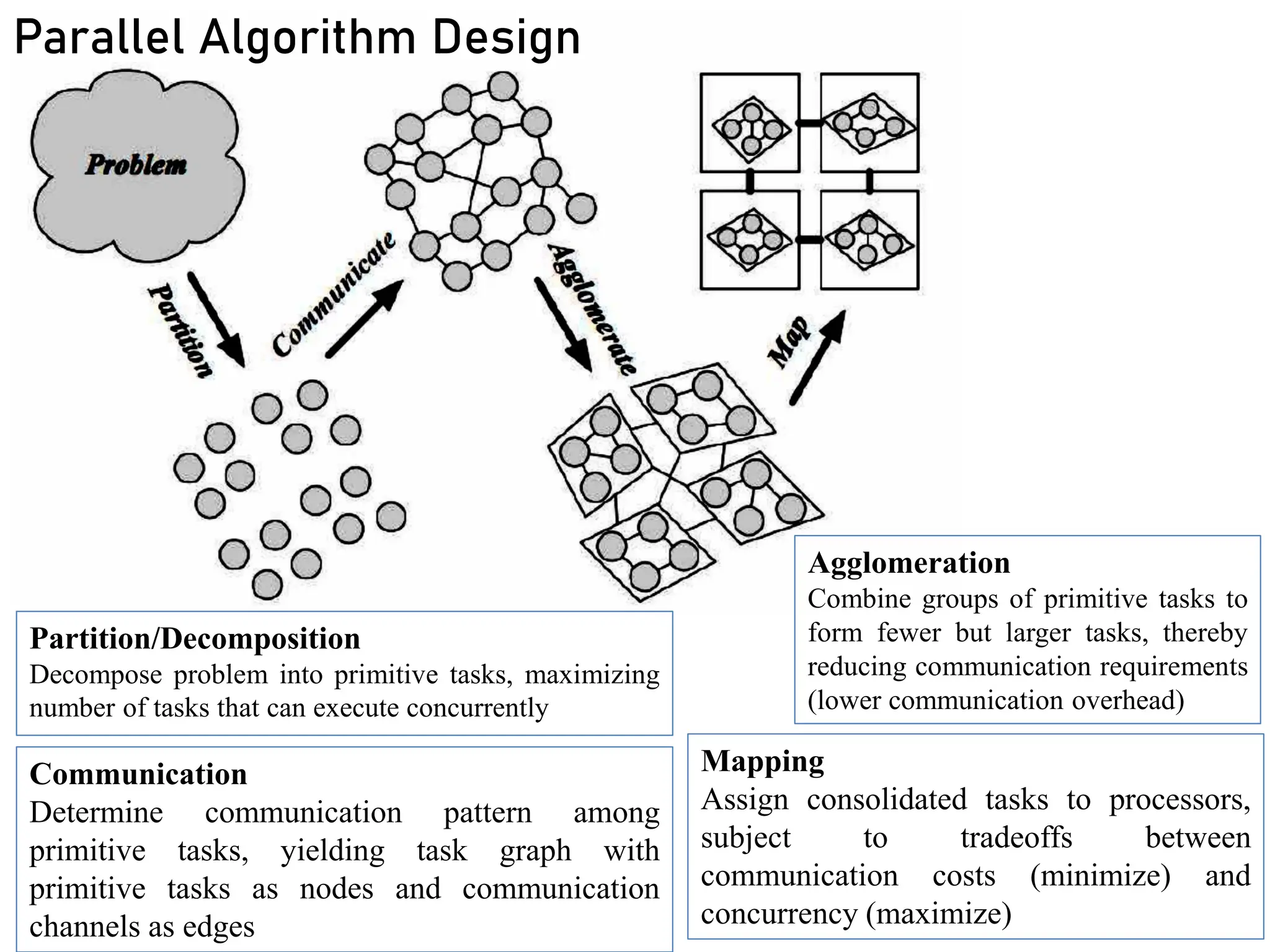
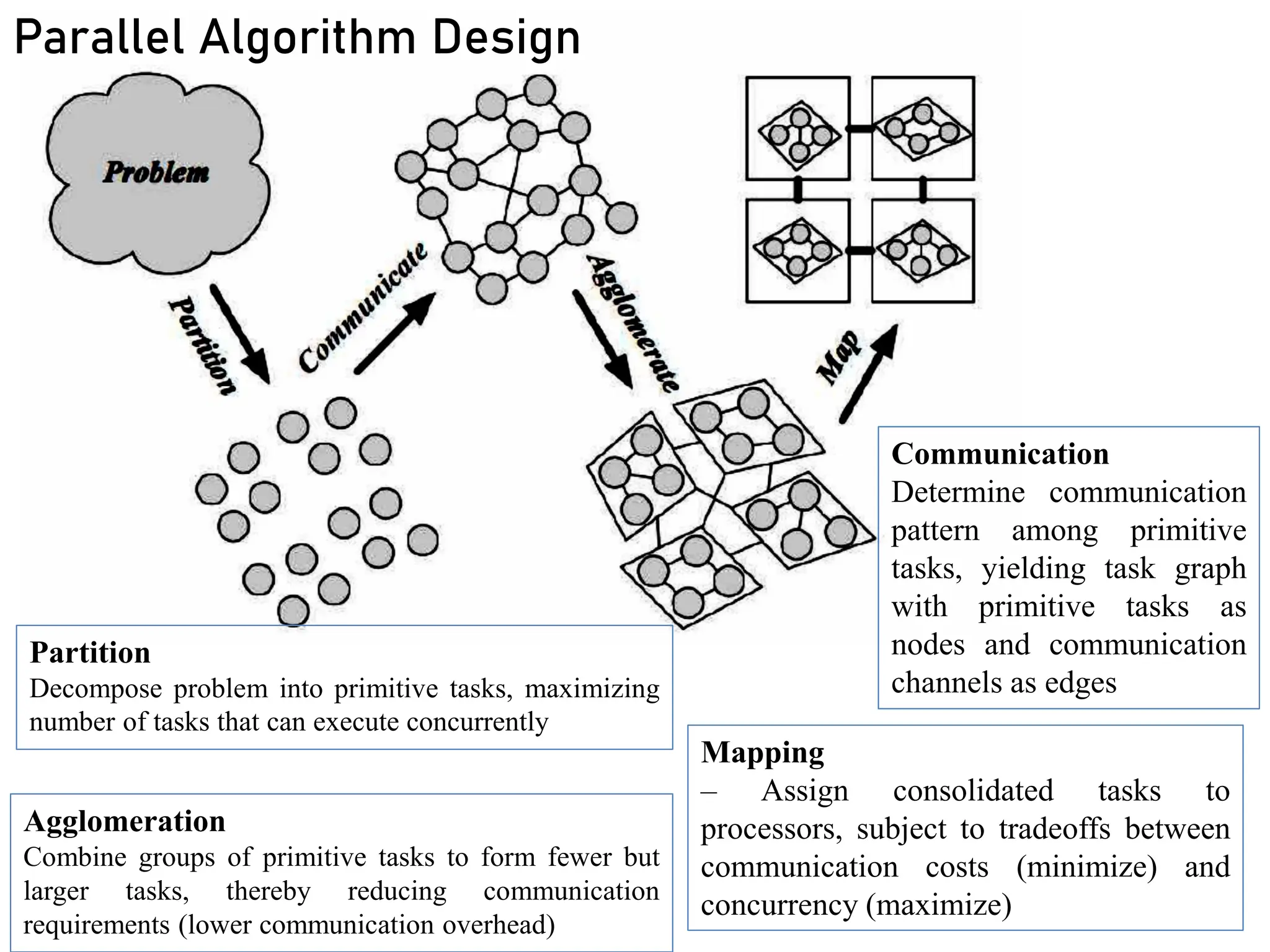
Partition/Decomposition
Decompose problem intoprimitive tasks, maximizing
number of tasks that can execute concurrently
Communication
Determine communication pattern among
primitive tasks, yielding task graph with
primitive tasks as nodes and communication
channels as edges
Agglomeration
Combine groups of primitive tasks to
form fewer but larger tasks, thereby
reducing communication requirements
(lower communication overhead)
Parallel Algorithm Design
Mapping
Assign consolidated tasks to processors,
subject to tradeoffs between
communication costs (minimize) and
concurrency (maximize)
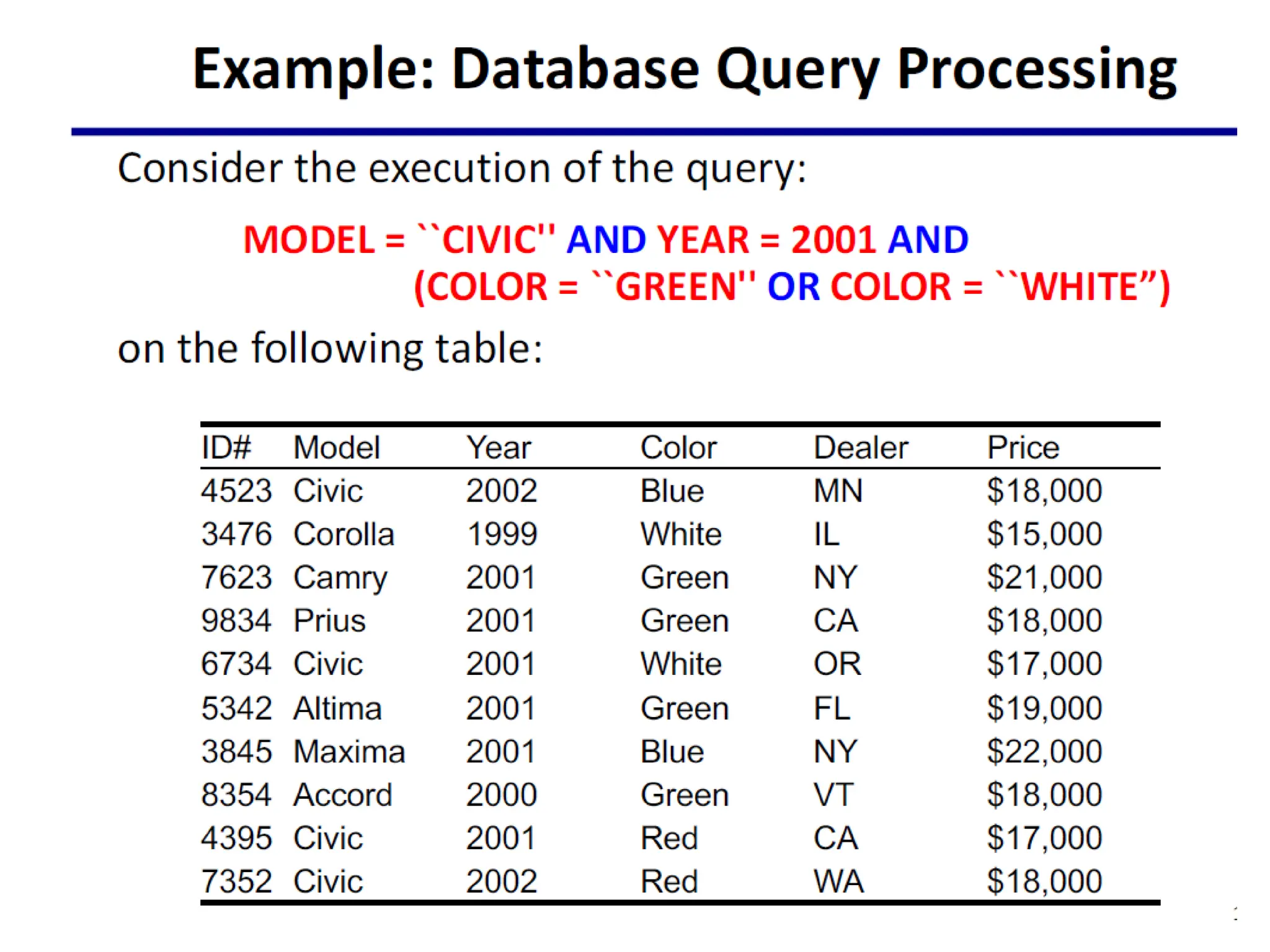
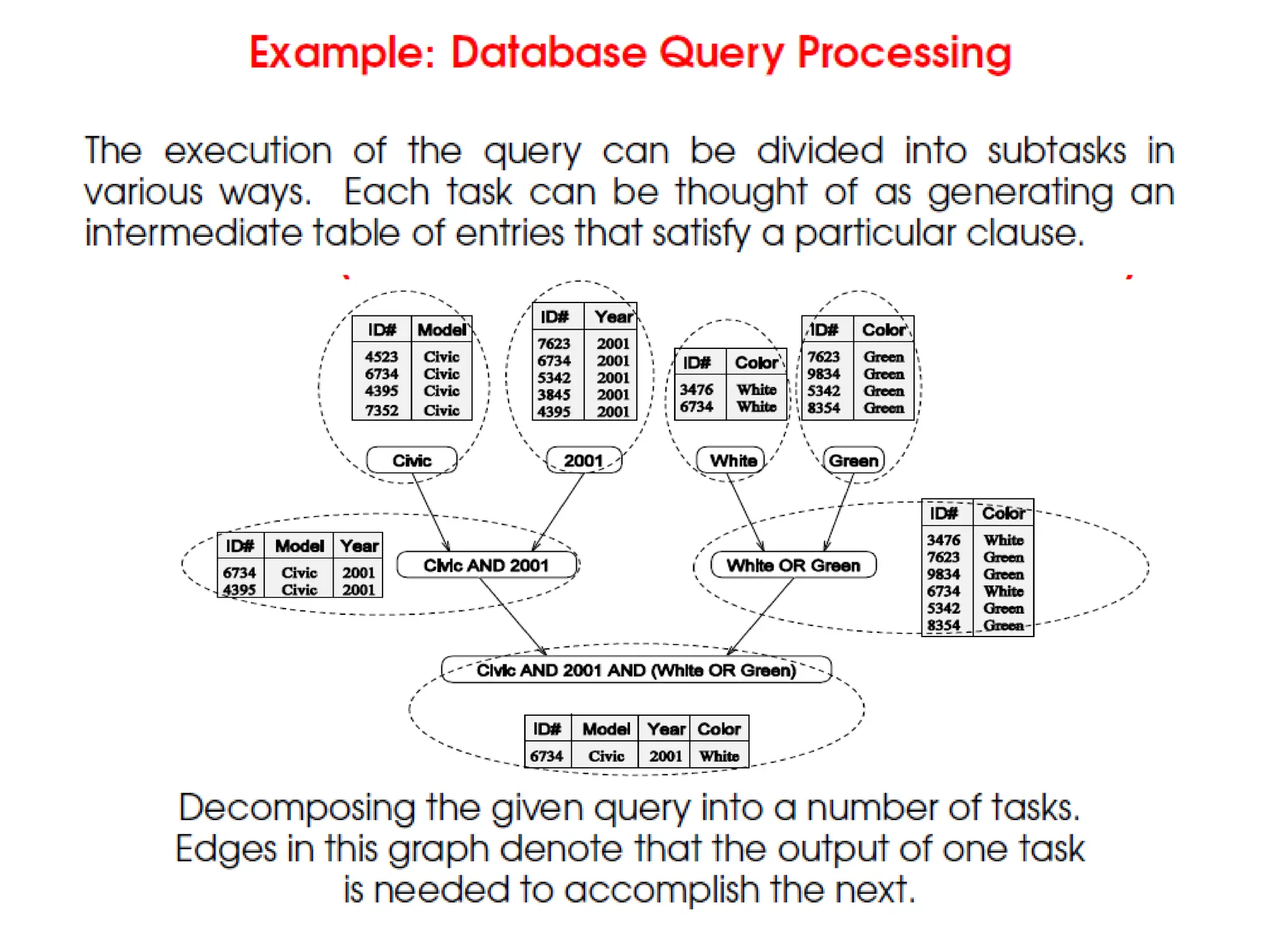
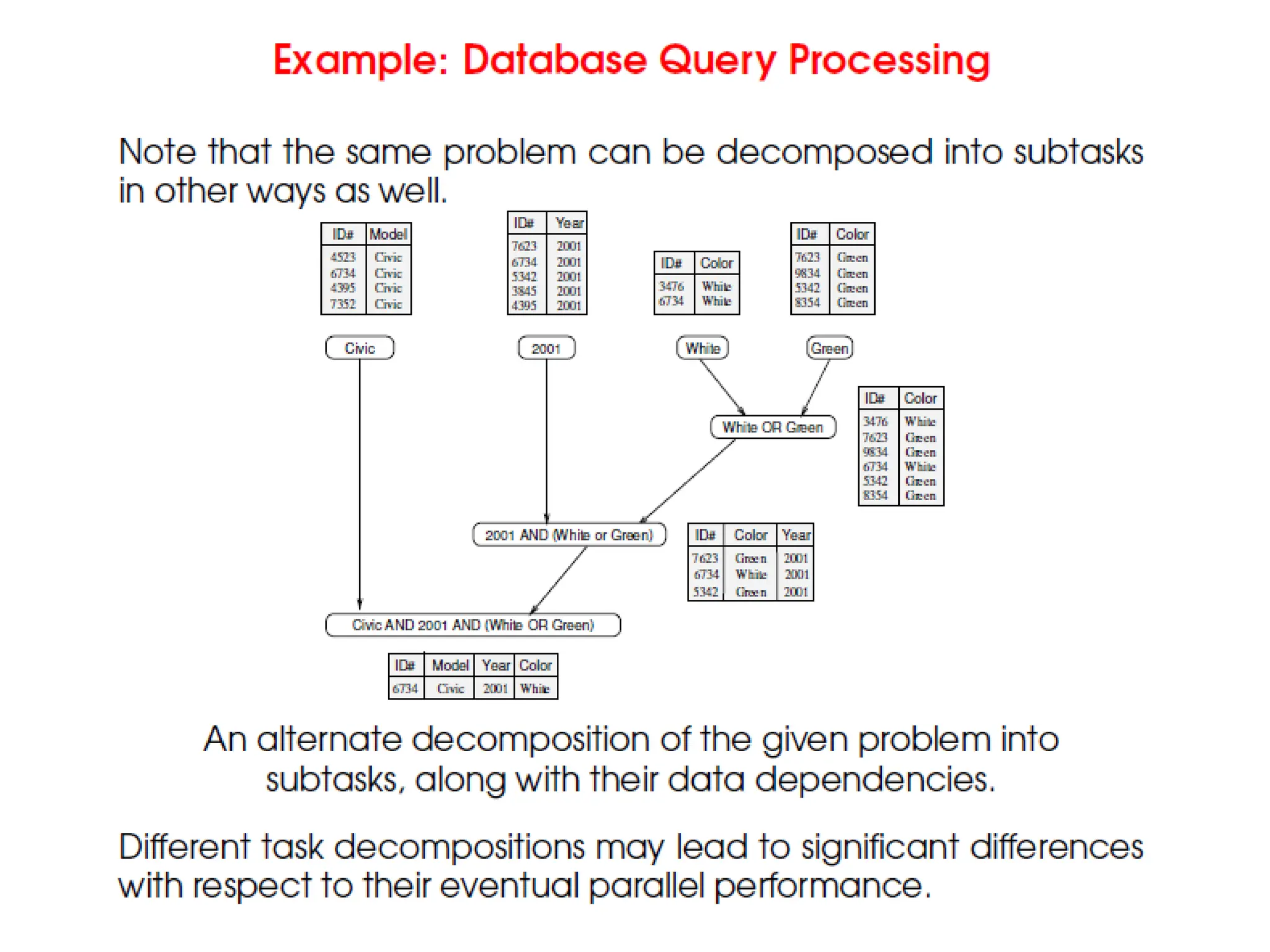
3.
Decomposition
• The firststep in developing a parallel algorithm is to
decompose the problem into tasks that can be
executed simultaneously.
• The process of dividing a computation into smaller
parts, some or all of which may potentially be executed
in parallel, is called decomposition.
• Tasks are programmer-defined units of computation
into which the main computation is subdivided by
means of decomposition.
• Create atleast enough tasks to all execution units busy.
• Key Challenge of decomposition is identifying
dependencies.
4.
Granularity
• The numberand size of tasks into which a problem is
decomposed determines the granularity of the
decomposition.
• Choosing granularity for a problem depends on the
computation time and communication time,
wherein, computation time is the time required to
perform the computation of a task and
communication time is the time required to exchange
data between processors.
• Depending on the amount of work which is performed
by a parallel task, parallelism can be classified into
three categories:
– fine-grained, medium-grained and coarse-grained
parallelism.
5.
Fine-grained parallelism
• Infine-grained parallelism, a program is broken down to a large
number of small tasks. These tasks are assigned individually to
many processors.
• The amount of work associated with a parallel task is low and
the work is evenly distributed among the processors. Hence,
fine-grained parallelism facilitates load balancing.
• As each task processes less data, the number of processors
required to perform the complete processing is high. This in
turn, increases the communication and synchronization
overhead.
• Shared memory architecture which has a low communication
overhead is most suitable for fine-grained parallelism.
6.
Coarse-grained parallelism
• Incoarse-grained parallelism, a program is
split into large tasks. Due to this, a large
amount of computation takes place in
processors.
• This might result in load imbalance, wherein
certain tasks process the bulk of the data
while others might be idle. The advantage of
this type of parallelism is low communication
and synchronization overhead.
Task-dependency graph.
• Anabstraction used to express the dependencies
among tasks and their relative order of execution
is known as task-dependency graph.
• A task-dependency graph is a directed acyclic
graph in which the nodes represent tasks and the
directed edges indicates the dependencies
amongst them.
• The task can be executed when all tasks
connected to this task-node by incoming edges
have completed.
• embarrassingly parallel: task-graph can be
disconnected and the edge-set can be empty.
13.
• The numberof tasks that can be executed in parallel is
the degree of concurrency of a decomposition.
• Since the number of tasks that can be executed in
parallel may change over program execution, the
maximum degree of concurrency is the maximum
number of such tasks at any point during execution.
Degree of Concurrency
maximum degree of concurrency=4
14.
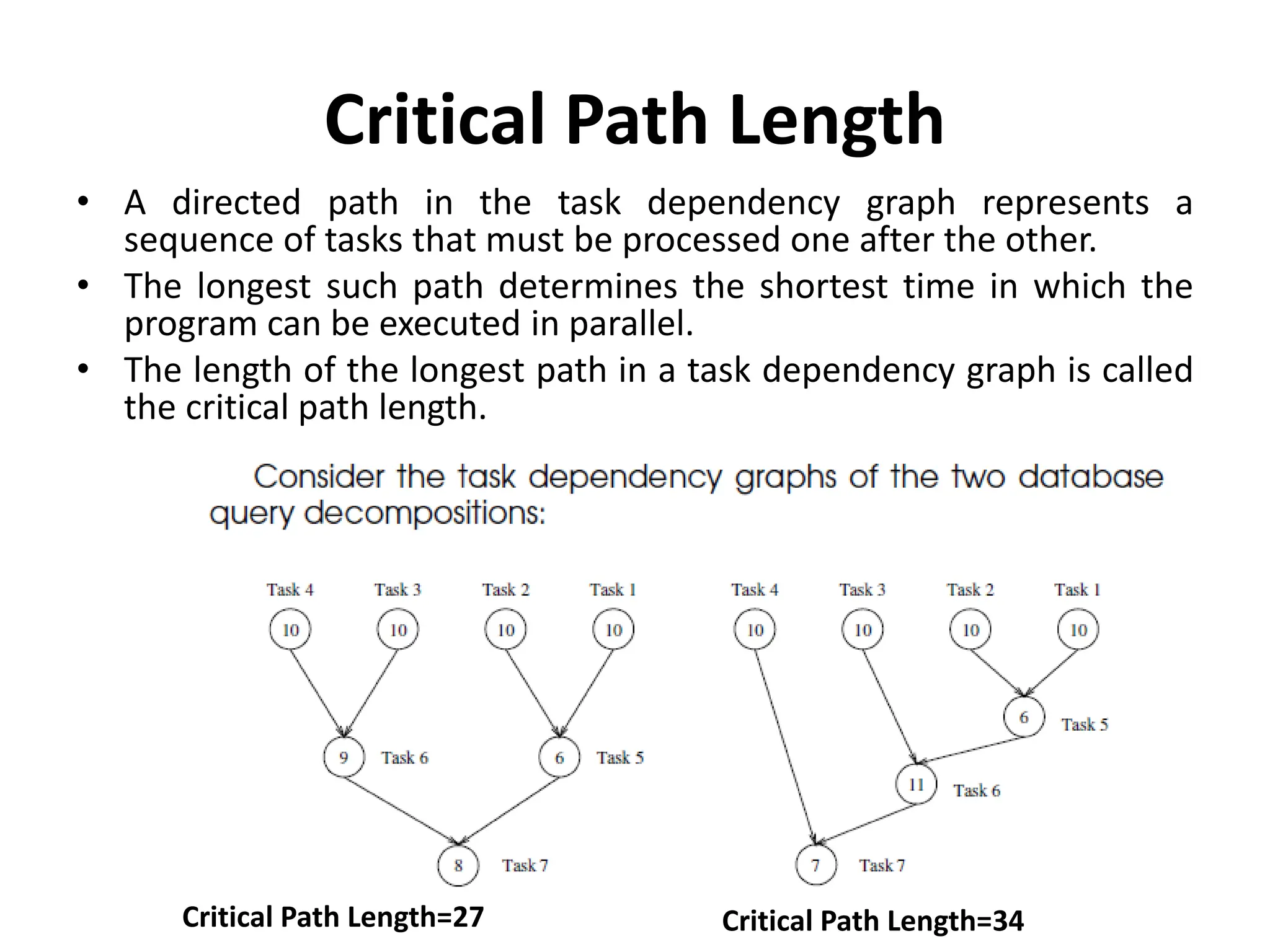
Critical Path Length
•A directed path in the task dependency graph represents a
sequence of tasks that must be processed one after the other.
• The longest such path determines the shortest time in which the
program can be executed in parallel.
• The length of the longest path in a task dependency graph is called
the critical path length.
Critical Path Length=27 Critical Path Length=34
15.
Decomposition Techniques
• Sohow does one decompose a task into
various subtasks?
• While there is no single recipe that works for
all problems, we present a set of commonly
used techniques that apply to broad classes of
problems. These include:
– data decomposition
– recursive decomposition
– exploratory decomposition
– speculative decomposition
16.
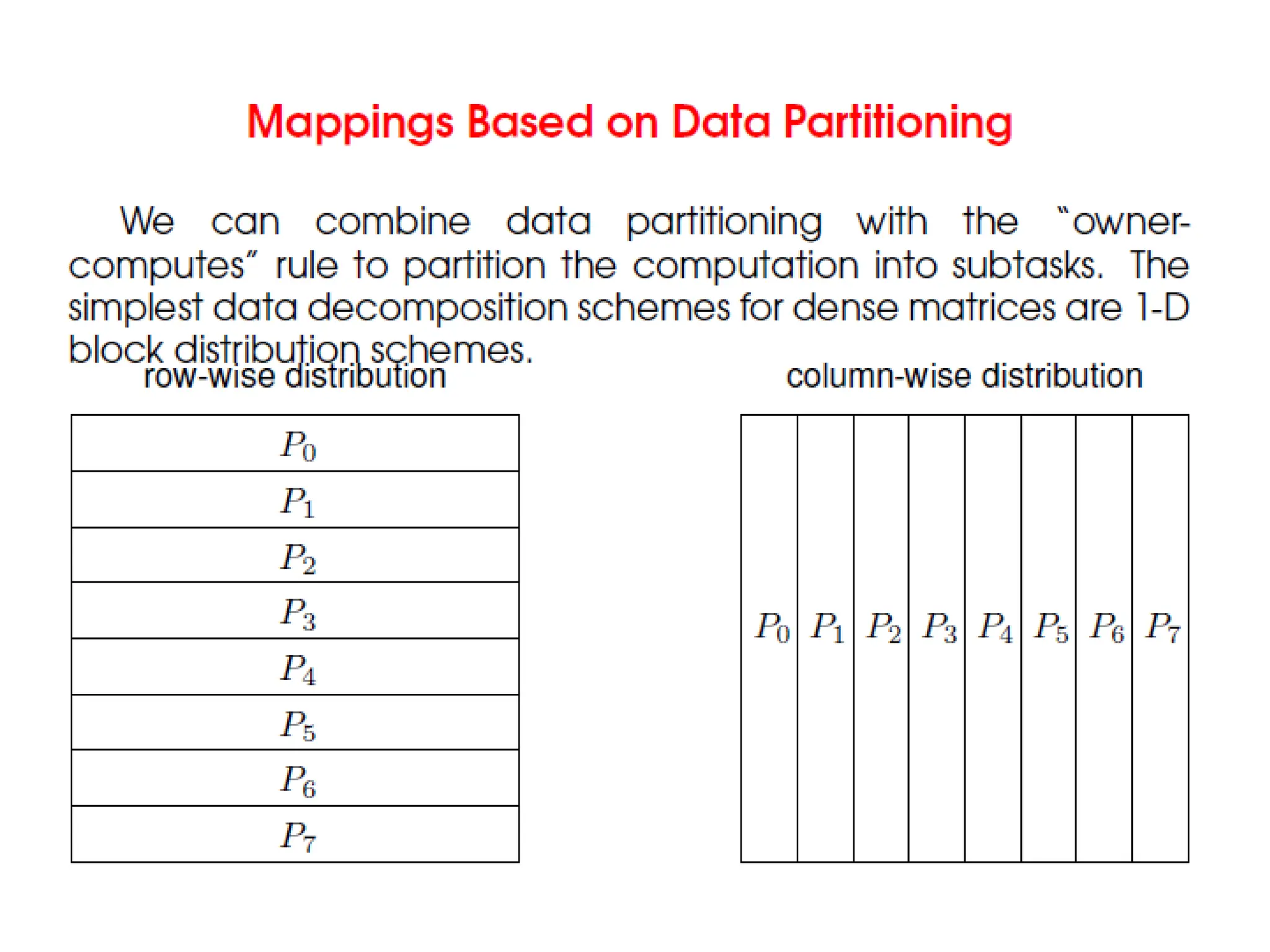
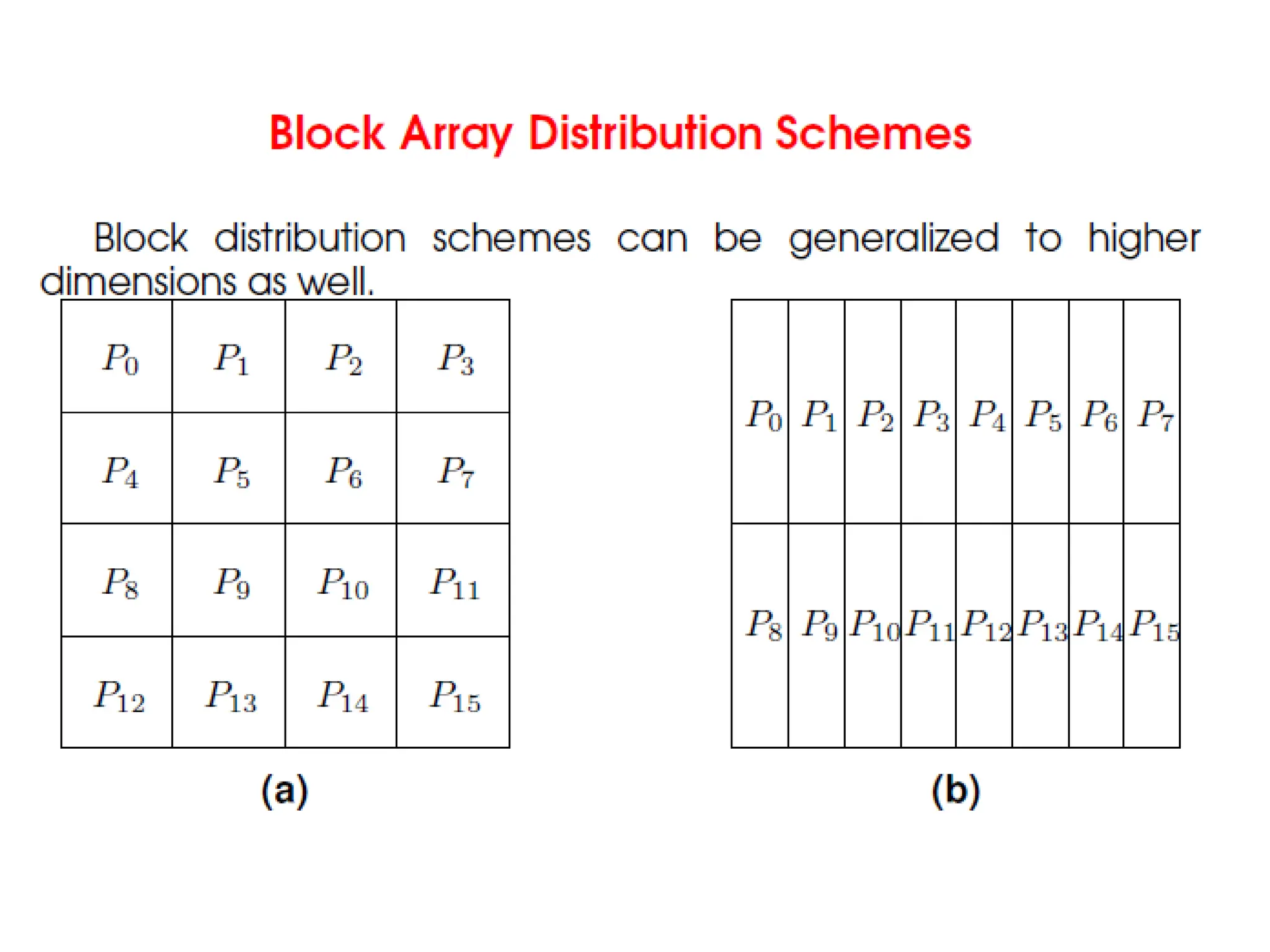
Data Decomposition
• Datadecomposition is a powerful and commonly
used method for deriving concurrency in
algorithms that operate on large data structures.
• Identify the data on which computations are
performed.
• Partition this data across various tasks.
• This partitioning induces a decomposition of the
problem.
• Data can be partitioned in various ways. This
critically impacts performance of a parallel
algorithm.
18.
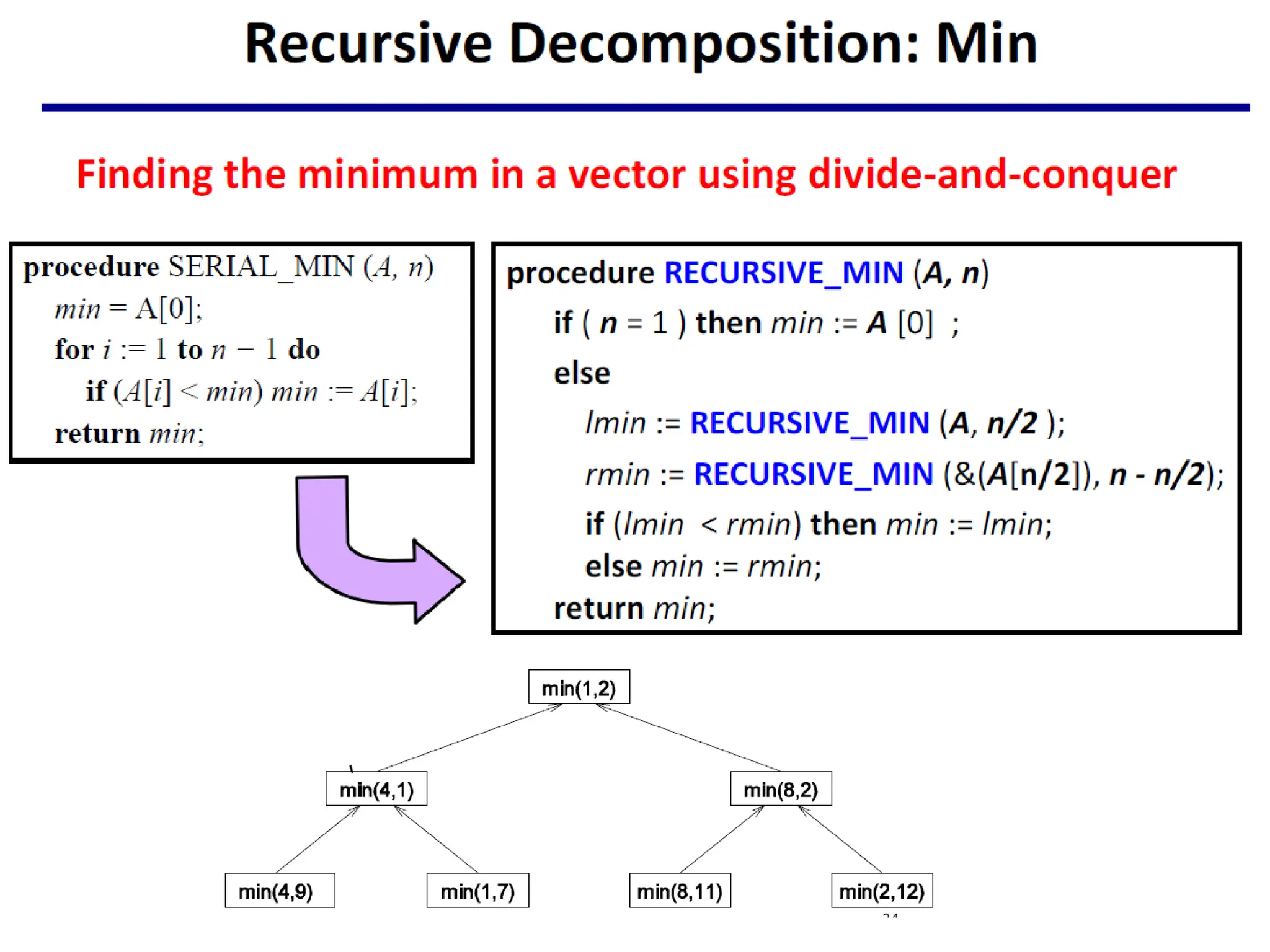
Input Data Partitioning
•Generally applicable if each output can be naturally
computed as a function of the input.
• In many cases, this is the only natural decomposition
because the output is not clearly known a-priori or it is
possible to partition the data.
– e.g., the problem of finding the minimum in a list, sorting a
given list, sum of a set of numbers (output is a singlvalue).
• A task is associated with each input data partition. The
task performs as much of the computation with its part
of the data (local Data).
• Input partitions may not directly solve the original
problem. Subsequent processing needed to combine
these partial results.
20.
Partitioning Output Data
•In many computations, each element of the
output can be computed independently of
others as a function of the input.
• In such computations, a partitioning of the
output data automatically induces a
decomposition of the problems into tasks,
where each task is assigned the work of
computing a portion of the output.
24.
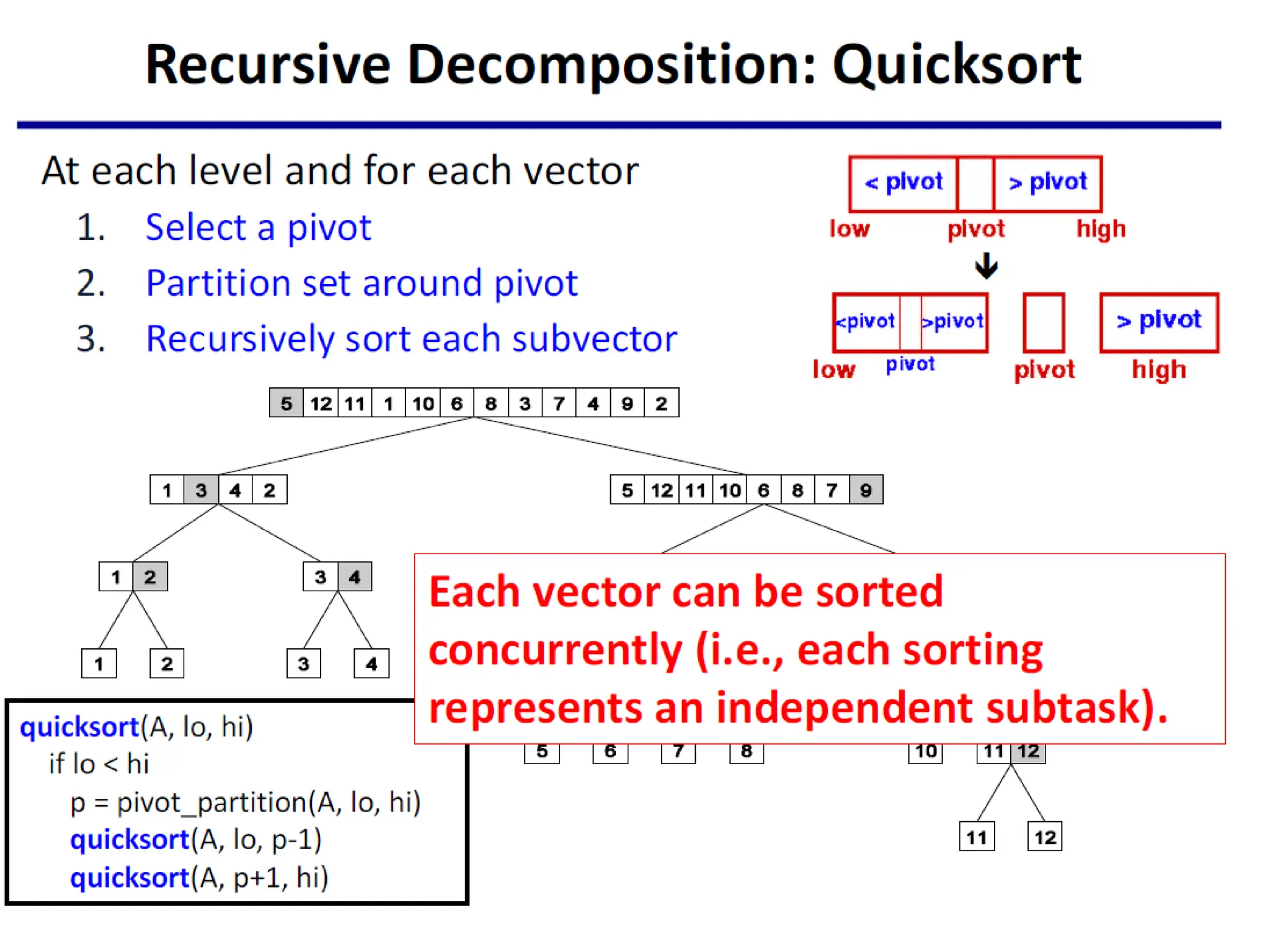
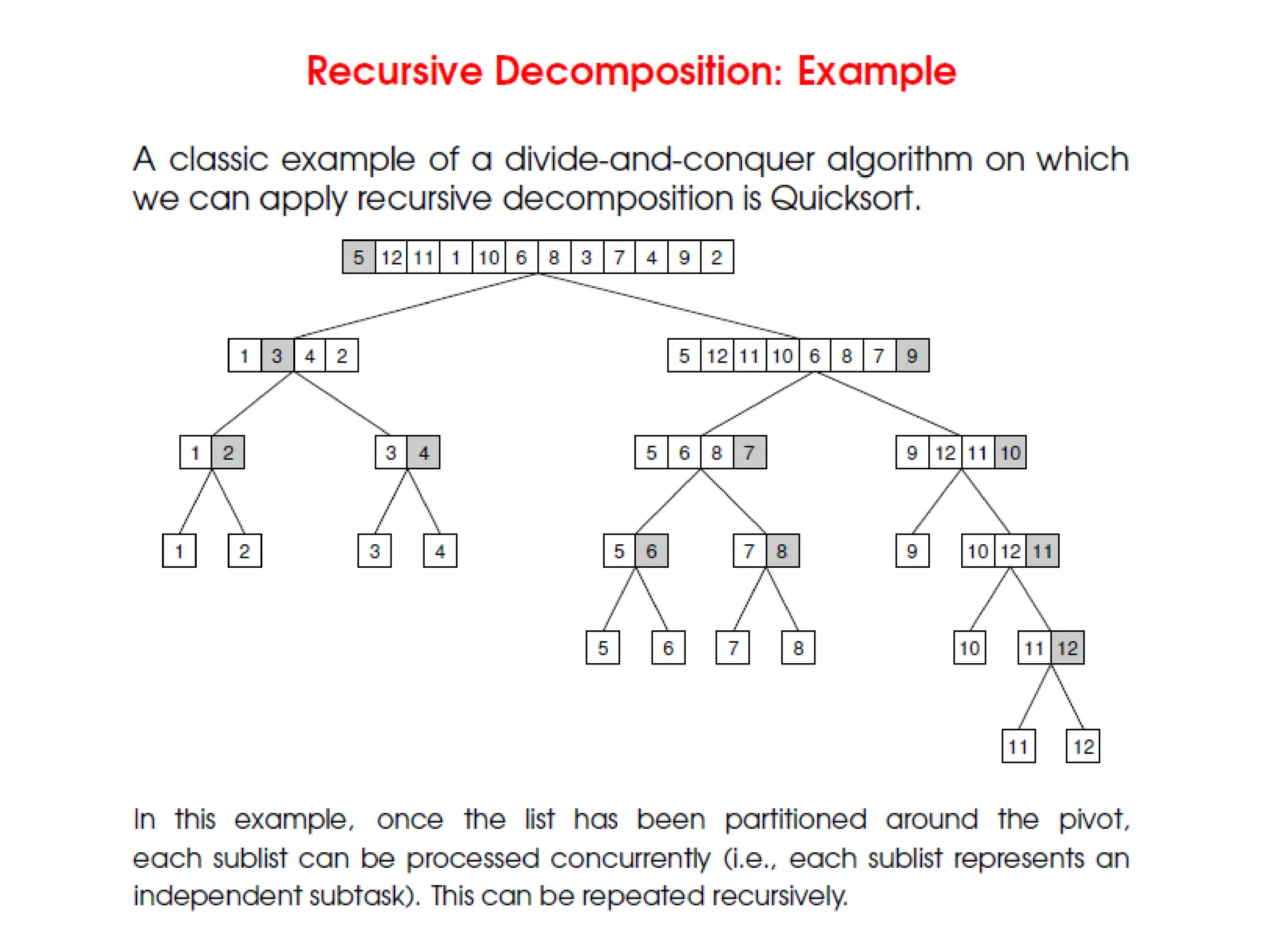
Recursive Decomposition
• RecursiveDecomposition is a method for inducing
concurrency in problems that can be solved using the
divide-and-conquer strategy.
• A given problem is first decomposed into a set of
sub-problems.
• These sub-problems are recursively decomposed
further until a desired granularity is reached.
25.
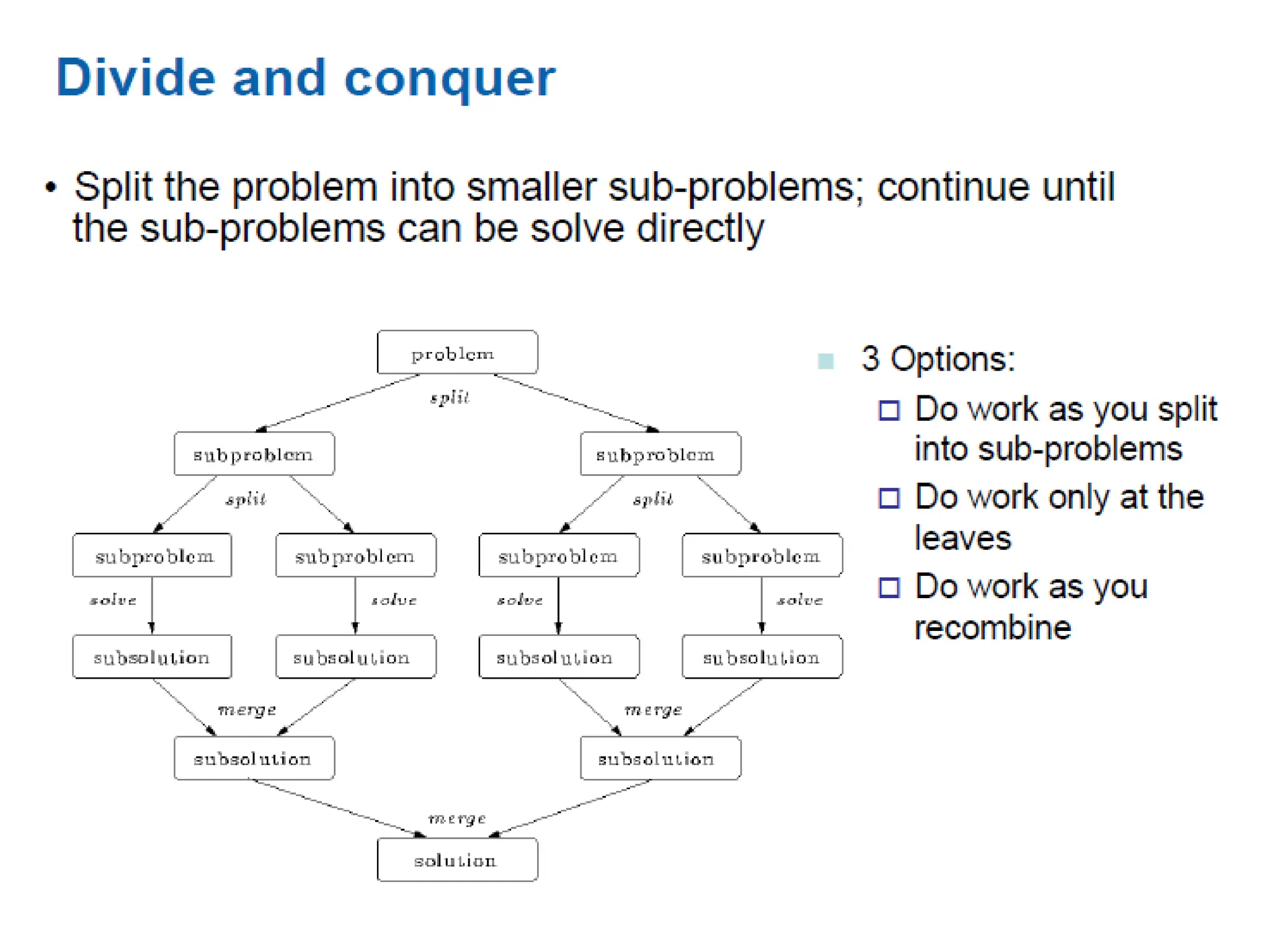
Divide and Conquer
•Divide and conquer is an important design pattern with two
distinct phases
– Use when a method to divide problem into sub-problems
and to recombine solutions of sub-problems into a global
solution is available.
• Divide phase:
– Breaks down problem into two or more sub-problems of the
same (or related) type
– Continue division until these sub-problems become simple
enough to be solved directly
• Conquer phase
– Executes the computations on each of the “indivisible” sub-
problems.
– May also combine solutions of sub-problems until the
solution of the original problem is reached.
30.
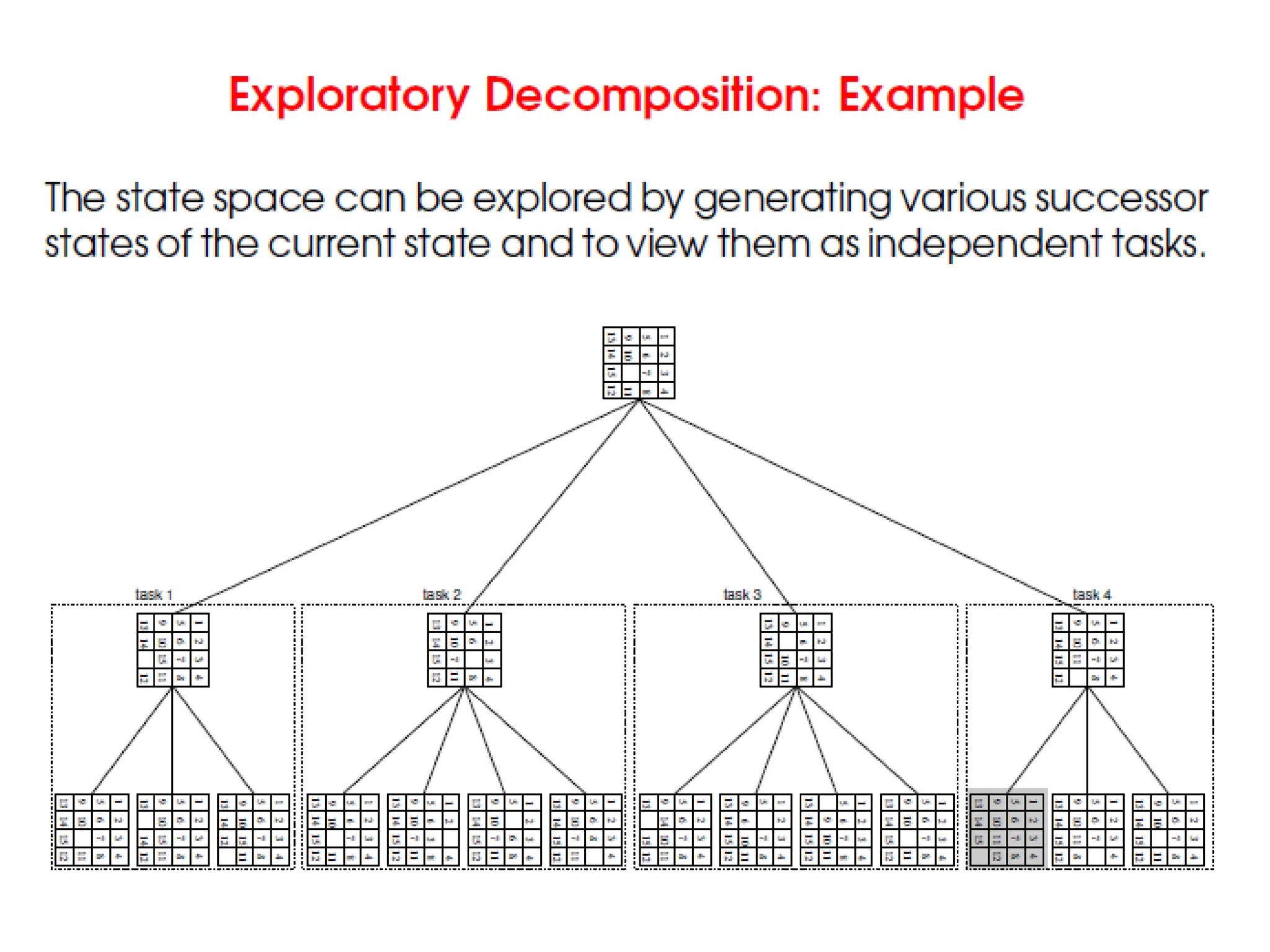
Exploratory Decomposition
• Inmany cases, the decomposition of the
problem goes hand in hand with its execution.
• These problems typically involve the
exploration (search) of a state space of
solutions.
• Problems in this category include a variety of
discrete optimization problem, theorem
proving, game playing, etc.
33.
Partition
Decompose problem intoprimitive tasks, maximizing
number of tasks that can execute concurrently
Communication
Determine communication
pattern among primitive
tasks, yielding task graph
with primitive tasks as
nodes and communication
channels as edges
Agglomeration
Combine groups of primitive tasks to form fewer but
larger tasks, thereby reducing communication
requirements (lower communication overhead)
Parallel Algorithm Design
Mapping
– Assign consolidated tasks to
processors, subject to tradeoffs between
communication costs (minimize) and
concurrency (maximize)
34.
Communication
• The tasksgenerated by a partition are intended to
execute concurrently but cannot, in general, execute
independently.
• The computation to be performed in one task will
typically require data associated with another task.
• Data must then be transferred between tasks so as to
allow computation to proceed. This information flow is
specified in the communication phase of a design.
• Determine communication pattern among primitive
tasks, yielding task graph with primitive tasks as nodes
and communication channels as edges
• Overhead in a parallel algorithm (not required in
sequential task)
35.
Agglomeration
• Combine groupsof primitive tasks to form fewer but larger tasks,
thereby reducing communication requirements (lower
communication overhead)
• Increasing the locality of parallel algorithm; lower communications
overhead
– Agglomerate primitive tasks that communicate with each other
– Eliminate communication because data values for primitive tasks are in memory of
consolidated task
• Combine groups of sending and receiving tasks
– Reduce the number of messages being sent
– Send fewer longer messages to reduce per message overhead (message latency)
• Maintain the scalability of parallel design
• Reduce the software engineering costs
36.
Mapping
• Processes arecollection of tasks with associated data.
• Goal: Assign consolidated tasks to processors, subject
to tradeoffs between communication costs (minimize)
and concurrency (maximize)
• Appropriate mapping of tasks to processes is critical to
the parallel performance of an algorithm.
• Task dependency graphs can be used to ensure that
work is equally spread across all processes at any point
(minimum idling and optimal load balance).
• Task interaction graphs can be used to make sure that
processes need minimum interaction with other
processes (minimum communication).
37.
• An appropriatemapping must minimize parallel execution
time by:
– Mapping independent tasks to different processes.
– Assigning tasks on critical path to processes as soon as they
become available.
– Minimizing interaction between processes by mapping tasks
with dense interactions to the same process.


























































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















