Downloaded 270 times




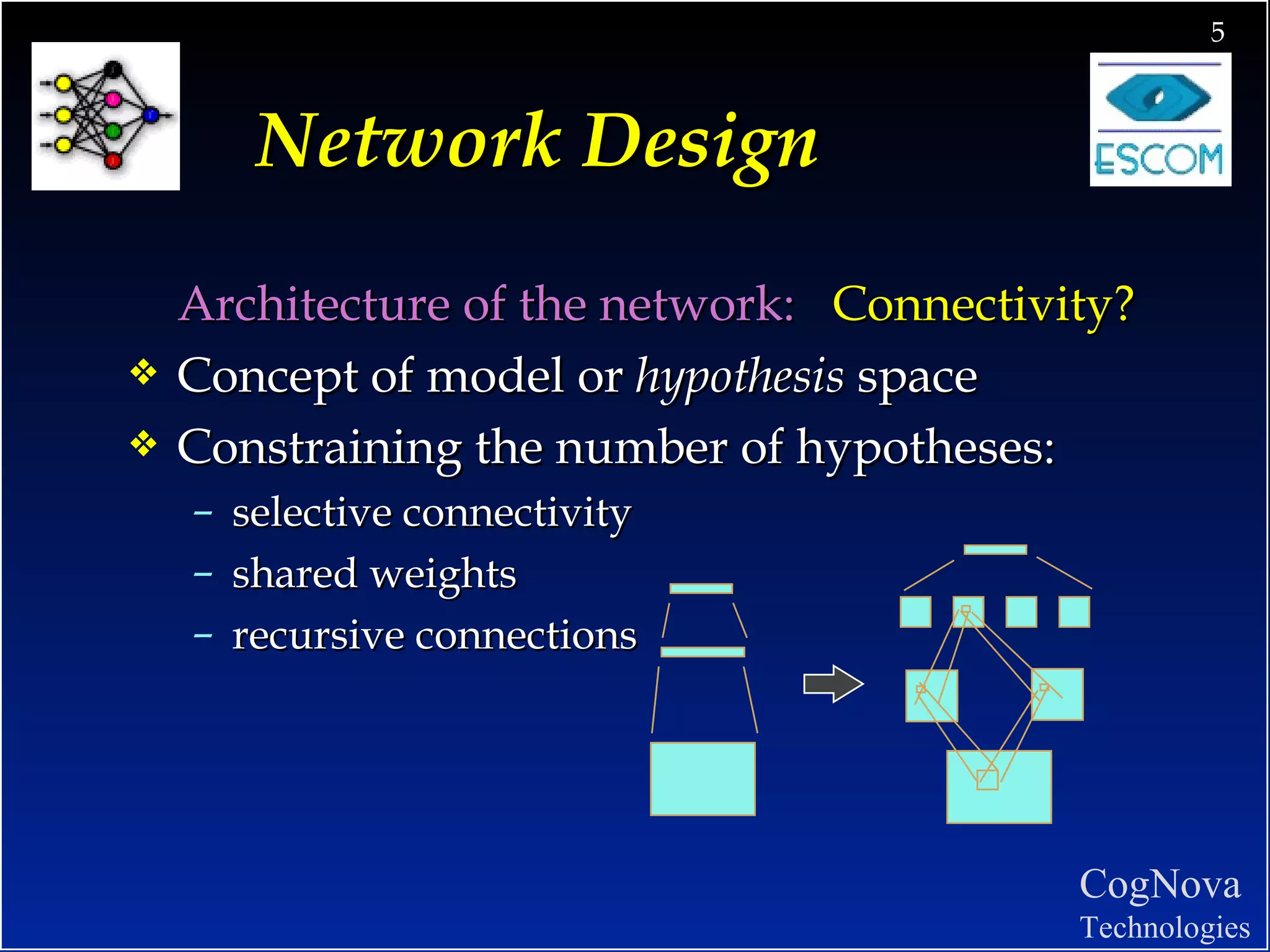
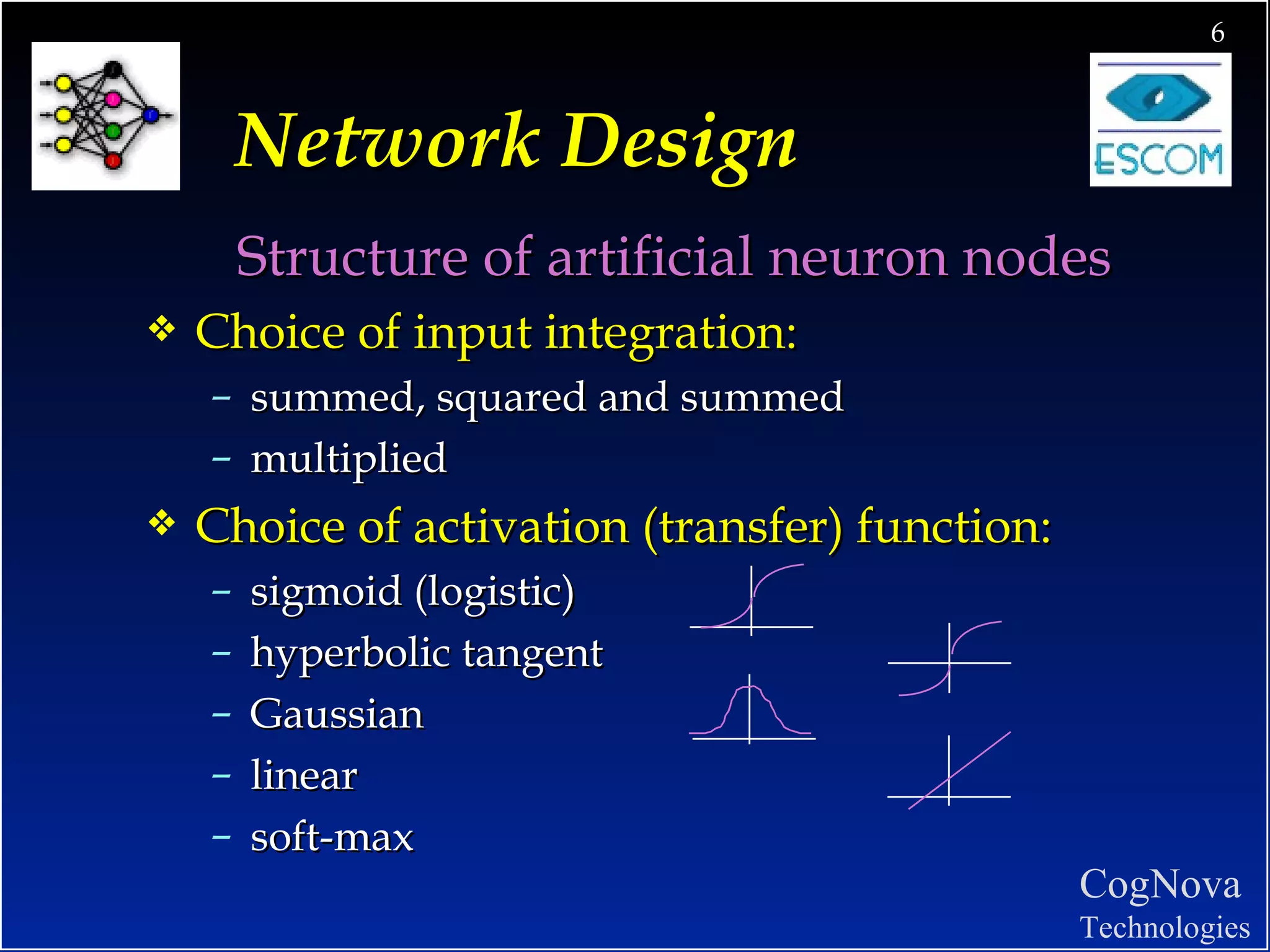




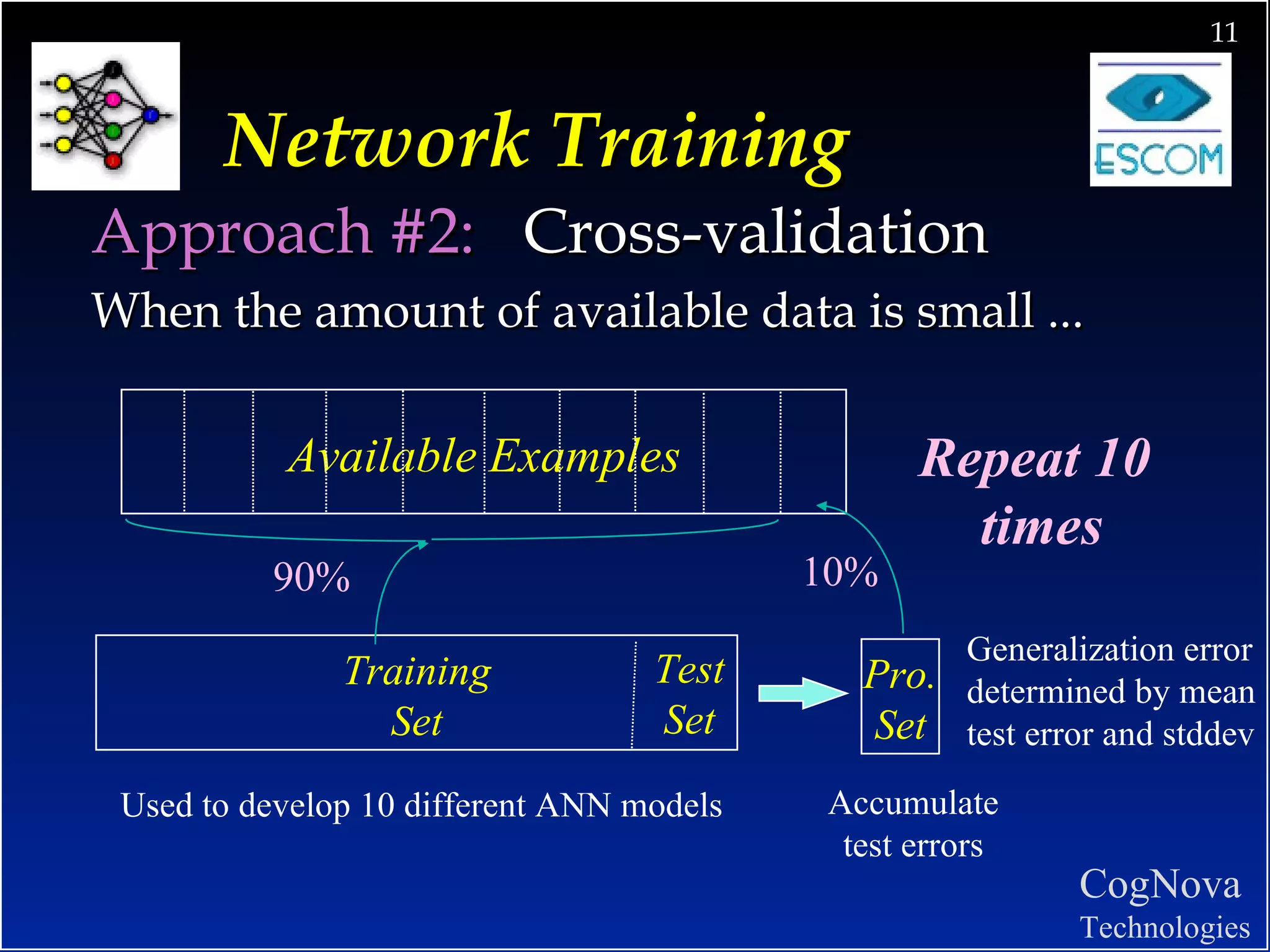















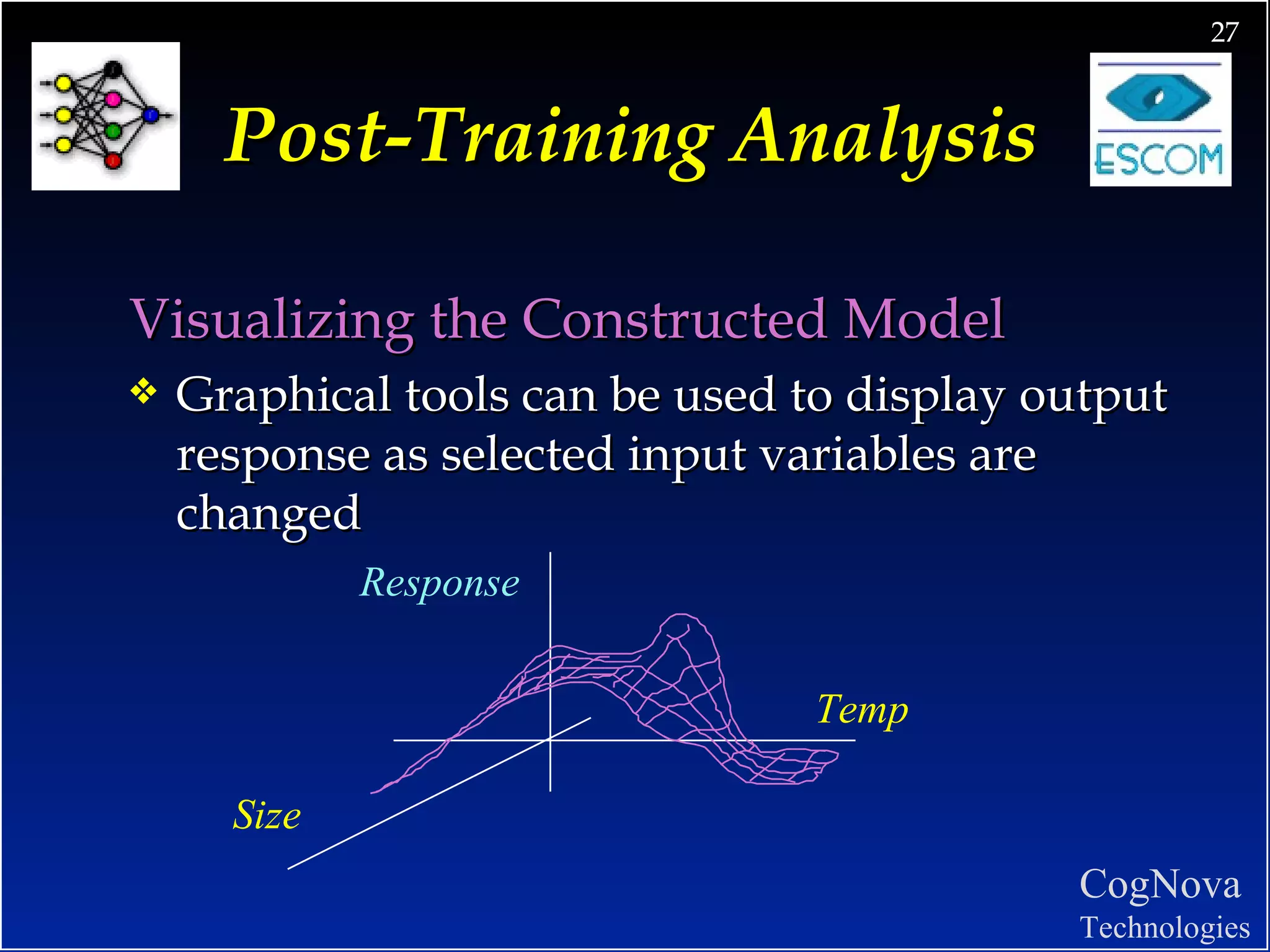


















































The document discusses network design and training issues for artificial neural networks. It covers architecture of the network including number of layers and nodes, learning rules, and ensuring optimal training. It also discusses data preparation including consolidation, selection, preprocessing, transformation and encoding of data before training the network.














































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)


























































