Downloaded 49 times













![Stream Processing History
• Tapestry – ’92
– Early inverted database (not Apache!)
• Materialized views – ‘95
– [A. Gupta and I. S. Mumick. “Maintenance of materialized views: Problems,
techniques, and applications.” 1995]
• David Luckham coined term CEP – “The Power Events”. 2001
– Logic-based CEP
– Company acquired by Avaya
• Michael Franklin
– Dataflow processing in PostgreSQL
– [“TelegraphCQ: continuous dataflow processing.” 2003]
• Aurora – ‘03
– [Cherniack et al – “Scalable distributed stream processing.” 2003]
• STREAM – ‘03
– [Arasu et al – “STREAM: The Stanford Stream Data Manager.” 2003]
• Borealis – ‘05
– [Abadi et al – “The design of the Borealis stream processing engine.” 2005]
Copyright Push Technology 2014](https://image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-15-2048.jpg)





![How can we define queries on windows?
• Describe queries on windows using a
SQL-like syntax
SELECT AVG(price) FROM stream [ROWS N]
• [Arasu et al. – “The CQL Continuous Query
Language: Semantic Foundations and Query
Execution” 2003]
Copyright Push Technology 2014](https://image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-23-2048.jpg)
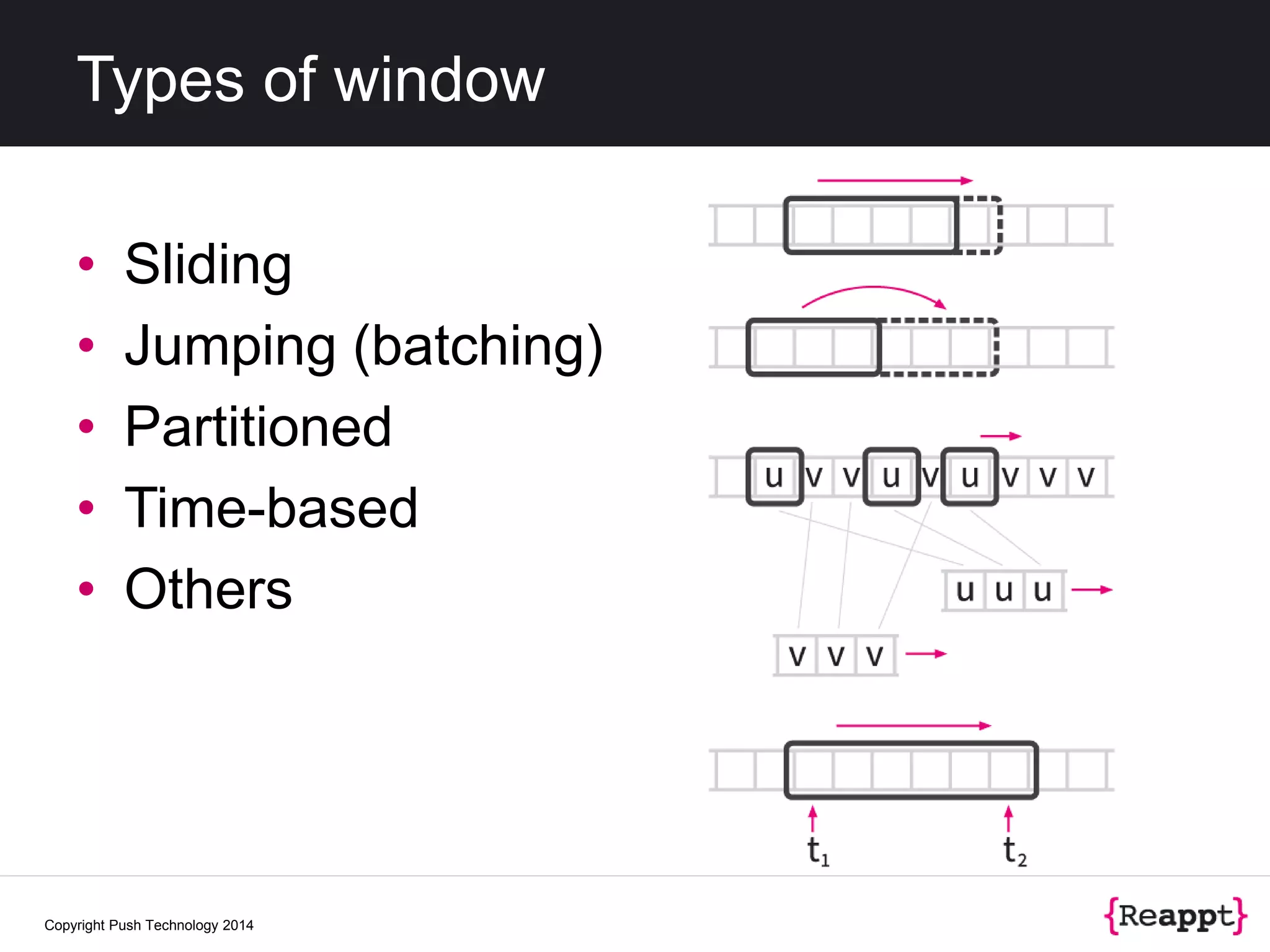
![Querying windows
• Sliding
SELECT * FROM s [ROWS 4 SLIDE 4]
• Partitioned
SELECT a, b FROM s
[PARTITION BY b ROWS 3]
• Time-based
SELECT * FROM s [RANGE 30 SECONDS]
Copyright Push Technology 2014](https://image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-24-2048.jpg)





![How do you reliably distribute?
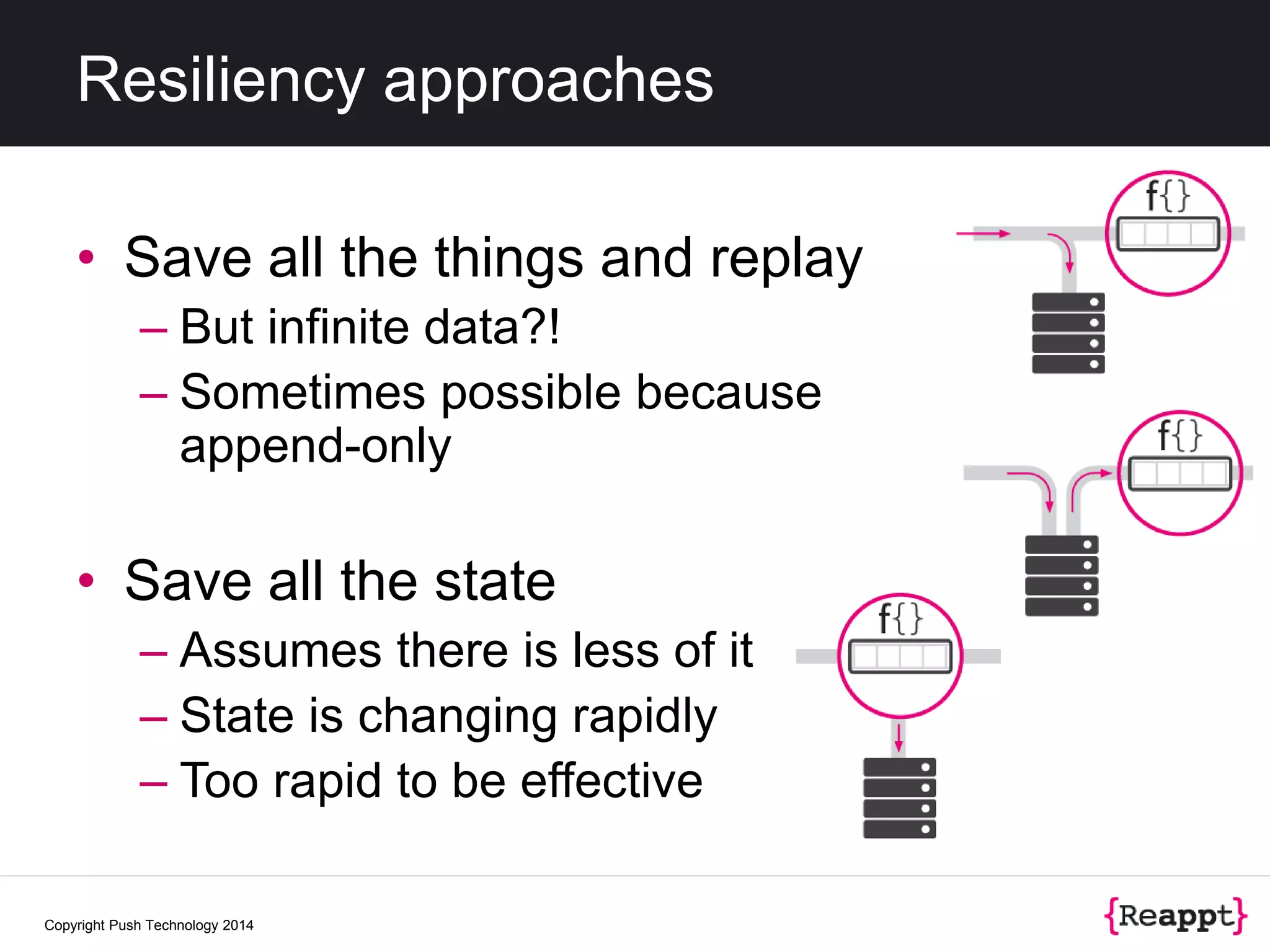
• State is now distributed
– Synchronization all but impossible
– Deterministic if relative order is preserved
• Depends on operators and their effect
• [L. Lamport - “Time, Clocks, and the Ordering of
Events in a Distributed System.” 1978]
– In theory a replay of things through the
network will recover the state
– Alternative of storing the state for all the
operators is harder
Copyright Push Technology 2014](https://image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-34-2048.jpg)
![How do you reliably distribute?
• Different classes of recovery
– [Hwang et al. – “High-Availability Algorithms
for Distributed Stream Processing”. 2005]
• Precise recovery – failure effects hidden perfectly
• Rollback recovery – no data loss, but outputs
may be duplicated
• Gap recovery – data lost during recovery
• Reliable distribution overlaps distribution
– Upstream backup, reactive streams?
Copyright Push Technology 2014](https://image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-35-2048.jpg)





















![Stream Processing History
• Tapestry – ’92
– Early inverted database (not Apache!)
• Materialized views – ‘95
– [A. Gupta and I. S. Mumick. “Maintenance of materialized views: Problems,
techniques, and applications.” 1995]
• David Luckham coined term CEP – “The Power Events”. 2001
– Logic-based CEP
– Company acquired by Avaya
• Michael Franklin
– Dataflow processing in PostgreSQL
– [“TelegraphCQ: continuous dataflow processing.” 2003]
• Aurora – ‘03
– [Cherniack et al – “Scalable distributed stream processing.” 2003]
• STREAM – ‘03
– [Arasu et al – “STREAM: The Stanford Stream Data Manager.” 2003]
• Borealis – ‘05
– [Abadi et al – “The design of the Borealis stream processing engine.” 2005]
Copyright Push Technology 2014](https://crownmelresort.com/image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-15-2048.jpg)







![How can we define queries on windows?
• Describe queries on windows using a
SQL-like syntax
SELECT AVG(price) FROM stream [ROWS N]
• [Arasu et al. – “The CQL Continuous Query
Language: Semantic Foundations and Query
Execution” 2003]
Copyright Push Technology 2014](https://crownmelresort.com/image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-23-2048.jpg)
![Querying windows
• Sliding
SELECT * FROM s [ROWS 4 SLIDE 4]
• Partitioned
SELECT a, b FROM s
[PARTITION BY b ROWS 3]
• Time-based
SELECT * FROM s [RANGE 30 SECONDS]
Copyright Push Technology 2014](https://crownmelresort.com/image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-24-2048.jpg)









![How do you reliably distribute?
• State is now distributed
– Synchronization all but impossible
– Deterministic if relative order is preserved
• Depends on operators and their effect
• [L. Lamport - “Time, Clocks, and the Ordering of
Events in a Distributed System.” 1978]
– In theory a replay of things through the
network will recover the state
– Alternative of storing the state for all the
operators is harder
Copyright Push Technology 2014](https://crownmelresort.com/image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-34-2048.jpg)
![How do you reliably distribute?
• Different classes of recovery
– [Hwang et al. – “High-Availability Algorithms
for Distributed Stream Processing”. 2005]
• Precise recovery – failure effects hidden perfectly
• Rollback recovery – no data loss, but outputs
may be duplicated
• Gap recovery – data lost during recovery
• Reliable distribution overlaps distribution
– Upstream backup, reactive streams?
Copyright Push Technology 2014](https://crownmelresort.com/image.slidesharecdn.com/reapptreact2014-pf2-141120170644-conversion-gate02/75/Reactconf-2014-Event-Stream-Processing-35-2048.jpg)











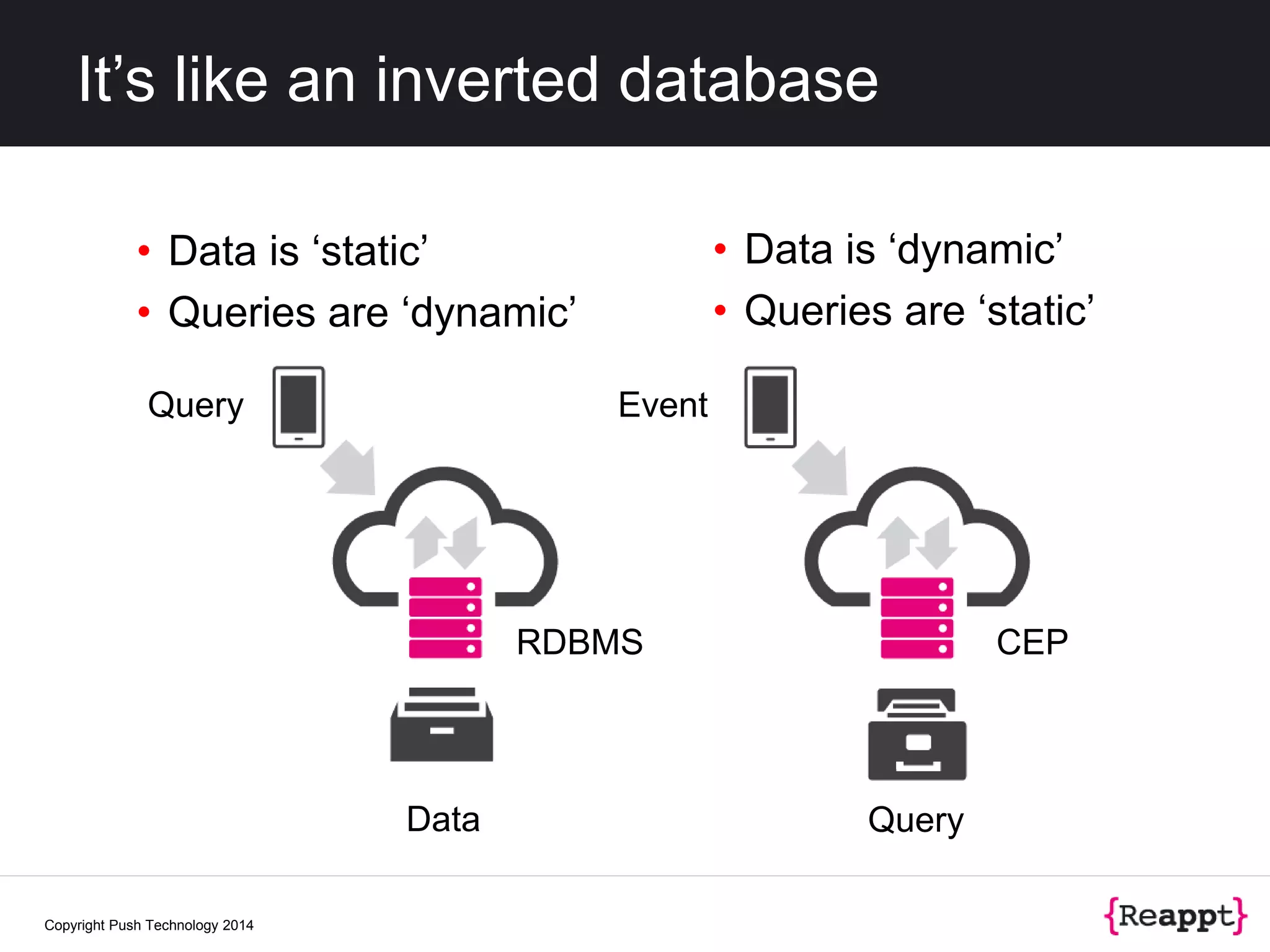
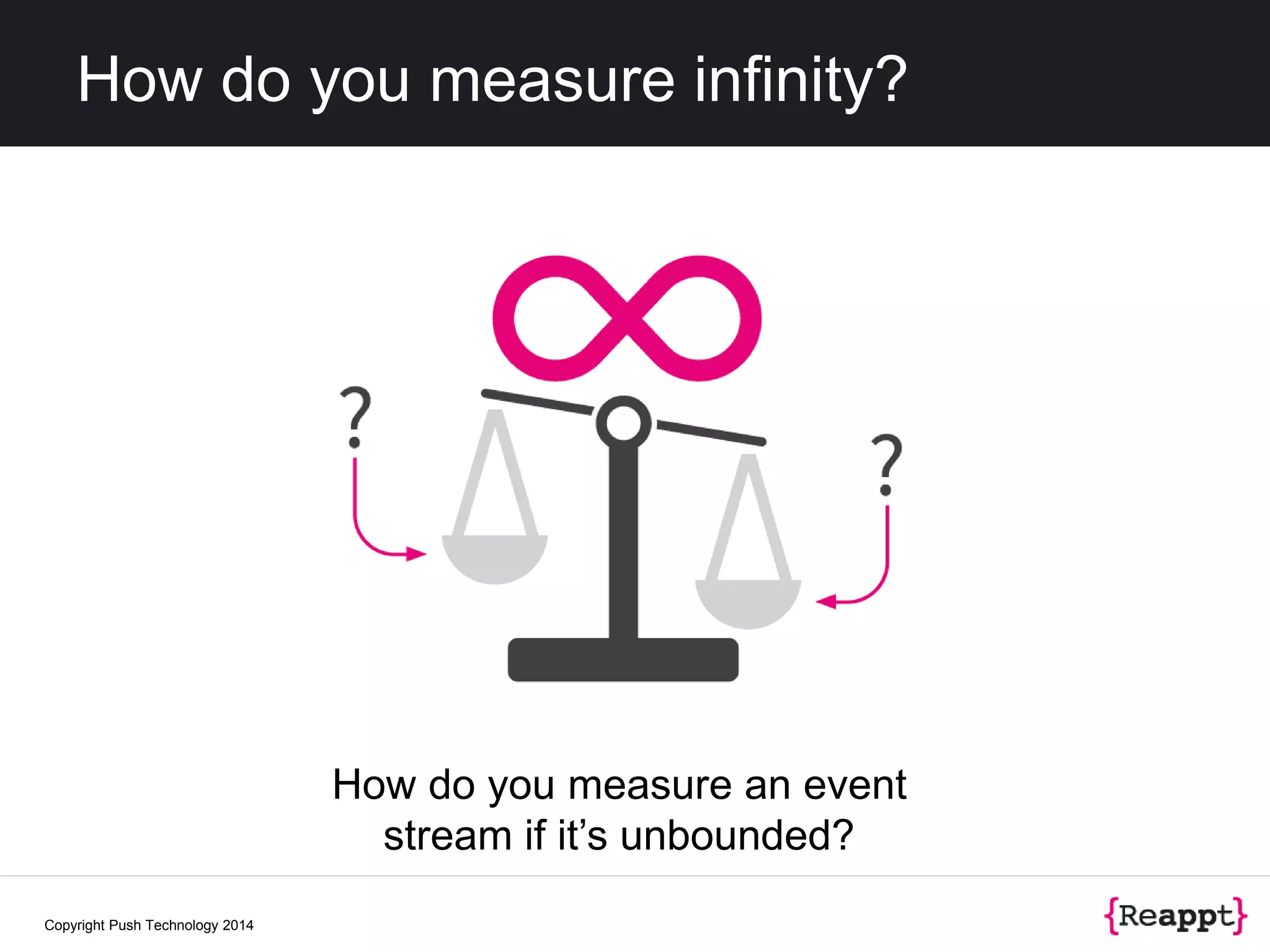
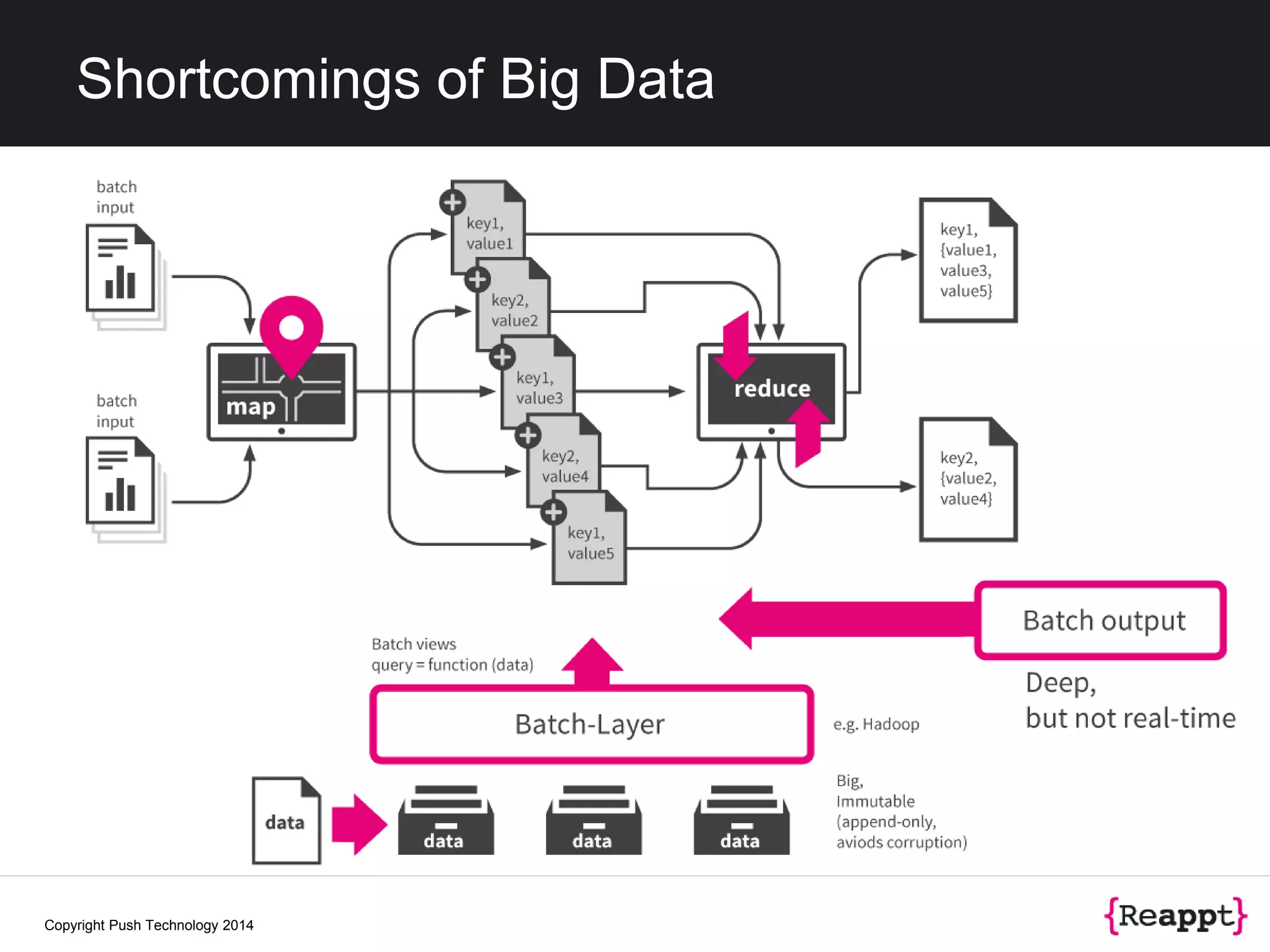
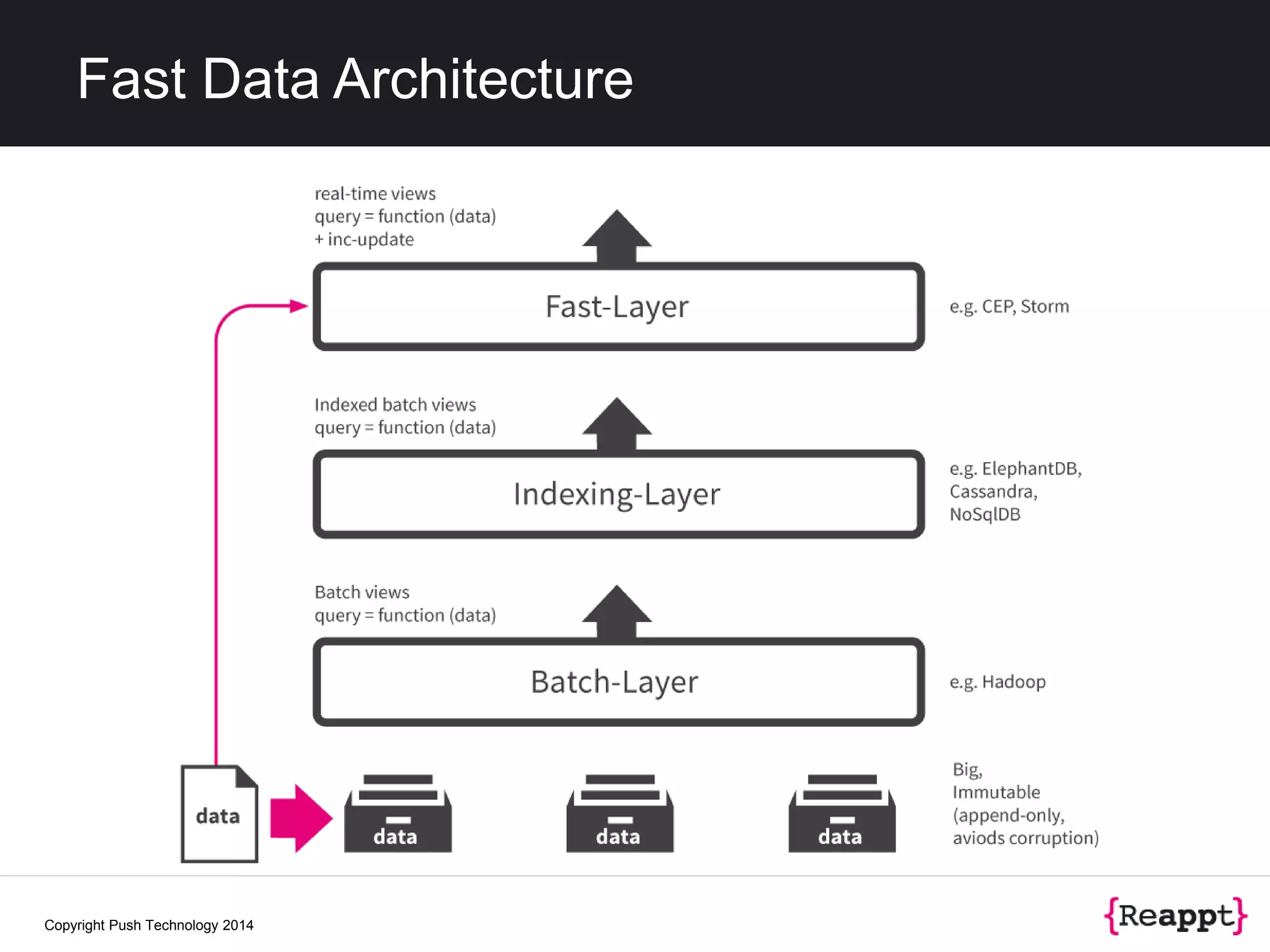
The document discusses event stream processing (ESP) and how it differs from other data processing methods, emphasizing its focus on identifying meaningful patterns in dynamic data streams. It outlines the historical context, definitions, and challenges related to measuring and processing unbounded event streams. Additionally, it explores scalability, resiliency, and future trends in stream processing technology, highlighting tools like Apache Storm and frameworks for integrating fast data architectures.




















![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)




























