Downloaded 31 times



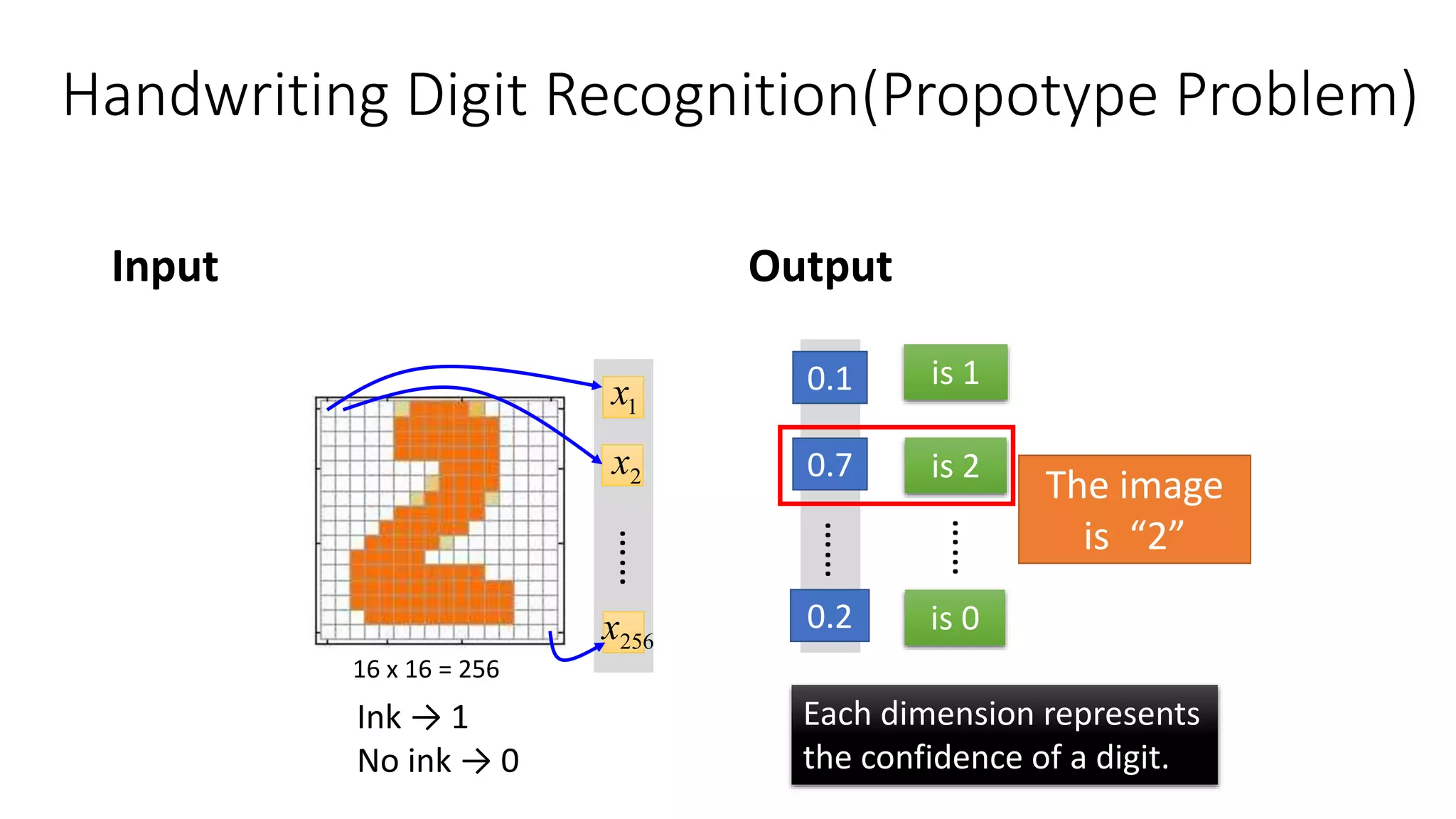
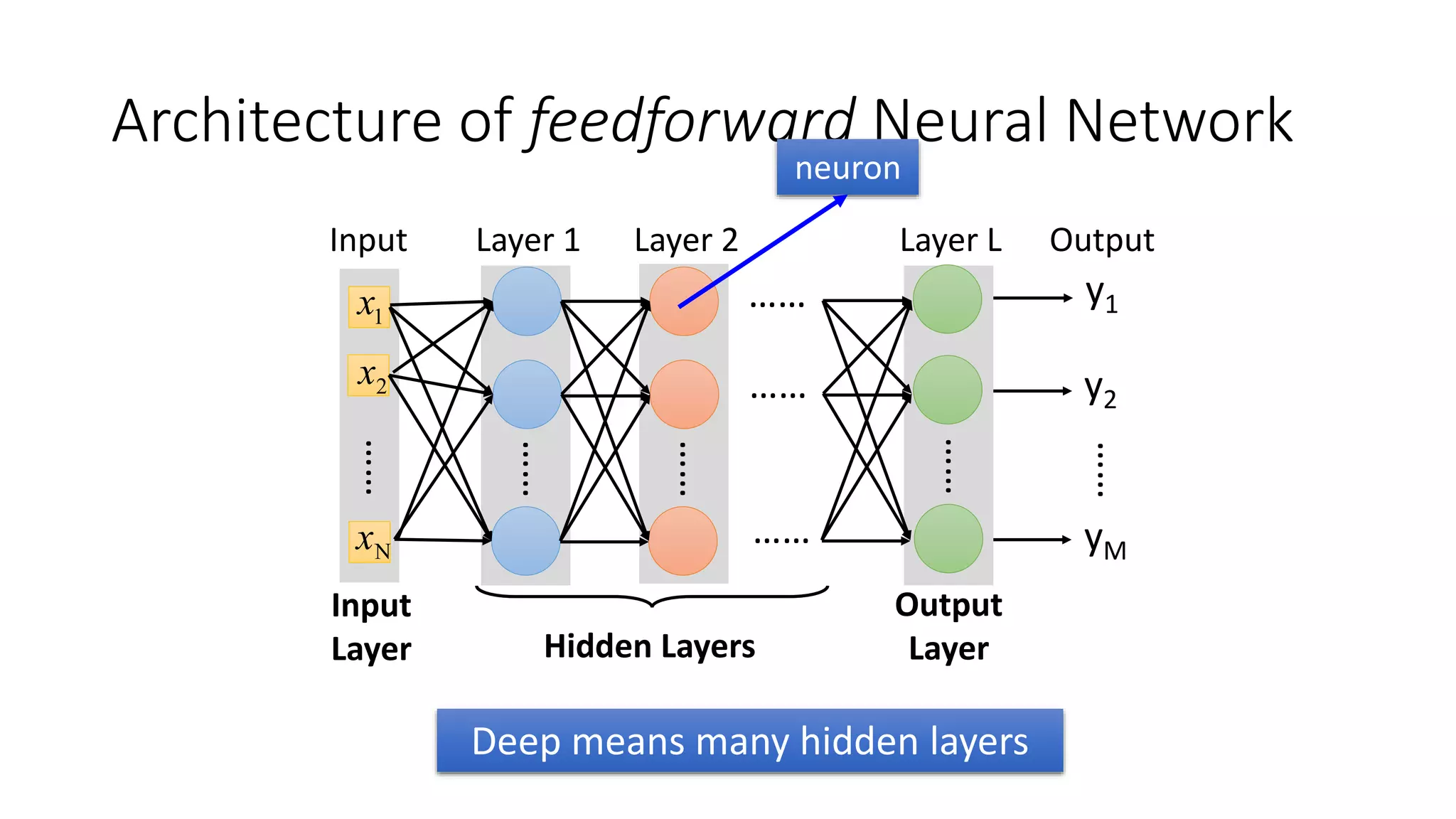
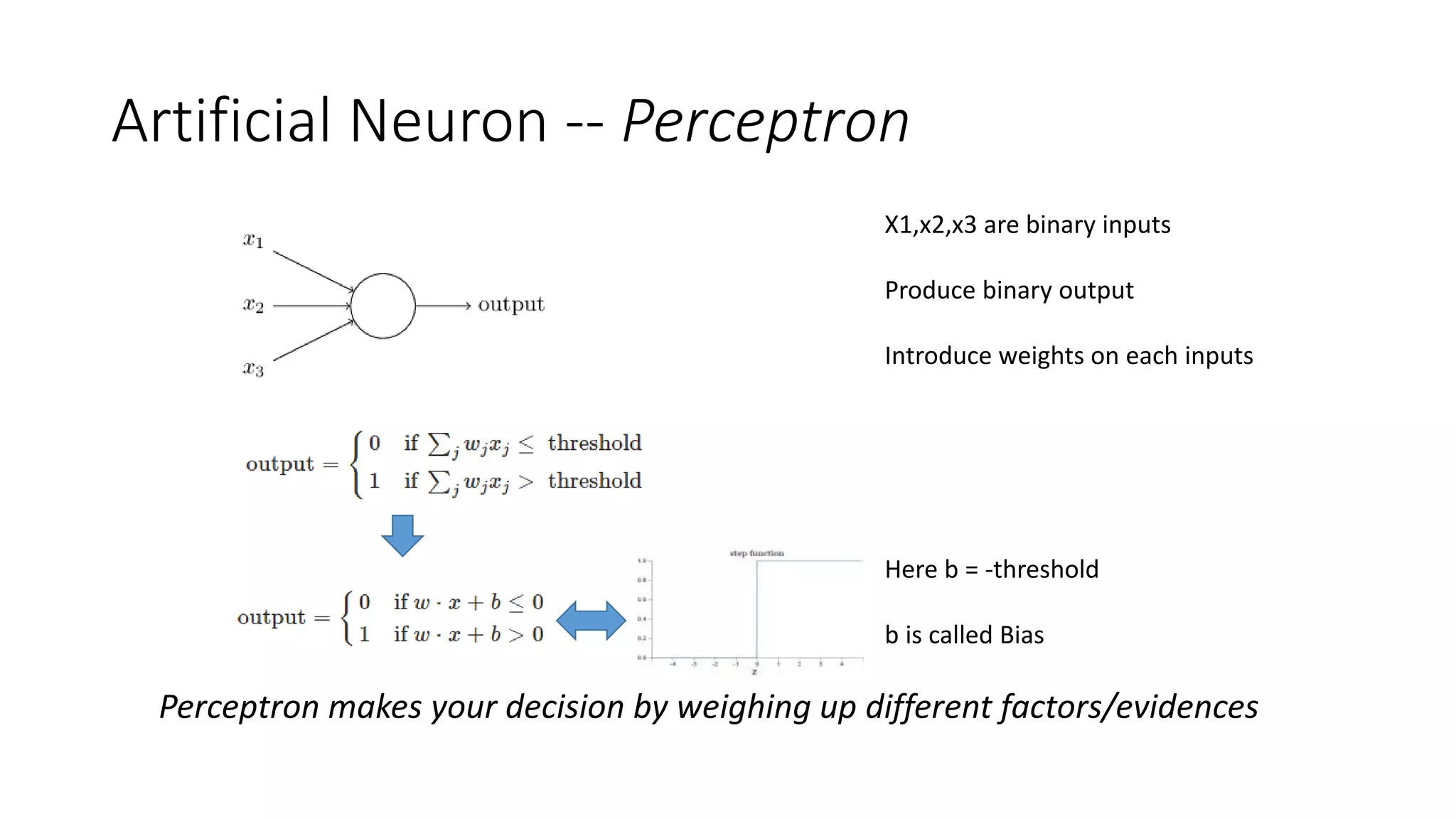




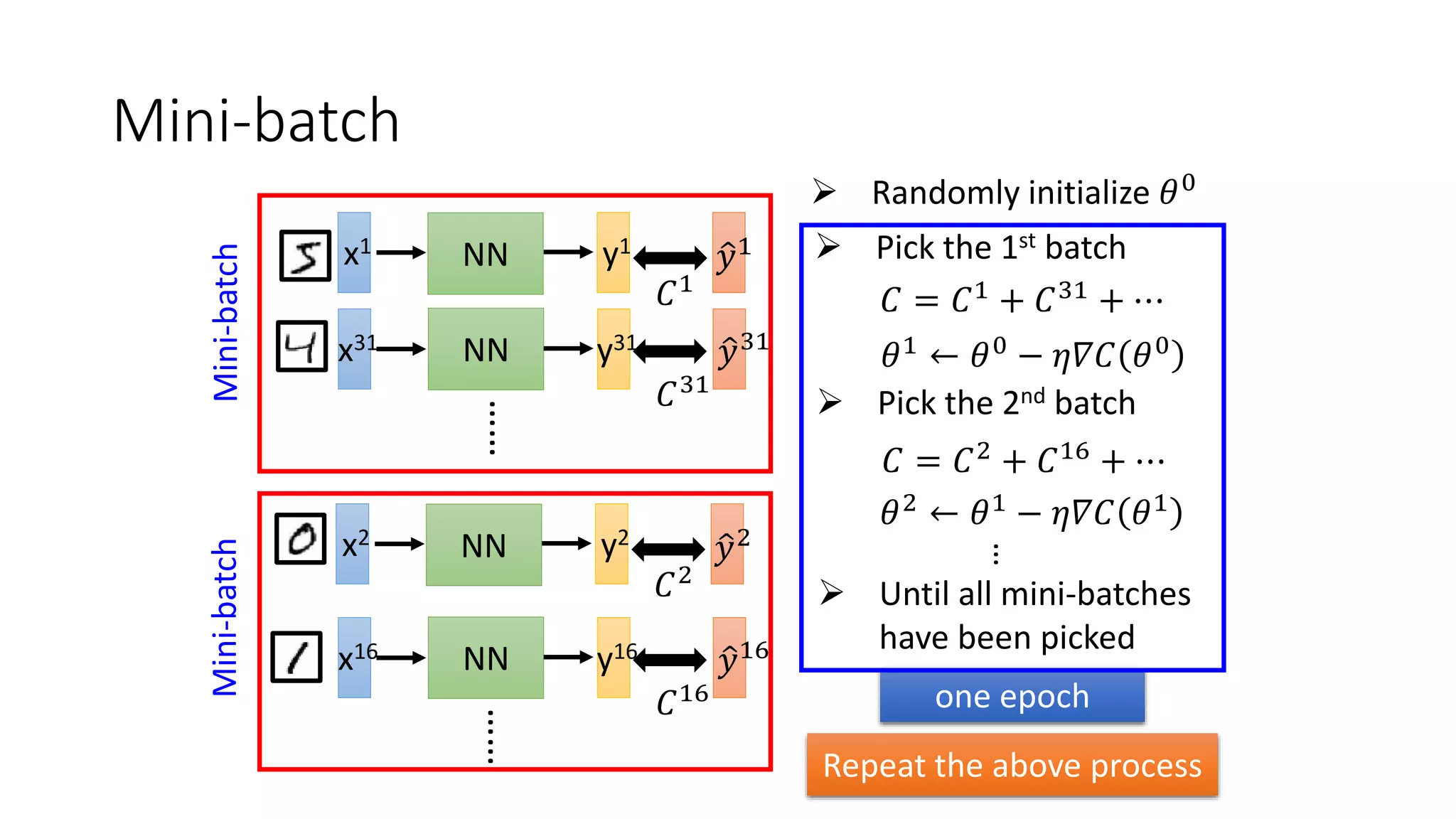


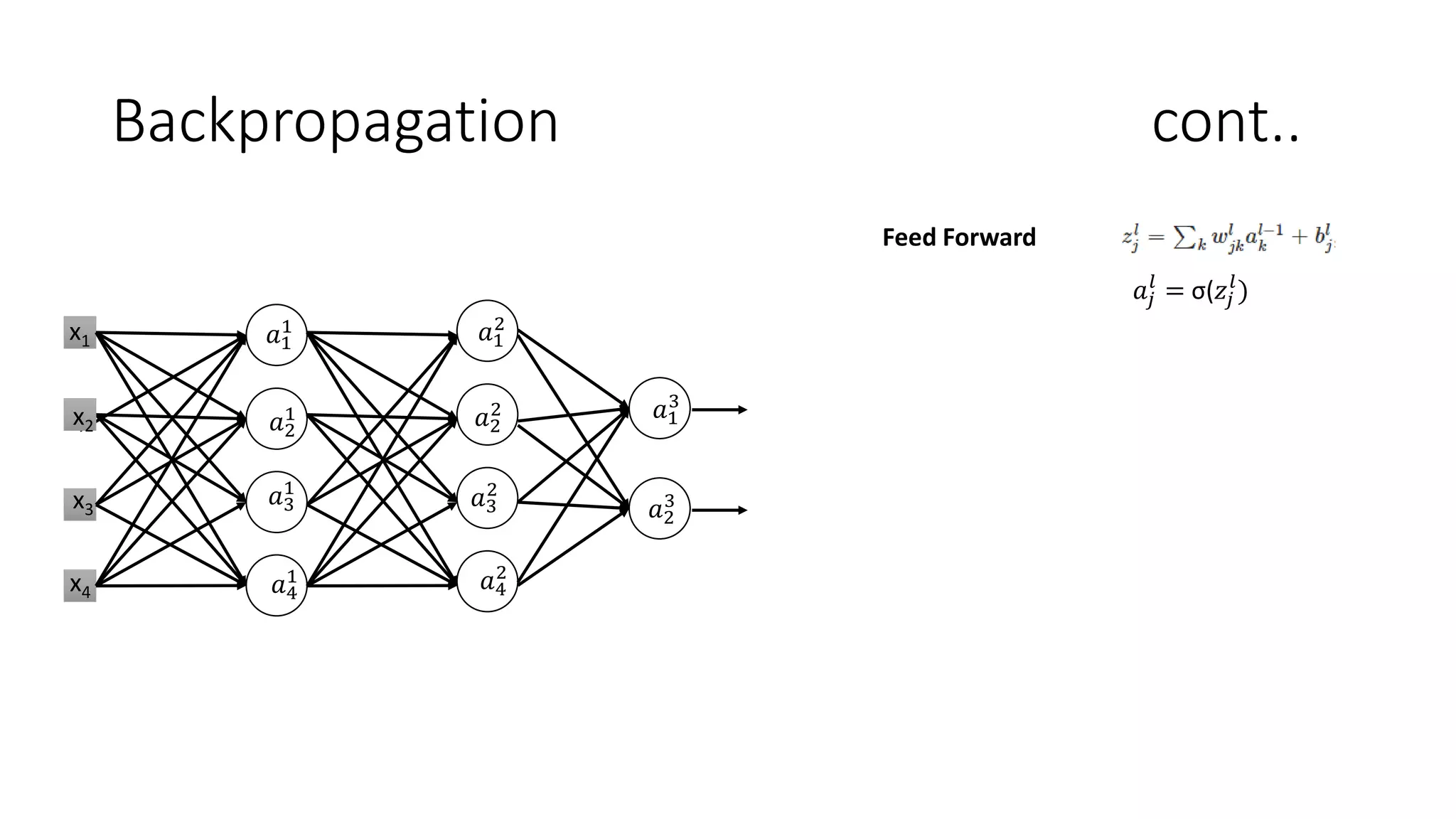
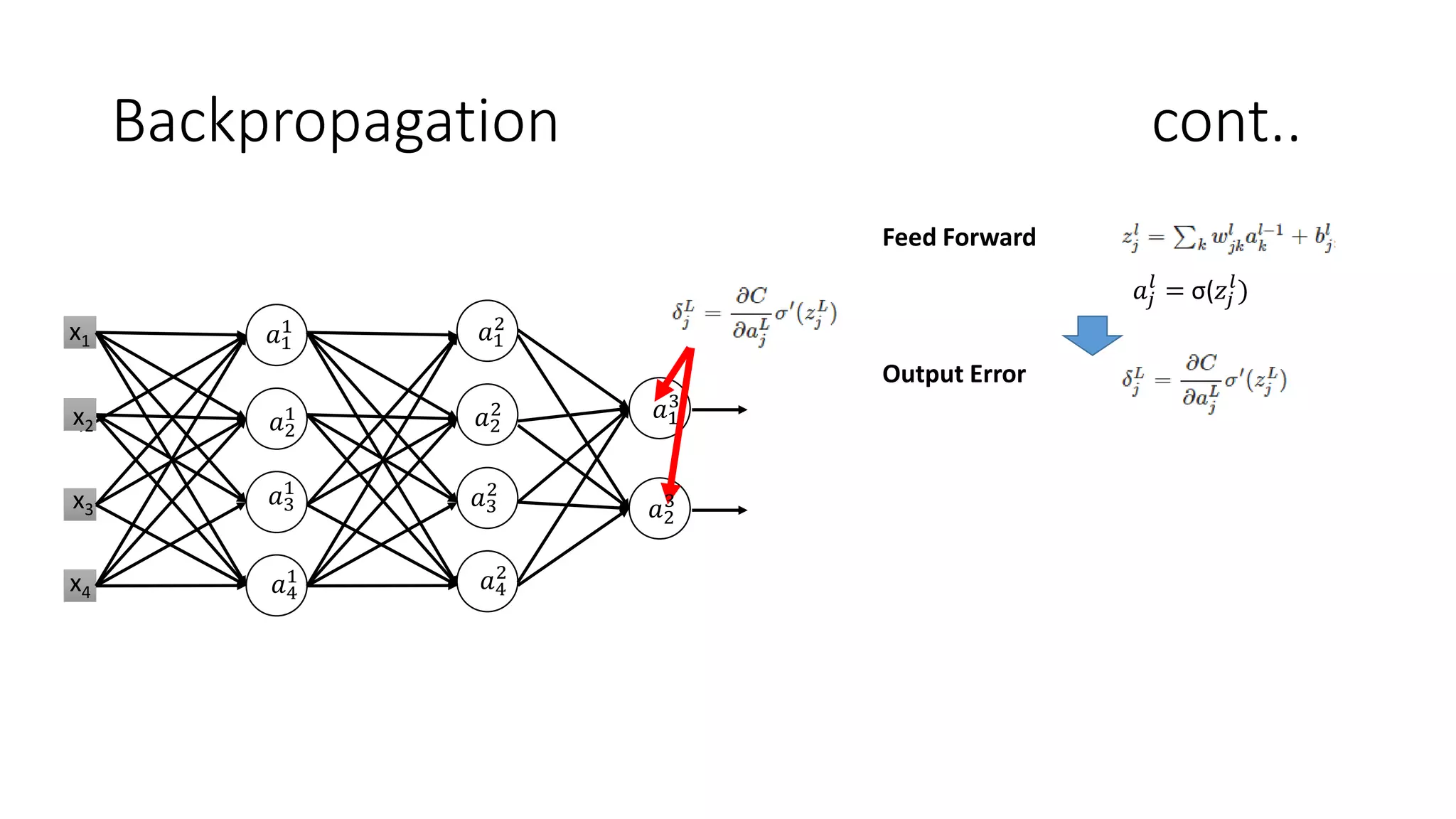
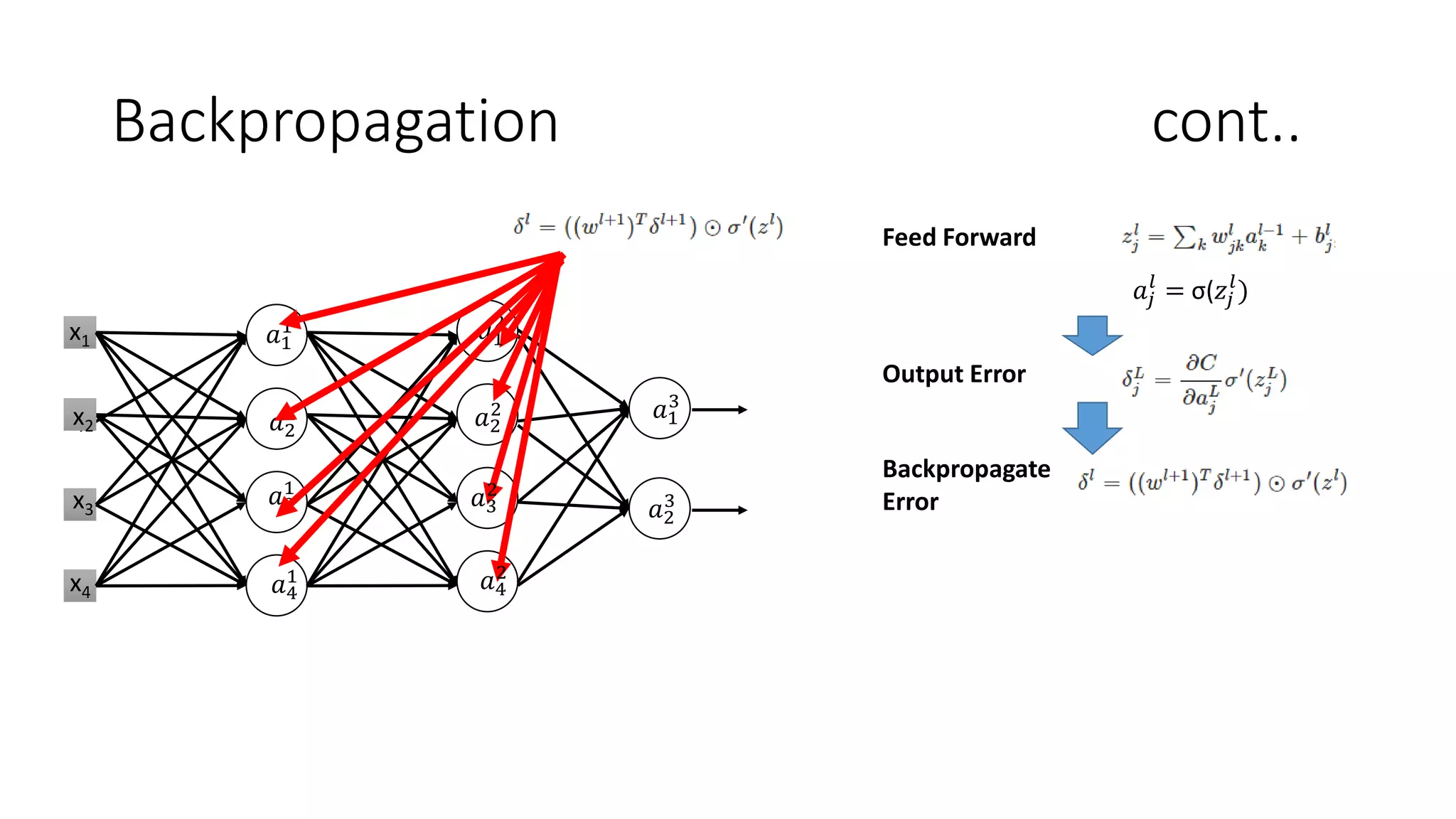
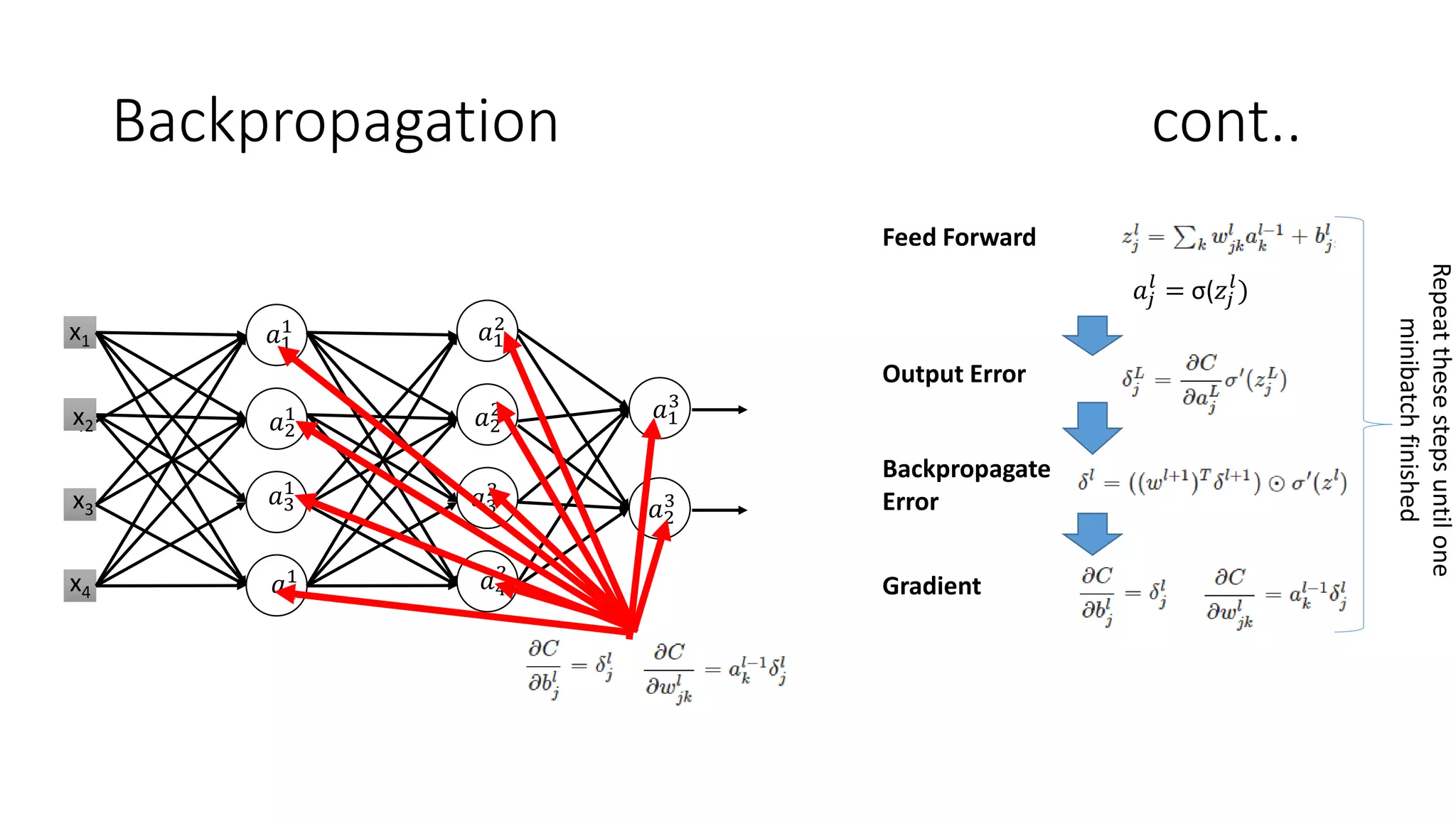
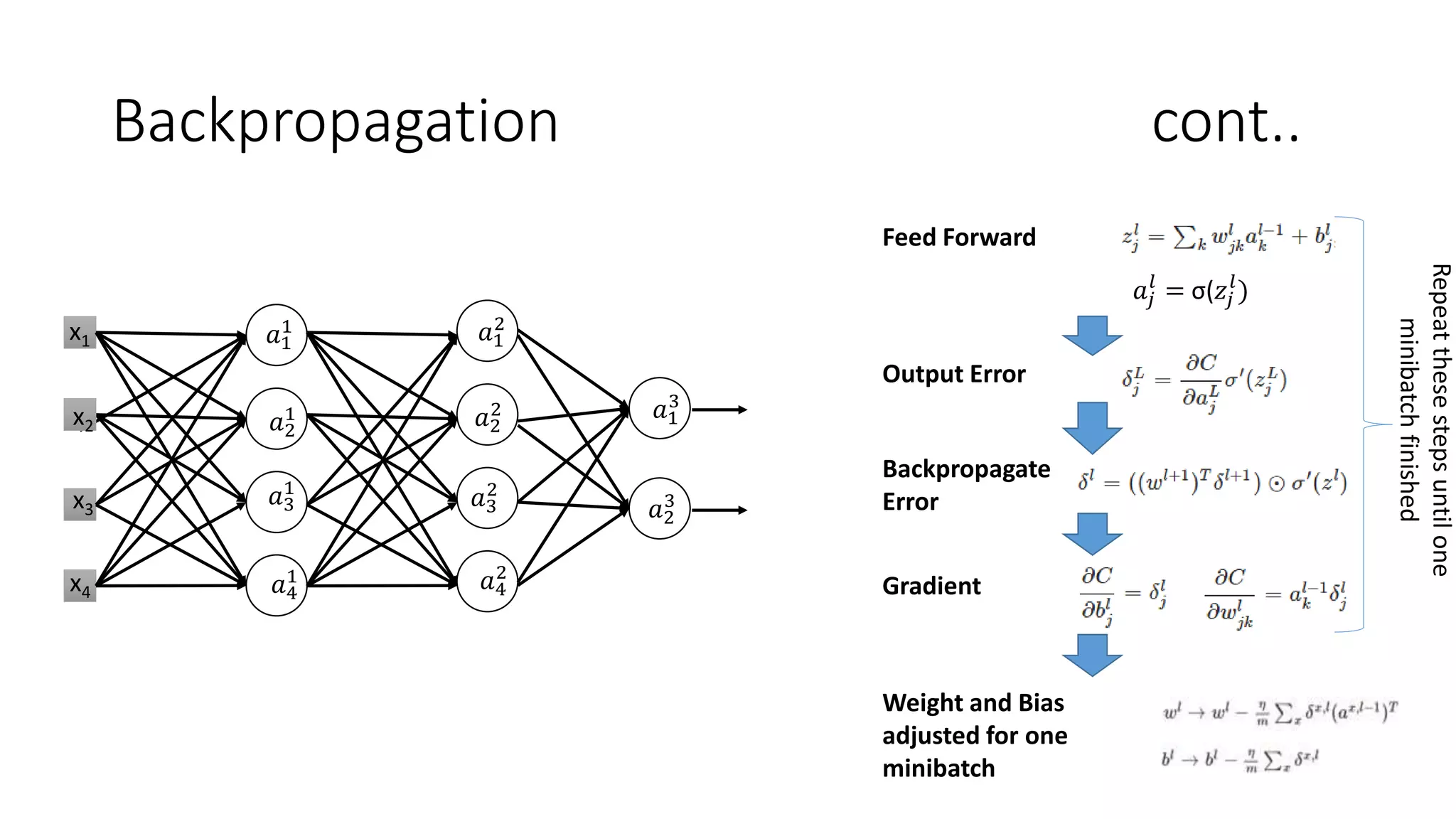






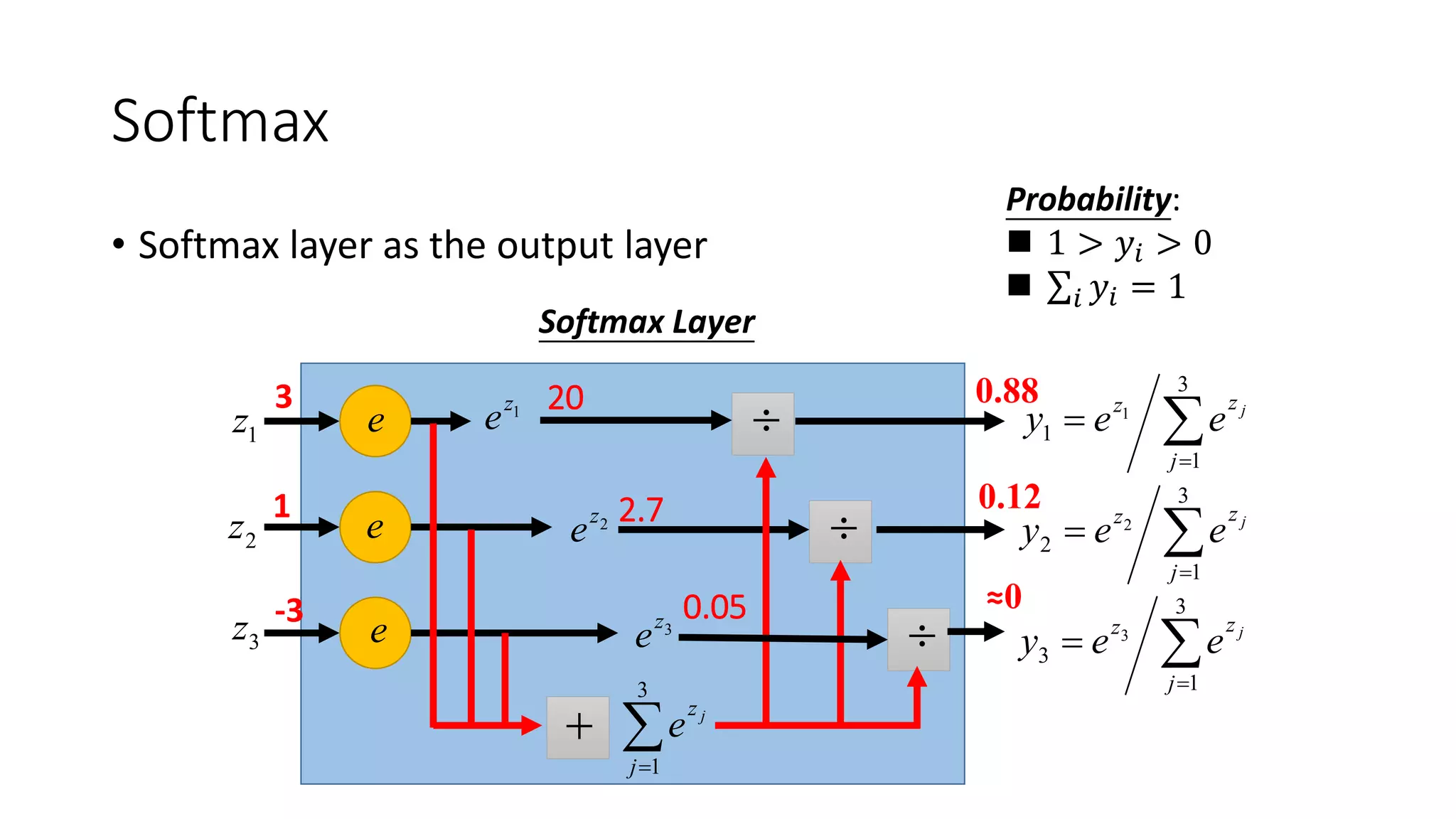




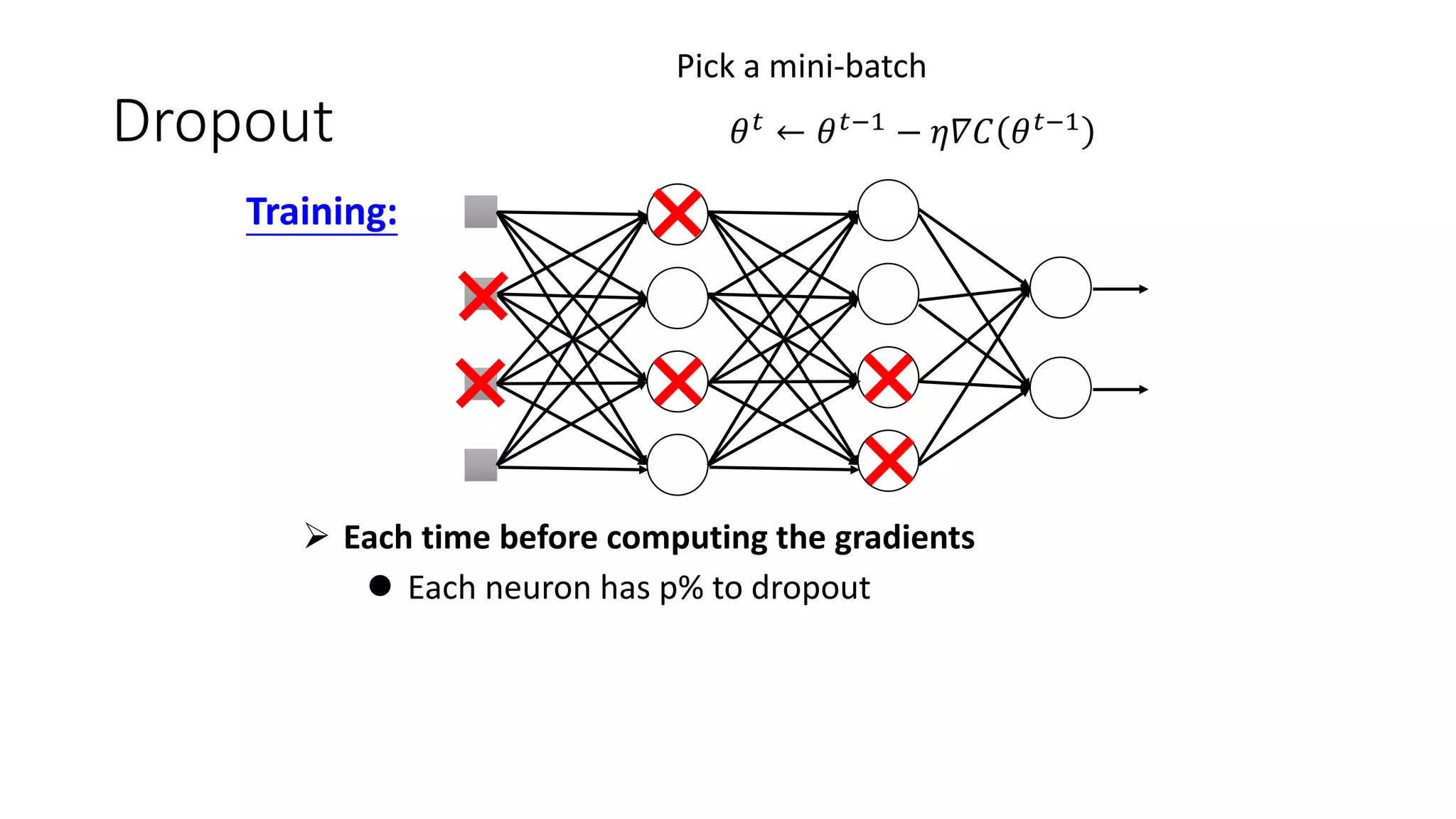
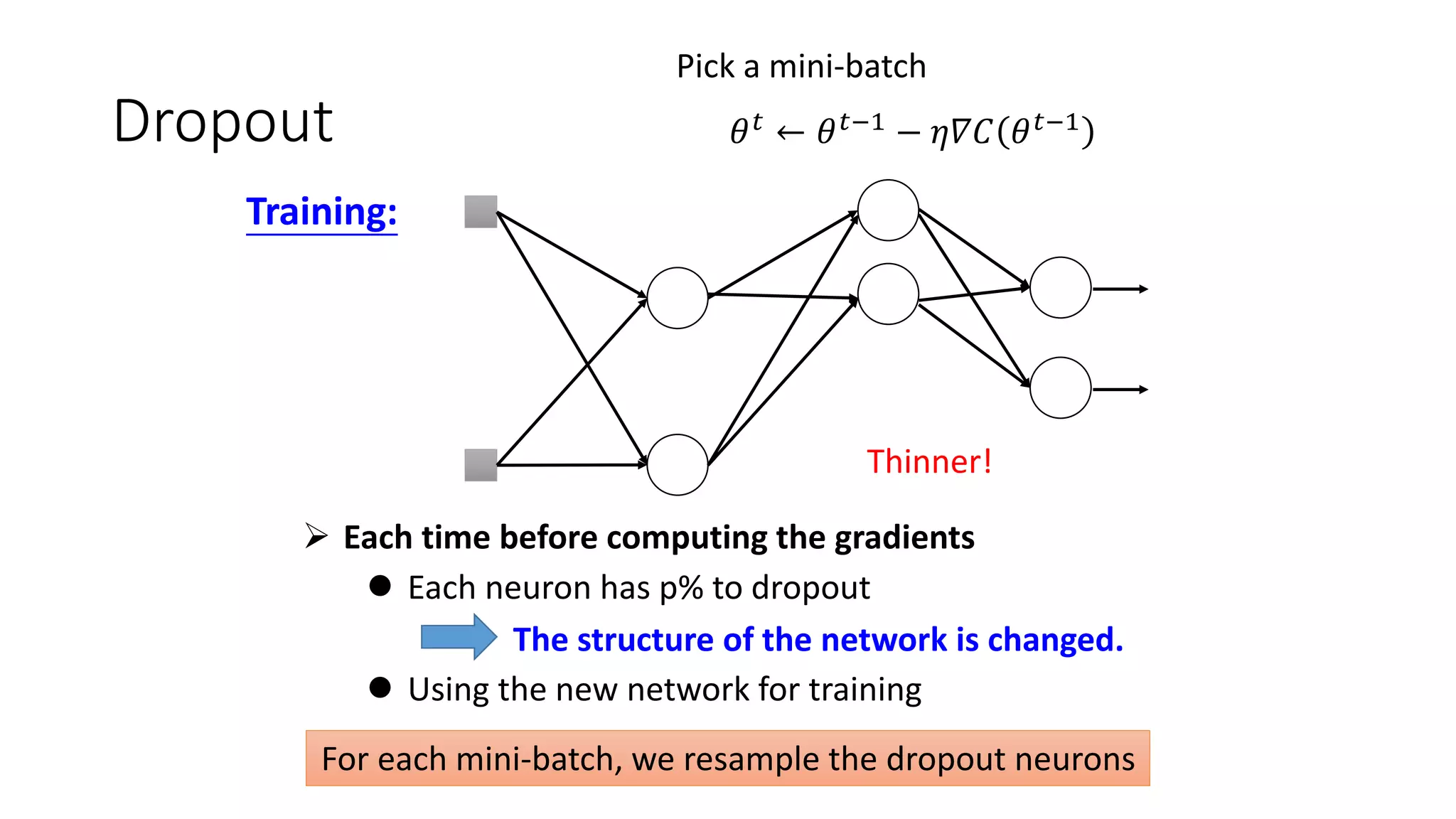
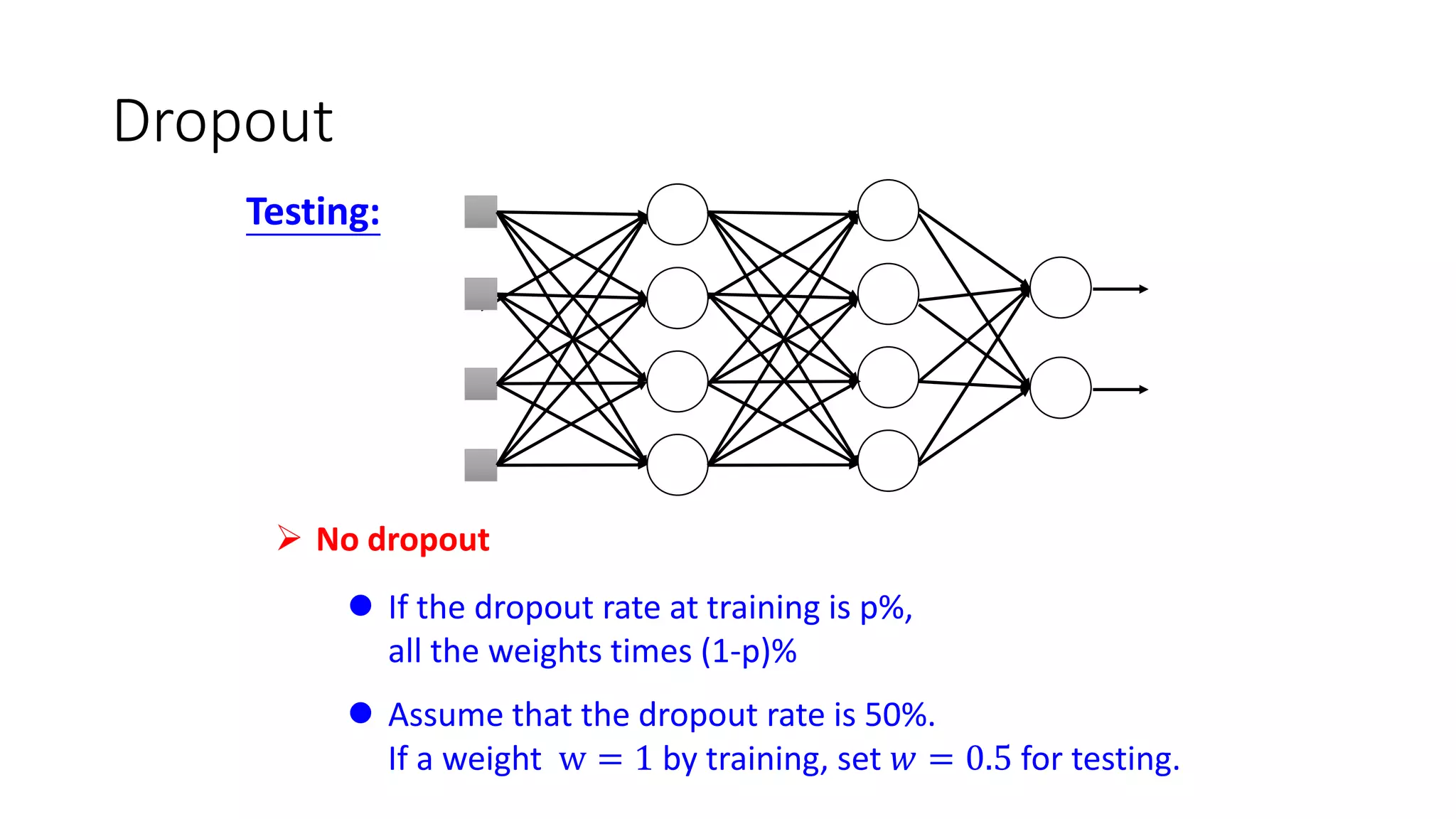
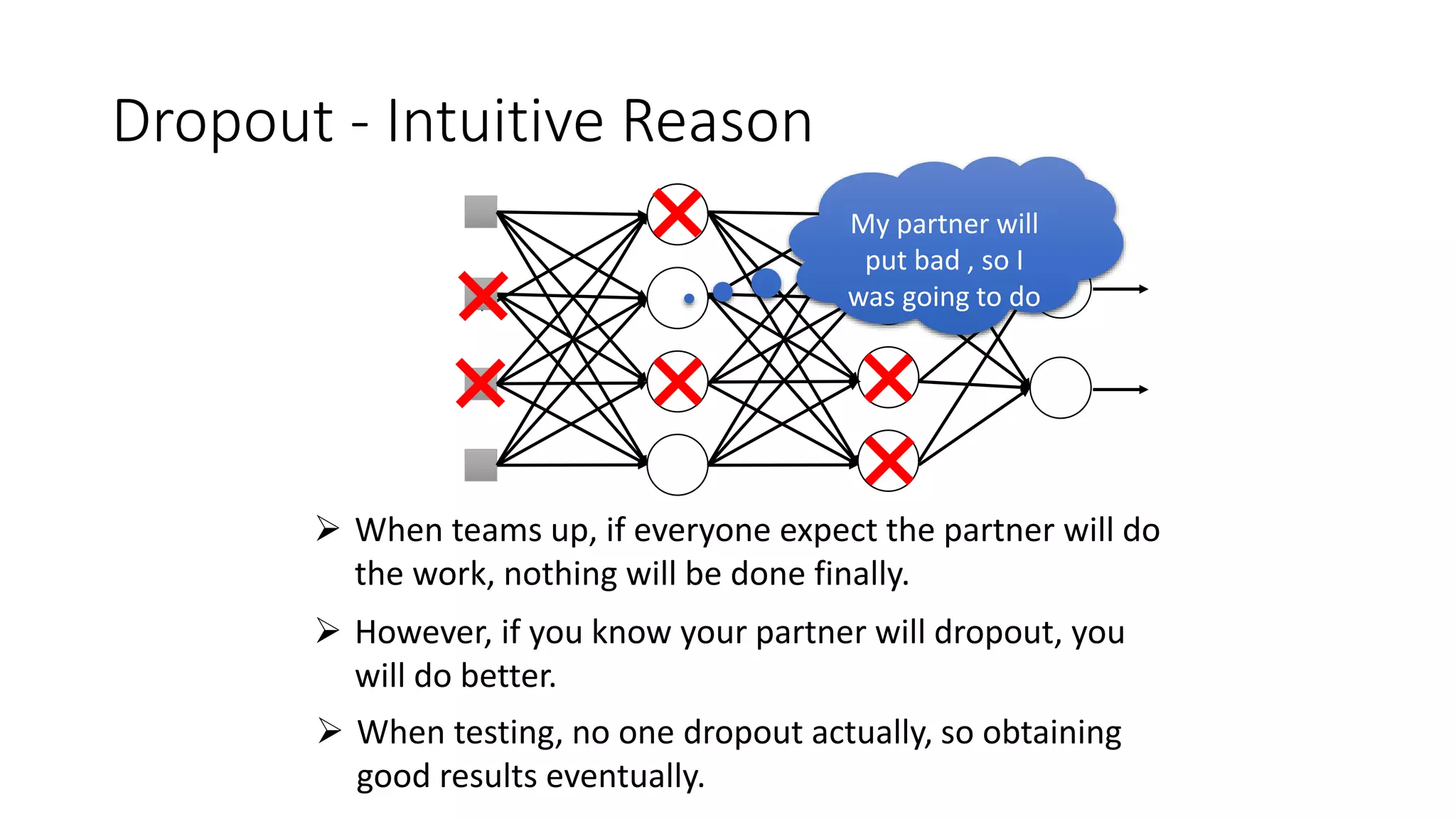

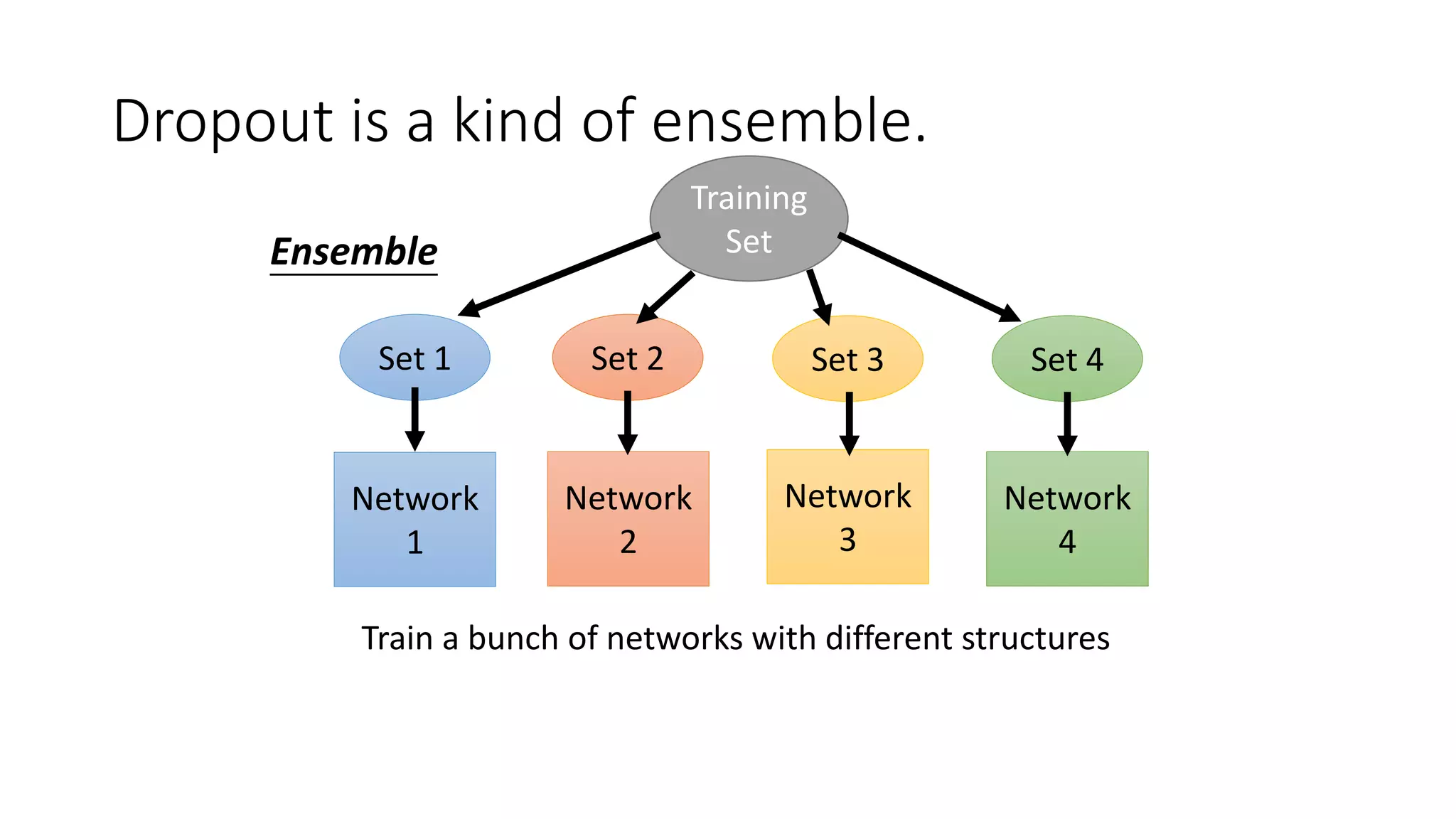






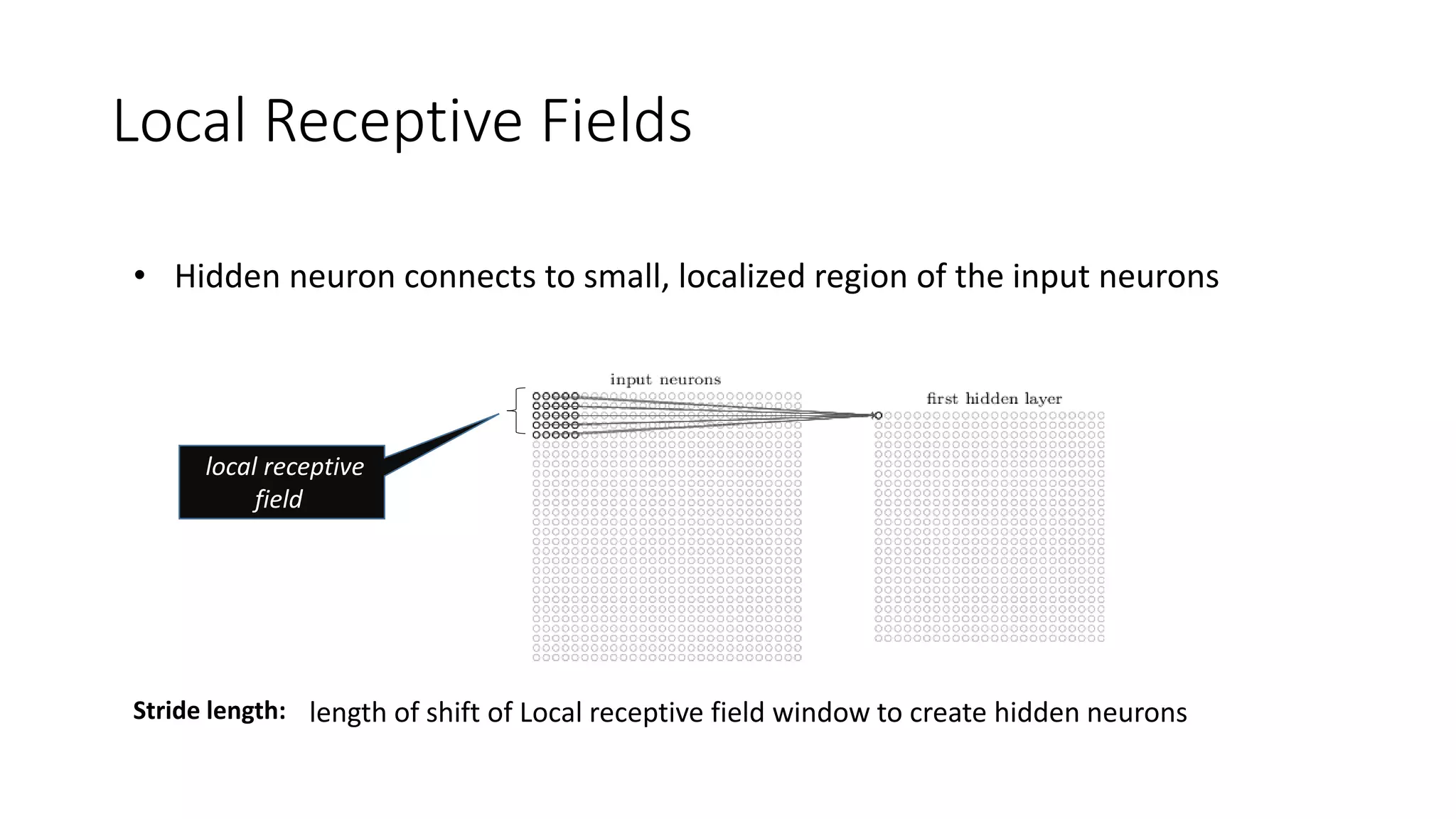


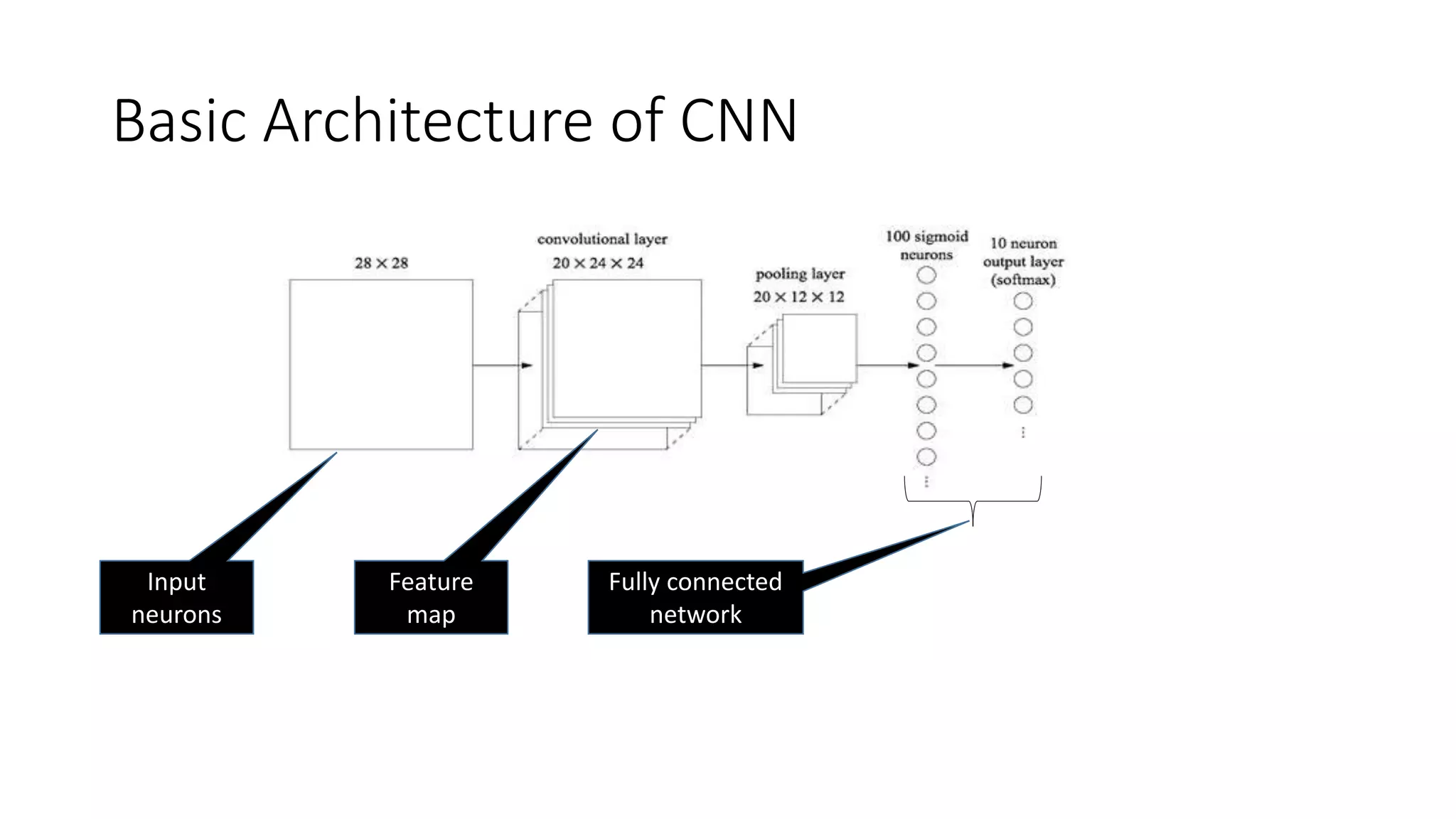

































































Deep learning tools and techniques can be used to build convolutional neural networks (CNNs). Neural networks learn from observational training data by automatically inferring rules to solve problems. Neural networks use multiple hidden layers of artificial neurons to process input data and produce output. Techniques like backpropagation, cross-entropy cost functions, softmax activations, and regularization help neural networks learn more effectively and avoid issues like overfitting.



































































