Downloaded 487 times
![Resume Parsing with Named Entity
Clustering Algorithm
Swapnil Sonar Bhagwan Bankar
1
iamswapnilsonar@yahoo.in 2
bhagwan.bankar1@gmail.com
SVPM College of Engineering Baramati, Maharashtra, India
Abstract:-
The paper gives an outlook of an ongoing project
on deploying information extraction techniques in
the process of resume information extraction into
compact and highly-structured data. This online
tool has been able to reduce lots of burden on the
shoulder of users of recruitment agency. The
Resume Parser automatically segregates
information on the basis of various fields and
parameters like name, phone / mobile nos. etc. and
huge volume of resumes is no problem for this
system and all work is done automatically without
any personal or human intervention.
The resume extraction process consists of four
phases. In the first phase, a resume is segmented
into blocks according to their information types. In
the second phase, named entities are found by
using special chunkers for each information type.
In the third phase, found named entities are
clustered according to their distance in text and
information type. In the fourth phase,
normalization methods are applied to the text.
I. INTRODUCTION
Large companies and recruitment agencies receive
process and manage hundreds of resumes from job
applicants. Besides, many people publish their
resumes on the web. These resumes can be
automatically retrieved and processed by a resume
information extraction system. Extracted information
such as name, phone / mobile nos., e-mails id.,
qualification, experience, skill sets etc. can be stored
as a structured information in a database and then
can be used in many different areas.
In contrast to many unstructured document types,
information in resumes is in a semi-structured
form where information is stored in blocks. Each
block contains related information about a person’s
contact, education or work experience. Even if it
is in a restricted domain and semi-structured form,
resume documents are not easy to parse
automatically. They tend to differ in information
types, information order, containing full sentences
or not, etc. Also, conversion from other document
formats (e.g. pdf ,doc, docx etc.) to text yields
unexpected layout of information. To parse resumes
effectively, the system should be independent of the
order and form of information in the document. We
assumed that resumes have a three level hierarchical
structure where top most level contains segments.
Segments consist of blocks that contain related
information. Each block can contain several chunks
which are named entities.
II. PREVIOUS WORK
Recent advances in information technology such as
Information Extraction (IE) provide dramatic
improvements in conversion of the overflow of raw
textual information into structured data which
constitute the input for discovering more complex
patterns in textual data collections.
Resume information extraction, also called
resume parsing, enables extraction of relevant
information from resumes which have relatively
structured form. Although, there are many
commercial products on resume information
extraction, some of the commercial products include
Sovren Resume/CV Parser [4], Akken Staffing ,
ALEX Resume parsing [5], ResumeGrabber Suite](https://image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-1-2048.jpg)
![and Daxtra CVX [6]. There are four types of
methods used in resume information extraction:
Named-entity-based,rule-based, statistical and
learning-based methods. Usually a combination of
these methods is used in many applications.
Named-entity-based information extraction
methods try to identify certain words,
phrases and patterns usually using regular
expressions or dictionaries. This is usually
used as a second step after lexical analysis
of a given document [2, 3]. Rule-based
information extraction is based on
grammars.
Rule-based information extraction methods
include a large number of grammatical
rules to extract information from a given
document [3].
Statistical information extraction methods
apply numerical models to identify
structures in given documents [3].
The learning-based methods employ
classification algorithms to extract
information from a document.
Many resume information extraction
systems employ a hybrid approach by using
a combination of different methods.
III.PROPOSED SYSTEM
Information Extraction Process:-
The designed Information Extraction System
consists of 4 phases: Text Segmentation, Named
Entity Recognition, Named Entity Clustering and
Text Normalization.
Figure1. Workflow of Resume Parser
1. Text Segmentation
Text Segmentation phase do work on the fact that
each heading in a resume contains a block of related
information following it. So in that case our resume
will separate out into segments named as contact
information, education information, professional
details and personal information segment as shown in
Figure 1.
Segment Type Related Info under the
Segment
Contact Name
Phone
Email
Web
Education Degree
Program
Institution
Experience Position
Company
Date Range
Table1. Segment containing extracted Information
Types
A data-dictionary is used to store common headings
in a resume which are definitely occurring in the
resume. These headings are searched in a given
resume to find segments of related information. All
of the text information between the heading and the
start of the next heading is accepted as a segment.
One exception will possible or may occur is the first
segment which contains the name of the person and](https://image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-2-2048.jpg)

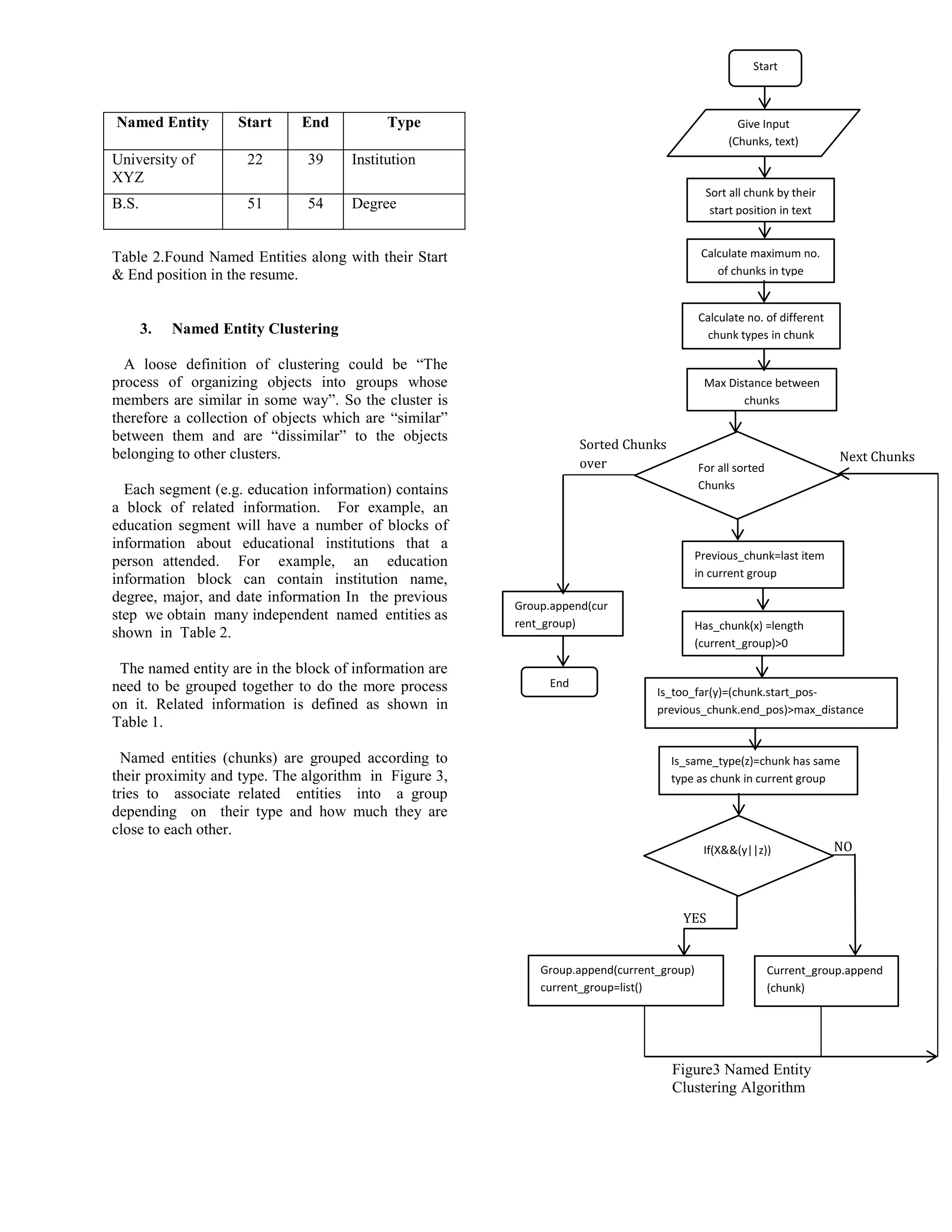
![4. Text Normalization
In text normalization, some of the named
entities are transformed to make it consistent.
Table 3 shows some of the transformations
performed on several text phrases.
In normalization phase, we expand some of
abbreviations using dictionaries similar to the
dictionary given in Table 4. For example, the
abbreviation “B.S.” is expanded as “Bachelor of
Science”. We also convert some of the text into a
new form. For example, the first letters in a person’s
name is capitalized as shown in Table 3.
Some of the phrases are also converted to its most
common form. For example, “University of ABC” is
converted to “ABC University” as shown in Table 3.
Input Output Type
B.S. Bachelor of
Science
Degree
JOHN DOE John Doe Name
University of
ABC
ABC University Institution
Table 3.Applying Text Normalization using Data-
Dictionary
Term (Full
Form/word)
Abbreviation
Bachelor of Science B.S.,BS ,BSc
Master of Science M.S.,MS ,MSc
Bachelor of Arts B.A., BA
Doctor of Philosophy Ph.D., PhD
Doctor of Medicine Medicine Doctor, M.D.
Bachelor of Computer
Application
BCA,B.C.A
Table 4.Sample Data-Dictionary of the degree
chunker
IV.PERFORMANCE EVALUATION
The focus in Information Retrieval research
lays on text classification systems which make
binary decisions for text document as either
relevant or non-relevant with respect to a user's
information need. Capturing the user information
need is not a trivial task. We used precision,
recall and F-measure metrics for performance
evaluation [7].
Precision measures the number of relevant
items retrieved as a percentage of the total
number of items retrieved.
Precision= #(relevant items retrieved)
#(retrieved items)
Recall measures the number of relevant
items retrieved as a percentage of the
number of relevant items in collection.
Recall= #(relevant items retrieved)
#(relevant items)
The F-measure is the harmonic mean of
precision and recall.
F-measure= 2* (Precision * Recall)
(Precision + Recall)
The Precision, Recall and F-measure rates for
segments will be predicted as follows. Segments will
recognize well by the system. F-measure for
segments is between 95% and 100%. This is because
of the fact that the segment data-dictionary
includes almost all of the common headers used in
the resumes. The identification rates of named
entities such as name, e-mail and education
program will in acceptable ranges or any tolerated
error includes in it so because these named entities
has specific or changed format .](https://image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-5-2048.jpg)
![V. ADVANTAGES
This online tool has been able to reduce lots of
burden on the shoulder of Applicant and HR
Managers as well. The Resume Parser automatically
segregates information on the basis of various fields
and parameters like name, phone / mobile nos., e-
mails id., qualification, experience, skill sets etc. and
huge volume of resumes is no problem for this
system and all work is done automatically without
any personal or human intervention.
So, in a Nutshell, The Resume Parser will behave as
a Suite, which will provide
1. A precise and Auto Profile fill-up Utility,
2. Extraction of predefined types of information from
unstructured documents based on IE
(Information Extraction) Technology,
3. As Recruitment Assistant,
4. Concise Information about Person.
VI. DISADVANTAGES
Complete system is dependent on web, computer and
modern facilities like internet so this not useful in
rural areas but now days with increasing
globalization this disadvantage easily minimized.
While used the auto profile fill-up utility some of the
error may occur during filling information or
someplace problem in extracting information.
VII. APPLICATIONS
This online tool has been able to reduce lots of
burden on the shoulder of jobseeker in Online
Recruitment System.
Maintain the basic information of employees in the
Company/Organization.
VIII. CONCLUSION
We presented a resume information extraction
system based on Named Entity Clustering Algorithm.
The developing system has a flexible and modular
structure that can be extended easily. This system is
use and test in Online Recruitment Agency project.
The resume extraction process consists of 4 phases.
In the first step, a resume is segmented into blocks
according to their information types. In the second
step, named entities are found using special chunkers
for each information type. In the third step, the found
named entities are clustered into groups according to
their distance in text and information type. In the
fourth step, normalization methods are applied to the
text.
After trying to work with Resume Parser it is
found that it reduces the time consumed for
generating a profile of user with extracted
information by almost 50%.
IX.FUTURE SCOPE AND ENHANCEMENT
As a future work, we will expand the resume data
collection set and improve the performance of the
proposed system. After success of proposed system
we also plan to extend it for other languages too.
REFERENCES
[1]. R.Grishman,“Information Extraction:
Techniques and Challenges”, Lecture Notes
In Computer Science, vol. 1299, Springer-
Verlag, London, 1997, pp. 10-27.
[2]. C. Siefkes and P. Siniakov, “An Overview
and Classification of Adaptive Approaches
to Information Extraction”, Journal on
Data Semantics, vol. 4, Springer, 2005, pp.
172–212.
[3]. S.Sarawagi,"Information Extraction",
Foundations and Trends in Databases, vol.
1, 2008, pp 261- 377.
[4]. Sovren Resume/CV Parser,
http://www. sovren.com/
(Accessed on Feb 2, 2012).
[5]. ALEX Resume Parsing,
http://www.hireability.com/ ALEX/
(Accessed on Feb 2, 2012).
[6]. Daxtra CVX, http://www.daxtra.com/
(Accessed on Feb 2, 2012).
[7]. Ertuğ Karamatlı, Selim Akyokuş “Resume
Information Extraction with Named Entity
Clustering based on Relationships”](https://image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-6-2048.jpg)
![Resume Parsing with Named Entity
Clustering Algorithm
Swapnil Sonar Bhagwan Bankar
1
iamswapnilsonar@yahoo.in 2
bhagwan.bankar1@gmail.com
SVPM College of Engineering Baramati, Maharashtra, India
Abstract:-
The paper gives an outlook of an ongoing project
on deploying information extraction techniques in
the process of resume information extraction into
compact and highly-structured data. This online
tool has been able to reduce lots of burden on the
shoulder of users of recruitment agency. The
Resume Parser automatically segregates
information on the basis of various fields and
parameters like name, phone / mobile nos. etc. and
huge volume of resumes is no problem for this
system and all work is done automatically without
any personal or human intervention.
The resume extraction process consists of four
phases. In the first phase, a resume is segmented
into blocks according to their information types. In
the second phase, named entities are found by
using special chunkers for each information type.
In the third phase, found named entities are
clustered according to their distance in text and
information type. In the fourth phase,
normalization methods are applied to the text.
I. INTRODUCTION
Large companies and recruitment agencies receive
process and manage hundreds of resumes from job
applicants. Besides, many people publish their
resumes on the web. These resumes can be
automatically retrieved and processed by a resume
information extraction system. Extracted information
such as name, phone / mobile nos., e-mails id.,
qualification, experience, skill sets etc. can be stored
as a structured information in a database and then
can be used in many different areas.
In contrast to many unstructured document types,
information in resumes is in a semi-structured
form where information is stored in blocks. Each
block contains related information about a person’s
contact, education or work experience. Even if it
is in a restricted domain and semi-structured form,
resume documents are not easy to parse
automatically. They tend to differ in information
types, information order, containing full sentences
or not, etc. Also, conversion from other document
formats (e.g. pdf ,doc, docx etc.) to text yields
unexpected layout of information. To parse resumes
effectively, the system should be independent of the
order and form of information in the document. We
assumed that resumes have a three level hierarchical
structure where top most level contains segments.
Segments consist of blocks that contain related
information. Each block can contain several chunks
which are named entities.
II. PREVIOUS WORK
Recent advances in information technology such as
Information Extraction (IE) provide dramatic
improvements in conversion of the overflow of raw
textual information into structured data which
constitute the input for discovering more complex
patterns in textual data collections.
Resume information extraction, also called
resume parsing, enables extraction of relevant
information from resumes which have relatively
structured form. Although, there are many
commercial products on resume information
extraction, some of the commercial products include
Sovren Resume/CV Parser [4], Akken Staffing ,
ALEX Resume parsing [5], ResumeGrabber Suite](https://crownmelresort.com/image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-1-2048.jpg)
![and Daxtra CVX [6]. There are four types of
methods used in resume information extraction:
Named-entity-based,rule-based, statistical and
learning-based methods. Usually a combination of
these methods is used in many applications.
Named-entity-based information extraction
methods try to identify certain words,
phrases and patterns usually using regular
expressions or dictionaries. This is usually
used as a second step after lexical analysis
of a given document [2, 3]. Rule-based
information extraction is based on
grammars.
Rule-based information extraction methods
include a large number of grammatical
rules to extract information from a given
document [3].
Statistical information extraction methods
apply numerical models to identify
structures in given documents [3].
The learning-based methods employ
classification algorithms to extract
information from a document.
Many resume information extraction
systems employ a hybrid approach by using
a combination of different methods.
III.PROPOSED SYSTEM
Information Extraction Process:-
The designed Information Extraction System
consists of 4 phases: Text Segmentation, Named
Entity Recognition, Named Entity Clustering and
Text Normalization.
Figure1. Workflow of Resume Parser
1. Text Segmentation
Text Segmentation phase do work on the fact that
each heading in a resume contains a block of related
information following it. So in that case our resume
will separate out into segments named as contact
information, education information, professional
details and personal information segment as shown in
Figure 1.
Segment Type Related Info under the
Segment
Contact Name
Phone
Email
Web
Education Degree
Program
Institution
Experience Position
Company
Date Range
Table1. Segment containing extracted Information
Types
A data-dictionary is used to store common headings
in a resume which are definitely occurring in the
resume. These headings are searched in a given
resume to find segments of related information. All
of the text information between the heading and the
start of the next heading is accepted as a segment.
One exception will possible or may occur is the first
segment which contains the name of the person and](https://crownmelresort.com/image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-2-2048.jpg)


![4. Text Normalization
In text normalization, some of the named
entities are transformed to make it consistent.
Table 3 shows some of the transformations
performed on several text phrases.
In normalization phase, we expand some of
abbreviations using dictionaries similar to the
dictionary given in Table 4. For example, the
abbreviation “B.S.” is expanded as “Bachelor of
Science”. We also convert some of the text into a
new form. For example, the first letters in a person’s
name is capitalized as shown in Table 3.
Some of the phrases are also converted to its most
common form. For example, “University of ABC” is
converted to “ABC University” as shown in Table 3.
Input Output Type
B.S. Bachelor of
Science
Degree
JOHN DOE John Doe Name
University of
ABC
ABC University Institution
Table 3.Applying Text Normalization using Data-
Dictionary
Term (Full
Form/word)
Abbreviation
Bachelor of Science B.S.,BS ,BSc
Master of Science M.S.,MS ,MSc
Bachelor of Arts B.A., BA
Doctor of Philosophy Ph.D., PhD
Doctor of Medicine Medicine Doctor, M.D.
Bachelor of Computer
Application
BCA,B.C.A
Table 4.Sample Data-Dictionary of the degree
chunker
IV.PERFORMANCE EVALUATION
The focus in Information Retrieval research
lays on text classification systems which make
binary decisions for text document as either
relevant or non-relevant with respect to a user's
information need. Capturing the user information
need is not a trivial task. We used precision,
recall and F-measure metrics for performance
evaluation [7].
Precision measures the number of relevant
items retrieved as a percentage of the total
number of items retrieved.
Precision= #(relevant items retrieved)
#(retrieved items)
Recall measures the number of relevant
items retrieved as a percentage of the
number of relevant items in collection.
Recall= #(relevant items retrieved)
#(relevant items)
The F-measure is the harmonic mean of
precision and recall.
F-measure= 2* (Precision * Recall)
(Precision + Recall)
The Precision, Recall and F-measure rates for
segments will be predicted as follows. Segments will
recognize well by the system. F-measure for
segments is between 95% and 100%. This is because
of the fact that the segment data-dictionary
includes almost all of the common headers used in
the resumes. The identification rates of named
entities such as name, e-mail and education
program will in acceptable ranges or any tolerated
error includes in it so because these named entities
has specific or changed format .](https://crownmelresort.com/image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-5-2048.jpg)
![V. ADVANTAGES
This online tool has been able to reduce lots of
burden on the shoulder of Applicant and HR
Managers as well. The Resume Parser automatically
segregates information on the basis of various fields
and parameters like name, phone / mobile nos., e-
mails id., qualification, experience, skill sets etc. and
huge volume of resumes is no problem for this
system and all work is done automatically without
any personal or human intervention.
So, in a Nutshell, The Resume Parser will behave as
a Suite, which will provide
1. A precise and Auto Profile fill-up Utility,
2. Extraction of predefined types of information from
unstructured documents based on IE
(Information Extraction) Technology,
3. As Recruitment Assistant,
4. Concise Information about Person.
VI. DISADVANTAGES
Complete system is dependent on web, computer and
modern facilities like internet so this not useful in
rural areas but now days with increasing
globalization this disadvantage easily minimized.
While used the auto profile fill-up utility some of the
error may occur during filling information or
someplace problem in extracting information.
VII. APPLICATIONS
This online tool has been able to reduce lots of
burden on the shoulder of jobseeker in Online
Recruitment System.
Maintain the basic information of employees in the
Company/Organization.
VIII. CONCLUSION
We presented a resume information extraction
system based on Named Entity Clustering Algorithm.
The developing system has a flexible and modular
structure that can be extended easily. This system is
use and test in Online Recruitment Agency project.
The resume extraction process consists of 4 phases.
In the first step, a resume is segmented into blocks
according to their information types. In the second
step, named entities are found using special chunkers
for each information type. In the third step, the found
named entities are clustered into groups according to
their distance in text and information type. In the
fourth step, normalization methods are applied to the
text.
After trying to work with Resume Parser it is
found that it reduces the time consumed for
generating a profile of user with extracted
information by almost 50%.
IX.FUTURE SCOPE AND ENHANCEMENT
As a future work, we will expand the resume data
collection set and improve the performance of the
proposed system. After success of proposed system
we also plan to extend it for other languages too.
REFERENCES
[1]. R.Grishman,“Information Extraction:
Techniques and Challenges”, Lecture Notes
In Computer Science, vol. 1299, Springer-
Verlag, London, 1997, pp. 10-27.
[2]. C. Siefkes and P. Siniakov, “An Overview
and Classification of Adaptive Approaches
to Information Extraction”, Journal on
Data Semantics, vol. 4, Springer, 2005, pp.
172–212.
[3]. S.Sarawagi,"Information Extraction",
Foundations and Trends in Databases, vol.
1, 2008, pp 261- 377.
[4]. Sovren Resume/CV Parser,
http://www. sovren.com/
(Accessed on Feb 2, 2012).
[5]. ALEX Resume Parsing,
http://www.hireability.com/ ALEX/
(Accessed on Feb 2, 2012).
[6]. Daxtra CVX, http://www.daxtra.com/
(Accessed on Feb 2, 2012).
[7]. Ertuğ Karamatlı, Selim Akyokuş “Resume
Information Extraction with Named Entity
Clustering based on Relationships”](https://crownmelresort.com/image.slidesharecdn.com/ieeepaperresumeparser-150125073603-conversion-gate01/75/Resume-Parsing-with-Named-Entity-Clustering-Algorithm-6-2048.jpg)

The paper presents a resume information extraction system that utilizes a named entity clustering algorithm to transform unstructured resume data into structured information, enhancing the efficiency of recruitment agencies. The extraction process involves four key phases: text segmentation, named entity recognition, named entity clustering, and text normalization. The proposed system effectively automates resume parsing, reducing the manual workload for HR managers and job seekers, though it relies on modern technological infrastructure.
















































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)

















