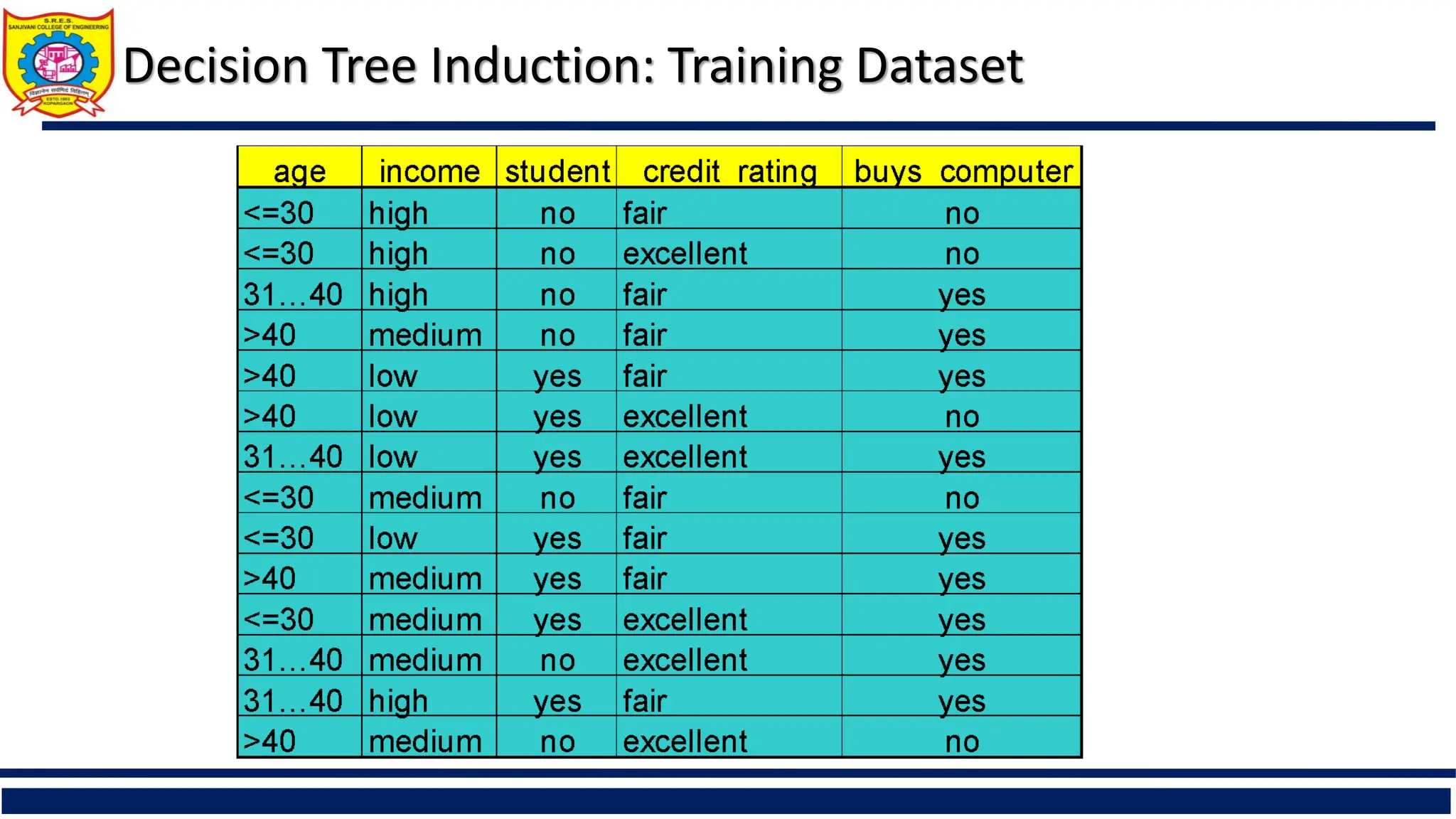
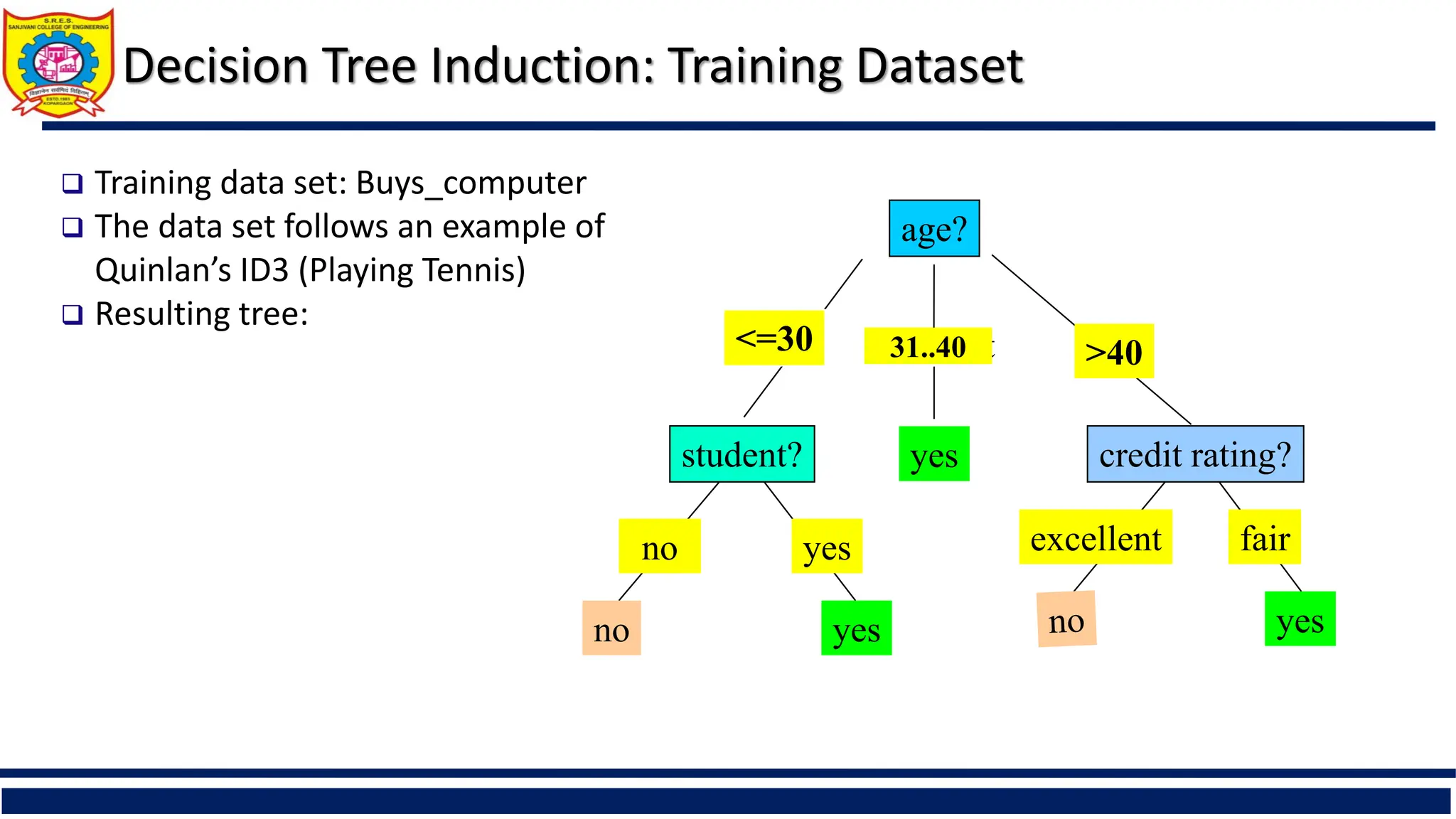
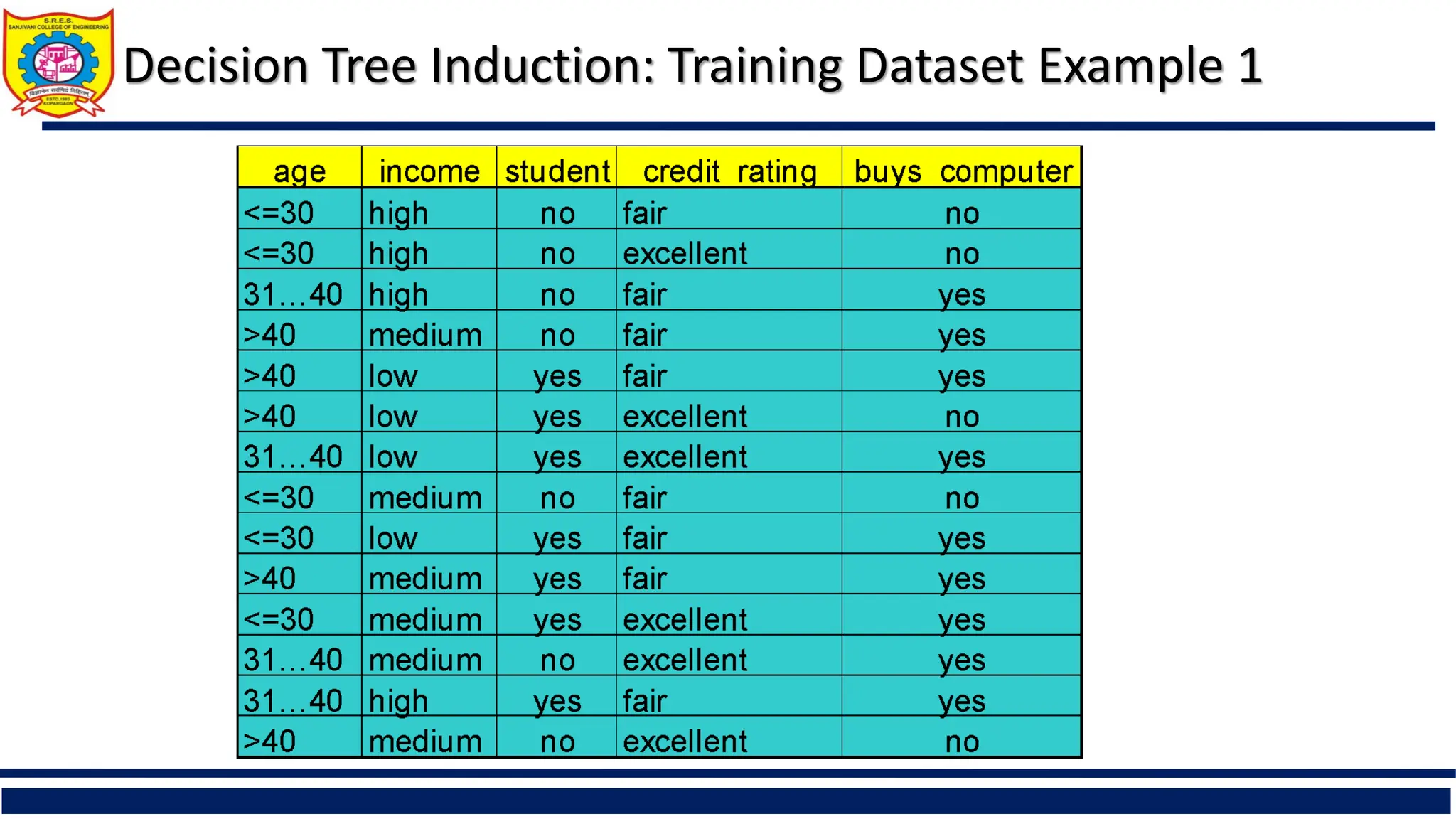
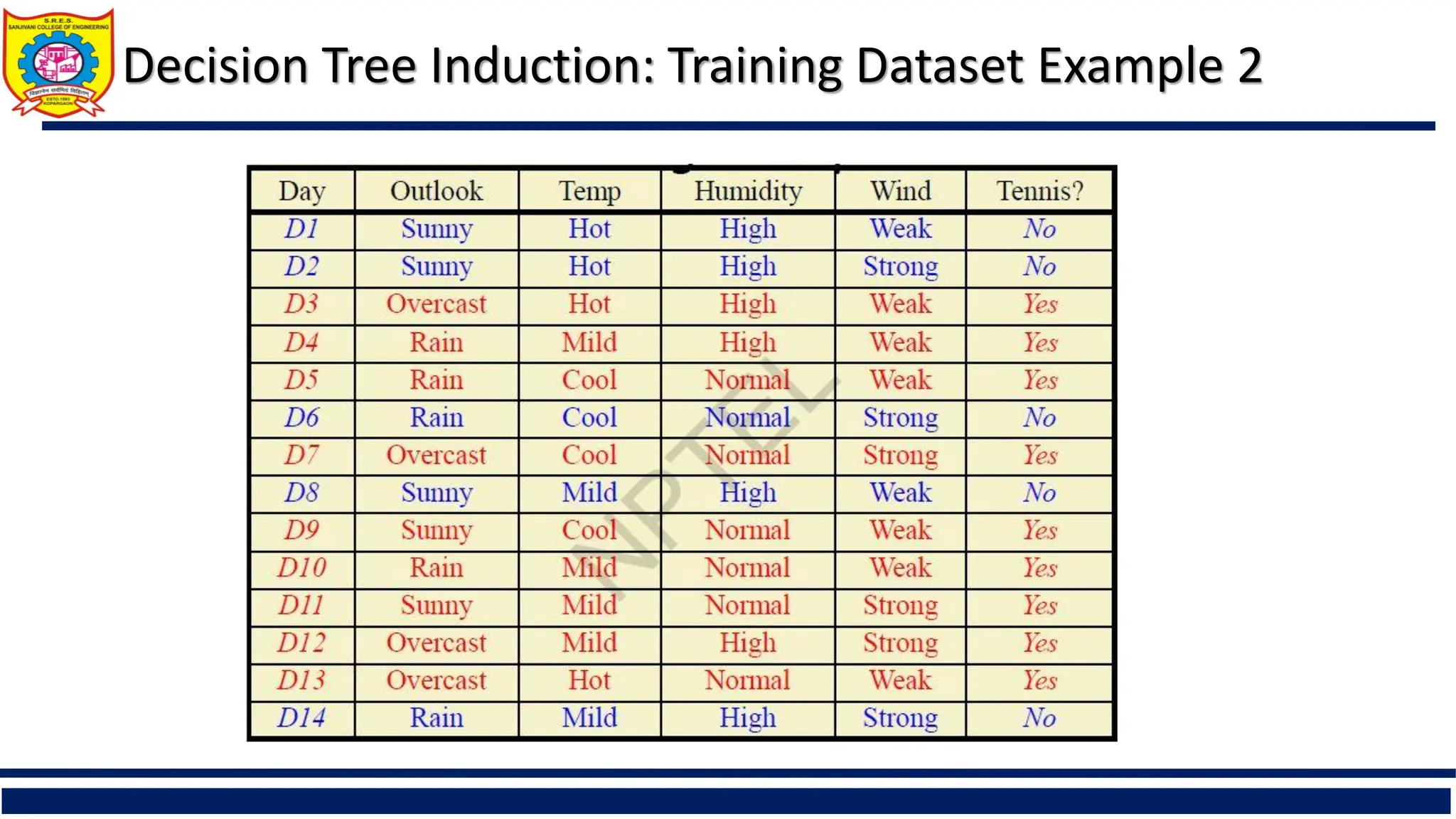
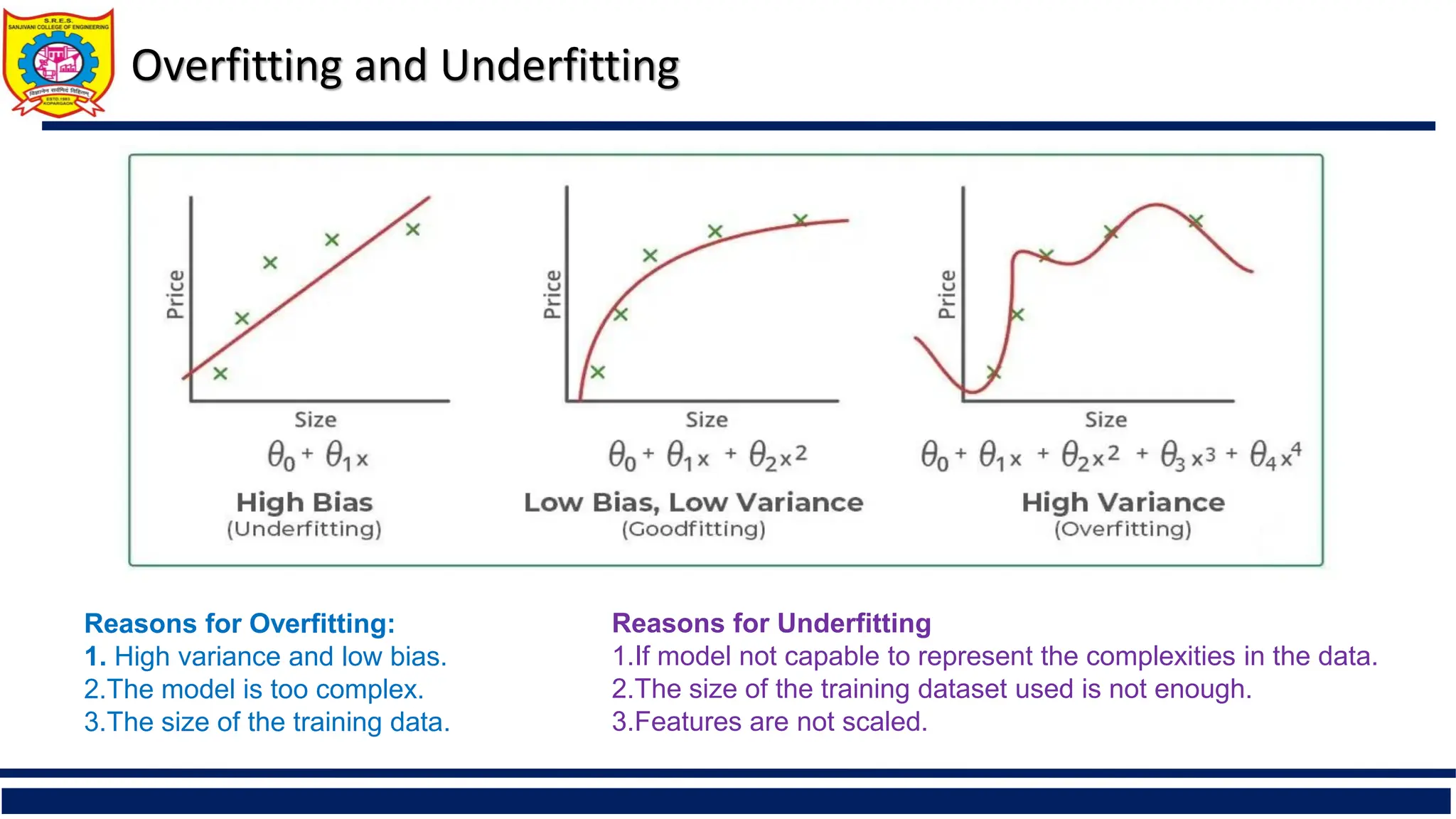
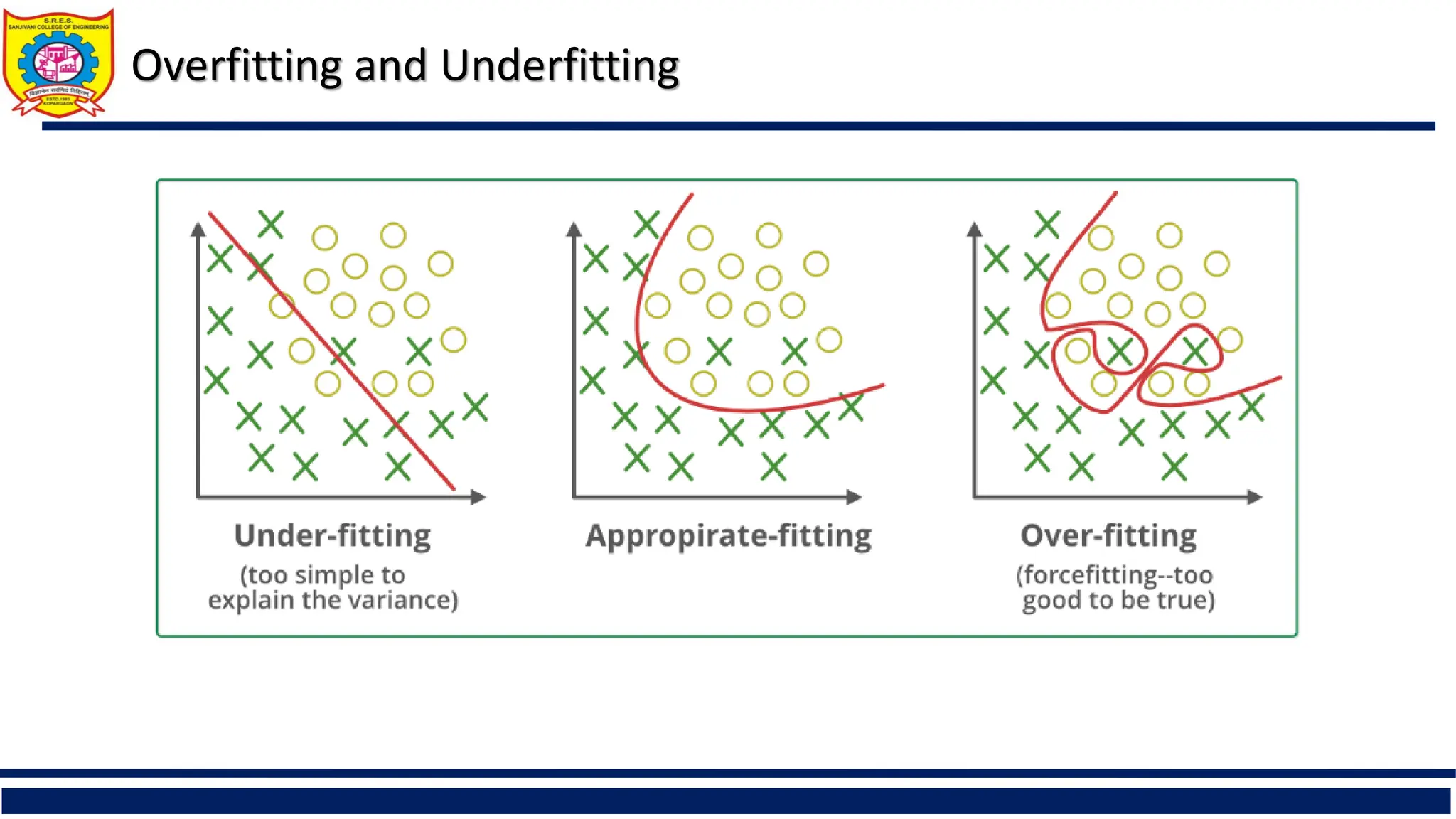
The document provides a comprehensive overview of supervised learning with a focus on decision trees, including their construction, key algorithms like ID3 and C4.5, and techniques for attribute selection such as entropy and Gini index. It also addresses challenges like overfitting and underfitting, offering solutions through pruning methods and strategies to enhance decision tree induction. Additionally, the document includes references to further reading and online resources related to data mining and machine learning.

































































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)










