Download as PDF, PPTX











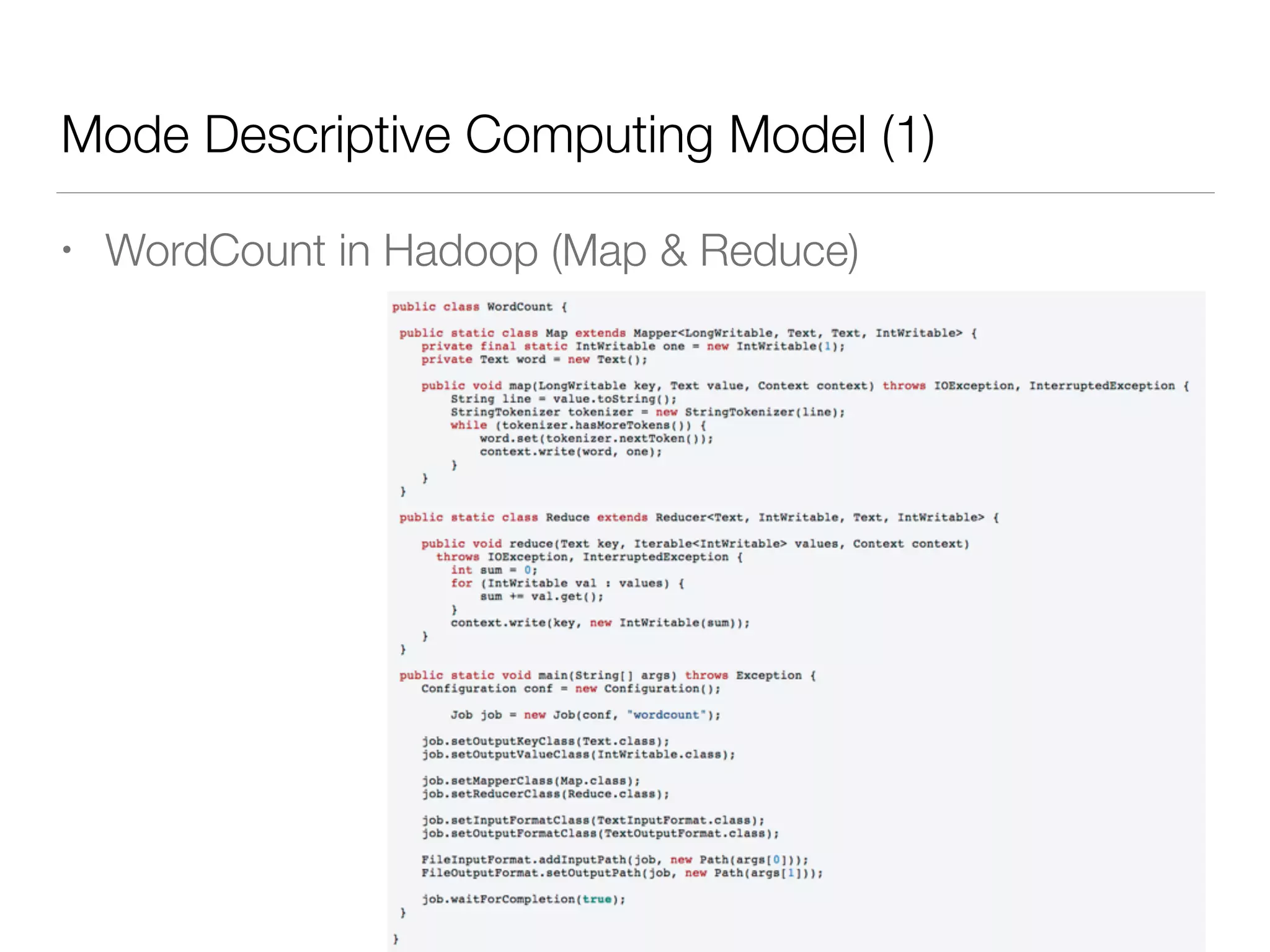
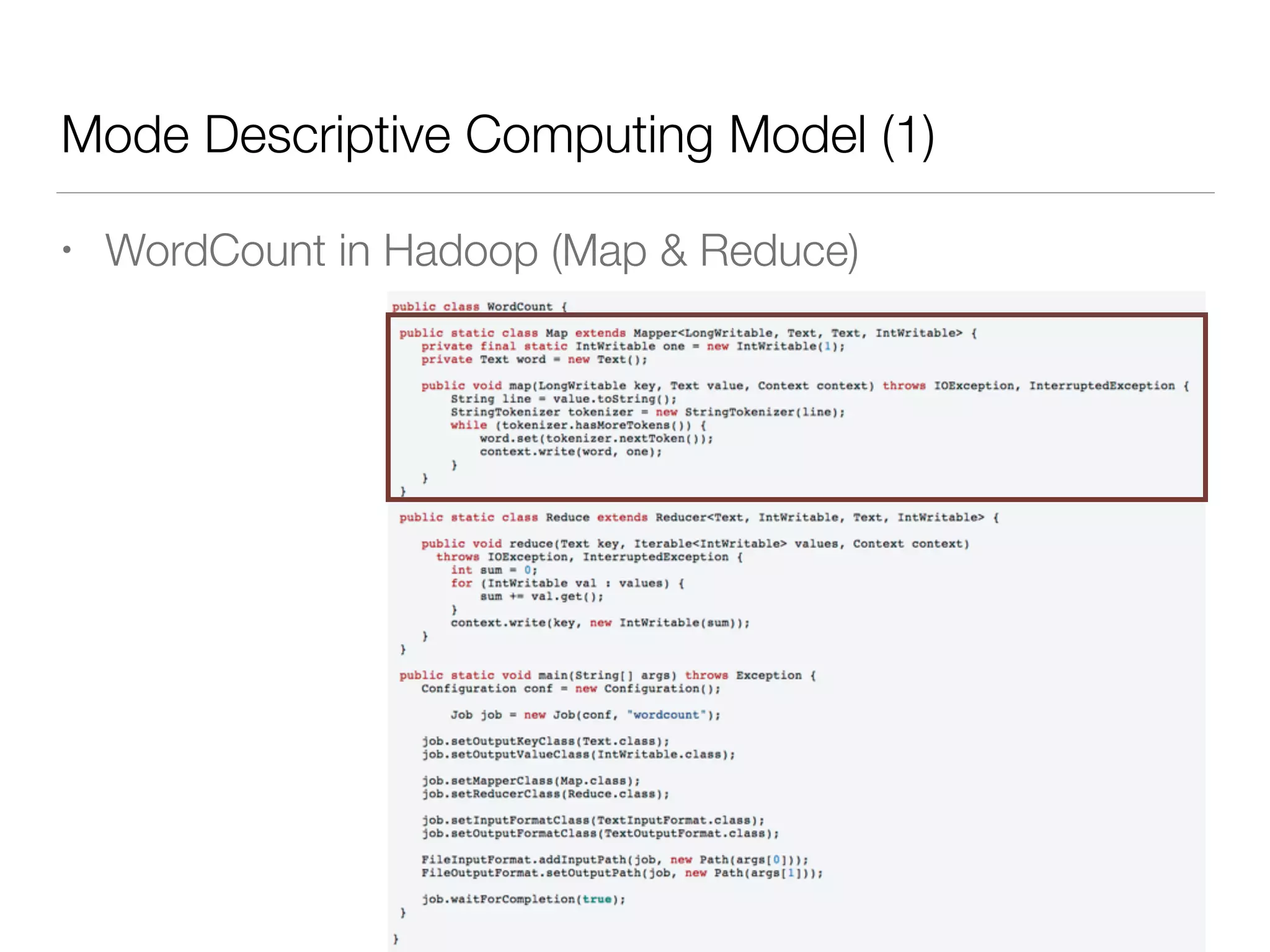
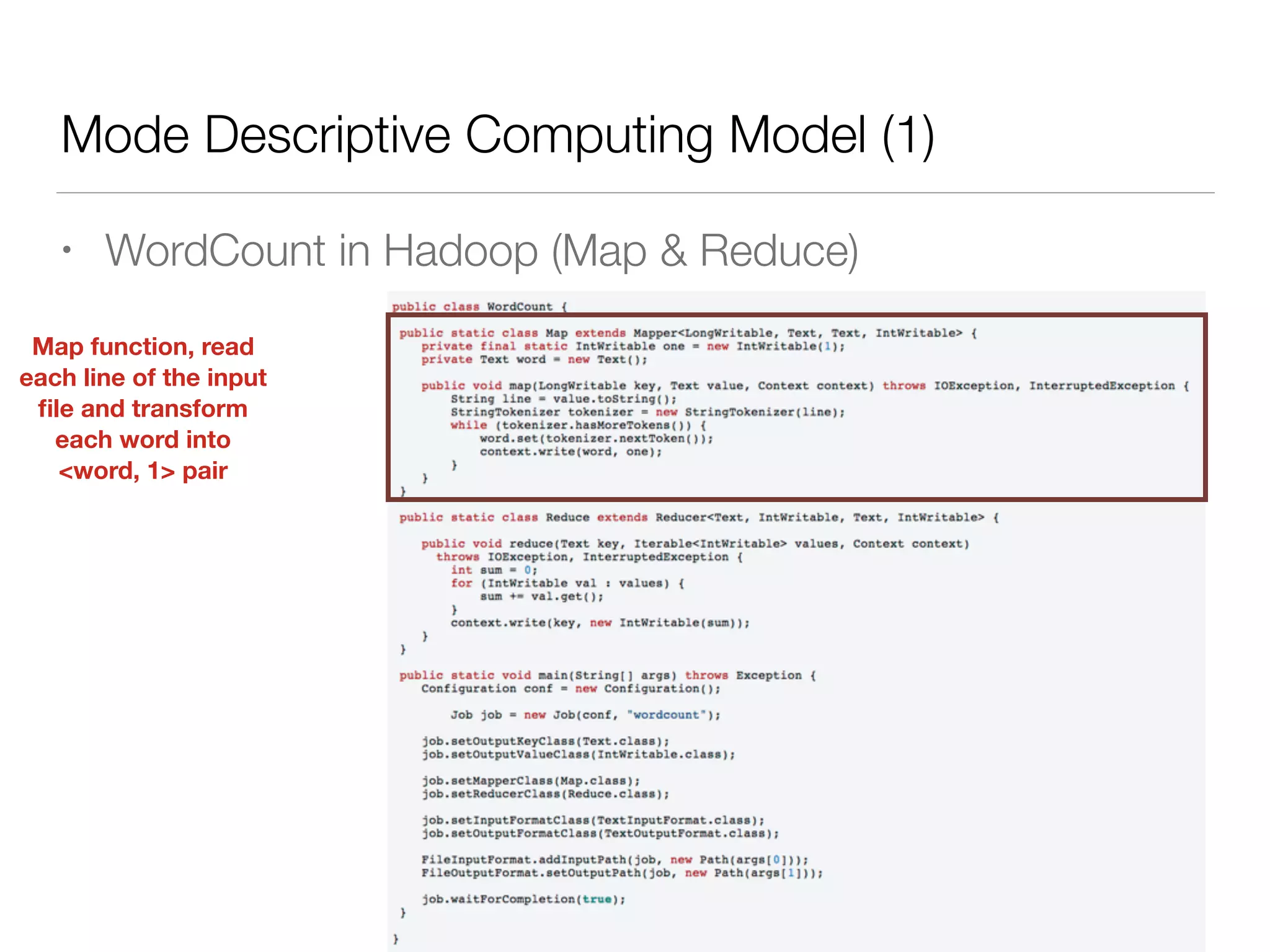
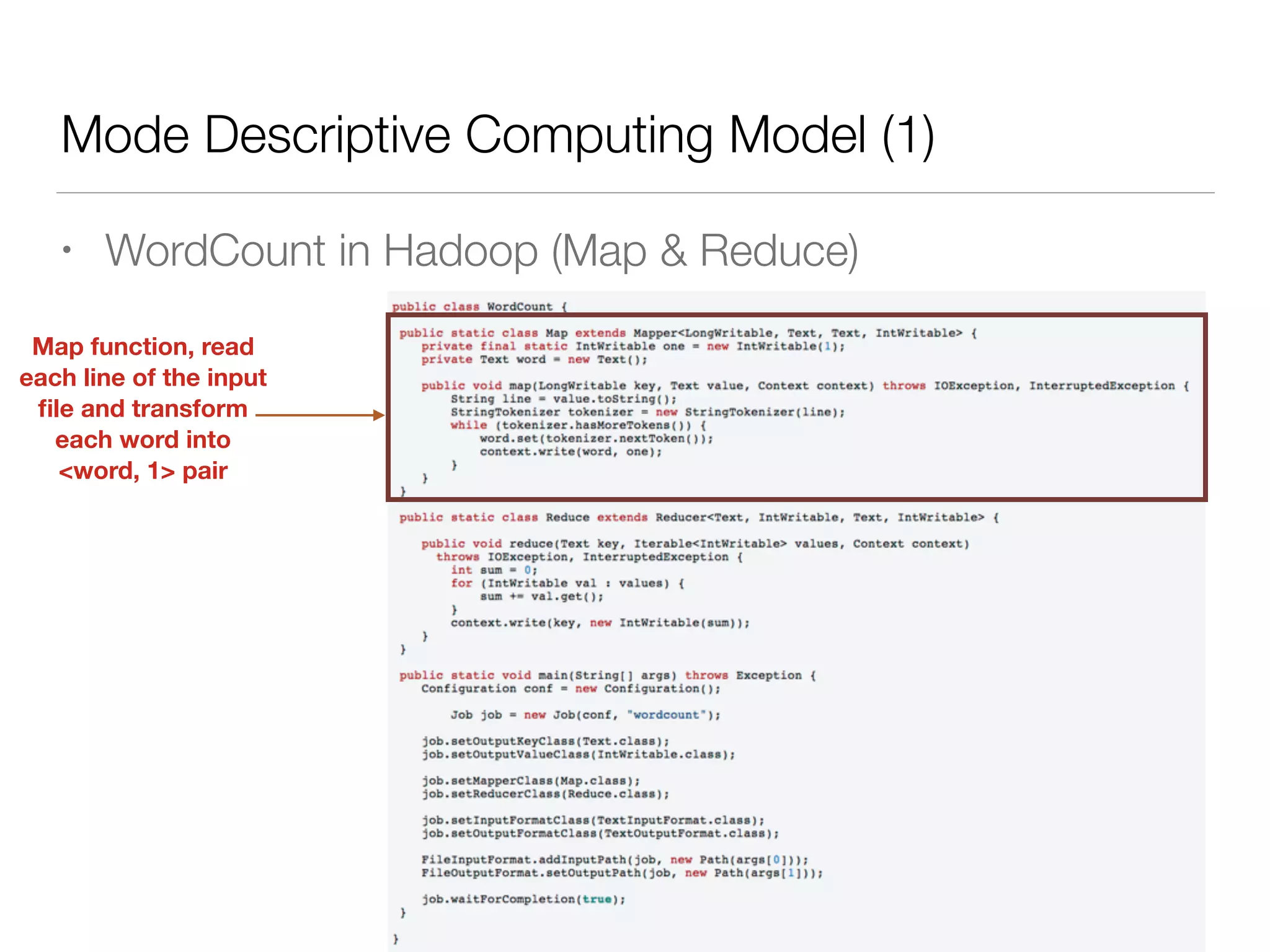
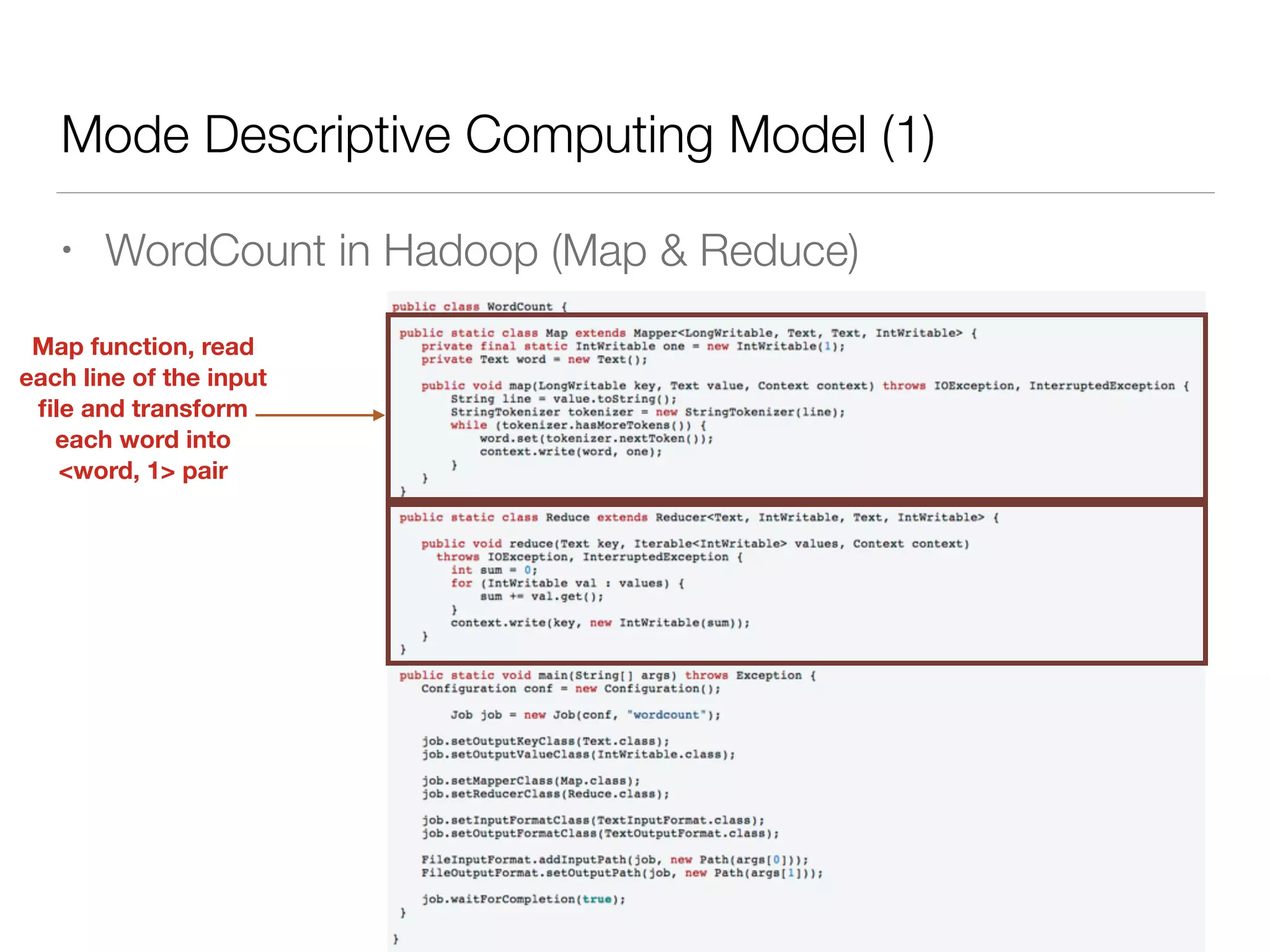
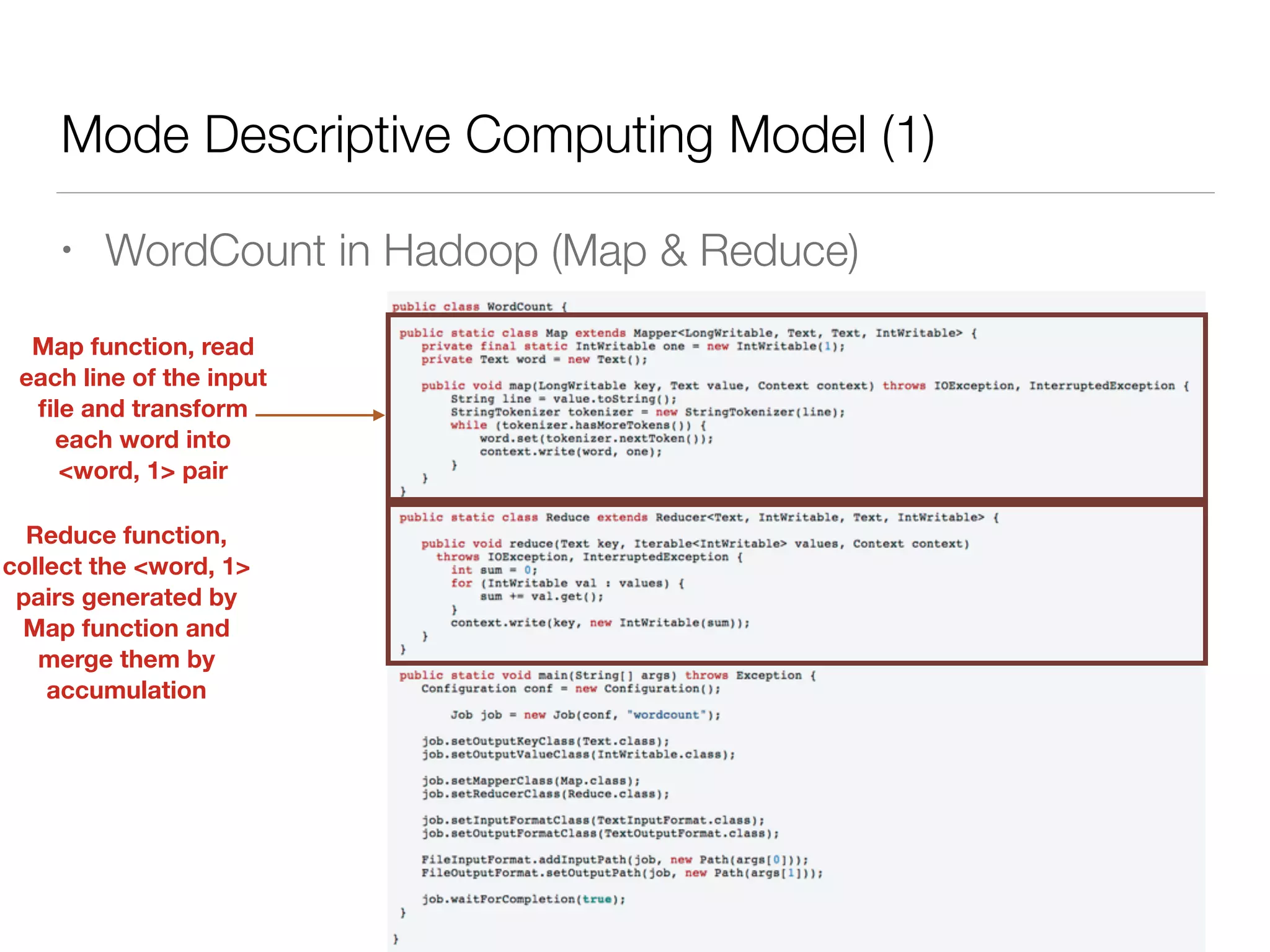
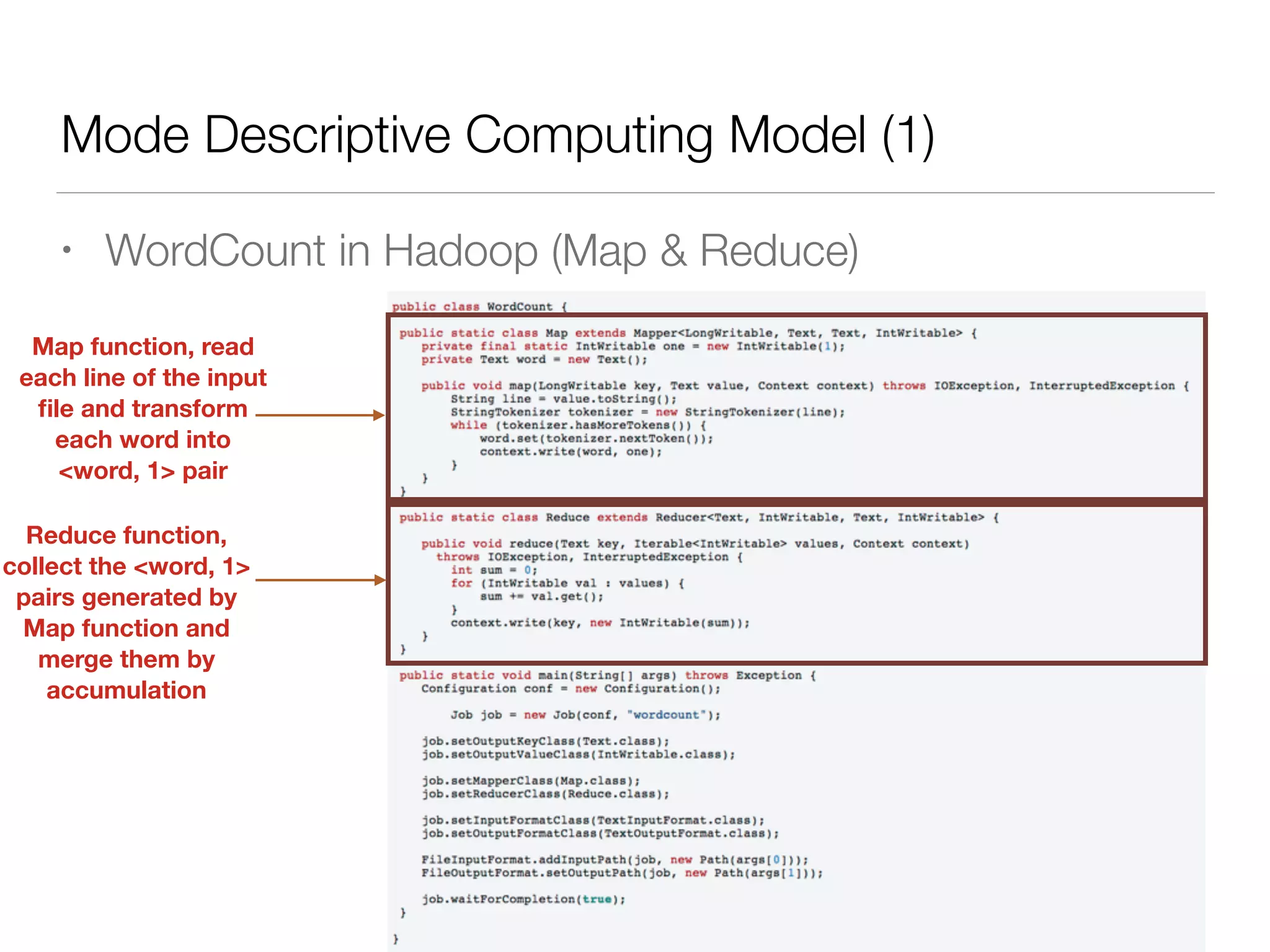
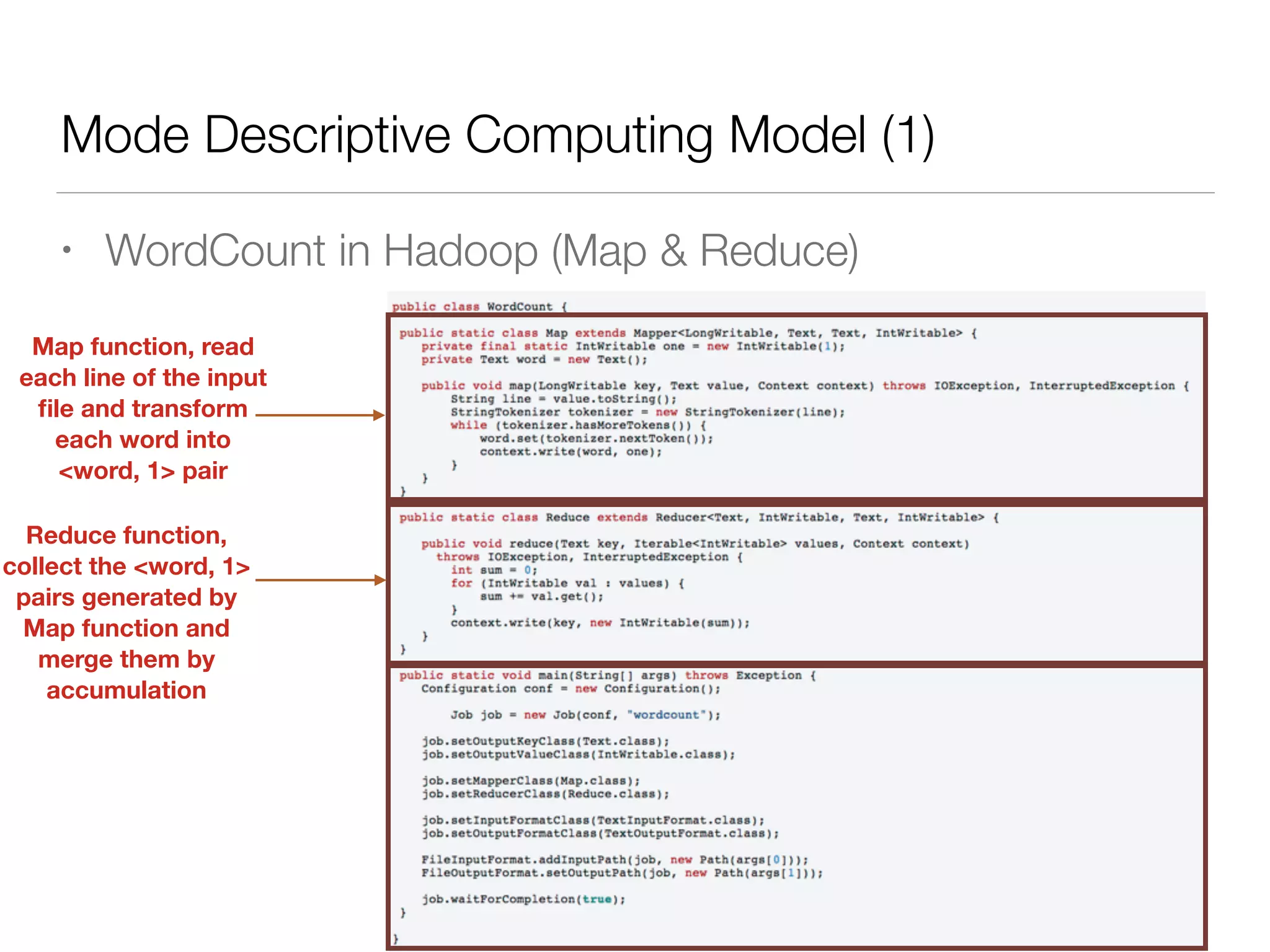
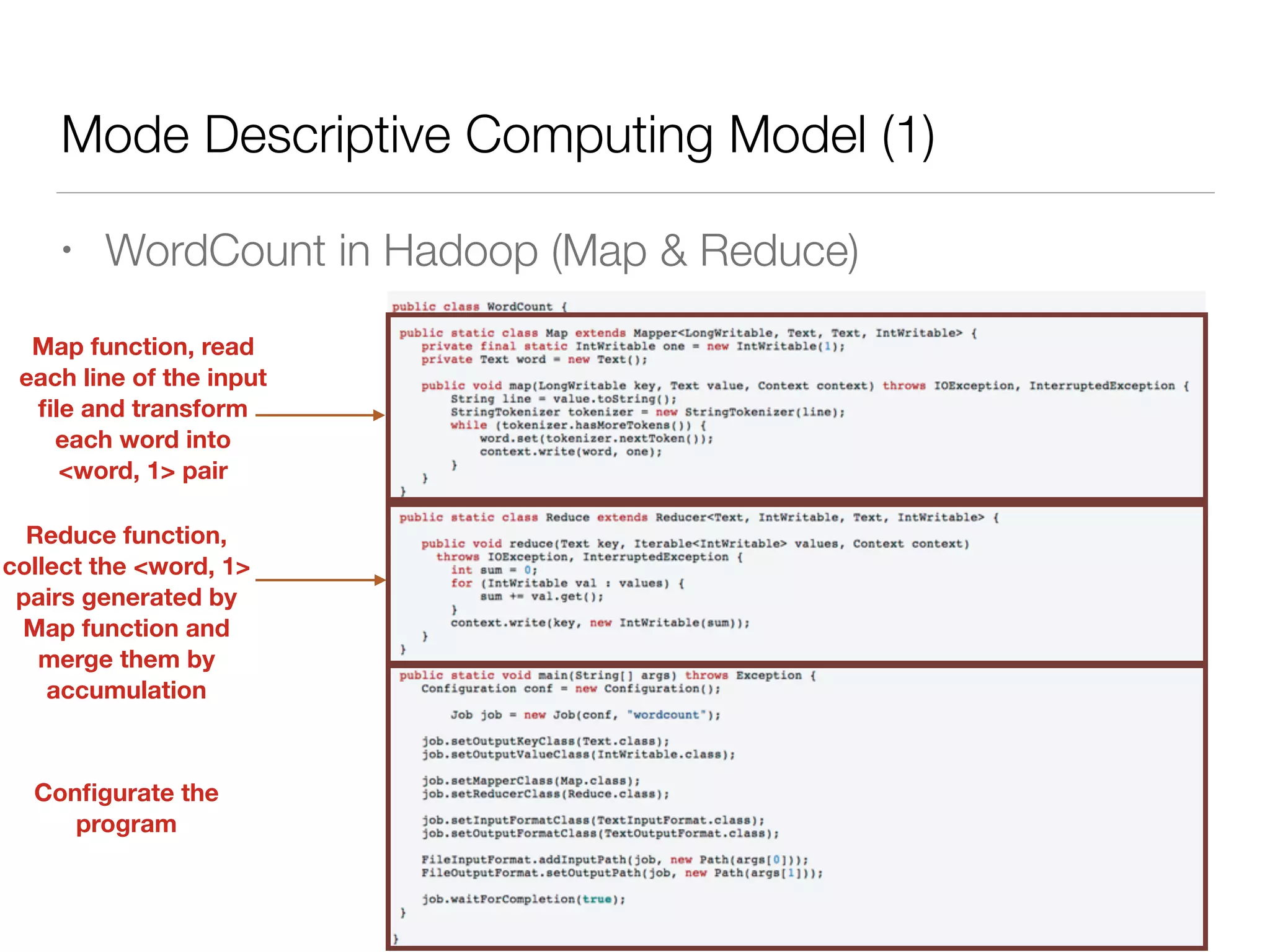
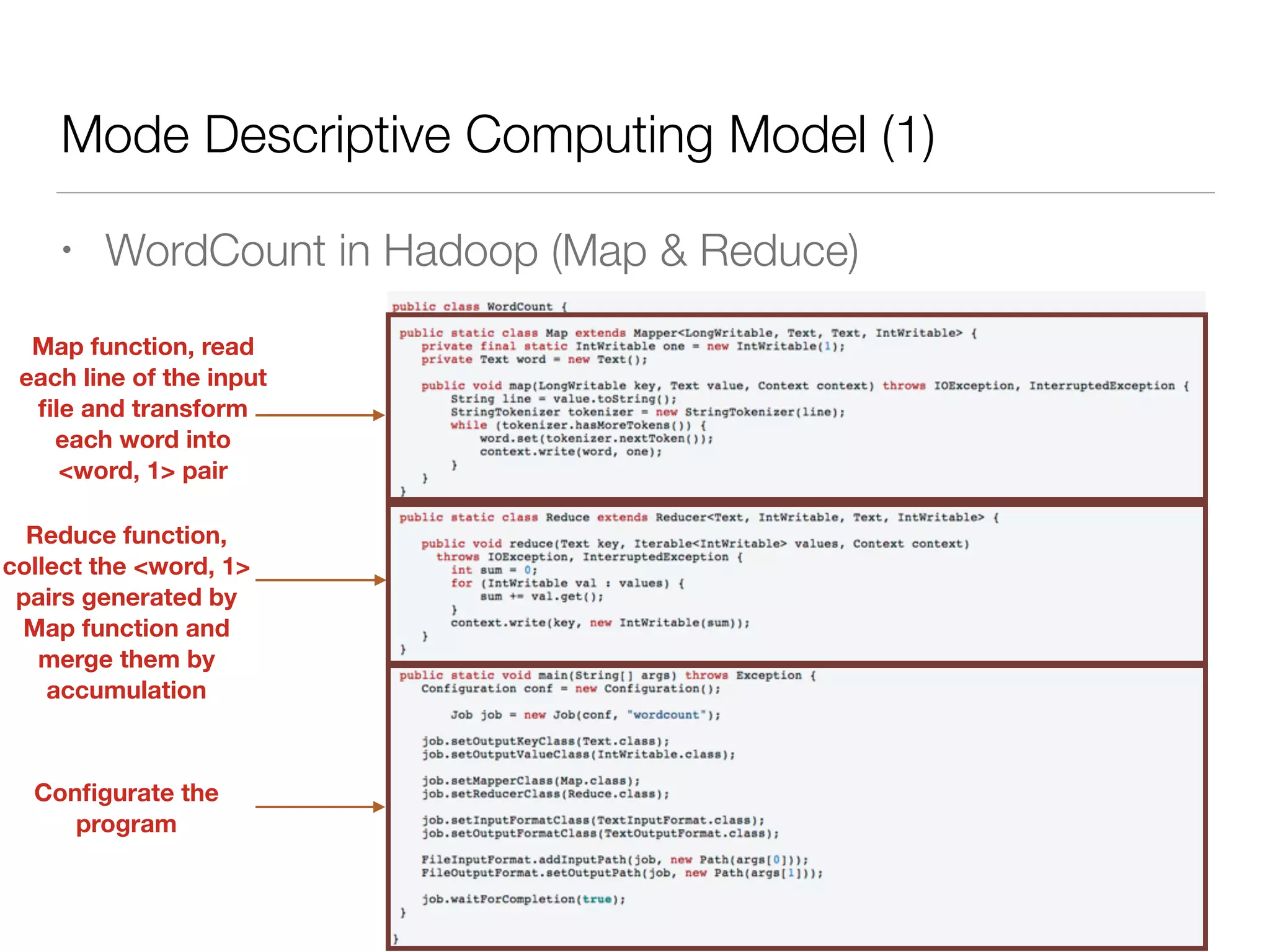



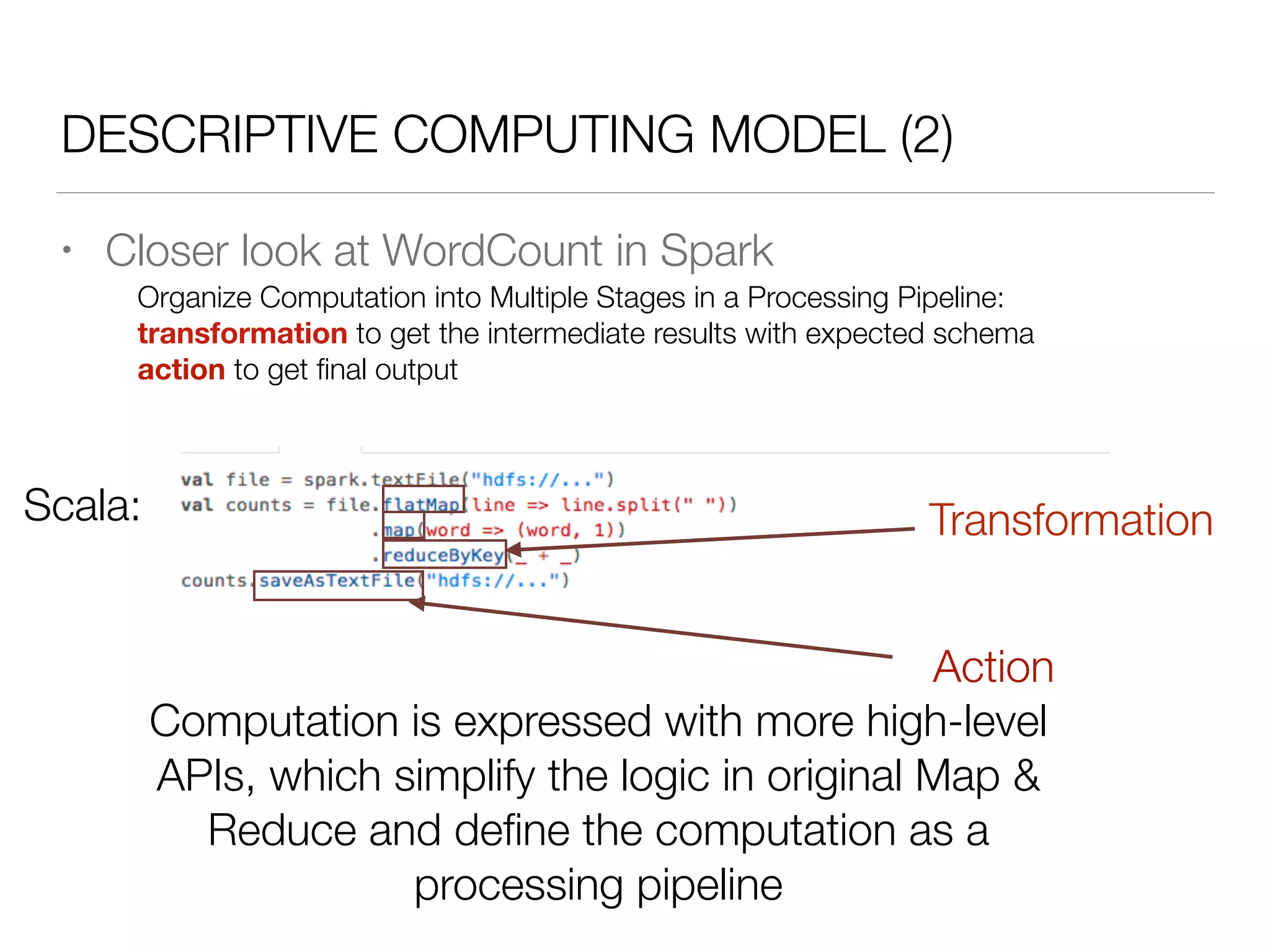
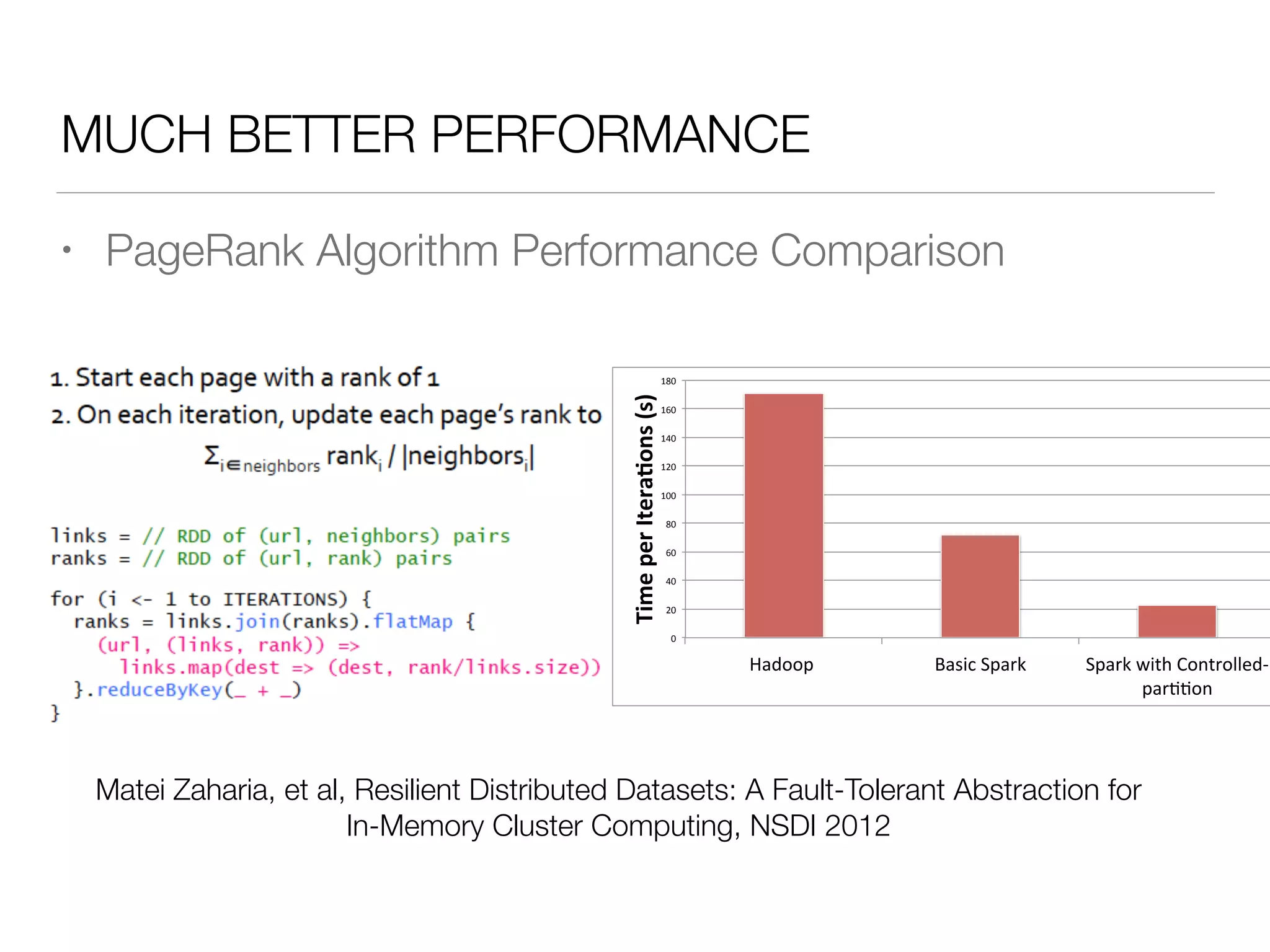
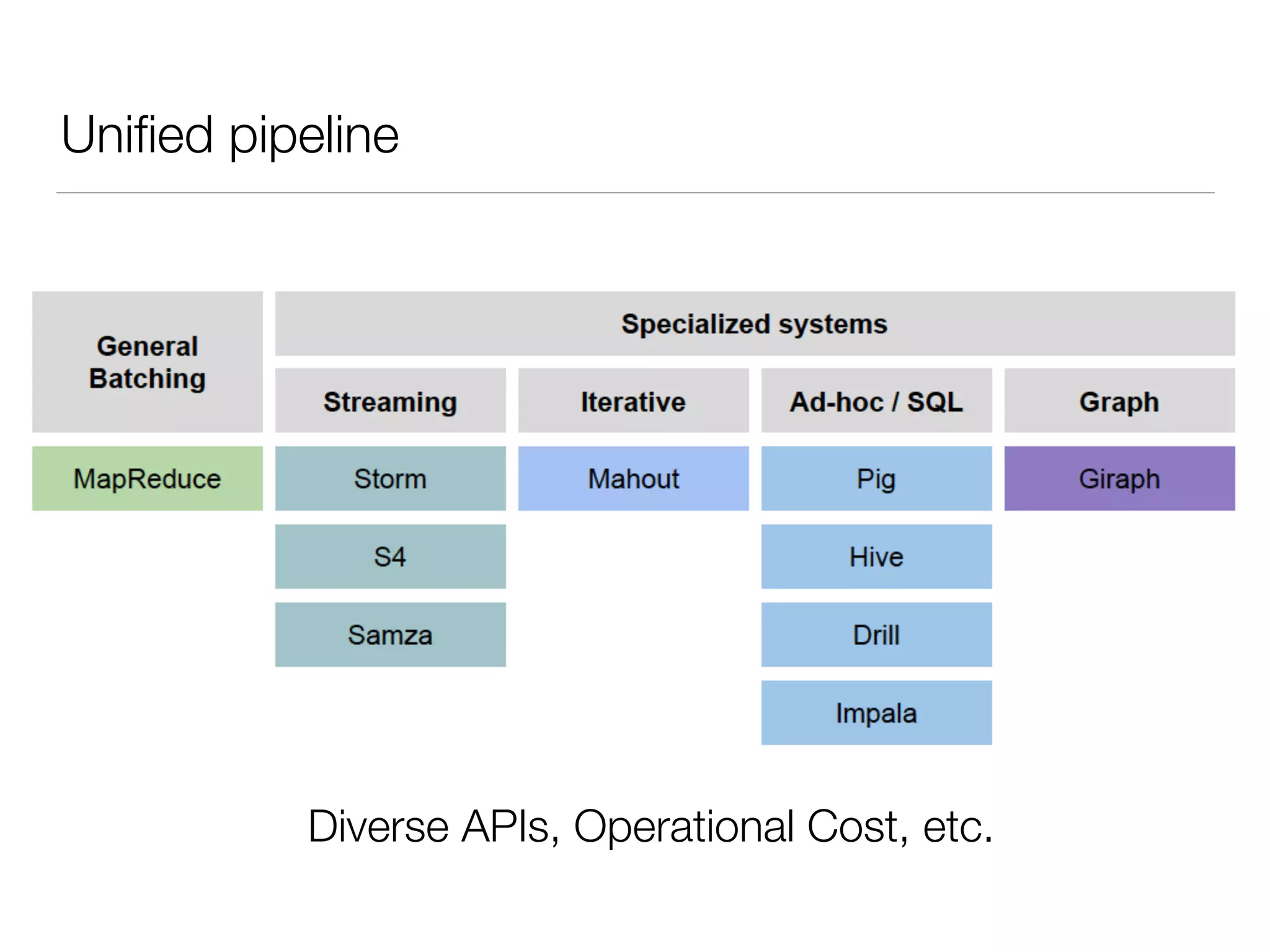

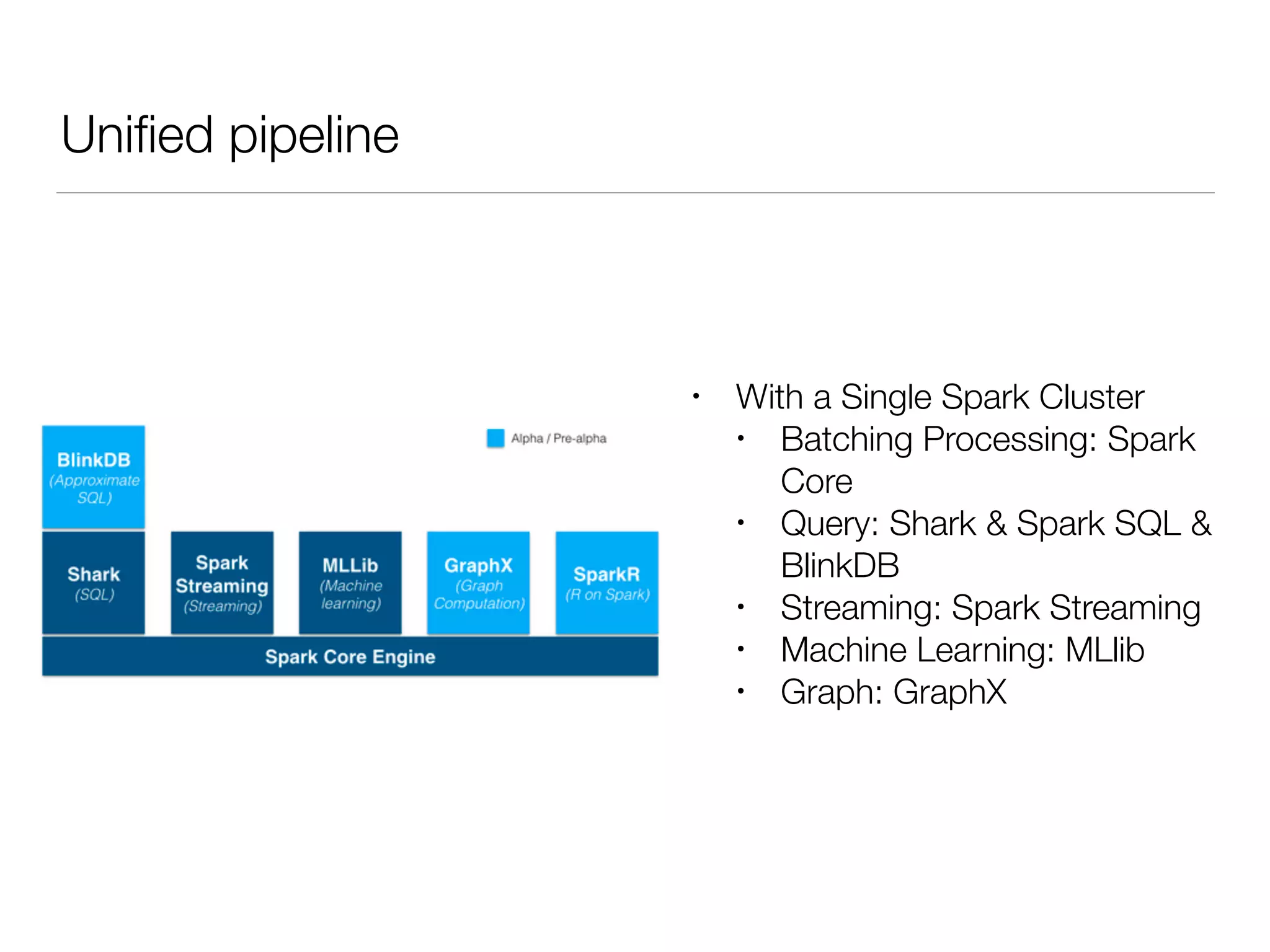

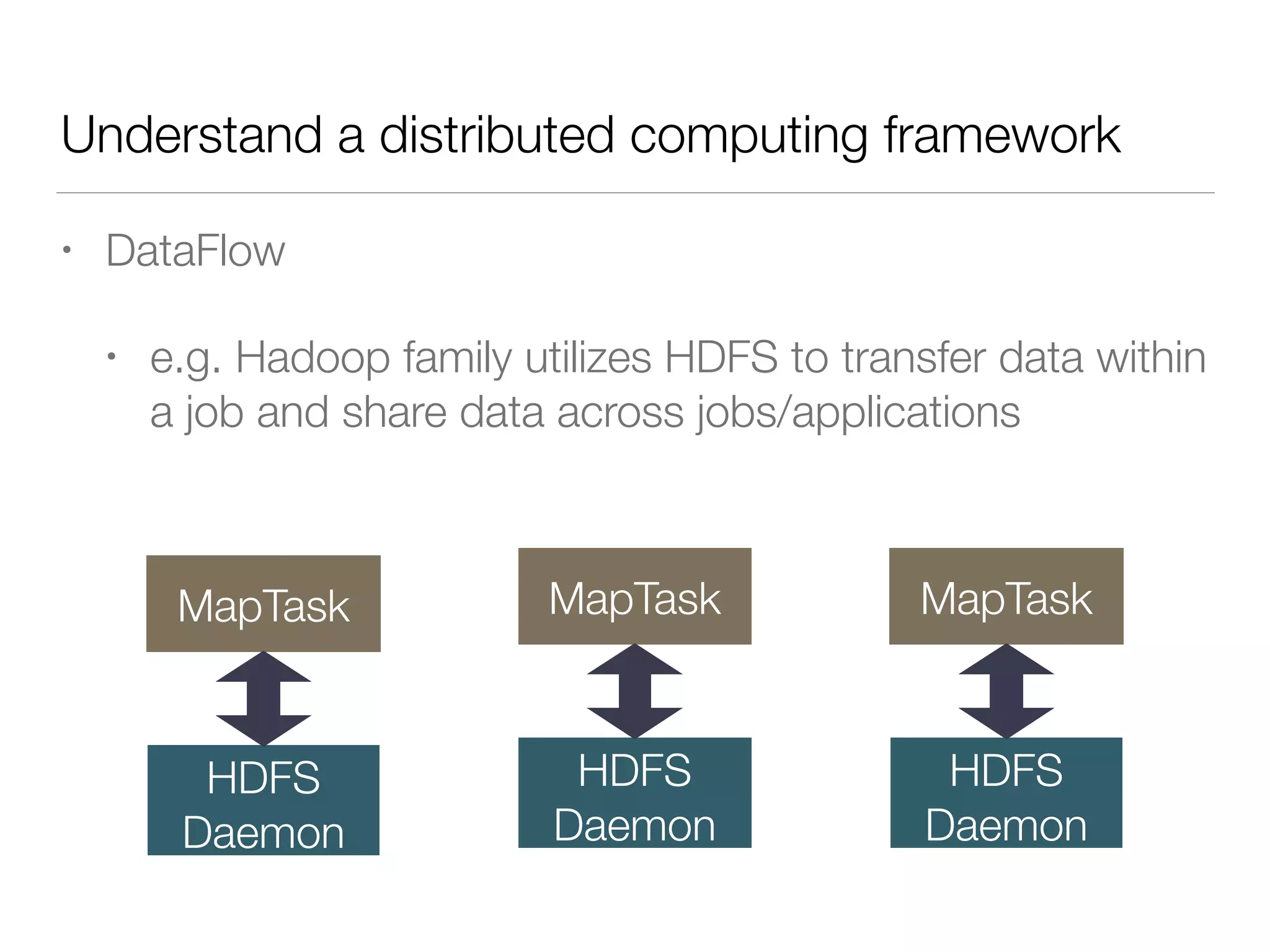

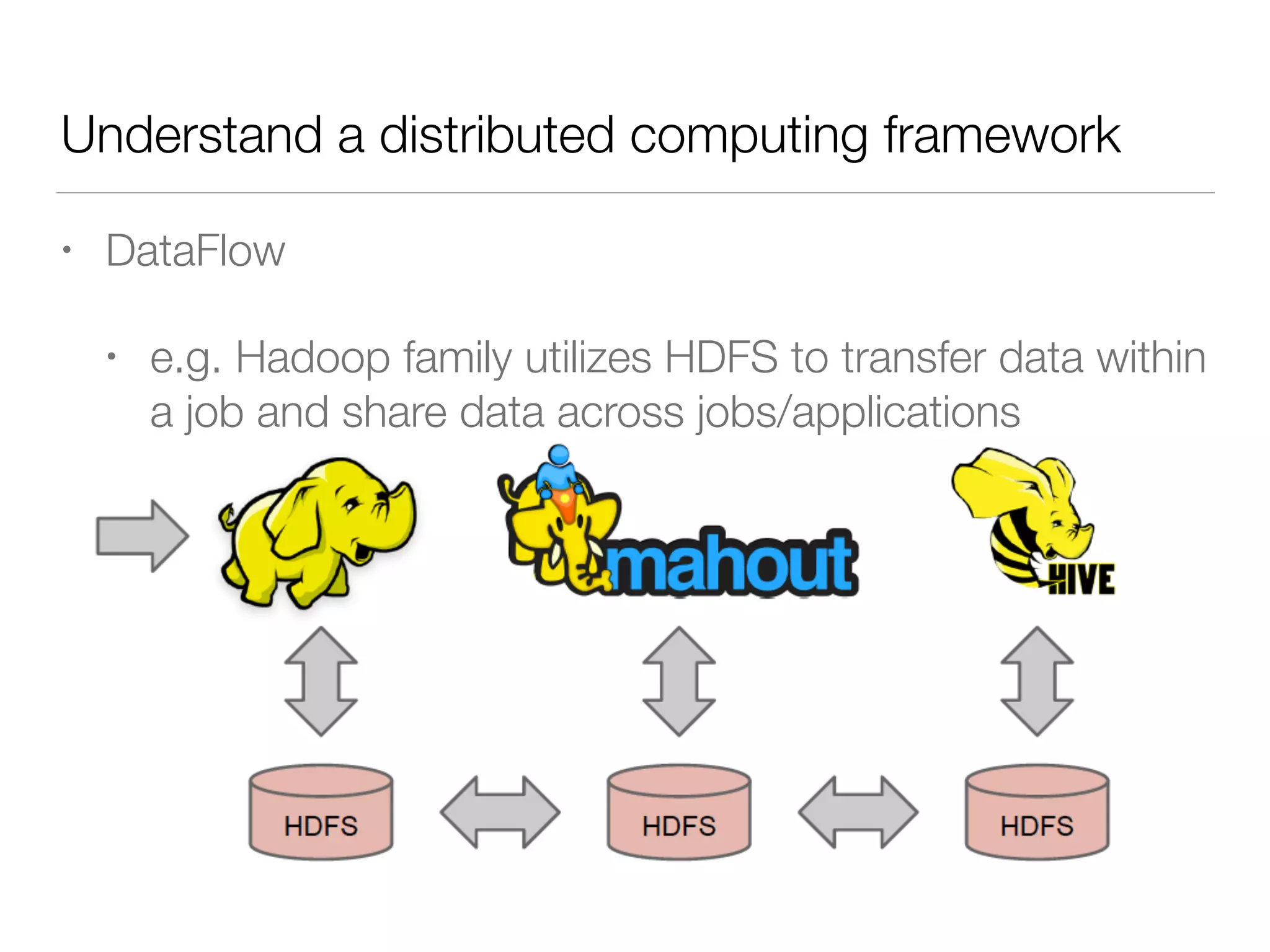




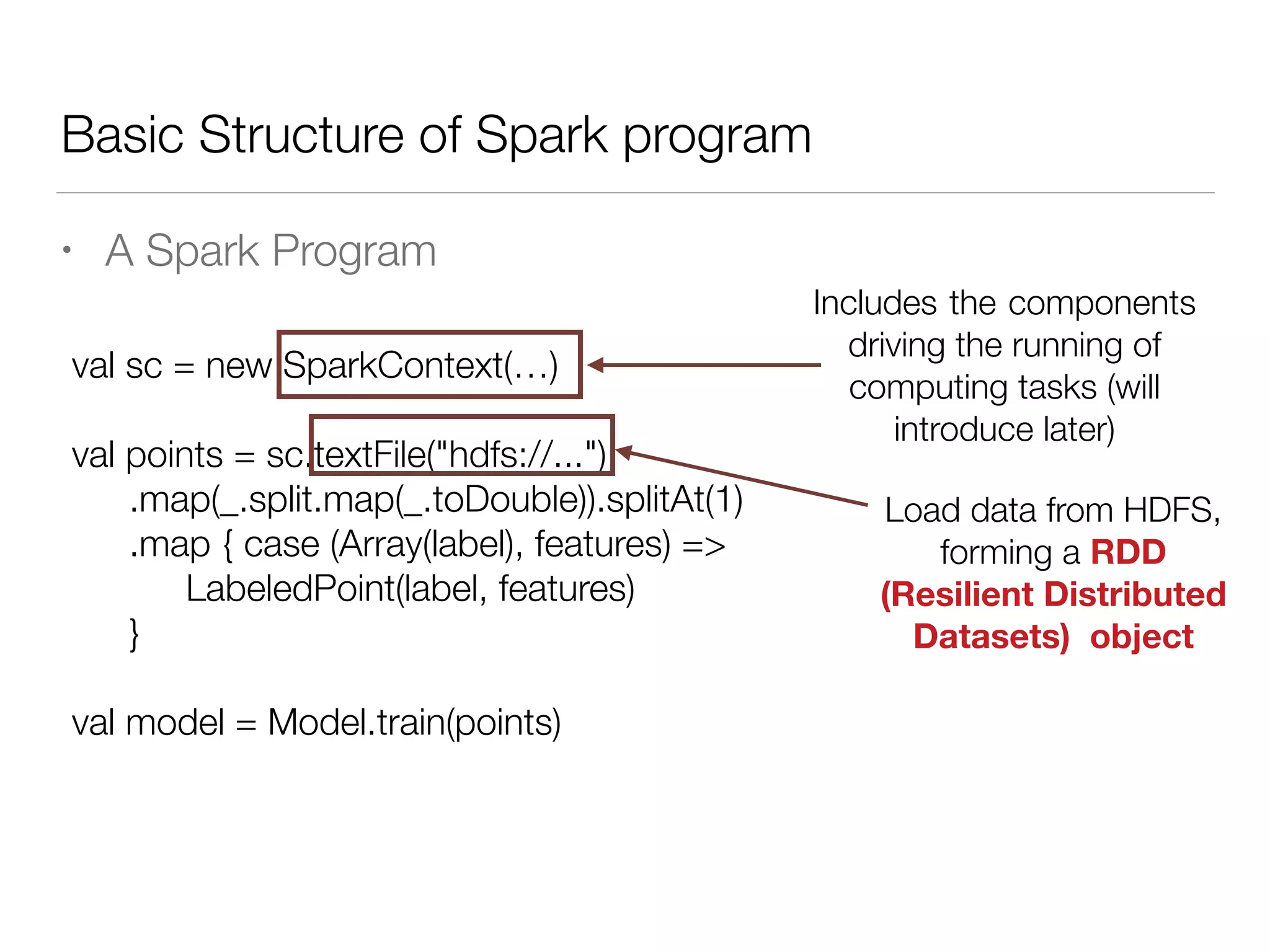
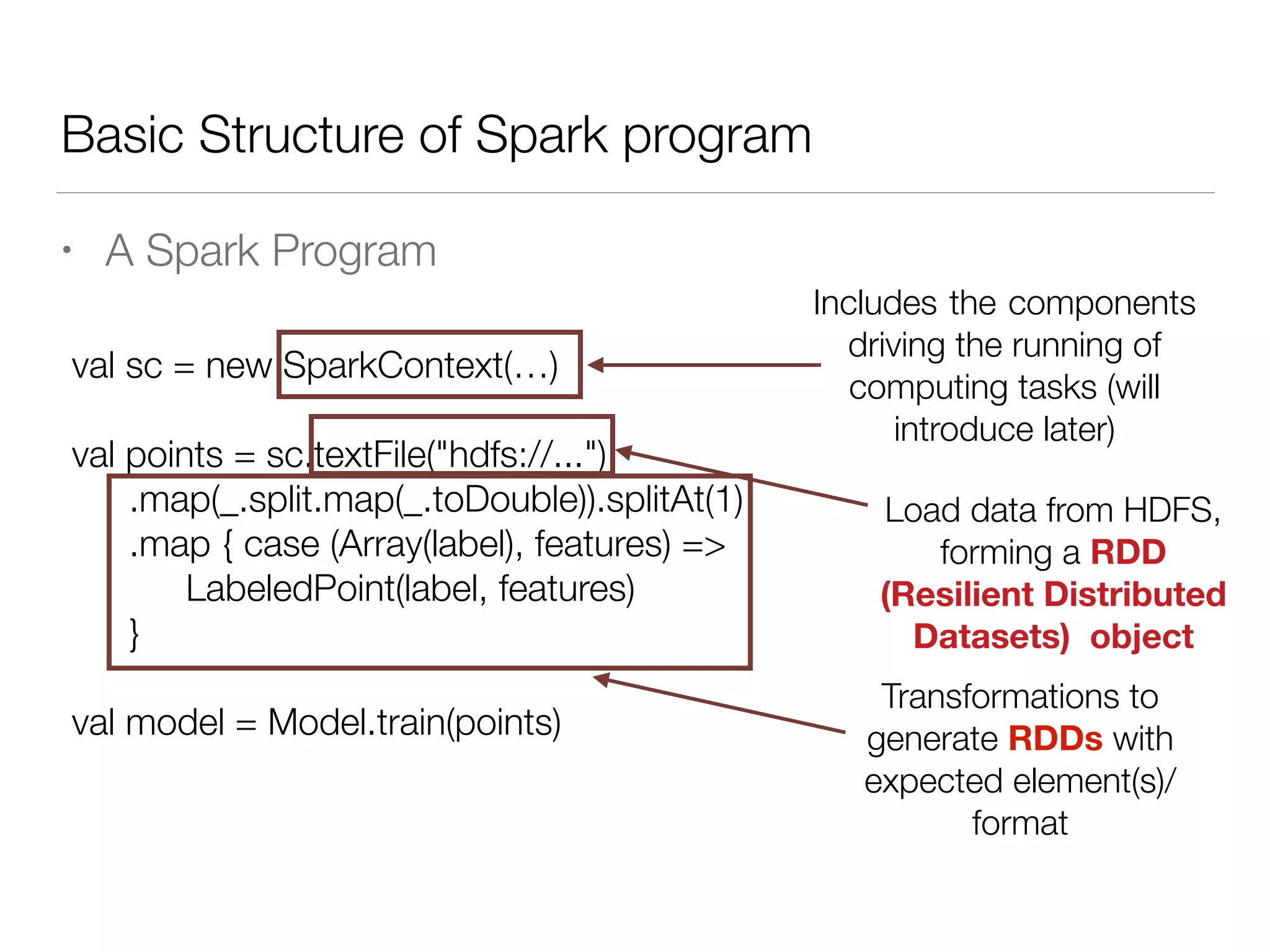
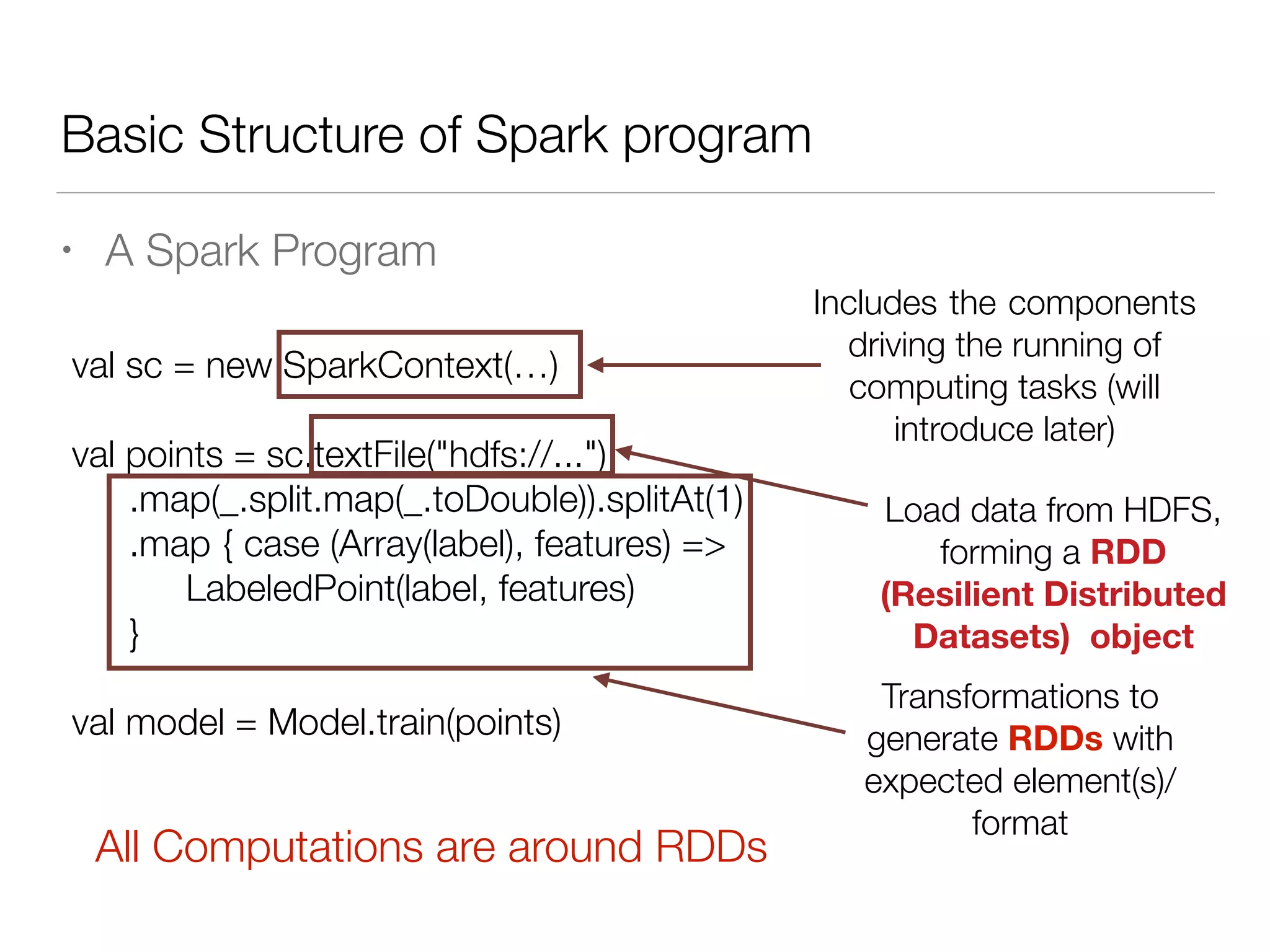
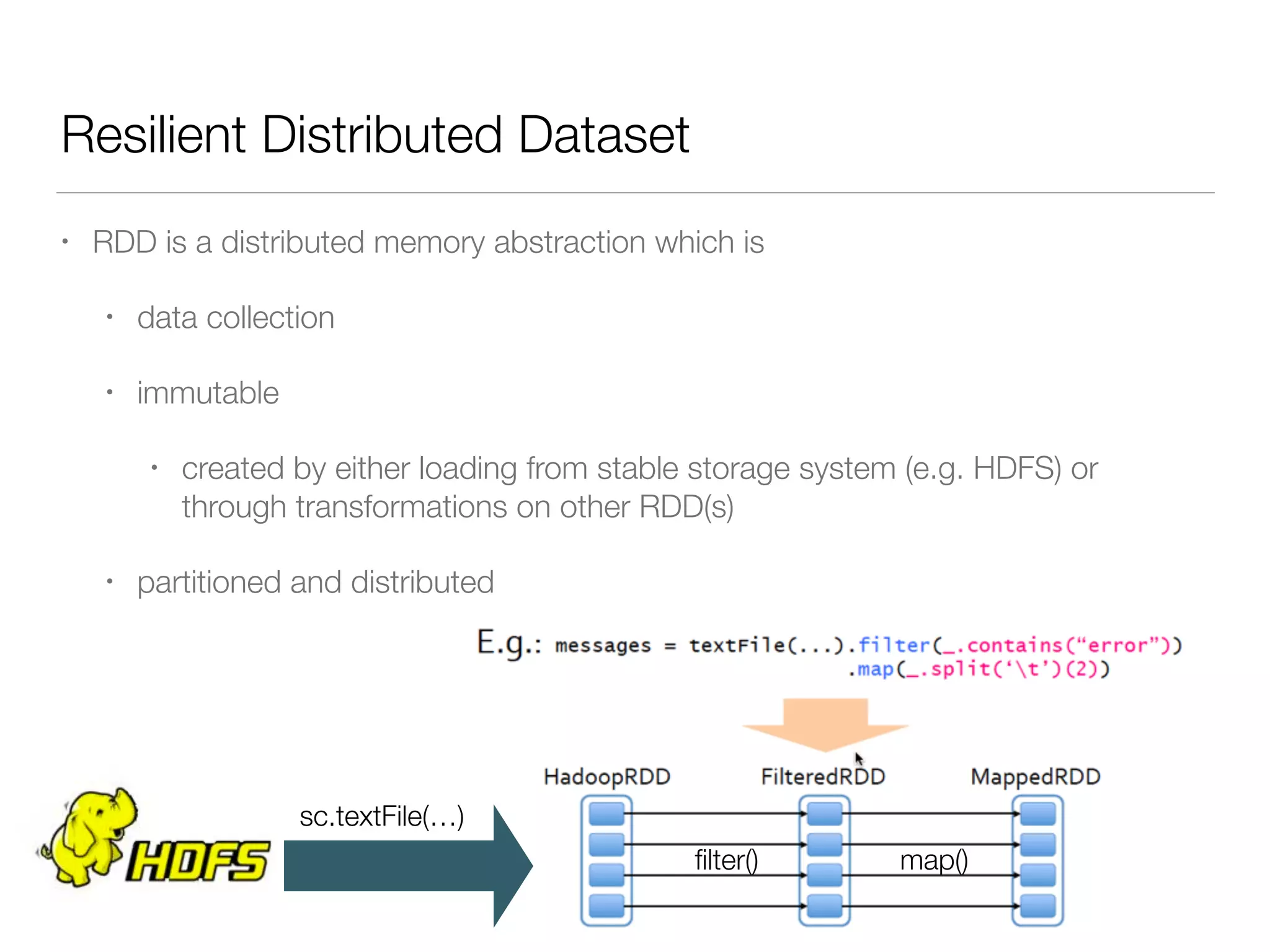
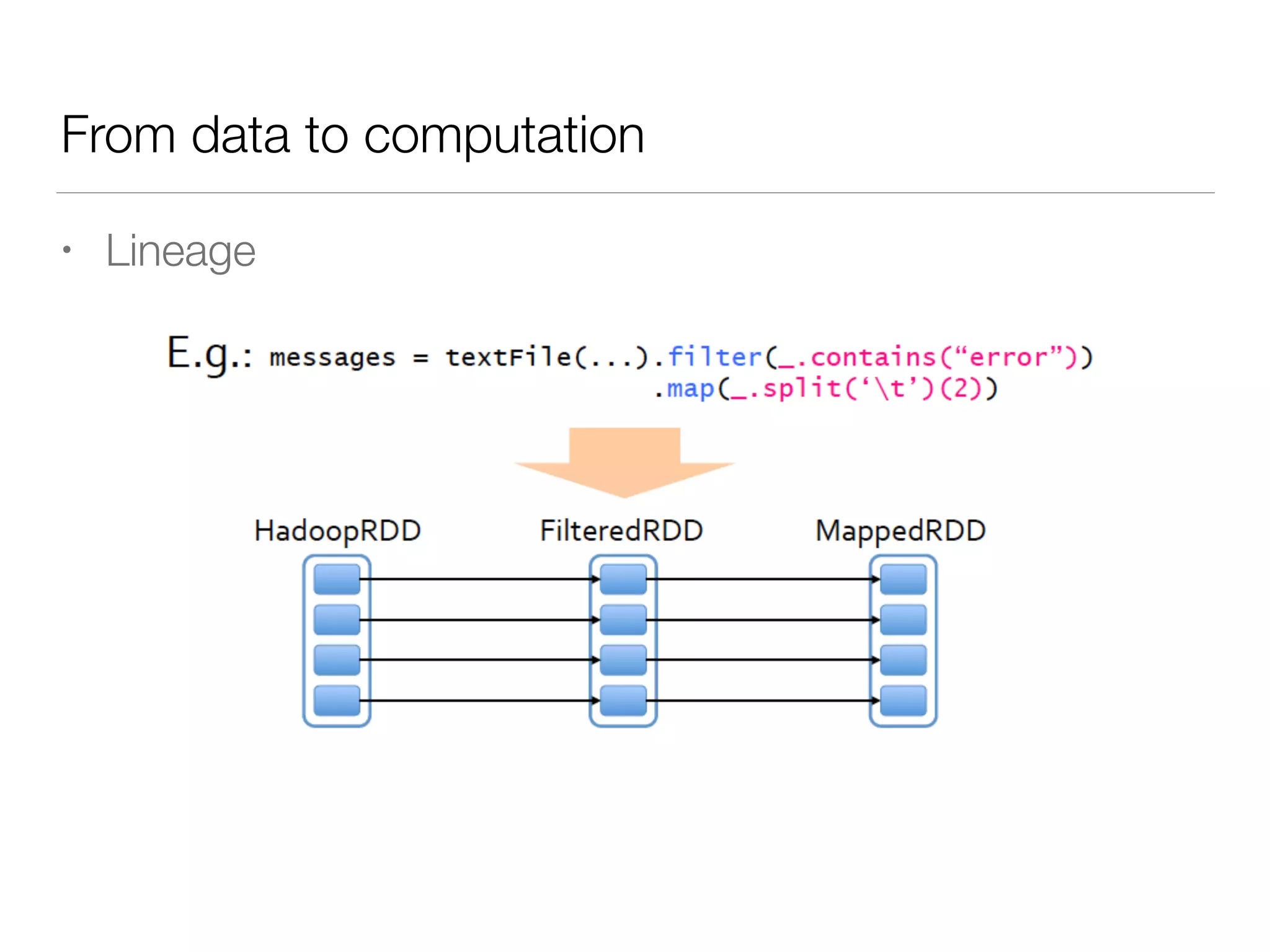
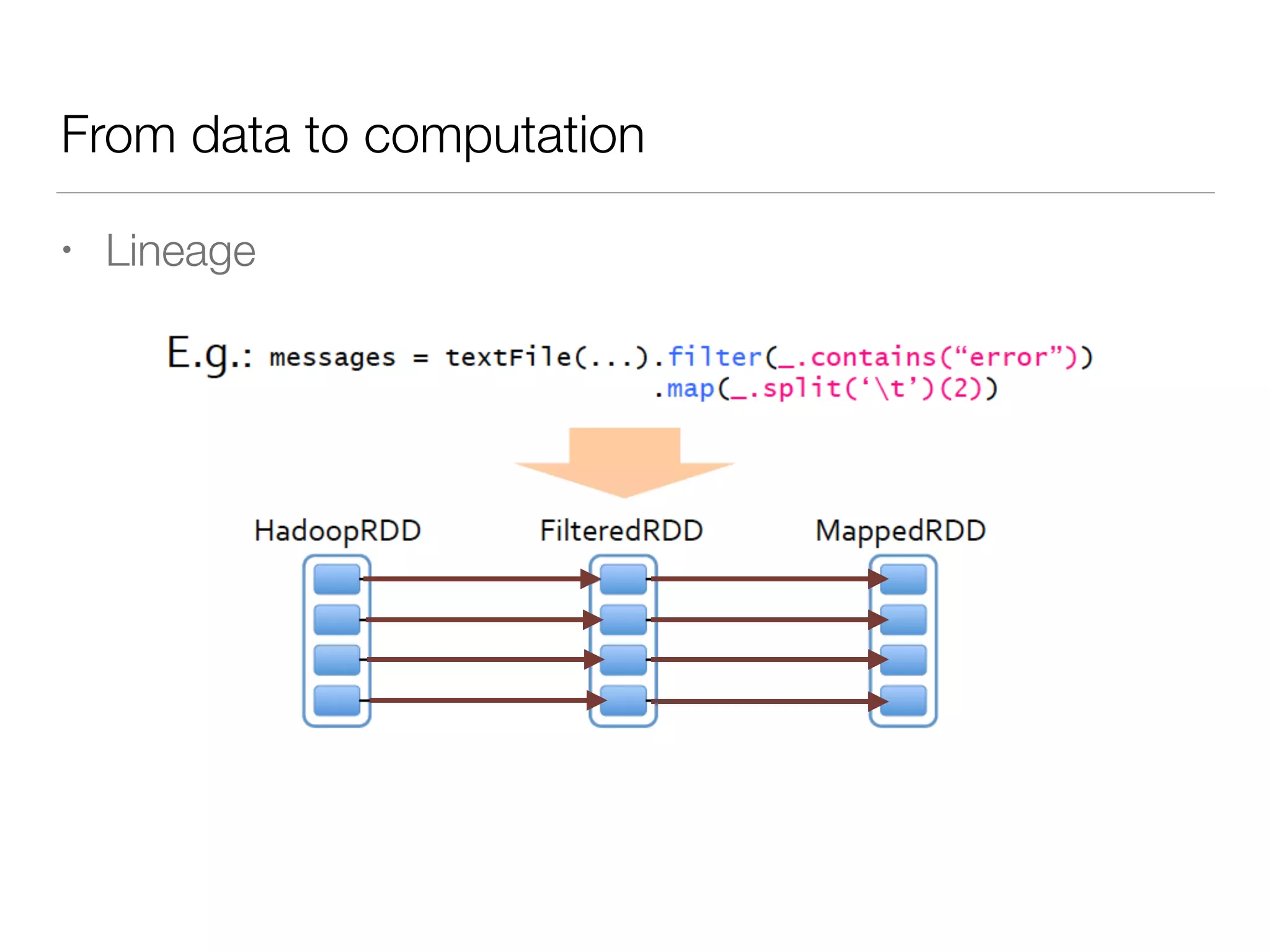
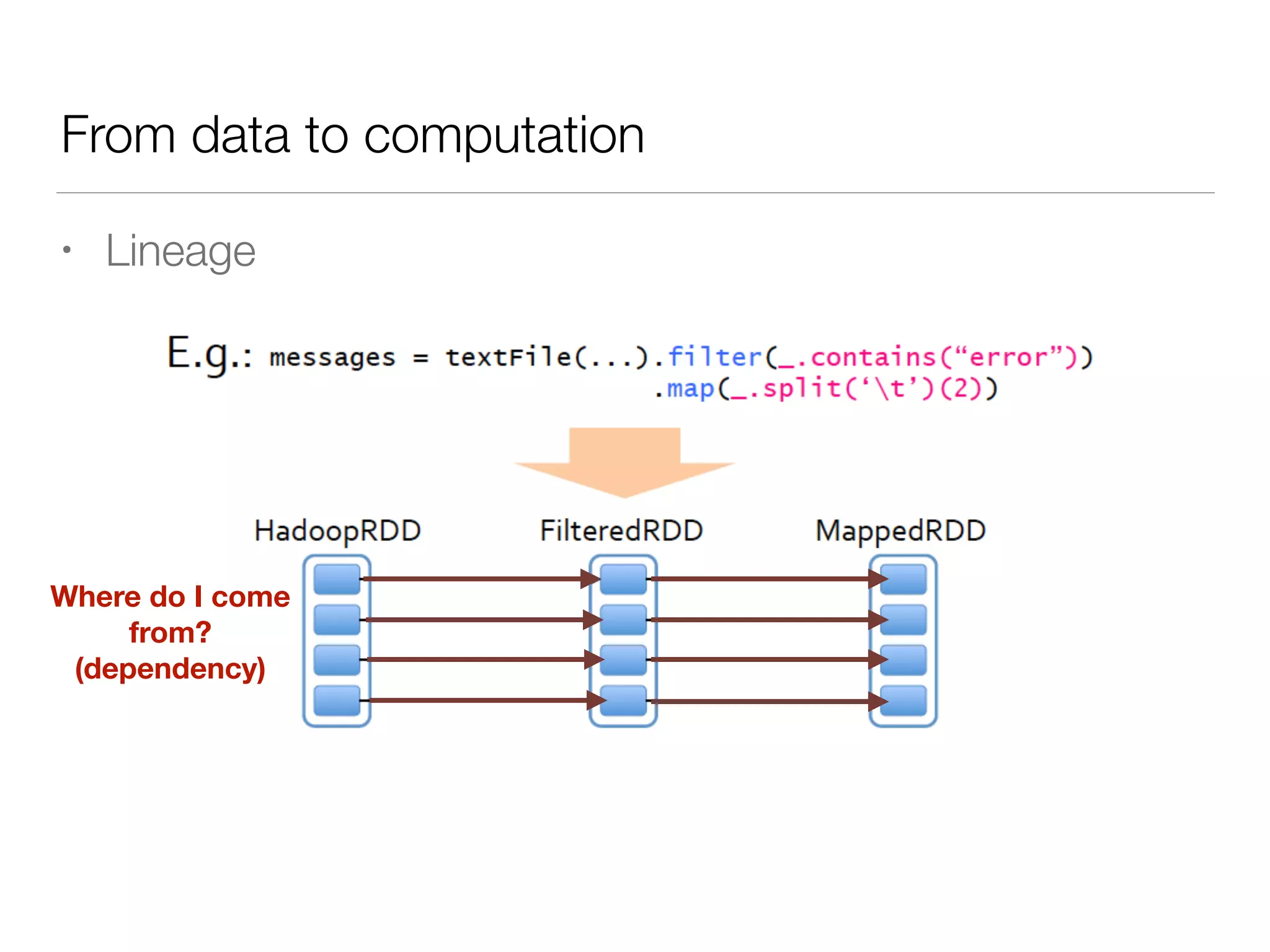
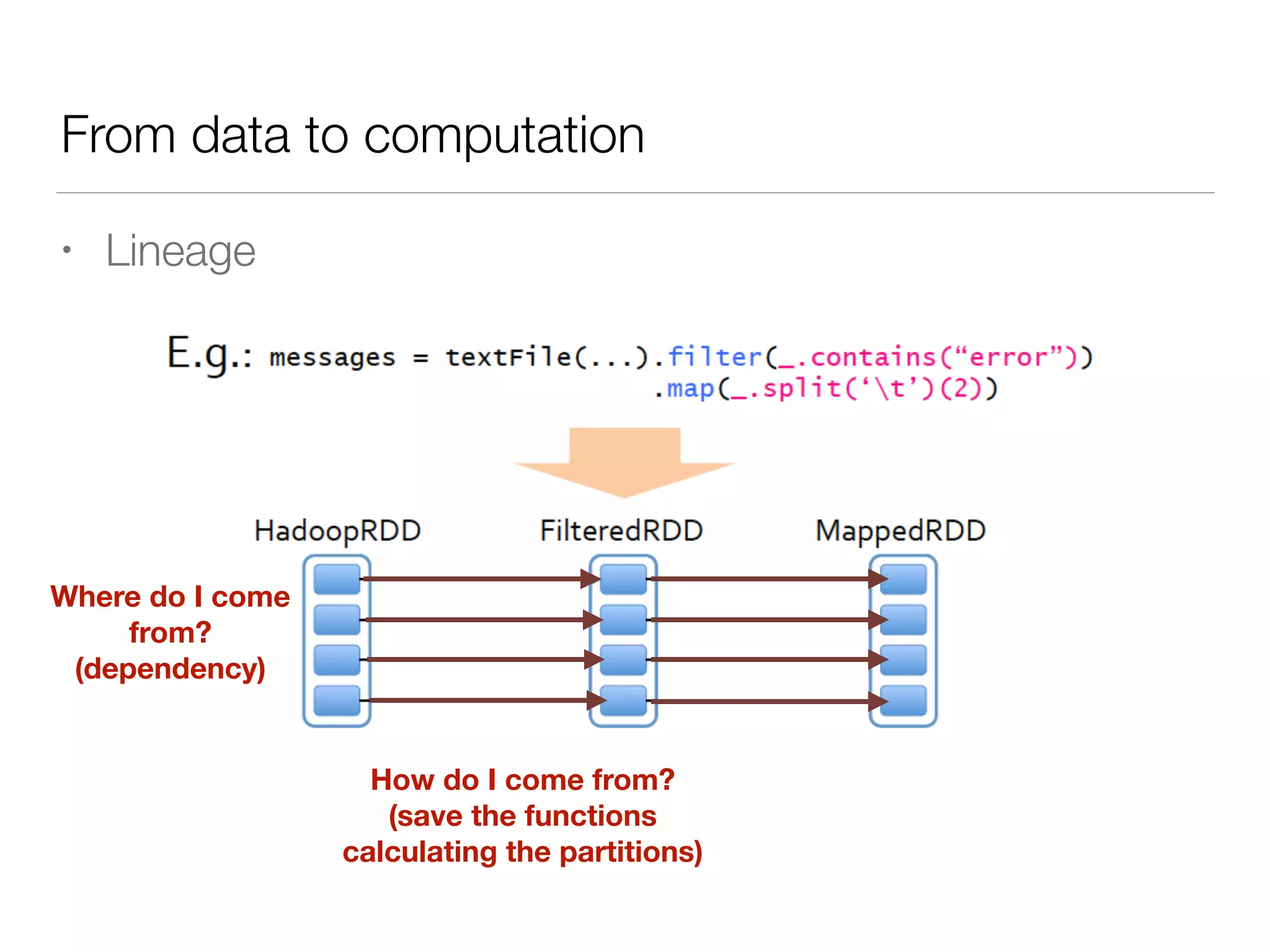
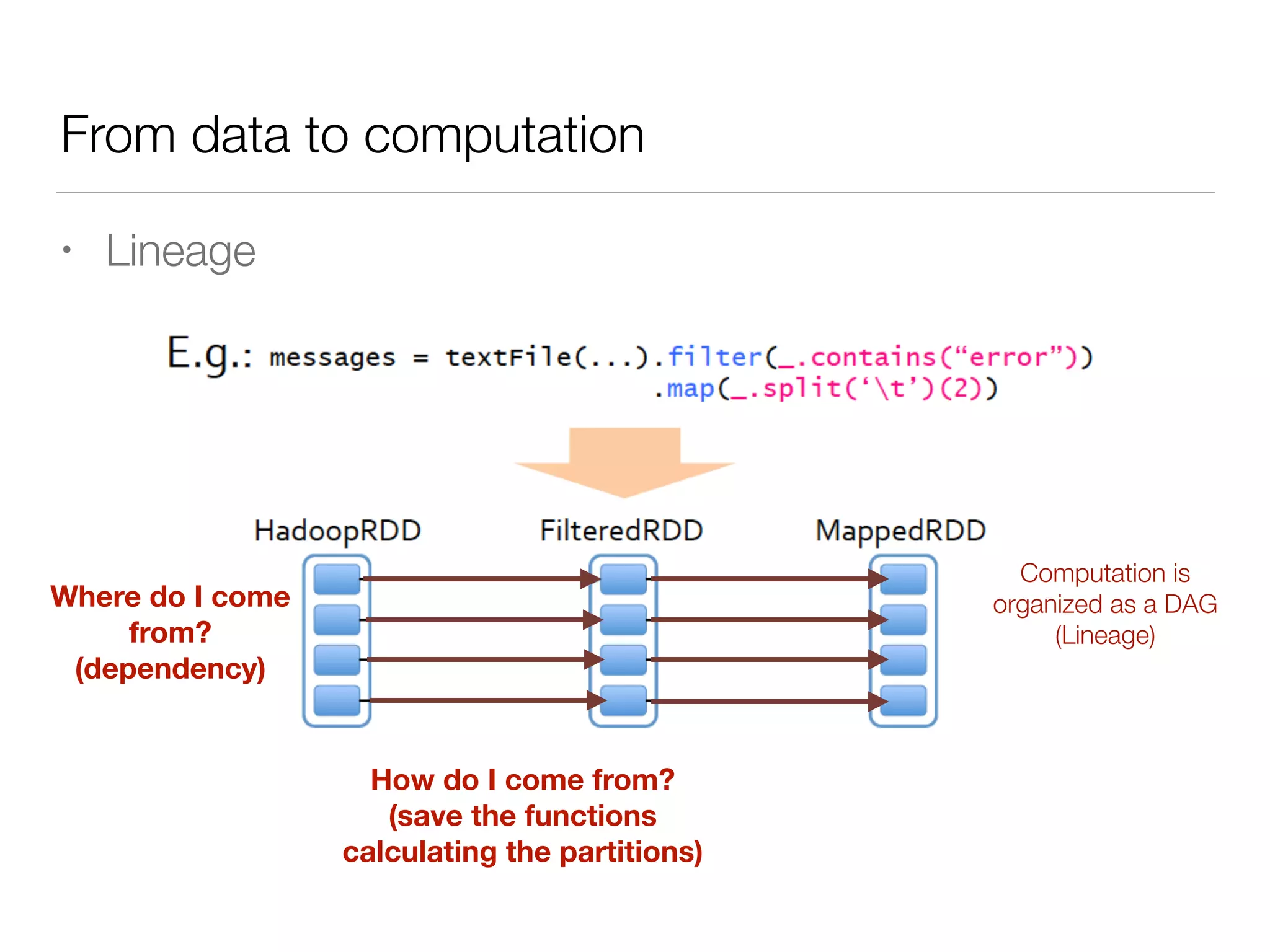
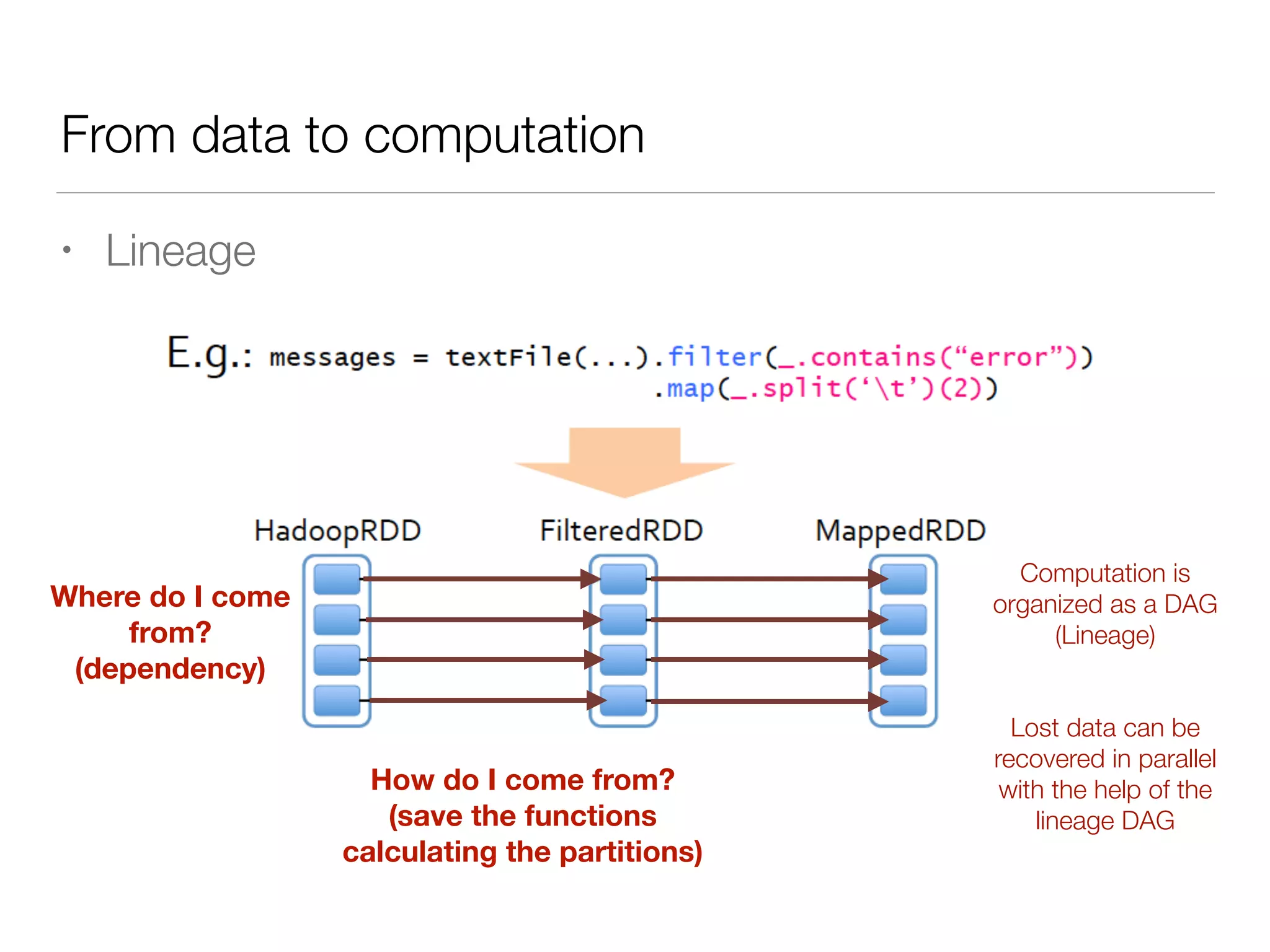





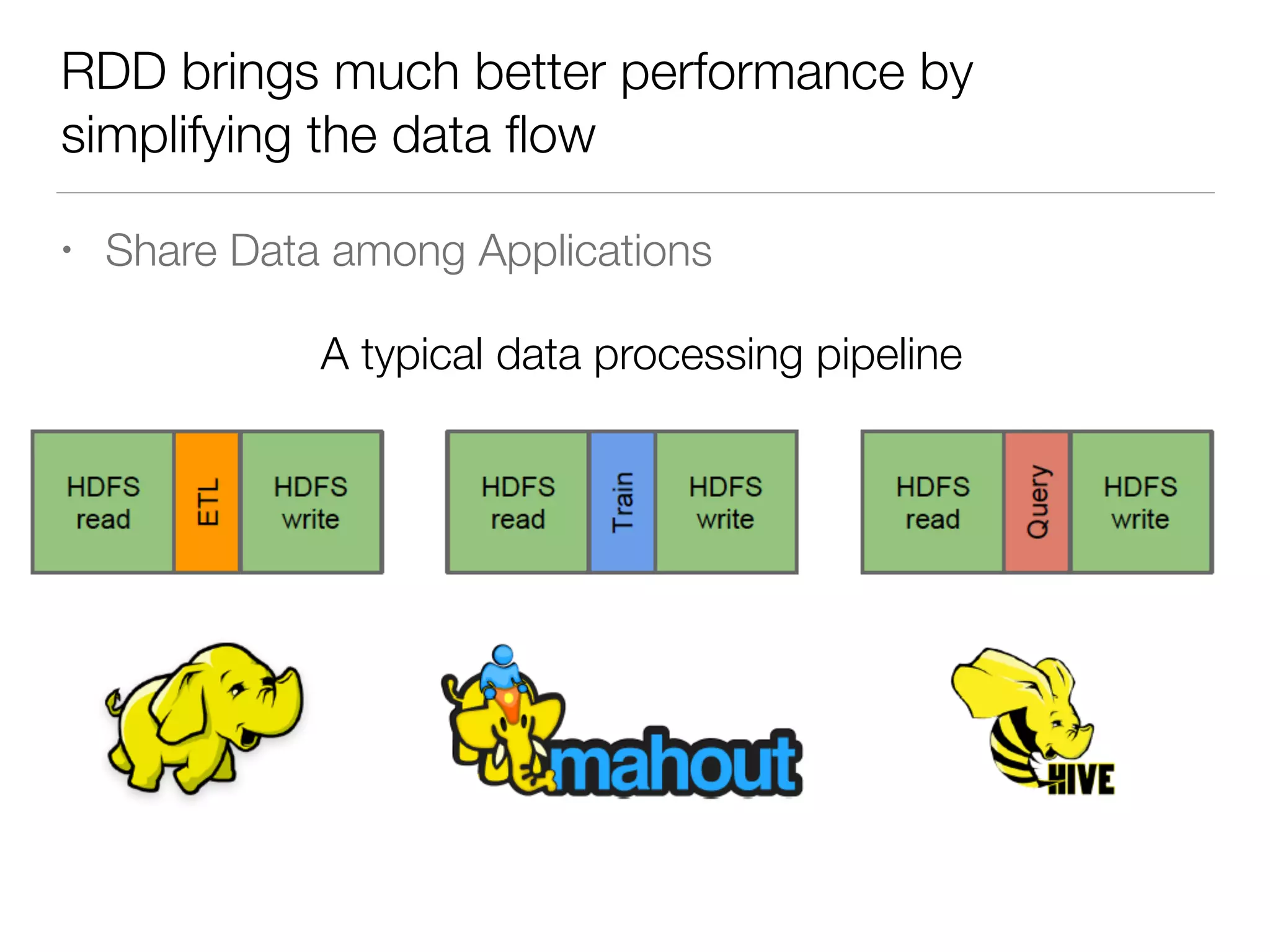
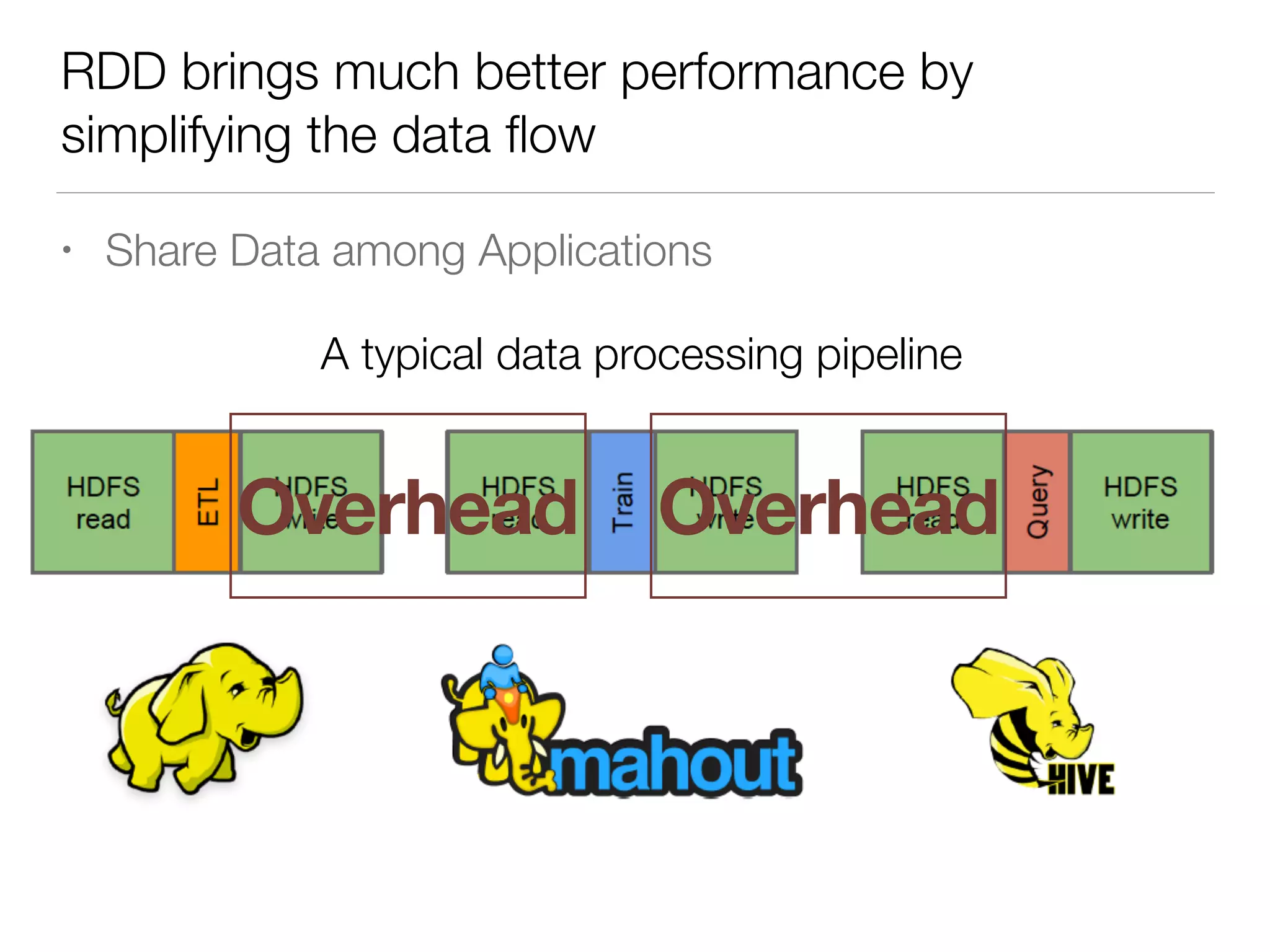


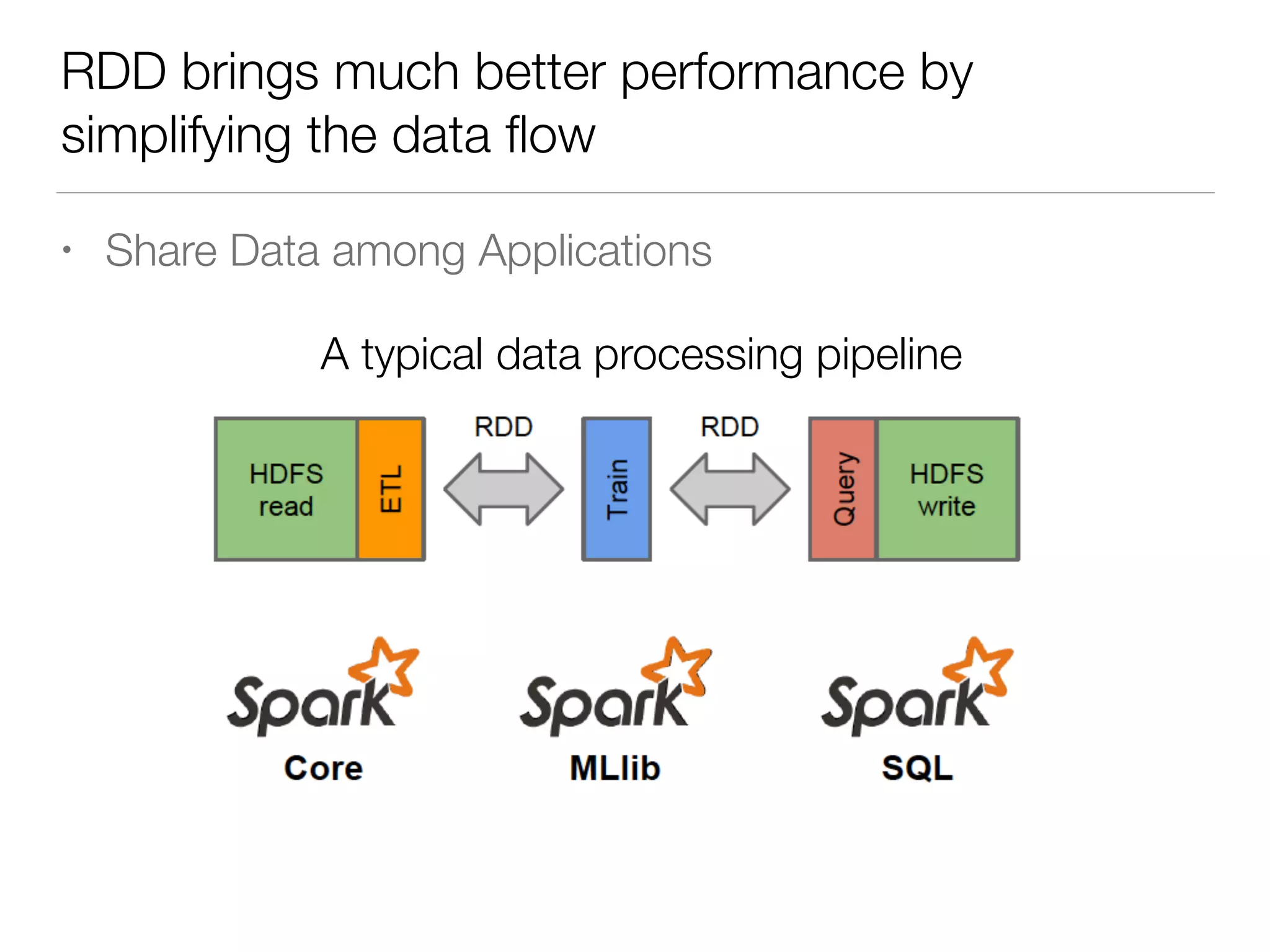


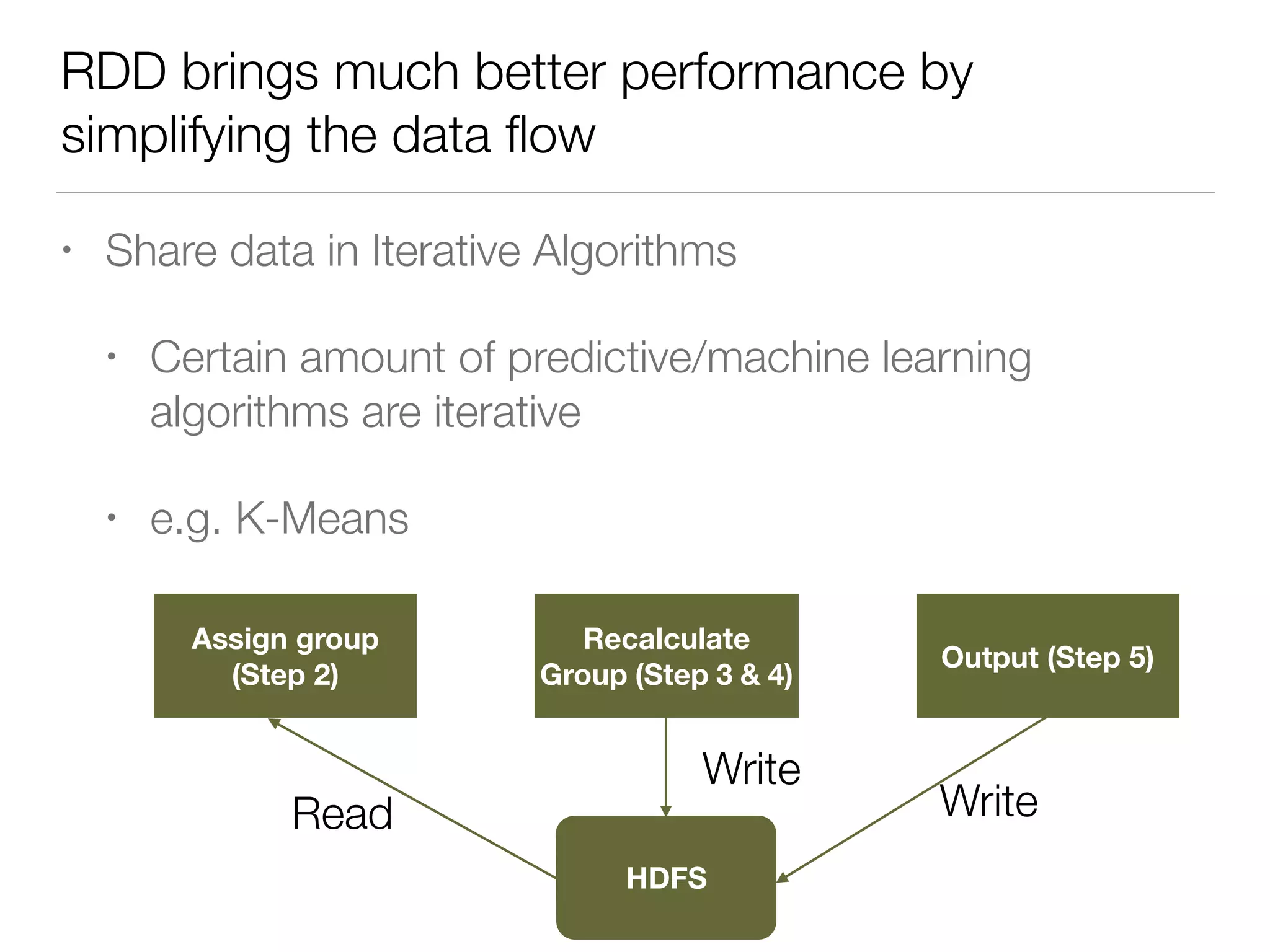

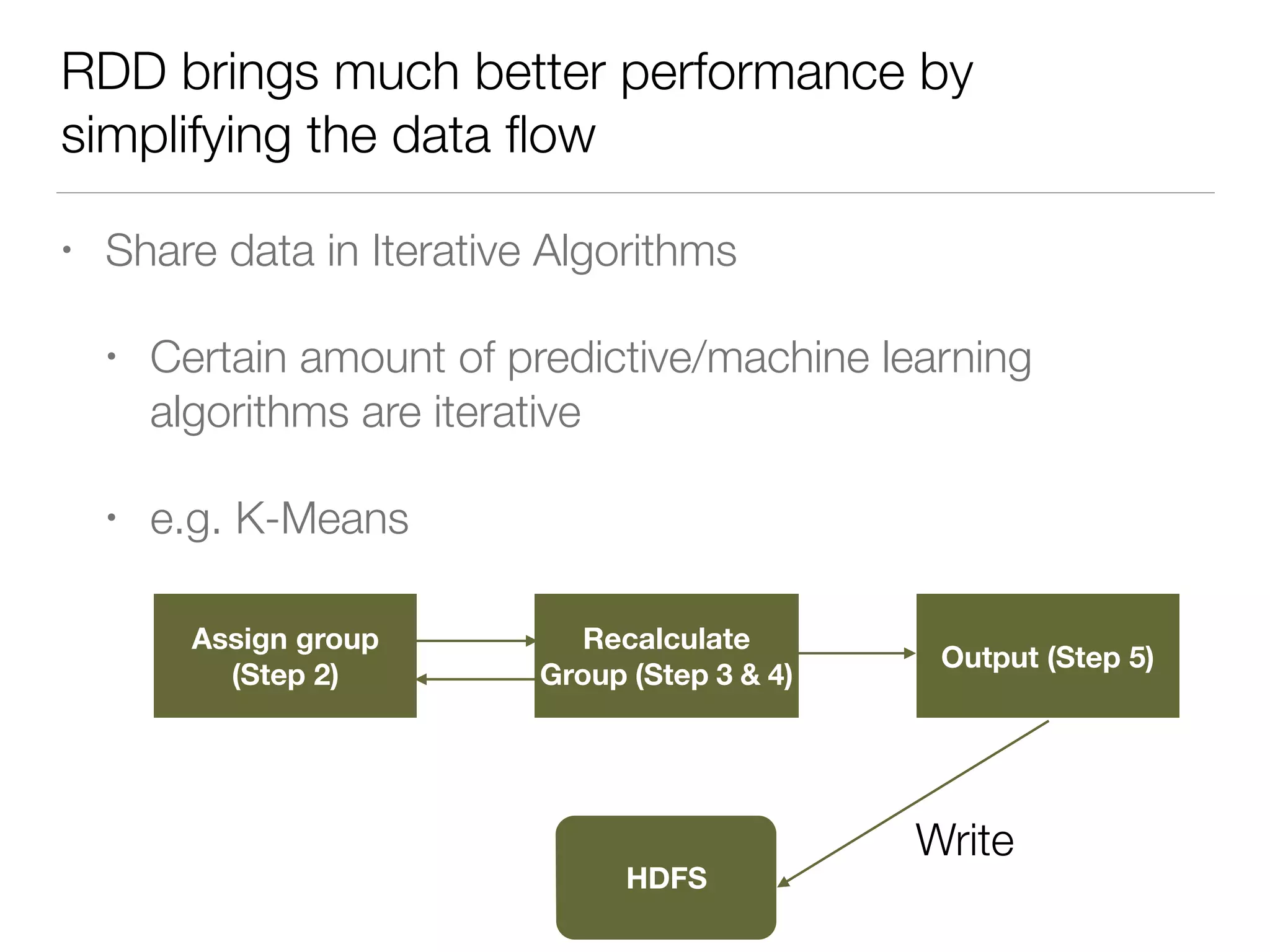


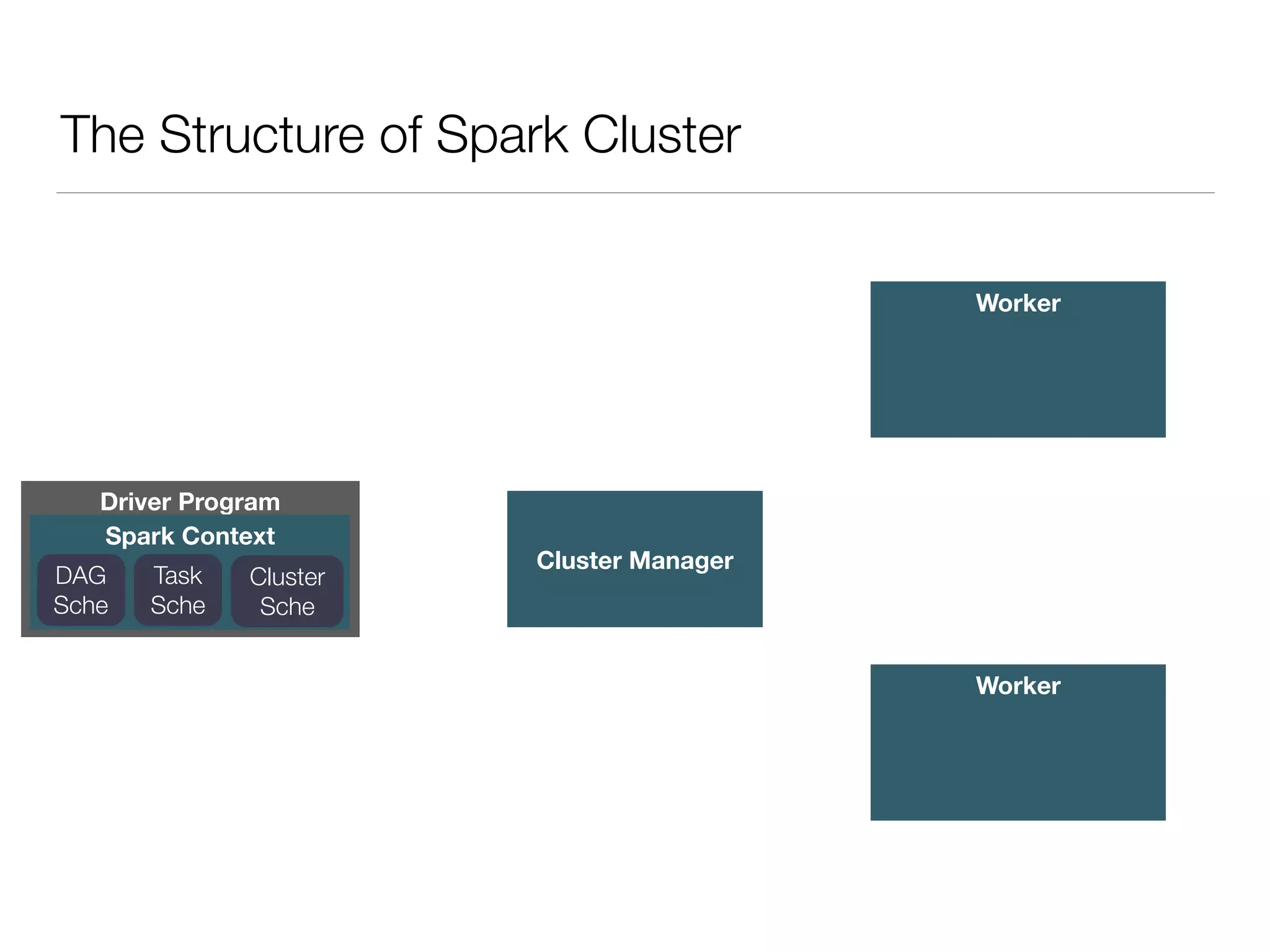
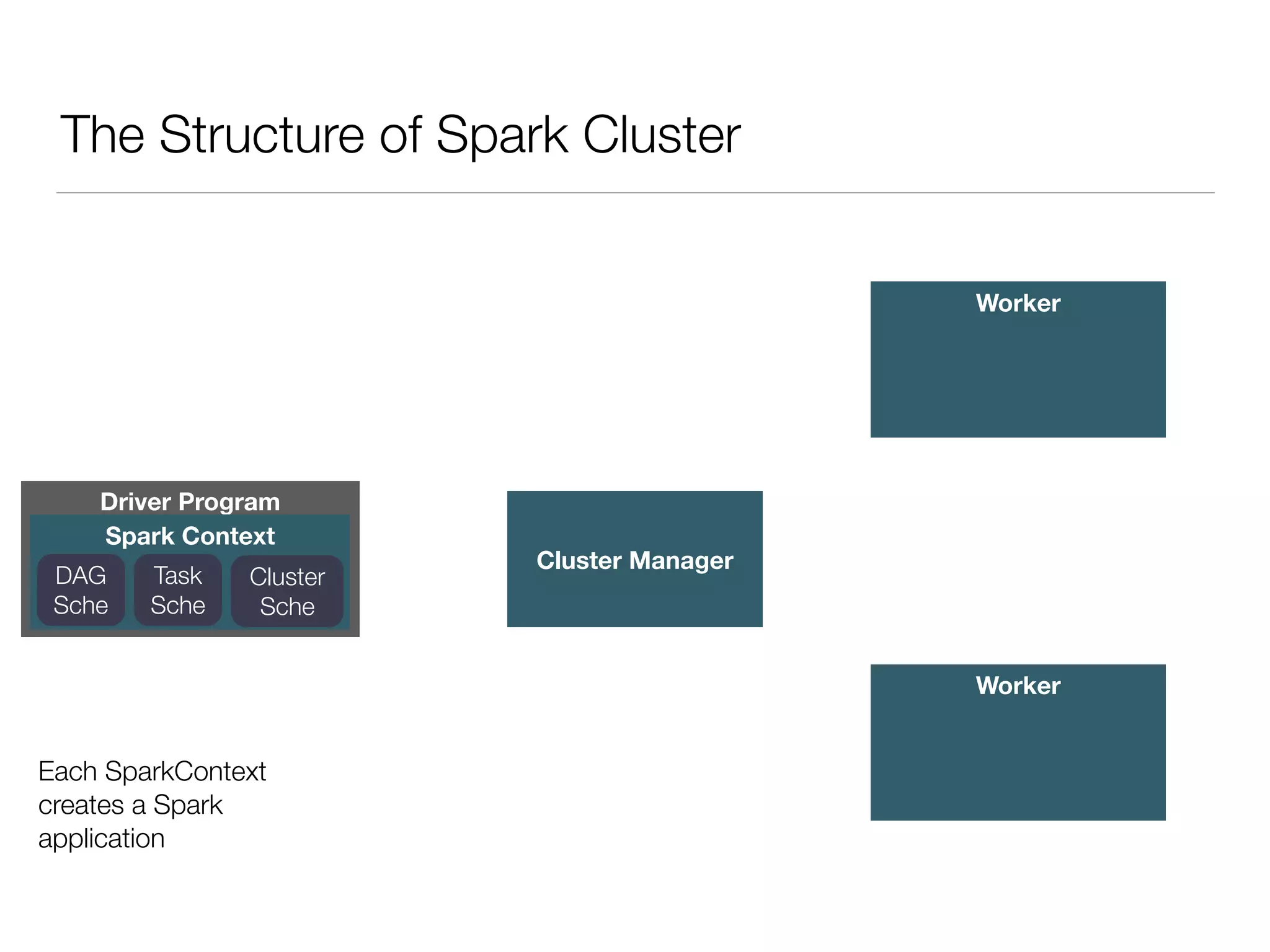
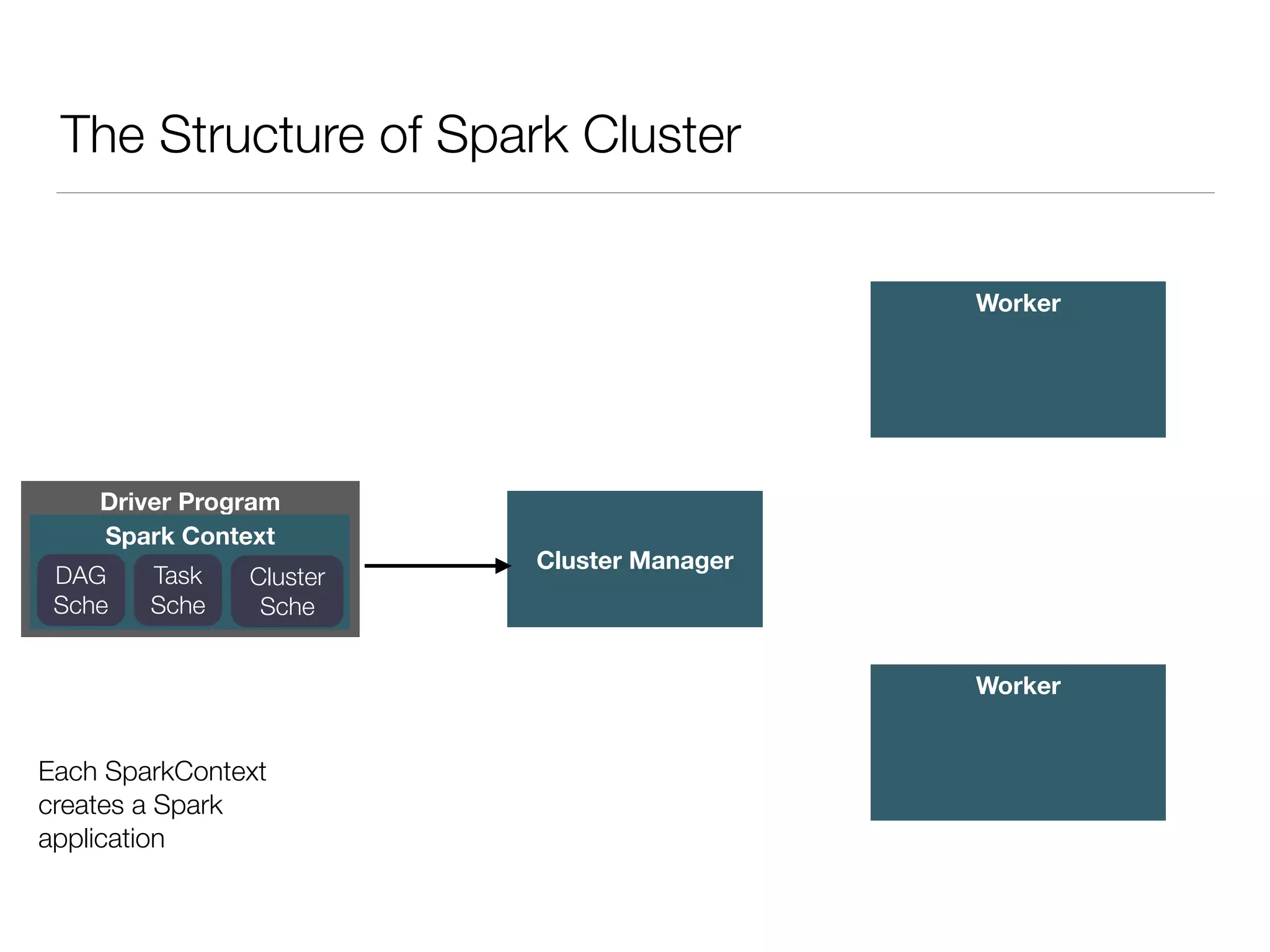
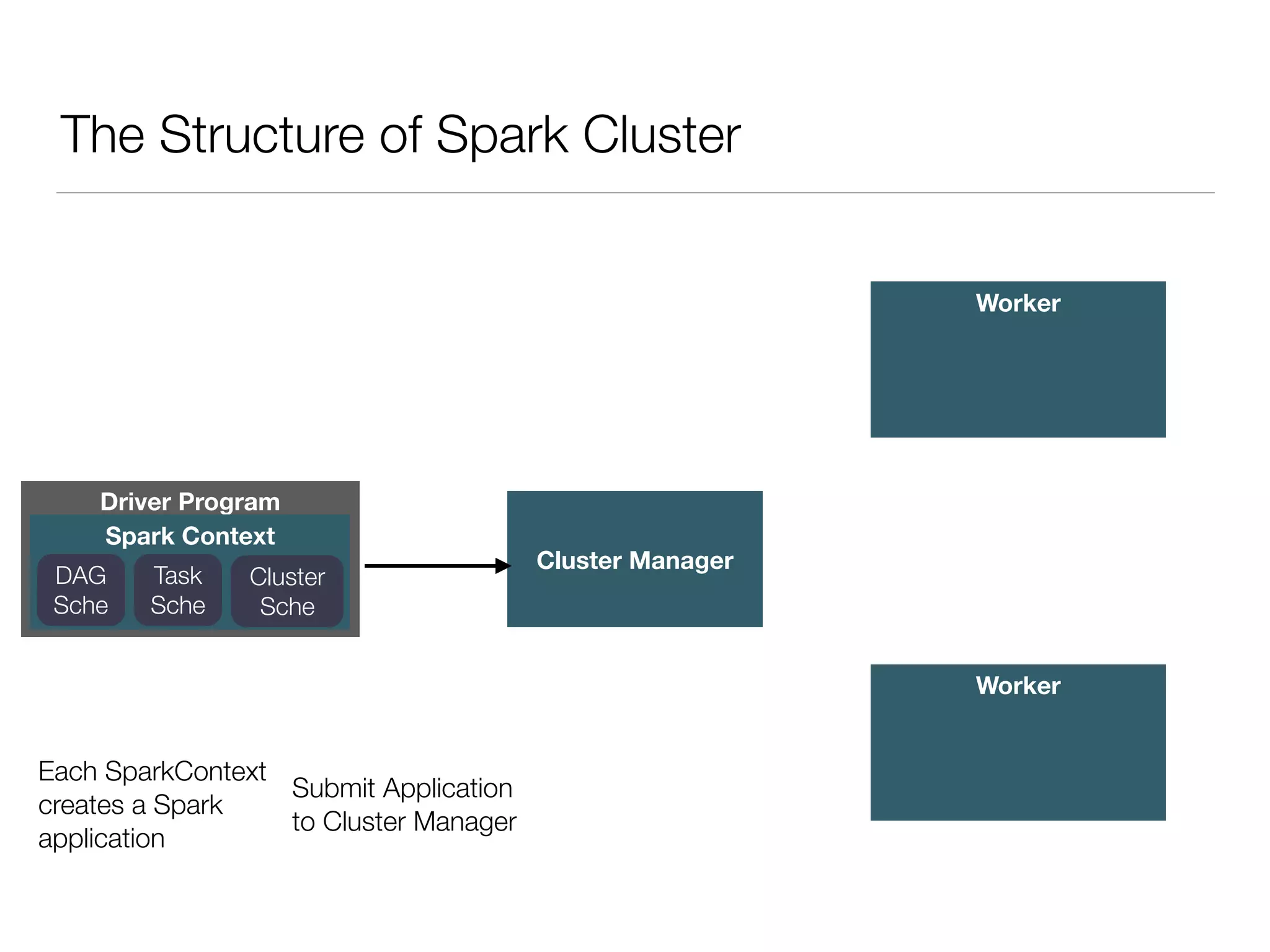
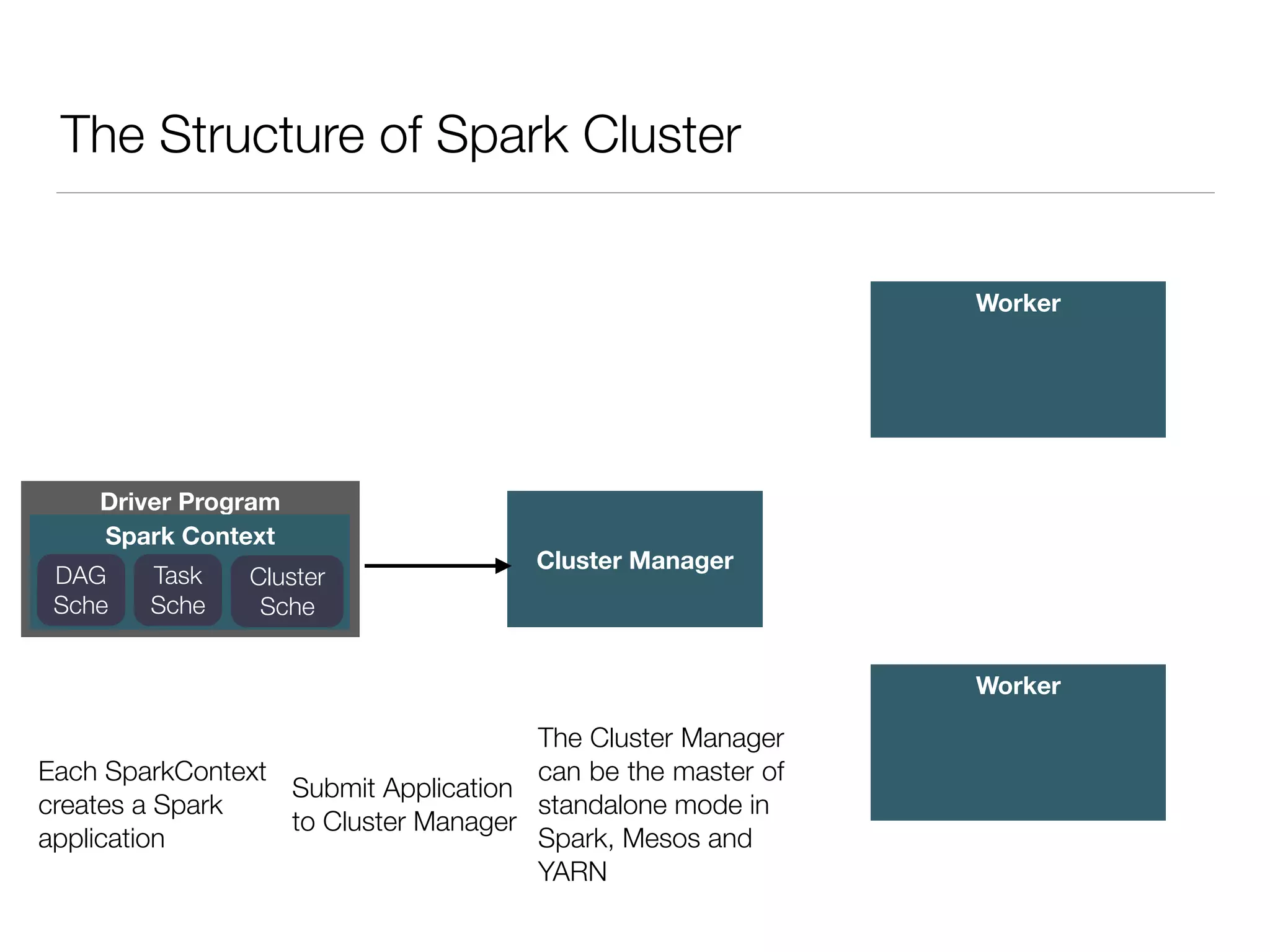
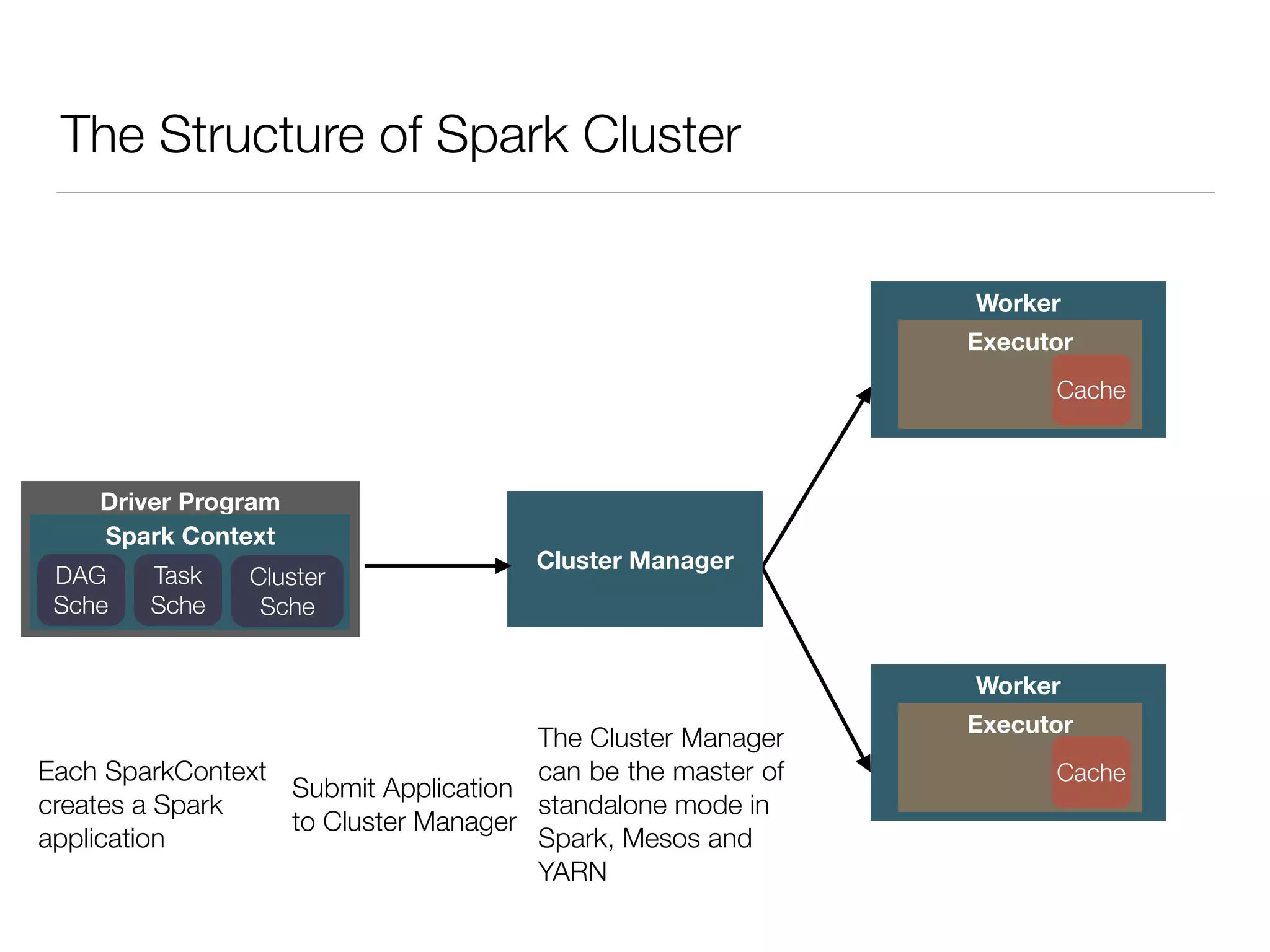
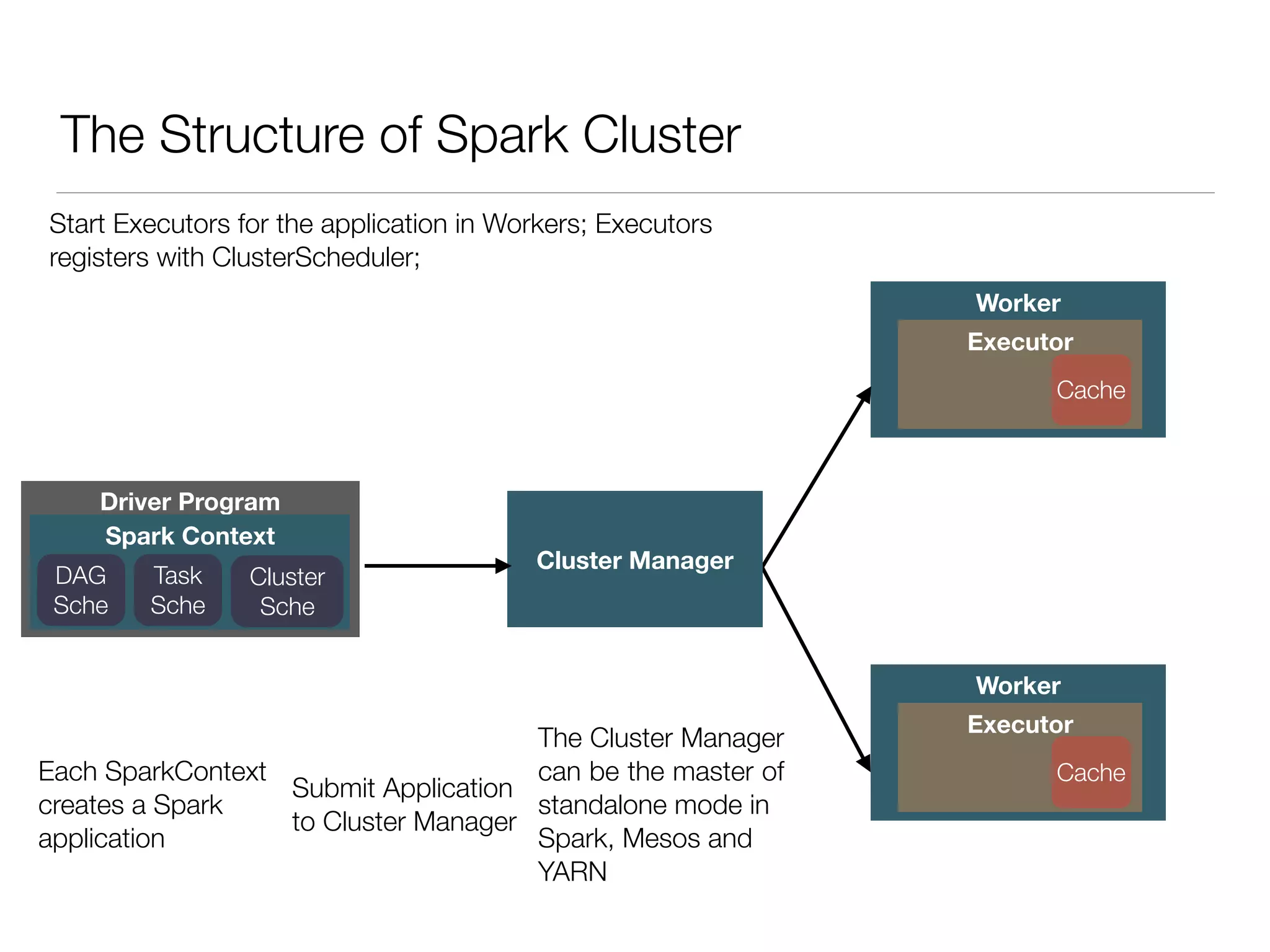
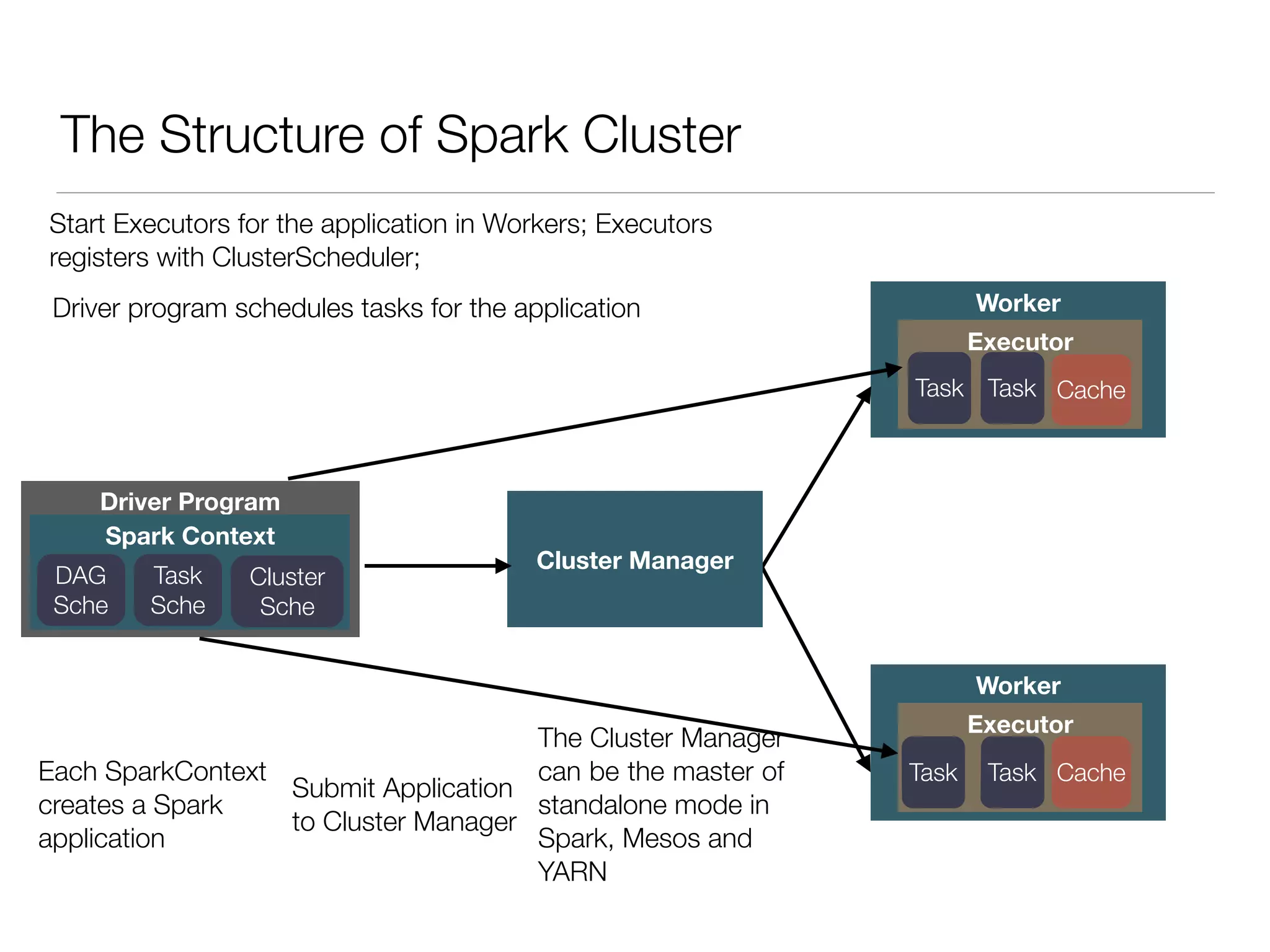
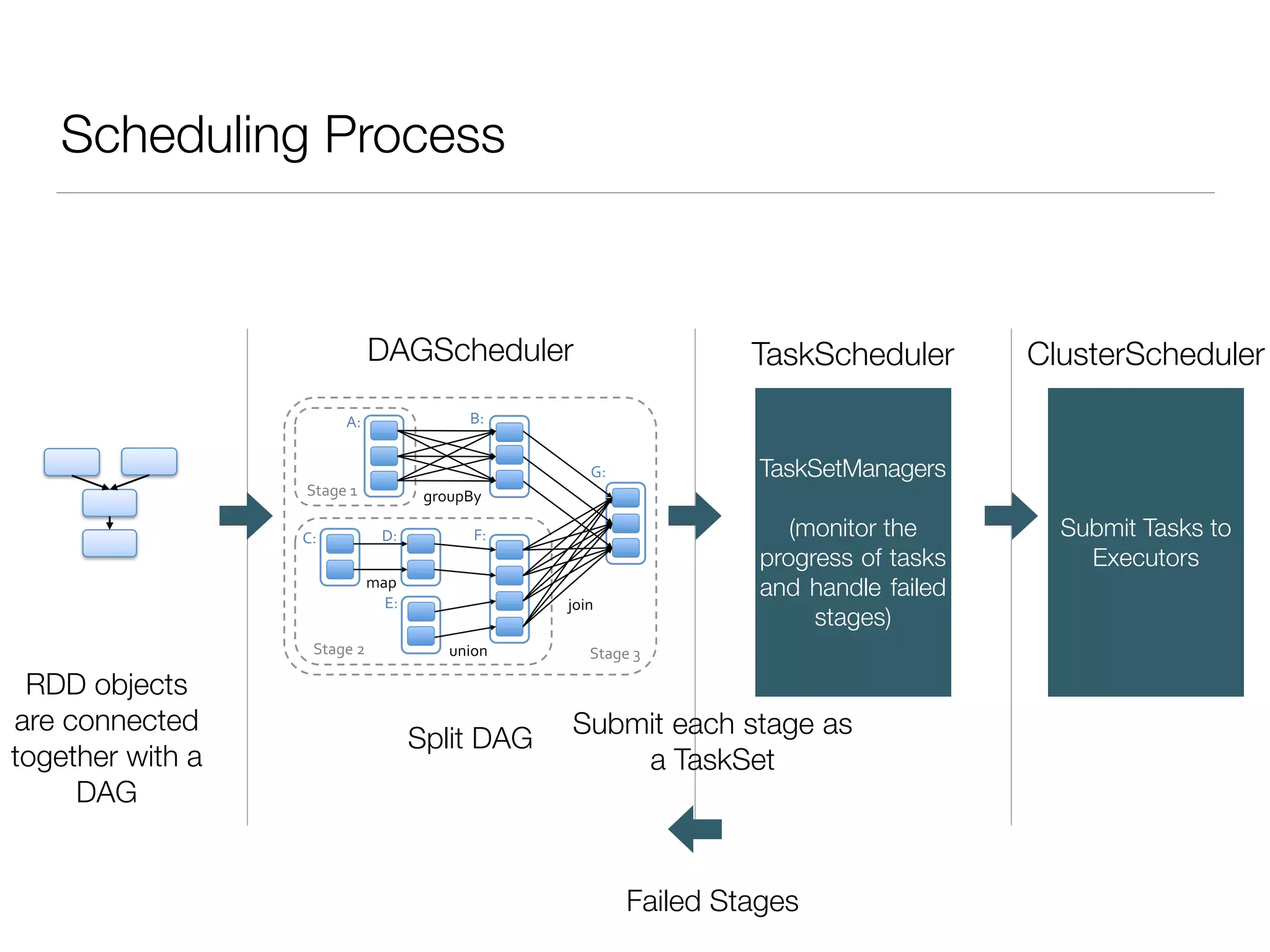
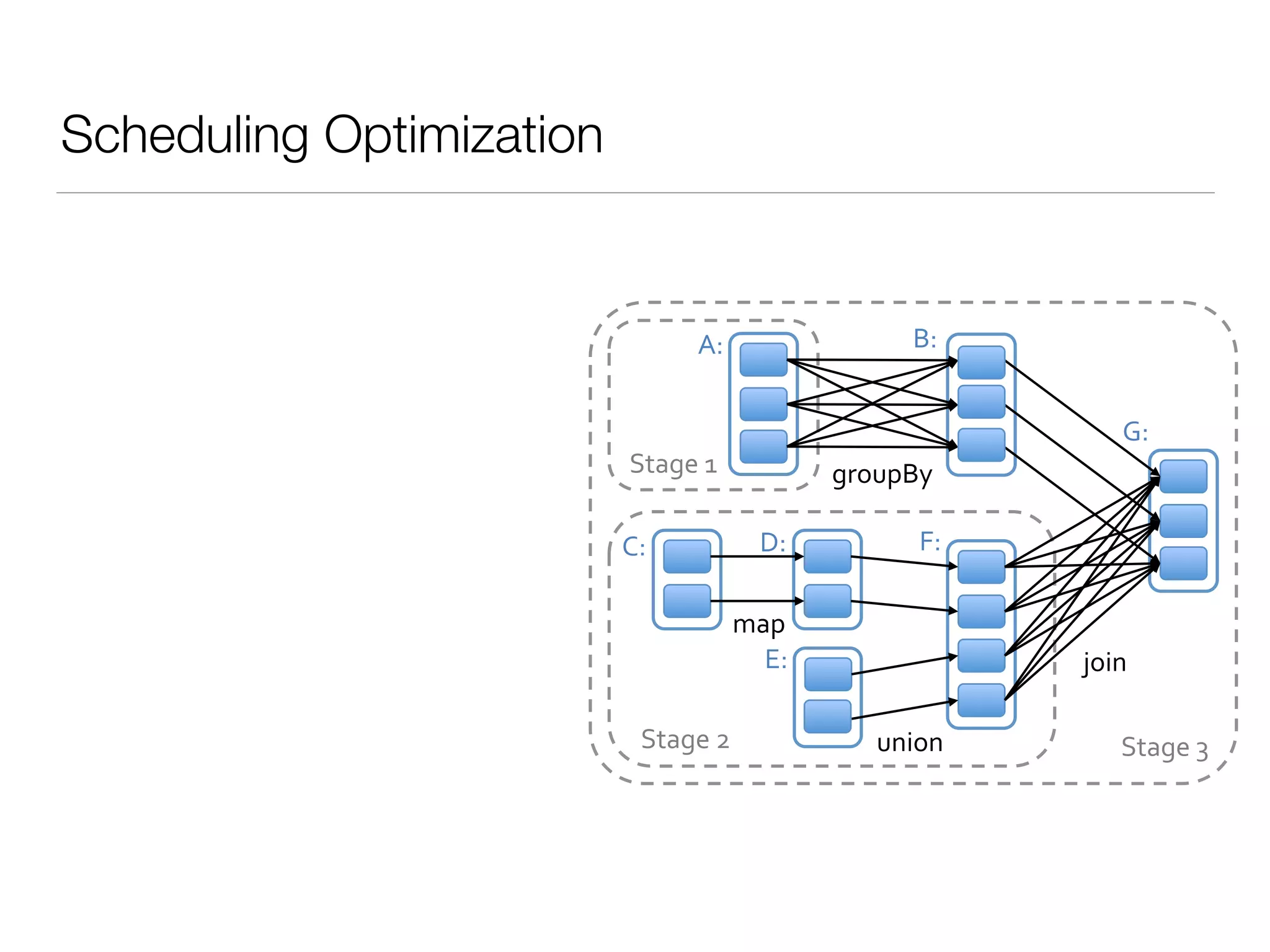
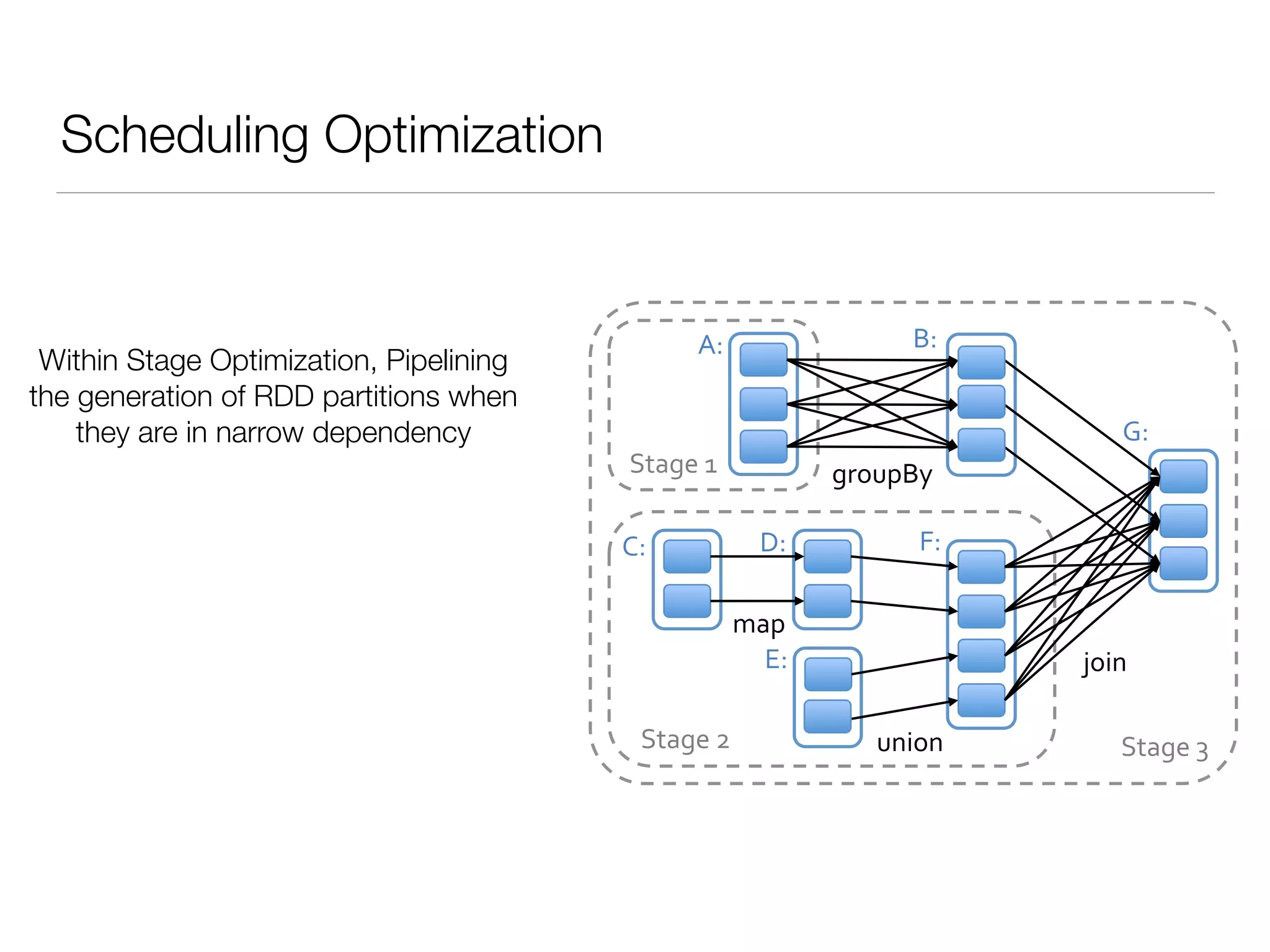
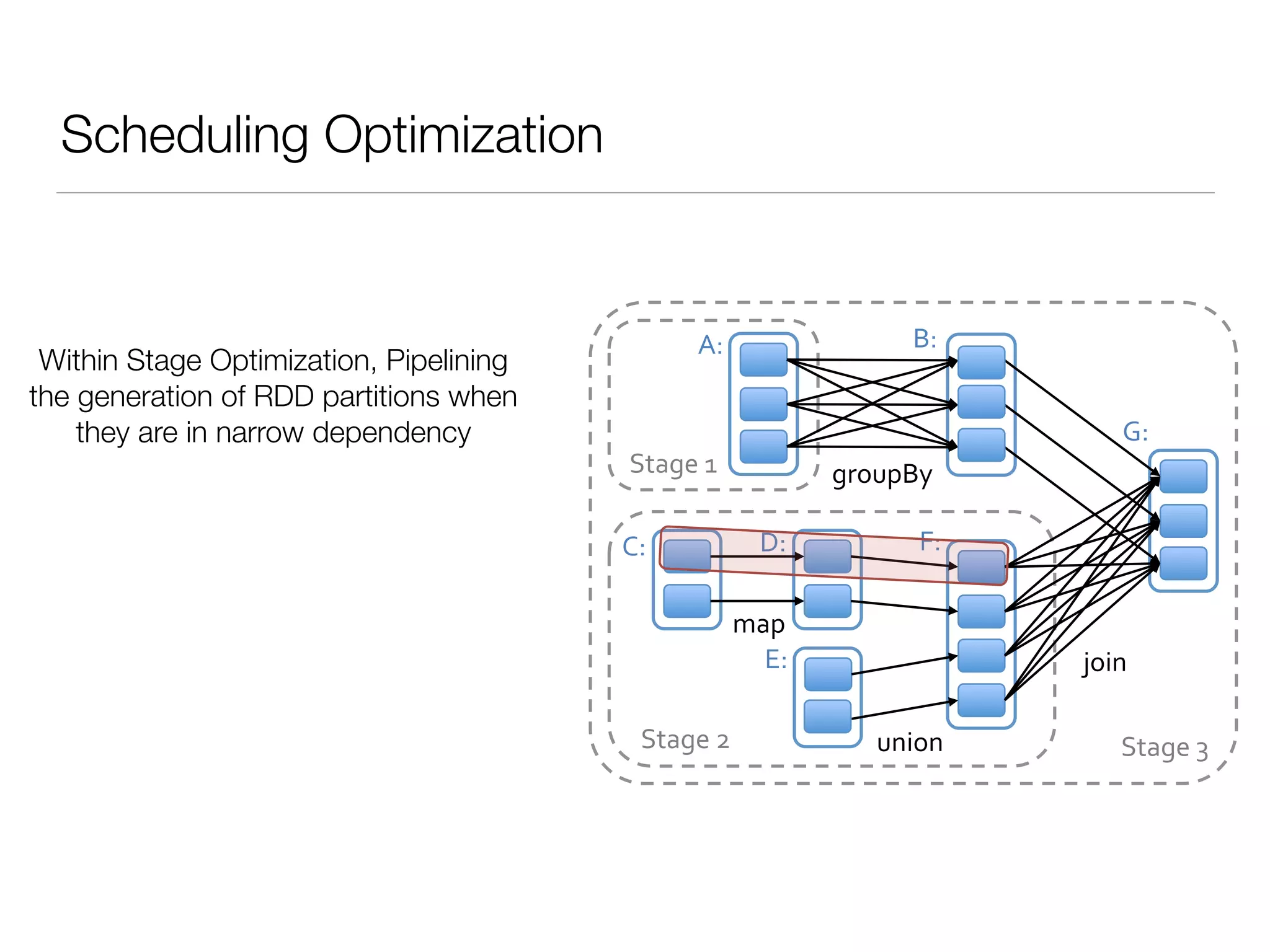
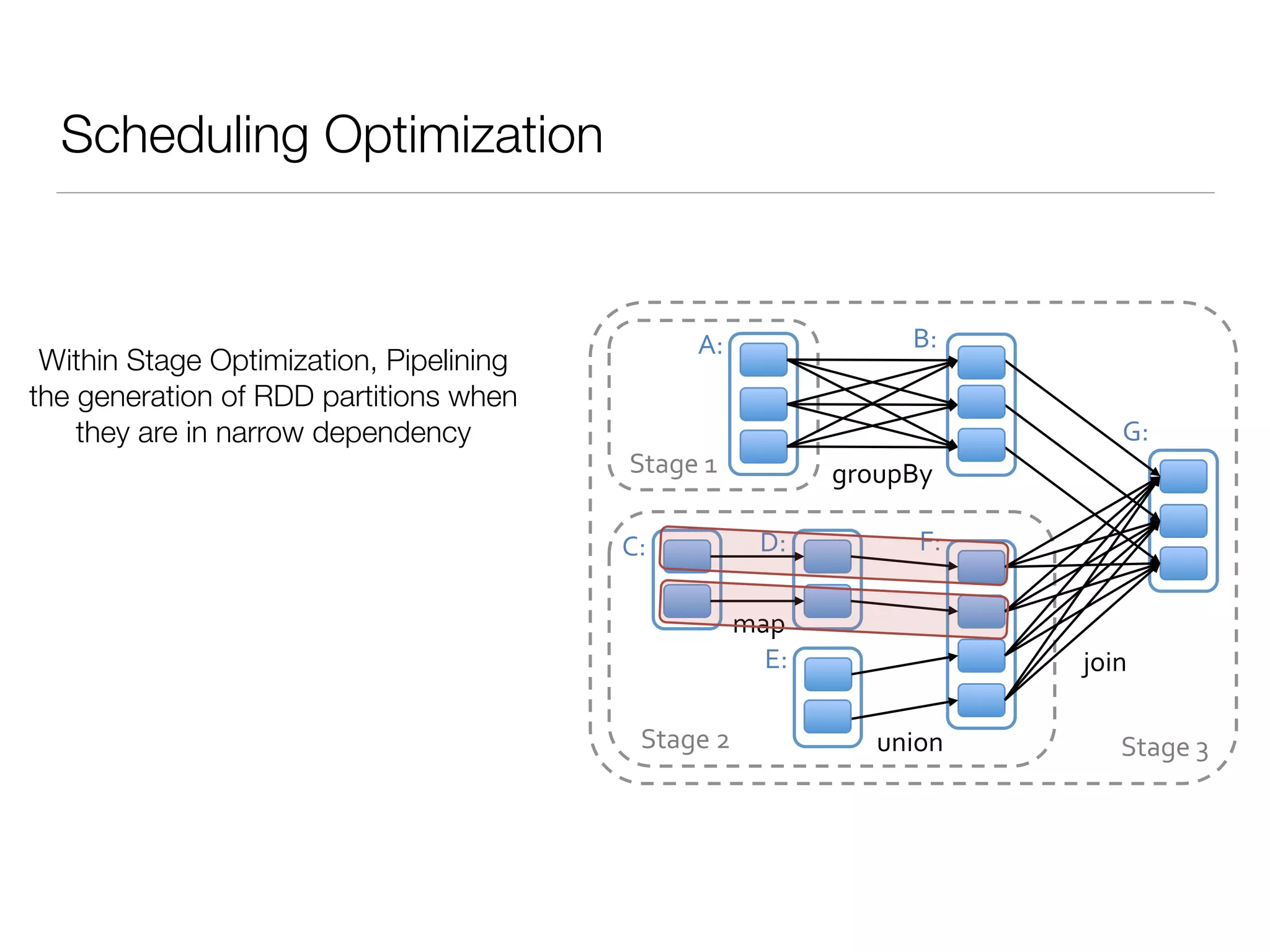
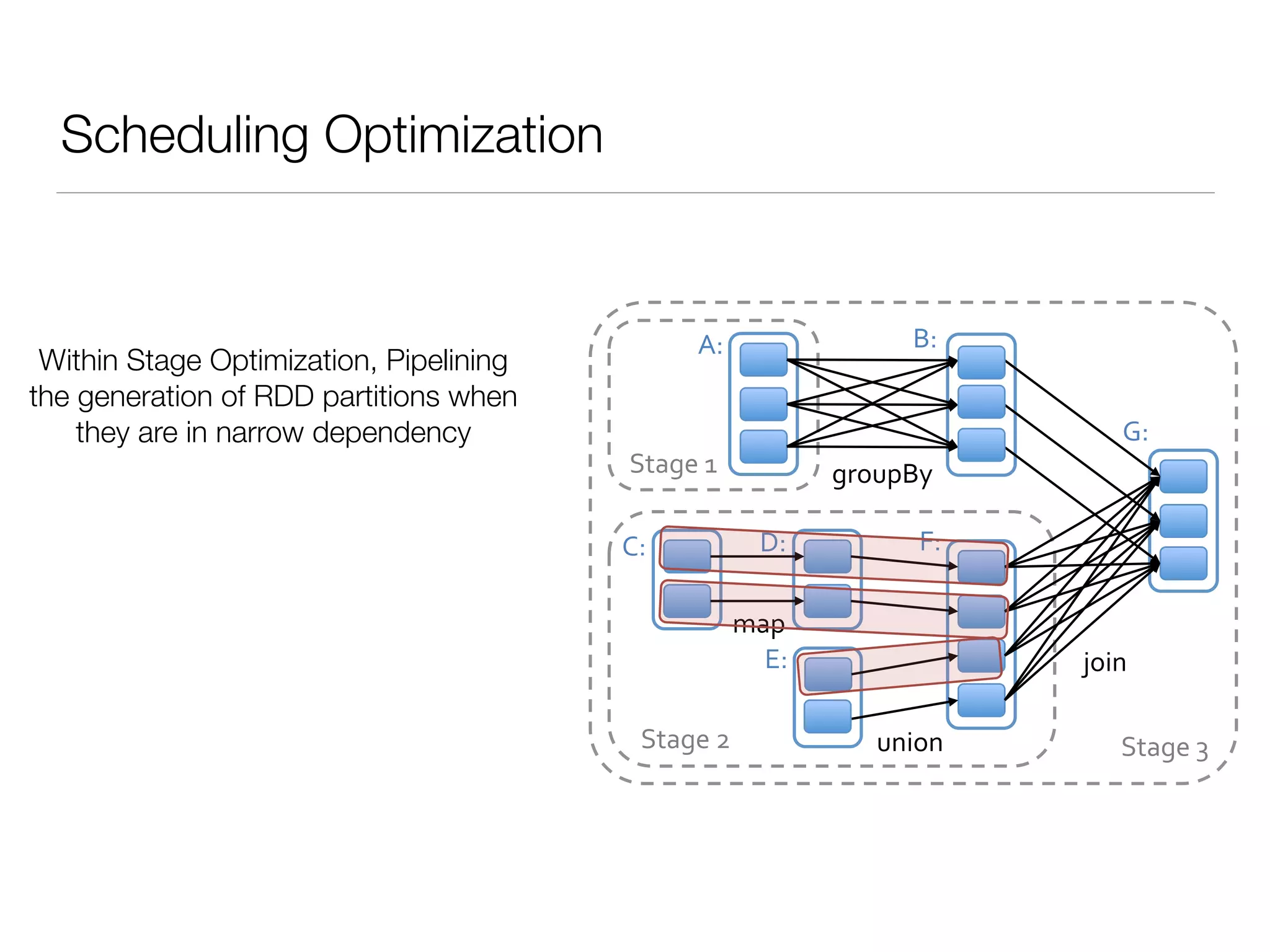
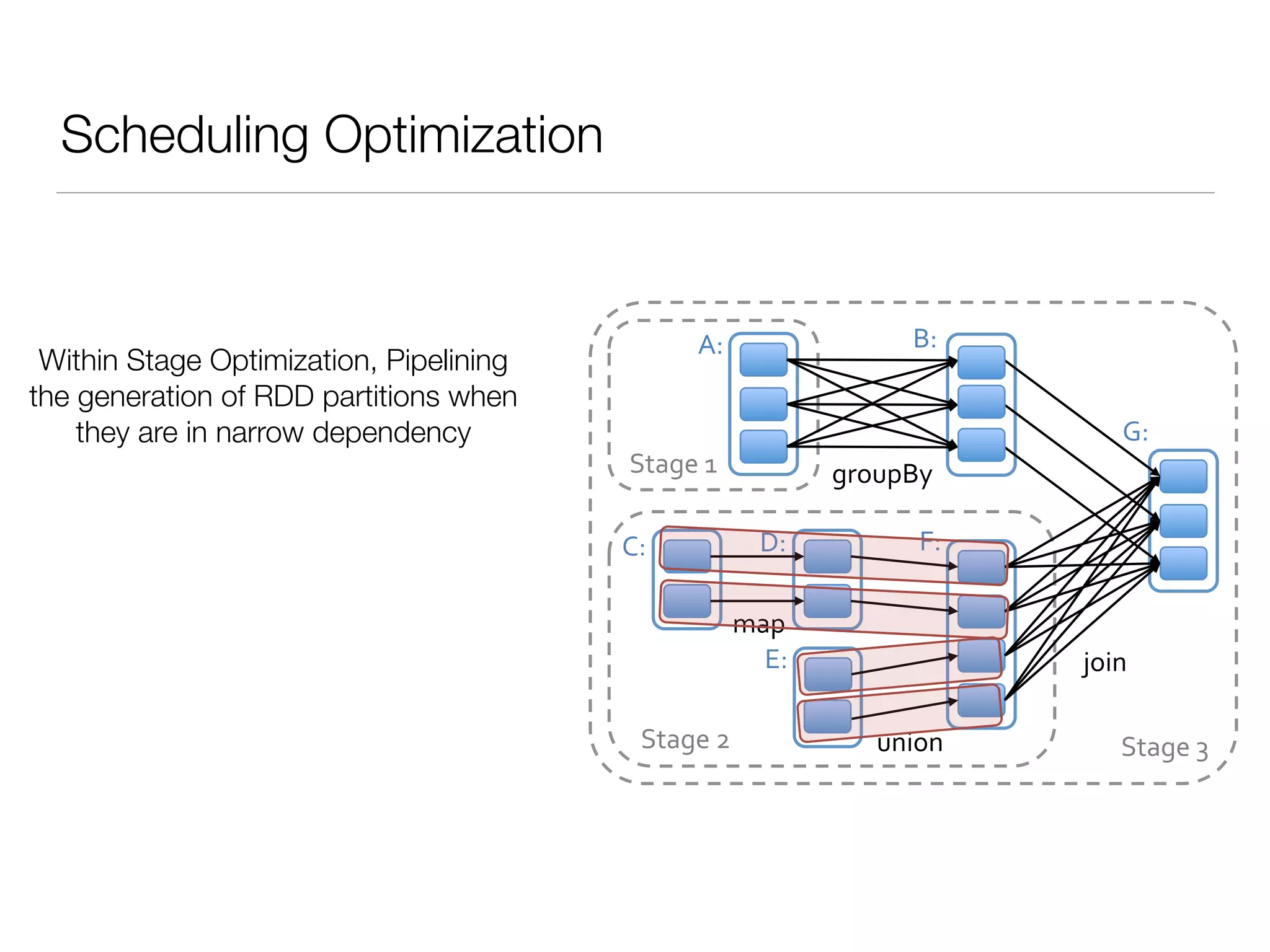
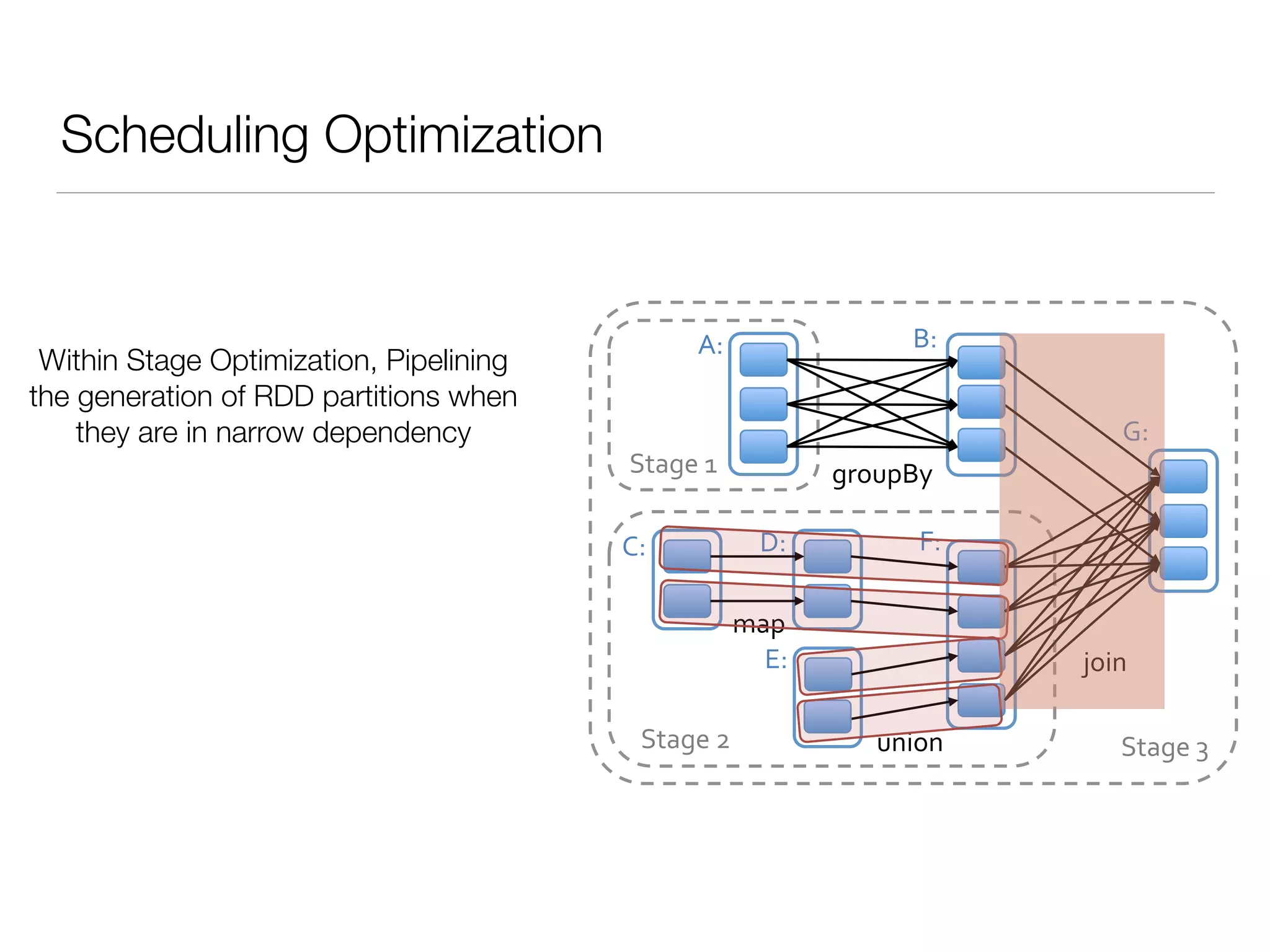
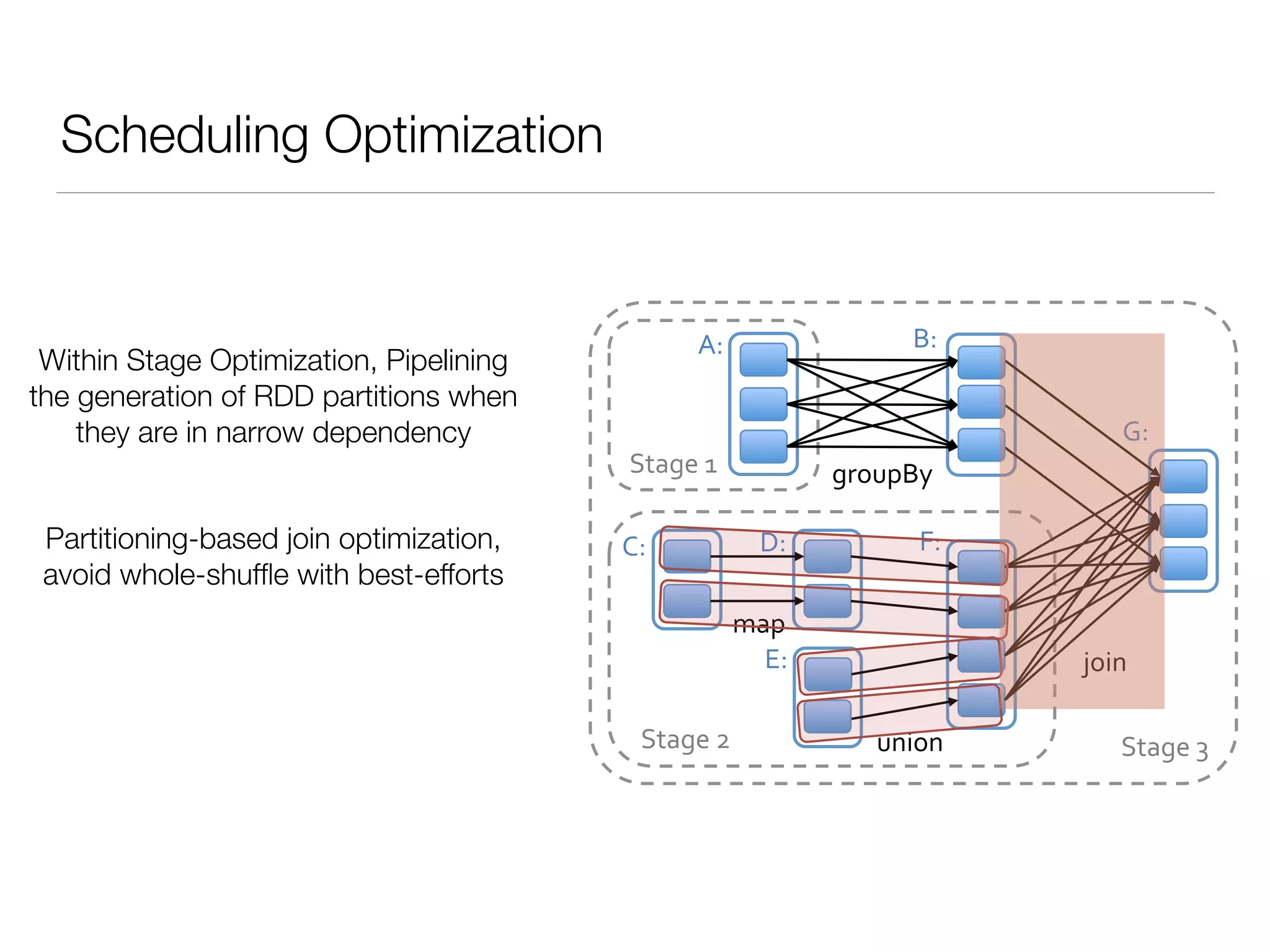
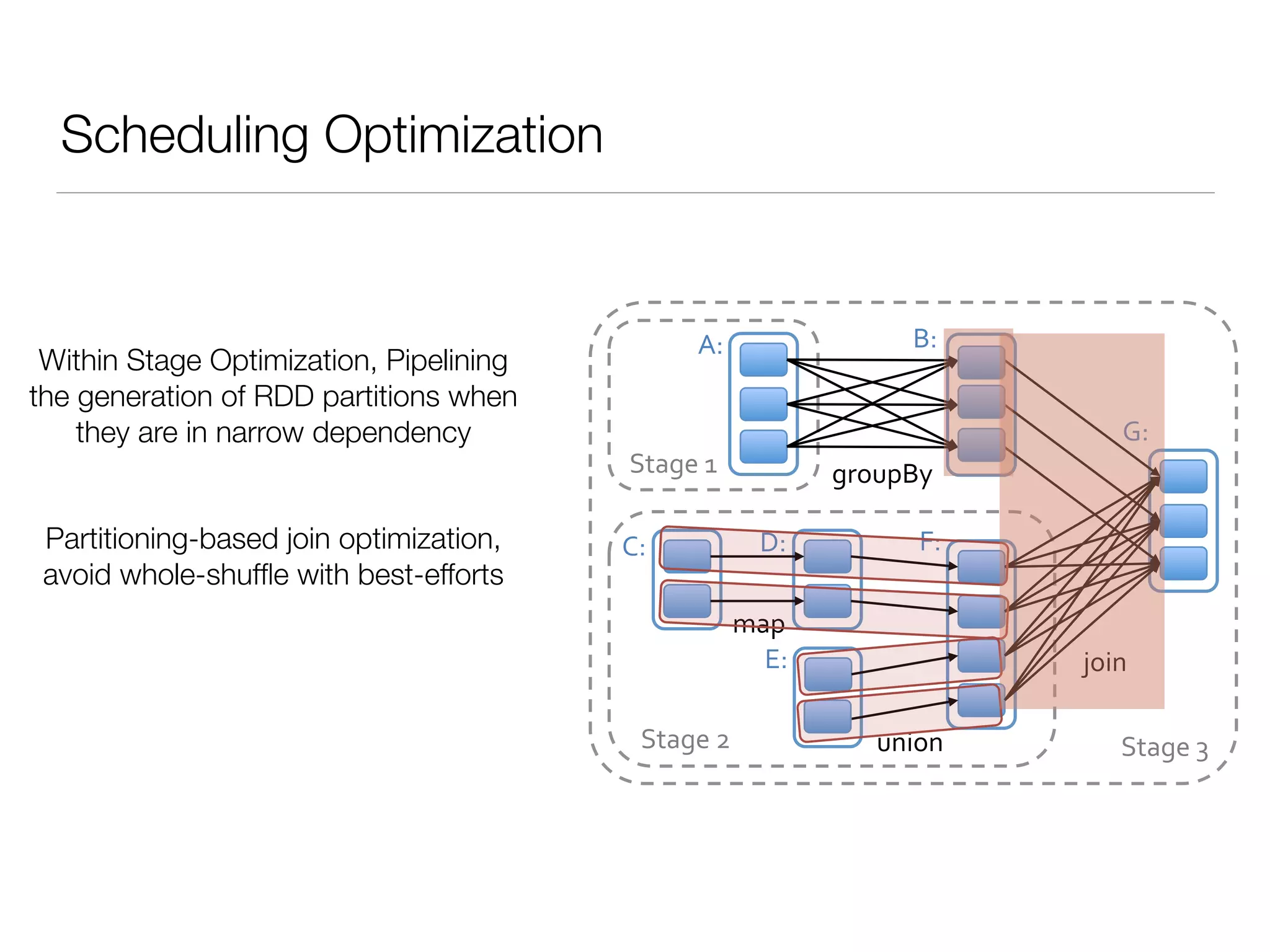
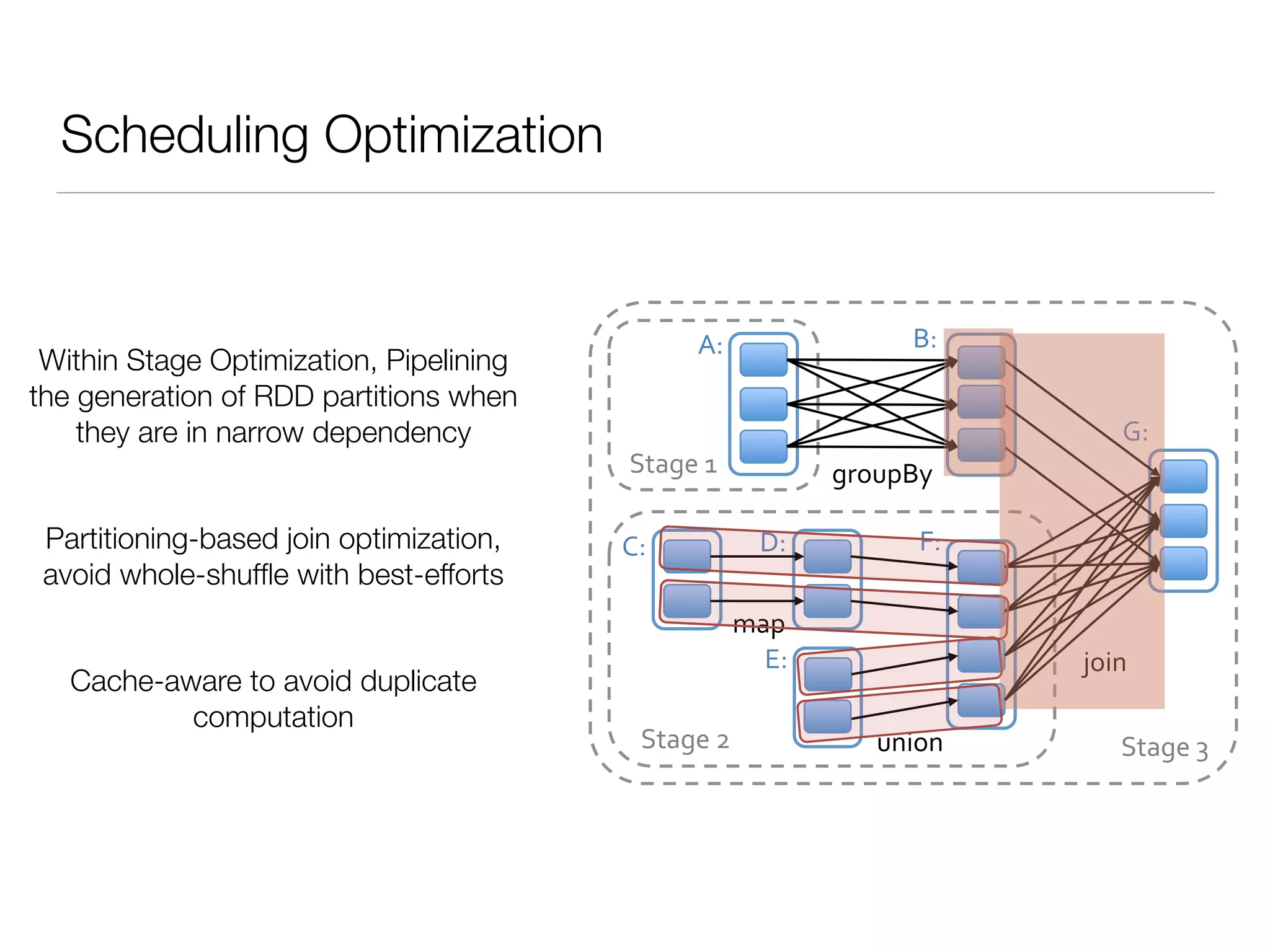


























































































Nan Zhu is a PhD candidate at McGill University, specializing in computer networks and large-scale data processing, contributing to Spark through various code patches. His work at the startup Faimdata involves building customer-centric analytical solutions. The document explains Spark's advantages as a distributed computing framework, emphasizing its resilient distributed datasets (RDD), fault-tolerance, and caching capabilities for improved performance.














































![Apache Spark 101 [in 50 min]](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark101-in50min1-150227110033-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








































