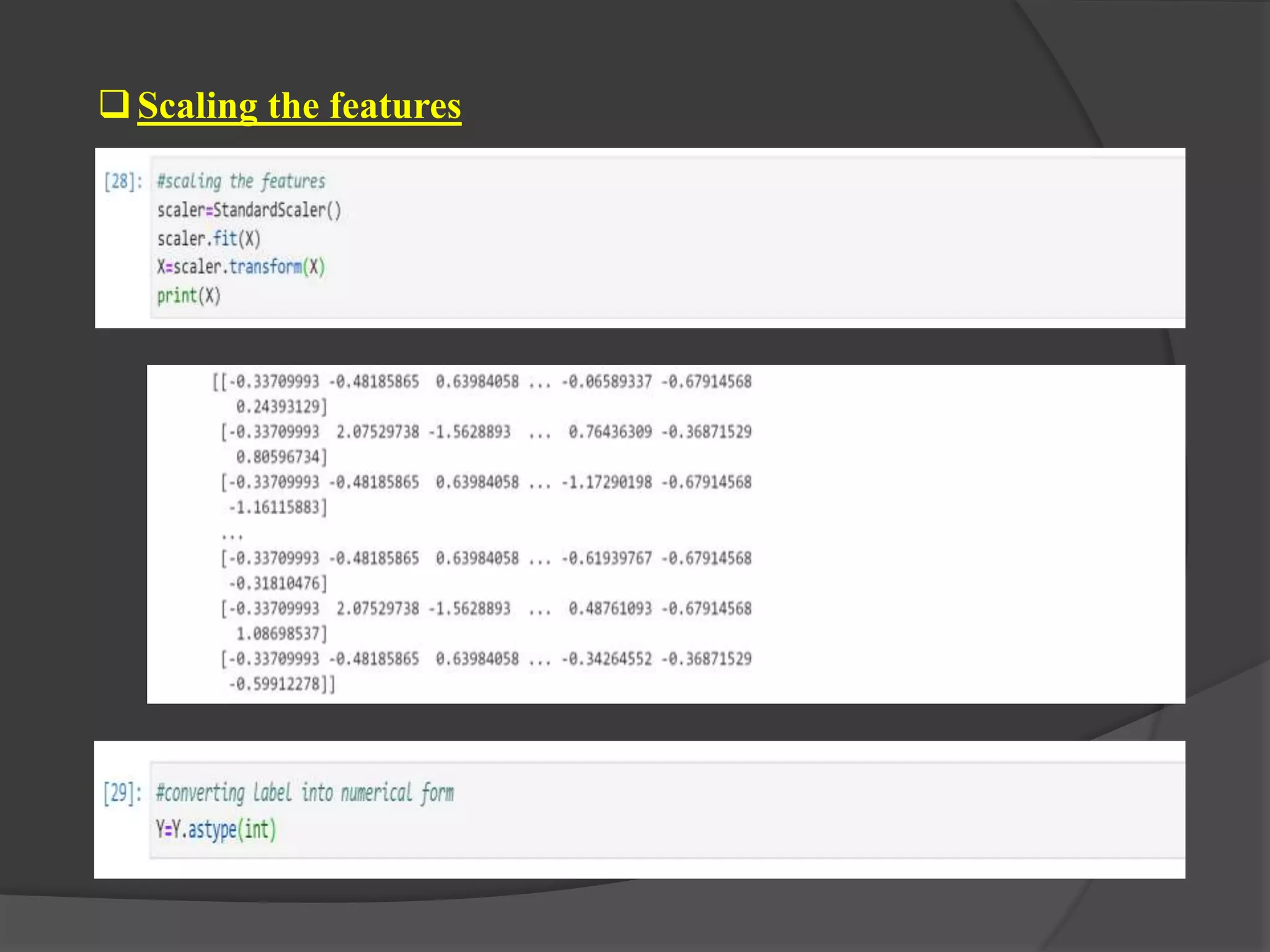
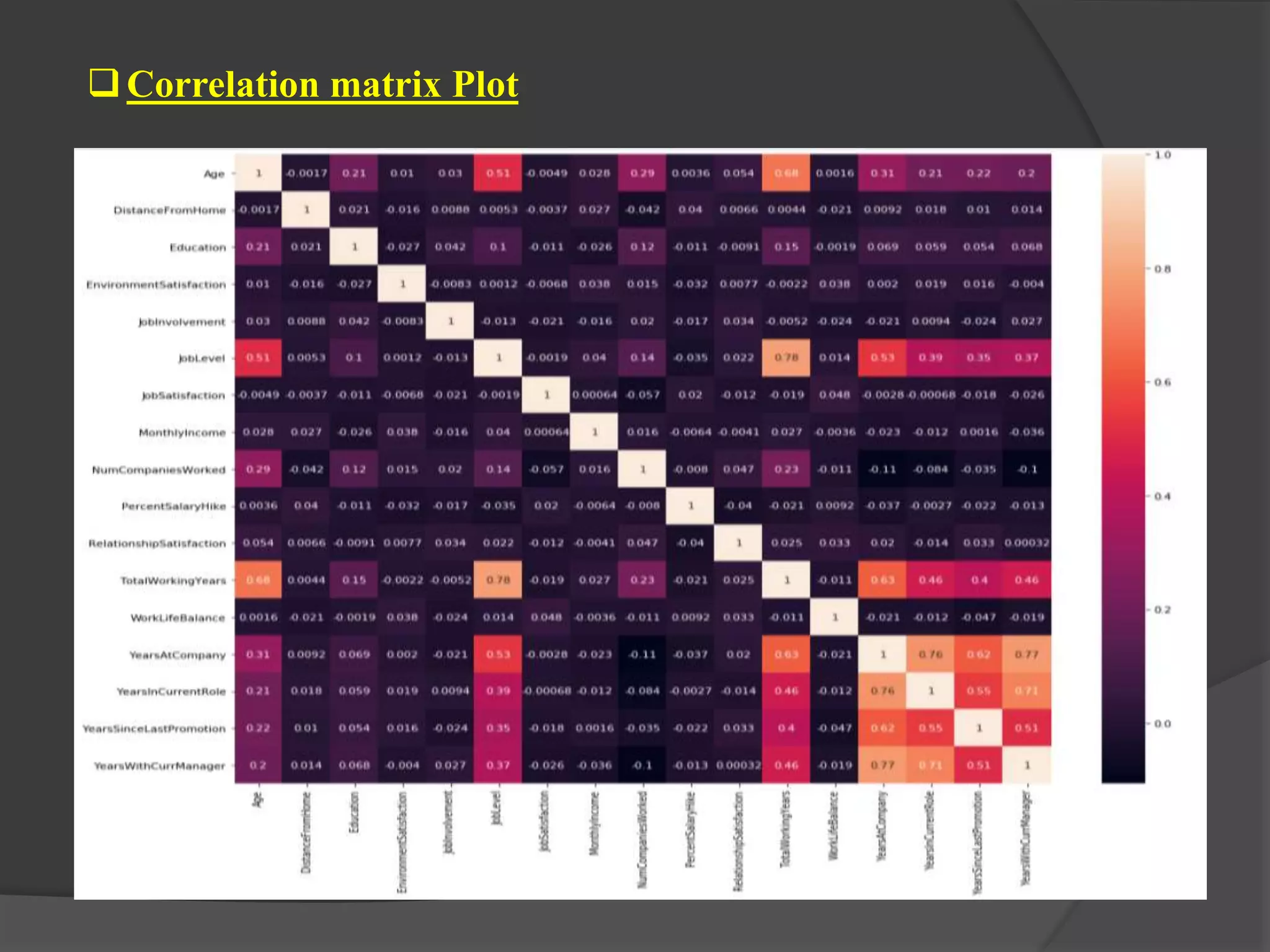
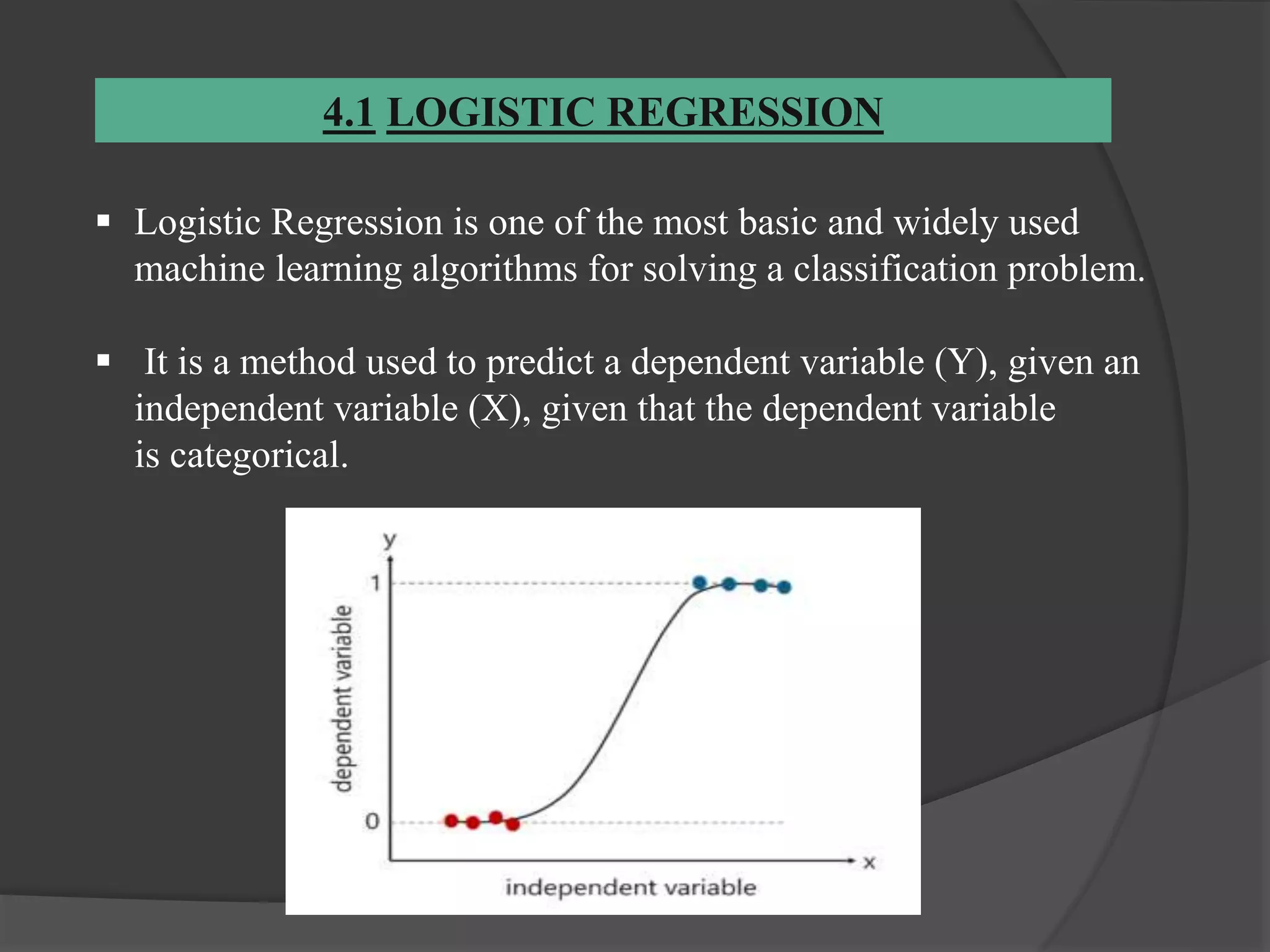
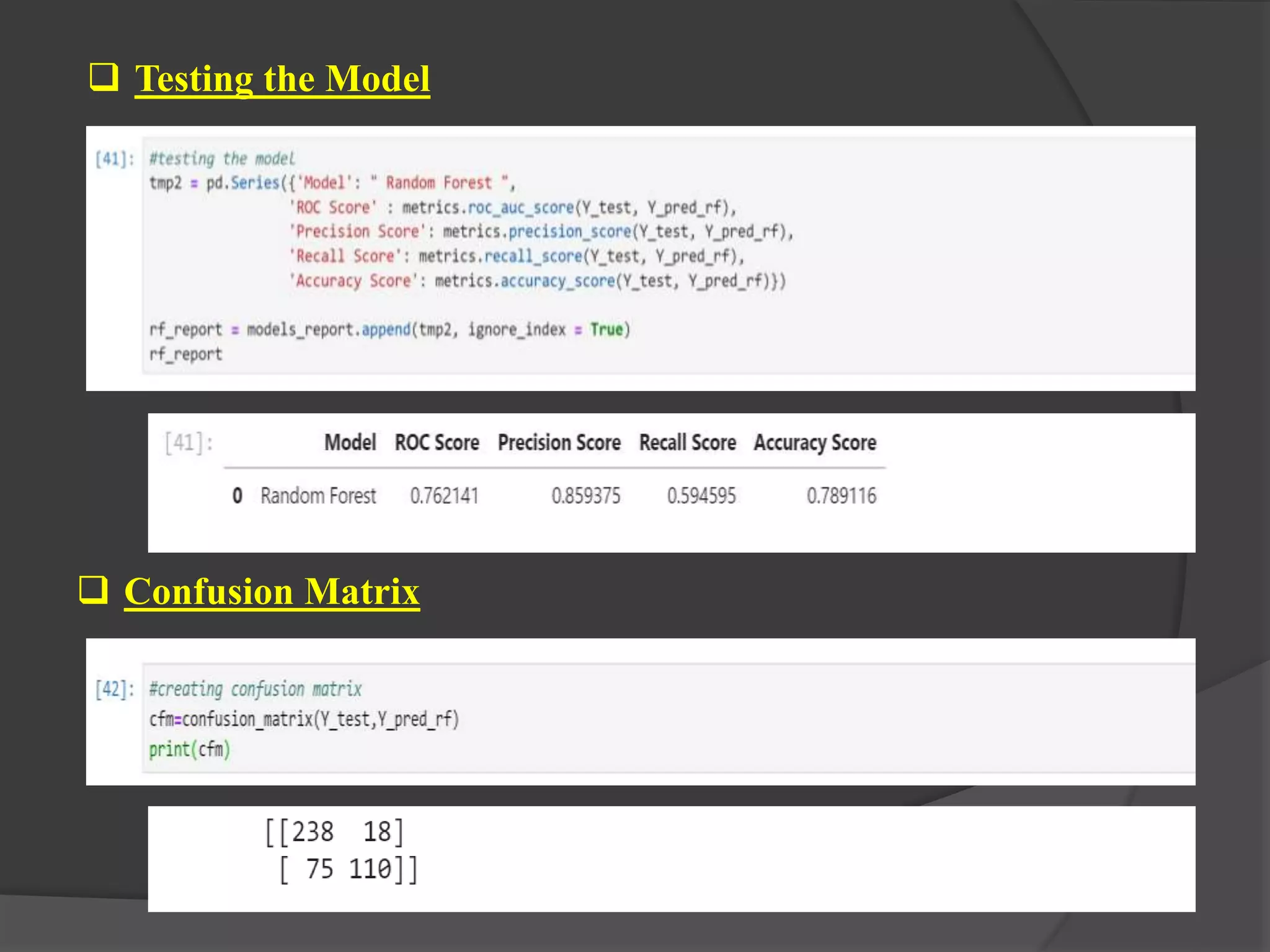
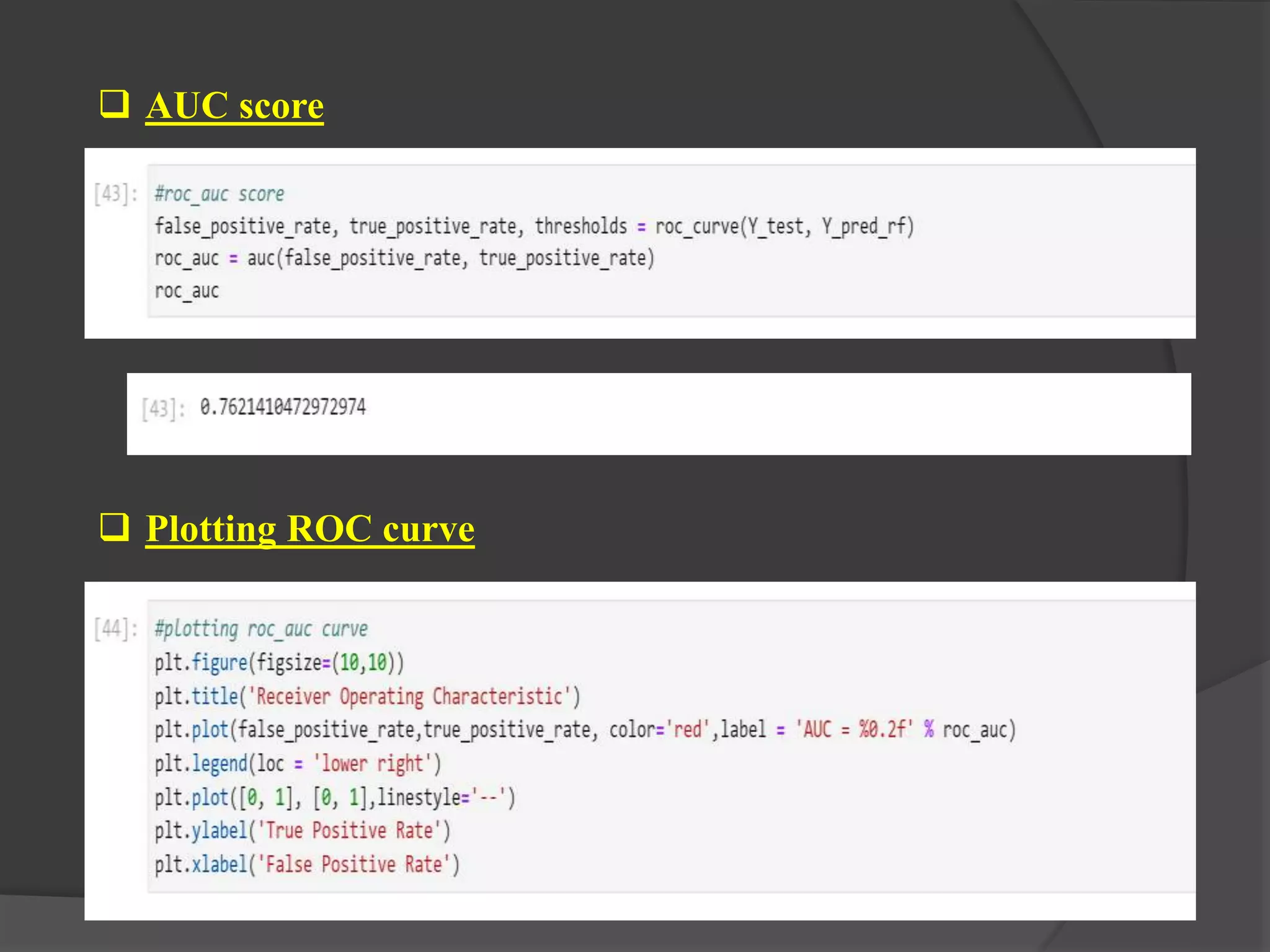
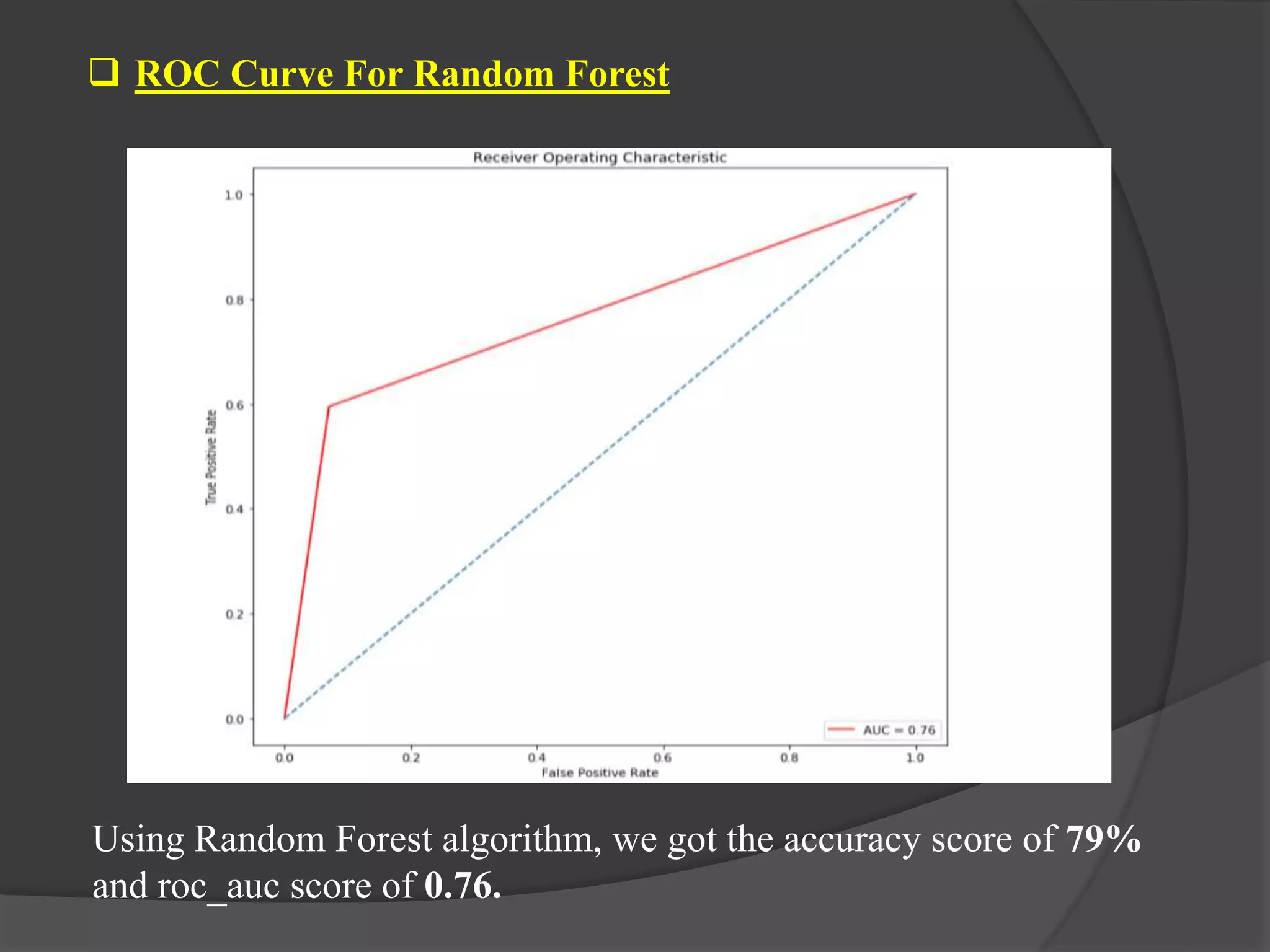
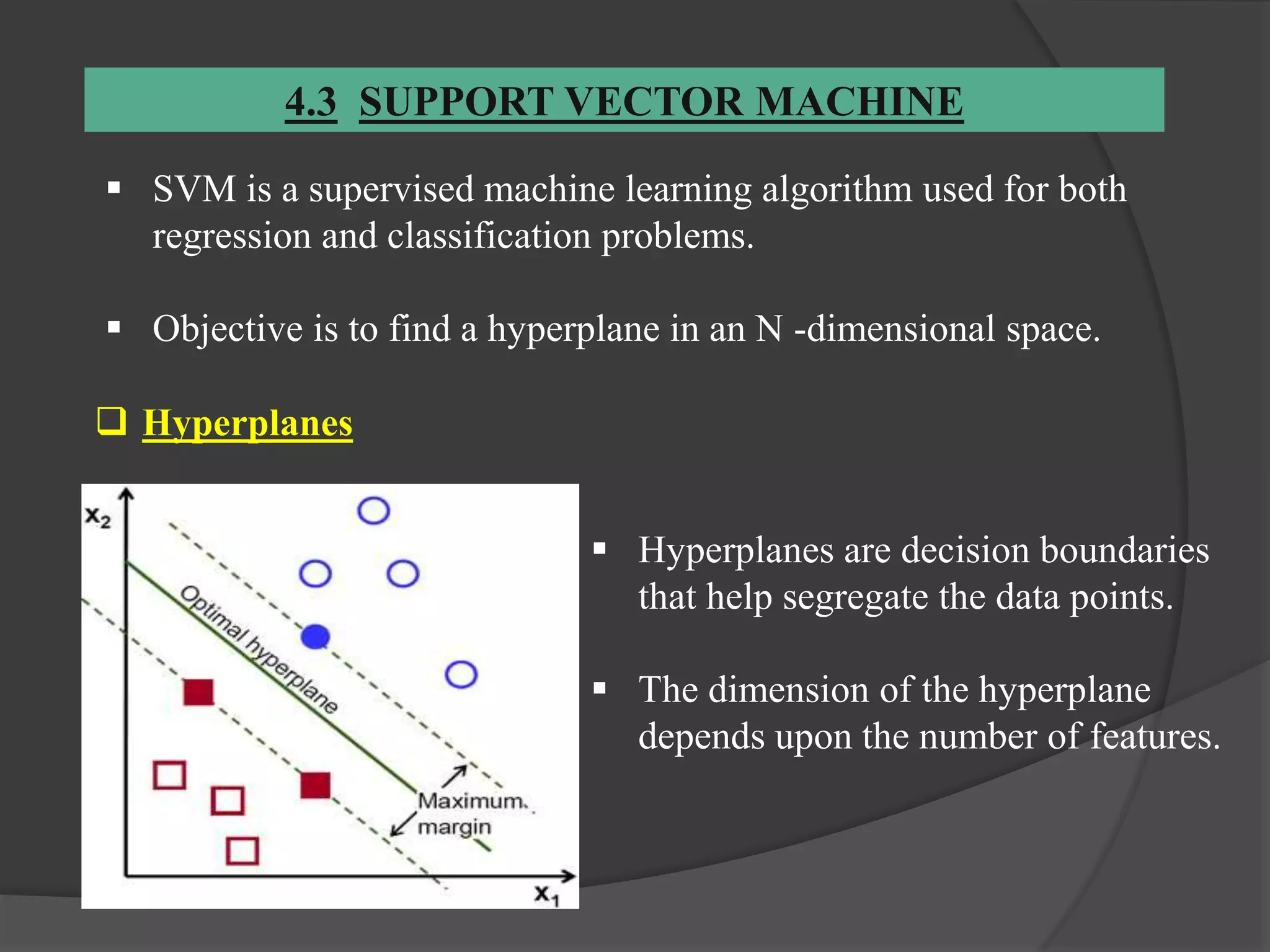
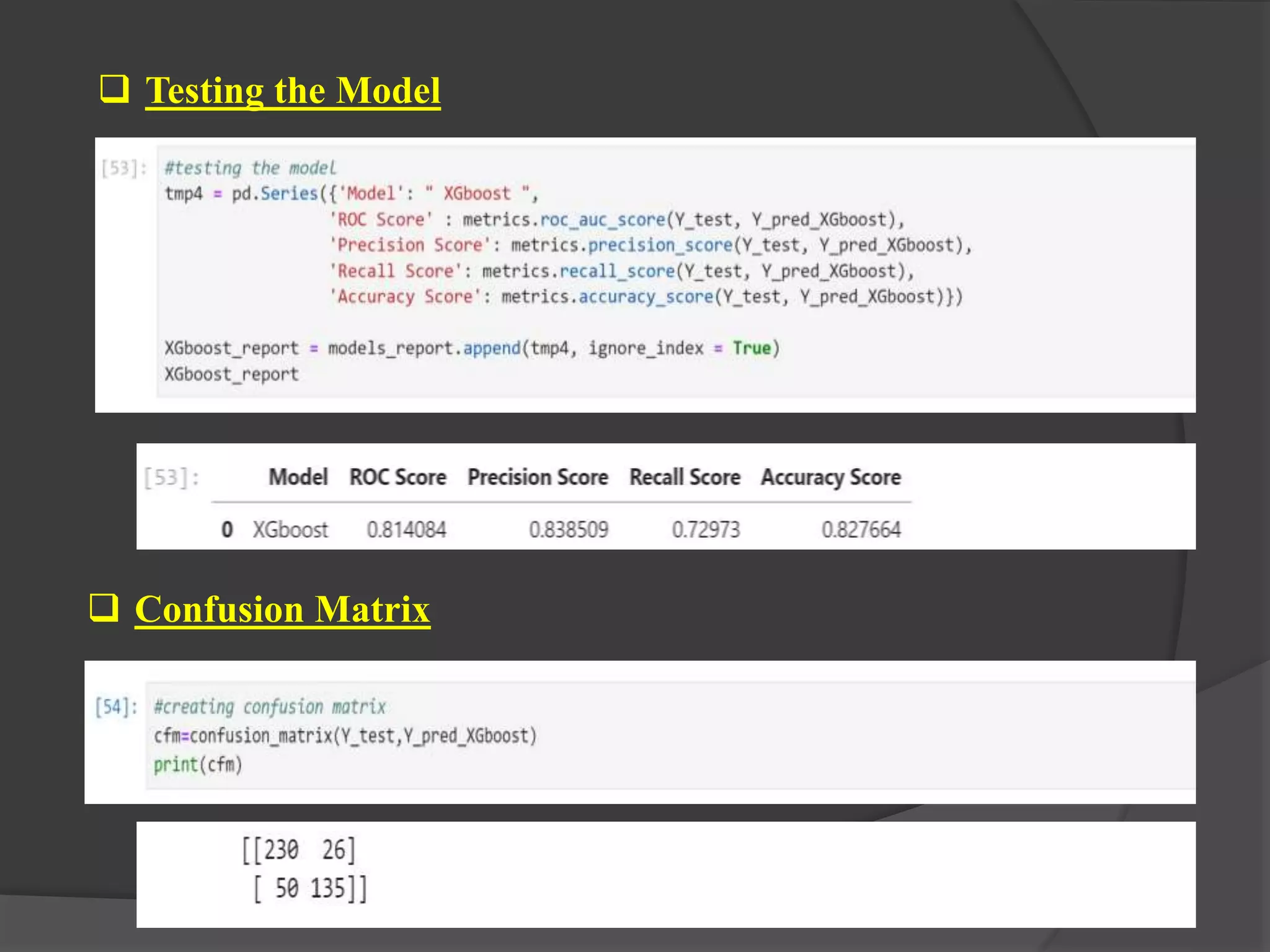
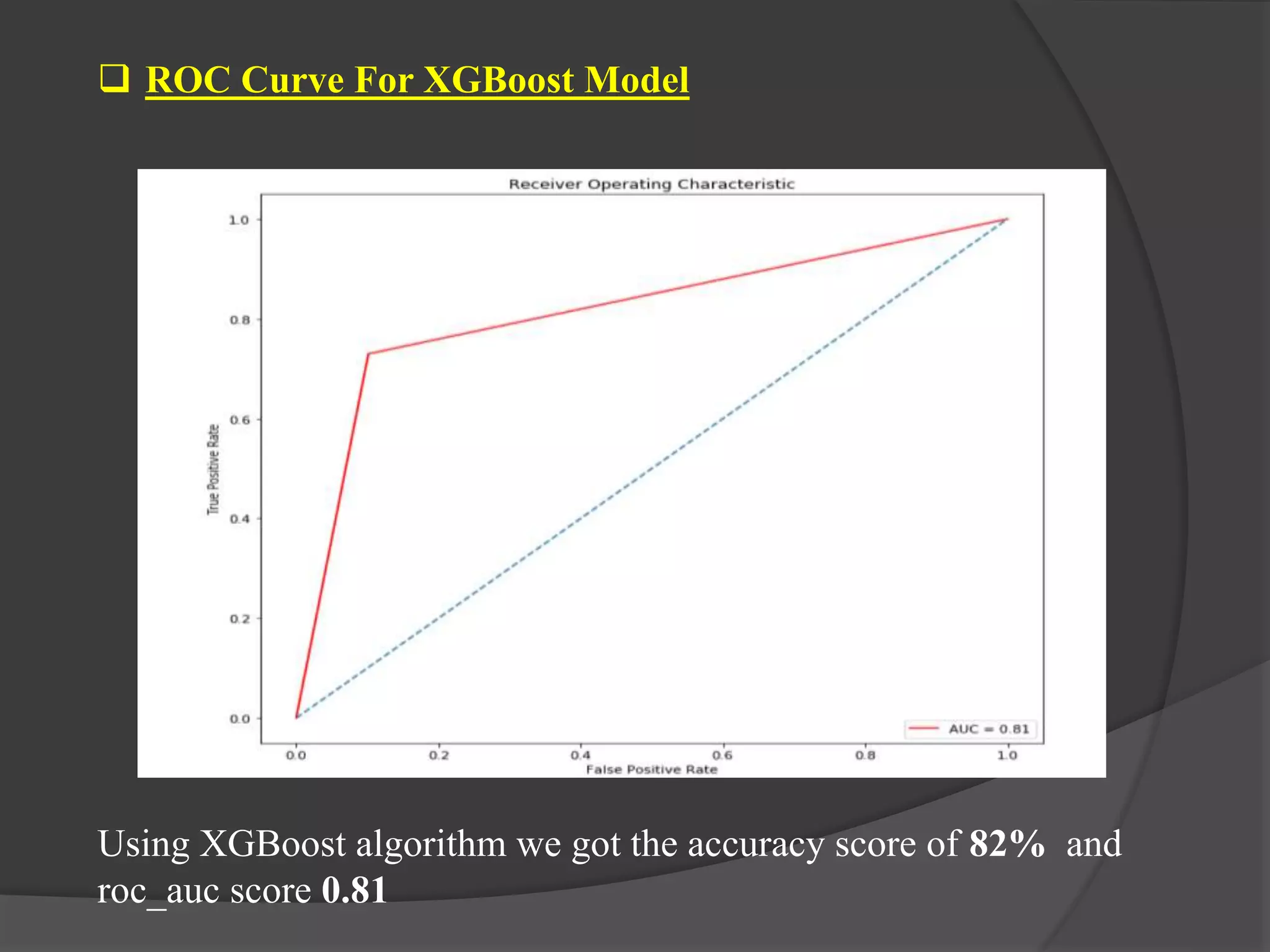
The document outlines a project aimed at predicting employee attrition rates to help organizations mitigate turnover and plan hiring strategies. It discusses the analytics approach, data sources, tools, and techniques used, including machine learning algorithms like logistic regression, random forest, support vector machine, and xgboost. Key findings indicate that xgboost performs best in predicting attrition, with recommendations for improving employee retention based on the analysis of employee data.













![Dropping non-relevant variables
#dropping all fixed and non-relevant variables
attrition_df.drop(['DailyRate','EmployeeCount','EmployeeNumber','HourlyRate','Month
lyRate','Over18','PerformanceRating','StandardHours','StockOptionLevel','TrainingTi
mesLastYear'], axis=1,inplace=True)
Check number of rows and columns](https://image.slidesharecdn.com/employeeattrition-190609080544/75/Predicting-Employee-Attrition-29-2048.jpg)























































![Dropping non-relevant variables
#dropping all fixed and non-relevant variables
attrition_df.drop(['DailyRate','EmployeeCount','EmployeeNumber','HourlyRate','Month
lyRate','Over18','PerformanceRating','StandardHours','StockOptionLevel','TrainingTi
mesLastYear'], axis=1,inplace=True)
Check number of rows and columns](https://crownmelresort.com/image.slidesharecdn.com/employeeattrition-190609080544/75/Predicting-Employee-Attrition-29-2048.jpg)
































































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)
















