Downloaded 10 times
![TEXT CLASSIFICATION
using
SUPPORT VECTOR MACHINES in R
by
Sai Srinivas Kotni
[14BM60083]
Under the guidance of
Prof. Susmita Mukhopadhyay](https://image.slidesharecdn.com/14bm60083saisrinivaskotni-180720132639/75/Presentation-on-Text-Classification-1-2048.jpg)










![TEXT CLASSIFICATION
using
SUPPORT VECTOR MACHINES in R
by
Sai Srinivas Kotni
[14BM60083]
Under the guidance of
Prof. Susmita Mukhopadhyay](https://crownmelresort.com/image.slidesharecdn.com/14bm60083saisrinivaskotni-180720132639/75/Presentation-on-Text-Classification-1-2048.jpg)













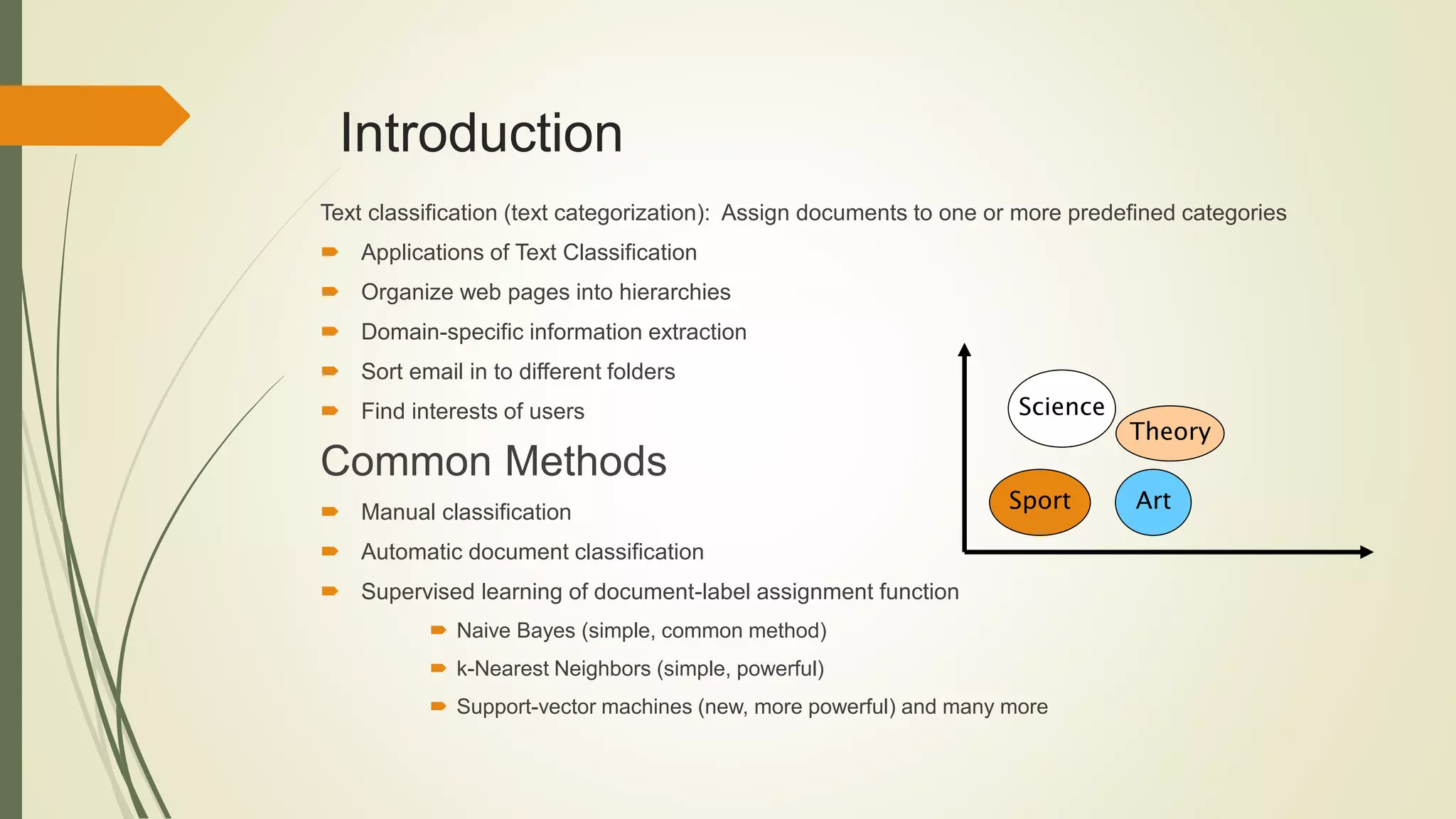
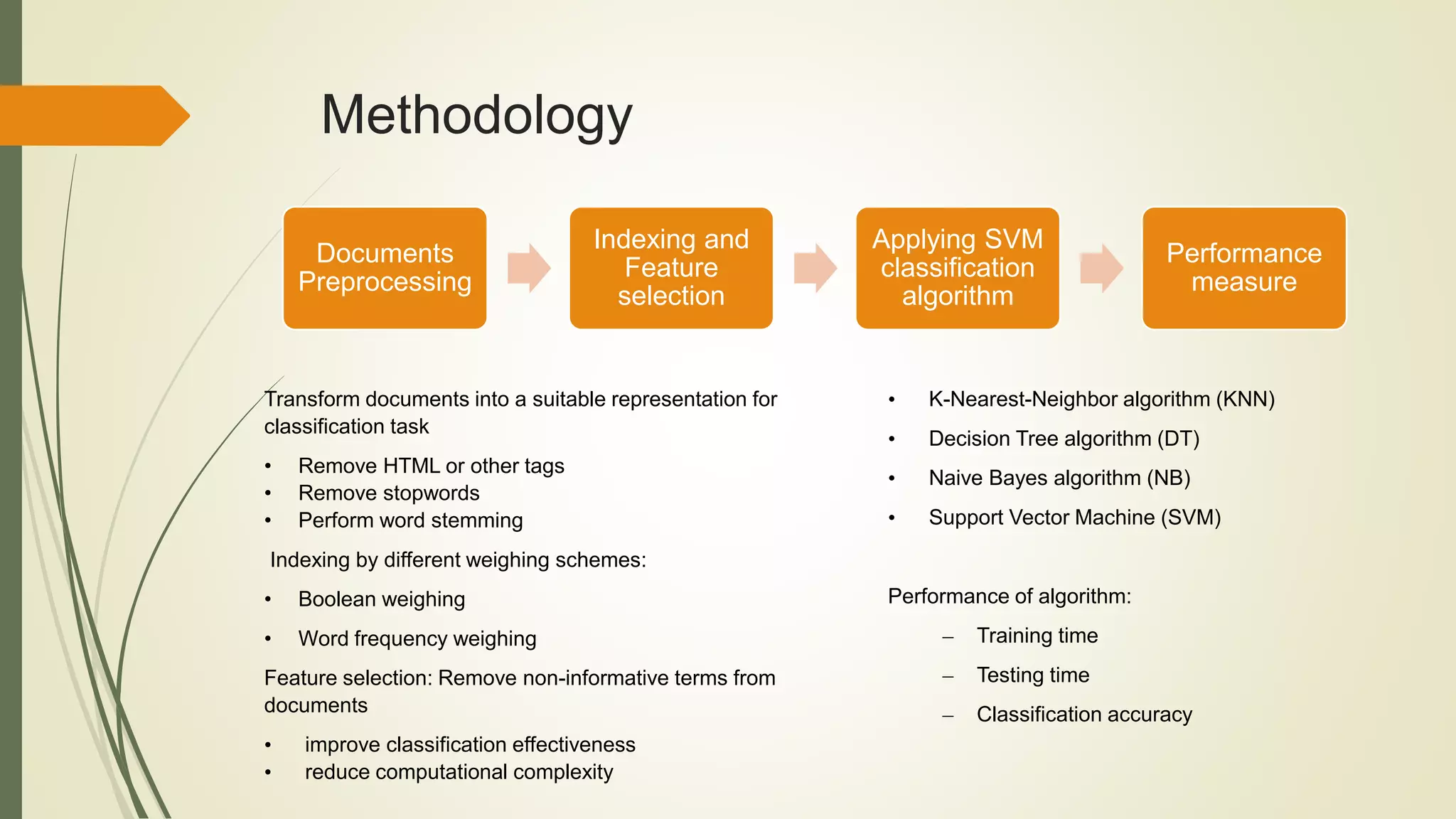
This document discusses using support vector machines (SVMs) for text classification. It begins by outlining the importance and applications of automated text classification. The objective is then stated as creating an efficient SVM model for text categorization and measuring its performance. Common text classification methods like Naive Bayes, k-Nearest Neighbors, and SVMs are introduced. The document then provides examples of different types of text classification labels and decisions involved. It proceeds to explain decision tree models, Naive Bayes algorithms, and the main ideas behind SVMs. The methodology section outlines the preprocessing, feature selection, and performance measurement steps involved in building an SVM text classification model in R.



































































