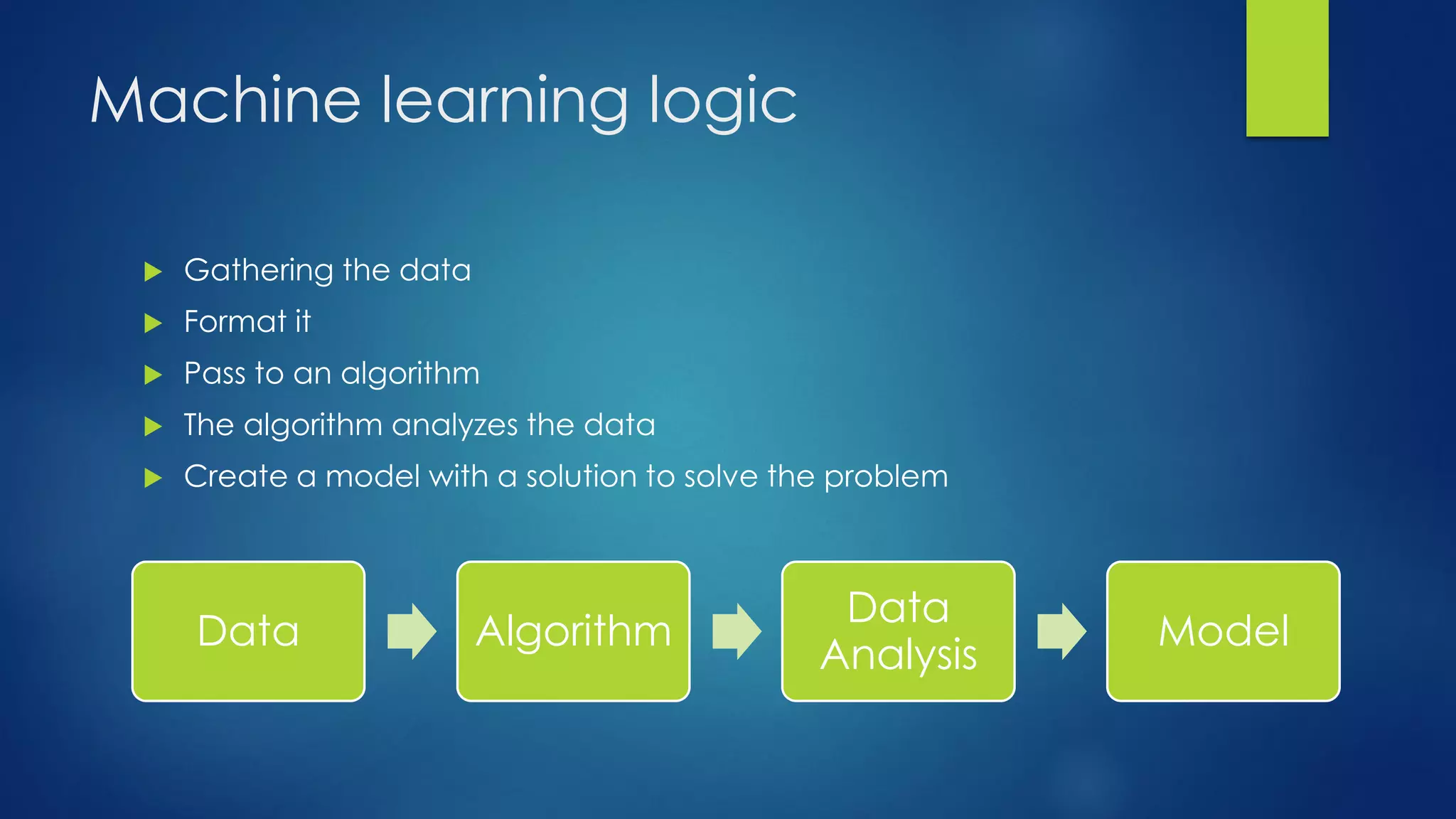
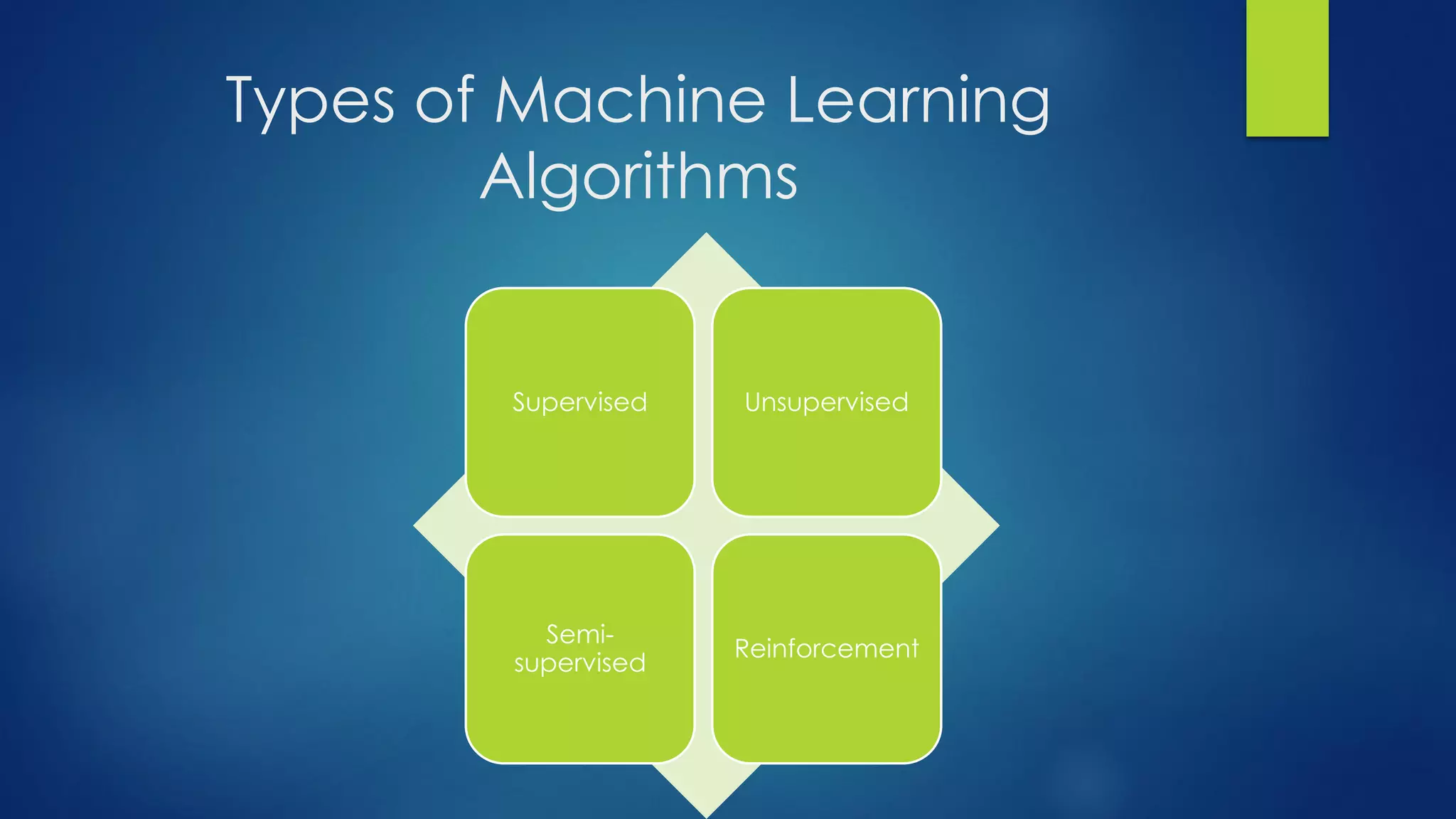
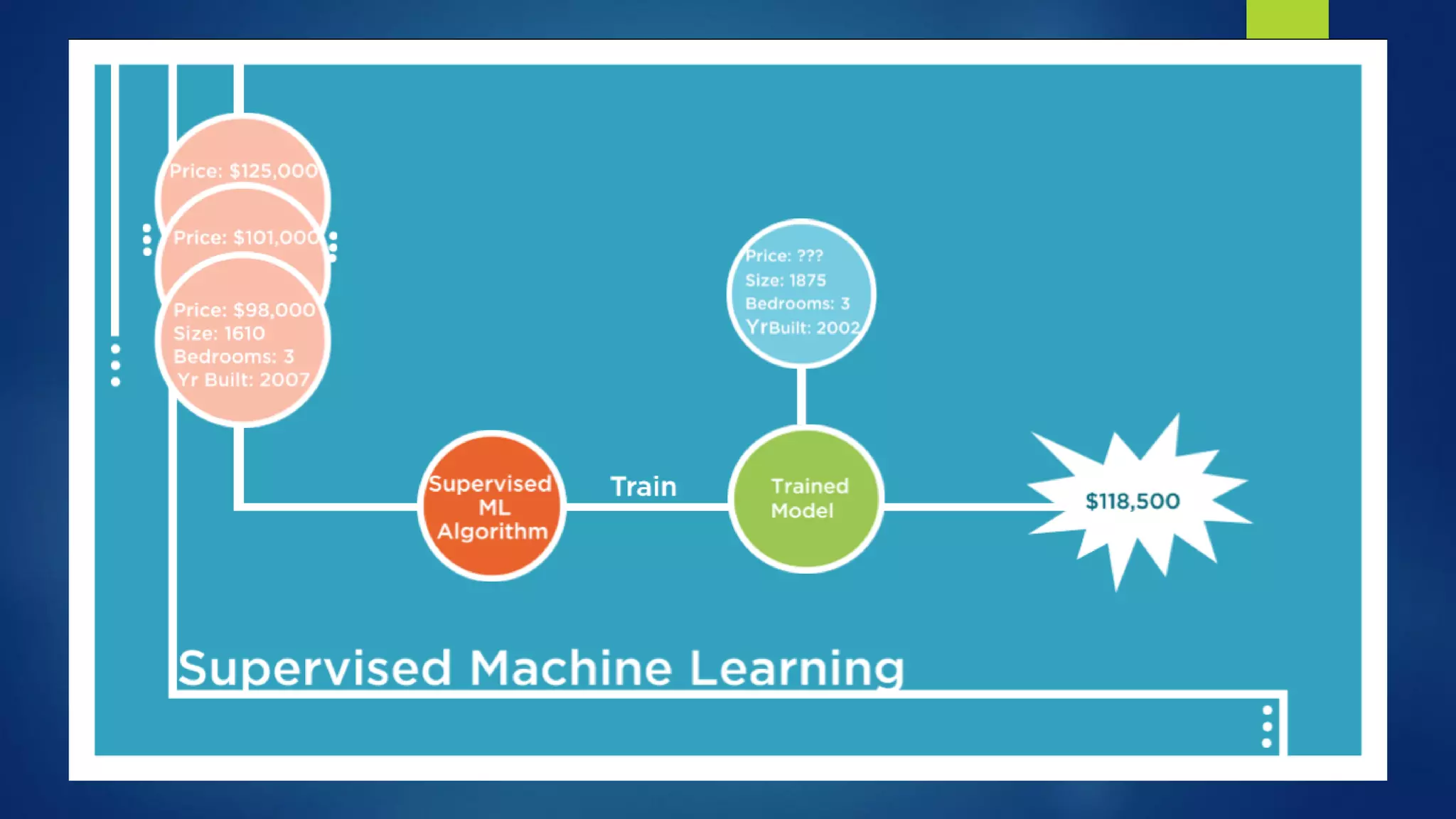
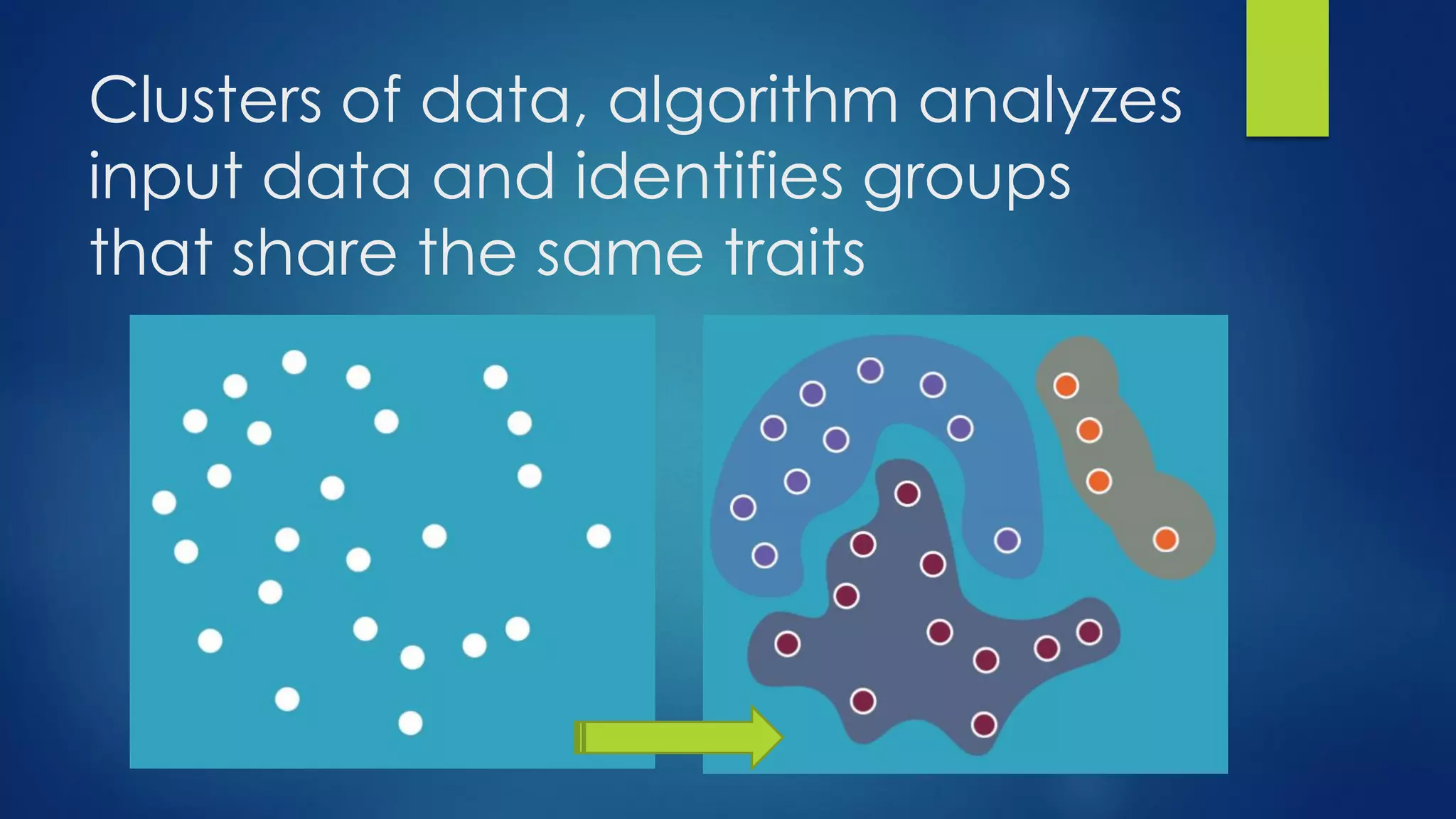
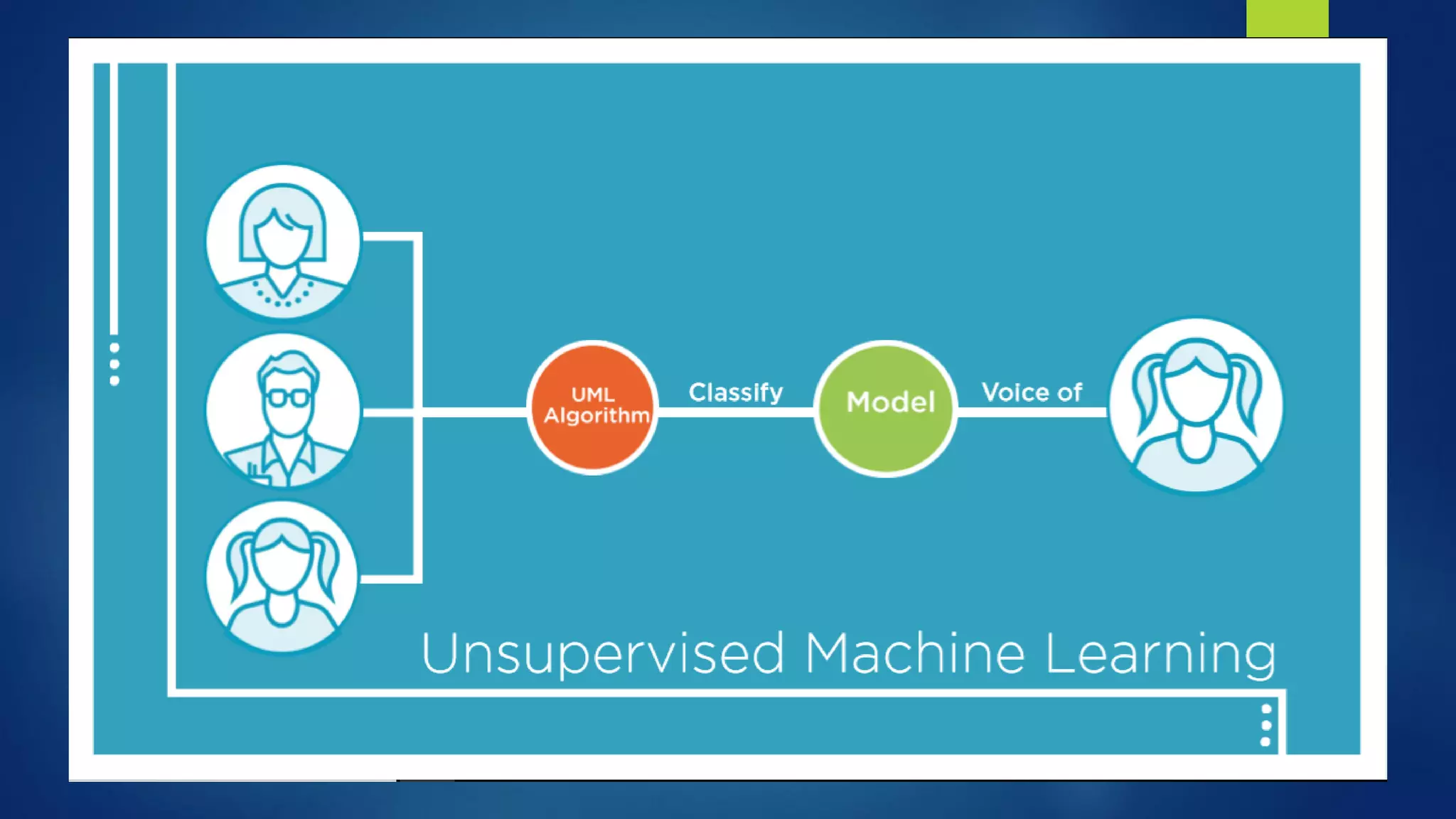
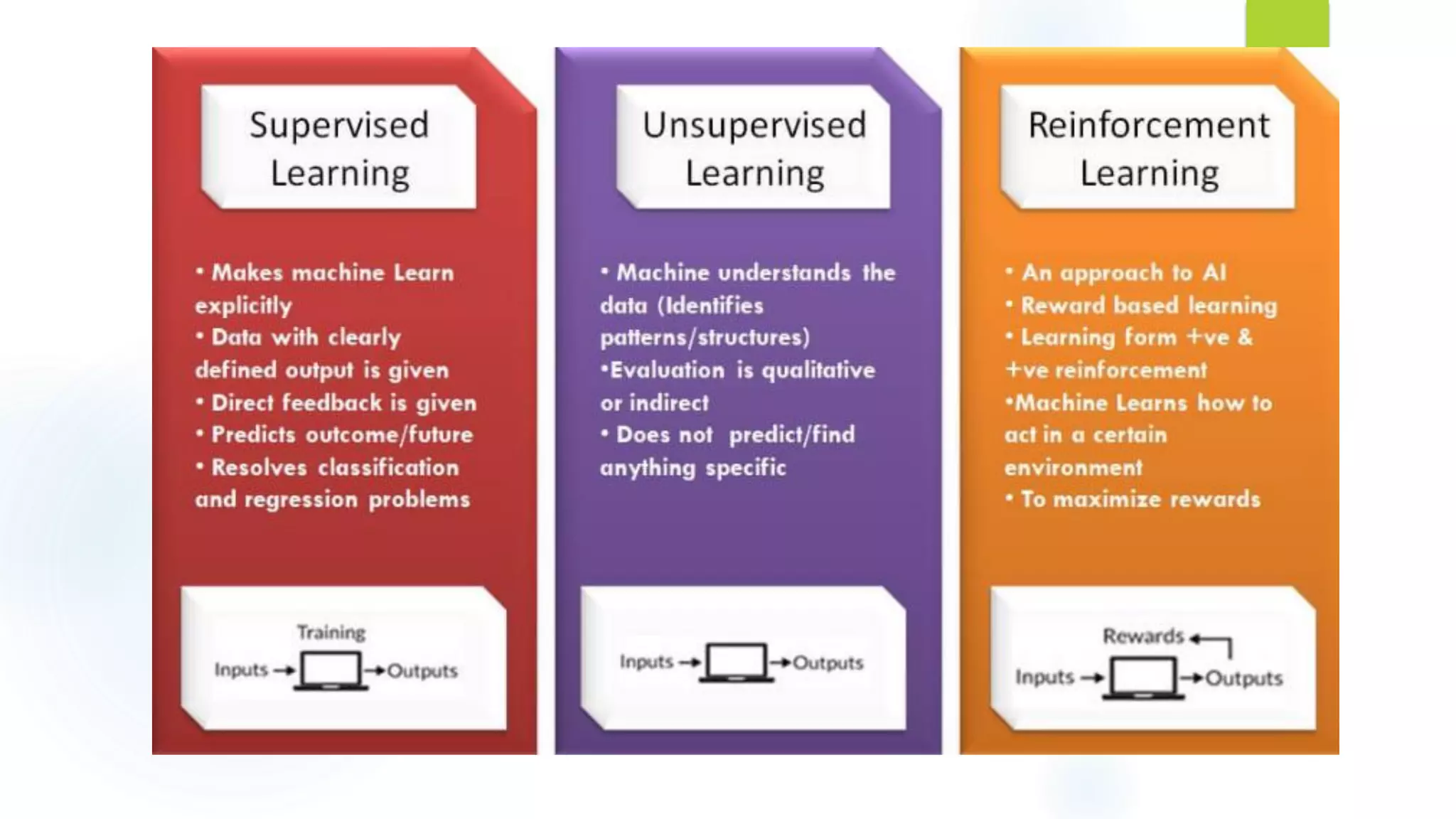
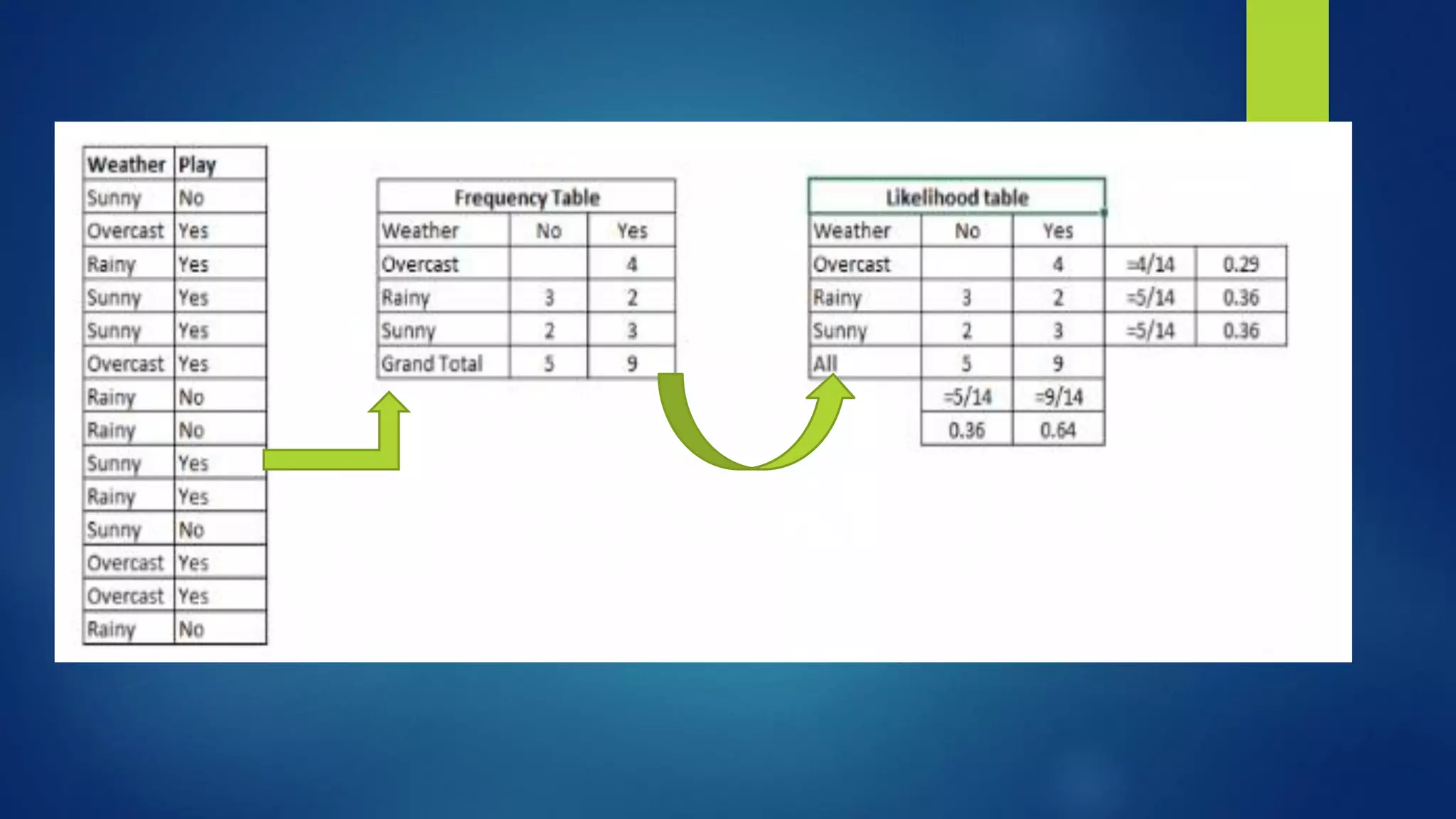
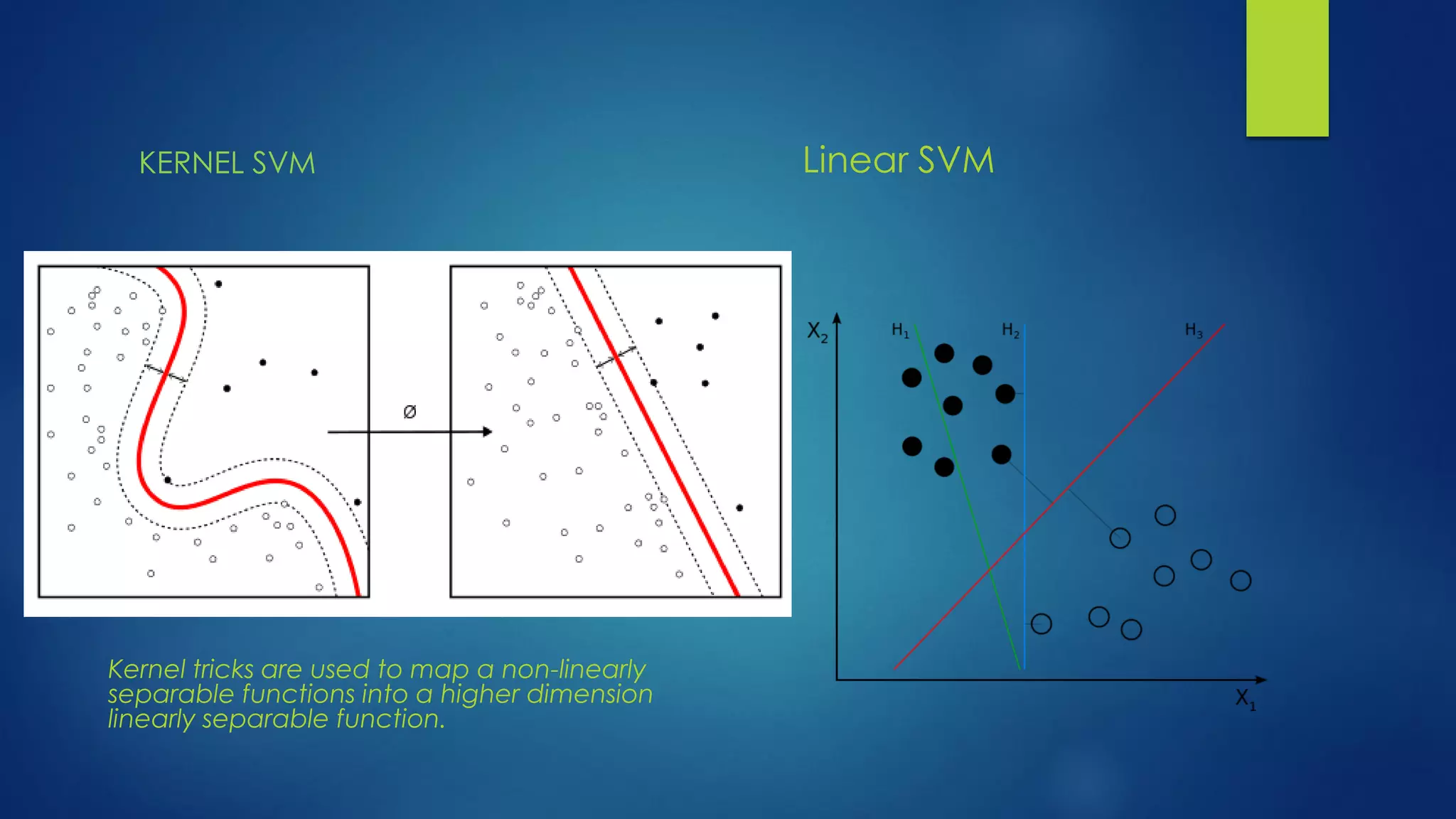
The document provides an overview of machine learning, defining it as the computer's ability to learn from data without explicit programming. It categorizes machine learning algorithms into supervised, unsupervised, semi-supervised, and reinforcement learning, detailing various algorithms like Naive Bayes, SVM, and linear regression, including their applications. Additionally, it emphasizes the importance of data preparation and algorithm selection based on factors like data size and accuracy.




















![import org.apache.spark.ml.regression.LinearRegression
// Load training data
val training = spark.read.format("libsvm")
.load("data/mllib/sample_linear_regression_data.txt")
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
// Print the coefficients and intercept for linear regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
// Summarize the model over the training set and print out some metrics
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]")
trainingSummary.residuals.show()
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
println(s"r2: ${trainingSummary.r2}")](https://image.slidesharecdn.com/machine-learning-algorithms-180815124257/75/Machine-learning-Algorithms-30-2048.jpg)










![Collaborative Filtering - Alternative
least squares
used for recommendation systems and personalized ranking
The DataFrame-based API for ALS currently only supports integers for
user and item id
Not in fully functionality in ML
It has two main implementations :
Implicit feedback
Asking a user to rank a collection of items from favorite to least
favorite or other things
Explicit feedback
Observing the items that a user views in an online store.
Analyzing item/user viewing times.[35]
Keeping a record of the items that a user purchases online.](https://image.slidesharecdn.com/machine-learning-algorithms-180815124257/75/Machine-learning-Algorithms-44-2048.jpg)






























![import org.apache.spark.ml.regression.LinearRegression
// Load training data
val training = spark.read.format("libsvm")
.load("data/mllib/sample_linear_regression_data.txt")
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// Fit the model
val lrModel = lr.fit(training)
// Print the coefficients and intercept for linear regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
// Summarize the model over the training set and print out some metrics
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]")
trainingSummary.residuals.show()
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
println(s"r2: ${trainingSummary.r2}")](https://crownmelresort.com/image.slidesharecdn.com/machine-learning-algorithms-180815124257/75/Machine-learning-Algorithms-30-2048.jpg)













![Collaborative Filtering - Alternative
least squares
used for recommendation systems and personalized ranking
The DataFrame-based API for ALS currently only supports integers for
user and item id
Not in fully functionality in ML
It has two main implementations :
Implicit feedback
Asking a user to rank a collection of items from favorite to least
favorite or other things
Explicit feedback
Observing the items that a user views in an online store.
Analyzing item/user viewing times.[35]
Keeping a record of the items that a user purchases online.](https://crownmelresort.com/image.slidesharecdn.com/machine-learning-algorithms-180815124257/75/Machine-learning-Algorithms-44-2048.jpg)
















































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


