Downloaded 99 times
















































































Spark SQL is a module of Apache Spark designed for handling structured and semi-structured data, improving upon the limitations of Apache Hive by offering better performance and fault tolerance. It features a robust architecture with support for multiple programming languages and data sources, leveraging DataFrames and a Catalyst optimizer for efficient query execution. Users can run SQL queries and process large datasets seamlessly using Spark's integrated capabilities.
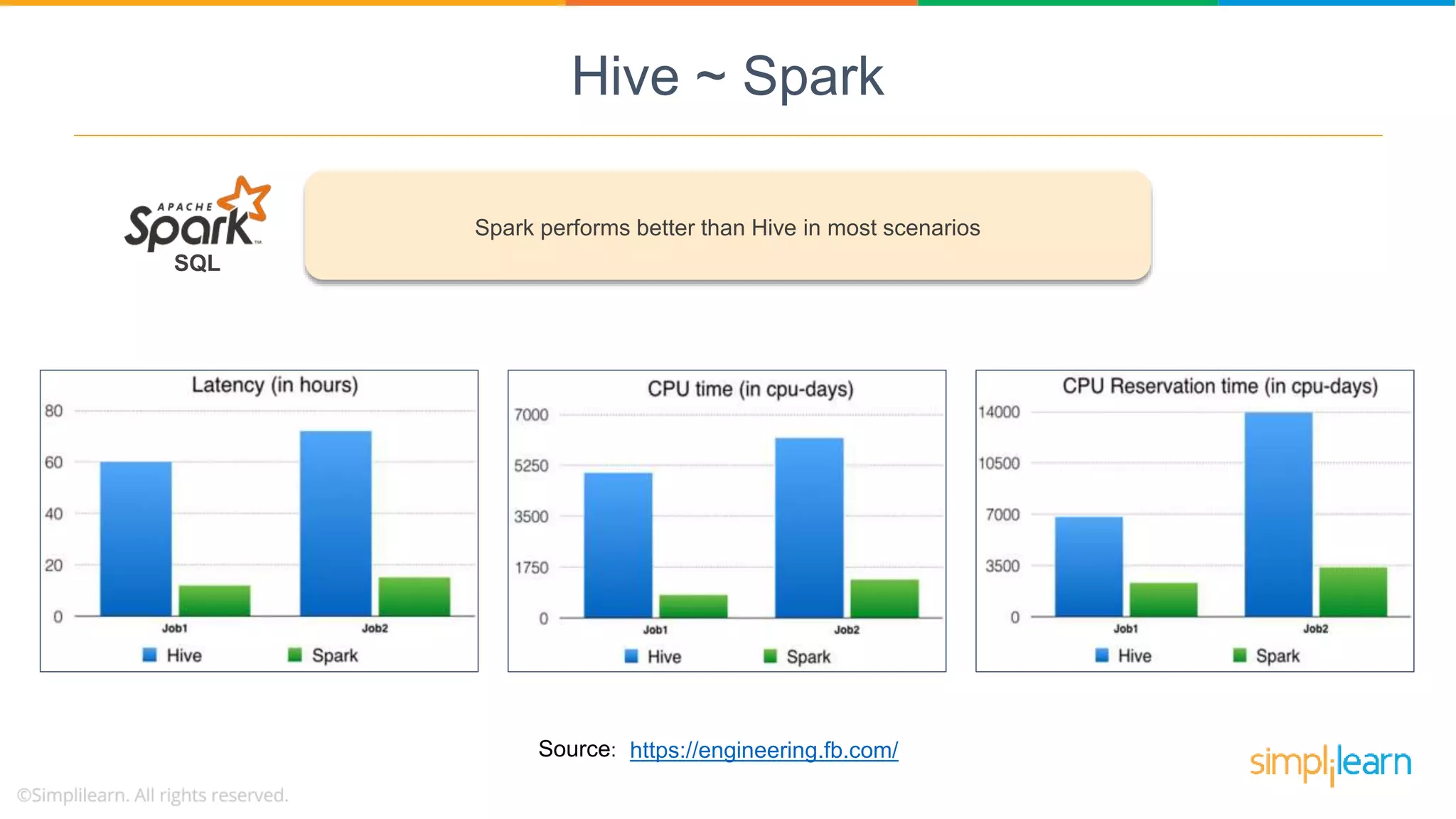
Spark SQL is Apache Spark's module for structured and semi-structured data, overcoming Hive's limits. It enhances performance and job resume capabilities.
Spark SQL is Apache Spark's module for structured and semi-structured data, overcoming Hive's limits. It enhances performance and job resume capabilities.
Spark SQL features include high compatibility, integration within Spark, scalability, and support for JDBC/ODBC connectivity.
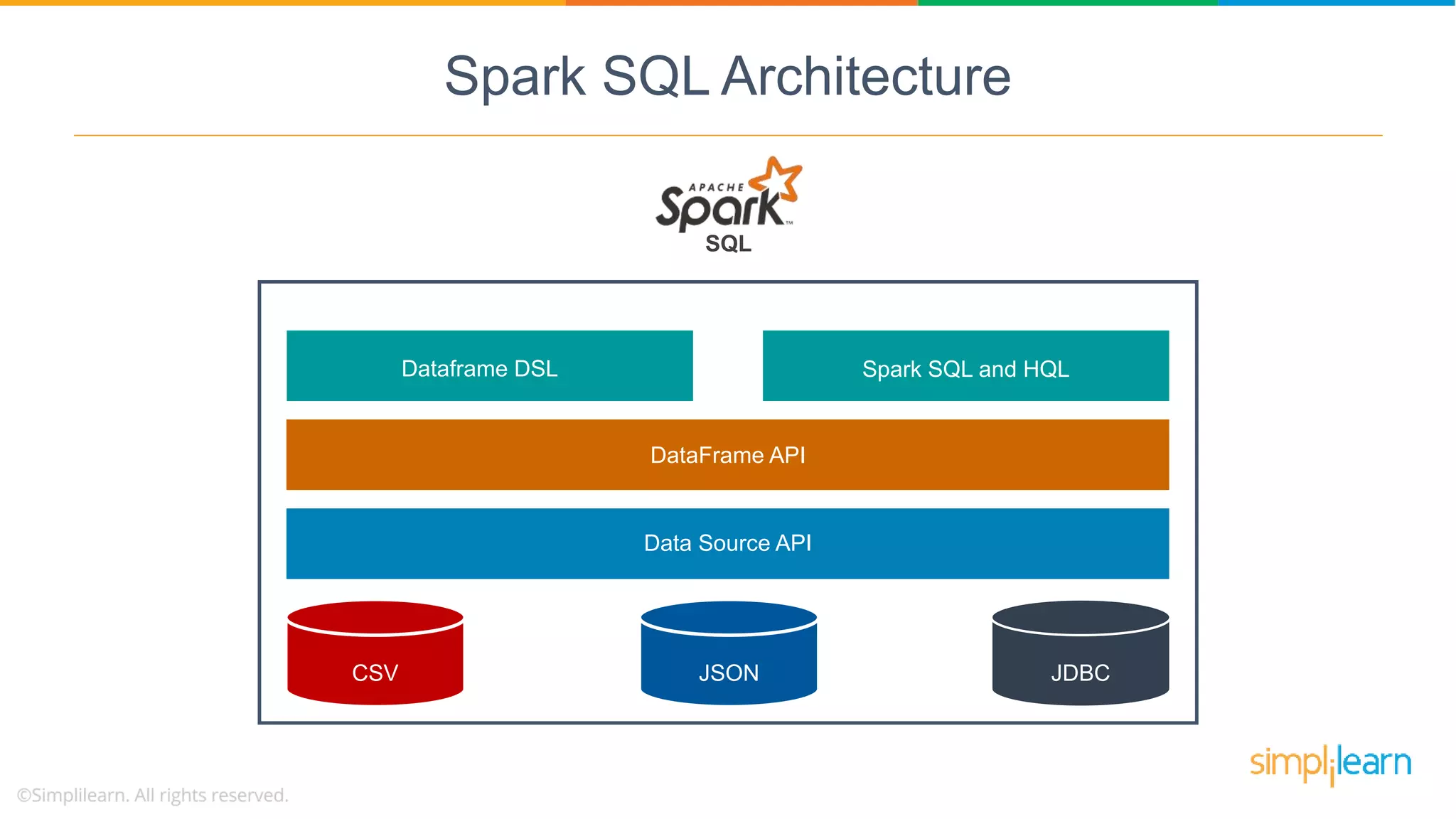
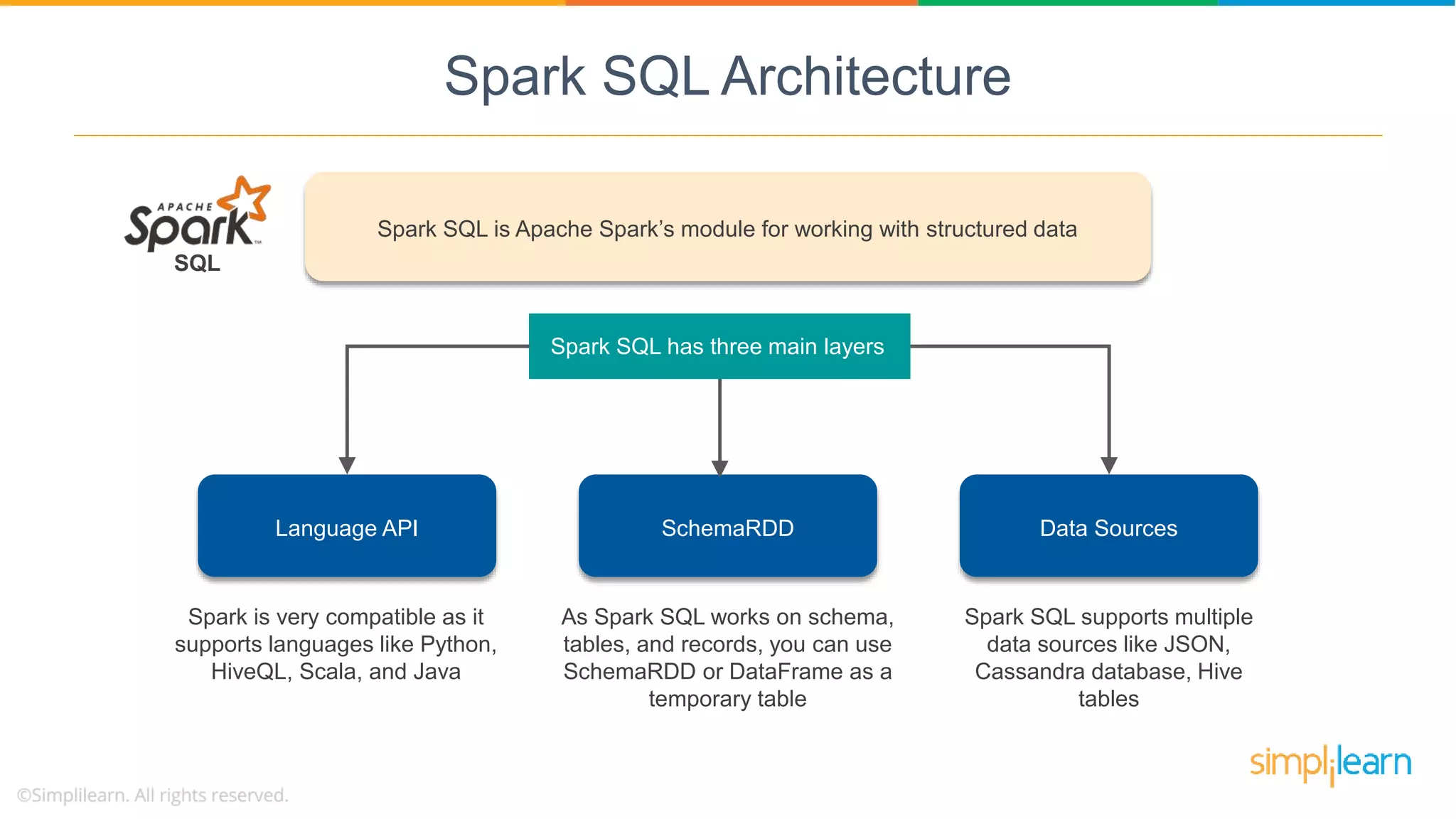
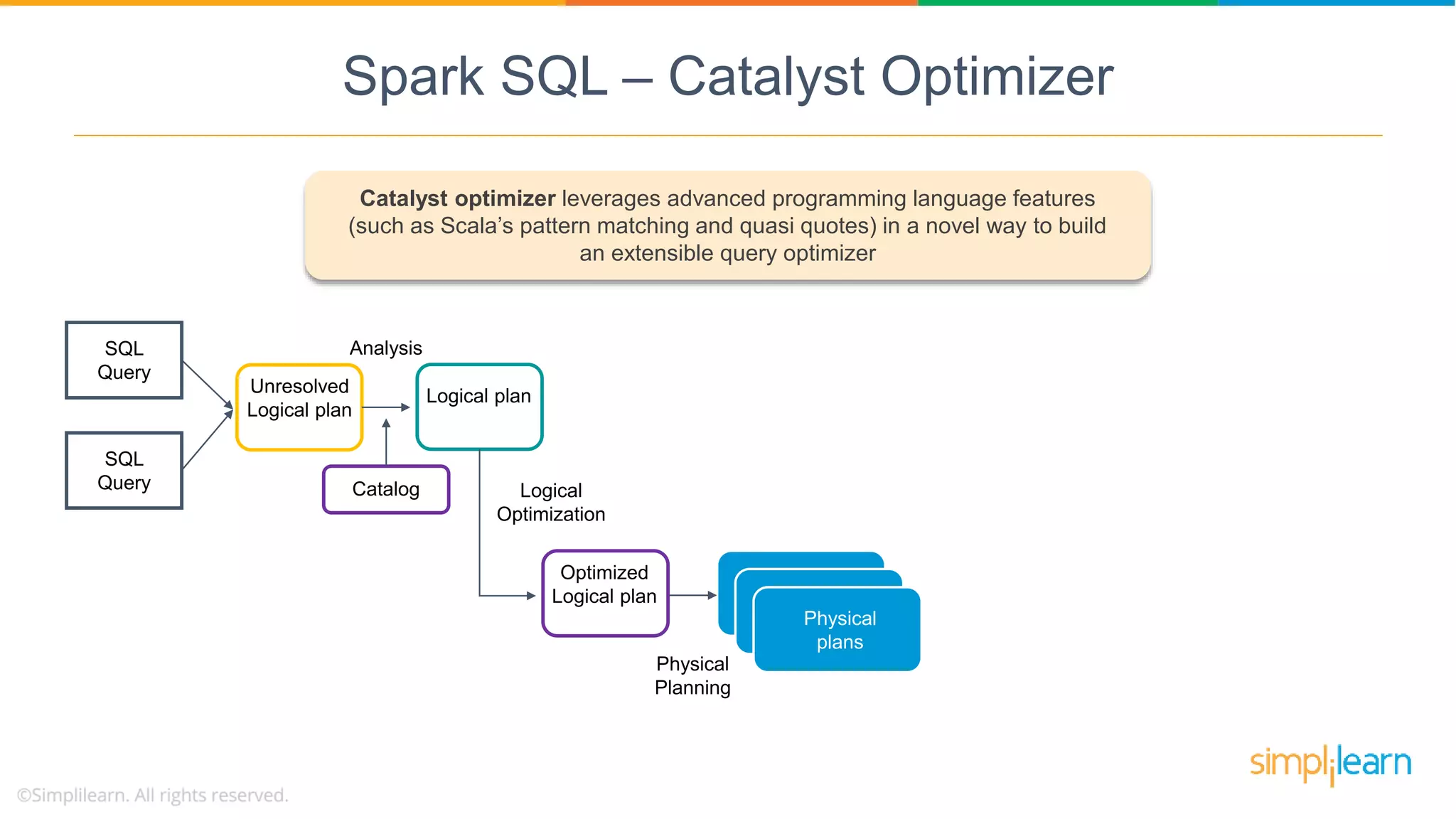
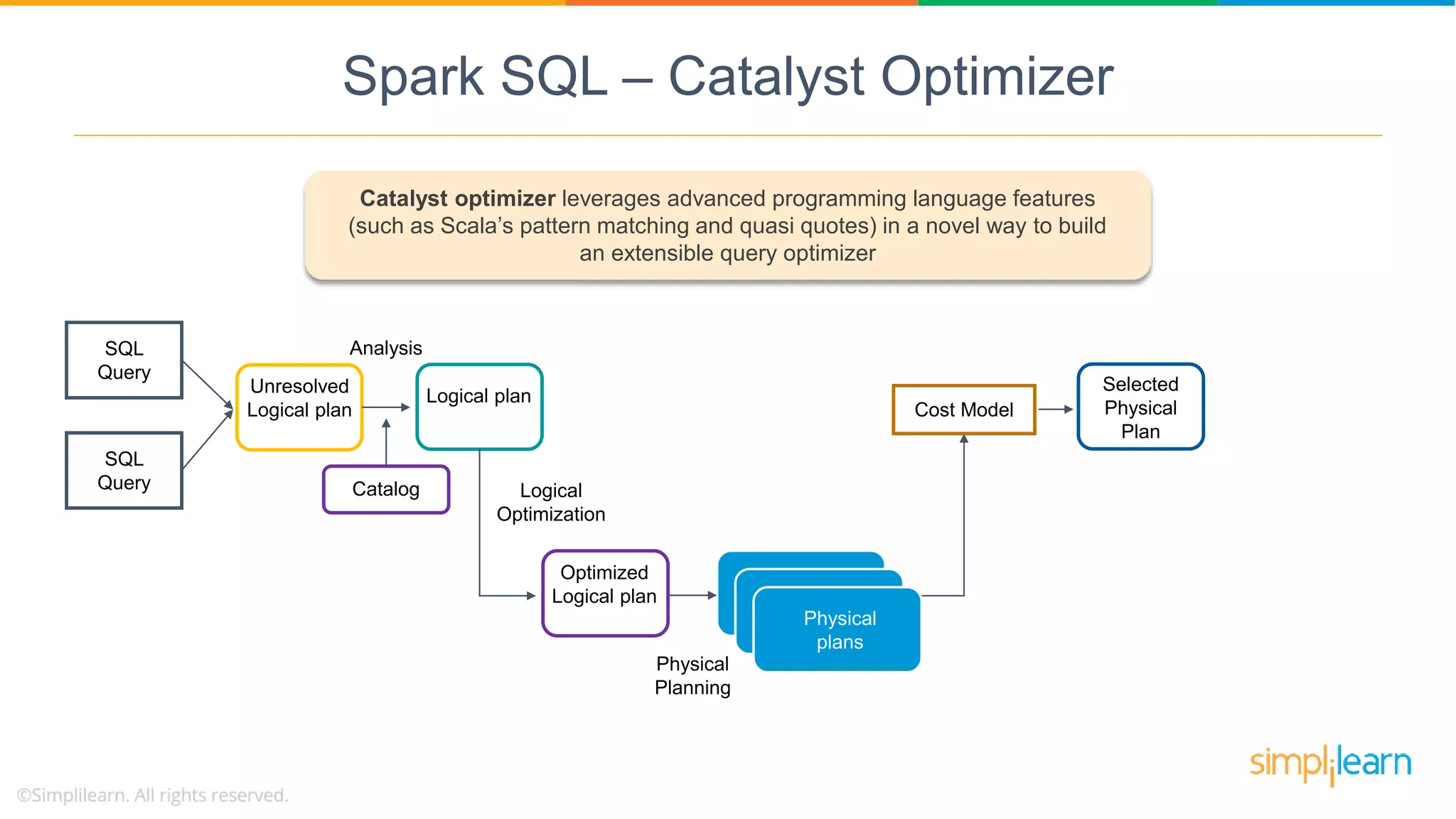
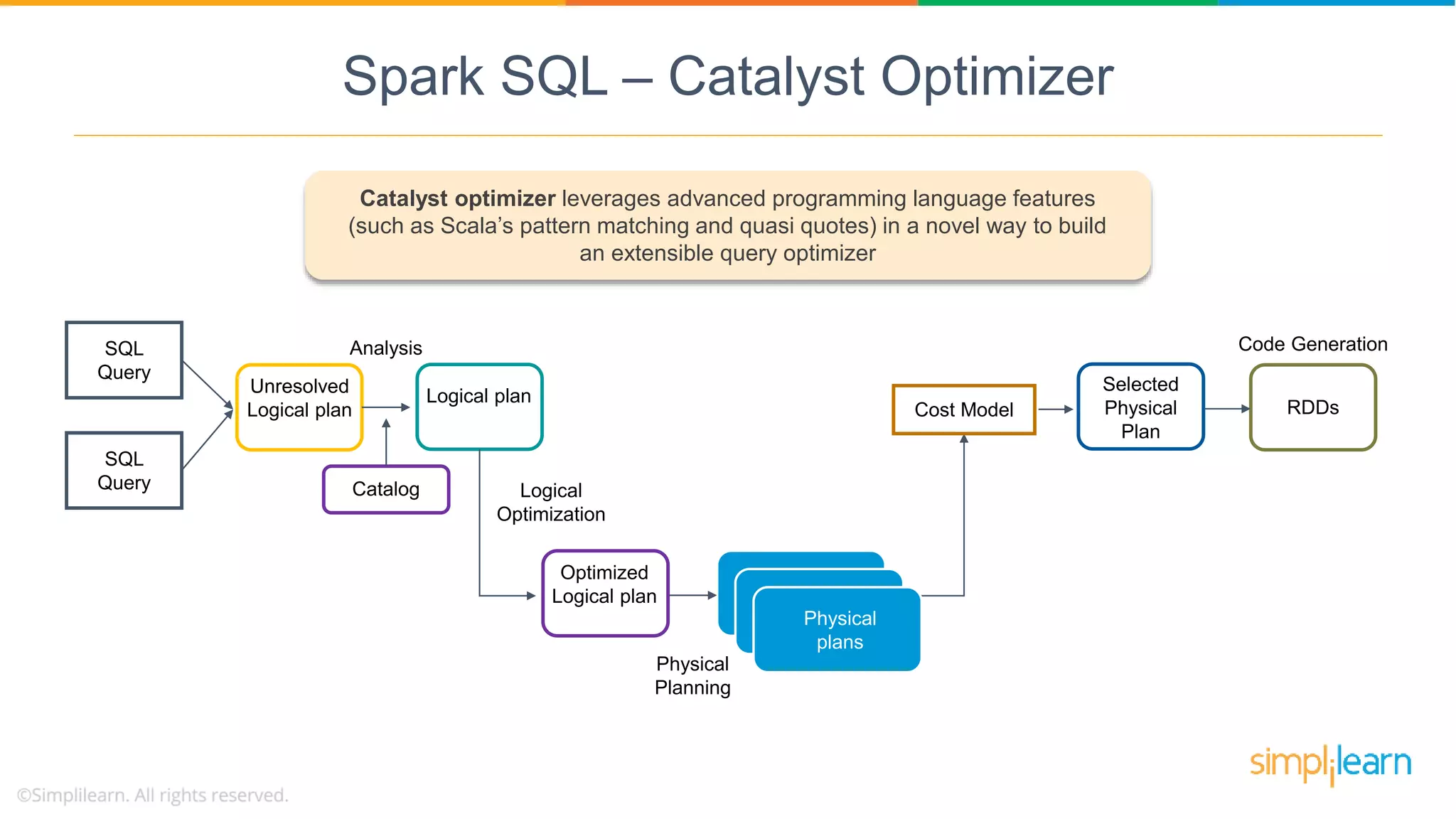
Spark SQL architecture consists of three layers supporting various data sources and programming languages, enabling structured data manipulation.
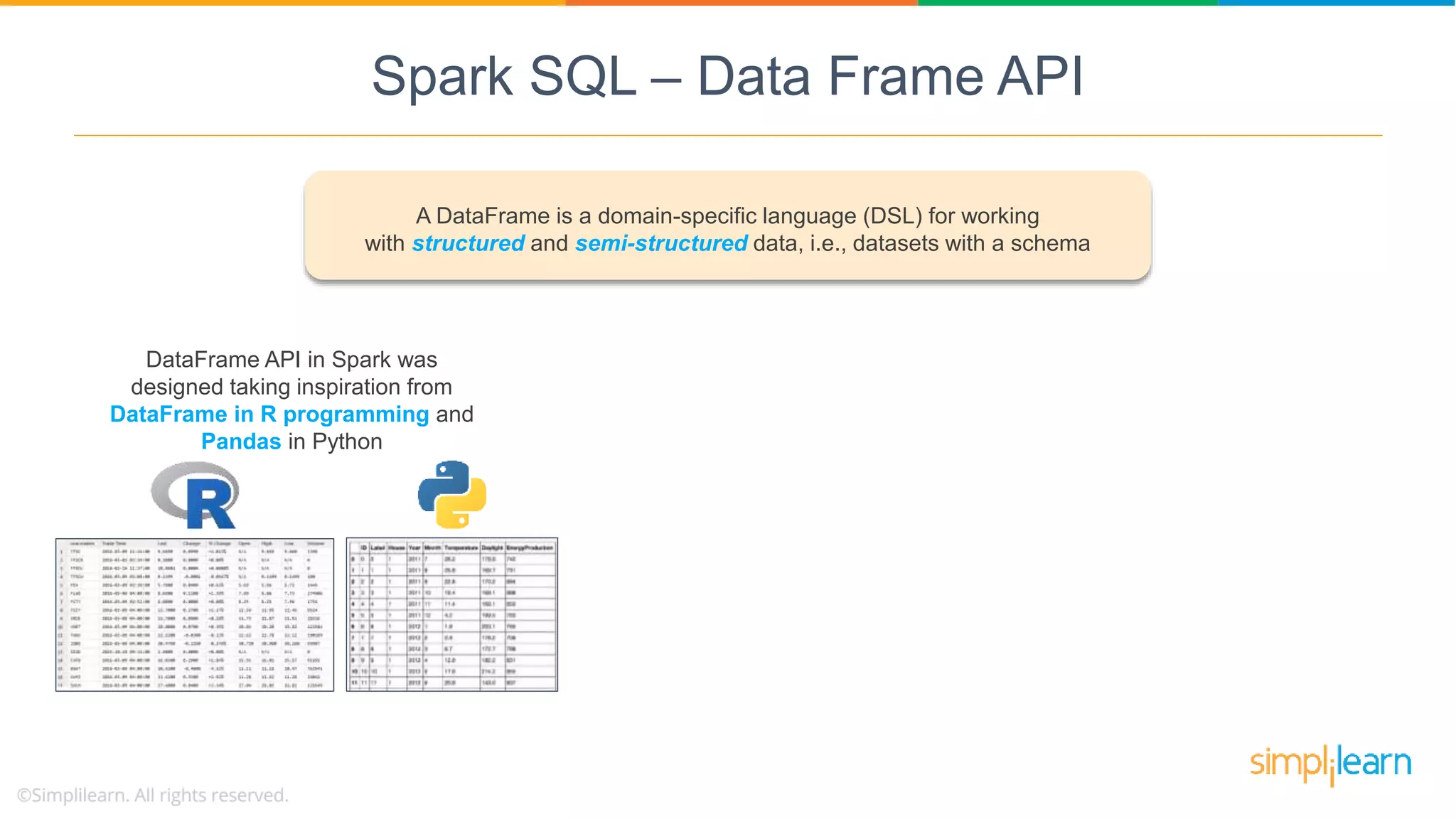
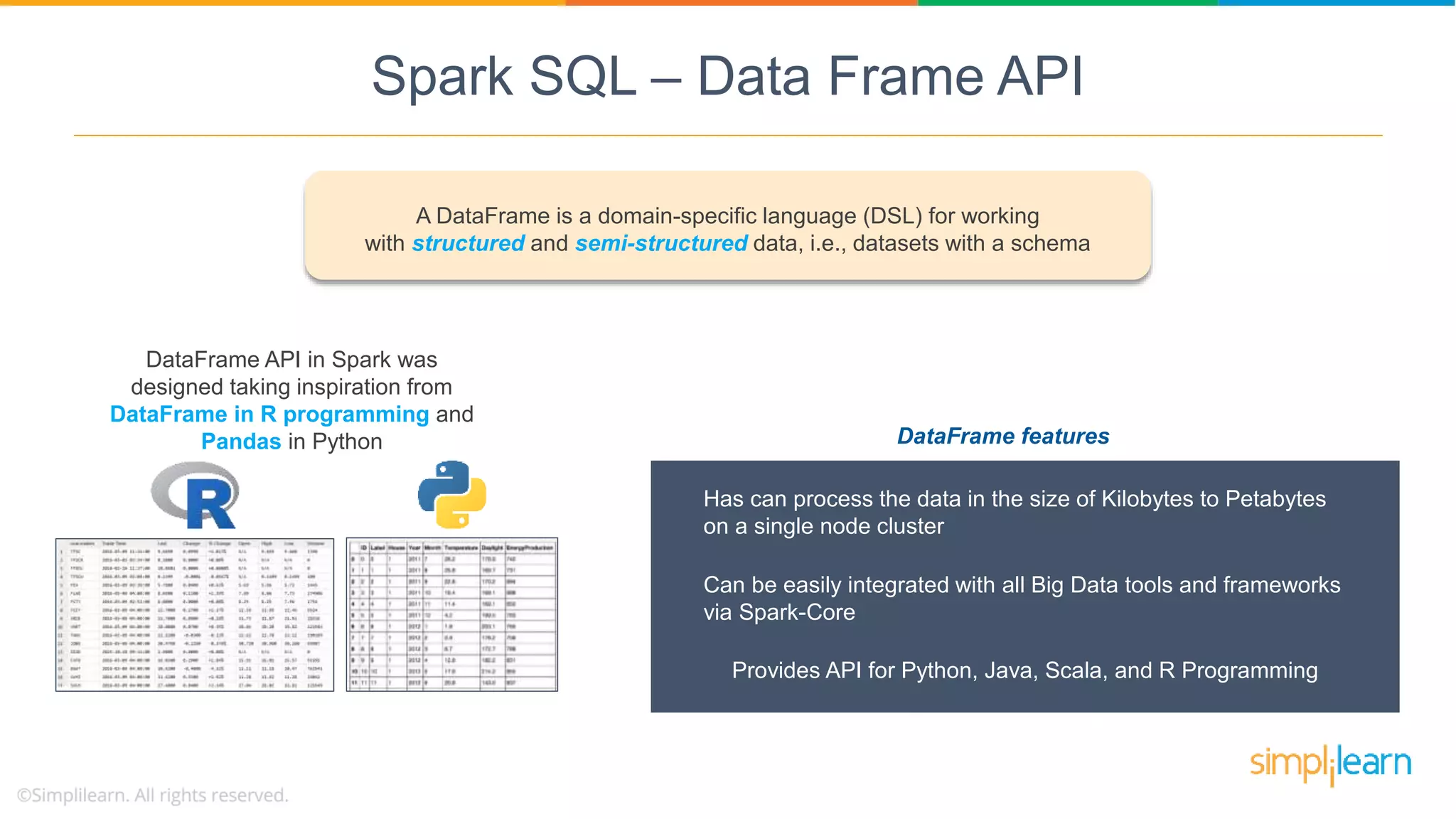
The DataFrame API facilitates working with structured/semi-structured data, inspired by R and Python, processing up to petabytes on a single cluster.
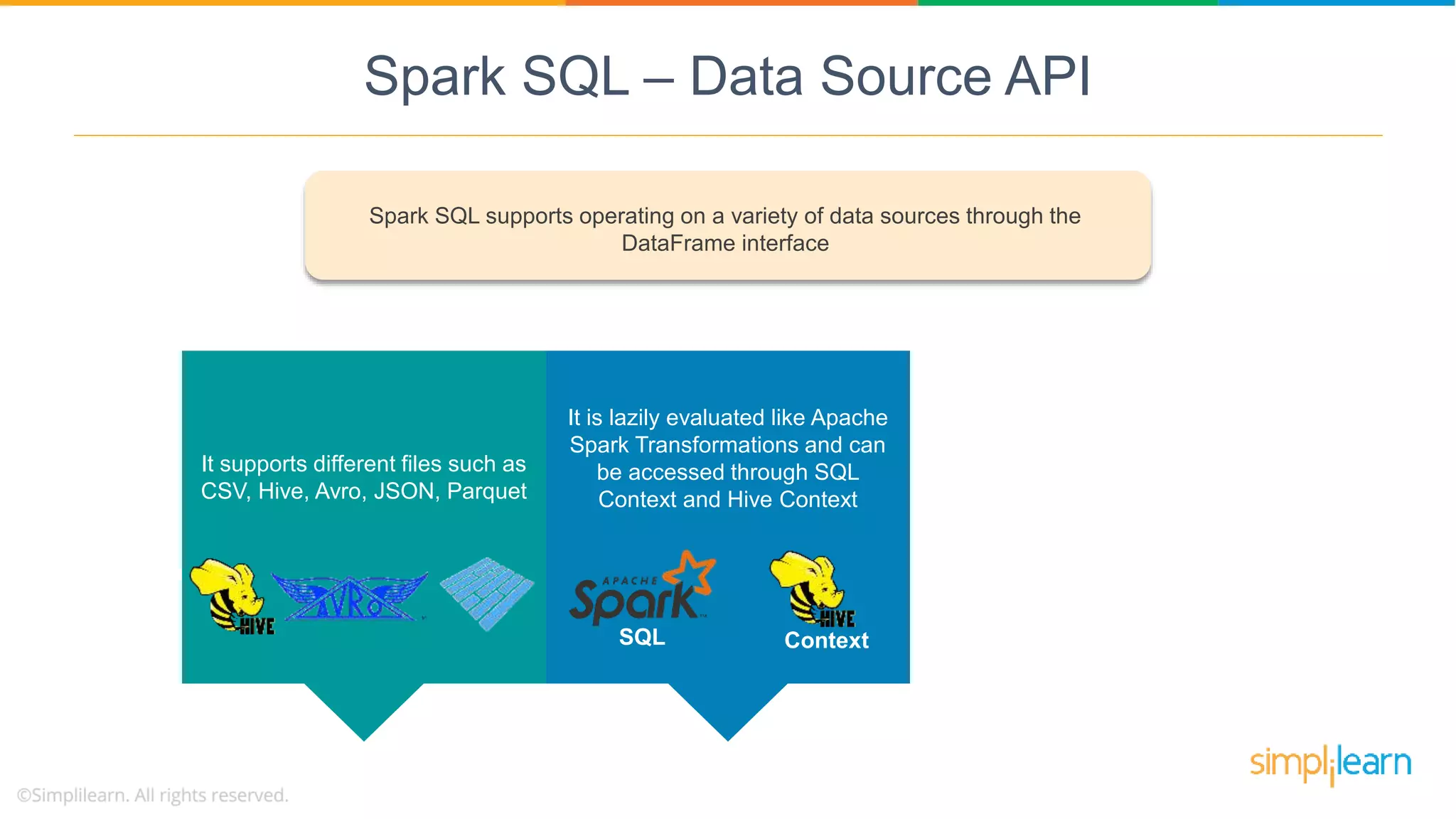
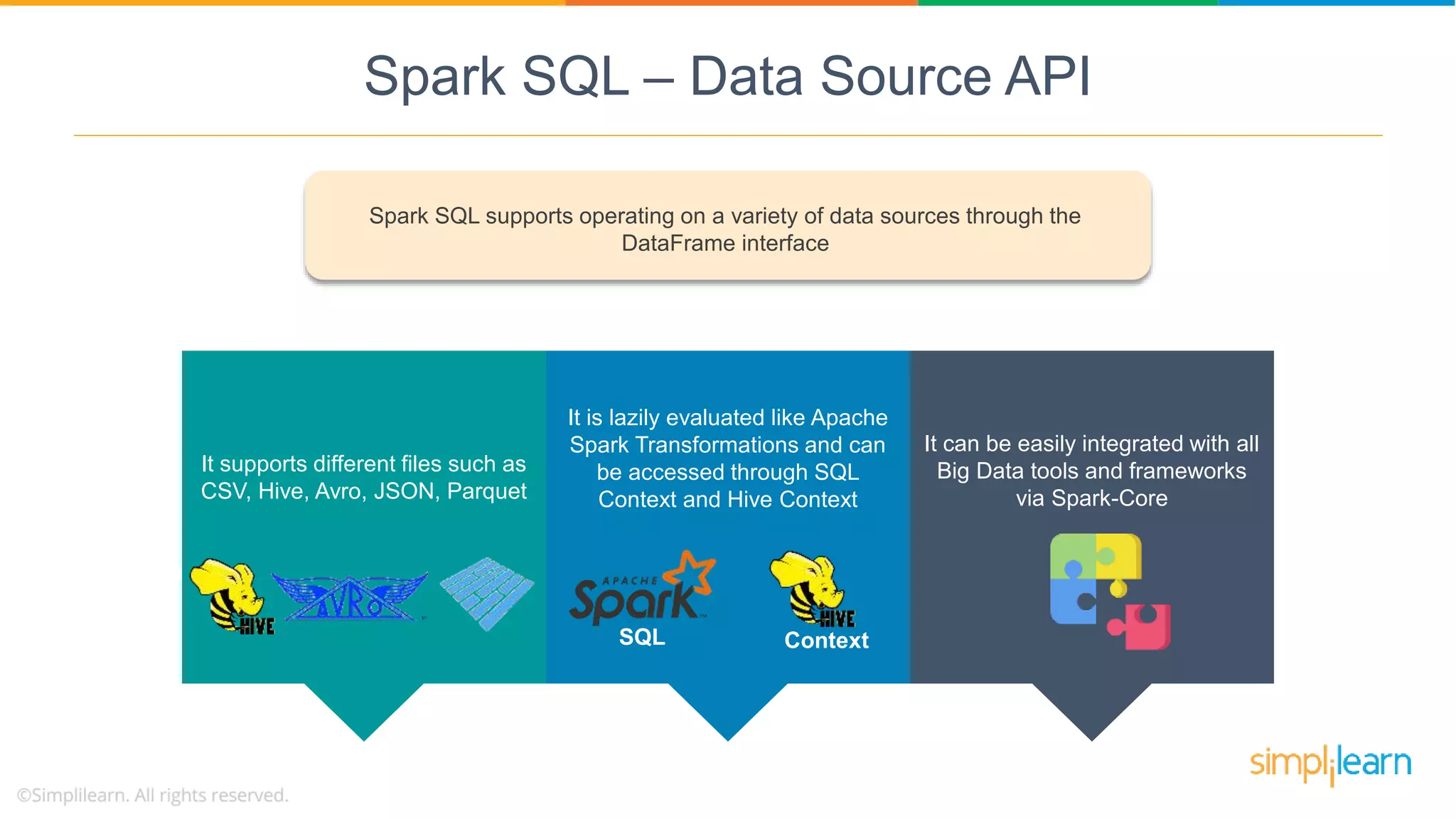
Spark SQL supports various data sources (CSV, Avro, etc.) via the DataFrame interface, lazily evaluated and integrating with Big Data tools.
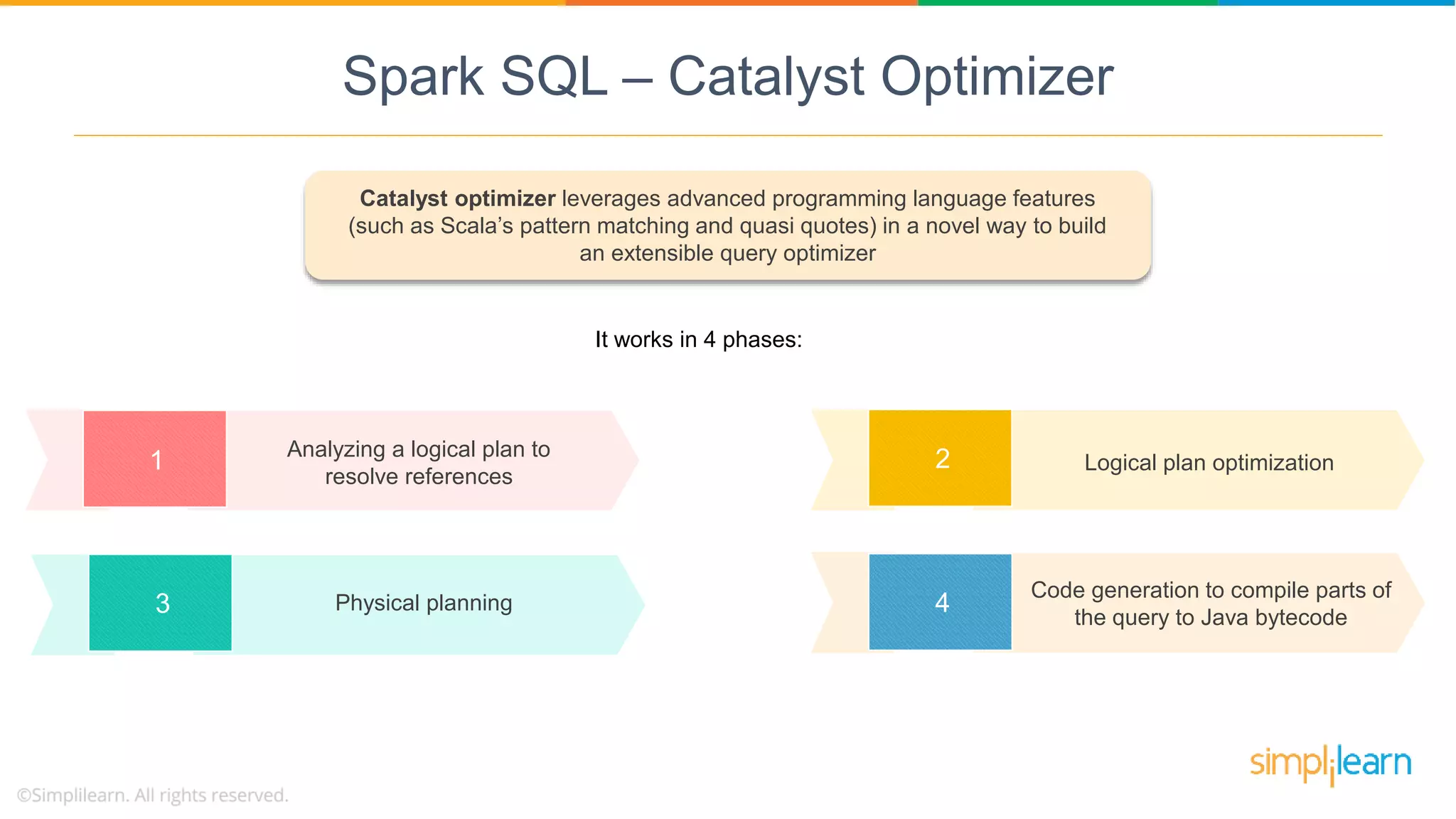
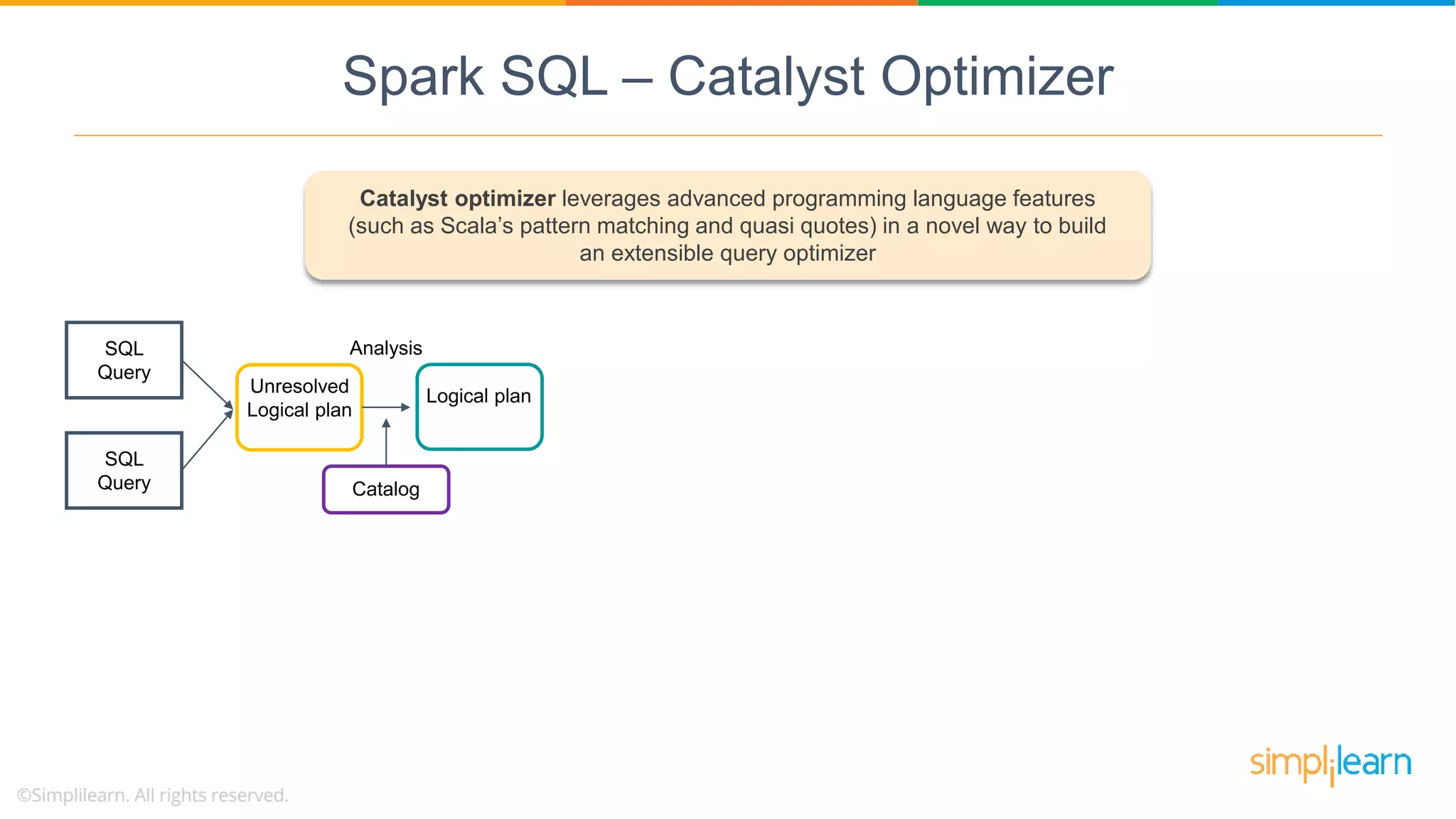
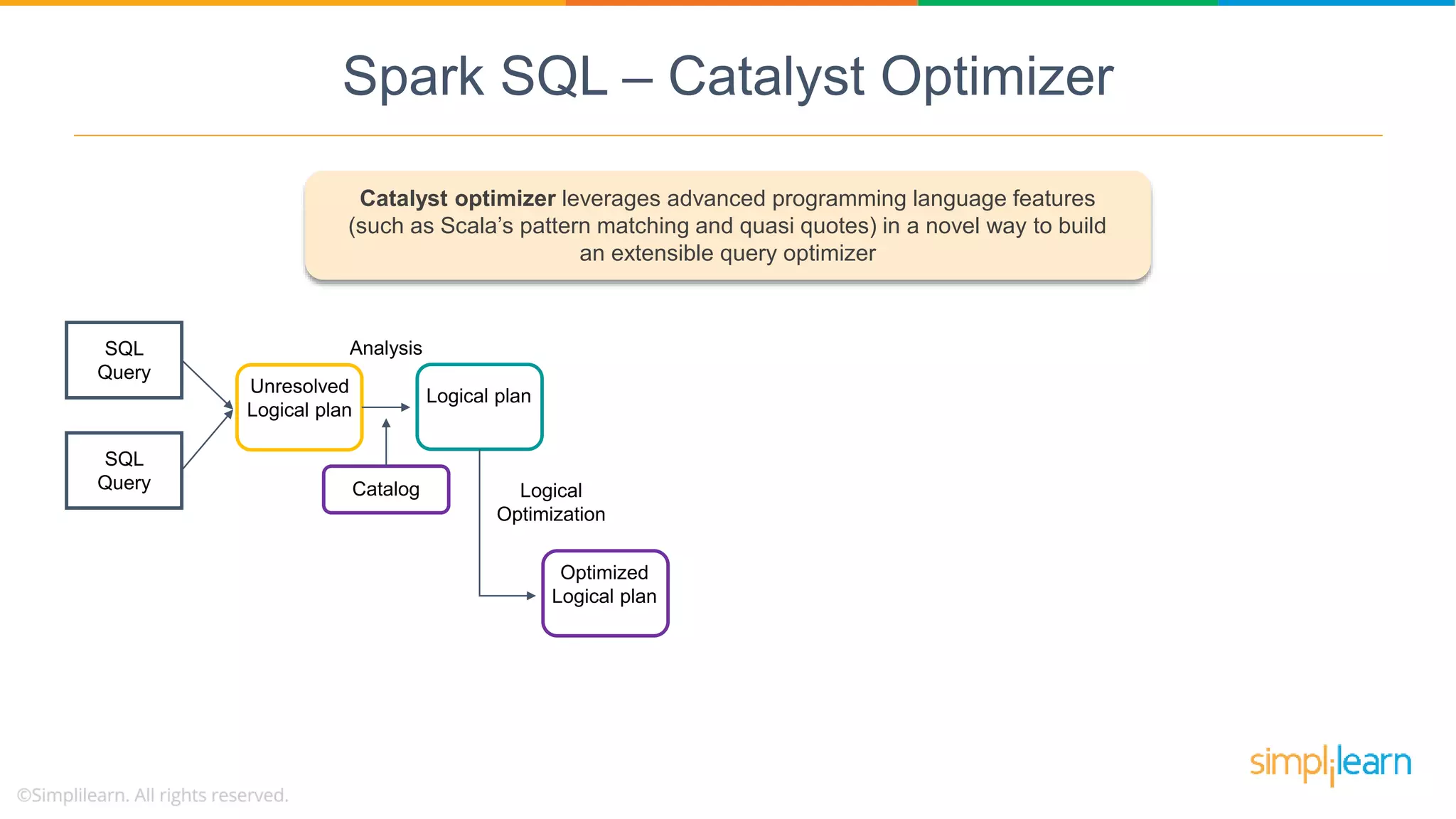
Catalyst Optimizer is a key feature of Spark SQL, enhancing query optimization through a multi-phase process leveraging Scala.
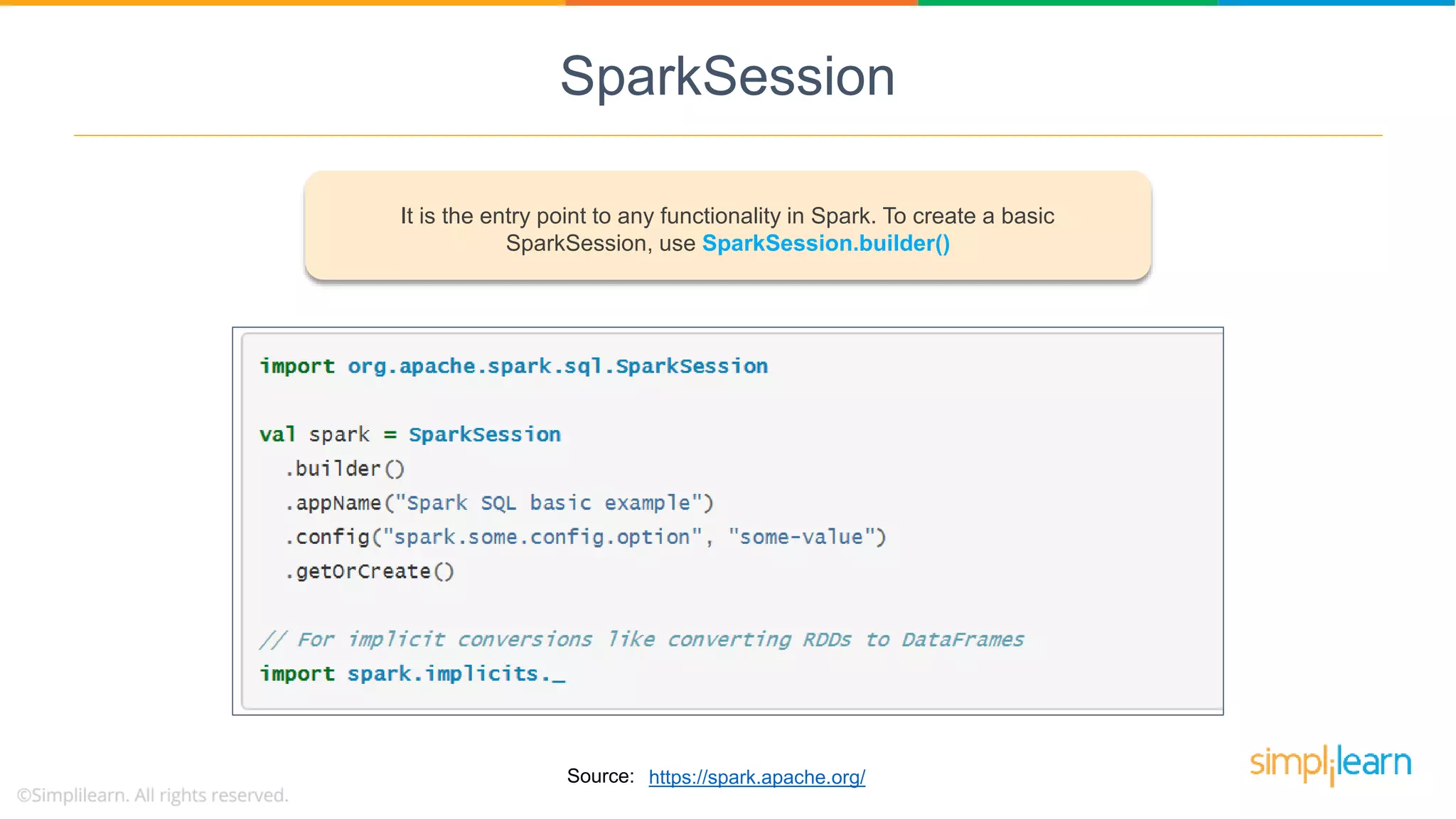
SQLContext initializes Spark SQL functionalities, requiring SparkContext, while SparkSession serves as the entry point for Spark applications.
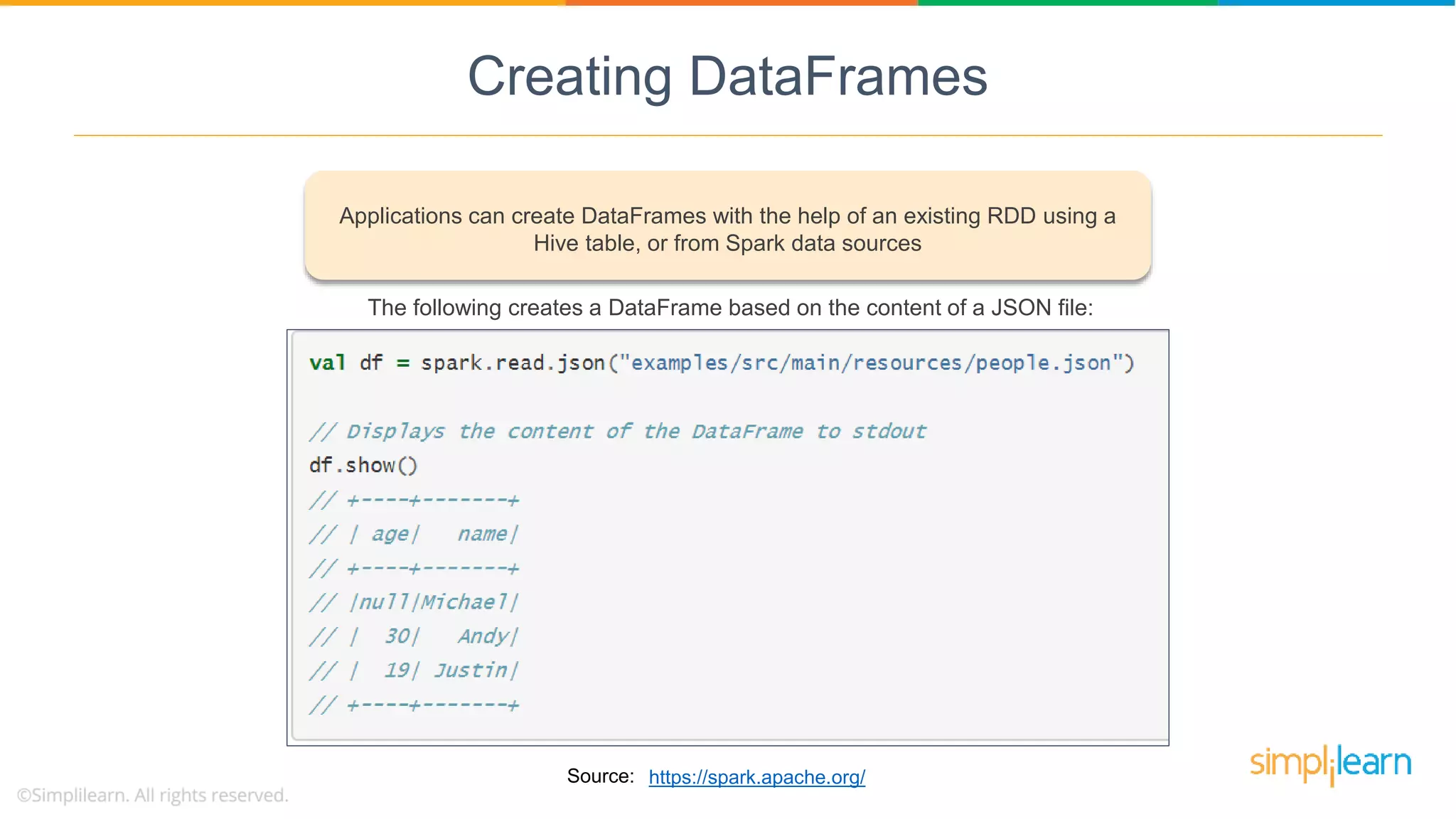
Applications can create DataFrames from RDDs or data sources, utilizing domain-specific language for structured data manipulation.
Spark SQL allows running SQL queries through the sql function on a SparkSession, returning results as DataFrames.























































































