Downloaded 11 times













![Rules or Queries to Detectors
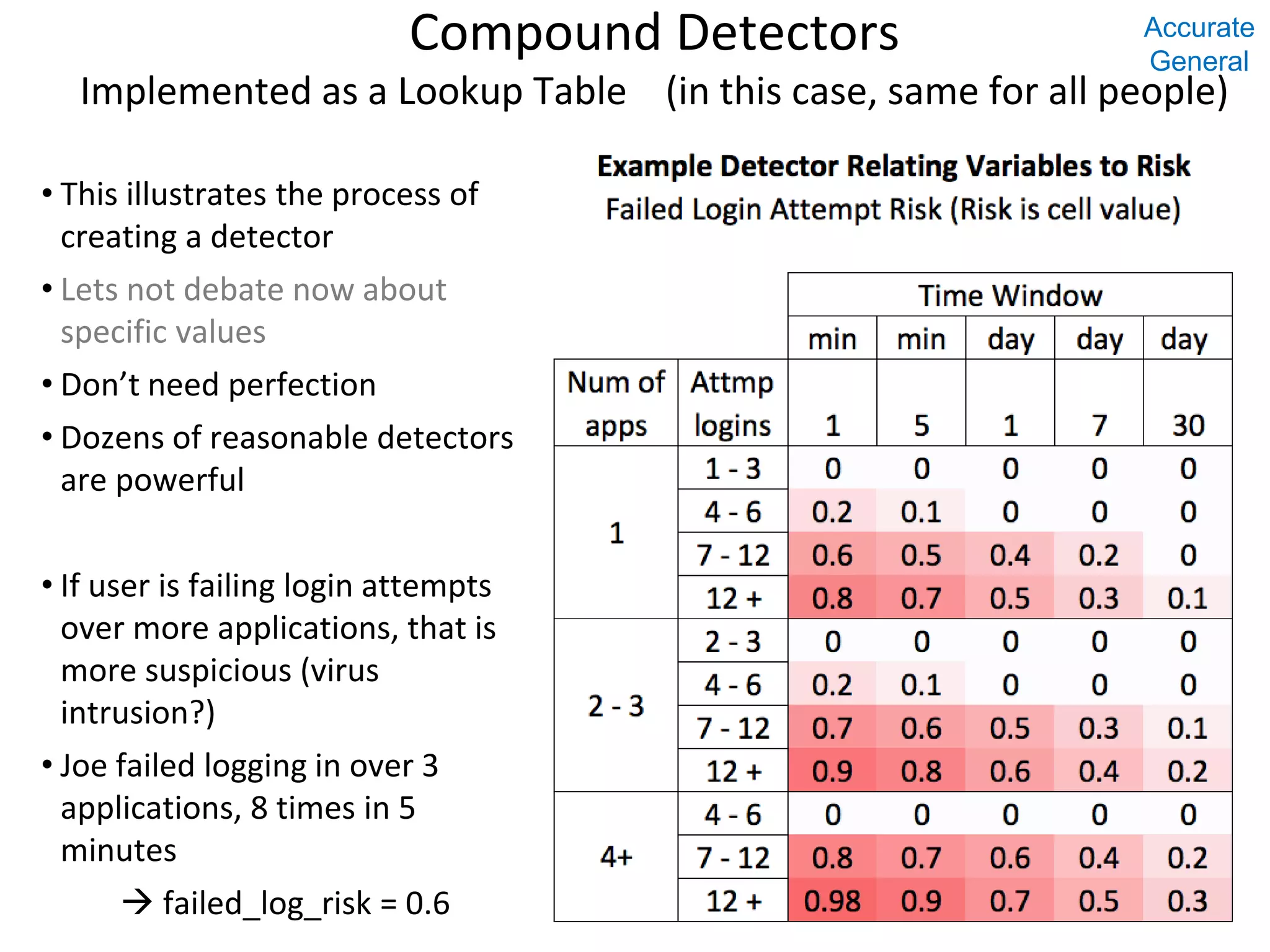
Simple Example
Select 1 as detect_prospect (result field has 0 or 1 values)
where (.6 < recency) and
(.7 < frequency) and
(.3 < time)
Select recency + frequency + time as detect_prospect
where (.6 < recency) and (has 100’s of values
(.7 < frequency) and in the [0..1] range)
(.3 < time)
Develop “fuzzy” detectors, result in [0..1]
22
Accurate
General](https://image.slidesharecdn.com/segmsensitivityanalysis-170612201048/75/Predictive-Model-and-Record-Description-with-Segmented-Sensitivity-Analysis-SSA-22-2048.jpg)





















![Rules or Queries to Detectors
Simple Example
Select 1 as detect_prospect (result field has 0 or 1 values)
where (.6 < recency) and
(.7 < frequency) and
(.3 < time)
Select recency + frequency + time as detect_prospect
where (.6 < recency) and (has 100’s of values
(.7 < frequency) and in the [0..1] range)
(.3 < time)
Develop “fuzzy” detectors, result in [0..1]
22
Accurate
General](https://crownmelresort.com/image.slidesharecdn.com/segmsensitivityanalysis-170612201048/75/Predictive-Model-and-Record-Description-with-Segmented-Sensitivity-Analysis-SSA-22-2048.jpg)


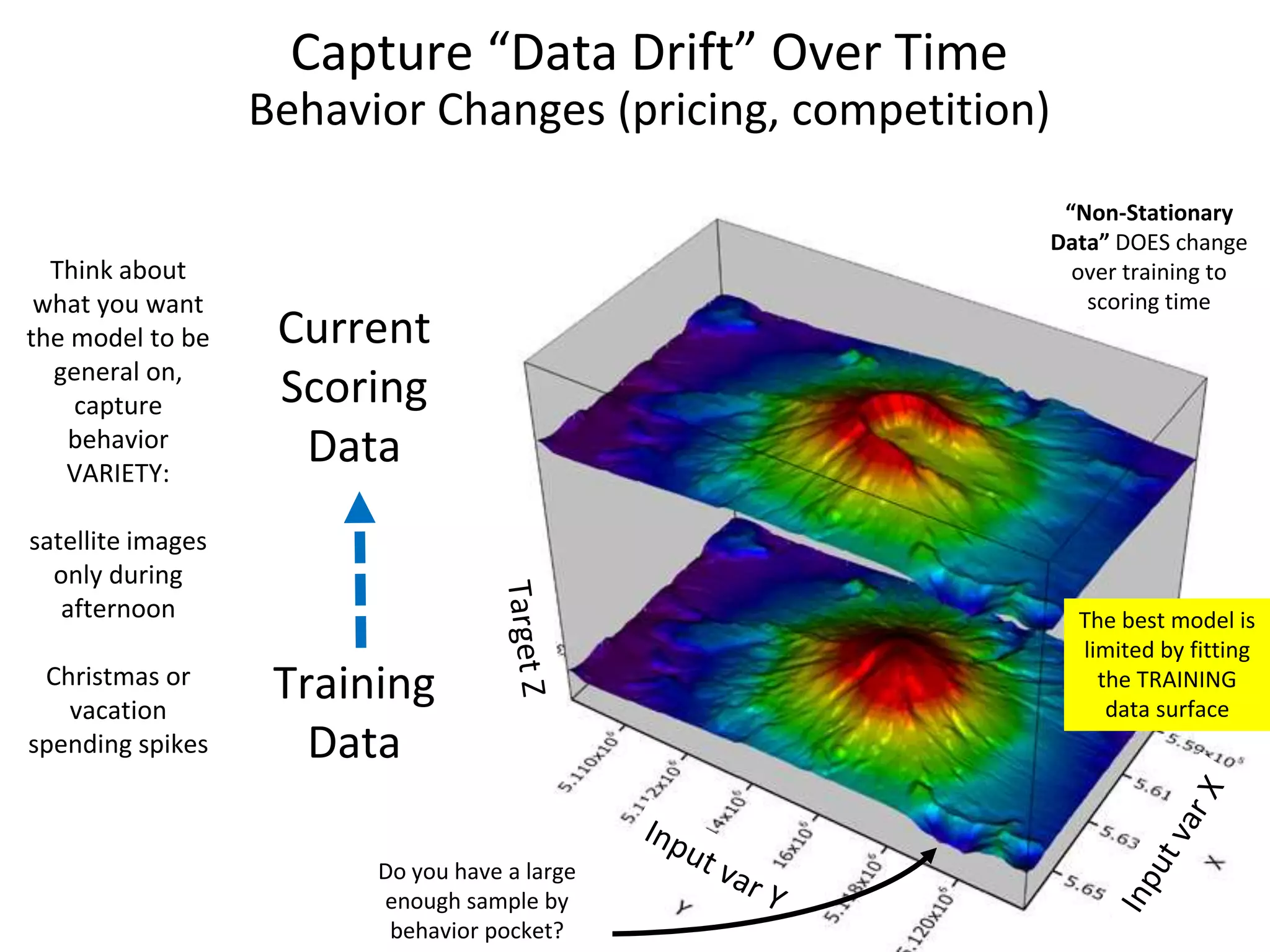
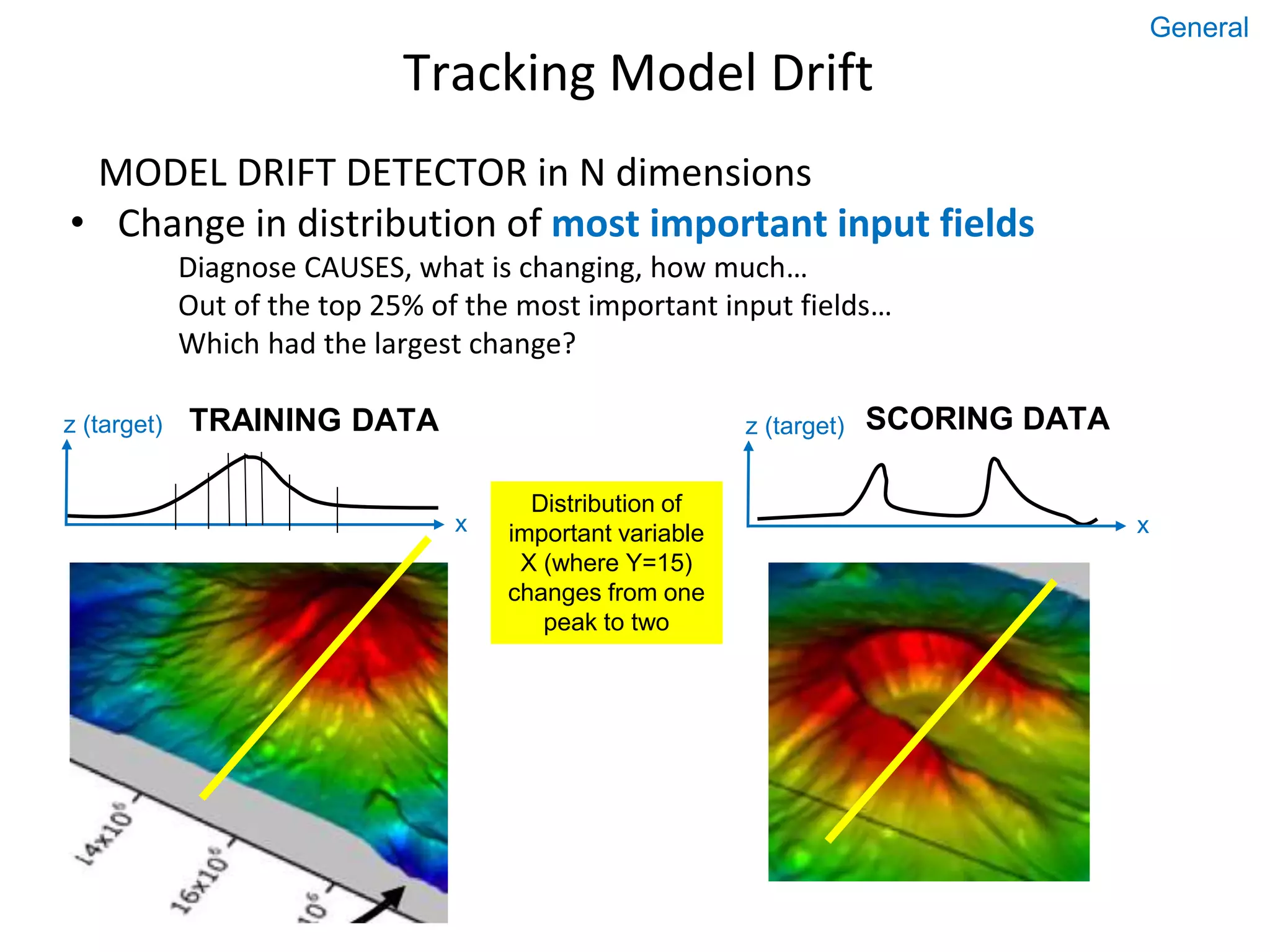
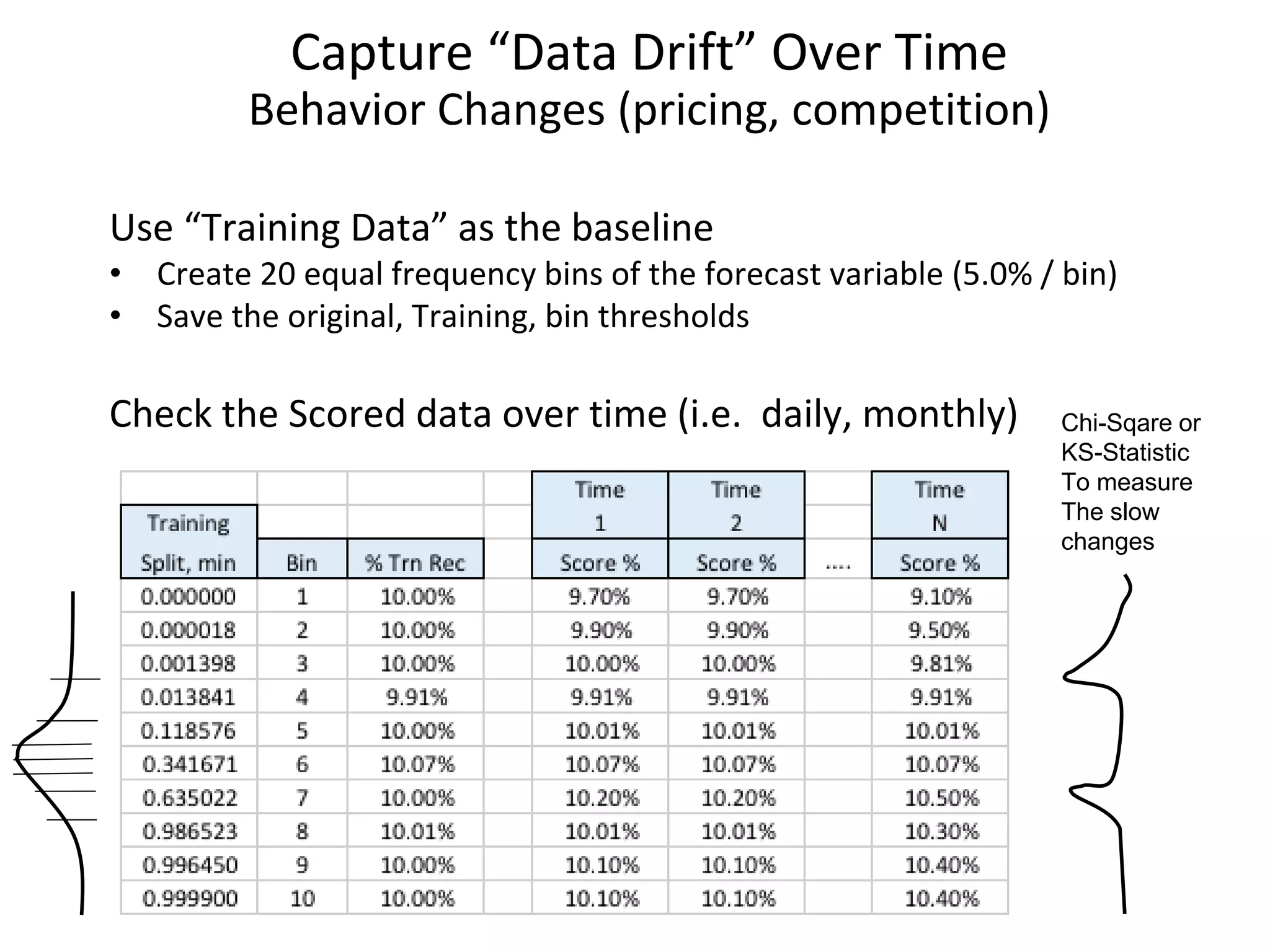
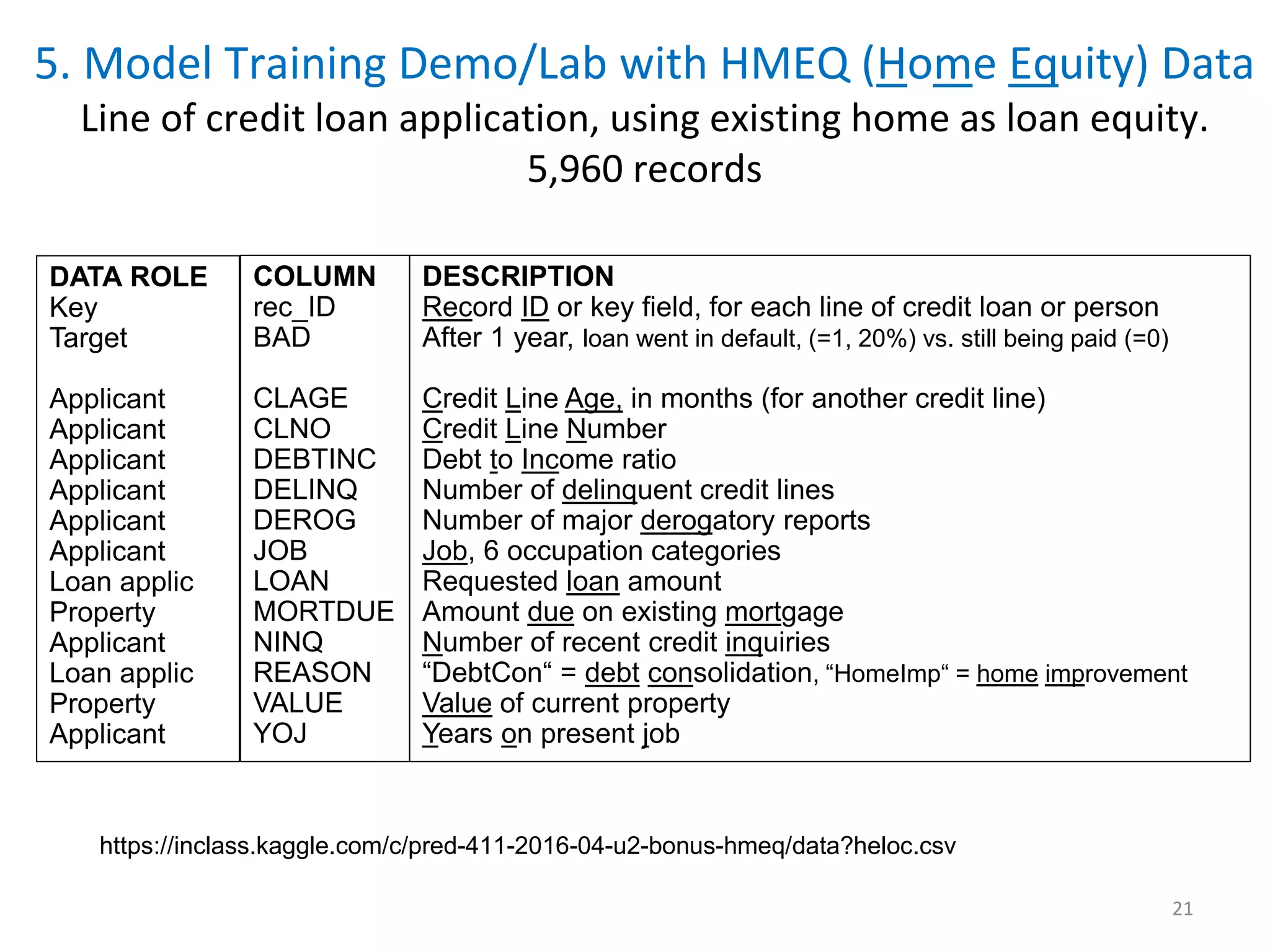
The document discusses the importance of predictive modeling and sensitivity analysis in data science. It highlights the growing demand for data scientists, the need for effective communication, and the challenges in data organization. Additionally, it outlines objectives for algorithm design, methods for conducting sensitivity analysis, and emphasizes the significance of monitoring model performance over time to adapt to data drift.
































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















