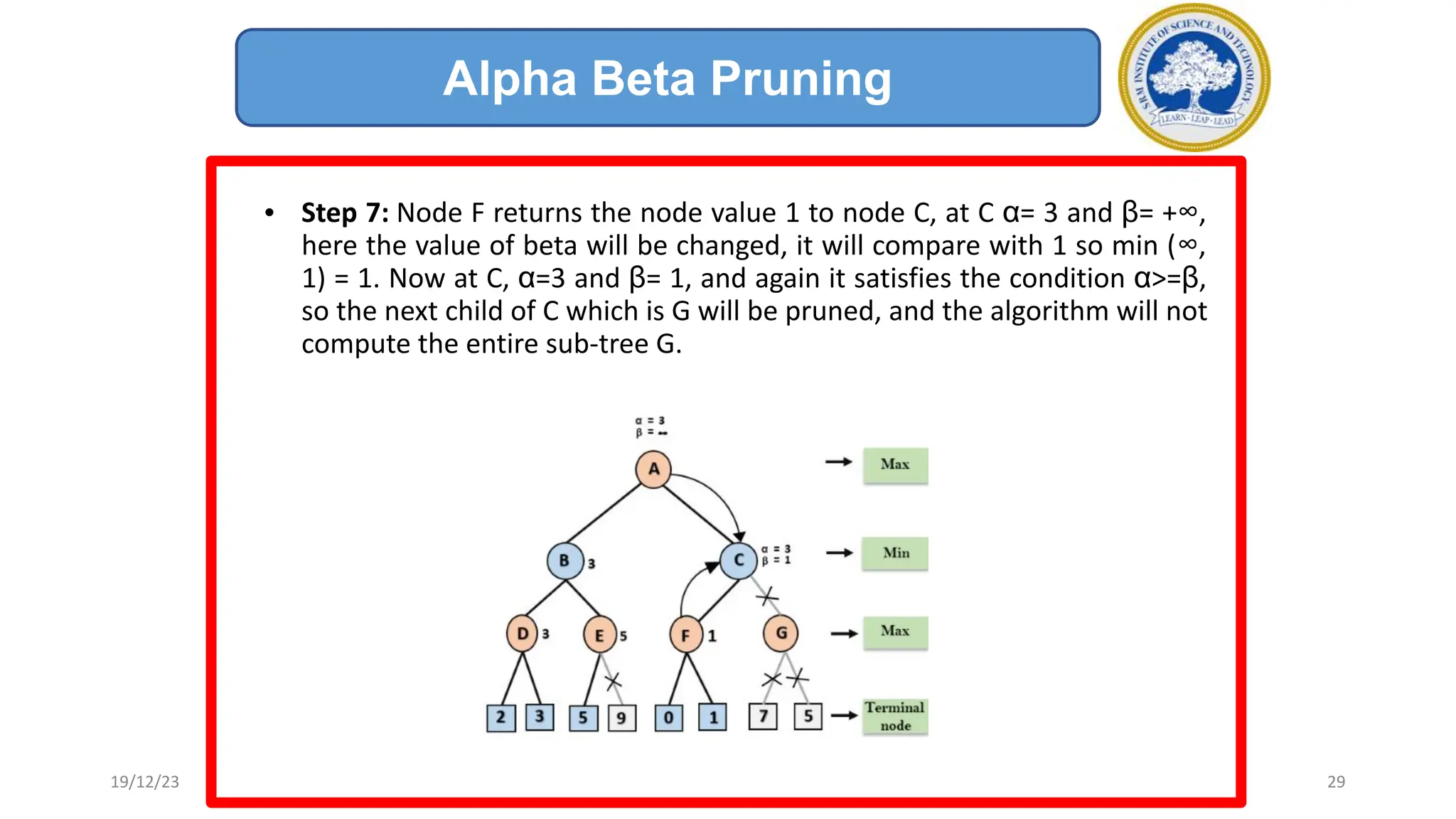
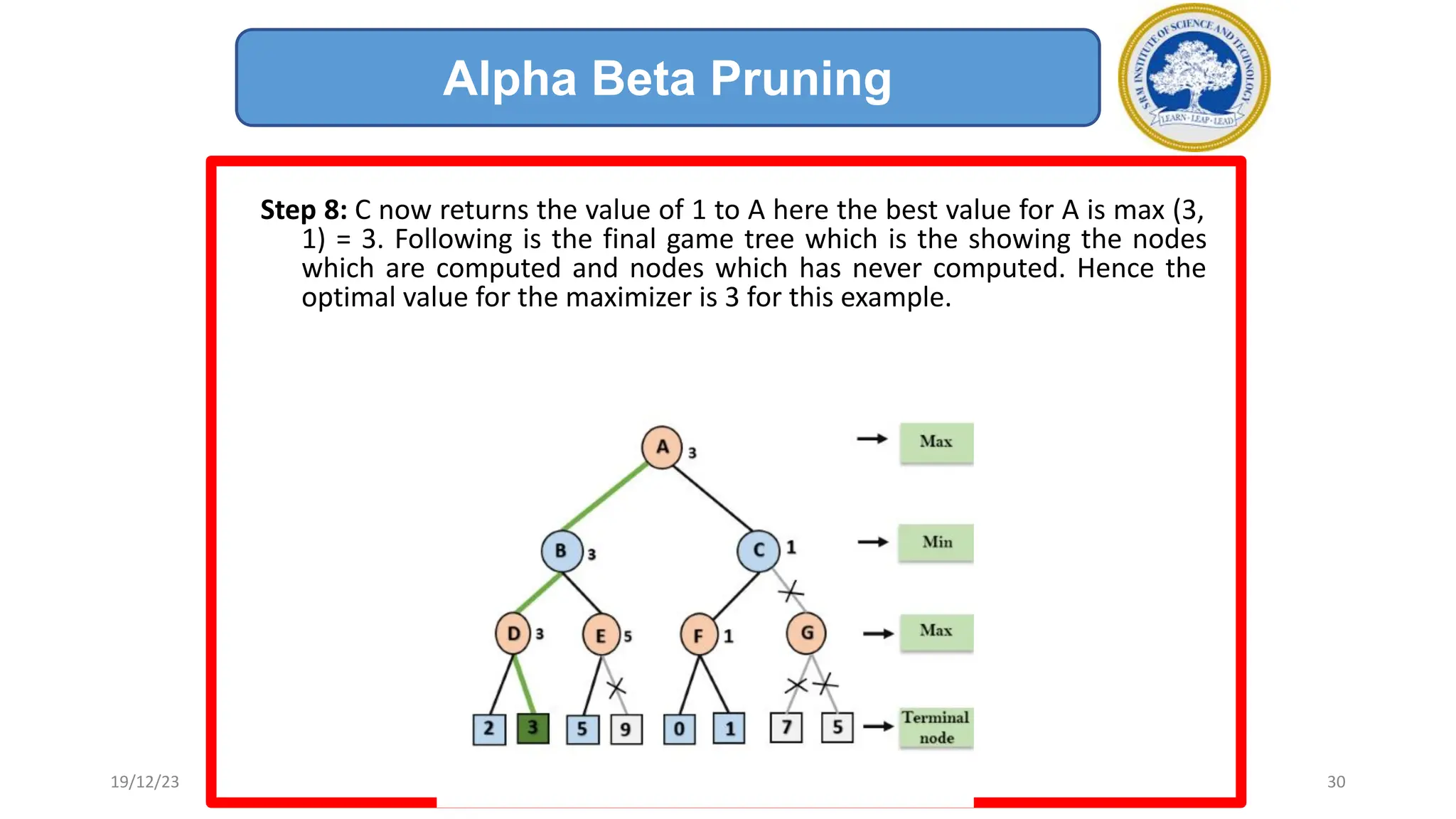
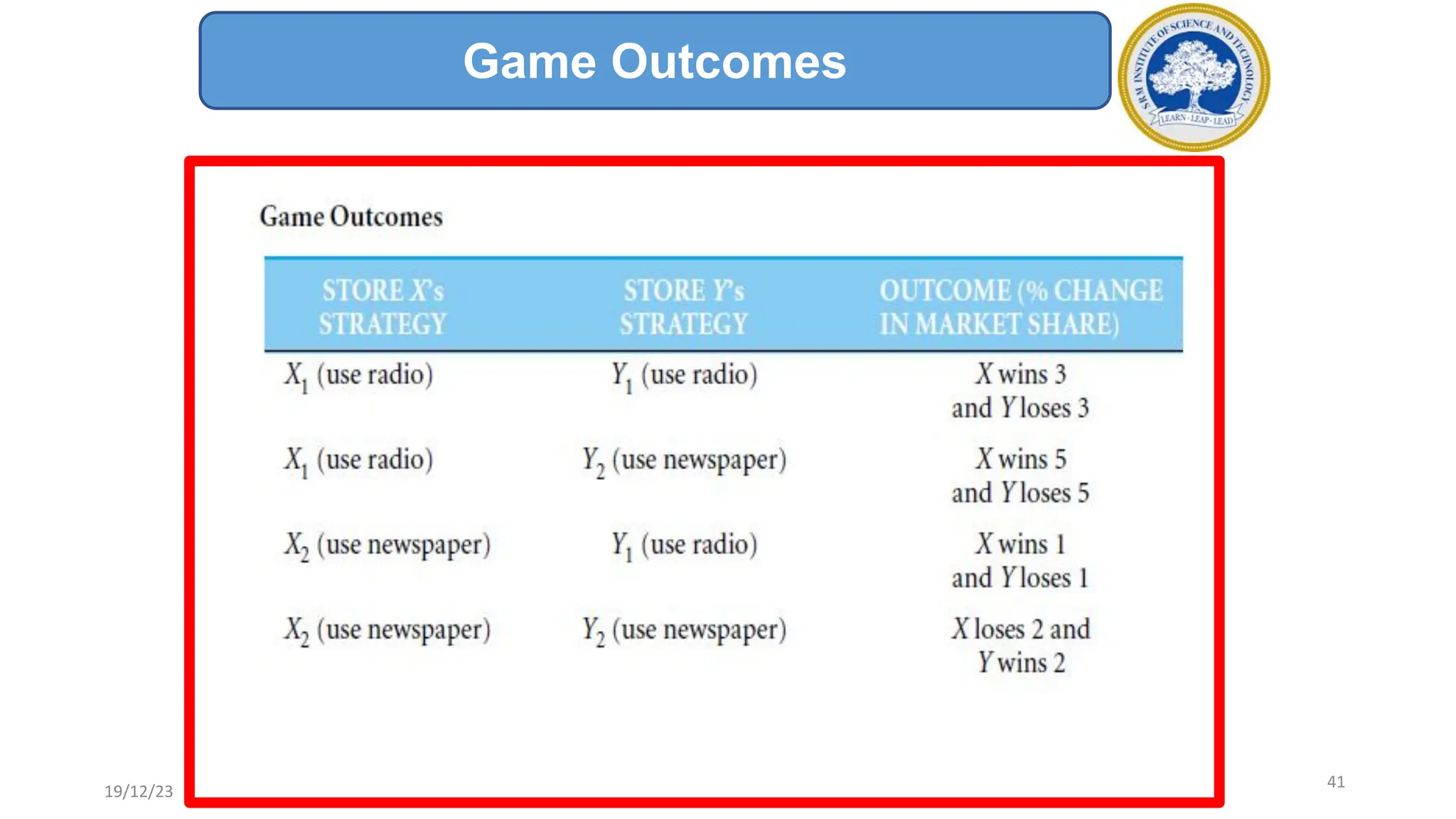
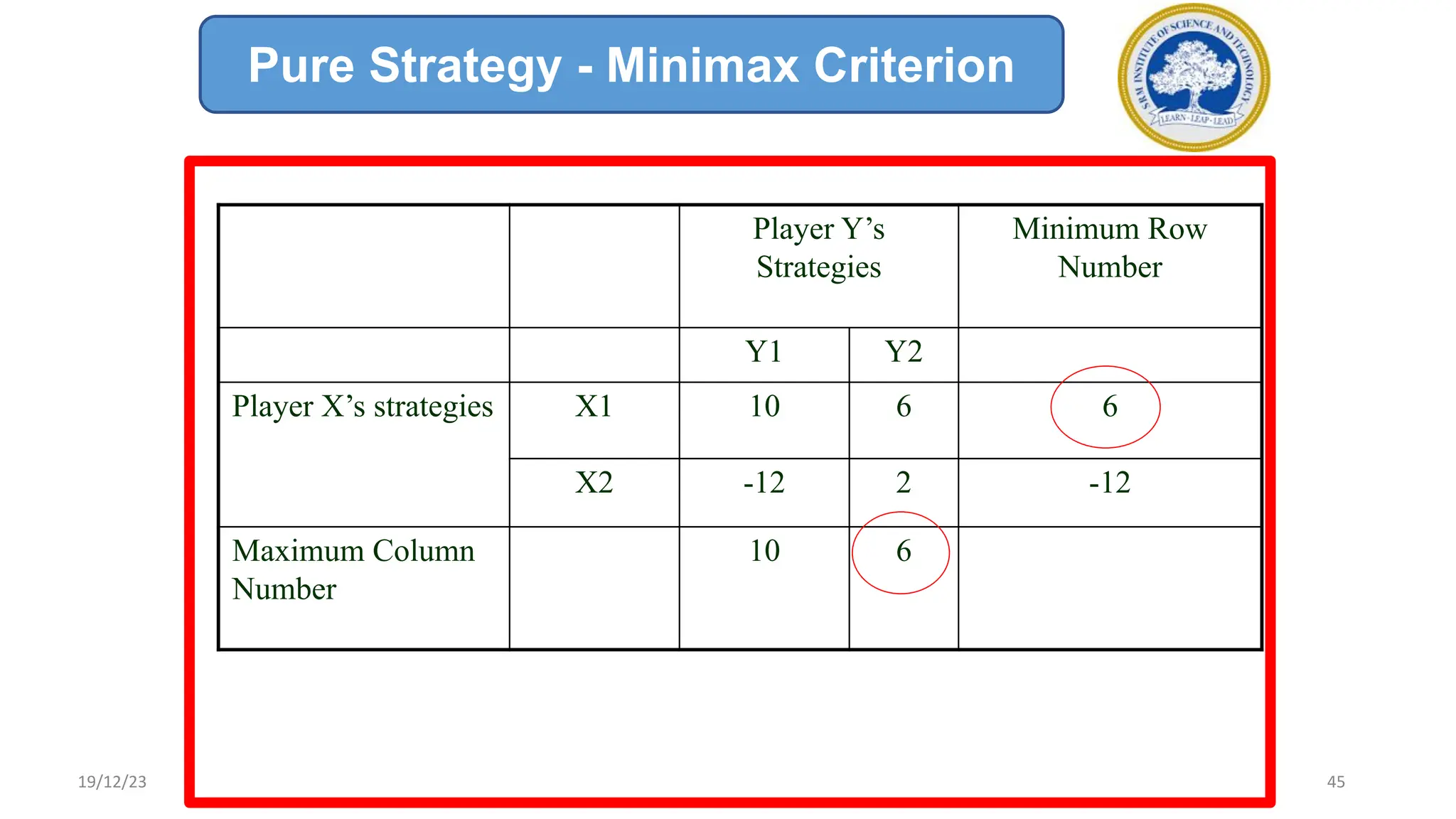
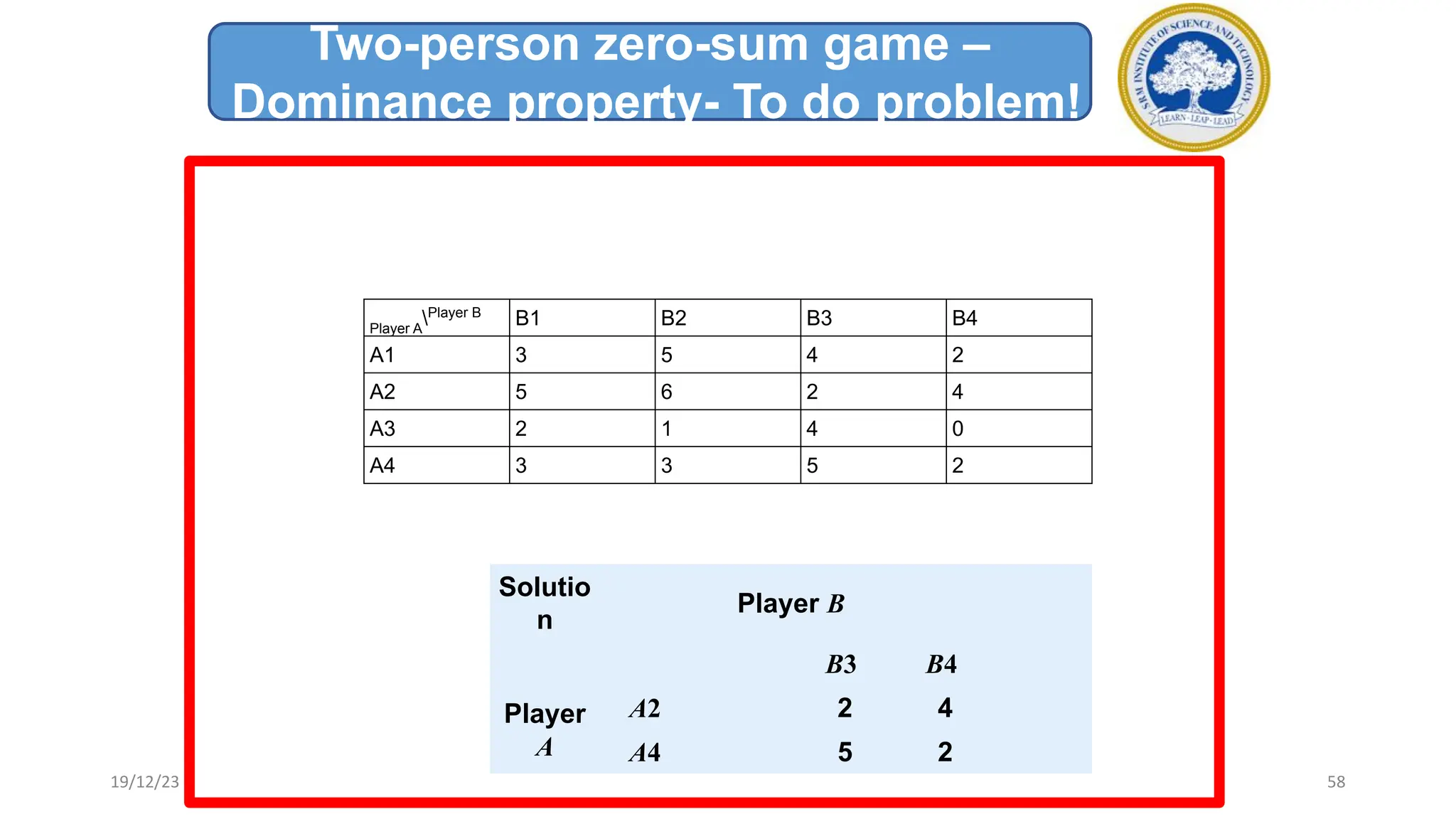
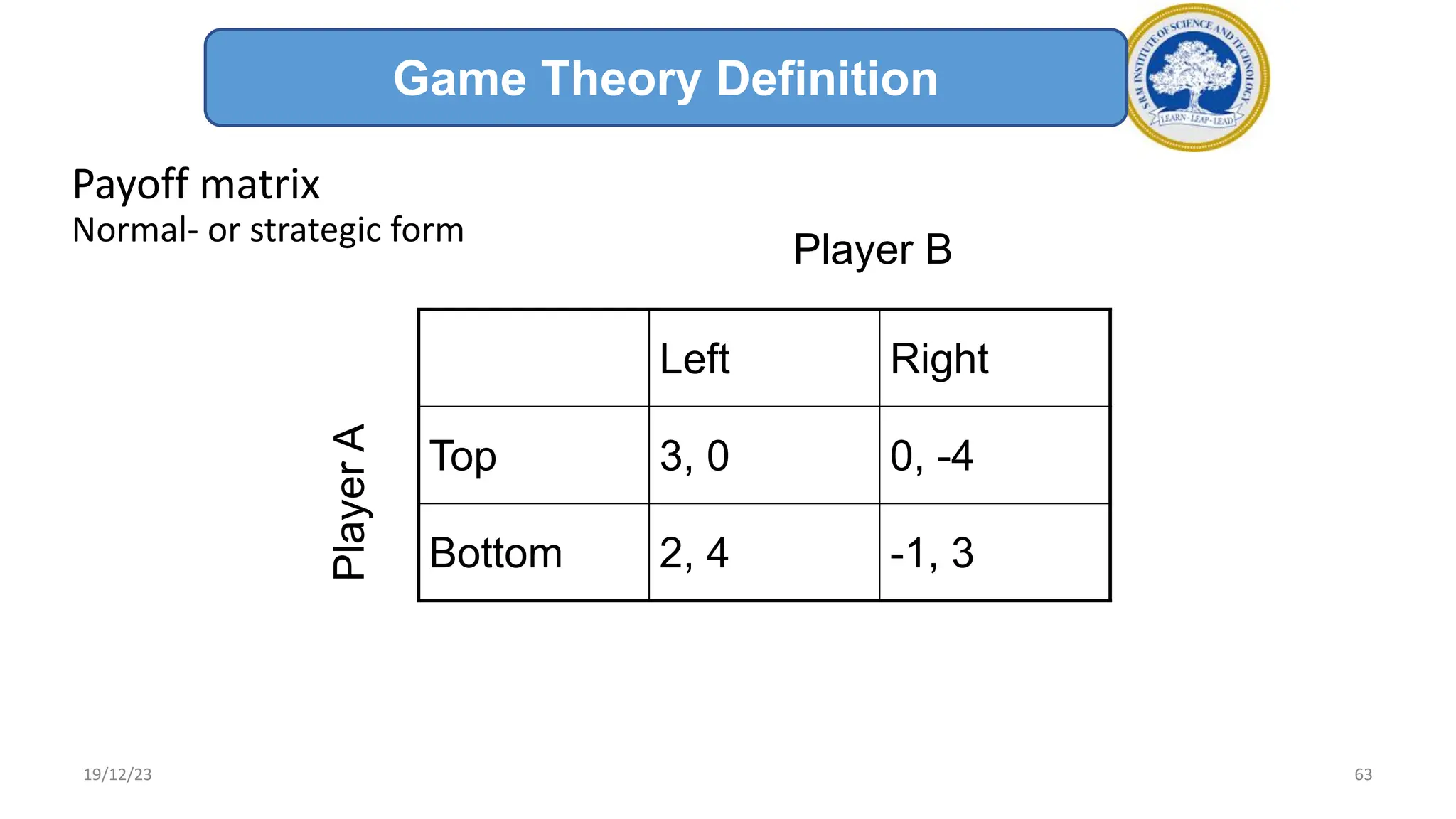
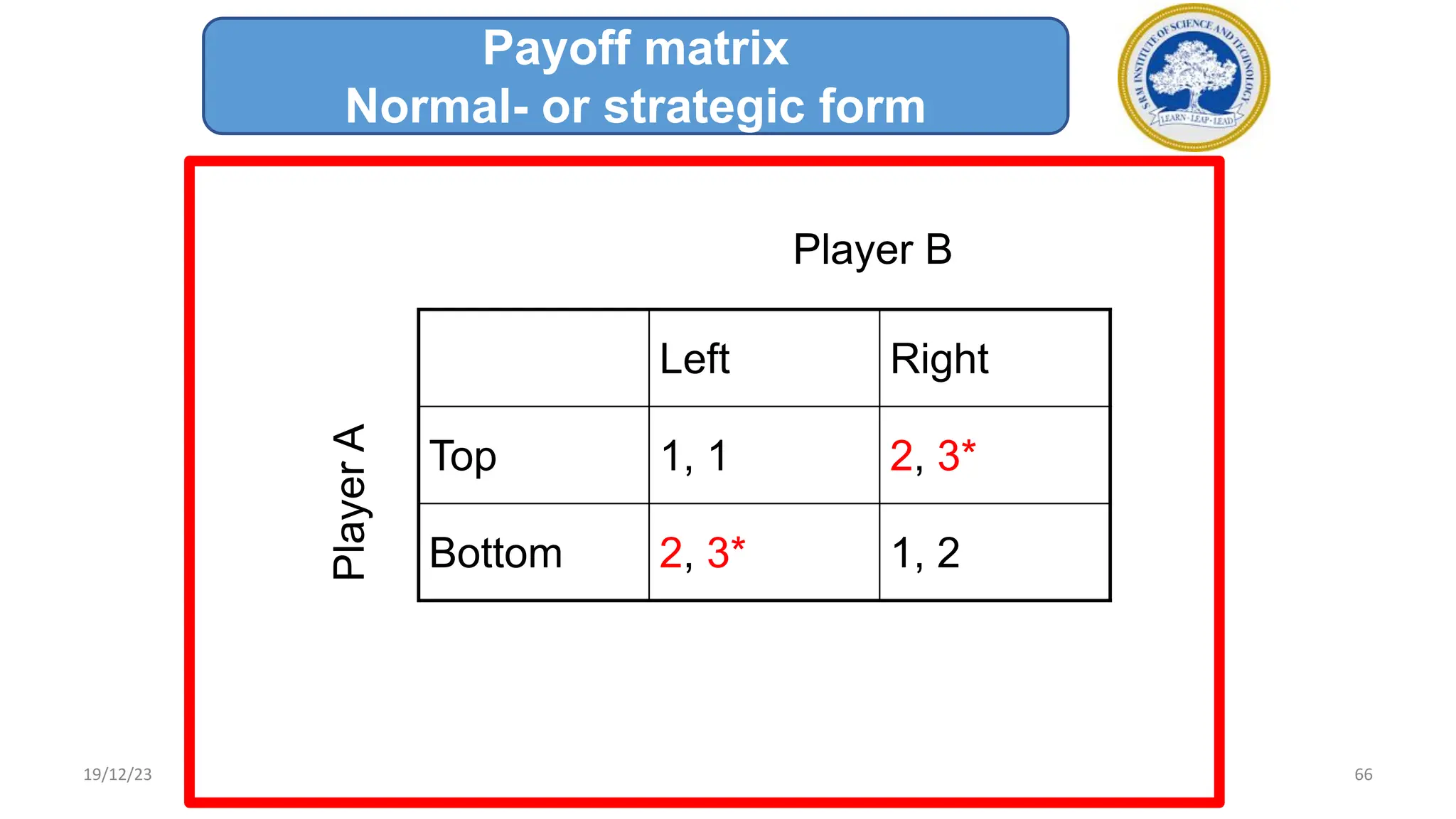
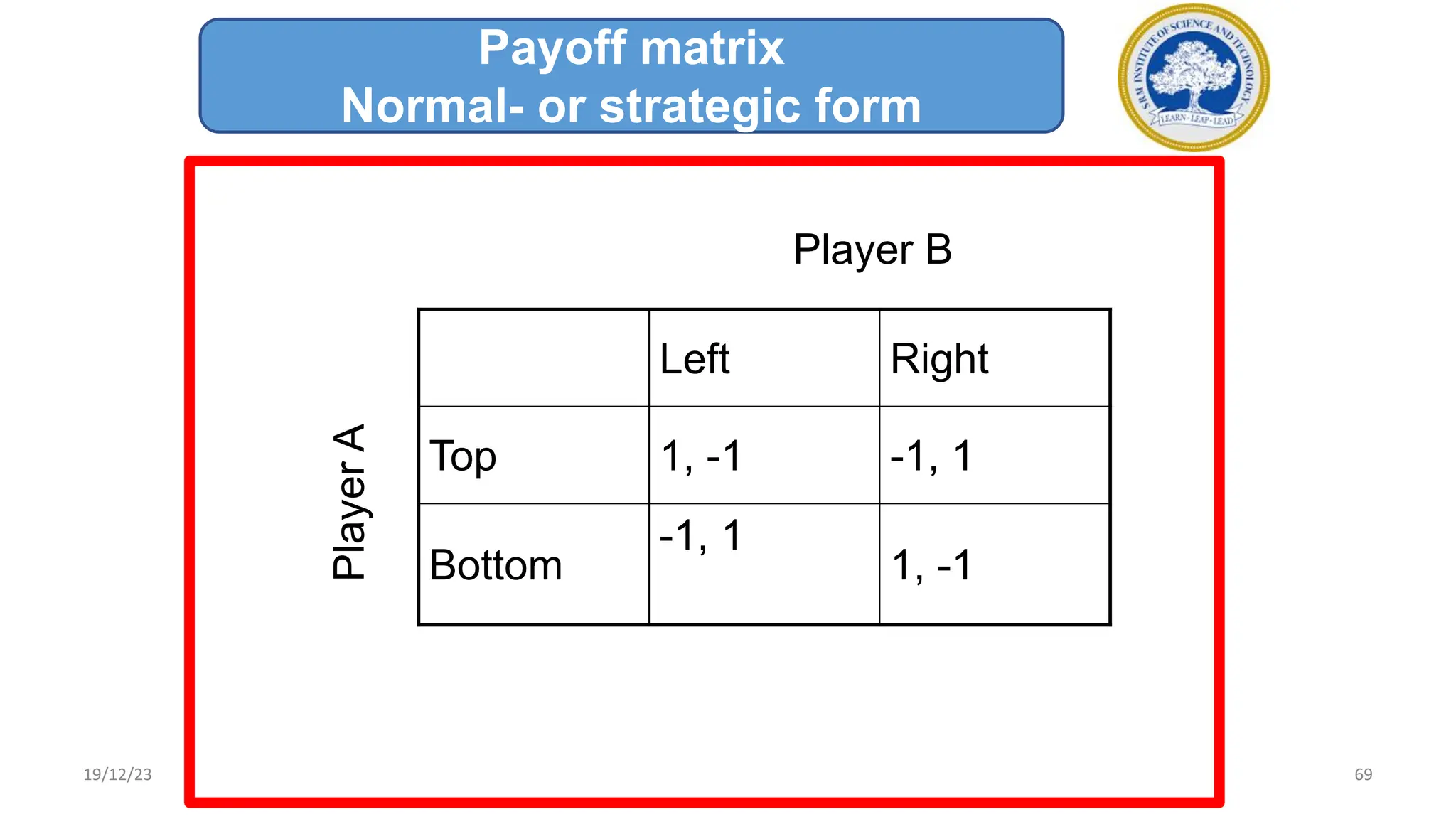
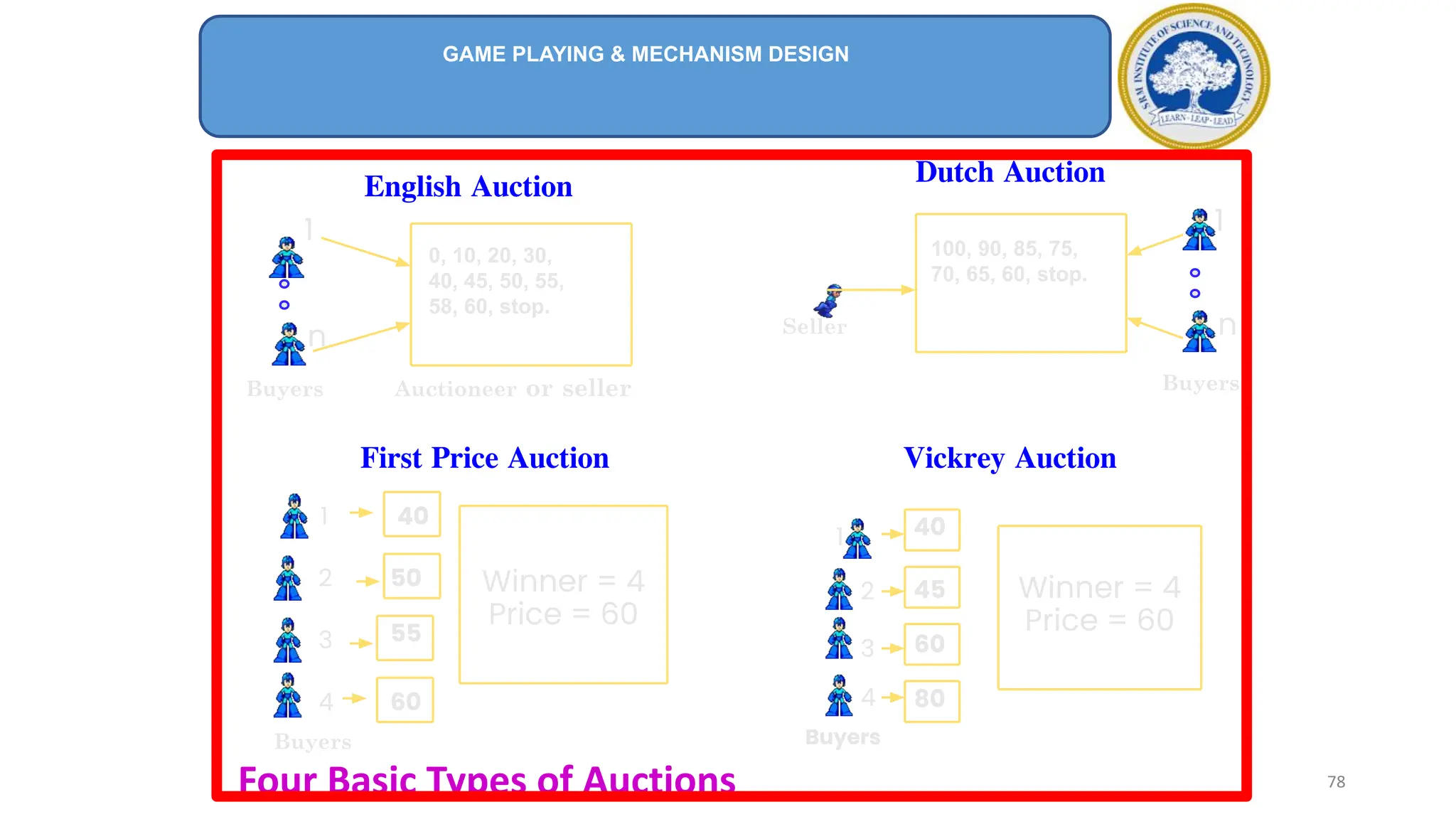
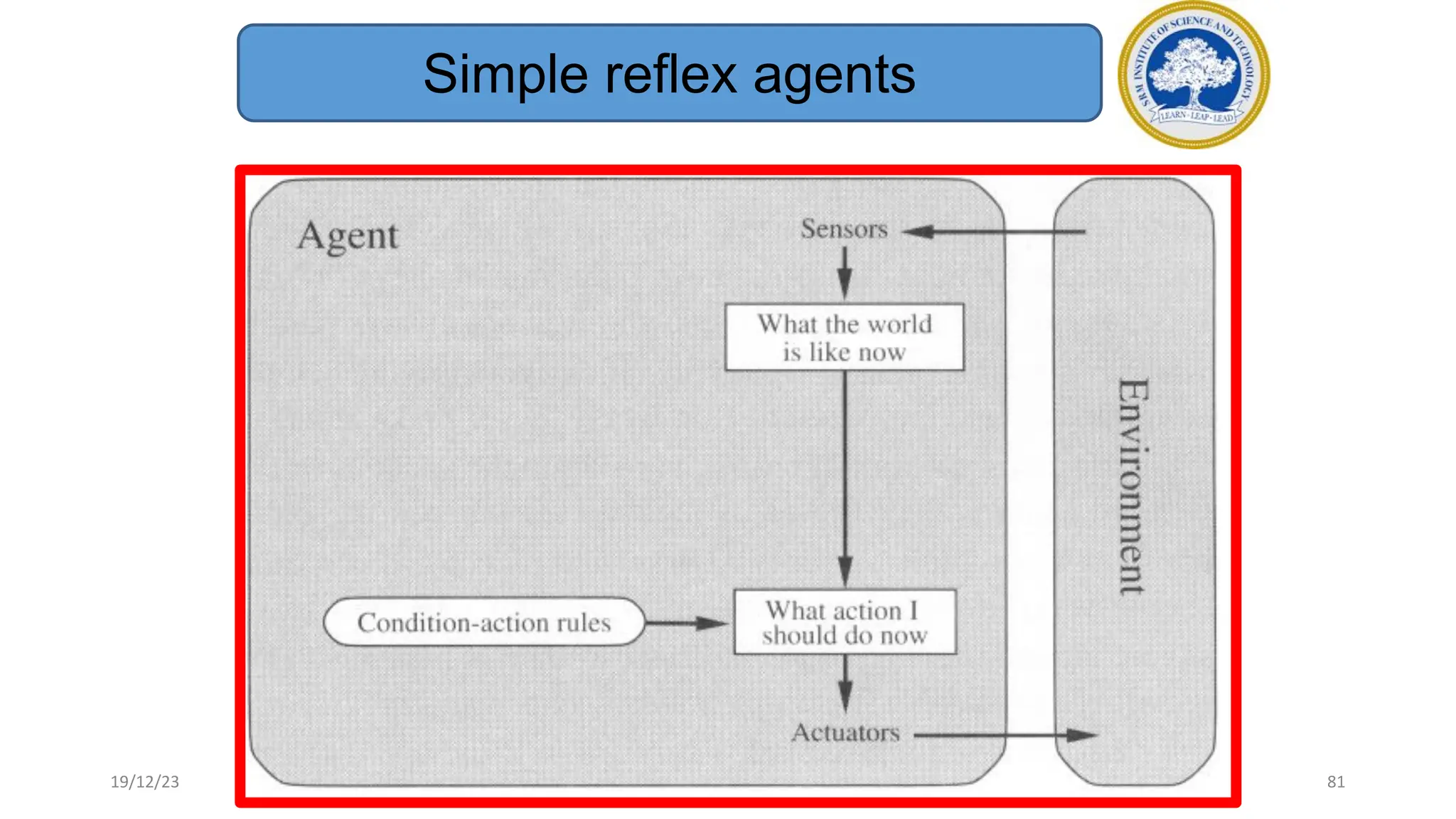
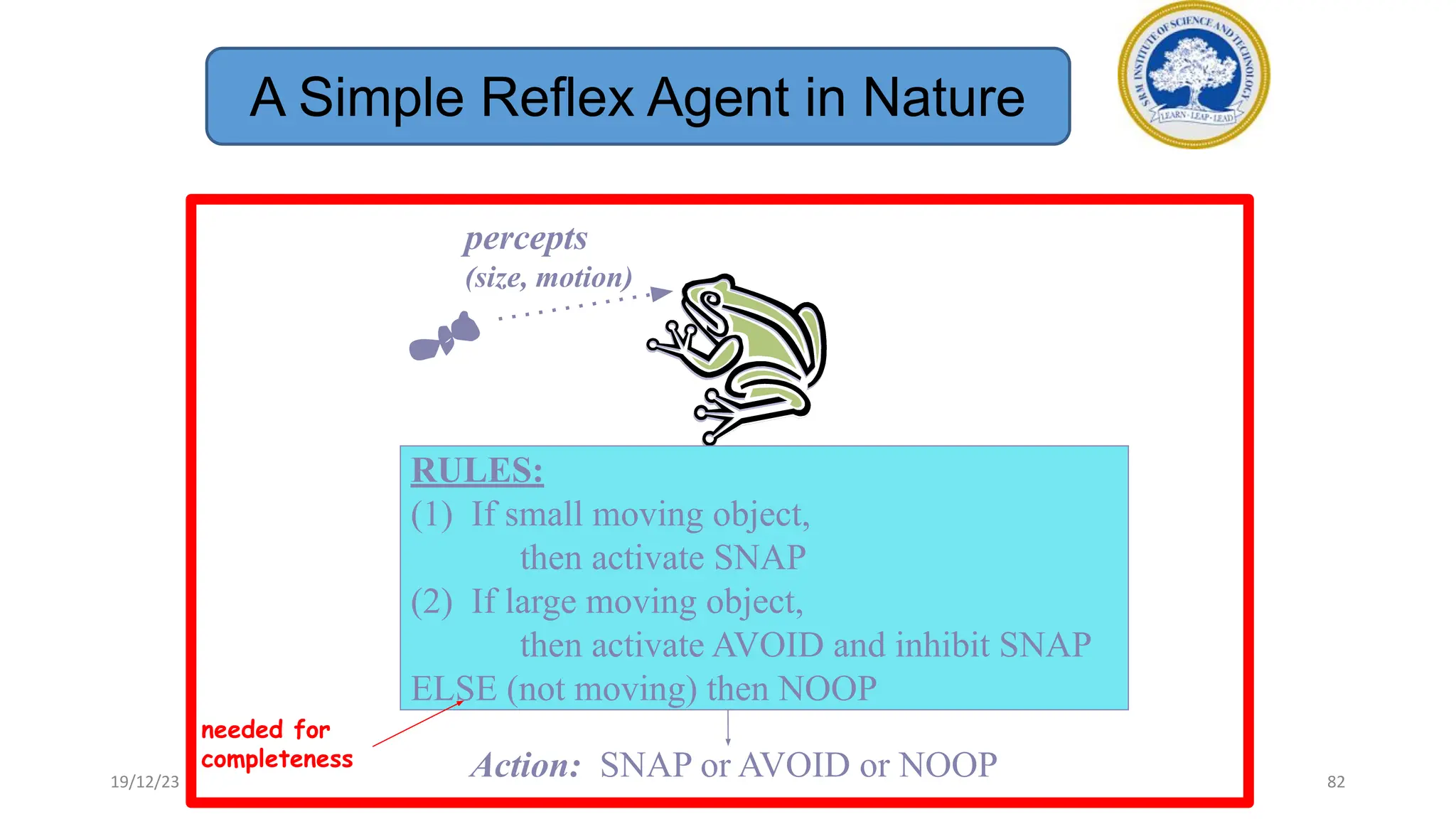
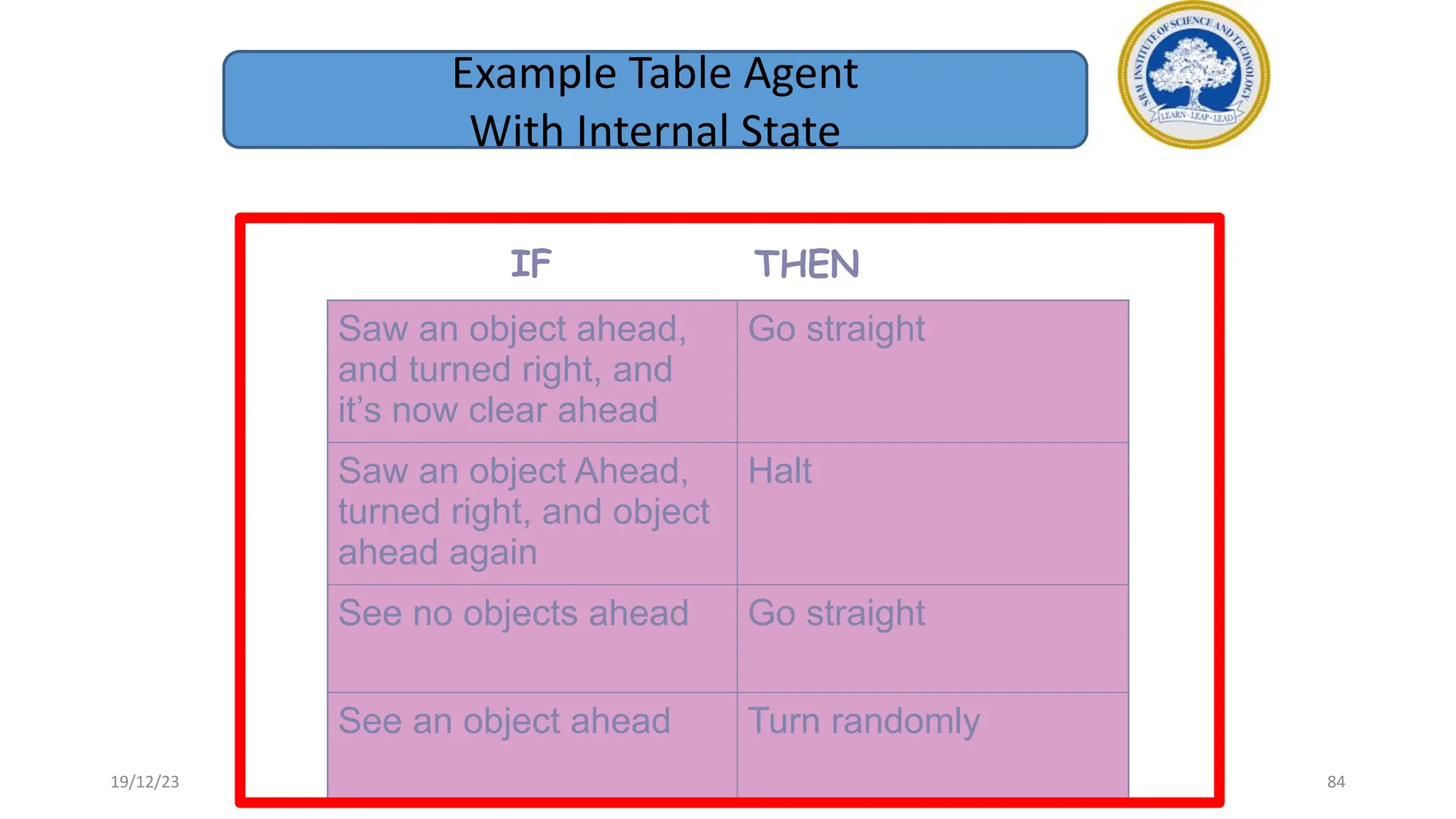
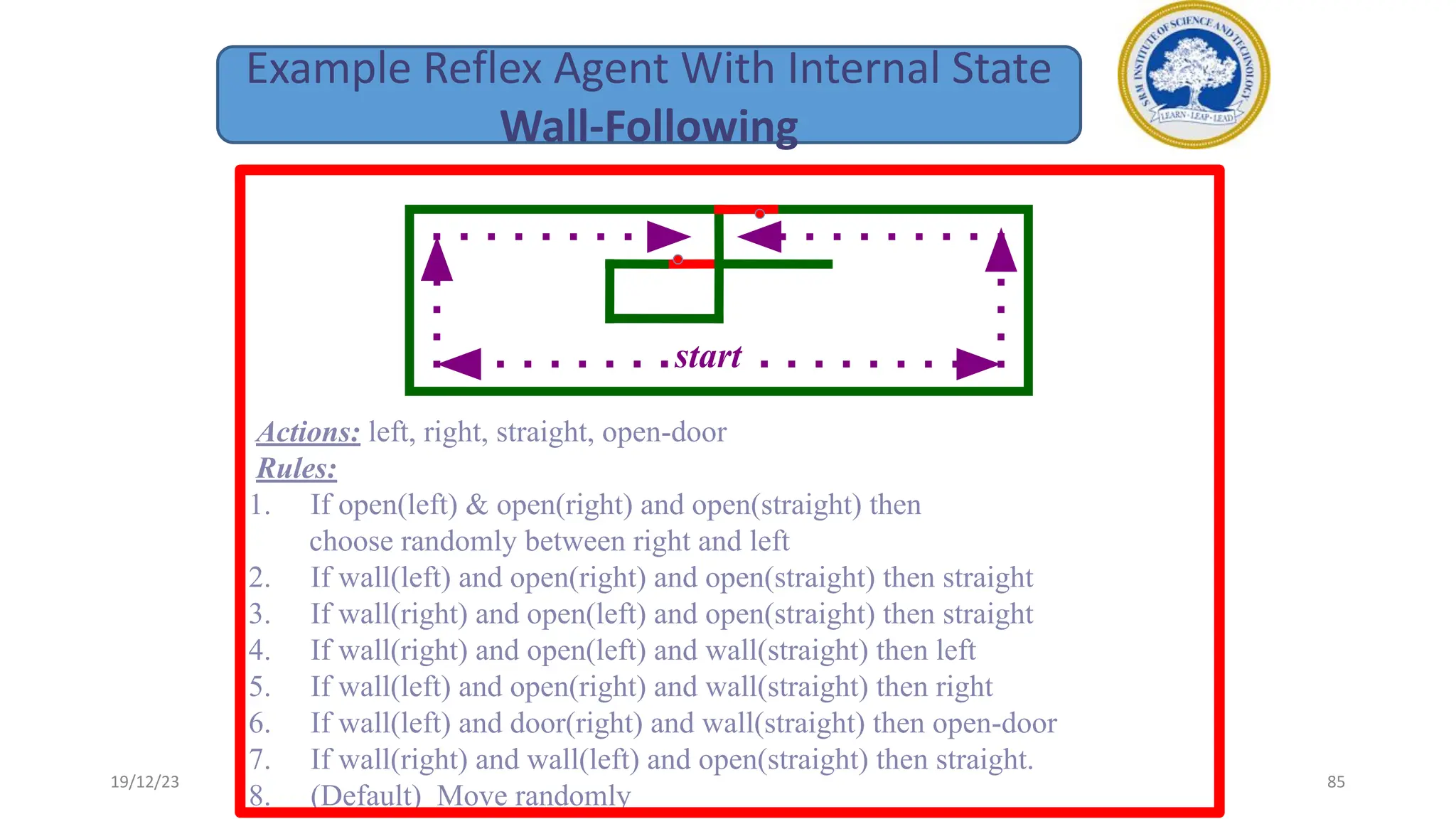
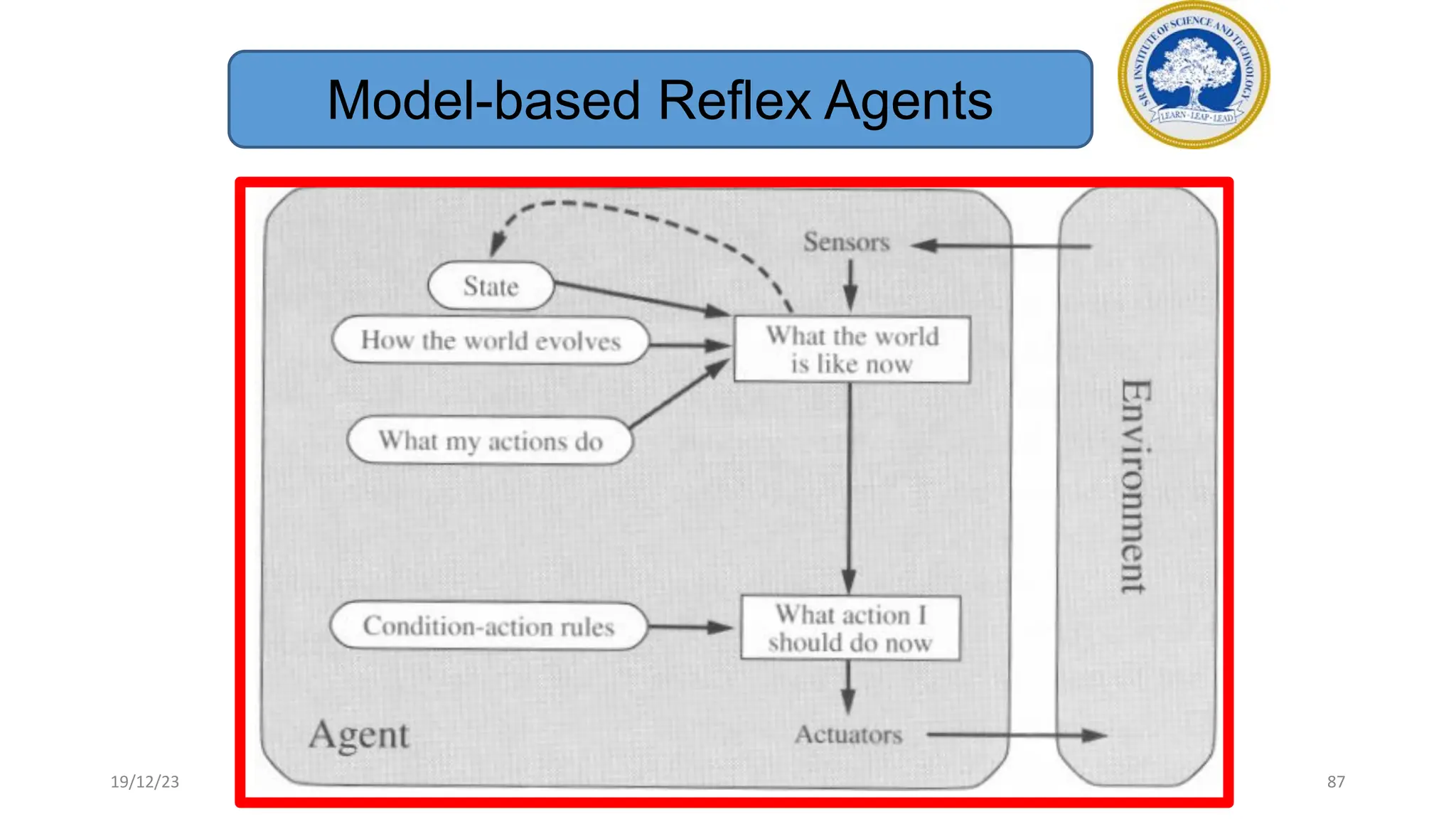
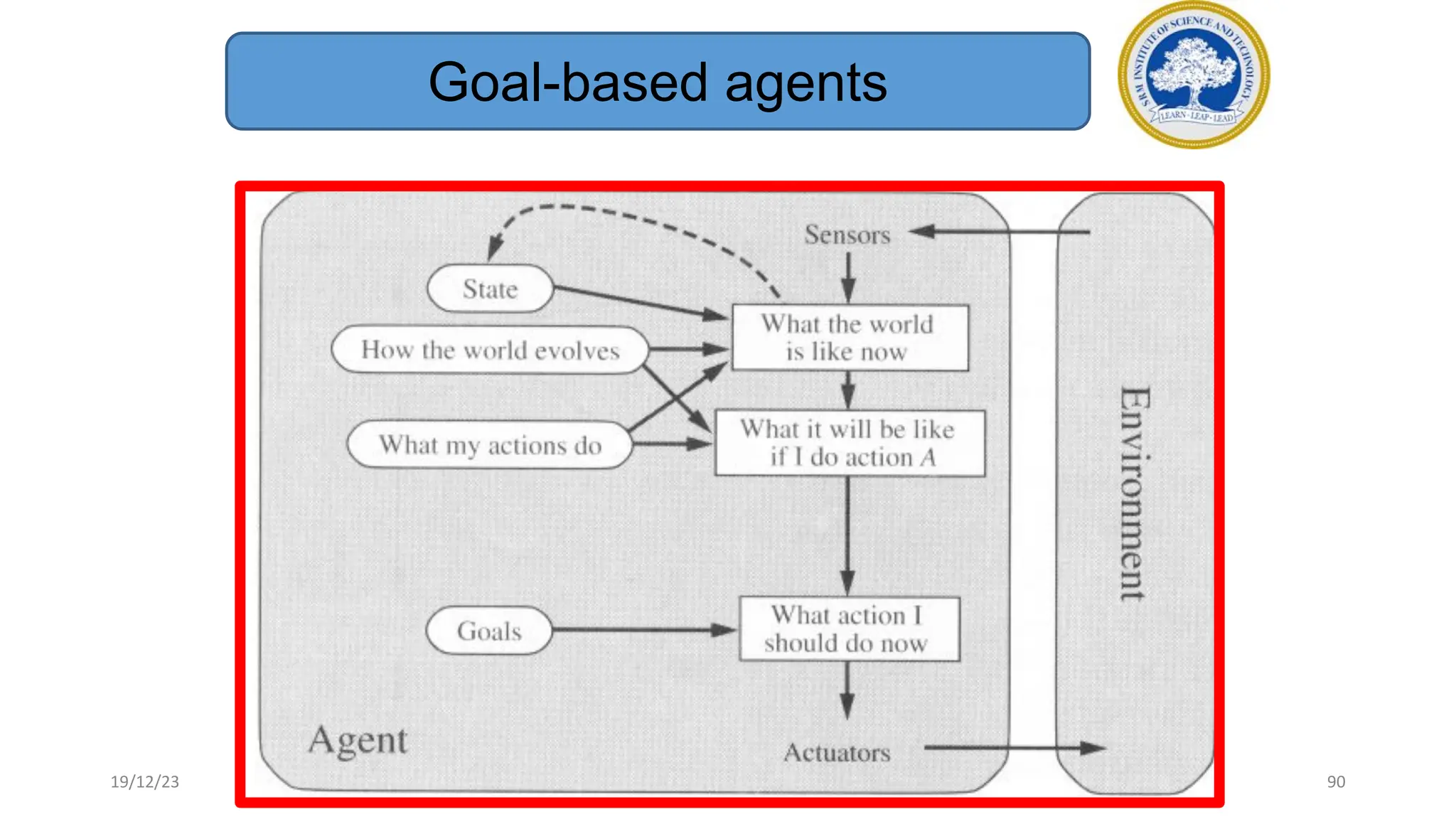
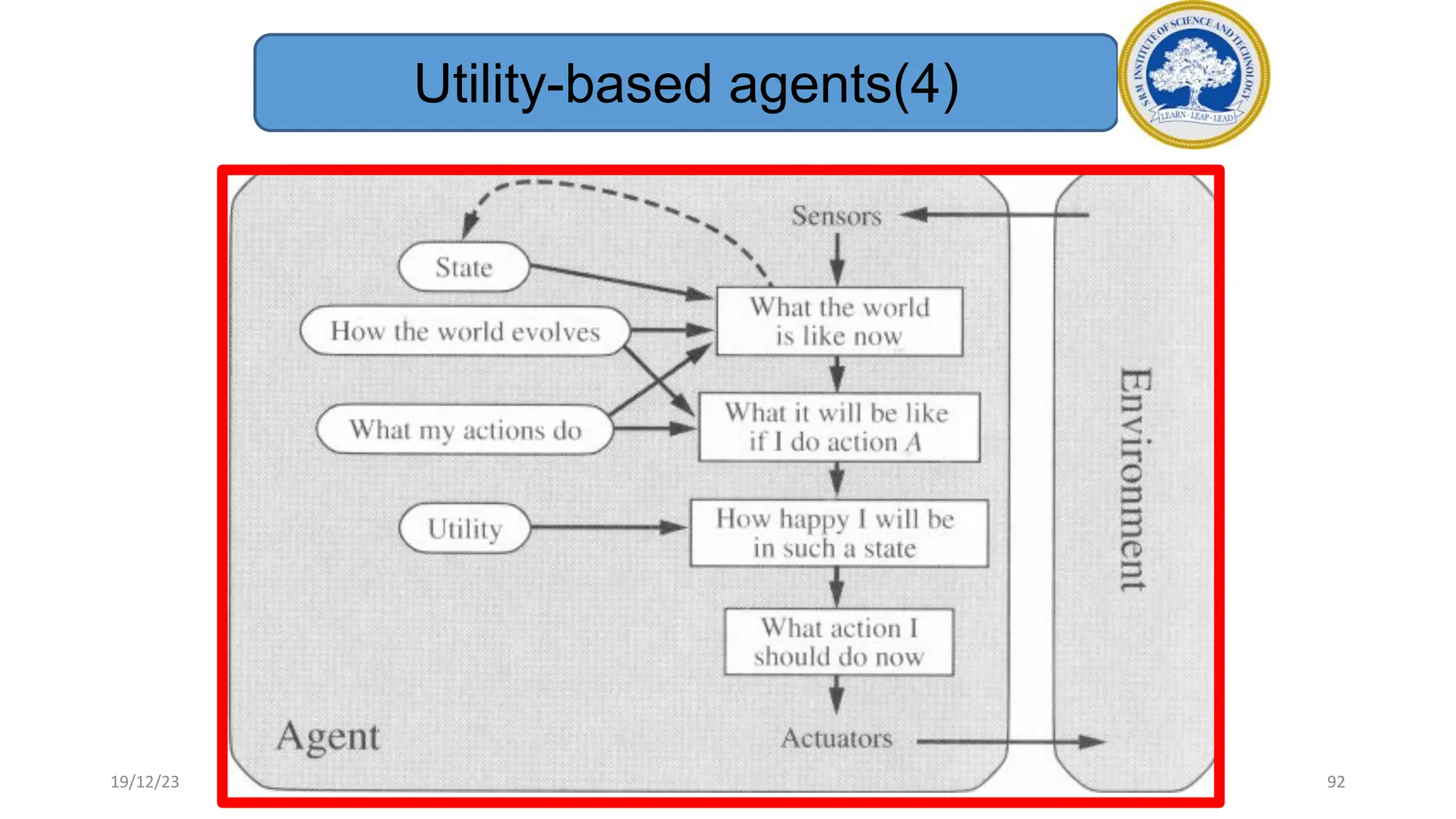
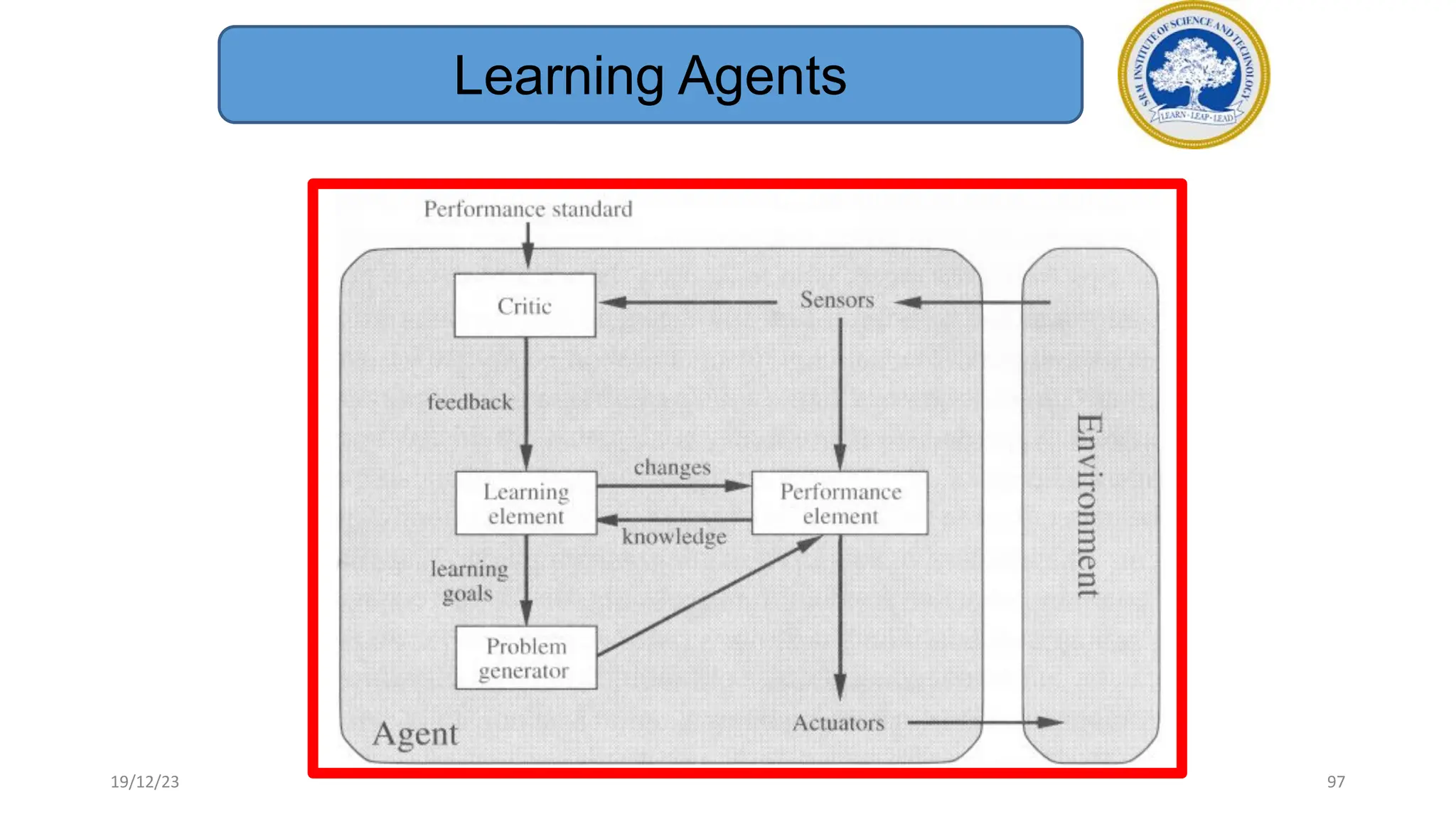
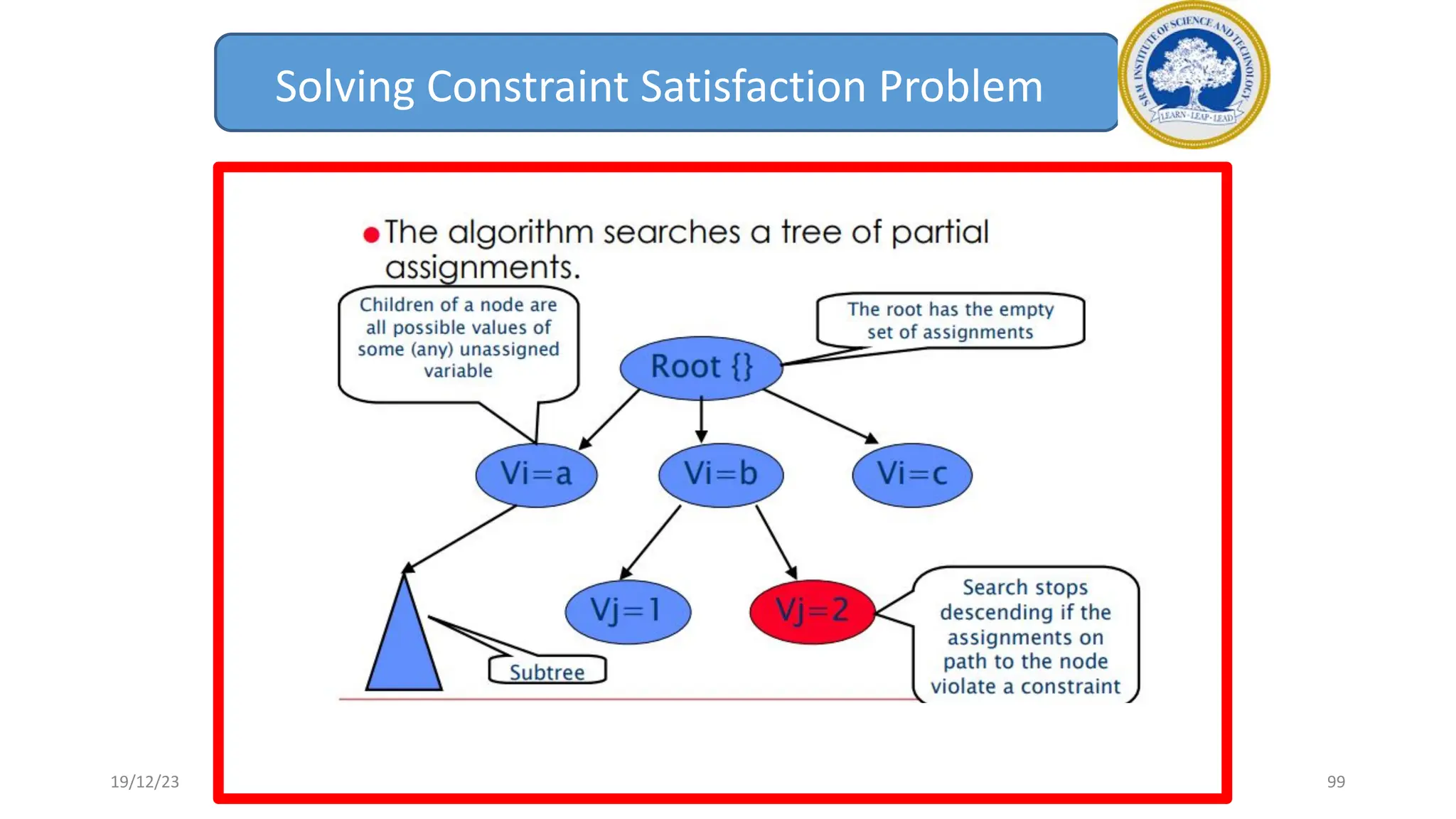
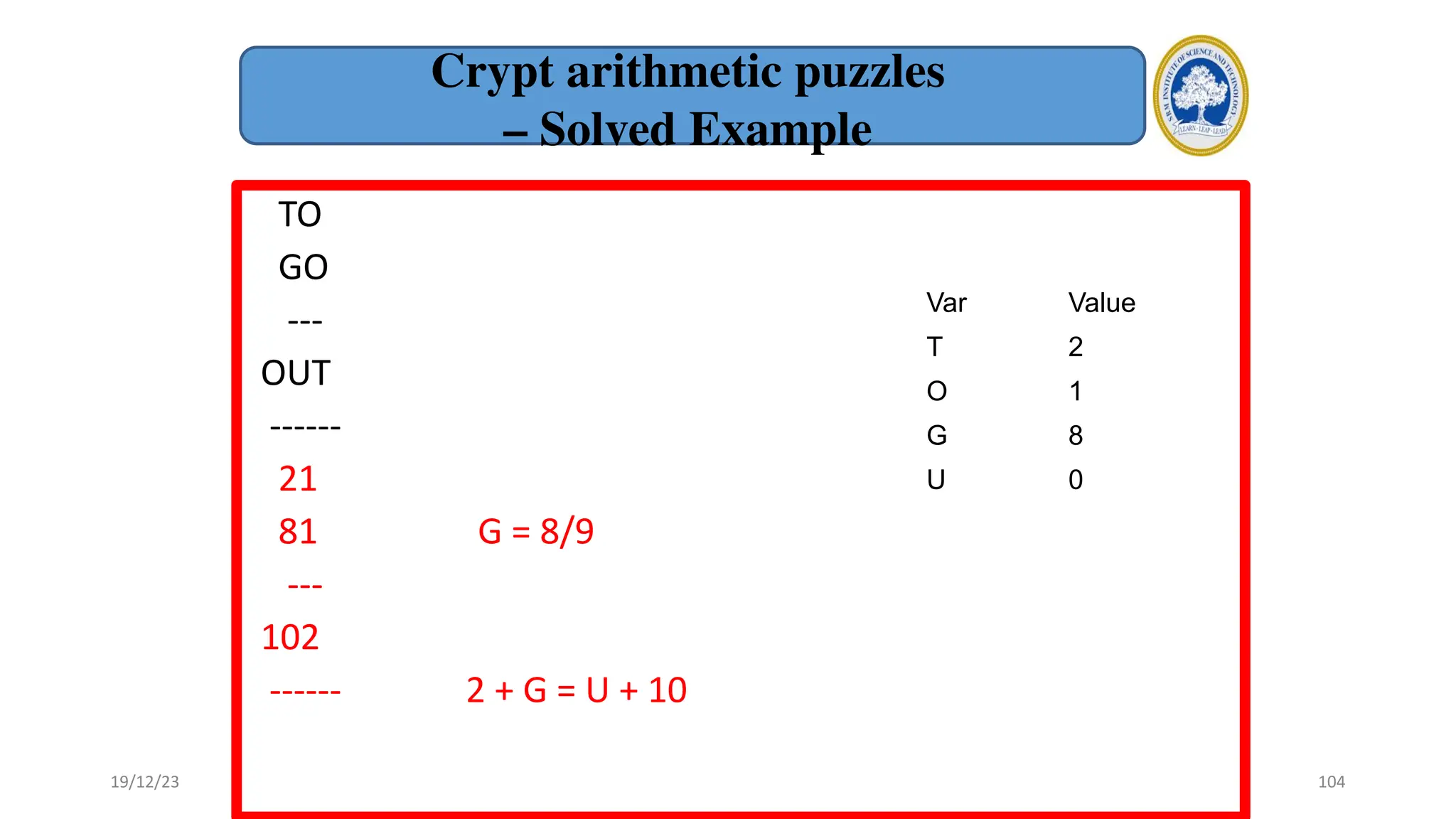
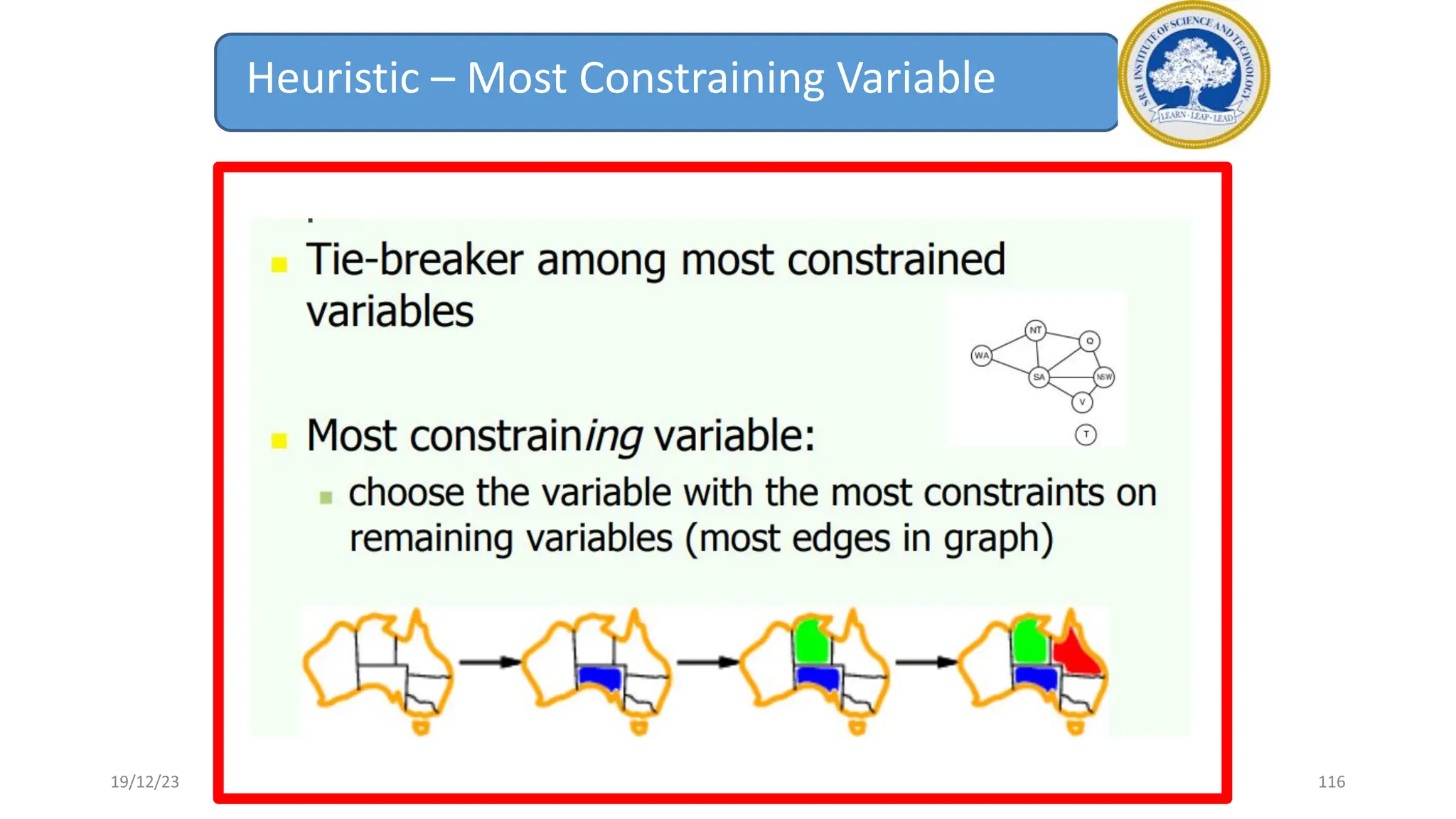
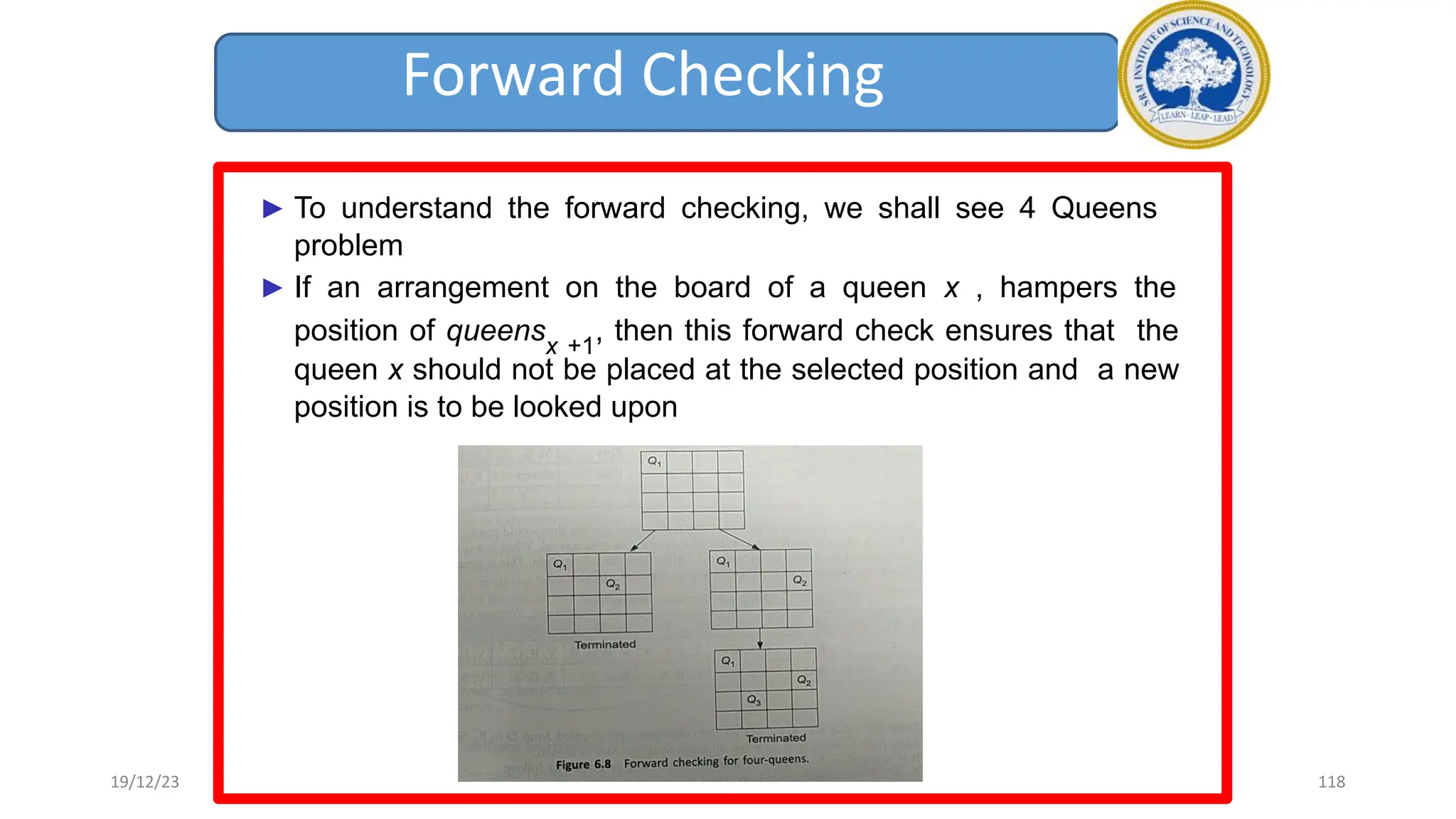
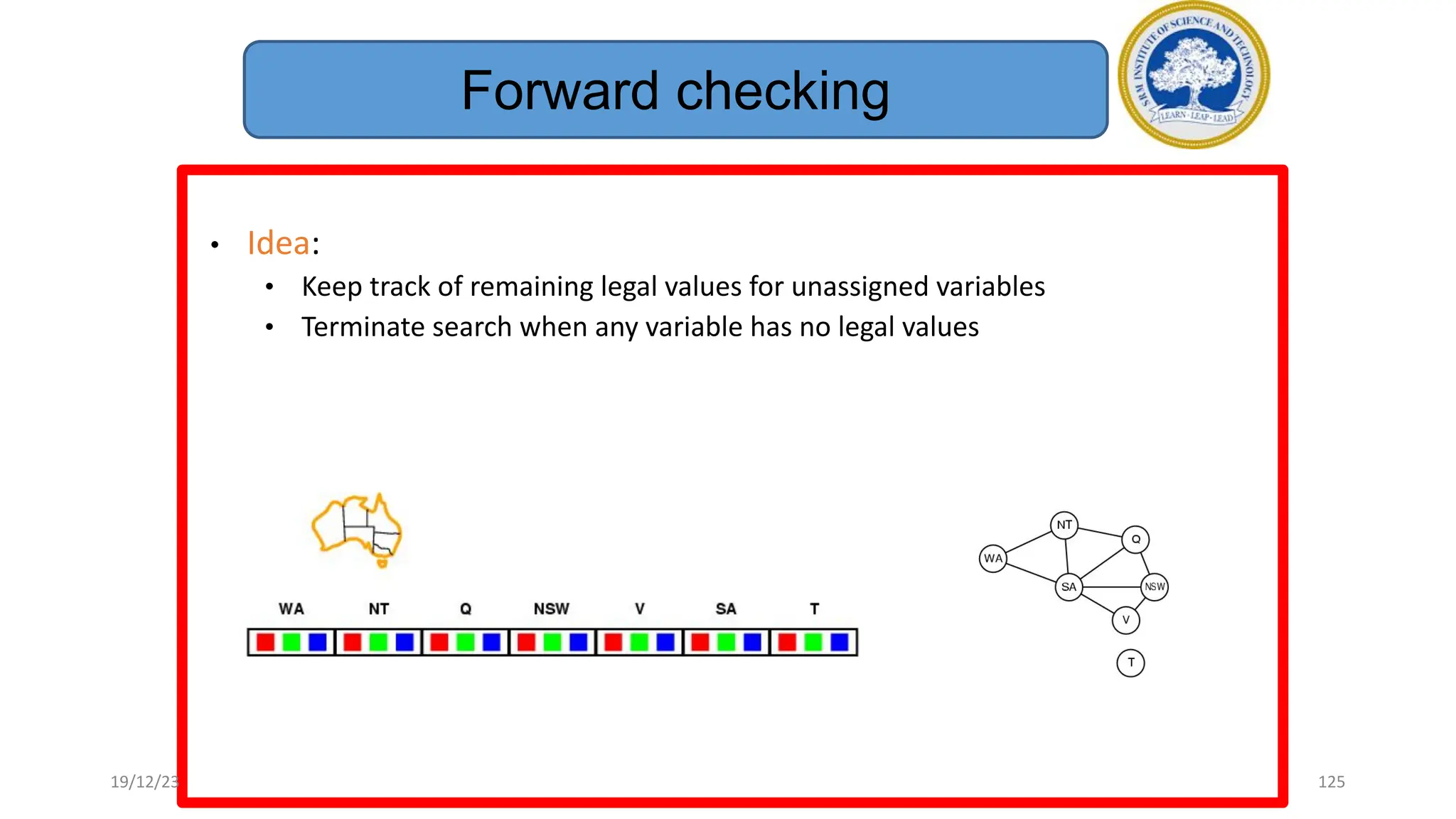
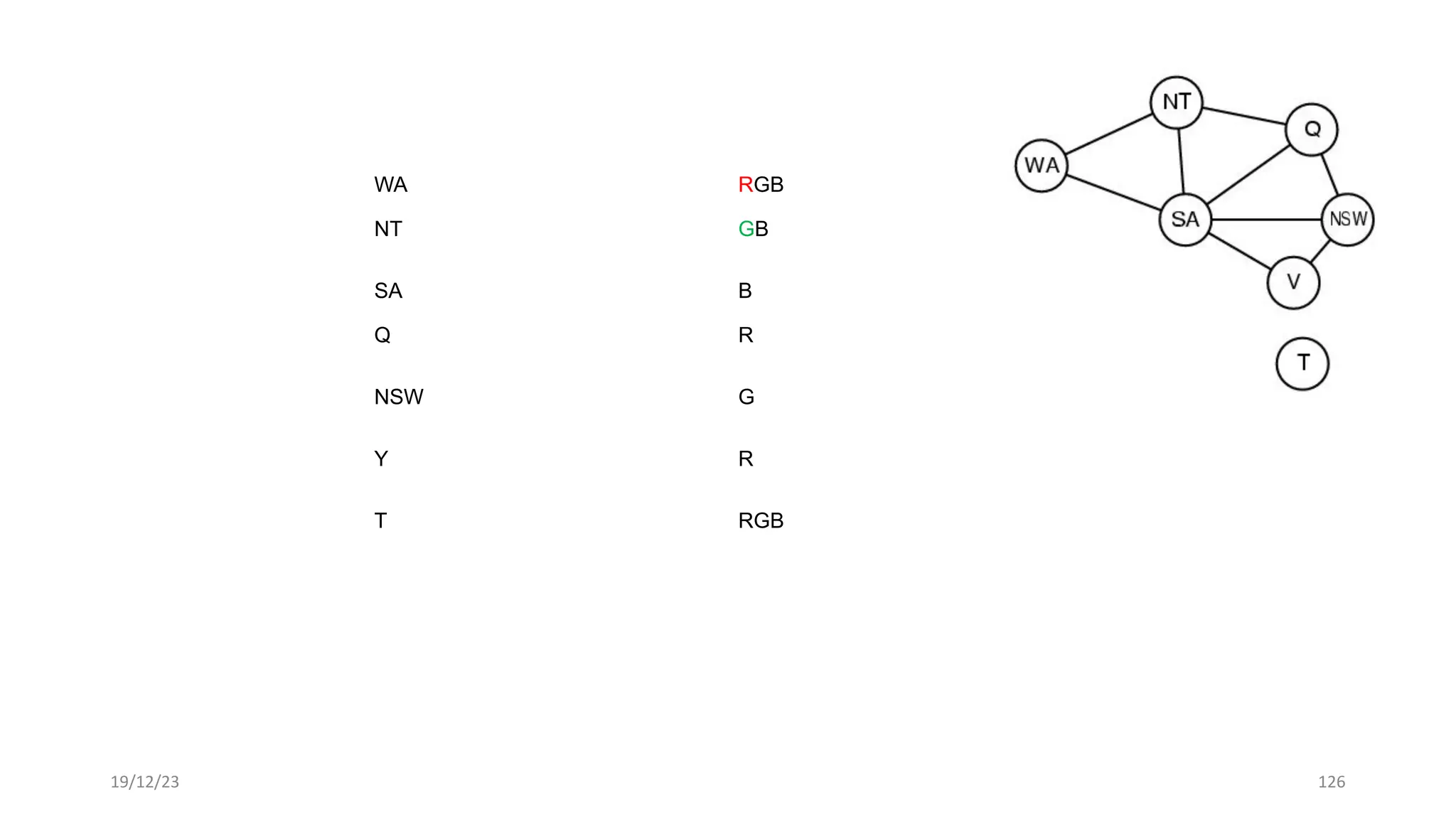
1) Adversarial search involves searching game trees to find the best move in games with competitive players like tic-tac-toe and chess. Important concepts include pruning unwanted search tree portions and heuristic evaluation functions.
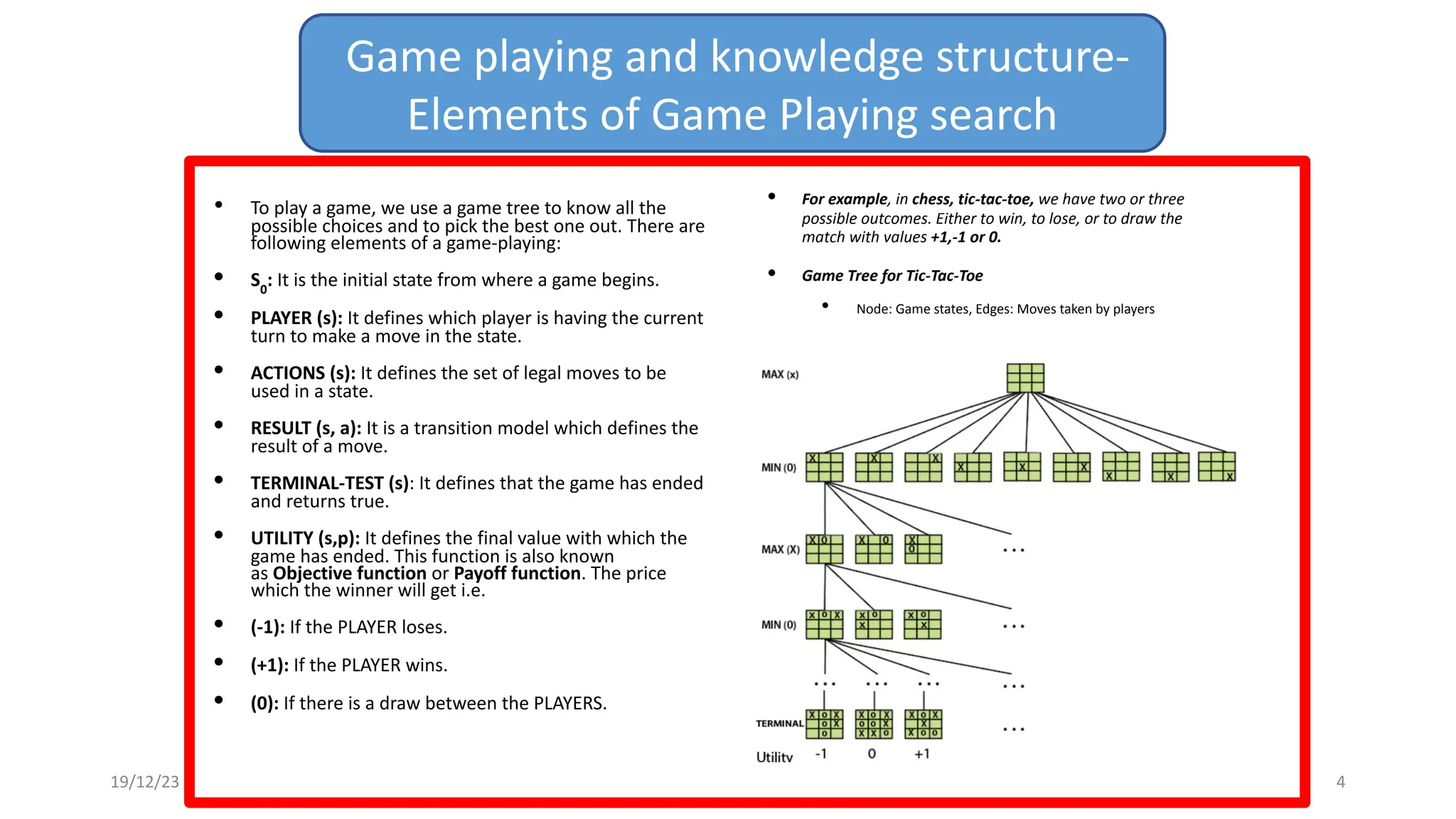
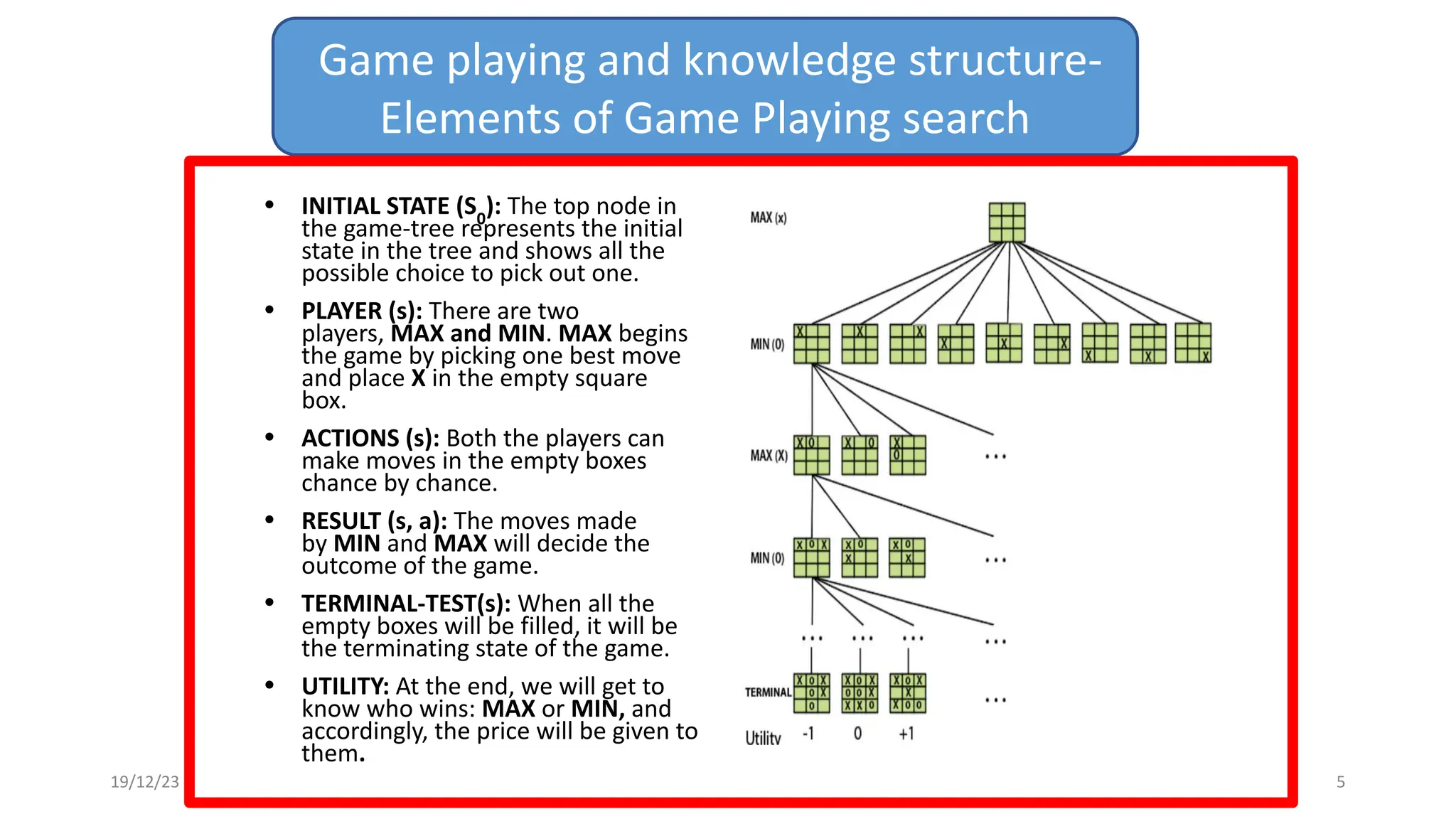
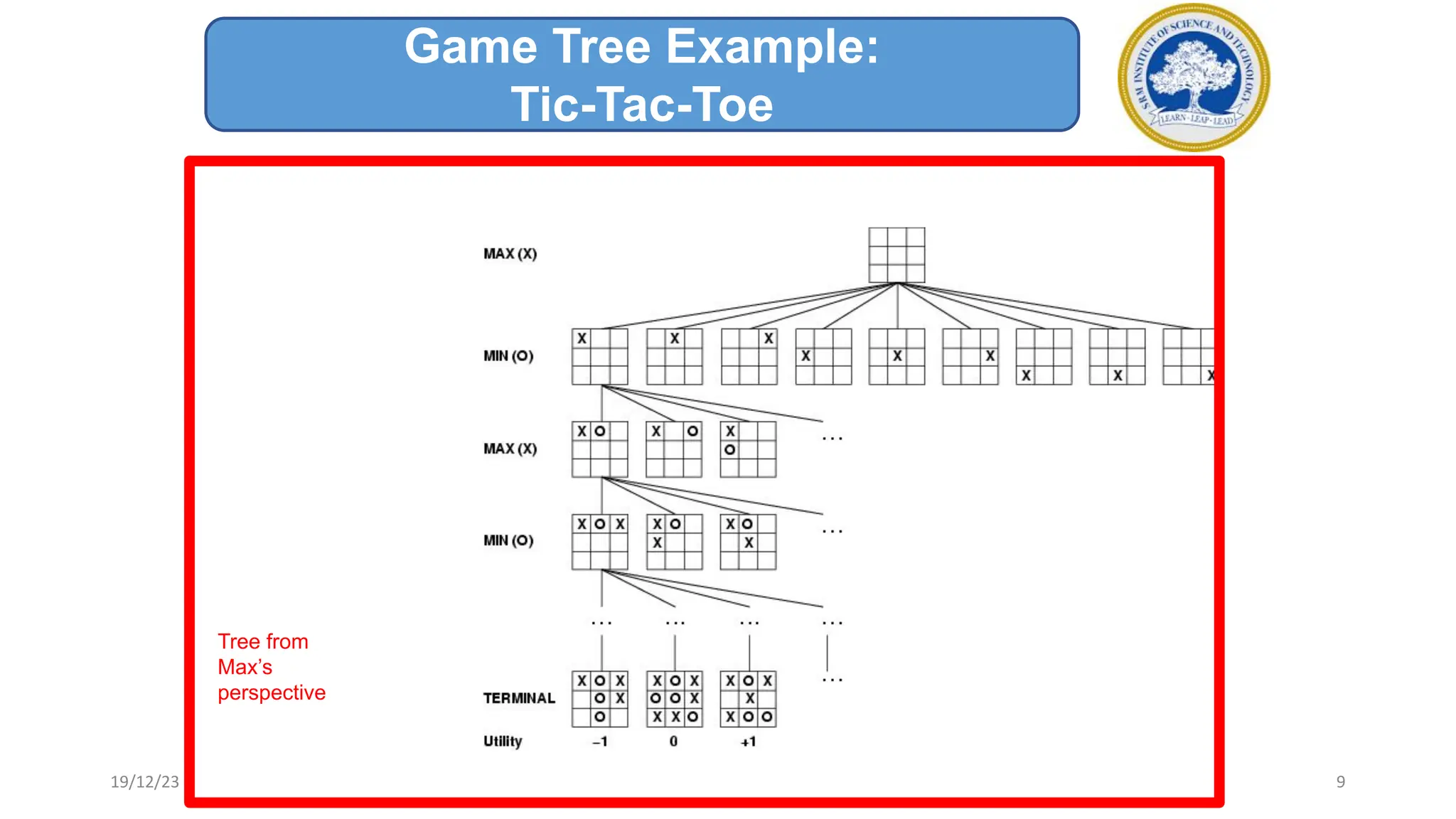
2) A game tree represents all possible game states, moves, and outcomes. Elements of game playing search include the initial state, players, legal moves, game results, end states, and payoffs for winning, losing, or drawing.
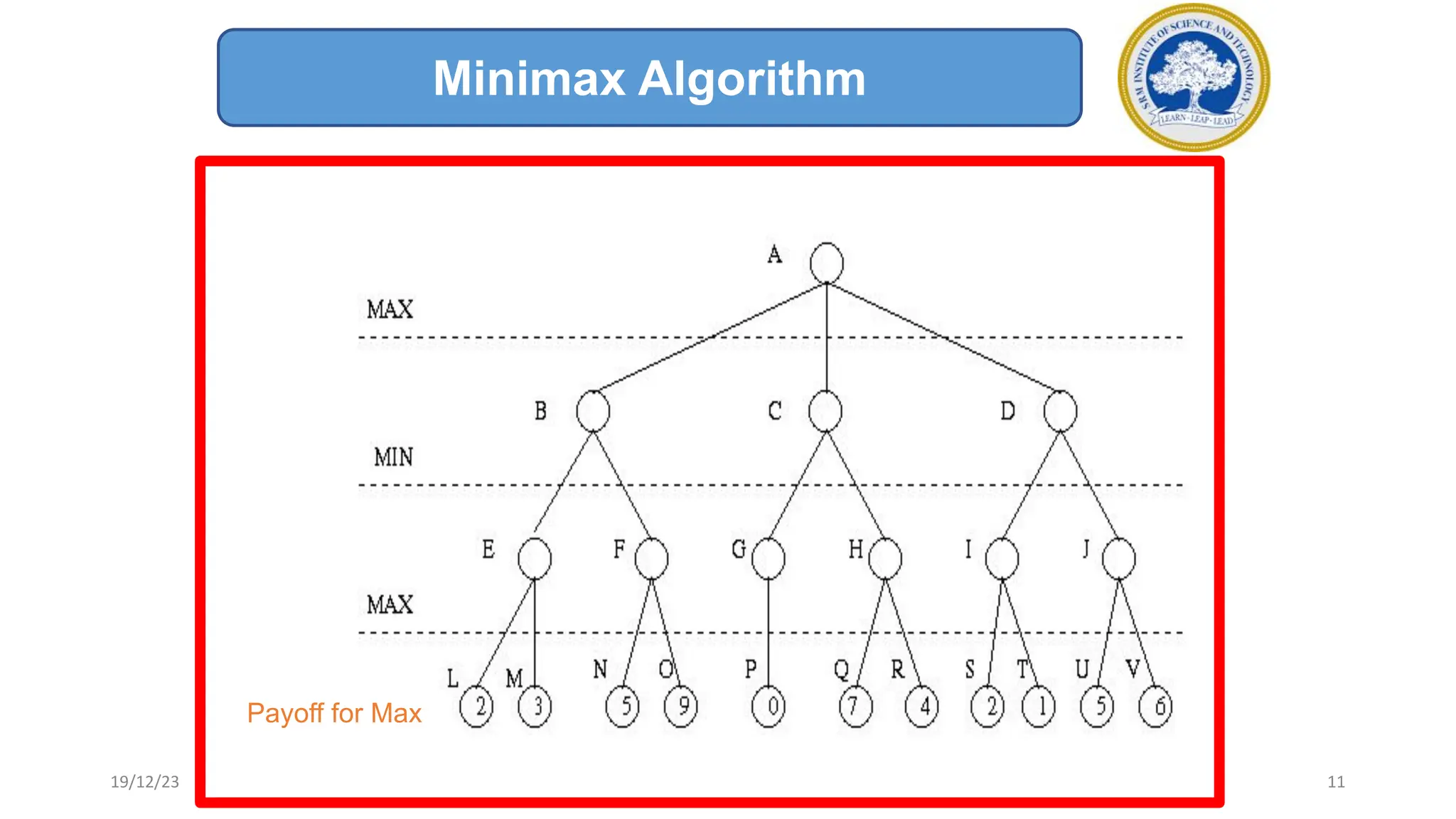
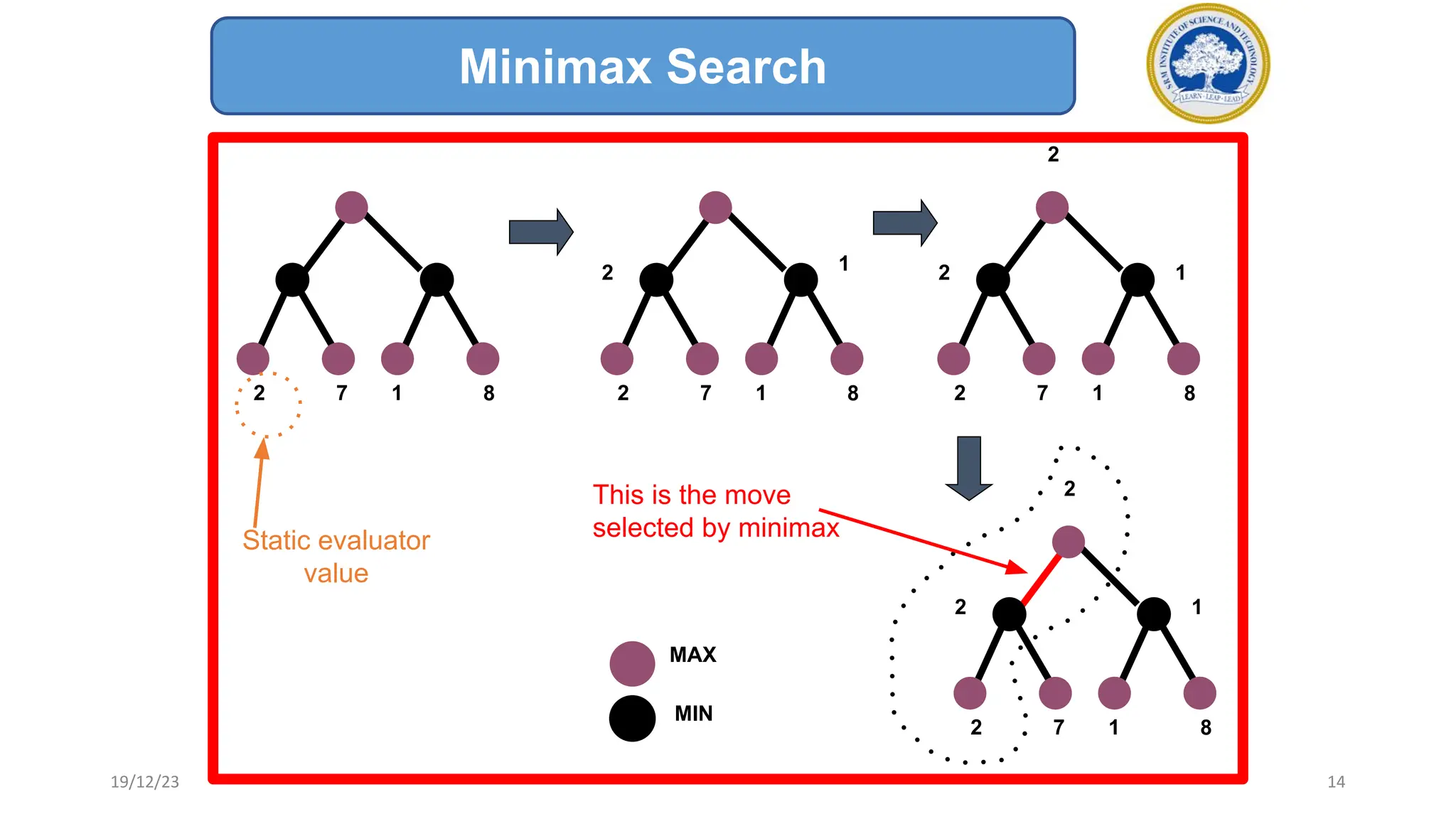
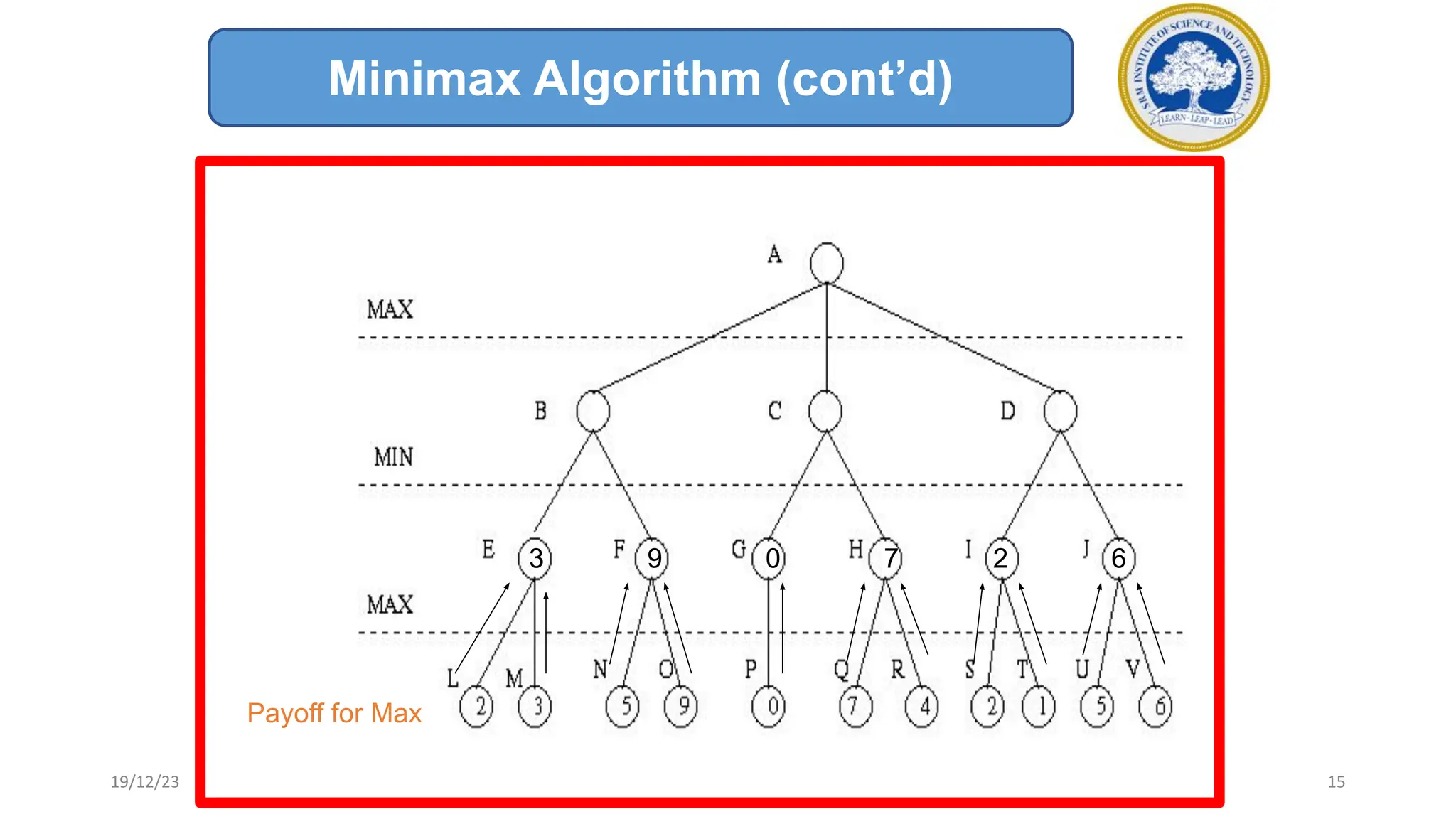
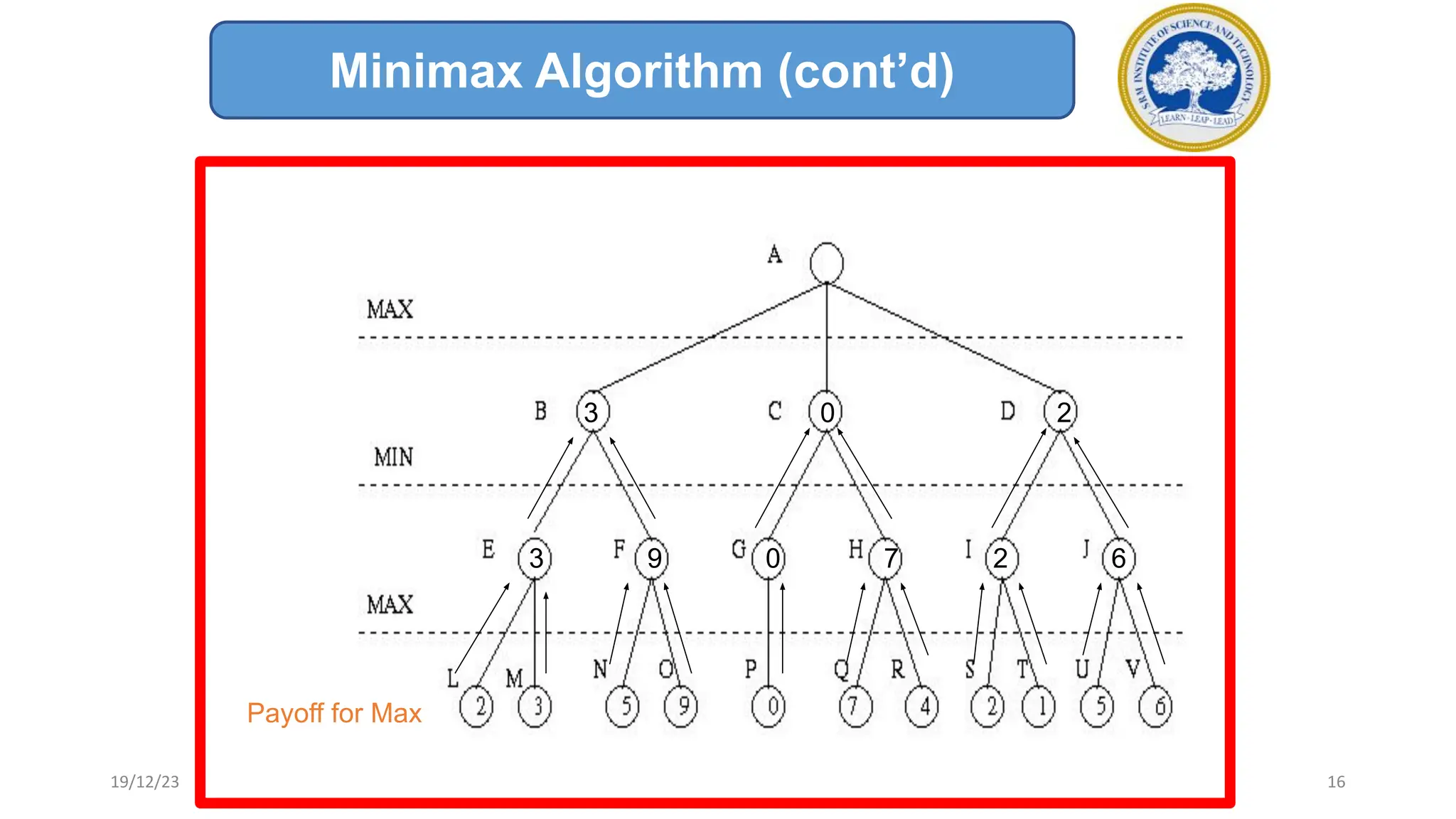
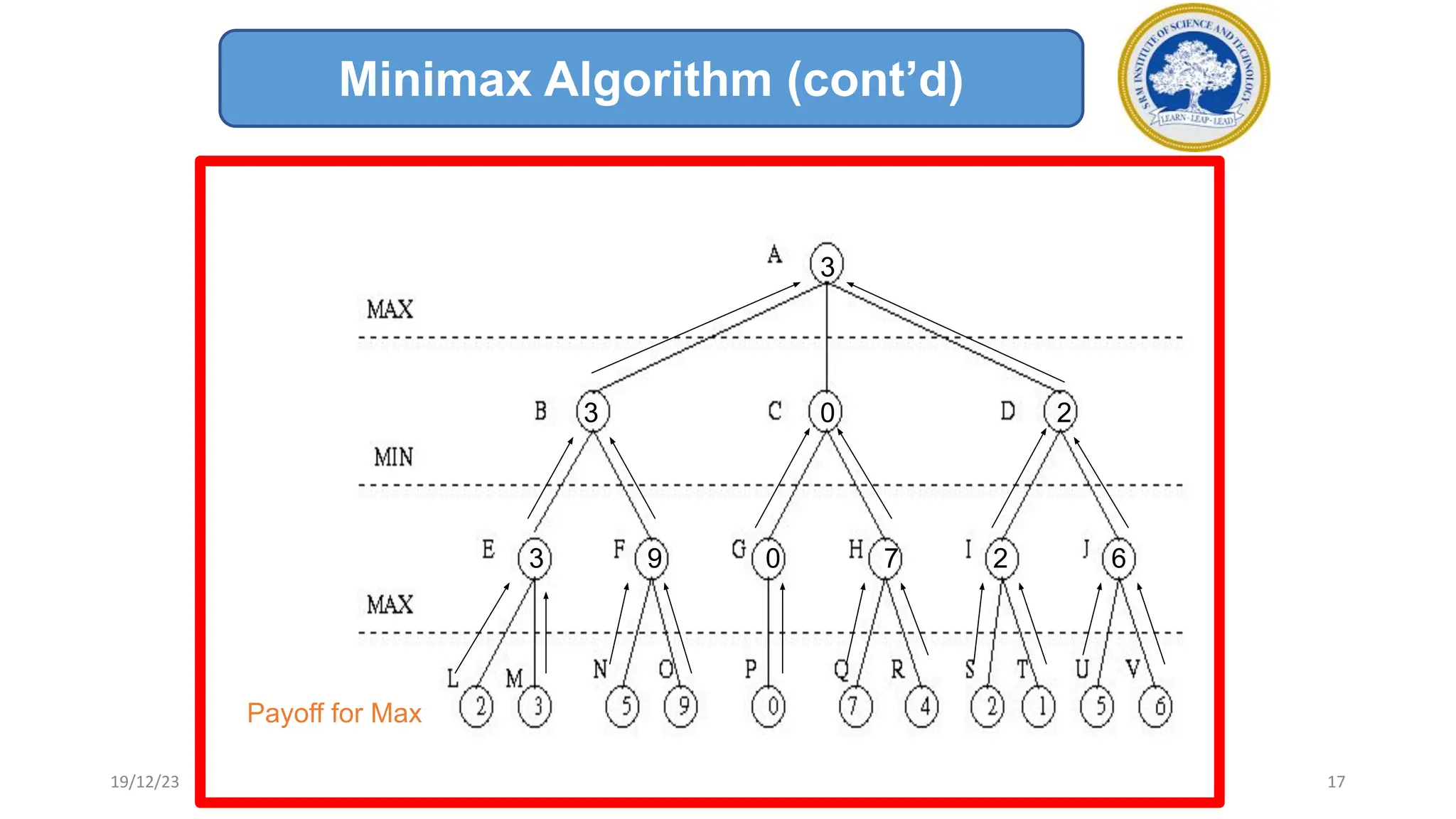
3) The minimax algorithm searches game trees to determine the best guaranteed outcome against an optimal opponent. It recursively evaluates nodes using the minimax rule to maximize the minimum payoff for the maximizing player.