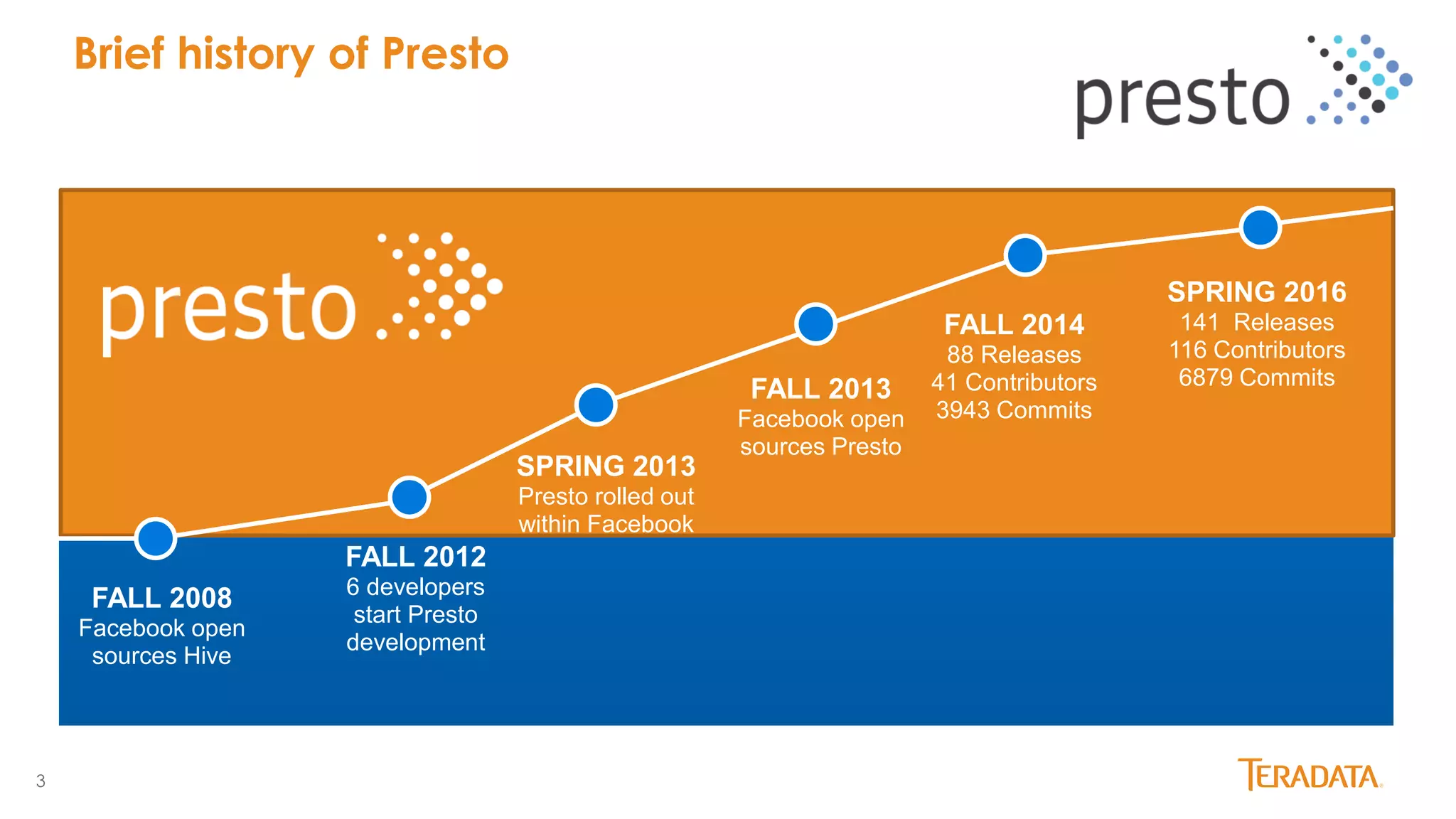
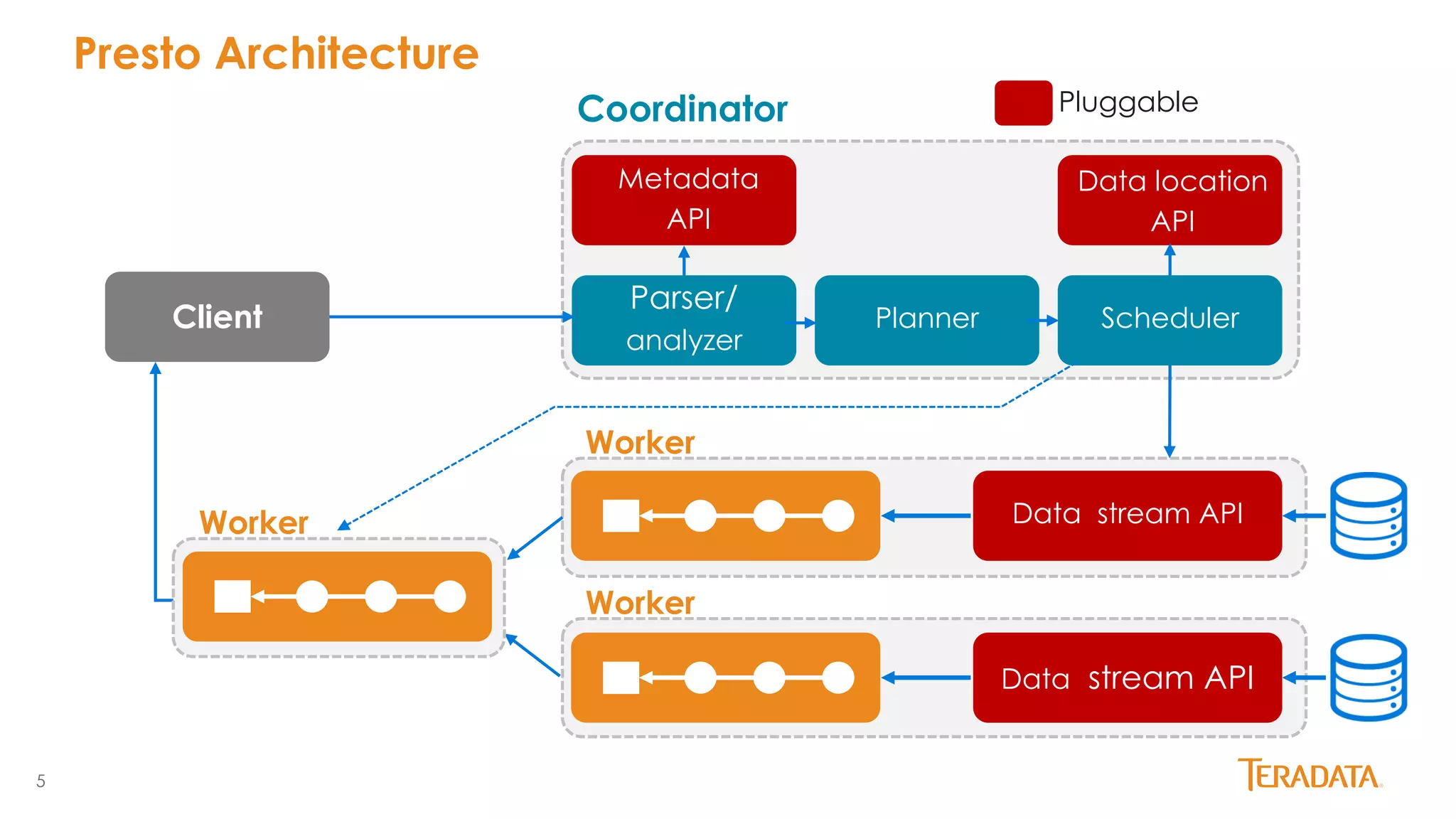
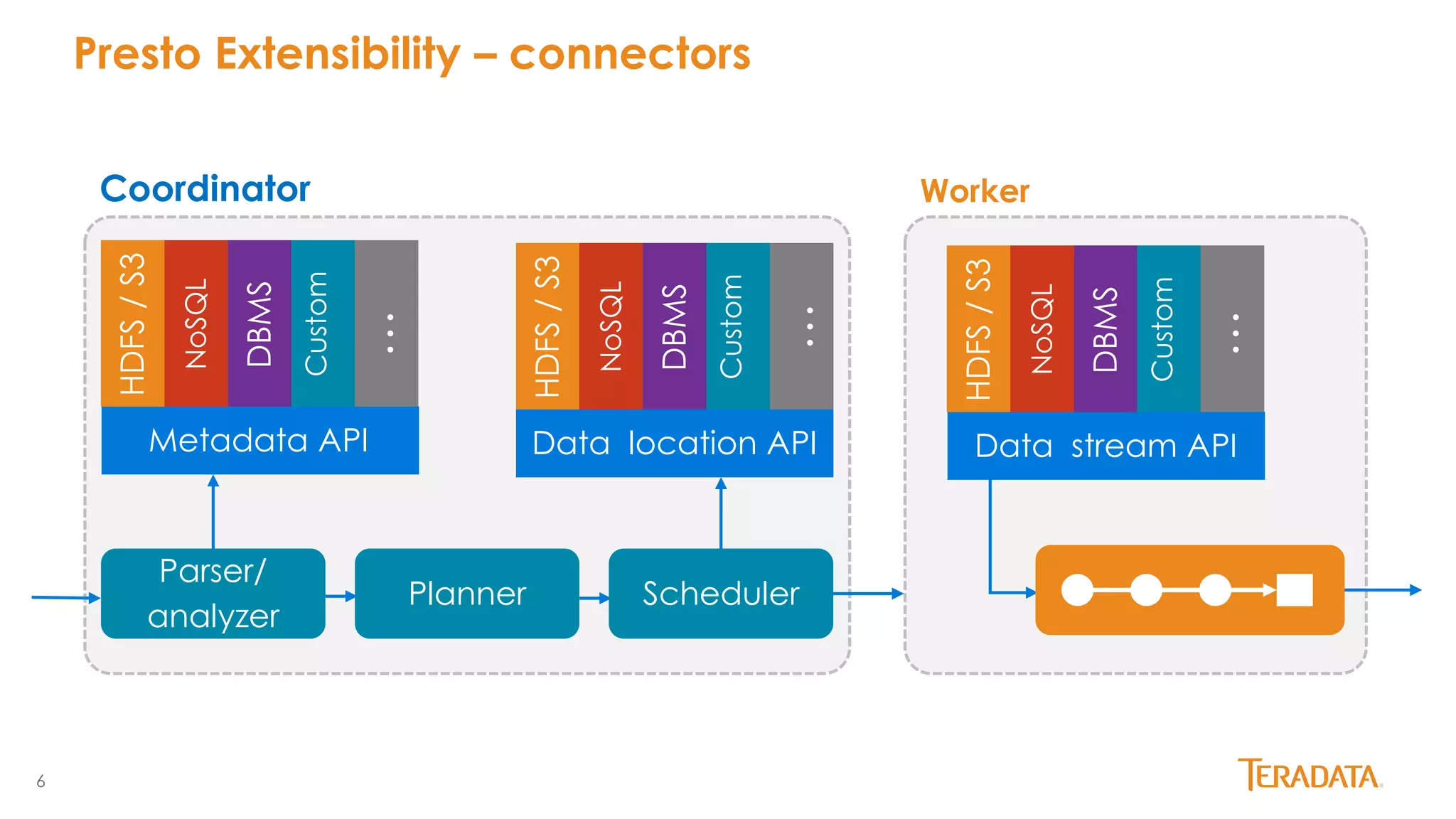
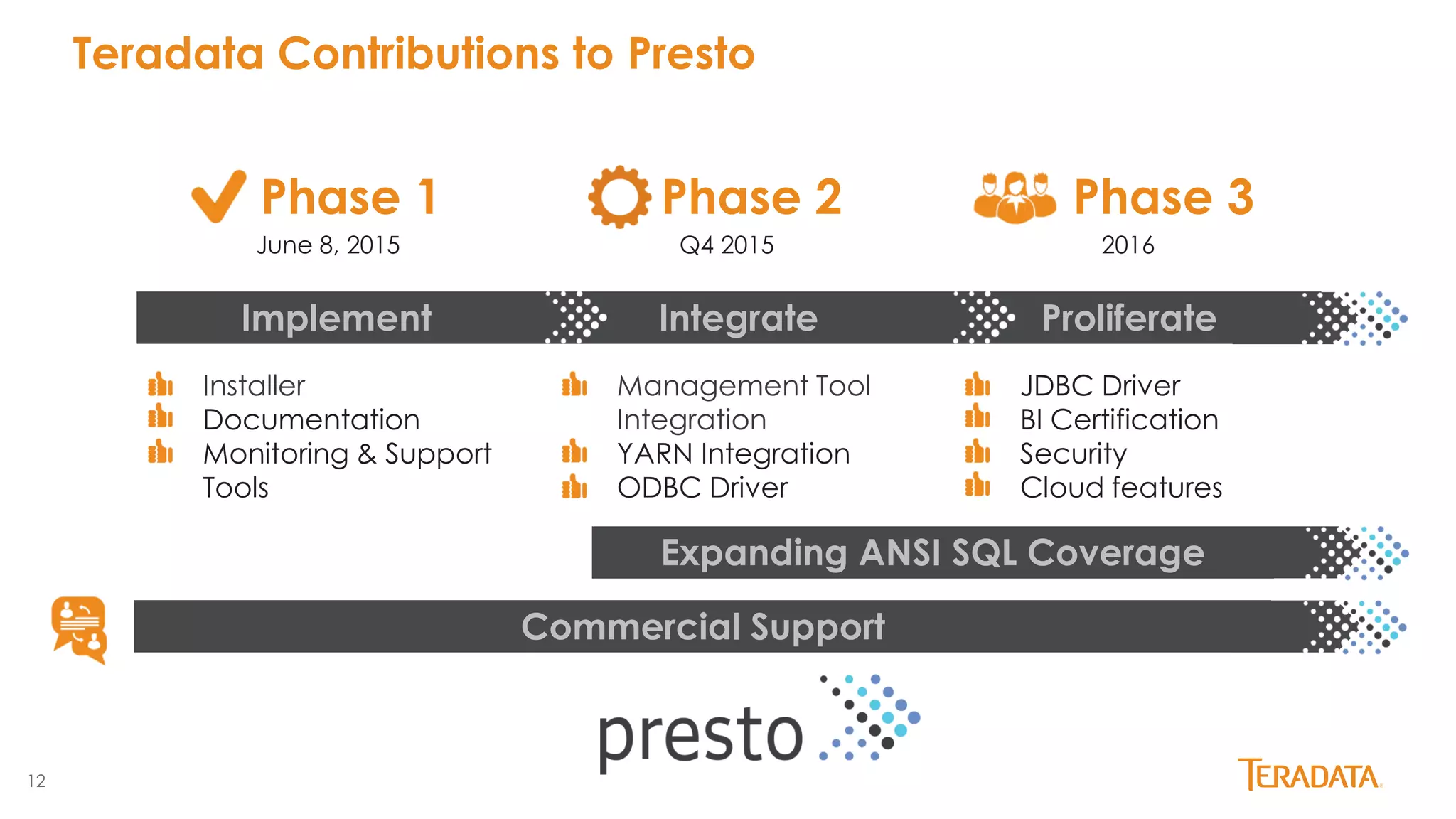
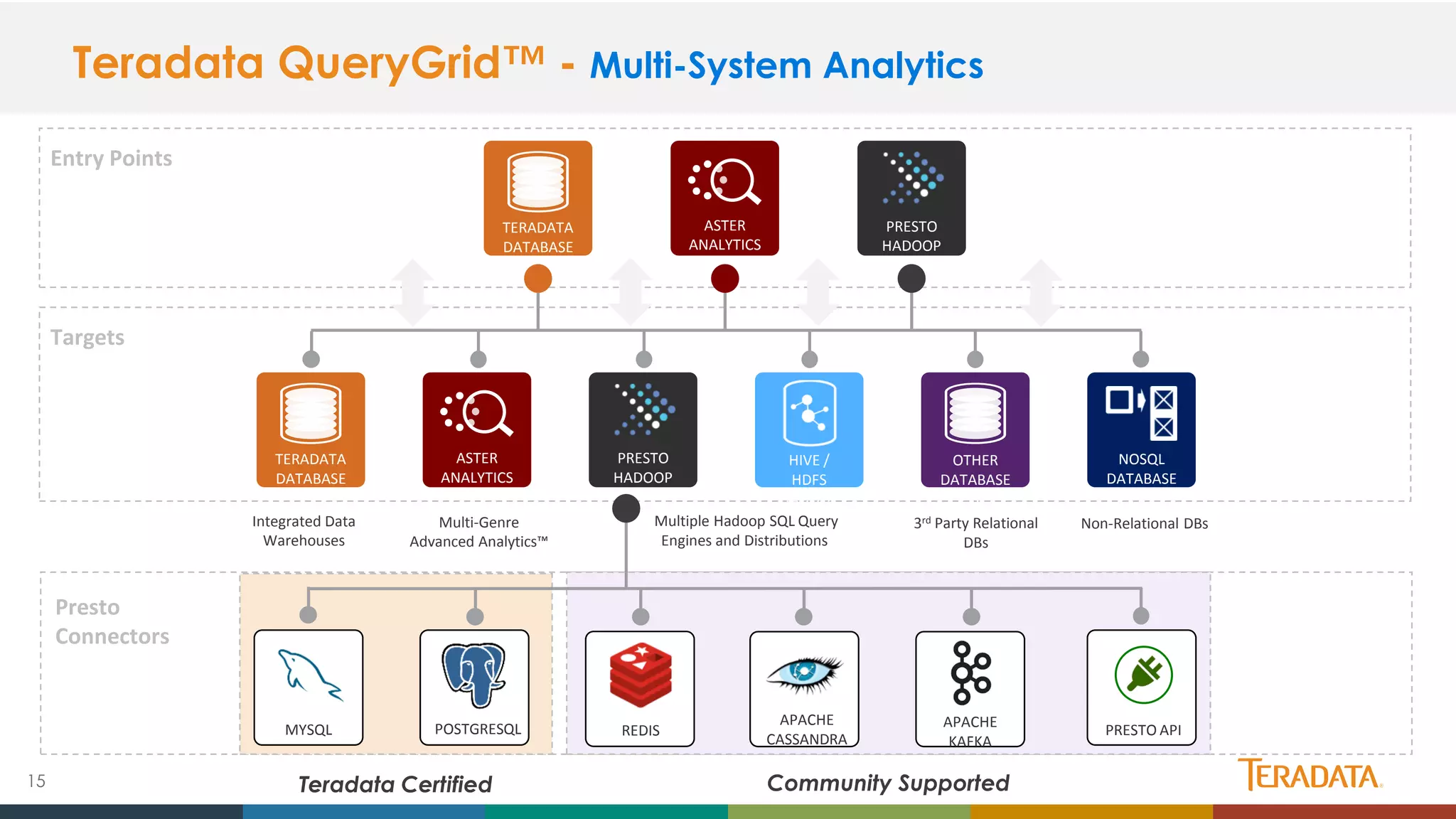
Presto is an open source distributed SQL query engine originally developed by Facebook. It allows querying of data across multiple data sources including HDFS, S3, MySQL, PostgreSQL and more. Presto has seen significant growth and adoption since its initial release, with over 100 releases and contributions from over 100 developers. It is used in production by Facebook and Netflix on very large datasets and clusters. Teradata has joined the Presto community and aims to enhance enterprise features and provide commercial support through its certified Presto distribution.





![9
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expr [, ...]
[ FROM table1 [[ INNER | OUTER ] JOIN table2 ON (…)]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition]
[ UNION [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count | ALL ] ]
In addition:
• Windowing functions
• Statistical and approximate aggregate functions
• UNNEST, TABLESAMPLE
In development:
• Complex subqueries
• EXISTS, INTERSECT, EXCEPT
• ROLLUP, CUBE
ANSI SQL Support](https://image.slidesharecdn.com/prestostratasjc2016shorttalk-160401160956/75/Presto-Strata-Hadoop-SJ-2016-short-talk-9-2048.jpg)












![9
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expr [, ...]
[ FROM table1 [[ INNER | OUTER ] JOIN table2 ON (…)]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition]
[ UNION [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count | ALL ] ]
In addition:
• Windowing functions
• Statistical and approximate aggregate functions
• UNNEST, TABLESAMPLE
In development:
• Complex subqueries
• EXISTS, INTERSECT, EXCEPT
• ROLLUP, CUBE
ANSI SQL Support](https://crownmelresort.com/image.slidesharecdn.com/prestostratasjc2016shorttalk-160401160956/75/Presto-Strata-Hadoop-SJ-2016-short-talk-9-2048.jpg)





















































































