Downloaded 49 times



















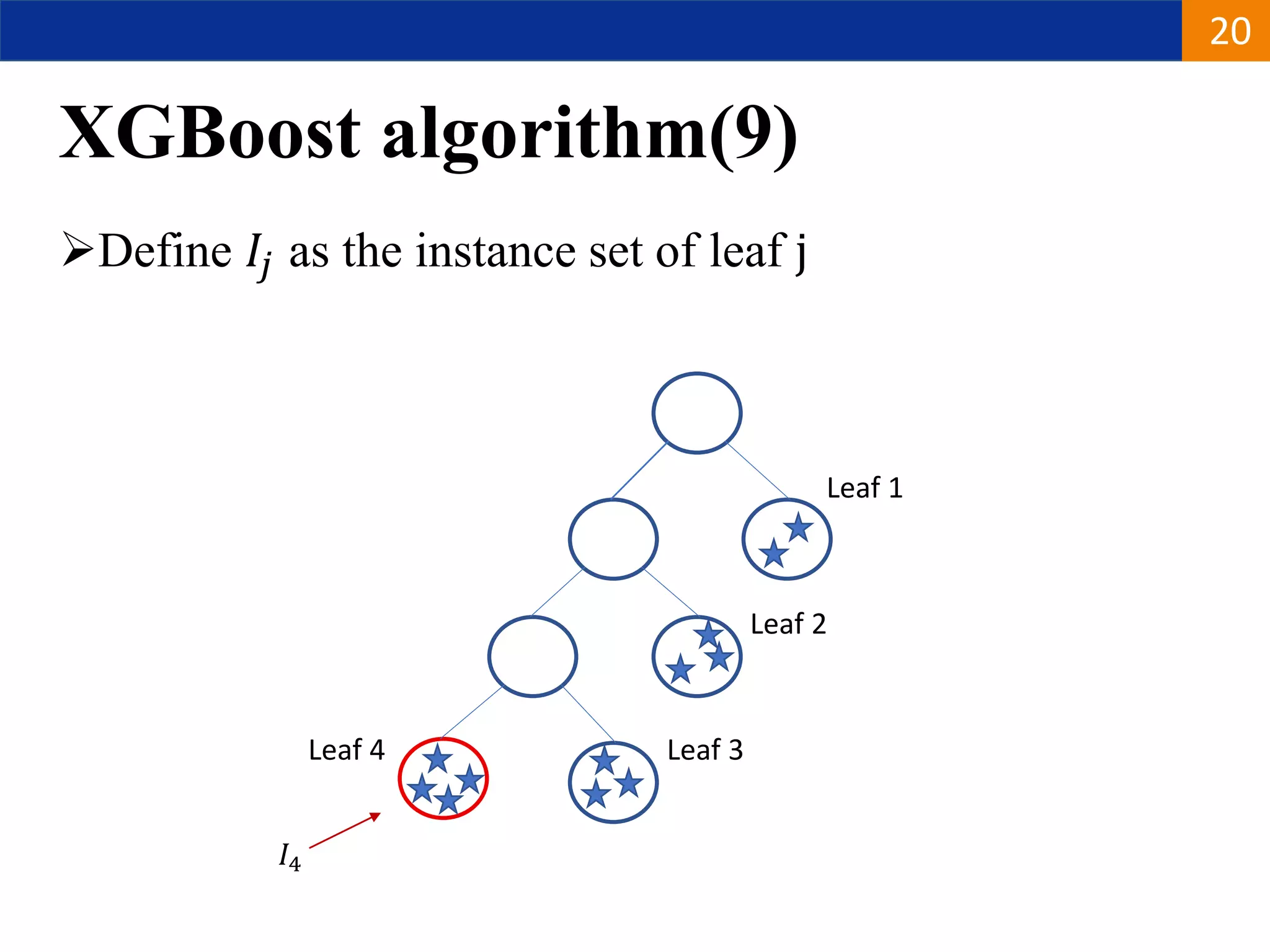







































XGBoost is a machine learning algorithm based on boosting decision trees. It builds decision trees sequentially to optimize a specified loss function. At each step, it fits a decision tree to the residuals of the previous tree to minimize the loss. It uses regularization to control overfitting by penalizing complex trees with many leaves and high weights. To determine the best split at each node, it calculates the loss reduction from splitting the node versus keeping it whole. The split that maximizes loss reduction is selected.



























![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)
![XGBOOST [Autosaved]12.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/xgboostautosaved12-230501140101-a562c3ba-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)











