Downloaded 30 times









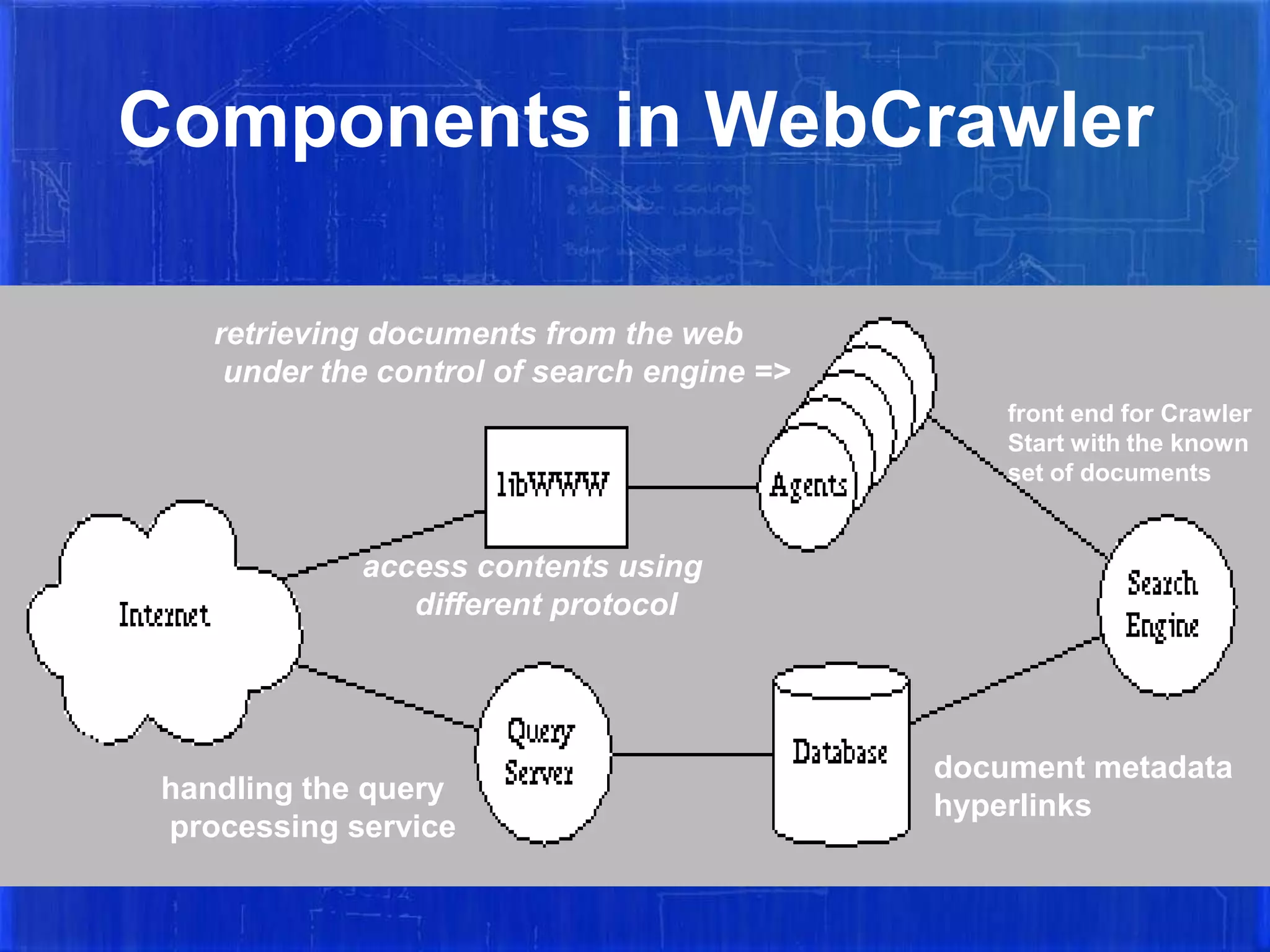
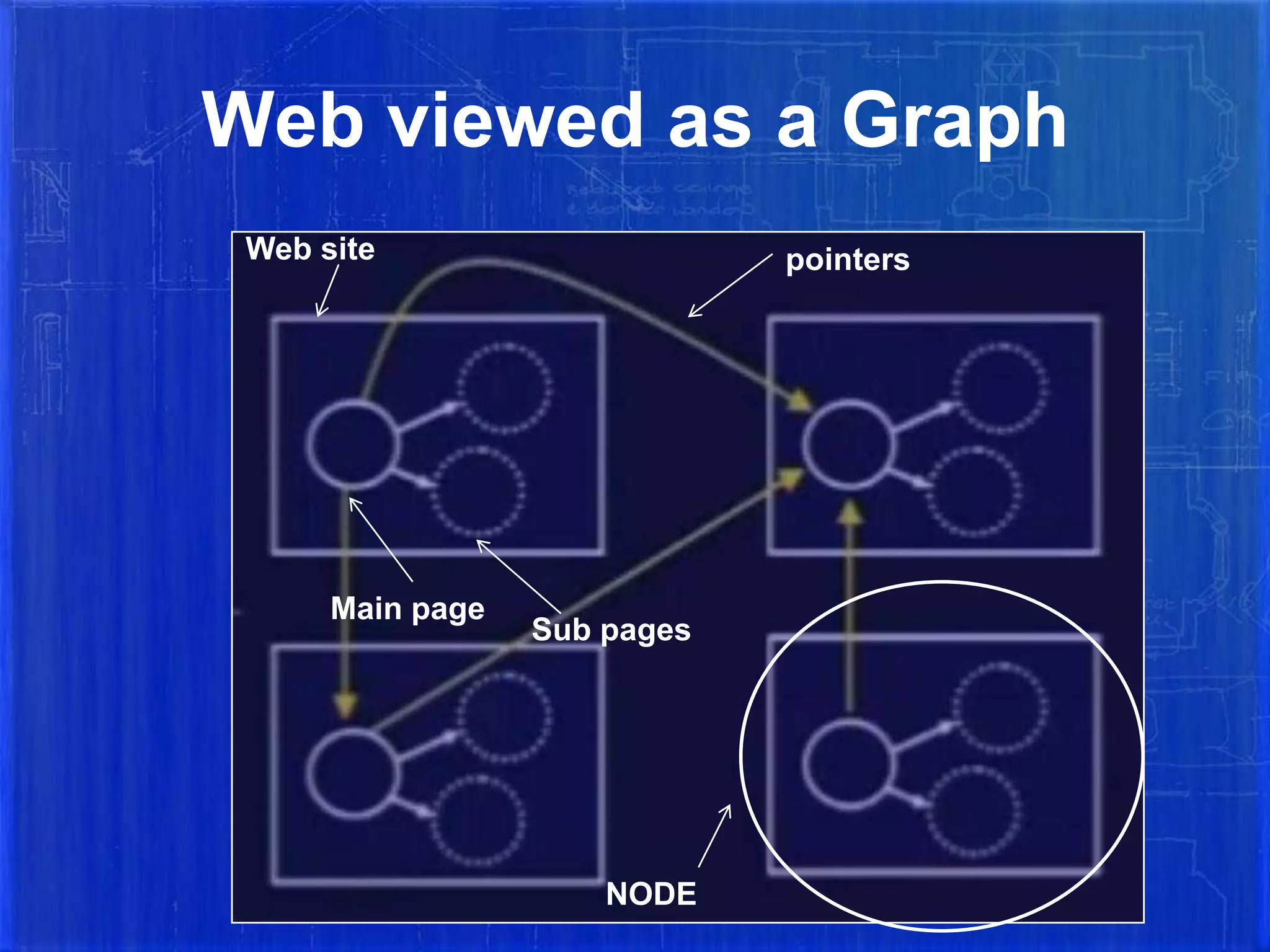

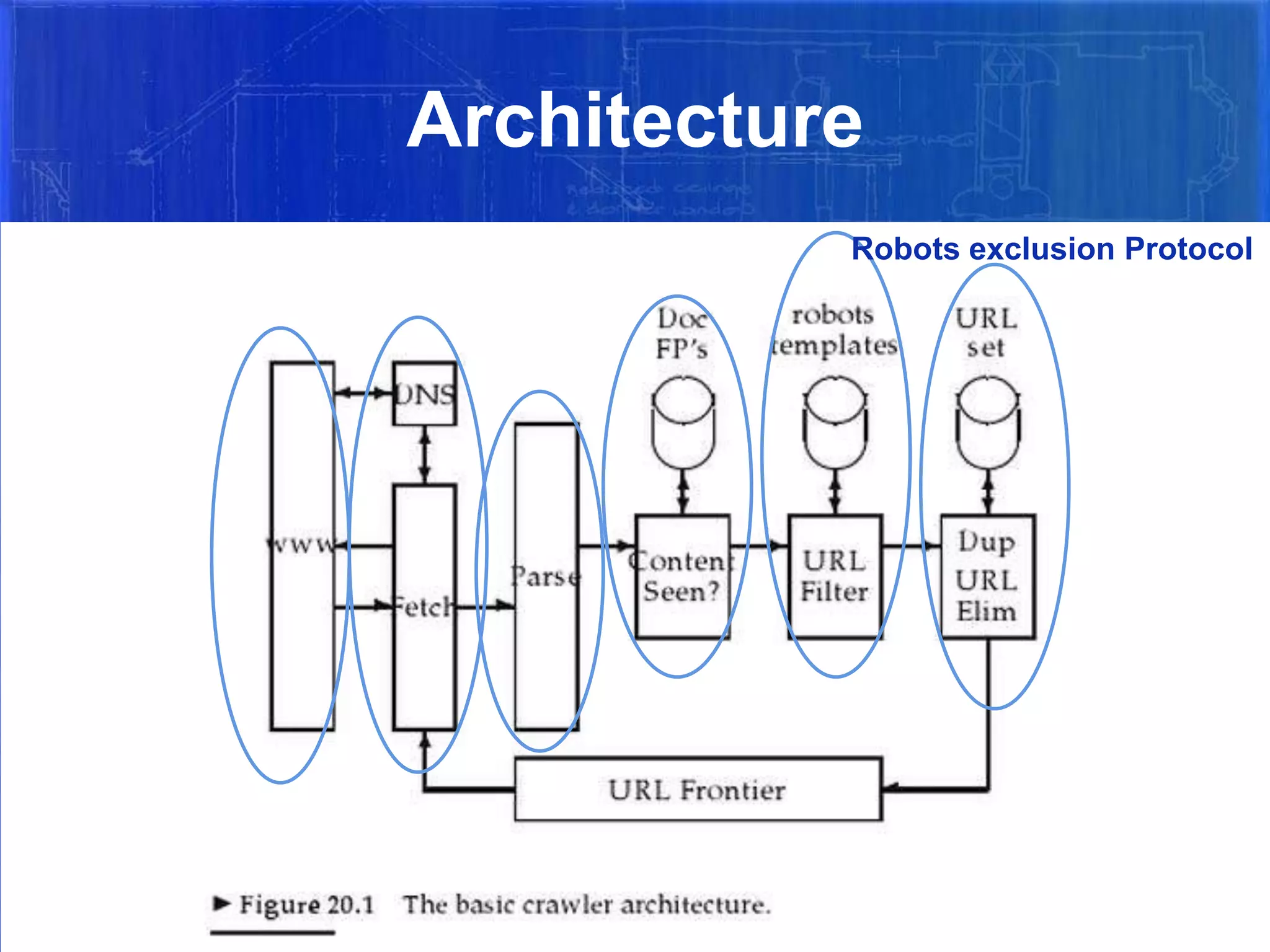
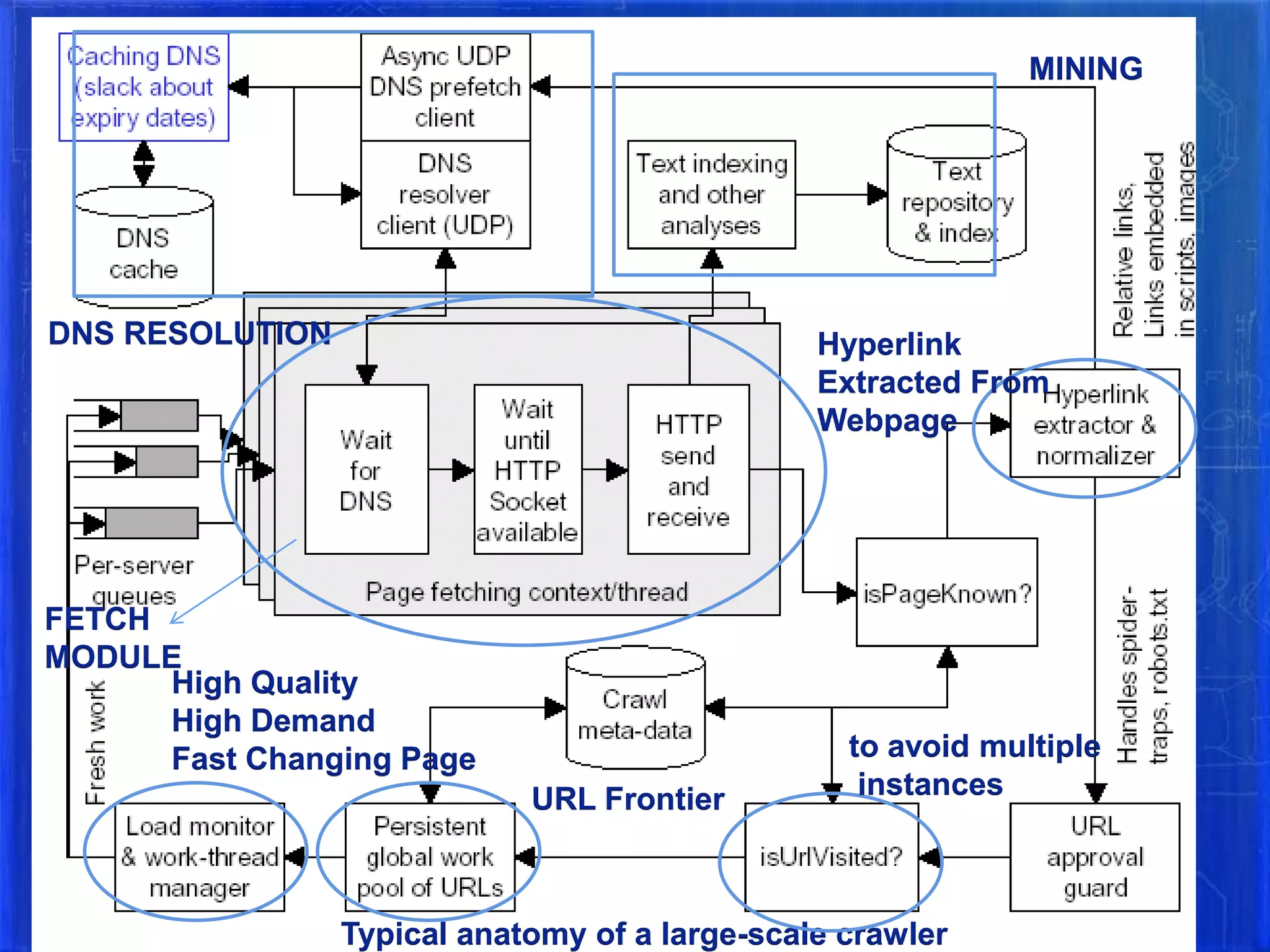

























The document summarizes the history and evolution of major web search engines. It discusses how early search engines like Archie in 1990 indexed anonymous FTP directories. Google introduced important concepts like link popularity and page rank around 2001. Yahoo used Google's search results until 2004 when it launched its own. MSN Search is owned by Microsoft. The document also defines search engines and different types like crawler-based (Google, Yahoo) which automatically index web pages versus human-powered directories. It provides details on how WebCrawler, an early search engine, worked as both an indexer and for real-time search using a breath-first search algorithm.
































































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)








