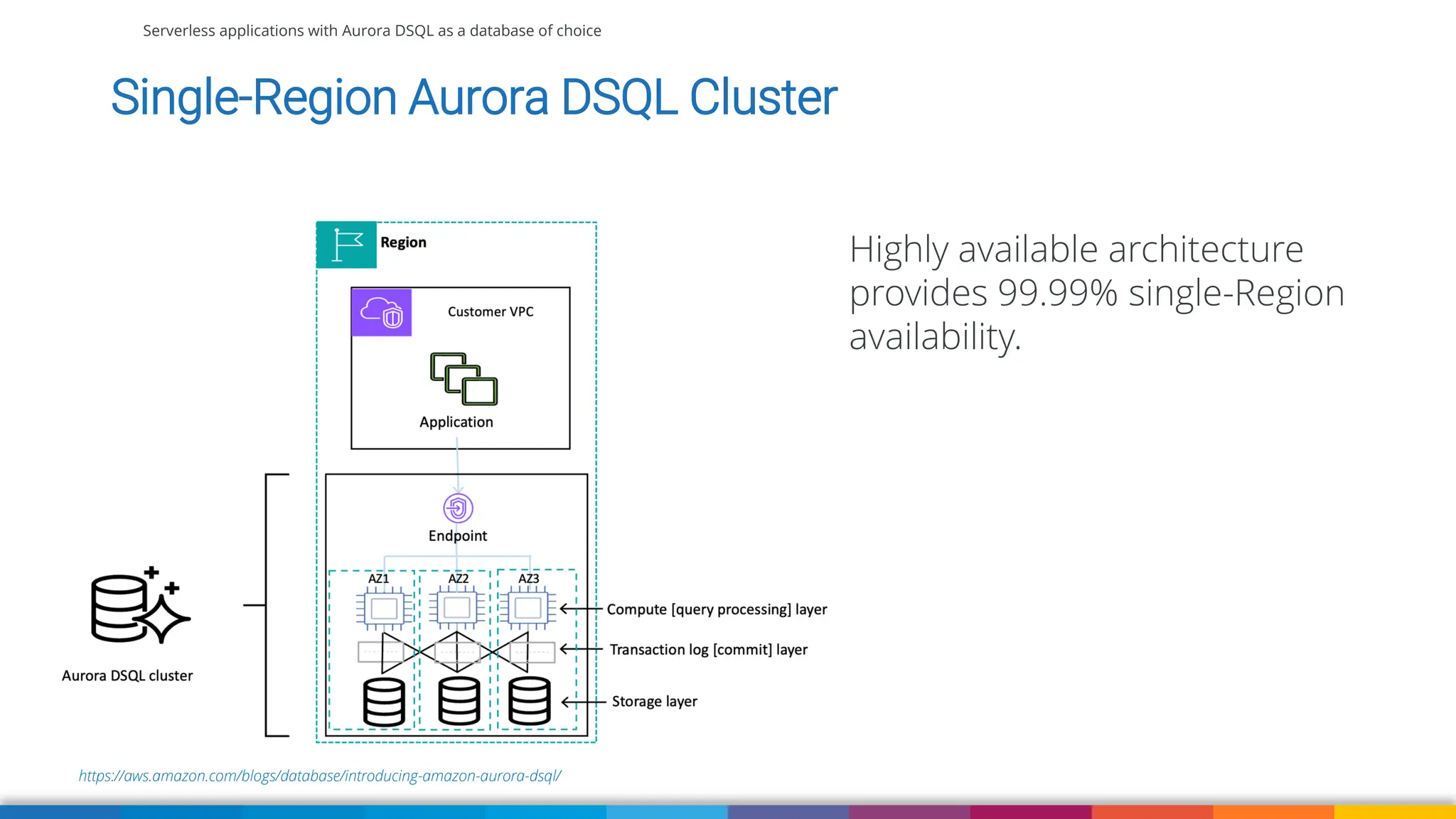
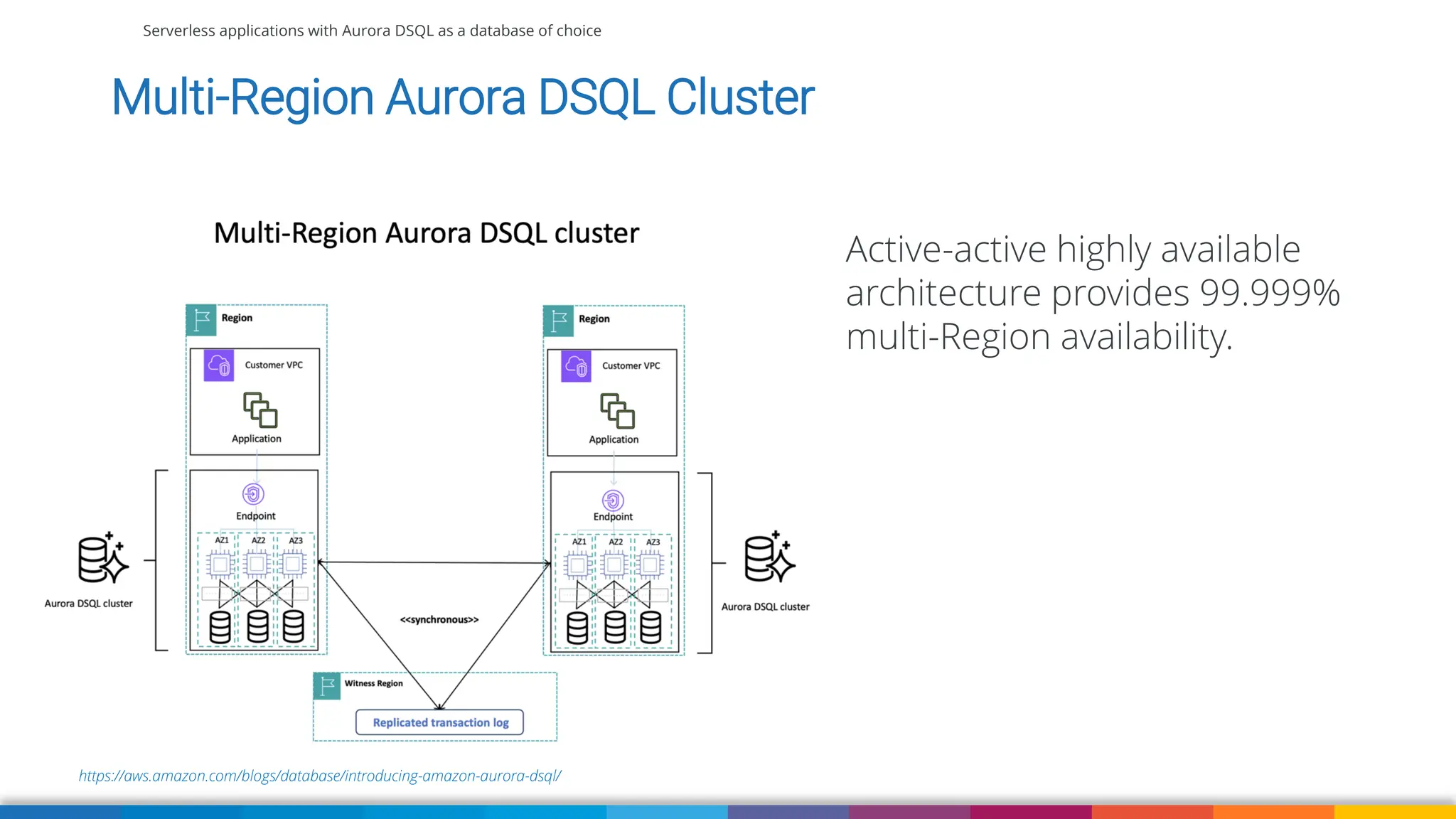
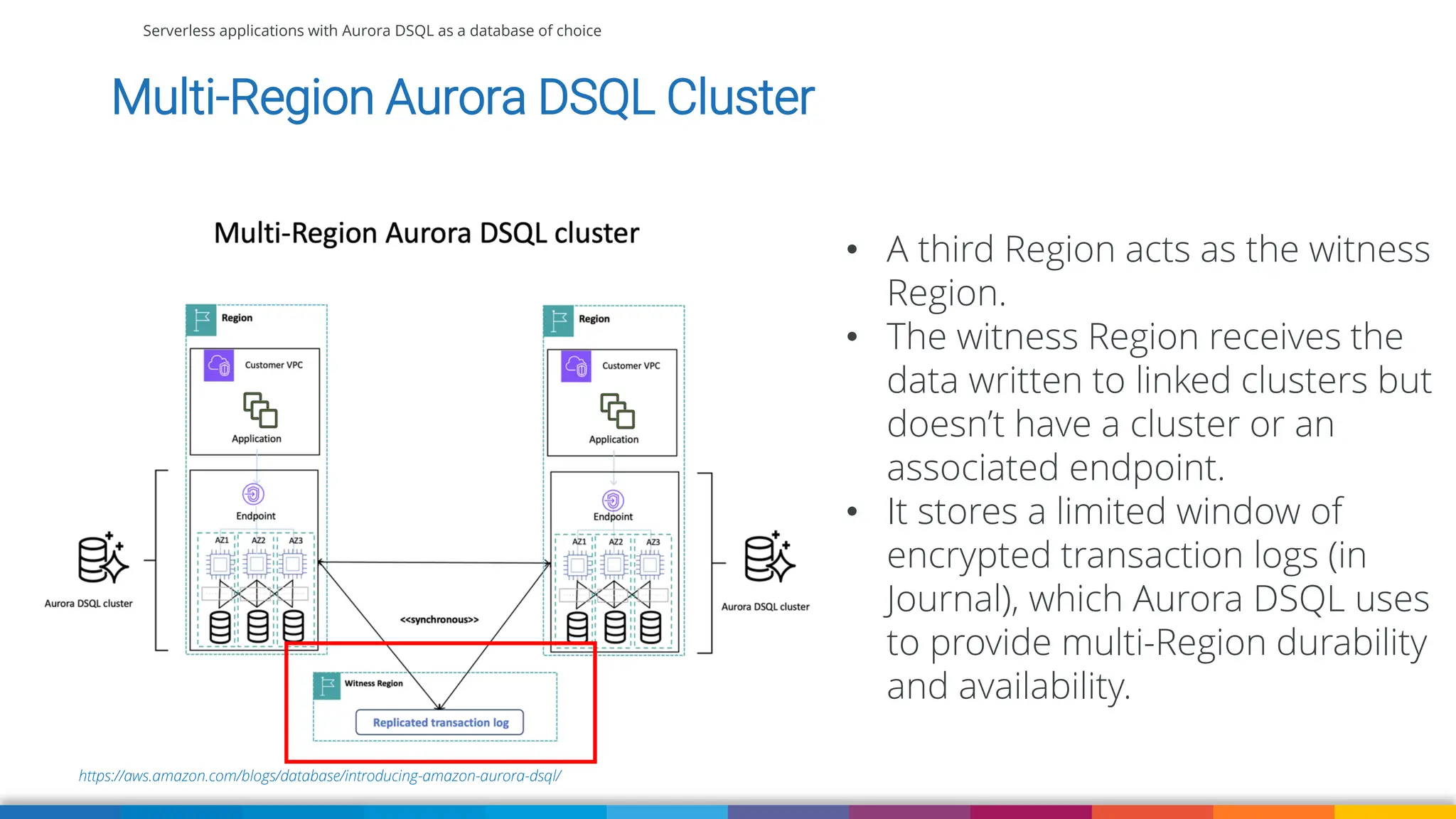
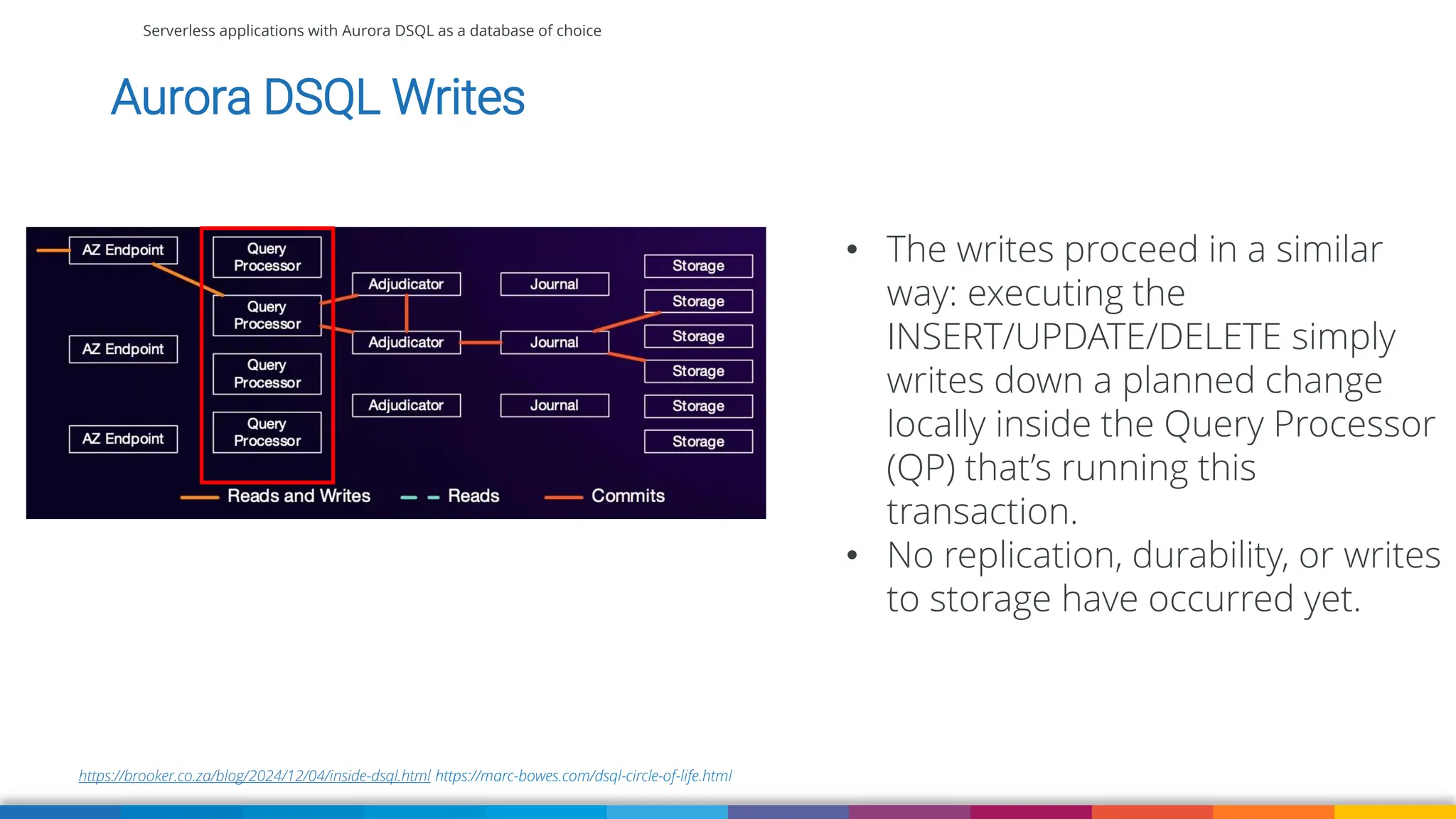
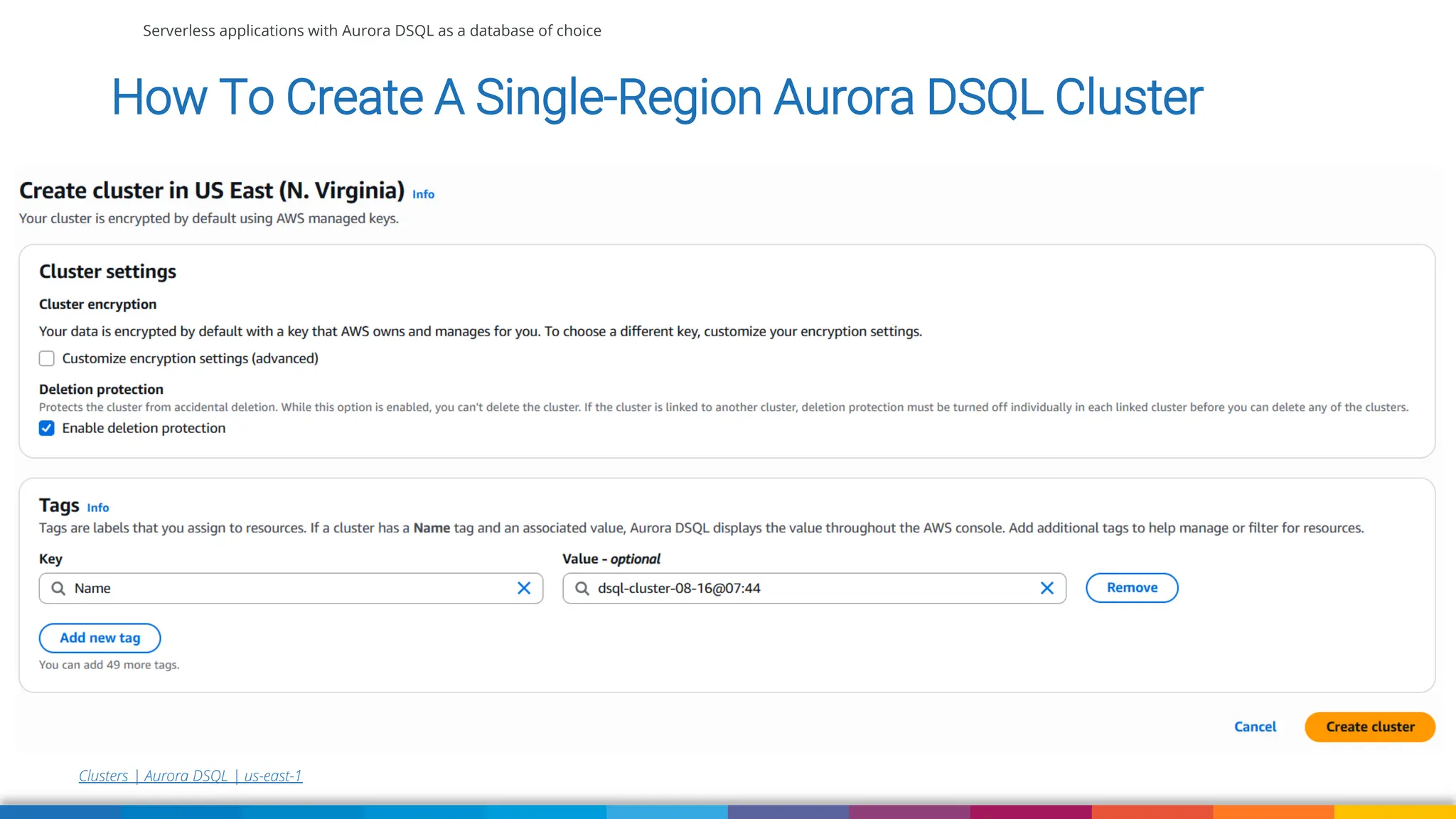
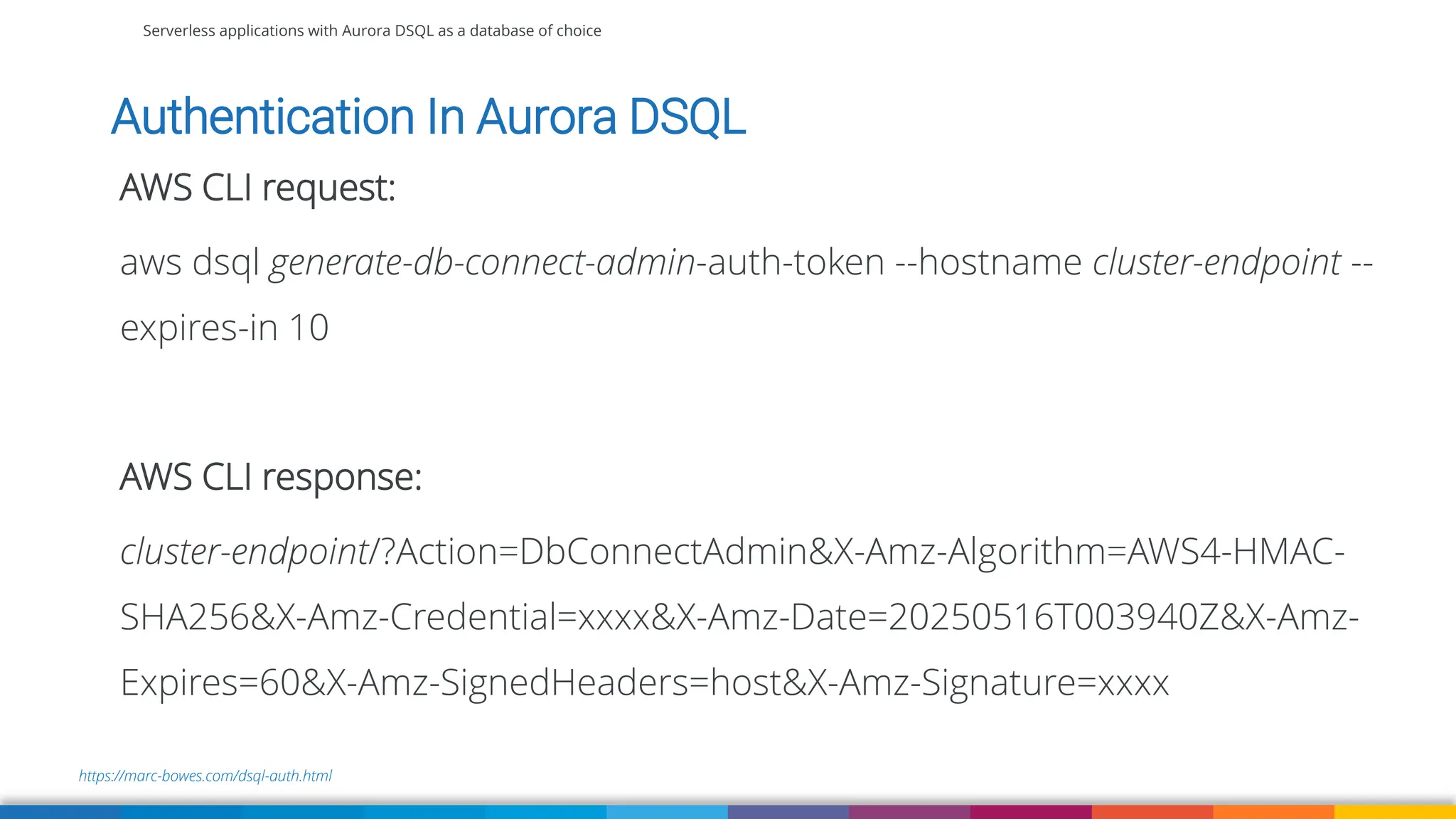
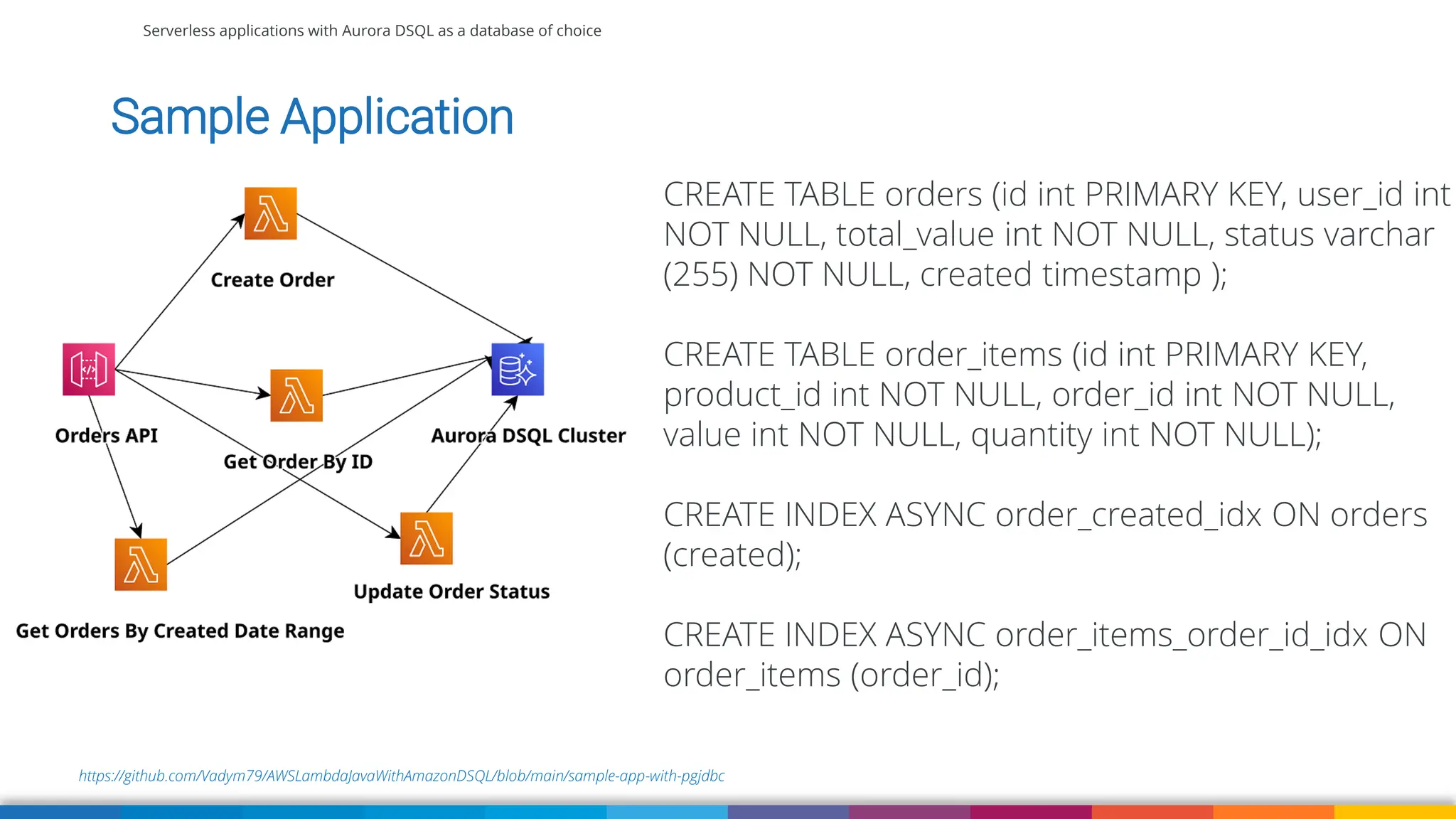
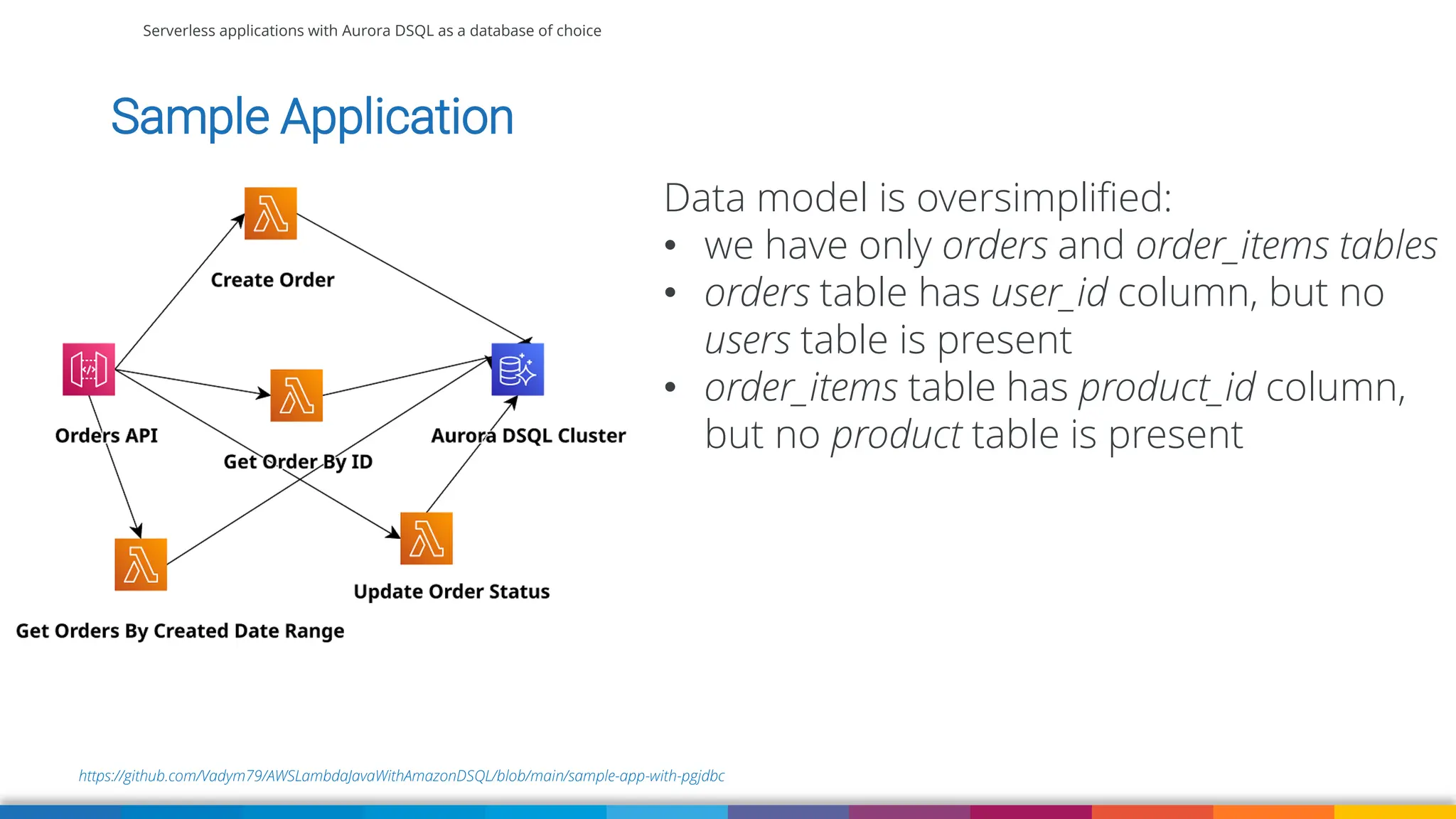
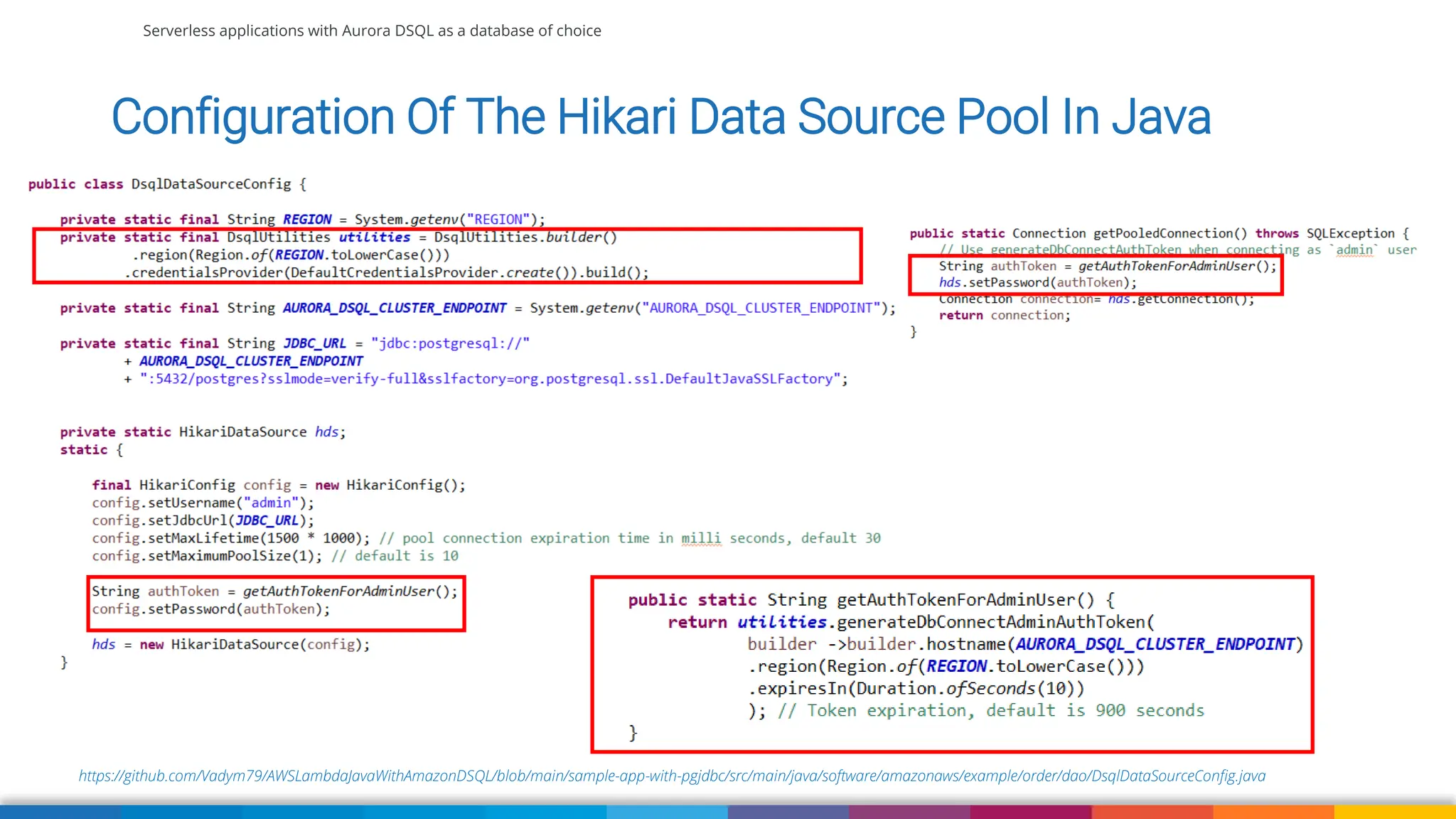
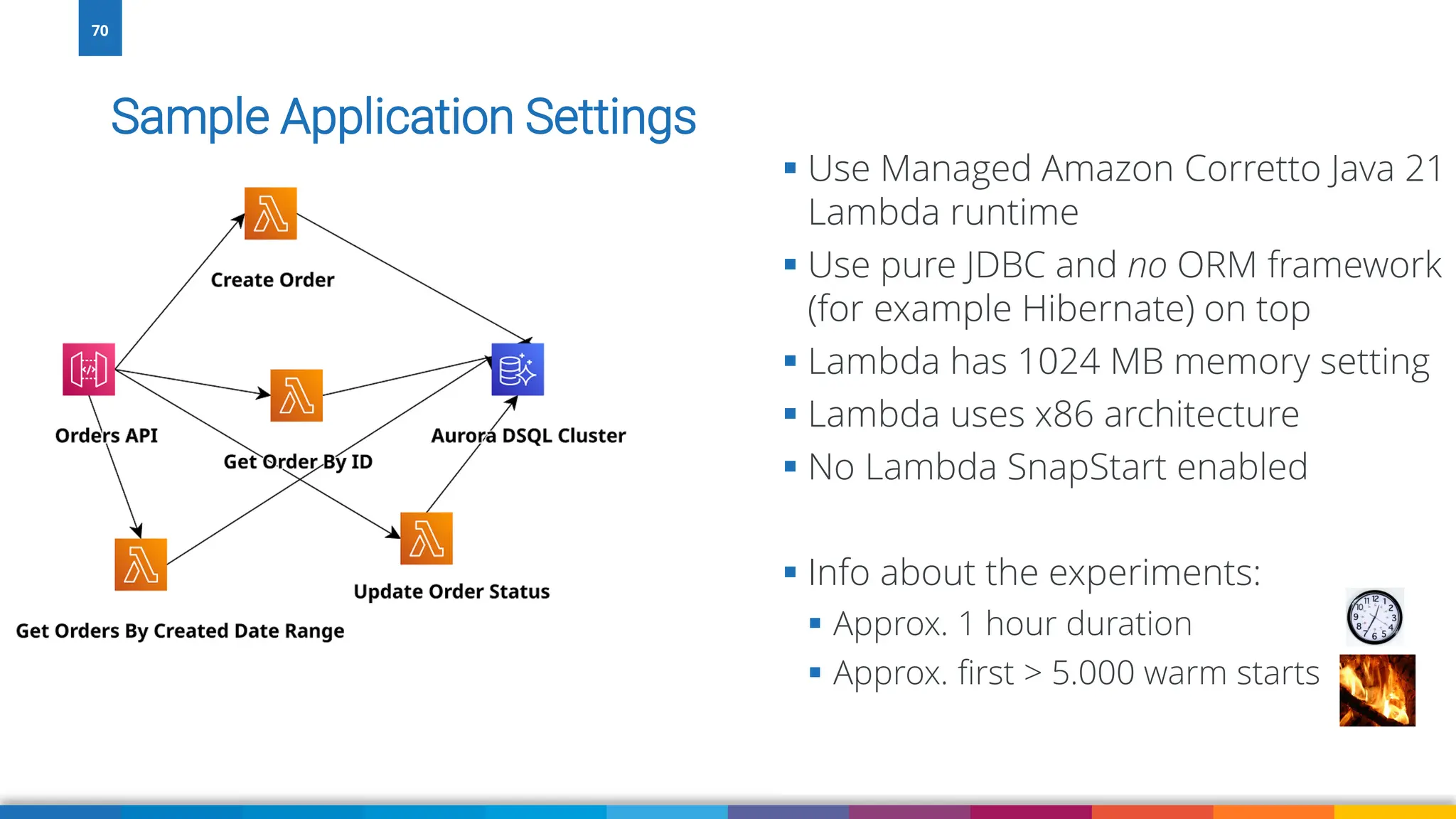
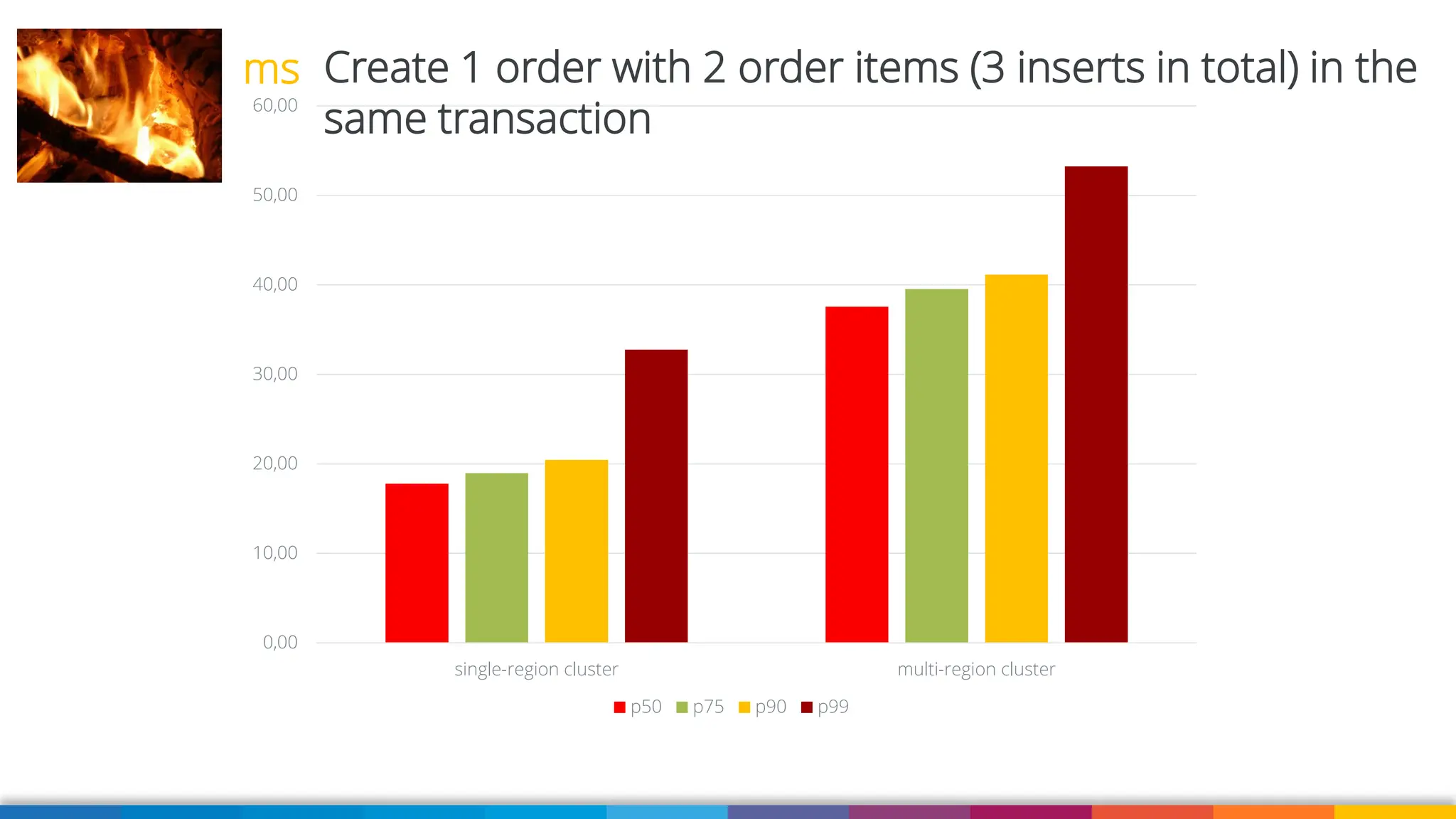
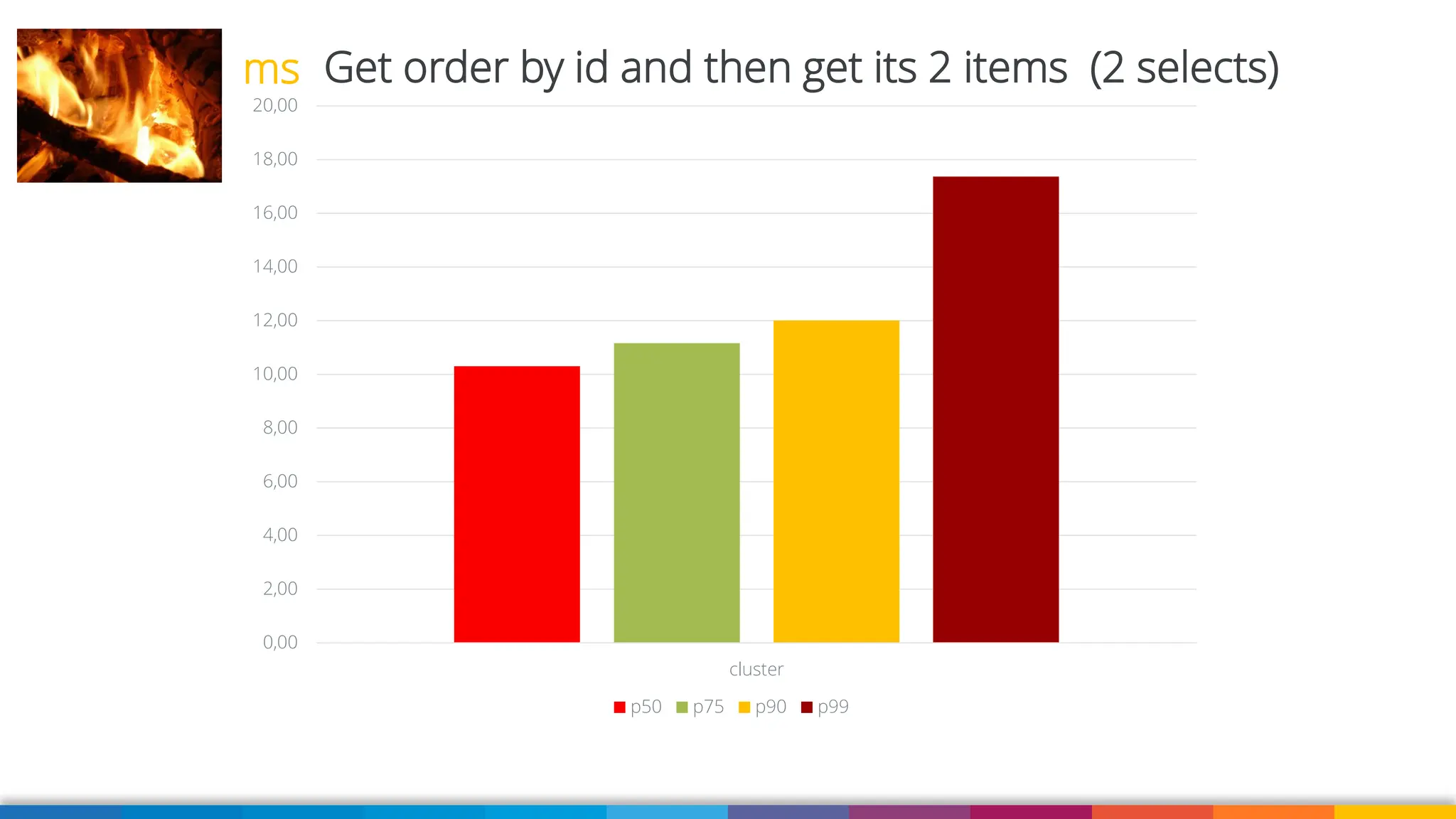
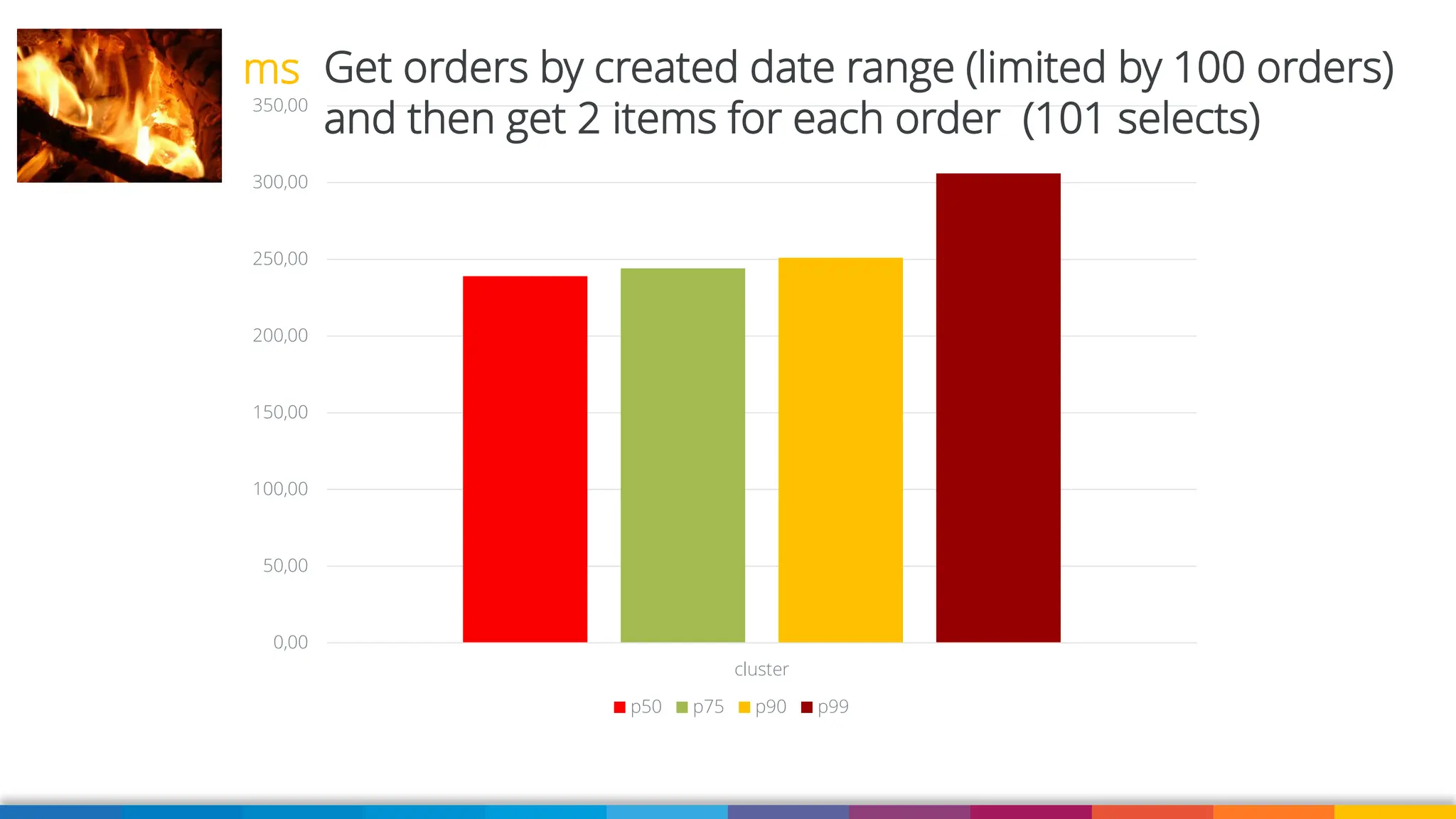
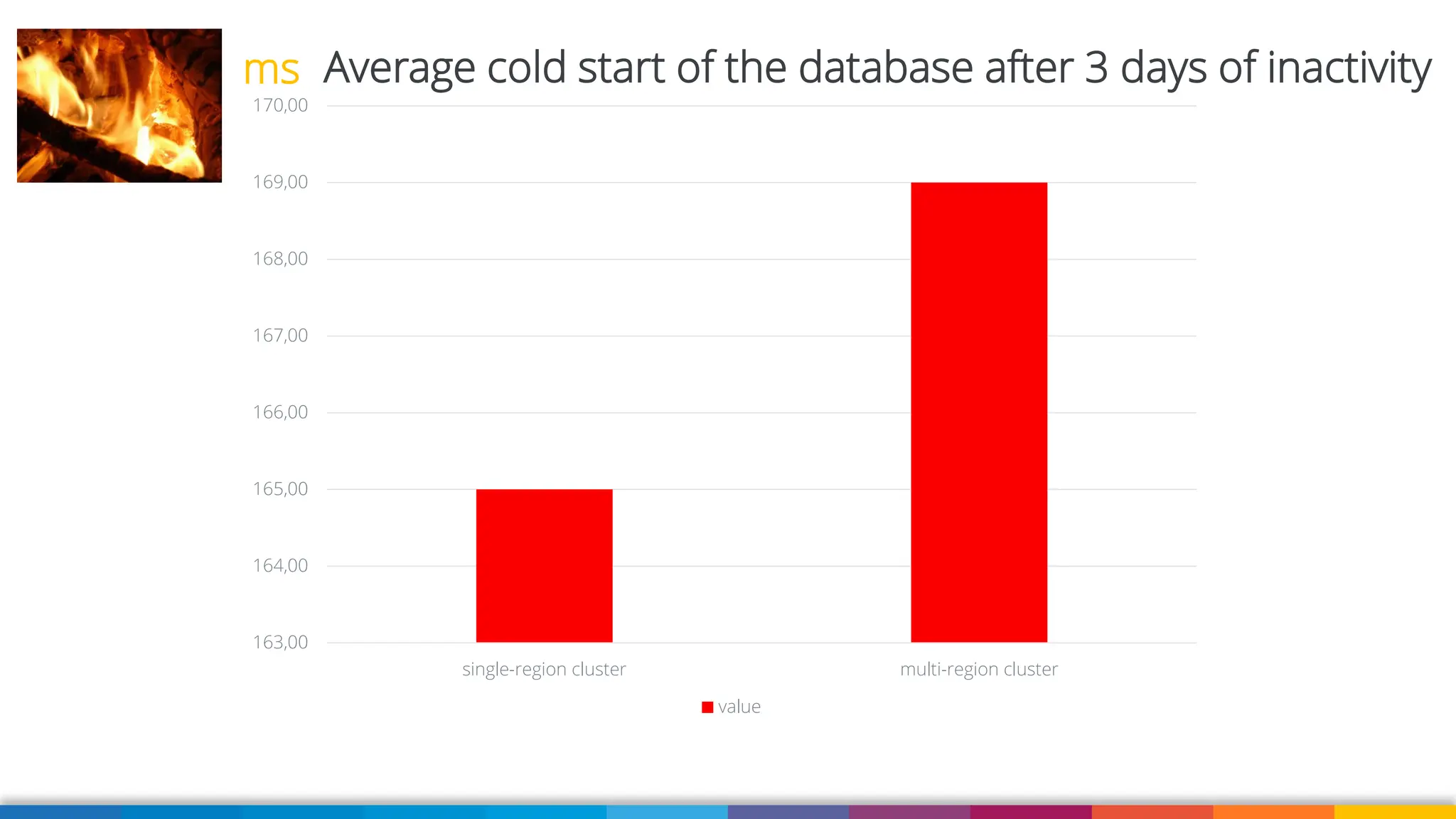
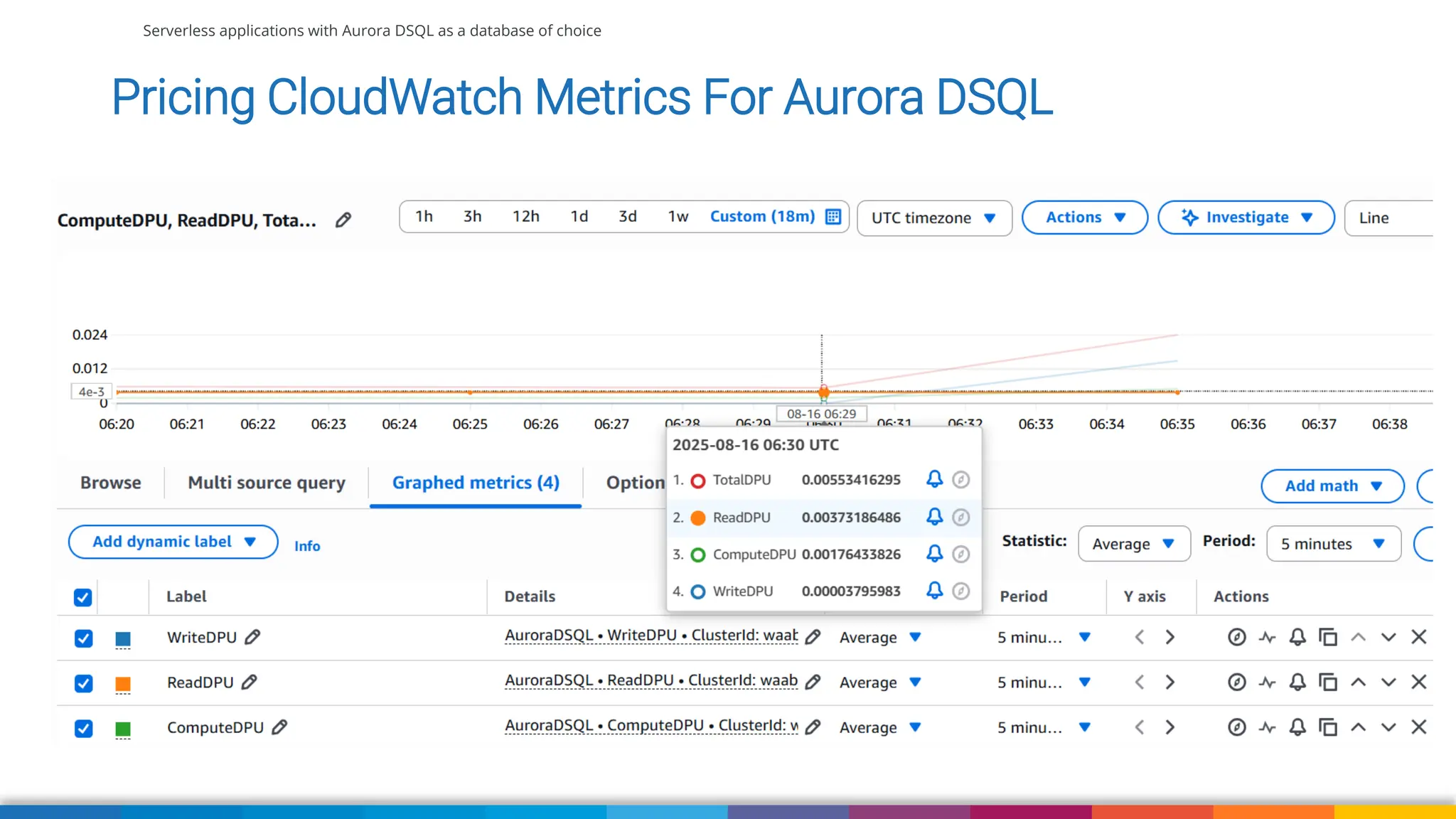
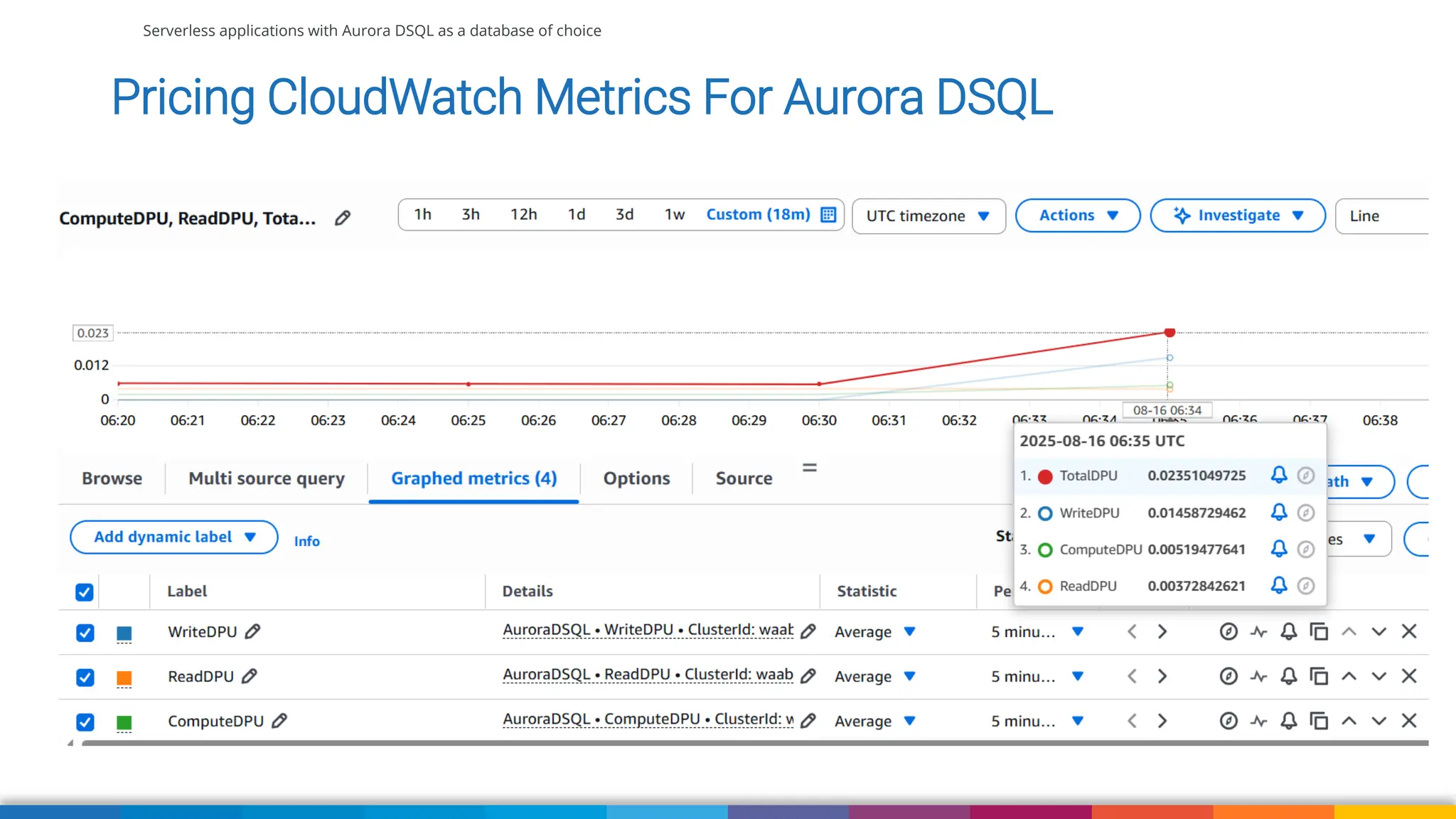
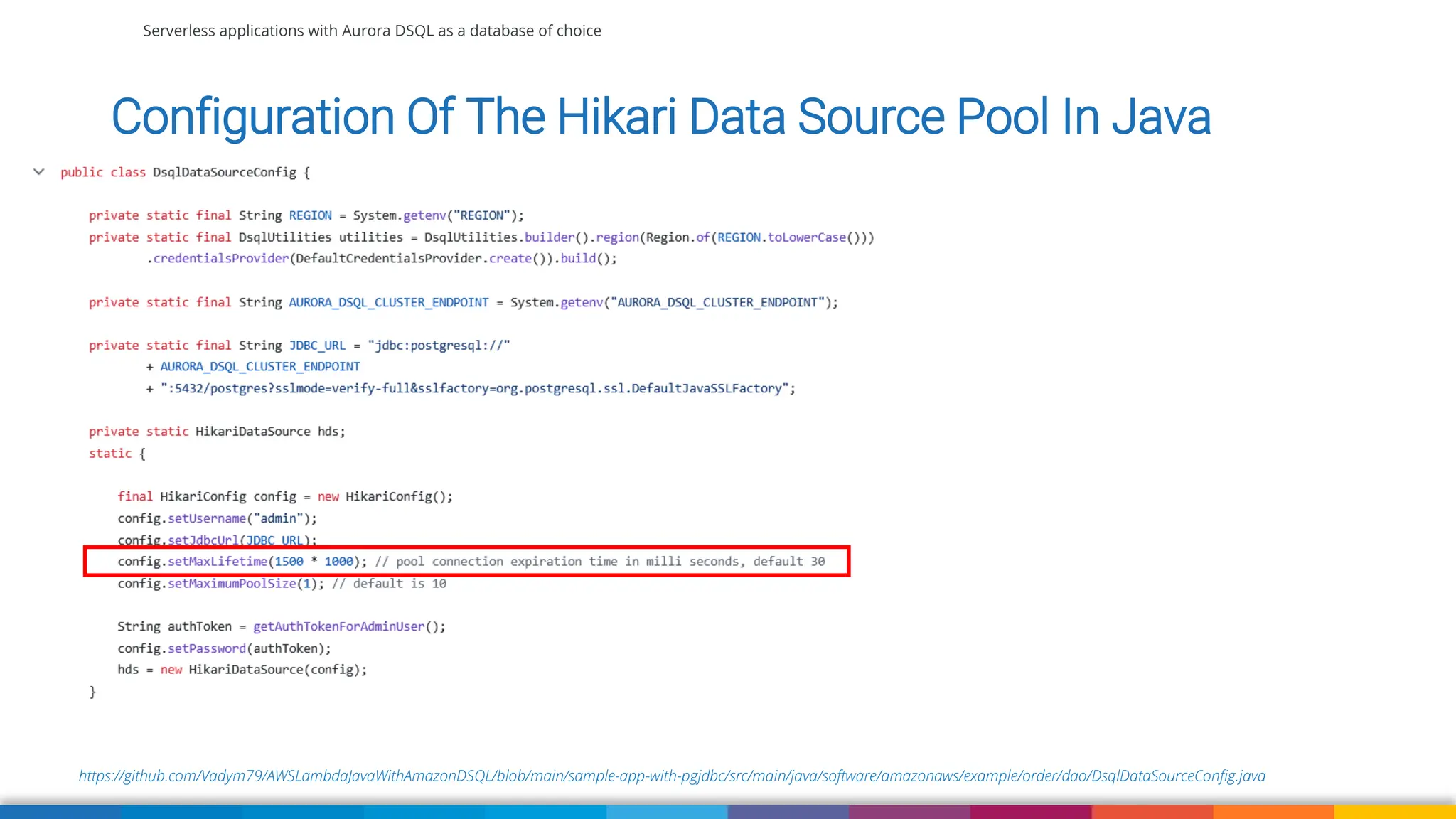
Amazon Aurora DSQL is a serverless distributed SQL database with virtually unlimited scale, highest availability, and zero infrastructure management. In this talk we’ll use a sample serverless application that uses Amazon API Gateway, AWS Lambda and Aurora DSQL to explore the architecture and features of this database. We'll explore the scaling behaviour of DSQL, measure performance including cold starts, deep dive into its pricing and current limitations.
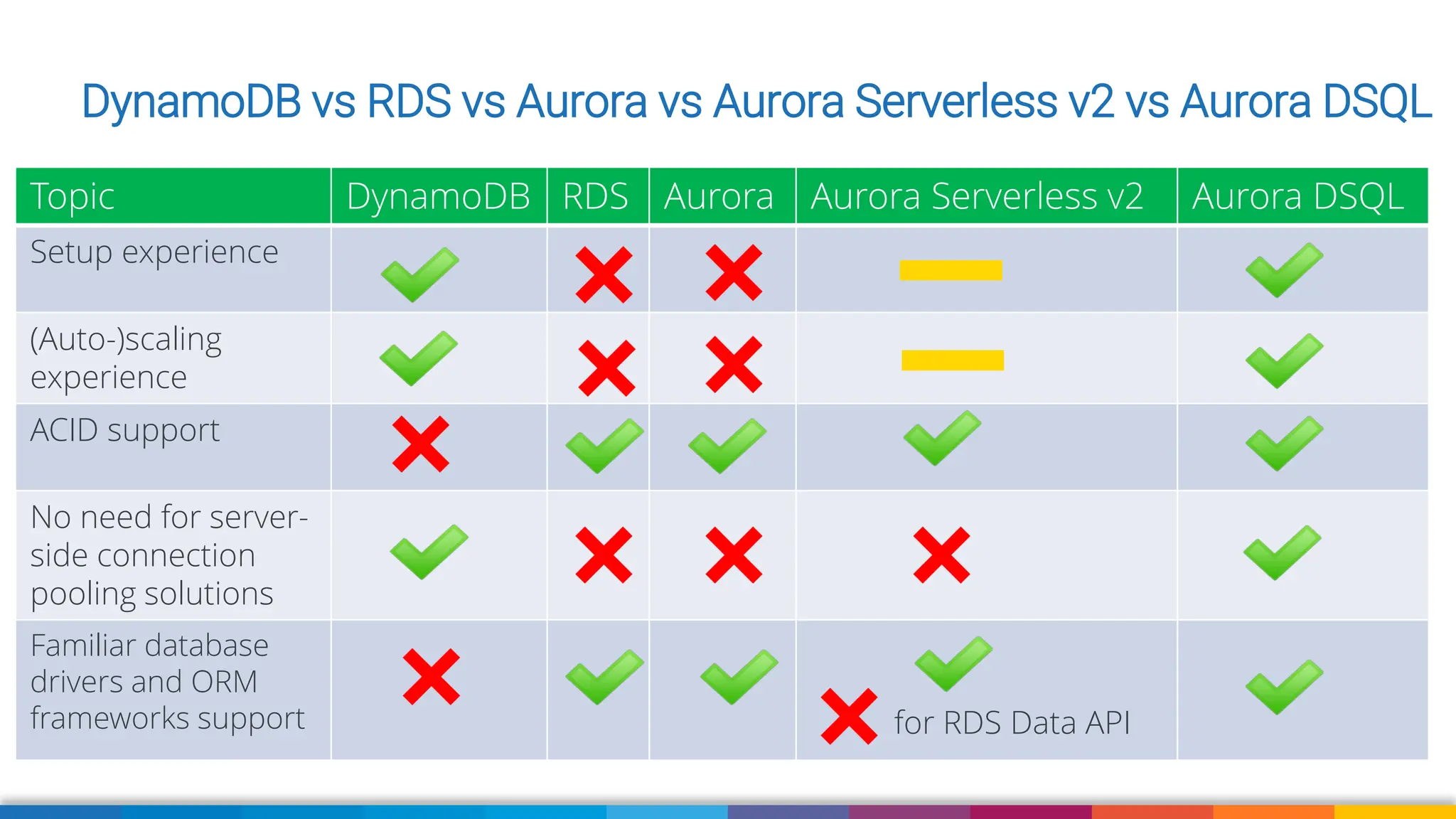
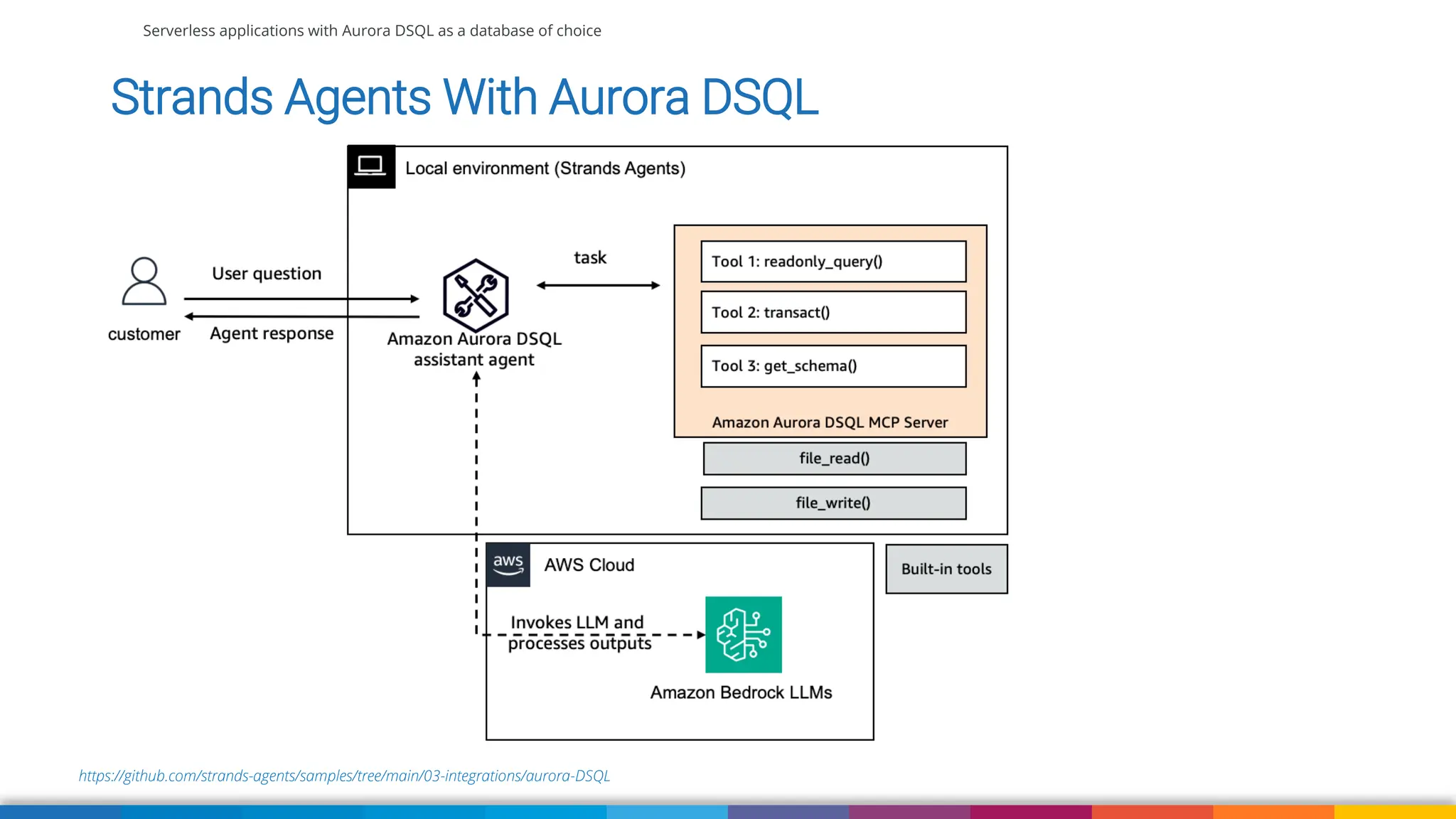
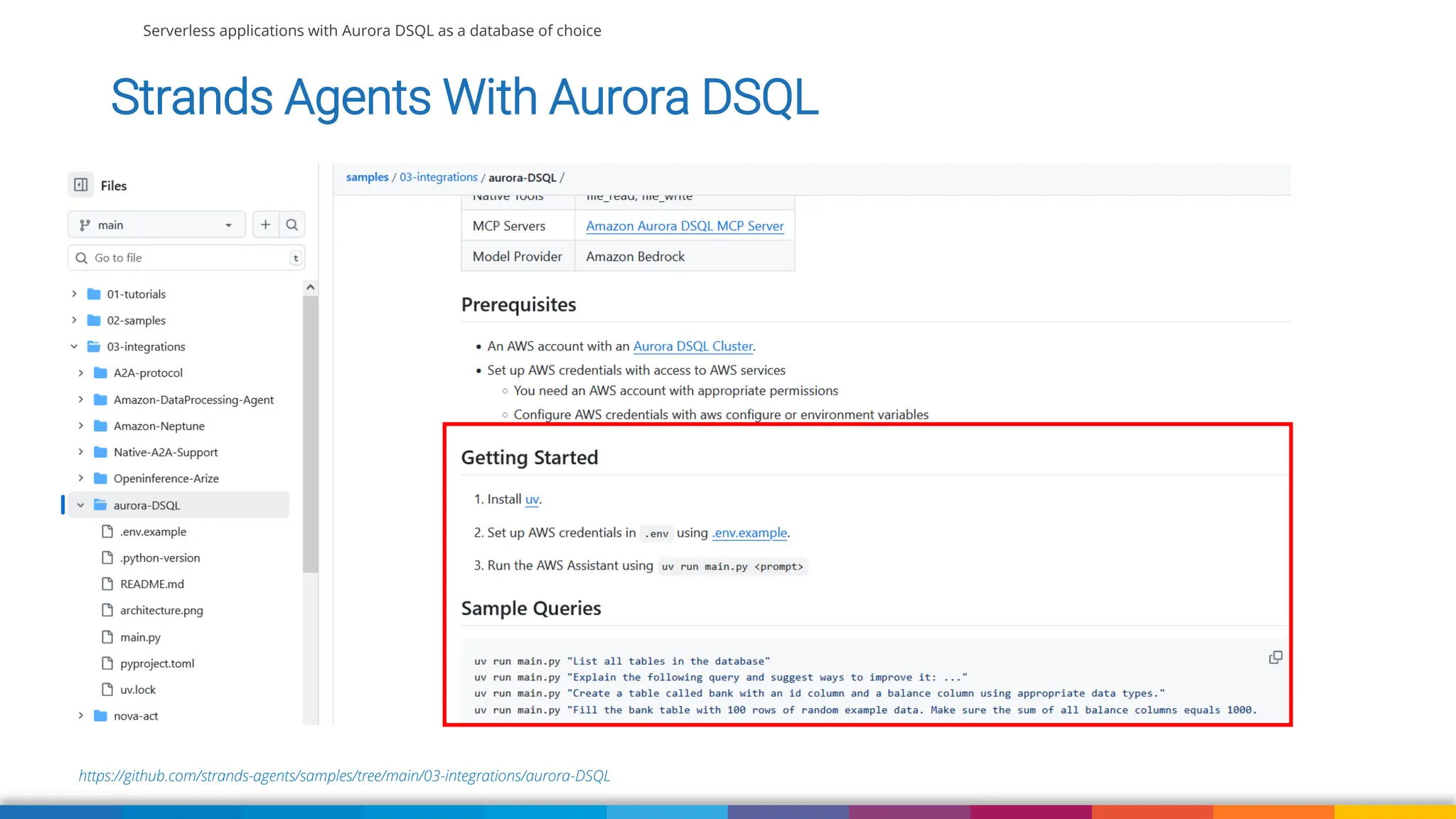
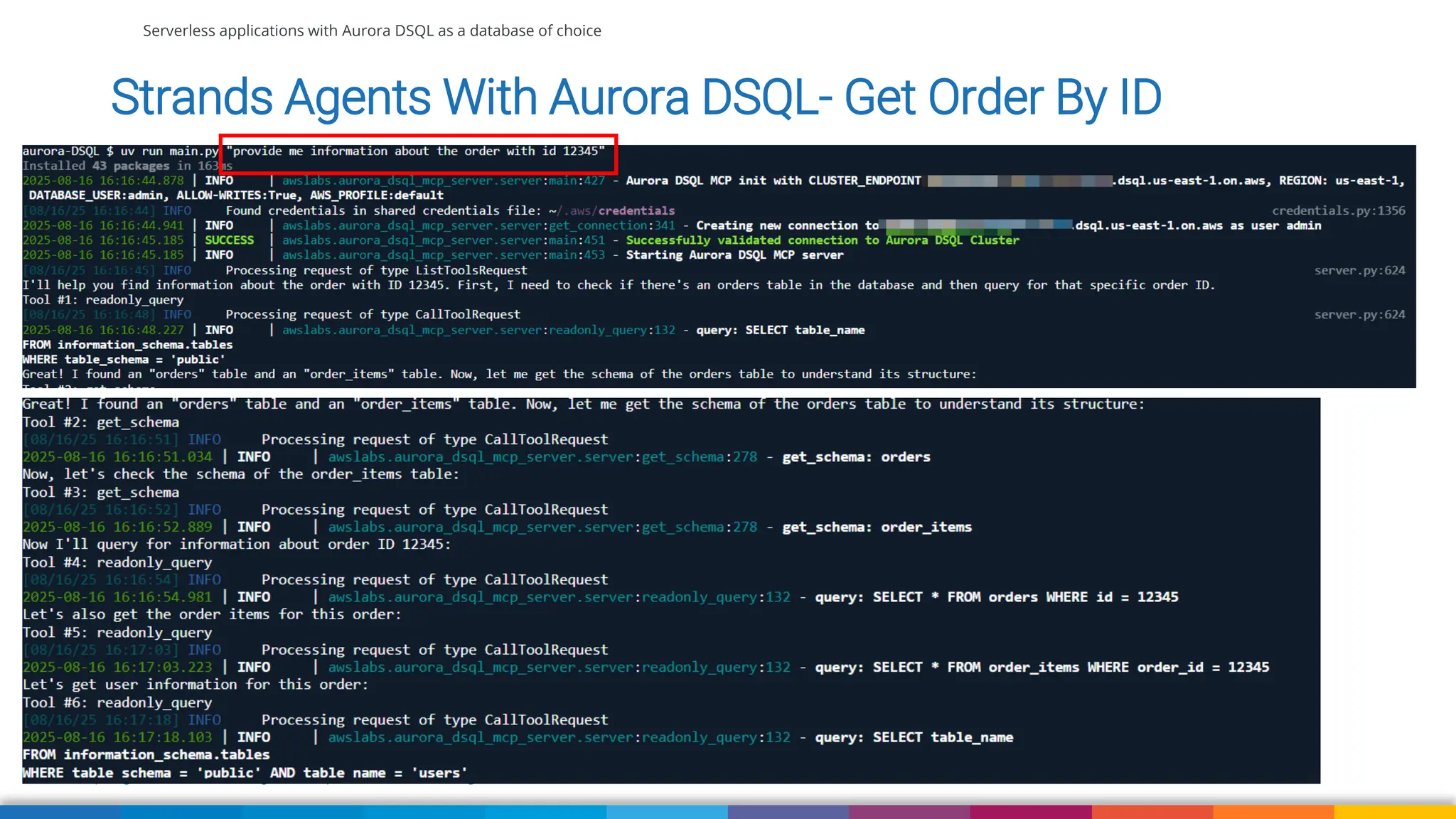
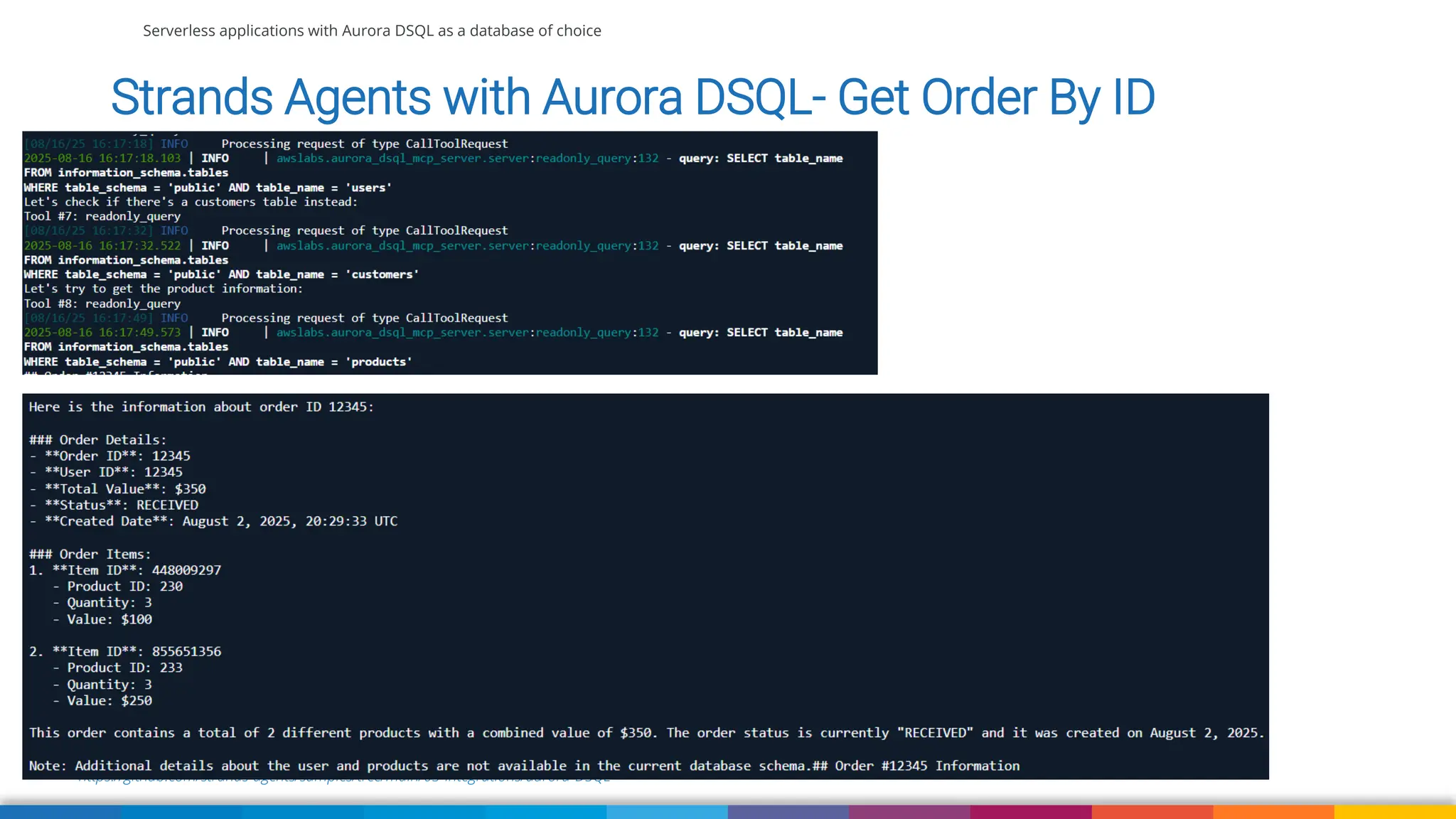
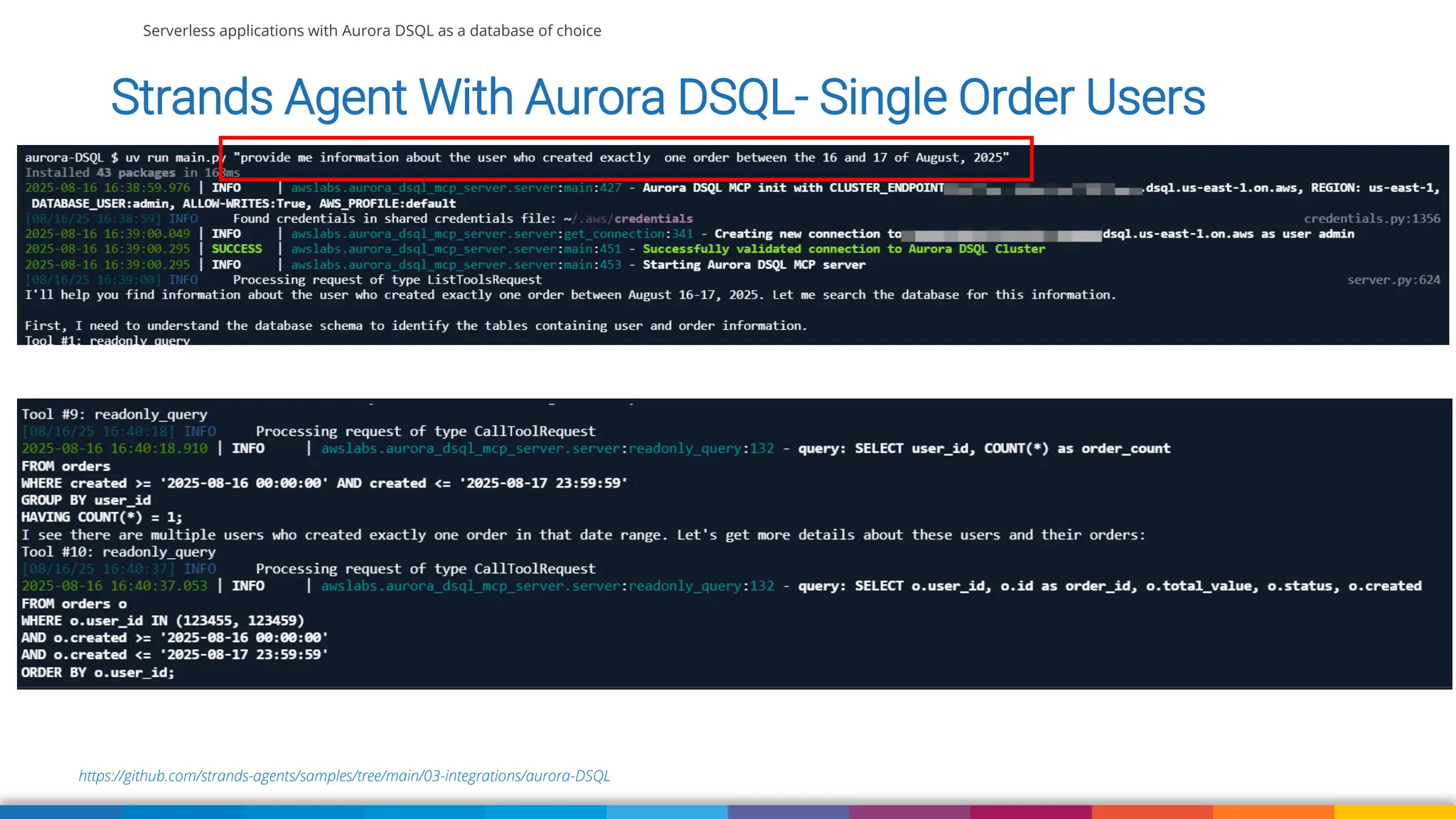
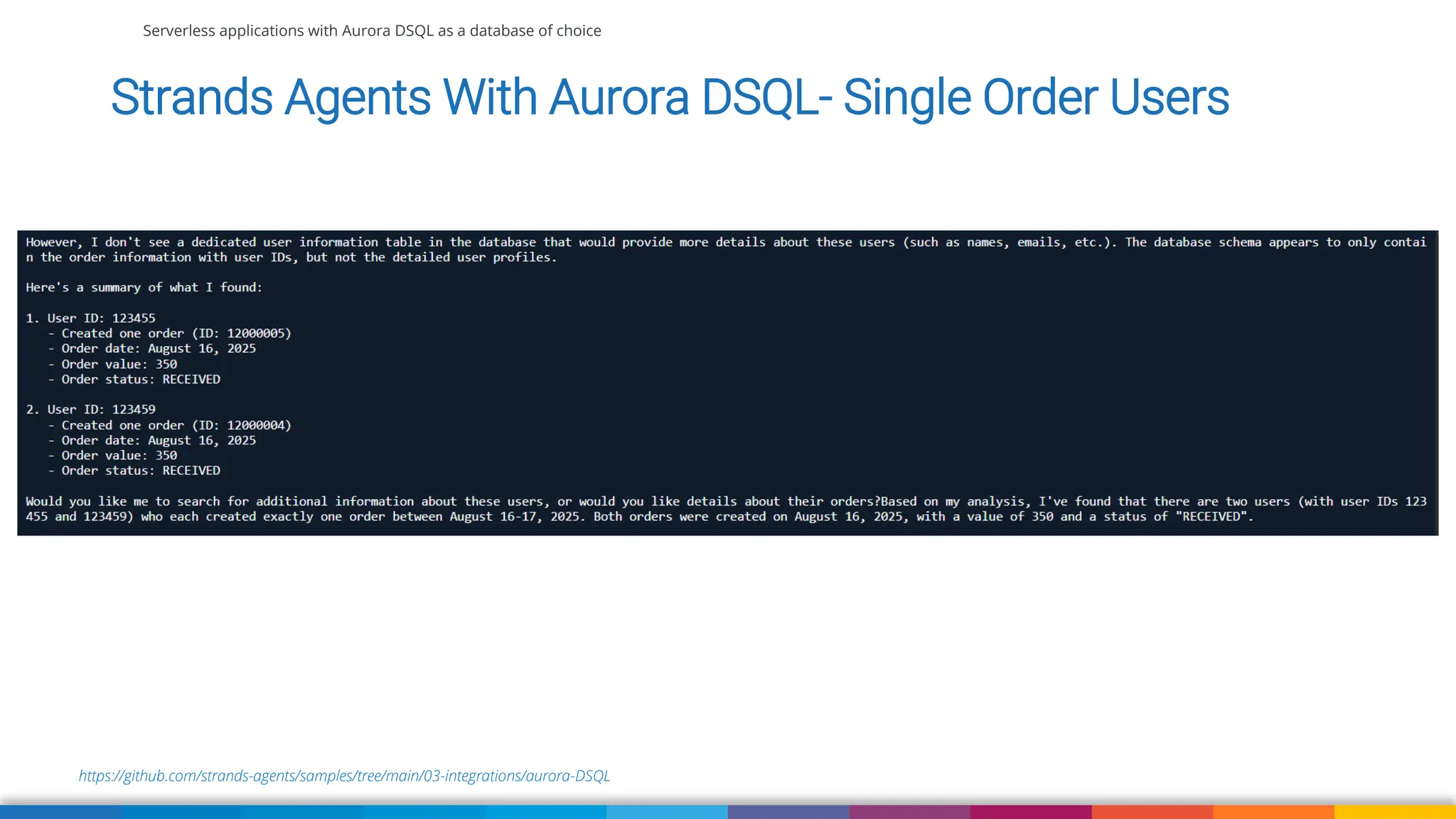
We'll also use Strands Agent with Amazon Aurora DSQL to talk to our application using natural language. We'll wrap up with some suggestions when currently to use DSQL comparing to DynamoDB, RDS and Aurora (Serverless) and what to pay attention to when migrating your existing application to Aurora DSQL.