Downloaded 86 times


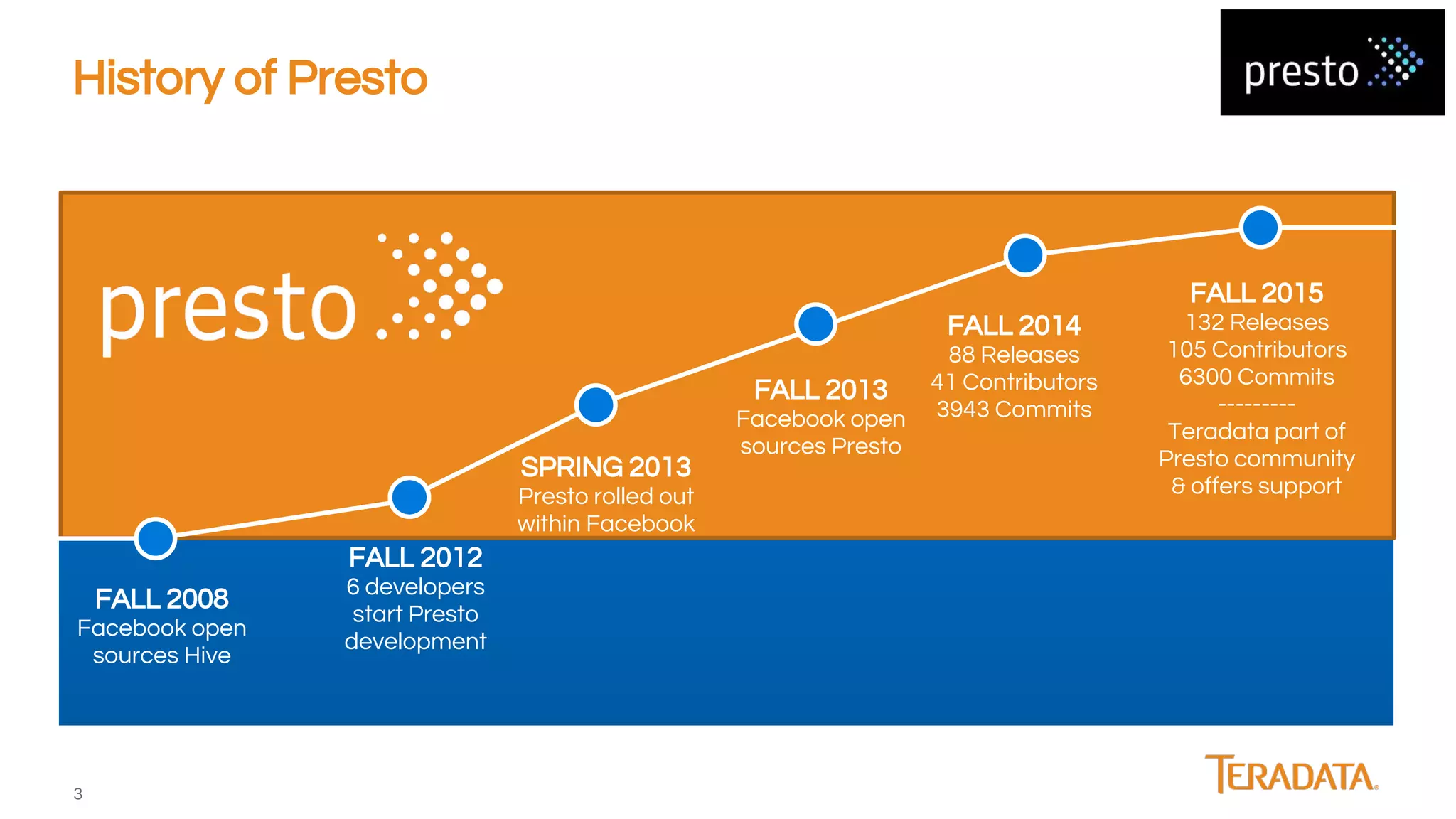

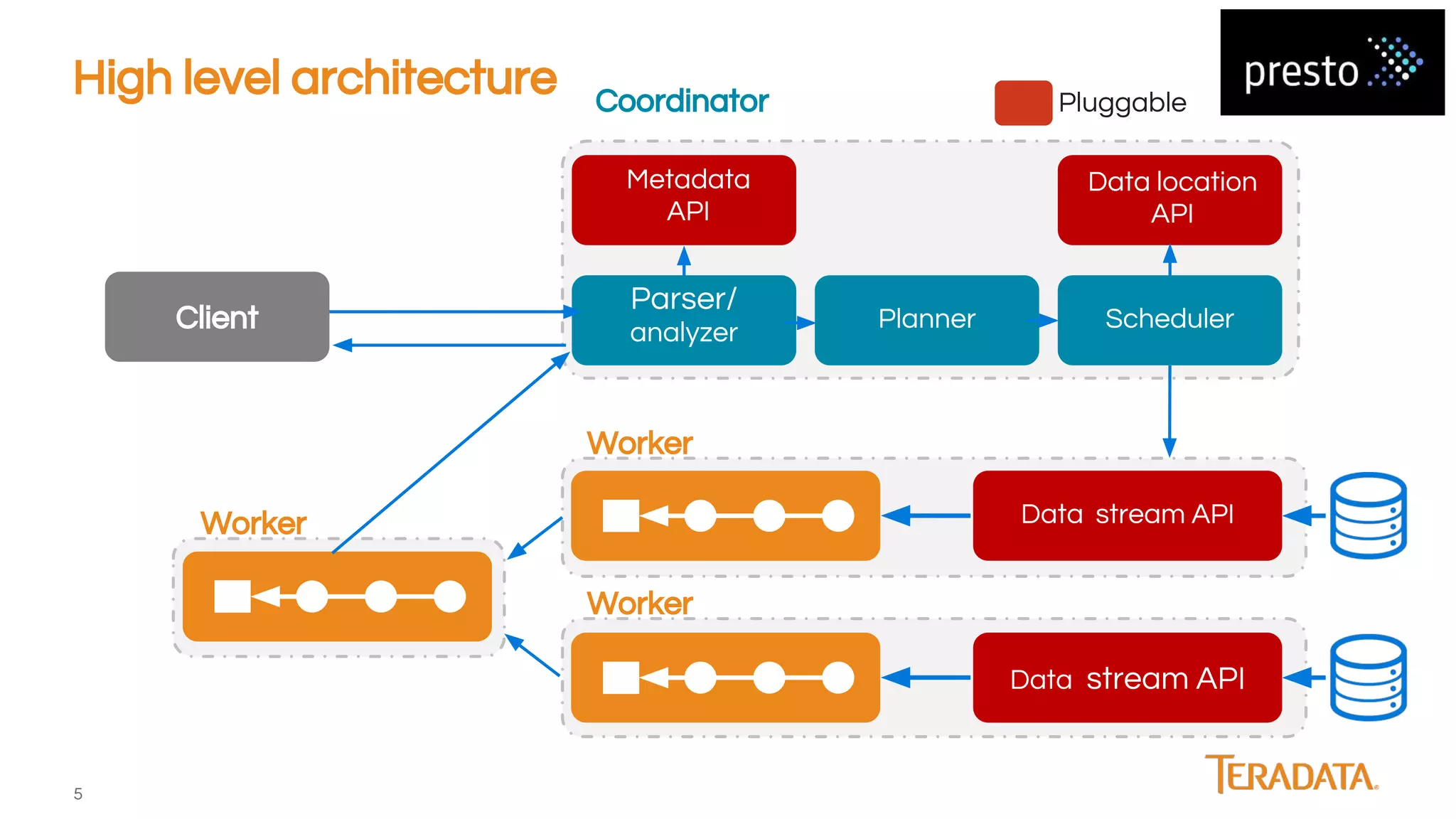
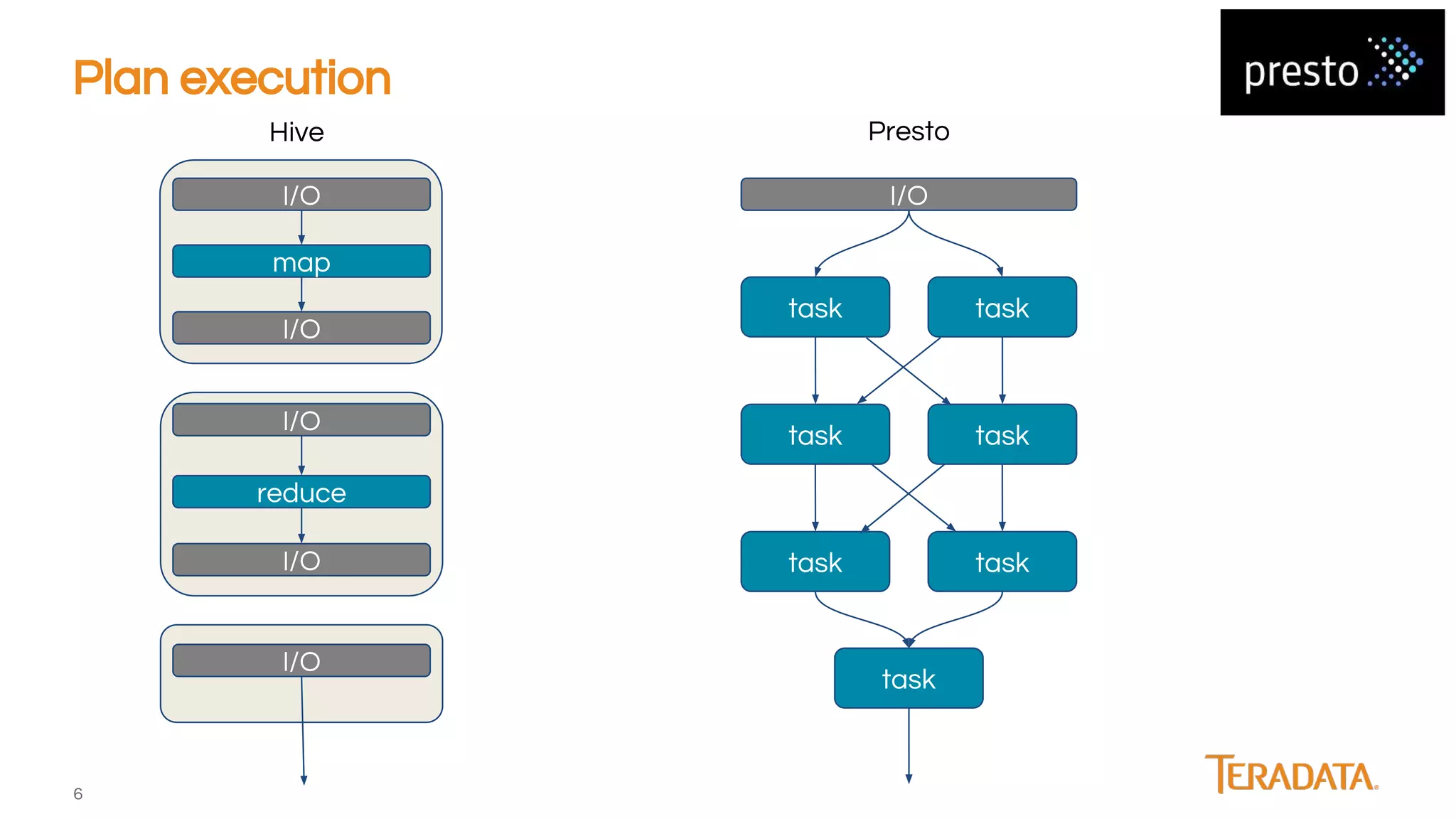
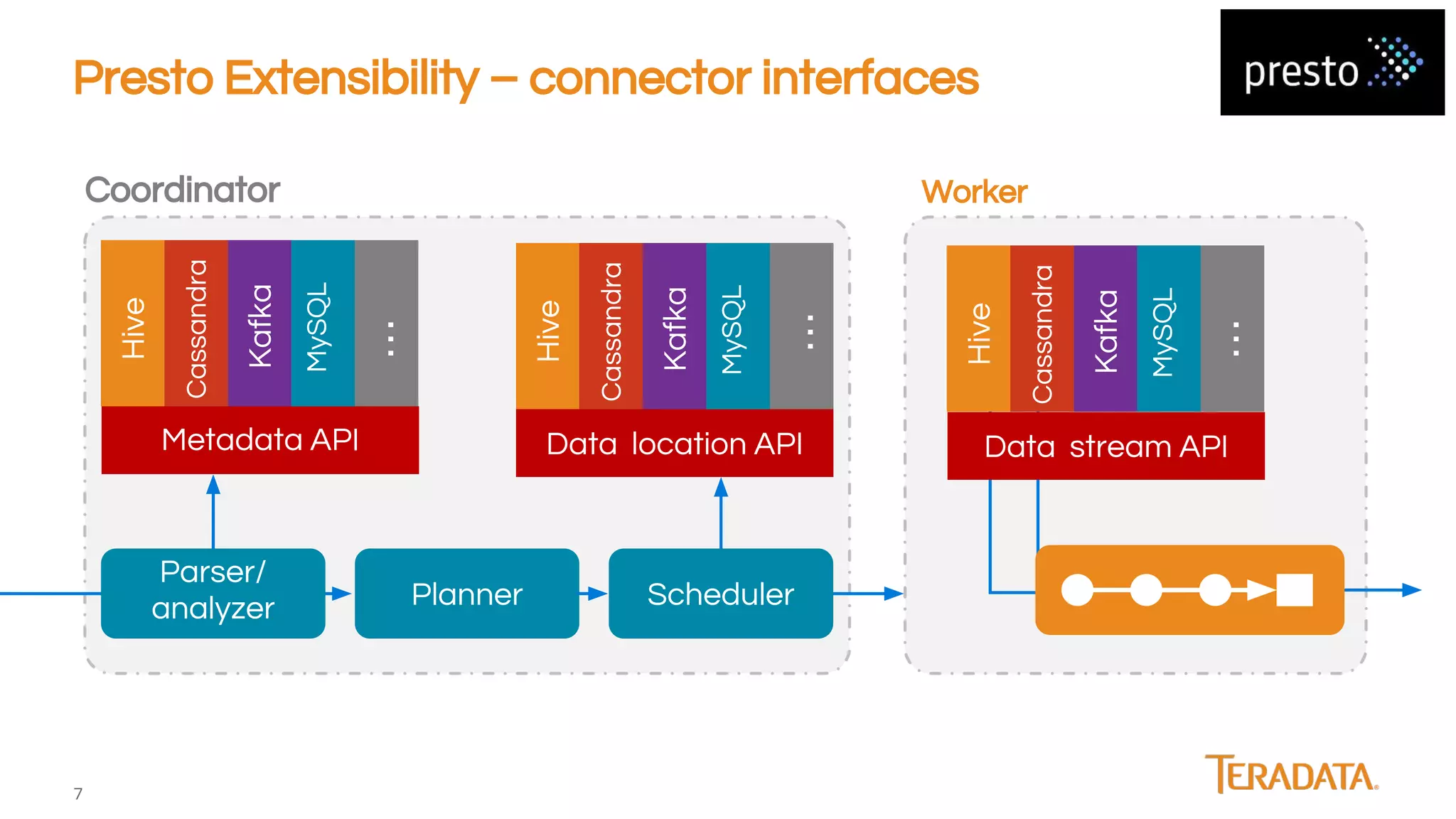


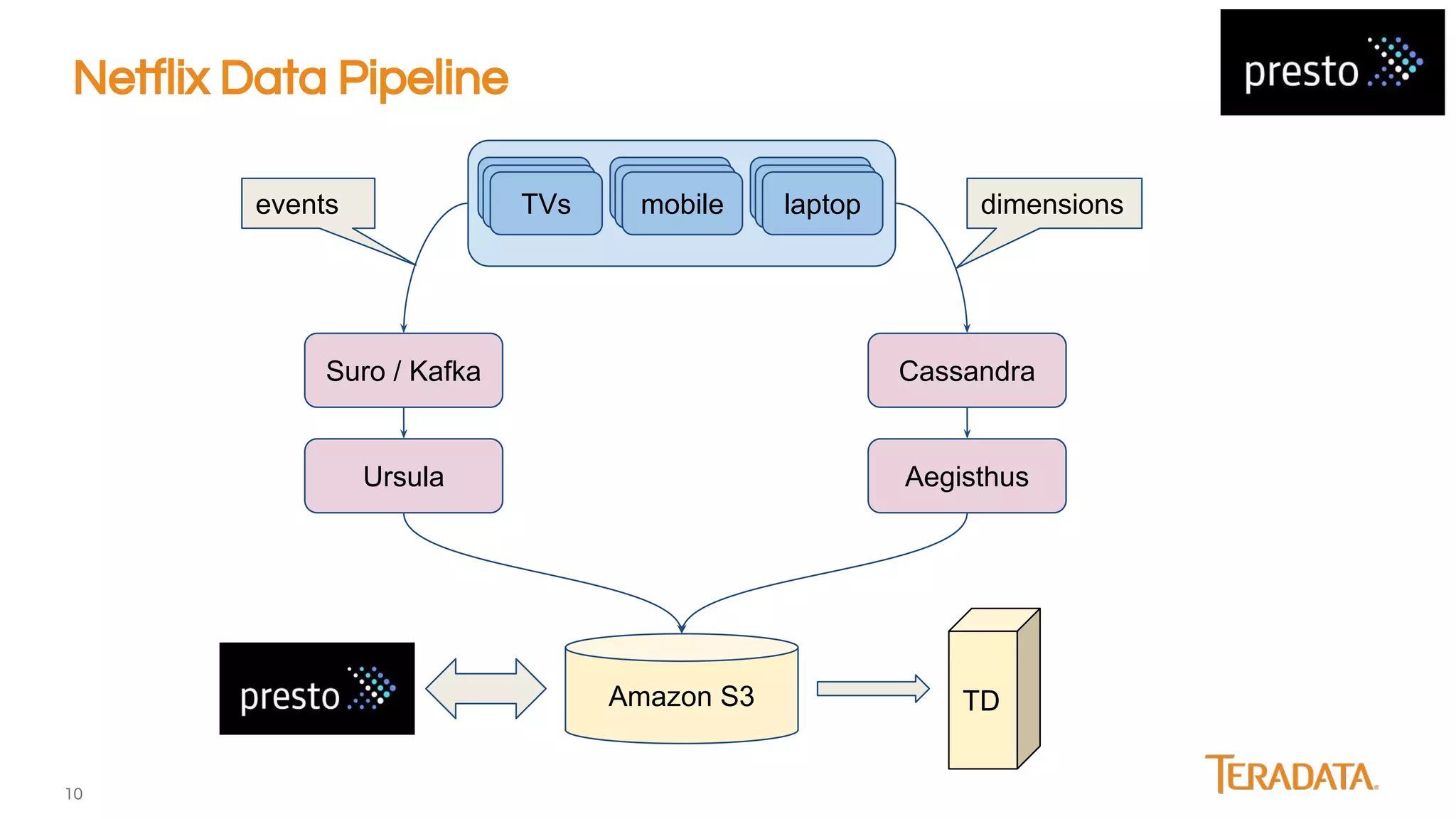



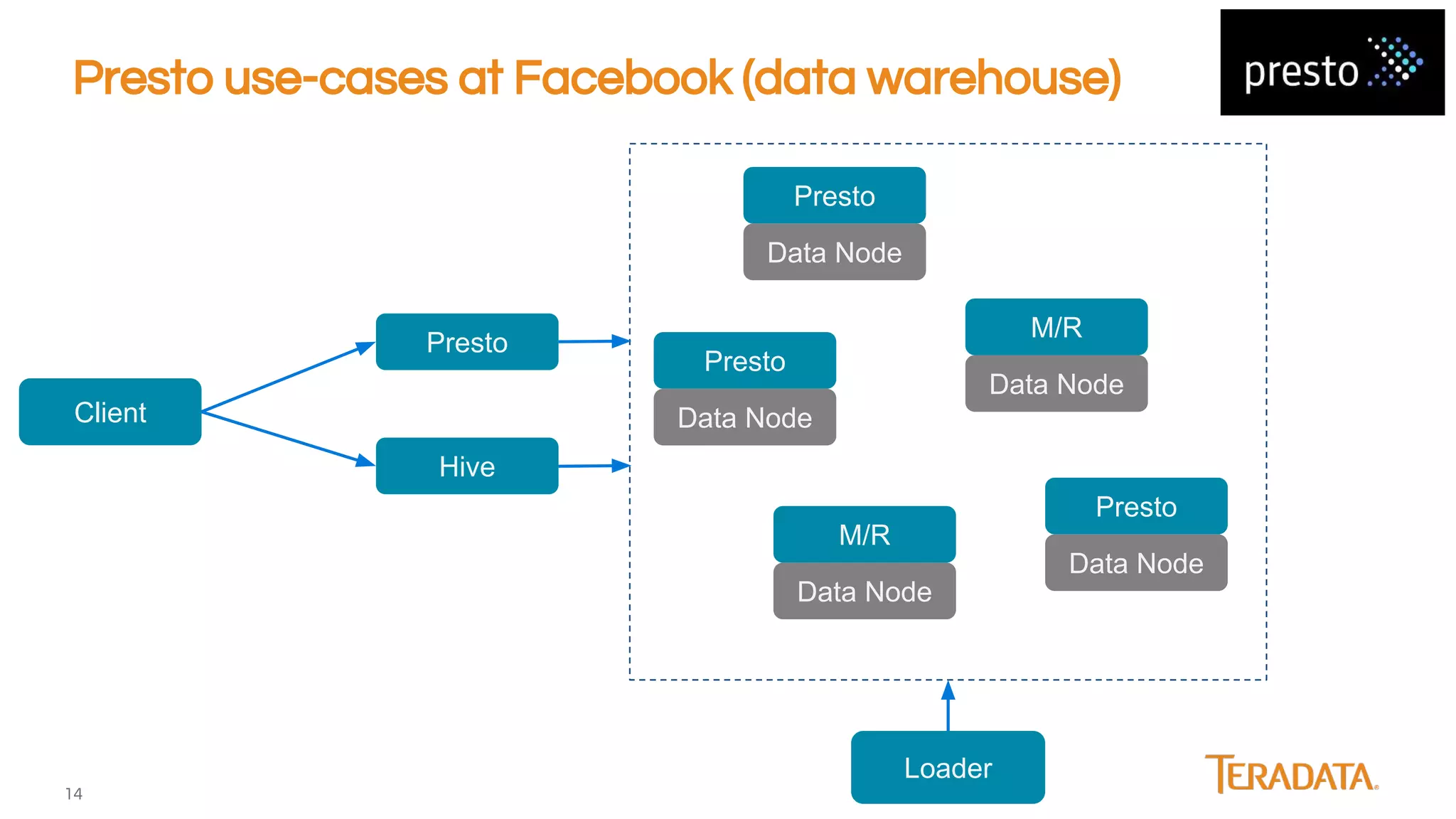
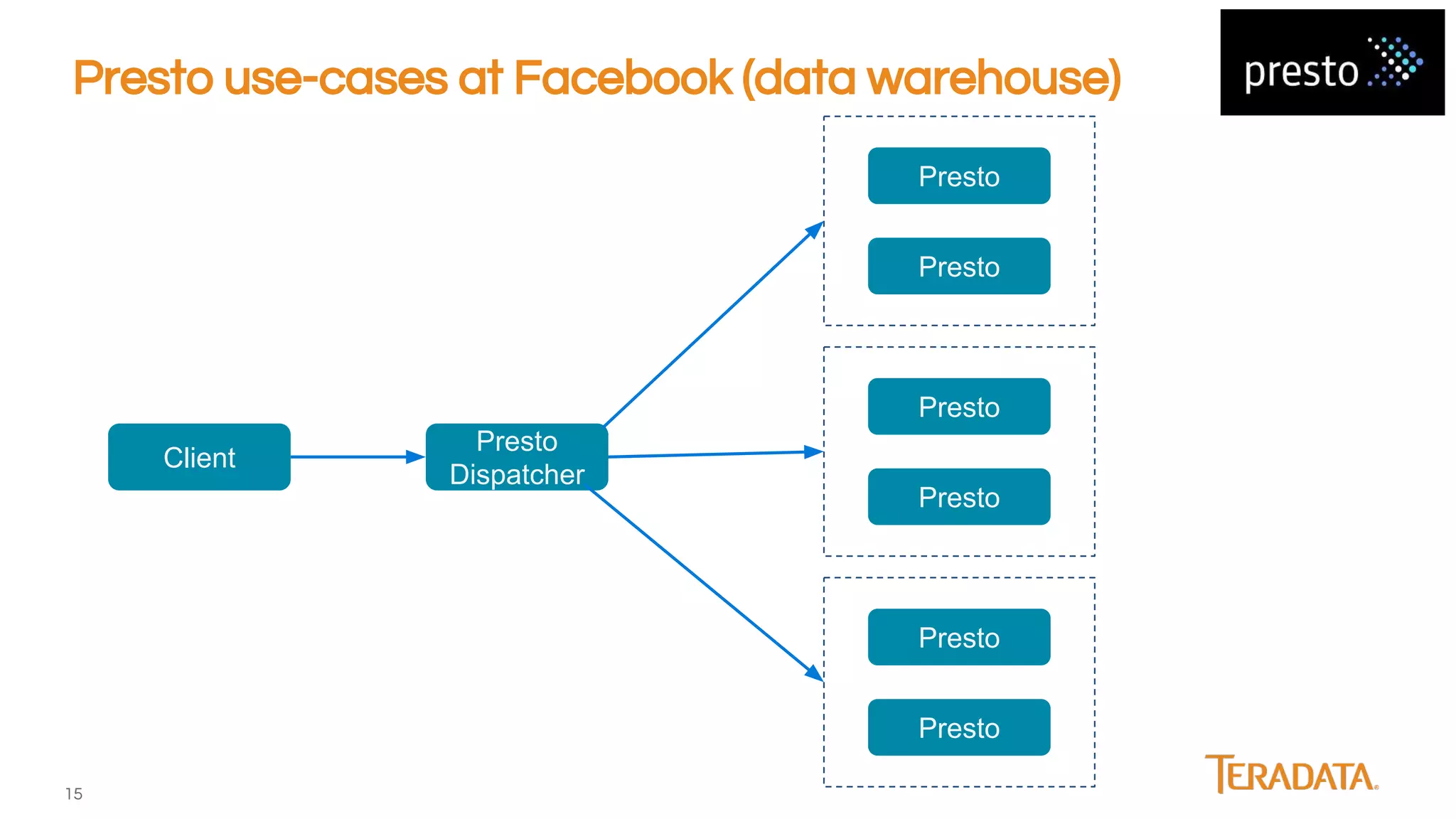


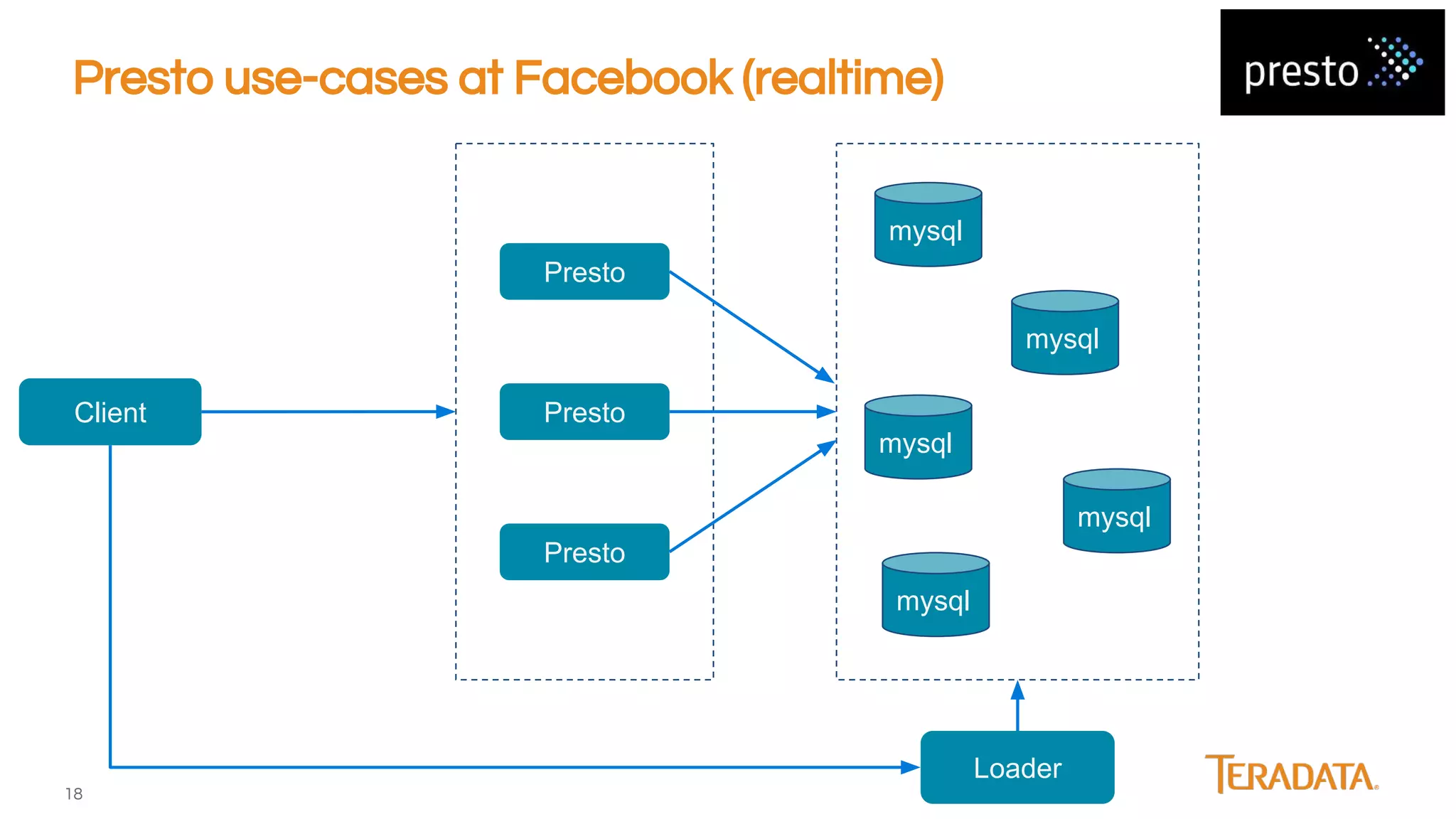


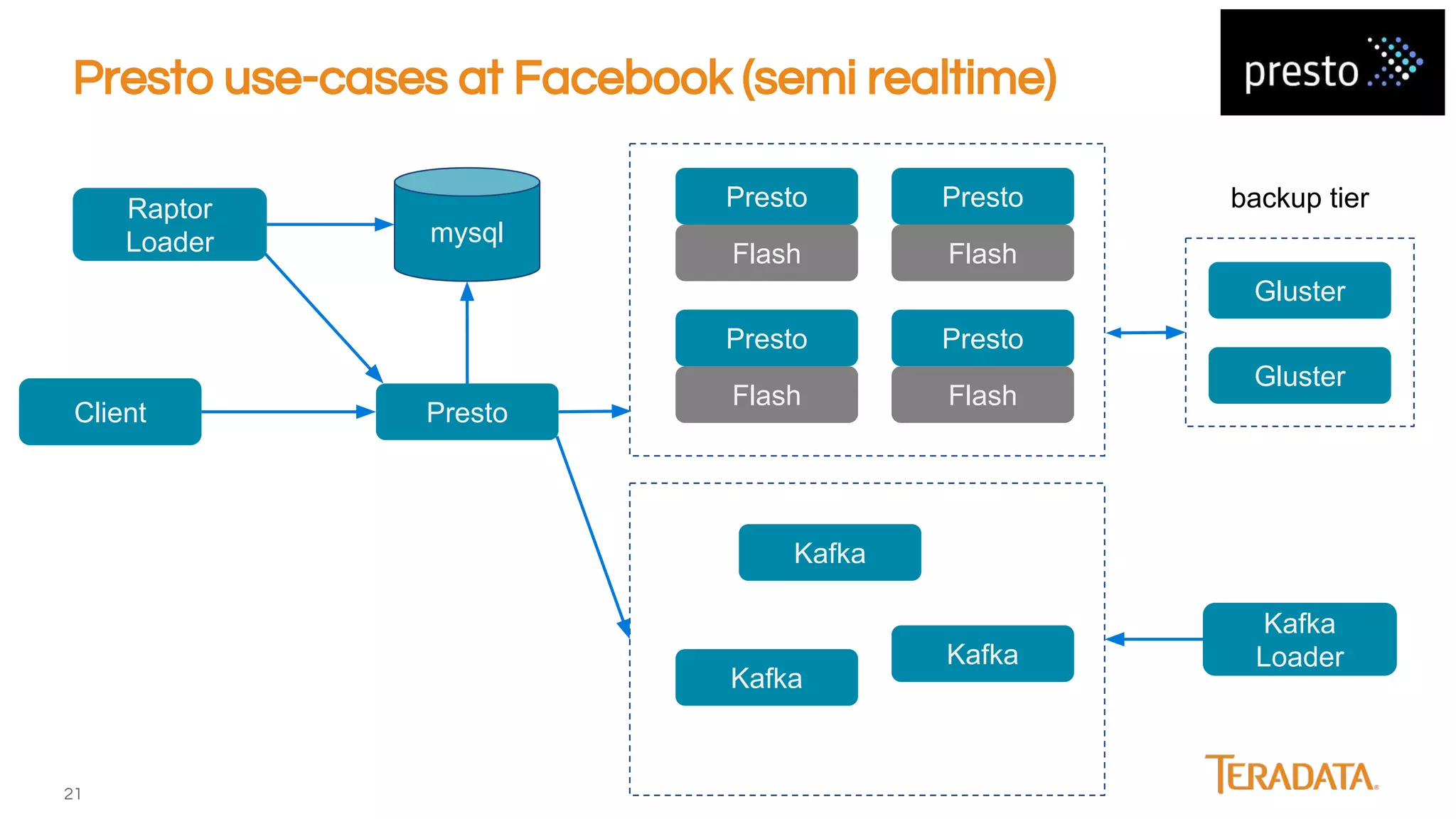
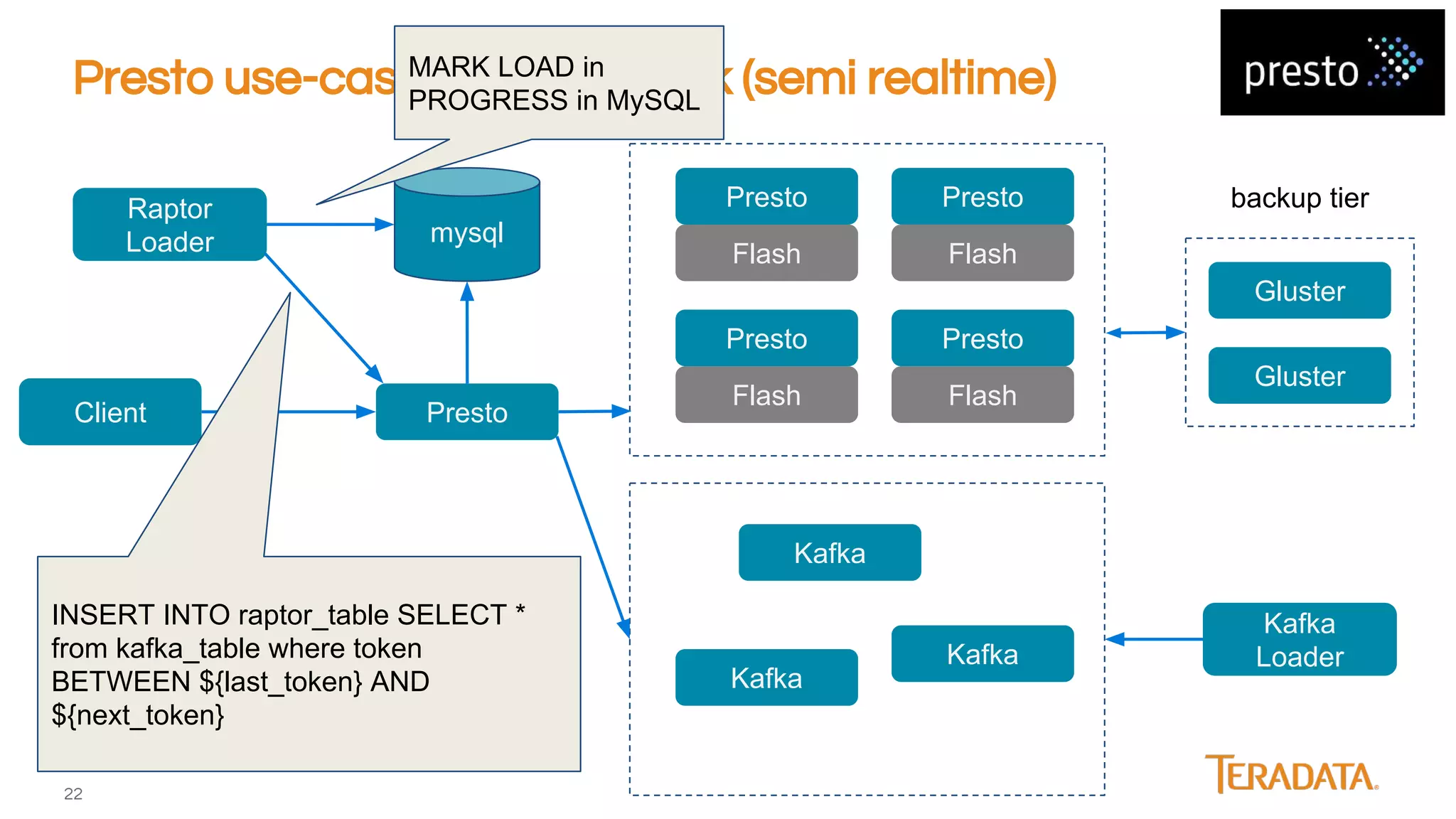































Presto is an open-source, distributed SQL engine optimized for low-latency interactive querying of large datasets, originally developed at Facebook and supported by companies like Teradata. The architecture features extensibility through various connector interfaces and has proven scalability in handling petabytes of data, with significant use cases at Facebook and Netflix. Presto is commonly employed for data warehouse analytics, real-time user queries, and semi-real-time data processing, leveraging optimized in-memory execution and vectorized processing.























































































