Downloaded 93 times


















































The document provides an introduction to machine learning, explaining its definition and significance in modern computing, alongside various methods like supervised and unsupervised learning. It details Support Vector Machine (SVM) as a classification algorithm that constructs hyperplanes to separate data points and introduces key concepts such as margin and support vectors. Additionally, it mentions Weka as a tool used for implementing machine learning practices, including SVM with the Iris dataset.
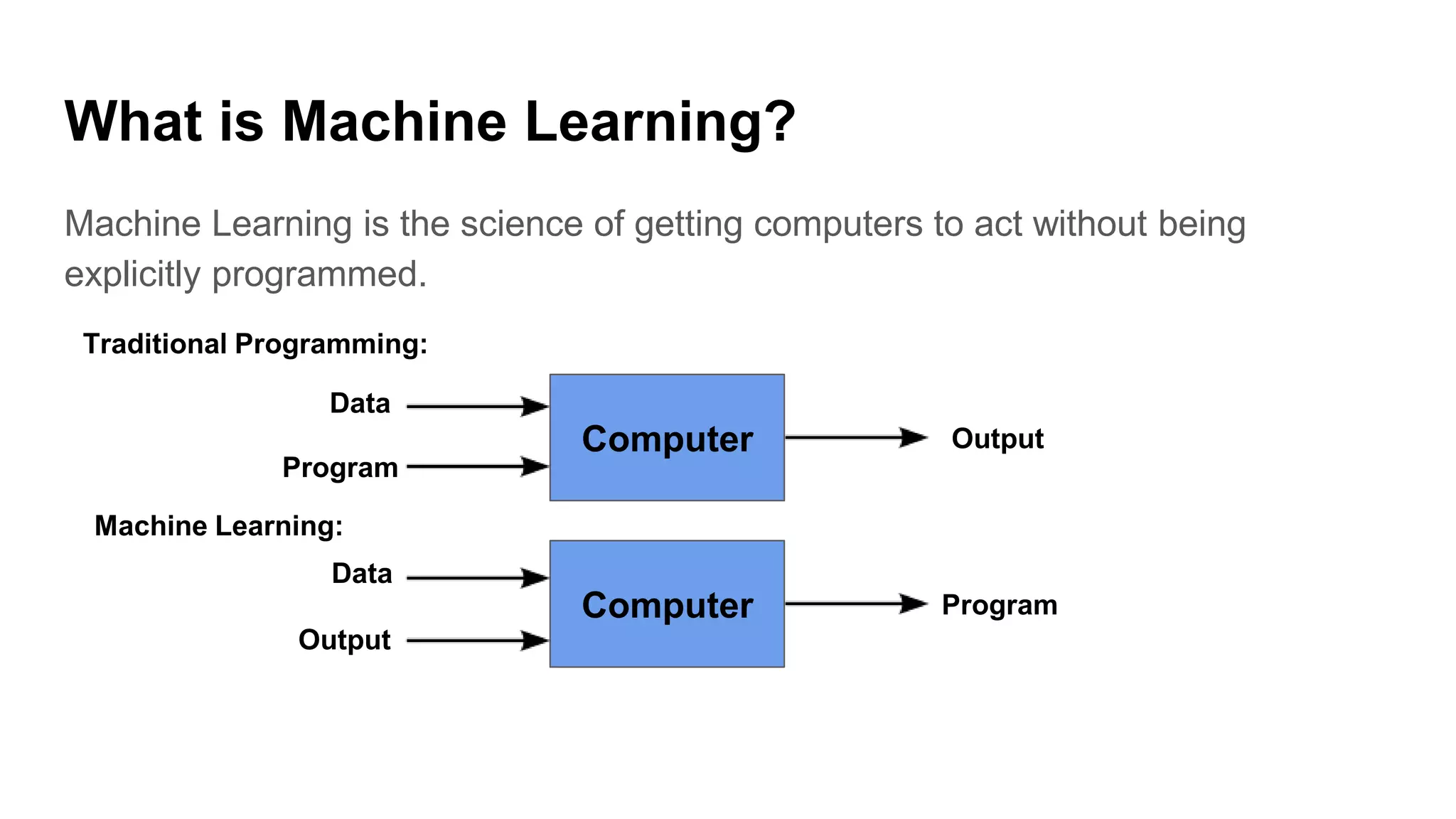
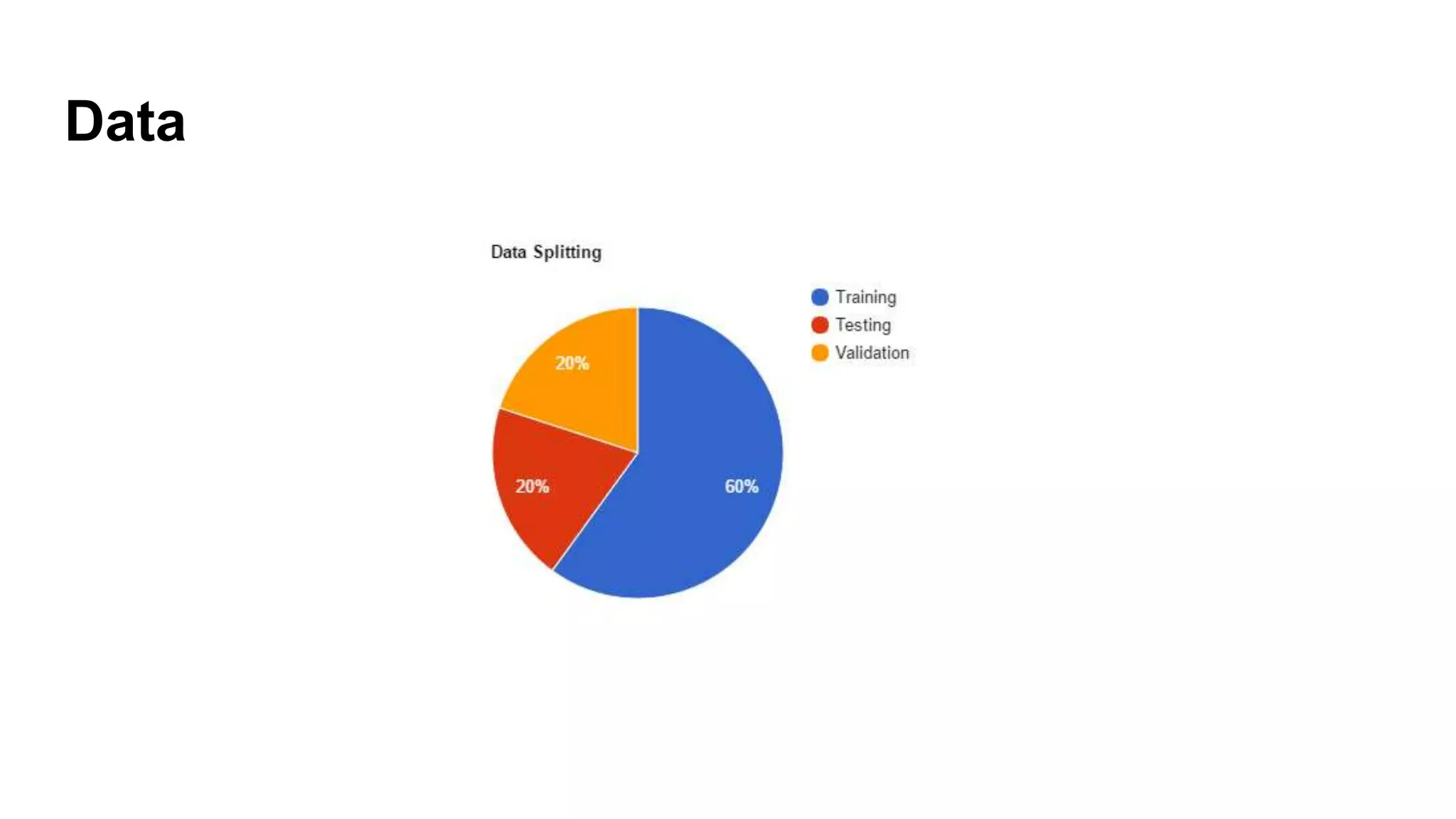
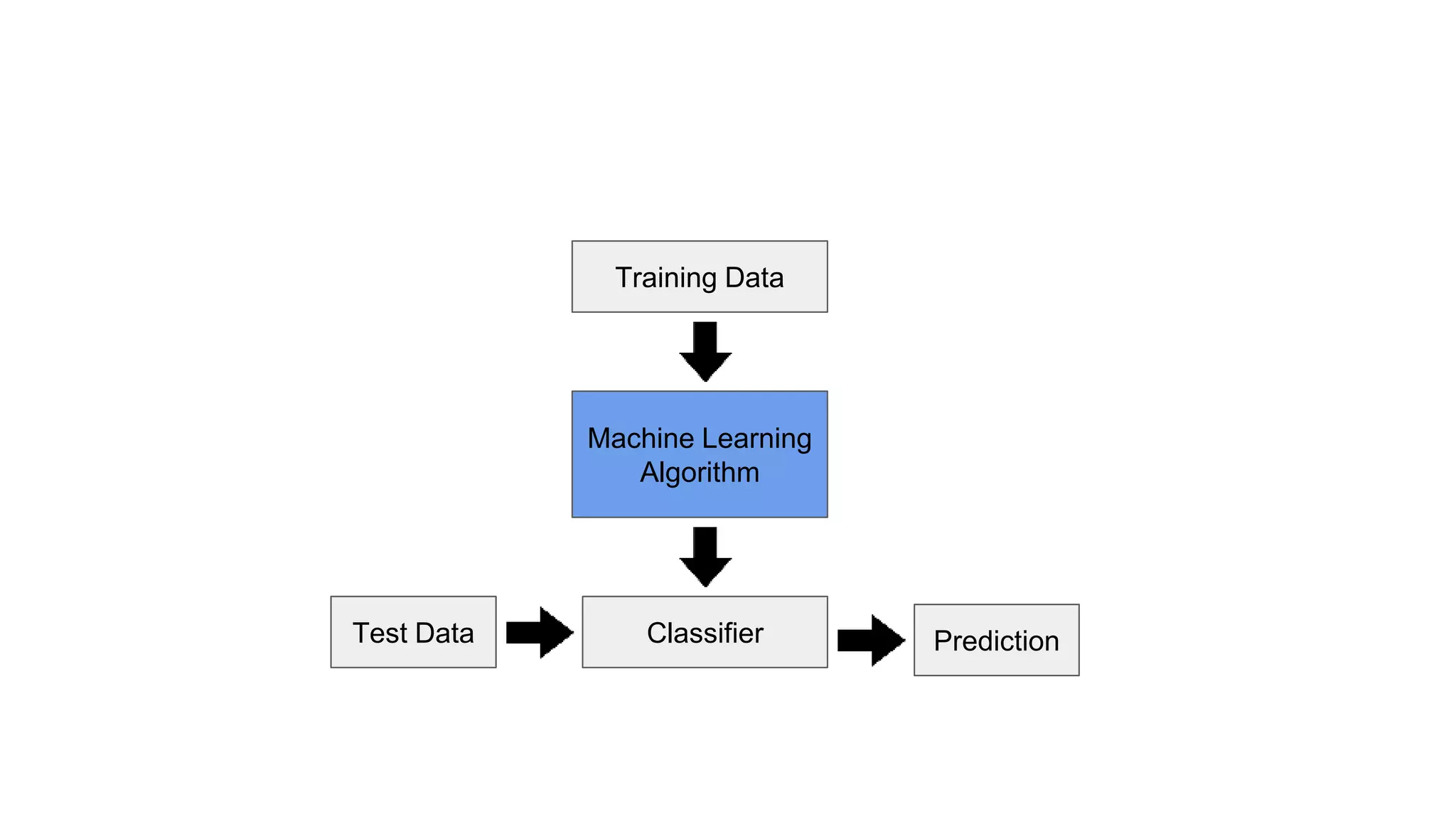
Introduction to SVM, basic machine learning concepts, availability of data, and increasing computational power.
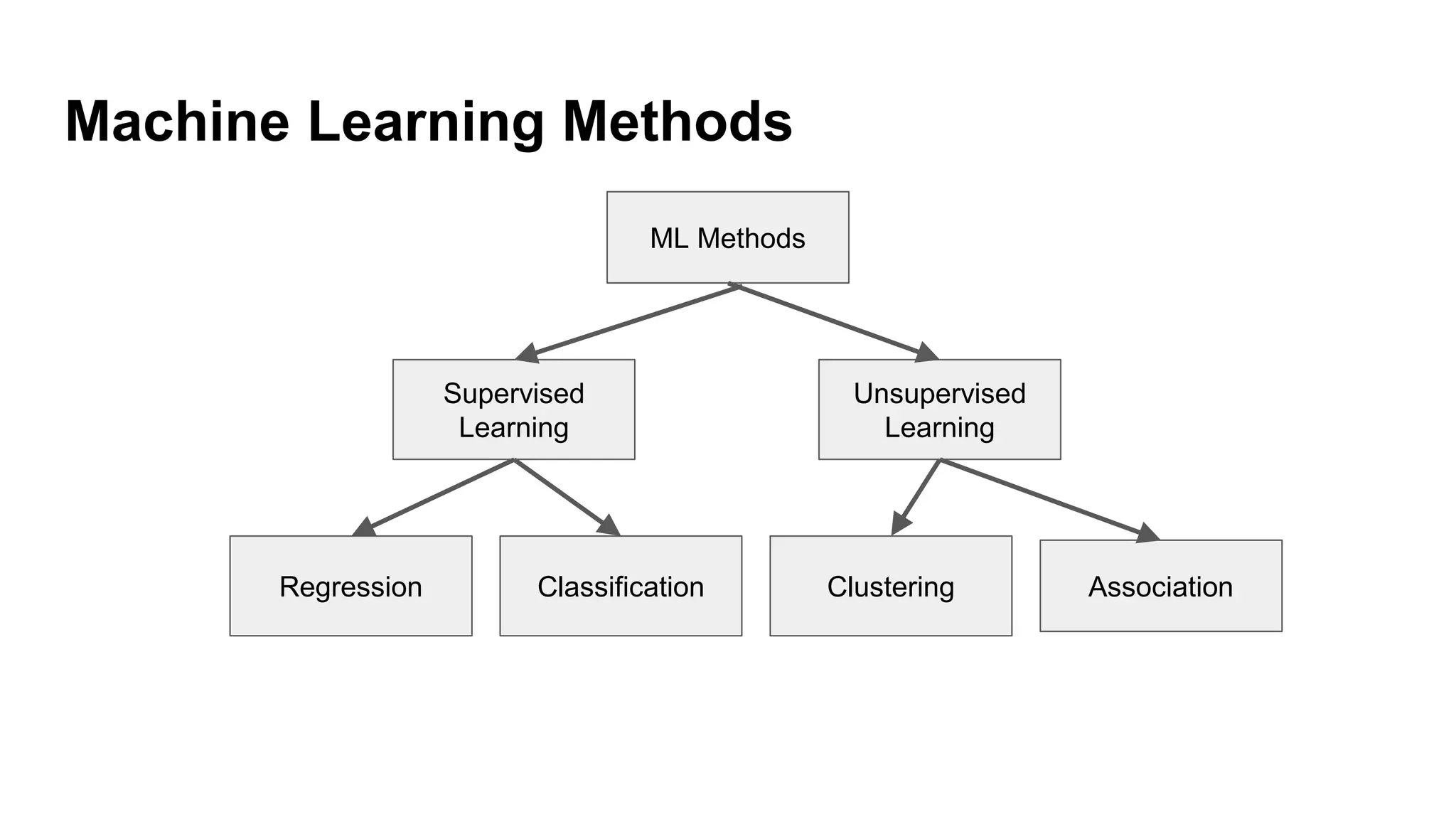
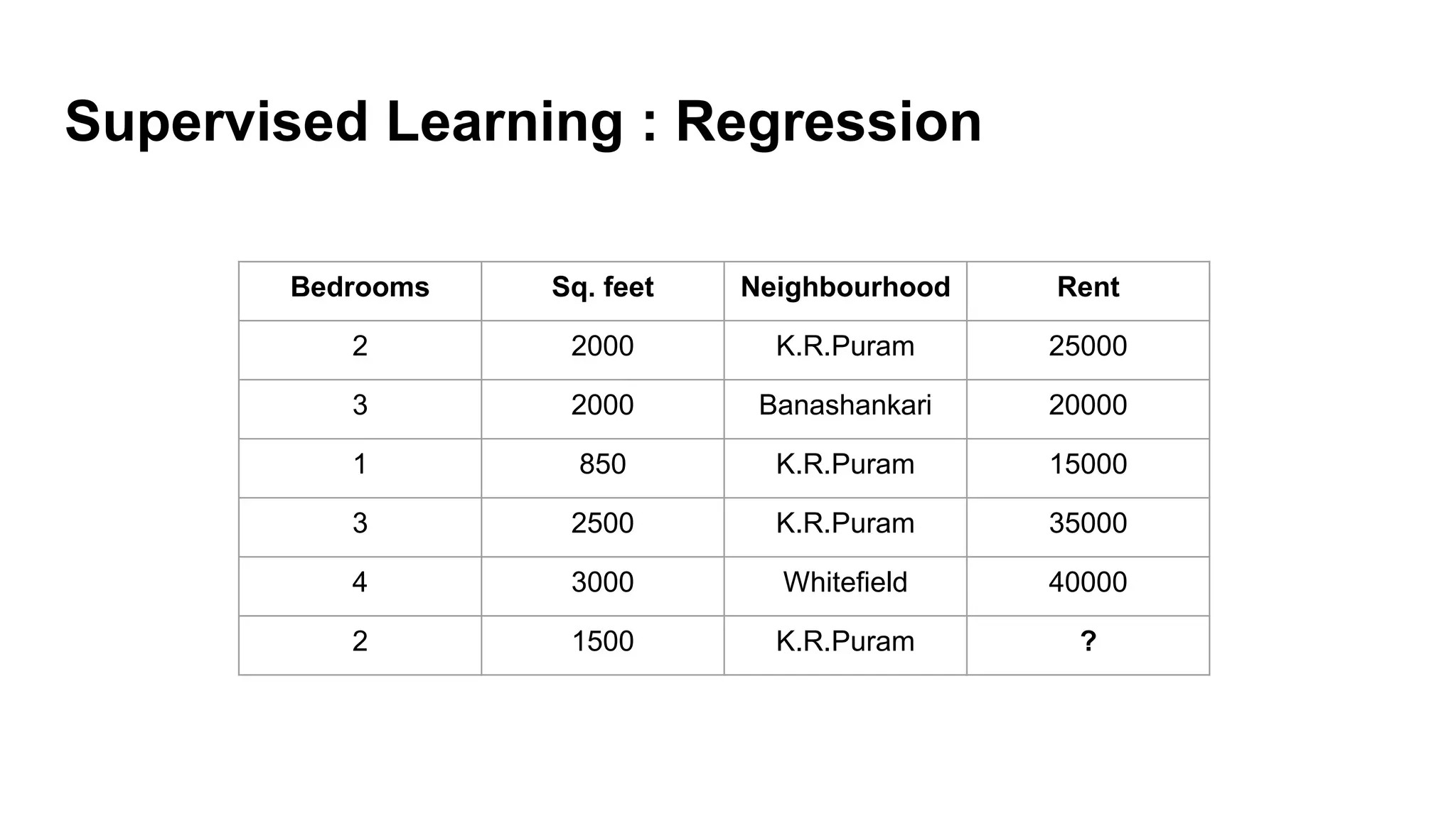
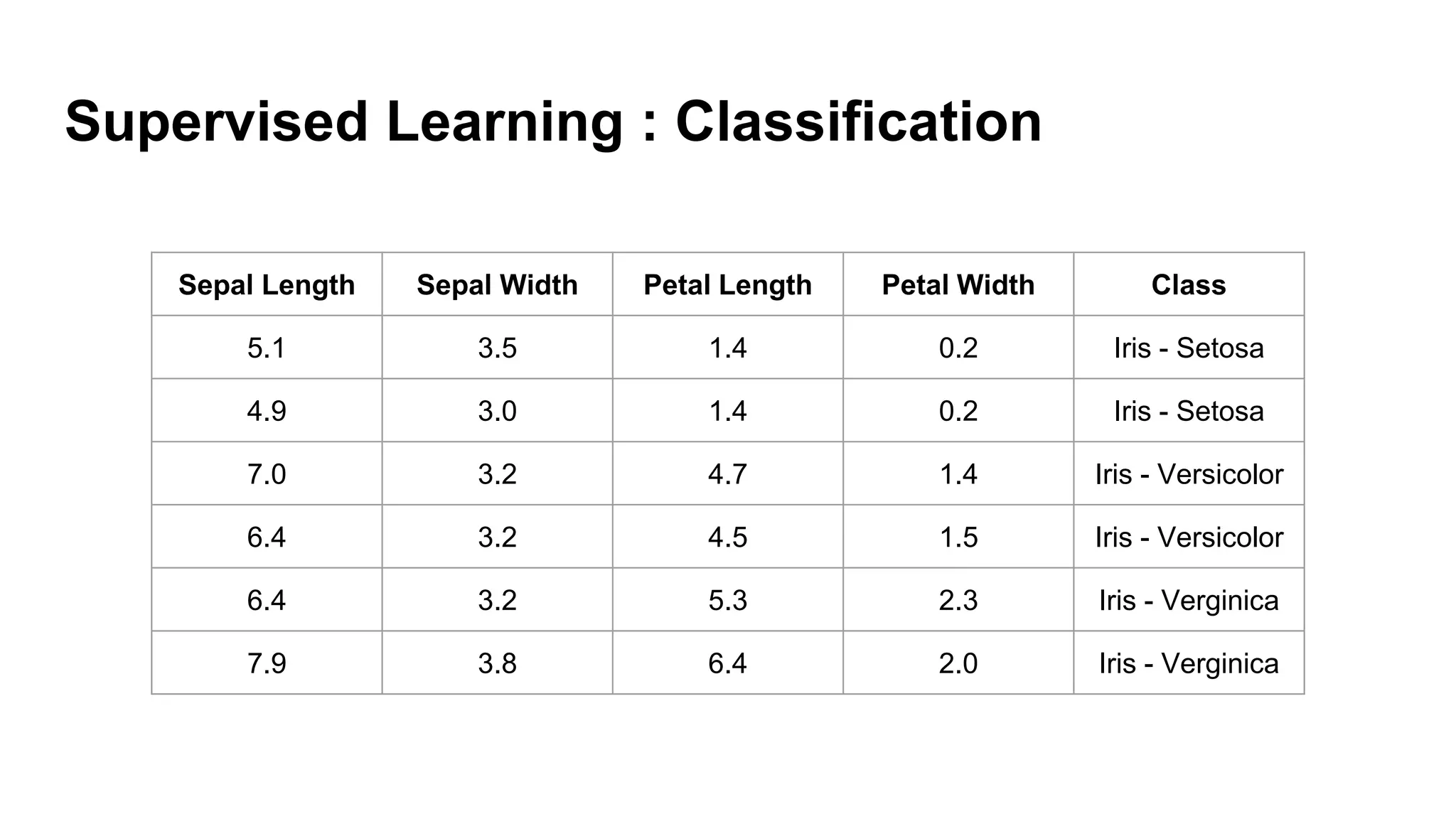
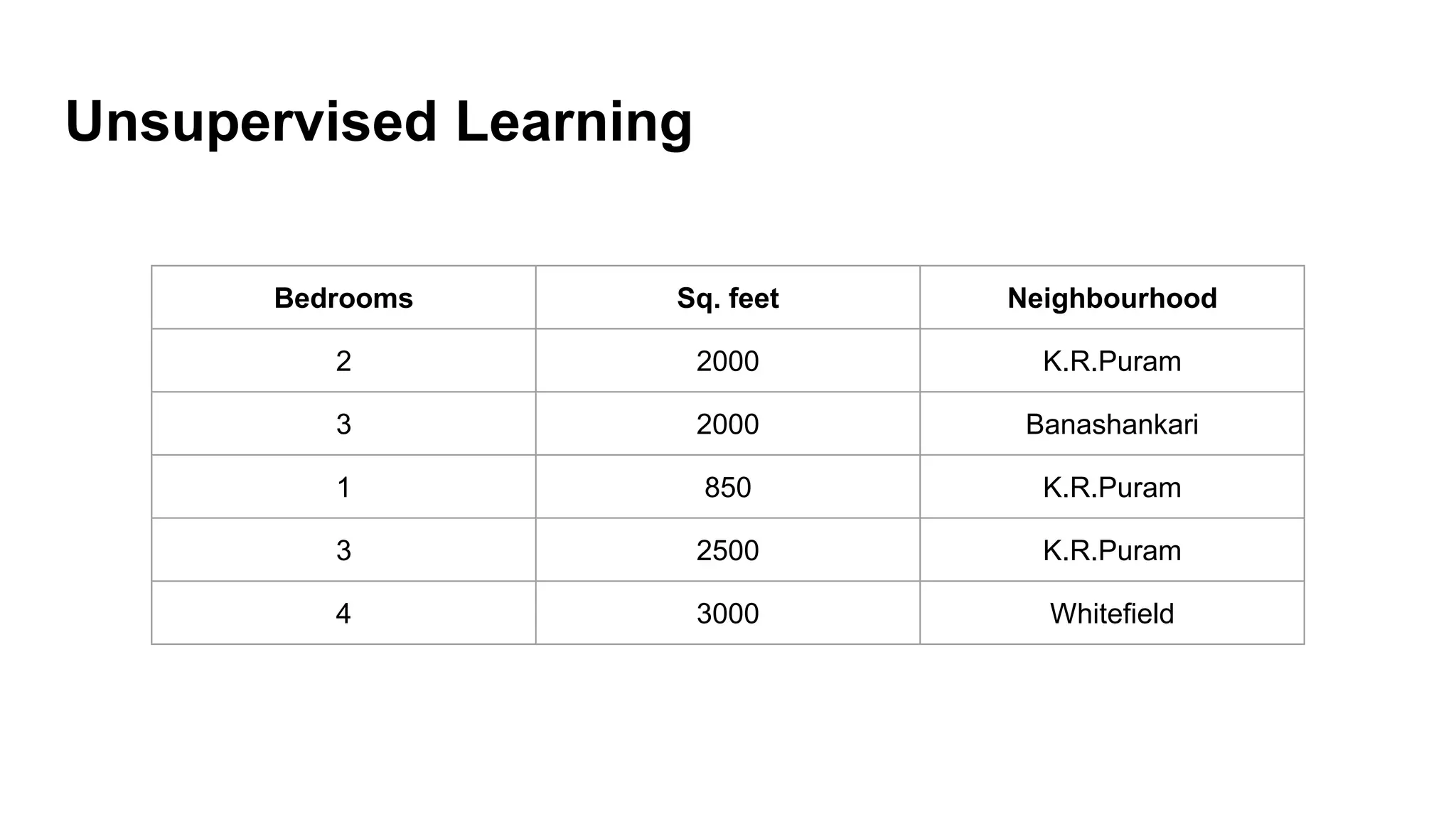
Overview of machine learning methods, including supervised (regression and classification) and unsupervised learning.
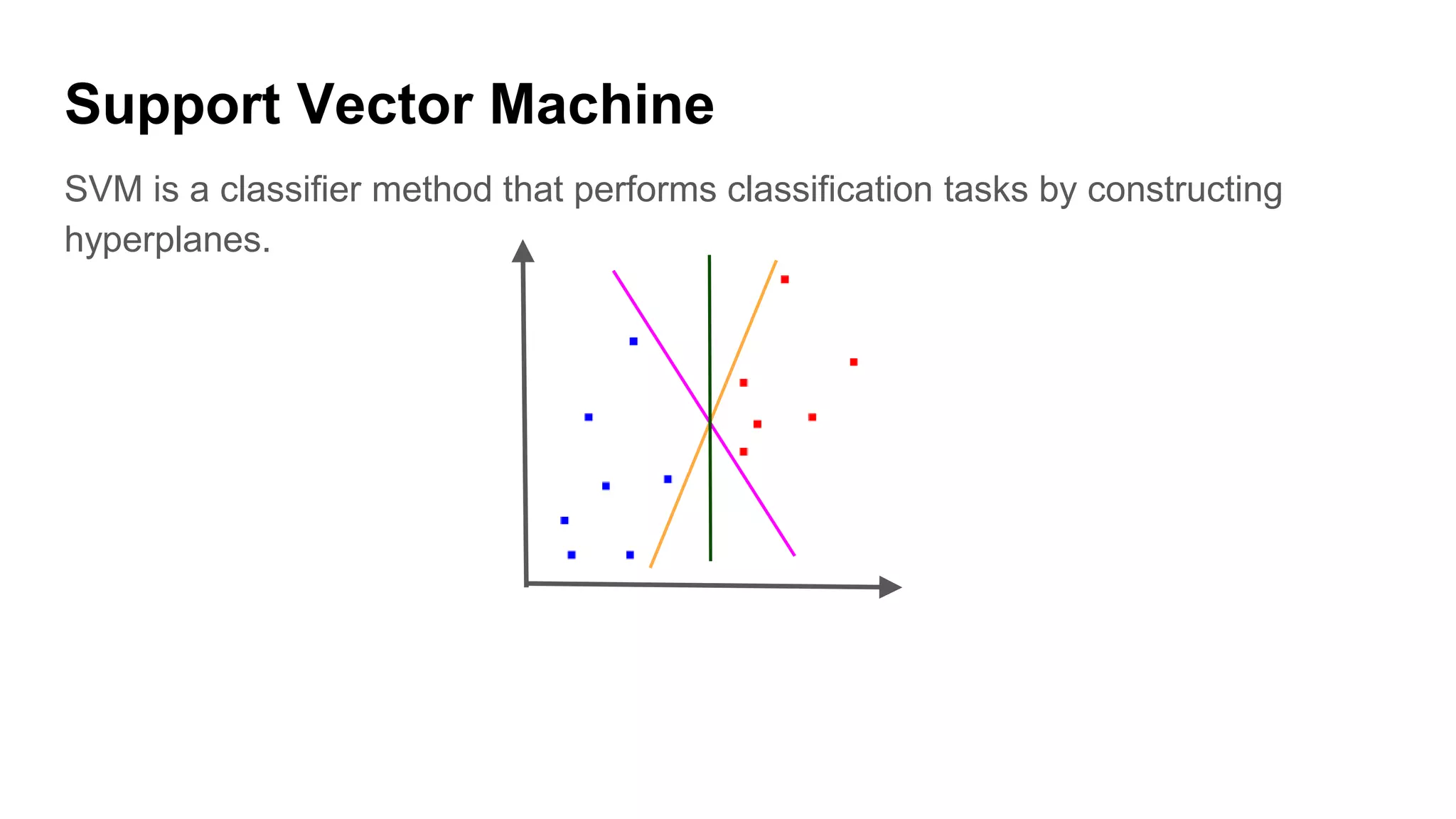
Introduction to SVM, a supervised algorithm for classification and regression, and its use of hyperplanes.
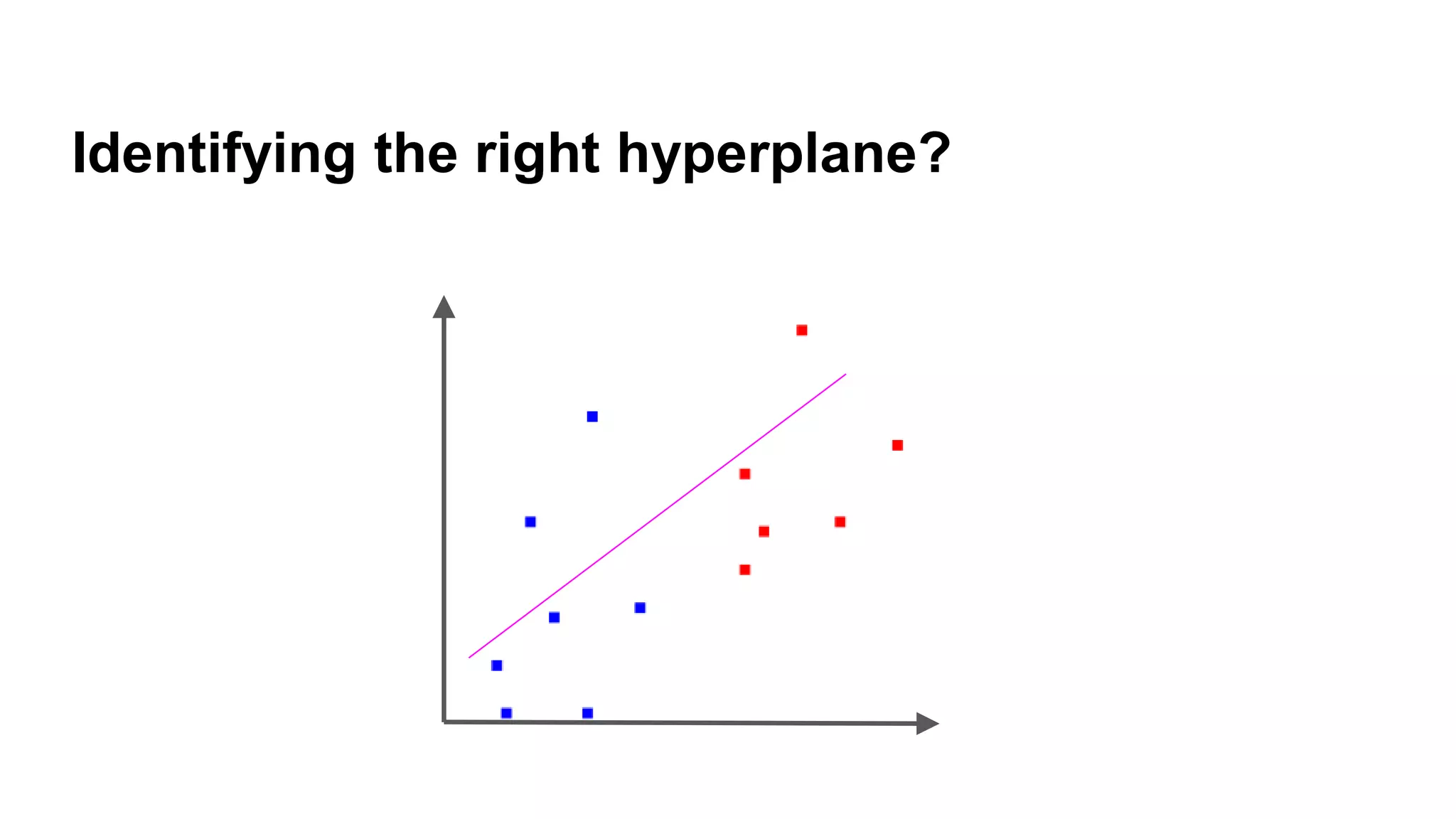
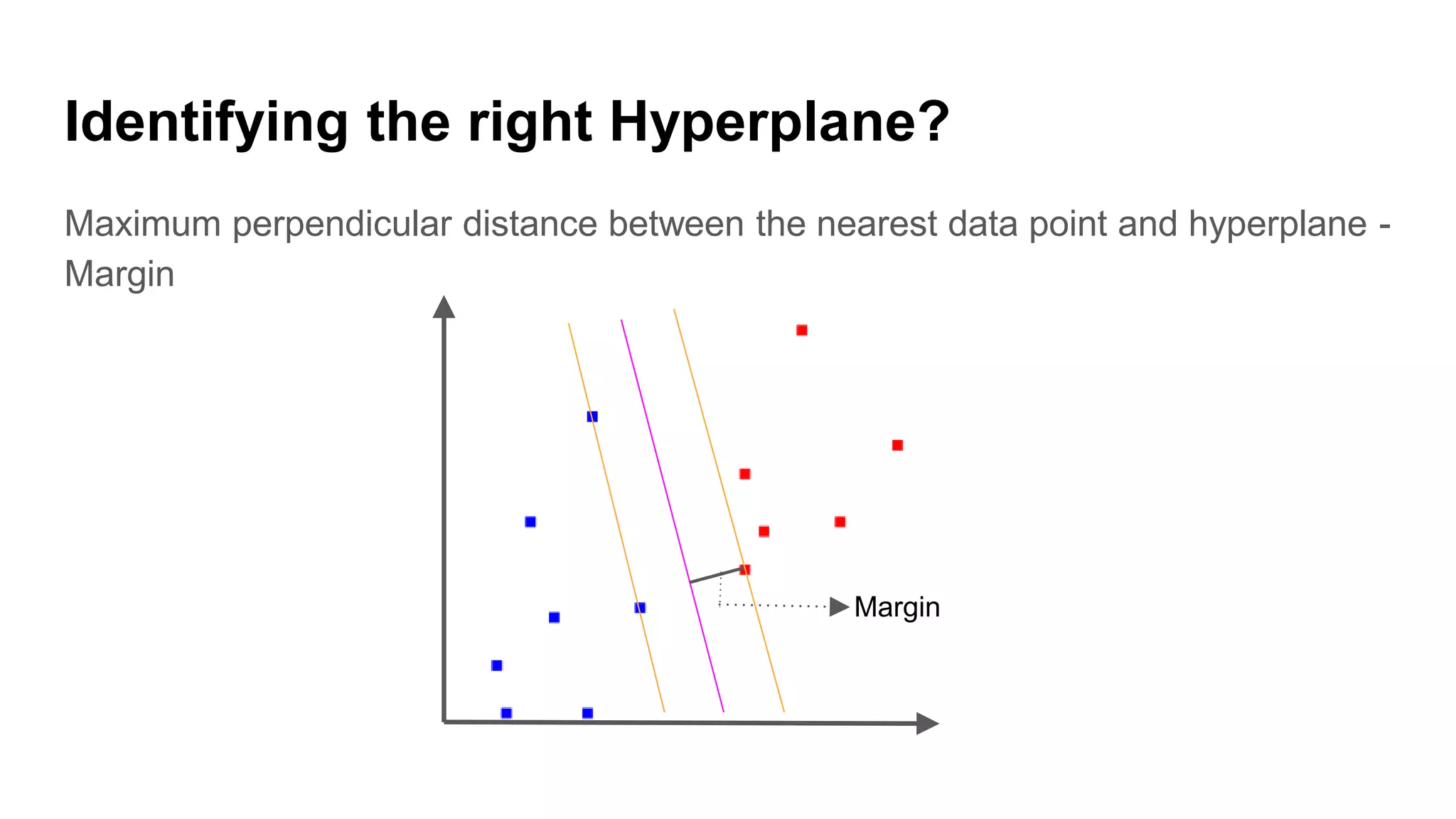
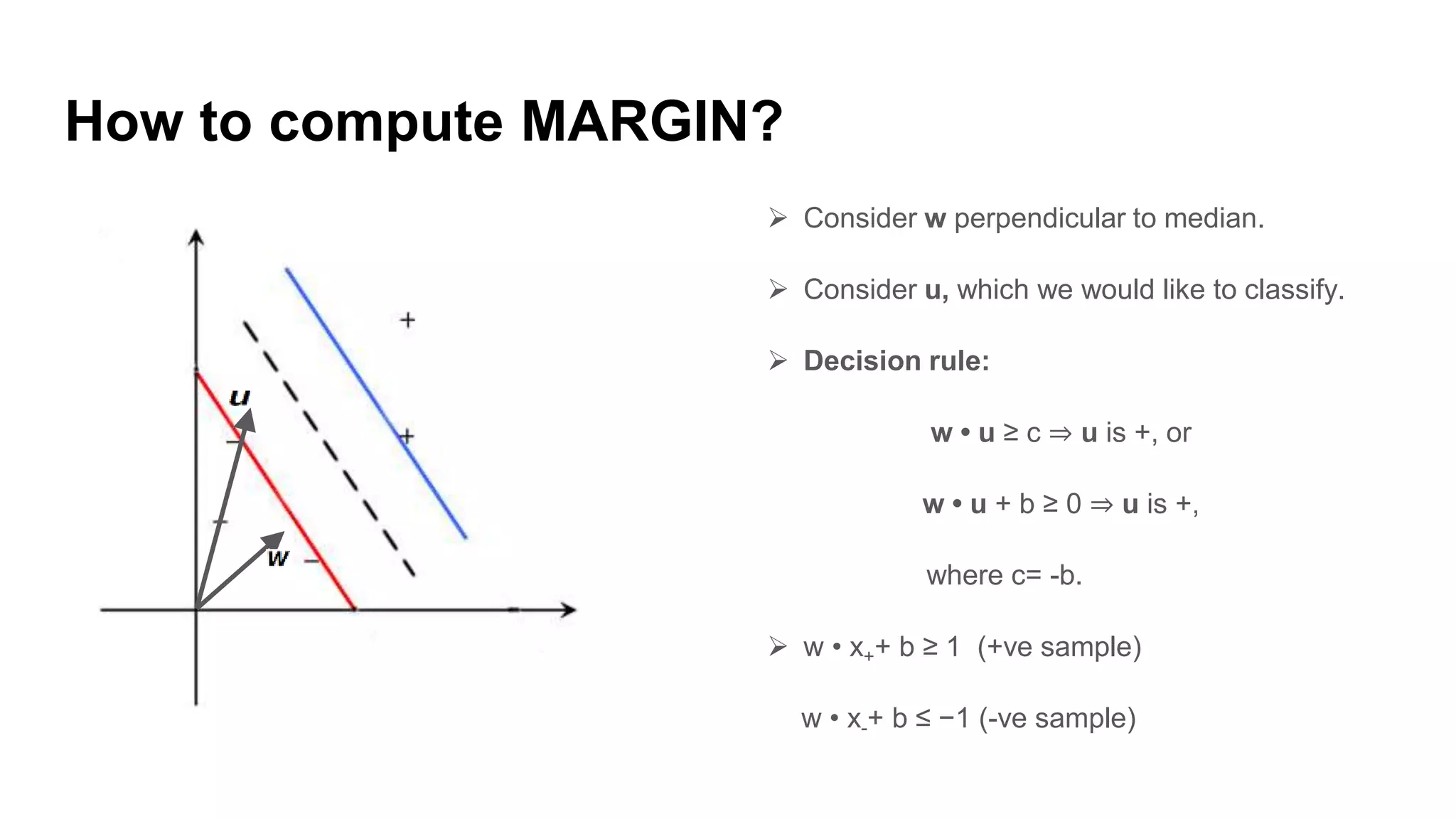
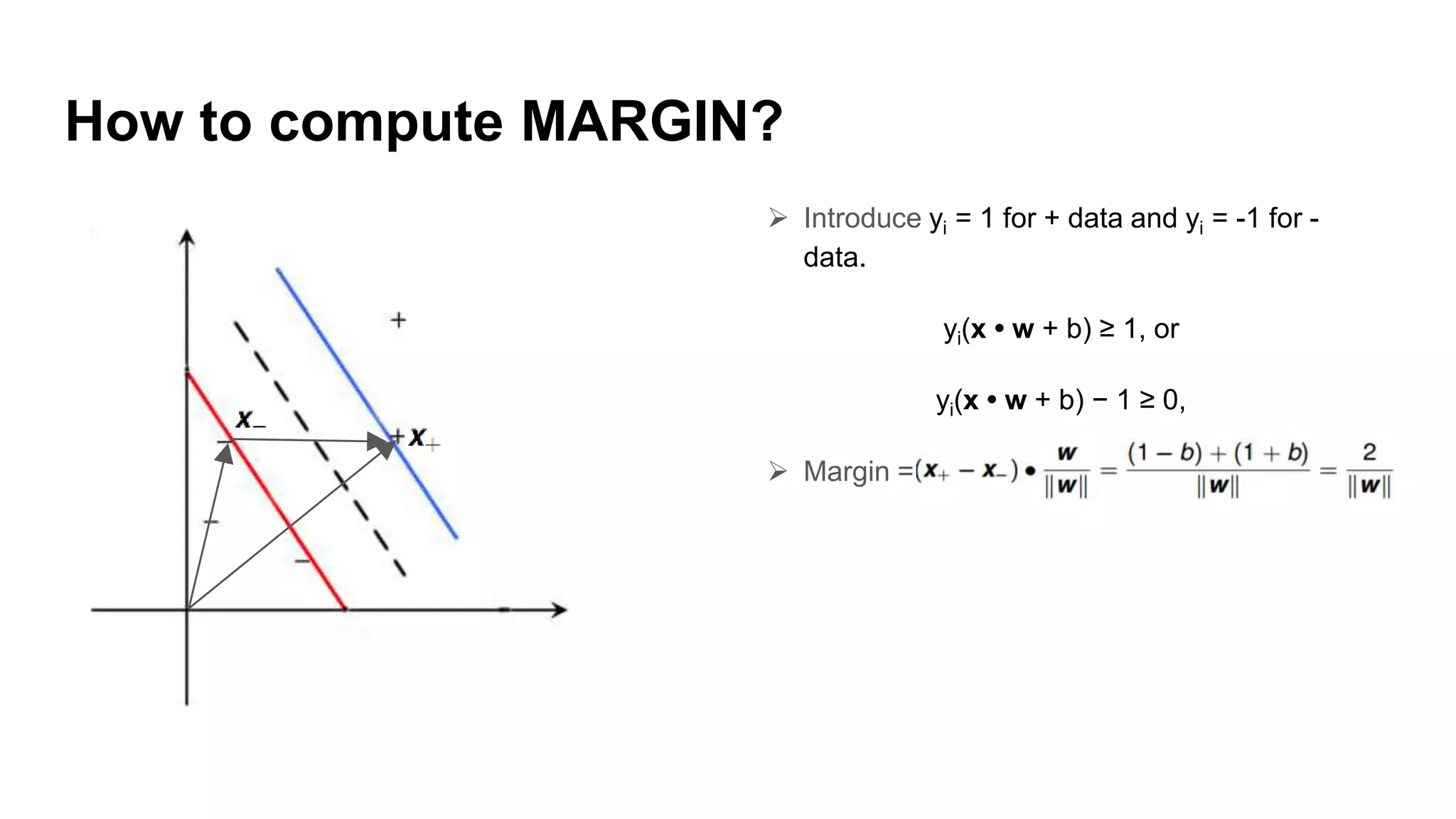
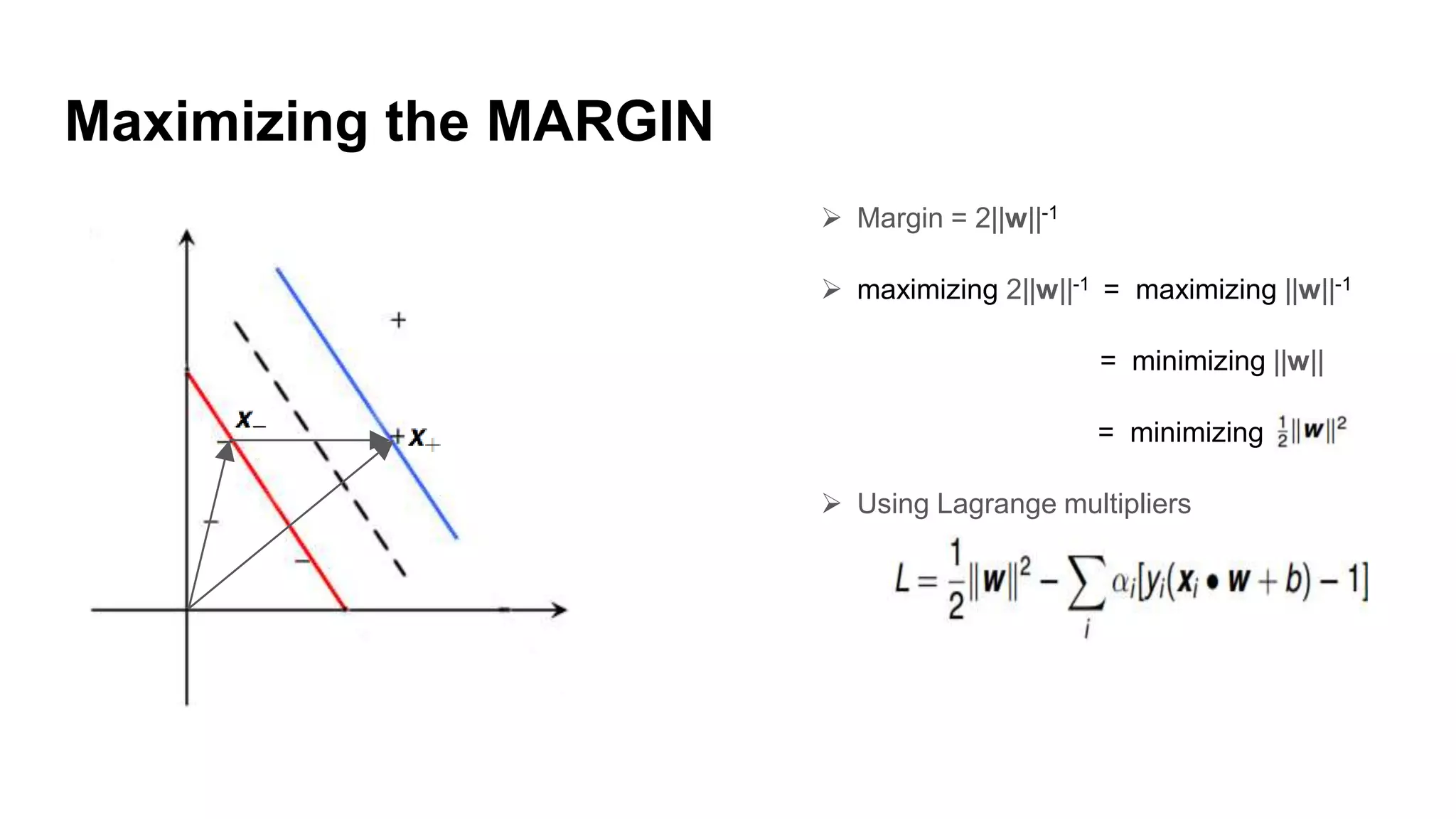
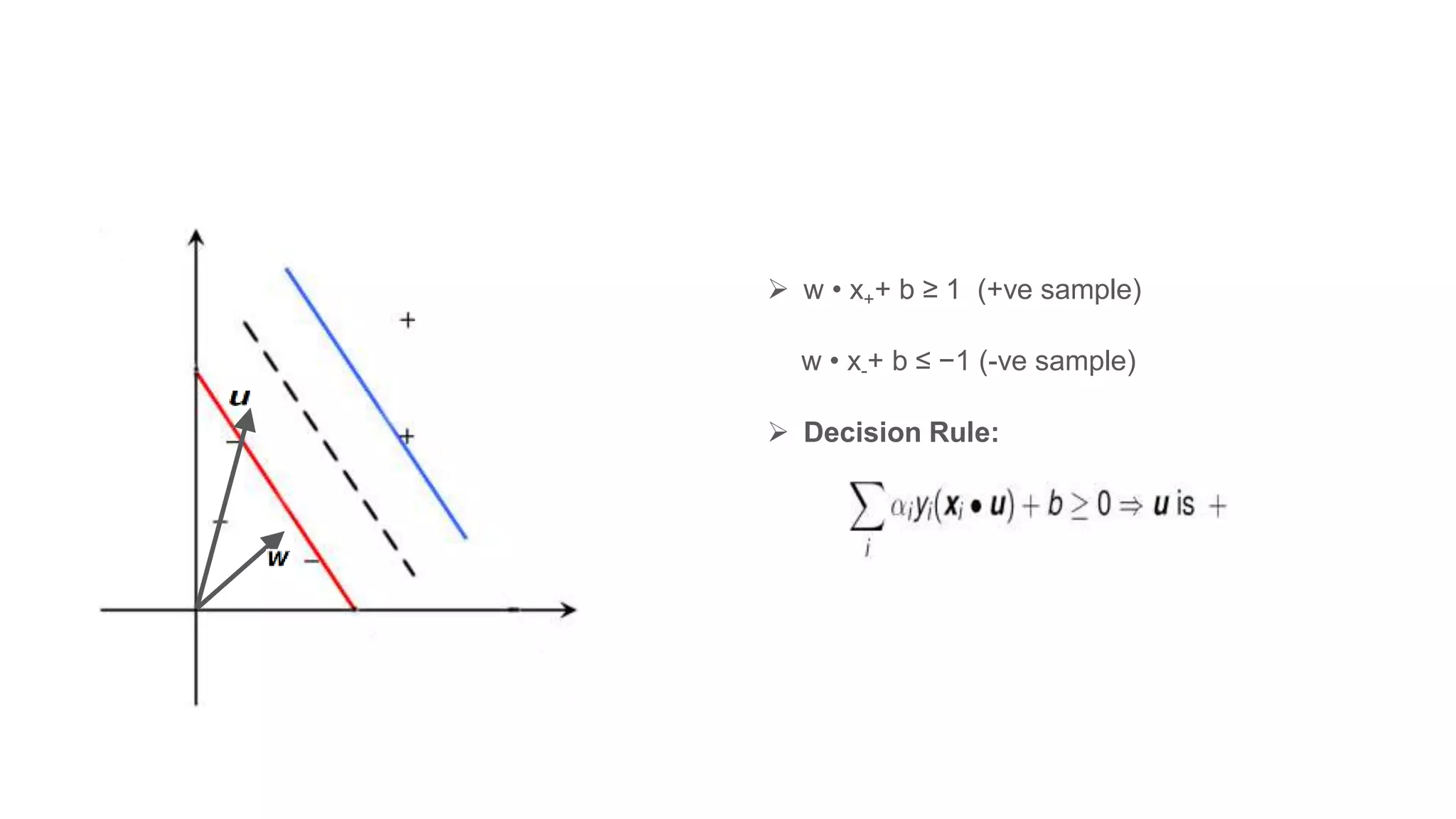
Explanation of how to identify the right hyperplane and compute the margin using decision rules.
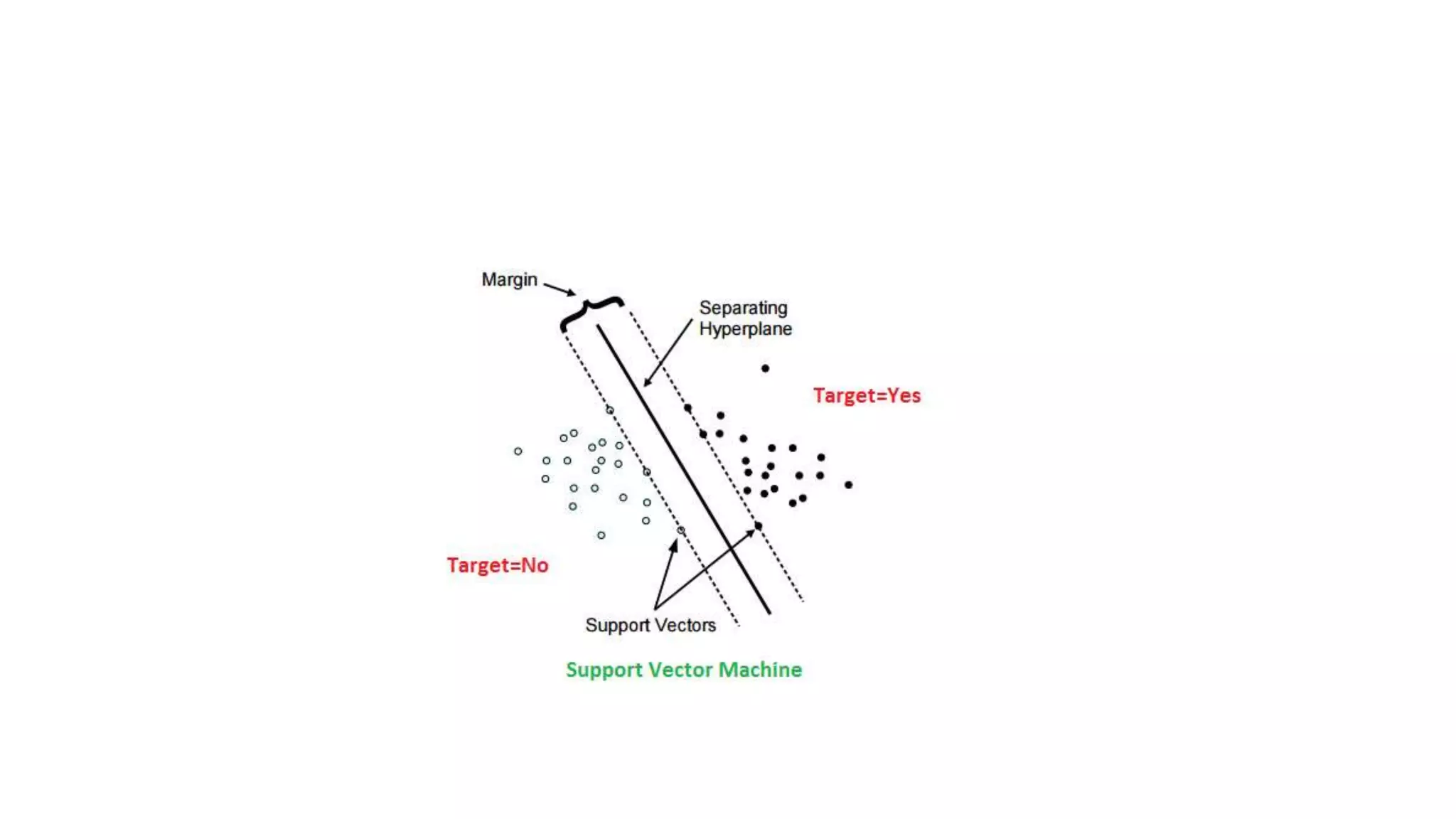
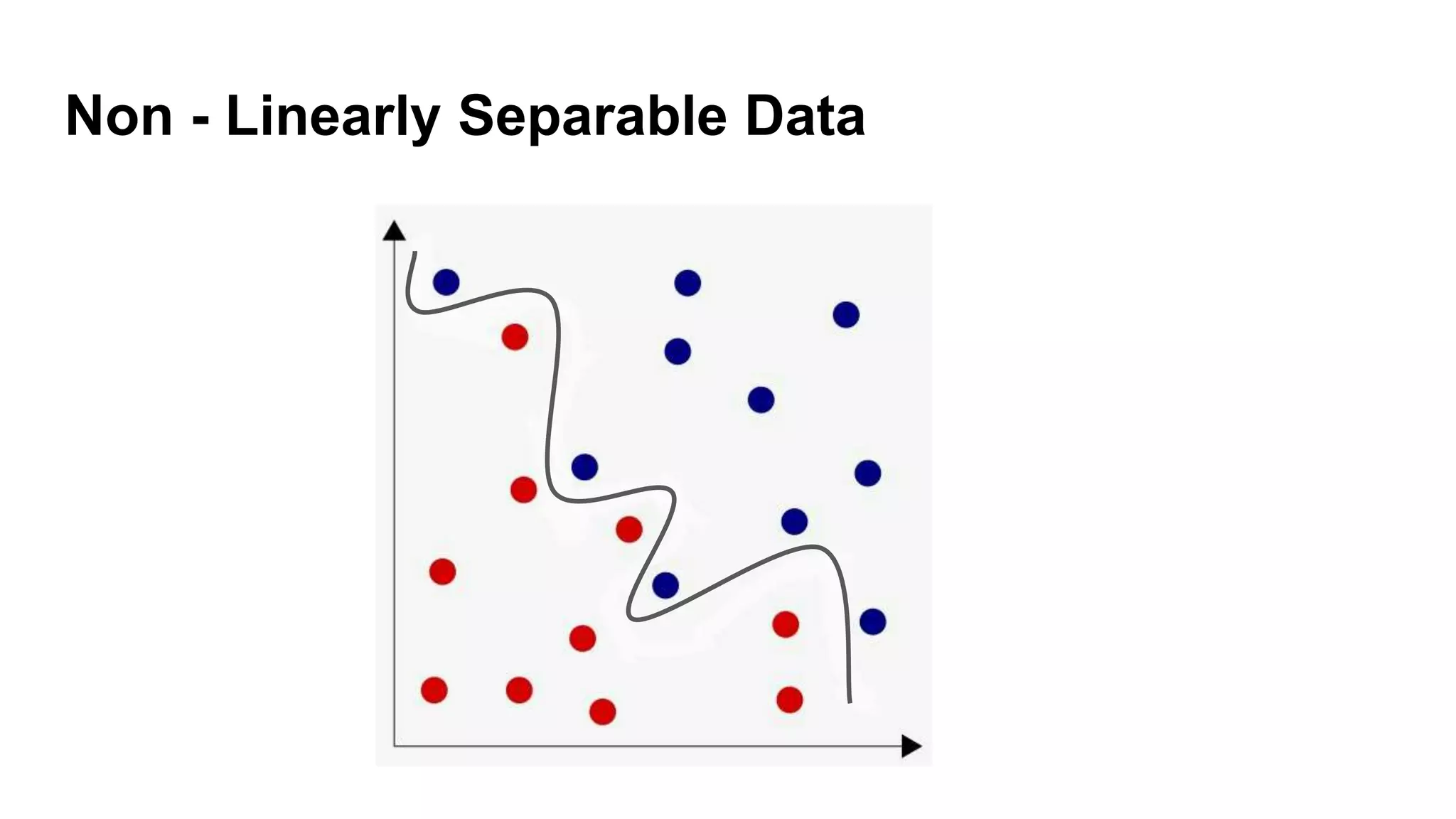
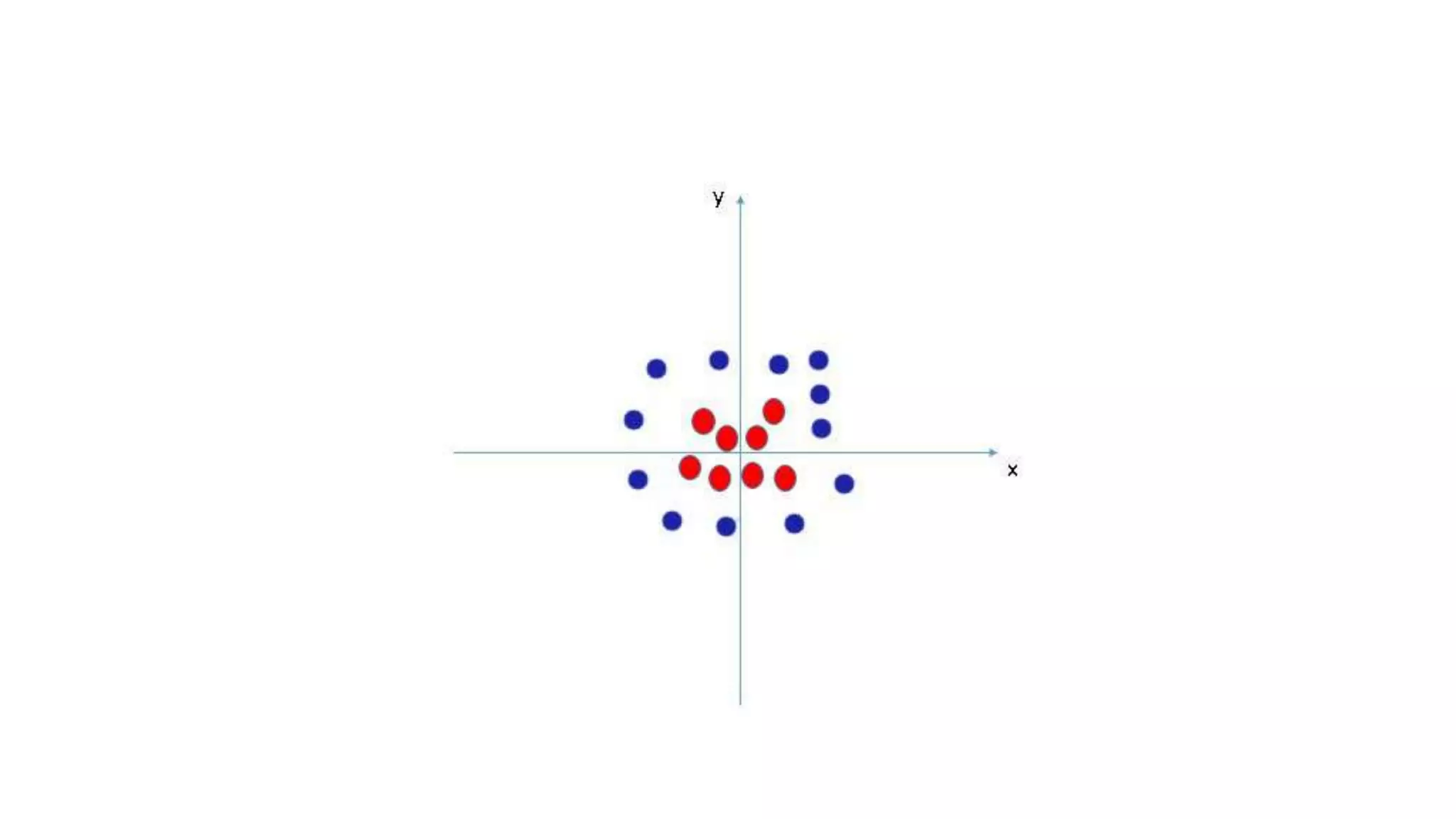
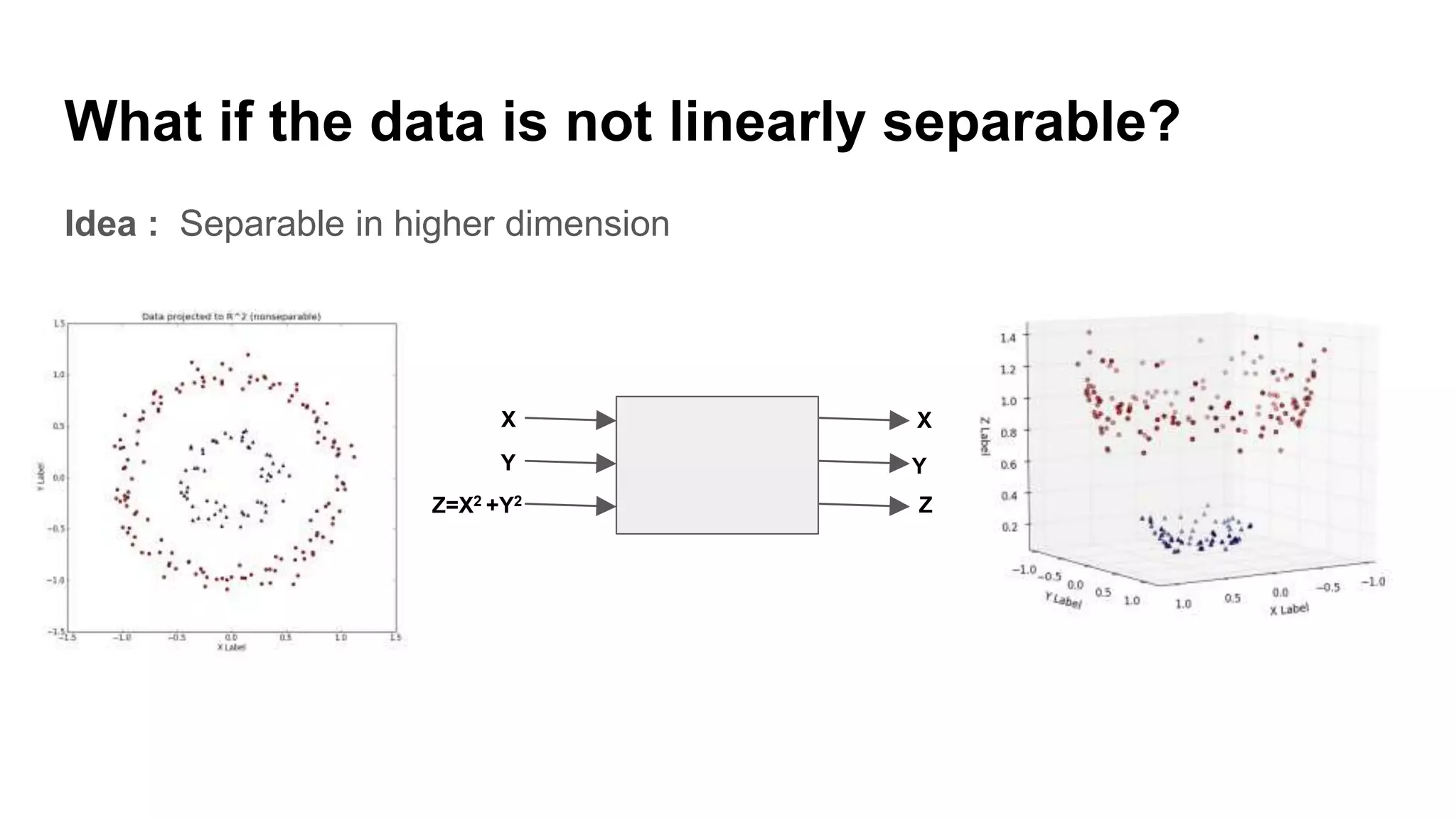
Discussion on linearly and non-linearly separable data, and the concept of support vectors.
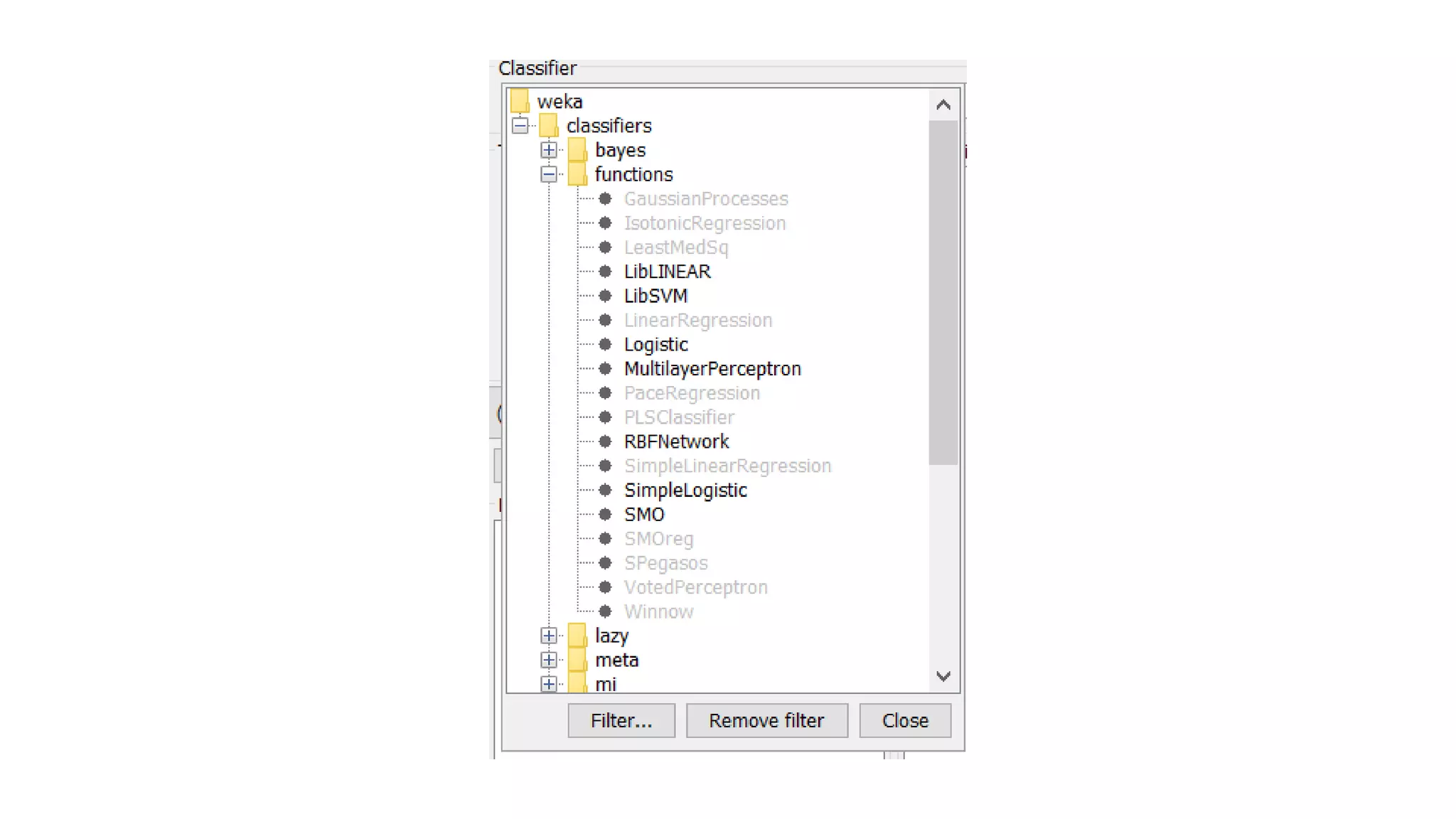
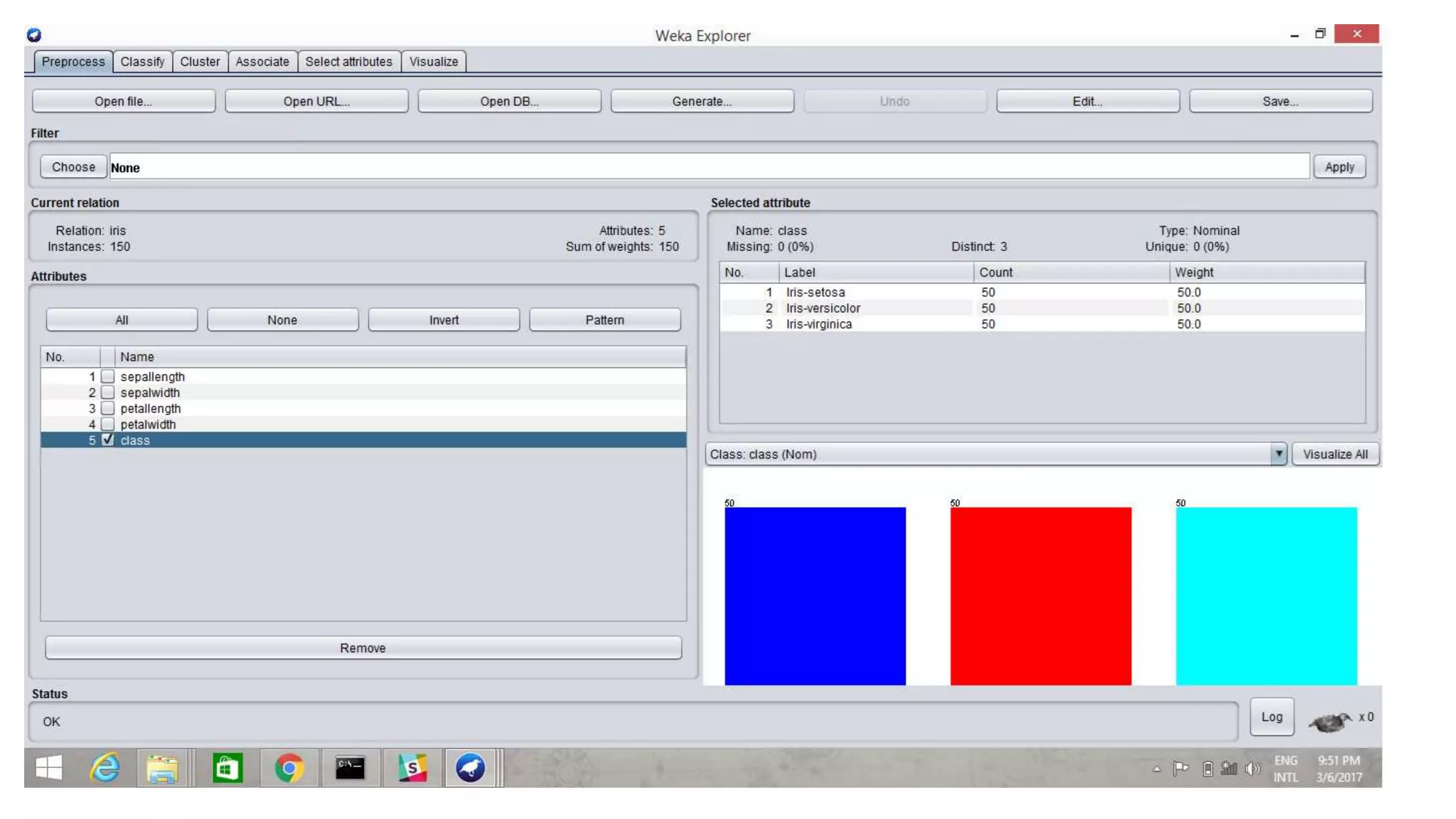
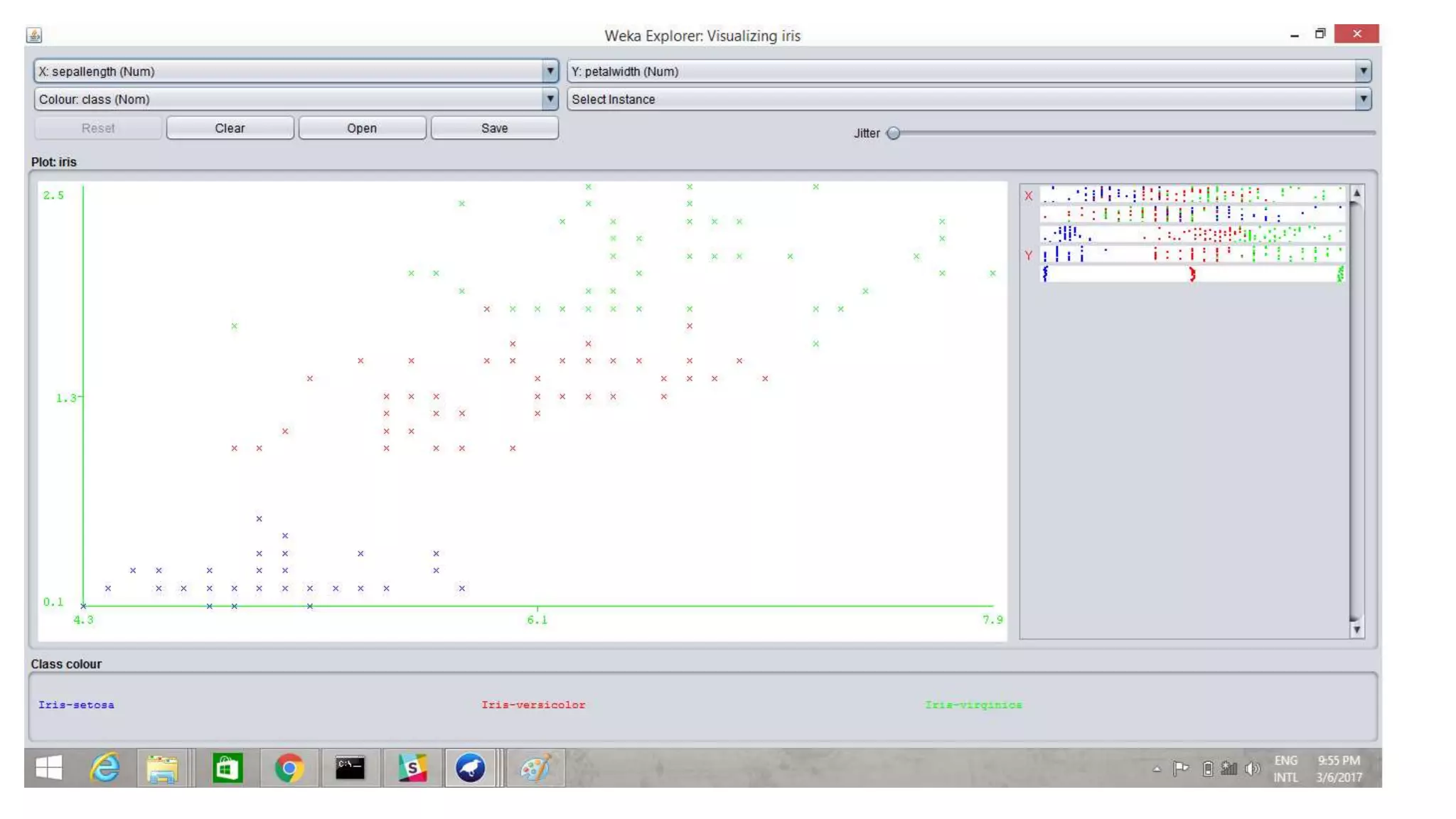
Overview of WEKA, an open-source machine learning tool, and the implementation of SVM using the IRIS dataset.
List of references for further learning and resources related to machine learning and SVM.




























![[ML]-SVM2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-svm2-230916145832-2580c8e3-thumbnail.jpg?width=640&height=640&fit=bounds)



![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)


