Download as PDF, PPTX

![A psychological point of view
• Transfer of Learning (学习迁移)in
Educa7on and Psychology
– The study of dependency of human conduct,
learning or performance on prior experience.
– [Thorndike and Woodworth, 1901] explored how individuals would
transfer in one context to another context that share similar
characteristics.
• E.g.
! C++ " Java
! Math/Physics " Computer Science/Economics
2](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-2-2048.jpg)


![Transfer Learning
Different fields
• Transfer learning for
reinforcement learning.
[Taylor and Stone, Transfer
Learning for Reinforcement
Learning Domains: A Survey,
JMLR 2009]
• Transfer learning for
classifica7on, and
regression problems.
[Pan and Yang, A Survey on
Transfer Learning, IEEE TKDE
2010]
6
Focus!](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-6-2048.jpg)






![Instance-based Approaches
Case I (cont.)
22
Correcting Sample Selection Bias / Covariate Shift
[Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press 2009]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-22-2048.jpg)
![Instance-based Approaches
Correcting sample selection bias (cont.)
• The distribu7on of the selector variable maps
the target onto the source distribu7on
23
! Label instances from the source domain with label 1
! Label instances from the target domain with label 0
! Train a binary classifier
[Zadrozny, ICML-04]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-23-2048.jpg)
![Instance-based Approaches
Kernel mean matching (KMM)
Maximum Mean Discrepancy (MMD)
[Alex Smola, Arthur Gretton and Kenji Kukumizu, ICML-08 tutorial]
24](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-24-2048.jpg)
![Instance-based Approaches
Direct density ratio estimation
25
[Sugiyama etal., NIPS-07, Kanamori etal., JMLR-09]
KL divergence loss Least squared loss
[Sugiyama etal., NIPS-07] [Kanamori etal., JMLR-09]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-25-2048.jpg)

![Instance-based Approaches
Case II (cont.)
! TrAdaBoost [Dai etal ICML-07]
– For each boosting iteration,
# Use the same strategy as AdaBoost to
update the weights of target domain data.
# Use a new mechanism to decrease the
weights of misclassified source domain
data.
27](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-27-2048.jpg)


![Feature-based Approaches
Encode application-specific knowledge (cont.)
31
compact sharp blurry hooked realistic boring
1 1 0 0 0 0
0 1 0 0 0 0
0 0 1 0 0 0
( ) sgn( ), [1,1, 1,0,0,0]T
y f x w x w= = ⋅ = −
compact sharp blurry hooked realistic boring
0 0 0 1 0 0
0 0 0 1 1 0
0 0 0 0 0 1
Electronics
Video Game
Training
Prediction](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-31-2048.jpg)

![Feature-based Approaches
Encode application-specific knowledge (cont.)
! How to identify pivot features?
! Term frequency on both domains
! Mutual information between features and labels (source
domain)
! Mutual information on between features and domains
! How to utilize pivots to align features across domains?
! Structural Correspondence Learning (SCL) [Biltzer etal.
EMNLP-06]
! Spectral Feature Alignment (SFA) [Pan etal. WWW-10]
34](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-34-2048.jpg)

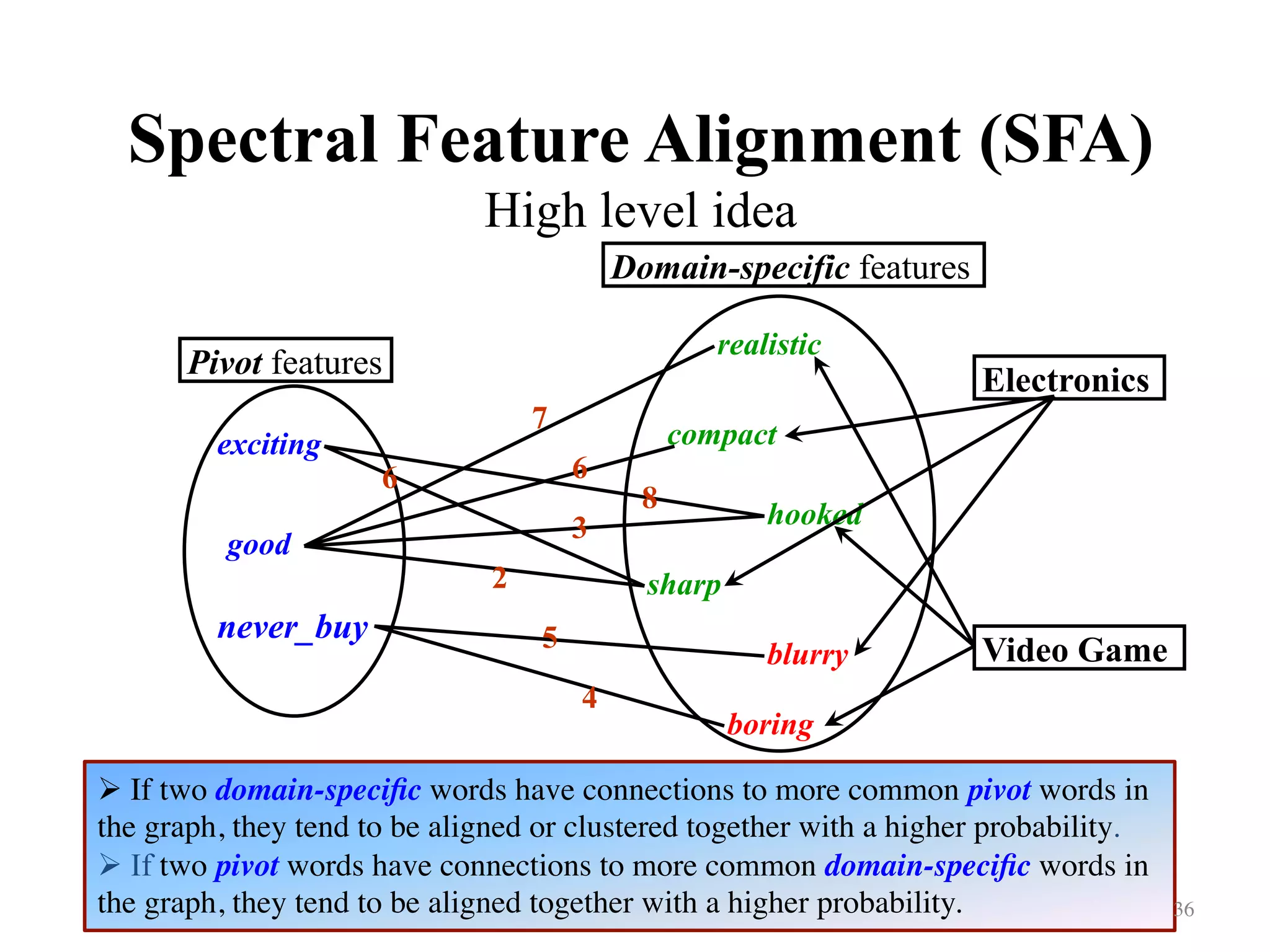
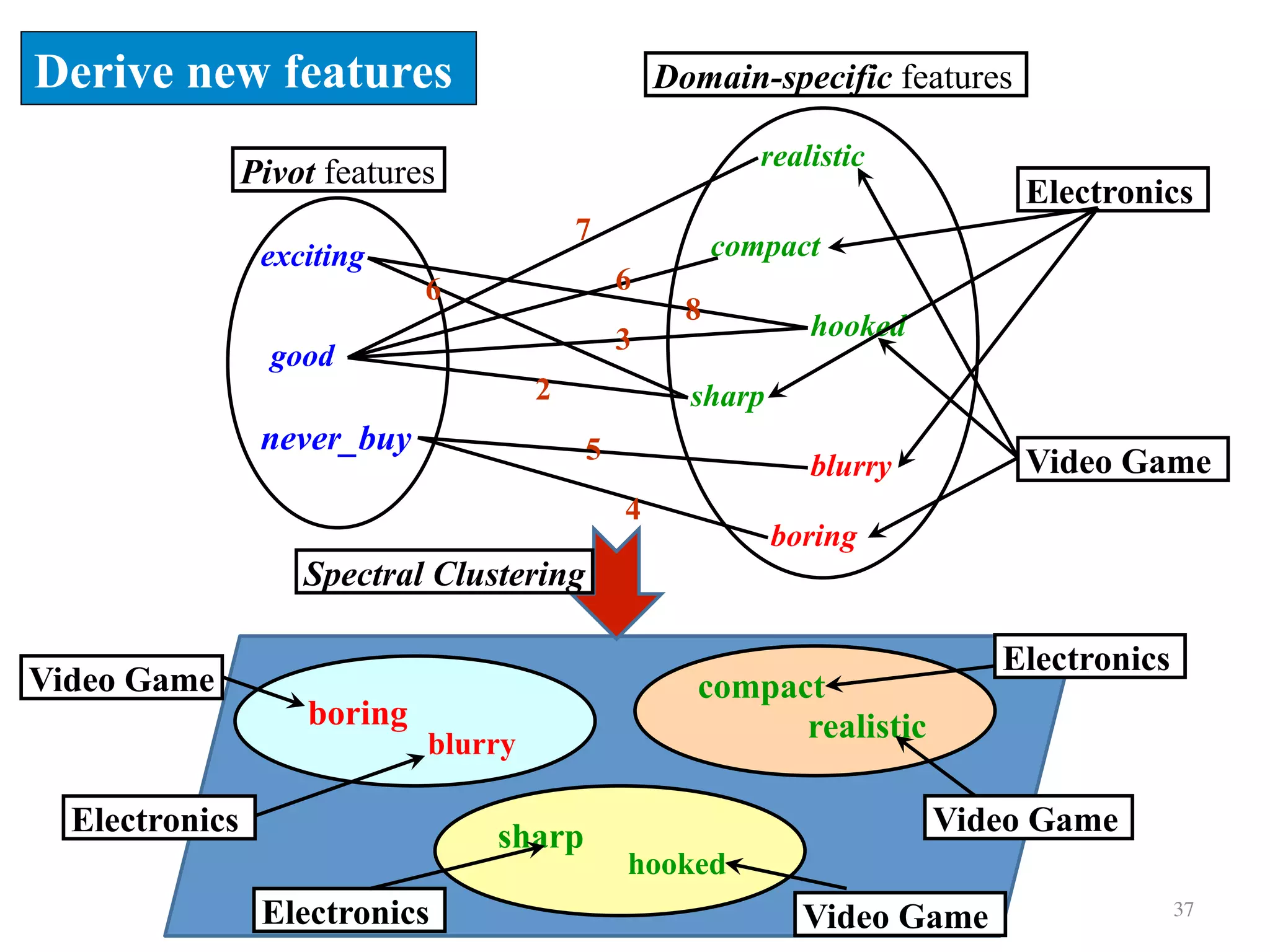
![Spectral Feature Alignment (SFA)
Derive new features (cont.)
sharp/hooked compact/realistic blurry/boring
1 1 0
1 0 0
0 0 1
38
( ) sgn( ), [1,1, 1]T
y f x w x w= = ⋅ = −
sharp/hooked compact/realistic blurry/boring
1 0 0
1 1 0
0 0 1
Electronics
Video Game
Training
Prediction](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-38-2048.jpg)

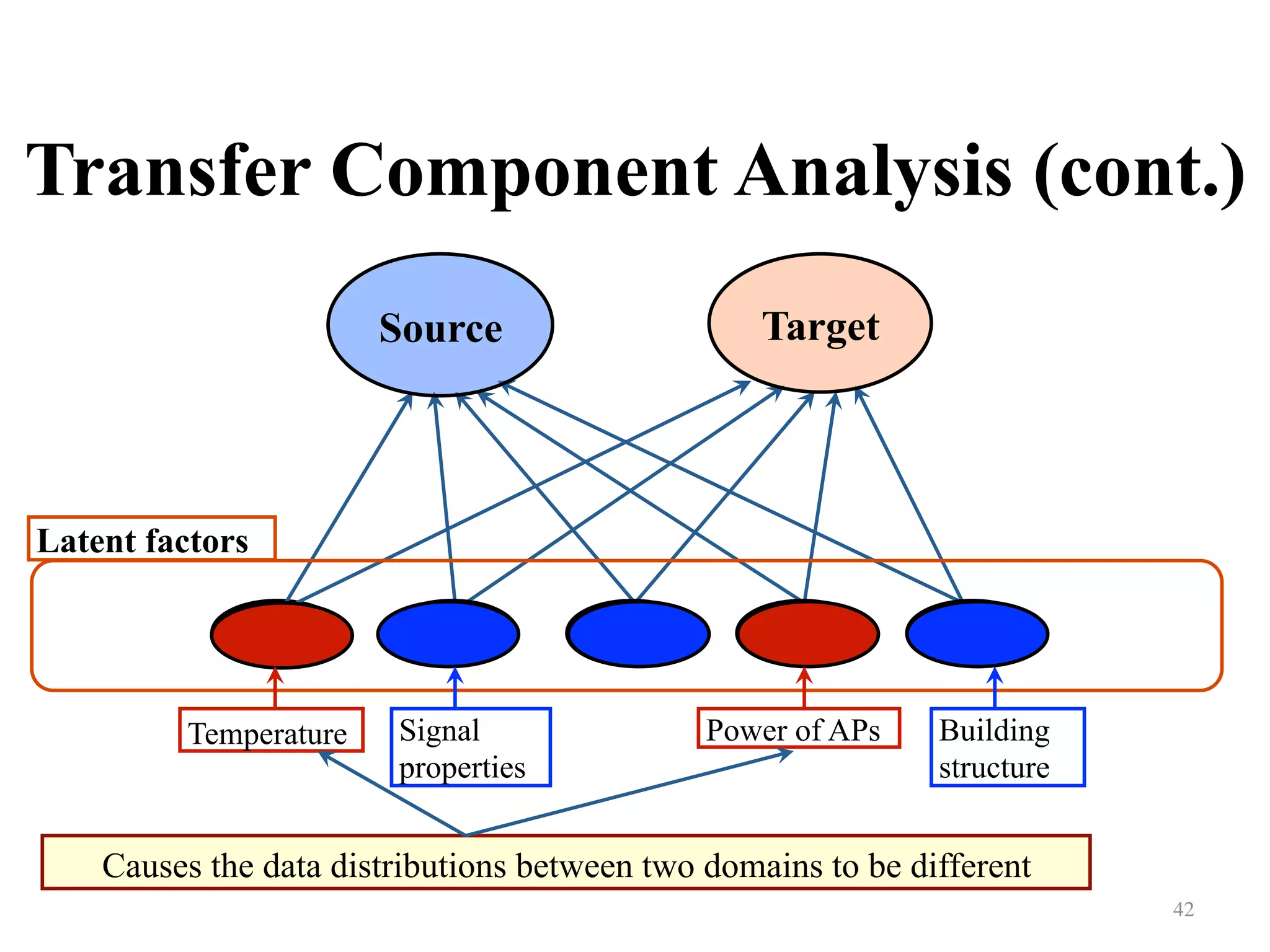
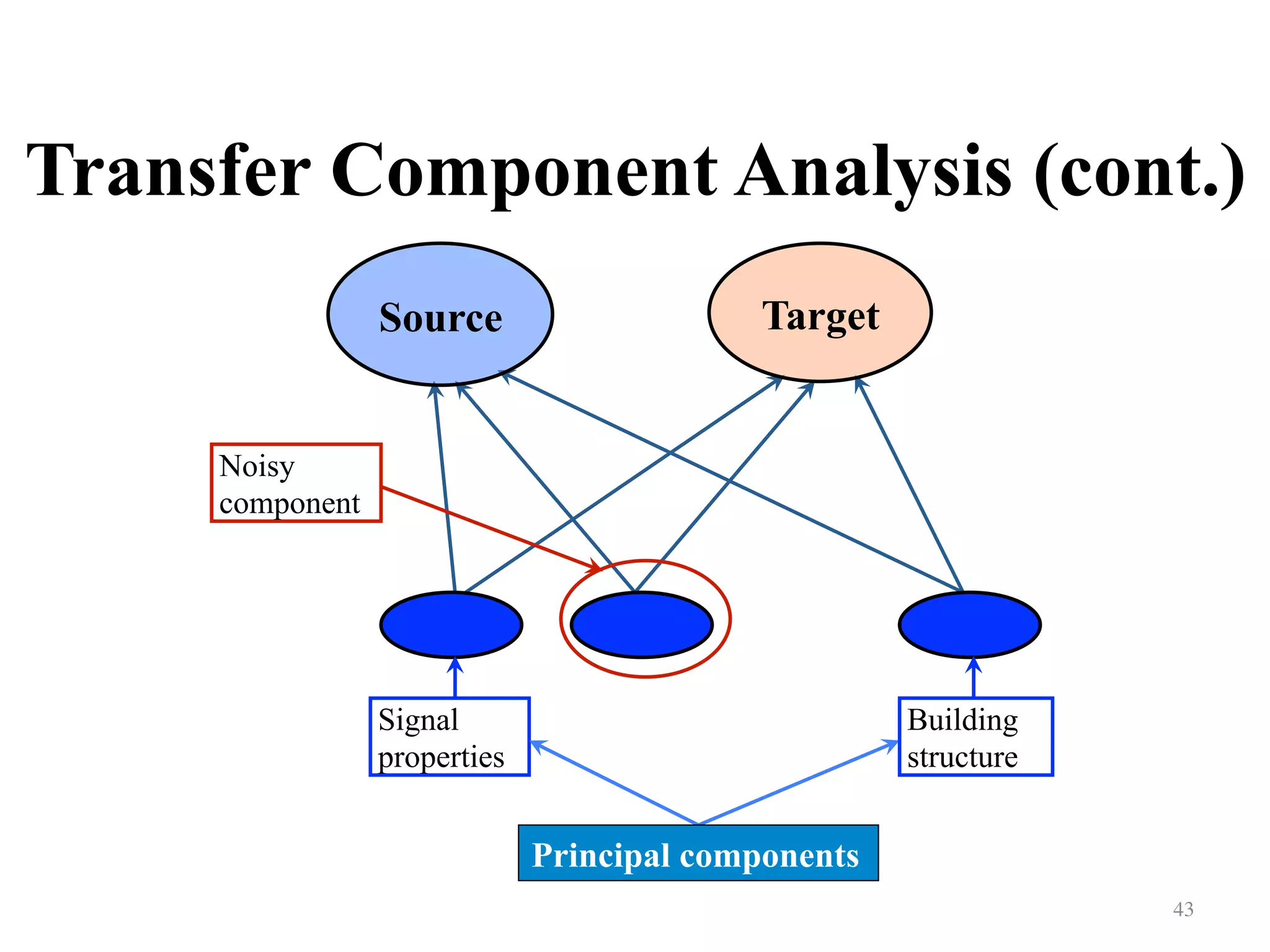
![Feature-based Approaches
Transfer Component Analysis [Pan etal., IJCAI-09, TNN-11]
41
TargetSource
Latent factors
Temperature Signal
properties
Building
structure
Power of APs
Motivation](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-41-2048.jpg)


![Feature-based Approaches
Self-taught Feature Learning (Andrew Ng. et al.)
! Intuition: Useful higher-level features can be learned from
unlabeled data.
! Steps:
1) Learn higher-level features from a lot of unlabeled data.
2) Use the learned higher-level features to represent the data of the
target task.
3) Train models from the new representations of the target task
(supervised)
! How to learn higher-level features
# Sparse Coding [Raina etal., 2007]
# Deep learning [Glorot etal., 2011]
48](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-48-2048.jpg)

![Multi-task Learning
Assumption:
If tasks are related, they may share similar parameter vectors.
For example, [Evgeniou and Pontil, KDD-04]
50
Common part
Specific part for individual task](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-50-2048.jpg)
![Mul7-task Feature Learning
51
[Argyriou etal., NIPS-07]
[Ando and Zhang, JMLR-05]
[Ji etal, KDD-08]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-51-2048.jpg)


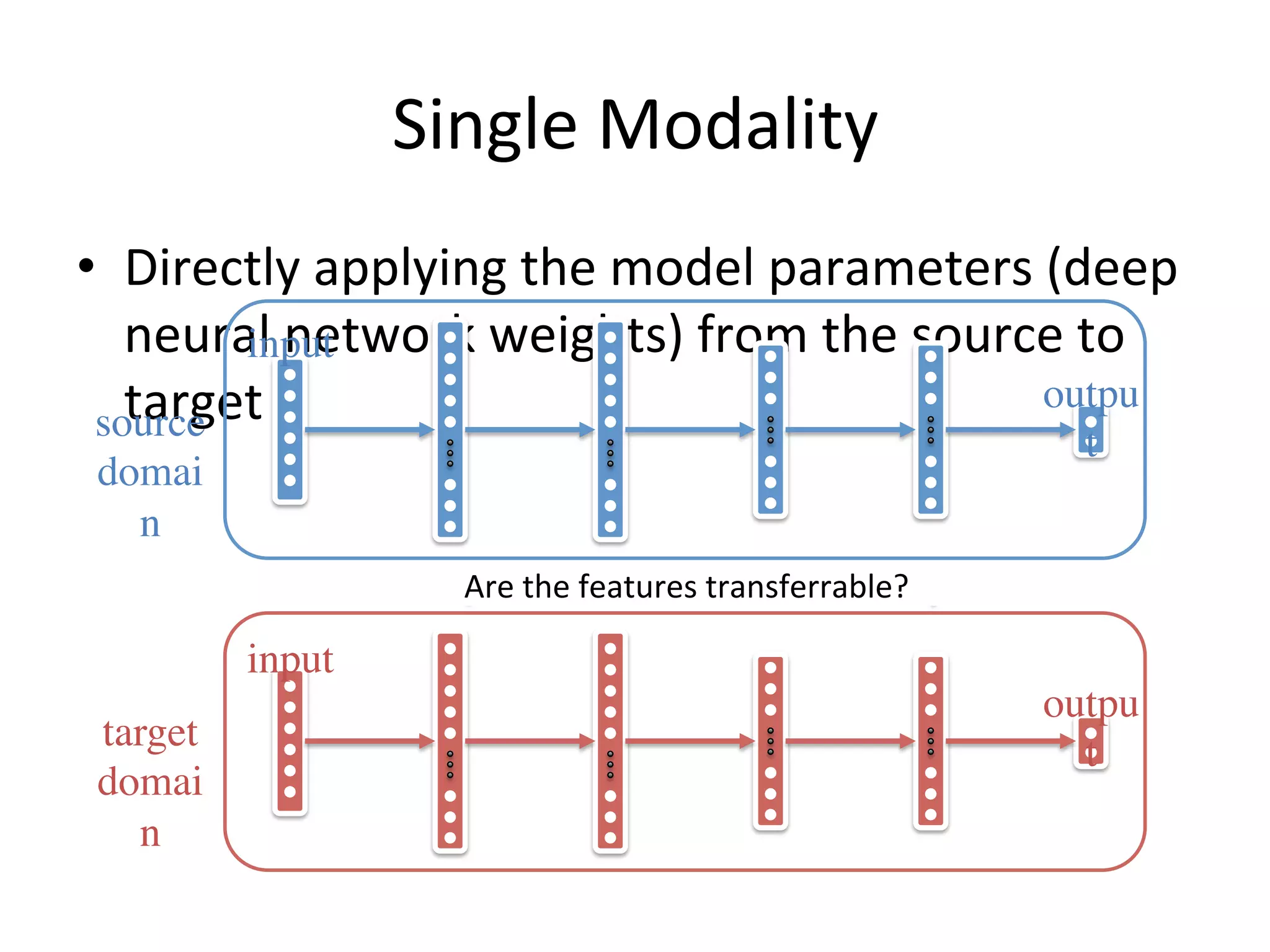
![DASH-N [1]
Finetuning [2,3]
SCNN [4]
Overview
• Overview
supervised unsupervised
single
modality
multiple
modalities
[5]
DLID [6]
DCC [7]
DAN [8]
BA [9]
SHL-MDNN [10]
ST [11]
Are there
labelled
target
data?
Are dimensions of source
and target domains equal?
[12] Ngiam, Jiquan, et al. "Multimodal deep
learning." ICML. 2011.
[13] Srivastava, Nitish, and Ruslan
Salakhutdinov. "Multimodal learning with deep
Boltzmann machines." JMLR. 2014
[14] Sohn, Kihyuk, Wenling Shang, and Honglak
Lee. "Improved multimodal deep learning
with variation of information." NIPS. 2014.
DBN [12]
DBM [13]
MDRNN [14]
[5] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio.
"Domain adaptation for large-scale sentiment
classification: A deep learning approach." ICML. 2011.
[6] Chopra, Sumit, Suhrid Balakrishnan, and
Raghuraman Gopalan. "Dlid: Deep learning for domain
adaptation by interpolating between domains." ICML.
2013.
[7] Tzeng, Eric, et al. "Deep domain confusion:
Maximizing for domain invariance." arXiv
preprint arXiv:1412.3474. 2014.
[8] Long, Mingsheng, and Jianmin Wang. "Learning
transferable features with deep adaptation
networks." arXiv preprint arXiv:1502.02791. 2015.
[9] Ganin, Yaroslav, and Victor Lempitsky.
"Unsupervised Domain Adaptation by
Backpropagation." ICML. 2015.
[10] Huang, Jui-Ting, et al. "Cross-language
knowledge transfer using multilingual deep
neural network with shared hidden
layers." ICASSP. 2013.
[11] Gupta, Saurabh, Judy Hoffman, and
Jitendra Malik. "Cross Modal
Distillation for Supervision Transfer."
arXiv preprint arXiv:1507.00448. 2015.
[1] Nguyen, Hien V., et al. "Joint hierarchical
domain adaptation and feature
learning." PAMI. 2013.
[2] Oquab, Maxime, et al. "Learning and
transferring mid-level image representations
using convolutional neural networks." CVPR
2014.
[3] Yosinski, Jason, et al. "How transferable
are features in deep neural networks?." NIPS
2014.
[4] Tzeng, Eric, et al. "Simultaneous
deep transfer across domains and
tasks." CVPR. 2015.](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-56-2048.jpg)
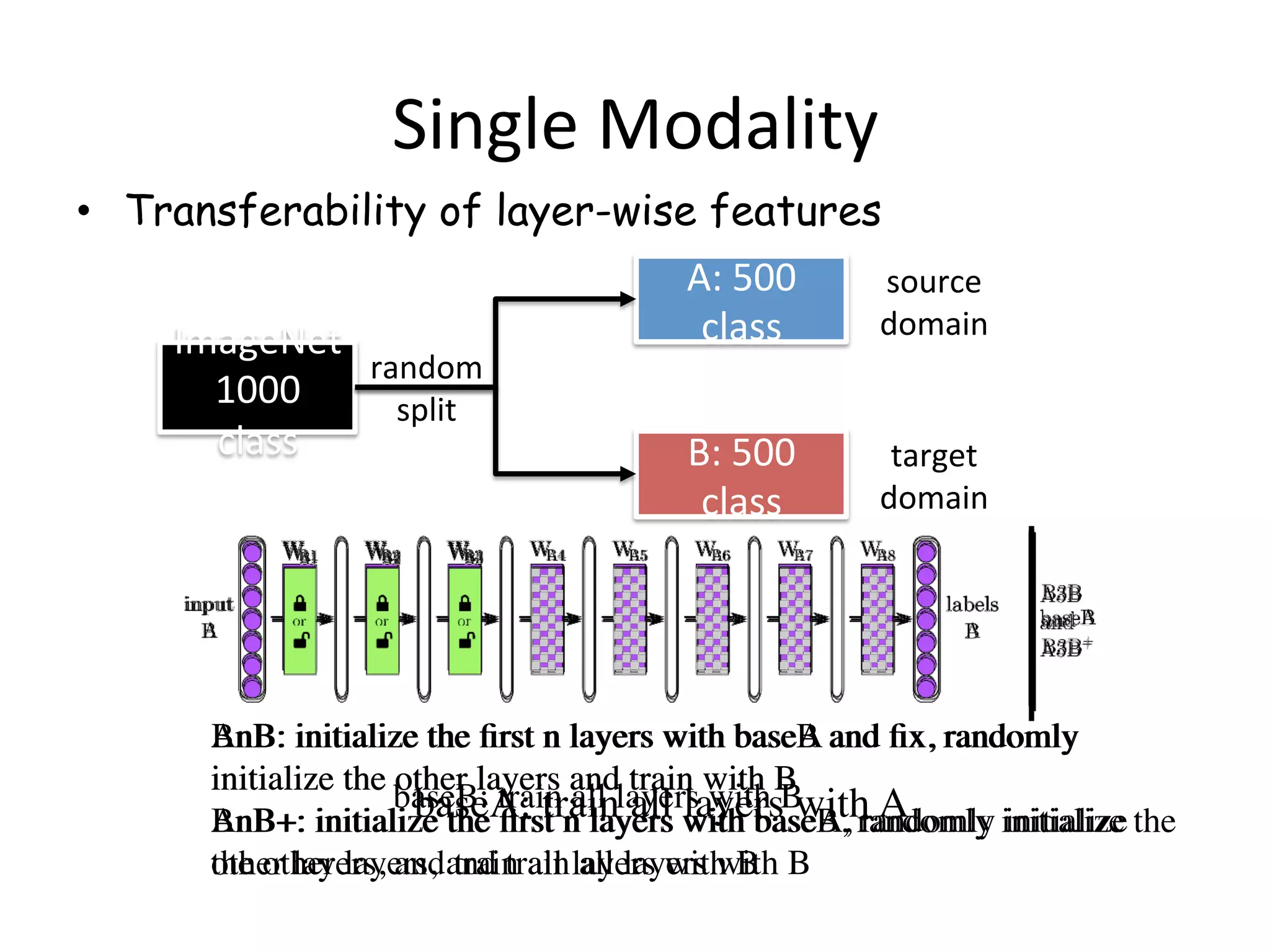
![Single Modality
• Transferability of layer-wise features
[3]
Conclusion 1: lower layer features are more general and transferrable, and higher
layer features are more specific and non-transferrable.
Conclusion 2: transferring features + fine-tuning always improve generalization. What if we do not have any labelled data to finetune in the target domain?
What happens if the source and target domain are very dissimilar?
ImageNet is not
randomly split, but
into A = {man-made
classes} and
B = {natural classes}](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-59-2048.jpg)
![Single Modality
• Overall training objec7ve
• Domain distance losses
– Maximum Mean Discrepancy [7]
source domain classification lossdomain distance loss
a particular representation, e.g. the representation after 5th
layer](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-61-2048.jpg)
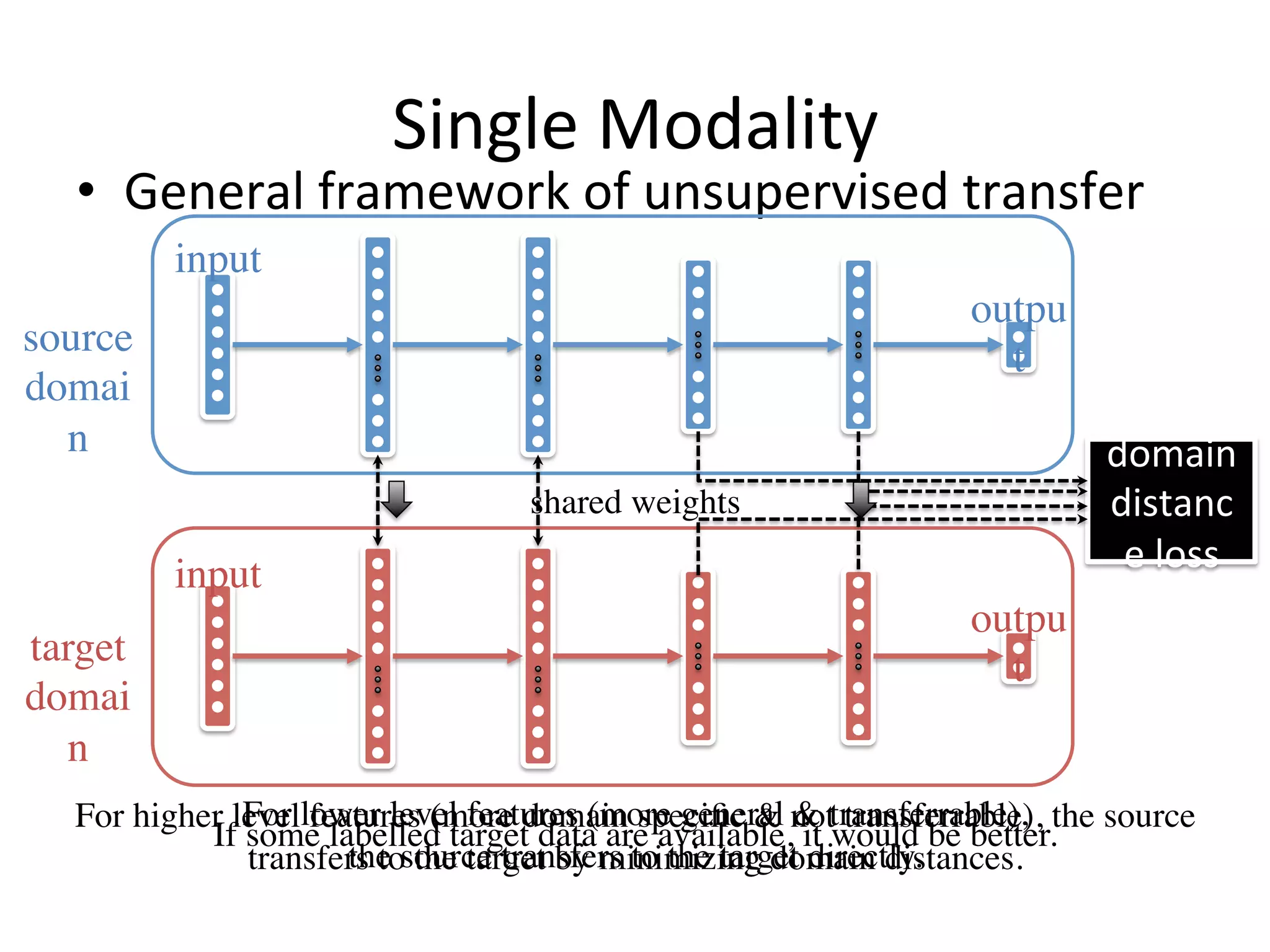
![Single Modality
• Domain distance losses
– MK-MMD (Mul7-kernel variant of MMD) [8]
– Domain classifier [4, 9]
an embedding
A distribution-free metric - maximizes the domain classification error
Learn a more flexible distance metric than MMD by adjusting](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-62-2048.jpg)
![Single Modality
• Other factors to improve transfer
– Which layers should the domain distance loss be considered?
• By learning, pinpoint the layer that minimizes the domain distance
among all specific layers, say the fourth. [7]
• All the specific layers, say the last two layers. [8]
source
domain
input
output
target
domain
inpu
t
domain
distanc
e loss](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-63-2048.jpg)
![Single Modality• Other factors to improve transfer
– When we have some training data in the target
domain?
• soj label supervision [4]: categories without any
labeled target data are s7ll updated to output non-zero
probabili7es
target
doma
in
inpu
t outpu
t
source
domain](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-64-2048.jpg)


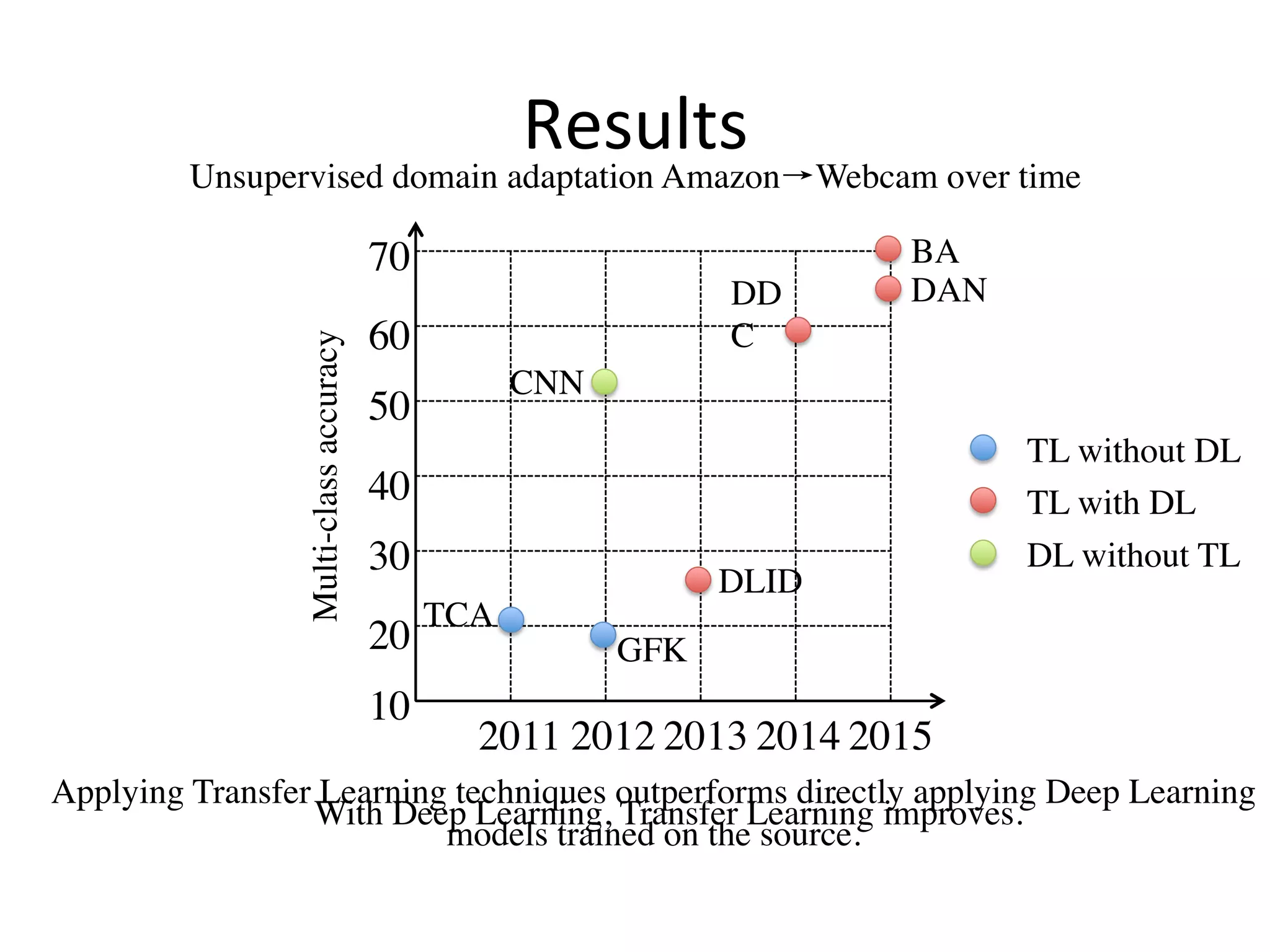
![Results
Mean Average Precision (MAP) by applying LR to different layers [13]
Transferring either one of the two domains to the other (joint hidden), outperforms the
domain itself (image_input OR text_input).
DBN [12]
DBM [13]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-70-2048.jpg)
![References
[1] Nguyen, Hien V., et al. "Joint hierarchical domain adaptation and feature learning." PAMI. 2013.
[2] Oquab, Maxime, et al. "Learning and transferring mid-level image representations using convolutional neural
networks." CVPR. 2014.
[3] Yosinski, Jason, et al. "How transferable are features in deep neural networks?." NIPS. 2014.
[4] Tzeng, Eric, et al. "Simultaneous deep transfer across domains and tasks." CVPR. 2015.
[5] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. "Domain adaptation for large-scale sentiment classification:
A deep learning approach." ICML. 2011.
[6] Chopra, Sumit, Suhrid Balakrishnan, and Raghuraman Gopalan. "Dlid: Deep learning for domain adaptation by
interpolating between domains." ICML. 2013.
[7] Tzeng, Eric, et al. "Deep domain confusion: Maximizing for domain invariance." arXiv preprint
arXiv:1412.3474. 2014.
[8] Long, Mingsheng, and Jianmin Wang. "Learning transferable features with deep adaptation
networks." arXiv preprint arXiv:1502.02791. 2015.
[9] Ganin, Yaroslav, and Victor Lempitsky. "Unsupervised Domain Adaptation by Backpropagation."
ICML. 2015.
[10] Huang, Jui-Ting, et al. "Cross-language knowledge transfer using multilingual deep neural network with
shared hidden layers." ICASSP. 2013.
[11] Gupta, Saurabh, Judy Hoffman, and Jitendra Malik. "Cross Modal Distillation for Supervision
Transfer." arXiv preprint arXiv:1507.00448. 2015.
[12] Ngiam, Jiquan, et al. "Multimodal deep learning." ICML. 2011.
[13] Srivastava, Nitish, and Ruslan Salakhutdinov. "Multimodal learning with deep Boltzmann machines." JMLR.
2014
[14] Sohn, Kihyuk, Wenling Shang, and Honglak Lee. "Improved multimodal deep learning with variation of
information." NIPS. 2014.](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-71-2048.jpg)

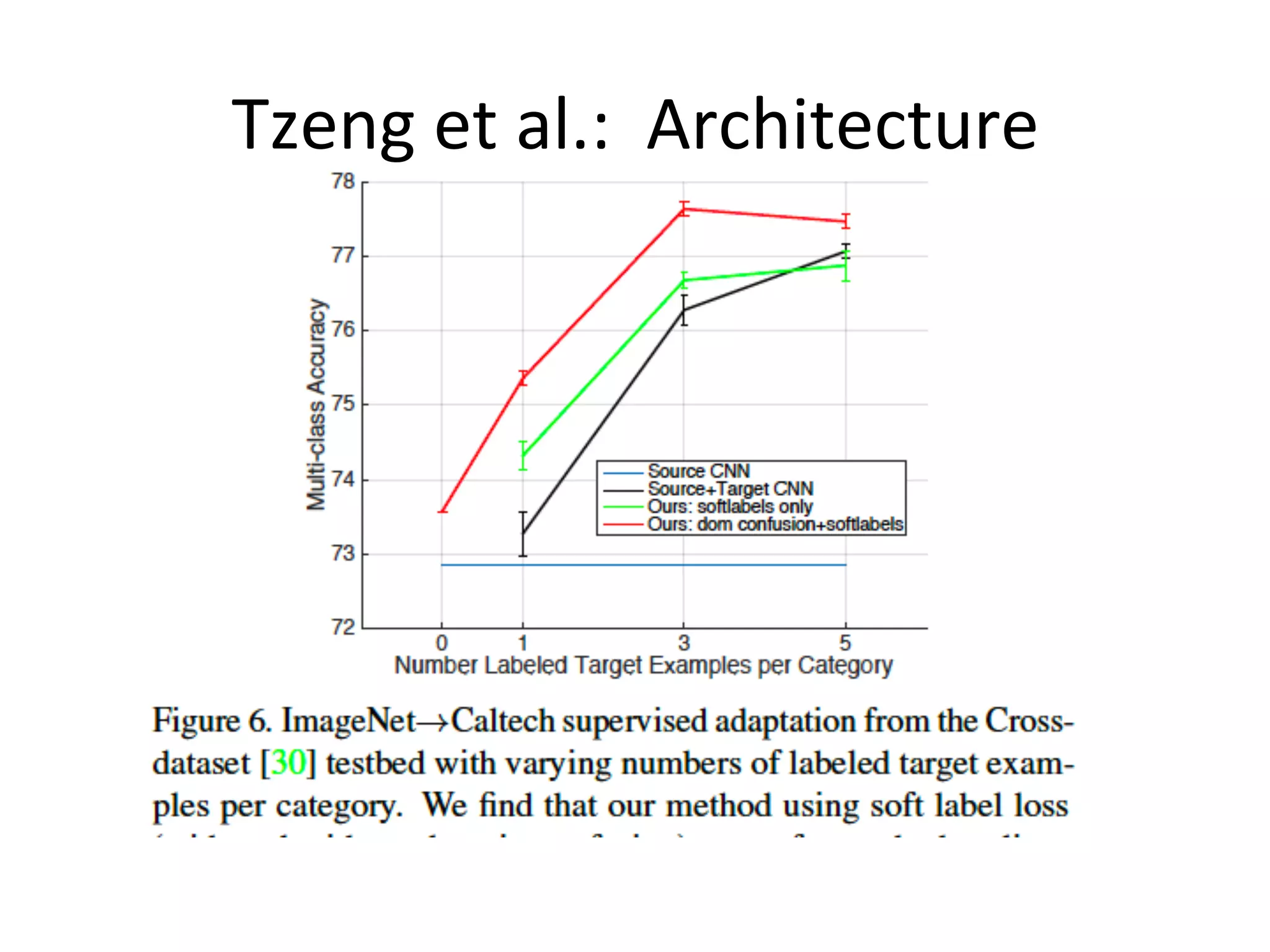
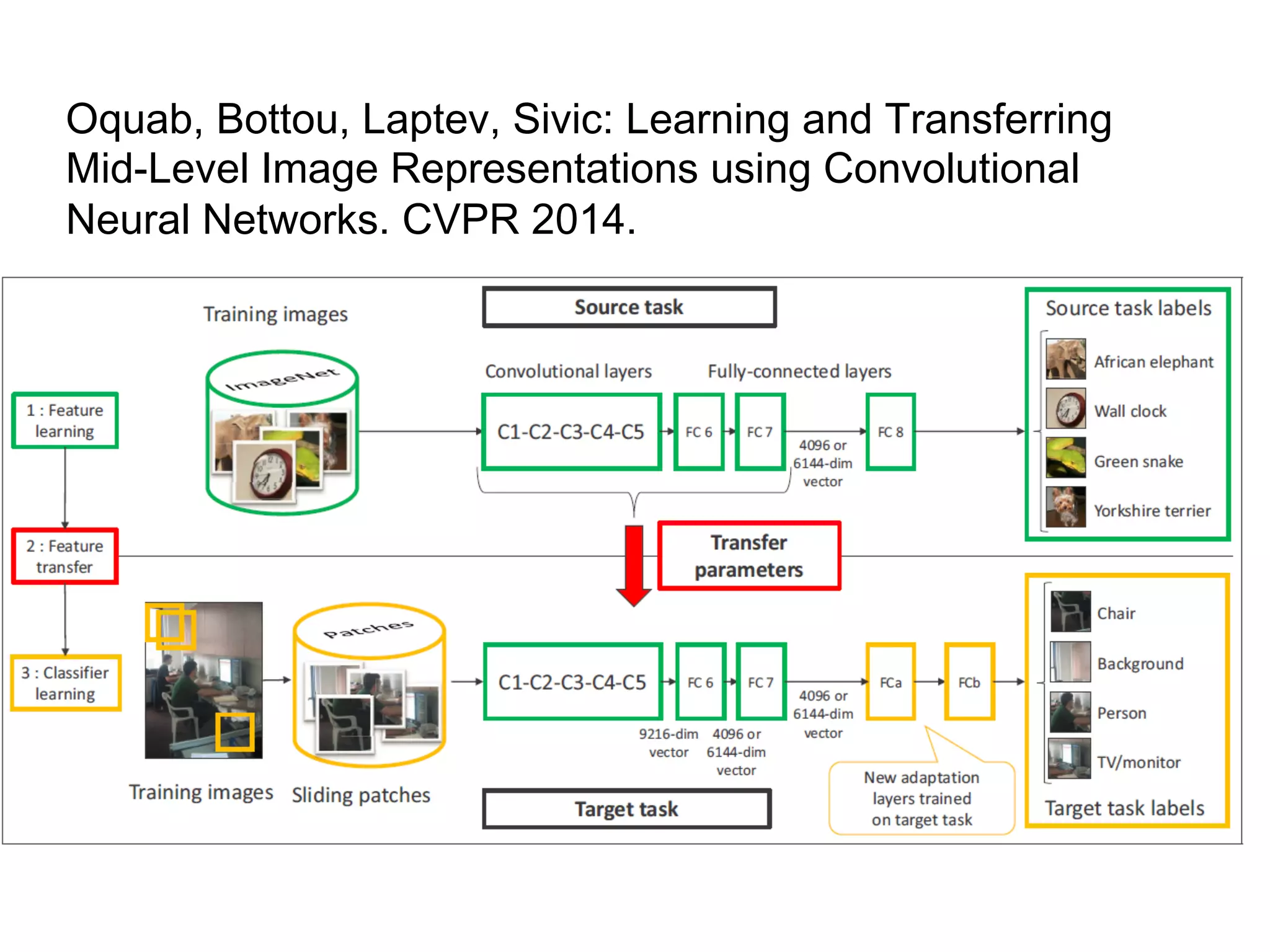
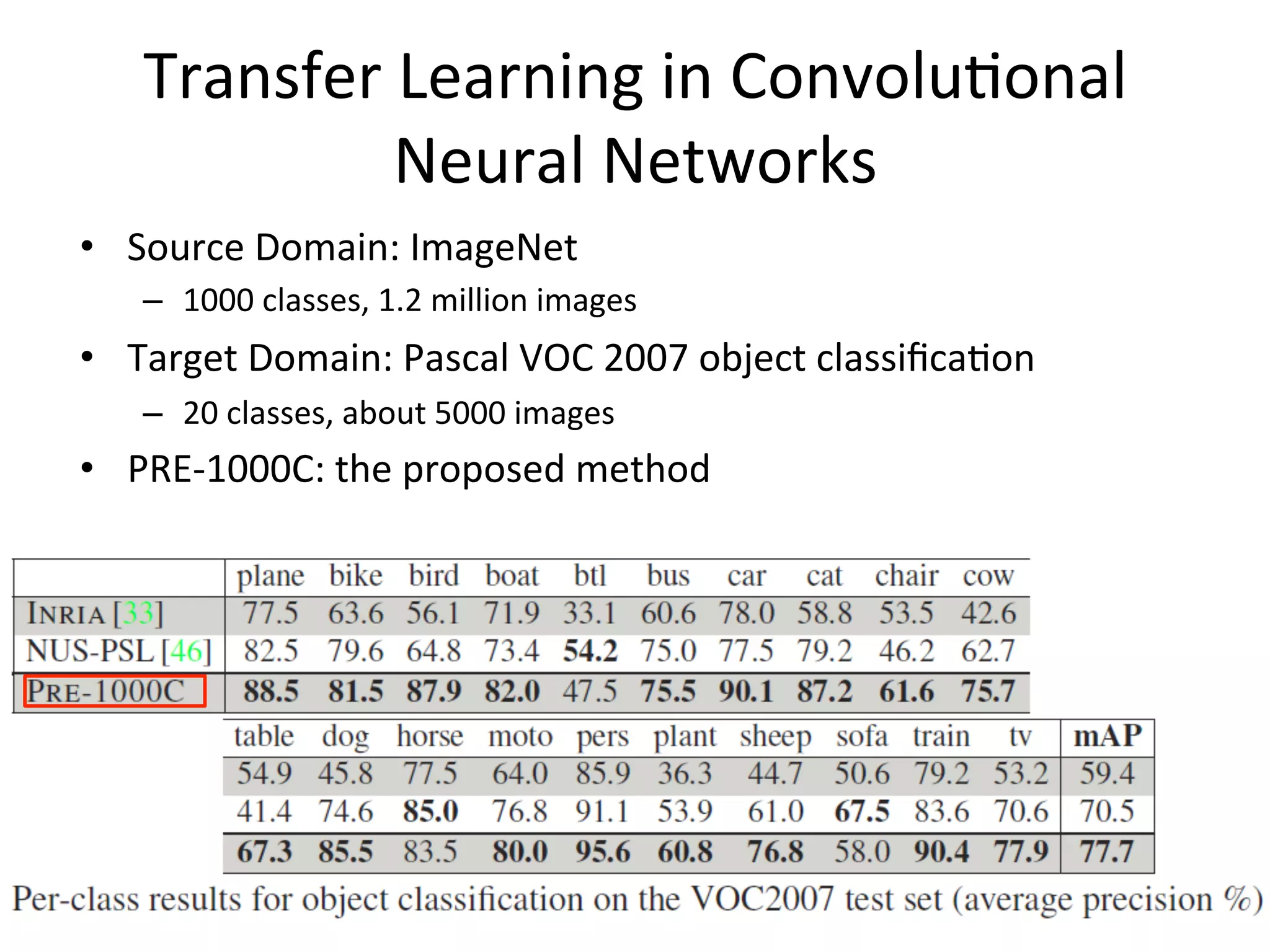

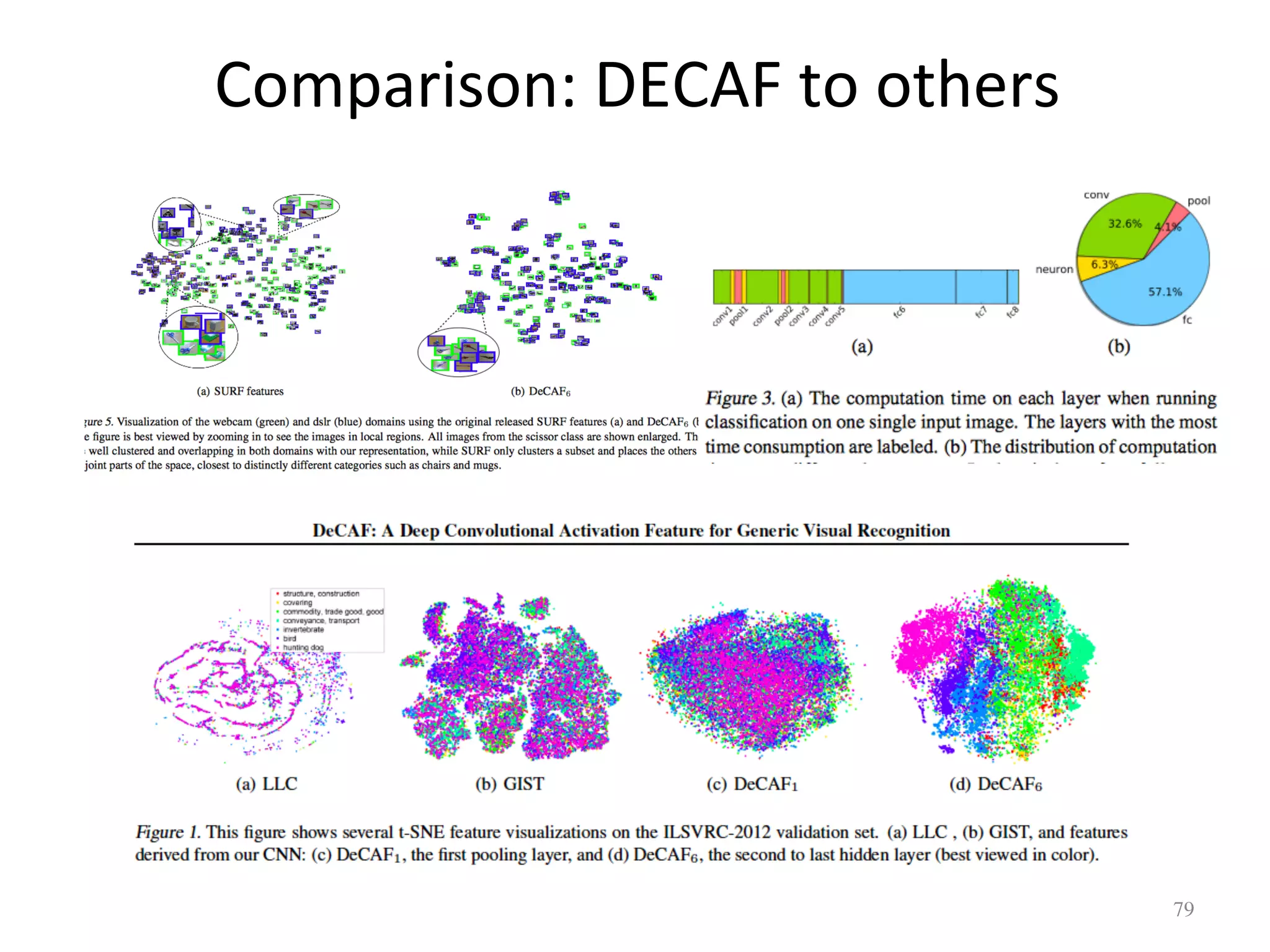

![Relational Transfer Learning
Approaches (cont.)
81
Actor(A) Director(B)
WorkedFor
Movie (M)
Student (B) Professor (A)
AdvisedBy
Paper (T)
Publication Publication
Academic domain (source) Movie domain (target)
MovieMember MovieMember
AdvisedBy (B, A) ˄ Publication (B, T)
=> Publication (A, T)
WorkedFor (A, B) ˄ MovieMember (A, M)
=> MovieMember (B, M)
P1(x, y) ˄ P2 (x, z) => P2 (y, z)
[Mihalkova etal., AAAI-07, Davis and Domingos, ICML-09]](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-81-2048.jpg)





![Cross Domain Ac7vity Recogni7on
[Zheng, Hu, Yang, Ubicomp 2009]
• Challenges:
– A new domain of
ac7vi7es without
labeled data
• Cross-domain ac7vity
recogni7on
– Transfer some available
labeled data from
source ac7vi7es to help
training the recognizer
for the target ac7vi7es.
92
Cleaning
Indoor
Laundry
Dishwashing](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-92-2048.jpg)












![Reference
! [Thorndike and Woodworth, The Influence of Improvement in one
mental function upon the efficiency of the other functions, 1901]
! [Taylor and Stone, Transfer Learning for Reinforcement Learning
Domains: A Survey, JMLR 2009]
! [Pan and Yang, A Survey on Transfer Learning, IEEE TKDE 2009]
! [Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press
2009]
! [Biltzer etal.. Domain Adapta7on with Structural Correspondence
Learning, EMNLP 2006]
! [Pan etal., Cross-Domain Sentiment Classification via Spectral Feature
Alignment, WWW 2010]
! [Pan etal., Transfer Learning via Dimensionality Reduction, AAAI
2008]
126](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-126-2048.jpg)
![Reference (cont.)
! [Pan etal., Domain Adaptation via Transfer Component Analysis,
IJCAI 2009]
! [Evgeniou and Pontil, Regularized Multi-Task Learning, KDD 2004]
! [Zhang and Yeung, A Convex Formulation for Learning Task
Relationships in Multi-Task Learning, UAI 2010]
! [Agarwal etal, Learning Multiple Tasks using Manifold
Regularization, NIPS 2010]
! [Argyriou etal., Multi-Task Feature Learning, NIPS 2007]
! [Ando and Zhang, A Framework for Learning Predictive Structures
from Multiple Tasks and Unlabeled Data, JMLR 2005]
! [Ji etal, Extracting Shared Subspace for Multi-label Classification,
KDD 2008]
127](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-127-2048.jpg)
![Reference (cont.)
! [Raina etal., Self-taught Learning: Transfer Learning from Unlabeled
Data, ICML 2007]
! [Dai etal., Boosting for Transfer Learning, ICML 2007]
! [Glorot etal., Domain Adaptation for Large-Scale Sentiment
Classification: A Deep Learning Approach, ICML 2011]
! [Davis and Domingos, Deep Transfer vis Second-order Markov Logic,
ICML 2009]
! [Mihalkova etal., Mapping and Revising Markov Logic Networks for
Transfer Learning, AAAI 2007]
! [Li etal., Cross-Domain Co-Extraction of Sentiment and Topic
Lexicons, ACL 2012]
128](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-128-2048.jpg)
![Reference (cont.)
! [Sugiyama etal., Direct Importance Estimation with Model Selection
and Its Application to Covariate Shift Adaptation, NIPS 2007]
! [Kanamori etal., A Least-squares Approach to Direct Importance
Estimation, JMLR 2009]
! [Cris7anini etal., On Kernel Target Alignment, NIPS 2002]
! [Huang etal., Correcting Sample Selection Bias by Unlabeled Data,
NIPS 2006]
! [Zadrozny, Learning and Evaluating Classifiers under Sample
Selection Bias, ICML 2004]
129](https://image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-129-2048.jpg)



![A psychological point of view
• Transfer of Learning (学习迁移)in
Educa7on and Psychology
– The study of dependency of human conduct,
learning or performance on prior experience.
– [Thorndike and Woodworth, 1901] explored how individuals would
transfer in one context to another context that share similar
characteristics.
• E.g.
! C++ " Java
! Math/Physics " Computer Science/Economics
2](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-2-2048.jpg)



![Transfer Learning
Different fields
• Transfer learning for
reinforcement learning.
[Taylor and Stone, Transfer
Learning for Reinforcement
Learning Domains: A Survey,
JMLR 2009]
• Transfer learning for
classifica7on, and
regression problems.
[Pan and Yang, A Survey on
Transfer Learning, IEEE TKDE
2010]
6
Focus!](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-6-2048.jpg)















![Instance-based Approaches
Case I (cont.)
22
Correcting Sample Selection Bias / Covariate Shift
[Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press 2009]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-22-2048.jpg)
![Instance-based Approaches
Correcting sample selection bias (cont.)
• The distribu7on of the selector variable maps
the target onto the source distribu7on
23
! Label instances from the source domain with label 1
! Label instances from the target domain with label 0
! Train a binary classifier
[Zadrozny, ICML-04]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-23-2048.jpg)
![Instance-based Approaches
Kernel mean matching (KMM)
Maximum Mean Discrepancy (MMD)
[Alex Smola, Arthur Gretton and Kenji Kukumizu, ICML-08 tutorial]
24](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-24-2048.jpg)
![Instance-based Approaches
Direct density ratio estimation
25
[Sugiyama etal., NIPS-07, Kanamori etal., JMLR-09]
KL divergence loss Least squared loss
[Sugiyama etal., NIPS-07] [Kanamori etal., JMLR-09]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-25-2048.jpg)

![Instance-based Approaches
Case II (cont.)
! TrAdaBoost [Dai etal ICML-07]
– For each boosting iteration,
# Use the same strategy as AdaBoost to
update the weights of target domain data.
# Use a new mechanism to decrease the
weights of misclassified source domain
data.
27](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-27-2048.jpg)



![Feature-based Approaches
Encode application-specific knowledge (cont.)
31
compact sharp blurry hooked realistic boring
1 1 0 0 0 0
0 1 0 0 0 0
0 0 1 0 0 0
( ) sgn( ), [1,1, 1,0,0,0]T
y f x w x w= = ⋅ = −
compact sharp blurry hooked realistic boring
0 0 0 1 0 0
0 0 0 1 1 0
0 0 0 0 0 1
Electronics
Video Game
Training
Prediction](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-31-2048.jpg)


![Feature-based Approaches
Encode application-specific knowledge (cont.)
! How to identify pivot features?
! Term frequency on both domains
! Mutual information between features and labels (source
domain)
! Mutual information on between features and domains
! How to utilize pivots to align features across domains?
! Structural Correspondence Learning (SCL) [Biltzer etal.
EMNLP-06]
! Spectral Feature Alignment (SFA) [Pan etal. WWW-10]
34](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-34-2048.jpg)



![Spectral Feature Alignment (SFA)
Derive new features (cont.)
sharp/hooked compact/realistic blurry/boring
1 1 0
1 0 0
0 0 1
38
( ) sgn( ), [1,1, 1]T
y f x w x w= = ⋅ = −
sharp/hooked compact/realistic blurry/boring
1 0 0
1 1 0
0 0 1
Electronics
Video Game
Training
Prediction](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-38-2048.jpg)


![Feature-based Approaches
Transfer Component Analysis [Pan etal., IJCAI-09, TNN-11]
41
TargetSource
Latent factors
Temperature Signal
properties
Building
structure
Power of APs
Motivation](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-41-2048.jpg)






![Feature-based Approaches
Self-taught Feature Learning (Andrew Ng. et al.)
! Intuition: Useful higher-level features can be learned from
unlabeled data.
! Steps:
1) Learn higher-level features from a lot of unlabeled data.
2) Use the learned higher-level features to represent the data of the
target task.
3) Train models from the new representations of the target task
(supervised)
! How to learn higher-level features
# Sparse Coding [Raina etal., 2007]
# Deep learning [Glorot etal., 2011]
48](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-48-2048.jpg)

![Multi-task Learning
Assumption:
If tasks are related, they may share similar parameter vectors.
For example, [Evgeniou and Pontil, KDD-04]
50
Common part
Specific part for individual task](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-50-2048.jpg)
![Mul7-task Feature Learning
51
[Argyriou etal., NIPS-07]
[Ando and Zhang, JMLR-05]
[Ji etal, KDD-08]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-51-2048.jpg)




![DASH-N [1]
Finetuning [2,3]
SCNN [4]
Overview
• Overview
supervised unsupervised
single
modality
multiple
modalities
[5]
DLID [6]
DCC [7]
DAN [8]
BA [9]
SHL-MDNN [10]
ST [11]
Are there
labelled
target
data?
Are dimensions of source
and target domains equal?
[12] Ngiam, Jiquan, et al. "Multimodal deep
learning." ICML. 2011.
[13] Srivastava, Nitish, and Ruslan
Salakhutdinov. "Multimodal learning with deep
Boltzmann machines." JMLR. 2014
[14] Sohn, Kihyuk, Wenling Shang, and Honglak
Lee. "Improved multimodal deep learning
with variation of information." NIPS. 2014.
DBN [12]
DBM [13]
MDRNN [14]
[5] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio.
"Domain adaptation for large-scale sentiment
classification: A deep learning approach." ICML. 2011.
[6] Chopra, Sumit, Suhrid Balakrishnan, and
Raghuraman Gopalan. "Dlid: Deep learning for domain
adaptation by interpolating between domains." ICML.
2013.
[7] Tzeng, Eric, et al. "Deep domain confusion:
Maximizing for domain invariance." arXiv
preprint arXiv:1412.3474. 2014.
[8] Long, Mingsheng, and Jianmin Wang. "Learning
transferable features with deep adaptation
networks." arXiv preprint arXiv:1502.02791. 2015.
[9] Ganin, Yaroslav, and Victor Lempitsky.
"Unsupervised Domain Adaptation by
Backpropagation." ICML. 2015.
[10] Huang, Jui-Ting, et al. "Cross-language
knowledge transfer using multilingual deep
neural network with shared hidden
layers." ICASSP. 2013.
[11] Gupta, Saurabh, Judy Hoffman, and
Jitendra Malik. "Cross Modal
Distillation for Supervision Transfer."
arXiv preprint arXiv:1507.00448. 2015.
[1] Nguyen, Hien V., et al. "Joint hierarchical
domain adaptation and feature
learning." PAMI. 2013.
[2] Oquab, Maxime, et al. "Learning and
transferring mid-level image representations
using convolutional neural networks." CVPR
2014.
[3] Yosinski, Jason, et al. "How transferable
are features in deep neural networks?." NIPS
2014.
[4] Tzeng, Eric, et al. "Simultaneous
deep transfer across domains and
tasks." CVPR. 2015.](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-56-2048.jpg)


![Single Modality
• Transferability of layer-wise features
[3]
Conclusion 1: lower layer features are more general and transferrable, and higher
layer features are more specific and non-transferrable.
Conclusion 2: transferring features + fine-tuning always improve generalization. What if we do not have any labelled data to finetune in the target domain?
What happens if the source and target domain are very dissimilar?
ImageNet is not
randomly split, but
into A = {man-made
classes} and
B = {natural classes}](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-59-2048.jpg)

![Single Modality
• Overall training objec7ve
• Domain distance losses
– Maximum Mean Discrepancy [7]
source domain classification lossdomain distance loss
a particular representation, e.g. the representation after 5th
layer](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-61-2048.jpg)
![Single Modality
• Domain distance losses
– MK-MMD (Mul7-kernel variant of MMD) [8]
– Domain classifier [4, 9]
an embedding
A distribution-free metric - maximizes the domain classification error
Learn a more flexible distance metric than MMD by adjusting](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-62-2048.jpg)
![Single Modality
• Other factors to improve transfer
– Which layers should the domain distance loss be considered?
• By learning, pinpoint the layer that minimizes the domain distance
among all specific layers, say the fourth. [7]
• All the specific layers, say the last two layers. [8]
source
domain
input
output
target
domain
inpu
t
domain
distanc
e loss](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-63-2048.jpg)
![Single Modality• Other factors to improve transfer
– When we have some training data in the target
domain?
• soj label supervision [4]: categories without any
labeled target data are s7ll updated to output non-zero
probabili7es
target
doma
in
inpu
t outpu
t
source
domain](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-64-2048.jpg)





![Results
Mean Average Precision (MAP) by applying LR to different layers [13]
Transferring either one of the two domains to the other (joint hidden), outperforms the
domain itself (image_input OR text_input).
DBN [12]
DBM [13]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-70-2048.jpg)
![References
[1] Nguyen, Hien V., et al. "Joint hierarchical domain adaptation and feature learning." PAMI. 2013.
[2] Oquab, Maxime, et al. "Learning and transferring mid-level image representations using convolutional neural
networks." CVPR. 2014.
[3] Yosinski, Jason, et al. "How transferable are features in deep neural networks?." NIPS. 2014.
[4] Tzeng, Eric, et al. "Simultaneous deep transfer across domains and tasks." CVPR. 2015.
[5] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. "Domain adaptation for large-scale sentiment classification:
A deep learning approach." ICML. 2011.
[6] Chopra, Sumit, Suhrid Balakrishnan, and Raghuraman Gopalan. "Dlid: Deep learning for domain adaptation by
interpolating between domains." ICML. 2013.
[7] Tzeng, Eric, et al. "Deep domain confusion: Maximizing for domain invariance." arXiv preprint
arXiv:1412.3474. 2014.
[8] Long, Mingsheng, and Jianmin Wang. "Learning transferable features with deep adaptation
networks." arXiv preprint arXiv:1502.02791. 2015.
[9] Ganin, Yaroslav, and Victor Lempitsky. "Unsupervised Domain Adaptation by Backpropagation."
ICML. 2015.
[10] Huang, Jui-Ting, et al. "Cross-language knowledge transfer using multilingual deep neural network with
shared hidden layers." ICASSP. 2013.
[11] Gupta, Saurabh, Judy Hoffman, and Jitendra Malik. "Cross Modal Distillation for Supervision
Transfer." arXiv preprint arXiv:1507.00448. 2015.
[12] Ngiam, Jiquan, et al. "Multimodal deep learning." ICML. 2011.
[13] Srivastava, Nitish, and Ruslan Salakhutdinov. "Multimodal learning with deep Boltzmann machines." JMLR.
2014
[14] Sohn, Kihyuk, Wenling Shang, and Honglak Lee. "Improved multimodal deep learning with variation of
information." NIPS. 2014.](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-71-2048.jpg)








![Relational Transfer Learning
Approaches (cont.)
81
Actor(A) Director(B)
WorkedFor
Movie (M)
Student (B) Professor (A)
AdvisedBy
Paper (T)
Publication Publication
Academic domain (source) Movie domain (target)
MovieMember MovieMember
AdvisedBy (B, A) ˄ Publication (B, T)
=> Publication (A, T)
WorkedFor (A, B) ˄ MovieMember (A, M)
=> MovieMember (B, M)
P1(x, y) ˄ P2 (x, z) => P2 (y, z)
[Mihalkova etal., AAAI-07, Davis and Domingos, ICML-09]](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-81-2048.jpg)










![Cross Domain Ac7vity Recogni7on
[Zheng, Hu, Yang, Ubicomp 2009]
• Challenges:
– A new domain of
ac7vi7es without
labeled data
• Cross-domain ac7vity
recogni7on
– Transfer some available
labeled data from
source ac7vi7es to help
training the recognizer
for the target ac7vi7es.
92
Cleaning
Indoor
Laundry
Dishwashing](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-92-2048.jpg)

































![Reference
! [Thorndike and Woodworth, The Influence of Improvement in one
mental function upon the efficiency of the other functions, 1901]
! [Taylor and Stone, Transfer Learning for Reinforcement Learning
Domains: A Survey, JMLR 2009]
! [Pan and Yang, A Survey on Transfer Learning, IEEE TKDE 2009]
! [Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press
2009]
! [Biltzer etal.. Domain Adapta7on with Structural Correspondence
Learning, EMNLP 2006]
! [Pan etal., Cross-Domain Sentiment Classification via Spectral Feature
Alignment, WWW 2010]
! [Pan etal., Transfer Learning via Dimensionality Reduction, AAAI
2008]
126](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-126-2048.jpg)
![Reference (cont.)
! [Pan etal., Domain Adaptation via Transfer Component Analysis,
IJCAI 2009]
! [Evgeniou and Pontil, Regularized Multi-Task Learning, KDD 2004]
! [Zhang and Yeung, A Convex Formulation for Learning Task
Relationships in Multi-Task Learning, UAI 2010]
! [Agarwal etal, Learning Multiple Tasks using Manifold
Regularization, NIPS 2010]
! [Argyriou etal., Multi-Task Feature Learning, NIPS 2007]
! [Ando and Zhang, A Framework for Learning Predictive Structures
from Multiple Tasks and Unlabeled Data, JMLR 2005]
! [Ji etal, Extracting Shared Subspace for Multi-label Classification,
KDD 2008]
127](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-127-2048.jpg)
![Reference (cont.)
! [Raina etal., Self-taught Learning: Transfer Learning from Unlabeled
Data, ICML 2007]
! [Dai etal., Boosting for Transfer Learning, ICML 2007]
! [Glorot etal., Domain Adaptation for Large-Scale Sentiment
Classification: A Deep Learning Approach, ICML 2011]
! [Davis and Domingos, Deep Transfer vis Second-order Markov Logic,
ICML 2009]
! [Mihalkova etal., Mapping and Revising Markov Logic Networks for
Transfer Learning, AAAI 2007]
! [Li etal., Cross-Domain Co-Extraction of Sentiment and Topic
Lexicons, ACL 2012]
128](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-128-2048.jpg)
![Reference (cont.)
! [Sugiyama etal., Direct Importance Estimation with Model Selection
and Its Application to Covariate Shift Adaptation, NIPS 2007]
! [Kanamori etal., A Least-squares Approach to Direct Importance
Estimation, JMLR 2009]
! [Cris7anini etal., On Kernel Target Alignment, NIPS 2002]
! [Huang etal., Correcting Sample Selection Bias by Unlabeled Data,
NIPS 2006]
! [Zadrozny, Learning and Evaluating Classifiers under Sample
Selection Bias, ICML 2004]
129](https://crownmelresort.com/image.slidesharecdn.com/random-160520003633/75/Transfer-Learning-An-overview-129-2048.jpg)



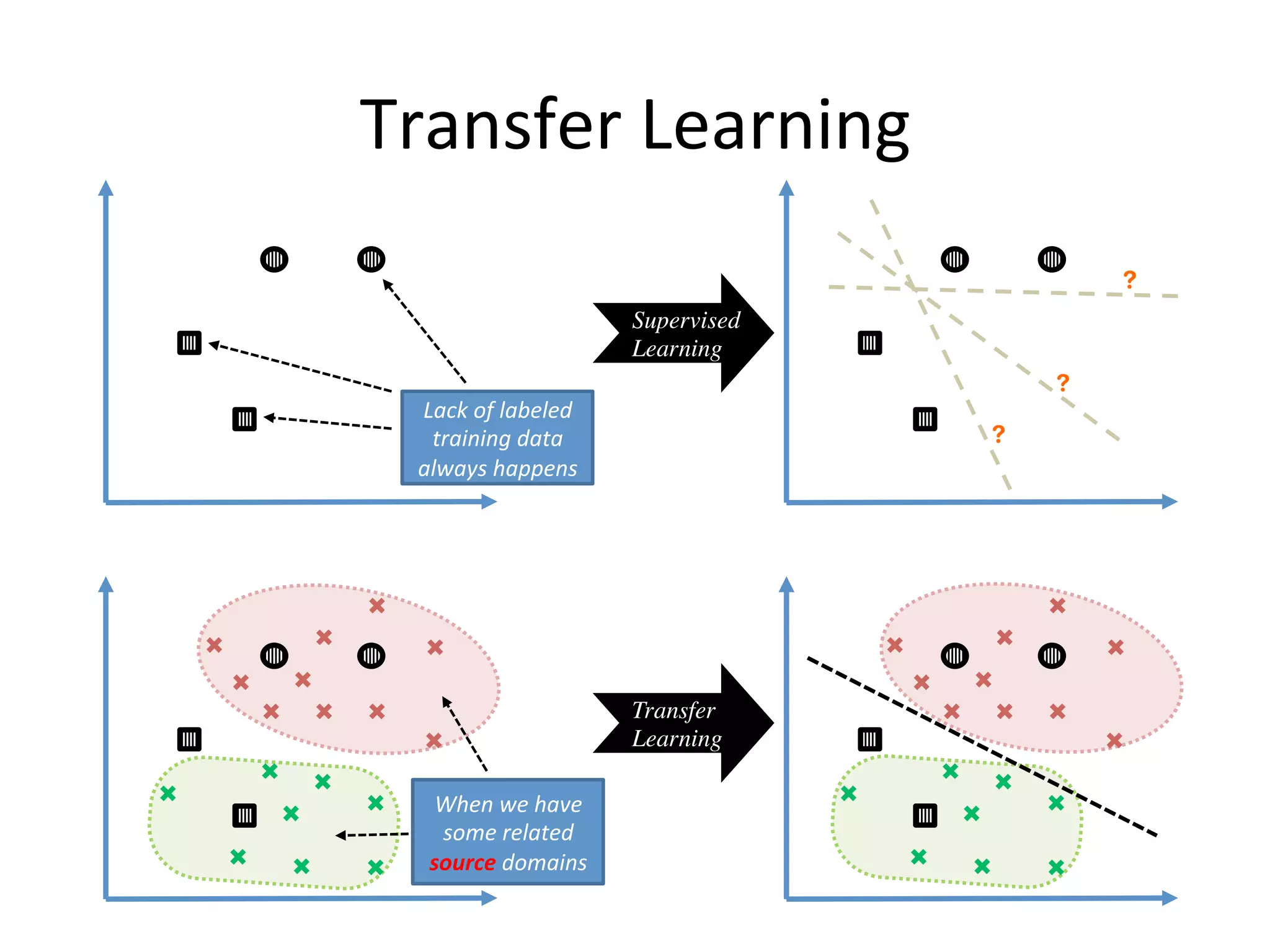
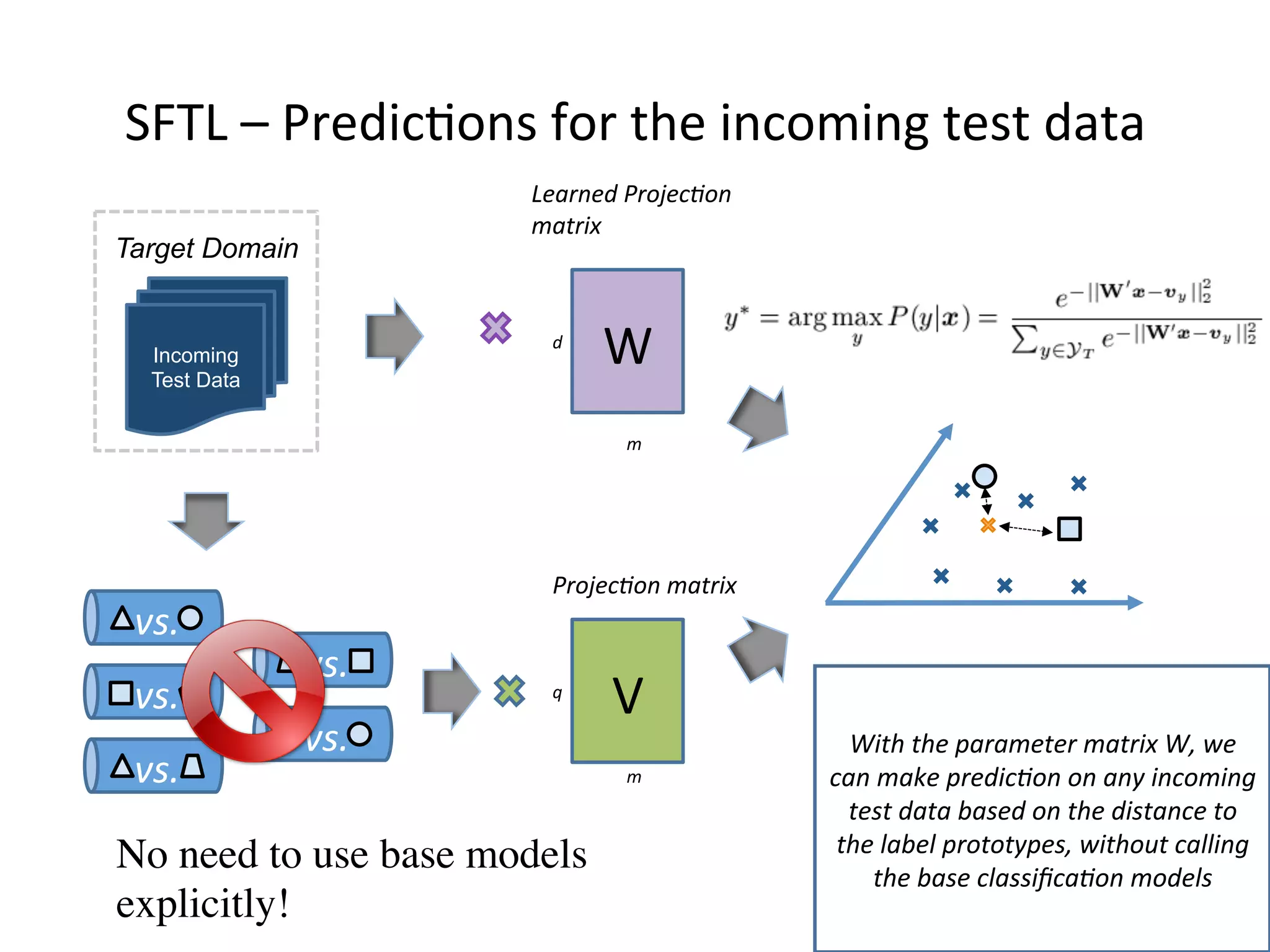
Transfer learning aims to improve learning in a target domain by leveraging knowledge from a related source domain. It is useful when the target domain has limited labeled data. There are several approaches, including instance-based approaches that reweight or resample source instances, and feature-based approaches that learn a transformation to align features across domains. Spectral feature alignment is one technique that builds a graph of correlations between pivot features shared across domains and domain-specific features, then applies spectral clustering to derive new shared features.
Introduction to transfer learning by Qiang Yang, HKUST, thanking collaborators.
Discusses transfer of learning in education and psychology, referencing Thorndike's research variations.
Defines transfer learning as applying knowledge from previous domains to new tasks based on similarities.
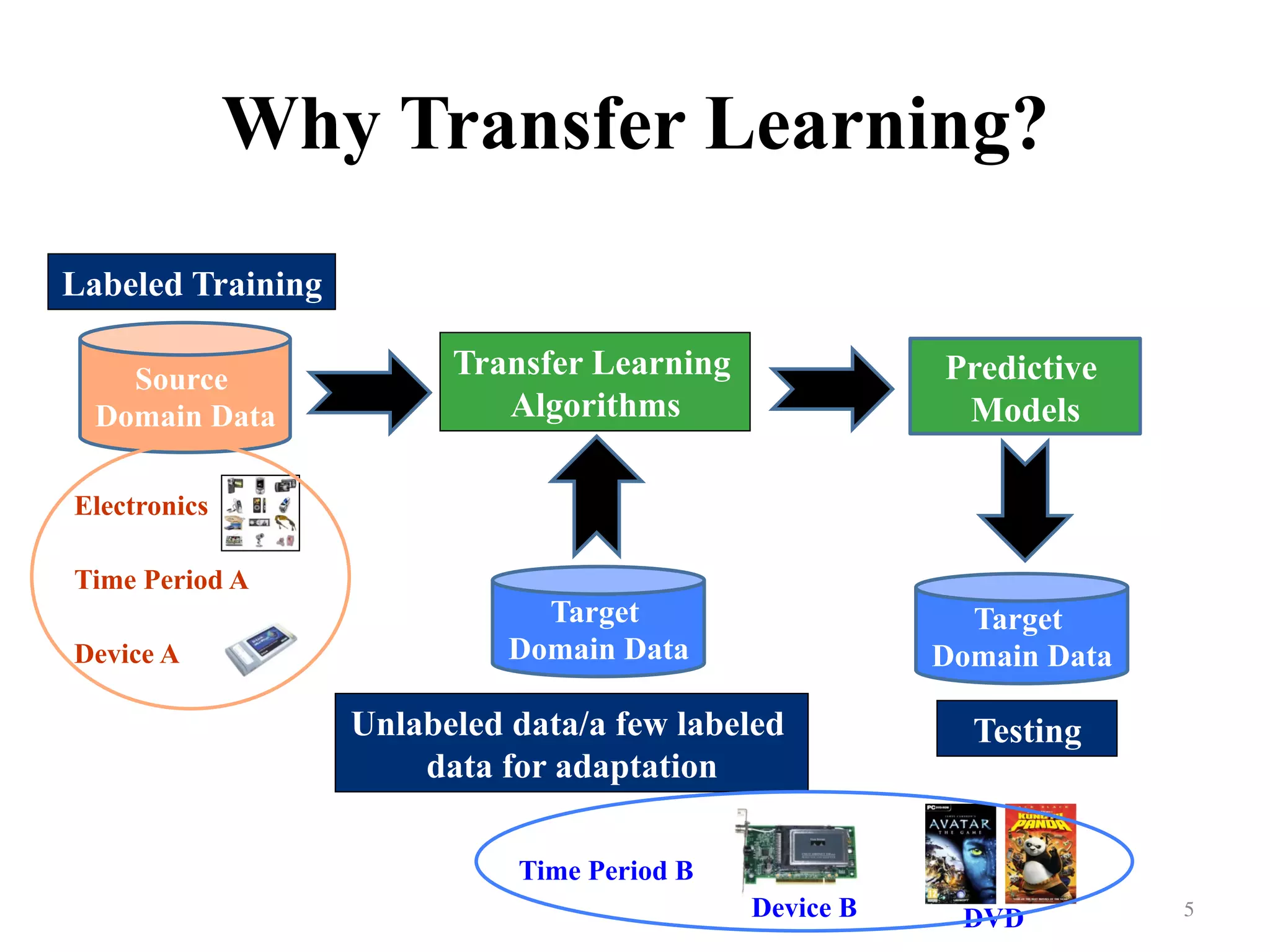
Highlights time-consuming model training, suggesting reusing existing knowledge for efficiency.
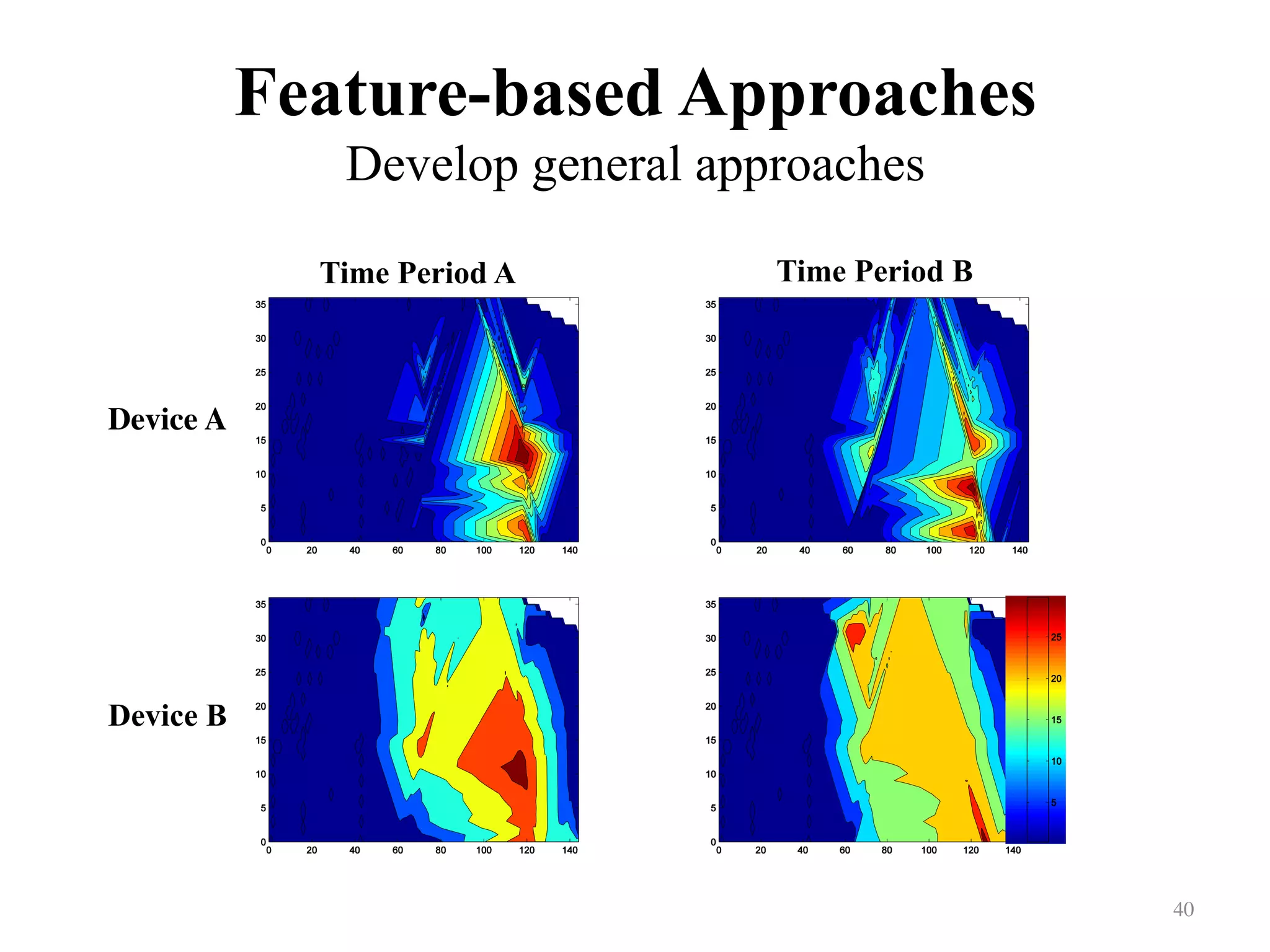
Illustrates the process of transfer learning using the example of electronics over differing time periods.
Describes various fields of transfer learning including reinforcement learning and classification tasks.
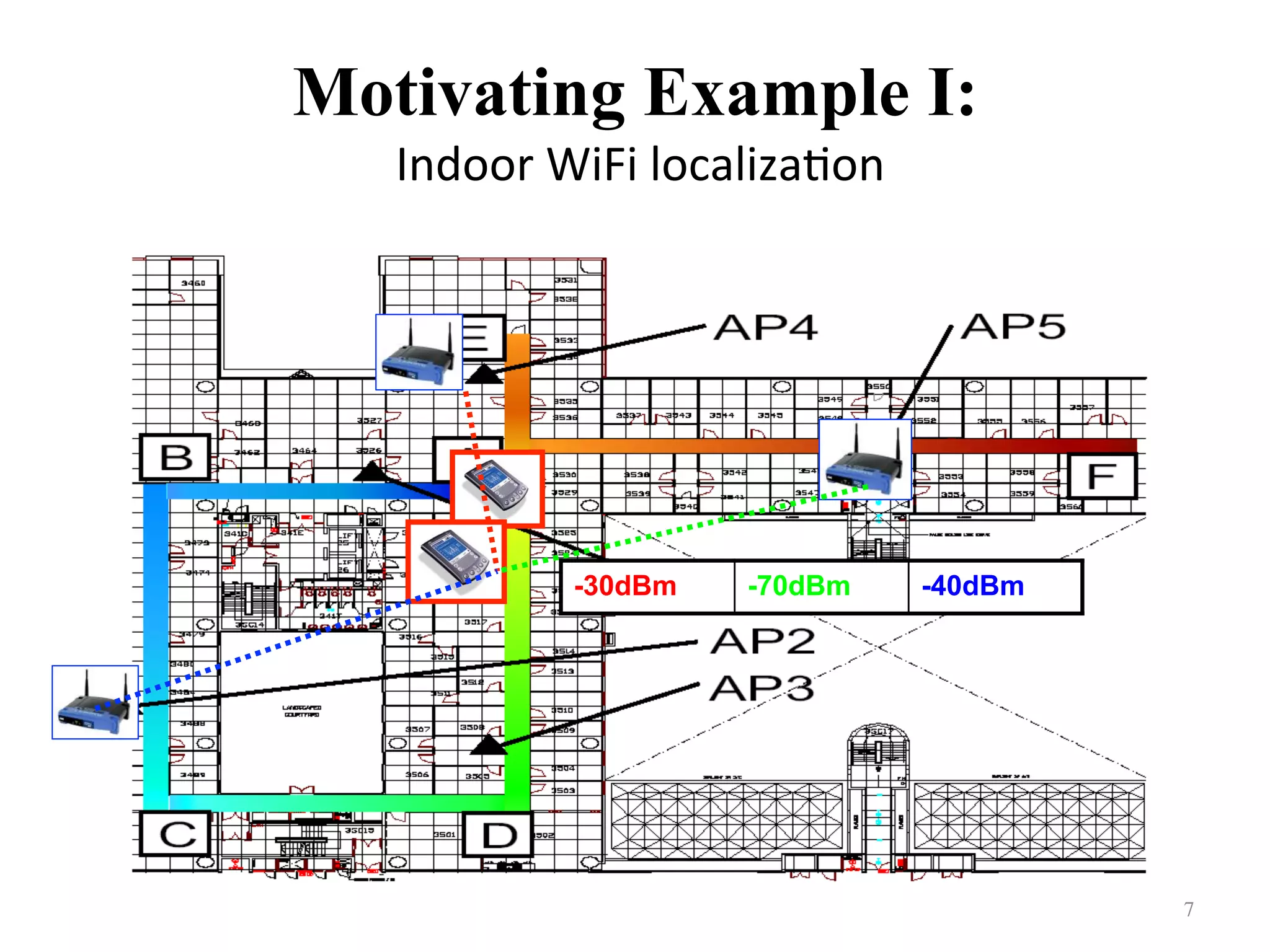
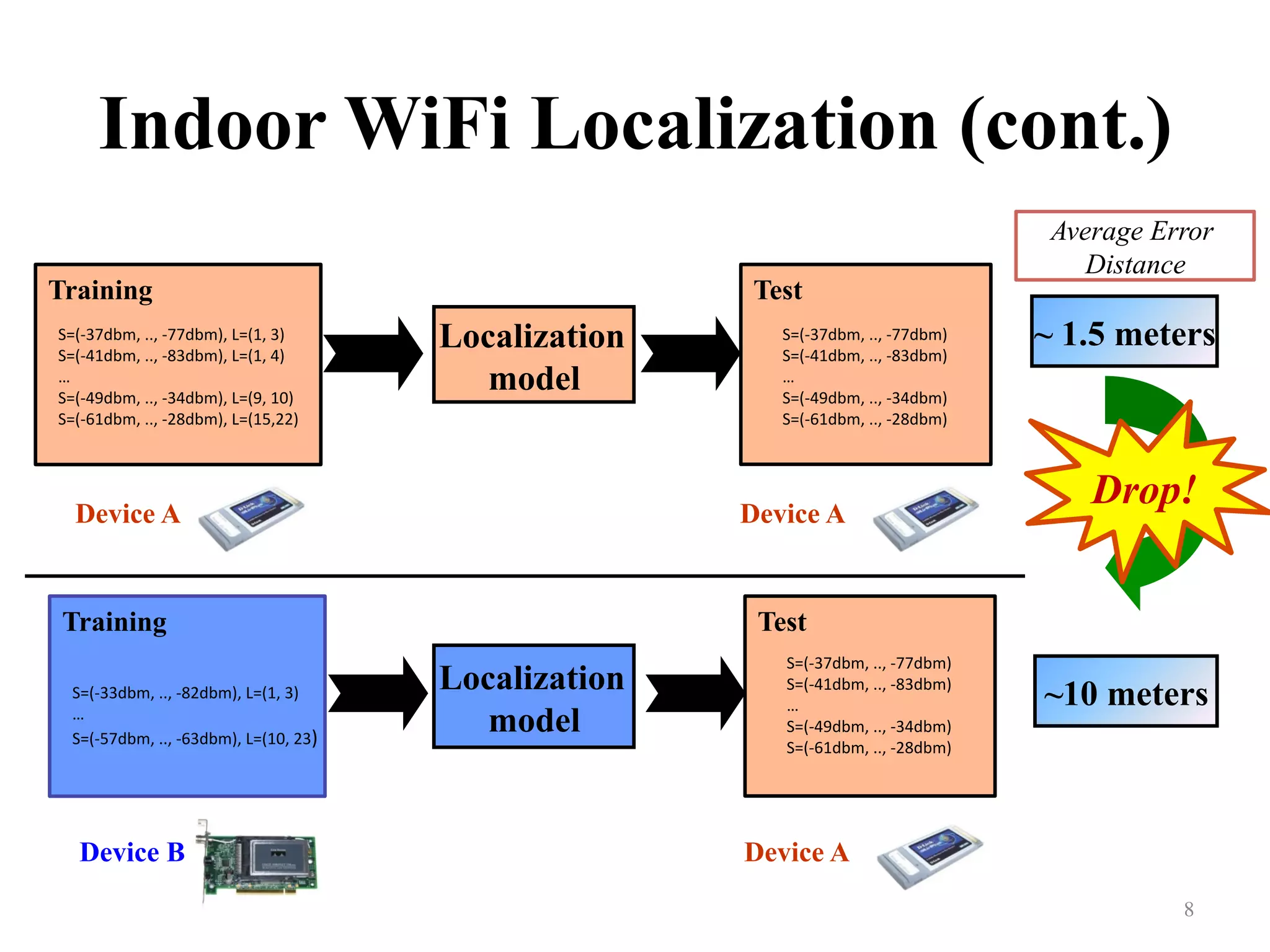
Presents a motivating example related to indoor WiFi localization and training-testing device comparisons.
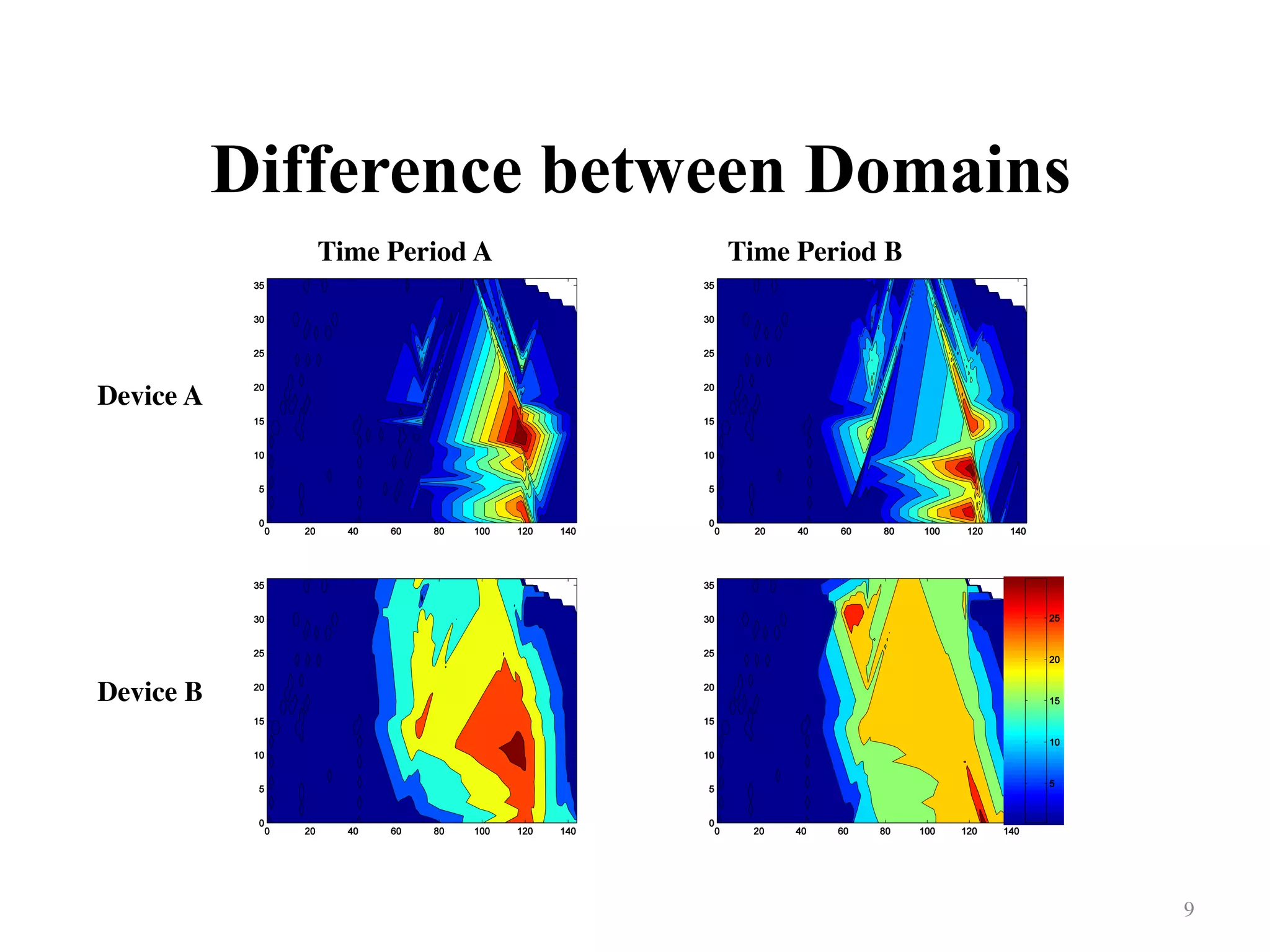
Contrasts two time periods with shifts in device functionalities and implications for learning.
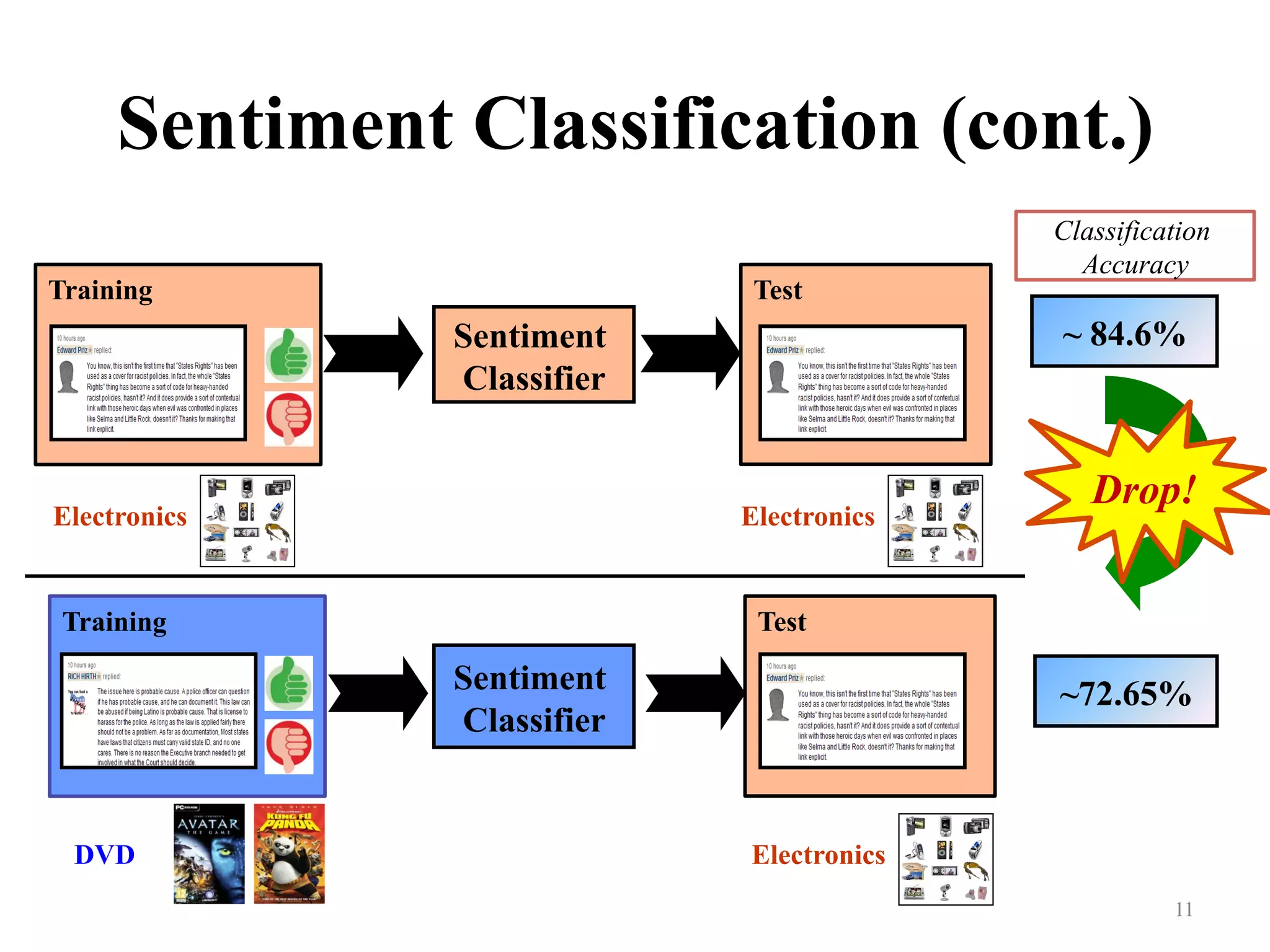
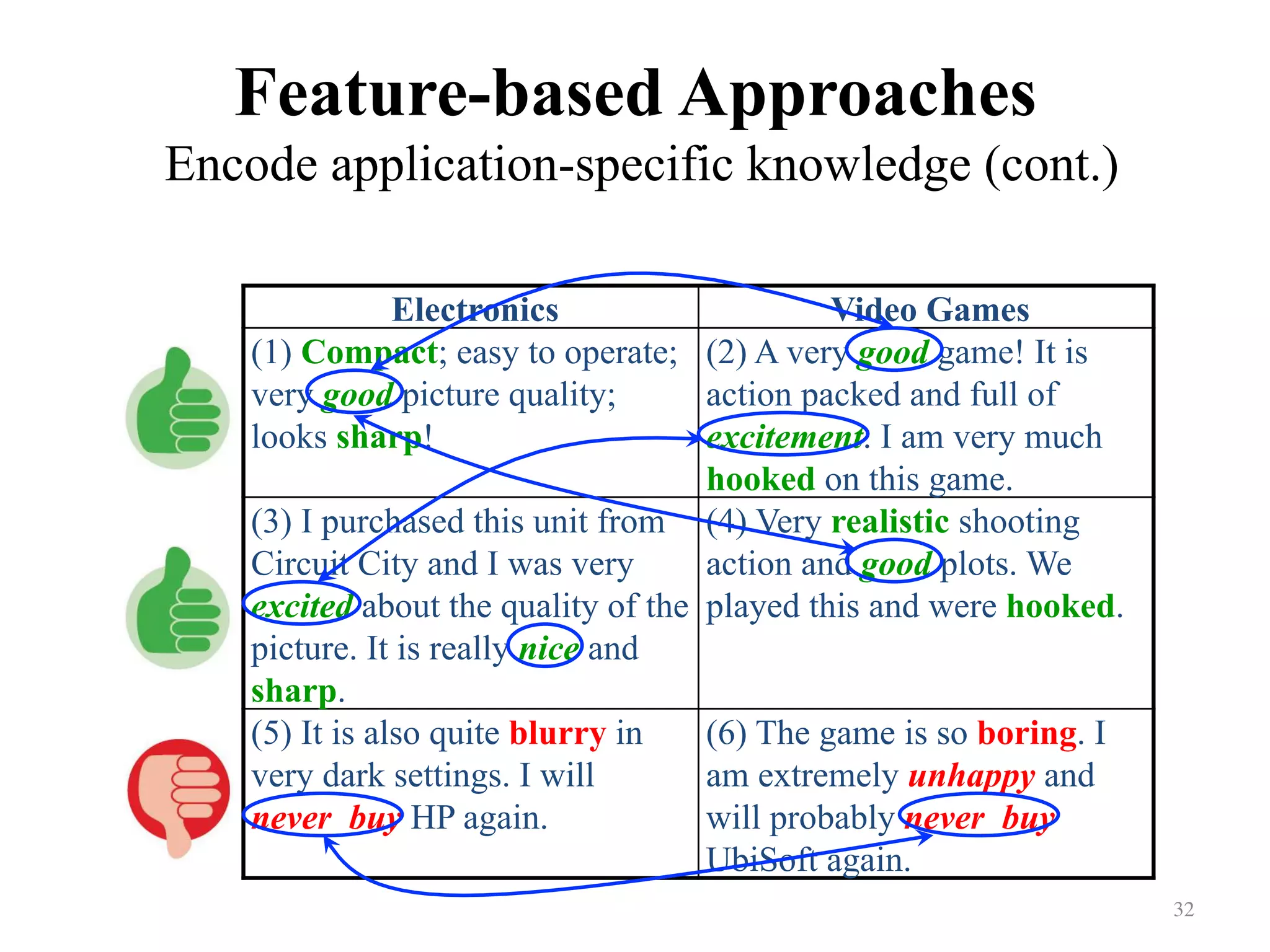
Facilitates understanding through an example of and training/testing on sentiment classification accuracy.
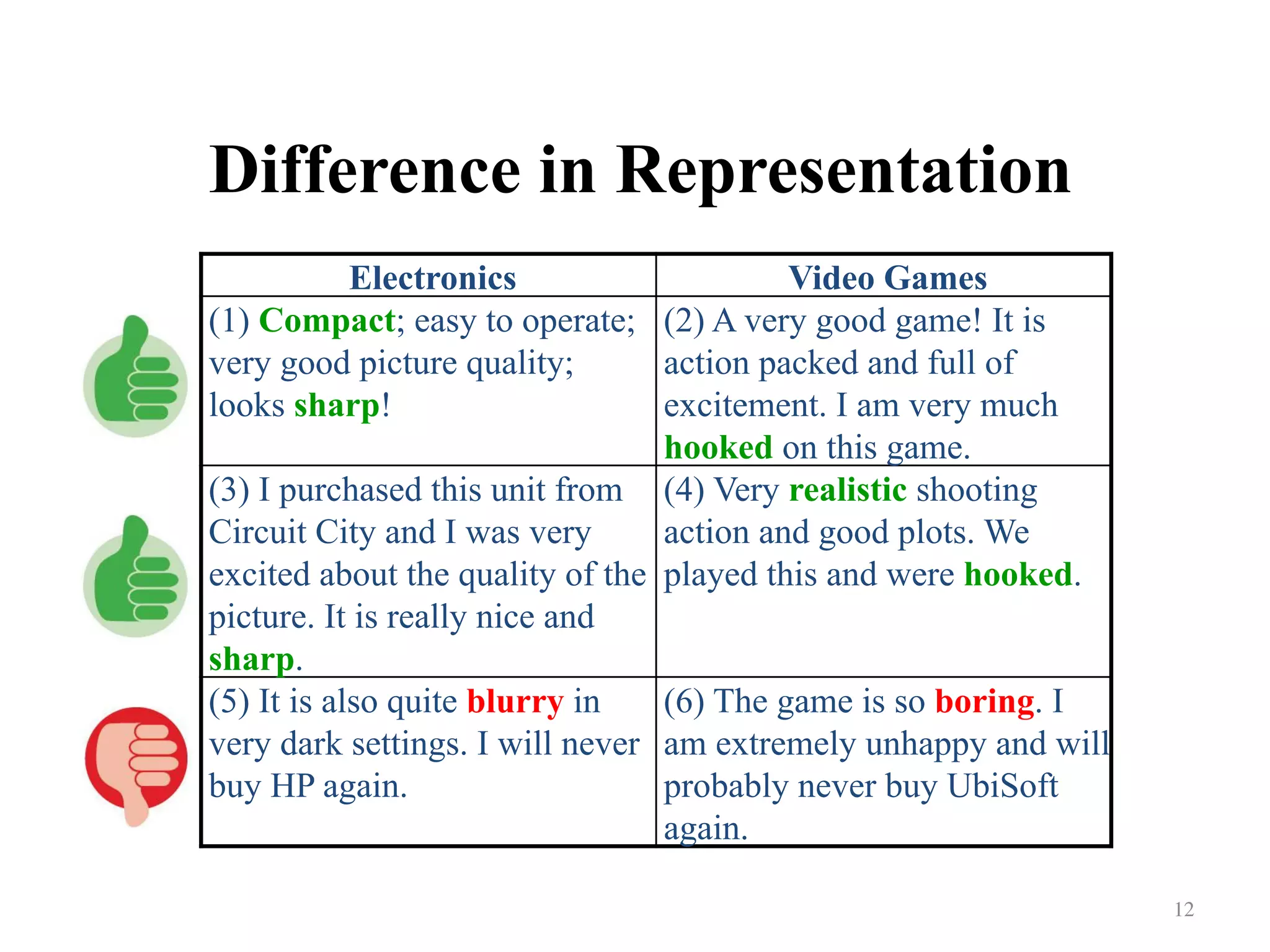
Addresses the discrepancies in feature representations between electronics and video games.
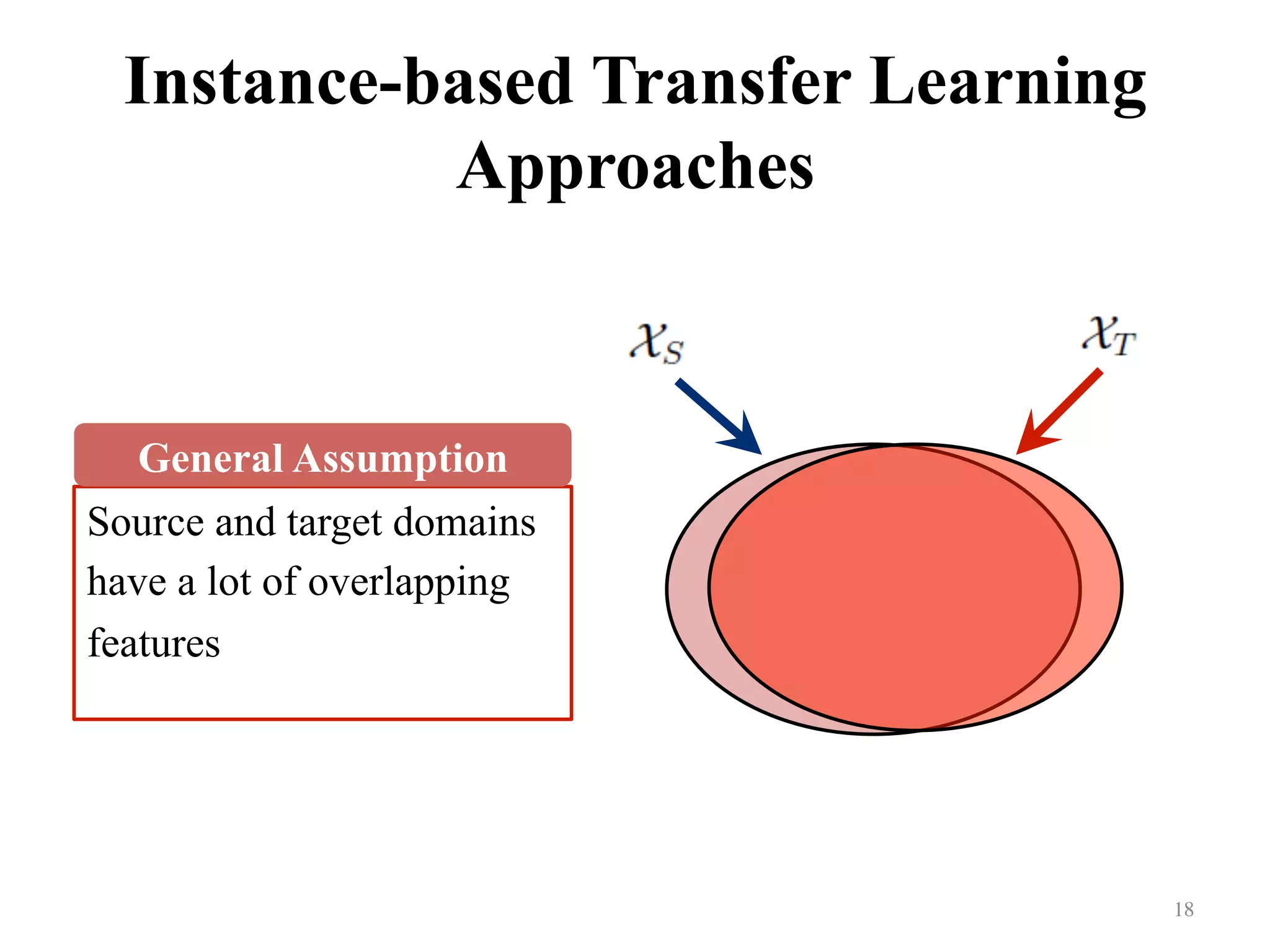
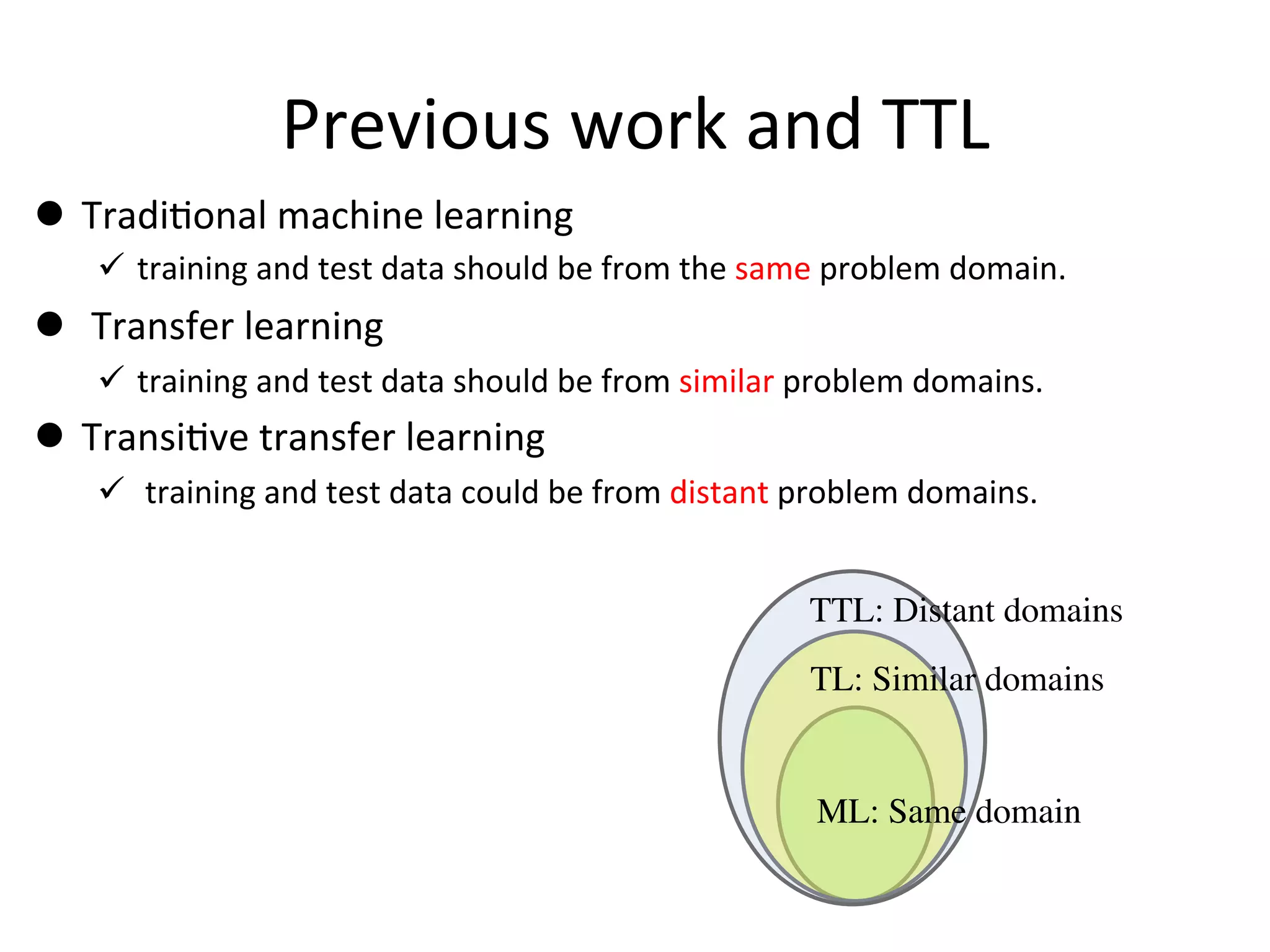
Explains the assumption that training and testing data must originate from the same domain.
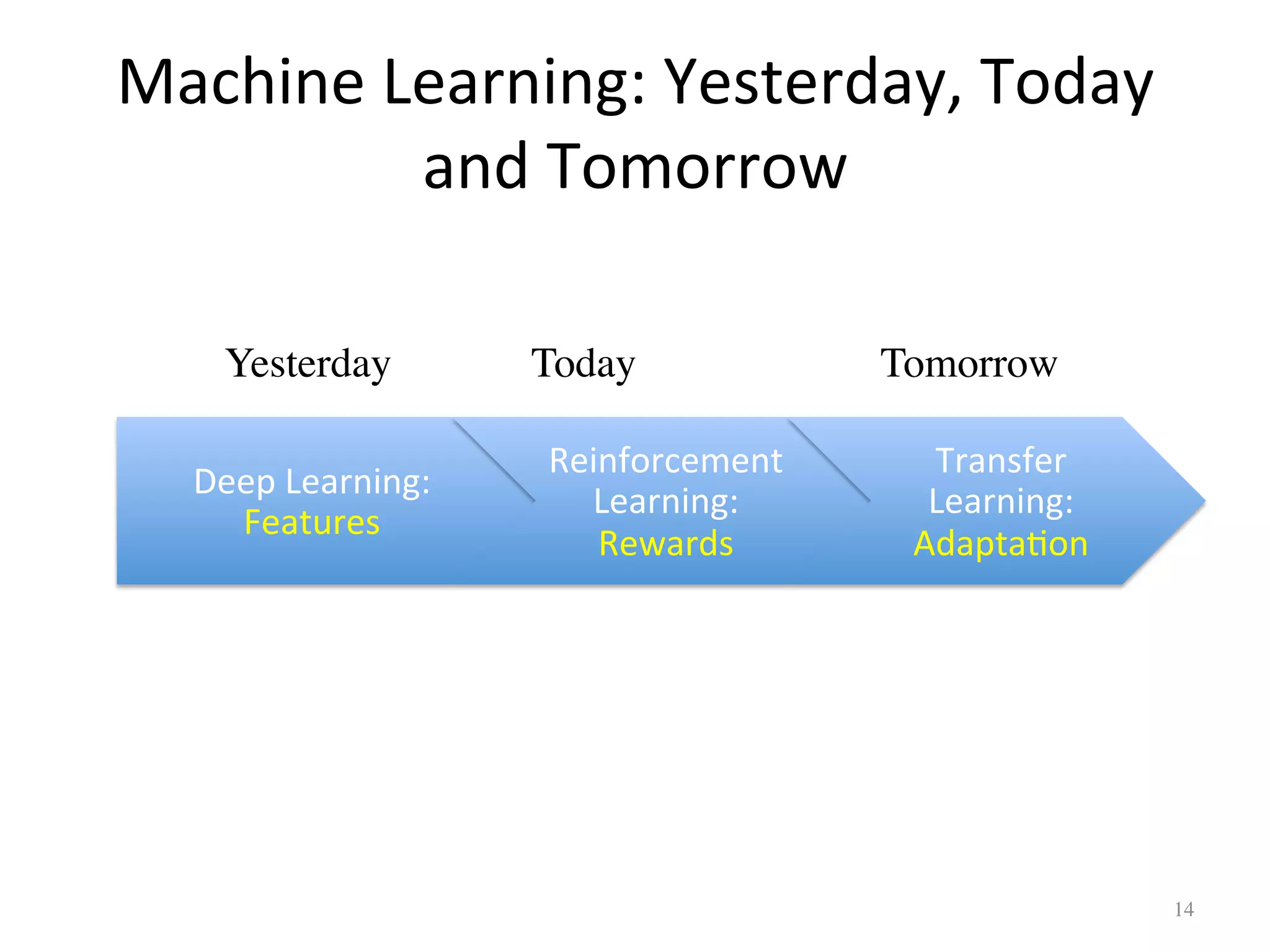
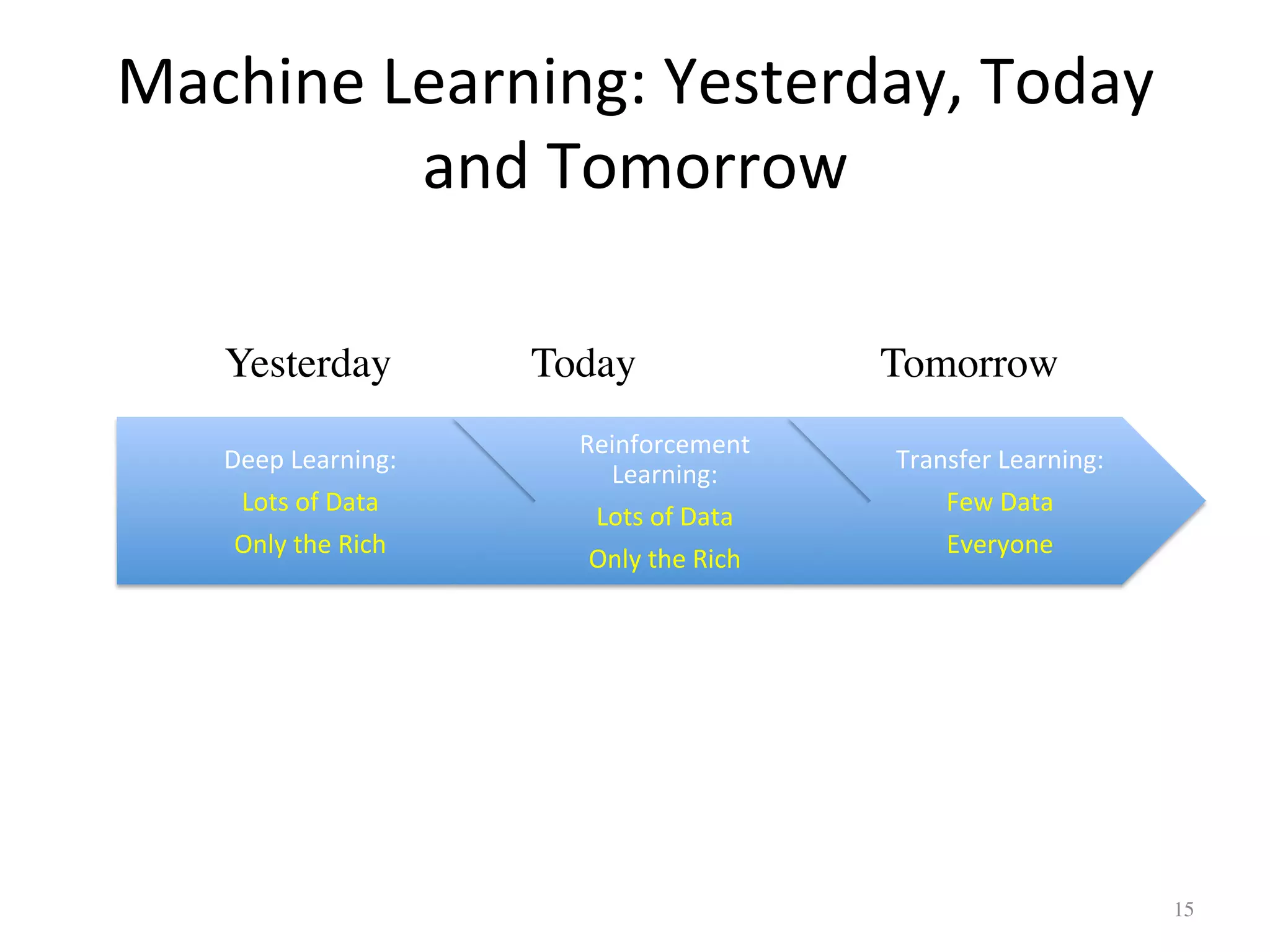
Parallels deep learning, reinforcement learning, and transfer learning approaches across timelines.
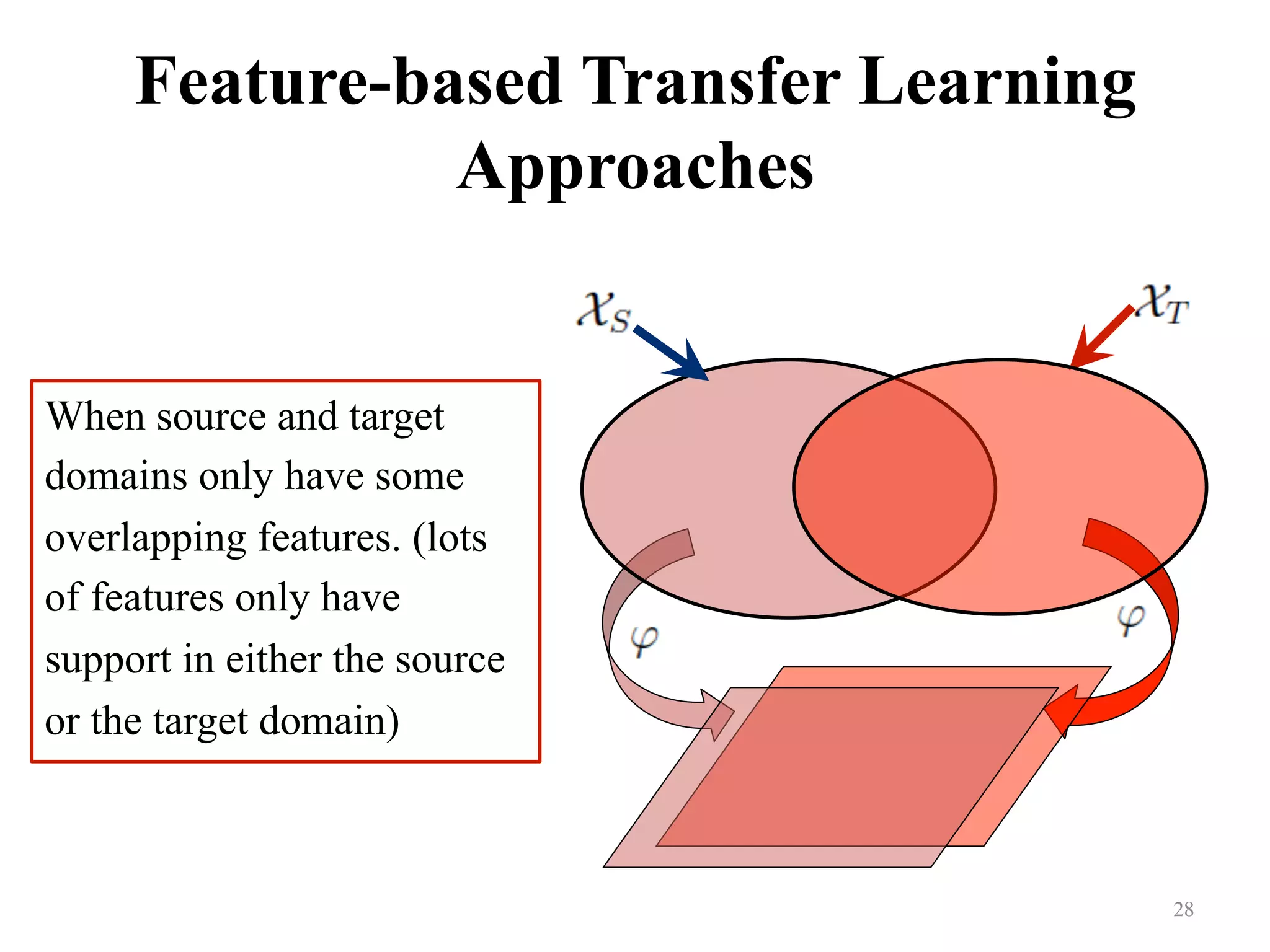
Explores the occurrence of training and testing data from varying domains and features.
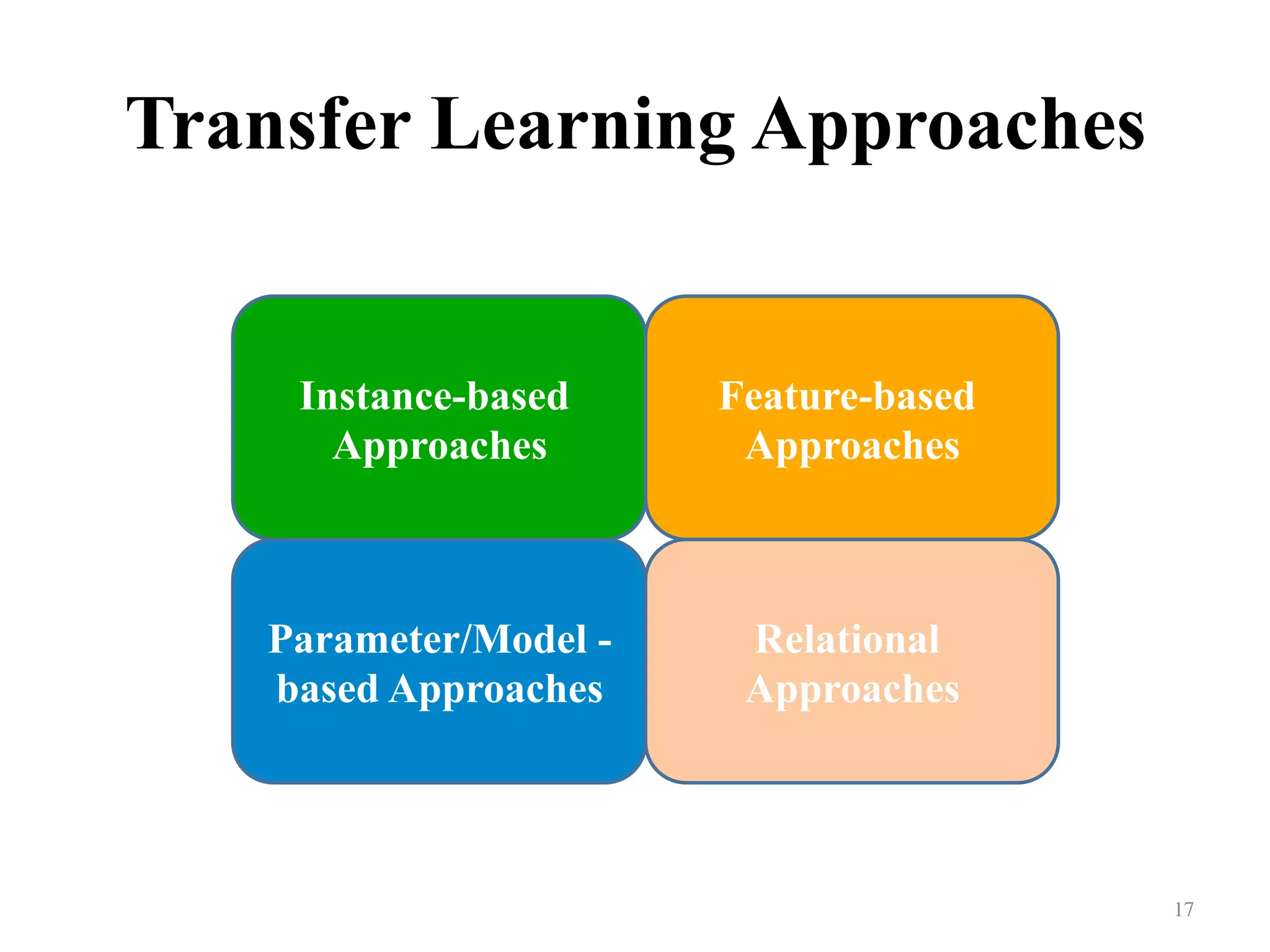
Categorizes transfer learning approaches into instance-based, feature-based, parameter/model based, and relational.
Introduces and discusses instance-based transfer learning approaches focusing on overlapping features.
Details sample selection bias corrections and outlines various techniques like kernel mean matching.
Further elaborates on kernel density estimation and the reuse of labeled data in target domains.
Focuses on learning transformations when features between source and target domains overlap.
Details the method for feature alignment across domains using bipartite graphs and spectral clustering.
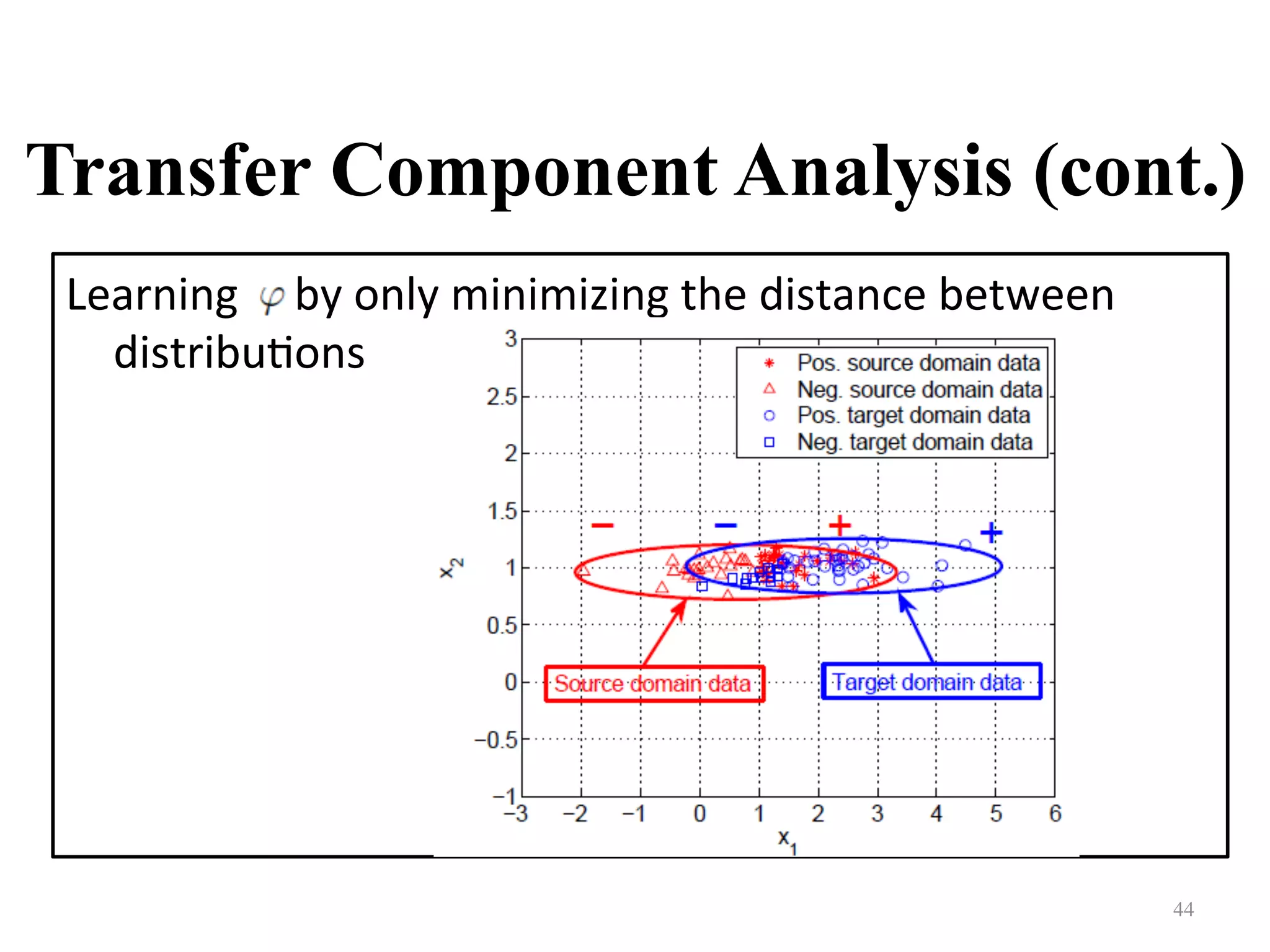
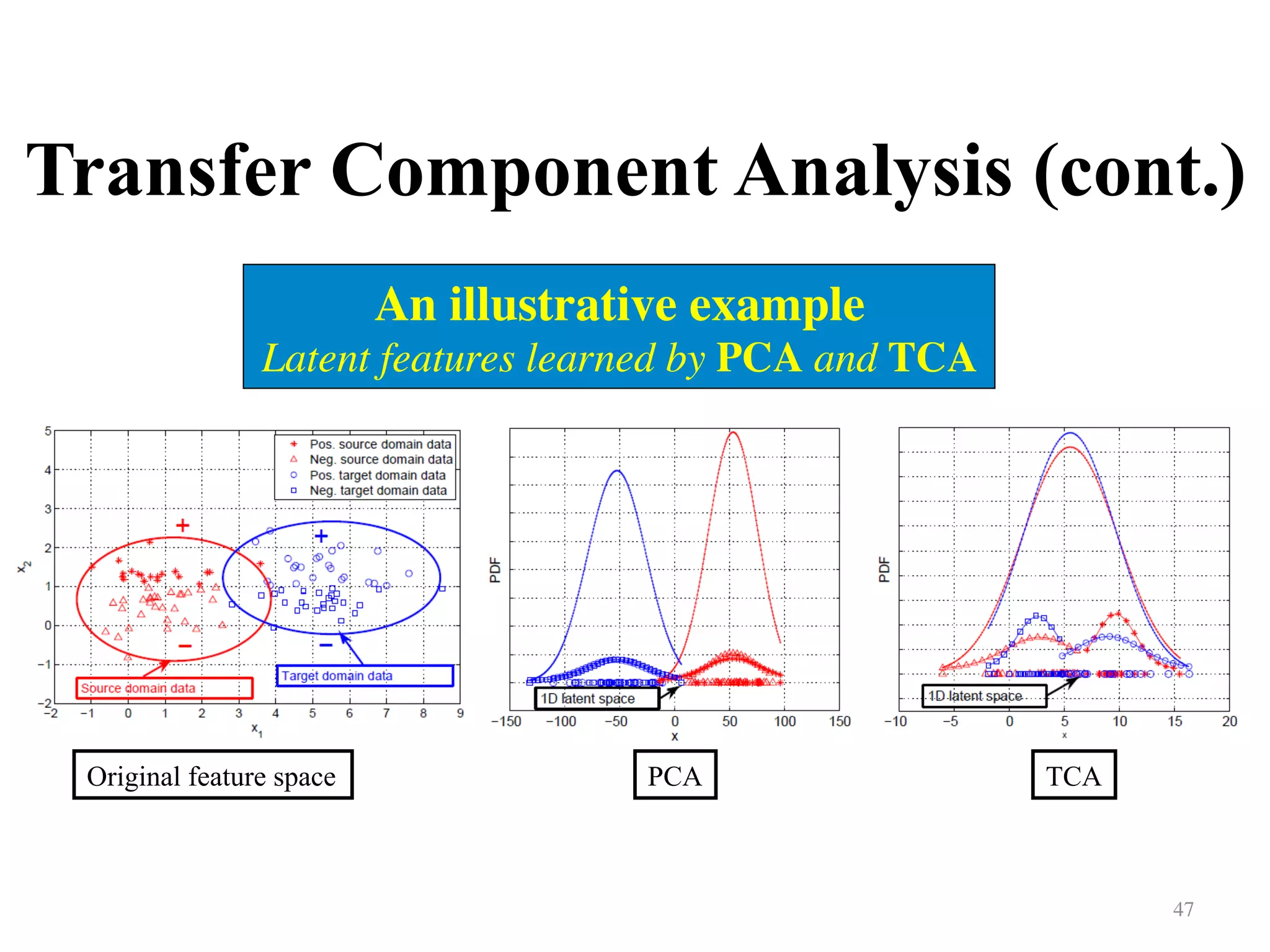
Explains transfer component analysis methods for aligning data distributions between two domains.
Overview of self-taught learning and multi-task feature learning concepts in transfer learning.
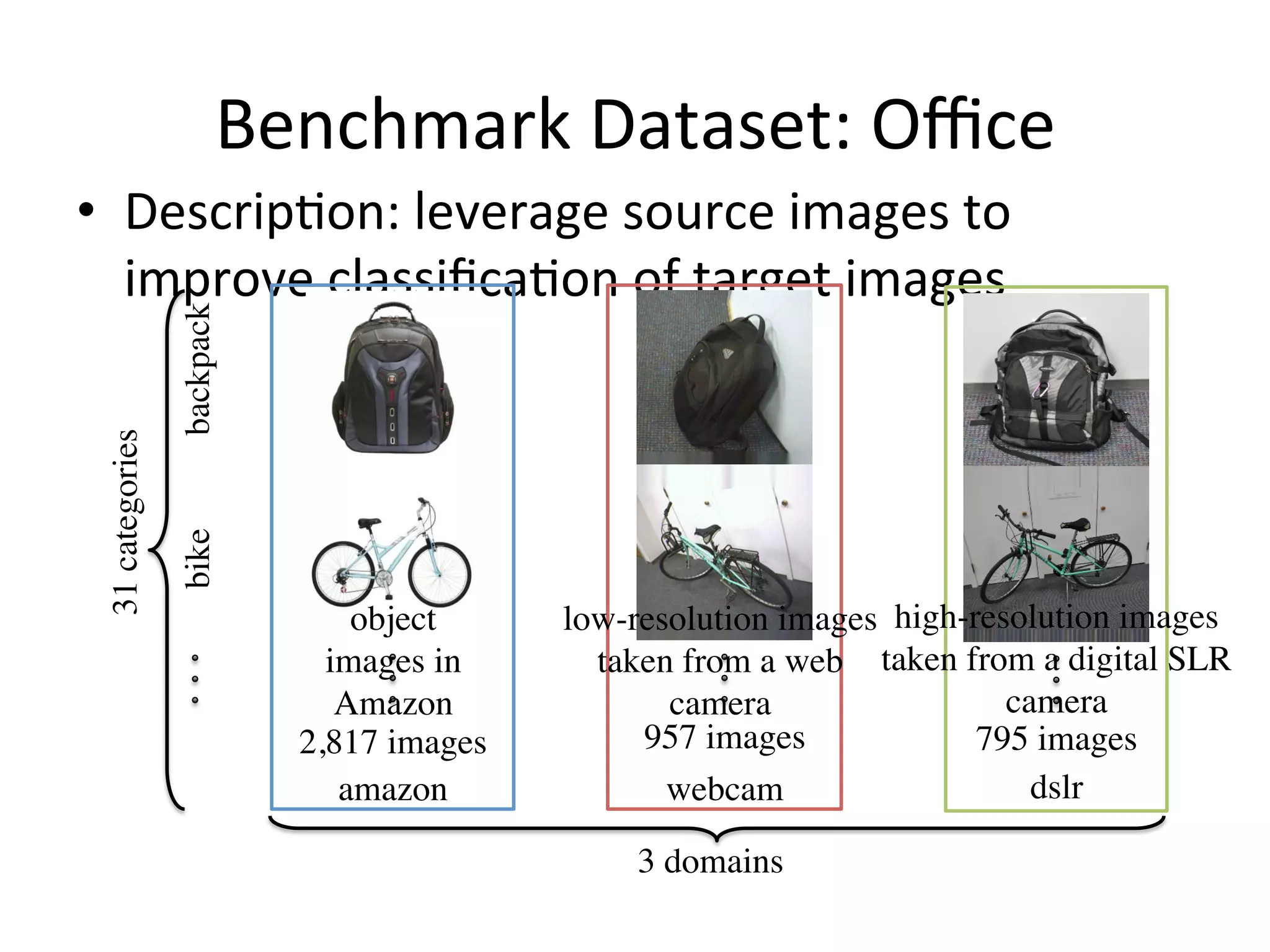
Discusses deep learning's role in transfer learning and its advantages on benchmark datasets.
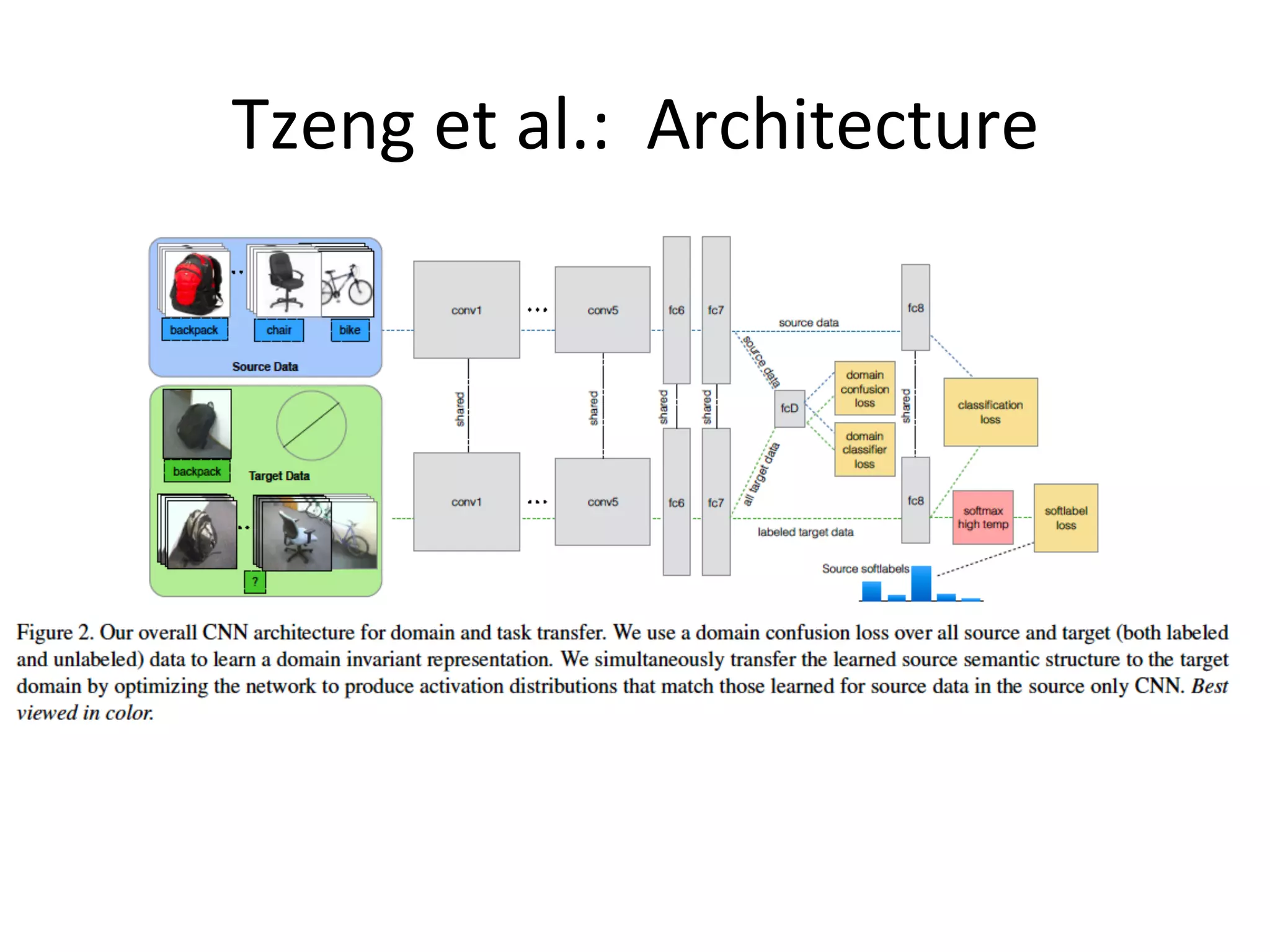
Explores the mechanisms of using deep learning for feature transfer across domains.
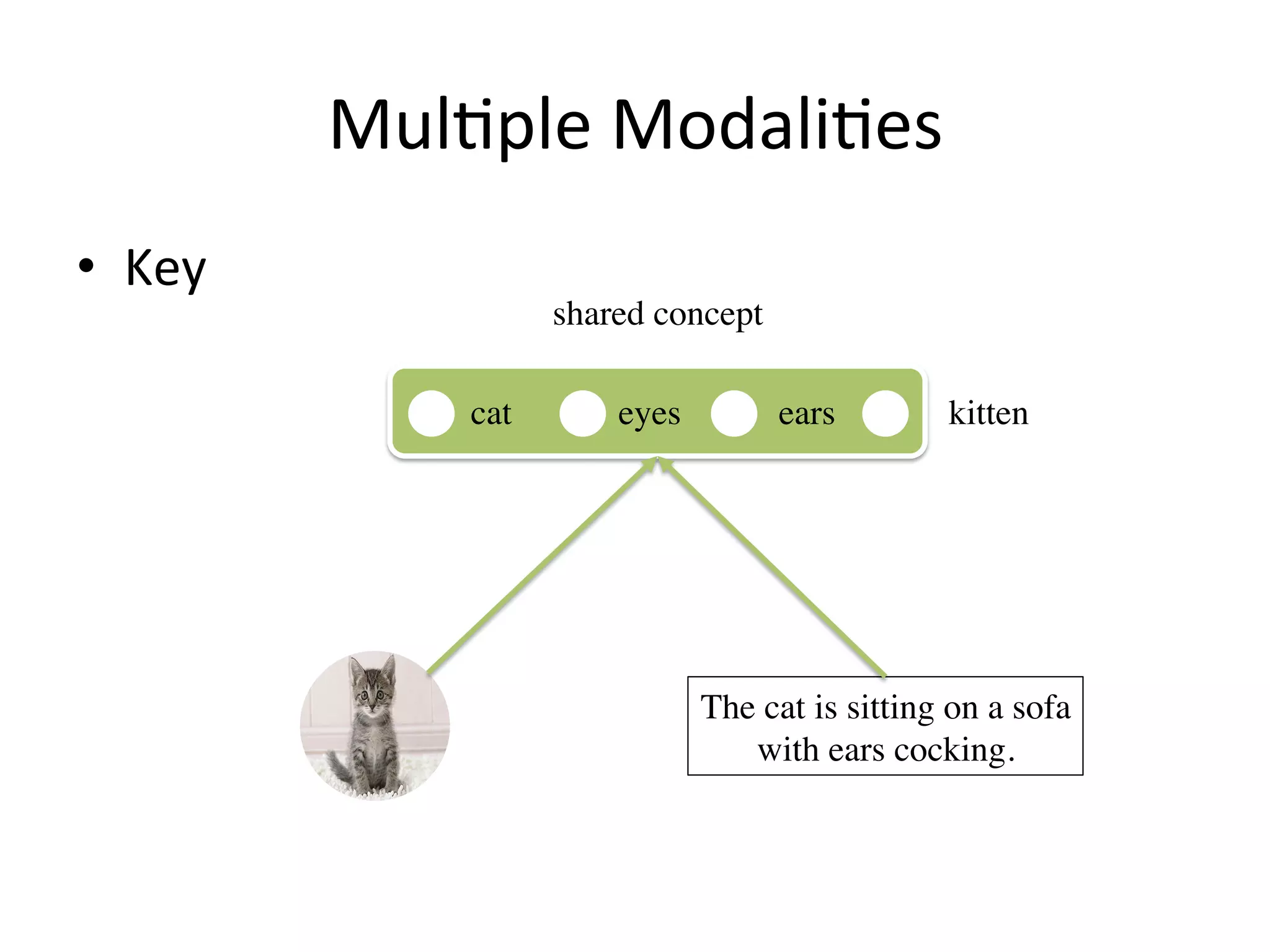
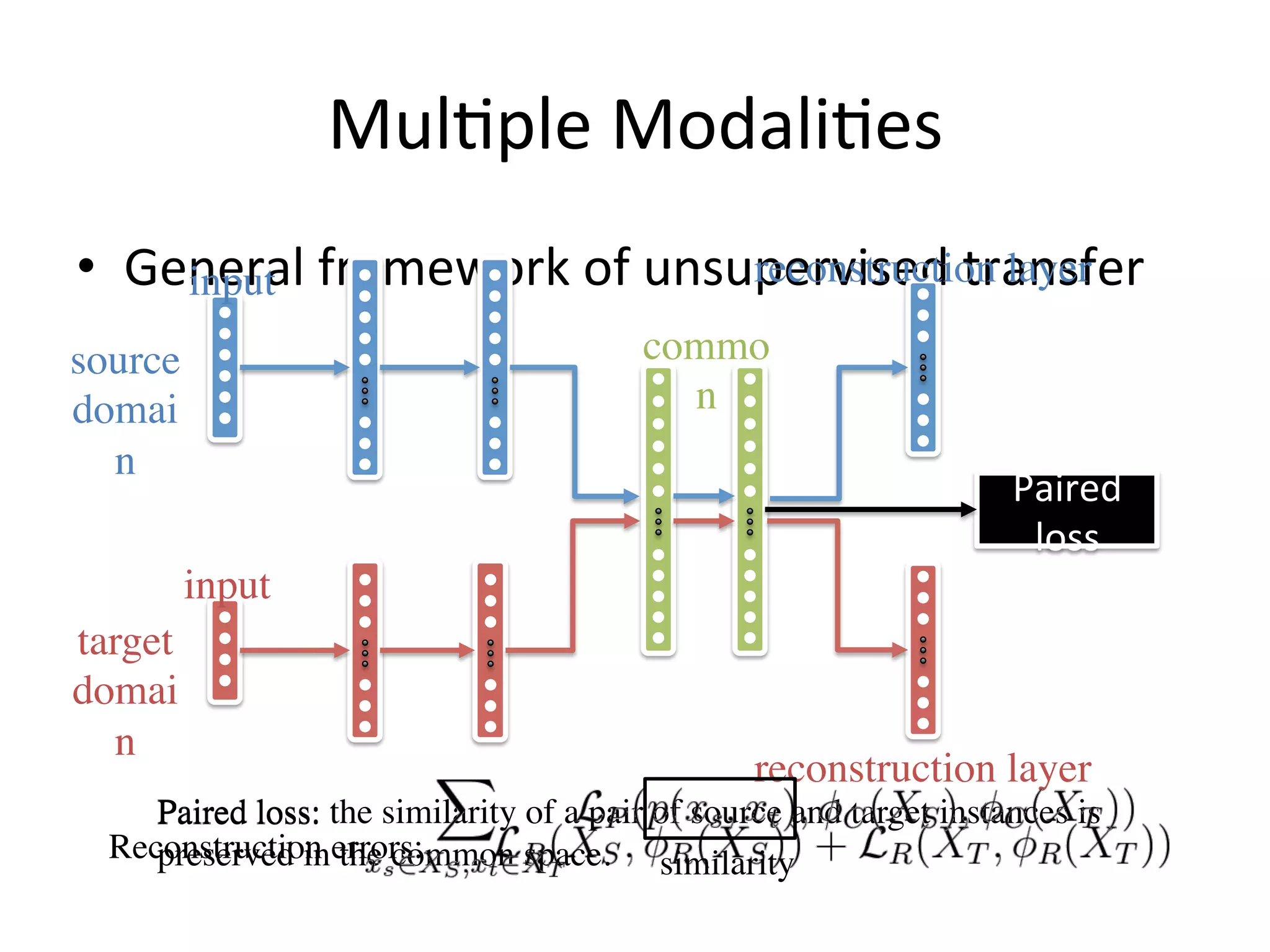
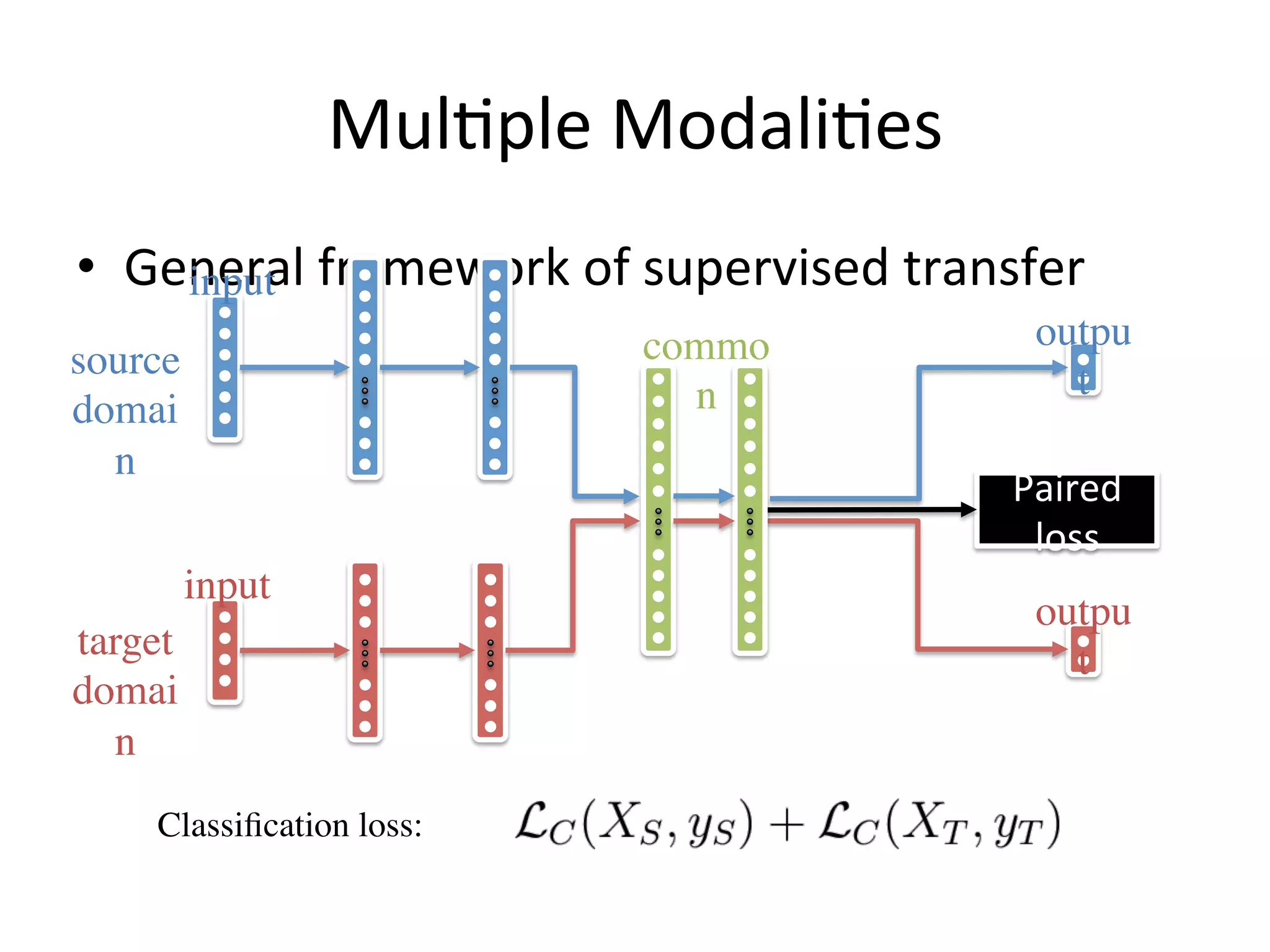
Introduces frameworks for handling multi-modal transfers, emphasizing paired and classification losses.
Analyzes the MIR-Flickr dataset for image classification and how it benefits from transfer learning.
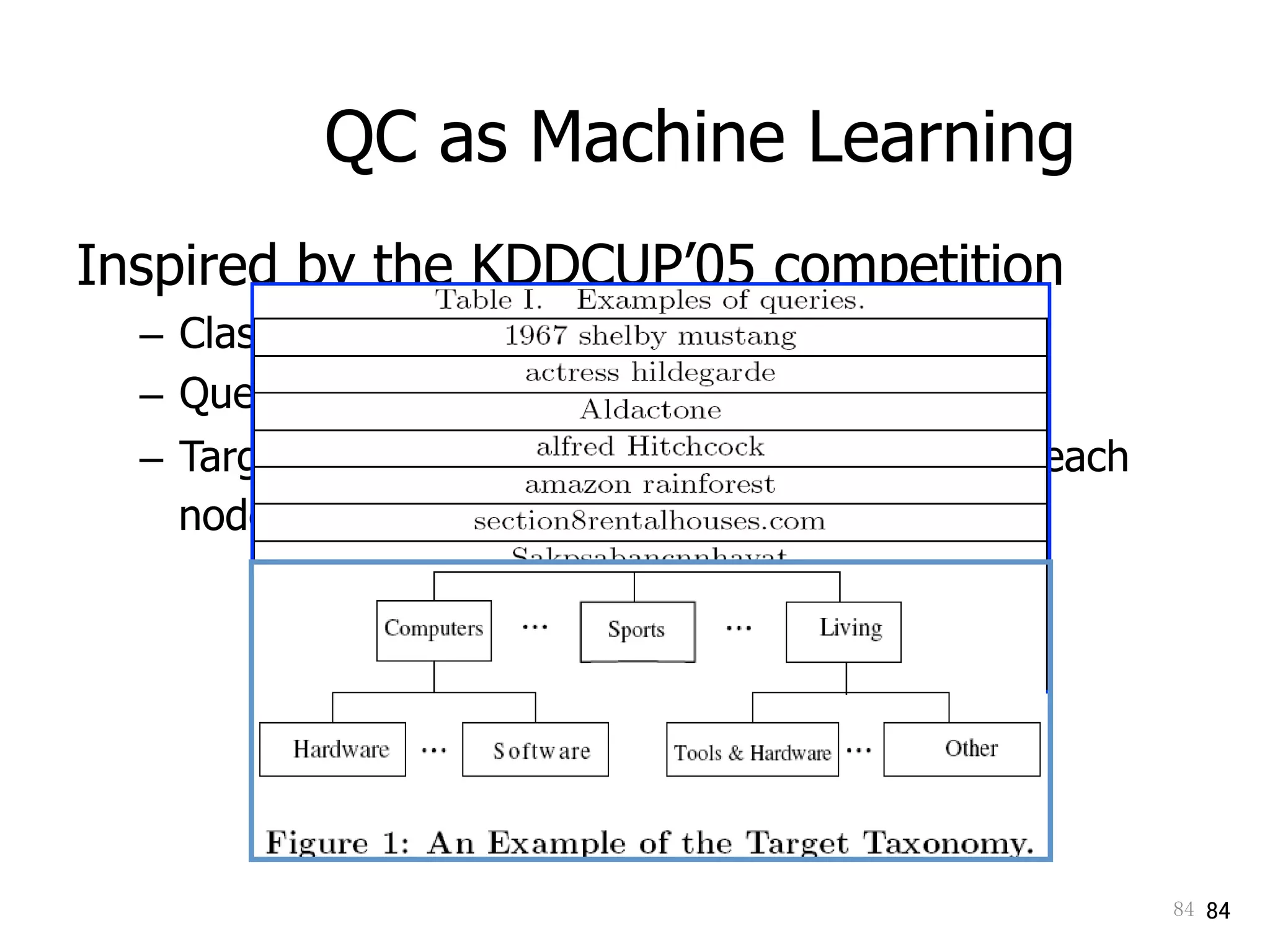
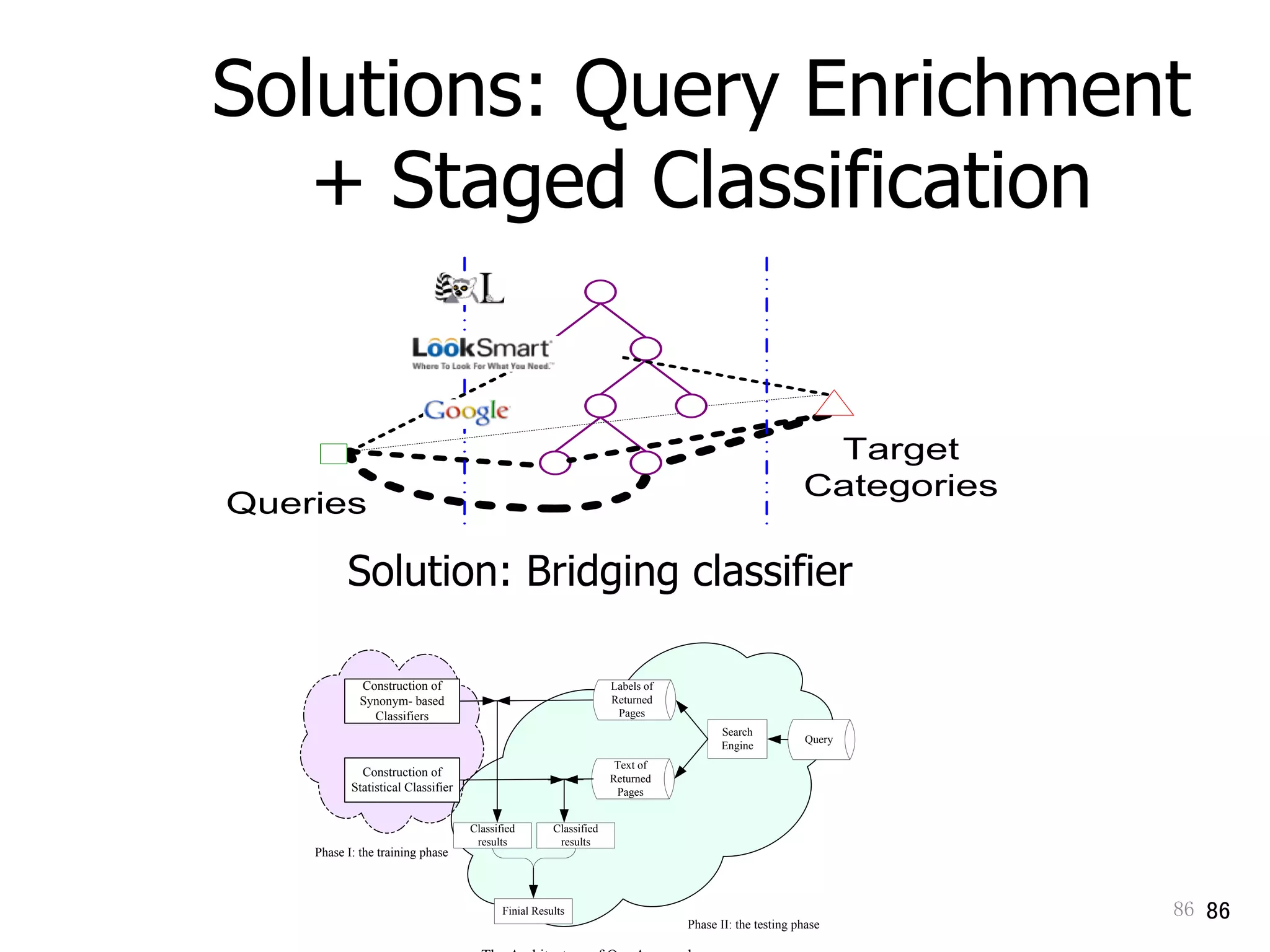
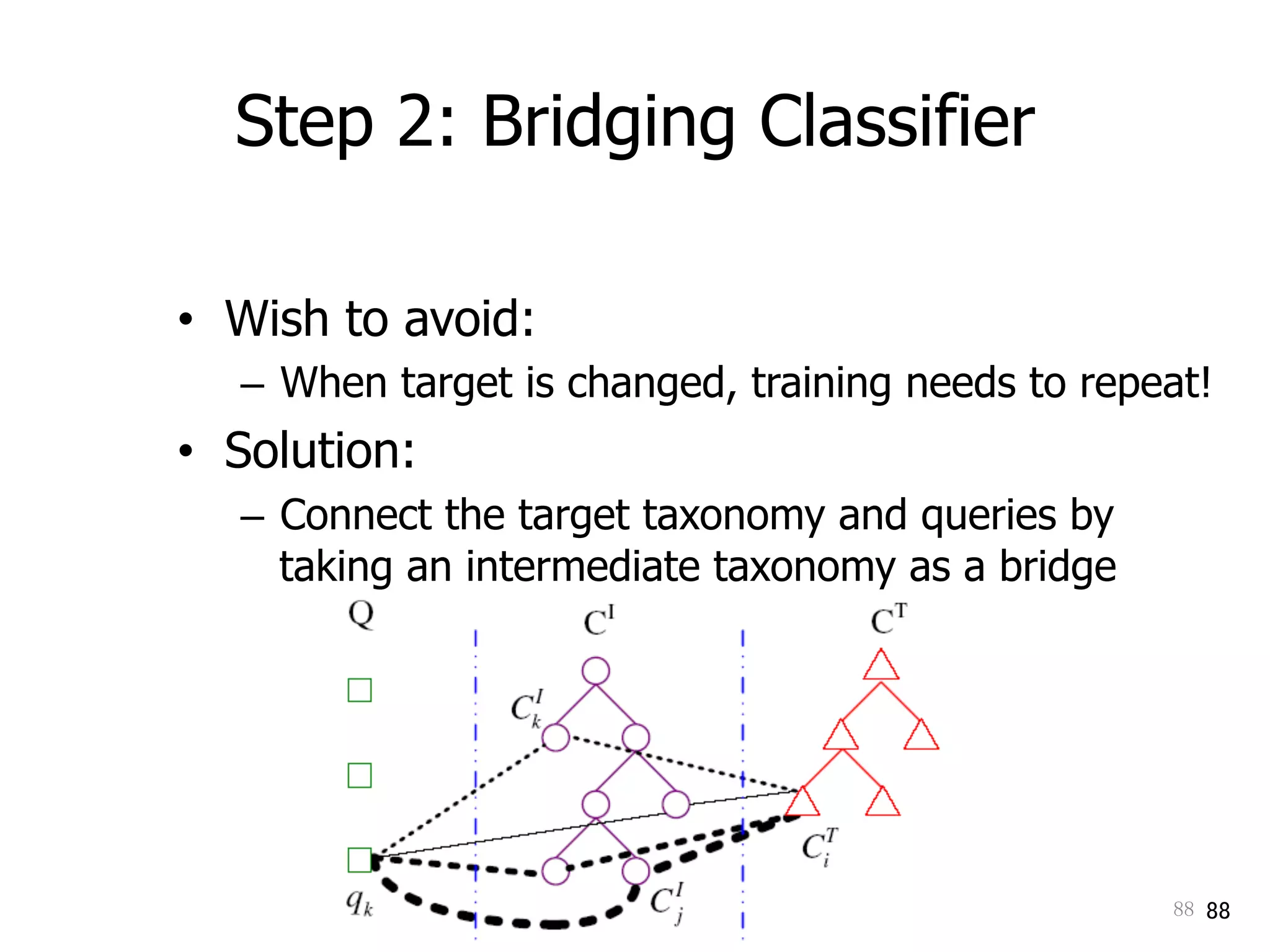
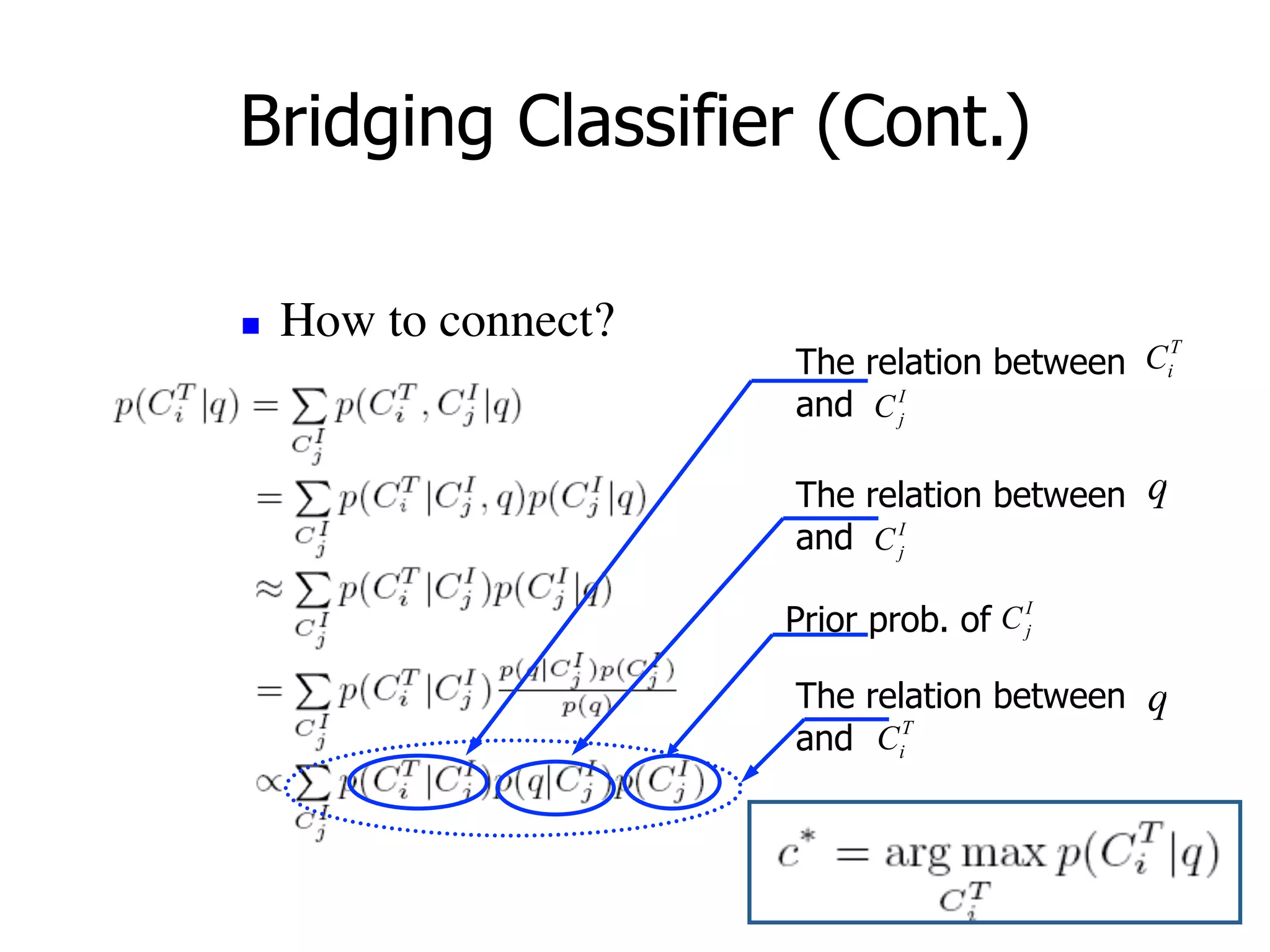
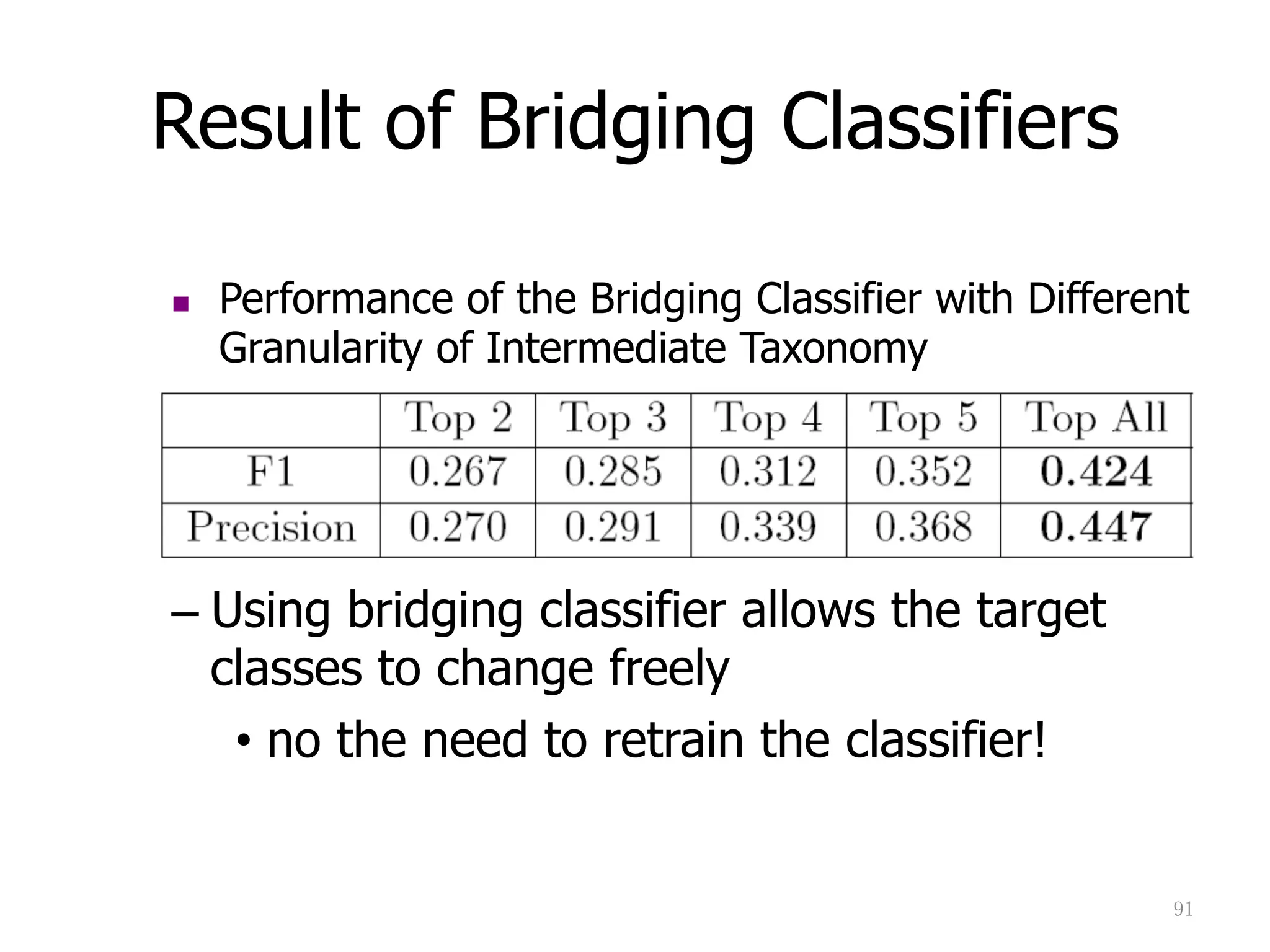
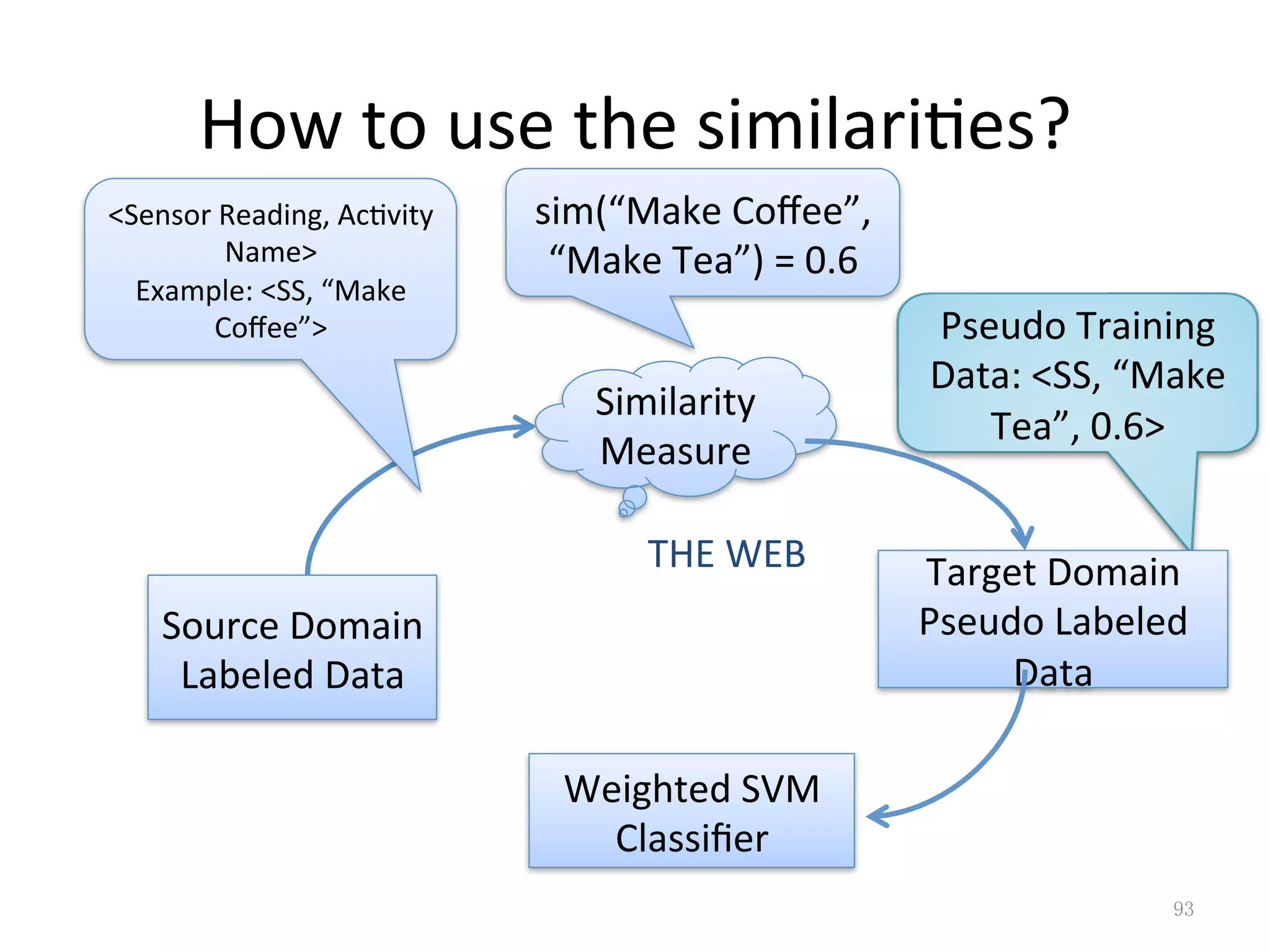
Discusses query classification and bridging classifiers for adapting queries in online systems.
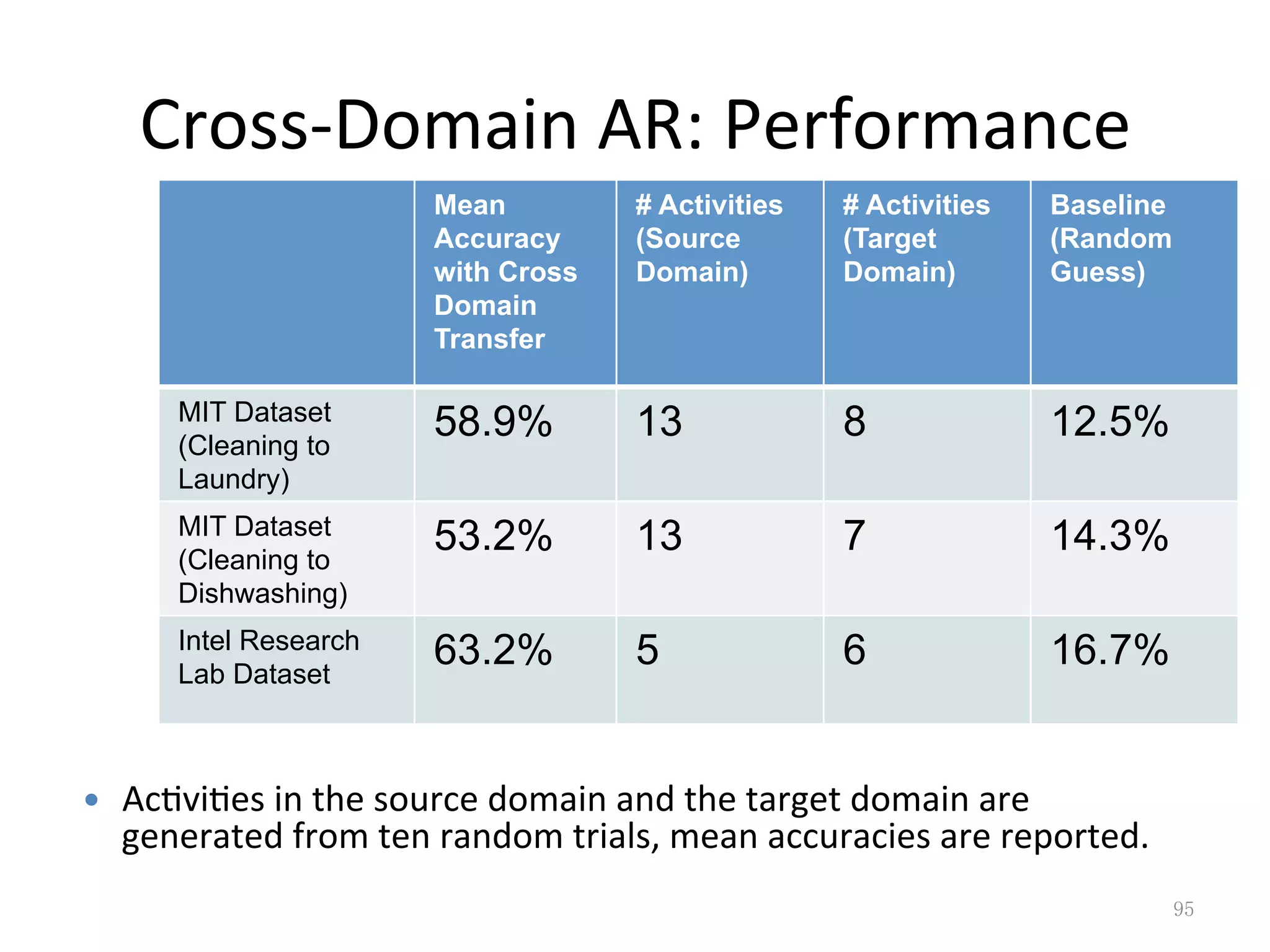
Looks at cross-domain activity recognition and how similarities between activities can aid learning.
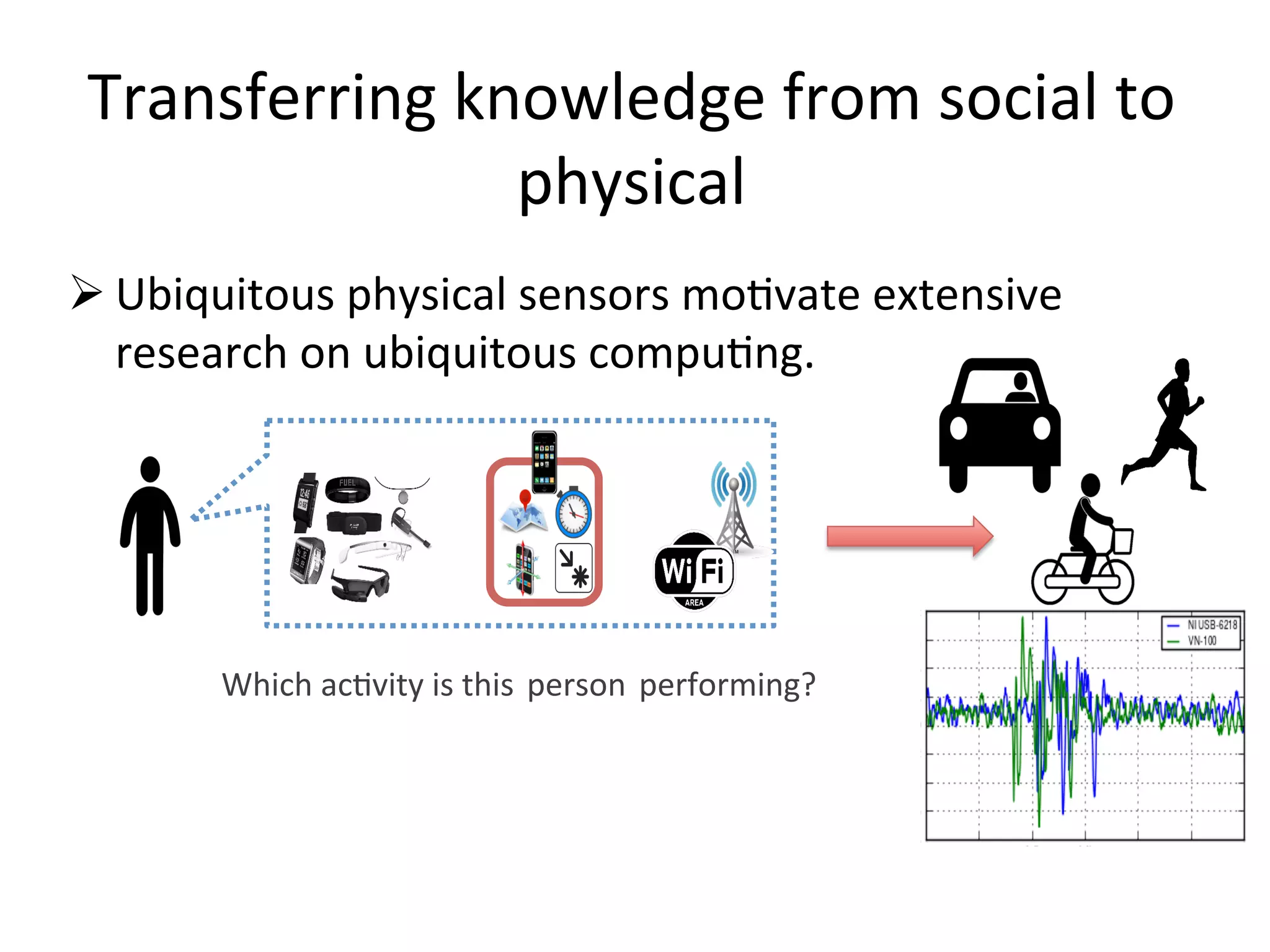
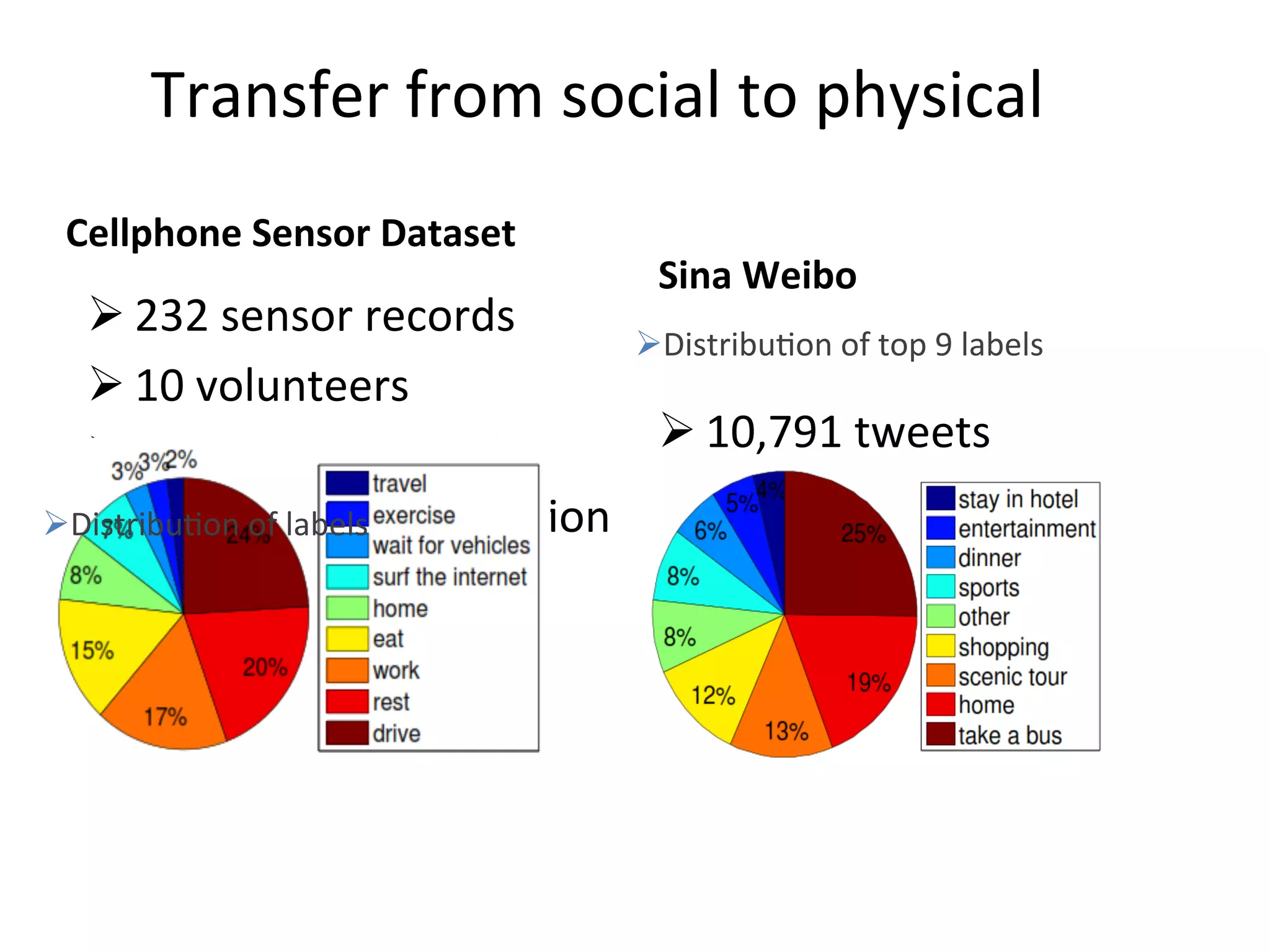
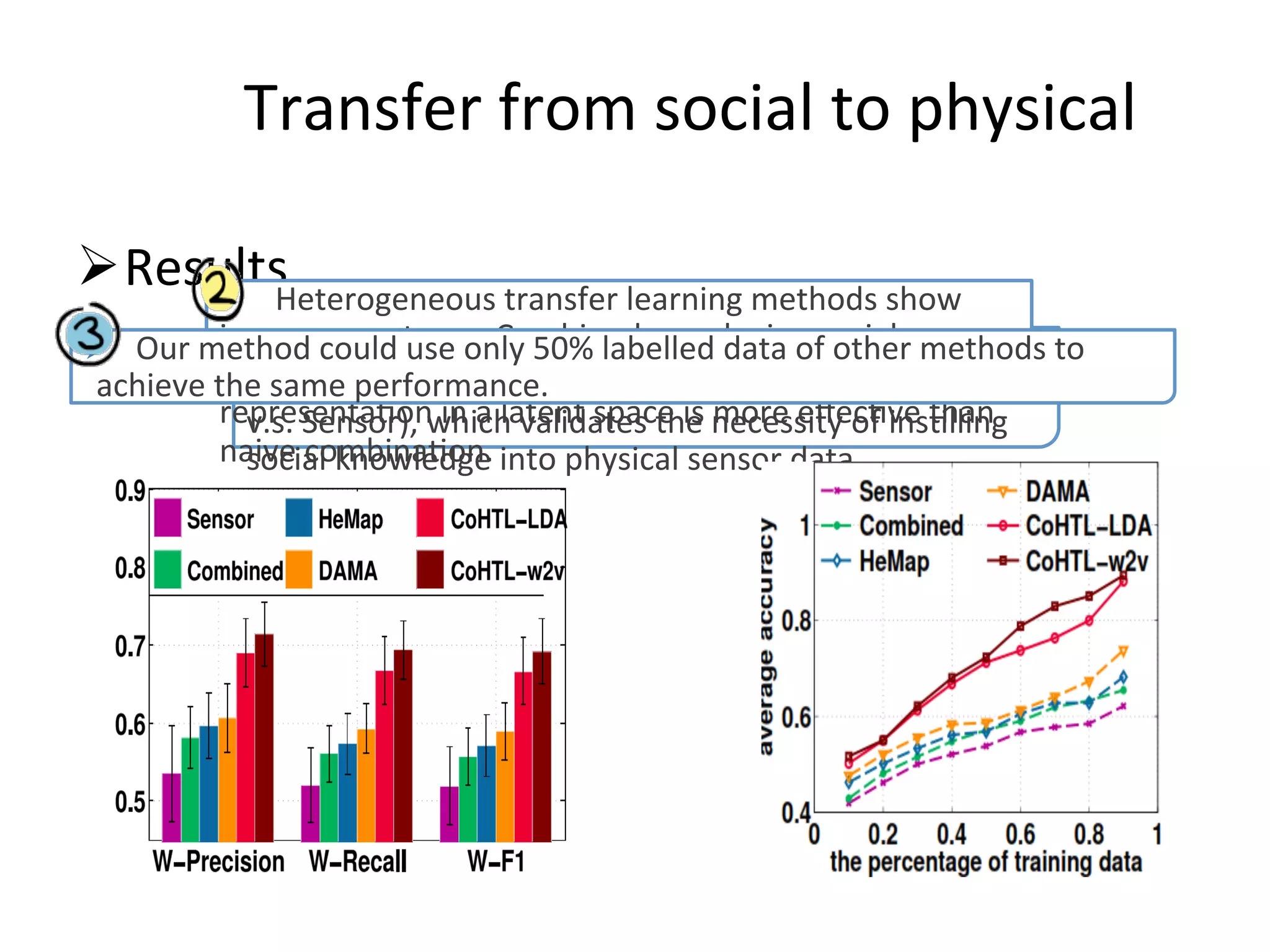
Highlights the significance of integrating social media data with physical domain knowledge.
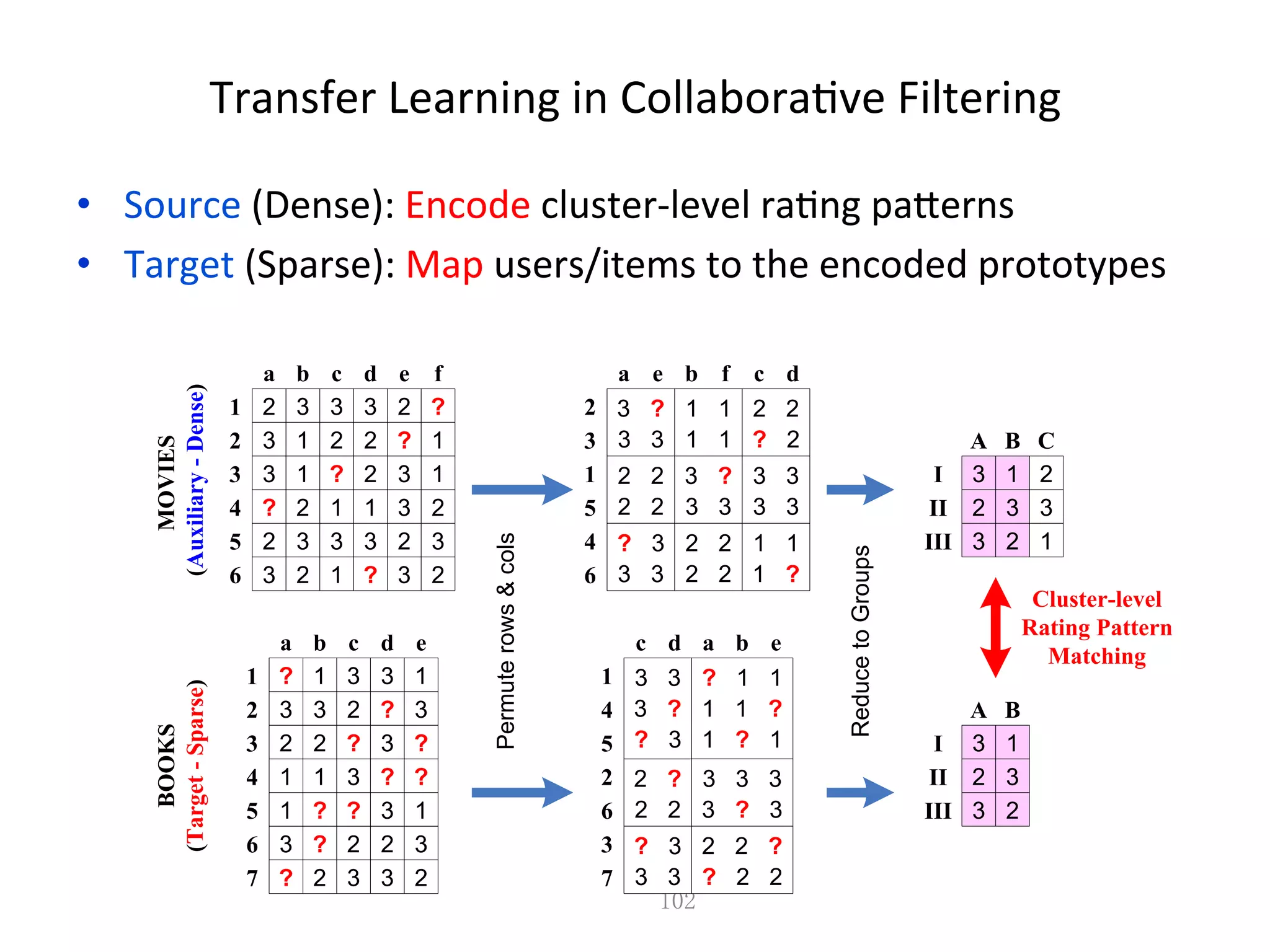
Explores the use of transfer learning in collaborative filtering methodologies.
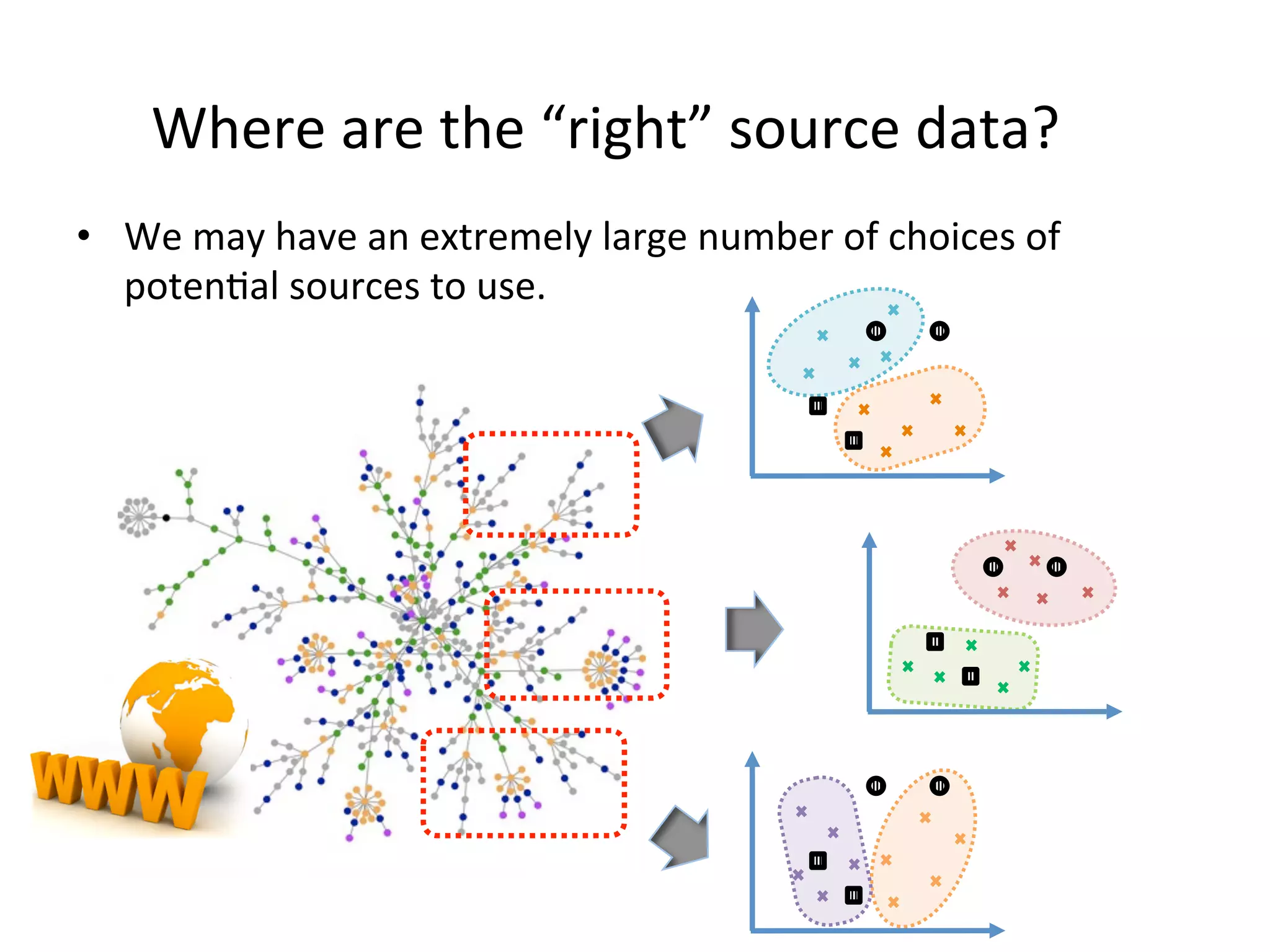
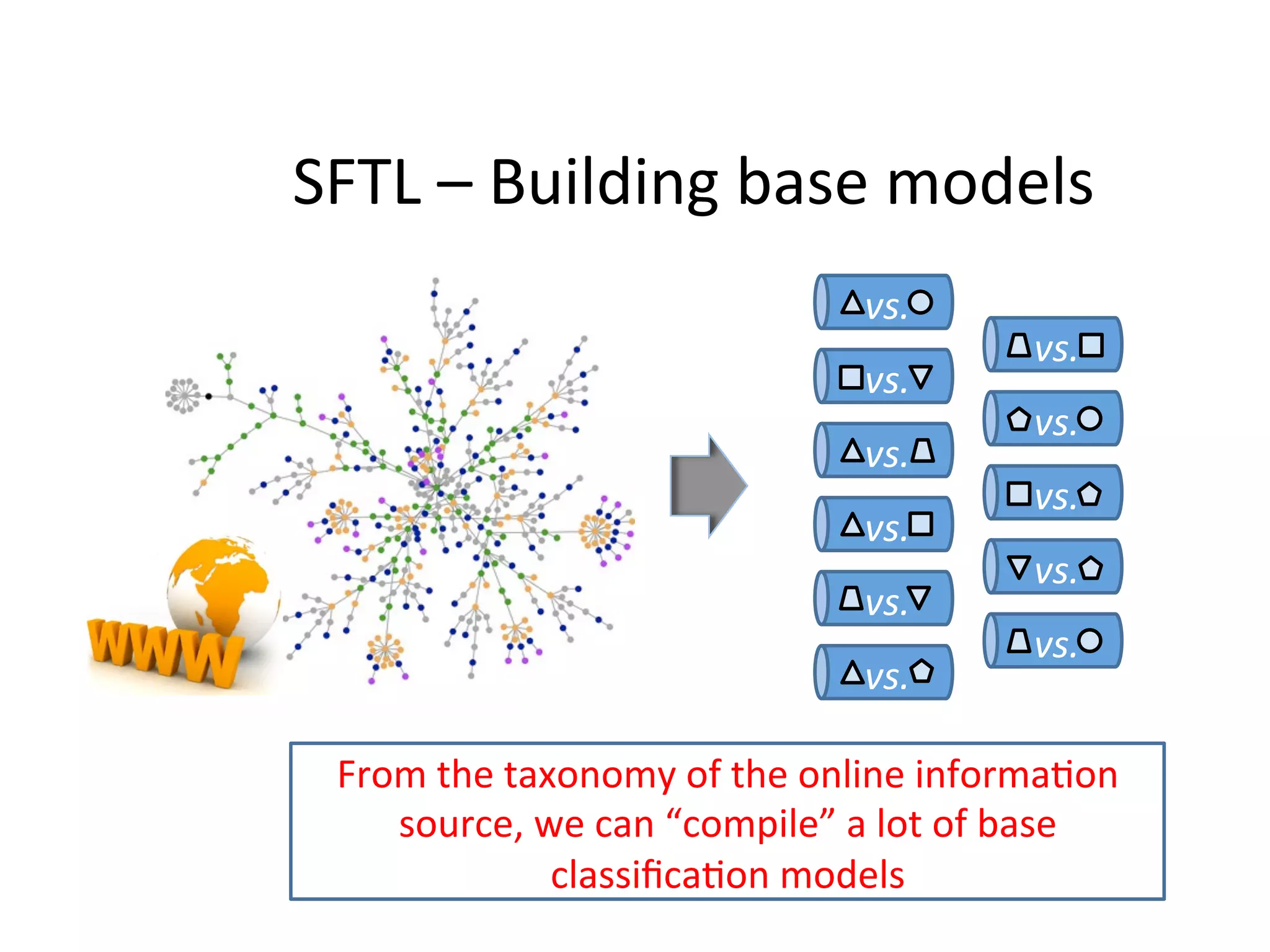
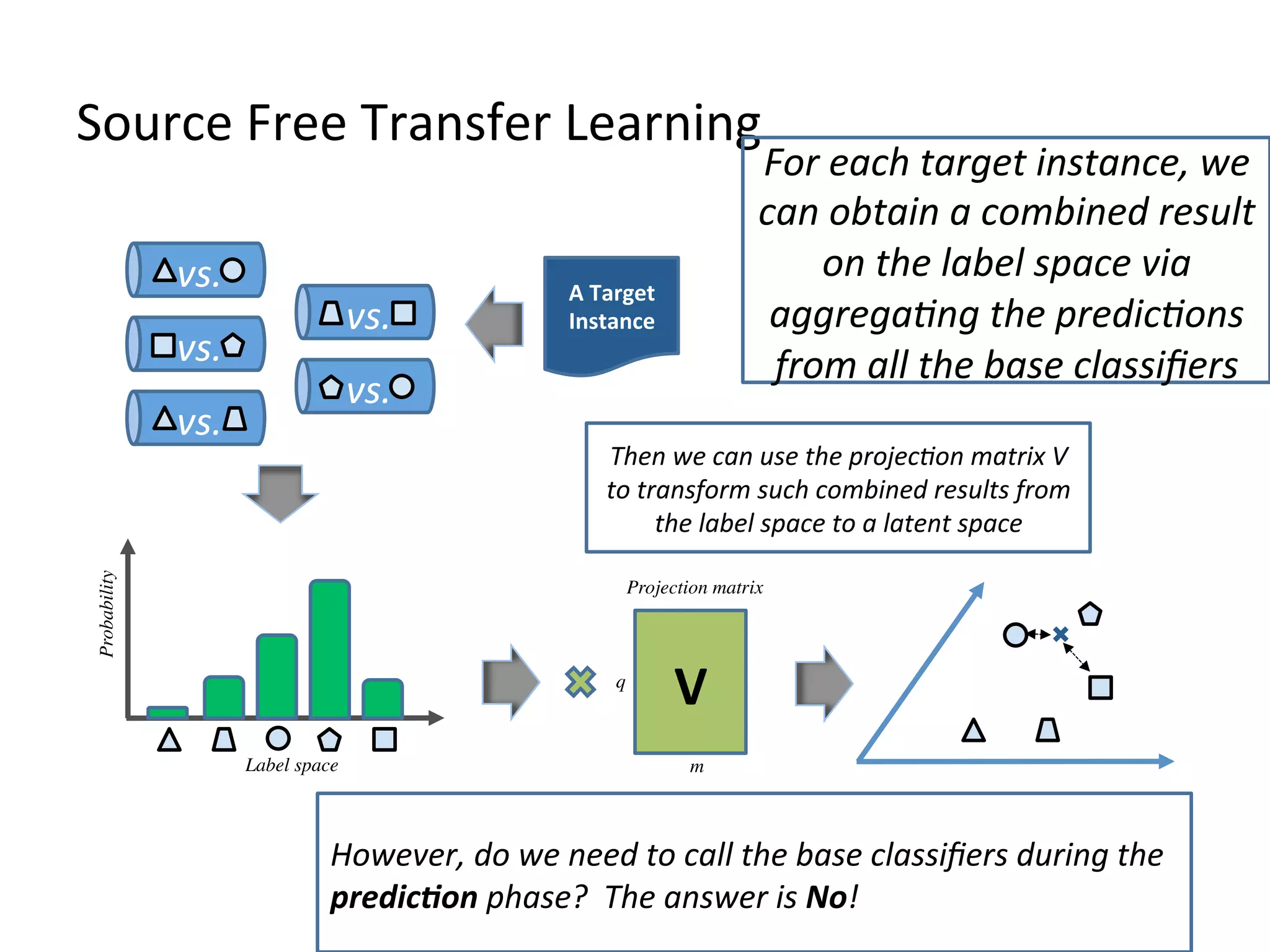
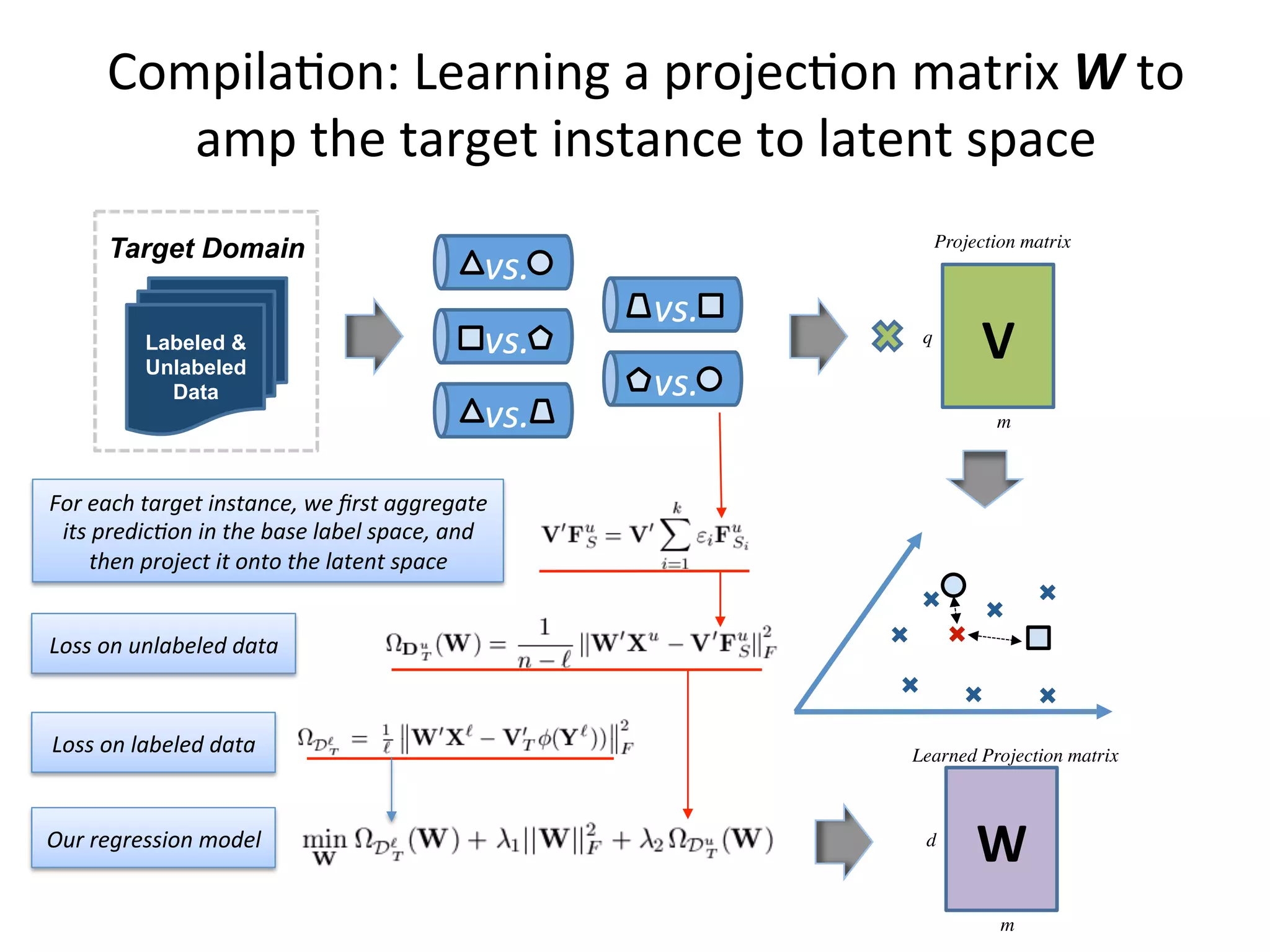
Presents source-free transfer learning strategies for dealing with unlabeled training data.
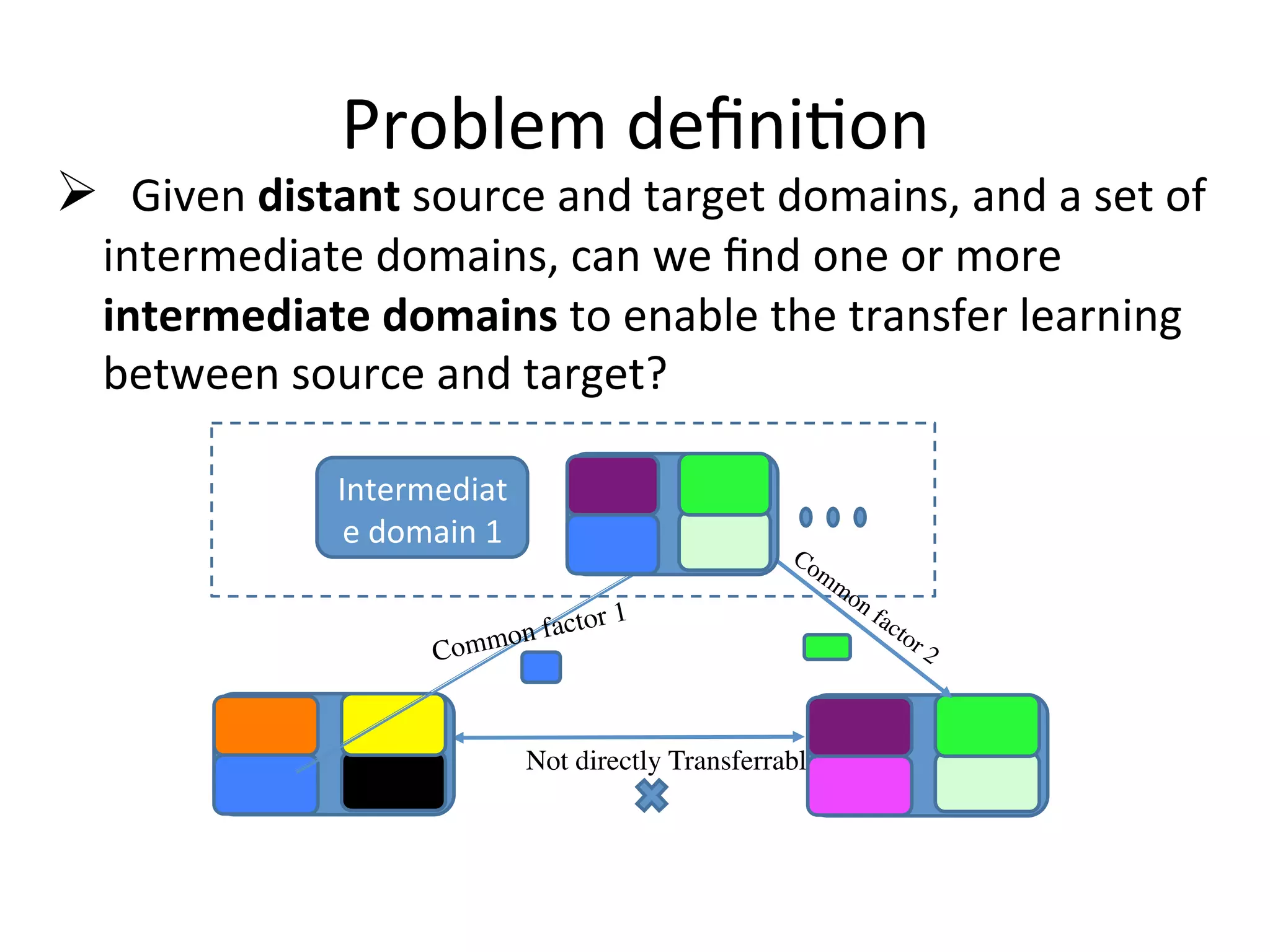
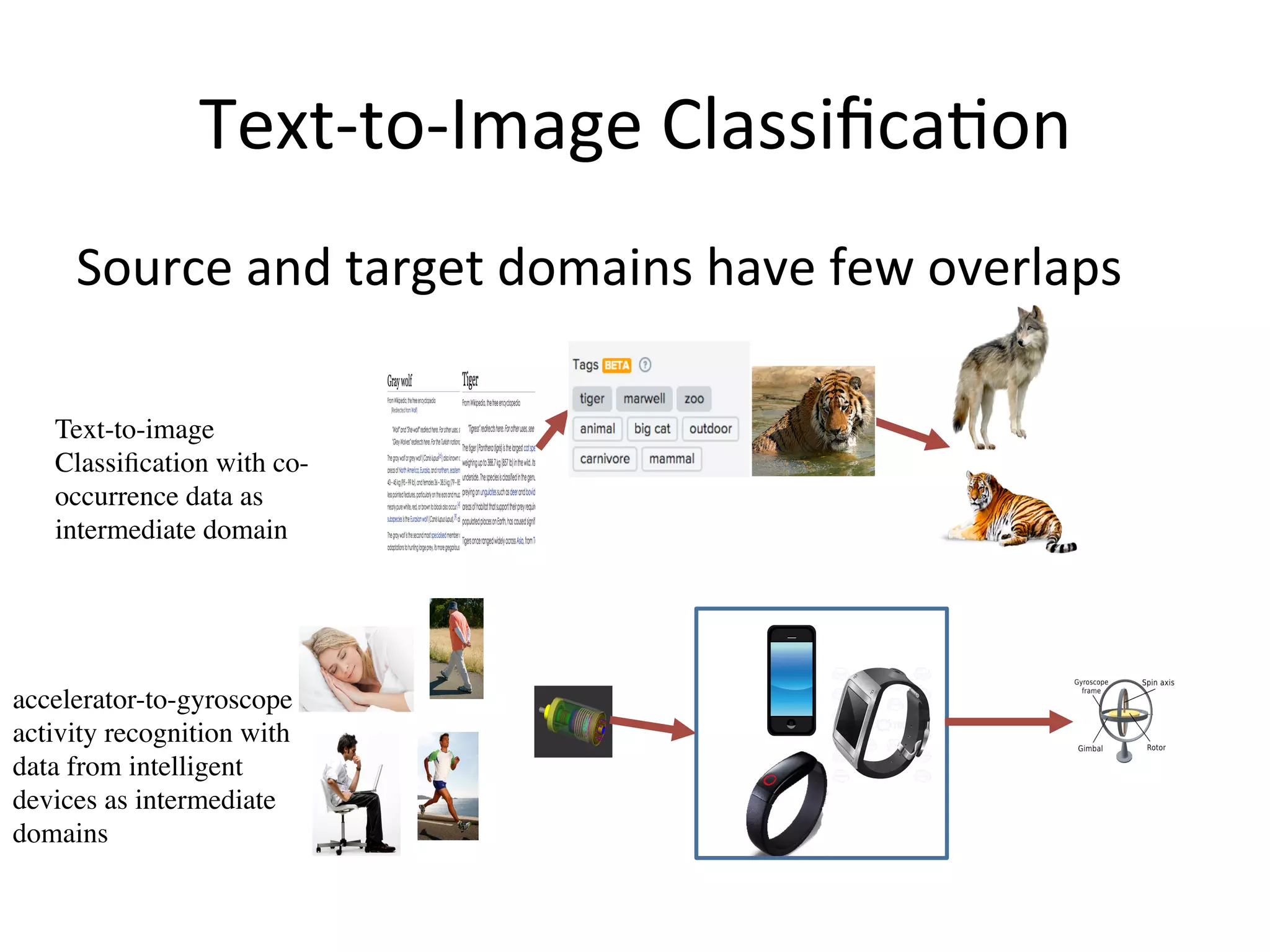
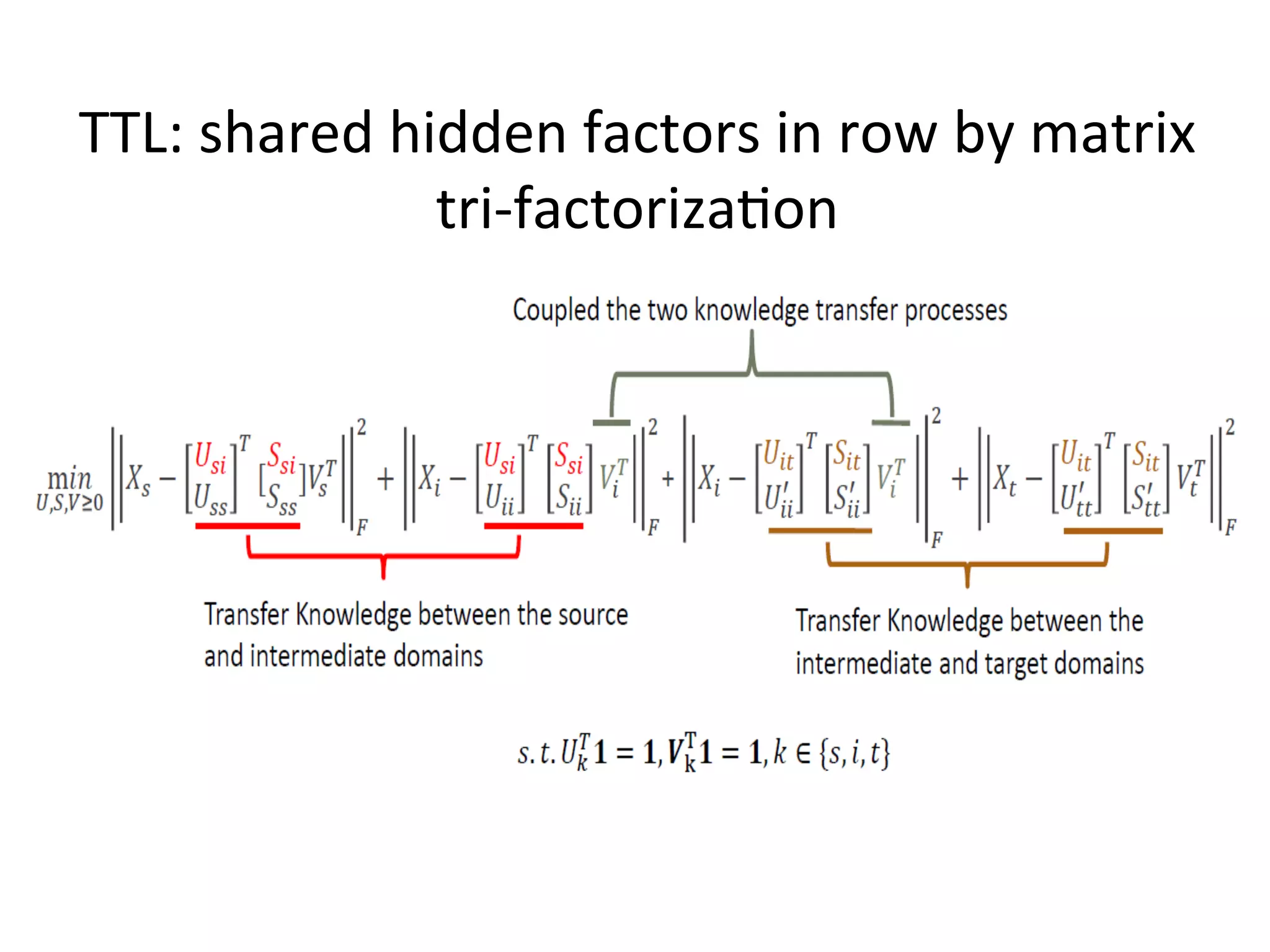
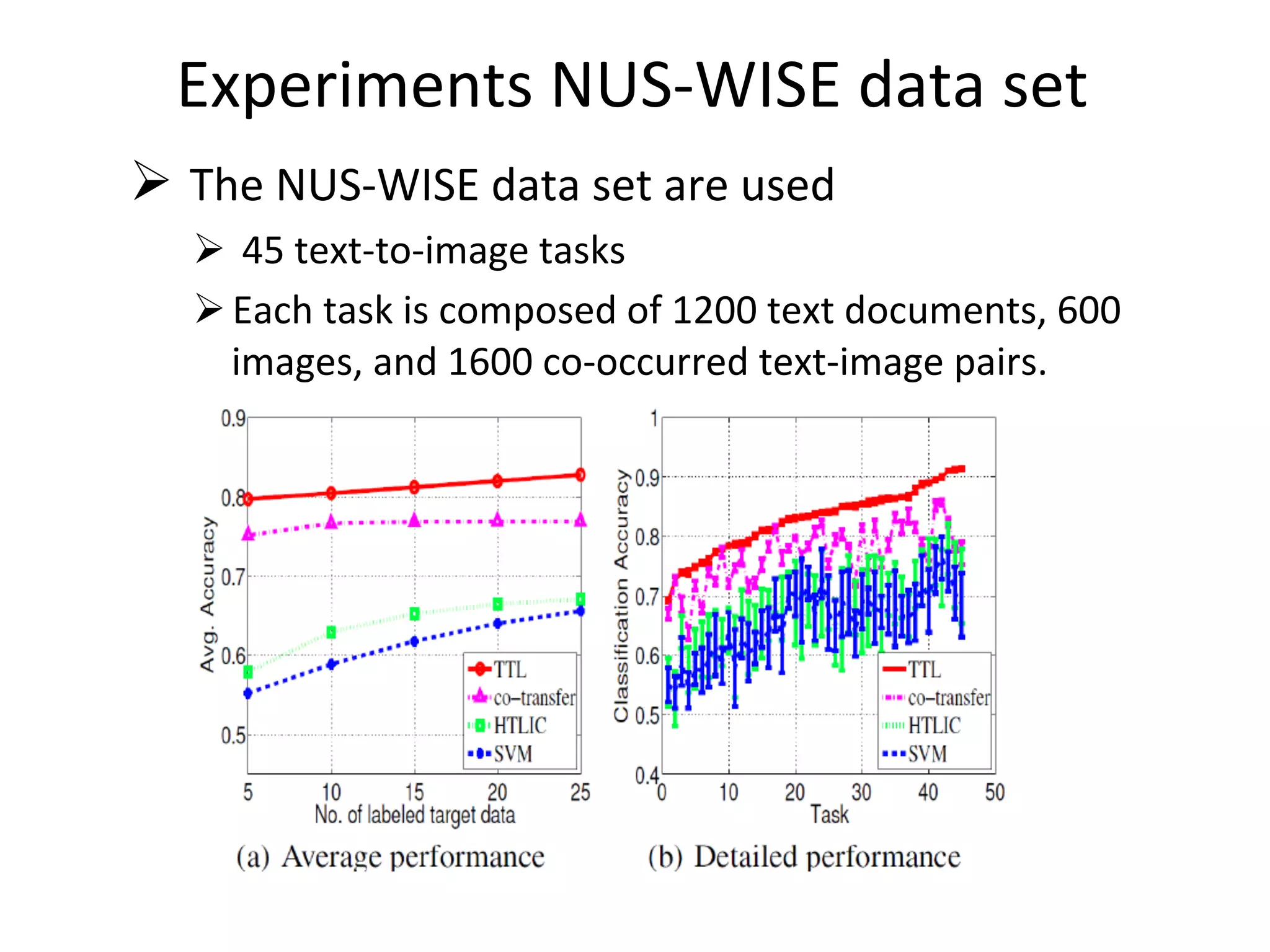
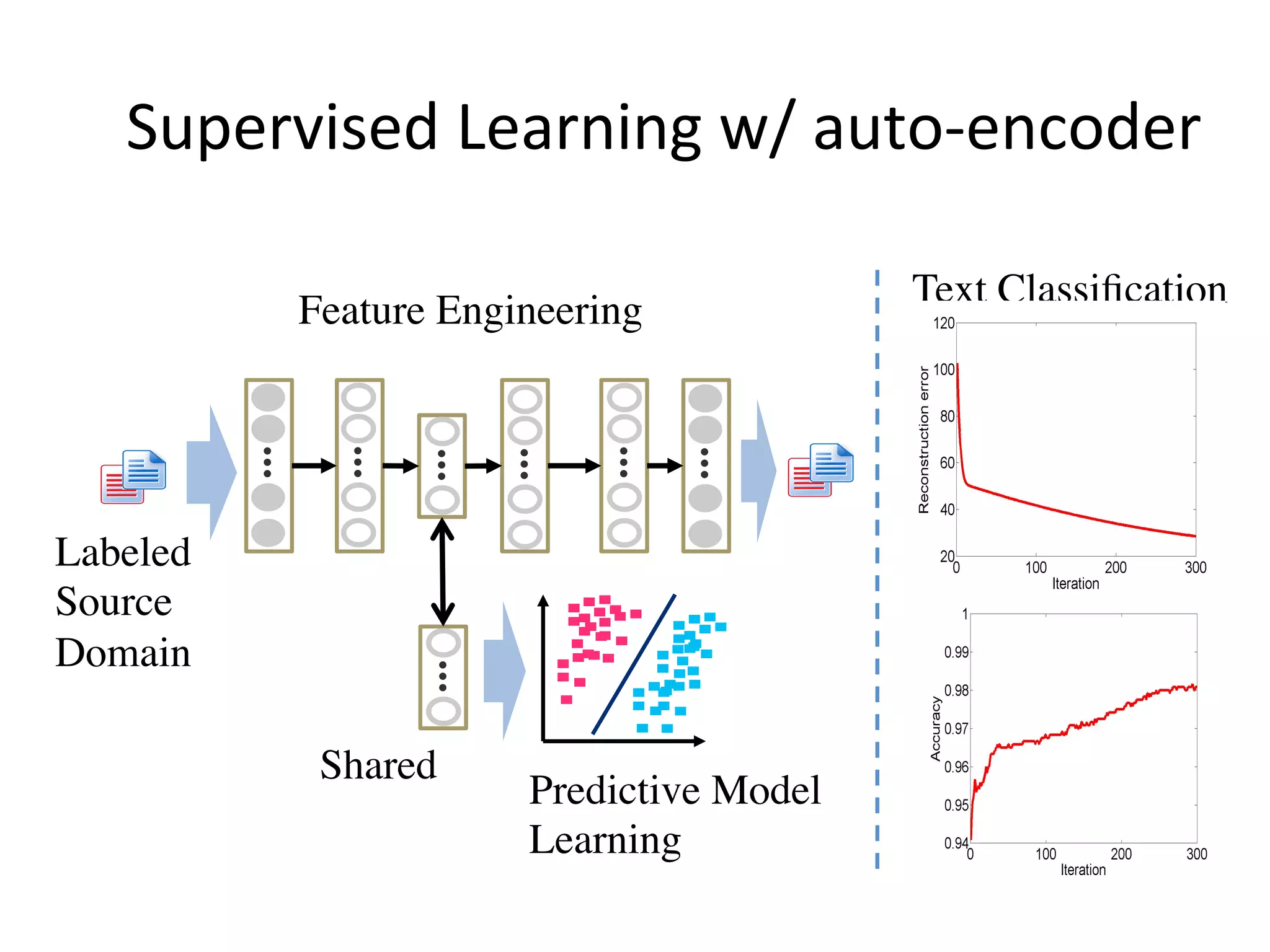
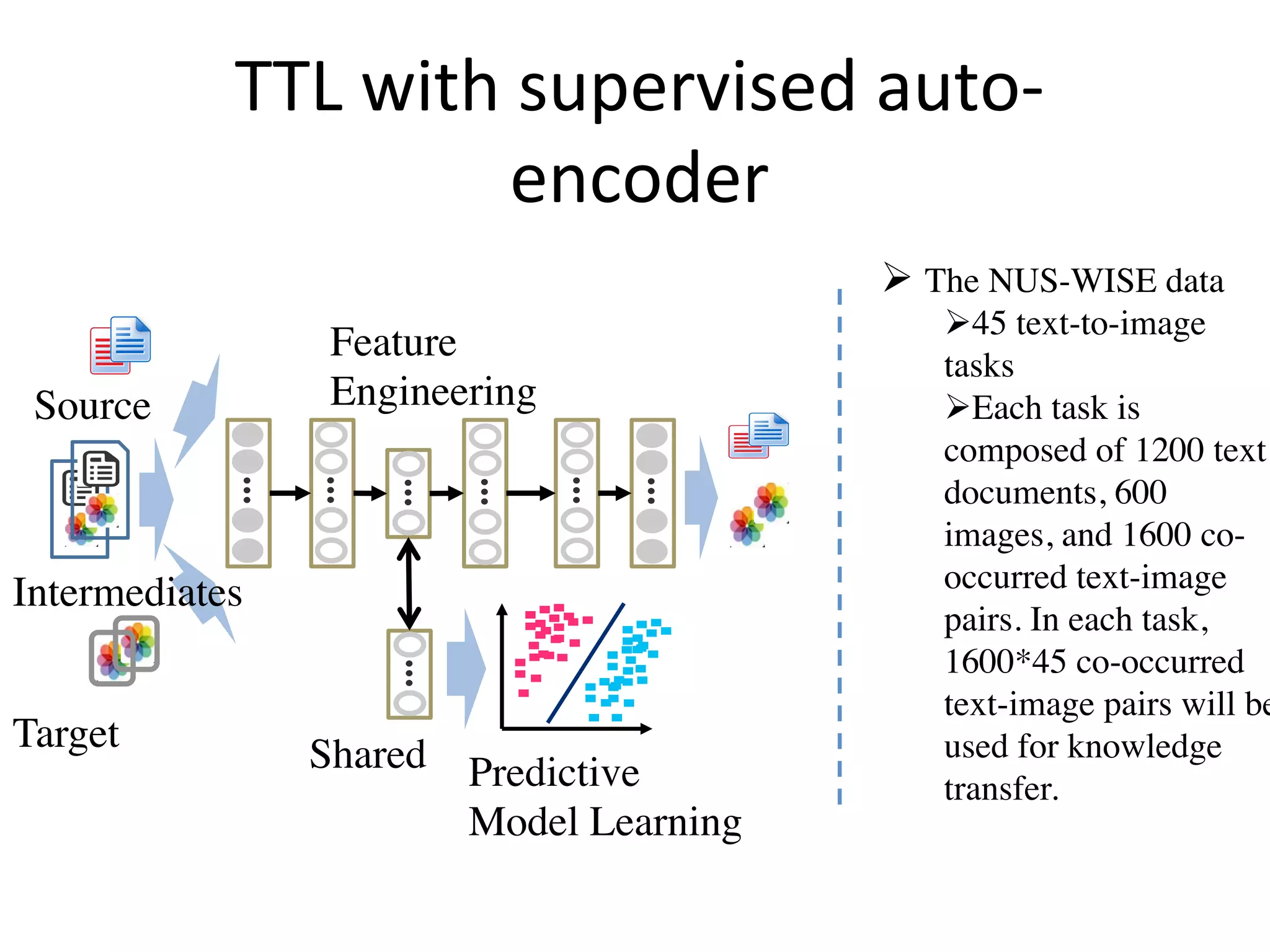
Introduces transitive transfer learning utilizing intermediate domains for distant source-target relationships.
Describes the combination of textual and visual data for enhanced transfer learning.
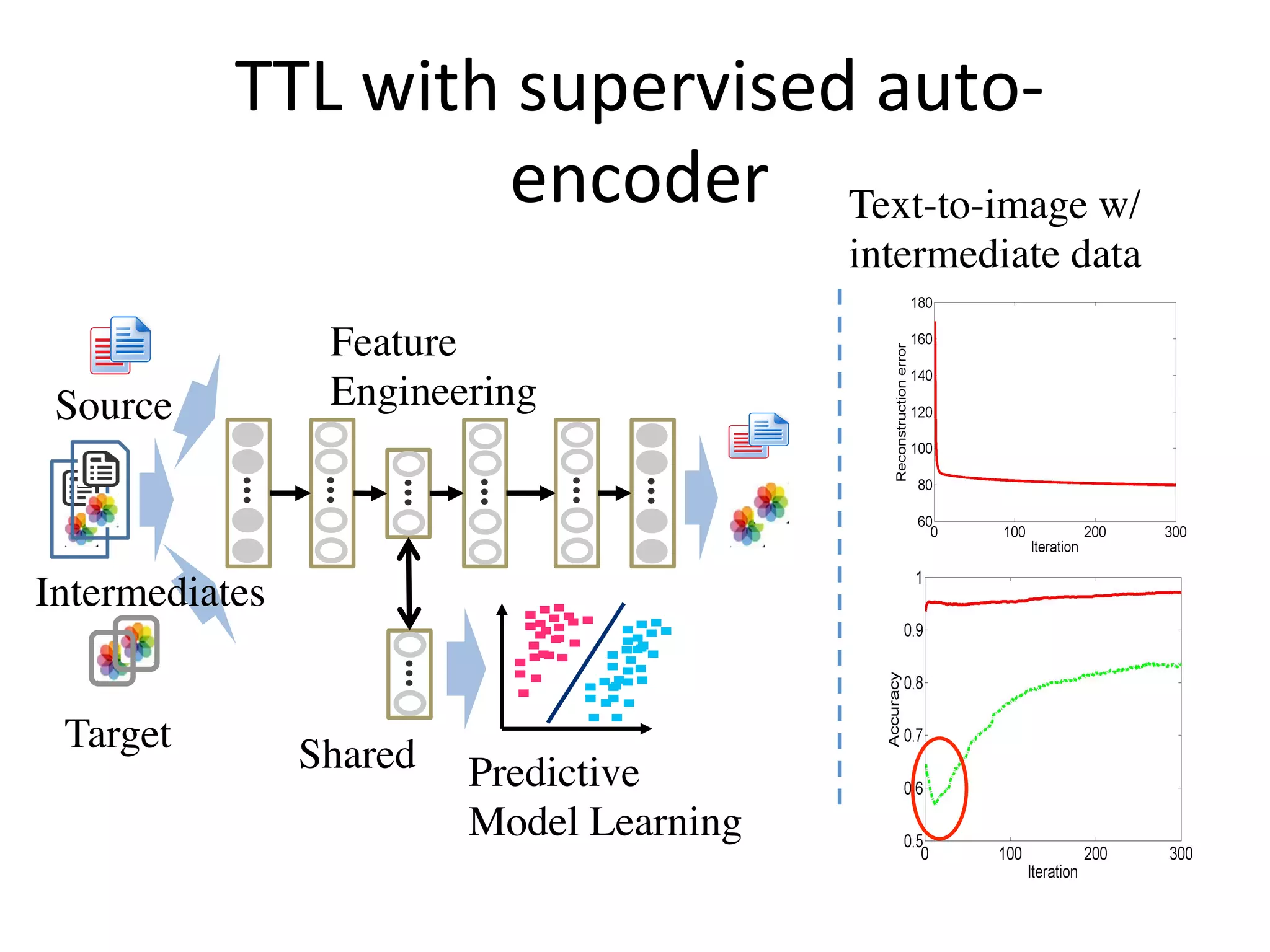
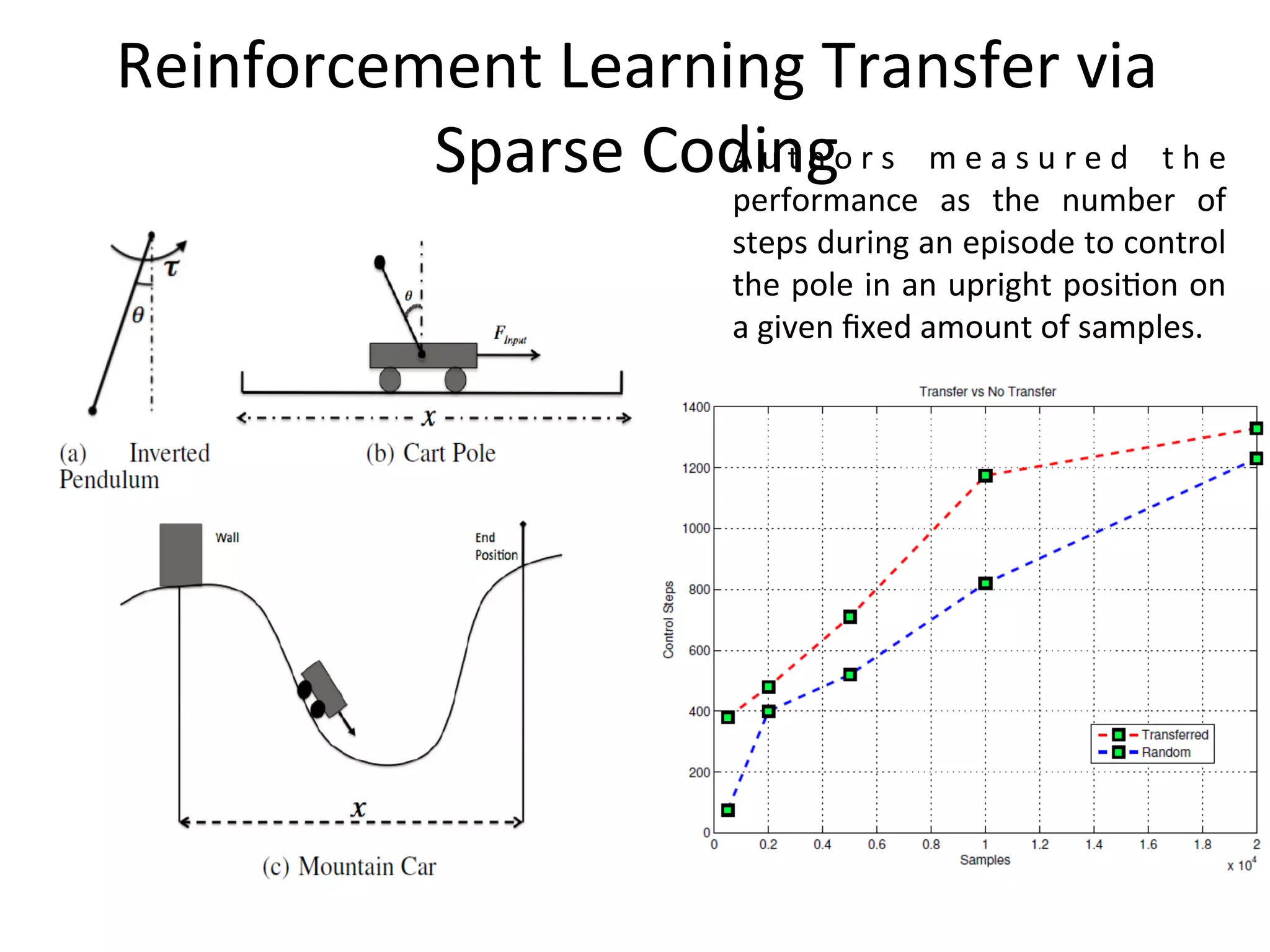
Elaborates on using sparse coding to enhance learning speed and task adaptability.
Summarizes critical references and essential acknowledgments in the field of transfer learning.


































































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt990-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















