Downloaded 30 times








![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
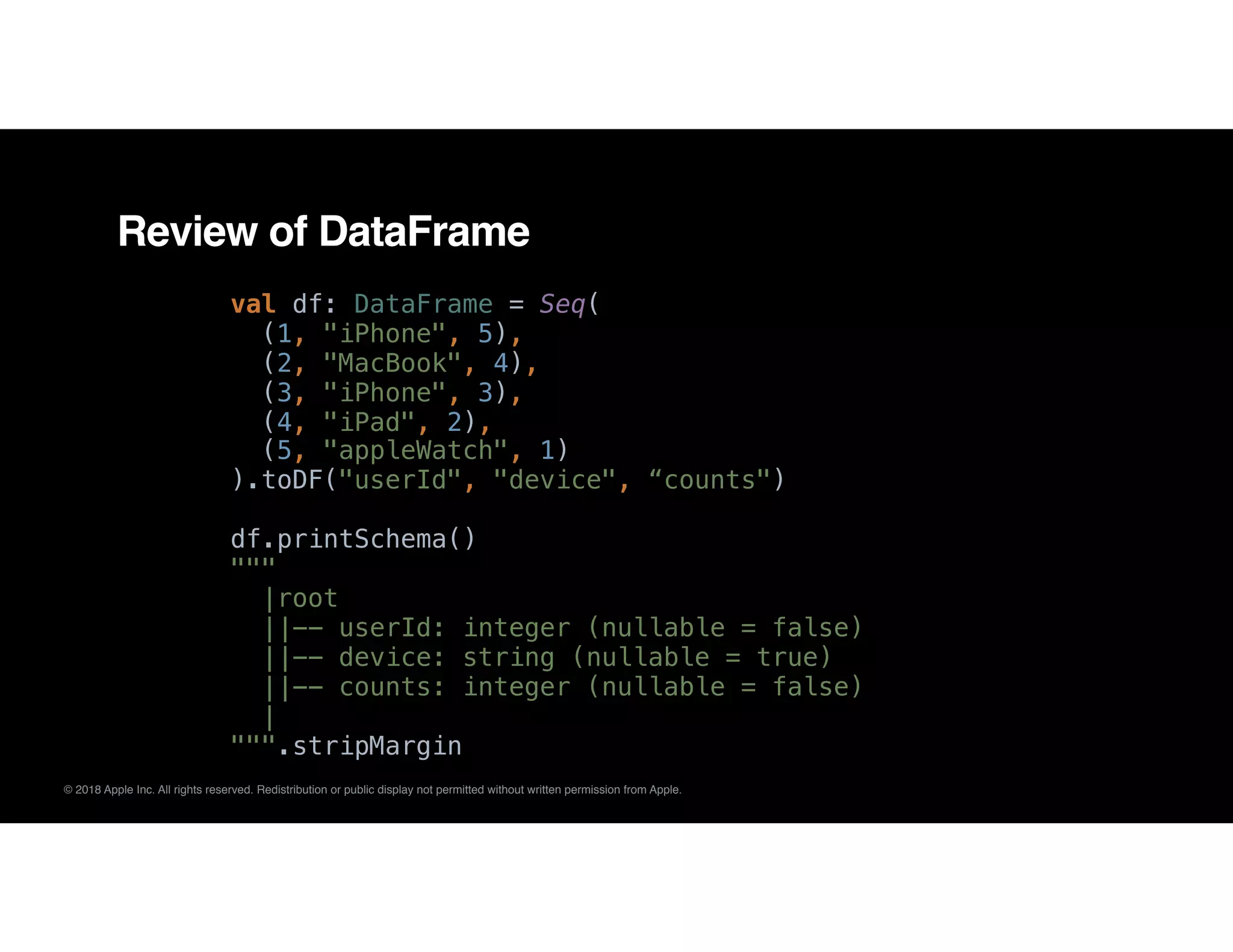
DataFrame: Relational untyped APIs introduced in
Spark 1.3. From Spark 2.0,
type DataFrame = Dataset[Row]
Dataset: Support all the untyped APIs in DataFrame
+ typed functional APIs
Review of APIs of Spark](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-9-2048.jpg)

![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Execution Plan - Dataframe Untyped APIs
df.withColumn("counts", $"counts" + 1).filter($”device" === “iPhone").explain(true)
"""
|== Parsed Logical Plan ==
|'Filter ('device = iPhone)
|+- Project [userId#3, device#4, (counts#5 + 1) AS counts#10]
| +- Relation[userId#3,device#4,counts#5] parquet
|
|== Physical Plan ==
|*Project [userId#3, device#4, (counts#5 + 1) AS counts#10]
|+- *Filter (isnotnull(device#4) && (device#4 = iPhone))
| +- *FileScan parquet [userId#3,device#4,counts#5]
| Batched: true, Format: Parquet,
| PartitionFilters: [],
| PushedFilters: [IsNotNull(device), EqualTo(device,iPhone)],
| ReadSchema: struct<userId:int,device:string,counts:int>
|
""".stripMargin
•](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-12-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Review of Dataset
case class ErrorEvent(userId: Long, device: String, counts: Long)
val ds = df.as[ErrorEvent]
ds.map(row => ErrorEvent(row.userId, row.device, row.counts + 1))
.filter(row => row.device == “iPhone").show()
"""
|+------+------+------+
||userId|device|counts|
|+------+------+------+
|| 1|iPhone| 6|
|| 3|iPhone| 4|
|+------+------+------+
“"".stripMargin
// It’s really easy to put existing Java / Scala code here.](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-13-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Execution Plan - Dataset Typed APIs
ds.map { row => ErrorEvent(row.userId, row.device, row.counts + 1) }.filter { row =>
row.device == "iPhone"
}.explain(true)
"""
|== Physical Plan ==
|*SerializeFromObject [
| assertnotnull(input[0, com.apple.ErrorEvent, true]).userId AS userId#27L,
| assertnotnull(input[0, com.apple.ErrorEvent, true]).device, true) AS device#28,
| assertnotnull(input[0, com.apple.ErrorEvent, true]).counts AS counts#29L]
|+- *Filter <function1>.apply
| +- *MapElements <function1>, obj#26: com.apple.ErrorEvent
| +- *DeserializeToObject newInstance(class com.apple.ErrorEvent), obj#25:
| com.apple.siri.ErrorEvent
| +- *FileScan parquet [userId#3,device#4,counts#5]
| Batched: true, Format: Parquet,
| PartitionFilters: [], PushedFilters: [],
| ReadSchema: struct<userId:int,device:string,counts:int>
""".stripMargin
•](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-14-2048.jpg)


![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.3.1
case class FullName(first: String, middle: String, last: String)
case class Contact(id: Int,
name: FullName,
address: String)
sql("select name.first from contacts").where("name.first = 'Jane'").explain(true)
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name)], ReadSchema:
struct<name:struct<first:string,middle:string,last:string>>
|
""".stripMargin](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-17-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.4 with Schema Pruning
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name)], ReadSchema:
struct<name:struct<first:string>>
|
""".stripMargin
• [SPARK-4502], [SPARK-25363] Parquet nested column pruning](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-18-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.4 with Schema Pruning + Predicate Pushdown
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name), EqualTo(name.first,Jane)],
ReadSchema: struct<name:struct<first:string>>
|
""".stripMargin
• [SPARK-4502], [SPARK-25363] Parquet nested column pruning
• [SPARK-17636] Parquet nested Predicate Pushdown](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-19-2048.jpg)

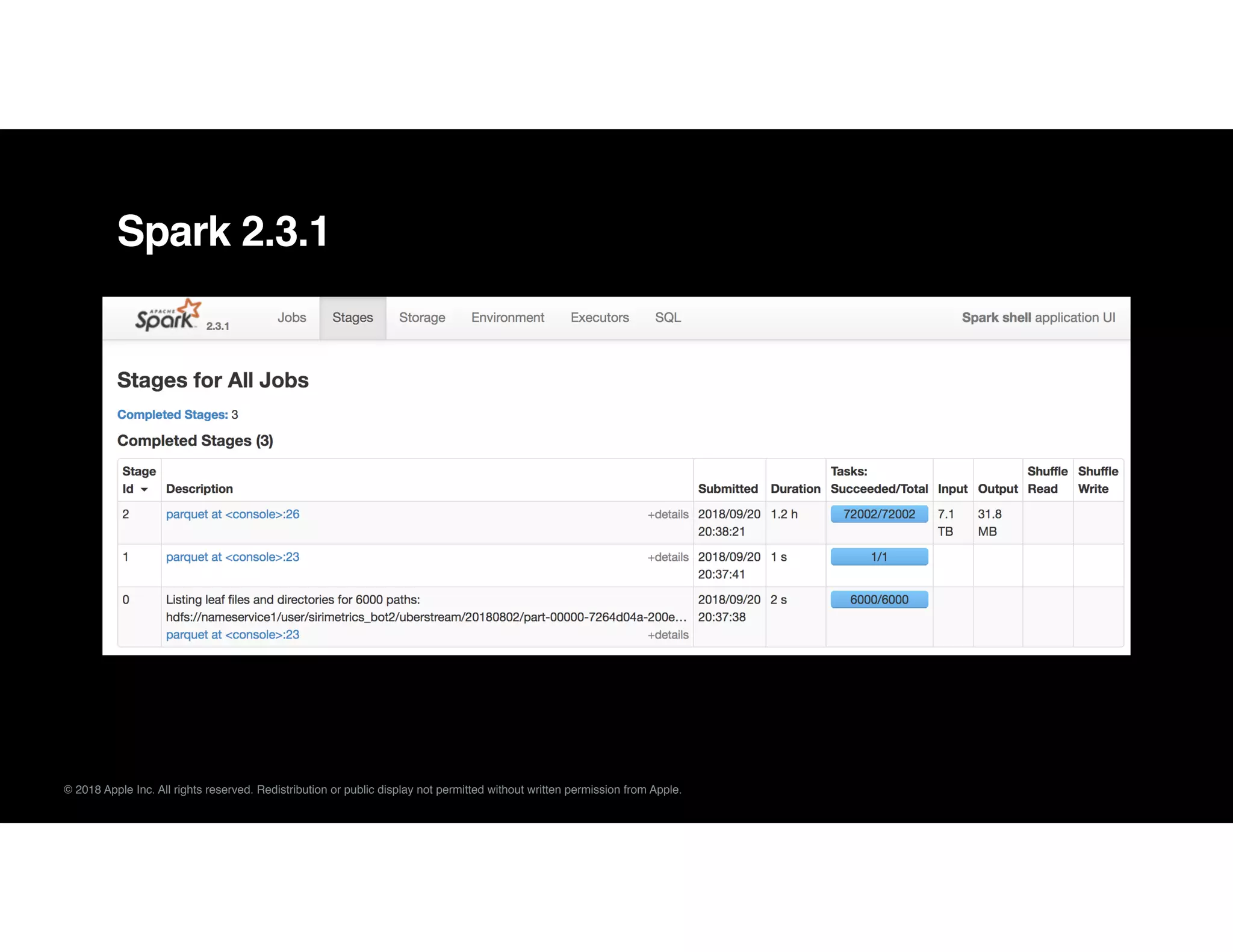
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Spark 2.4 with [SPARK-4502], [SPARK-25363], and [SPARK-17636]](https://image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-22-2048.jpg)












![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
DataFrame: Relational untyped APIs introduced in
Spark 1.3. From Spark 2.0,
type DataFrame = Dataset[Row]
Dataset: Support all the untyped APIs in DataFrame
+ typed functional APIs
Review of APIs of Spark](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-9-2048.jpg)


![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Execution Plan - Dataframe Untyped APIs
df.withColumn("counts", $"counts" + 1).filter($”device" === “iPhone").explain(true)
"""
|== Parsed Logical Plan ==
|'Filter ('device = iPhone)
|+- Project [userId#3, device#4, (counts#5 + 1) AS counts#10]
| +- Relation[userId#3,device#4,counts#5] parquet
|
|== Physical Plan ==
|*Project [userId#3, device#4, (counts#5 + 1) AS counts#10]
|+- *Filter (isnotnull(device#4) && (device#4 = iPhone))
| +- *FileScan parquet [userId#3,device#4,counts#5]
| Batched: true, Format: Parquet,
| PartitionFilters: [],
| PushedFilters: [IsNotNull(device), EqualTo(device,iPhone)],
| ReadSchema: struct<userId:int,device:string,counts:int>
|
""".stripMargin
•](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-12-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Review of Dataset
case class ErrorEvent(userId: Long, device: String, counts: Long)
val ds = df.as[ErrorEvent]
ds.map(row => ErrorEvent(row.userId, row.device, row.counts + 1))
.filter(row => row.device == “iPhone").show()
"""
|+------+------+------+
||userId|device|counts|
|+------+------+------+
|| 1|iPhone| 6|
|| 3|iPhone| 4|
|+------+------+------+
“"".stripMargin
// It’s really easy to put existing Java / Scala code here.](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-13-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Execution Plan - Dataset Typed APIs
ds.map { row => ErrorEvent(row.userId, row.device, row.counts + 1) }.filter { row =>
row.device == "iPhone"
}.explain(true)
"""
|== Physical Plan ==
|*SerializeFromObject [
| assertnotnull(input[0, com.apple.ErrorEvent, true]).userId AS userId#27L,
| assertnotnull(input[0, com.apple.ErrorEvent, true]).device, true) AS device#28,
| assertnotnull(input[0, com.apple.ErrorEvent, true]).counts AS counts#29L]
|+- *Filter <function1>.apply
| +- *MapElements <function1>, obj#26: com.apple.ErrorEvent
| +- *DeserializeToObject newInstance(class com.apple.ErrorEvent), obj#25:
| com.apple.siri.ErrorEvent
| +- *FileScan parquet [userId#3,device#4,counts#5]
| Batched: true, Format: Parquet,
| PartitionFilters: [], PushedFilters: [],
| ReadSchema: struct<userId:int,device:string,counts:int>
""".stripMargin
•](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-14-2048.jpg)


![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.3.1
case class FullName(first: String, middle: String, last: String)
case class Contact(id: Int,
name: FullName,
address: String)
sql("select name.first from contacts").where("name.first = 'Jane'").explain(true)
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name)], ReadSchema:
struct<name:struct<first:string,middle:string,last:string>>
|
""".stripMargin](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-17-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.4 with Schema Pruning
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name)], ReadSchema:
struct<name:struct<first:string>>
|
""".stripMargin
• [SPARK-4502], [SPARK-25363] Parquet nested column pruning](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-18-2048.jpg)
![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
In Spark 2.4 with Schema Pruning + Predicate Pushdown
"""
|== Physical Plan ==
|*(1) Project [name#10.first AS first#23]
|+- *(1) Filter (isnotnull(name#10) && (name#10.first = Jane))
| +- *(1) FileScan parquet [name#10] Batched: false, Format: Parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name), EqualTo(name.first,Jane)],
ReadSchema: struct<name:struct<first:string>>
|
""".stripMargin
• [SPARK-4502], [SPARK-25363] Parquet nested column pruning
• [SPARK-17636] Parquet nested Predicate Pushdown](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-19-2048.jpg)


![© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
Spark 2.4 with [SPARK-4502], [SPARK-25363], and [SPARK-17636]](https://crownmelresort.com/image.slidesharecdn.com/01cesardelgadodbtsai-181010231824/75/Pitfalls-of-Apache-Spark-at-Scale-with-Cesar-Delgado-and-DB-Tsai-22-2048.jpg)





The document discusses the implementation and challenges of using Apache Spark at scale within Apple's Siri, highlighting their strategies for managing massive data requests and ensuring privacy. It details the evolution of their data processing pipelines, with a focus on standardizing data models and optimizing query performance through schema management and pipeline enhancements. The presentation concludes with insights into future optimizations and the overall success of scaling Spark for efficient data processing.



































































