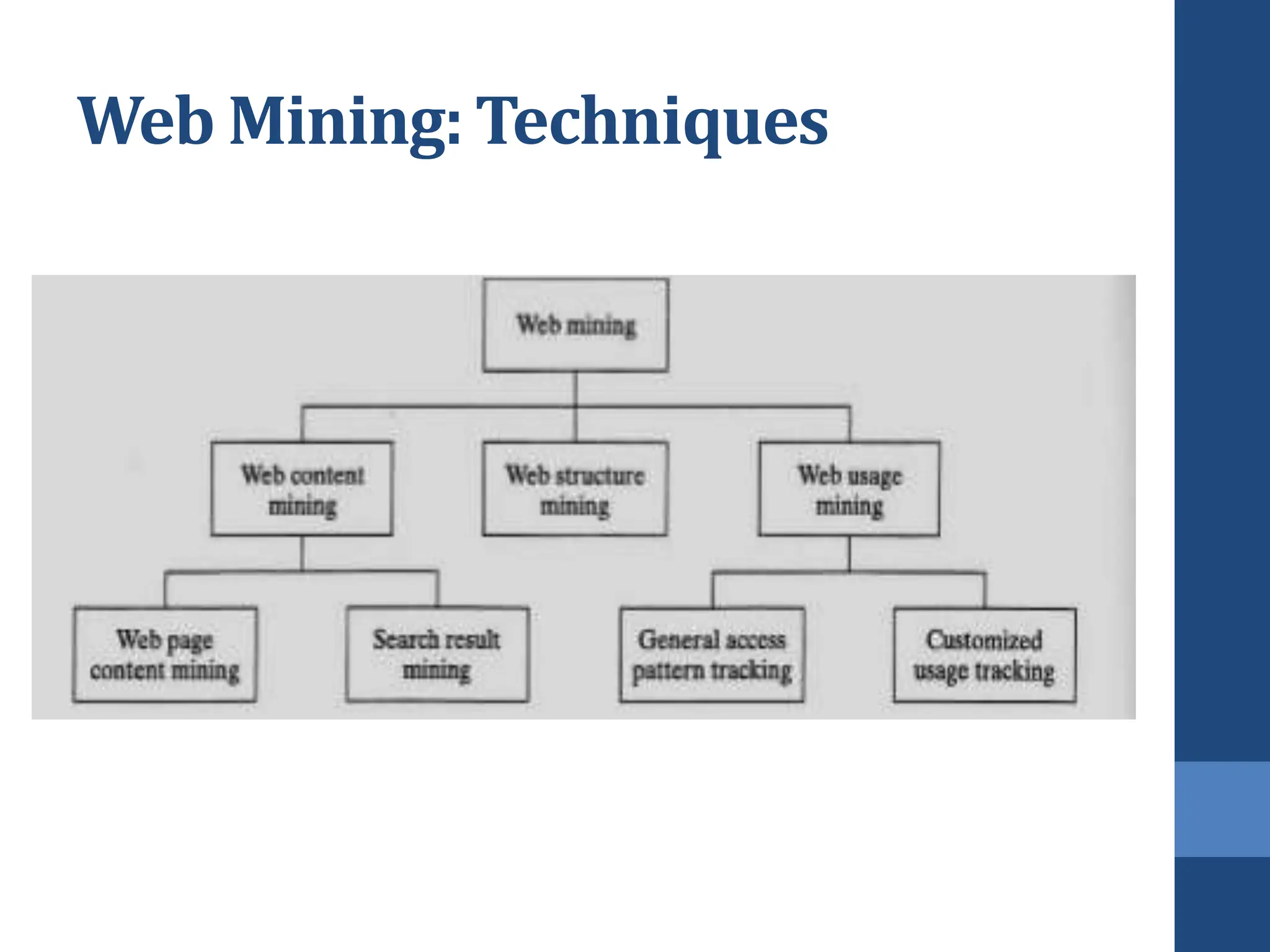
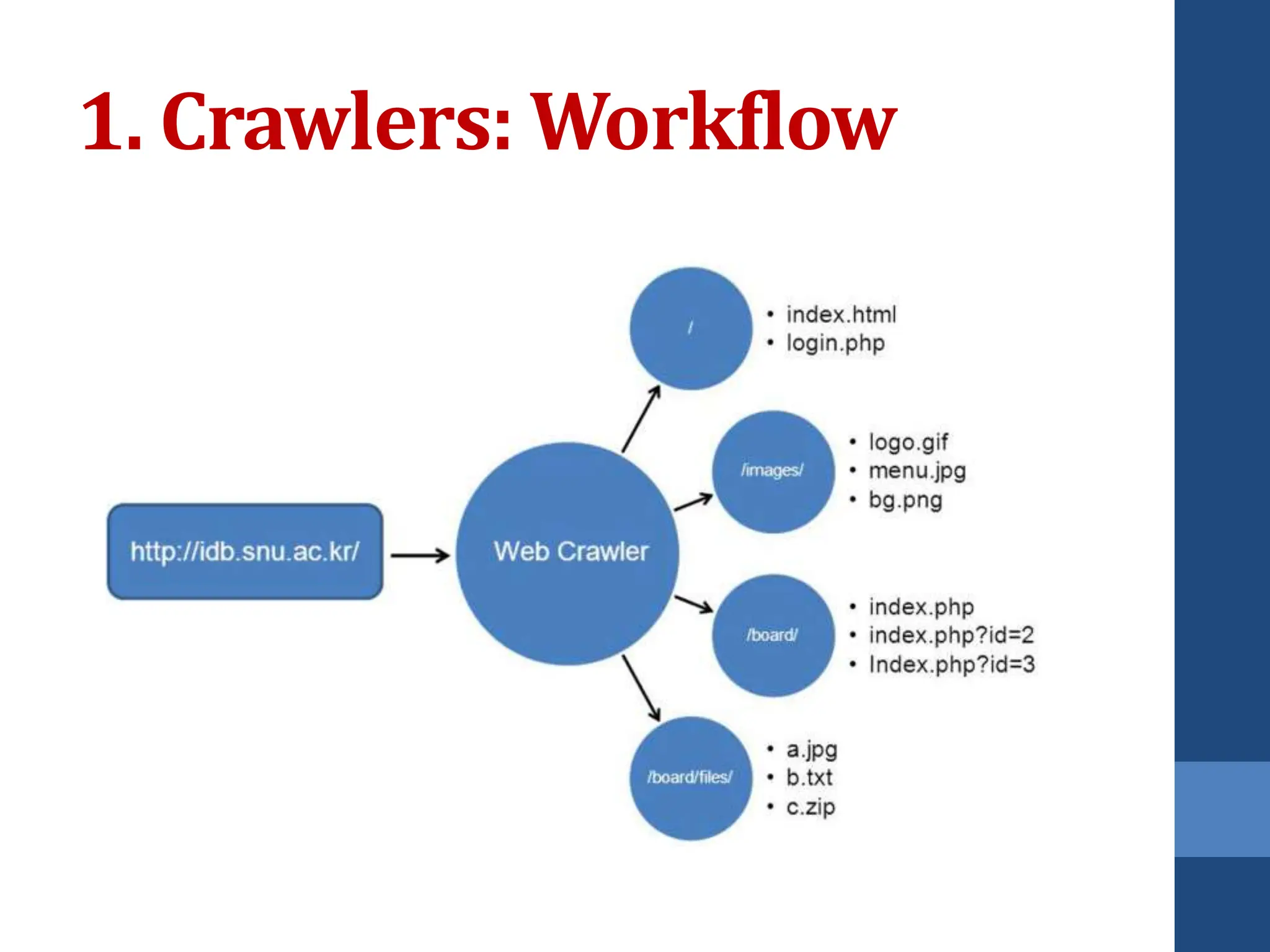
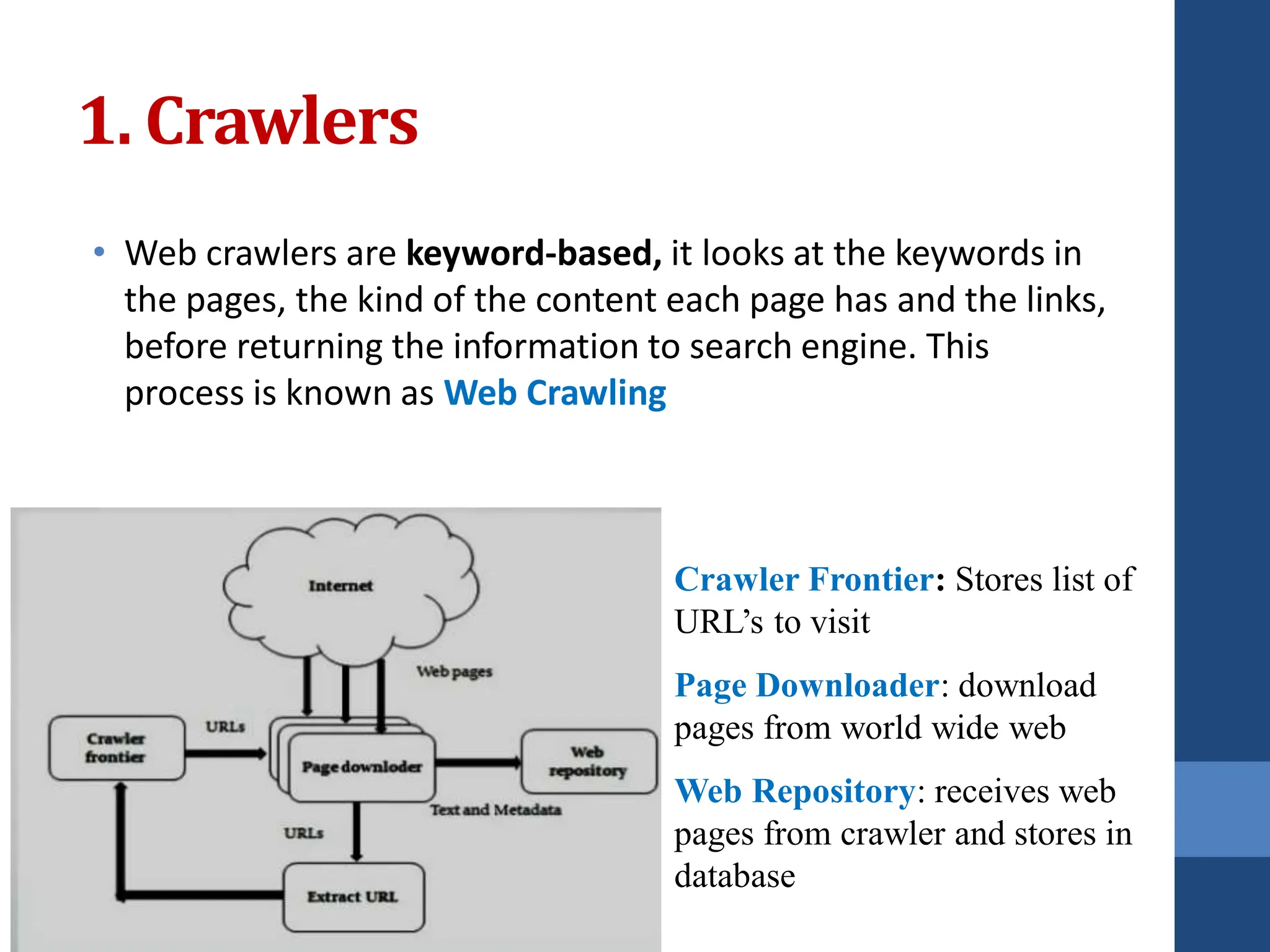
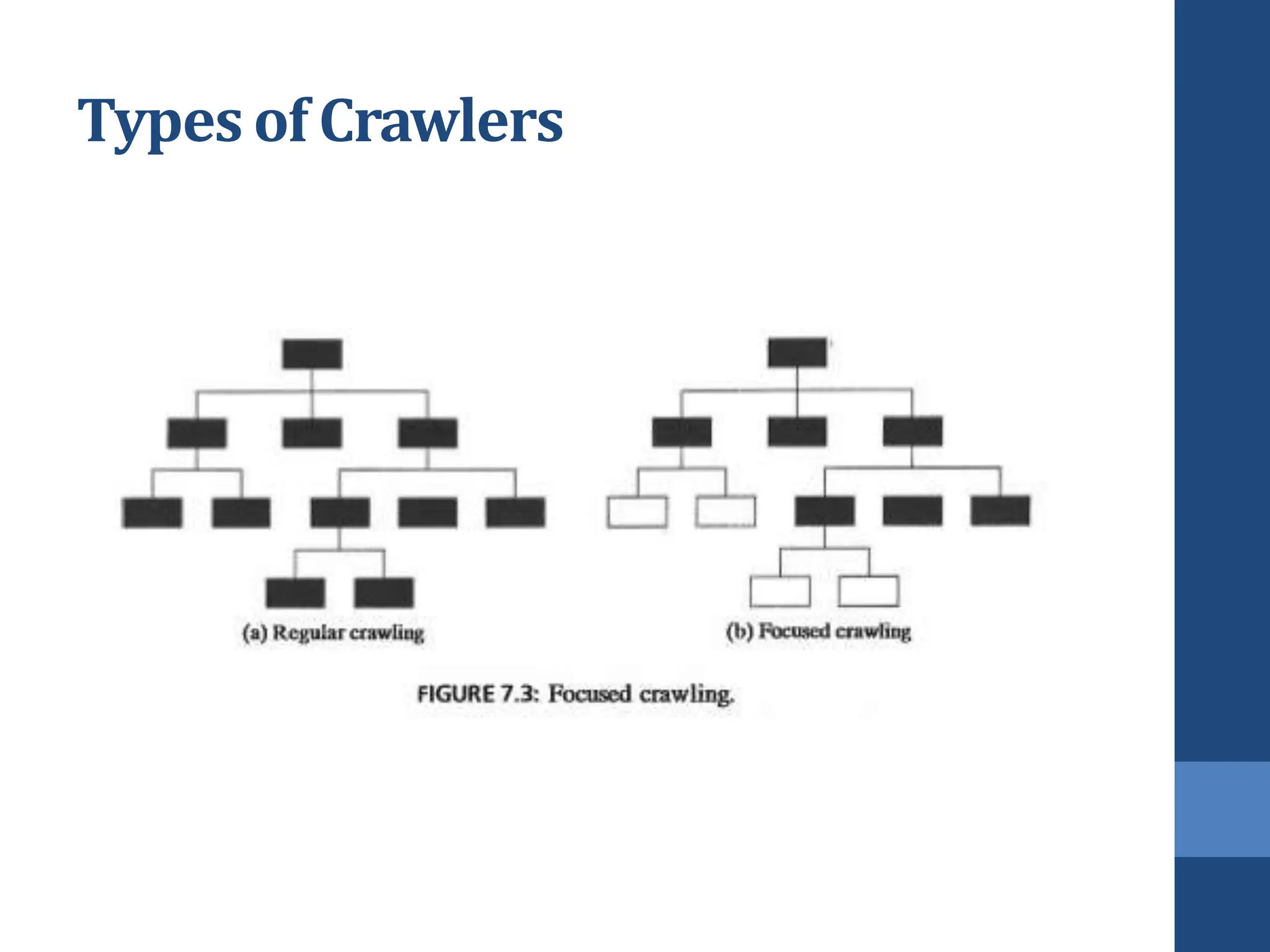
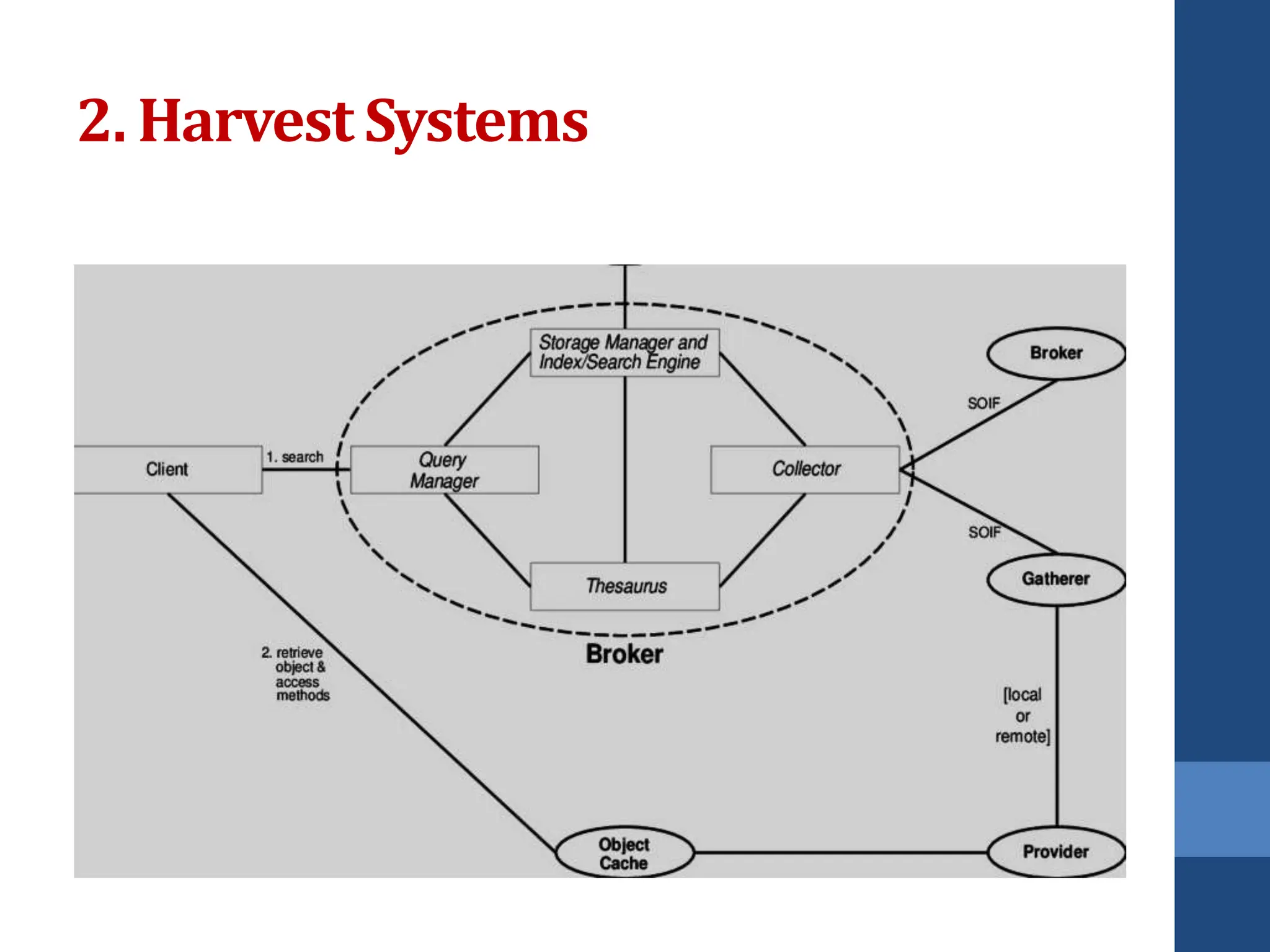
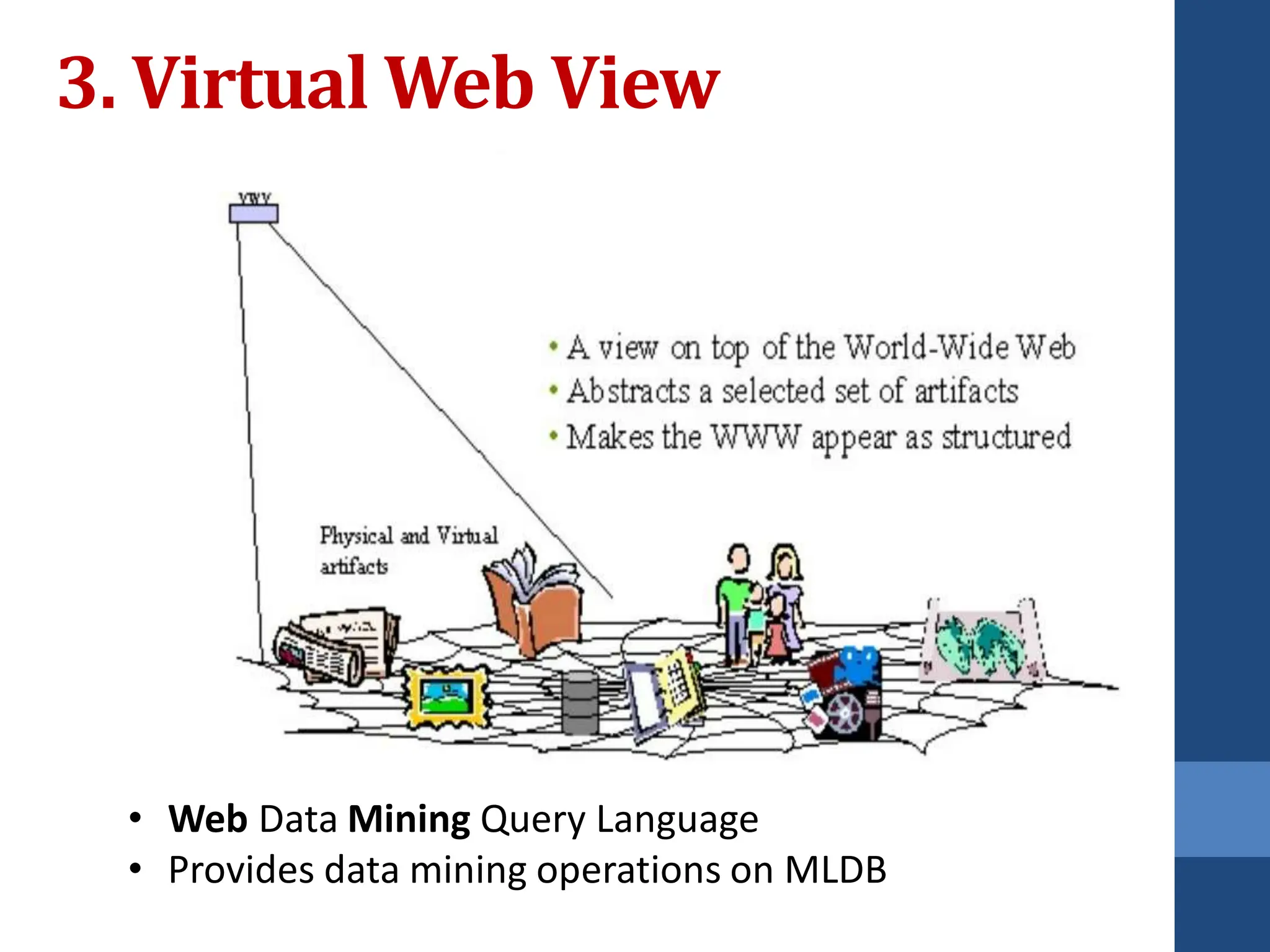
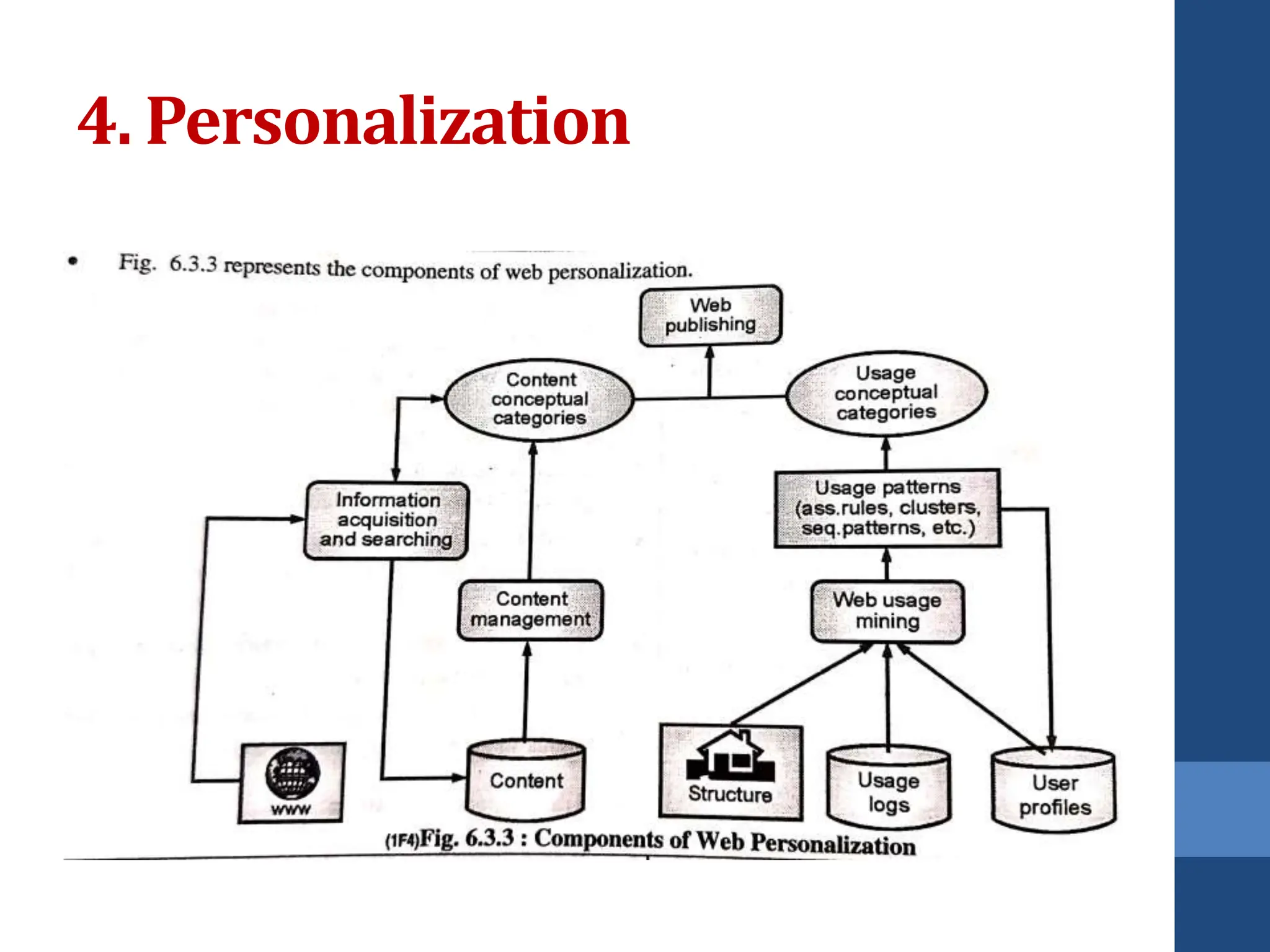
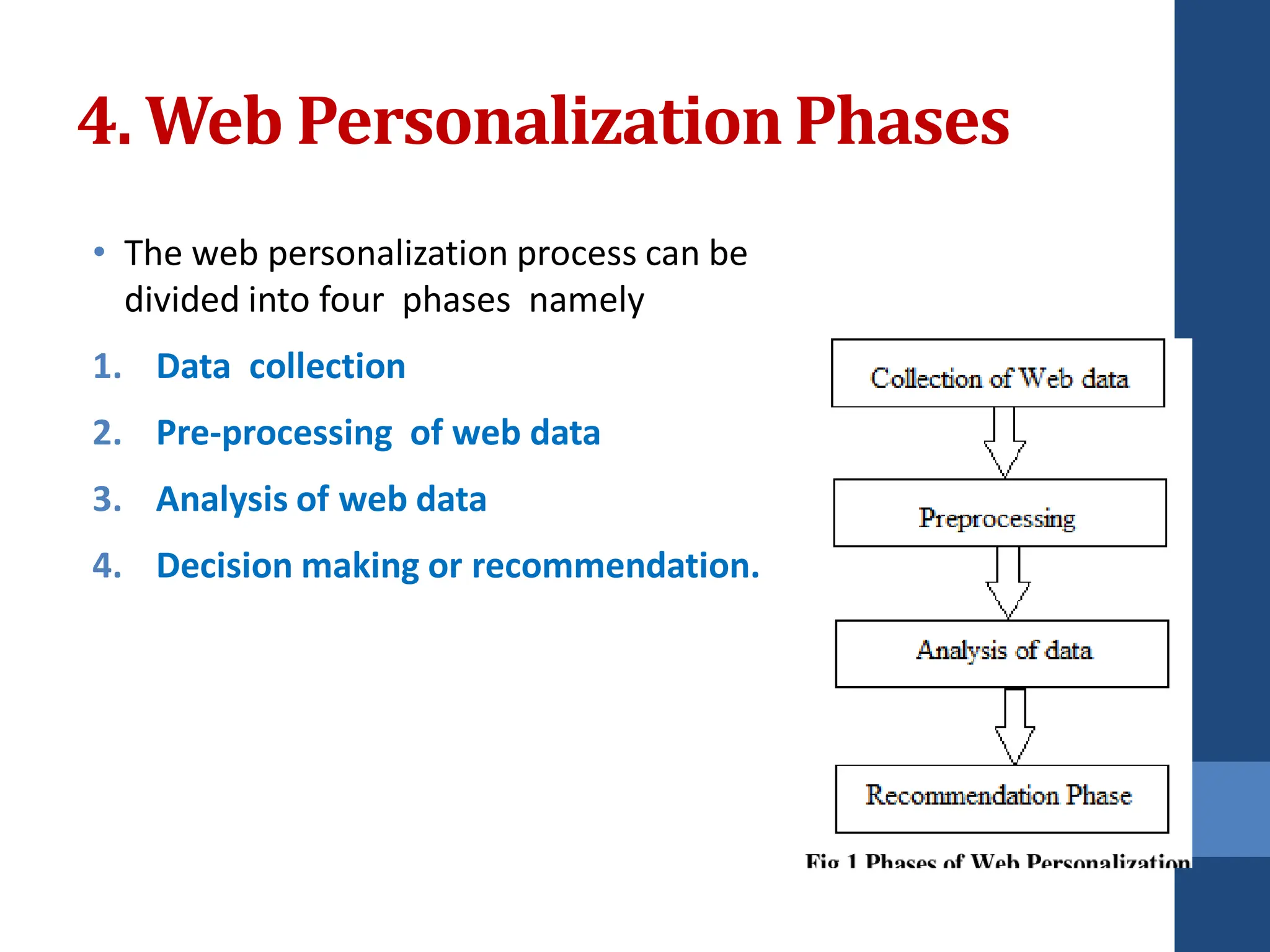
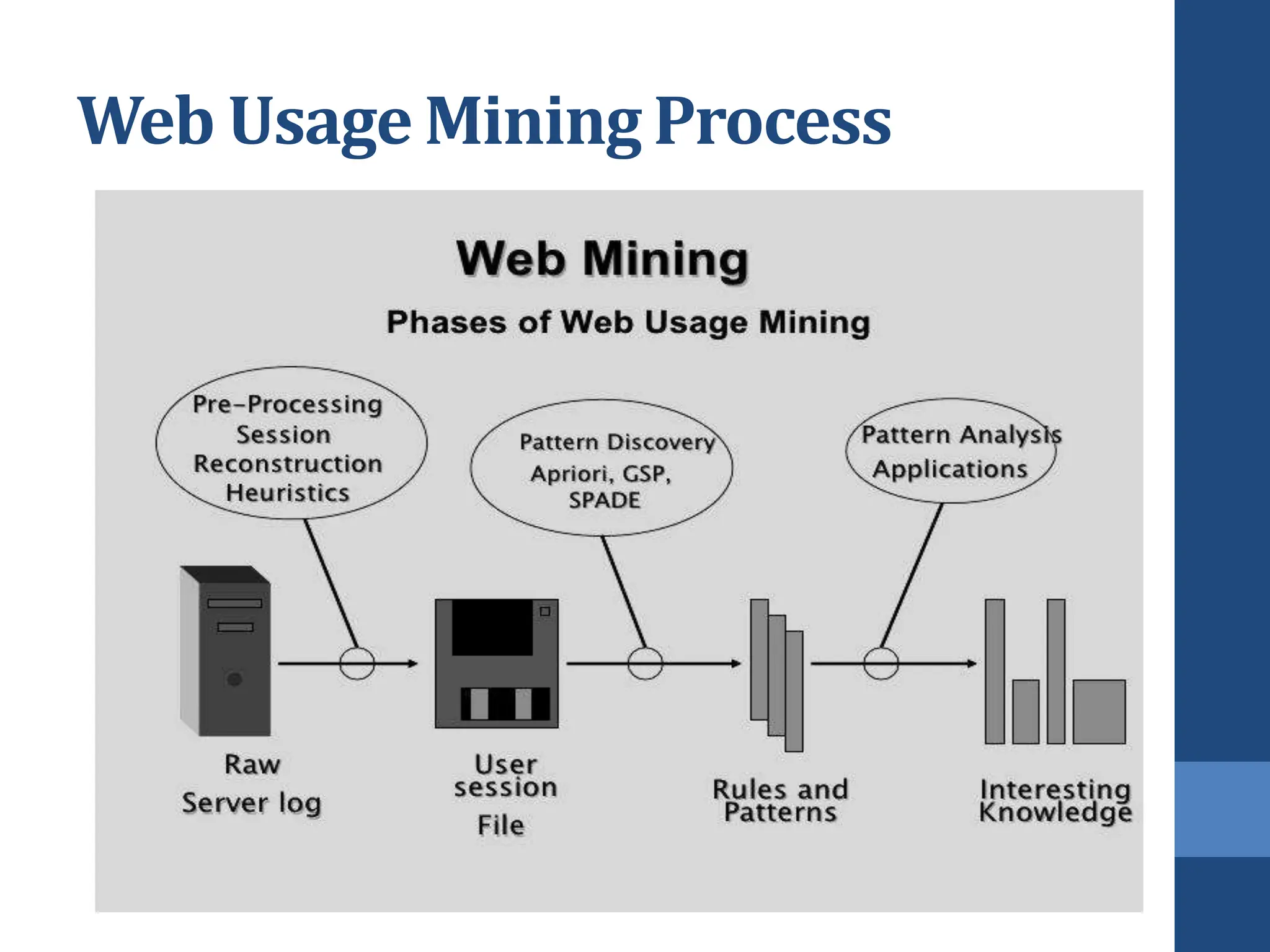
This document covers web mining, detailing its techniques including web content, structure, and usage mining. It elaborates on the roles of web crawlers, data harvesting, and personalization within the web ecosystem, and discusses various algorithms like PageRank for analyzing web structures. Additionally, it outlines methods for understanding user behavior through web usage mining and the importance of preprocessing data for effective pattern discovery.











































































































































![[NDC 발표] 모바일 게임데이터분석 및 실전 활용](https://cdn.slidesharecdn.com/ss_thumbnails/20140529-140529031622-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)
















