Downloaded 41 times



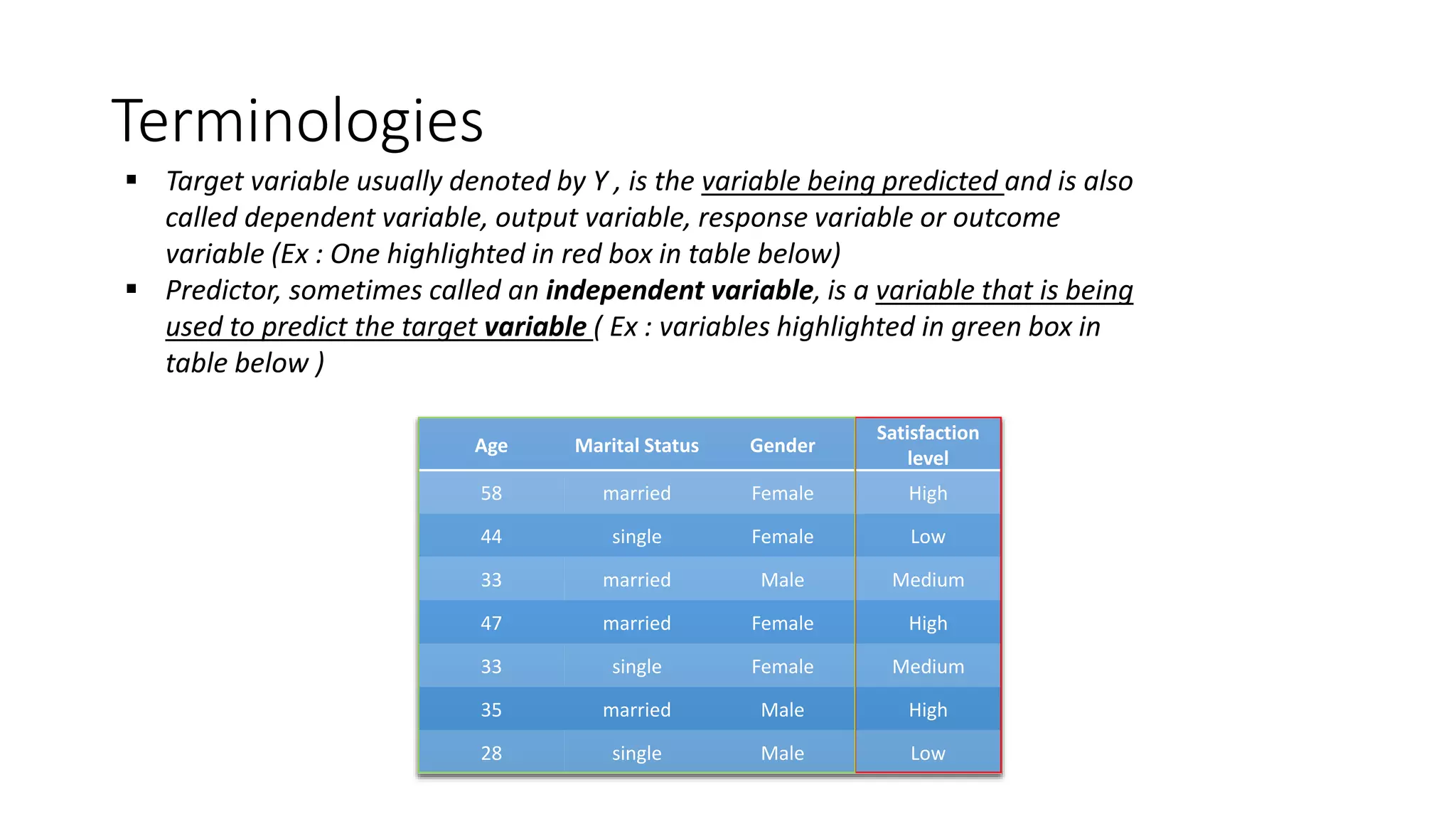






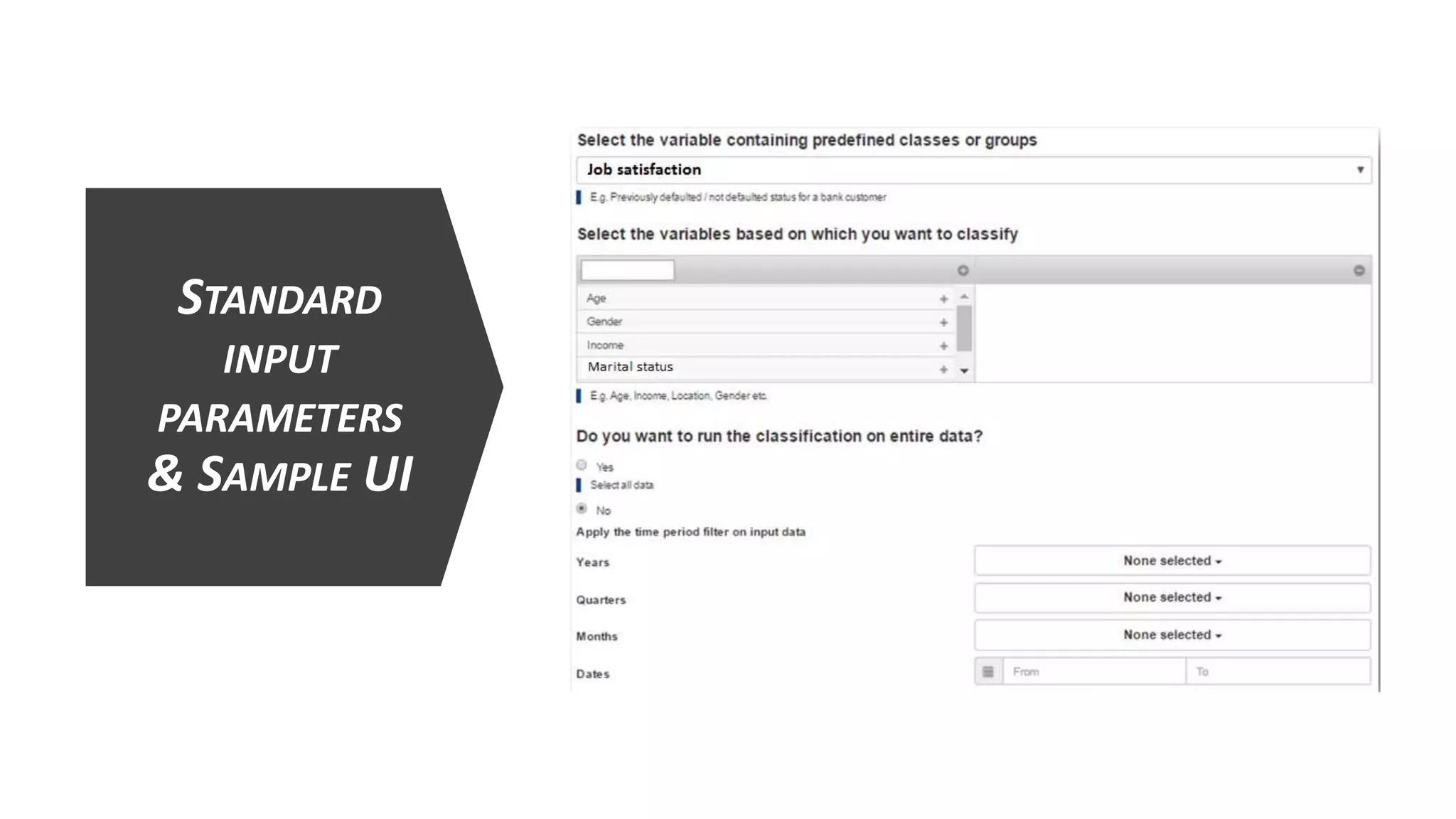


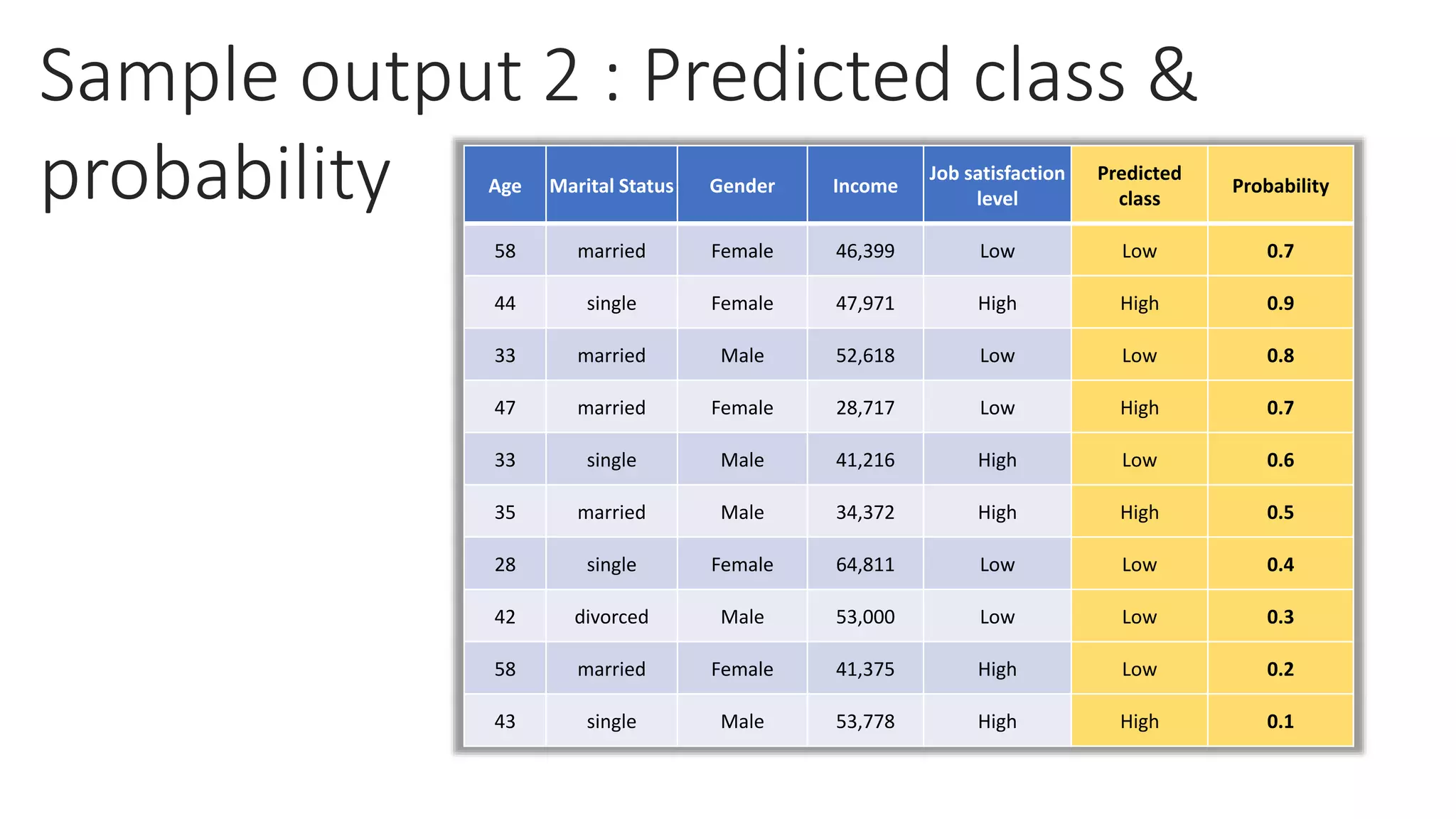
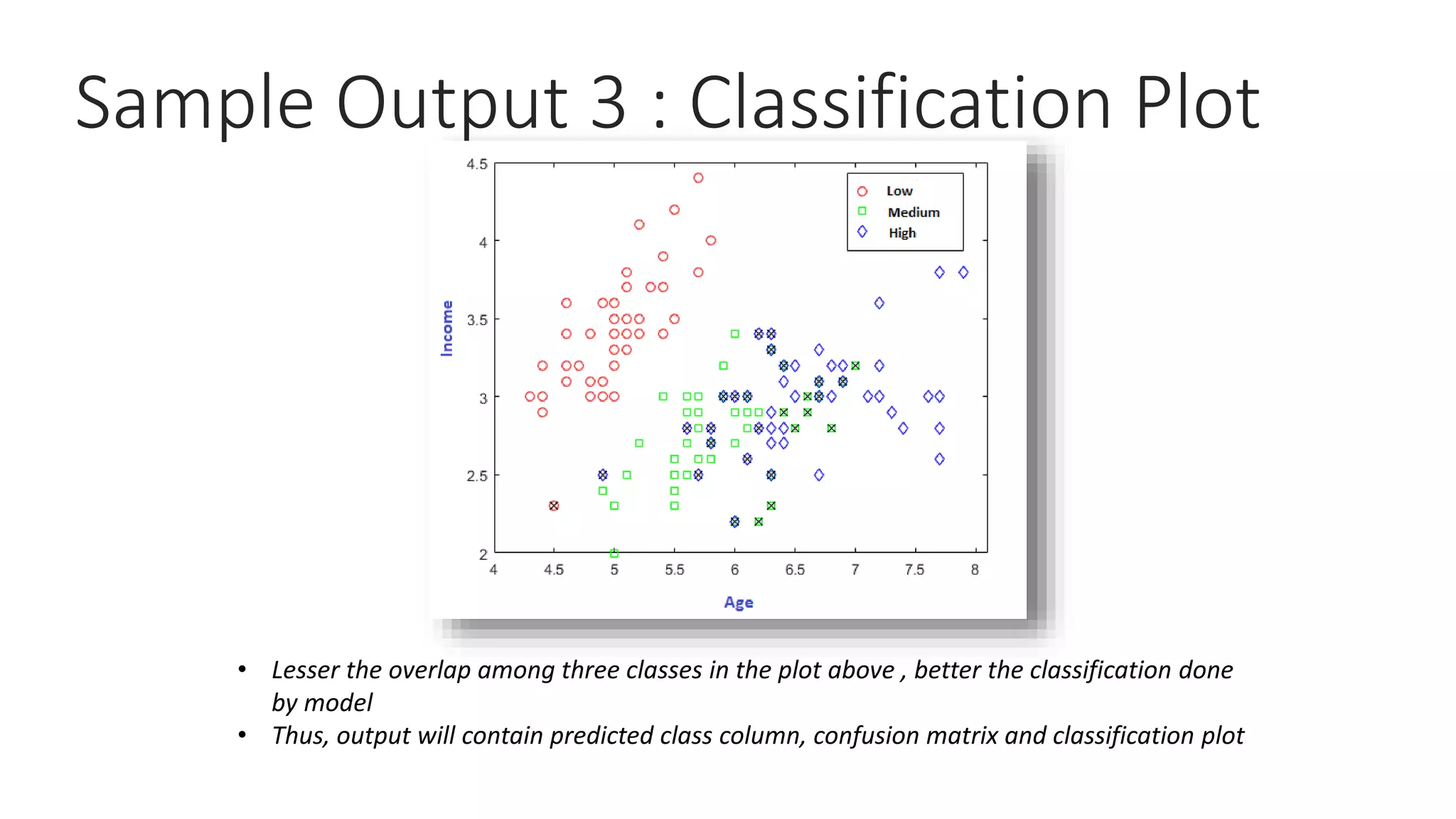





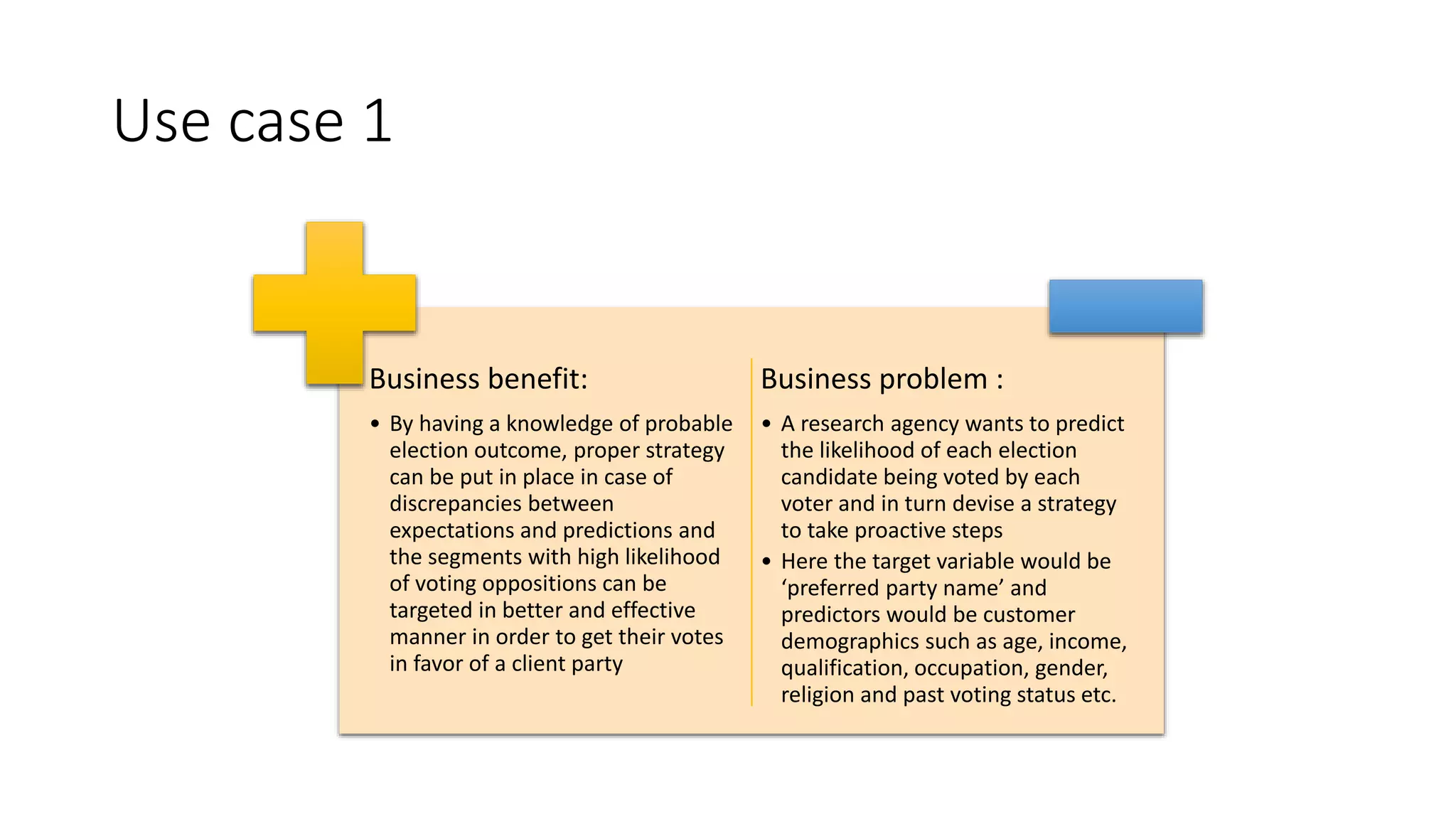
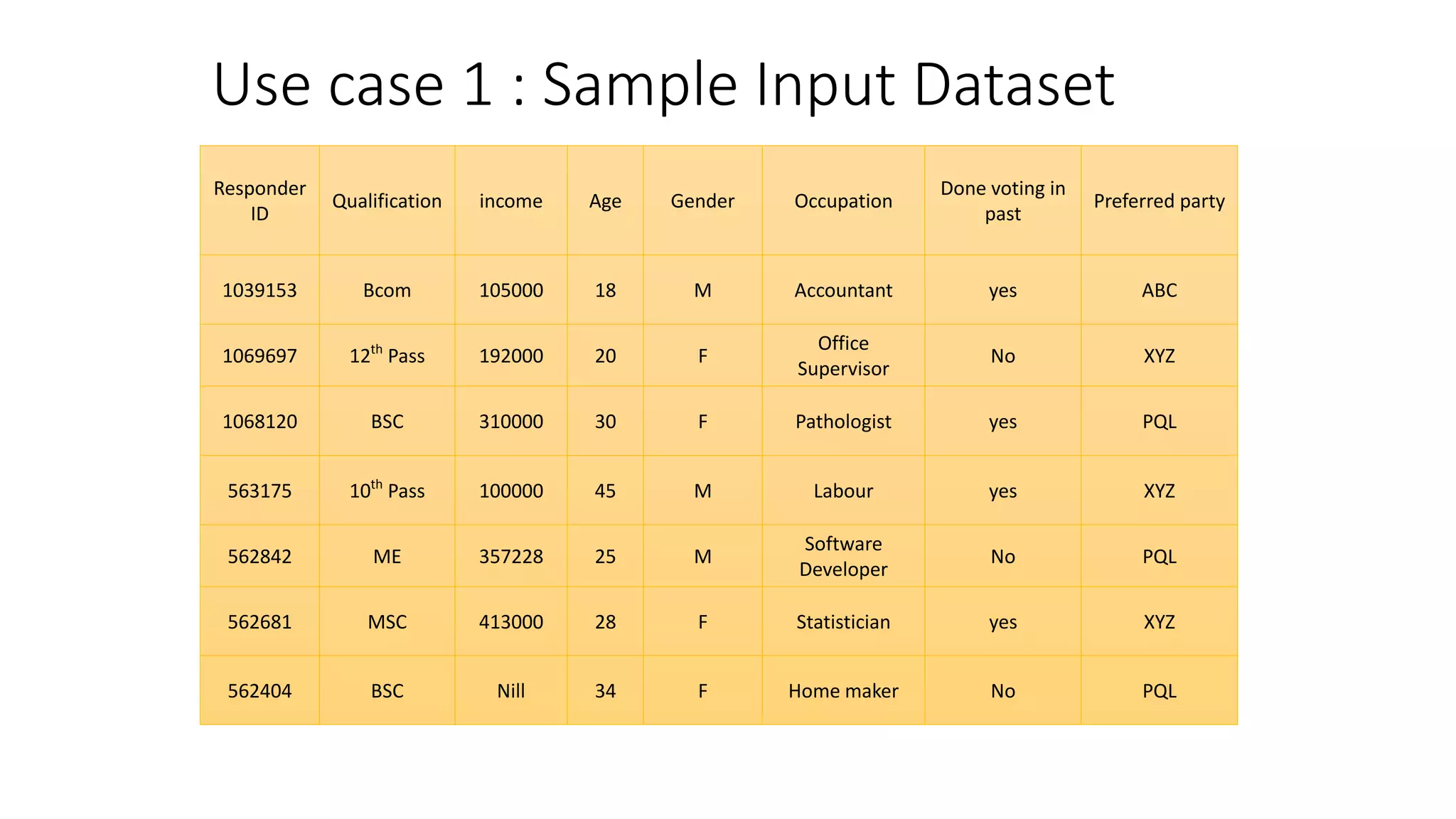
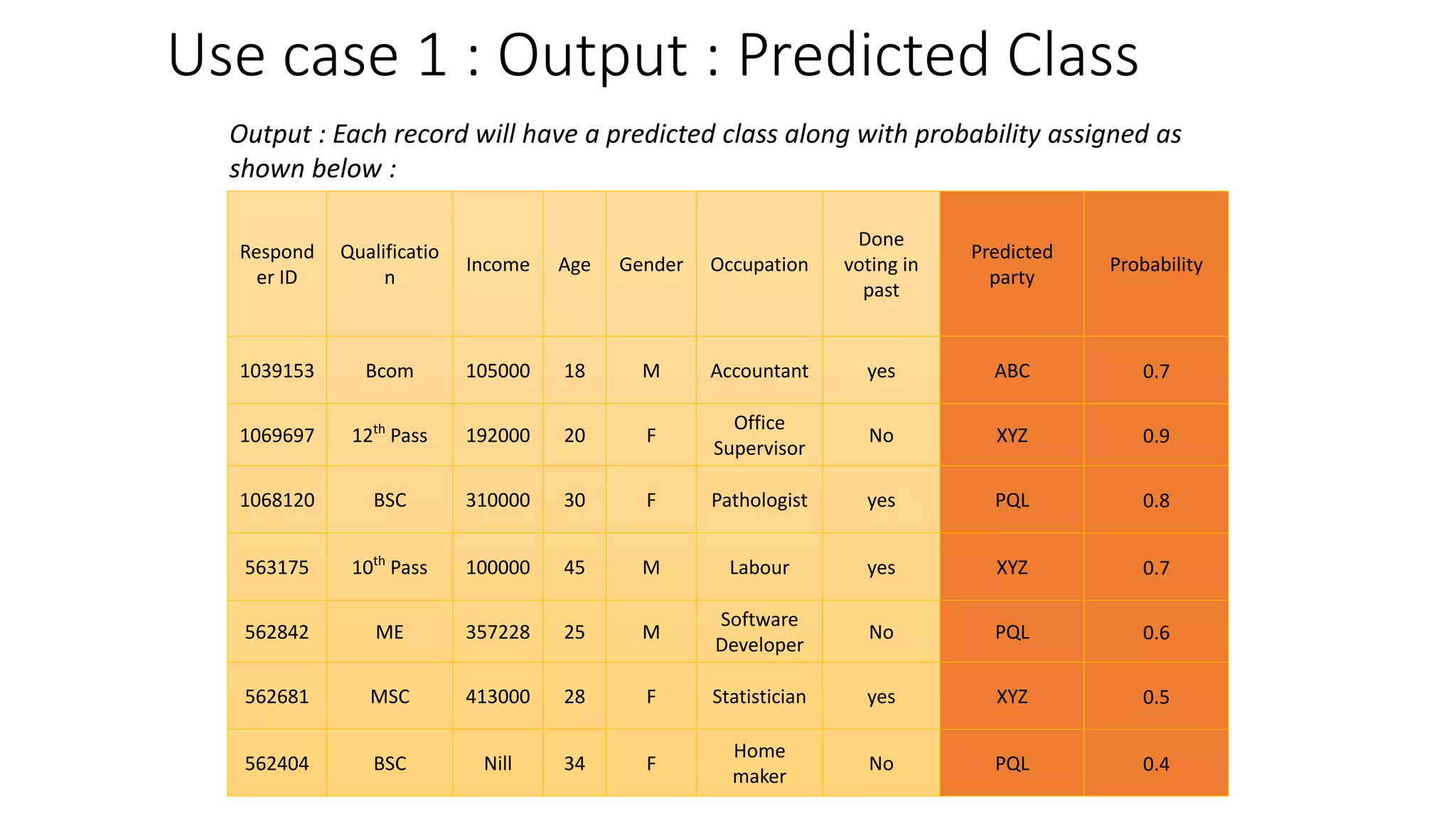
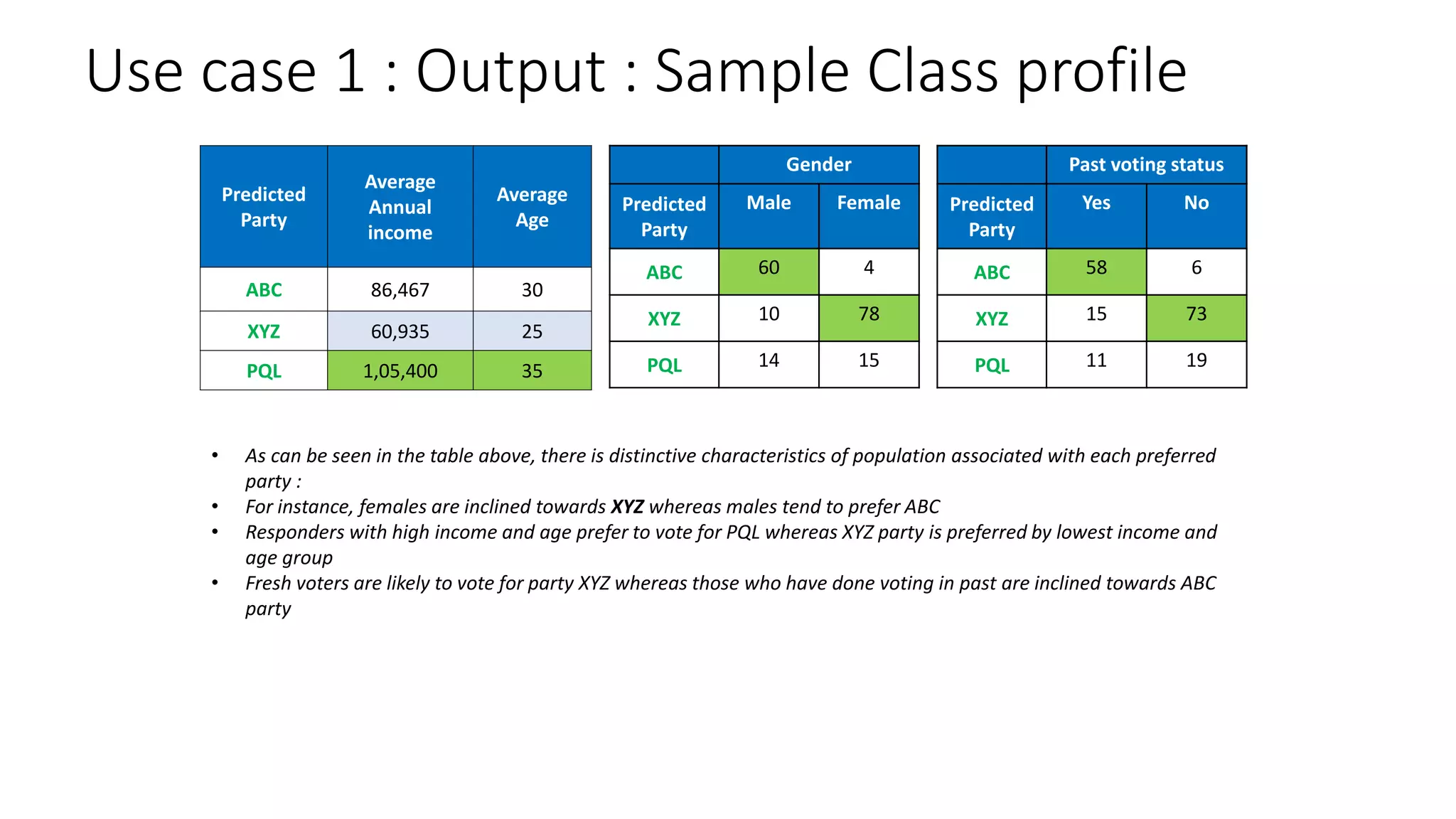
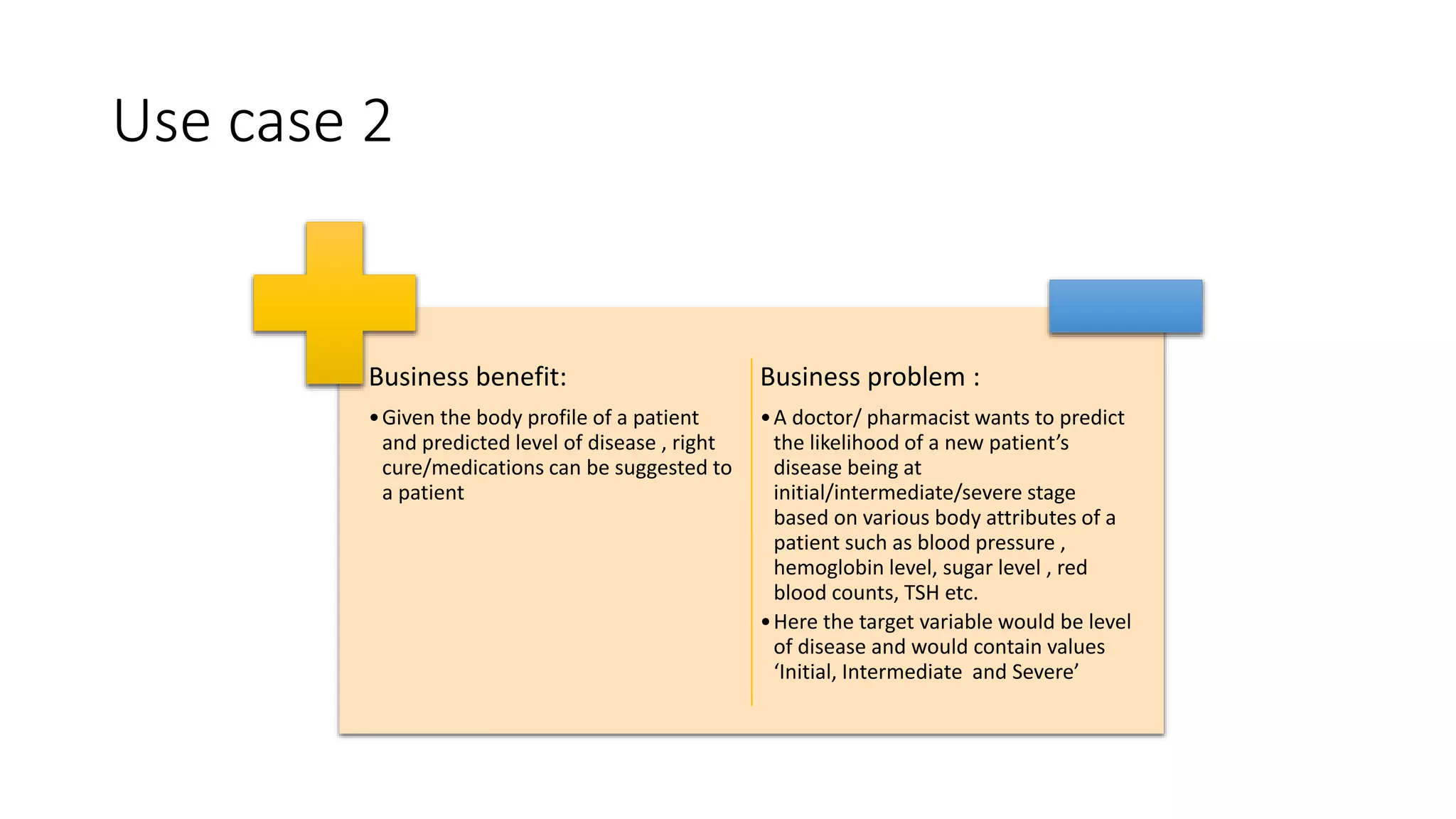





























This document provides a comprehensive overview of multinomial logistic regression aimed at citizen data scientists, including key terminologies, example analyses, and interpretations of model outputs. It highlights the significance of independent variables in predicting a categorical target variable, along with the importance of model accuracy in assessing the effectiveness of predictions. Additionally, the document outlines business use cases for applying logistic regression in election forecasting and medical diagnosis.






















































































