Downloaded 27 times




![Importing the
dataset
• dataset = pd.read_csv('Data.csv')
• X = dataset.iloc[:, :-1].values
• y = dataset.iloc[:, 3].values](https://image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-6-2048.jpg)
![missing data
• from sklearn.preprocessing import Imputer
• imputer = Imputer(missing_values = 'NaN',
strategy = 'mean', axis = 0)
• imputer = imputer.fit(X[:, 1:3])
• X[:, 1:3] = imputer.transform(X[:, 1:3])](https://image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-7-2048.jpg)
![Encoding
categorical
data
• from sklearn.preprocessing import
LabelEncoder, OneHotEncoder
• labelencoder_X = LabelEncoder()
• X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
• onehotencoder =
OneHotEncoder(categorical_features = [0])
• X = onehotencoder.fit_transform(X).toarray()](https://image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-8-2048.jpg)




![# Data Preprocessing Python
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Taking care of missing data
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
# Splitting the dataset into the Training set and Test set
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)](https://image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-13-2048.jpg)





![R: Feature Scaling
training_set = scale(training_set)
test_set = scale(test_set)
NOTE : we cant apply the feature scaling to
categorical data in R like python. Here we
have to apply feature selection to only non
categorical features. So our code becomes :
training_set[, 2:3] = scale(training_set [, 2:3])
test_set = scale(test_set [, 2:3])](https://image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-19-2048.jpg)





![Importing the
dataset
• dataset = pd.read_csv('Data.csv')
• X = dataset.iloc[:, :-1].values
• y = dataset.iloc[:, 3].values](https://crownmelresort.com/image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-6-2048.jpg)
![missing data
• from sklearn.preprocessing import Imputer
• imputer = Imputer(missing_values = 'NaN',
strategy = 'mean', axis = 0)
• imputer = imputer.fit(X[:, 1:3])
• X[:, 1:3] = imputer.transform(X[:, 1:3])](https://crownmelresort.com/image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-7-2048.jpg)
![Encoding
categorical
data
• from sklearn.preprocessing import
LabelEncoder, OneHotEncoder
• labelencoder_X = LabelEncoder()
• X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
• onehotencoder =
OneHotEncoder(categorical_features = [0])
• X = onehotencoder.fit_transform(X).toarray()](https://crownmelresort.com/image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-8-2048.jpg)




![# Data Preprocessing Python
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Taking care of missing data
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
# Splitting the dataset into the Training set and Test set
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)](https://crownmelresort.com/image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-13-2048.jpg)





![R: Feature Scaling
training_set = scale(training_set)
test_set = scale(test_set)
NOTE : we cant apply the feature scaling to
categorical data in R like python. Here we
have to apply feature selection to only non
categorical features. So our code becomes :
training_set[, 2:3] = scale(training_set [, 2:3])
test_set = scale(test_set [, 2:3])](https://crownmelresort.com/image.slidesharecdn.com/datapreprocessing-171226232009/75/Data-preprocessing-for-Machine-Learning-with-R-and-Python-19-2048.jpg)


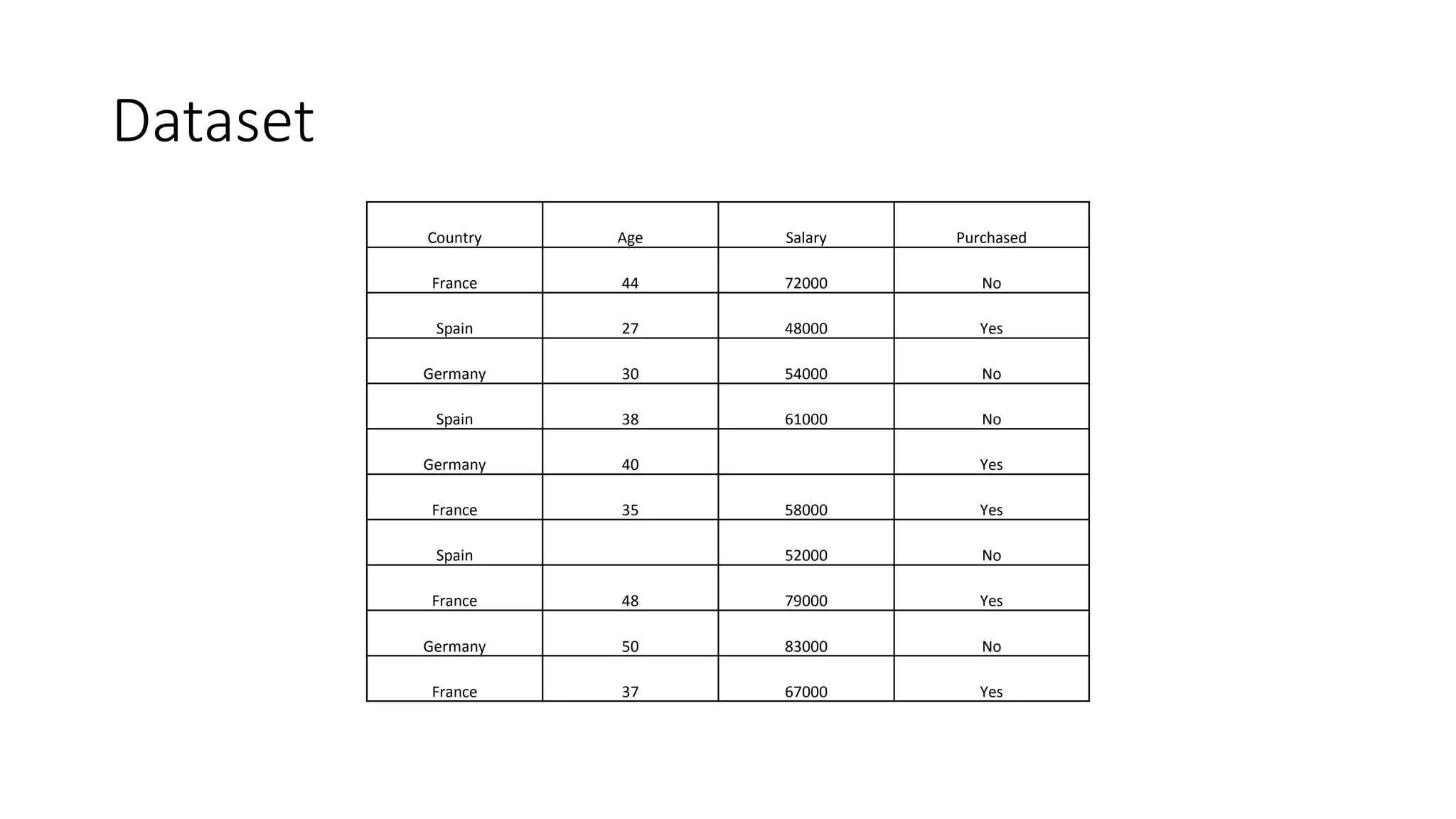
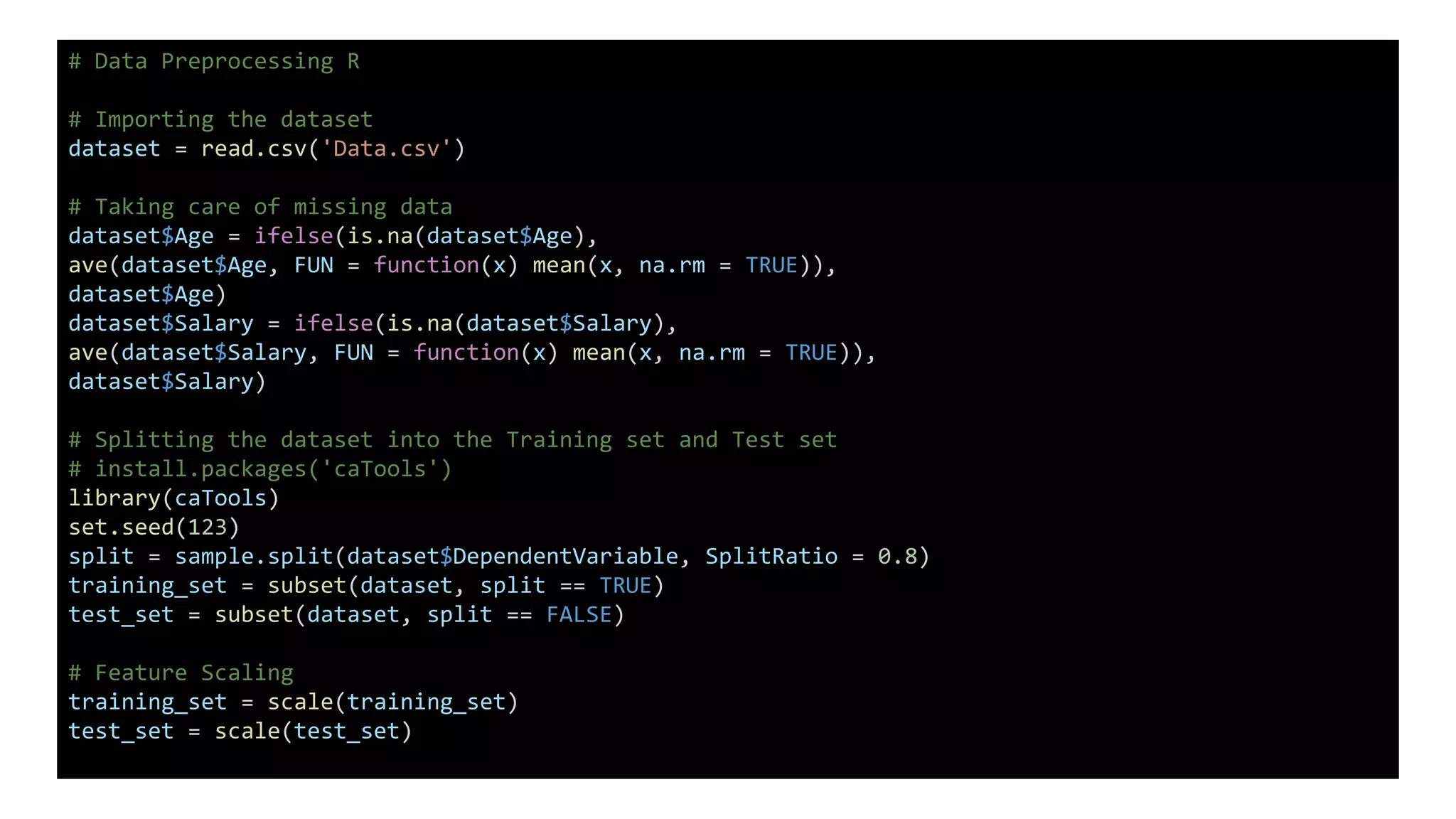
The document describes the steps for data preprocessing in Python and R. These include importing and reading the dataset, handling missing data through imputation, encoding categorical variables, splitting the data into training and test sets, and scaling numeric features. Key preprocessing steps are performed similarly in both languages, such as imputing missing values, splitting data, and feature scaling. However, encoding categorical variables differs between one-hot encoding in Python versus factorizing in R.

















































































