Download as PDF, PPTX








![ Windows CUDA 7.5 SDK
New text file: Hola.cu, create a sequence of characters, send to the GPU, run our program, copy the
result back and get a result
nvcc Hola.cu (build it), run the a.exe next
Unsafe, we're in the CUDA world now! Can get errors on Windows and seg faults on Linux
char myHostChars[16] = "Hello0000000";
int myHostOffsets[16] = {0,0,0,0,0,32,77,97,108,97,103,97};
shar* myDeviceChars, myDeviceInts;
cudaMalloc(&myDeviceChars, numBytesForChars); // Omitted amount calculating
cudaMalloc(&myDeviceInts, numBytesForOffsets);
cudaMemcpy(myDeviceChars, myHostChars, numBytesForChars,
cudaMemcpyHostToDevice);
cudaMemcpy(myDeviceInts, myHostOffsets, numBytesForOffsets,
cudaMemcpyHostToDevice);
myKernel<<<dimGrid, dimBlock>>>(myDeviceChars, myDeviceInts);
cudaMemcpy(myHostChars, myDeviceChars, numBytesForChars,
cudaMemcpyDeviceToHost);
Thanks to Ingemar Ragnehalm for this idea: http://computer-
graphics.se/hello-world-for-cuda.html
Hello Malaga](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-11-2048.jpg)
![__global__ void a(char* inputChars,int* offsetAmounts){
inputChars[threadIdx.x]+= offsetAmounts[threadIdx.x];
}
__global__ : it's a function we can call on the host, it's available to be
called from everywhere
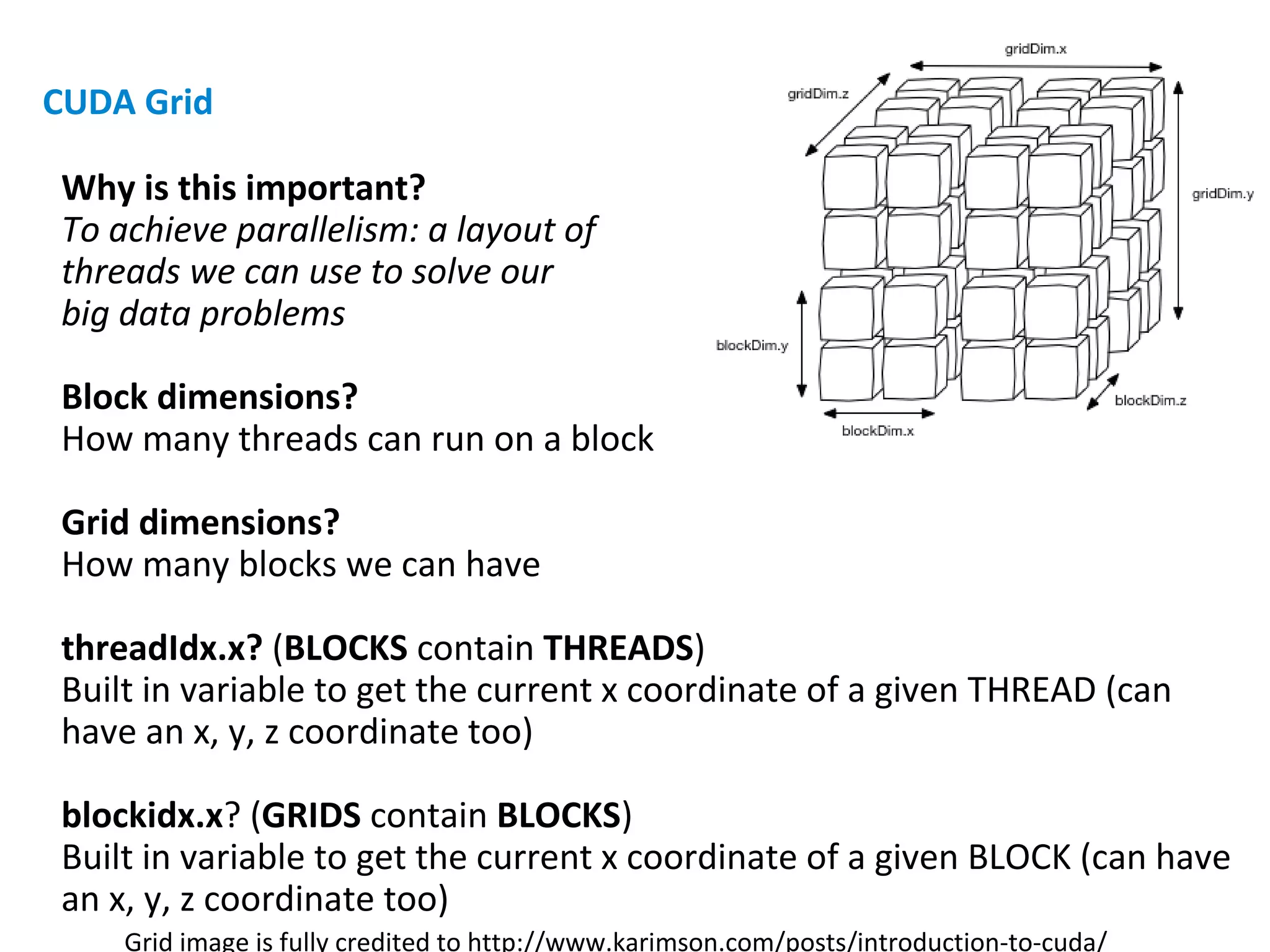
What's a grid again?
A kernel runs on a grid and it's how we can run many threads that work
on different parts of the data
char*? A pointer to a bunch of characters we'll send to the GPU
int*? A pointer to a bunch of ints we'll send to the GPU
threadIdx.x?
We use this as an index to our array, remember lots of threads run on
the GPU. Access each item for our example here](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-12-2048.jpg)





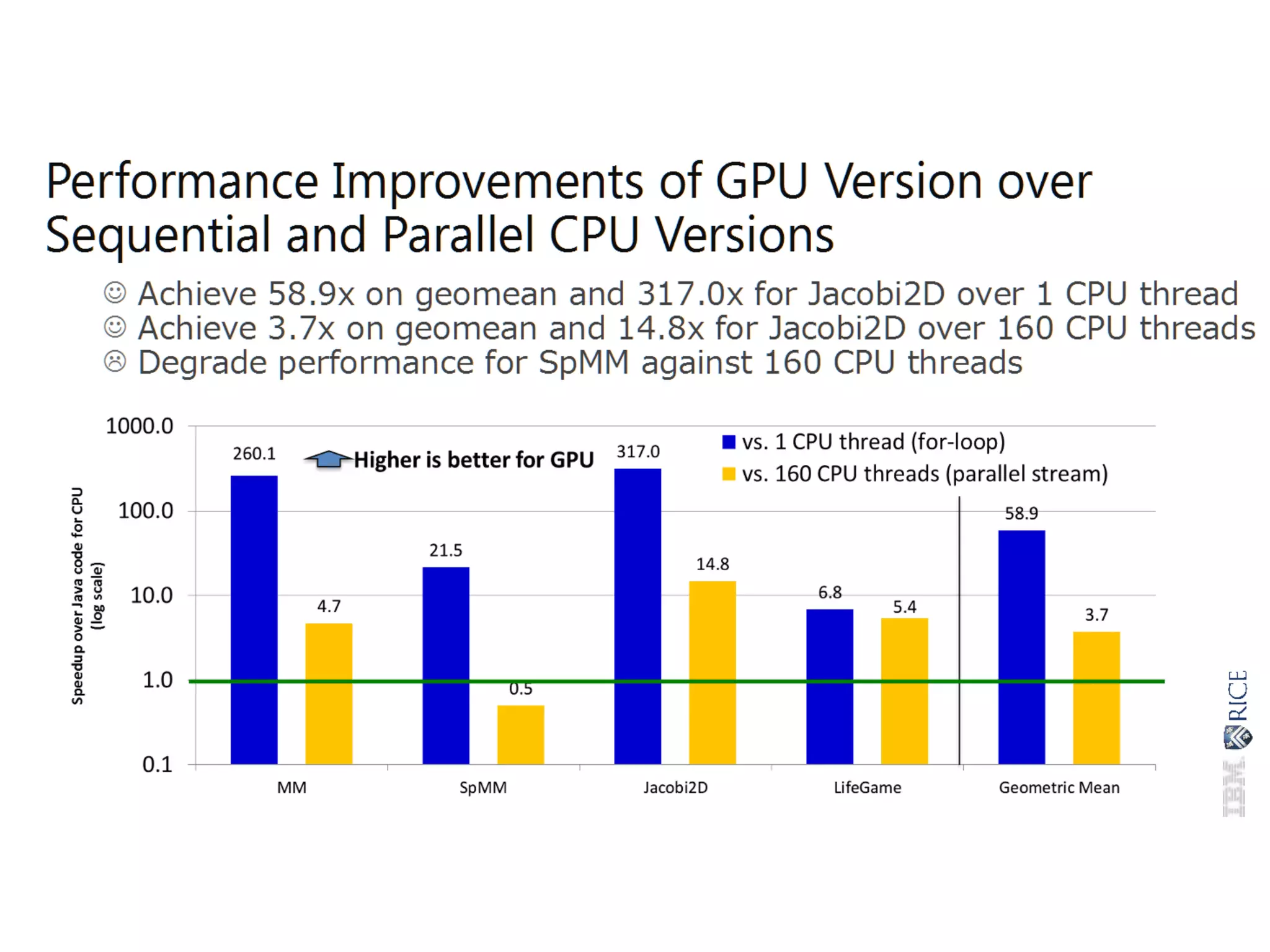




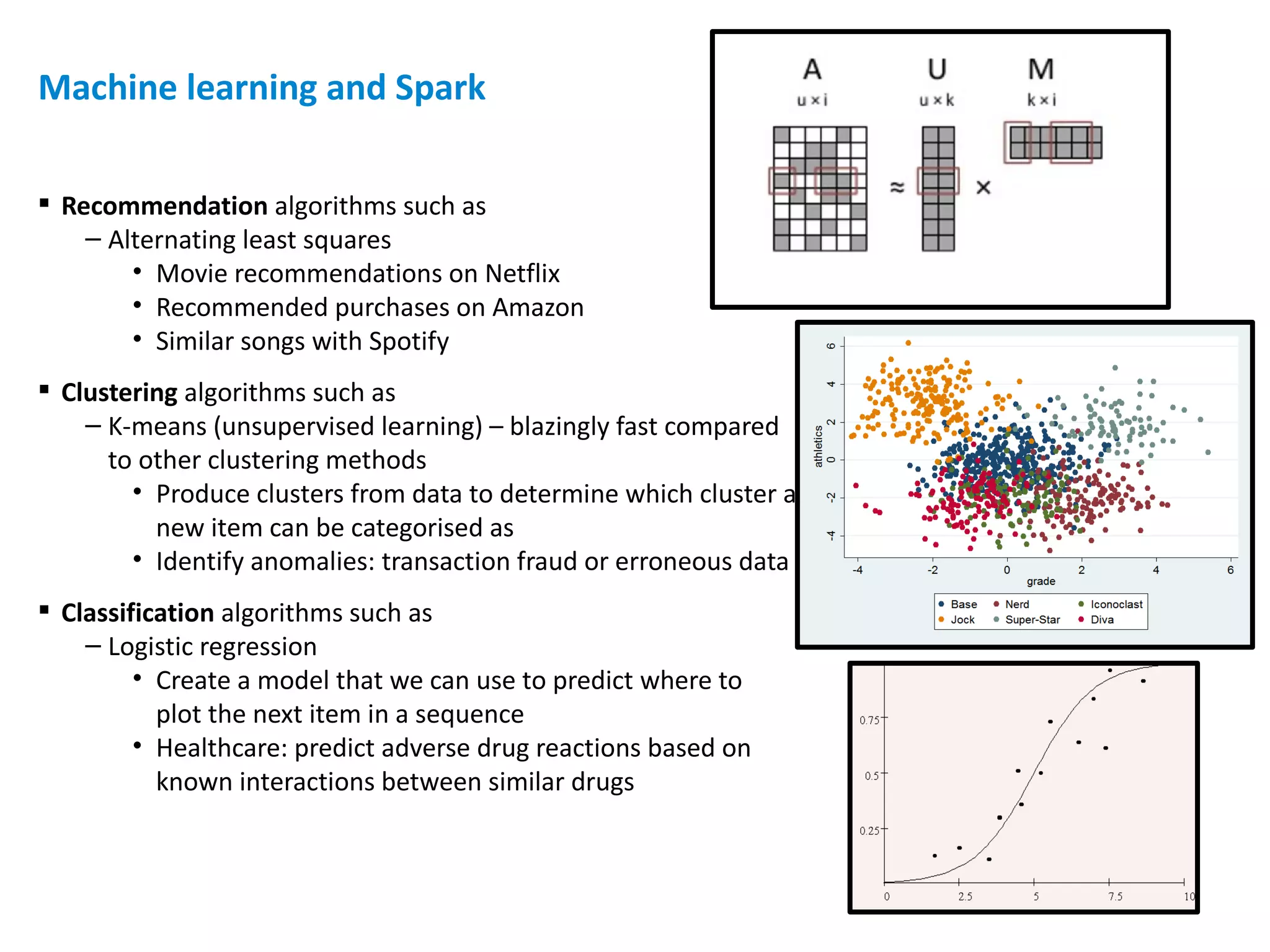
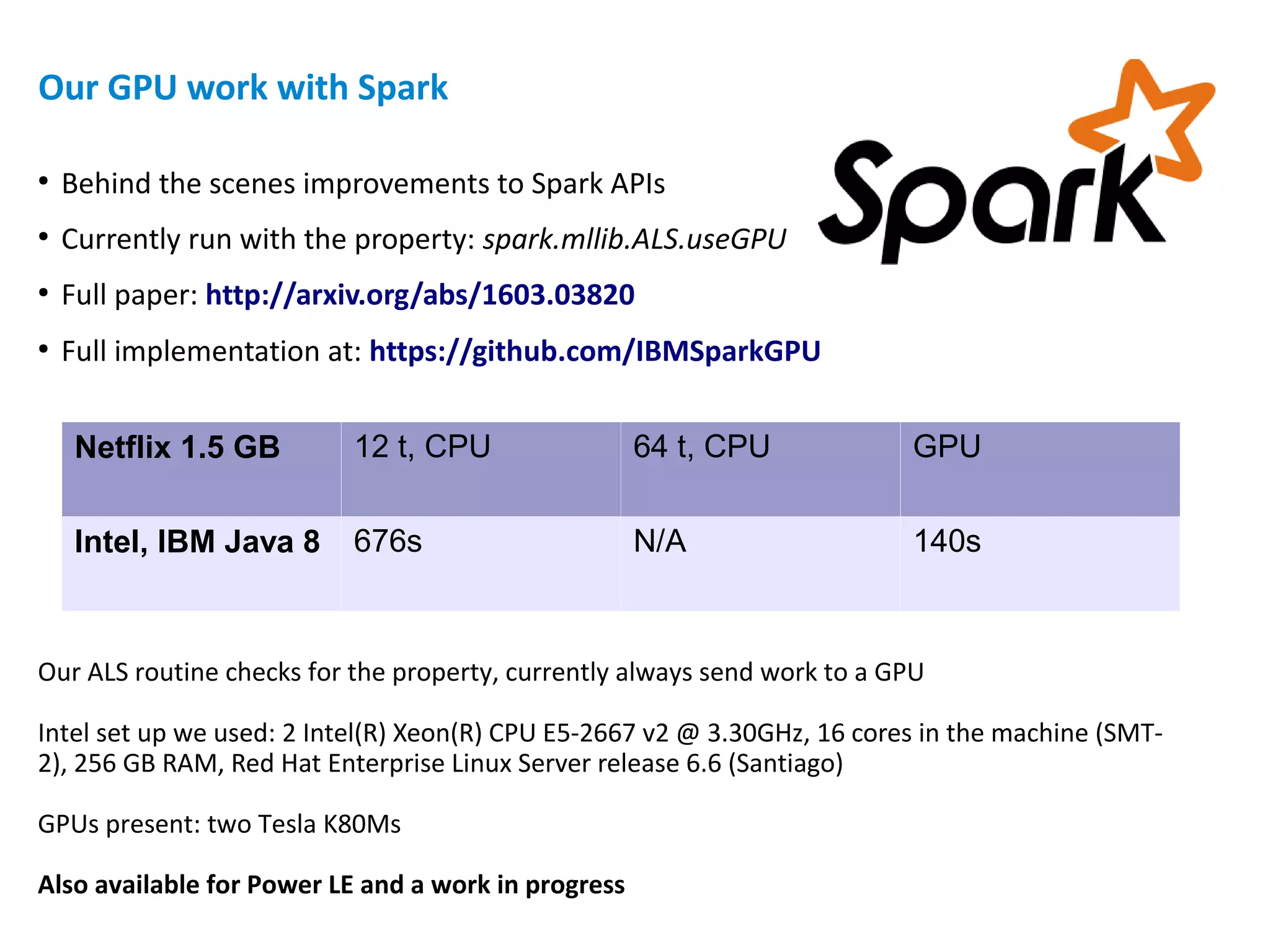





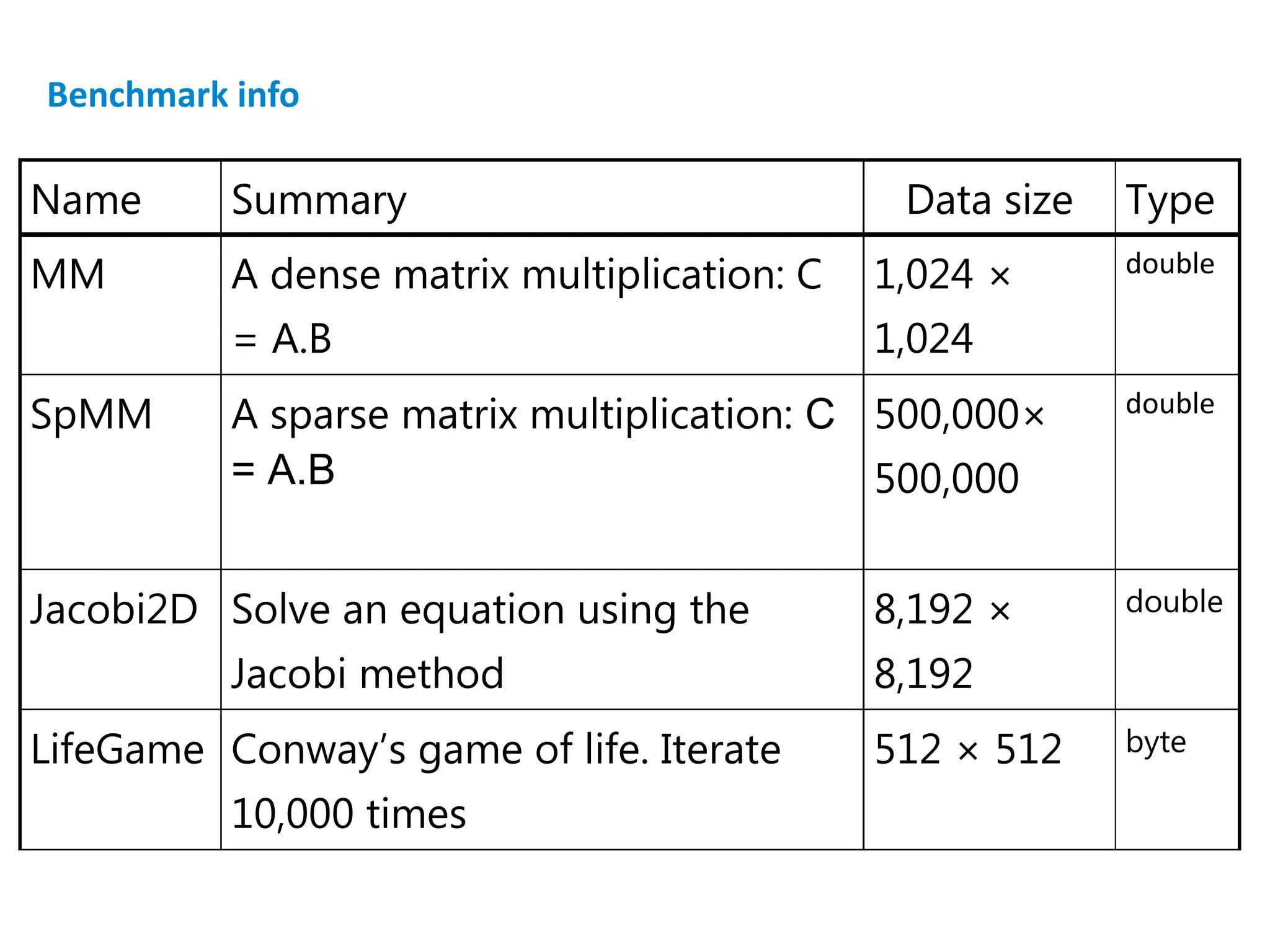


![Code in the demo – Sample.java part 1 of 3
import com.ibm.cuda.*;
import com.ibm.cuda.CudaKernel.*;
public class Sample {
private static final boolean PRINT_DATA = false;
private static int numElements;
private static int[] myData;
private static CudaBuffer buffer1;
private static CudaDevice device = new CudaDevice(0);
private static CudaModule module;
private static CudaKernel kernel;
private static CudaStream stream;
public static void main(String[] args) {
try {
module = new Loader().loadModule("AdamDoubler.fatbin", device);
kernel = new CudaKernel(module, "Cuda_cuda4j_AdamDoubler_Strider");
stream = new CudaStream(device);
doSmallProblem();
doMediumProblem();
doChunkingProblem();
} catch (CudaException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void doSmallProblem() throws Exception {
System.out.println("Doing the small sized problem");
numElements = 100;
myData = new int[numElements];
Util.fillWithInts(myData);
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
buffer1.copyFrom(myData);
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
}](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-35-2048.jpg)
![private static void doMediumProblem() throws Exception {
System.out.println("Doing the medium sized problem");
numElements = 5_000_000;
myData = new int[numElements];
Util.fillWithInts(myData);
// This is only when handling more than max blocks * max threads per kernel
// Grid dim is the number of blocks in the grid
// Block dim is the number of threads in a block
// buffer1 is how we'll use our data on the GPU
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
// myData is on CPU, transfer it
buffer1.copyFrom(myData);
// Our stream executes the kernel, can launch many streams at once
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
}
Code in the demo – Sample.java part 2 of 3](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-36-2048.jpg)
![private static void doChunkingProblem() throws Exception {
// I know 5m doesn't require chunking on the GPU but this does
System.out.println("Doing the too big to handle in one kernel problem");
numElements = 70_000_000;
myData = new int[numElements];
Util.fillWithInts(myData);
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
buffer1.copyFrom(myData);
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
// Check we can actually launch a kernel with this grid size
try {
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[numElements];
System.arraycopy(myData, 0, originalArrayCopy, 0, numElements);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
} catch (CudaException ce) {
if (ce.getMessage().equals("invalid argument")) {
System.out.println("it was invalid argument, too big!");
int maxThreadsPerBlockX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_BLOCK_DIM_X);
int maxBlocksPerGridX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_GRID_DIM_Y);
long maxThreadsPerGrid = maxThreadsPerBlockX * maxBlocksPerGridX;
// 67,107,840 on my Windows box
System.out.println("Max threads per grid: " + maxThreadsPerGrid);
long numElementsAtOnce = maxThreadsPerGrid;
long elementsDone = 0;
grid = new CudaGrid(maxBlocksPerGridX, maxThreadsPerBlockX, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
while (elementsDone < numElements) {
if ( (elementsDone + numElementsAtOnce) > numElements) {
numElementsAtOnce = numElements - elementsDone; // Just do the remainder
}
long toOffset = numElementsAtOnce + elementsDone;
// It's the byte offset not the element index offset
CudaBuffer slicedSection = buffer1.slice(elementsDone * Integer.BYTES, toOffset * Integer.BYTES);
Parameters kernelParams = new Parameters(2).set(0, slicedSection).set(1, numElementsAtOnce);
kernel.launch(grid, kernelParams);
elementsDone += numElementsAtOnce;
}
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
} else {
System.out.println(ce.getMessage());
}
}
}
Code in the demo – Sample.java part 3 of 3](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-37-2048.jpg)
![Code in the demo – Lambda.java part 1 of 2
import java.util.stream.IntStream;
public class Lambda {
private static long startTime = 0;
// -Xjit:enableGPU is our JVM option
public static void main(String[] args) {
boolean timeIt = true;
int numElements = 500_000_000;
int[] toDouble = new int[numElements];
Util.fillWithInts(toDouble);
myDoublerWithALambda(toDouble, timeIt);
double[] toHalf = new double[numElements];
Util.fillWithDoubles(toHalf);
myHalverWithALambda(toHalf, timeIt);
double[] toRandomFunc = new double[numElements];
Util.fillWithDoubles(toRandomFunc);
myRandomFuncWithALambda(toRandomFunc, timeIt);
}
private static void myDoublerWithALambda(int[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] * 2; // Done on GPU for us
});
if (timeIt) {
System.out.println("Done doubling with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-38-2048.jpg)
![private static void myHalverWithALambda(double[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] / 2; // Again on GPU
});
if (timeIt) {
System.out.println("Done halving with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}
private static void myRandomFuncWithALambda(double[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] * 3.142; // Double so we don't lose precision
});
if (timeIt) {
System.out.println("Done with the random func with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}
}
Code in the demo – Lambda.java part 2 of 2](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-39-2048.jpg)
![Code in the demo – Util.java part 1 of 2
import com.ibm.cuda.*;
public class Util {
protected static void fillWithInts(int[] toFill) {
for (int i = 0; i < toFill.length; i++) {
toFill[i] = i;
}
}
protected static void fillWithDoubles(double[] toFill) {
for (int i = 0; i < toFill.length; i++) {
toFill[i] = i;
}
}
protected static void printArray(int[] toPrint) {
System.out.println();
for (int i = 0; i < toPrint.length; i++) {
if (i == toPrint.length - 1) {
System.out.print(toPrint[i] + ".");
} else {
System.out.print(toPrint[i] + ", ");
}
}
System.out.println();
}
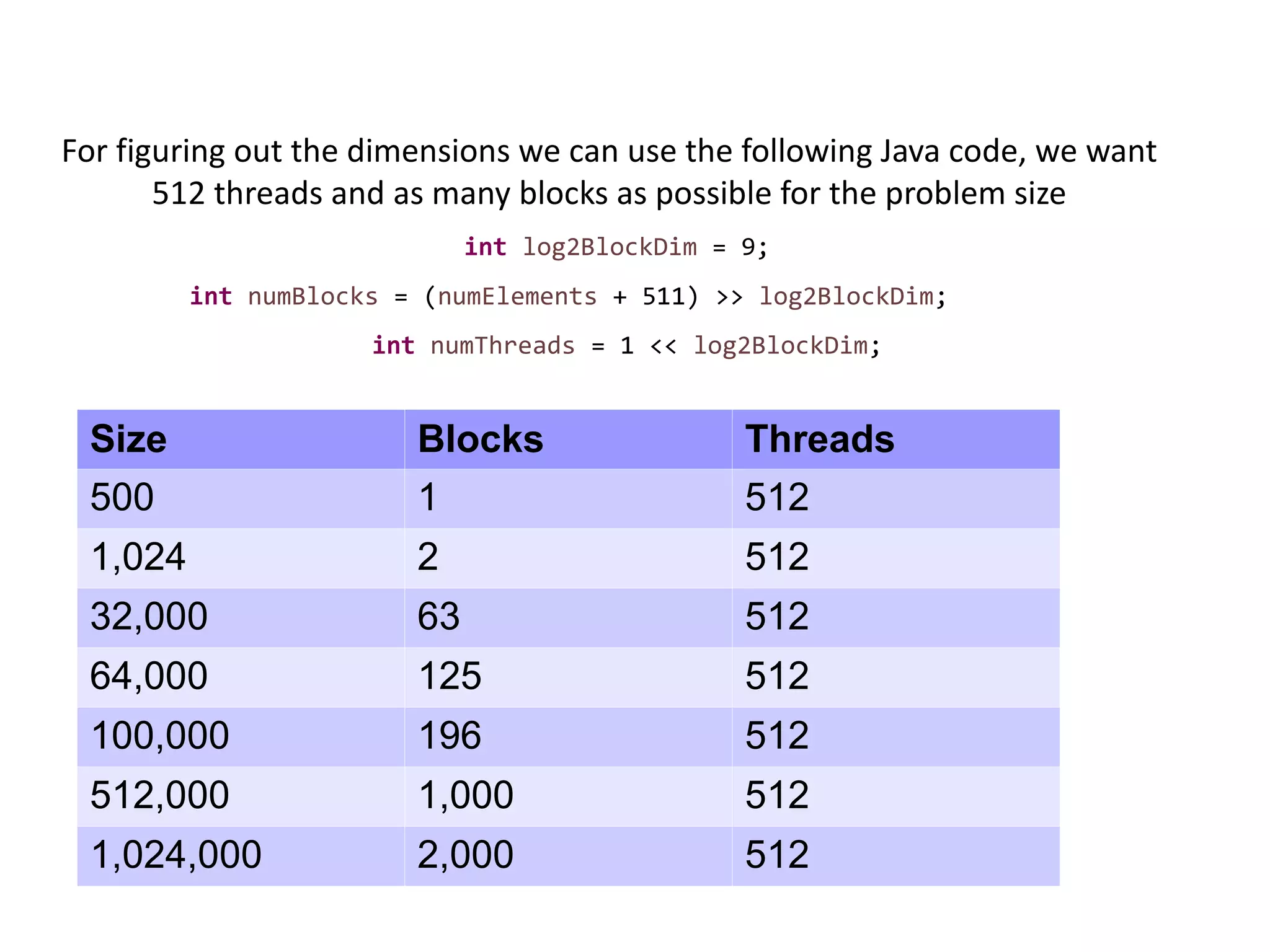
protected static CudaGrid makeGrid(int numElements, CudaStream stream) {
int numThreads = 512;
int numBlocks = (numElements + (numThreads - 1)) / numThreads;
return new CudaGrid(numBlocks, numThreads, stream);
}](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-40-2048.jpg)
![/*
* Array will have been doubled at this point
*/
protected static void checkArrayResultsDoubler(int[] toCheck, int[] originalArray) {
long errorCount = 0;
// Check result, data has been copied back here
if (toCheck.length != originalArray.length) {
System.err.println("Something's gone horribly wrong, different array length");
}
for (int i = 0; i < originalArray.length; i++) {
if (toCheck[i] != (originalArray[i] * 2) ) {
errorCount++;
/*
System.err.println("Got an error, " + originalArray[i] +
" is incorrect: wasn't doubled correctly!" +
" Got " + toCheck[i] + " but should be " + originalArray[i] * 2);
*/
} else {
//System.out.println("Correct, doubled " + originalArray[i] + " and it became " + toCheck[i]);
}
}
System.err.println("Incorrect results: " + errorCount);
}
}
Code in the demo – Util.java part 2 of 2](https://image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-41-2048.jpg)











![ Windows CUDA 7.5 SDK
New text file: Hola.cu, create a sequence of characters, send to the GPU, run our program, copy the
result back and get a result
nvcc Hola.cu (build it), run the a.exe next
Unsafe, we're in the CUDA world now! Can get errors on Windows and seg faults on Linux
char myHostChars[16] = "Hello0000000";
int myHostOffsets[16] = {0,0,0,0,0,32,77,97,108,97,103,97};
shar* myDeviceChars, myDeviceInts;
cudaMalloc(&myDeviceChars, numBytesForChars); // Omitted amount calculating
cudaMalloc(&myDeviceInts, numBytesForOffsets);
cudaMemcpy(myDeviceChars, myHostChars, numBytesForChars,
cudaMemcpyHostToDevice);
cudaMemcpy(myDeviceInts, myHostOffsets, numBytesForOffsets,
cudaMemcpyHostToDevice);
myKernel<<<dimGrid, dimBlock>>>(myDeviceChars, myDeviceInts);
cudaMemcpy(myHostChars, myDeviceChars, numBytesForChars,
cudaMemcpyDeviceToHost);
Thanks to Ingemar Ragnehalm for this idea: http://computer-
graphics.se/hello-world-for-cuda.html
Hello Malaga](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-11-2048.jpg)
![__global__ void a(char* inputChars,int* offsetAmounts){
inputChars[threadIdx.x]+= offsetAmounts[threadIdx.x];
}
__global__ : it's a function we can call on the host, it's available to be
called from everywhere
What's a grid again?
A kernel runs on a grid and it's how we can run many threads that work
on different parts of the data
char*? A pointer to a bunch of characters we'll send to the GPU
int*? A pointer to a bunch of ints we'll send to the GPU
threadIdx.x?
We use this as an index to our array, remember lots of threads run on
the GPU. Access each item for our example here](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-12-2048.jpg)






















![Code in the demo – Sample.java part 1 of 3
import com.ibm.cuda.*;
import com.ibm.cuda.CudaKernel.*;
public class Sample {
private static final boolean PRINT_DATA = false;
private static int numElements;
private static int[] myData;
private static CudaBuffer buffer1;
private static CudaDevice device = new CudaDevice(0);
private static CudaModule module;
private static CudaKernel kernel;
private static CudaStream stream;
public static void main(String[] args) {
try {
module = new Loader().loadModule("AdamDoubler.fatbin", device);
kernel = new CudaKernel(module, "Cuda_cuda4j_AdamDoubler_Strider");
stream = new CudaStream(device);
doSmallProblem();
doMediumProblem();
doChunkingProblem();
} catch (CudaException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void doSmallProblem() throws Exception {
System.out.println("Doing the small sized problem");
numElements = 100;
myData = new int[numElements];
Util.fillWithInts(myData);
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
buffer1.copyFrom(myData);
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
}](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-35-2048.jpg)
![private static void doMediumProblem() throws Exception {
System.out.println("Doing the medium sized problem");
numElements = 5_000_000;
myData = new int[numElements];
Util.fillWithInts(myData);
// This is only when handling more than max blocks * max threads per kernel
// Grid dim is the number of blocks in the grid
// Block dim is the number of threads in a block
// buffer1 is how we'll use our data on the GPU
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
// myData is on CPU, transfer it
buffer1.copyFrom(myData);
// Our stream executes the kernel, can launch many streams at once
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
}
Code in the demo – Sample.java part 2 of 3](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-36-2048.jpg)
![private static void doChunkingProblem() throws Exception {
// I know 5m doesn't require chunking on the GPU but this does
System.out.println("Doing the too big to handle in one kernel problem");
numElements = 70_000_000;
myData = new int[numElements];
Util.fillWithInts(myData);
buffer1 = new CudaBuffer(device, numElements * Integer.BYTES);
buffer1.copyFrom(myData);
CudaGrid grid = Util.makeGrid(numElements, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
// Check we can actually launch a kernel with this grid size
try {
Parameters kernelParams = new Parameters(2).set(0, buffer1).set(1, numElements);
kernel.launch(grid, kernelParams);
int[] originalArrayCopy = new int[numElements];
System.arraycopy(myData, 0, originalArrayCopy, 0, numElements);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
} catch (CudaException ce) {
if (ce.getMessage().equals("invalid argument")) {
System.out.println("it was invalid argument, too big!");
int maxThreadsPerBlockX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_BLOCK_DIM_X);
int maxBlocksPerGridX = device.getAttribute(CudaDevice.ATTRIBUTE_MAX_GRID_DIM_Y);
long maxThreadsPerGrid = maxThreadsPerBlockX * maxBlocksPerGridX;
// 67,107,840 on my Windows box
System.out.println("Max threads per grid: " + maxThreadsPerGrid);
long numElementsAtOnce = maxThreadsPerGrid;
long elementsDone = 0;
grid = new CudaGrid(maxBlocksPerGridX, maxThreadsPerBlockX, stream);
System.out.println("Kernel grid: <<<" + grid.gridDimX + ", " + grid.blockDimX + ">>>");
while (elementsDone < numElements) {
if ( (elementsDone + numElementsAtOnce) > numElements) {
numElementsAtOnce = numElements - elementsDone; // Just do the remainder
}
long toOffset = numElementsAtOnce + elementsDone;
// It's the byte offset not the element index offset
CudaBuffer slicedSection = buffer1.slice(elementsDone * Integer.BYTES, toOffset * Integer.BYTES);
Parameters kernelParams = new Parameters(2).set(0, slicedSection).set(1, numElementsAtOnce);
kernel.launch(grid, kernelParams);
elementsDone += numElementsAtOnce;
}
int[] originalArrayCopy = new int[myData.length];
System.arraycopy(myData, 0, originalArrayCopy, 0, myData.length);
buffer1.copyTo(myData);
Util.checkArrayResultsDoubler(myData, originalArrayCopy);
} else {
System.out.println(ce.getMessage());
}
}
}
Code in the demo – Sample.java part 3 of 3](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-37-2048.jpg)
![Code in the demo – Lambda.java part 1 of 2
import java.util.stream.IntStream;
public class Lambda {
private static long startTime = 0;
// -Xjit:enableGPU is our JVM option
public static void main(String[] args) {
boolean timeIt = true;
int numElements = 500_000_000;
int[] toDouble = new int[numElements];
Util.fillWithInts(toDouble);
myDoublerWithALambda(toDouble, timeIt);
double[] toHalf = new double[numElements];
Util.fillWithDoubles(toHalf);
myHalverWithALambda(toHalf, timeIt);
double[] toRandomFunc = new double[numElements];
Util.fillWithDoubles(toRandomFunc);
myRandomFuncWithALambda(toRandomFunc, timeIt);
}
private static void myDoublerWithALambda(int[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] * 2; // Done on GPU for us
});
if (timeIt) {
System.out.println("Done doubling with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-38-2048.jpg)
![private static void myHalverWithALambda(double[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] / 2; // Again on GPU
});
if (timeIt) {
System.out.println("Done halving with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}
private static void myRandomFuncWithALambda(double[] myArray, boolean timeIt) {
if (timeIt) startTime = System.currentTimeMillis();
IntStream.range(0, myArray.length).parallel().forEach(i -> {
myArray[i] = myArray[i] * 3.142; // Double so we don't lose precision
});
if (timeIt) {
System.out.println("Done with the random func with a lambda, time taken: " +
(System.currentTimeMillis() - startTime) + " milliseconds");
}
}
}
Code in the demo – Lambda.java part 2 of 2](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-39-2048.jpg)
![Code in the demo – Util.java part 1 of 2
import com.ibm.cuda.*;
public class Util {
protected static void fillWithInts(int[] toFill) {
for (int i = 0; i < toFill.length; i++) {
toFill[i] = i;
}
}
protected static void fillWithDoubles(double[] toFill) {
for (int i = 0; i < toFill.length; i++) {
toFill[i] = i;
}
}
protected static void printArray(int[] toPrint) {
System.out.println();
for (int i = 0; i < toPrint.length; i++) {
if (i == toPrint.length - 1) {
System.out.print(toPrint[i] + ".");
} else {
System.out.print(toPrint[i] + ", ");
}
}
System.out.println();
}
protected static CudaGrid makeGrid(int numElements, CudaStream stream) {
int numThreads = 512;
int numBlocks = (numElements + (numThreads - 1)) / numThreads;
return new CudaGrid(numBlocks, numThreads, stream);
}](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-40-2048.jpg)
![/*
* Array will have been doubled at this point
*/
protected static void checkArrayResultsDoubler(int[] toCheck, int[] originalArray) {
long errorCount = 0;
// Check result, data has been copied back here
if (toCheck.length != originalArray.length) {
System.err.println("Something's gone horribly wrong, different array length");
}
for (int i = 0; i < originalArray.length; i++) {
if (toCheck[i] != (originalArray[i] * 2) ) {
errorCount++;
/*
System.err.println("Got an error, " + originalArray[i] +
" is incorrect: wasn't doubled correctly!" +
" Got " + toCheck[i] + " but should be " + originalArray[i] * 2);
*/
} else {
//System.out.println("Correct, doubled " + originalArray[i] + " and it became " + toCheck[i]);
}
}
System.err.println("Incorrect results: " + errorCount);
}
}
Code in the demo – Util.java part 2 of 2](https://crownmelresort.com/image.slidesharecdn.com/adamroberts-gpusjavabigdata-160707122238/75/Using-GPUs-to-handle-Big-Data-with-Java-by-Adam-Roberts-41-2048.jpg)



The document discusses how to leverage GPUs for big data processing using Java, detailing GPU programming concepts, traditional CUDA programming, and integrating CUDA with Java through JNI. It outlines the advantages of parallel processing with GPUs, including performance benefits, and provides code examples for using GPU functions. Additionally, it references the IBM Java API for GPUs and discusses practical applications within Spark for machine learning and recommendation algorithms.






















































































