Downloaded 12 times



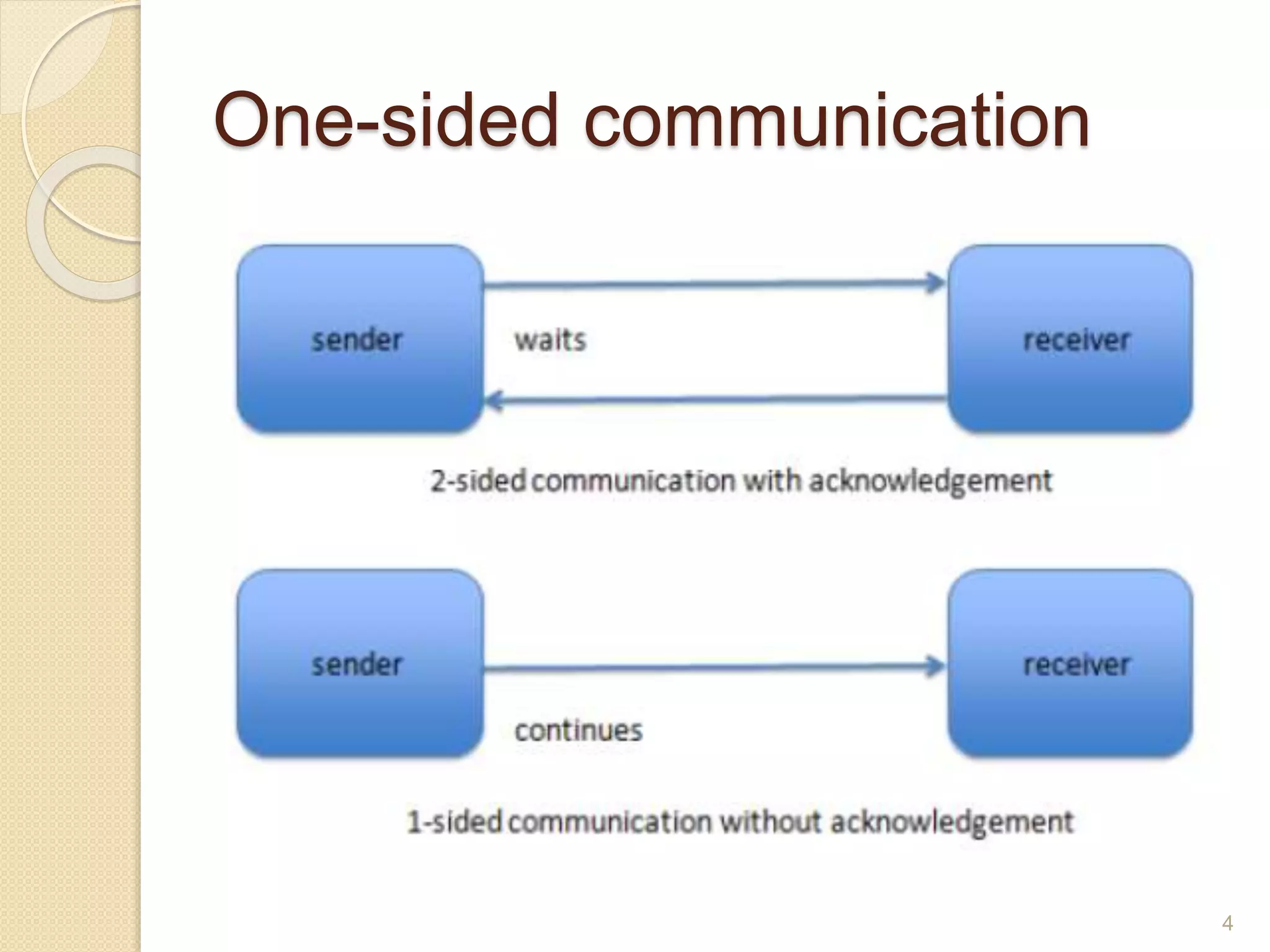


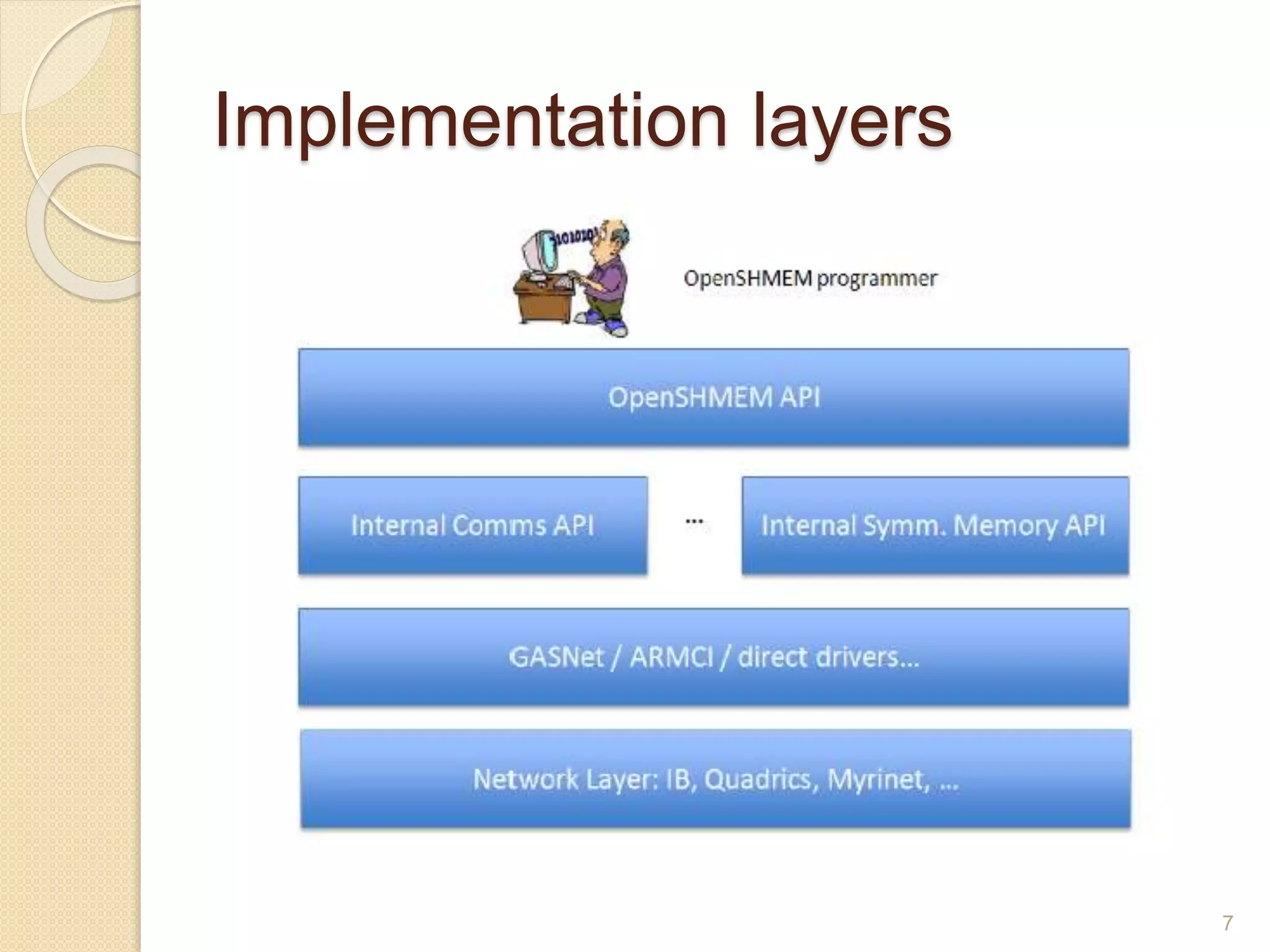





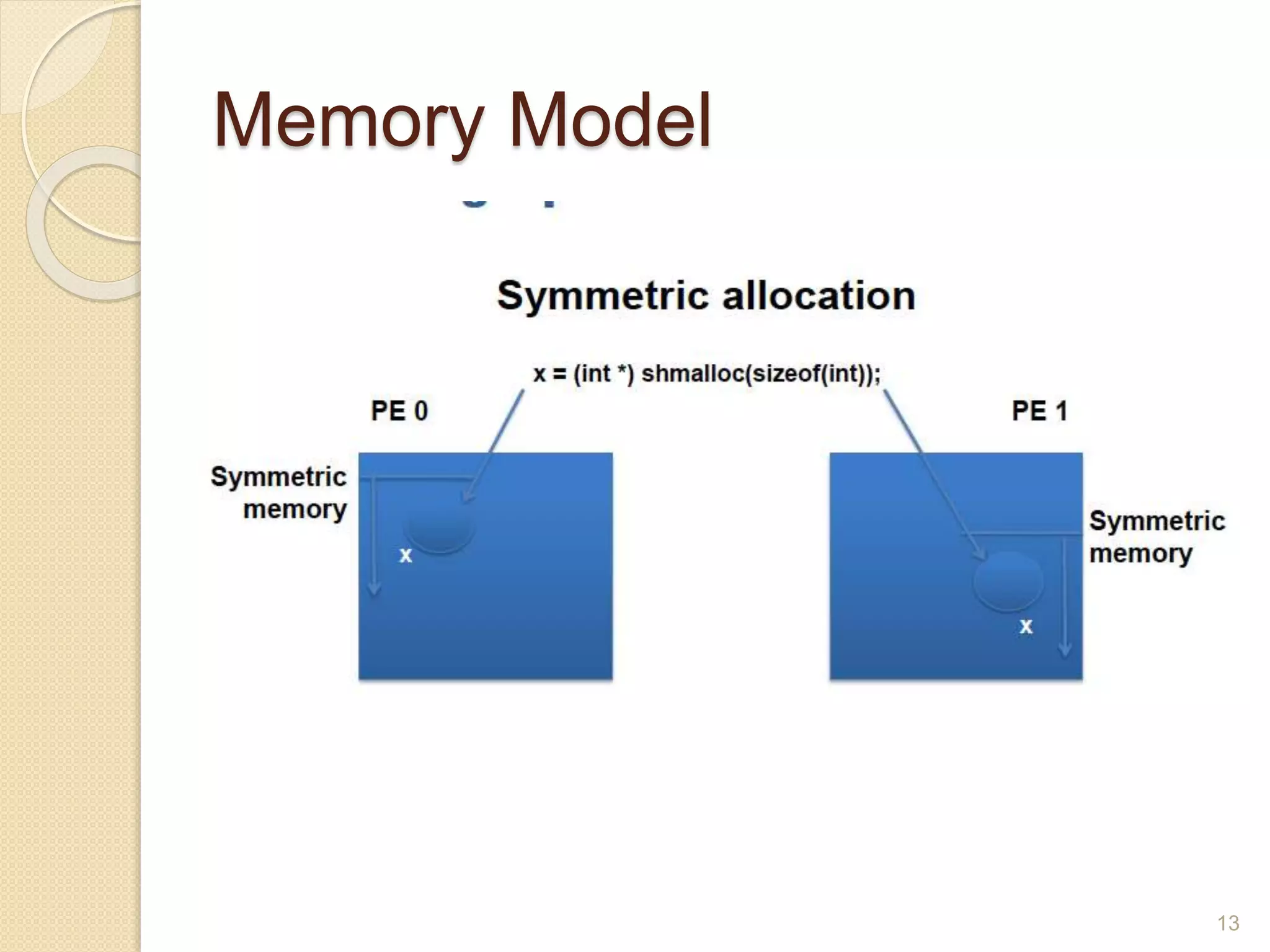
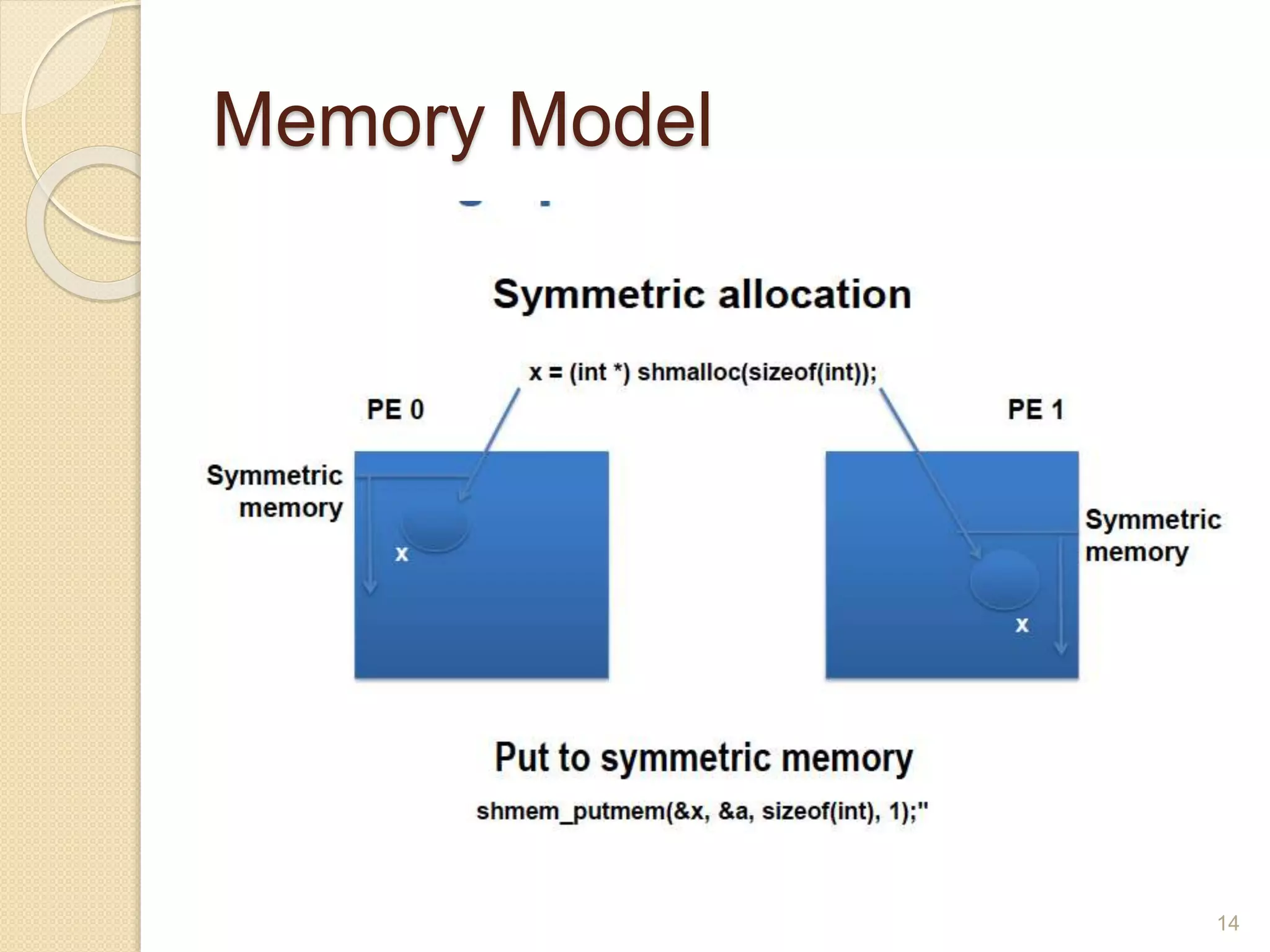
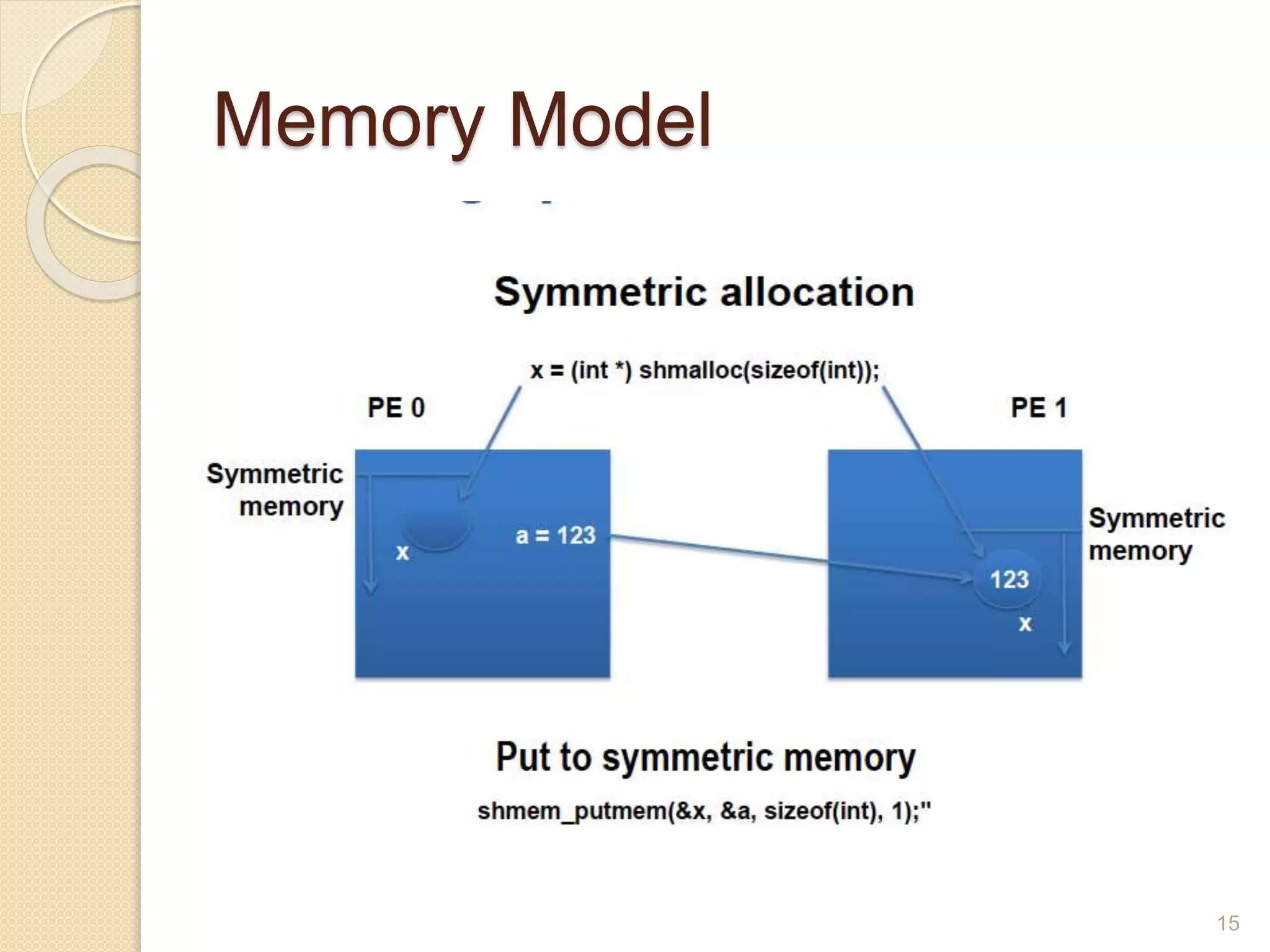







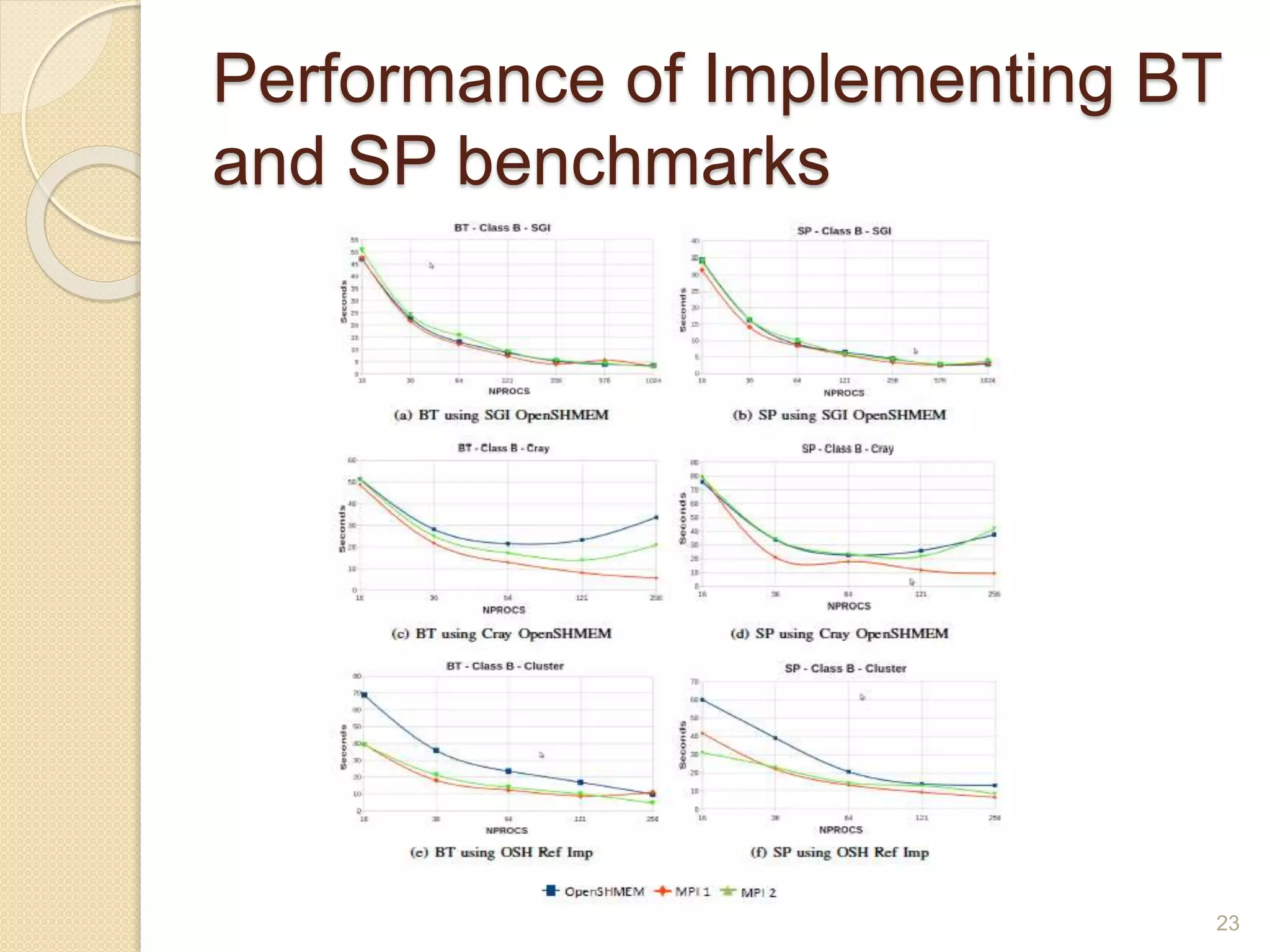








































OpenSHMEM is a library specification for PGAS-style programming that provides shared memory semantics across distributed memory systems. It defines a standardized API for one-sided communication, synchronization, atomic operations and collectives in C/C++ and Fortran. OpenSHMEM implementations exist for various platforms and can take advantage of hardware offload capabilities for high performance. It provides an alternative to MPI for programming large-scale parallel systems in a shared memory style.
























![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)

















































