
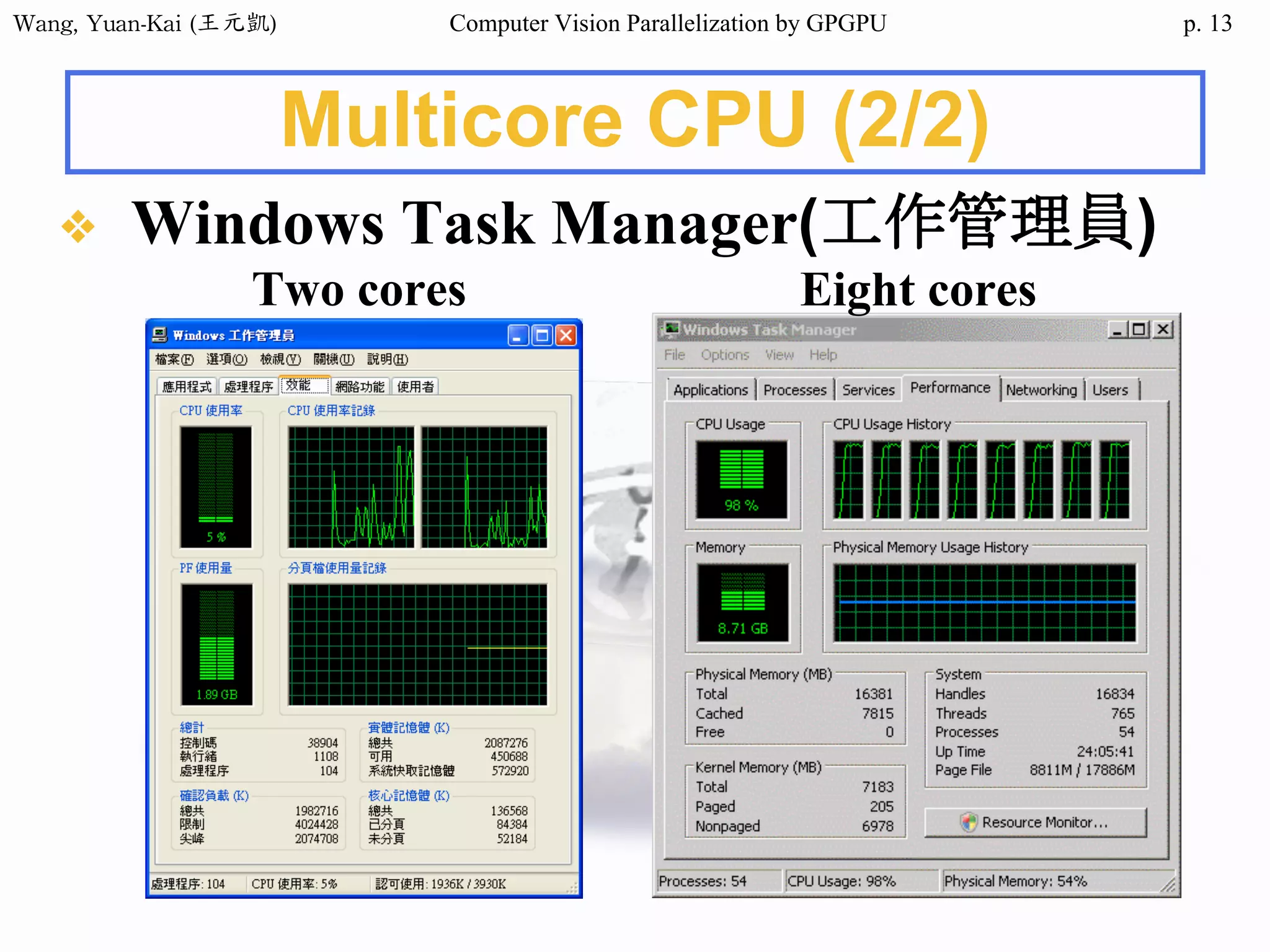
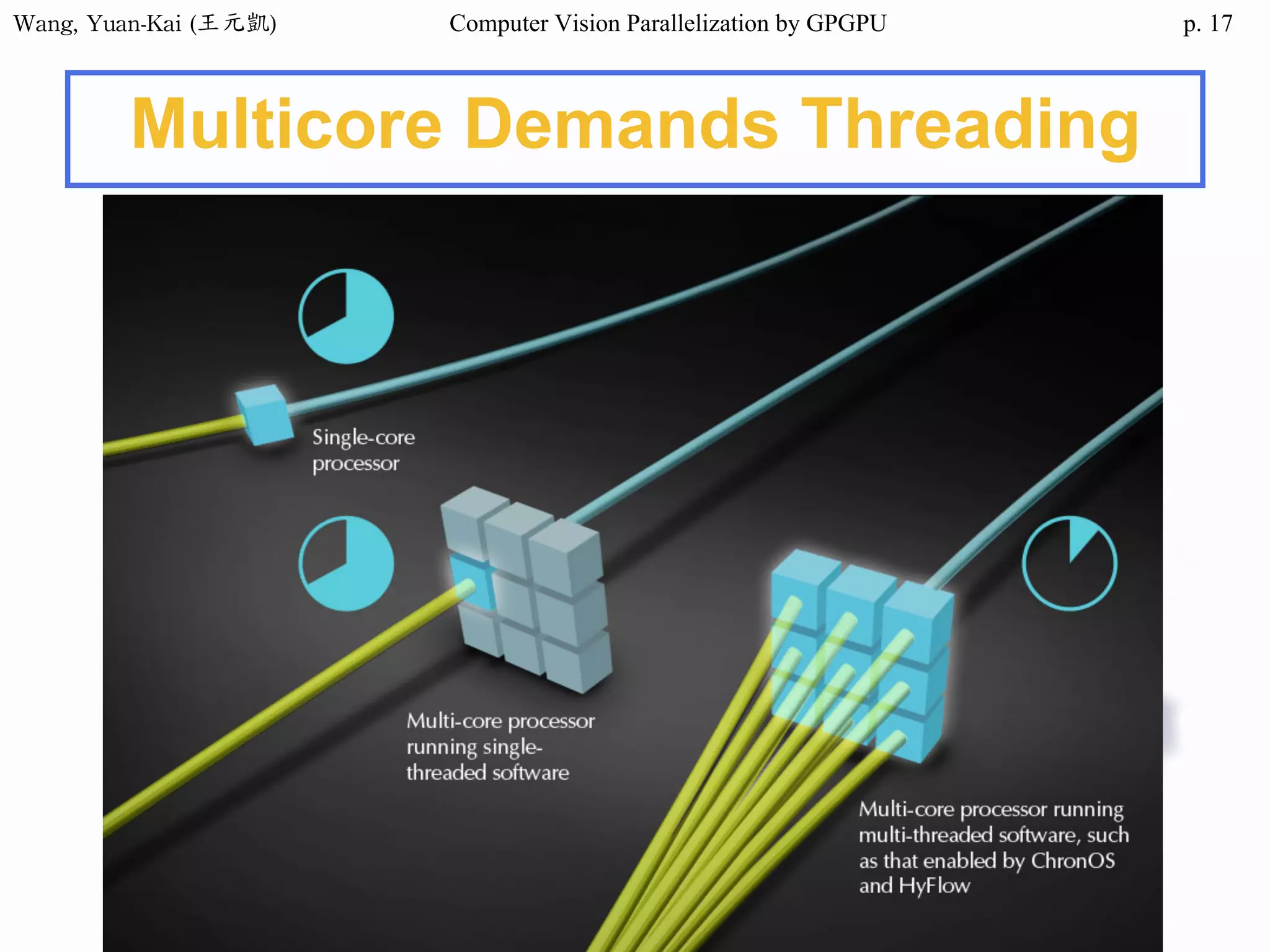
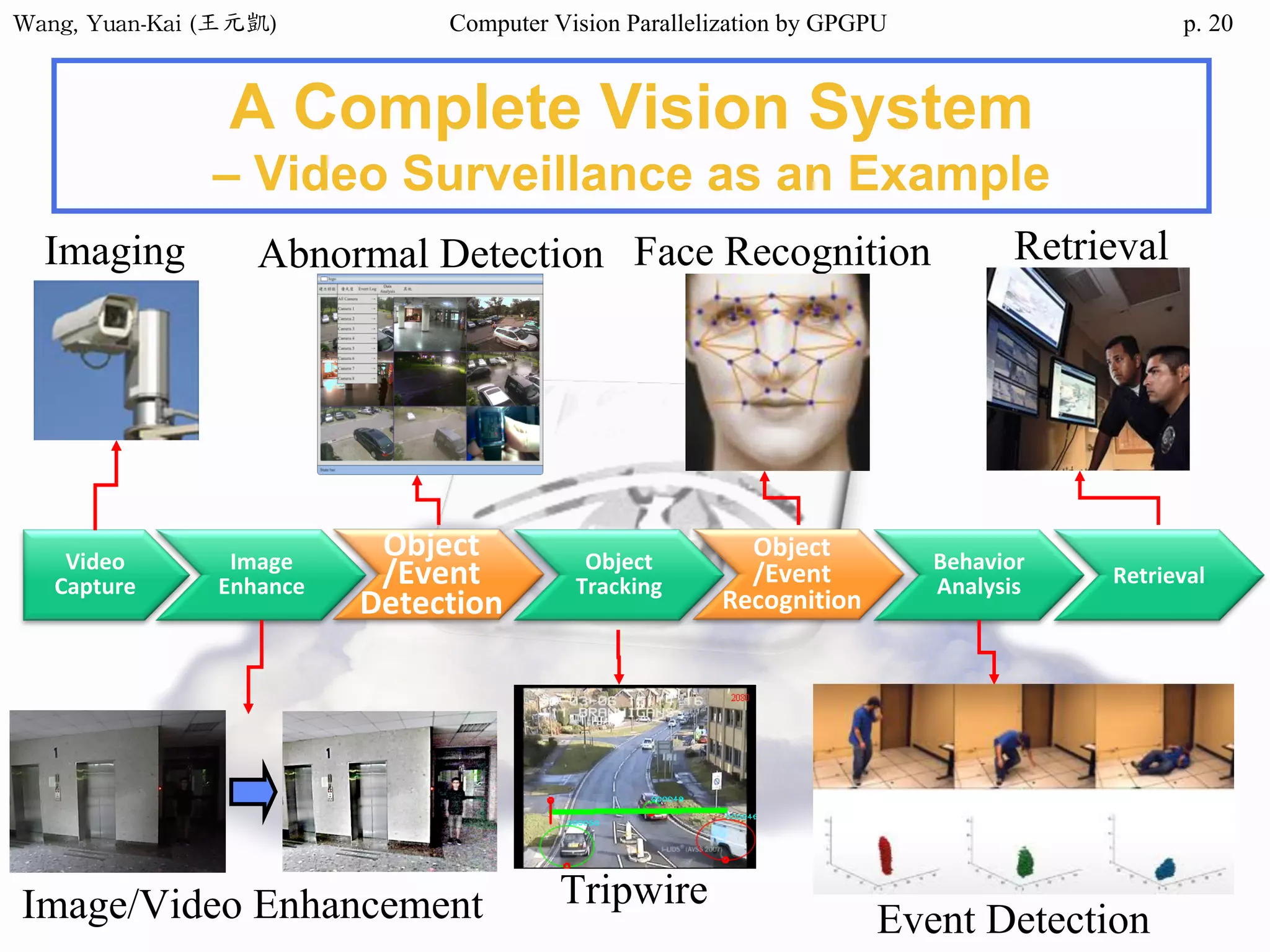
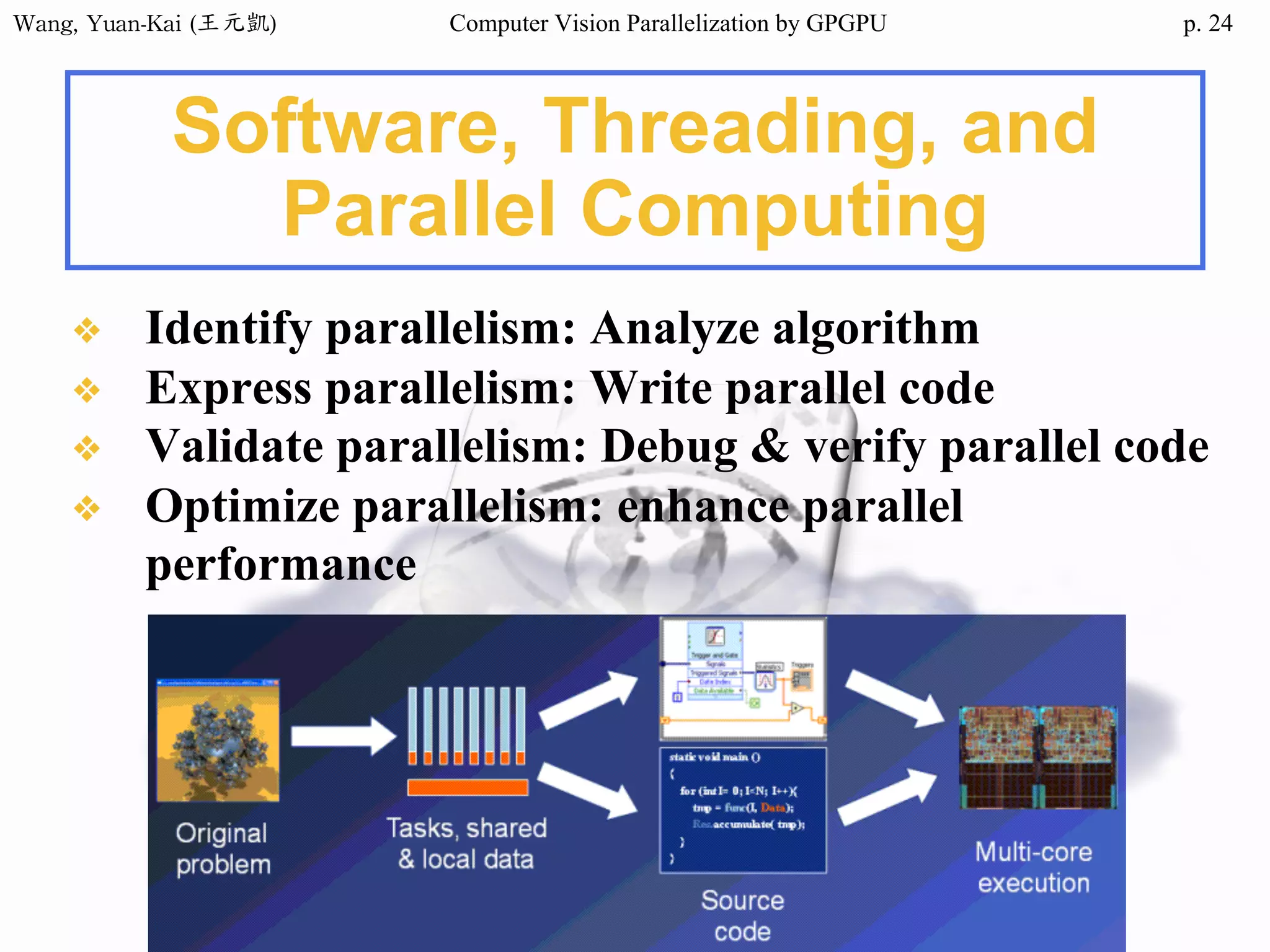
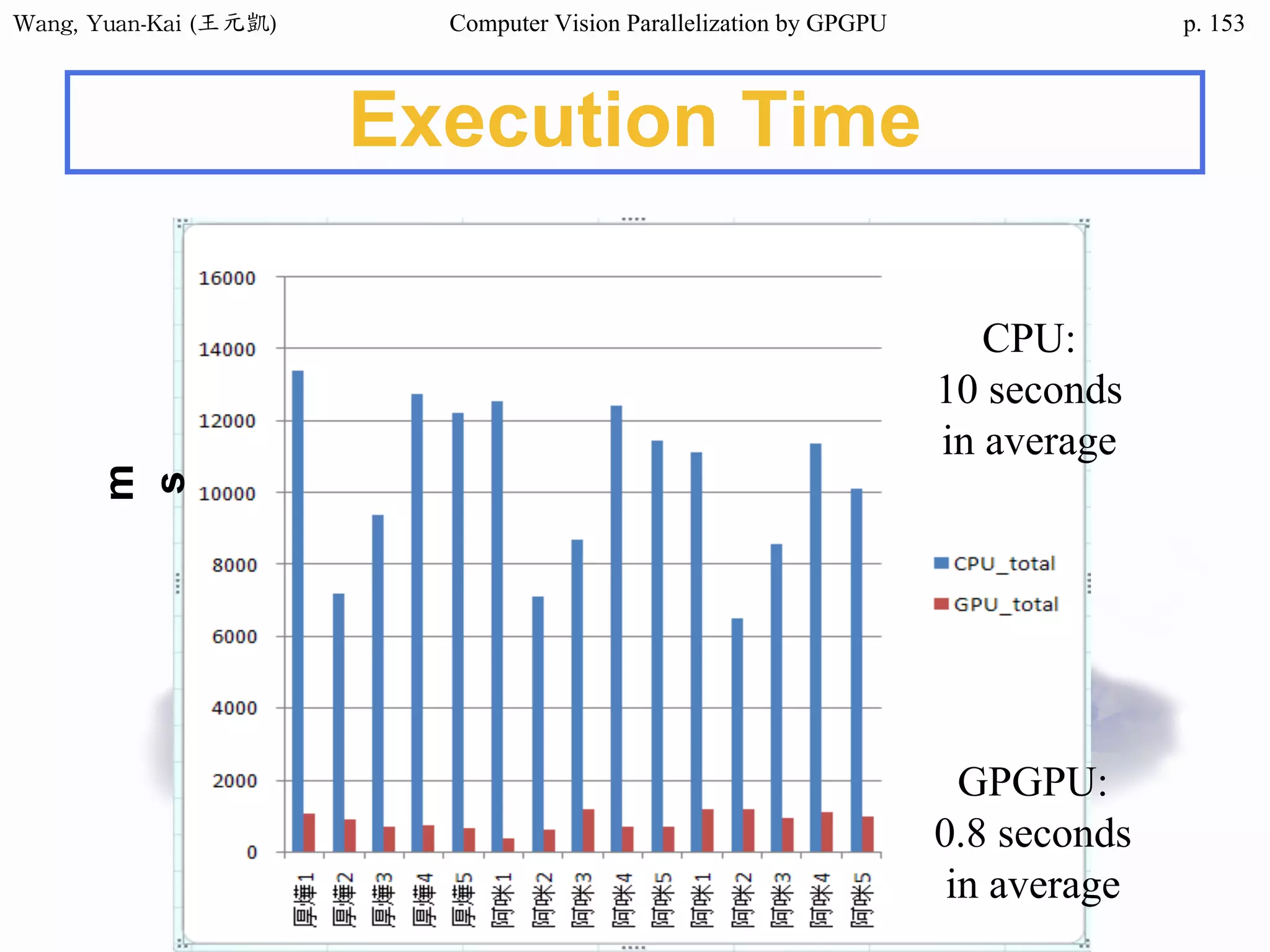
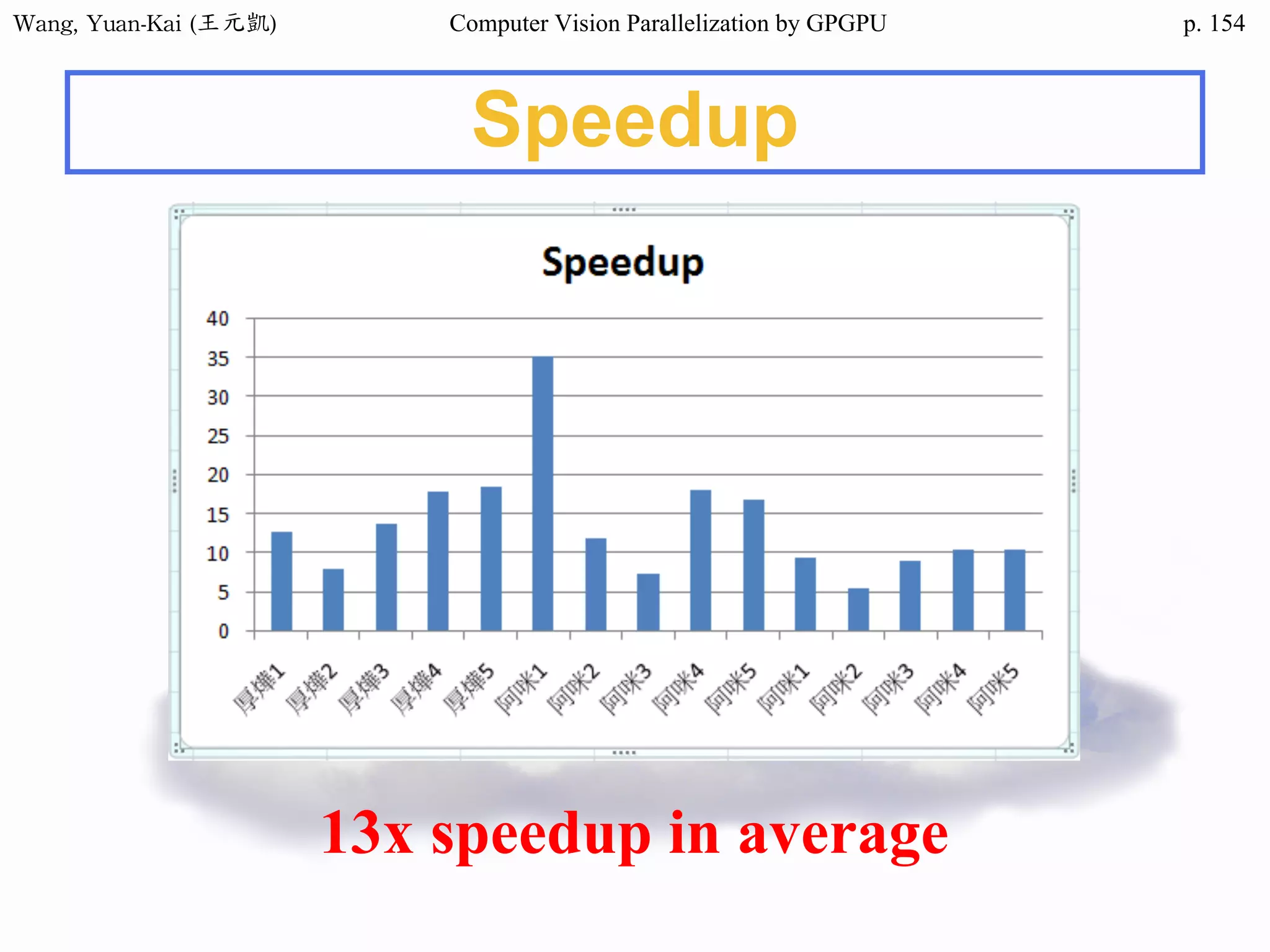
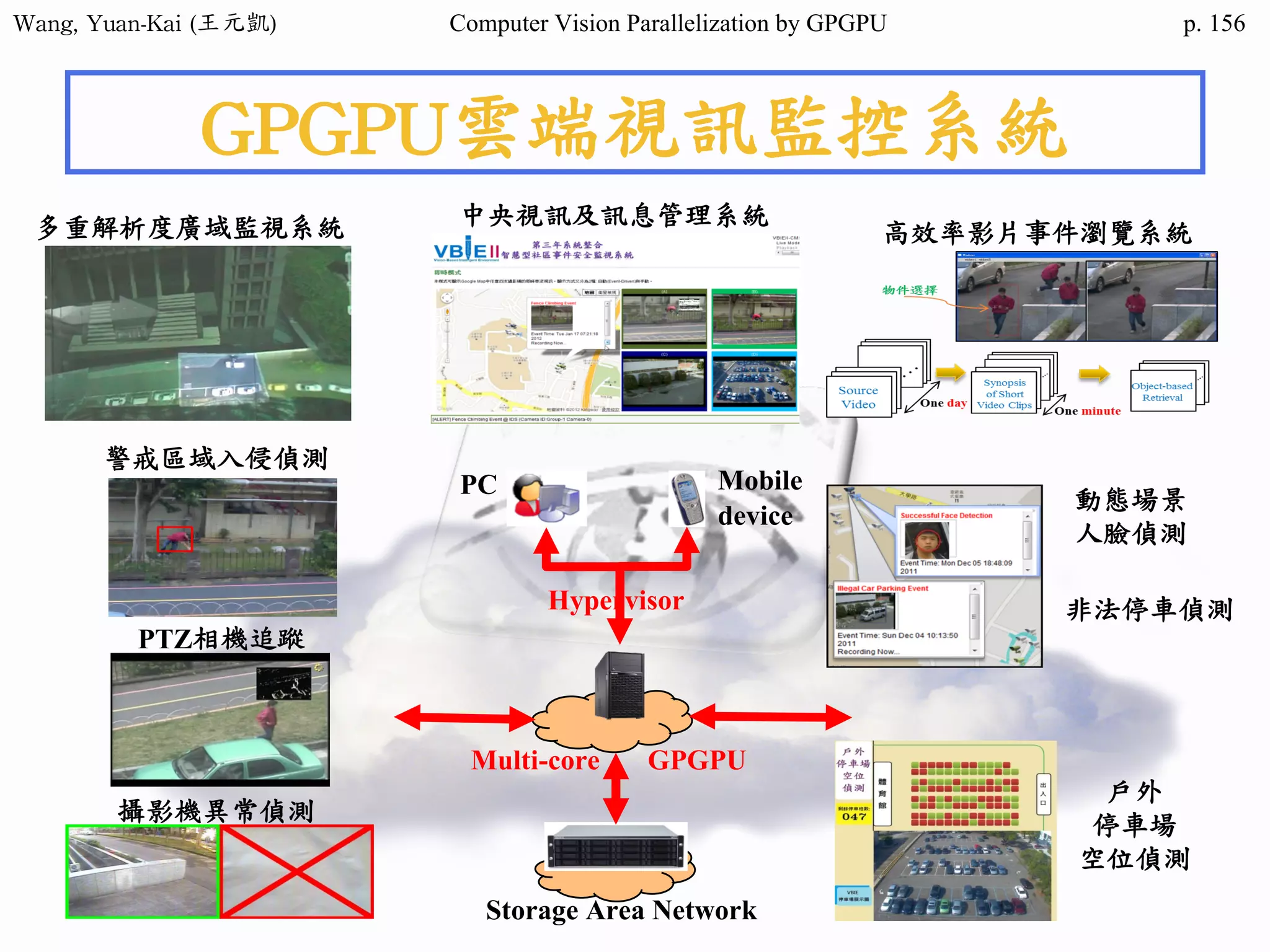
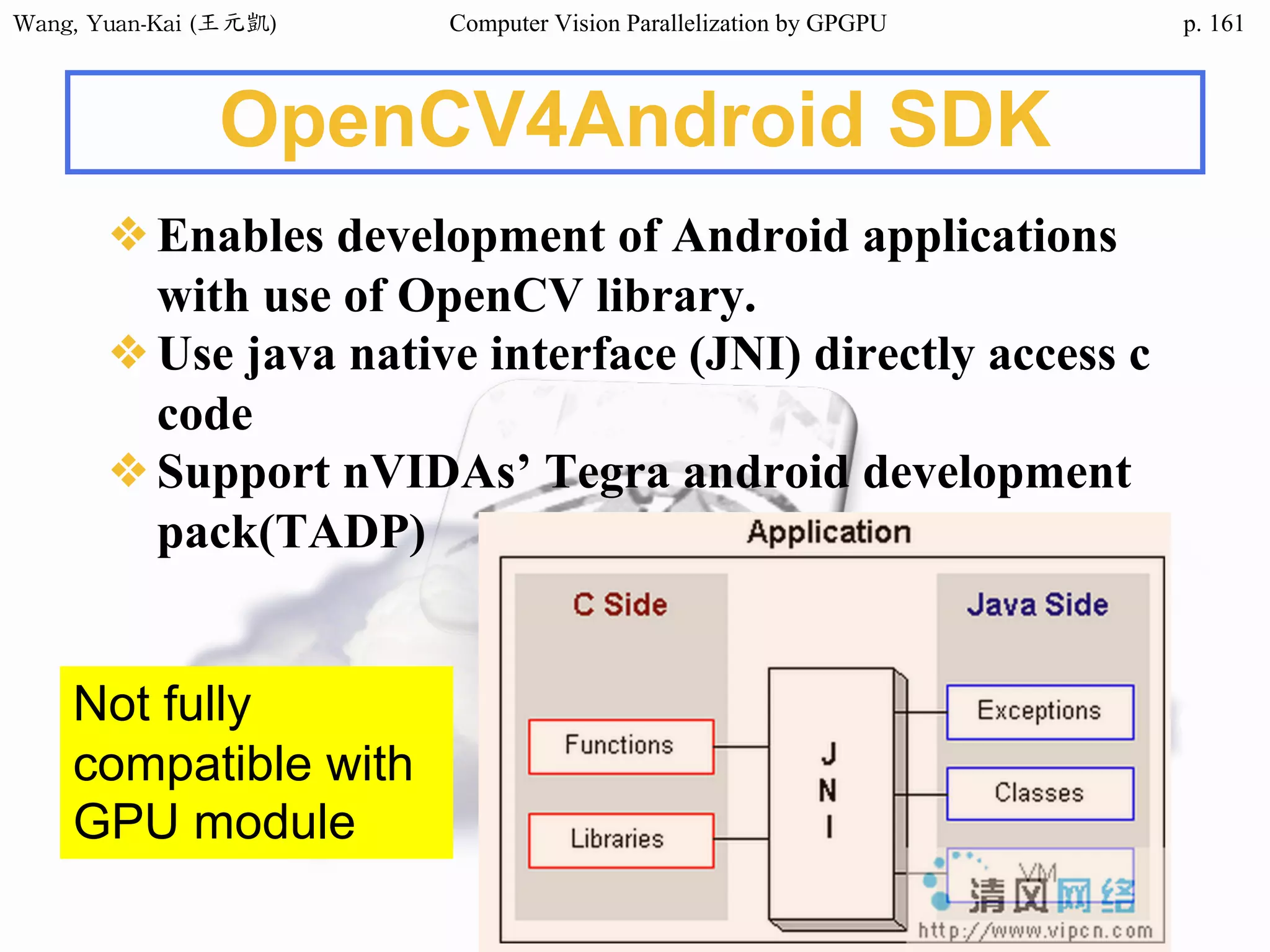
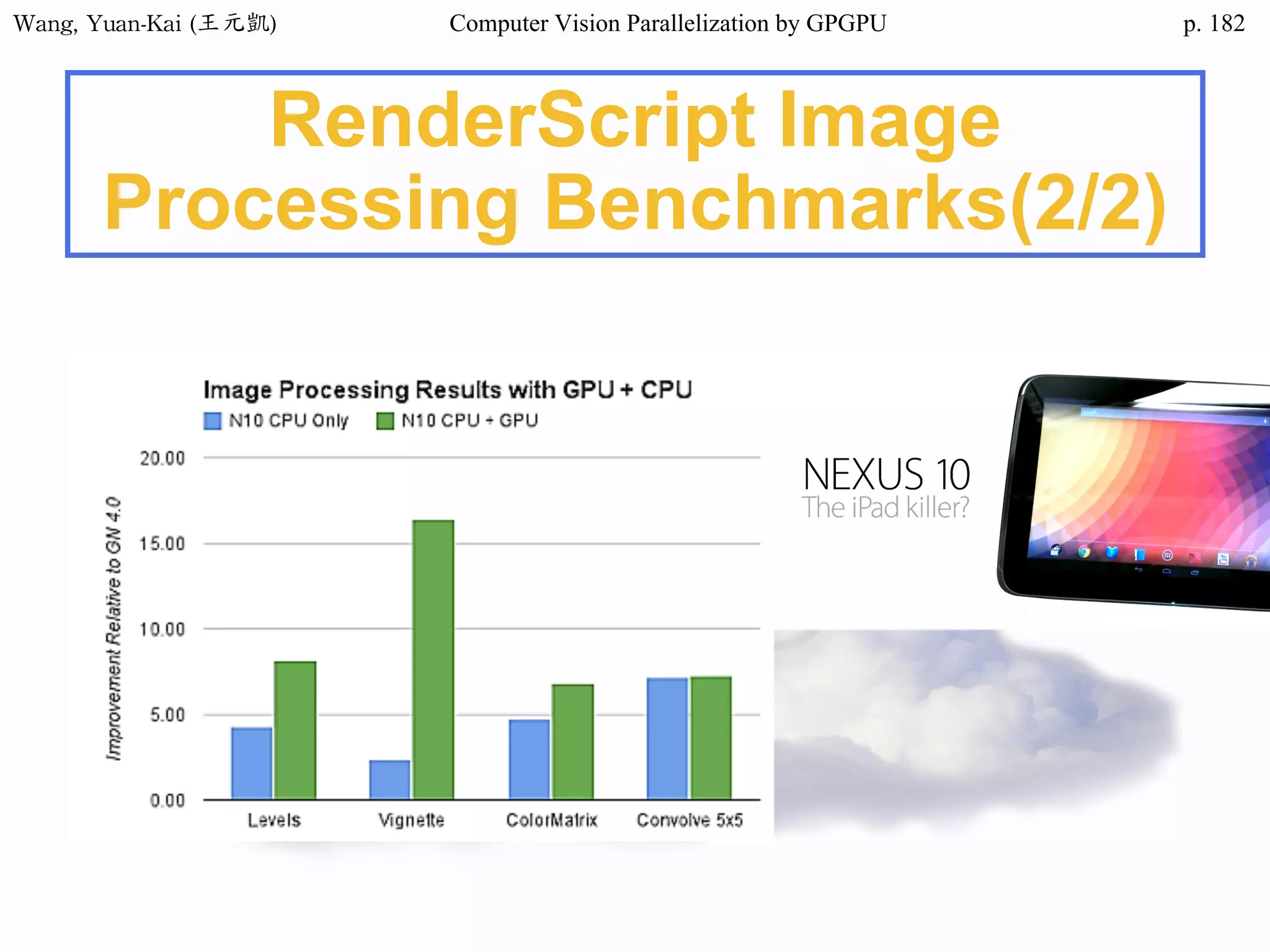
Downloaded 34 times






































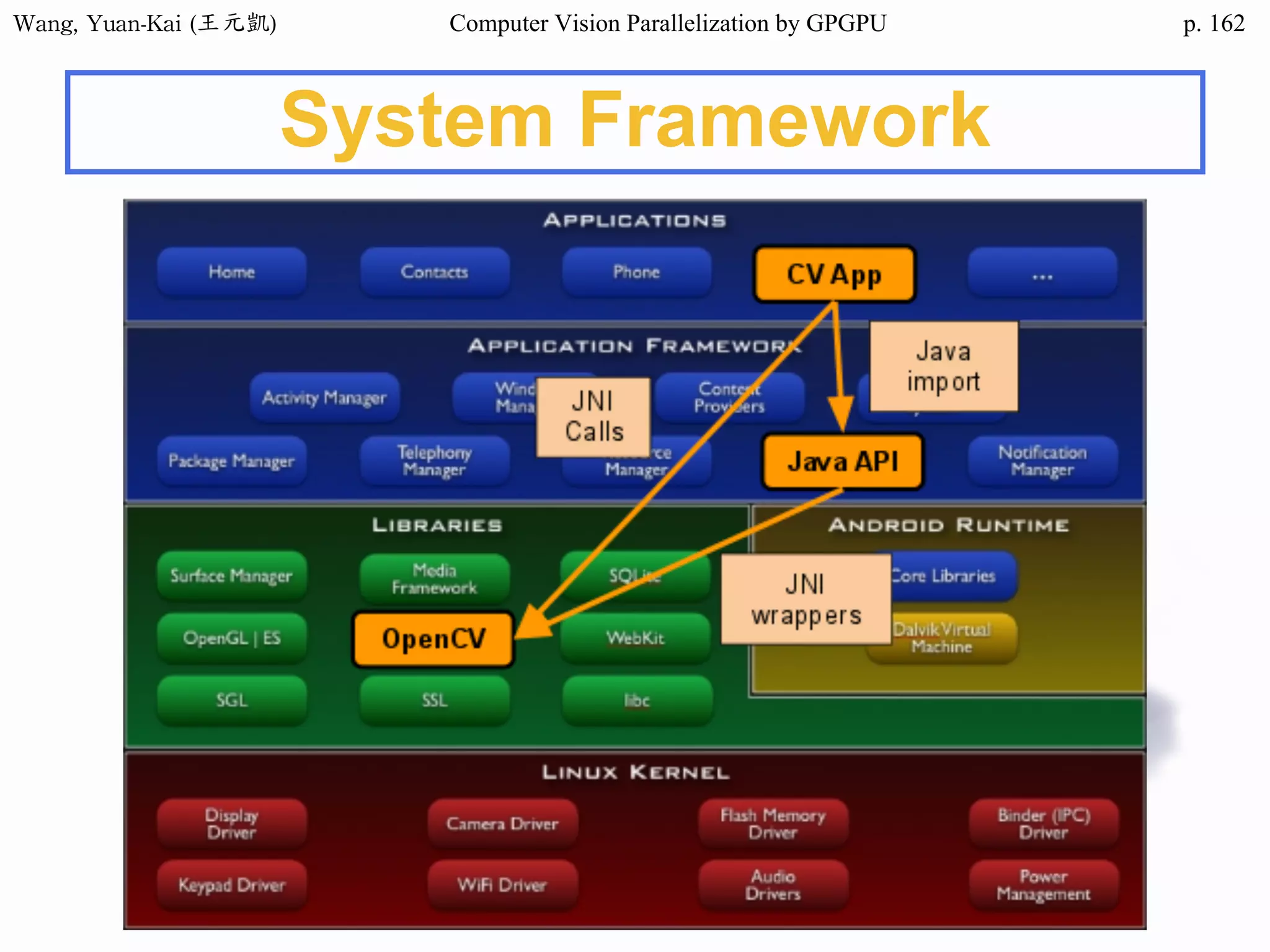
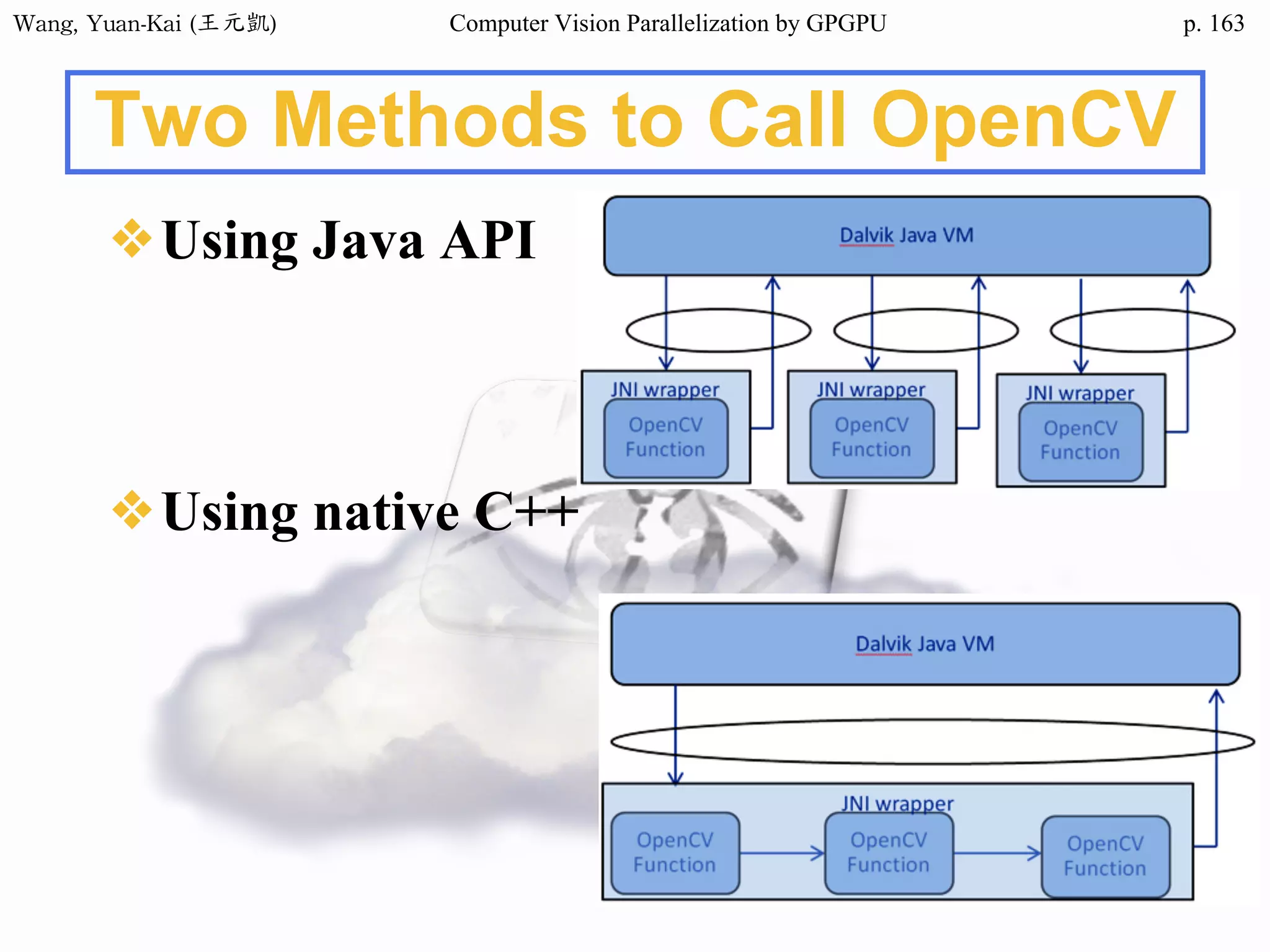
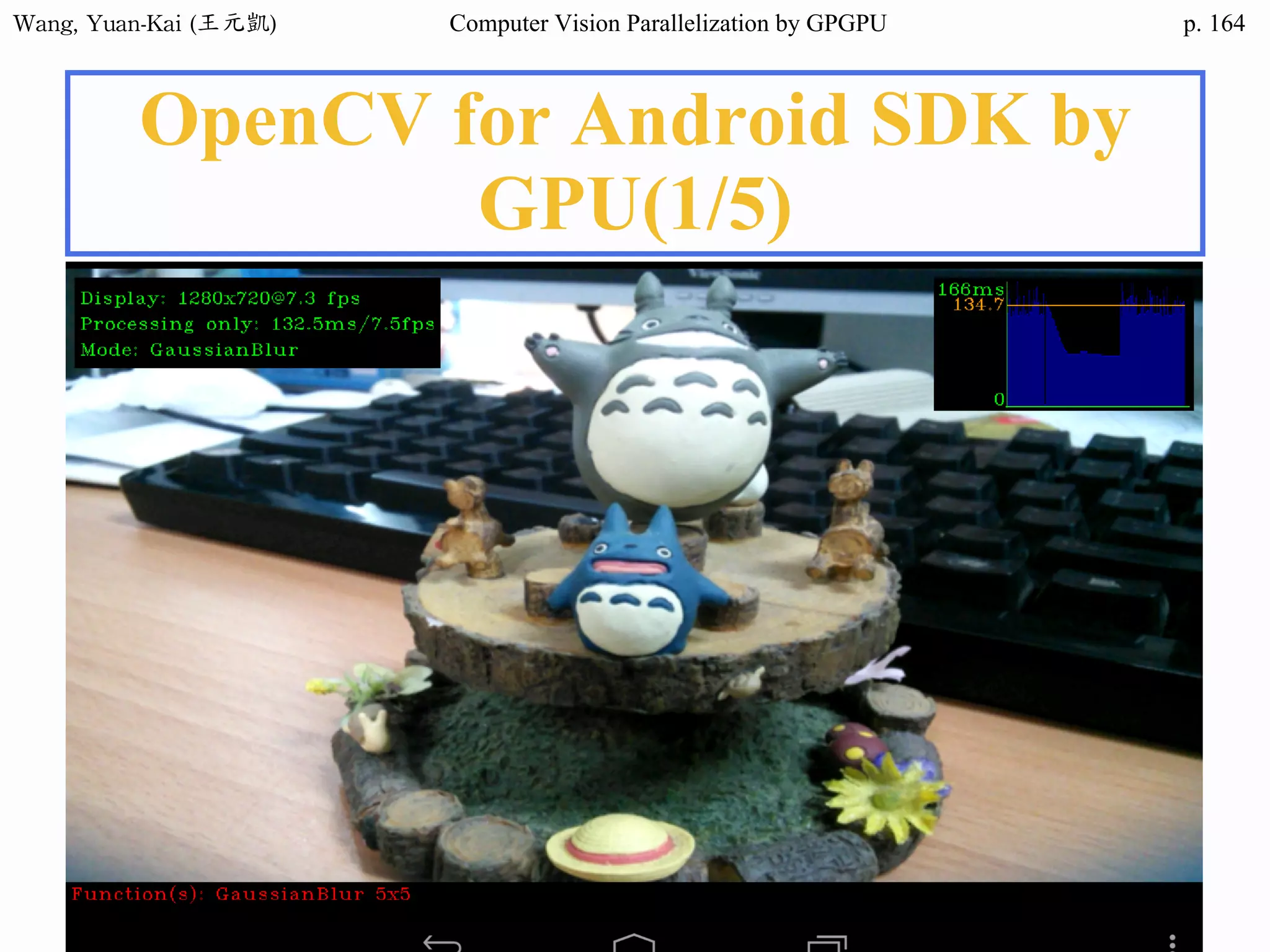
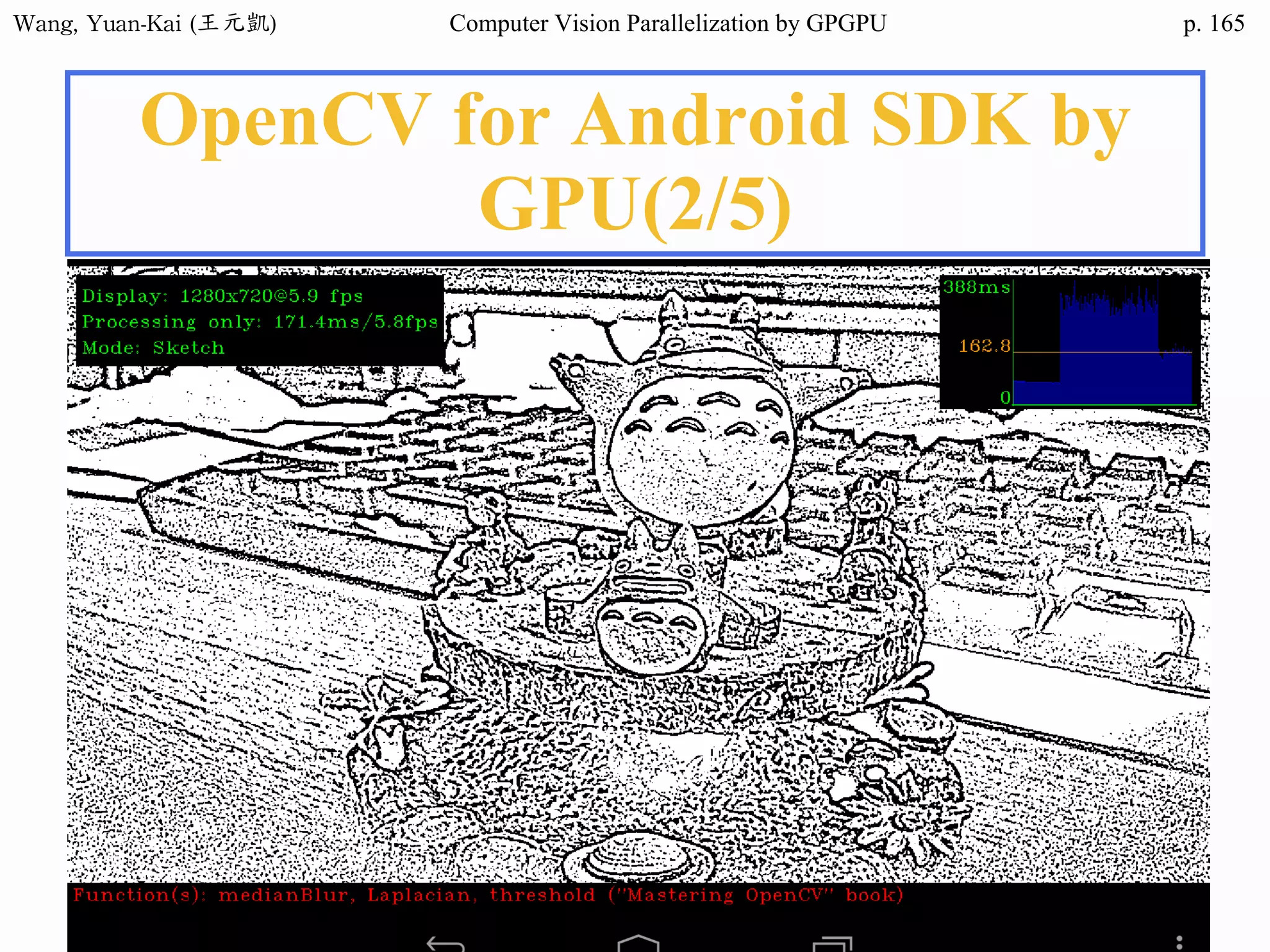
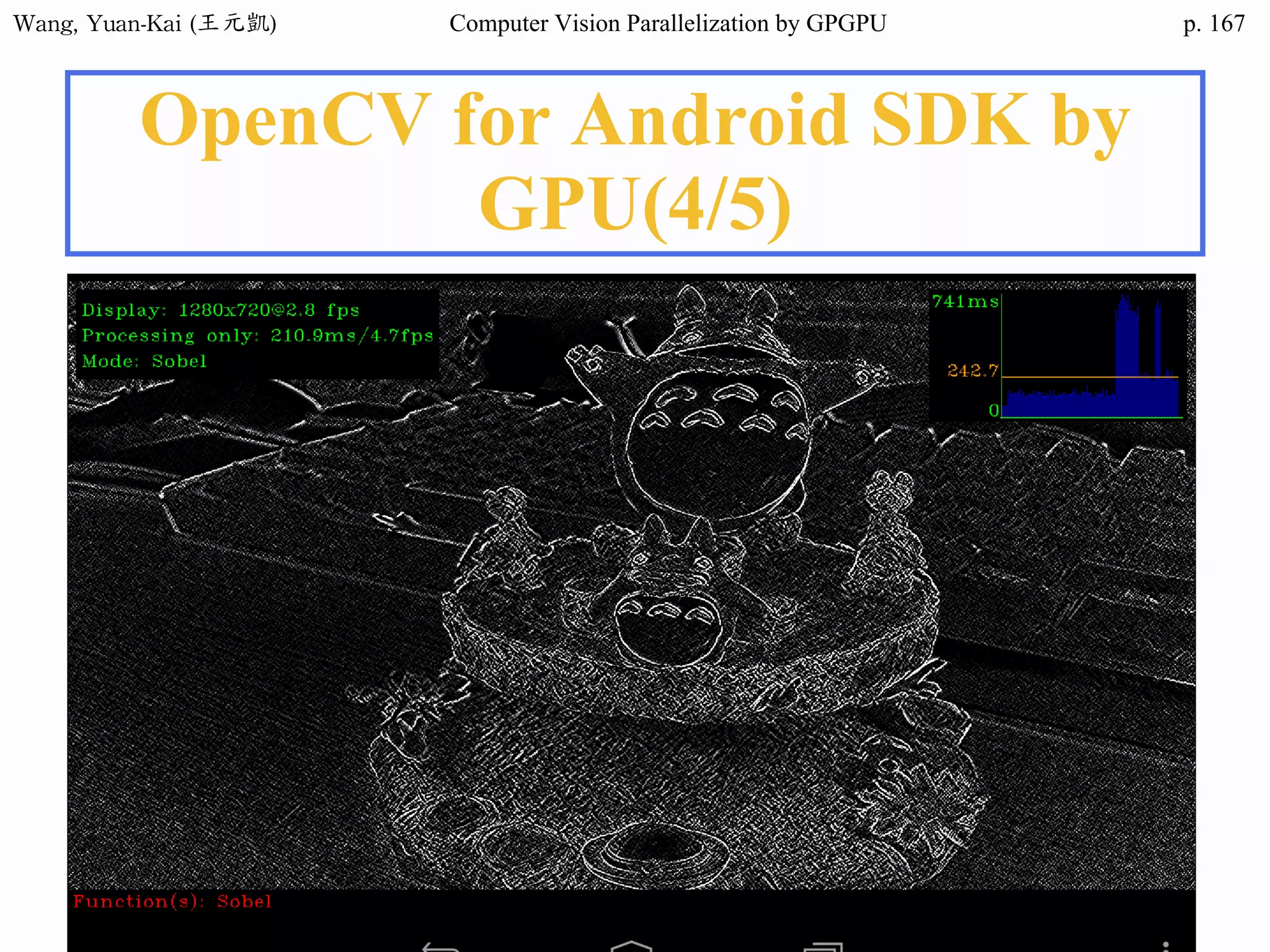
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
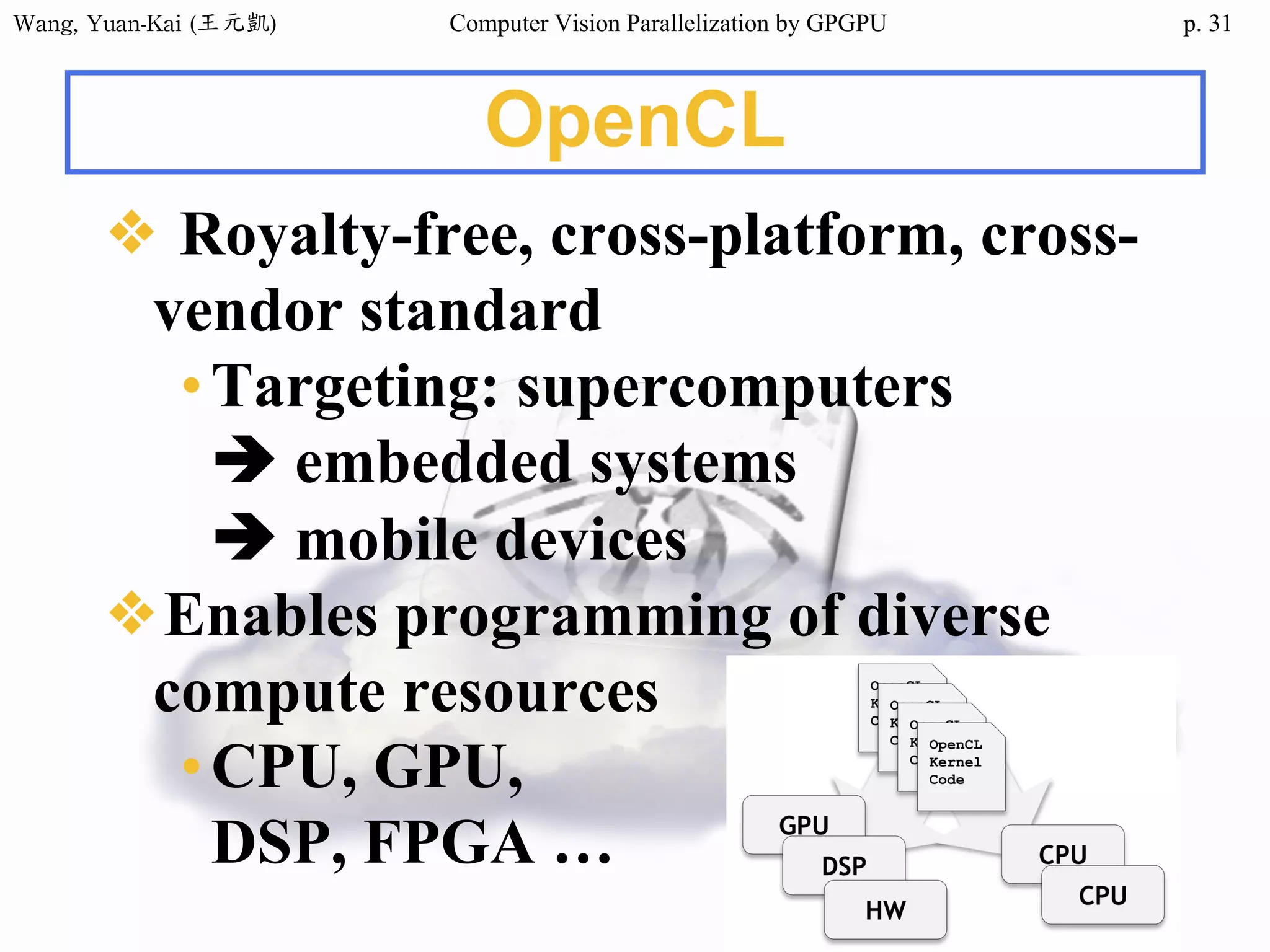
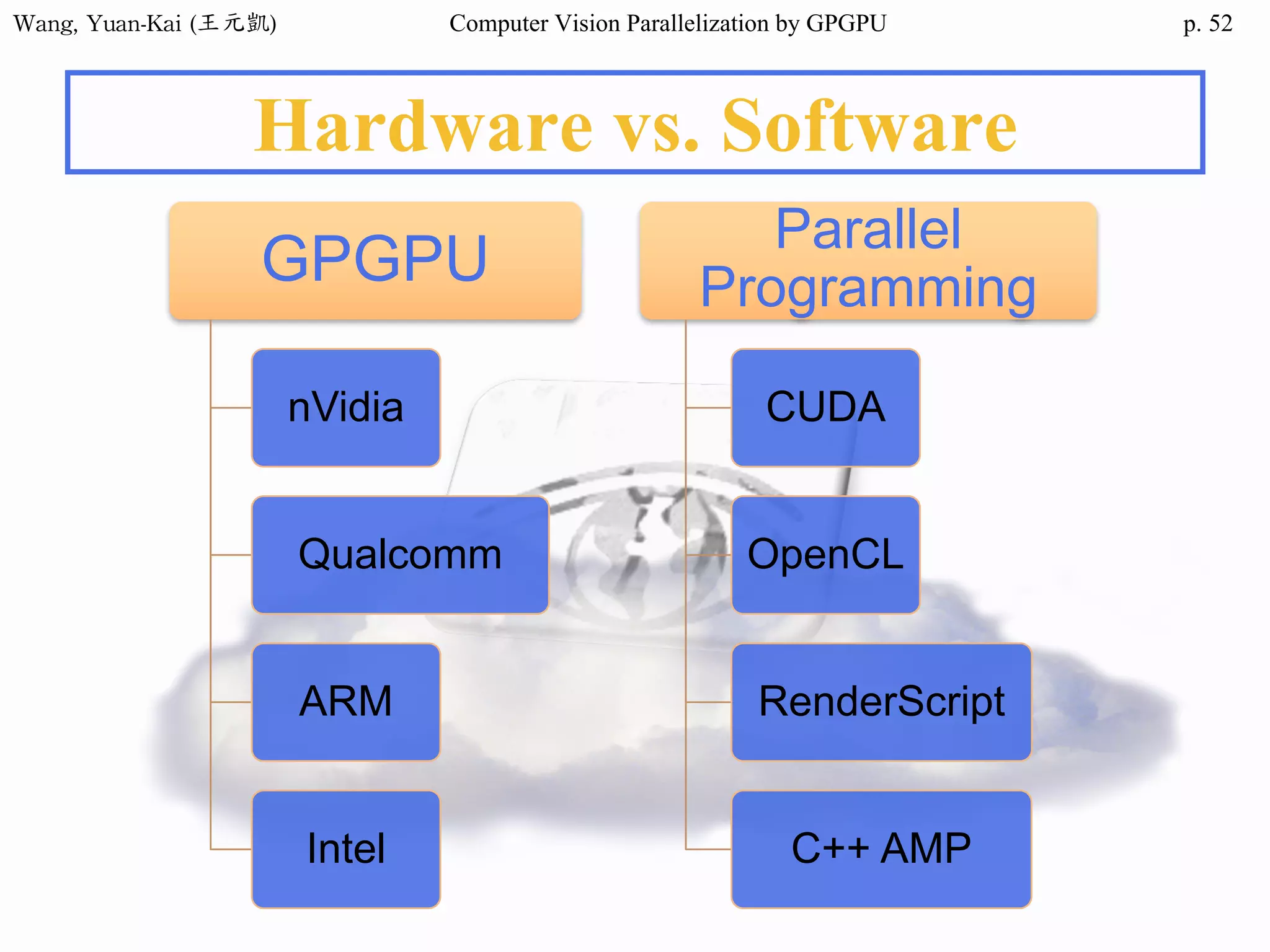
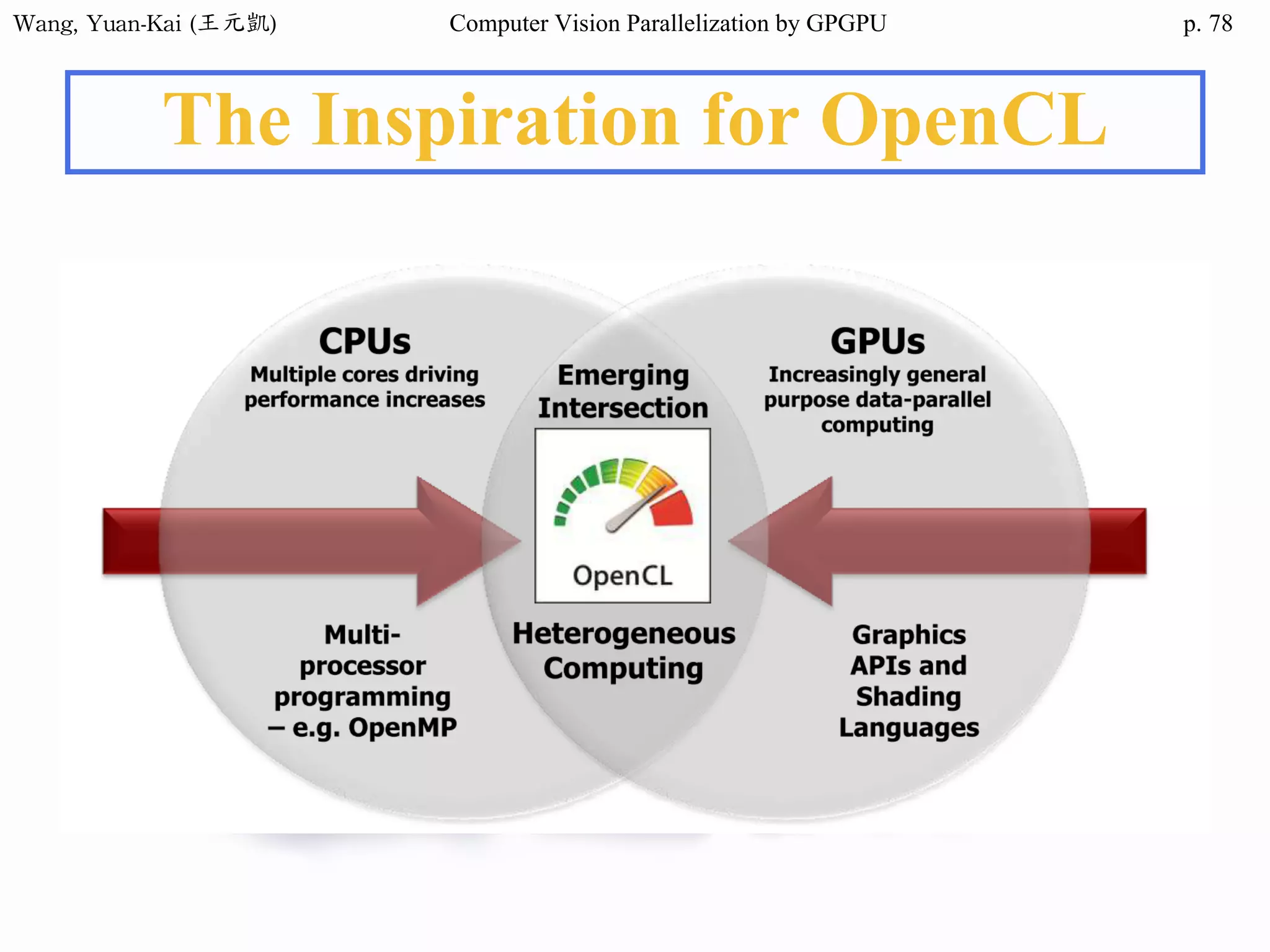
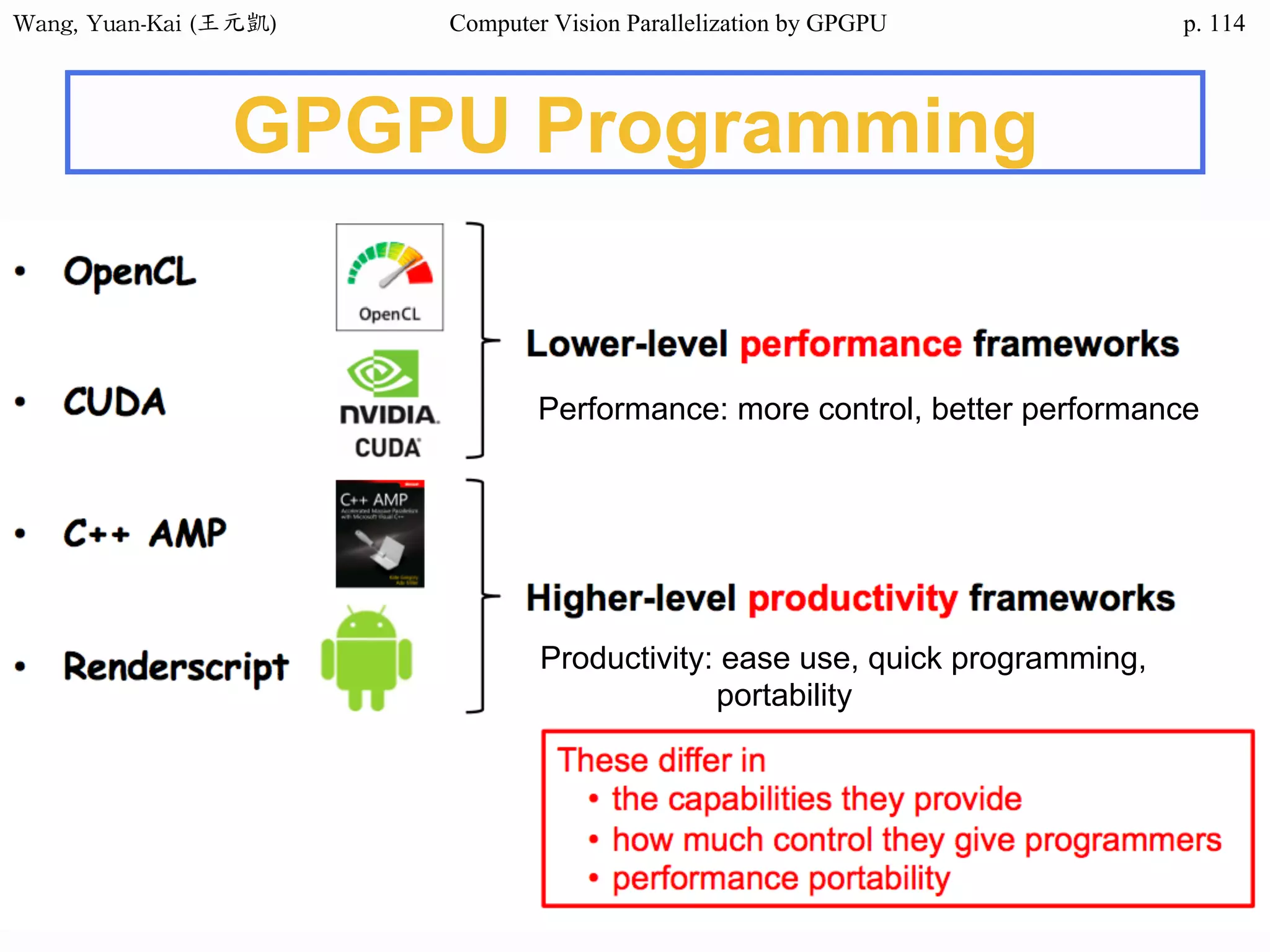
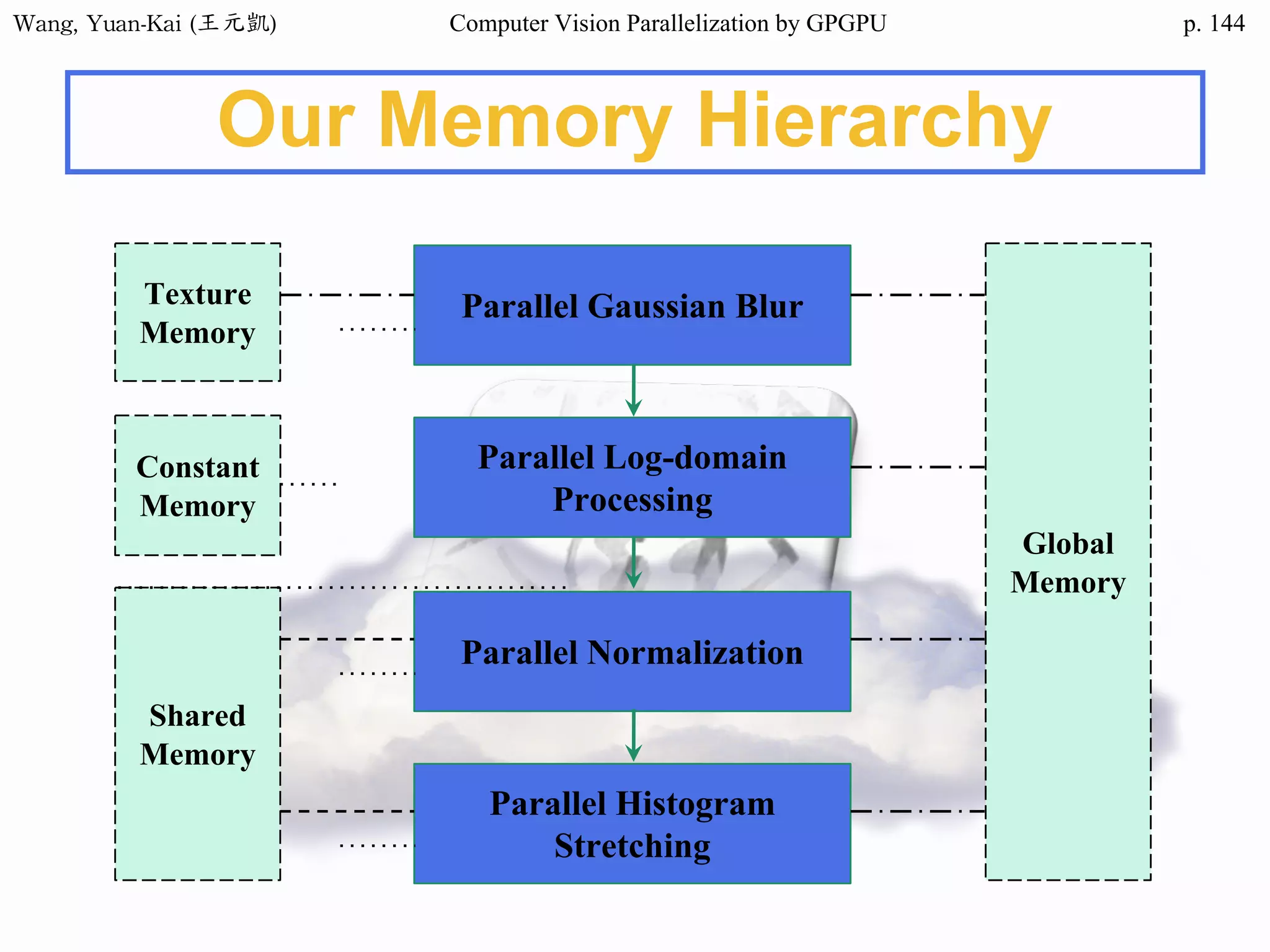
Domain Decomposition (2/3)
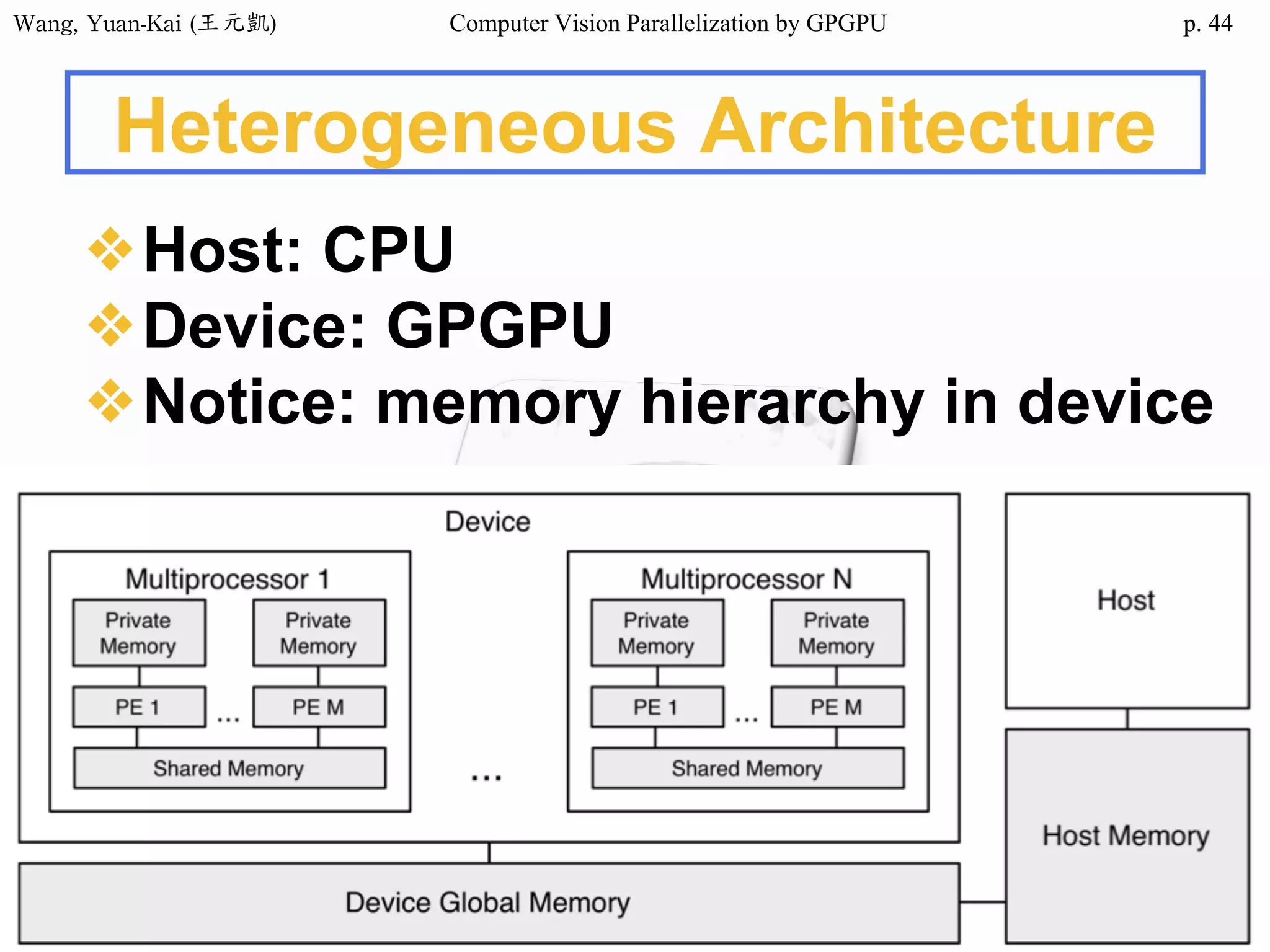
❖Domain data are usually processed
by loop
• for (i=0; i<height; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
Original image(img1) Enhanced image(img2)
The X-ray image
of a circuit board
i
j
SIMD
SPMD
SIMT
63](https://image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-63-2048.jpg)
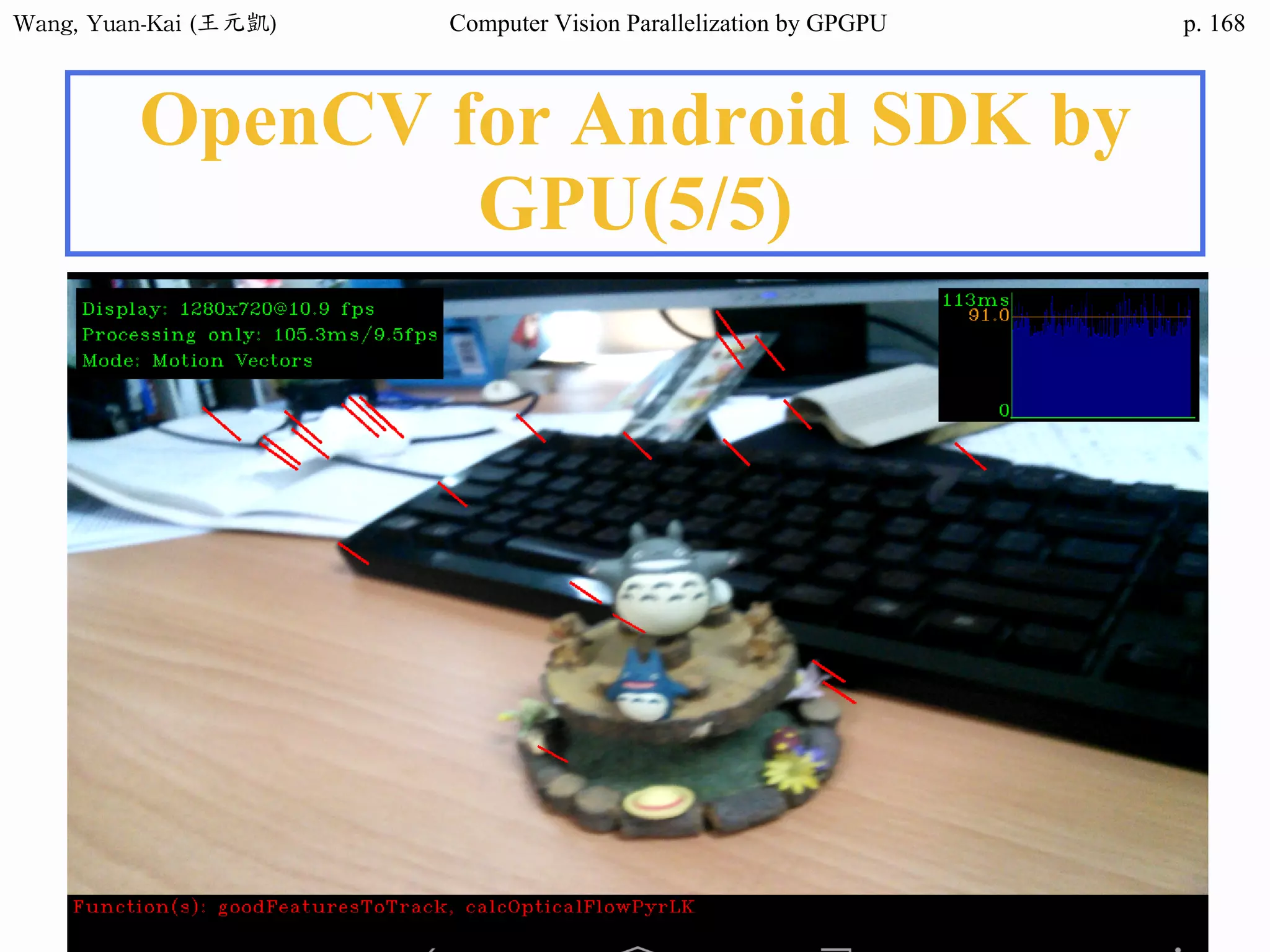
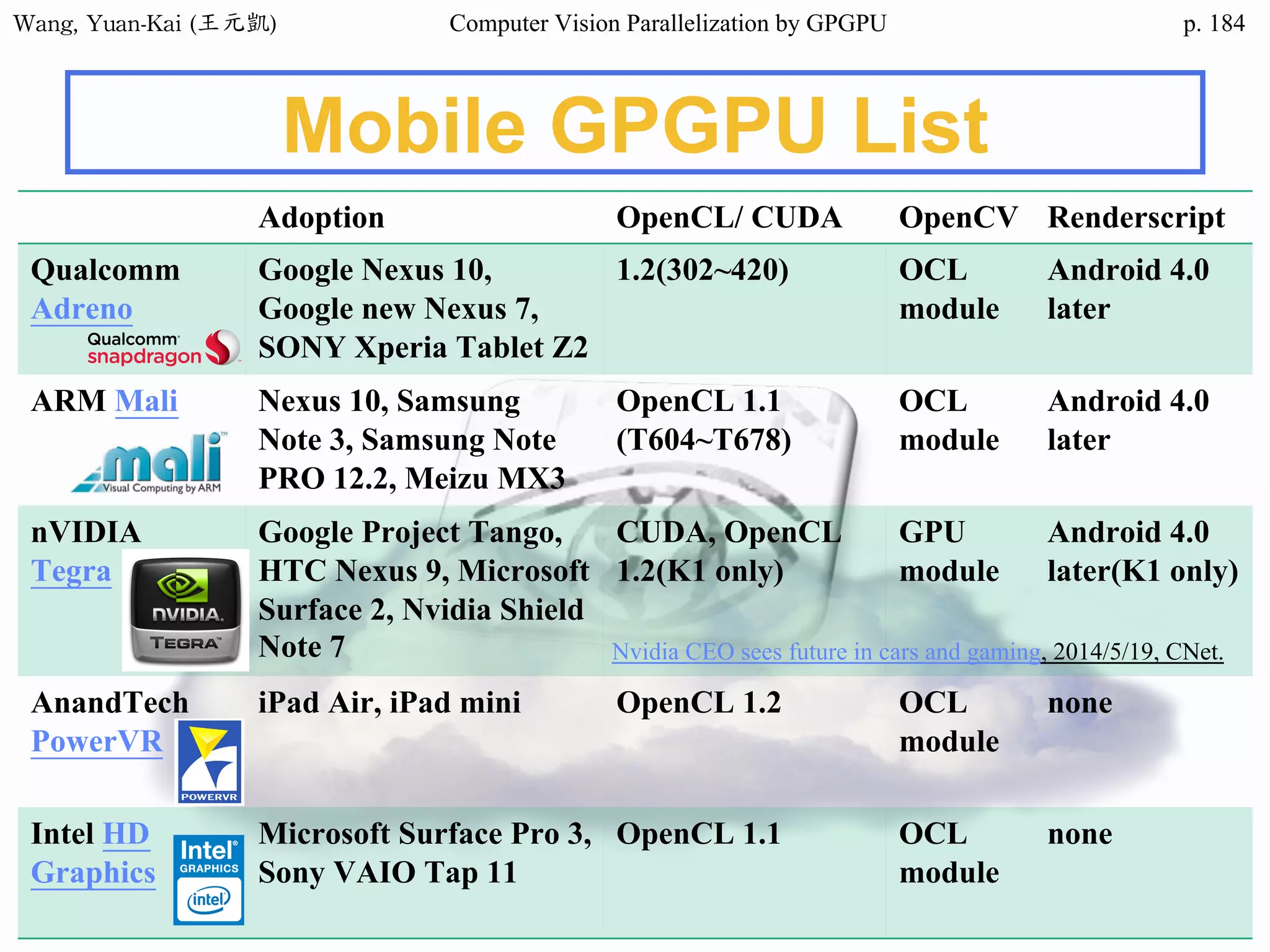
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
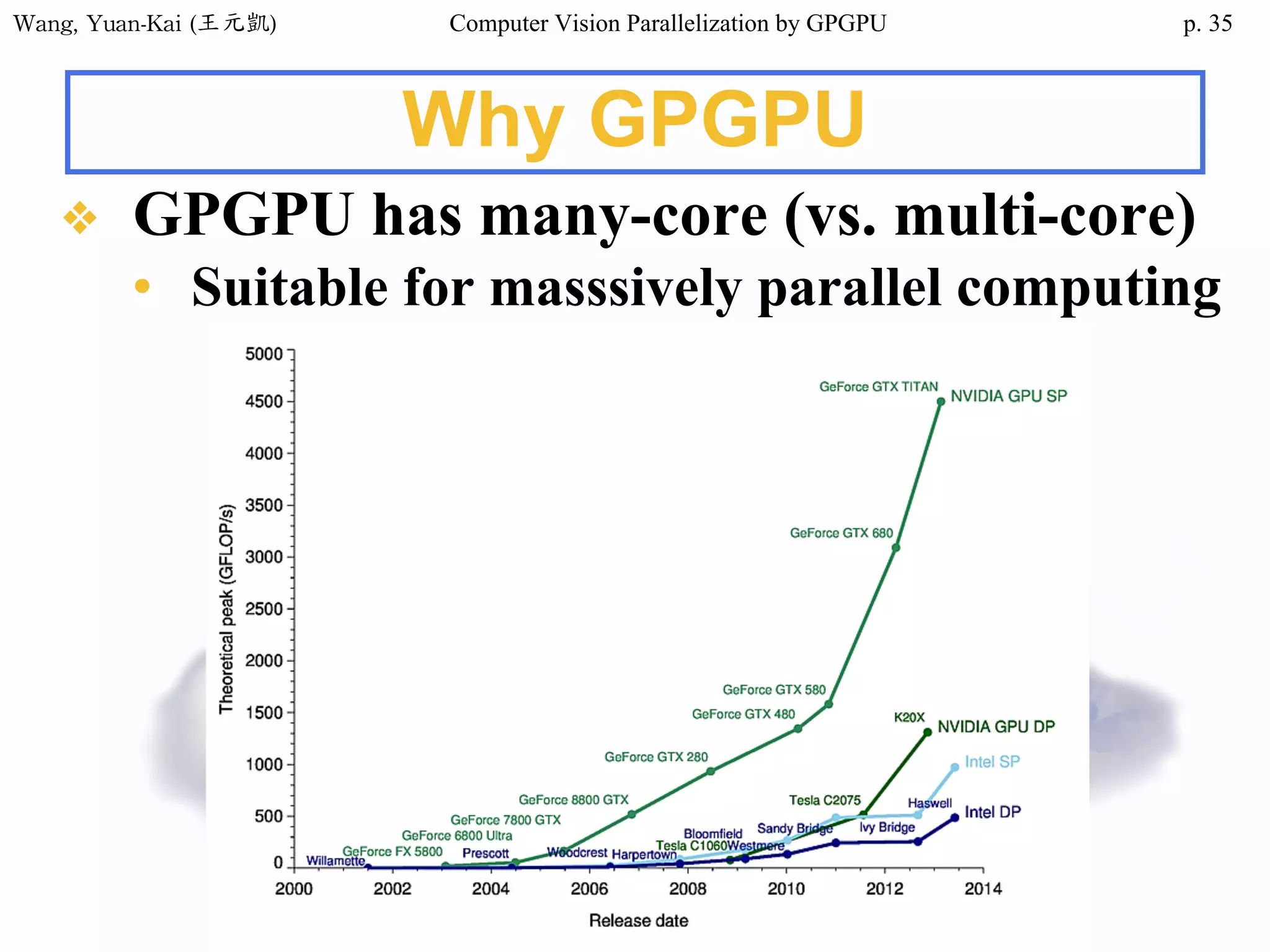
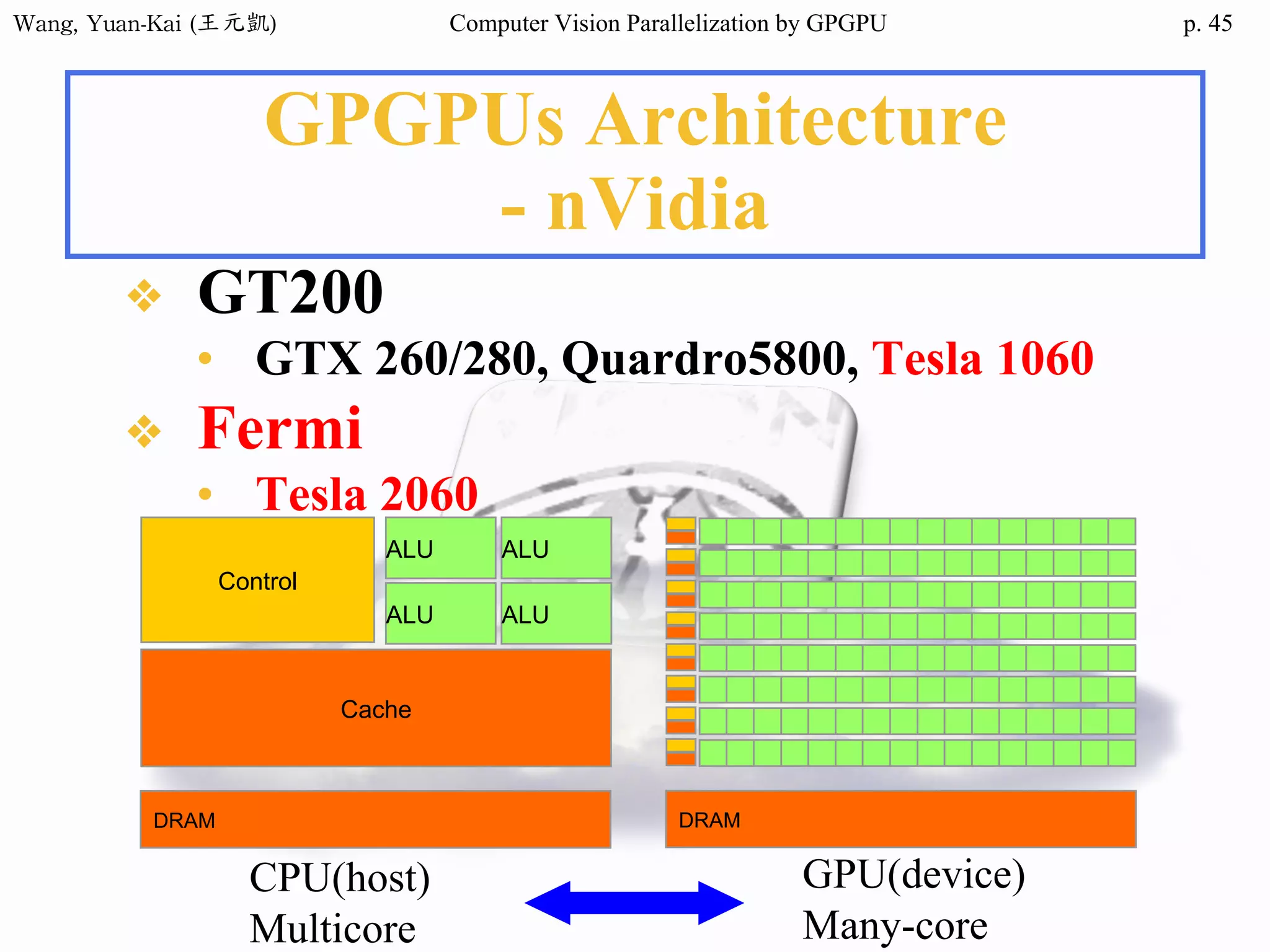
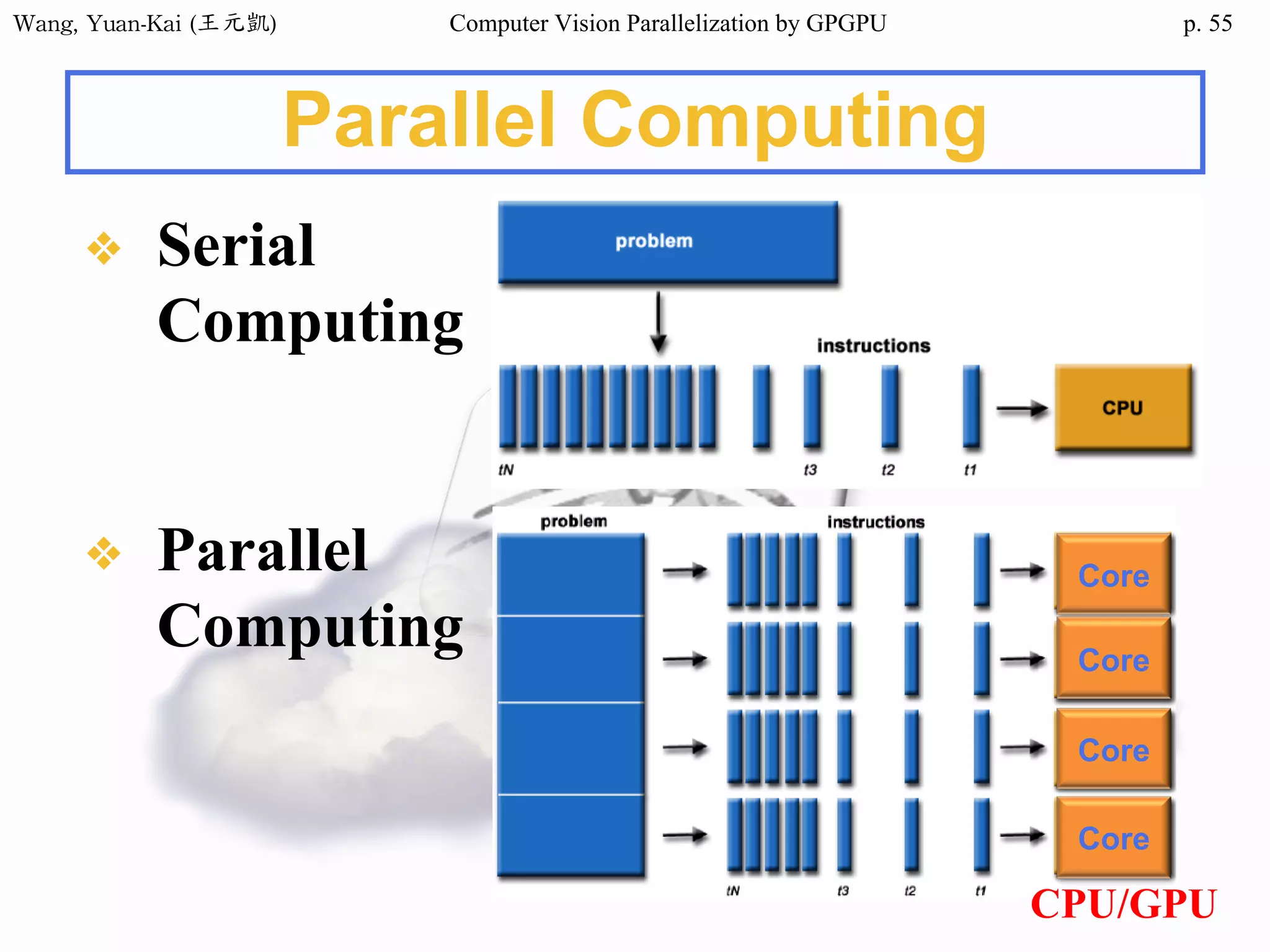
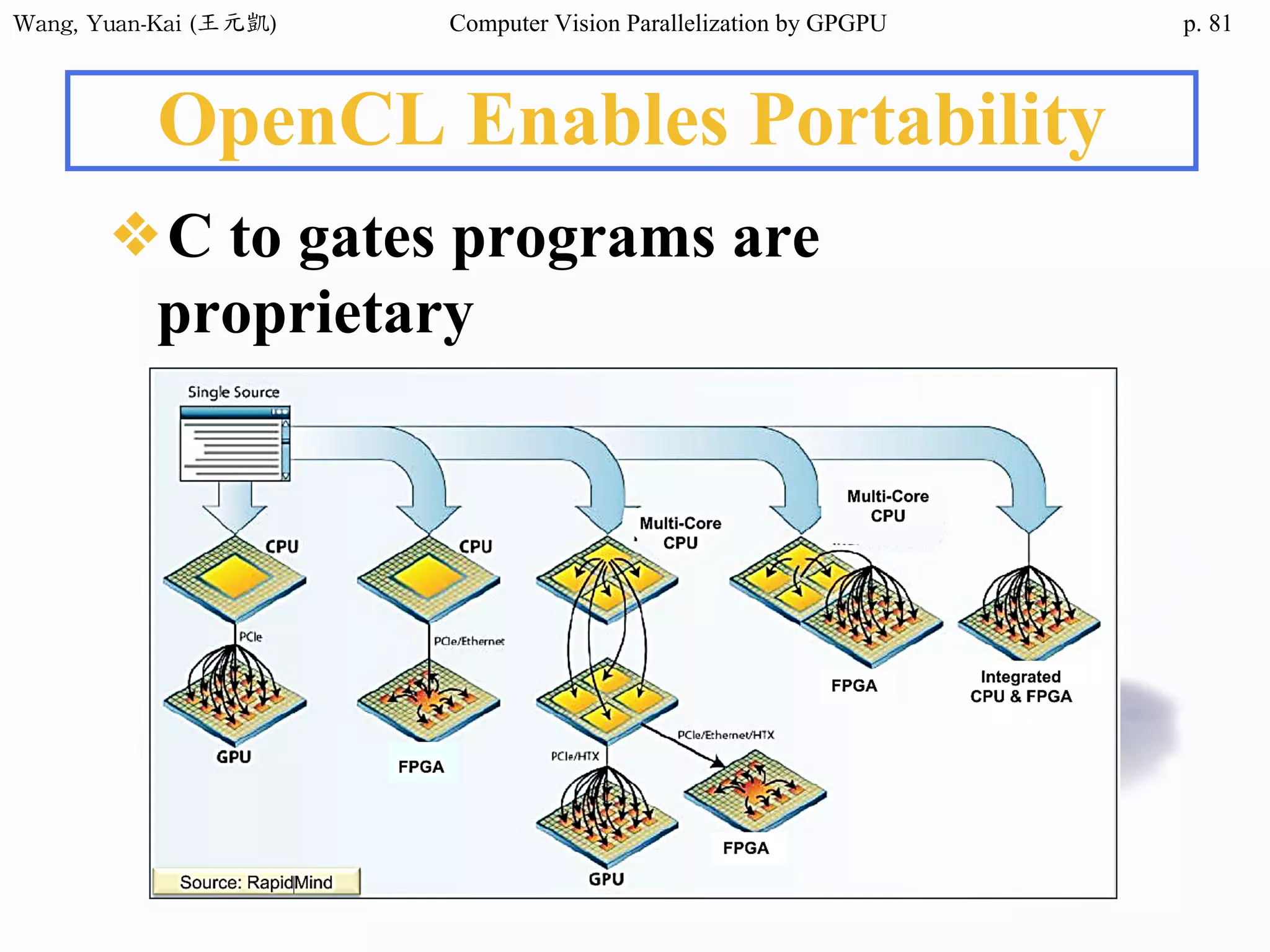
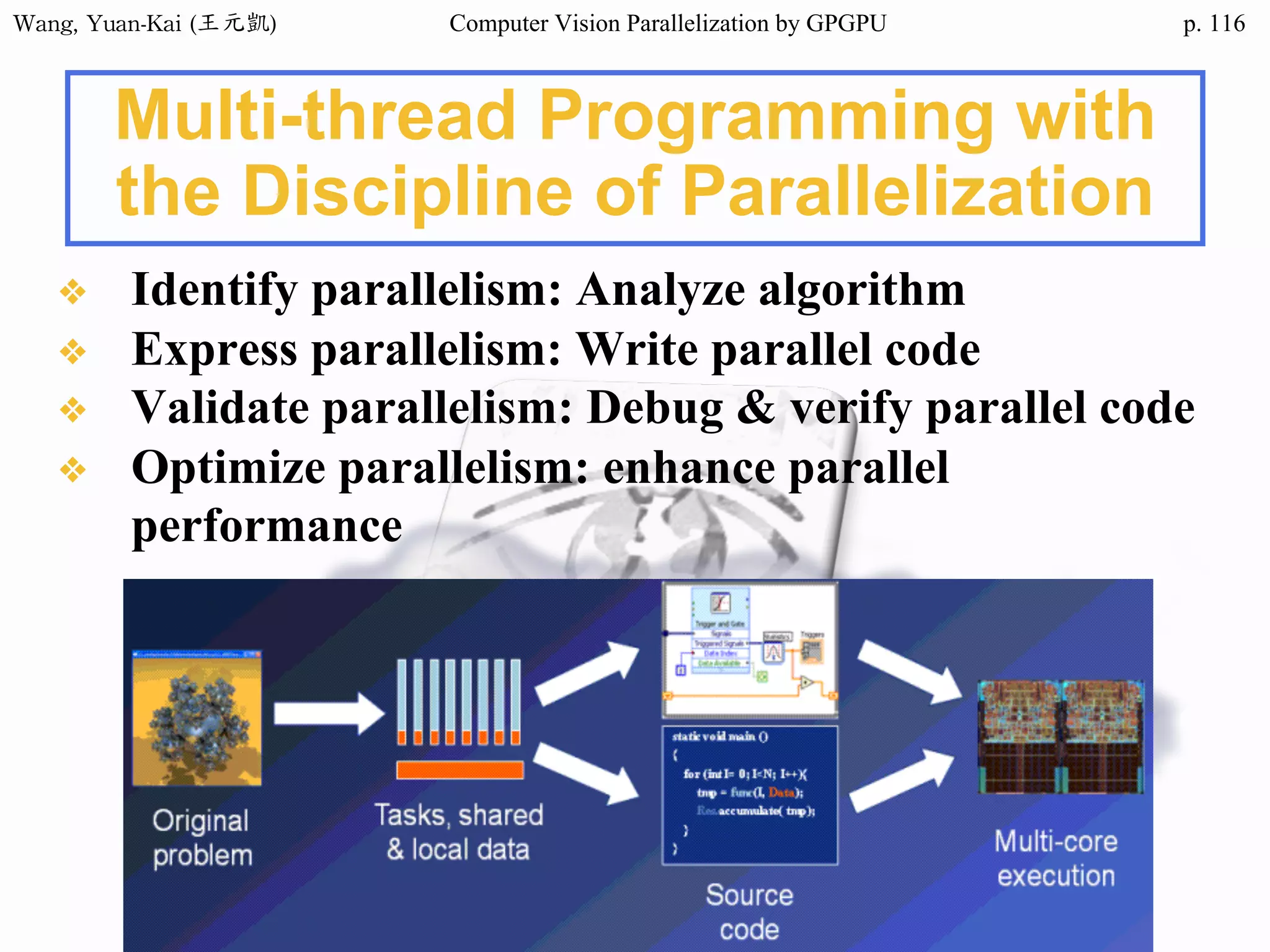
Domain Decomposition (3/3)
❖A three-block partition
example
• // Thread 1
for (i=0; i<height/3; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
• // Thread 2
for (i=height/3; i<height*2/3; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
• // Thread 3
for (i=height*2/3; i<height; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
i
j
OpenMP
CUDA(SPMD)
fork(threads)
join(barrier)
i=0
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
i=10
i=11
subdomain 1 subdomain 2 subdomain 3
64](https://image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-64-2048.jpg)





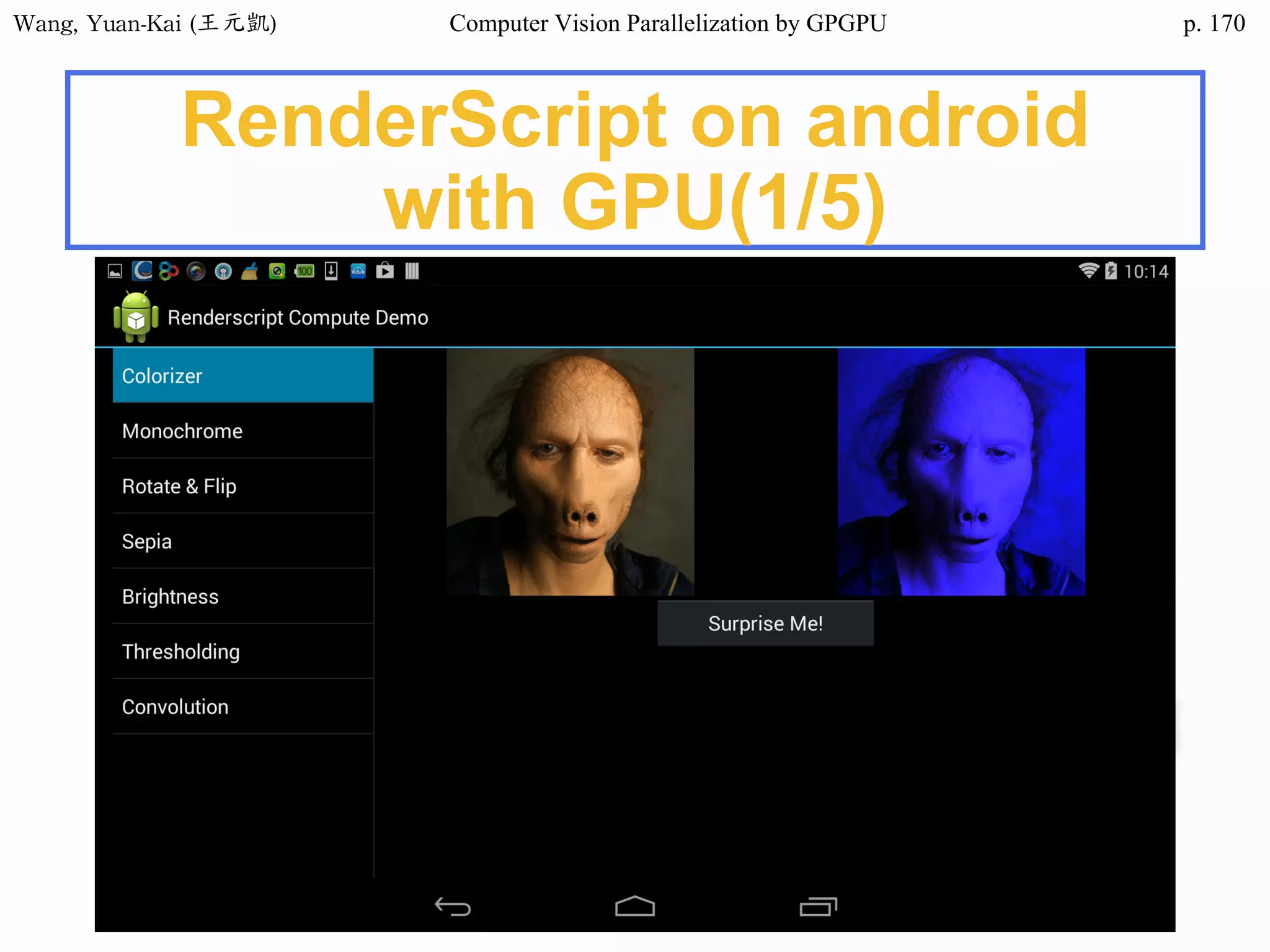
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
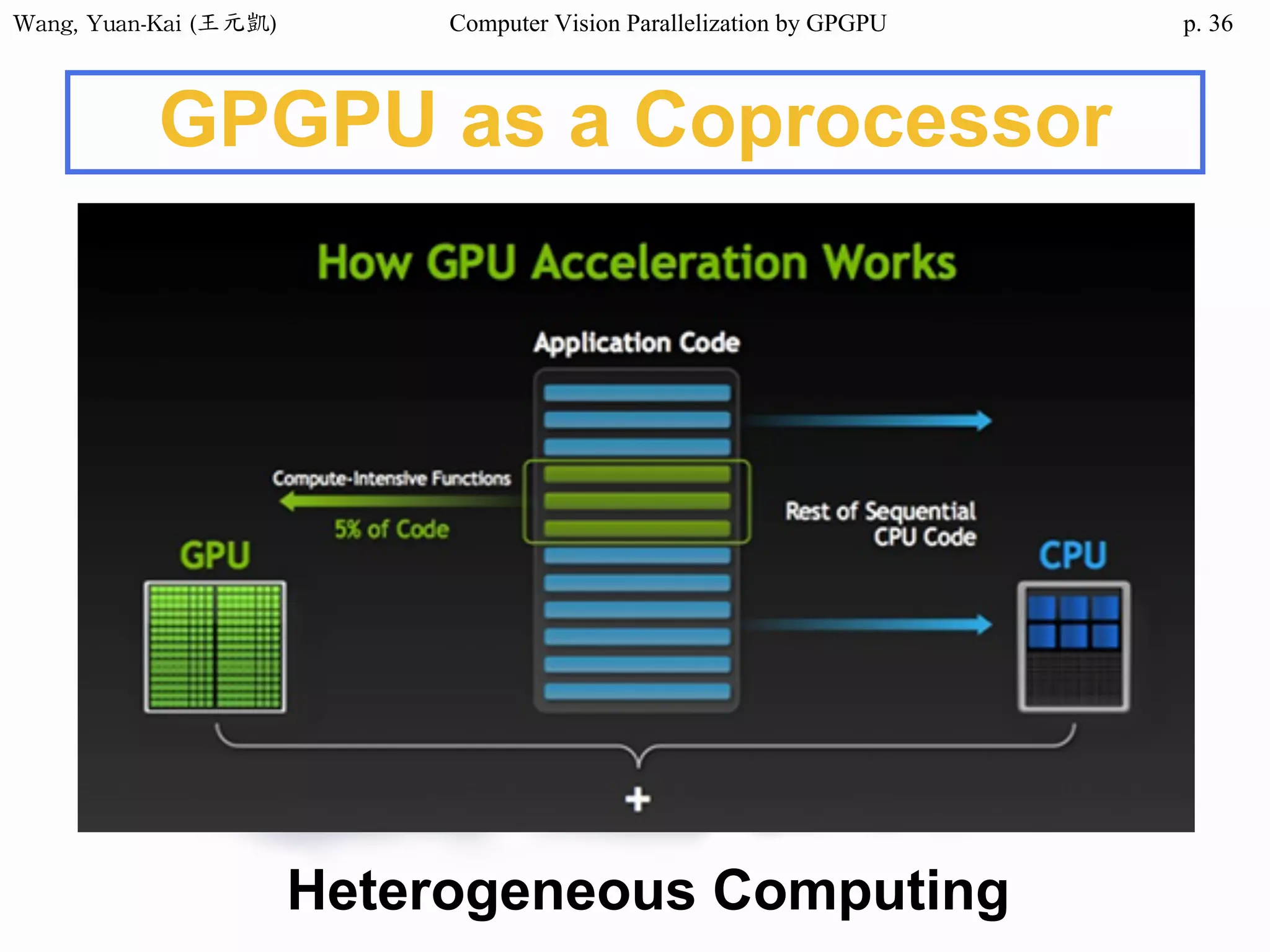
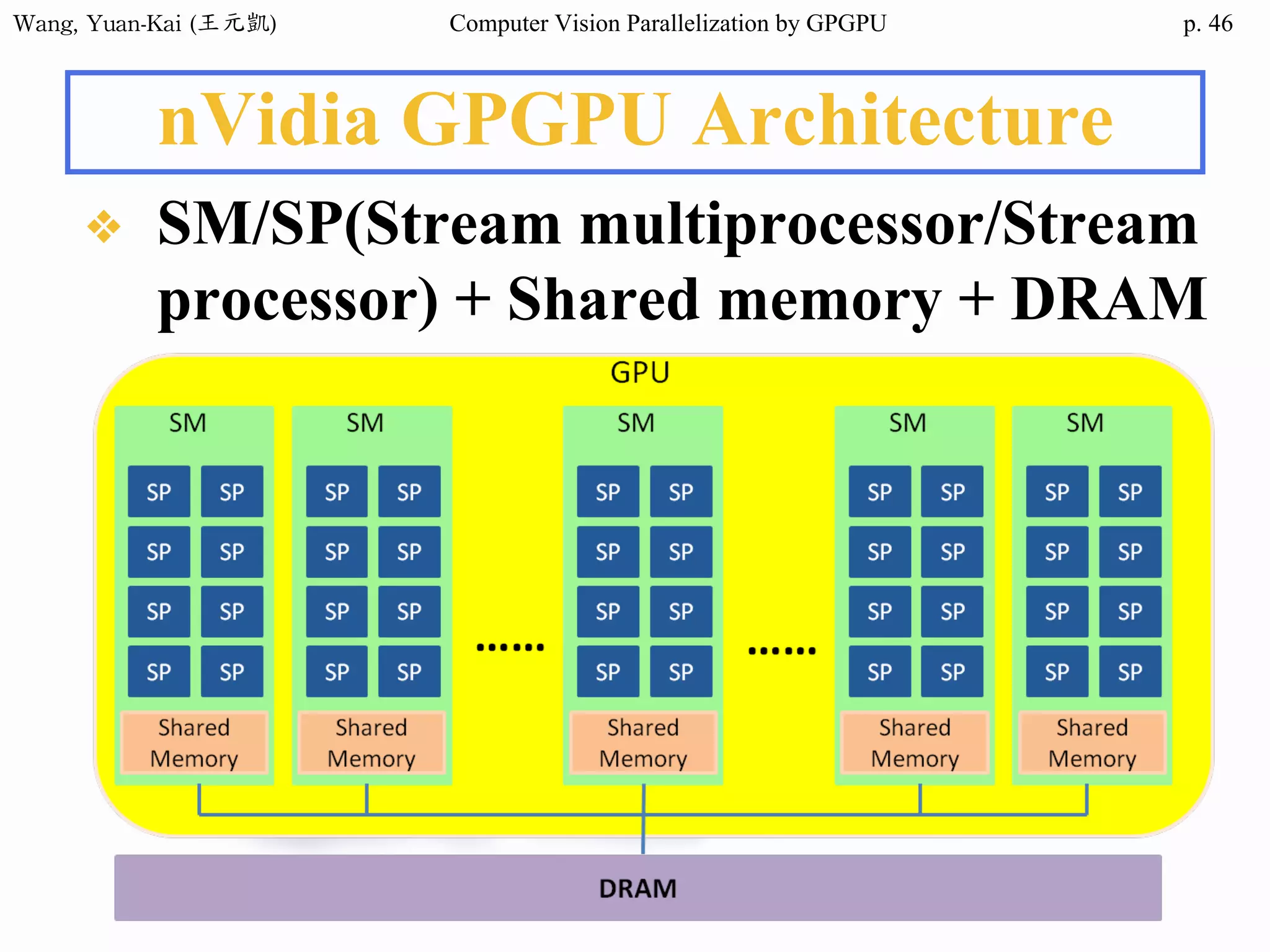
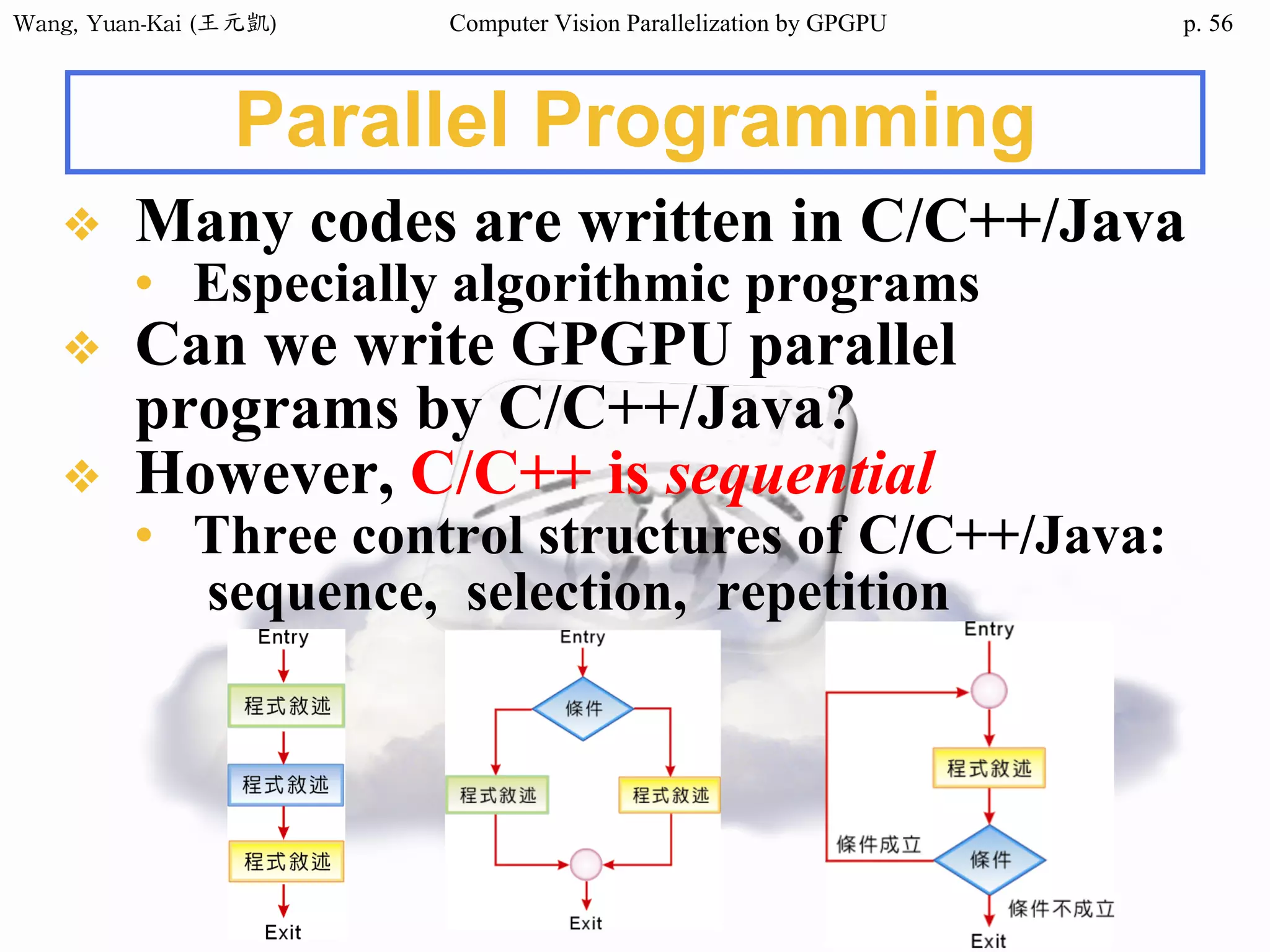
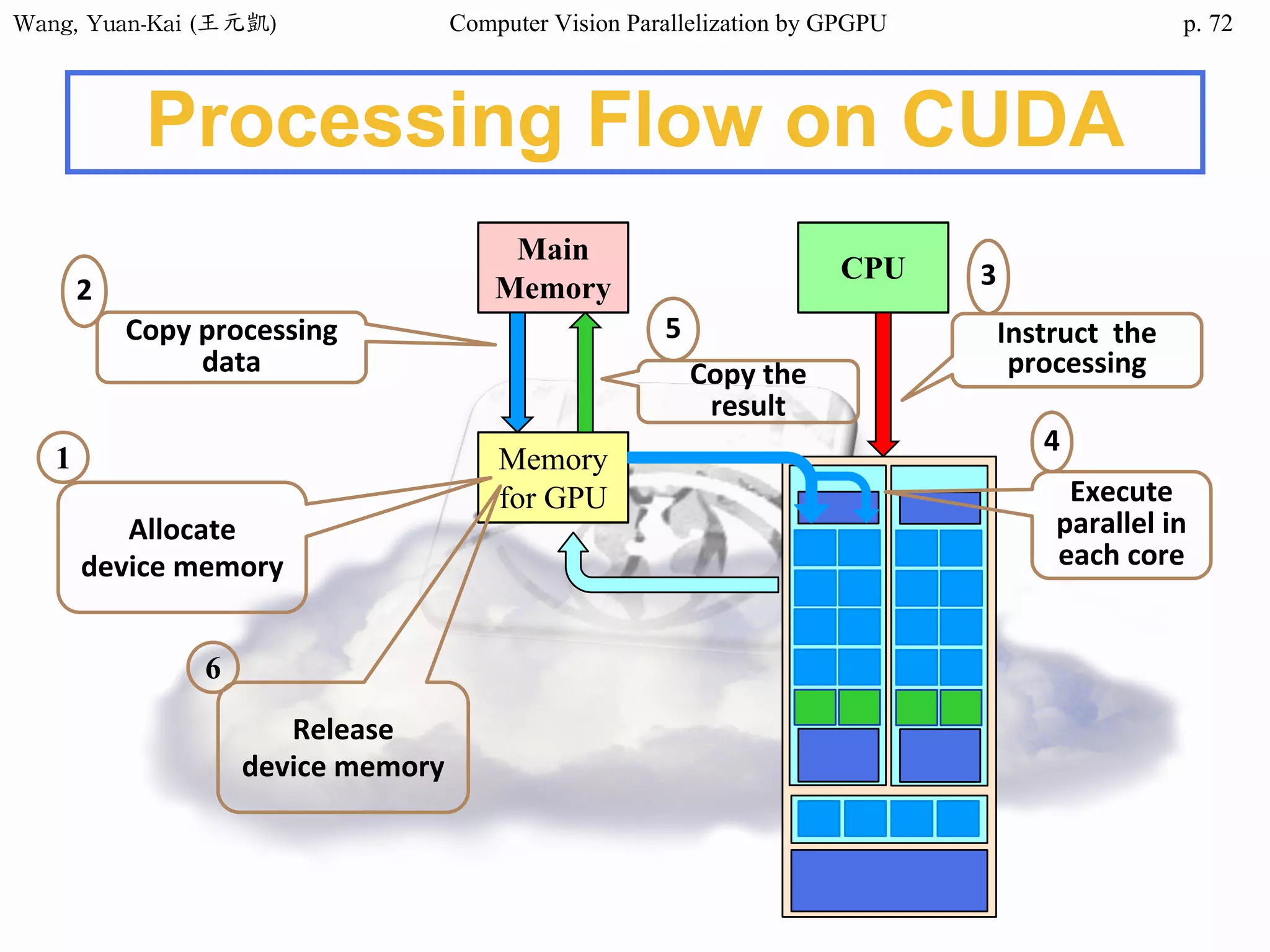
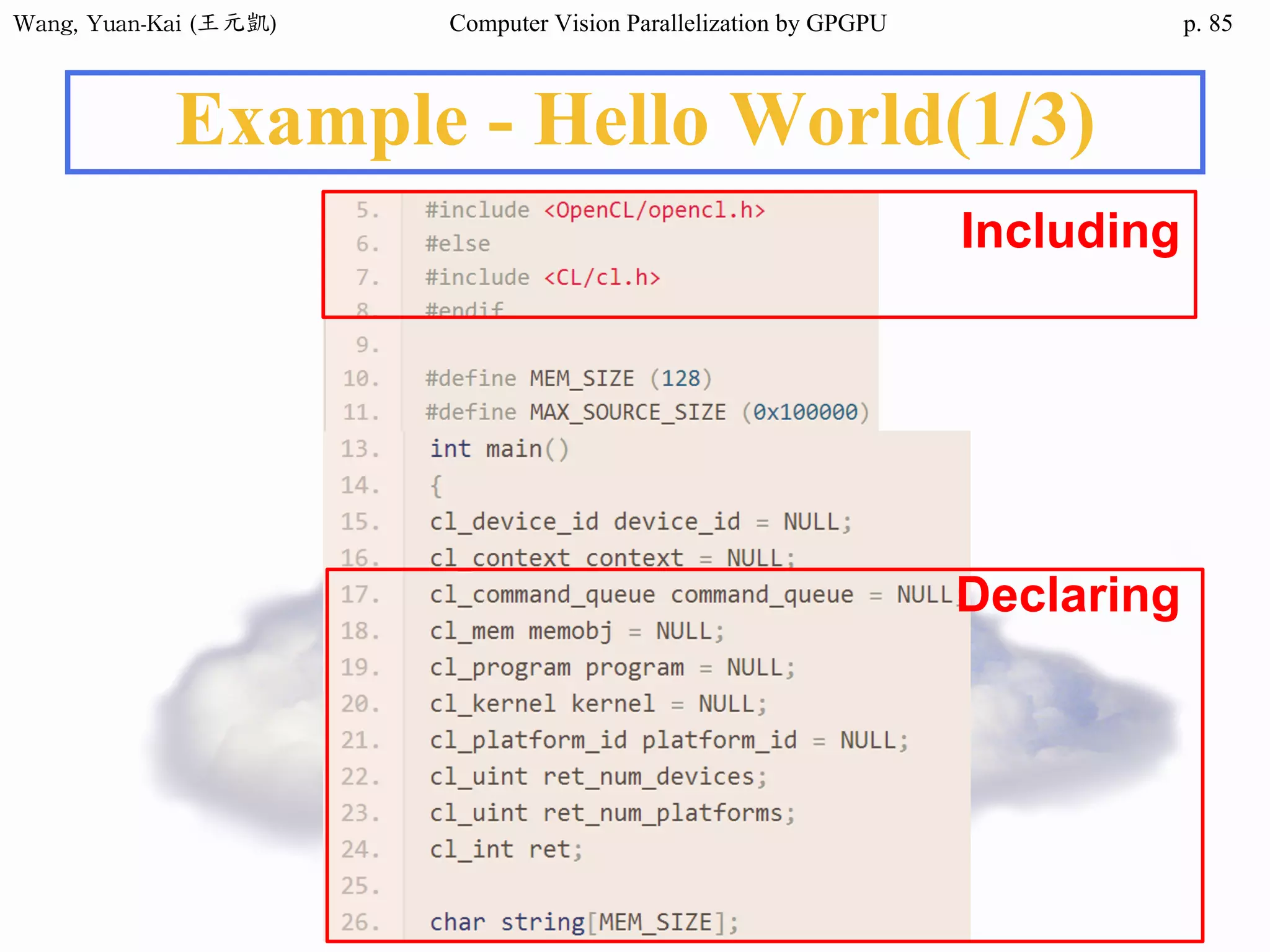
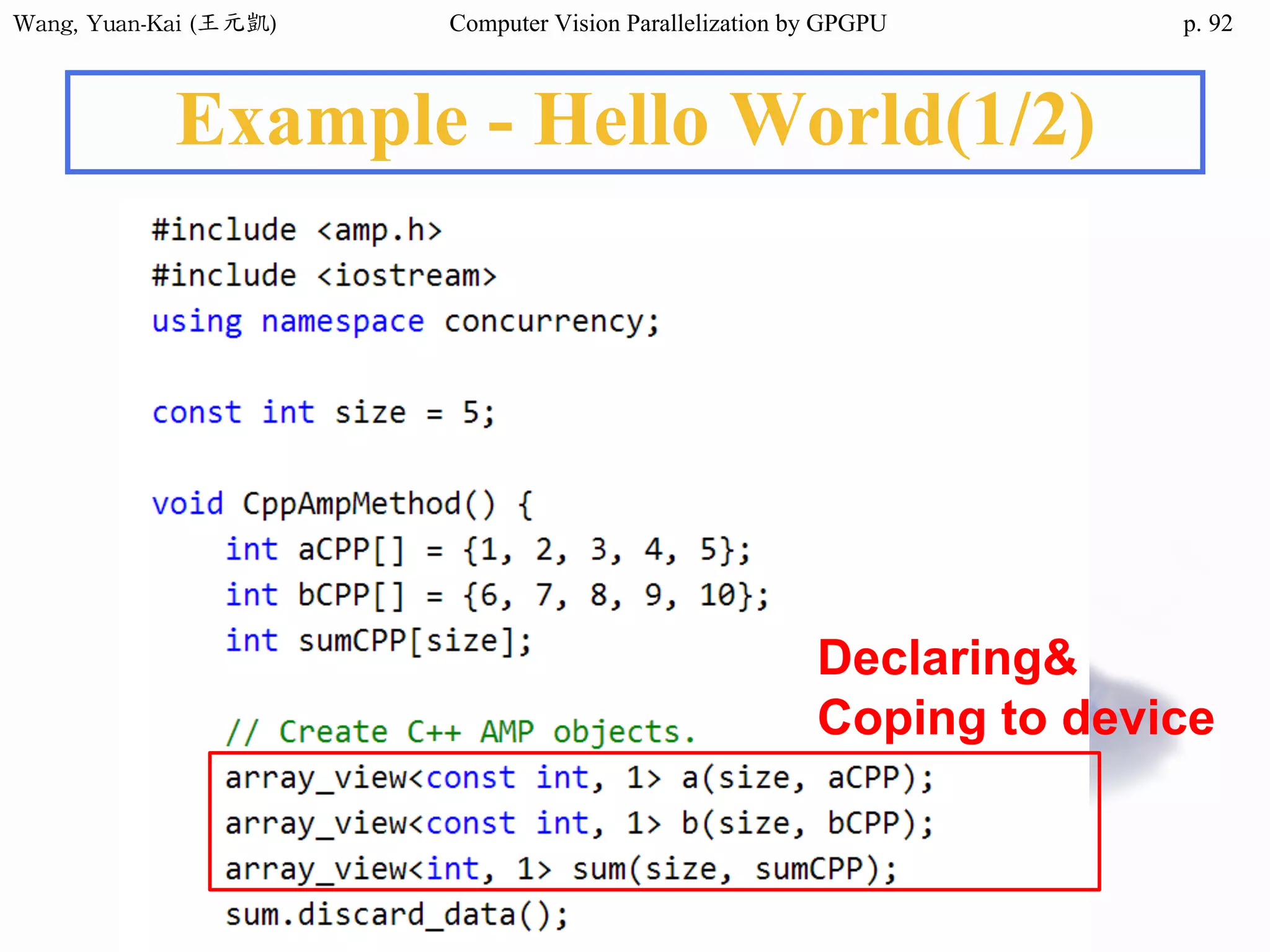
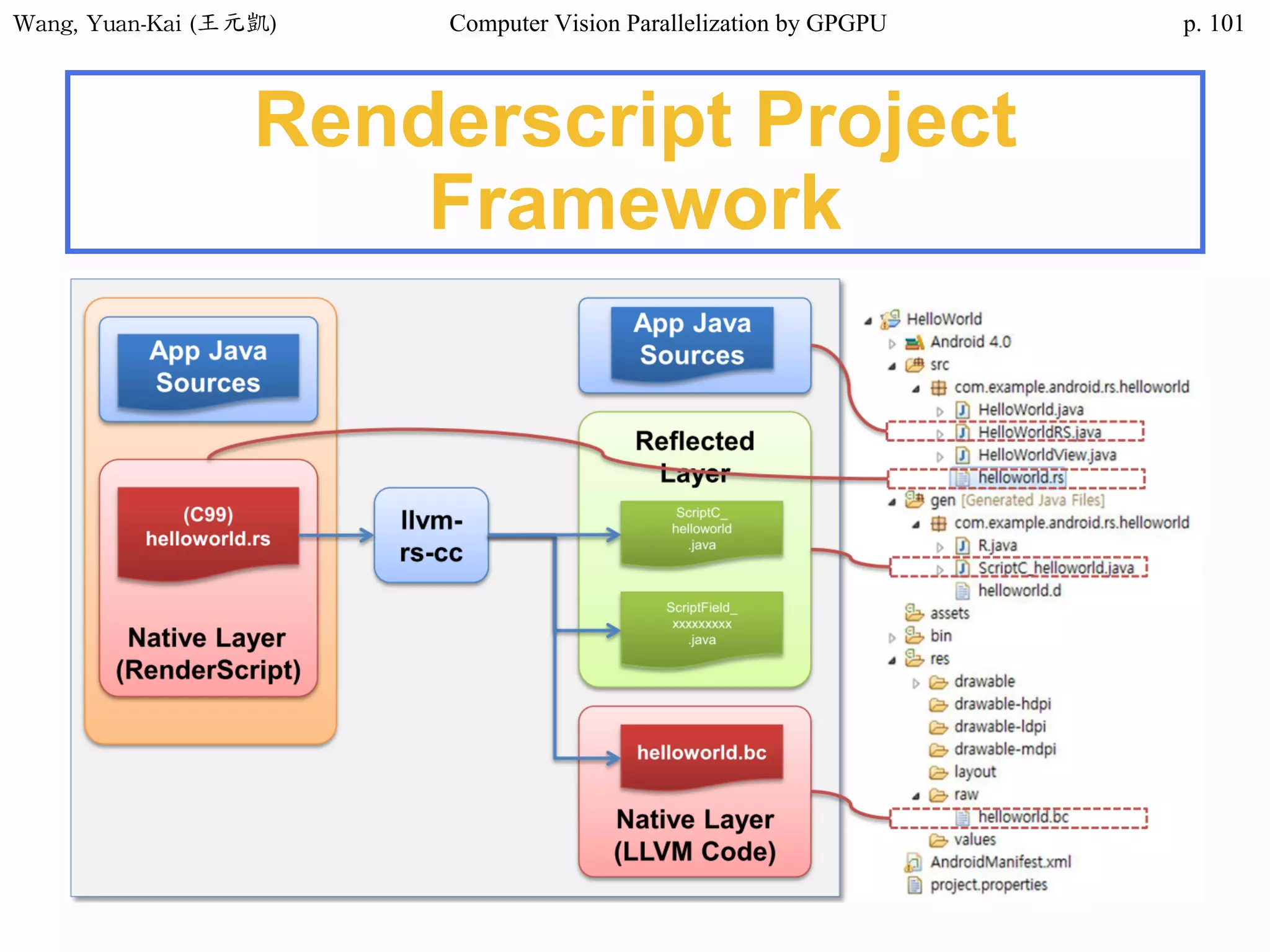
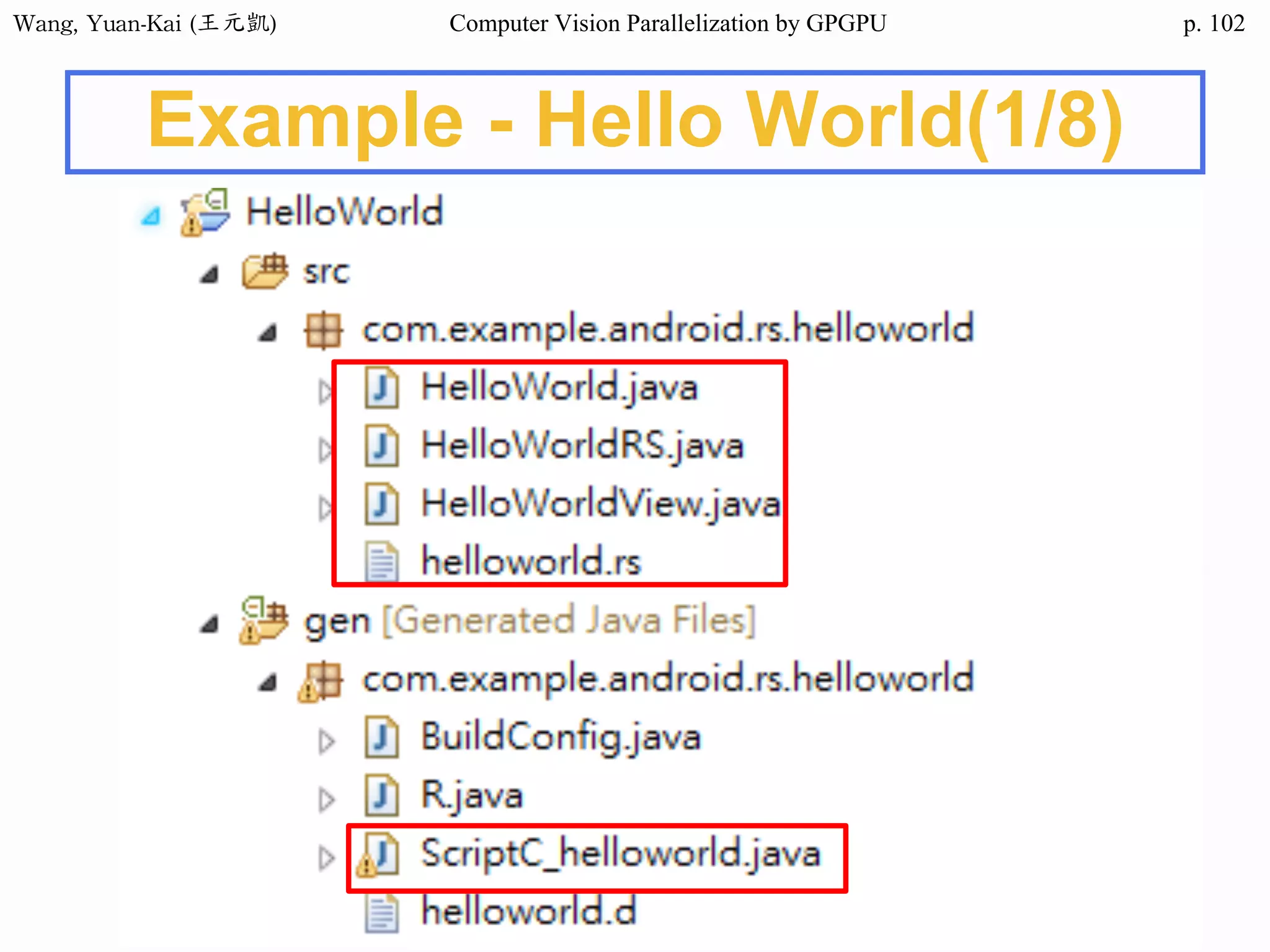
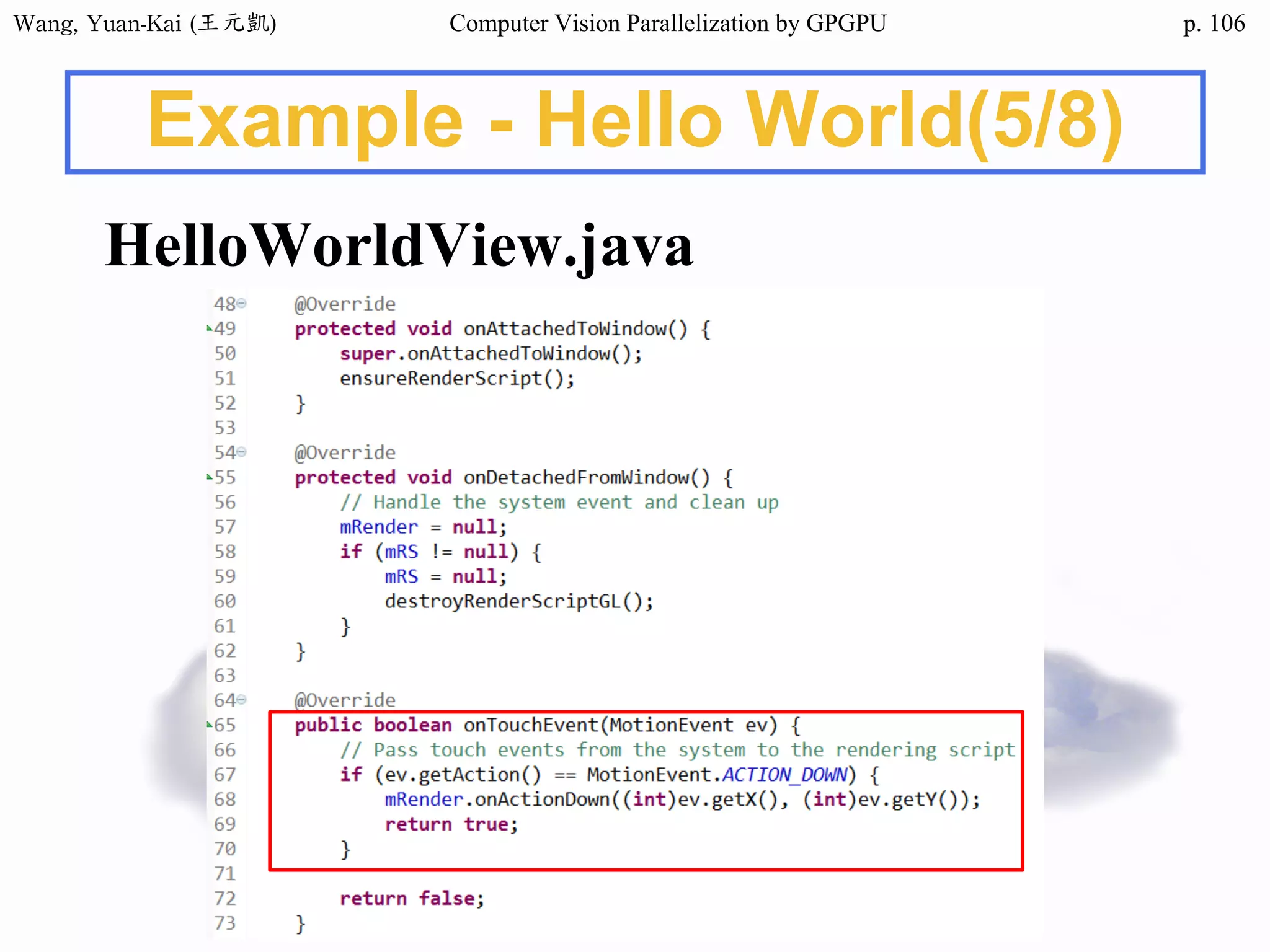
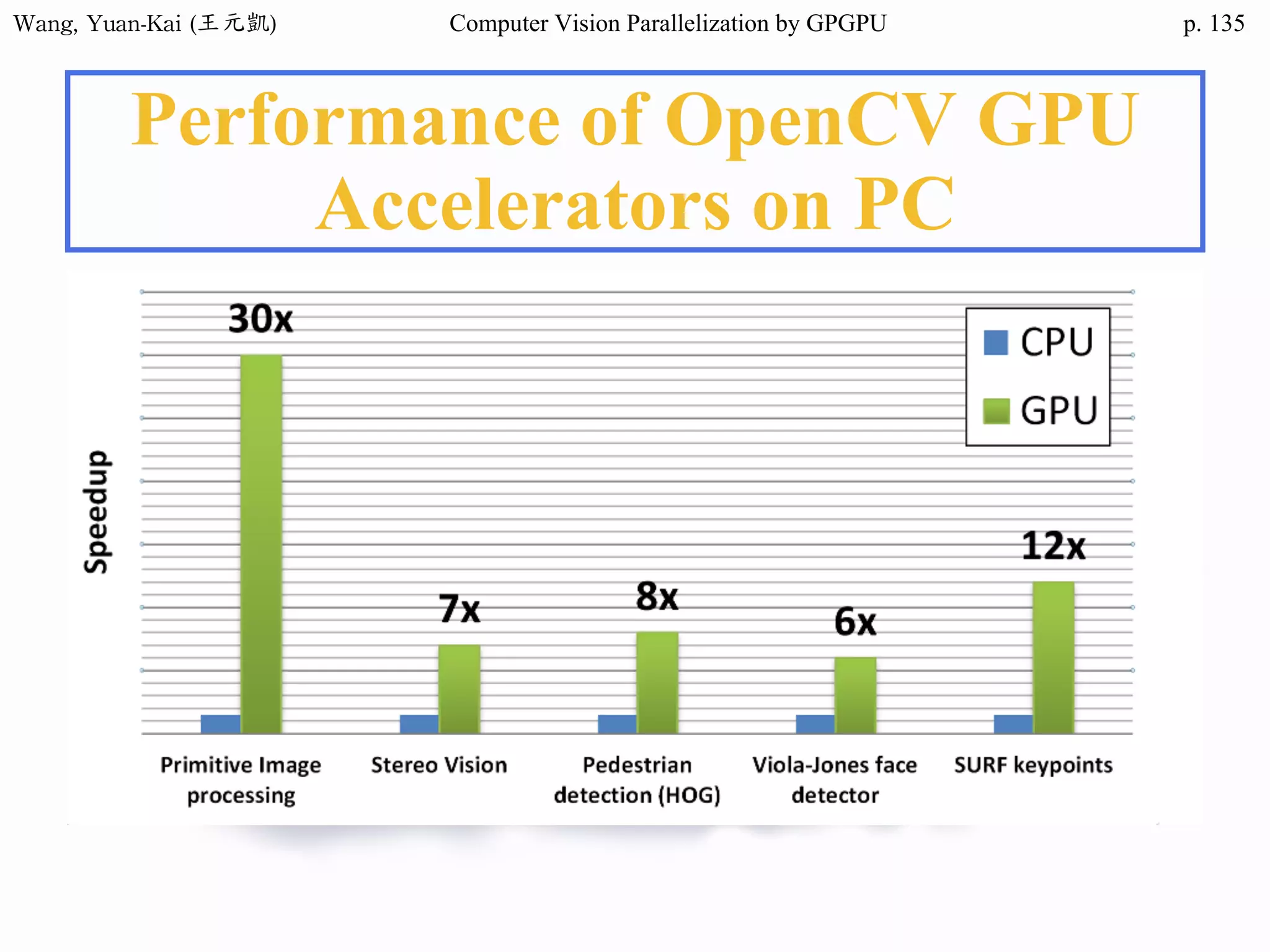
Example - Hello World(1/3)
int main()
{
char src[12]="Hello World";
char h_hello[12];
char* d_hello1;
char* d_hello2;
cudaMalloc((void**) &d_hello1, sizeof(char)*12);
cudaMalloc((void**) &d_hello2, sizeof(char)*12);
cudaMemcpy(d_hello1 , src , sizeof(char)* 12 ,
cudaMemcpyHostToDevice);
hello<<<1,1>>>(d_hello1 , d_hello2 );
Host
src
h_hello
Device
d_hello1
d_hello2
call the kernel function
74](https://image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-74-2048.jpg)
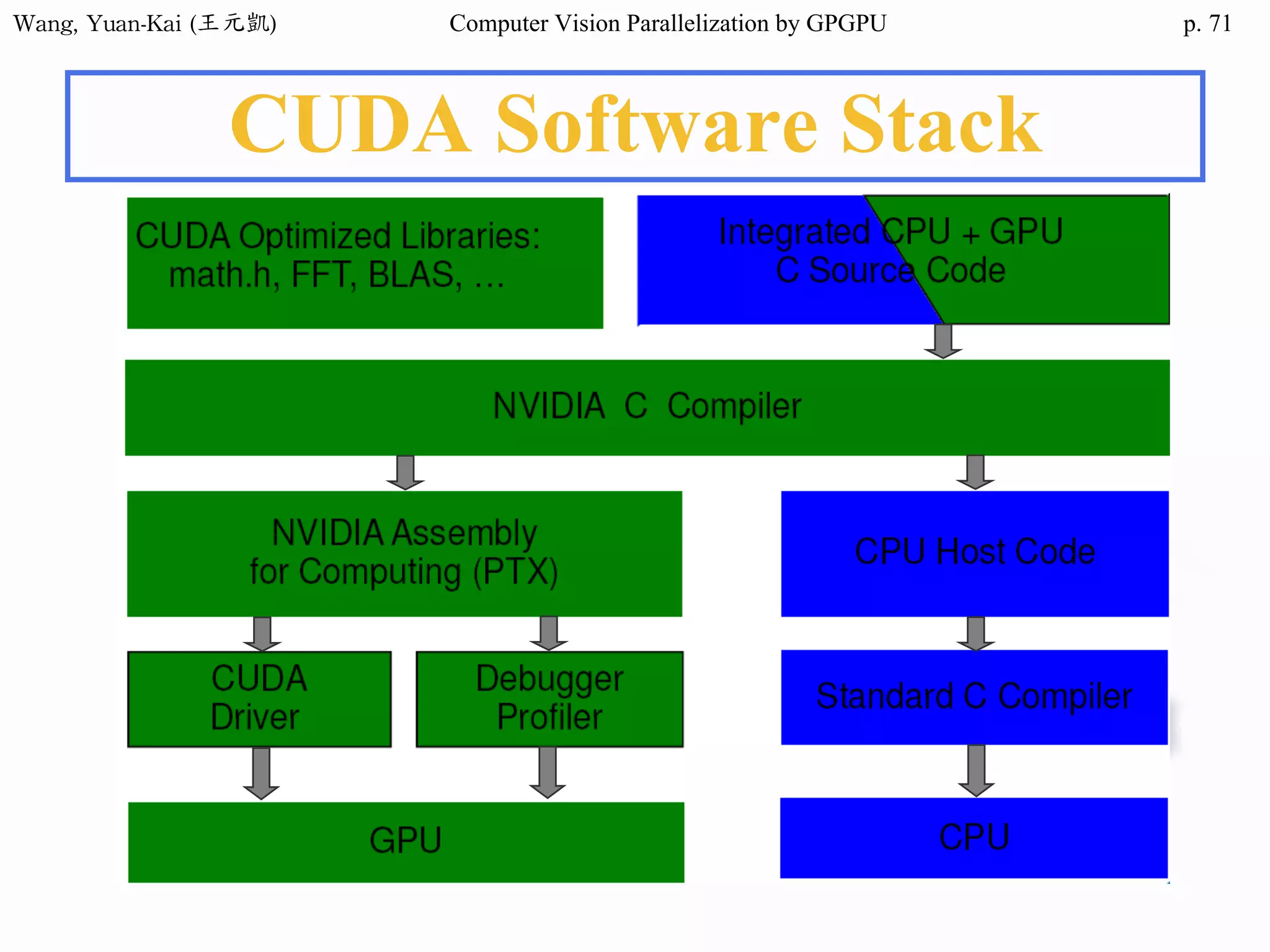
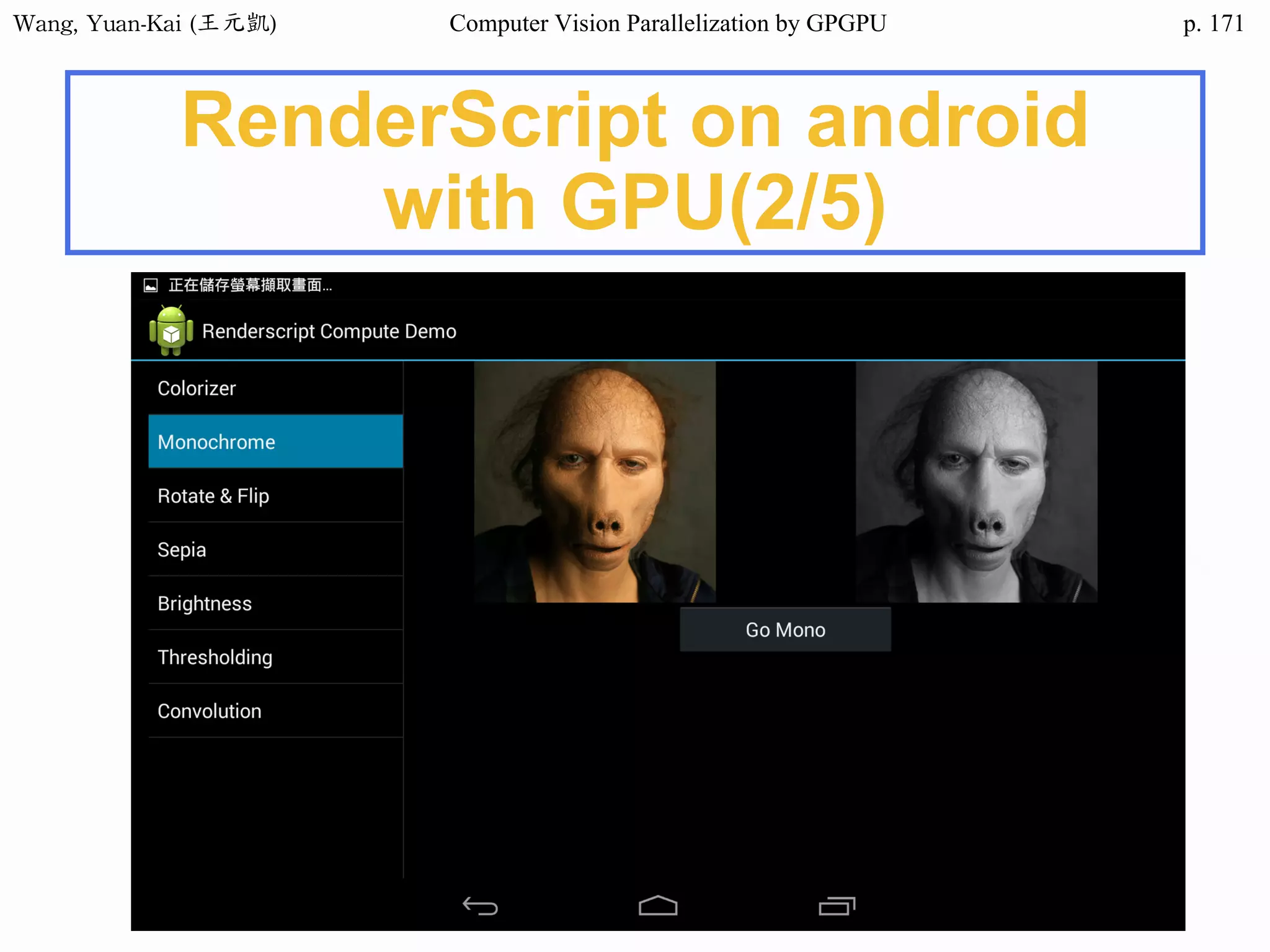
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
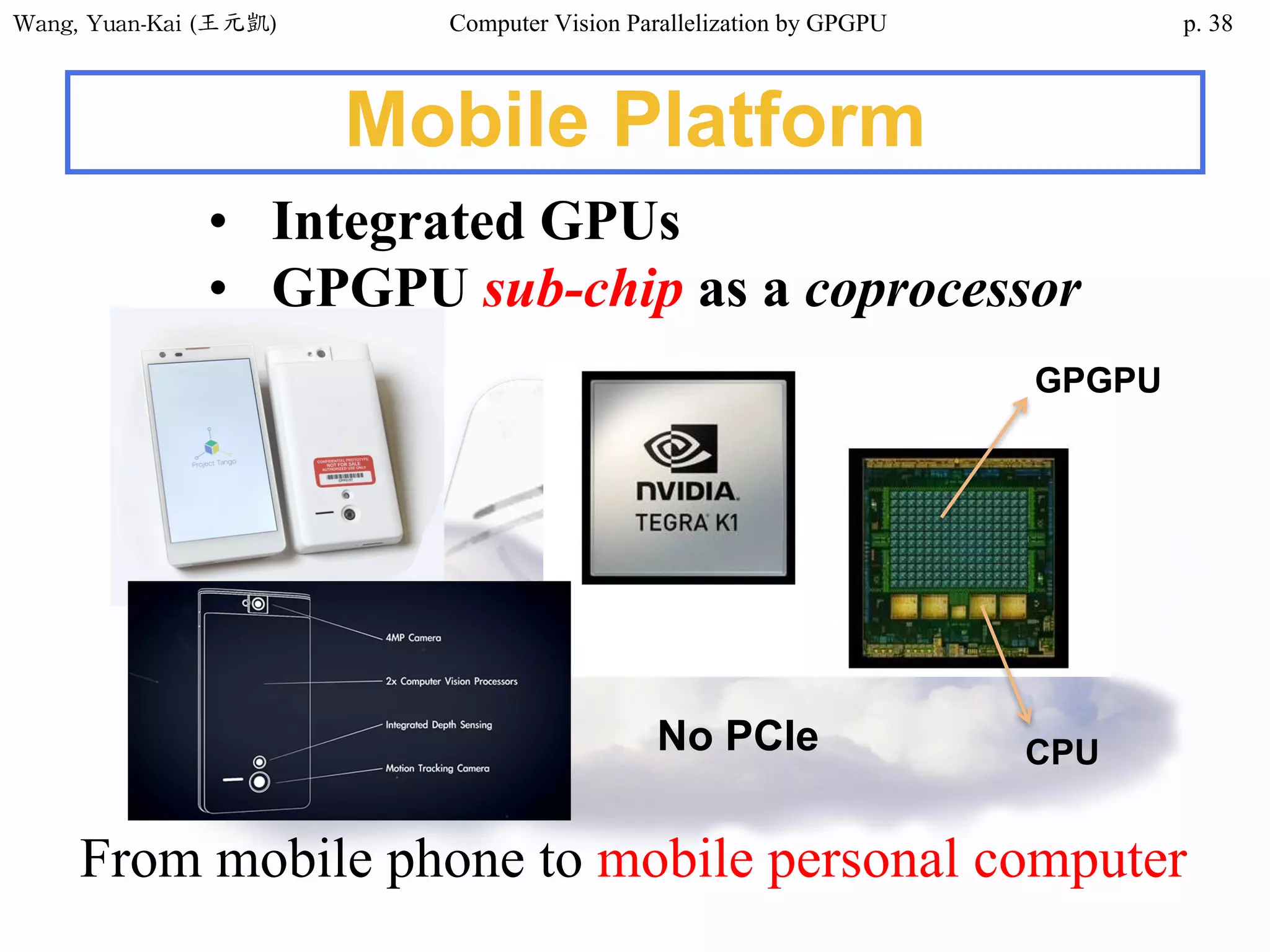
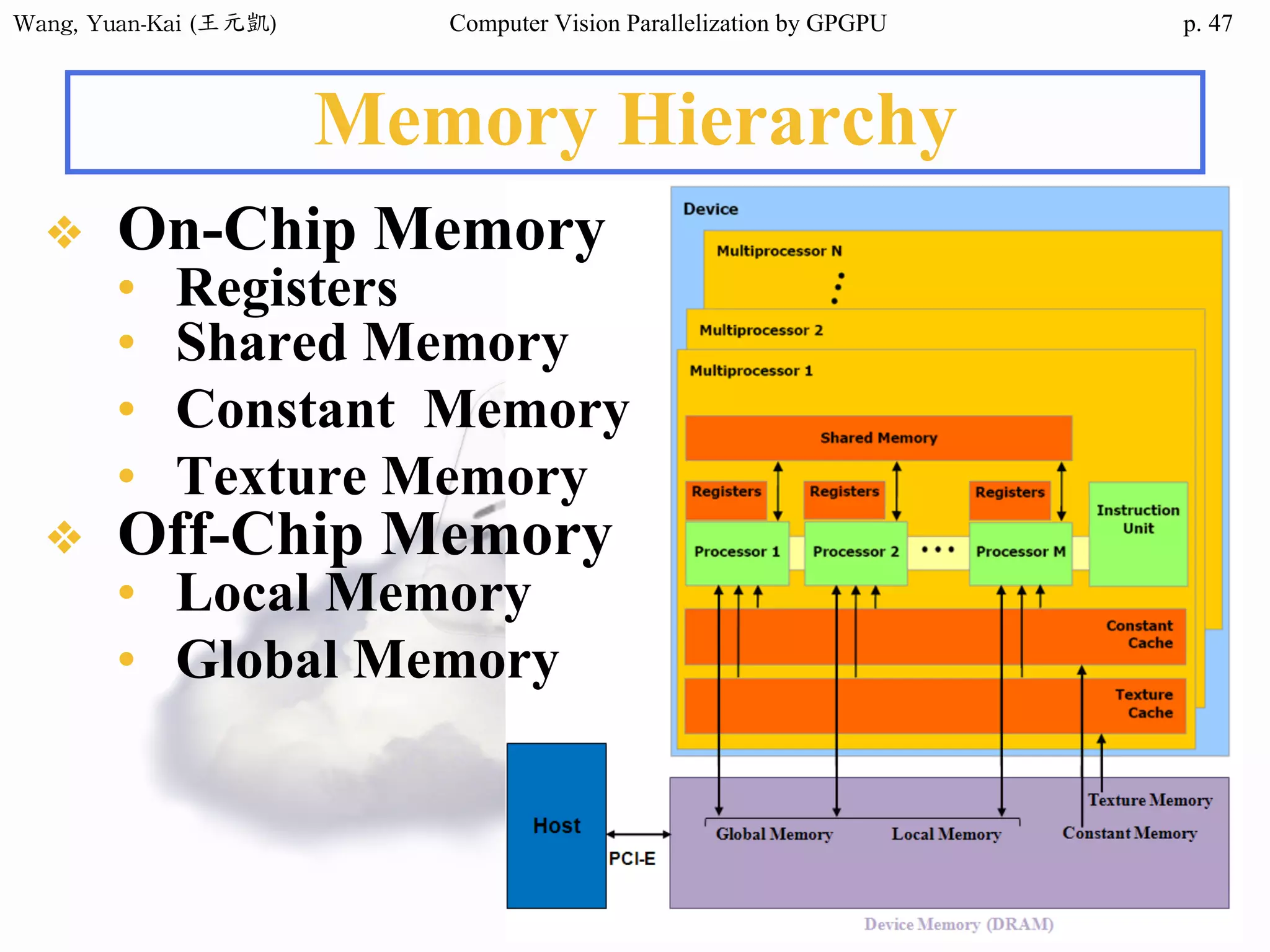
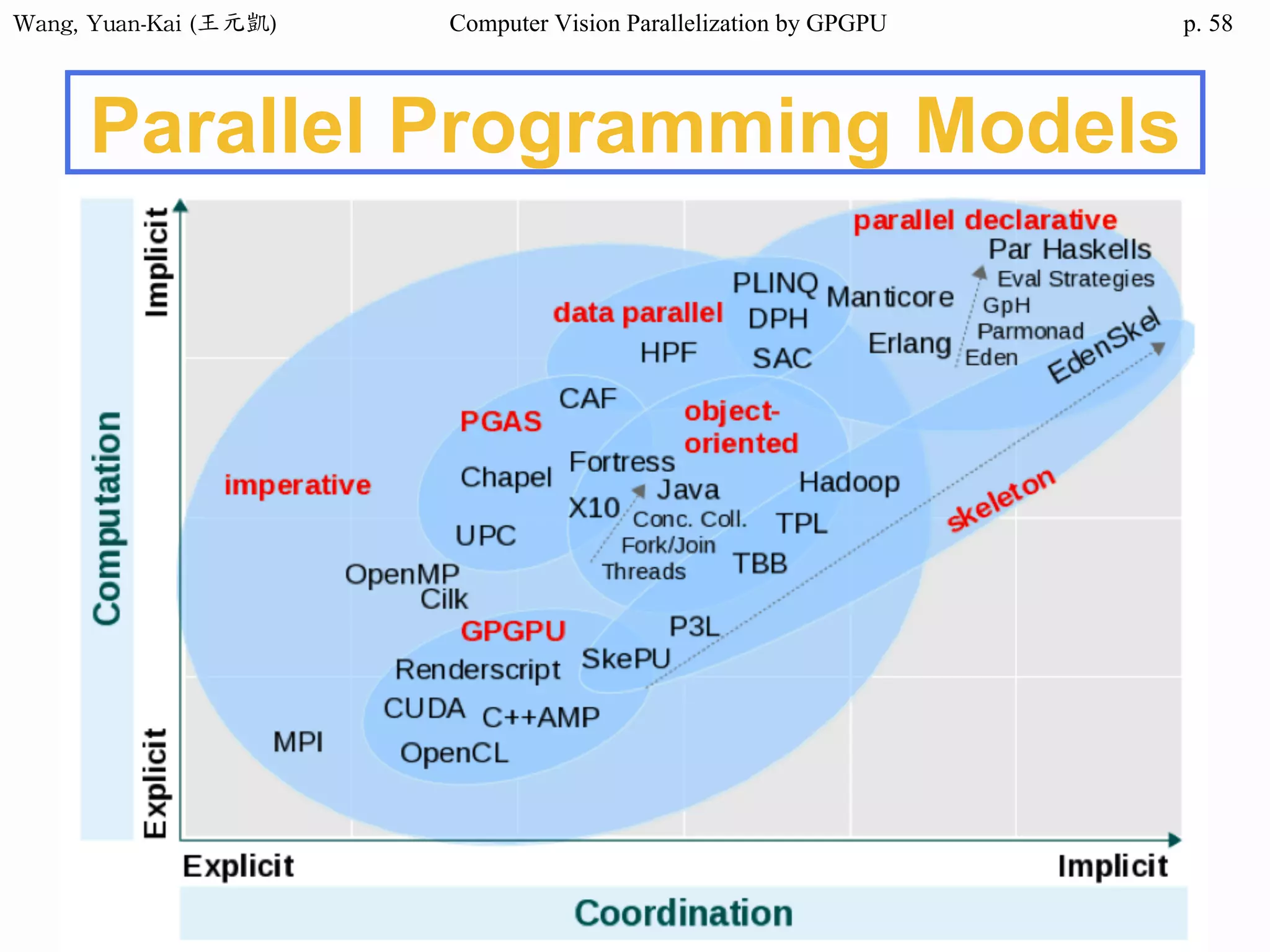
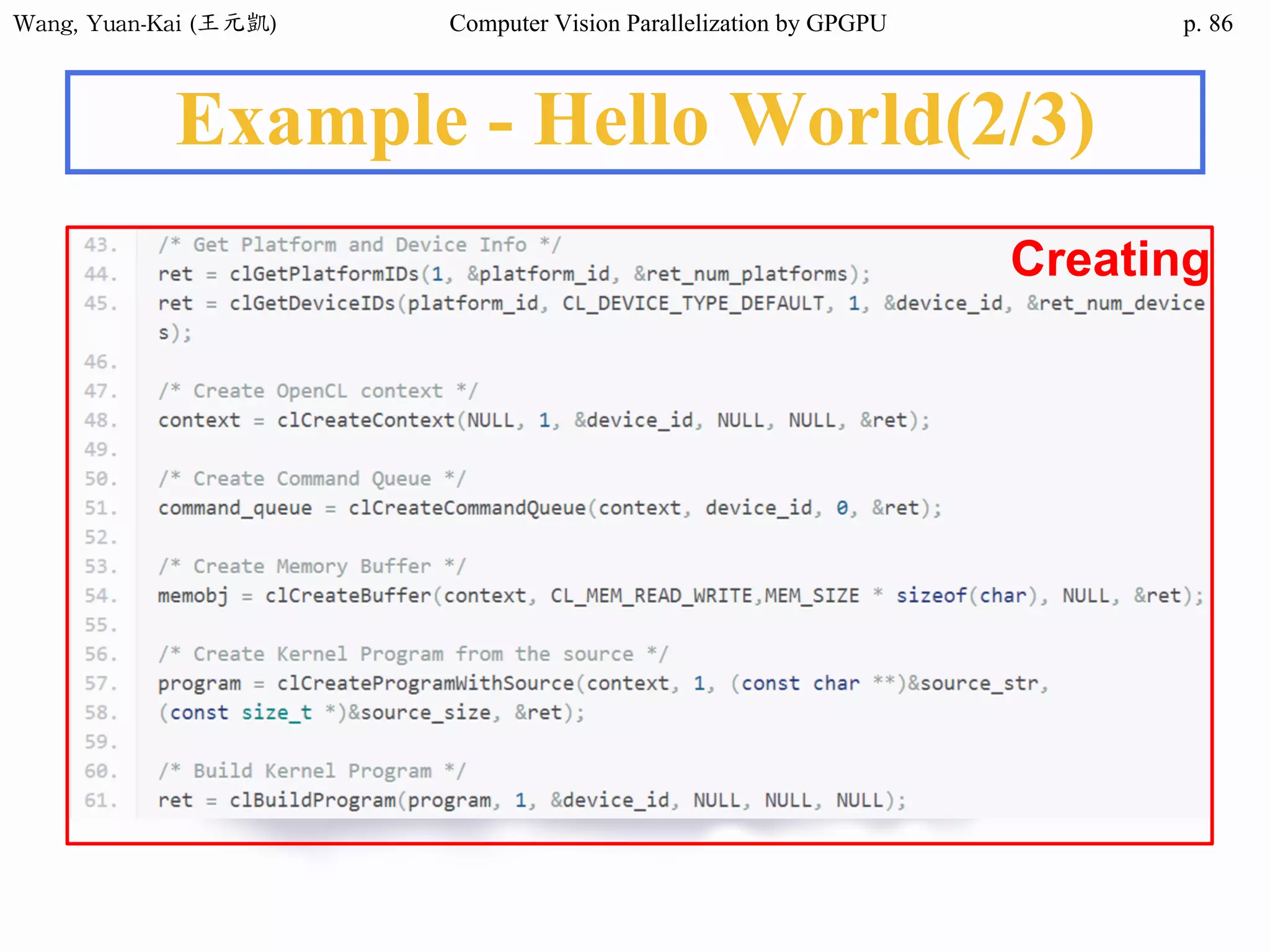
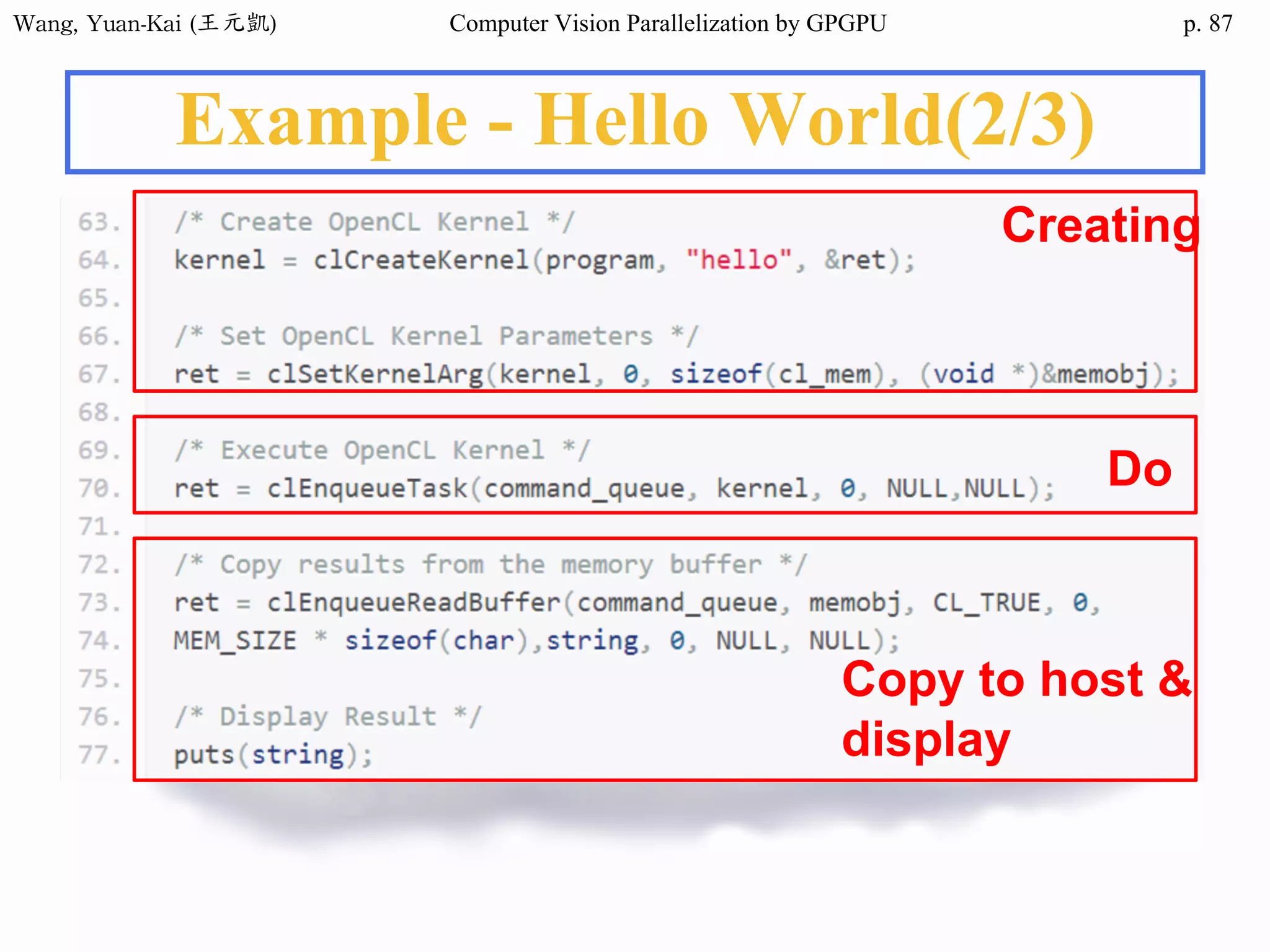
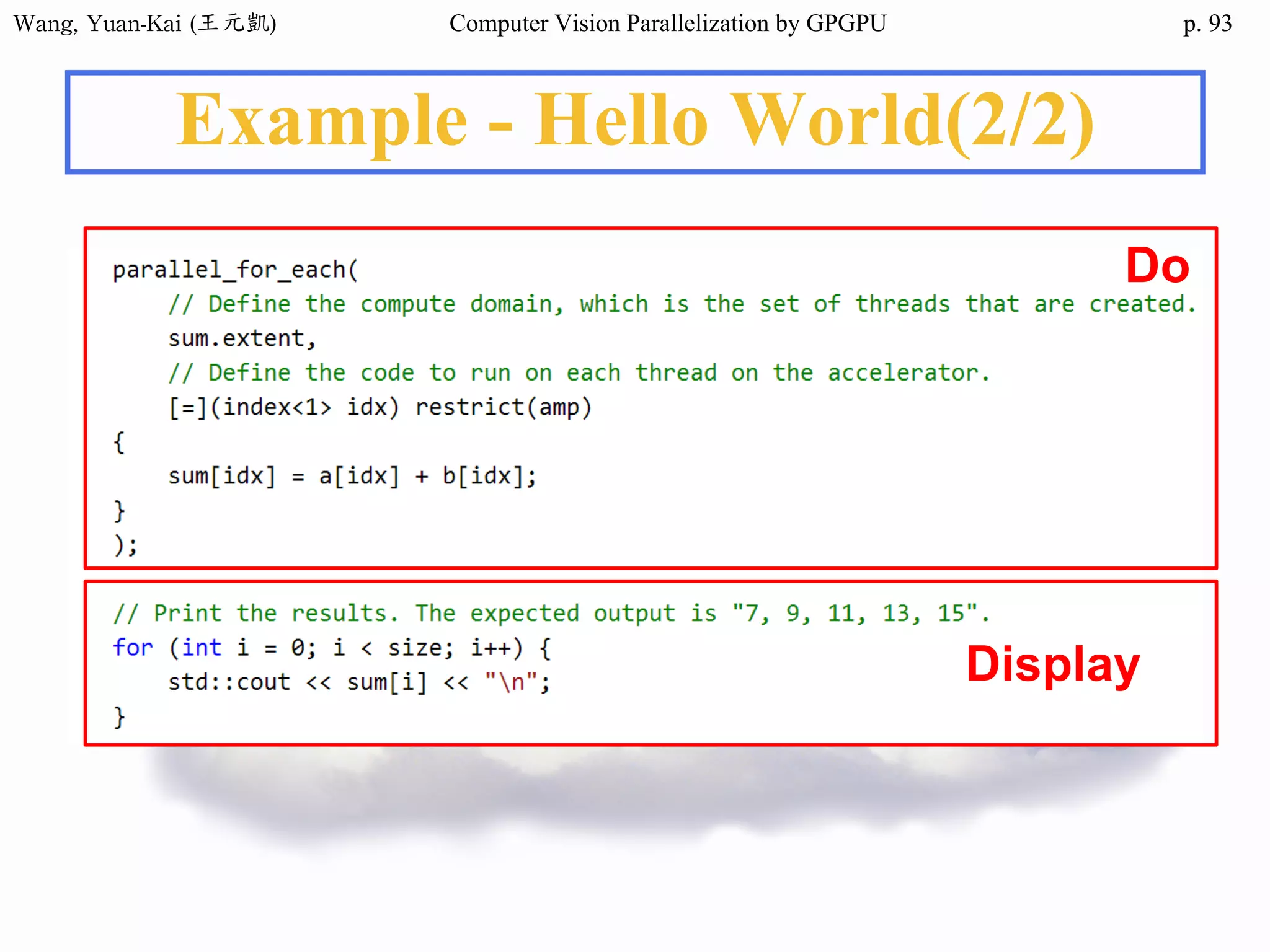
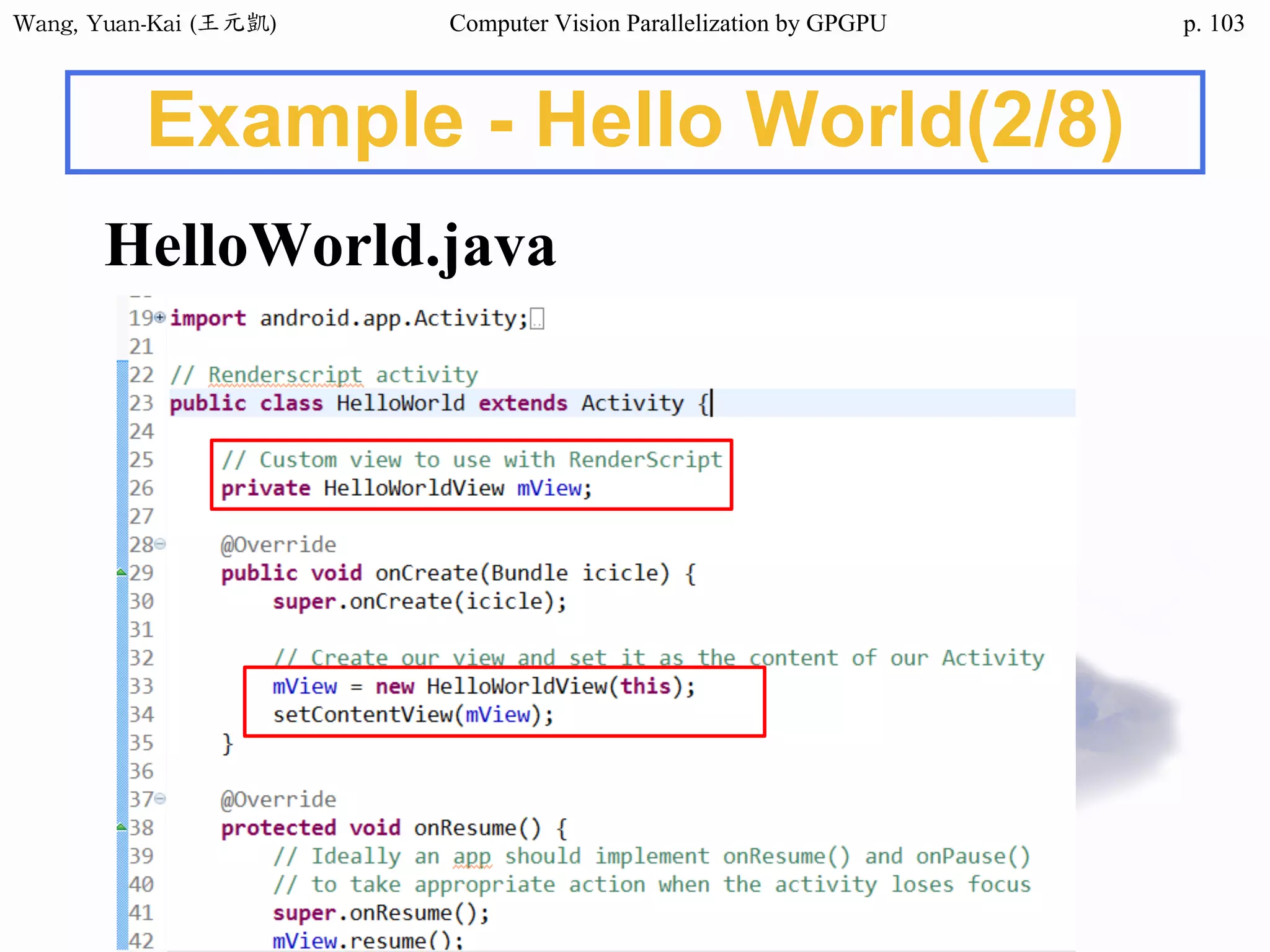
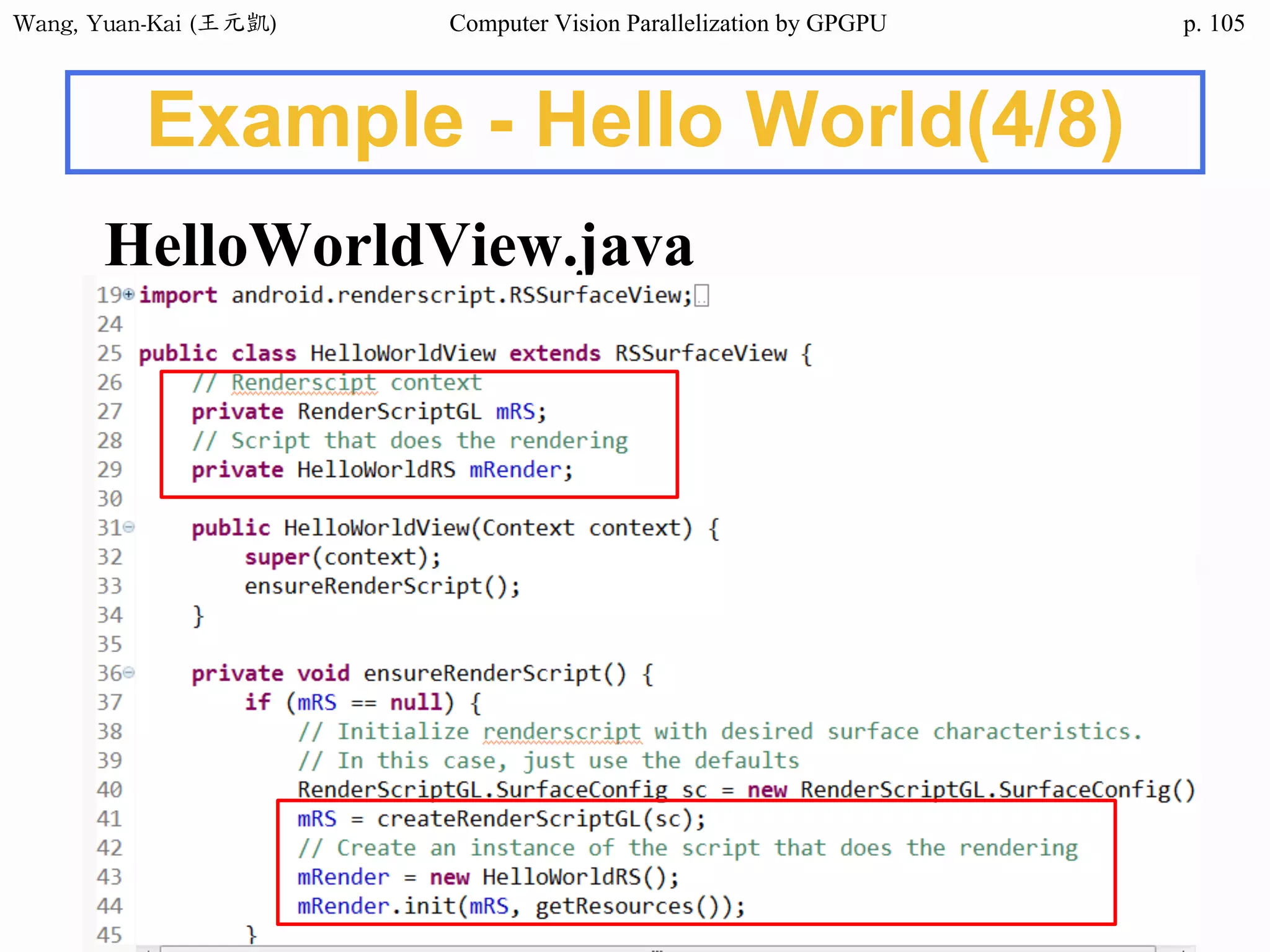
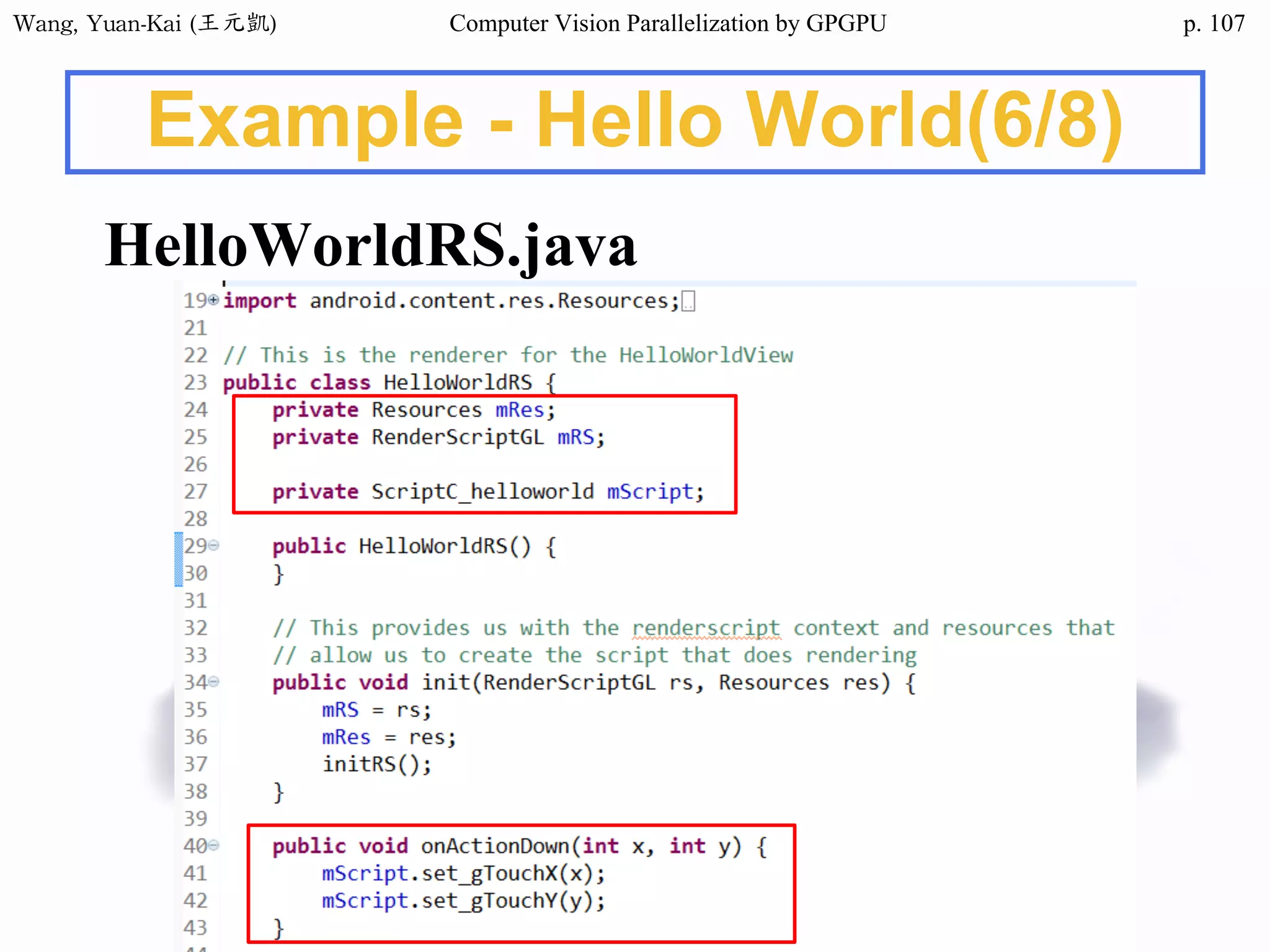
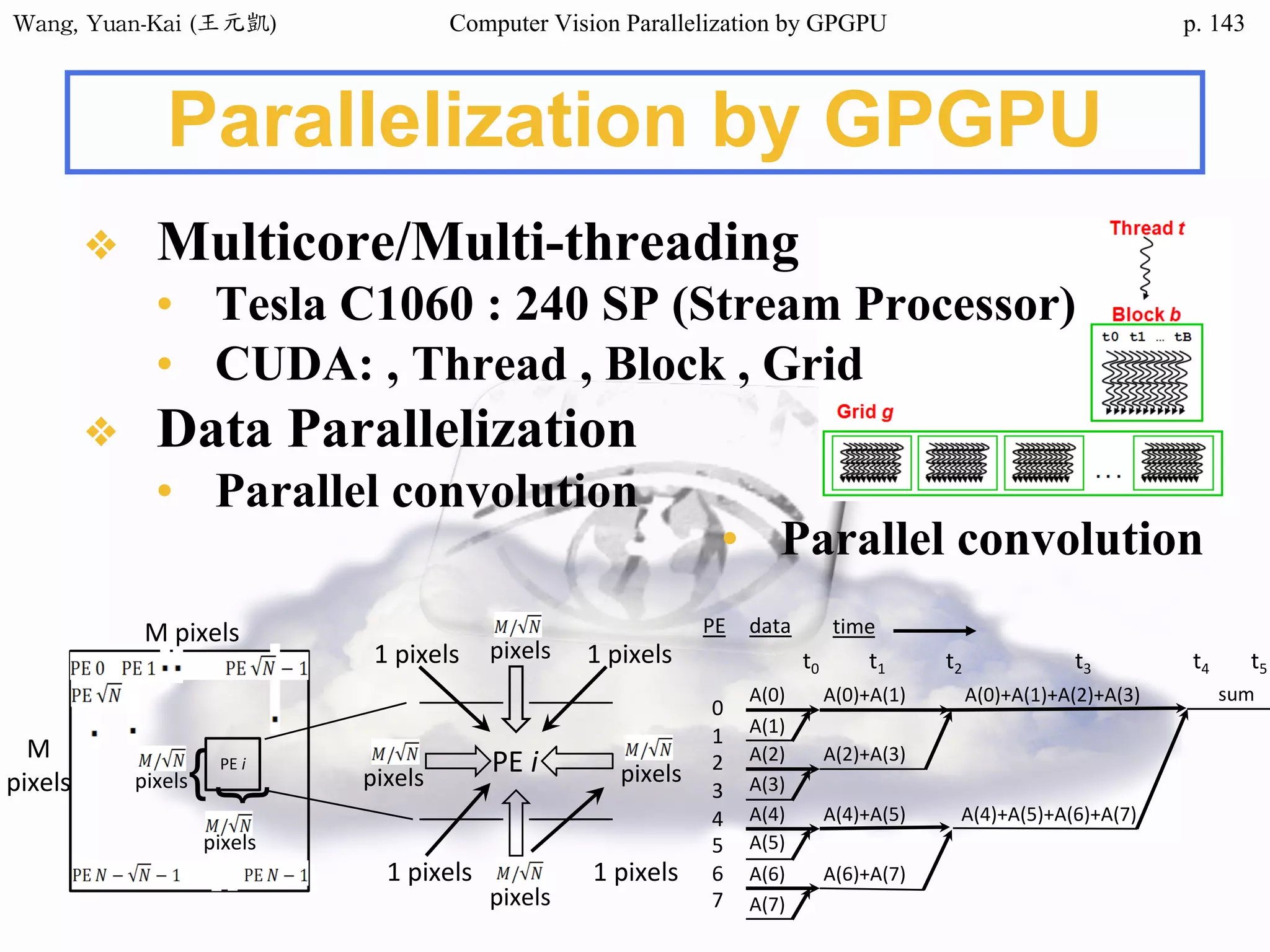
Example - Hello World(2/3)
❖ Kernel Function
__global__ void hello(char* hello1 , char* hello2 )
{
int k;
for(k = 0 ; hello1[k] != '0' ; k++){
hello2[k] = hello1[k];
}
}
Host
src
h_hello
Device
d_hello1
d_hello2
No parallel processing in this example
75](https://image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-75-2048.jpg)













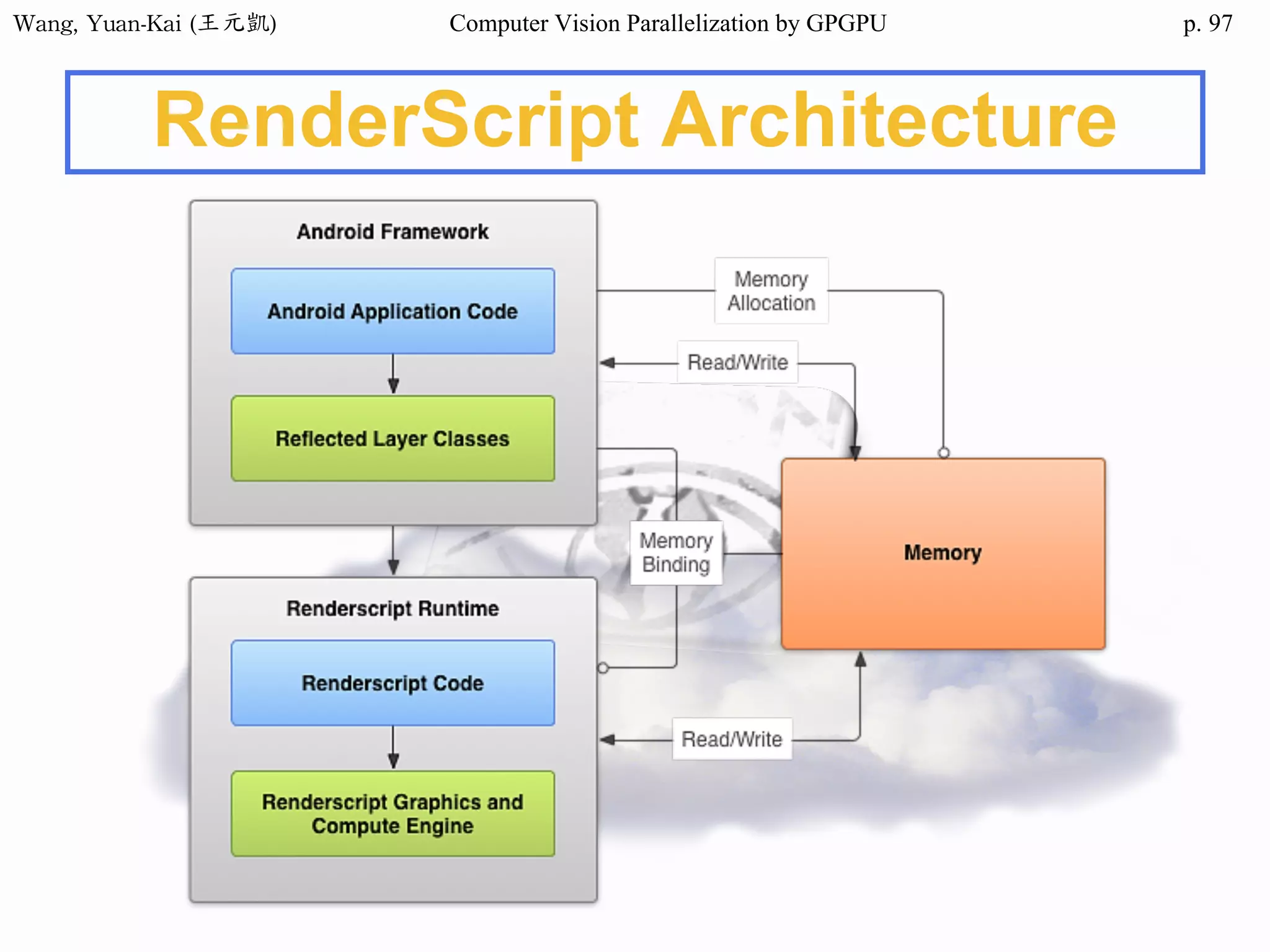
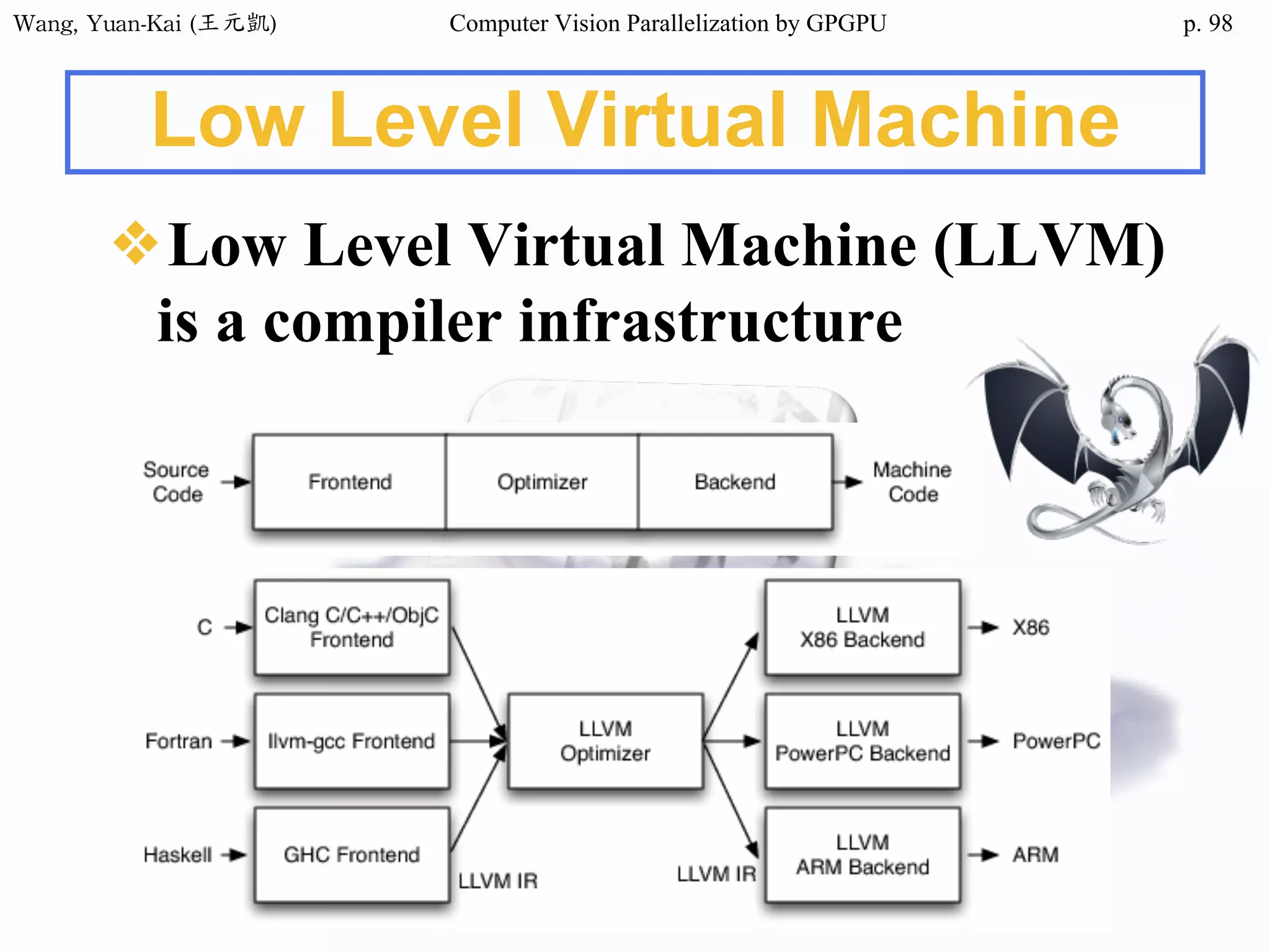
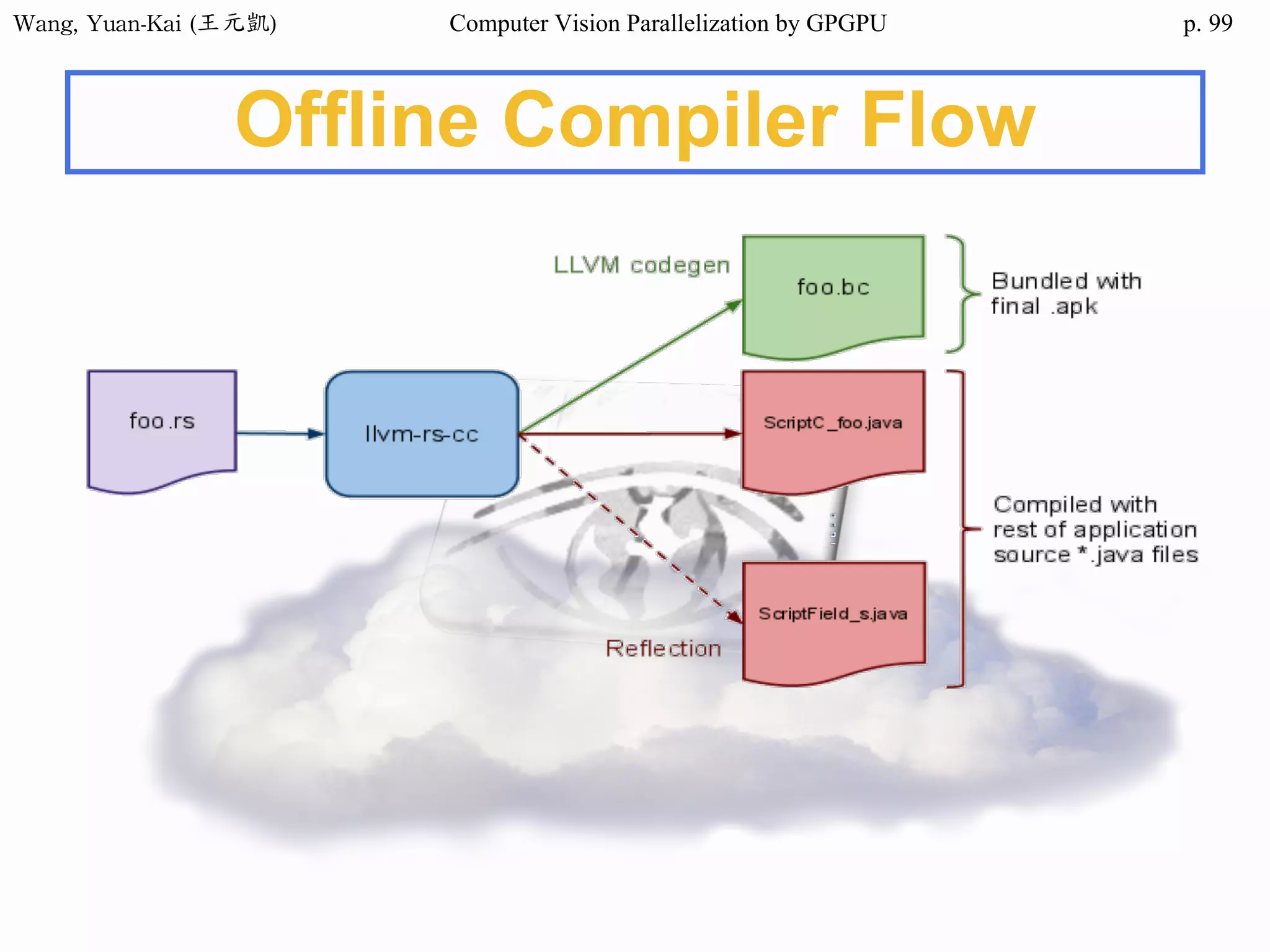
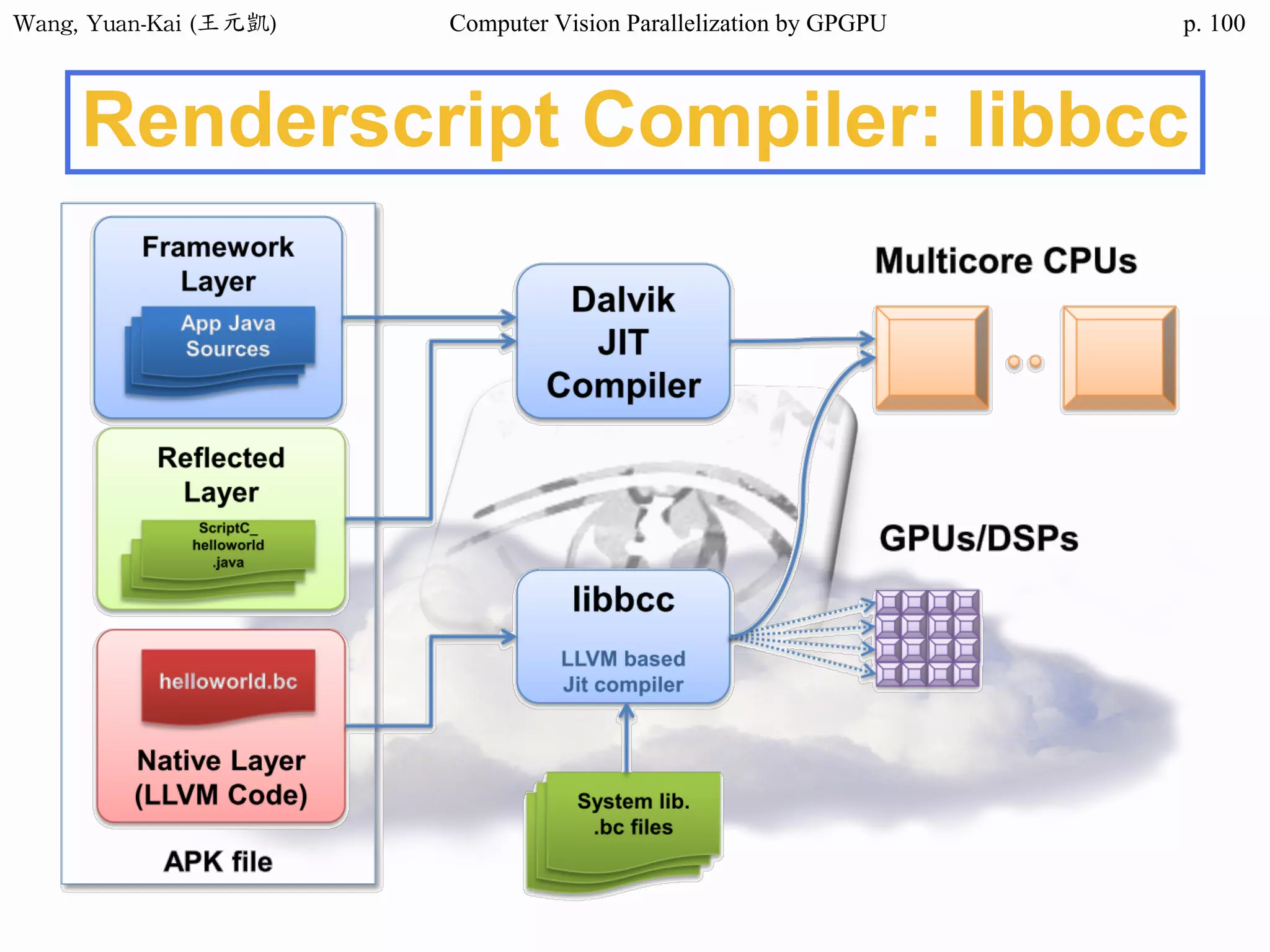




























![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
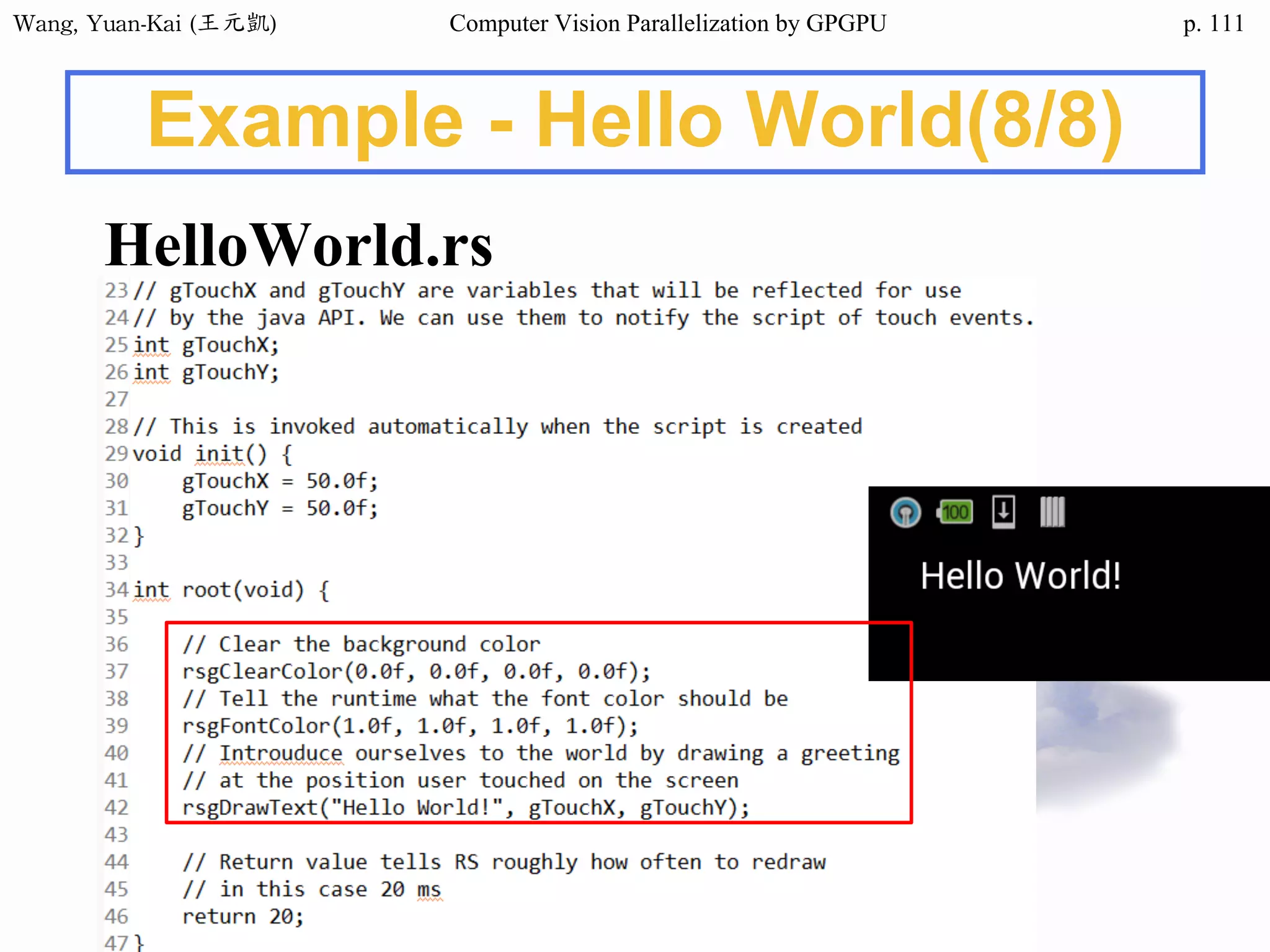
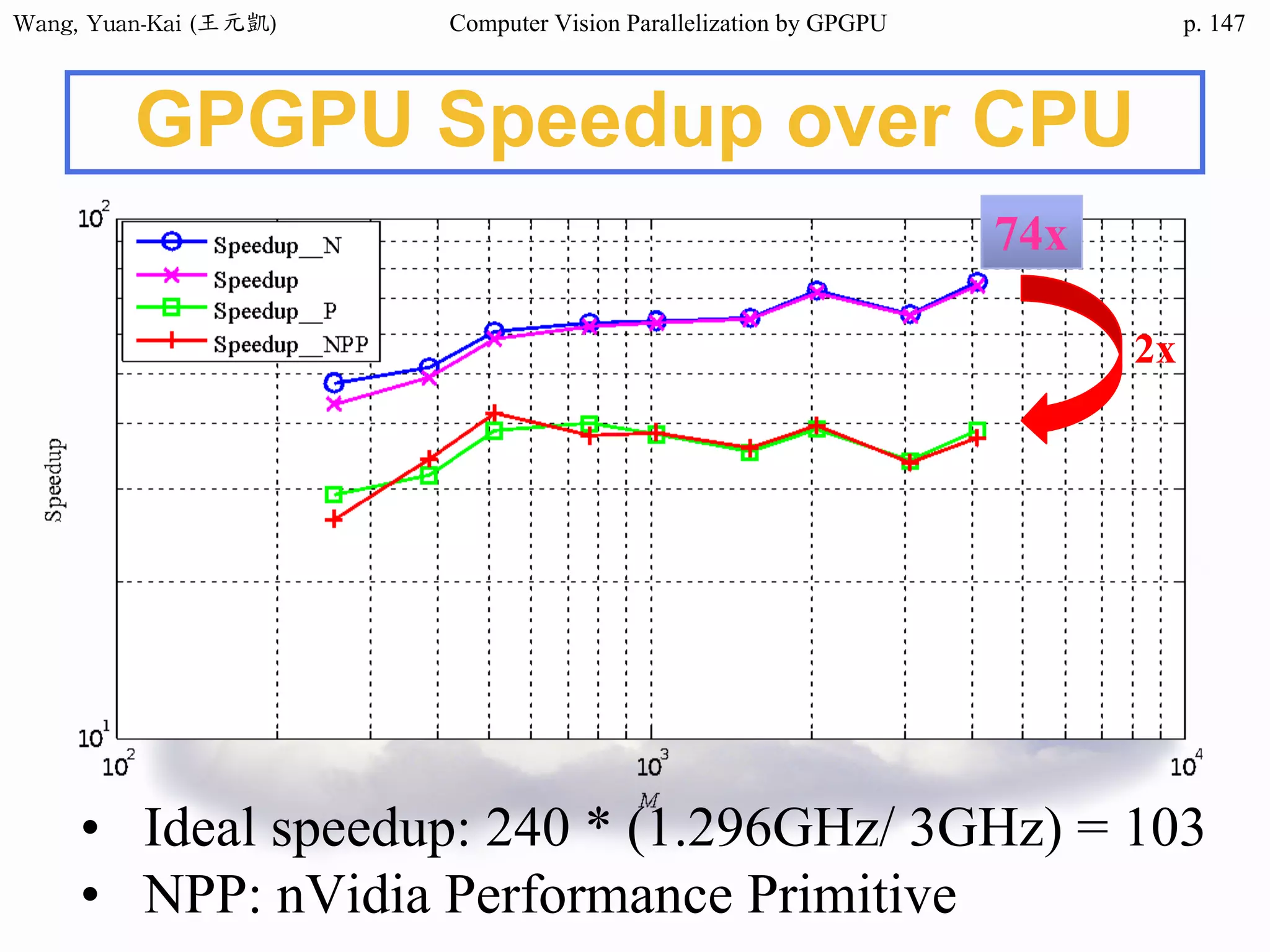
Algorithms for
Image Restoration
❖ Wiener Filter
❖ Histogram Based Approach
• Histogram Equalization,
Histogram Modification, …
❖ Retinex
• Path-based Retinex
• Recursive Retinex
• Center/surround Retinex
• No iterative process and is suitable for parallelization
• Multi-Scale Retinex with Color Restoration (MSRCR)
[Rahman et al. 1997]
140](https://image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-140-2048.jpg)






































































































![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
Domain Decomposition (2/3)
❖Domain data are usually processed
by loop
• for (i=0; i<height; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
Original image(img1) Enhanced image(img2)
The X-ray image
of a circuit board
i
j
SIMD
SPMD
SIMT
63](https://crownmelresort.com/image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-63-2048.jpg)
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
Domain Decomposition (3/3)
❖A three-block partition
example
• // Thread 1
for (i=0; i<height/3; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
• // Thread 2
for (i=height/3; i<height*2/3; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
• // Thread 3
for (i=height*2/3; i<height; i++)
for (j=0; j<width; j++)
img2[i][j] = RemoveNoise(img1[i][j]);
i
j
OpenMP
CUDA(SPMD)
fork(threads)
join(barrier)
i=0
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
i=10
i=11
subdomain 1 subdomain 2 subdomain 3
64](https://crownmelresort.com/image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-64-2048.jpg)









![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
Example - Hello World(1/3)
int main()
{
char src[12]="Hello World";
char h_hello[12];
char* d_hello1;
char* d_hello2;
cudaMalloc((void**) &d_hello1, sizeof(char)*12);
cudaMalloc((void**) &d_hello2, sizeof(char)*12);
cudaMemcpy(d_hello1 , src , sizeof(char)* 12 ,
cudaMemcpyHostToDevice);
hello<<<1,1>>>(d_hello1 , d_hello2 );
Host
src
h_hello
Device
d_hello1
d_hello2
call the kernel function
74](https://crownmelresort.com/image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-74-2048.jpg)
![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
Example - Hello World(2/3)
❖ Kernel Function
__global__ void hello(char* hello1 , char* hello2 )
{
int k;
for(k = 0 ; hello1[k] != '0' ; k++){
hello2[k] = hello1[k];
}
}
Host
src
h_hello
Device
d_hello1
d_hello2
No parallel processing in this example
75](https://crownmelresort.com/image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-75-2048.jpg)
































































![Wang, Yuan-Kai (王元凱) Computer Vision Parallelization by GPGPU p.
Algorithms for
Image Restoration
❖ Wiener Filter
❖ Histogram Based Approach
• Histogram Equalization,
Histogram Modification, …
❖ Retinex
• Path-based Retinex
• Recursive Retinex
• Center/surround Retinex
• No iterative process and is suitable for parallelization
• Multi-Scale Retinex with Color Restoration (MSRCR)
[Rahman et al. 1997]
140](https://crownmelresort.com/image.slidesharecdn.com/1030717-parallelizecomputervisionbygpgpuparallelcomputing-161212131657/75/2014-07-17-Parallelize-computer-vision-by-GPGPU-computing-140-2048.jpg)































































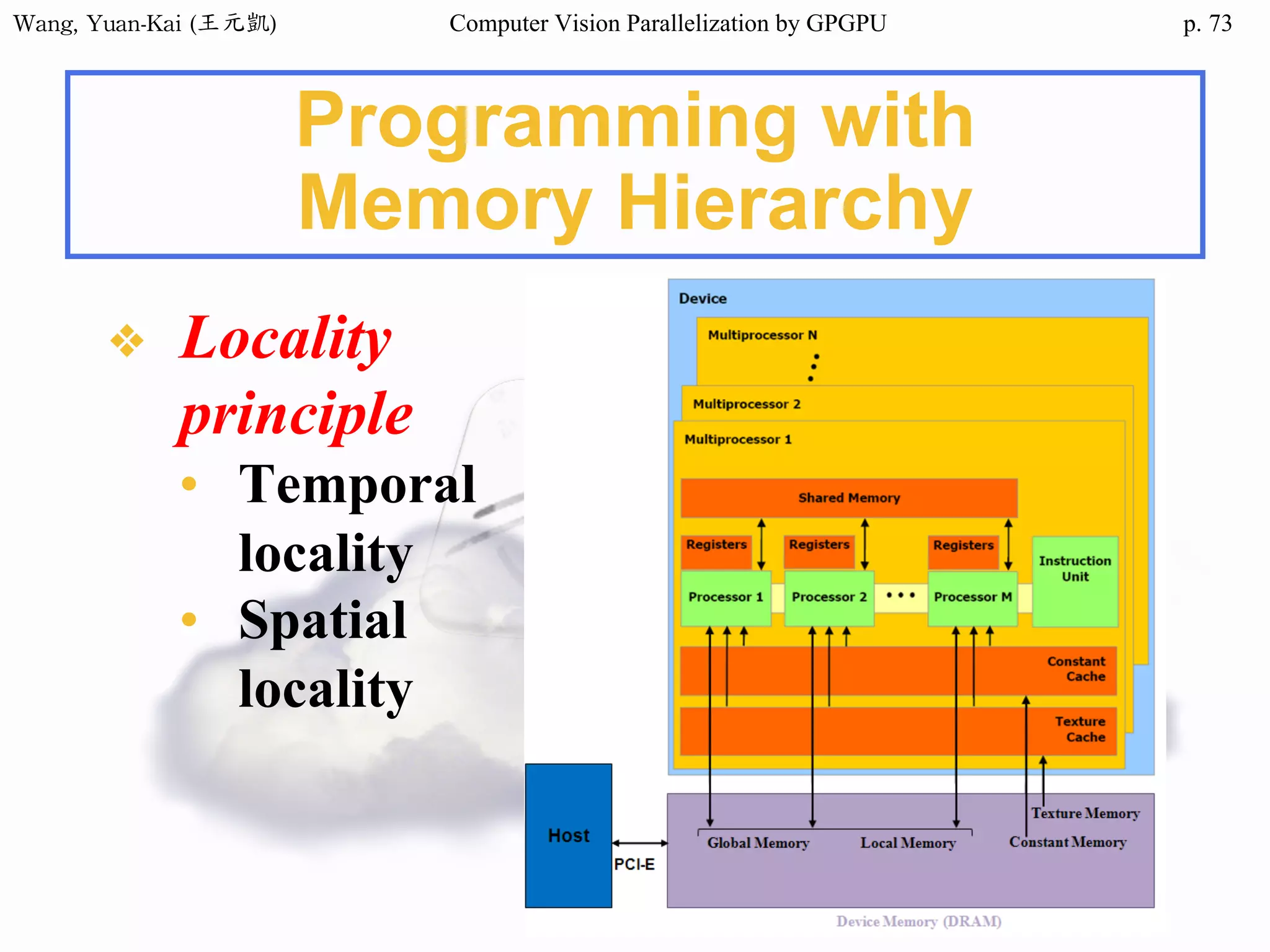
This document discusses parallelizing computer vision algorithms using GPGPU computing. It begins with an introduction to multicore computing and GPUs. It explains that as CPU clock speeds can no longer increase due to power constraints, the industry has shifted to multicore CPUs and GPUs to continue improving performance. Computer vision algorithms are well-suited to parallelization on GPUs due to their massive data processing needs. The document reviews GPU architectures from Nvidia, Qualcomm, AMD, and ARM that can be used to accelerate computer vision. It also discusses parallel programming frameworks for GPUs like CUDA, OpenCL, and OpenACC.

























































![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































