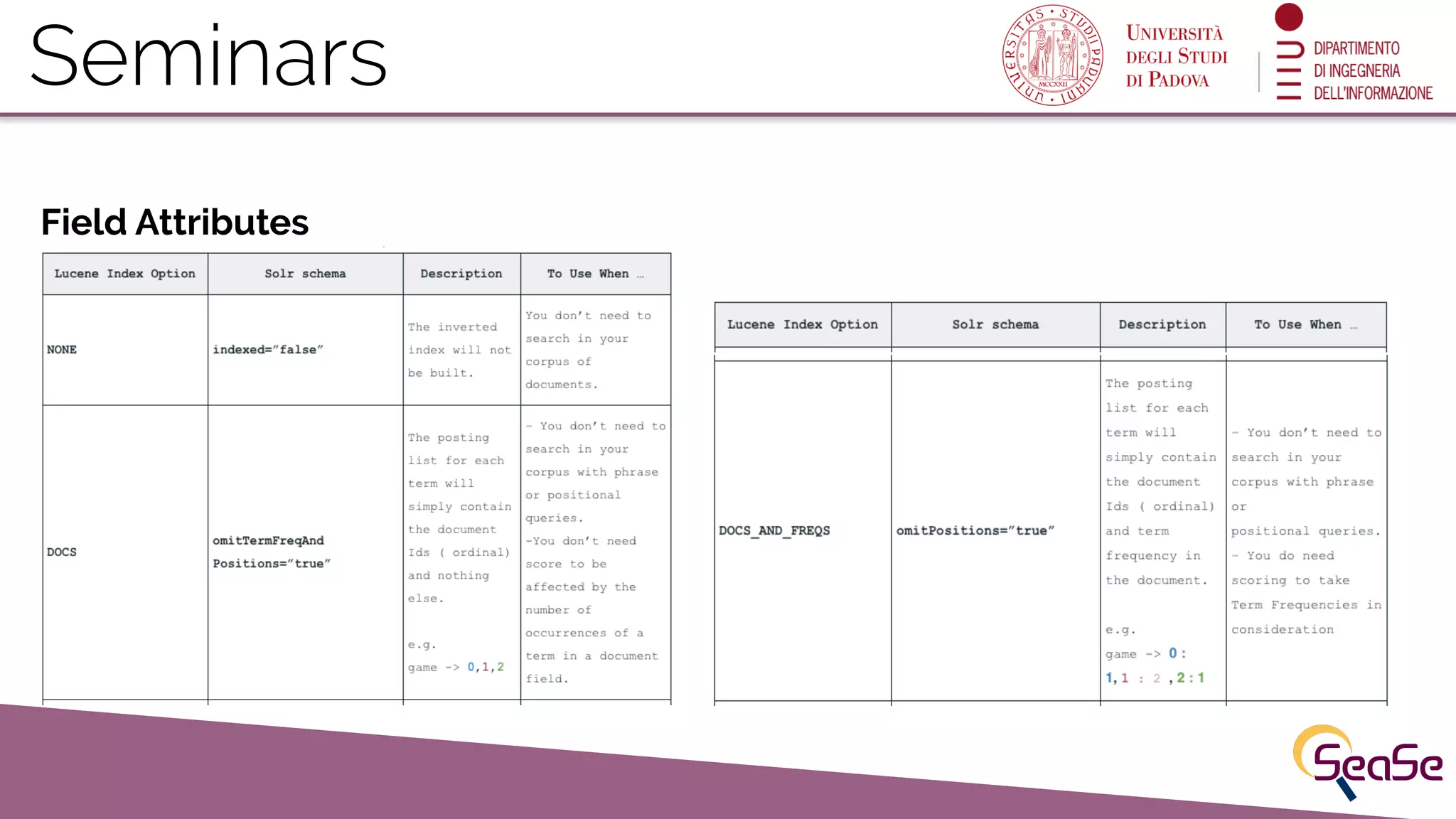
Overview of field attributes affecting searches and hands-on exploration of schema.xml in Solr.
Discussion on how documents are indexed in Solr, including usage of Solr Cell framework and transaction log management.
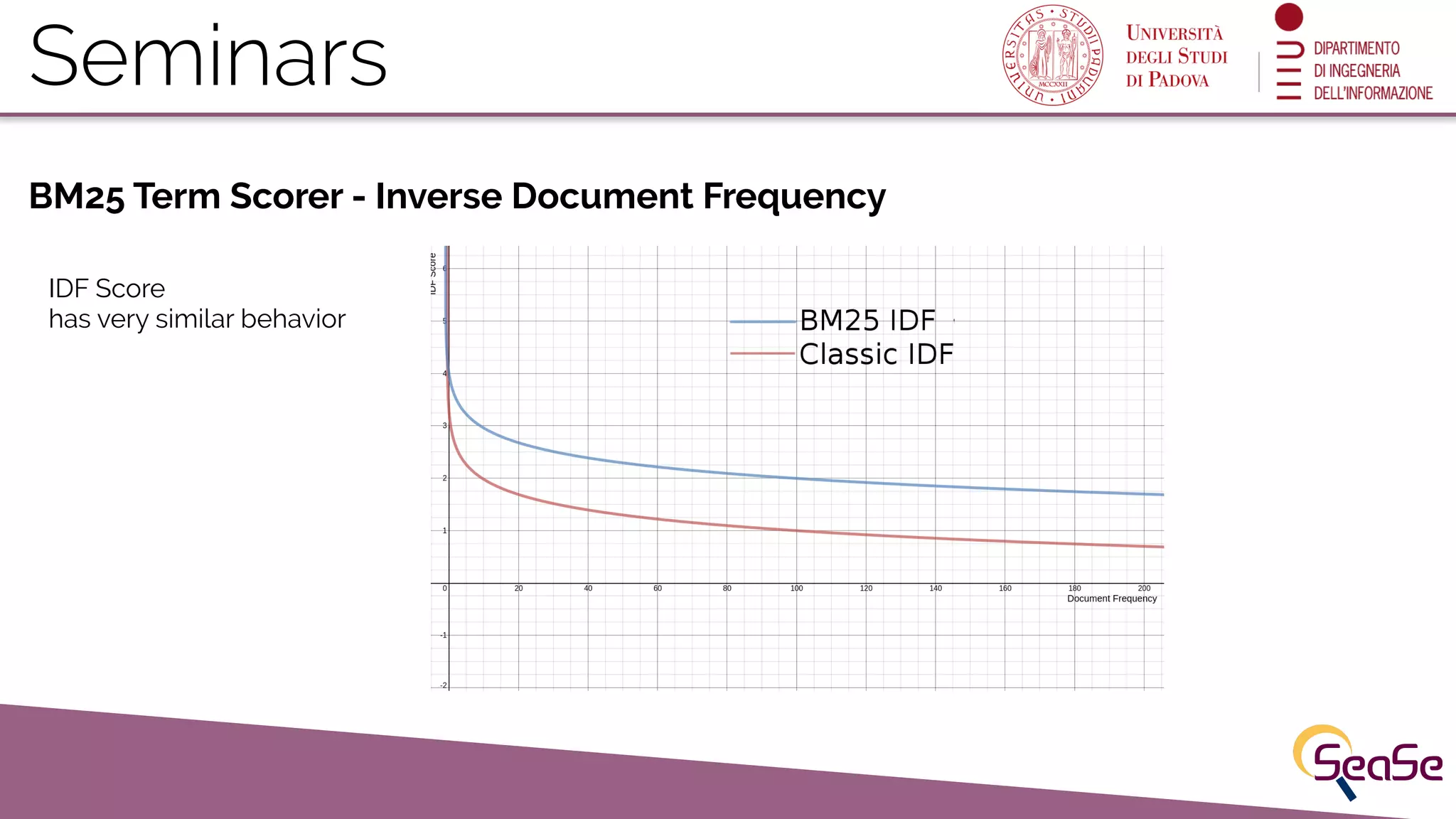
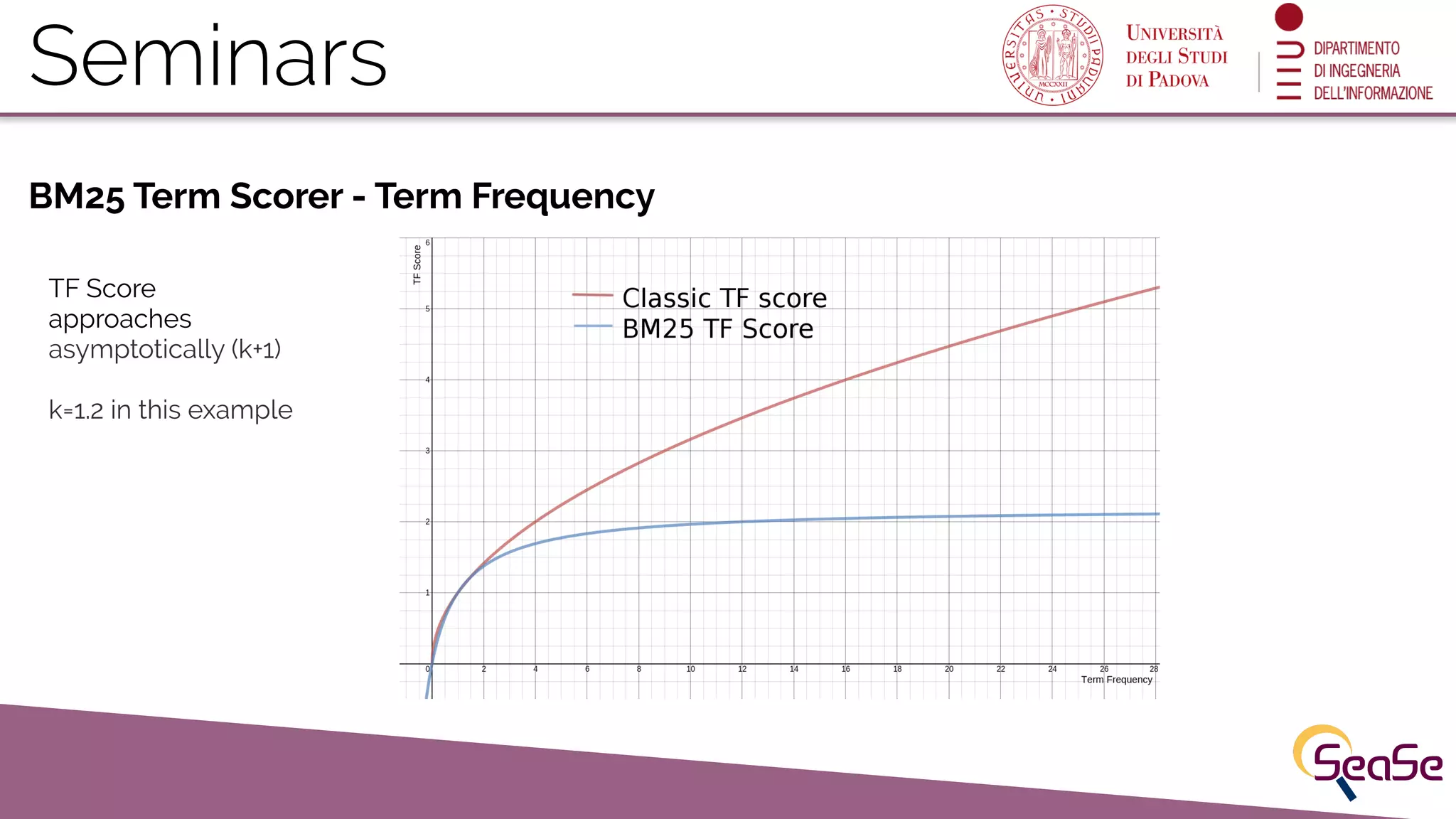
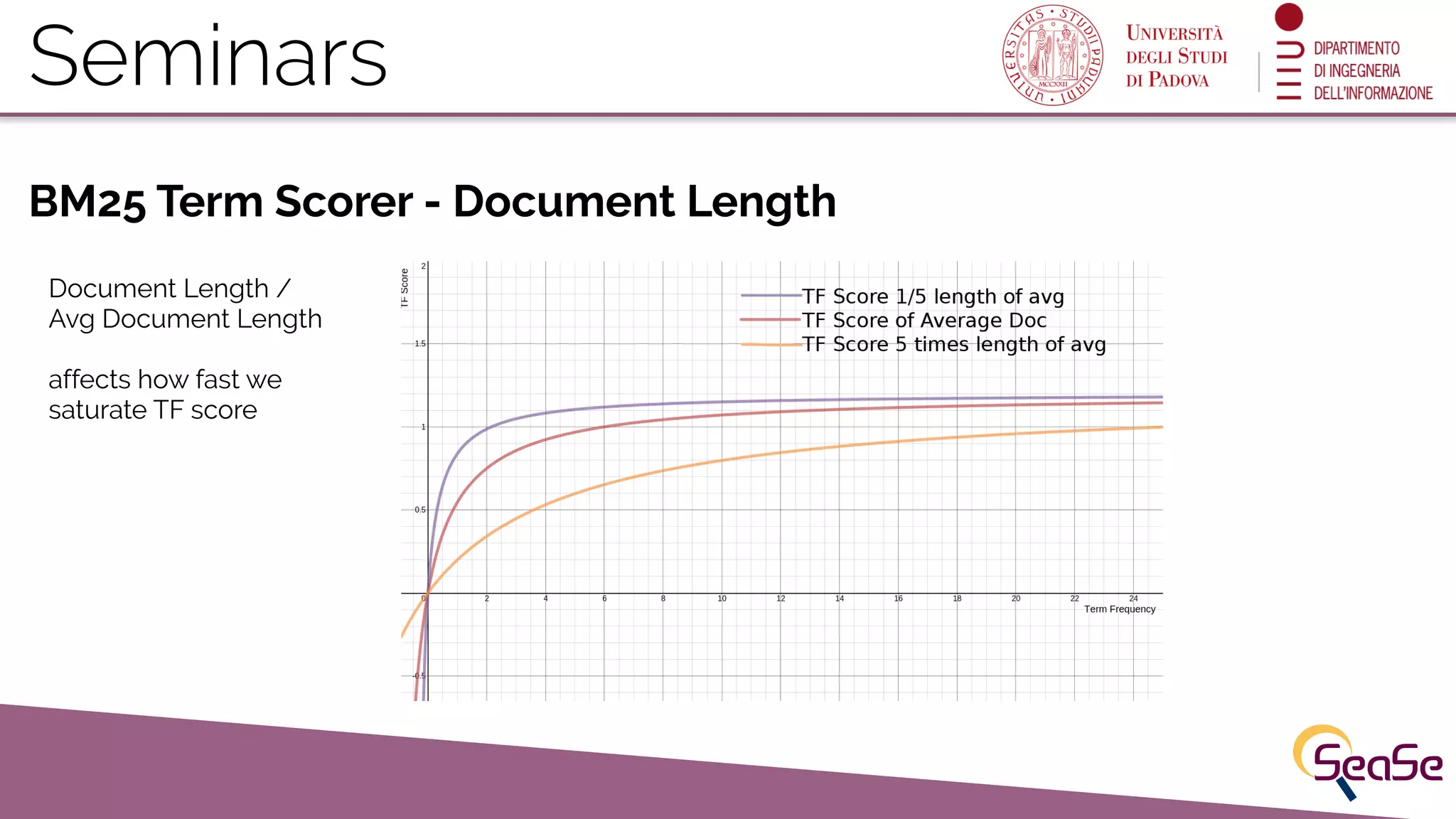
Lucene assigns scores to results based on term frequency, document frequency, and BM25 scoring mechanisms.
Detailed explanation of BM25 scoring factors and the list of query parameters available in Solr.
Query parsing includes the use of various query filters that determine score calculations and result caching.
Overview of date query syntax for Solr and debugging options to troubleshoot query processing.
Descriptions of two master thesis projects focused on click models and search quality evaluation in software development.









![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)













































































