















![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
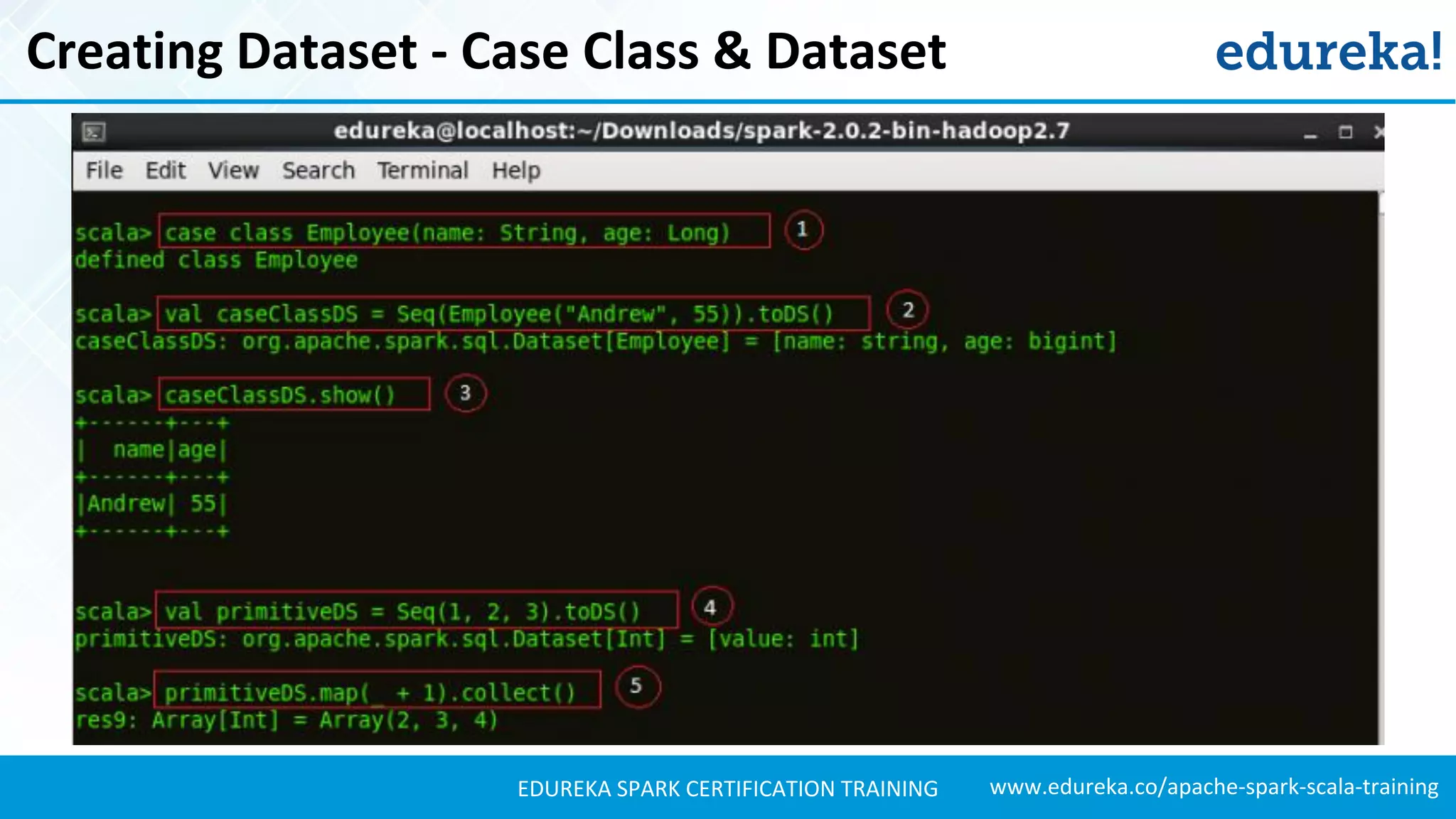
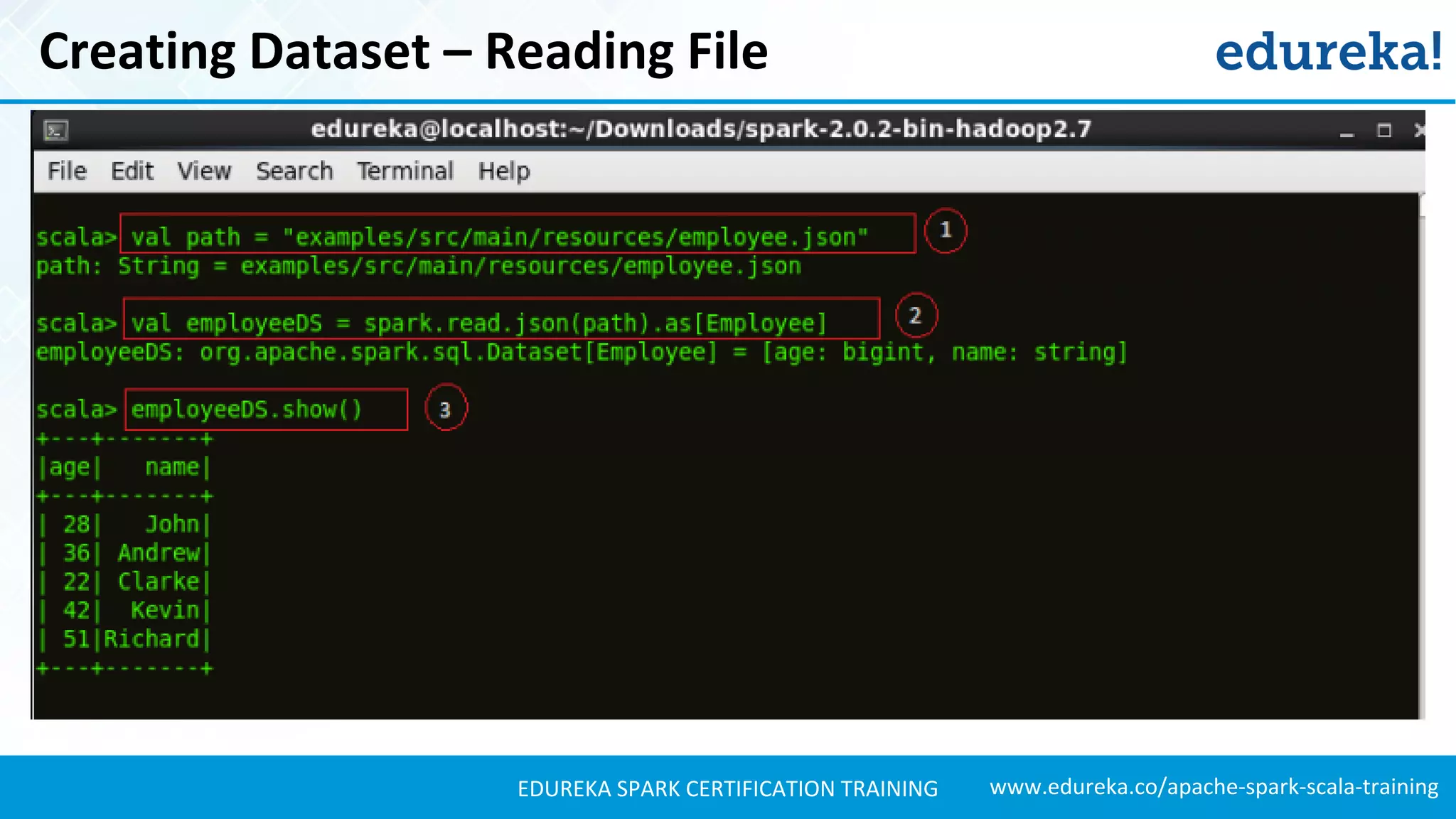
Creating Dataset – Reading File
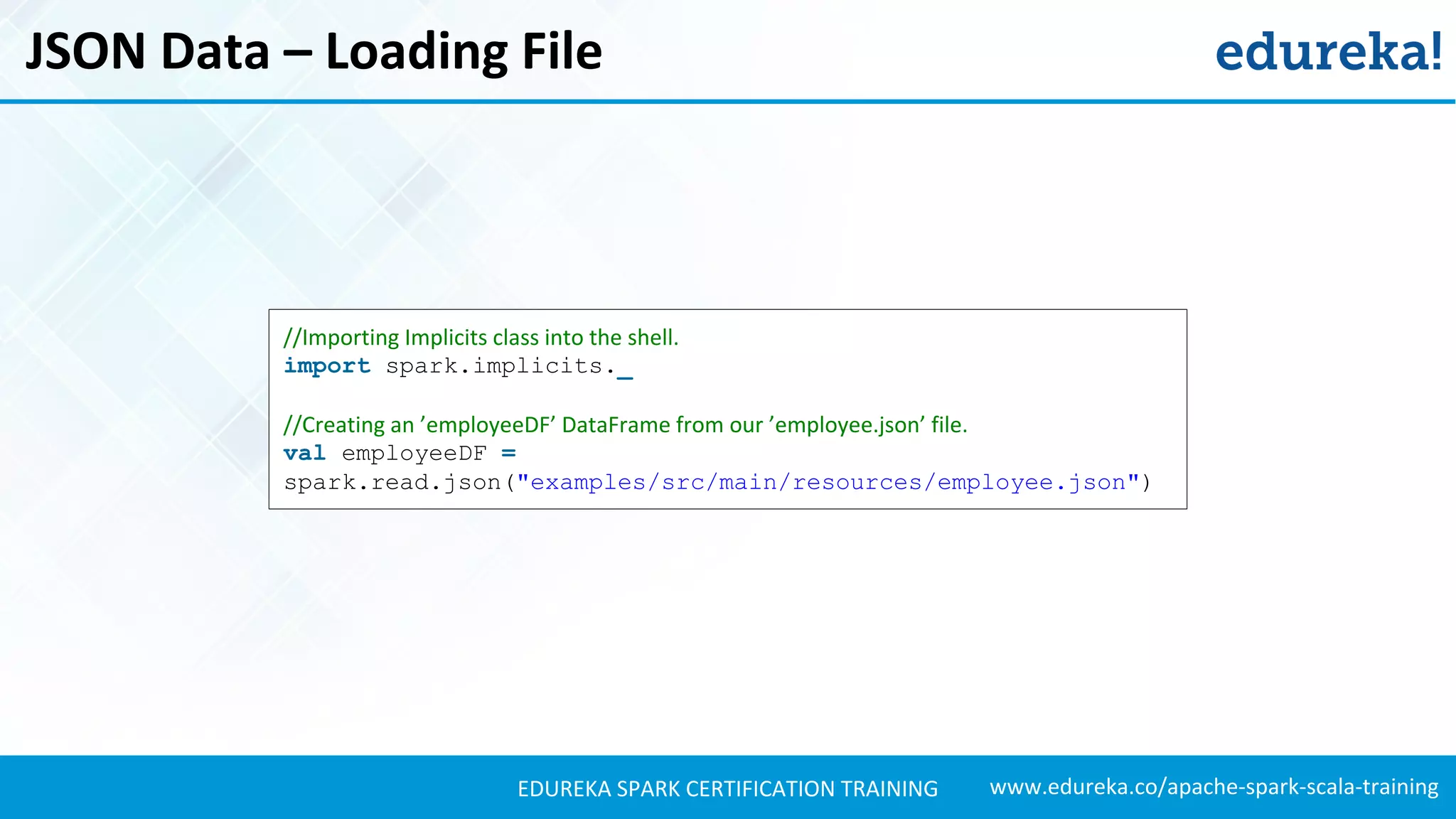
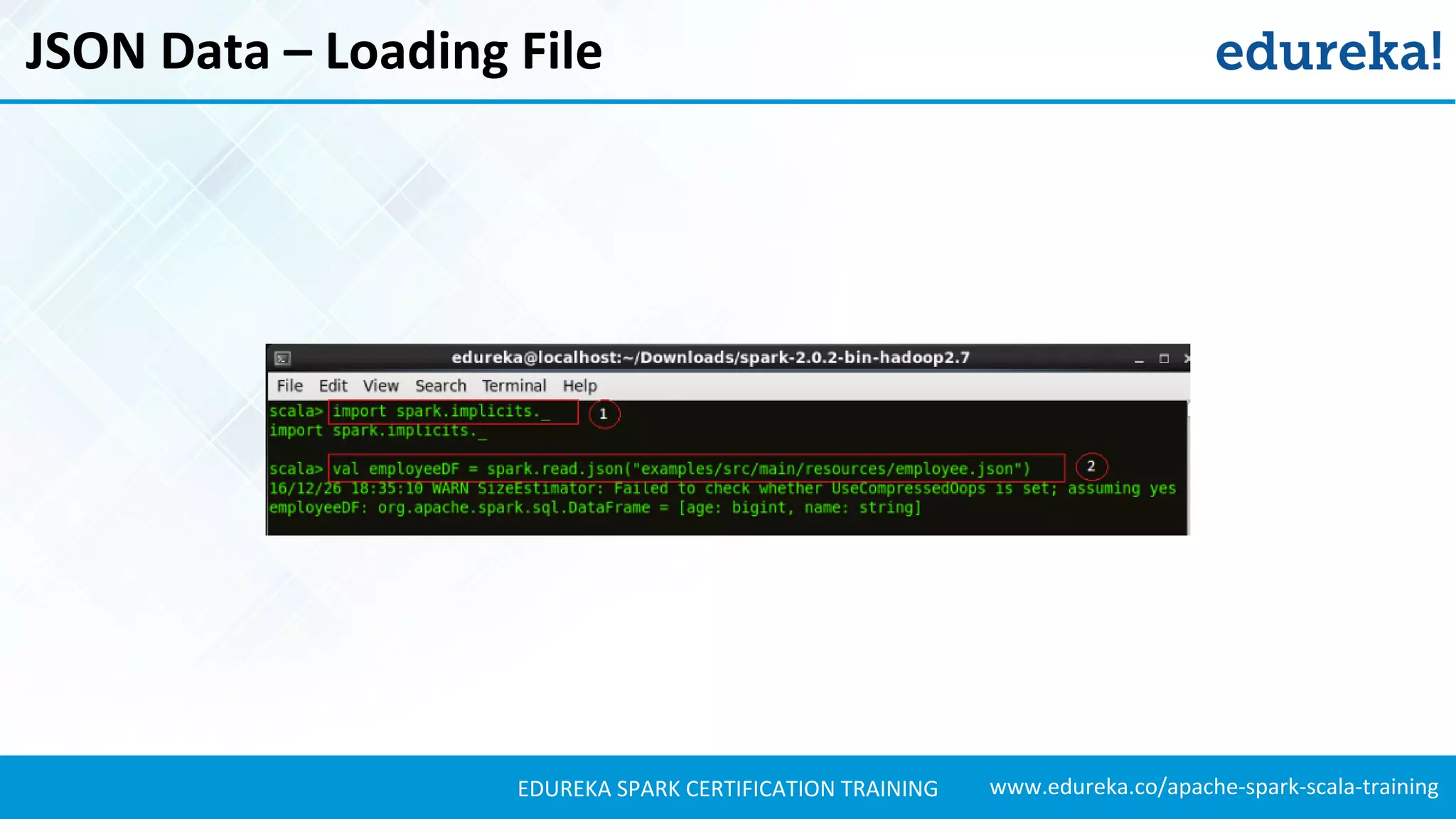
//Setting the path to our JSON file ’employee.json’.
val path = "examples/src/main/resources/employee.json"
//Creating a Dataset and from the file.
val employeeDS = spark.read.json(path).as[Employee]
//Displaying the contents of ’employeeDS’ Dataset.
employeeDS.show()](https://image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/75/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-33-2048.jpg)



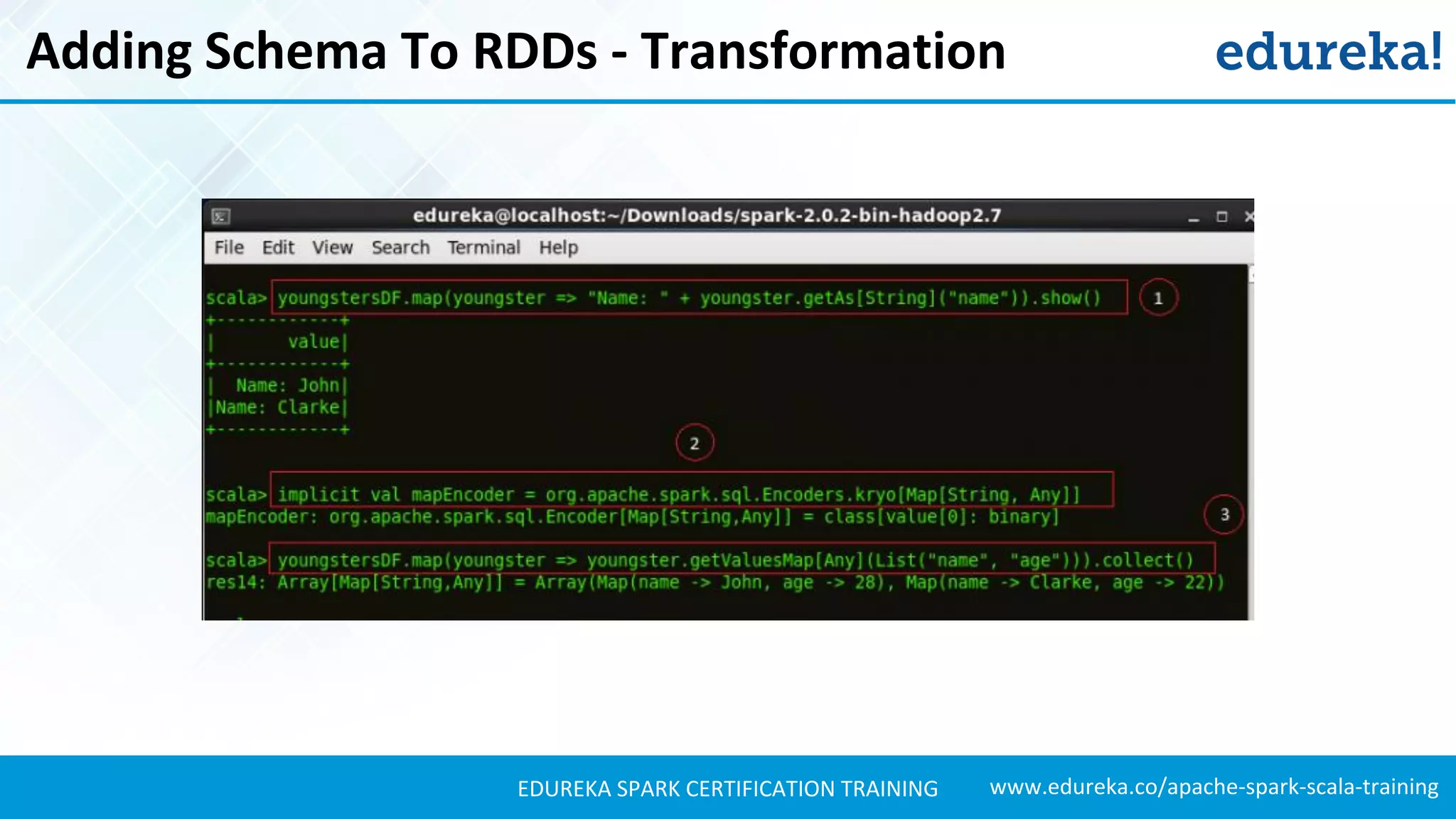
).show()
//Using the mapEncoder from Implicits class to map the names to the ages.
implicit val mapEncoder =
org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
//Mapping the names to the ages of our ‘youngstersDF’ DataFrame. The result is an array with names
mapped to their respective ages.
youngstersDF.map(youngster =>
youngster.getValuesMap[Any](List("name", "age"))).collect()](https://image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/75/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-38-2048.jpg)


















































![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Creating Dataset – Reading File
//Setting the path to our JSON file ’employee.json’.
val path = "examples/src/main/resources/employee.json"
//Creating a Dataset and from the file.
val employeeDS = spark.read.json(path).as[Employee]
//Displaying the contents of ’employeeDS’ Dataset.
employeeDS.show()](https://crownmelresort.com/image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/75/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-33-2048.jpg)




).show()
//Using the mapEncoder from Implicits class to map the names to the ages.
implicit val mapEncoder =
org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
//Mapping the names to the ages of our ‘youngstersDF’ DataFrame. The result is an array with names
mapped to their respective ages.
youngstersDF.map(youngster =>
youngster.getValuesMap[Any](List("name", "age"))).collect()](https://crownmelresort.com/image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/75/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-38-2048.jpg)















































The document provides an extensive overview of Spark SQL, including its advantages over Apache Hive, features, architecture, and libraries. It discusses how Spark SQL improves performance through real-time querying and integration with various data formats, while offering practical use cases like Twitter sentiment analysis and stock market data analysis. Additionally, it outlines the steps for initializing a Spark shell, creating datasets, and executing SQL operations within Spark.
Introduction to Spark Certification Training including best practices in DevOps culture and an overview of what to expect.
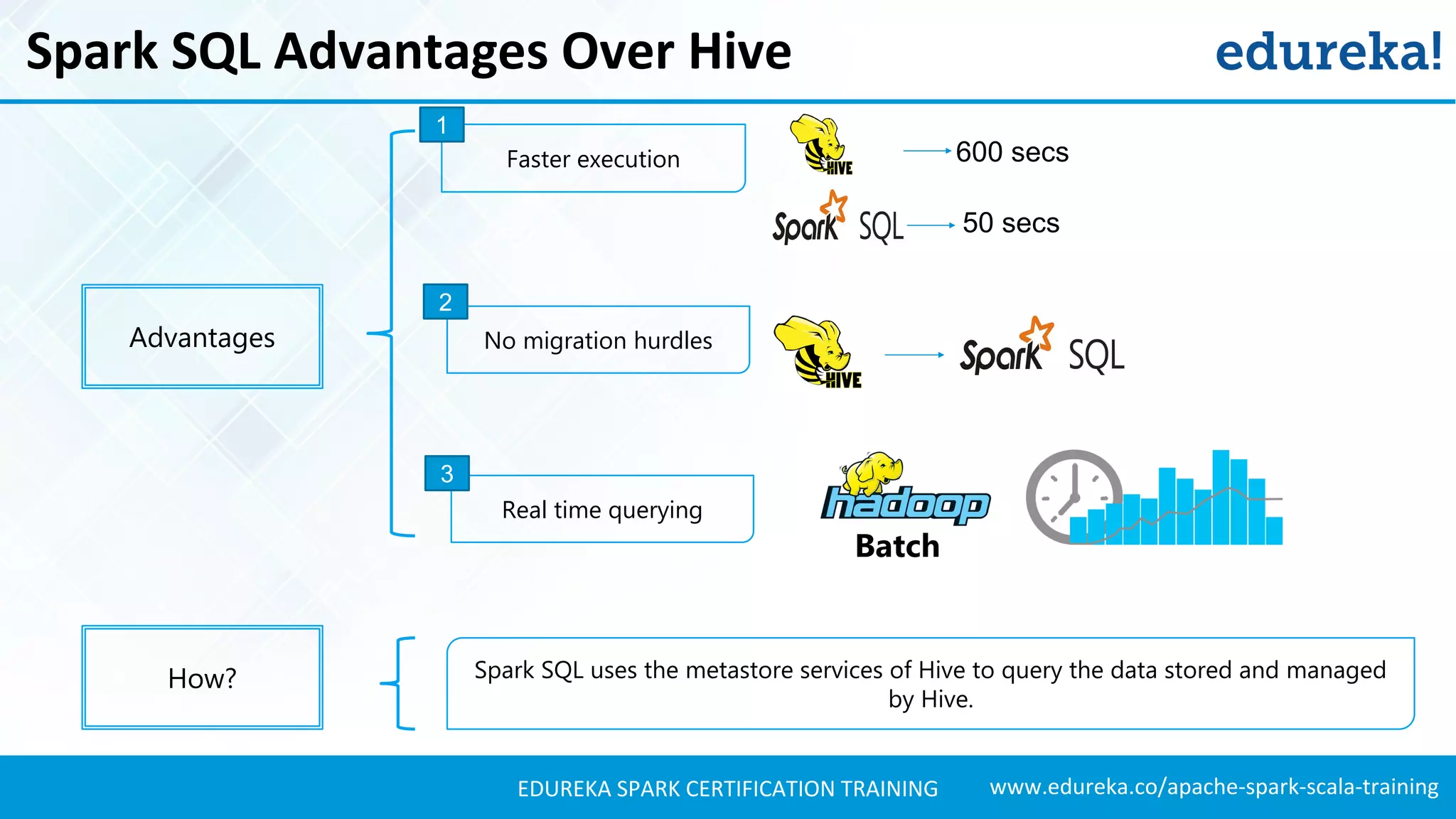
Discusses the limitations of Apache Hive and reasons for Spark SQL's development to facilitate improved performance and capabilities.
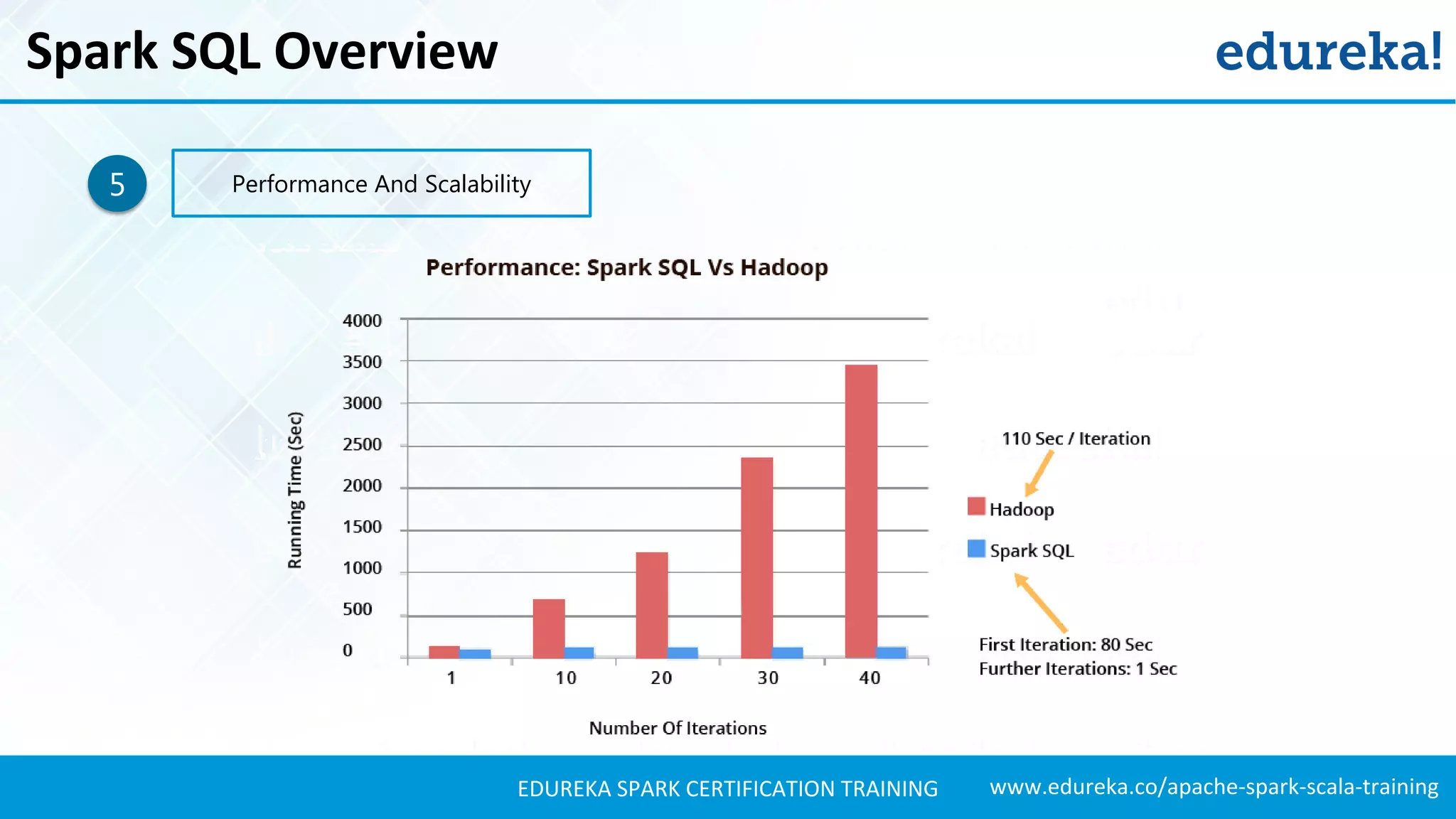
Highlights the advantages of Spark SQL over Hive, including faster execution and real-time querying, with use cases like Twitter sentiment analysis.
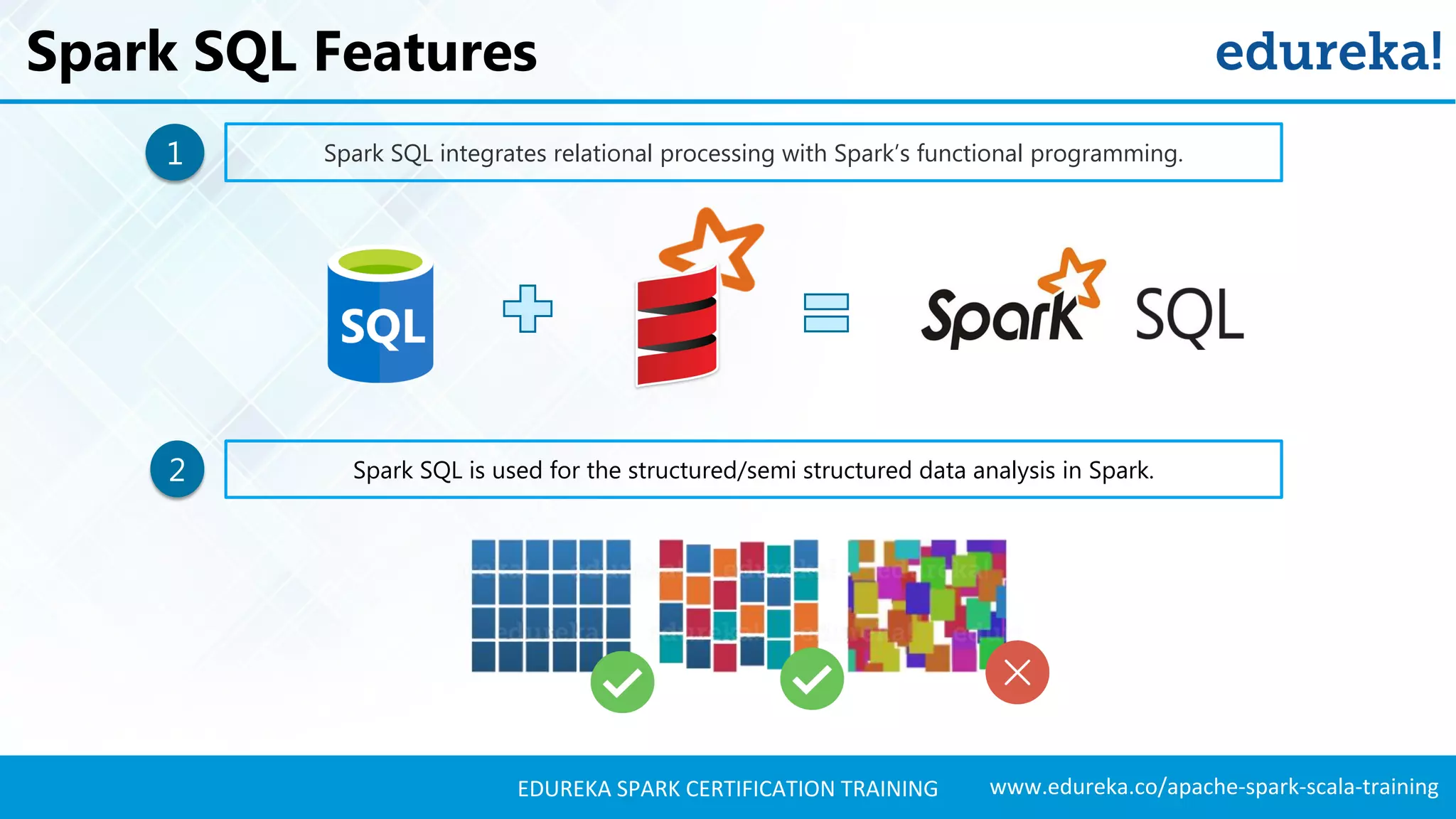
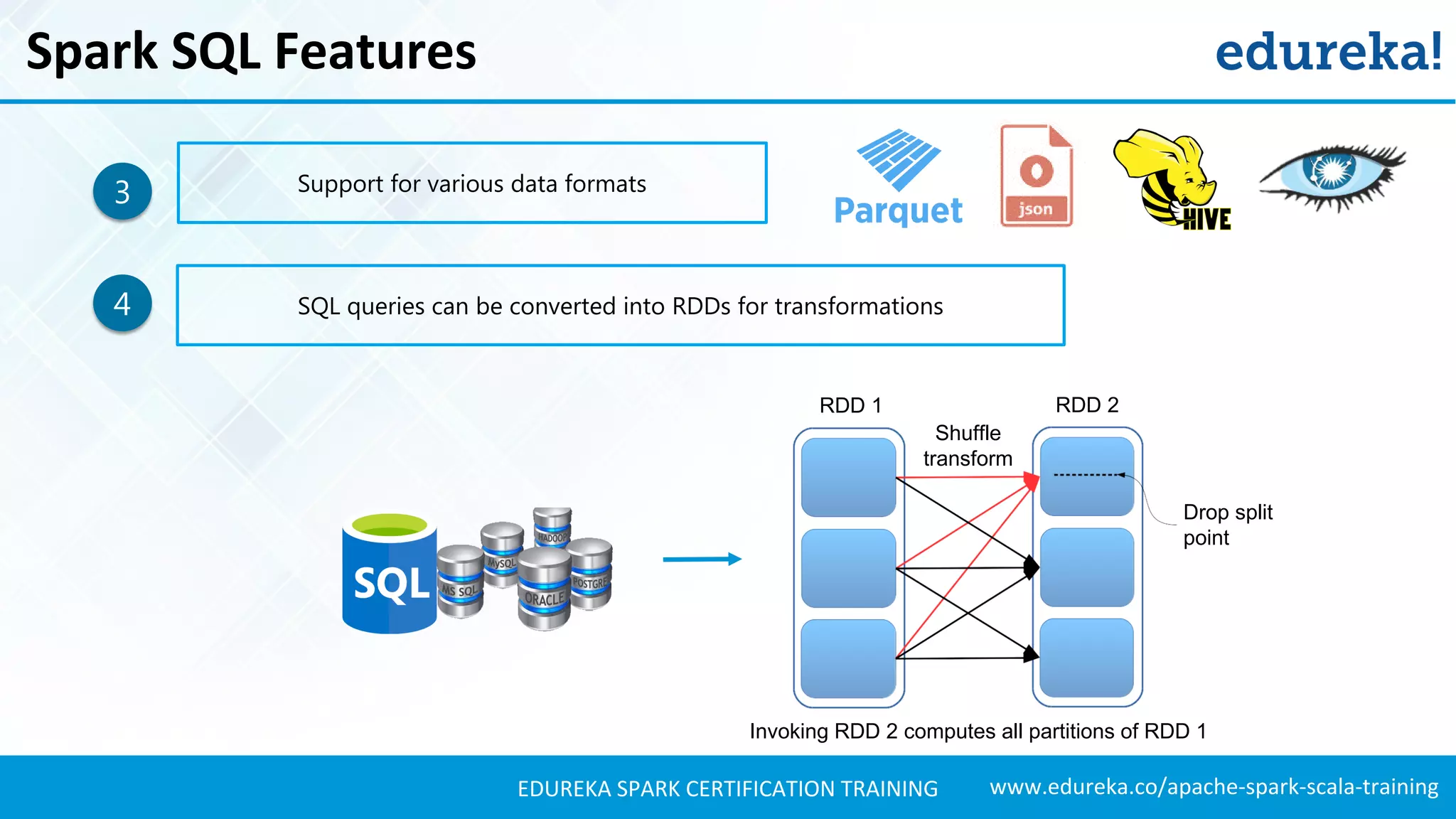
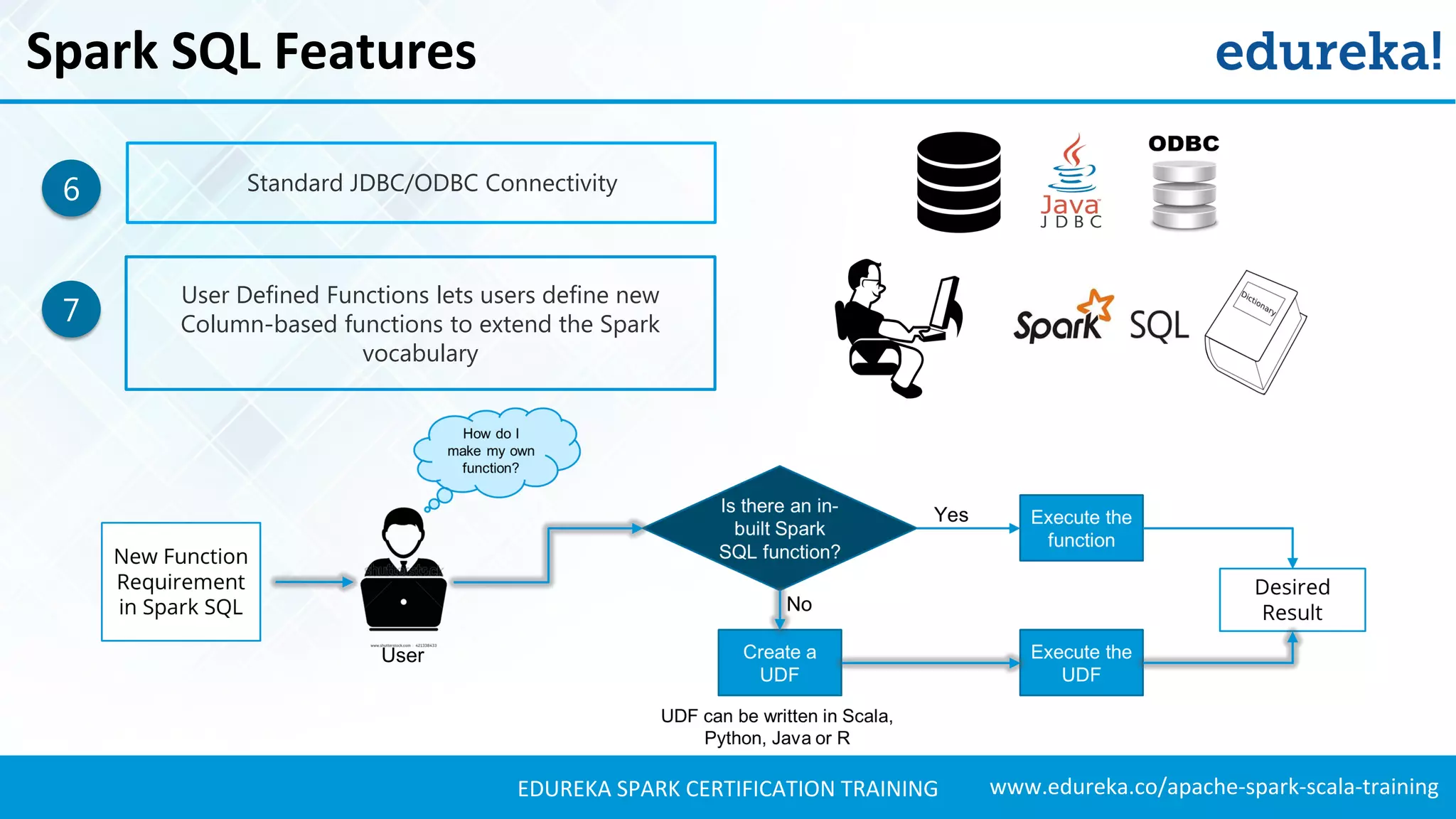
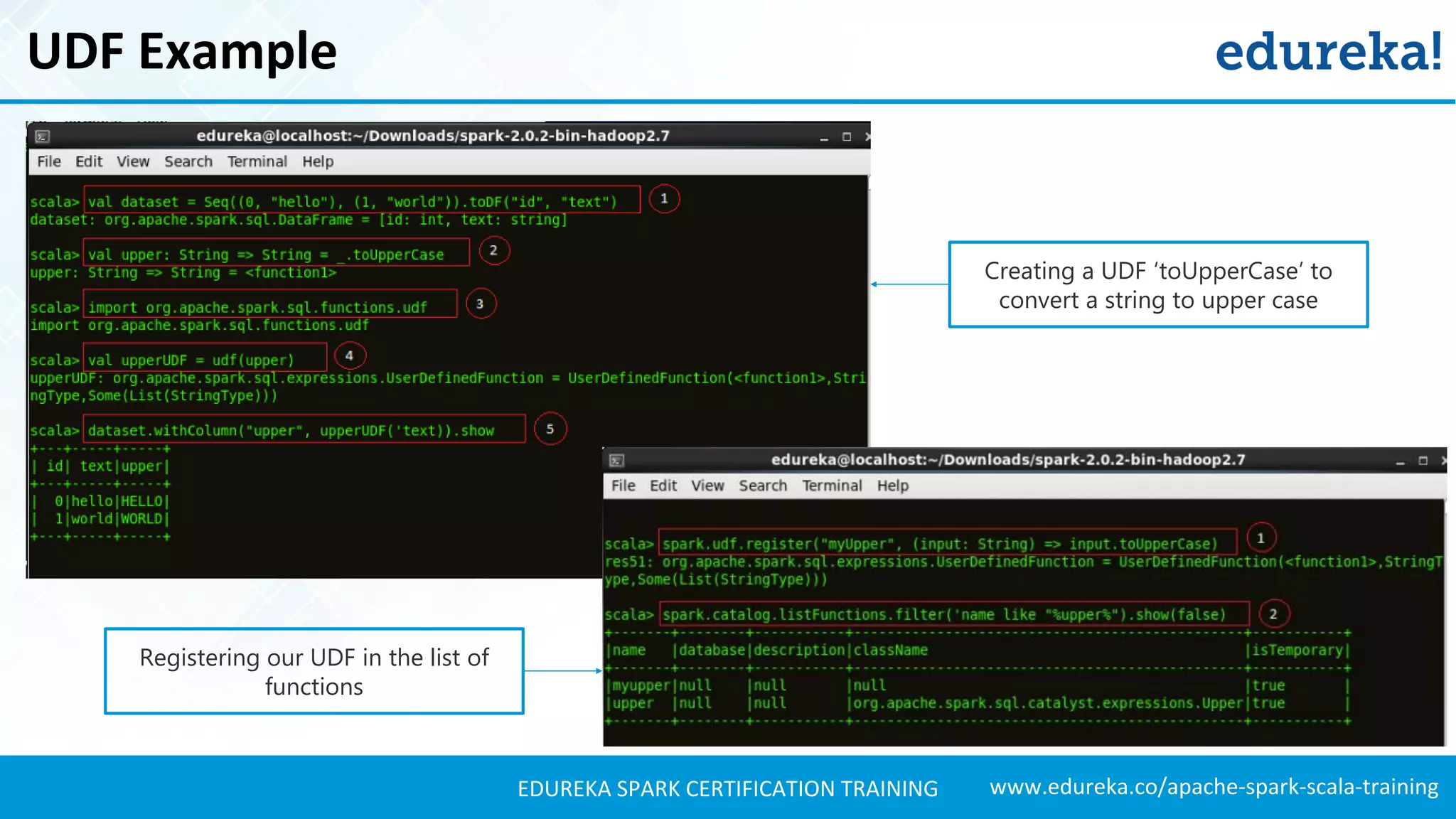
Describes key features of Spark SQL, including integration with Spark, support for various data formats, and defining user functions.
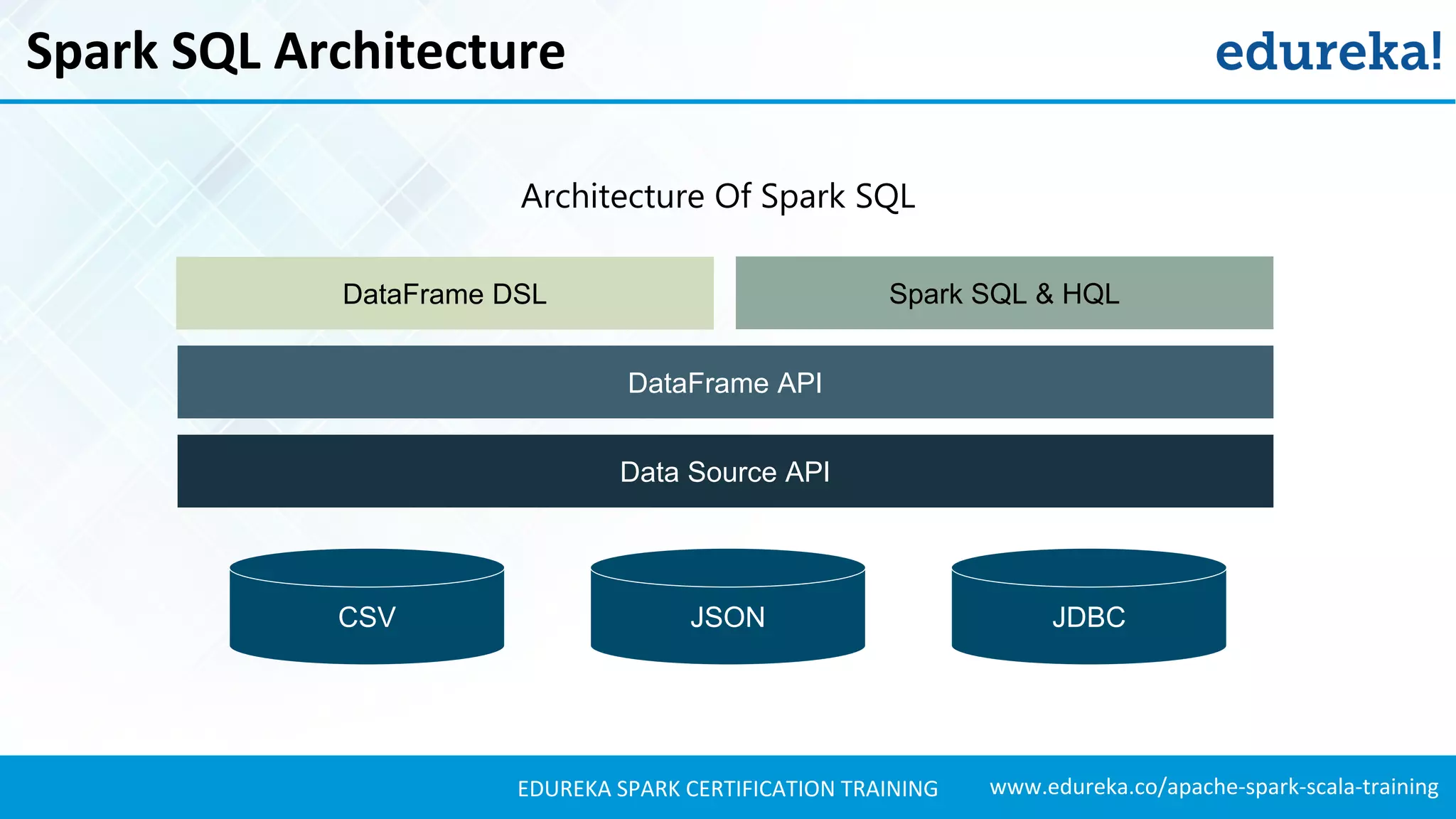
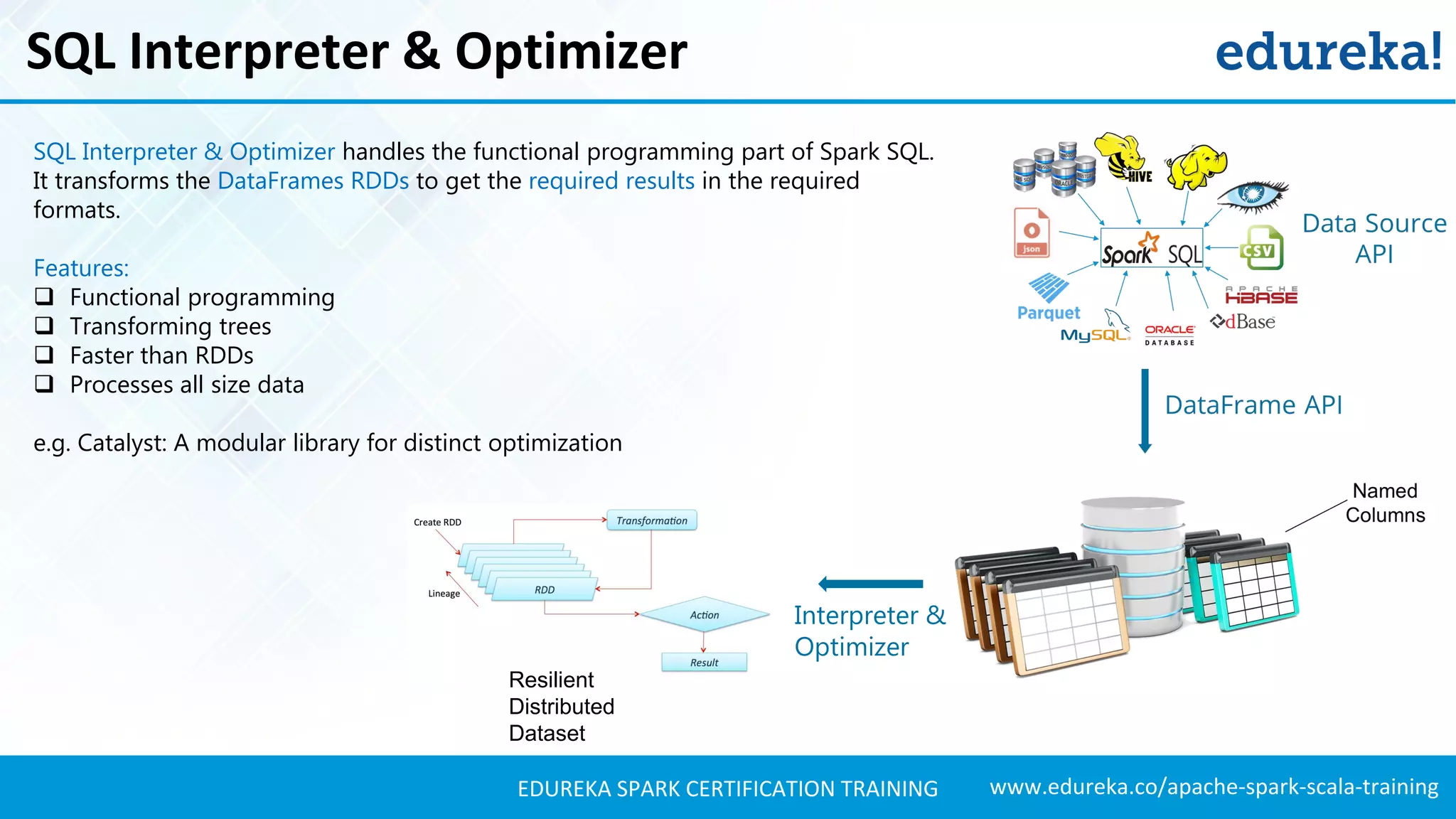
Outlines the architecture of Spark SQL, including DataFrame DSL and APIs for data processing.
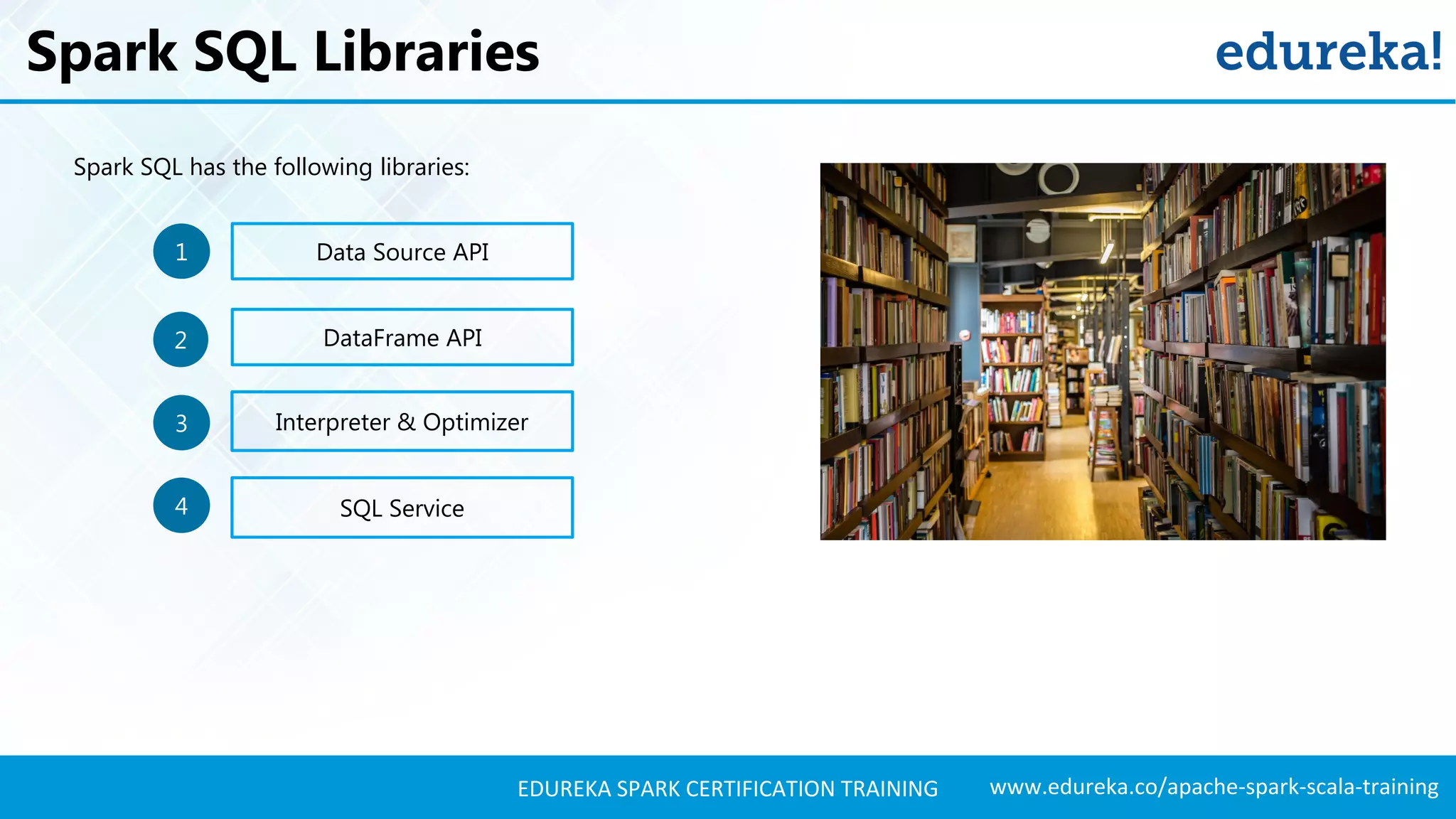
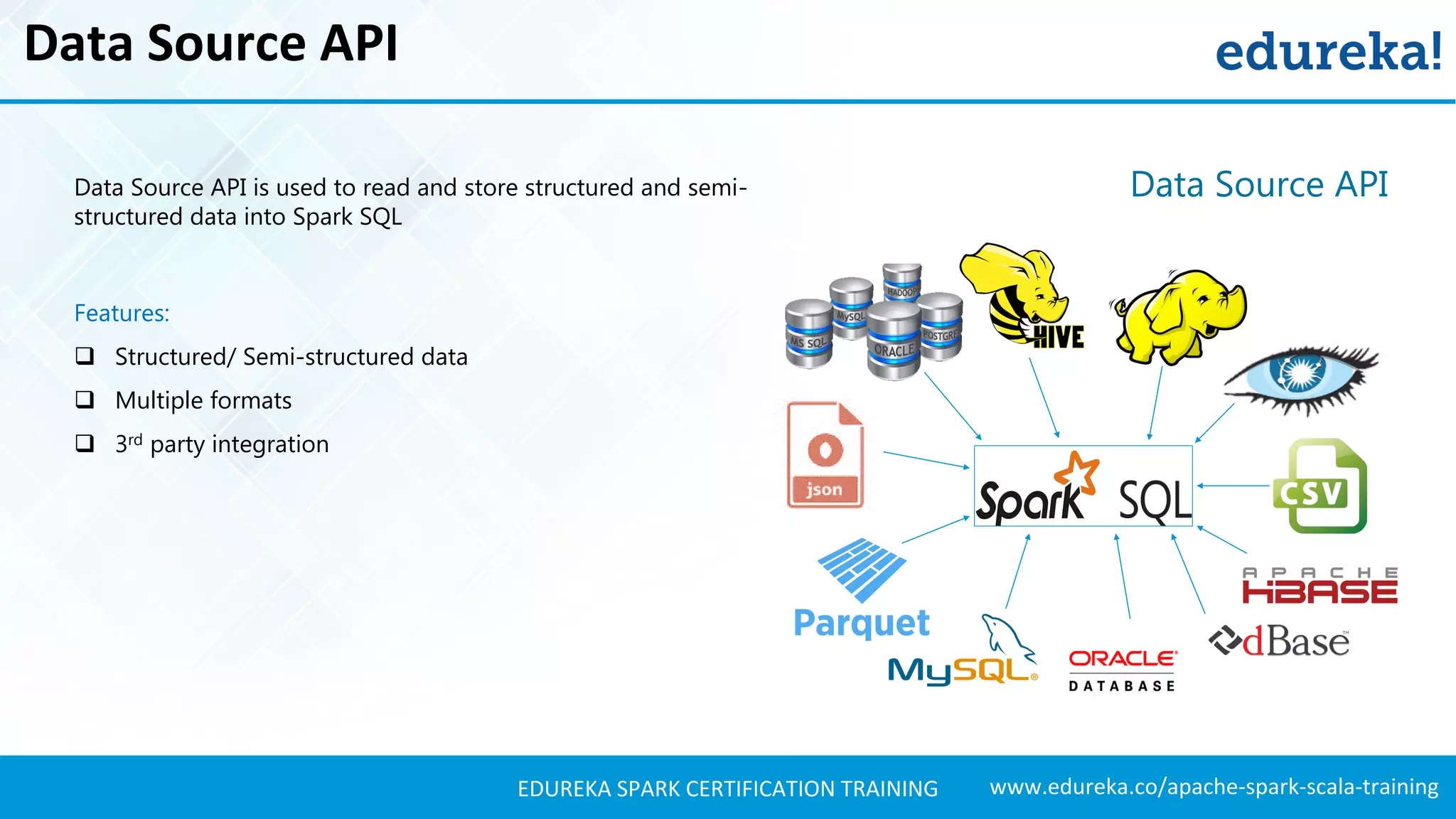
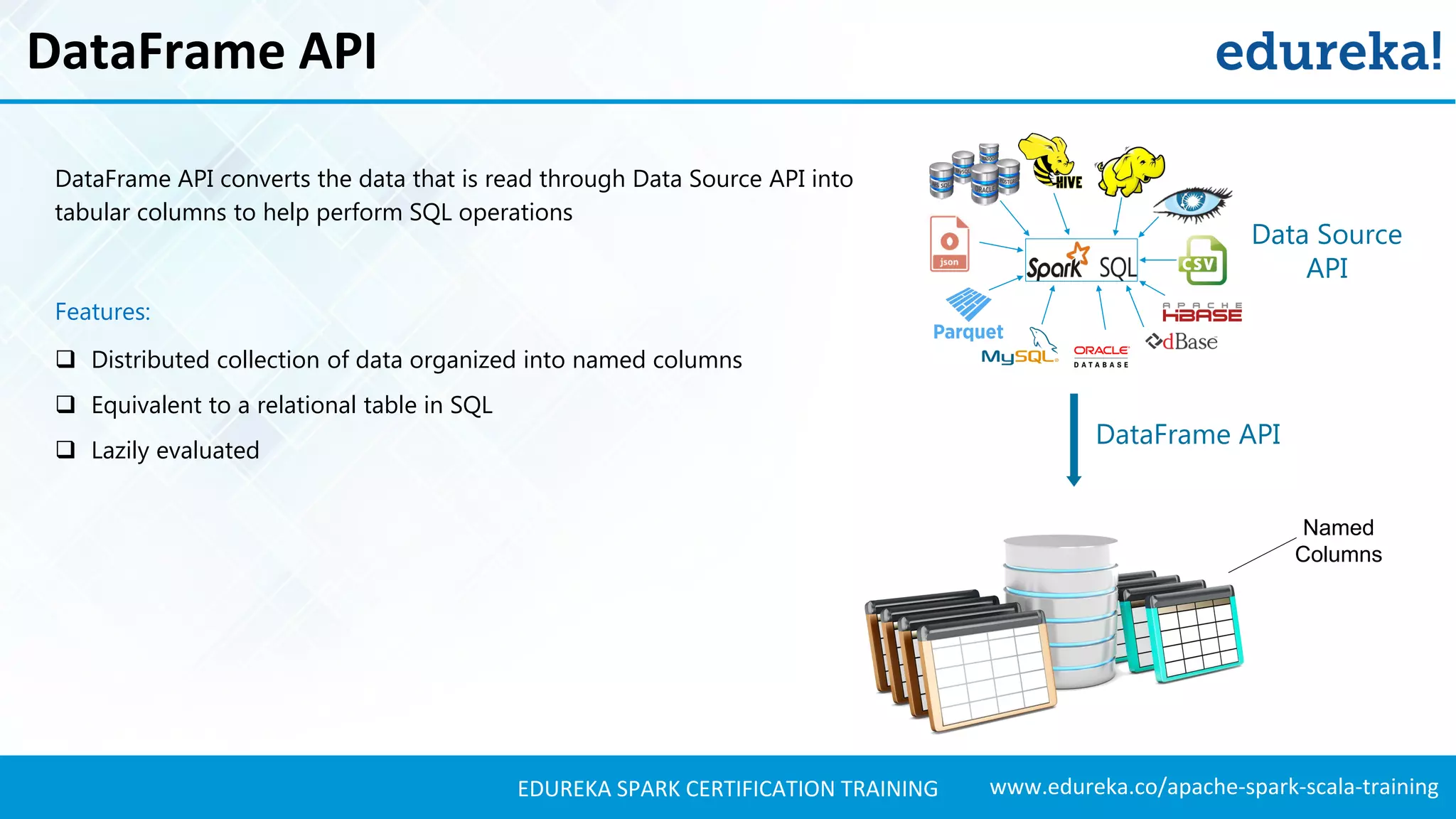
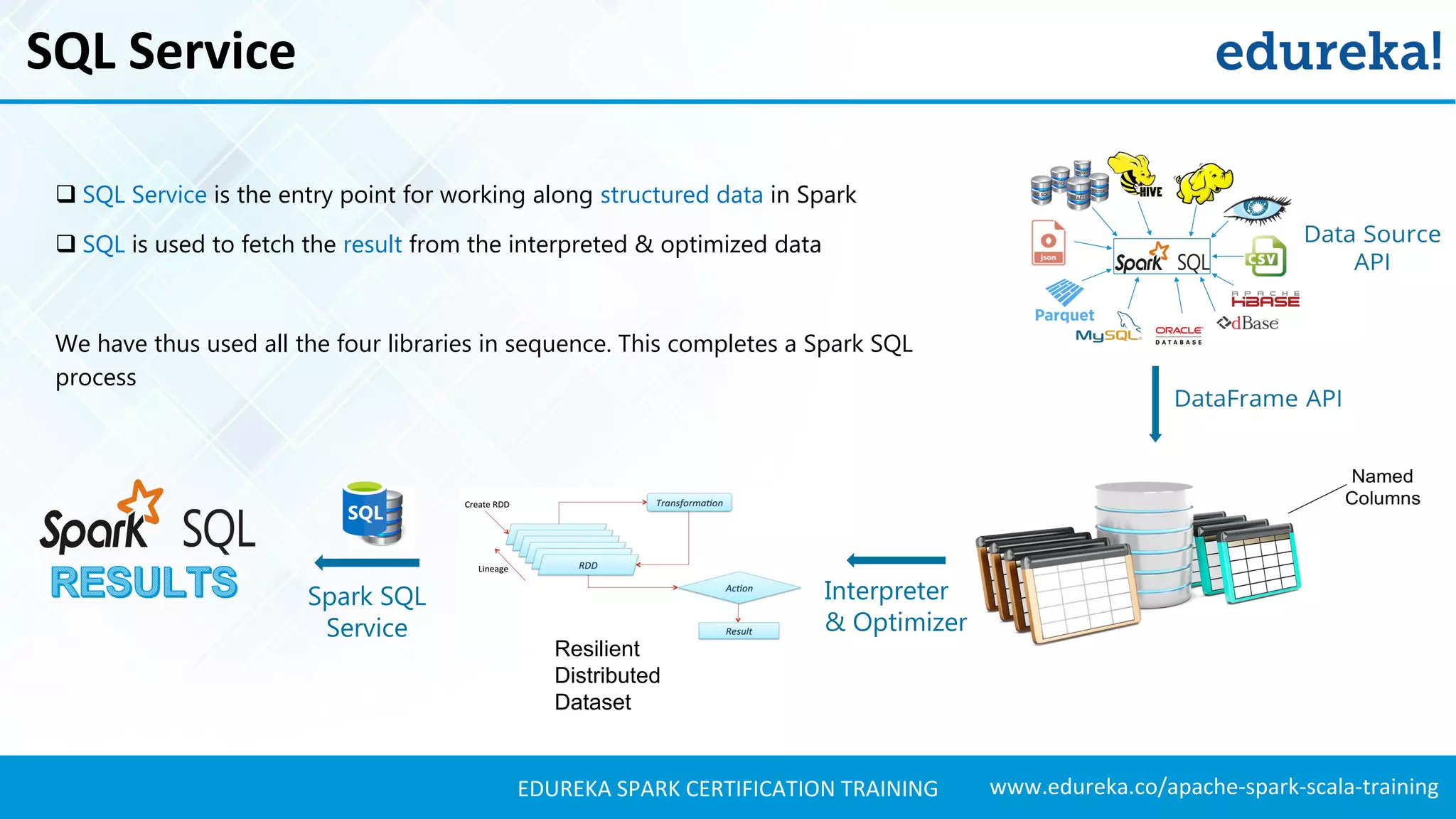
Details the libraries available in Spark SQL, including Data Source API and DataFrame API, and their functionalities.
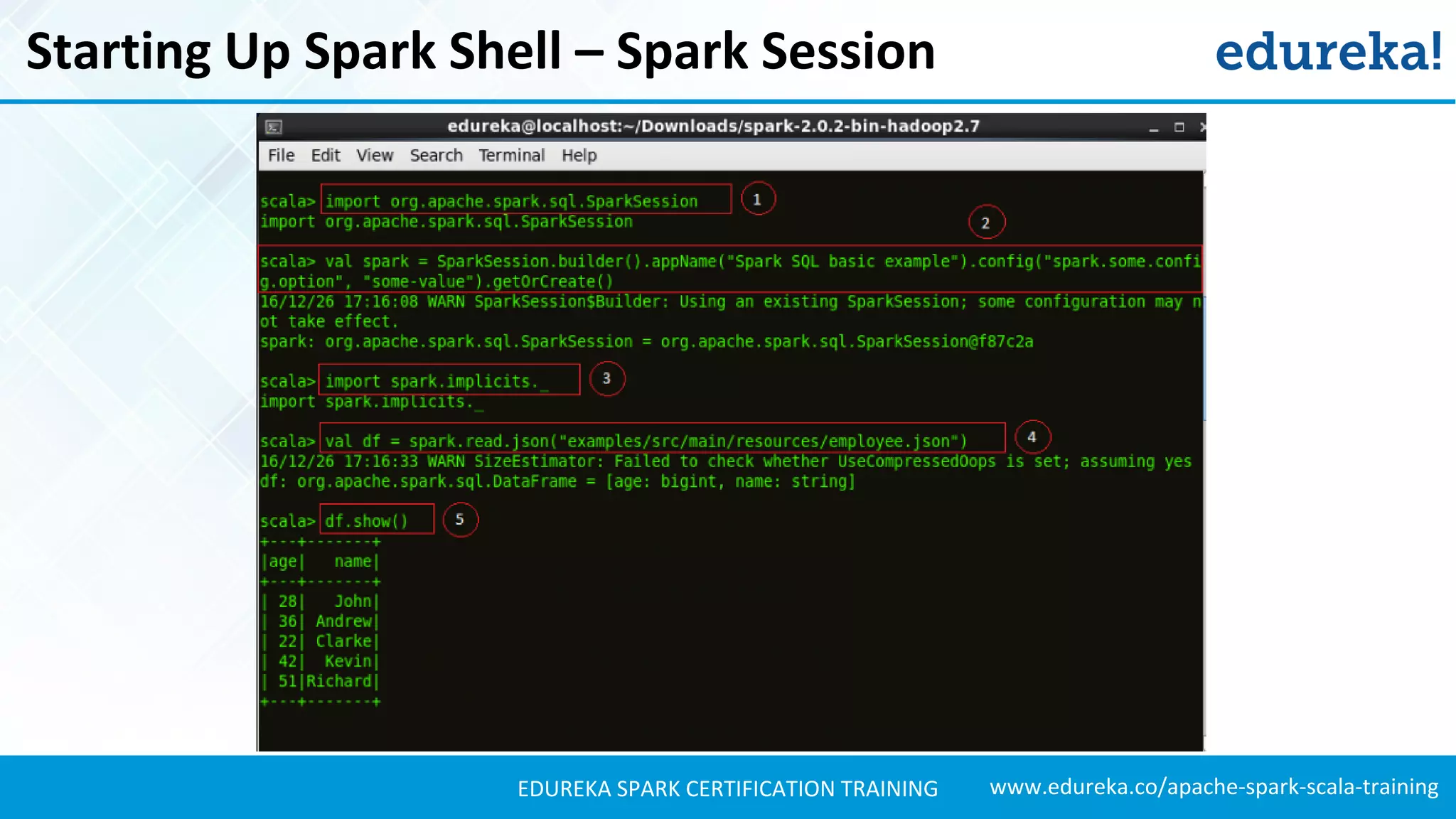
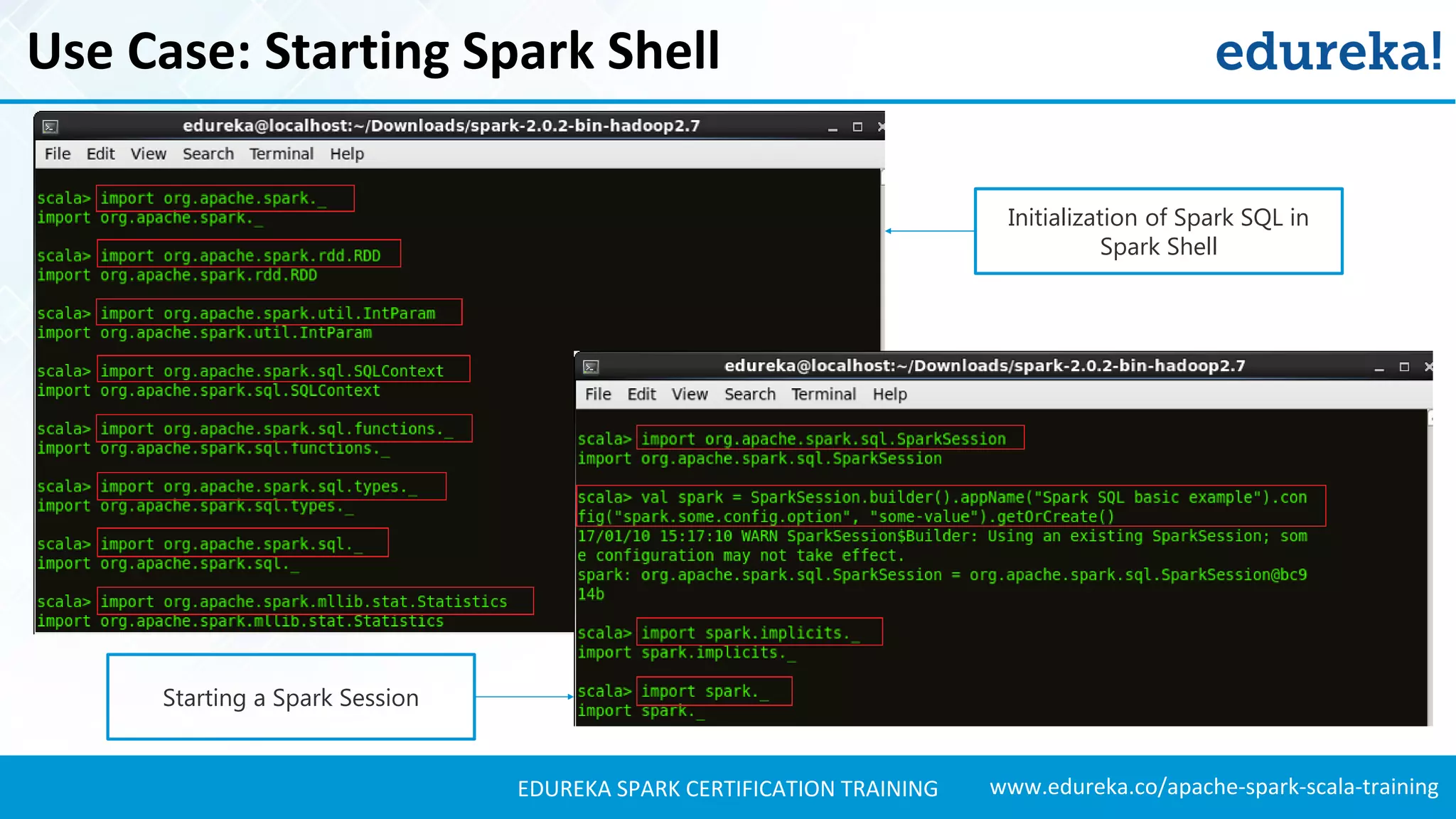
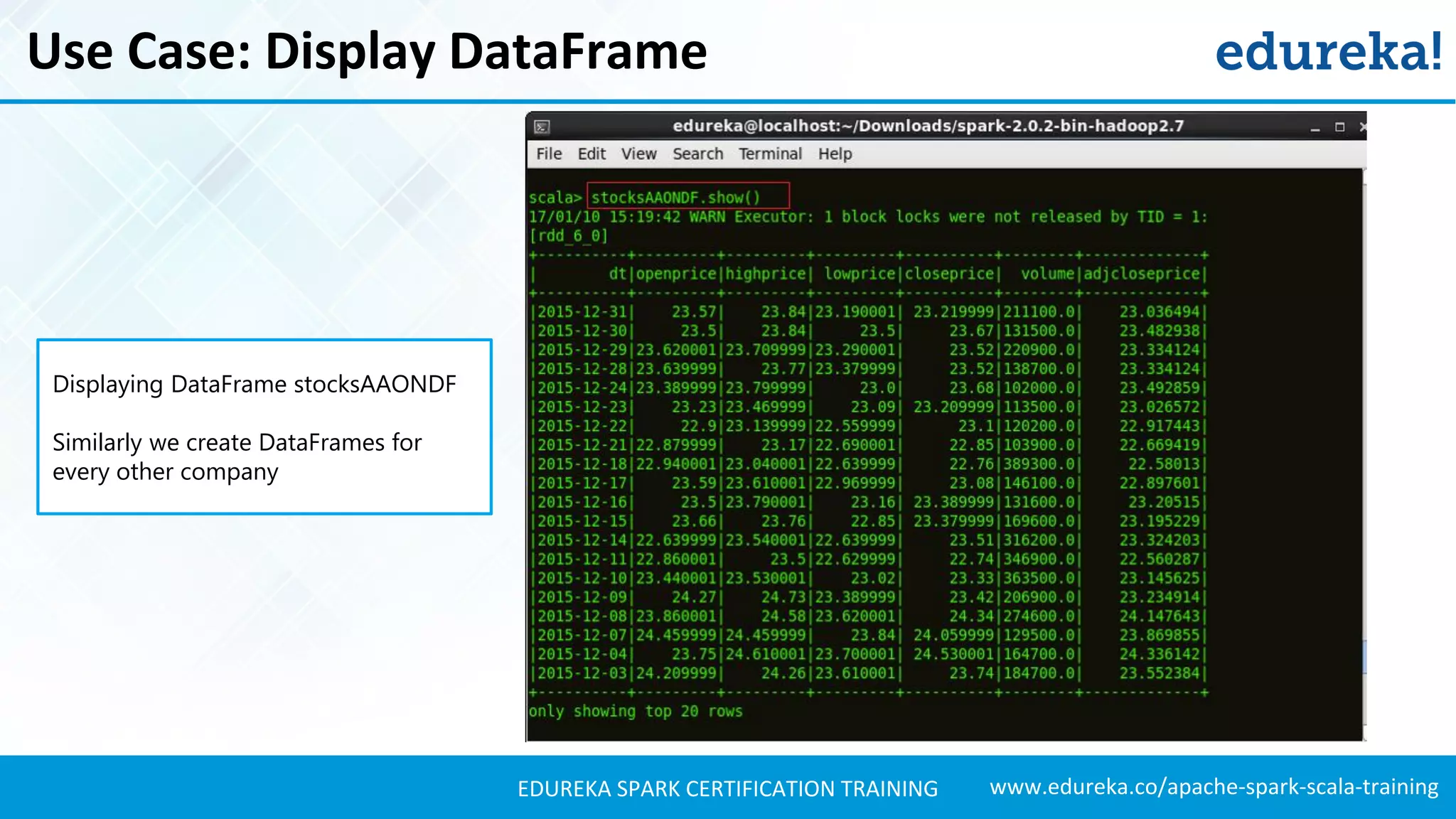
Demonstrates the process of starting Spark shell, creating datasets, and using JSON files for structured data.
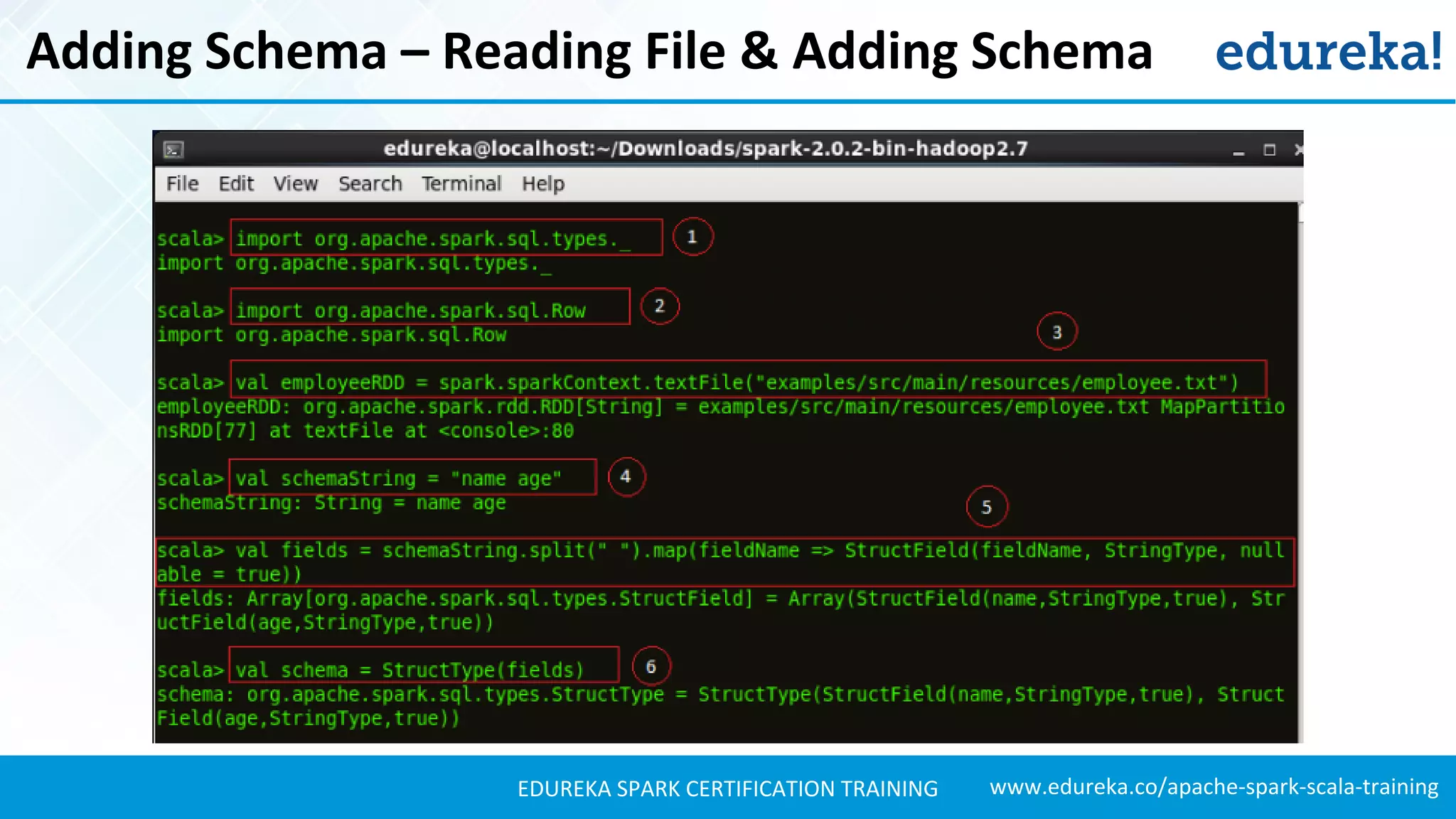
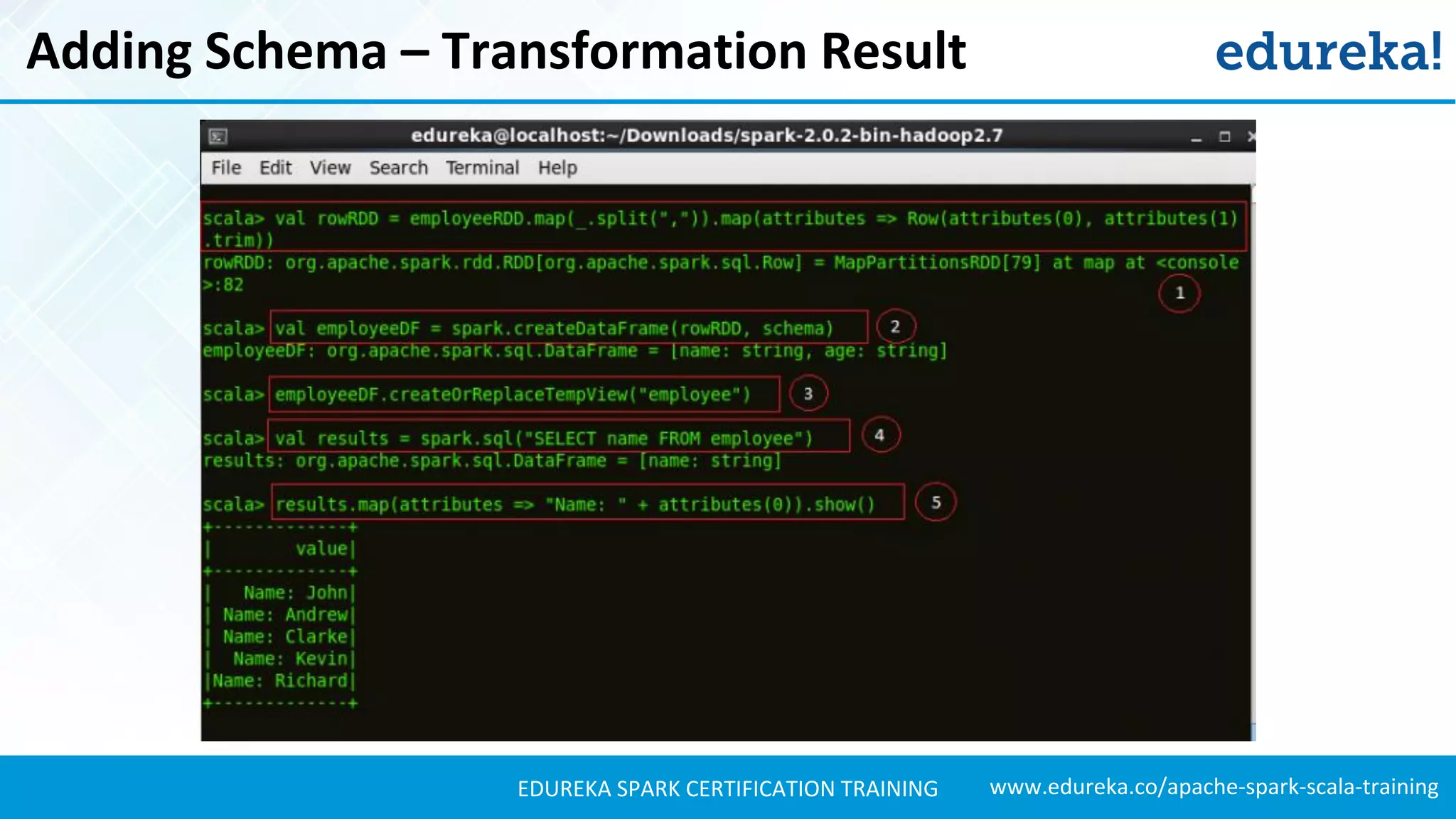
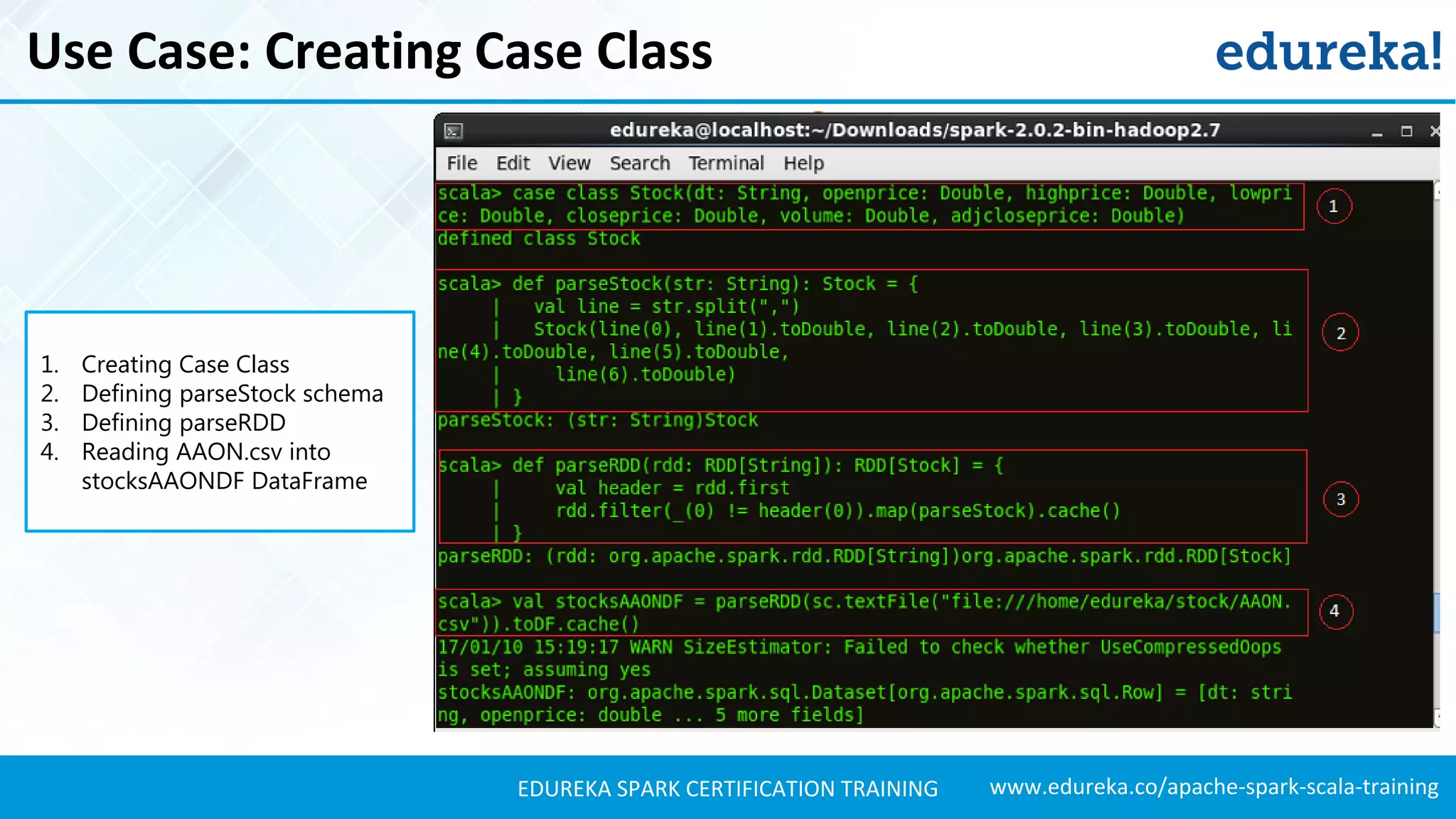
Shows how to add schemas to RDDs, perform transformations, and create DataFrames using structured data.
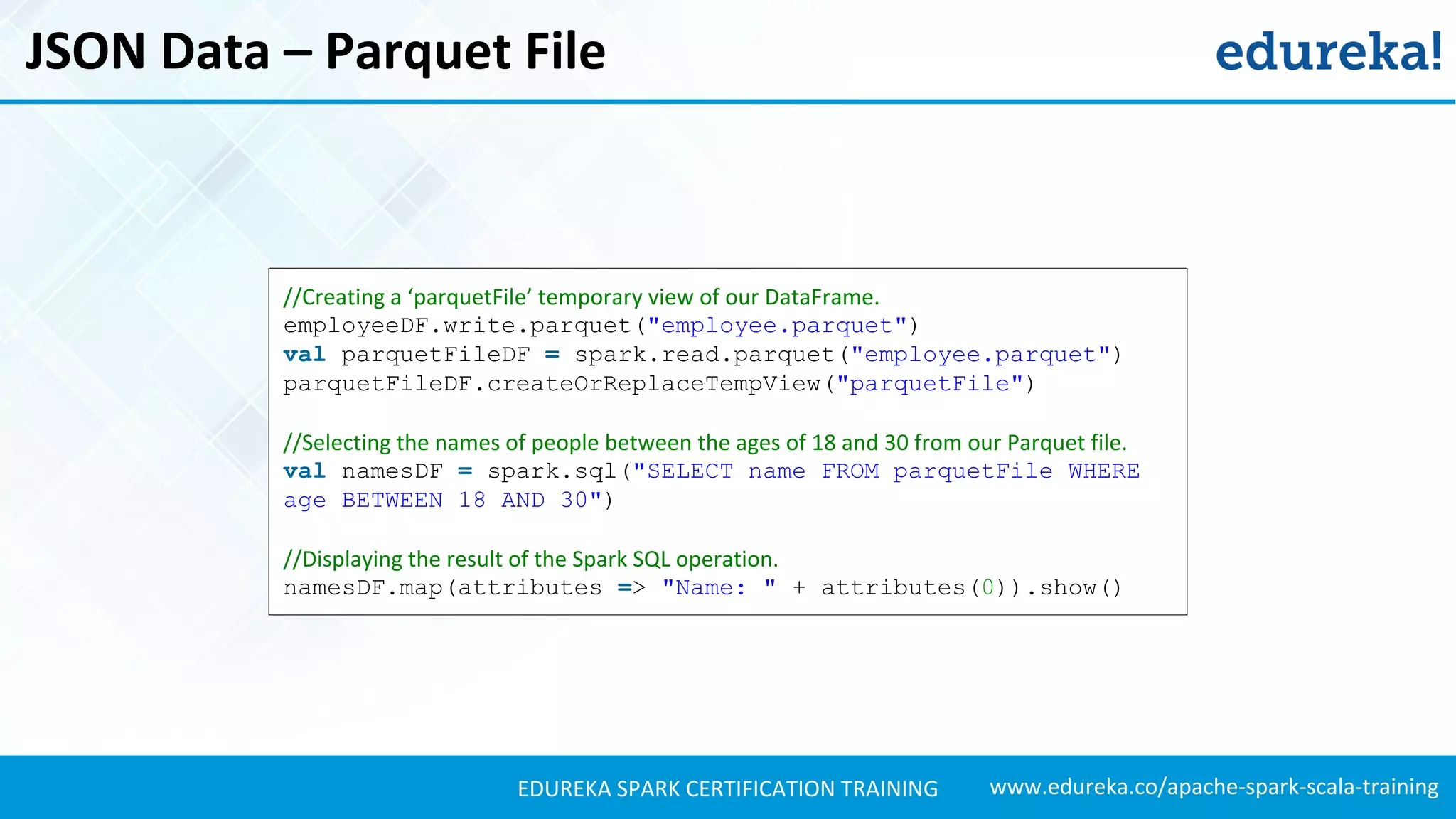
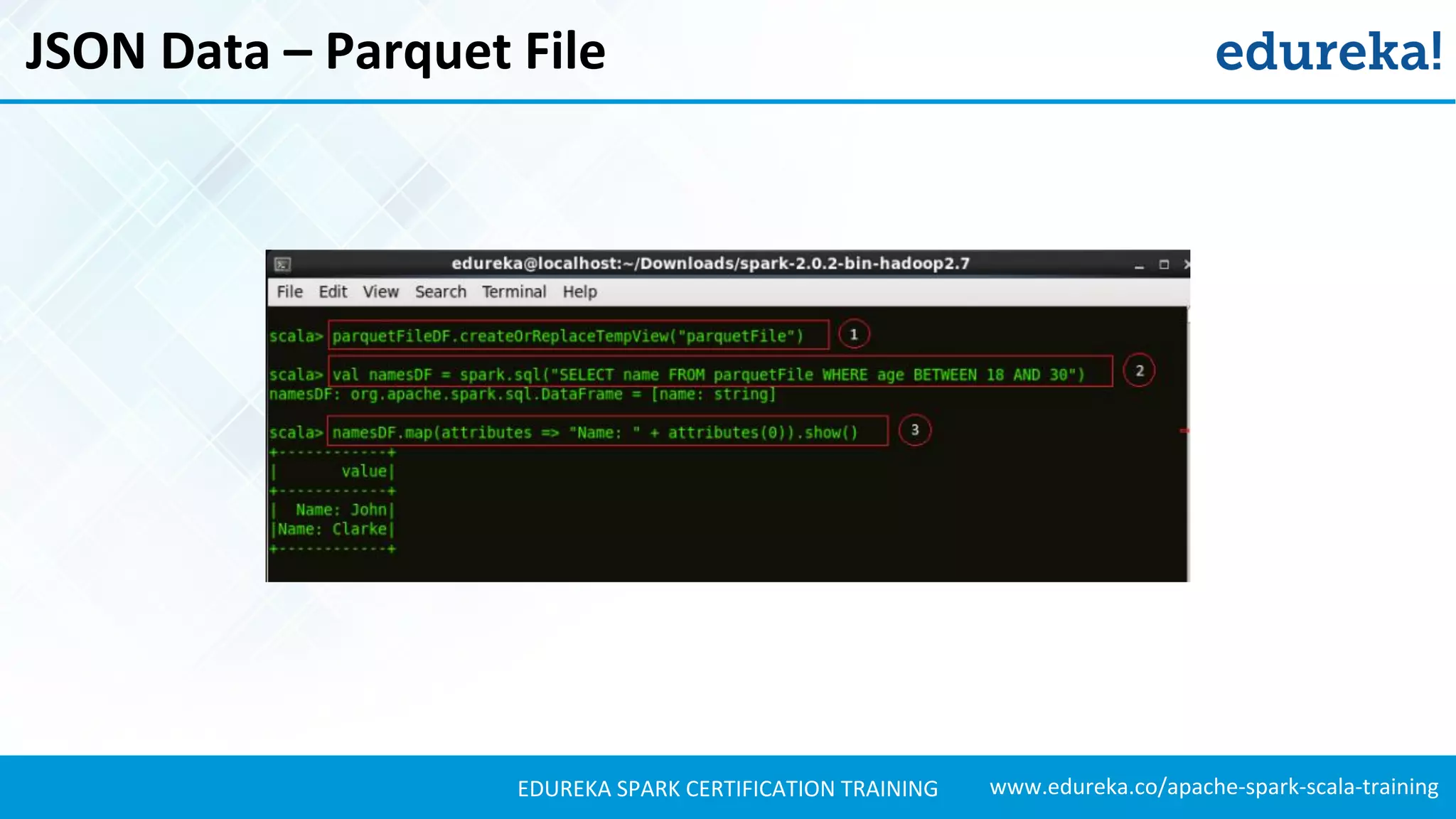
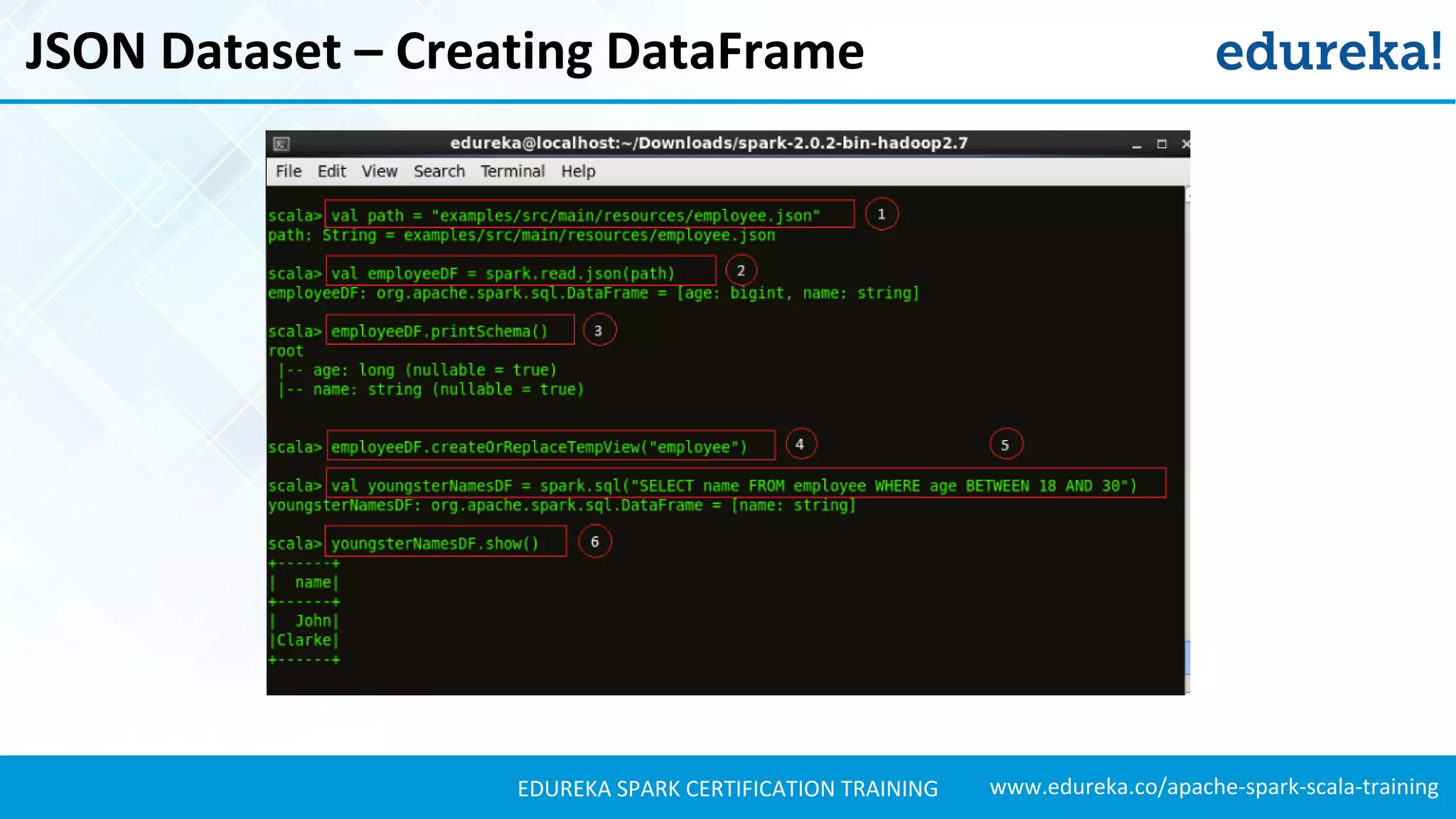
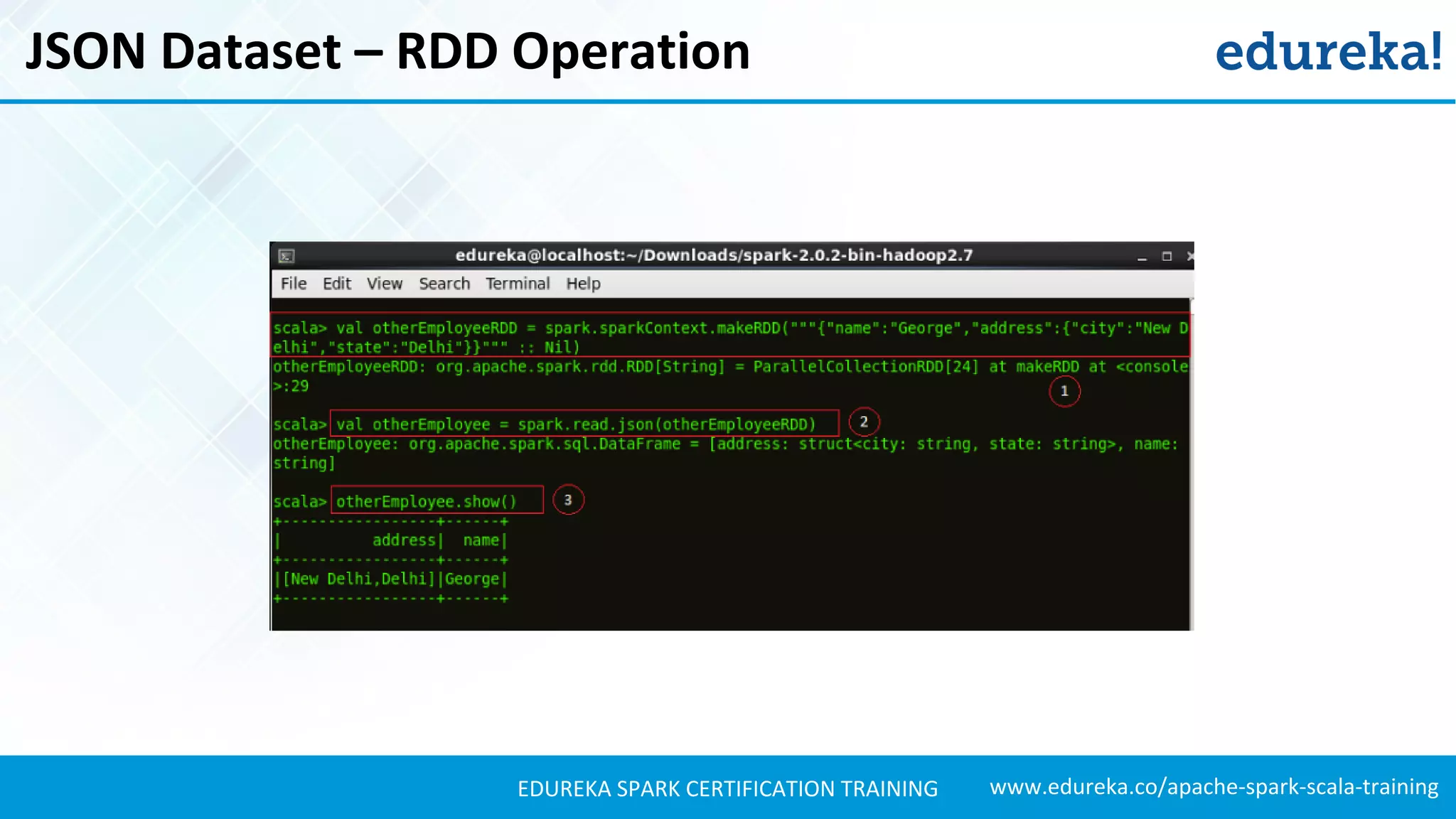
Explains how to load JSON data, create DataFrames, and manipulate the schema for data analysis.
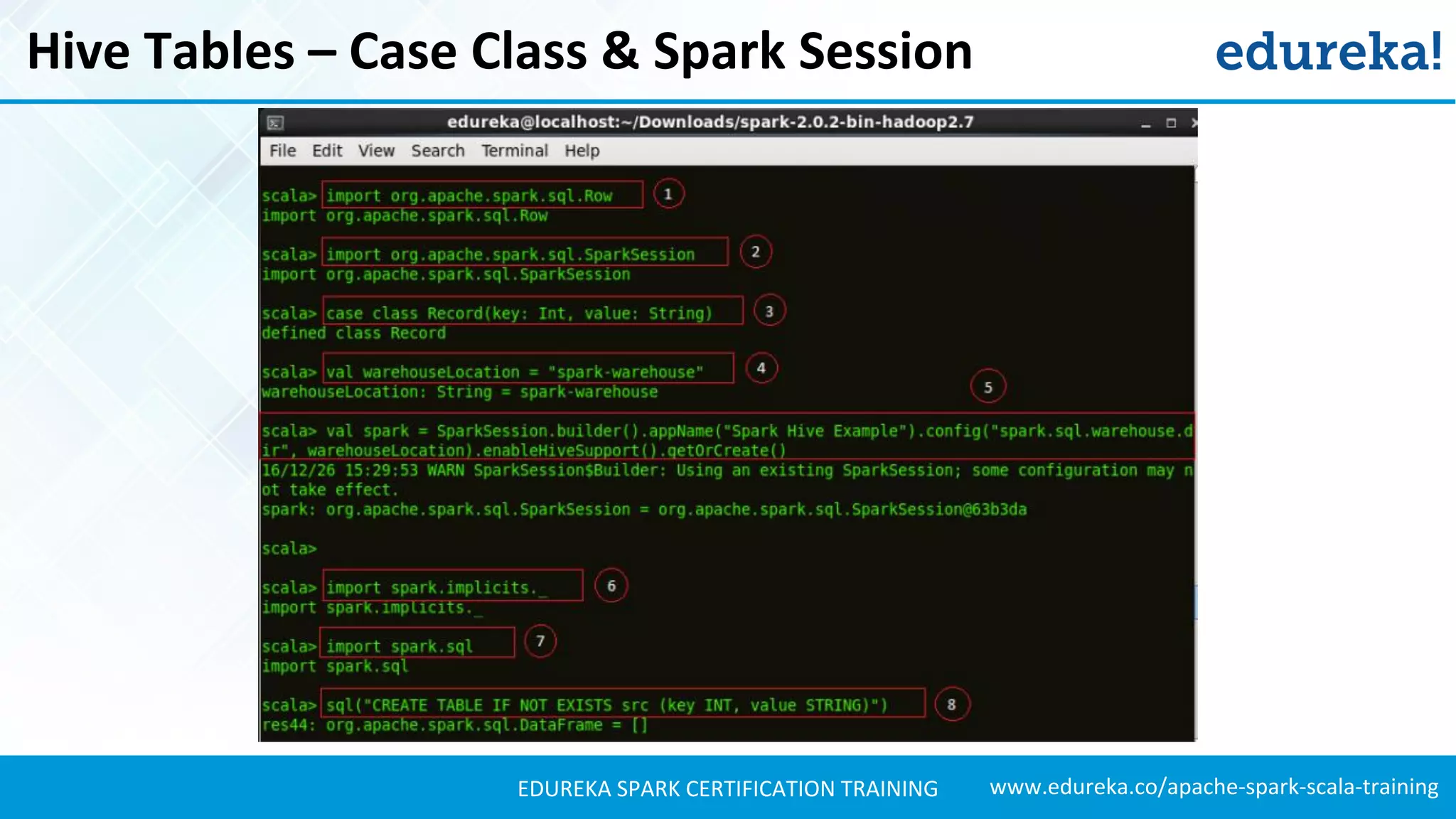
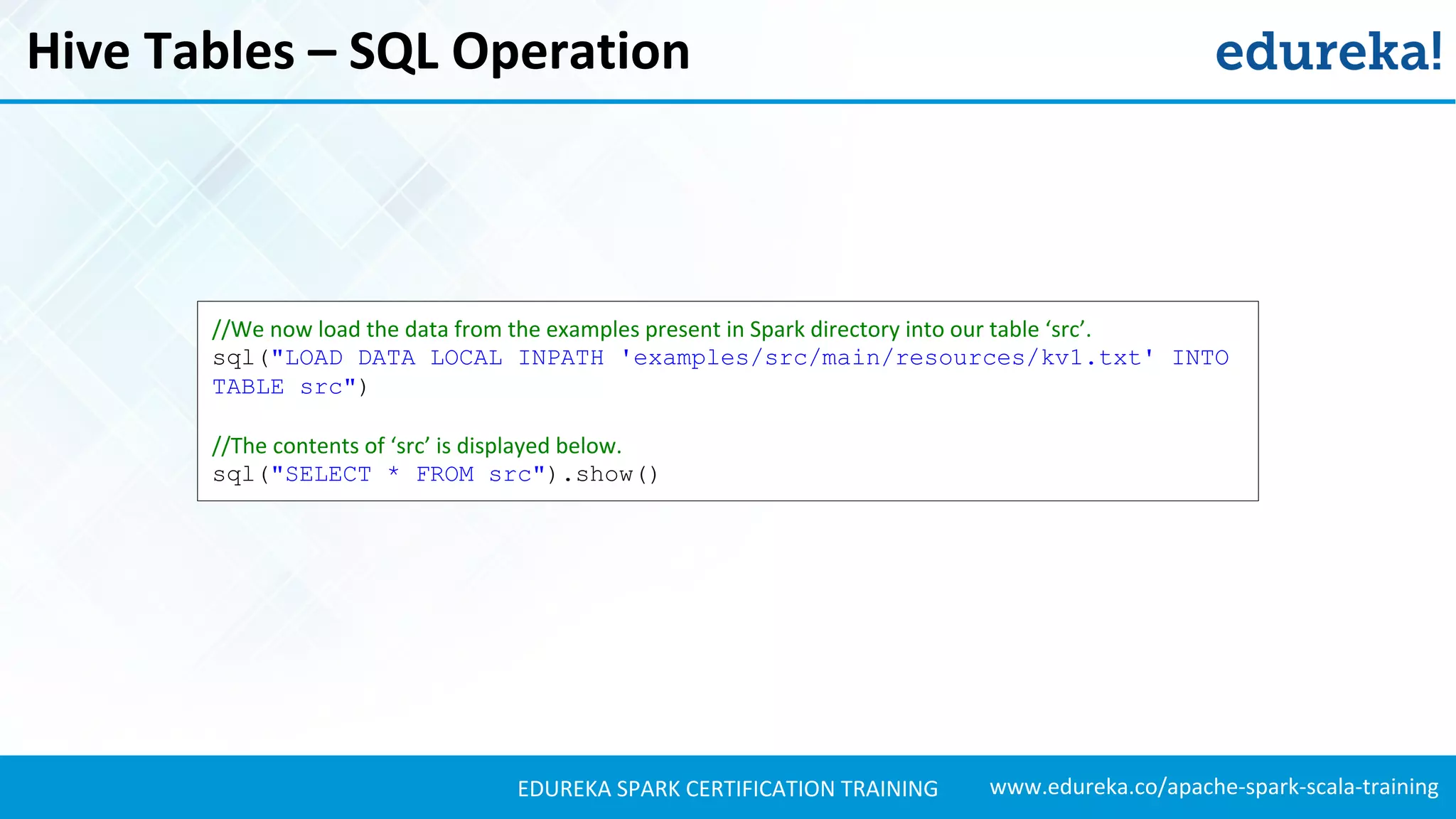
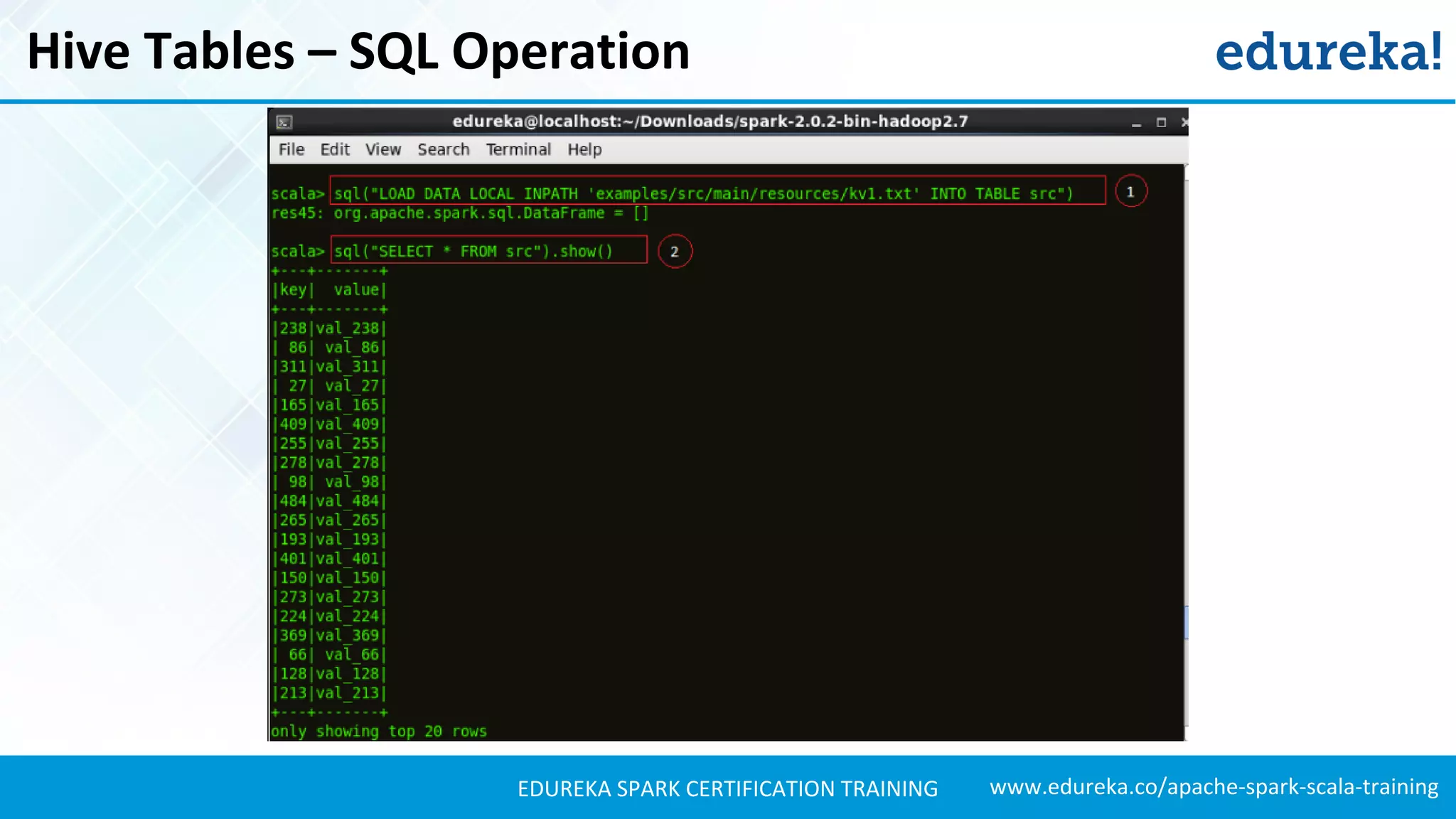
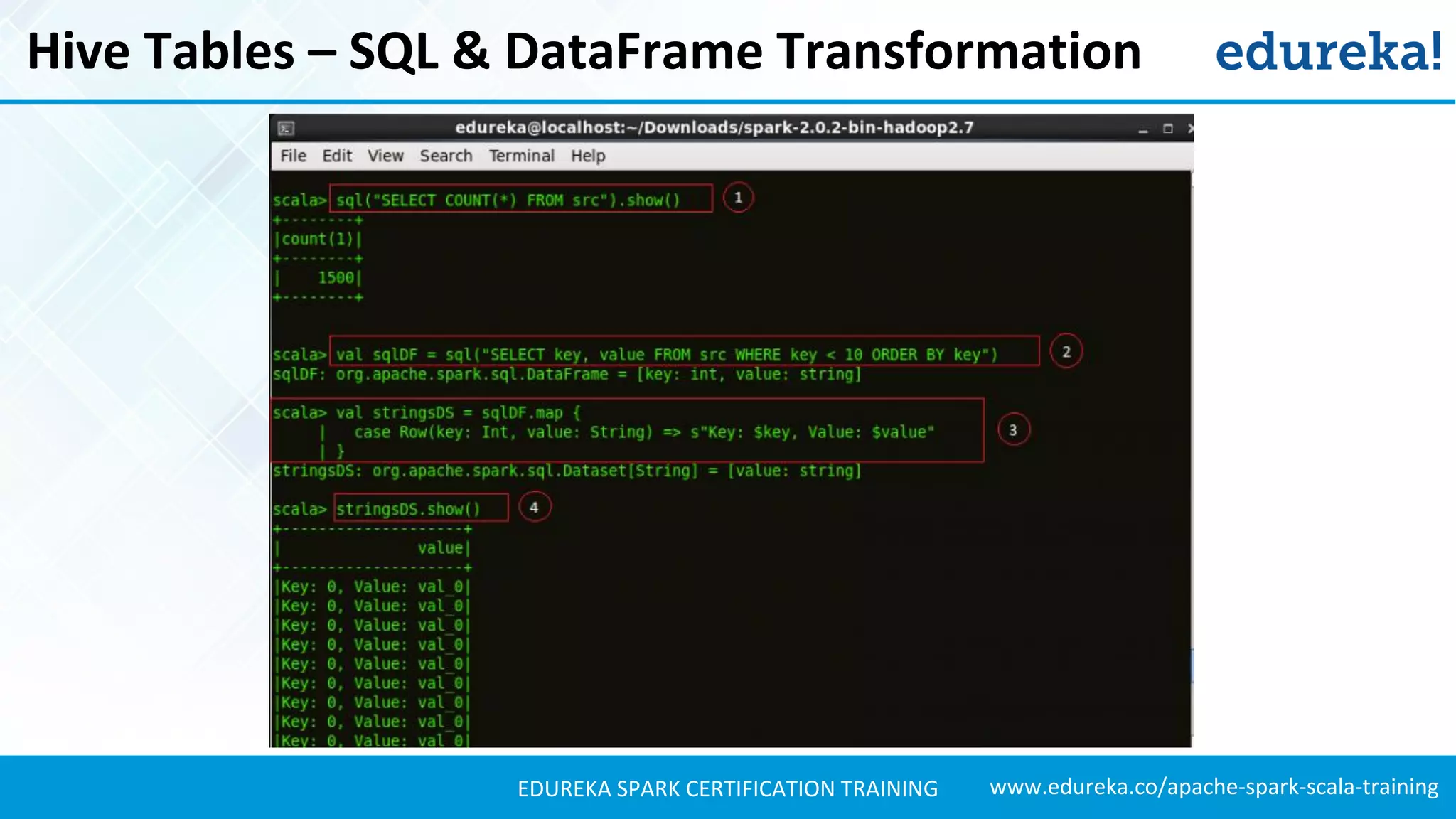
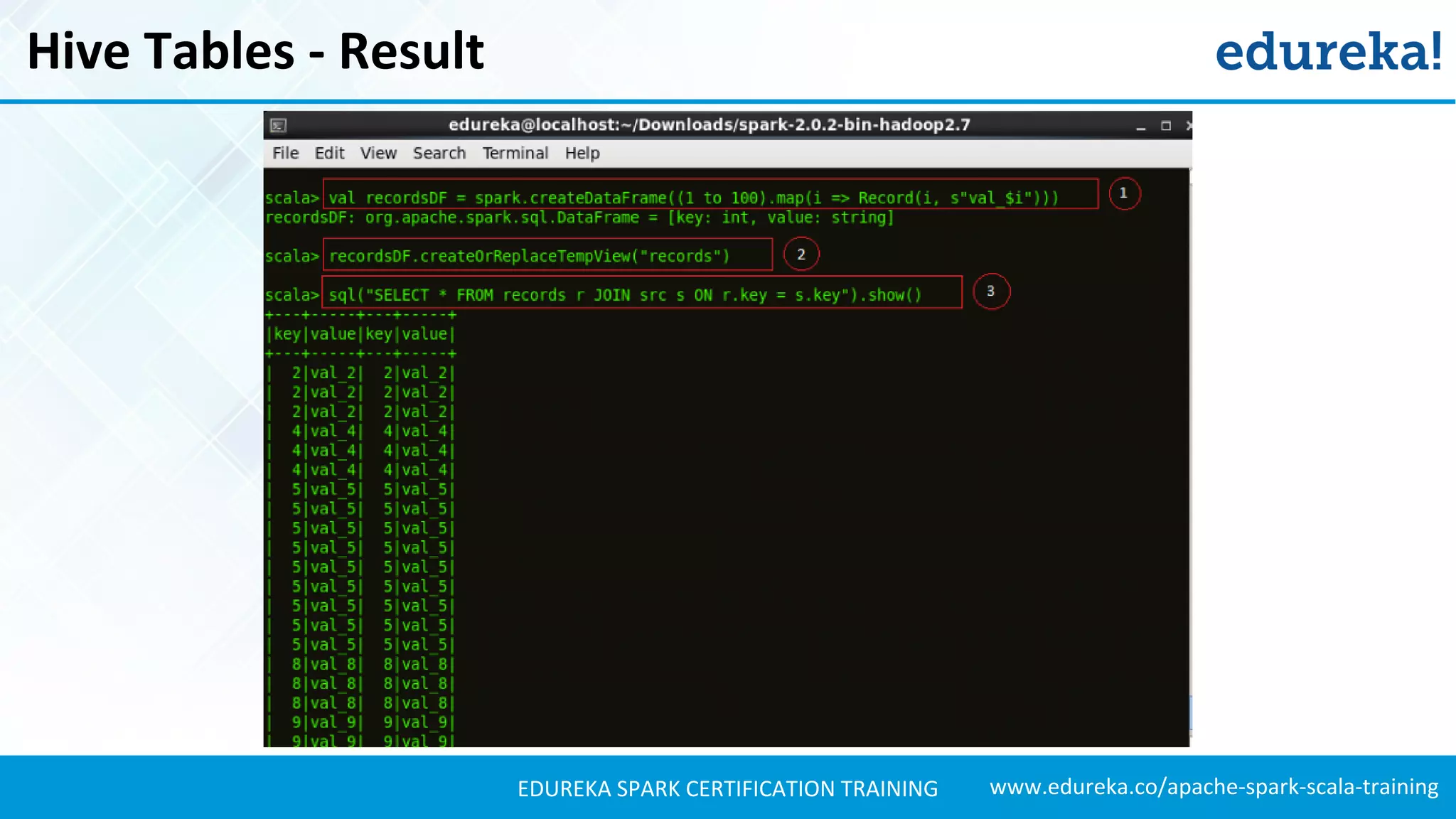
Illustrates the process of creating and interacting with Hive tables in Spark SQL, including SQL operations.
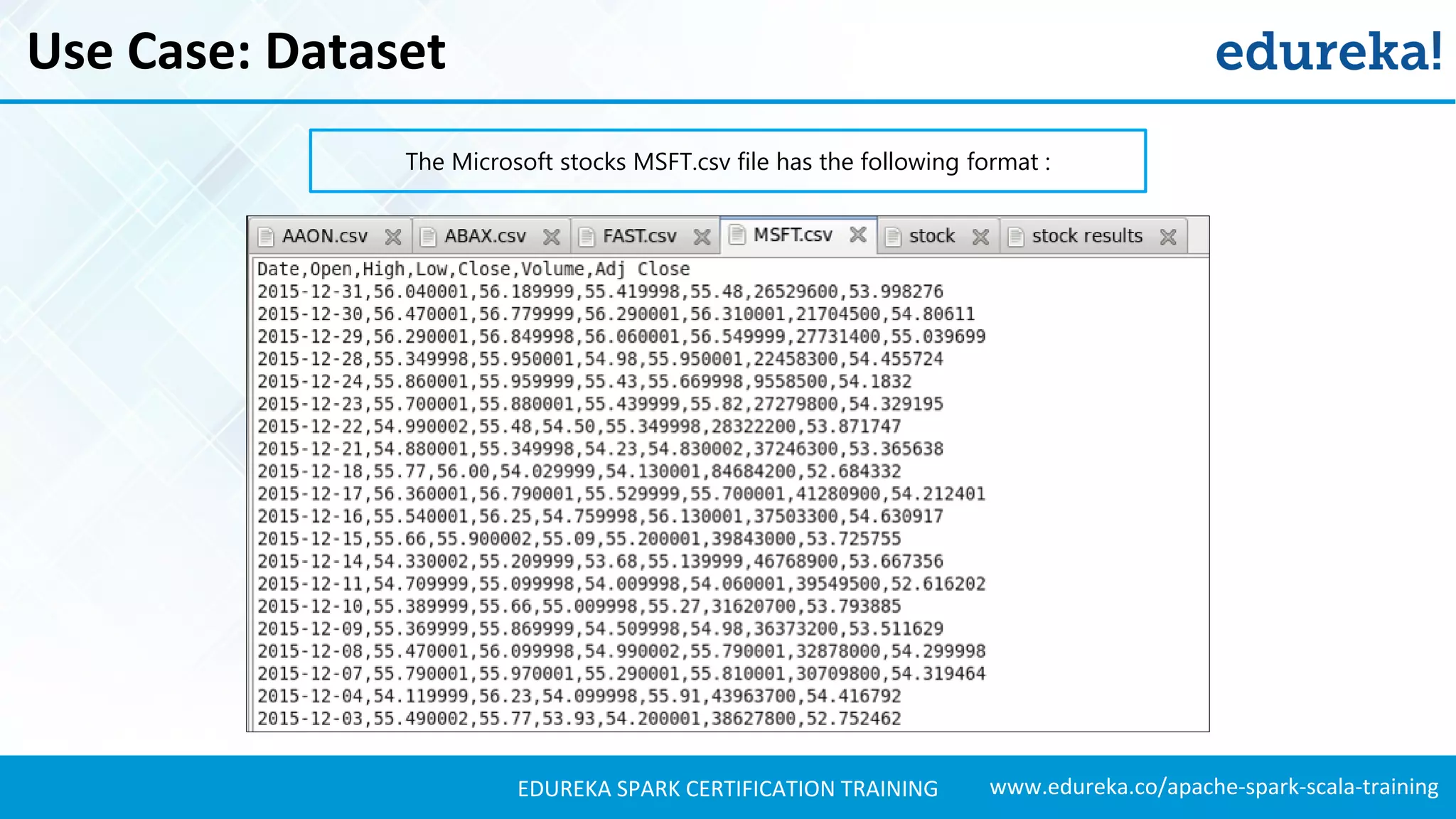
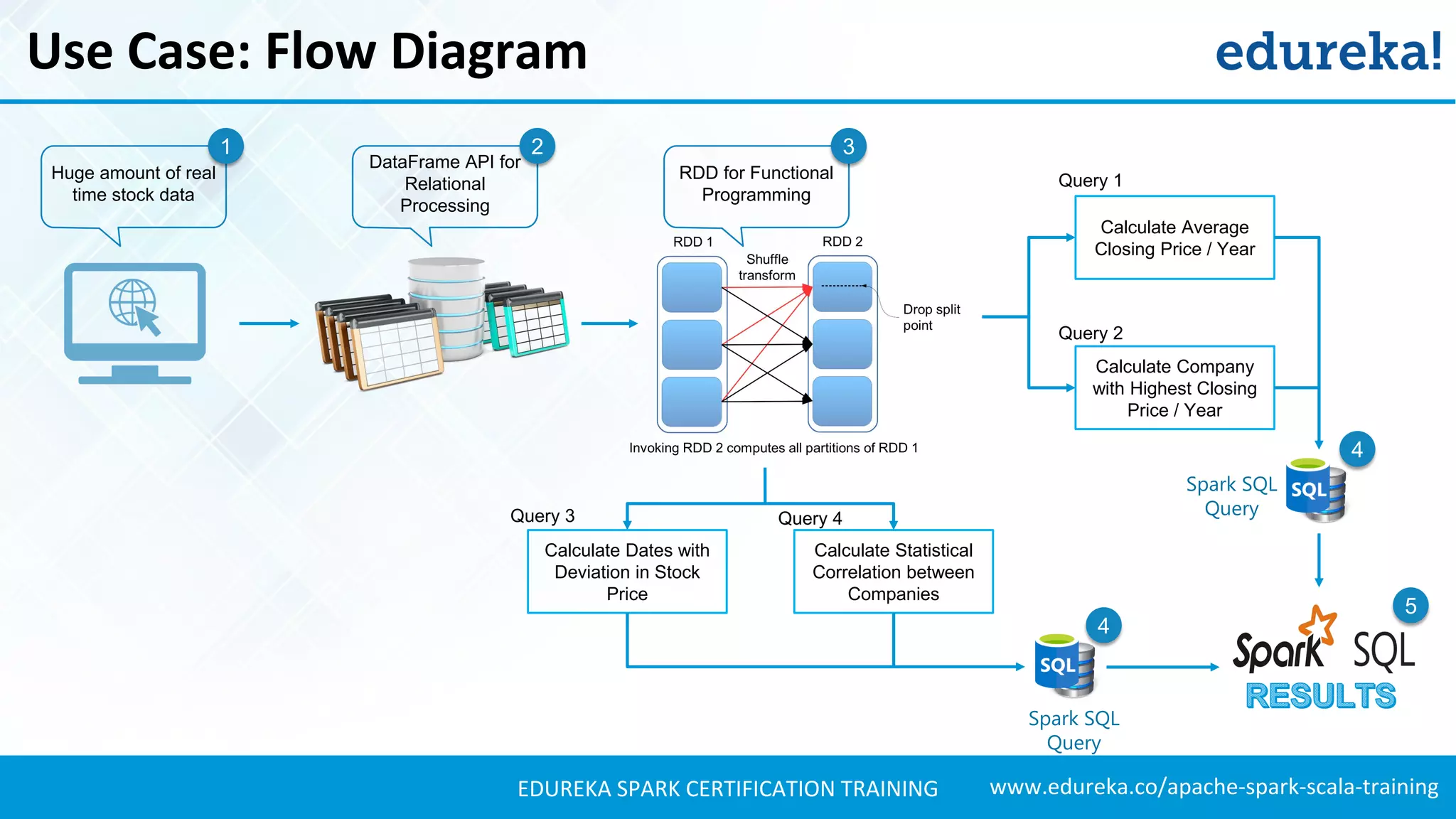
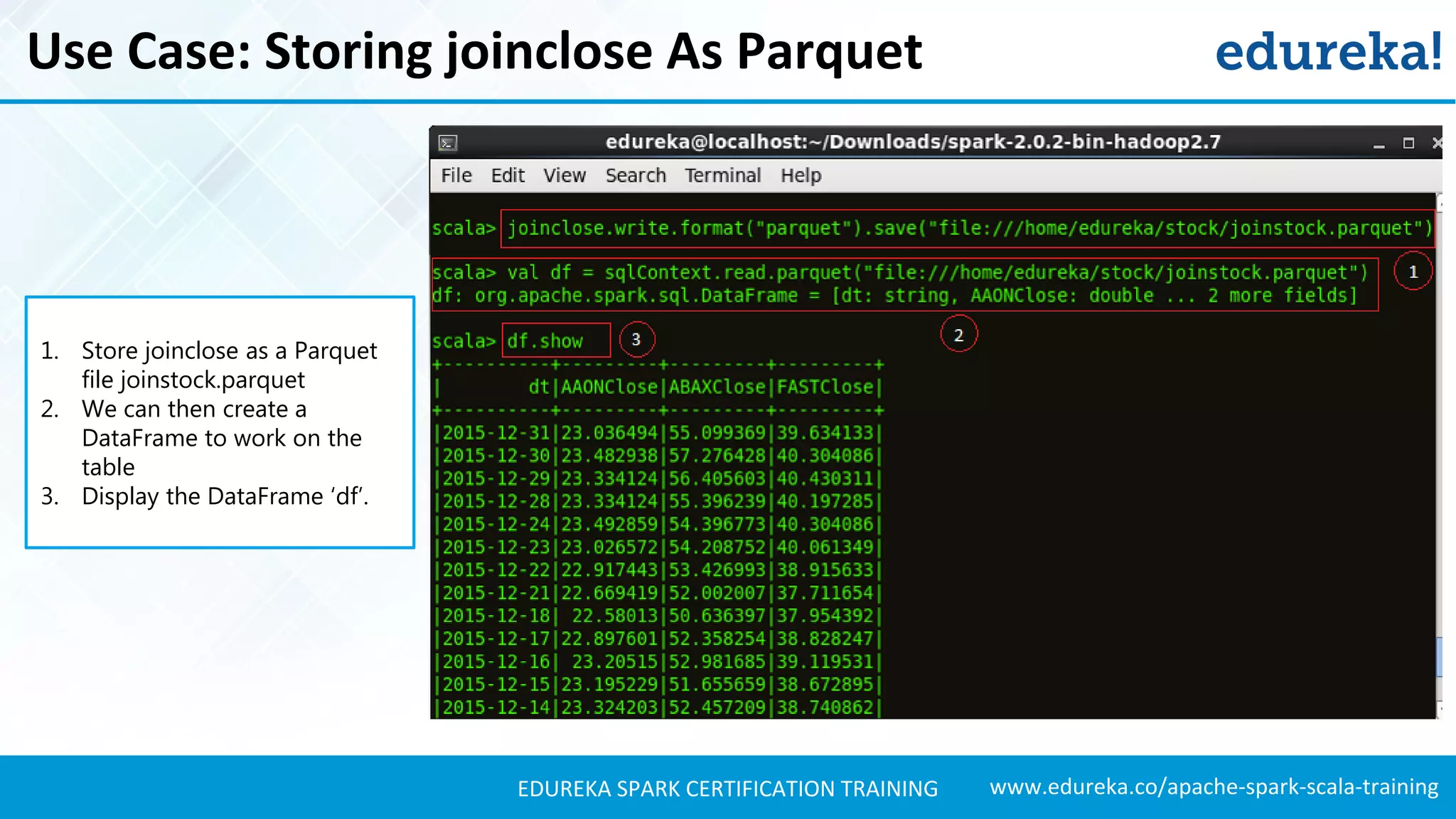
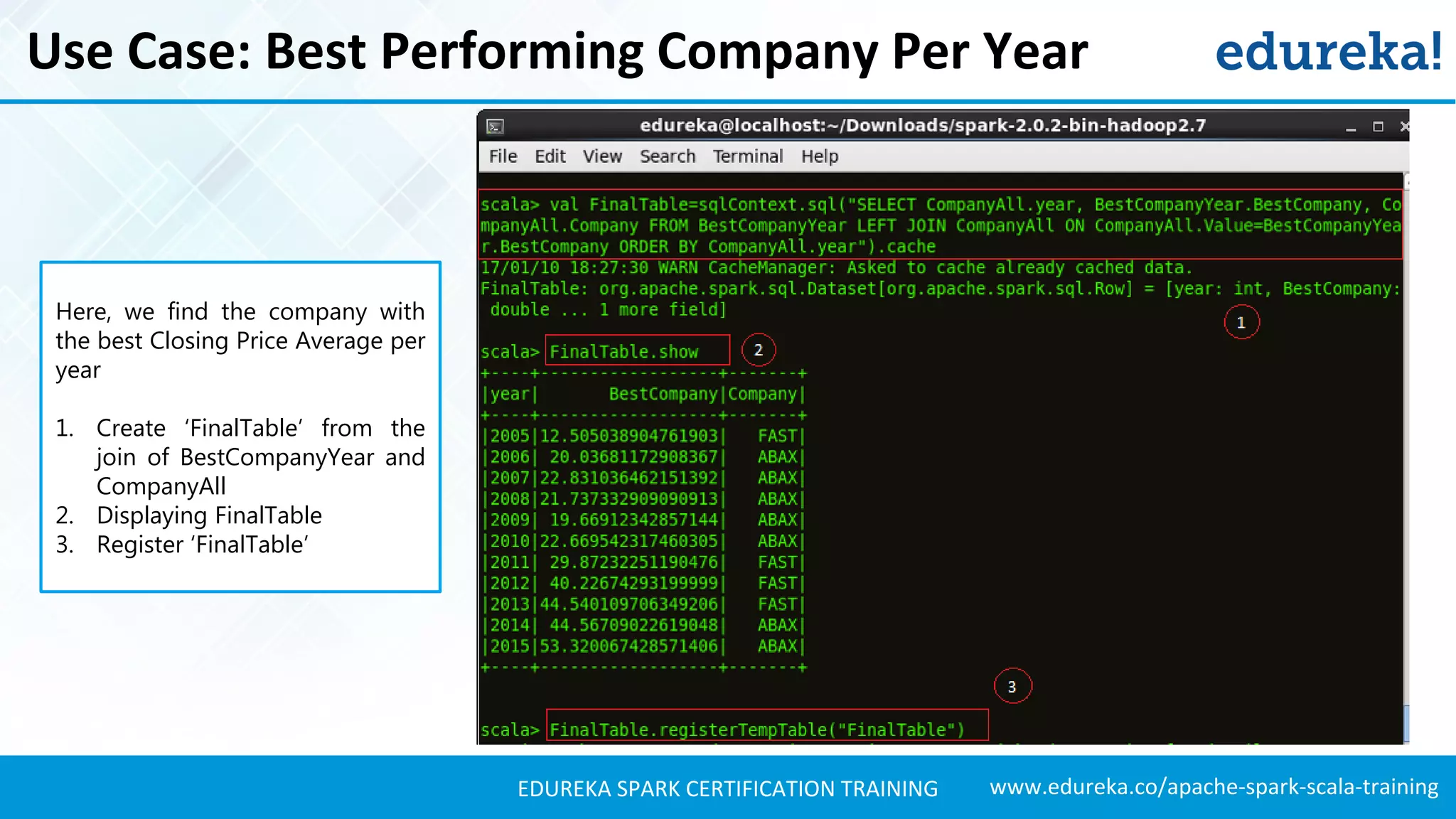
Introduces a use case for stock market analysis using Spark SQL to process large datasets effectively.Details stock data used for analysis, including information about the companies involved.
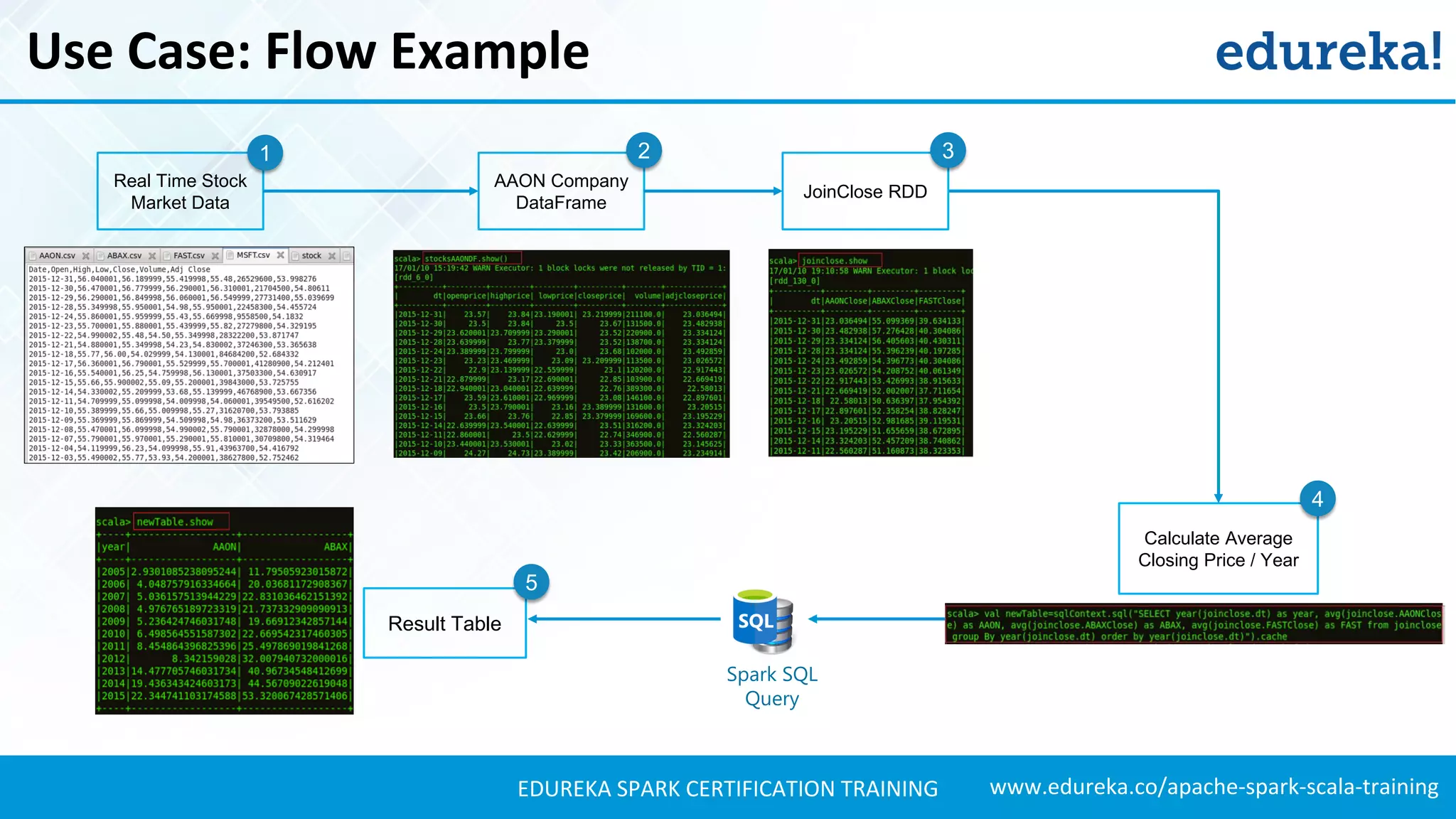
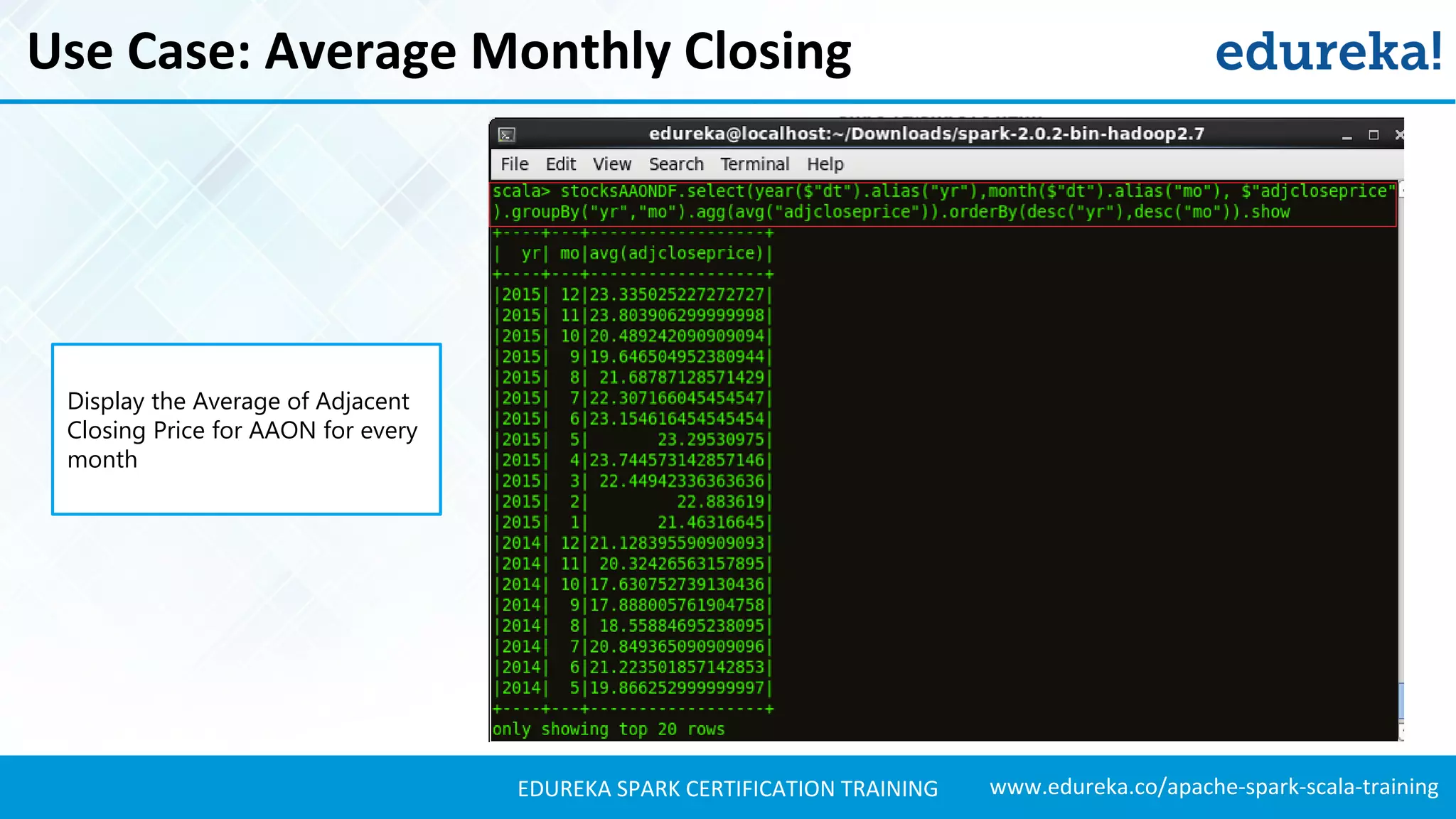
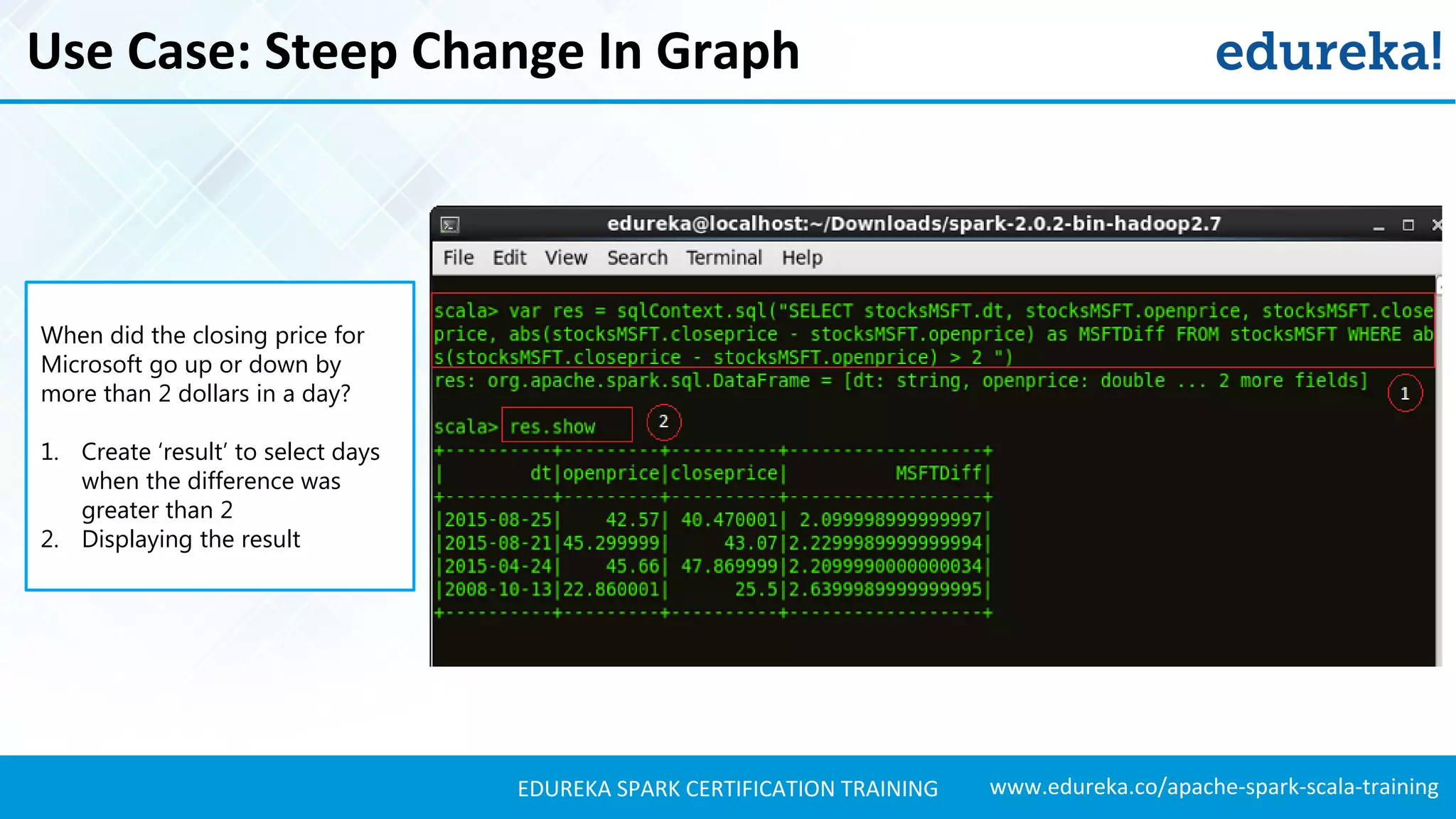
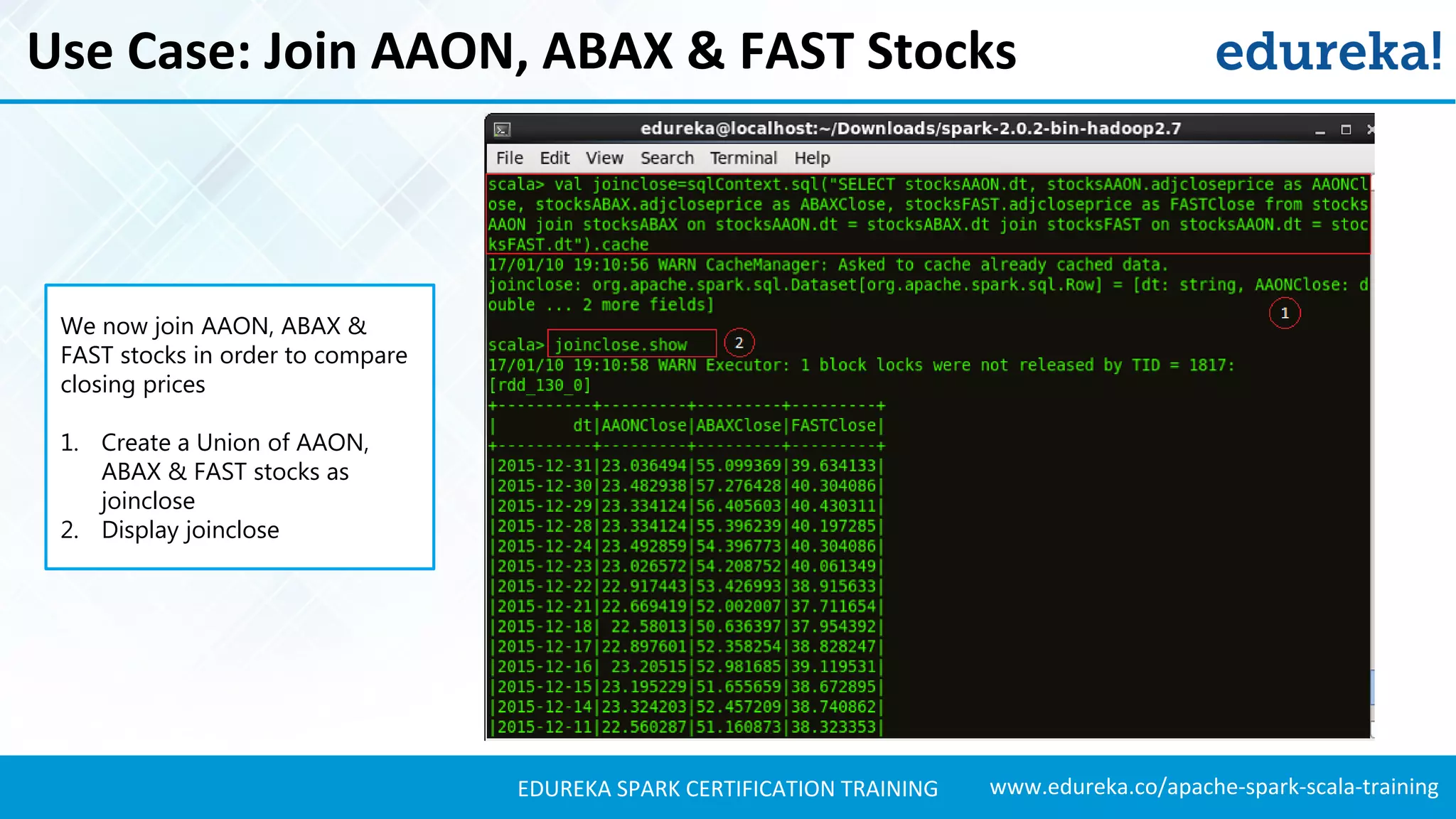
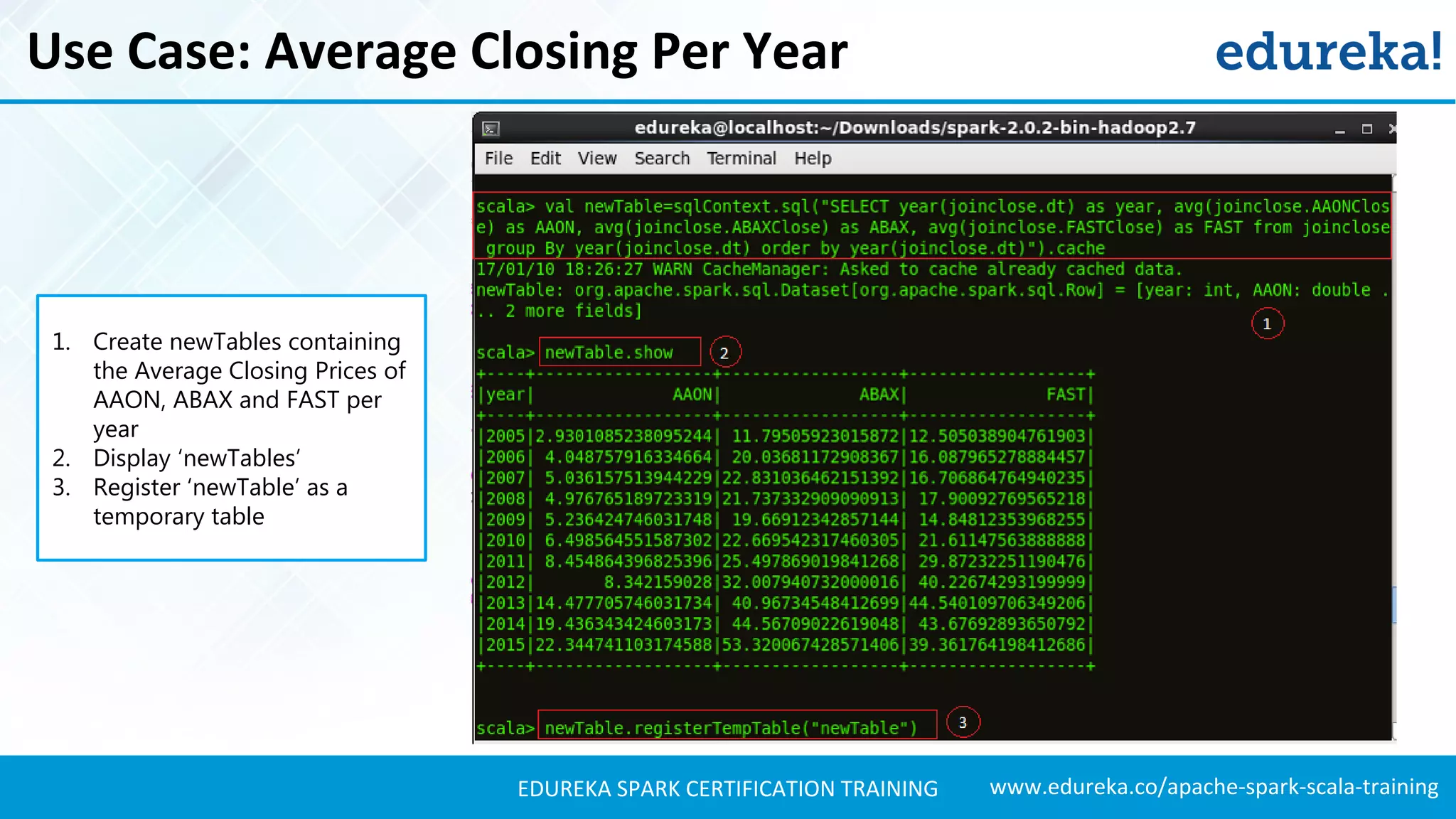
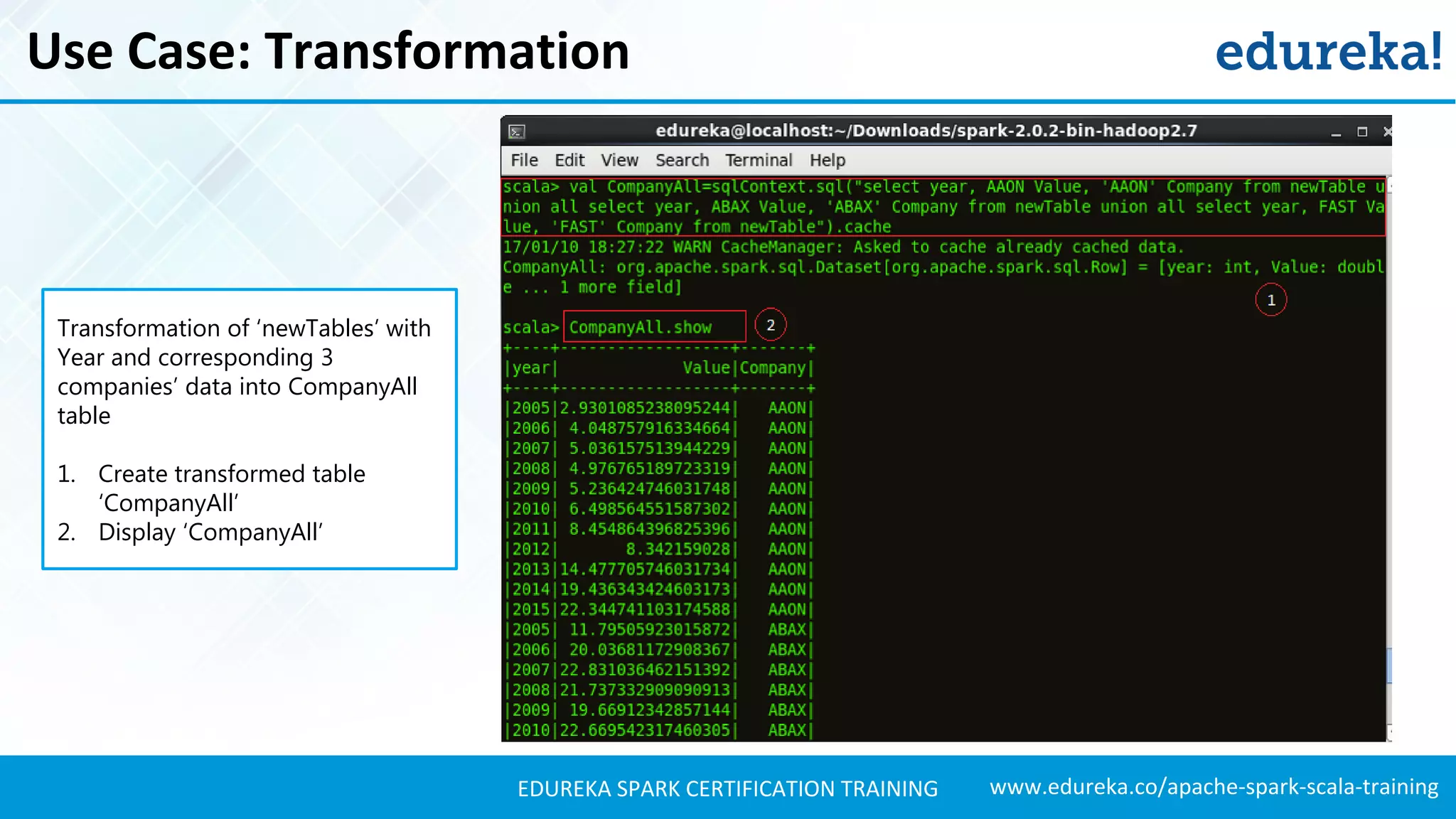
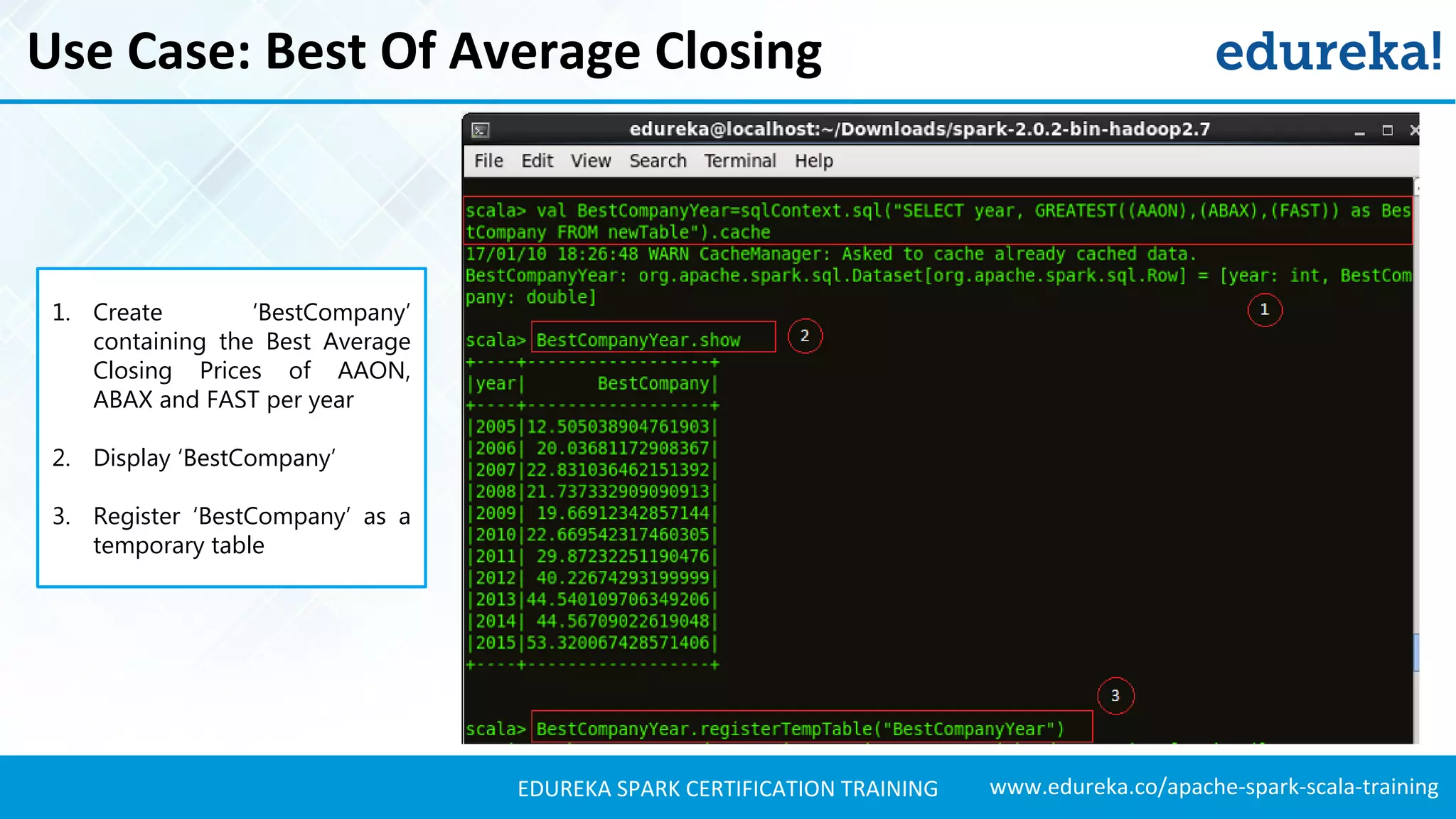
Presents techniques for advanced stock analysis including joining stock data, transformations, and calculating averages.
Celebrates the completion of training, demonstrates Spark SQL's power in real-time analytics.
Encourages questions, queries, and feedback from participants.


















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




