Download as PDF, PPTX



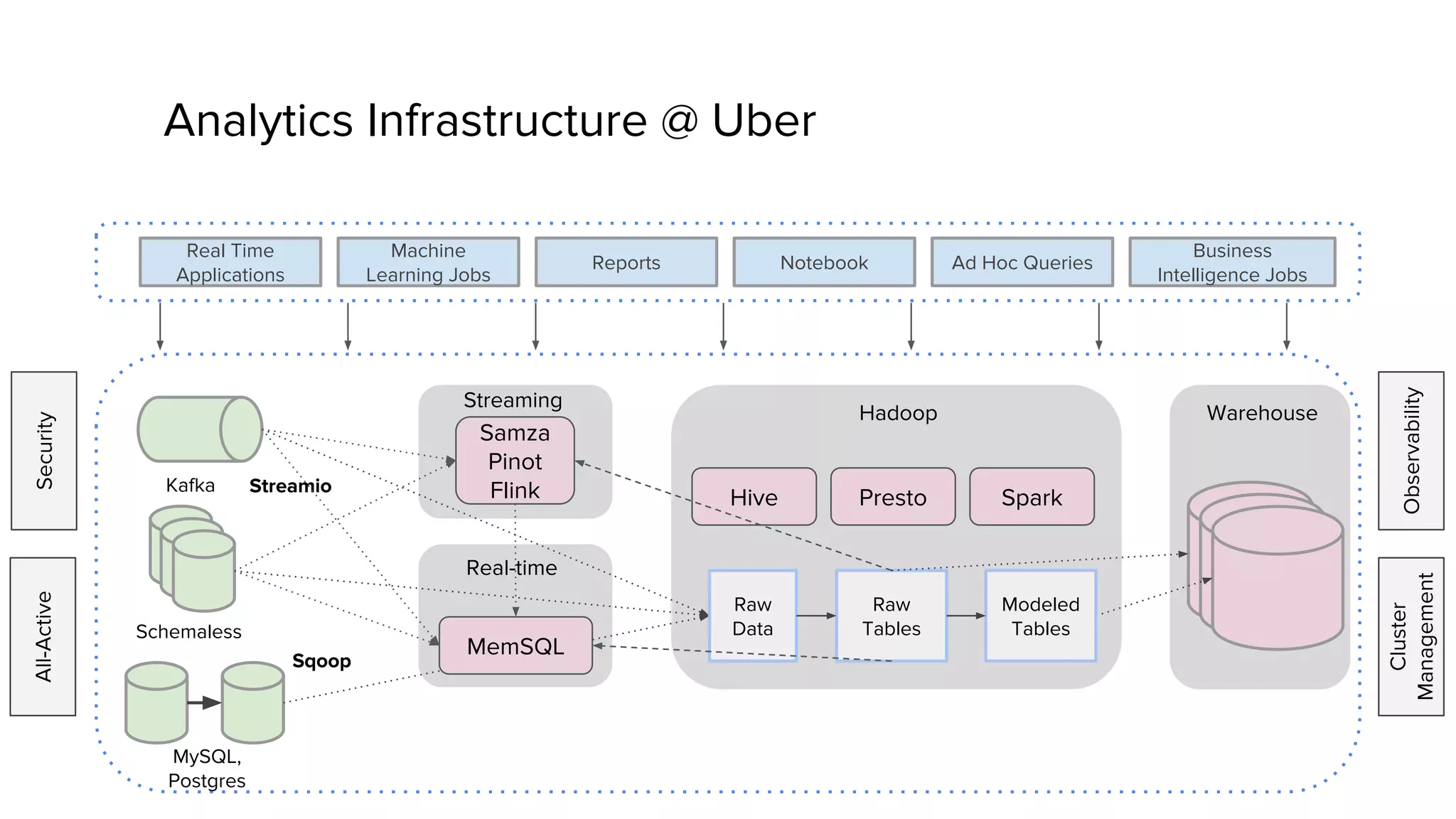




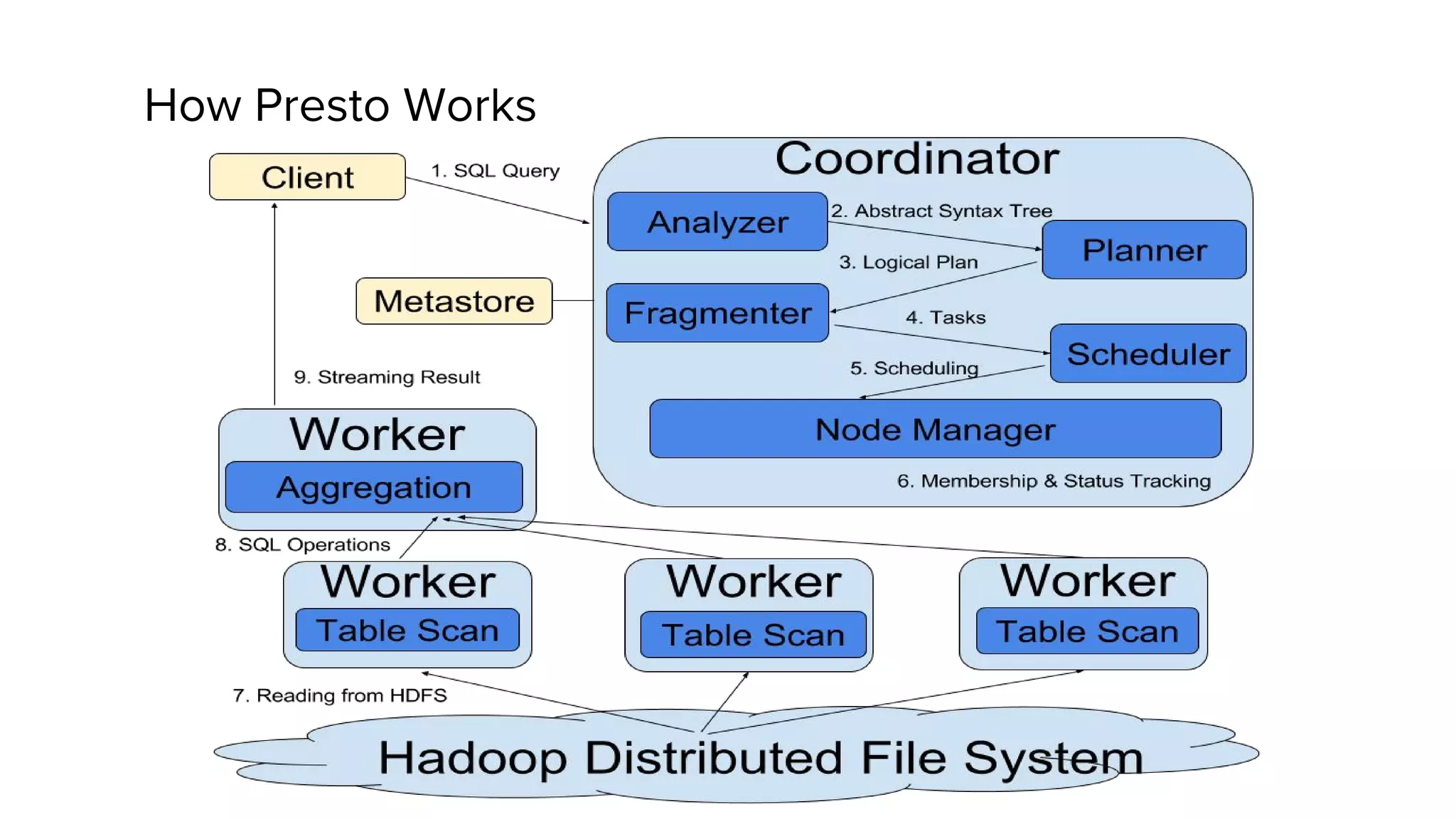



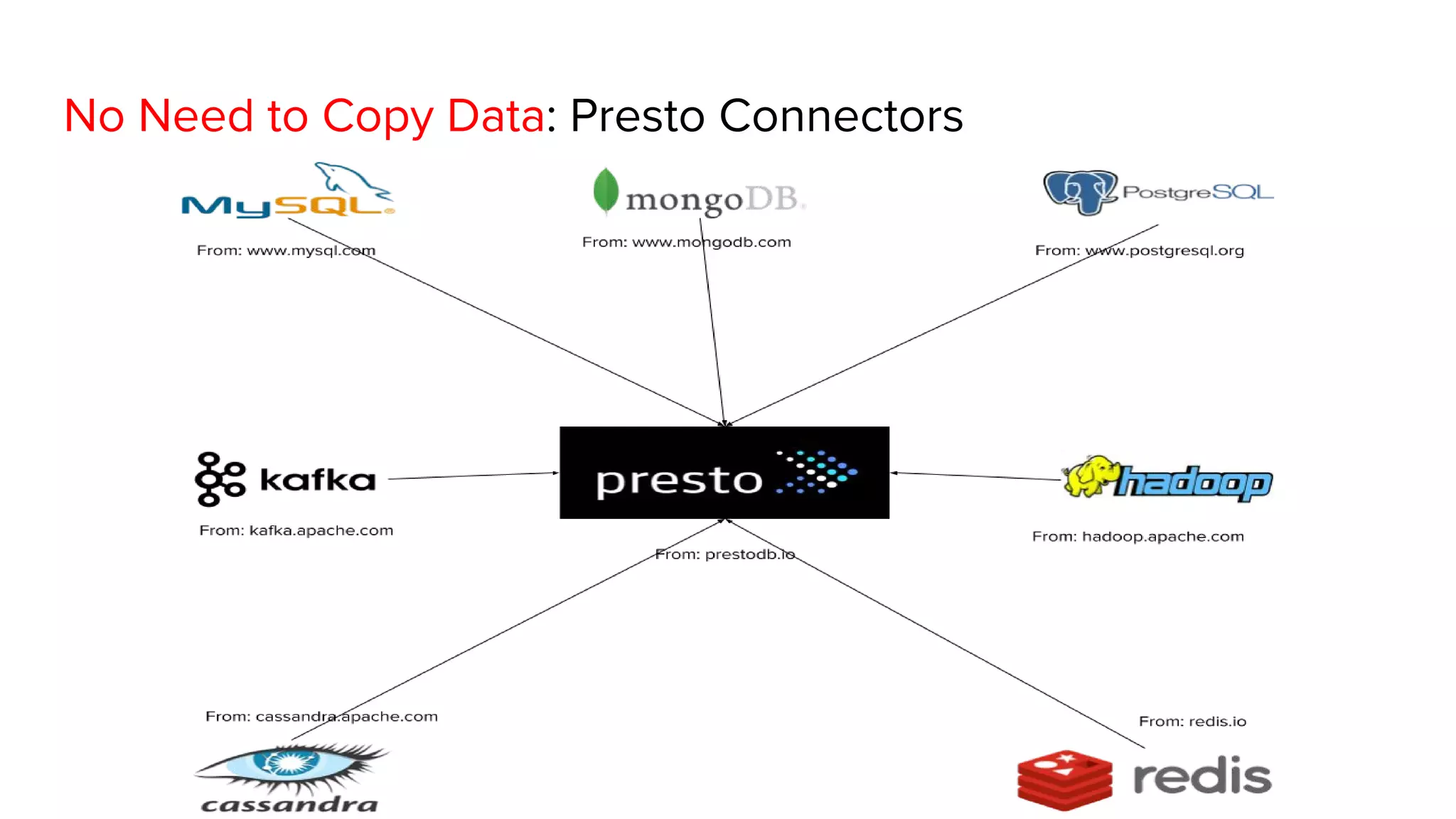
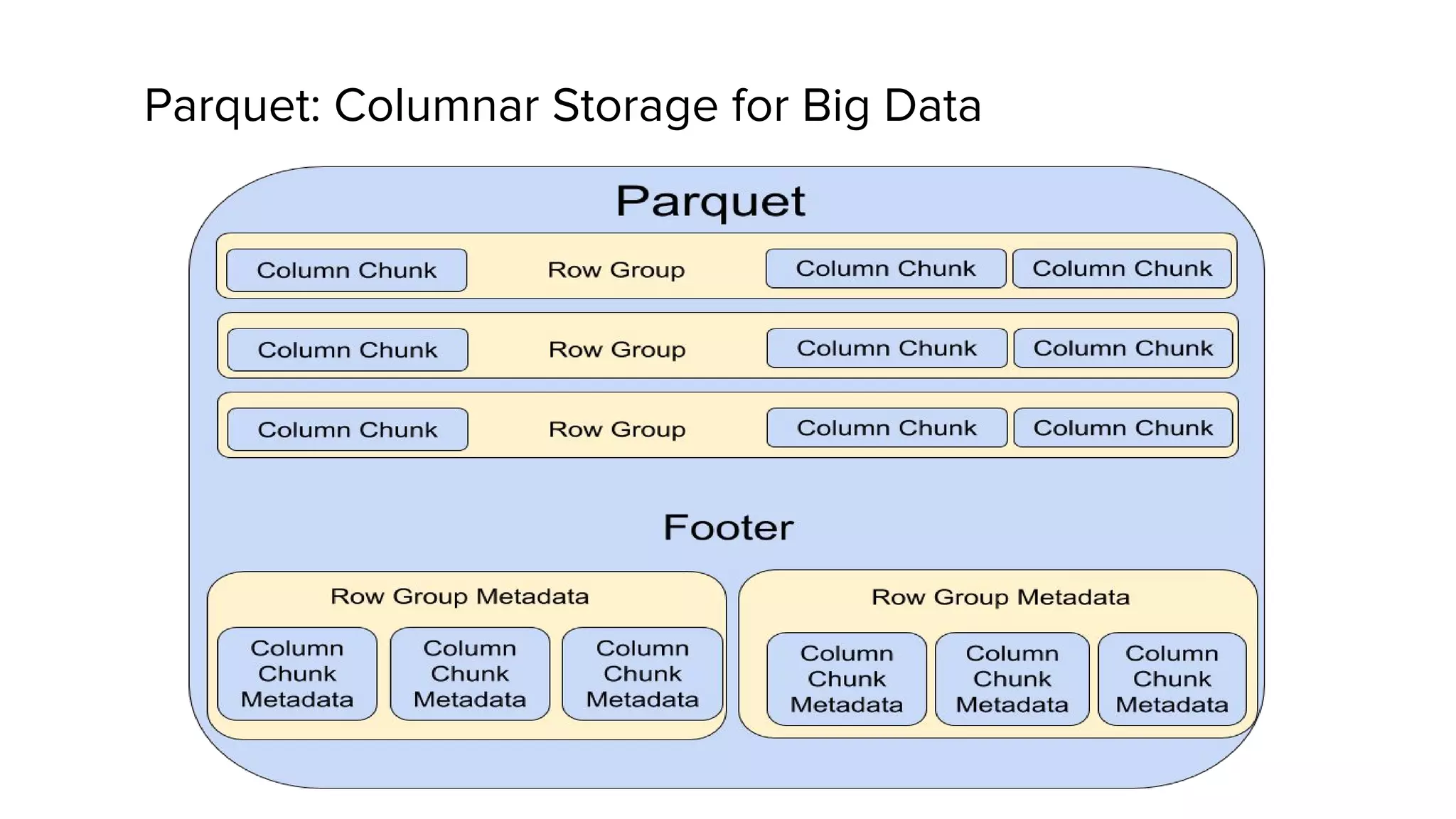

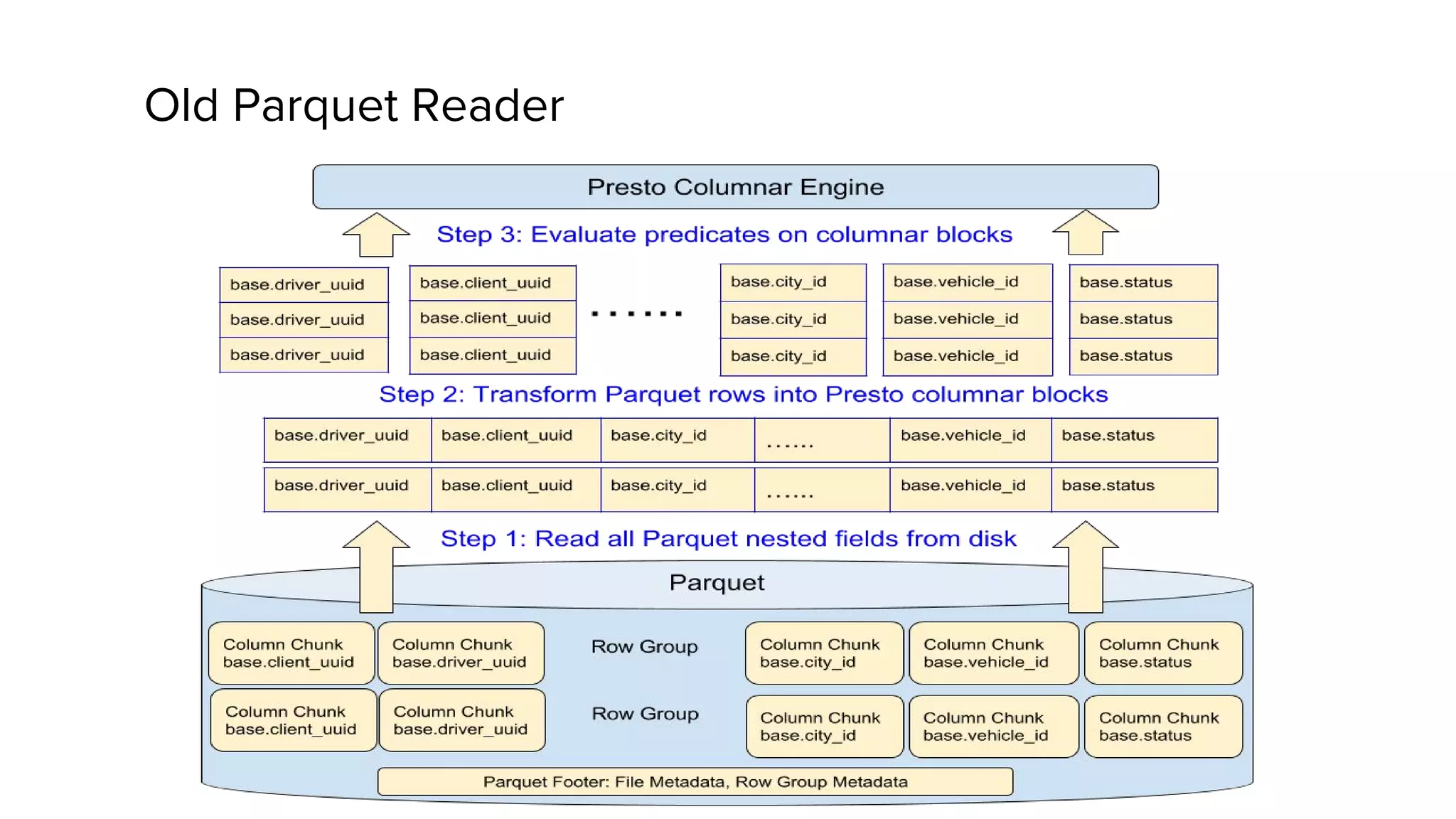
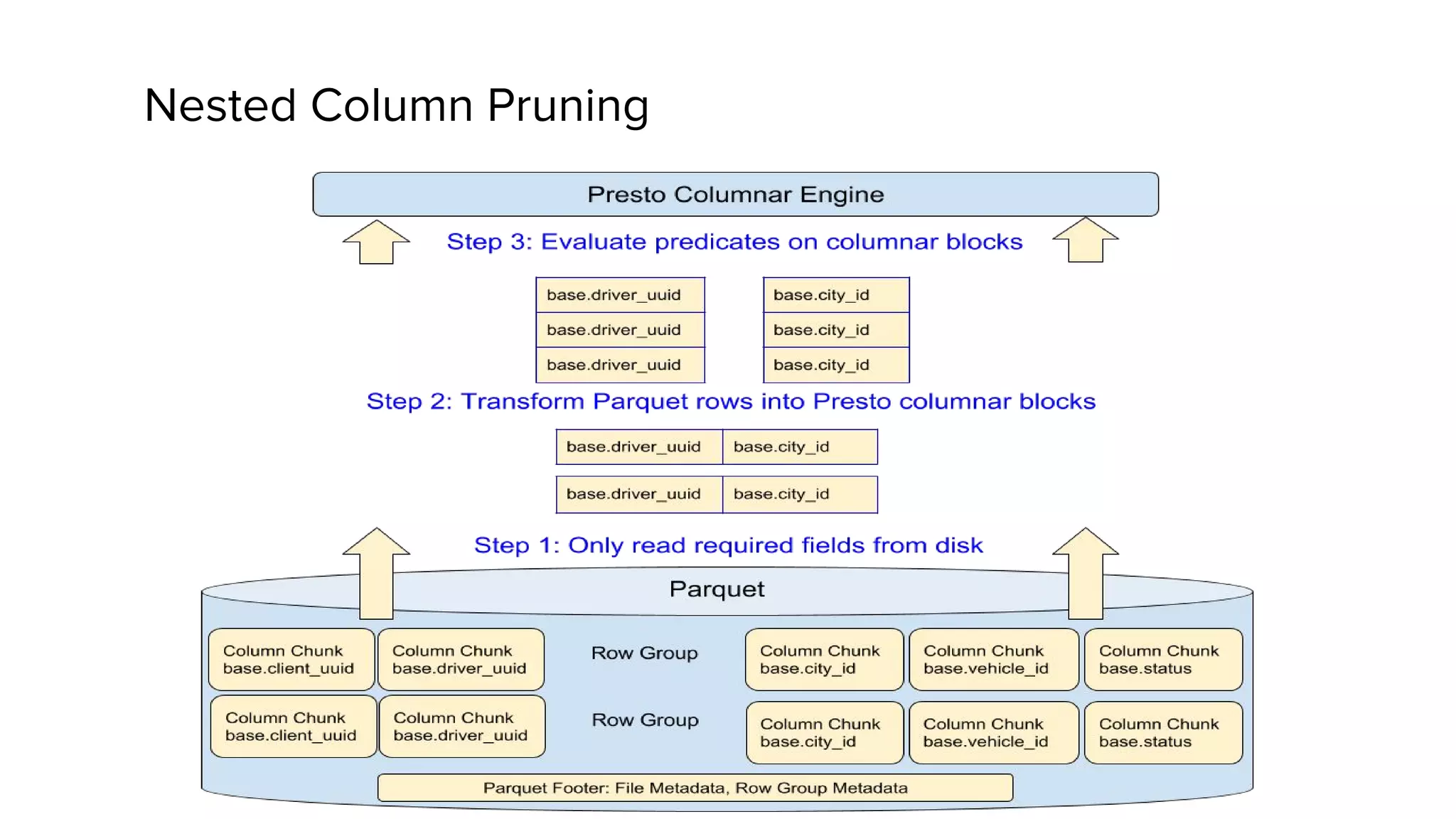
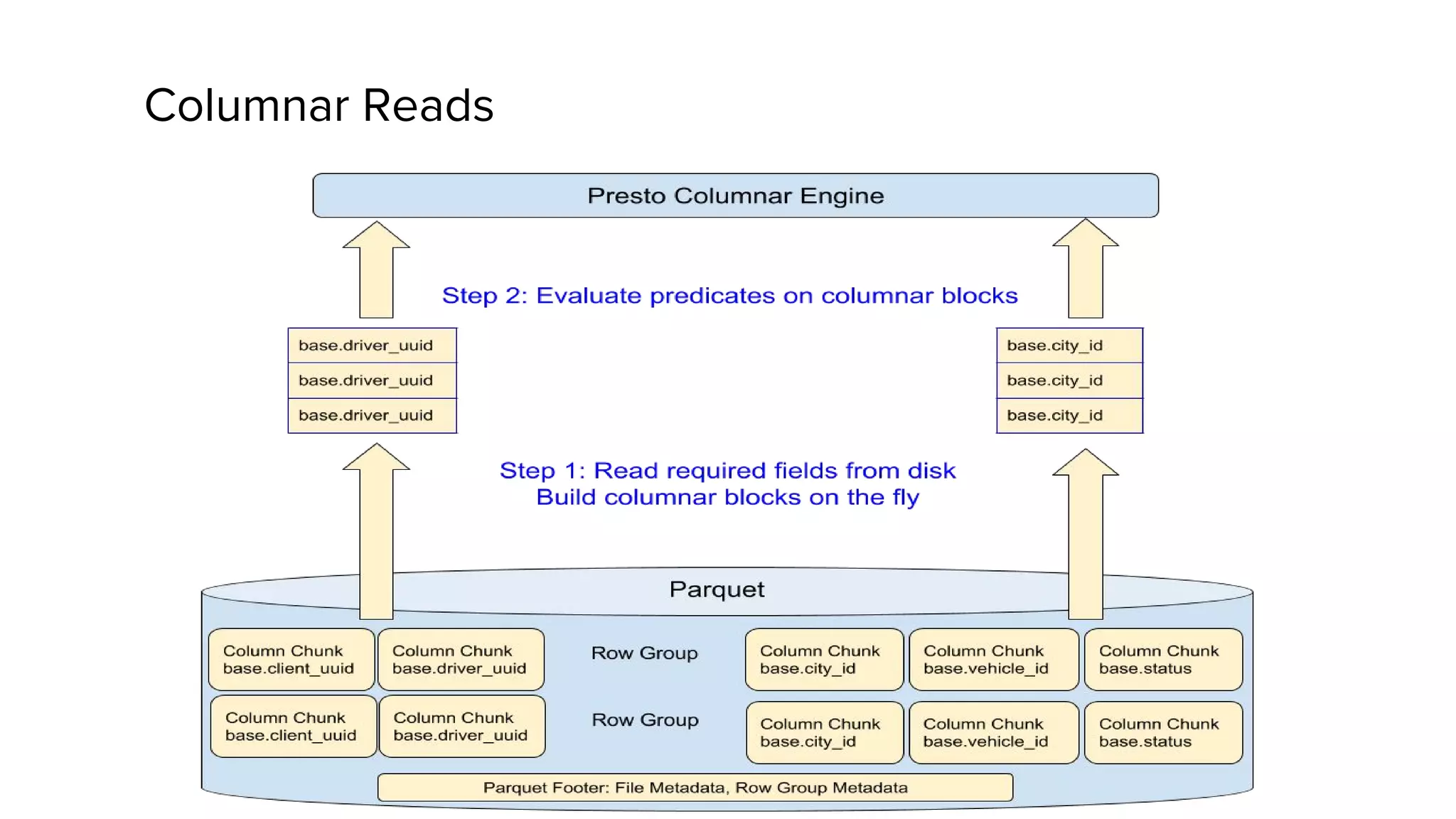
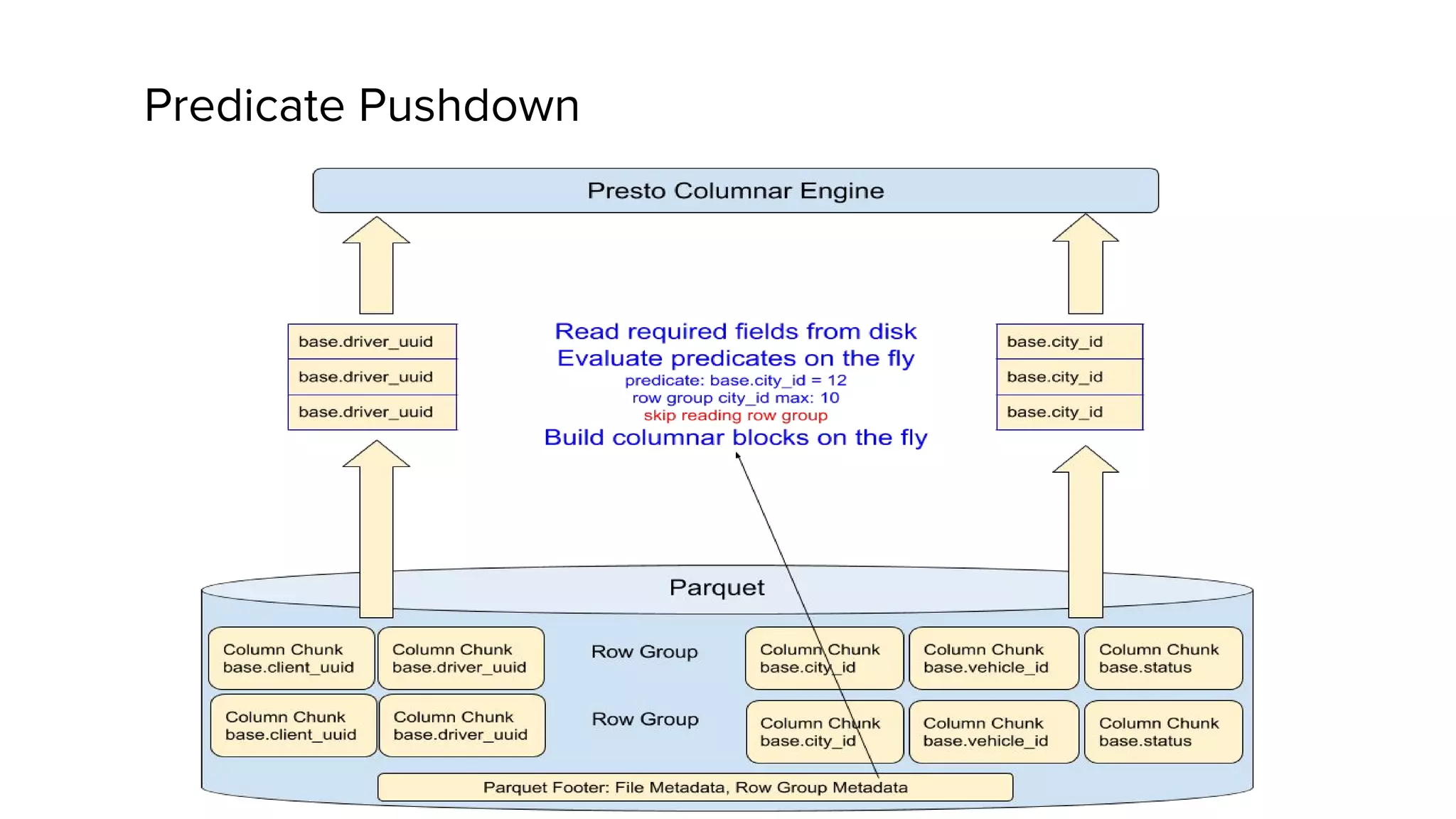
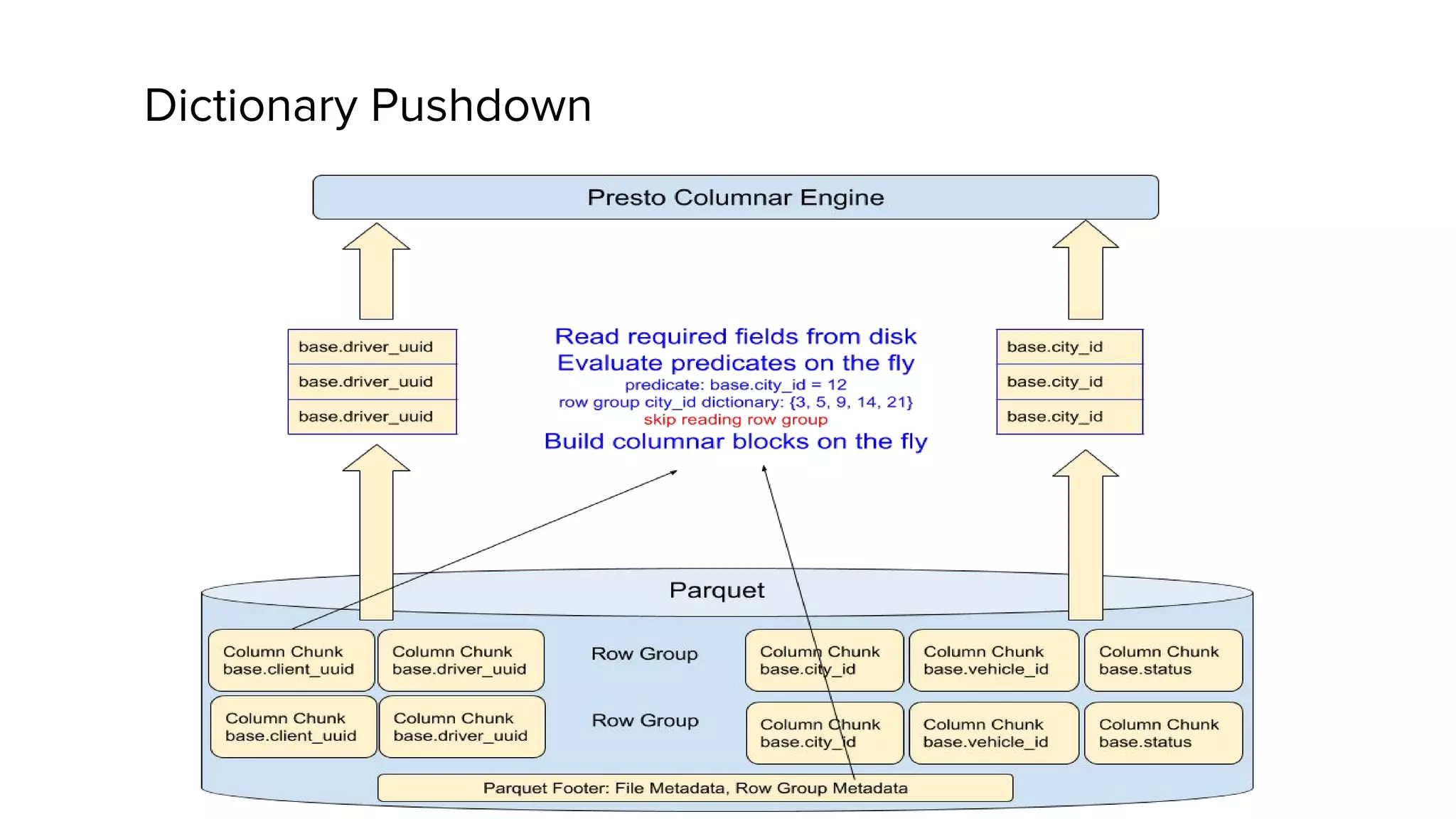
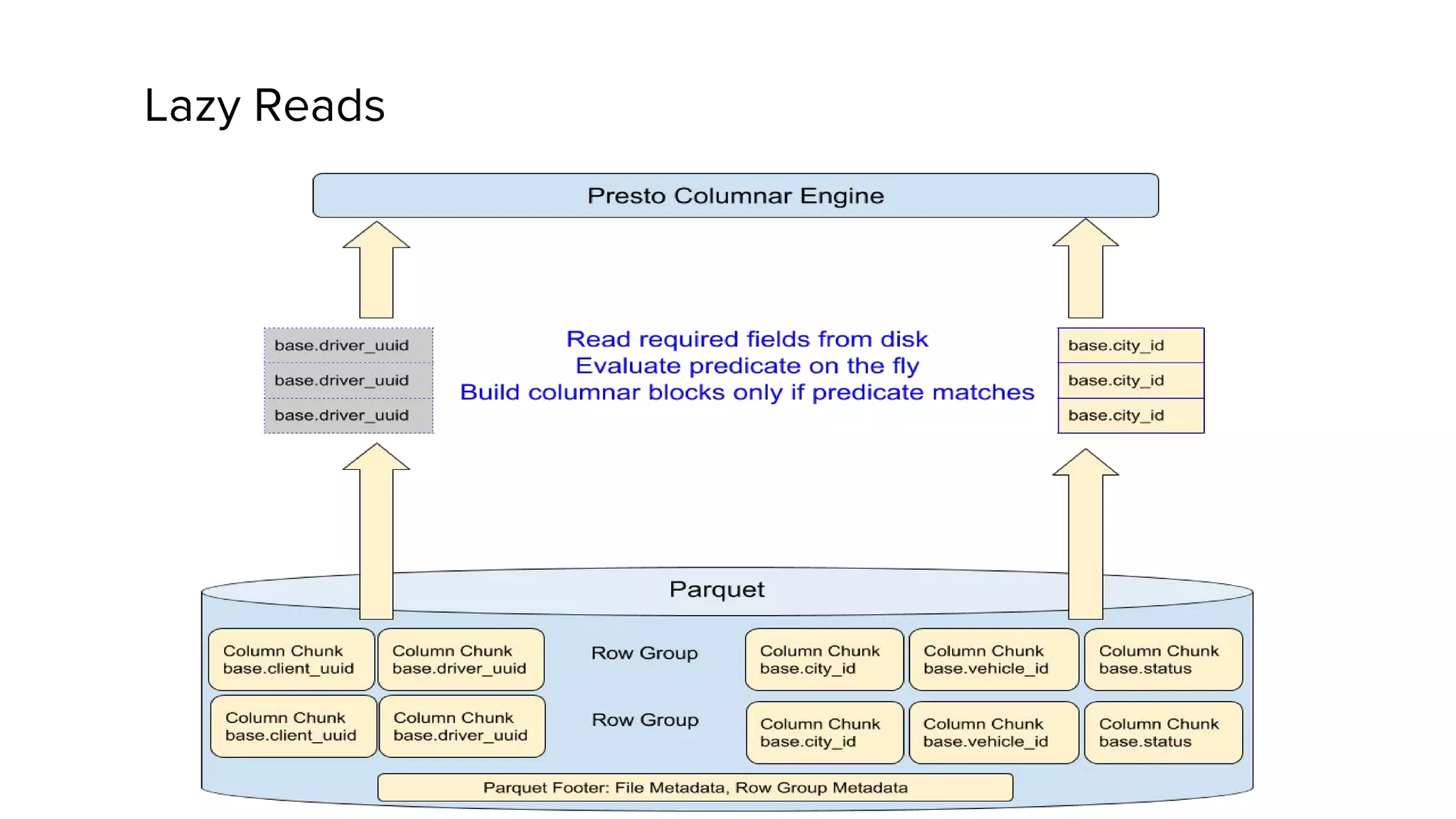
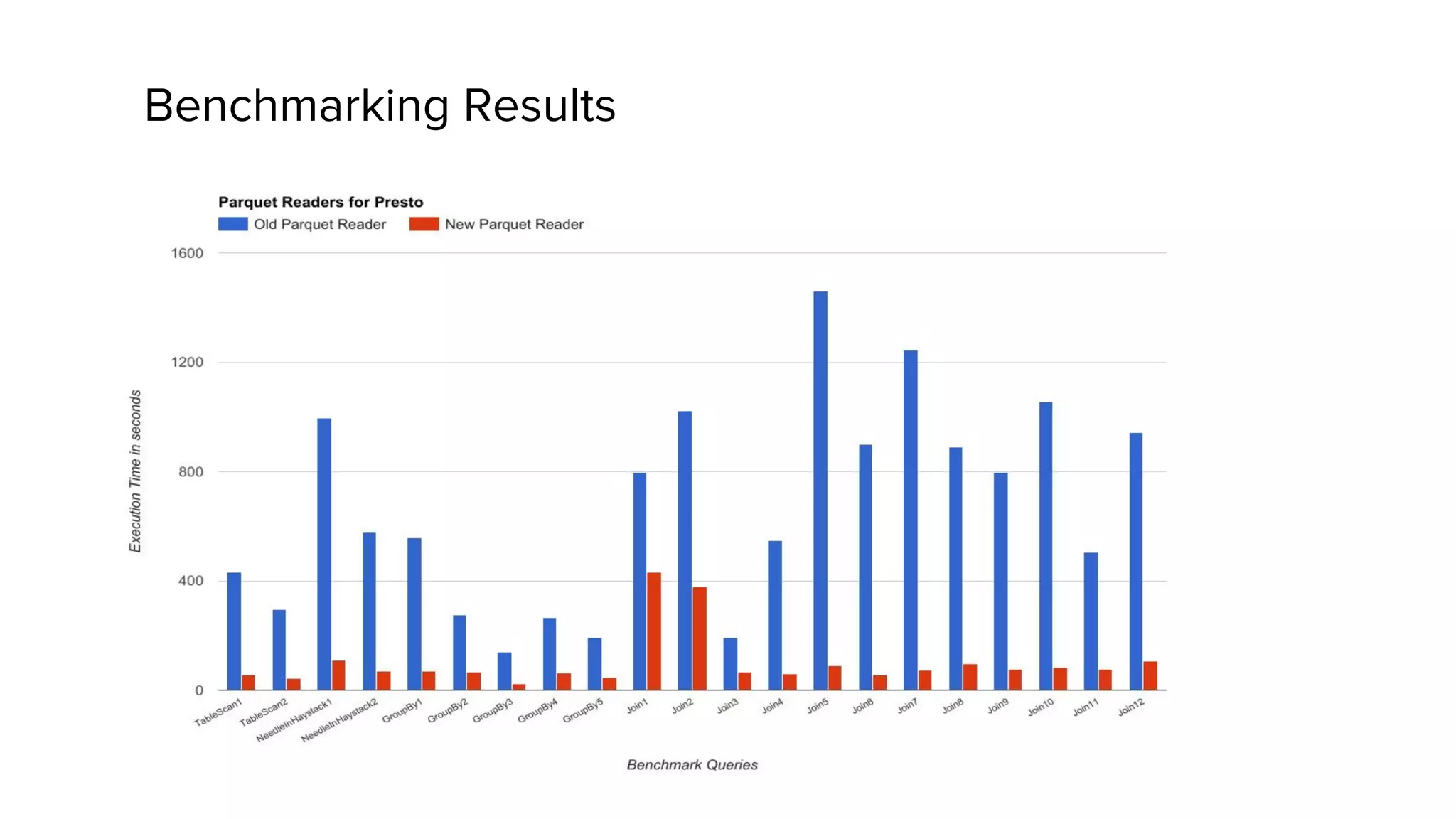





























This document discusses Presto, an interactive SQL query engine for big data. It describes how Presto is optimized to quickly query data stored in Parquet format at Uber. Key optimizations for Parquet include nested column pruning, columnar reads, predicate pushdown, dictionary pushdown, and lazy reads. Benchmark results show these optimizations improve Presto query performance. The document also provides an overview of Uber's analytics infrastructure, applications of Presto, and ongoing work to further optimize Presto and Hadoop.



































































