Downloaded 13 times


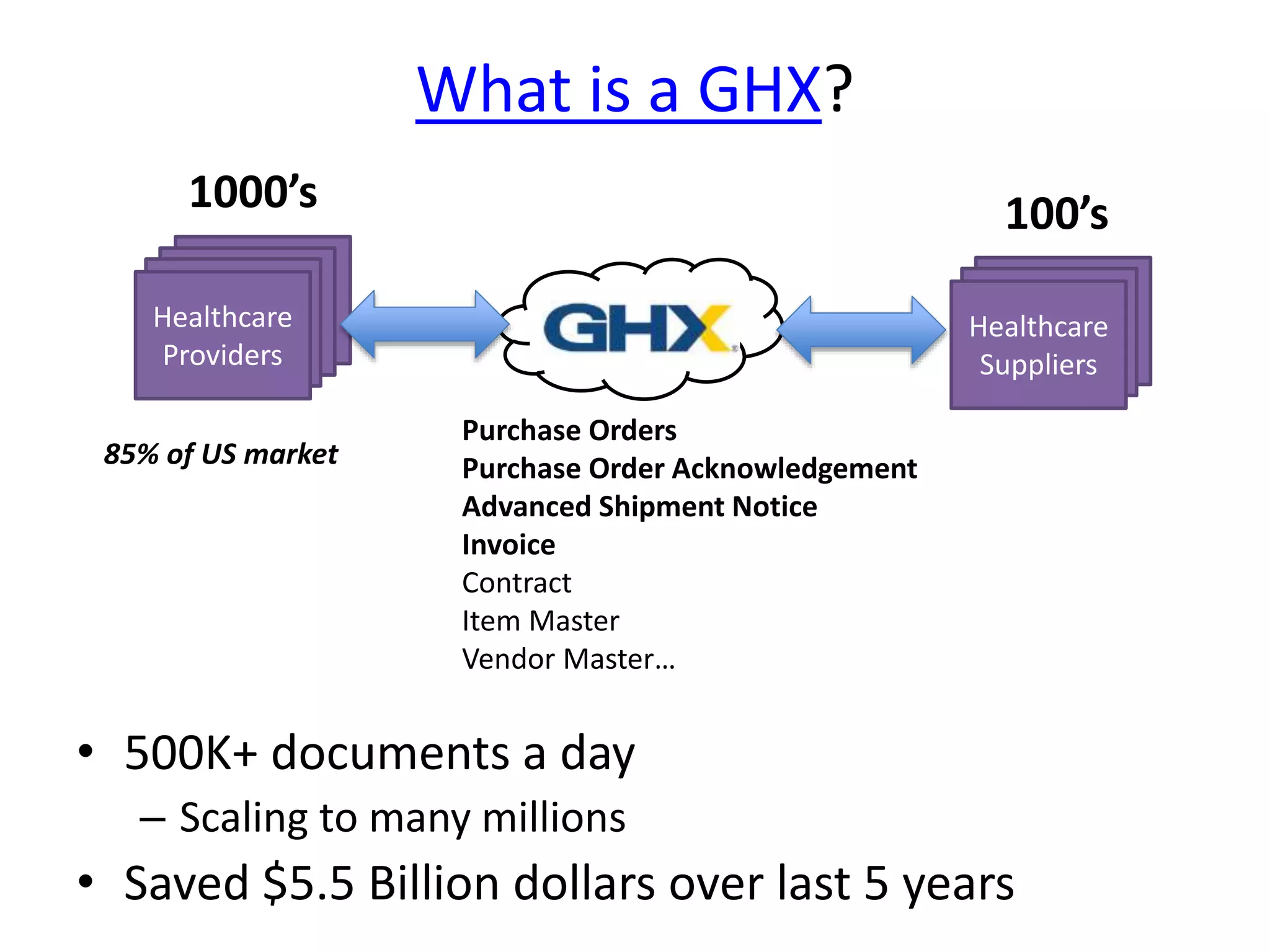






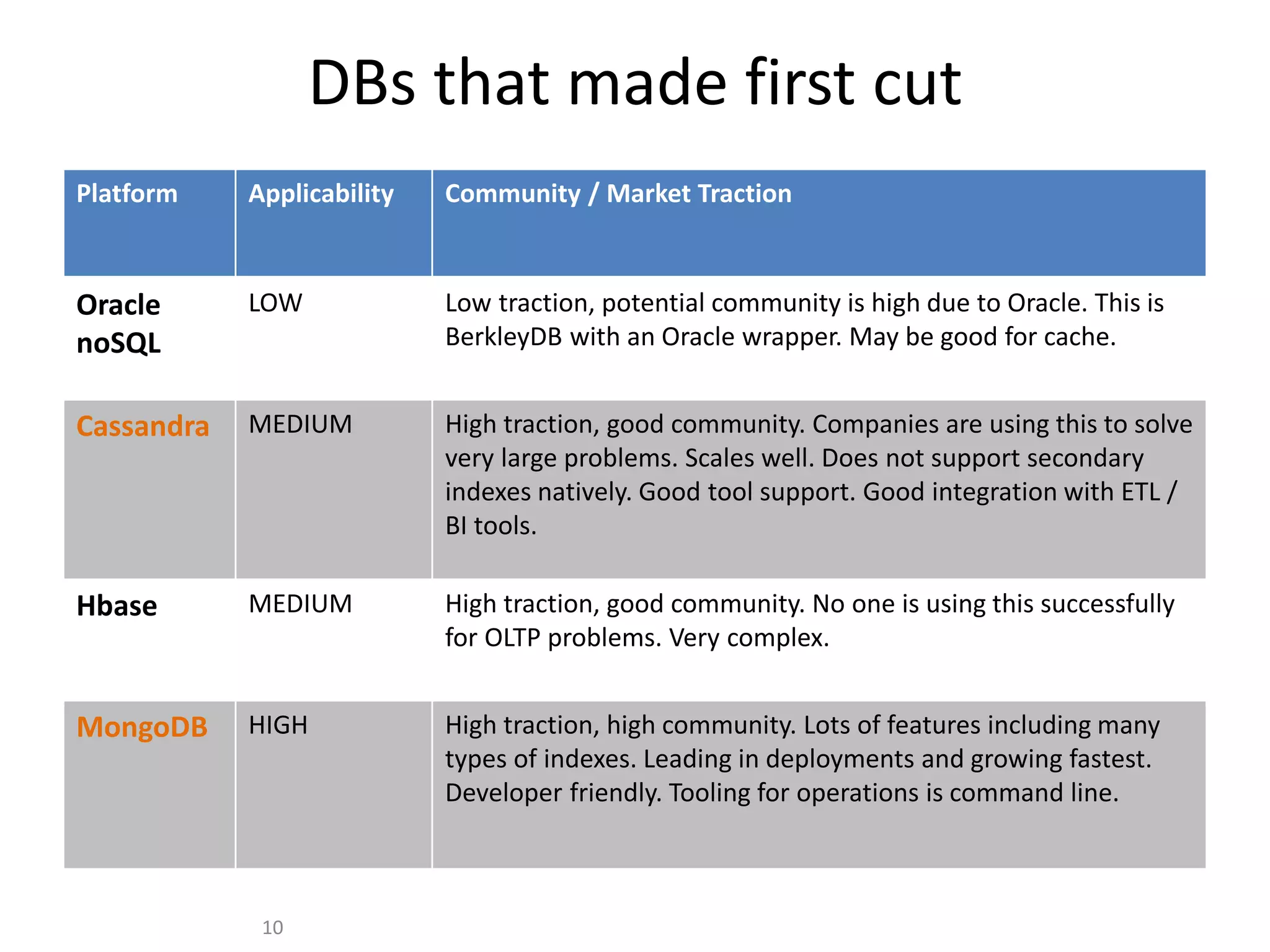



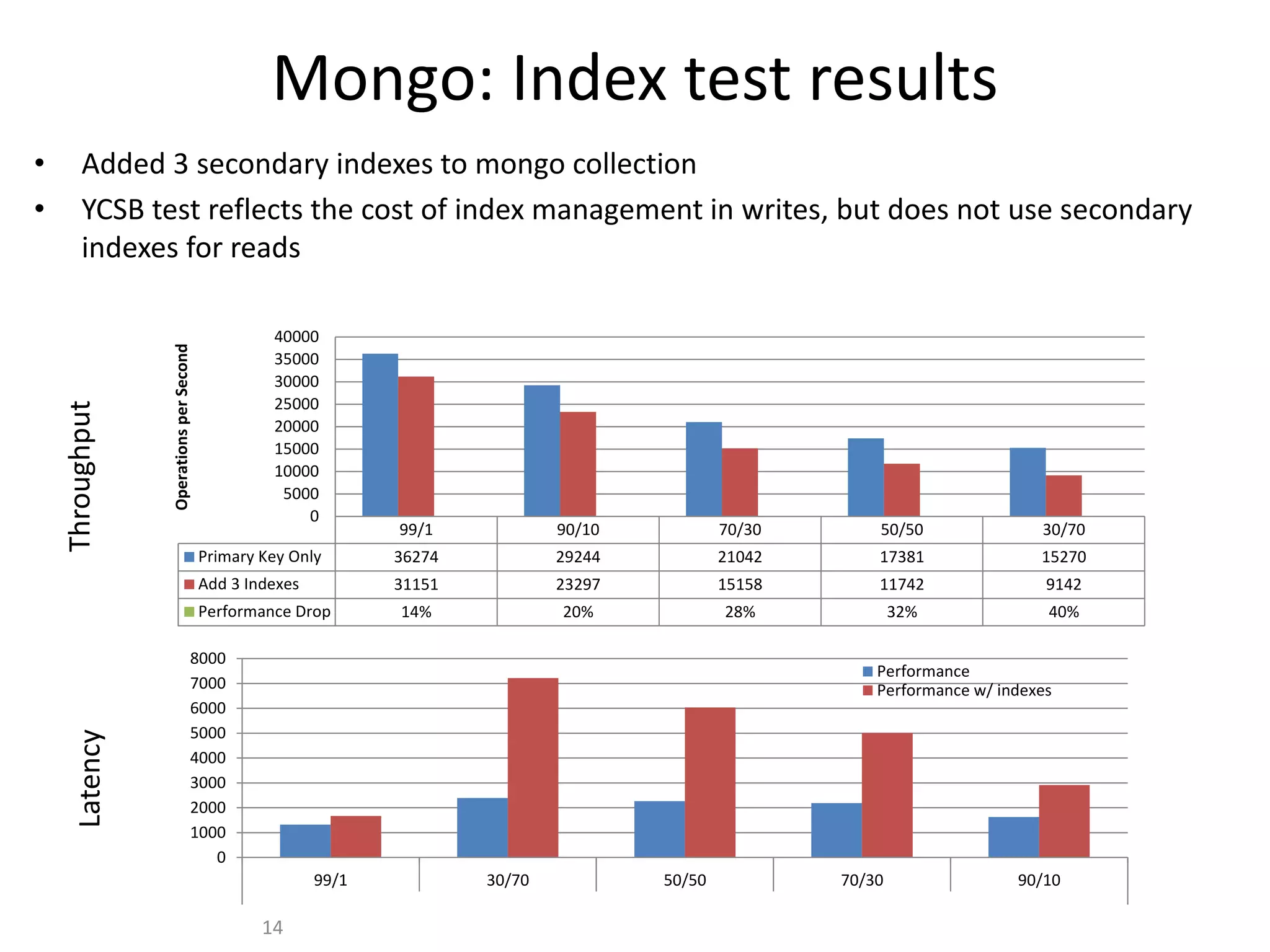




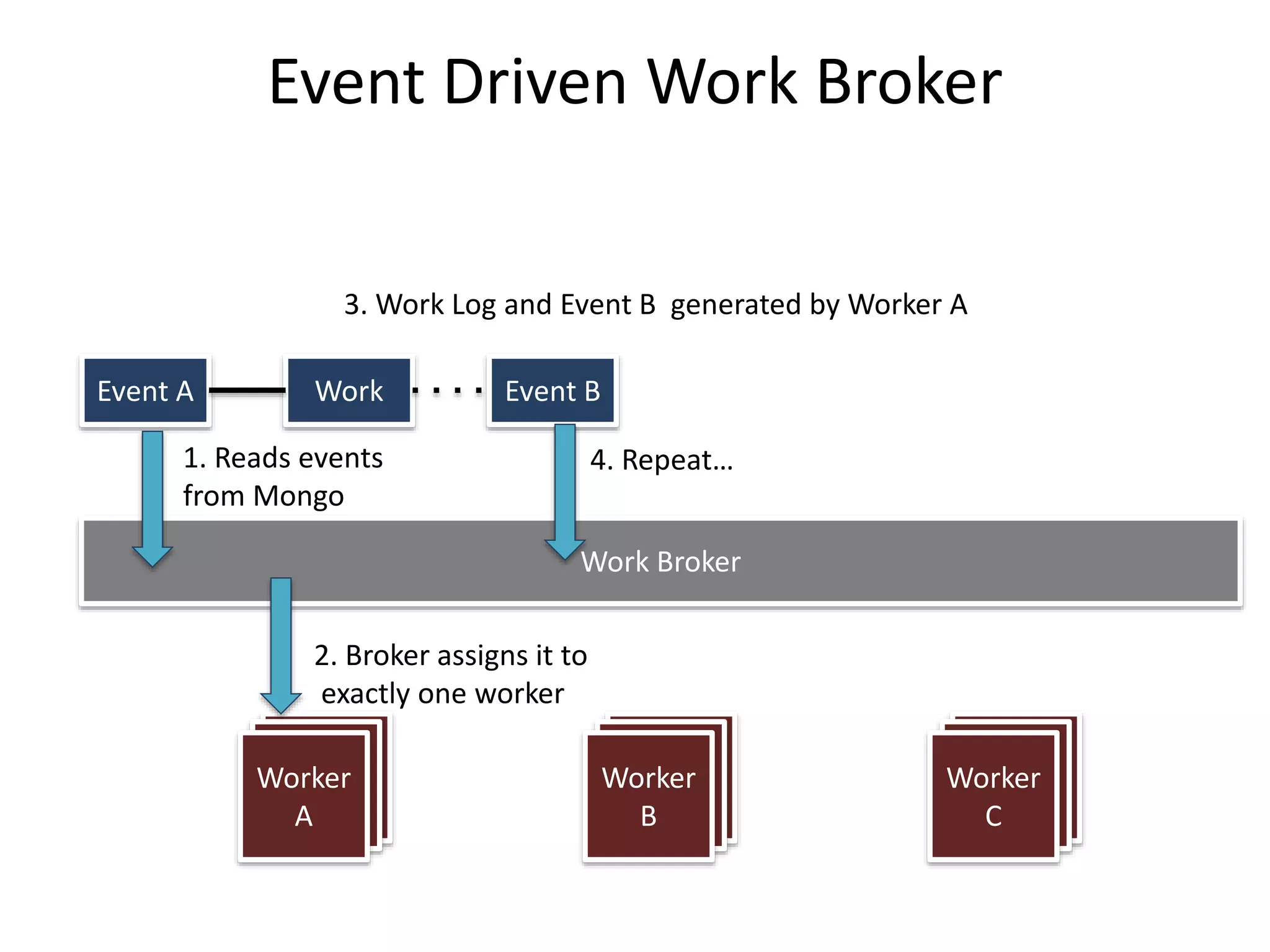
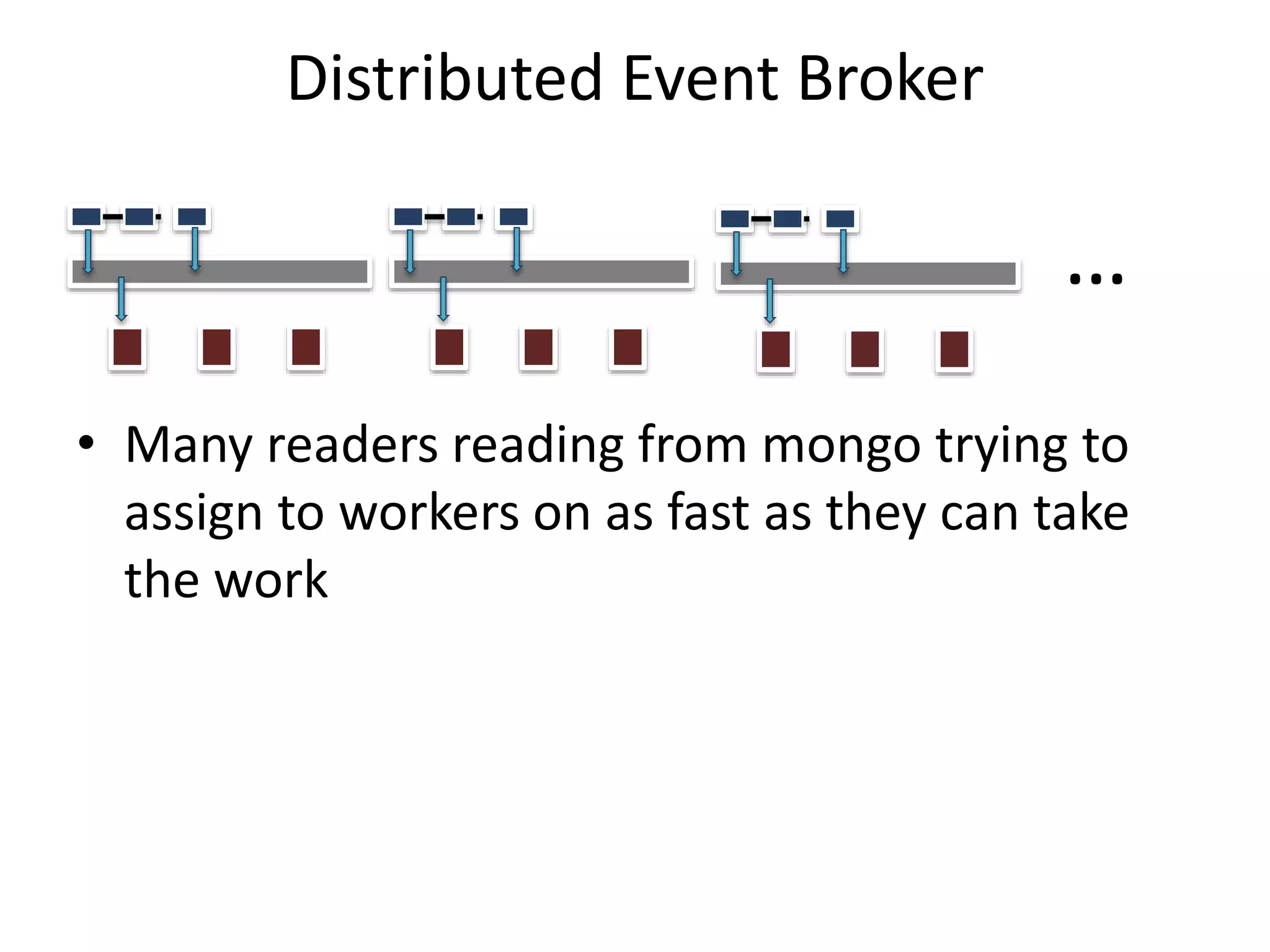




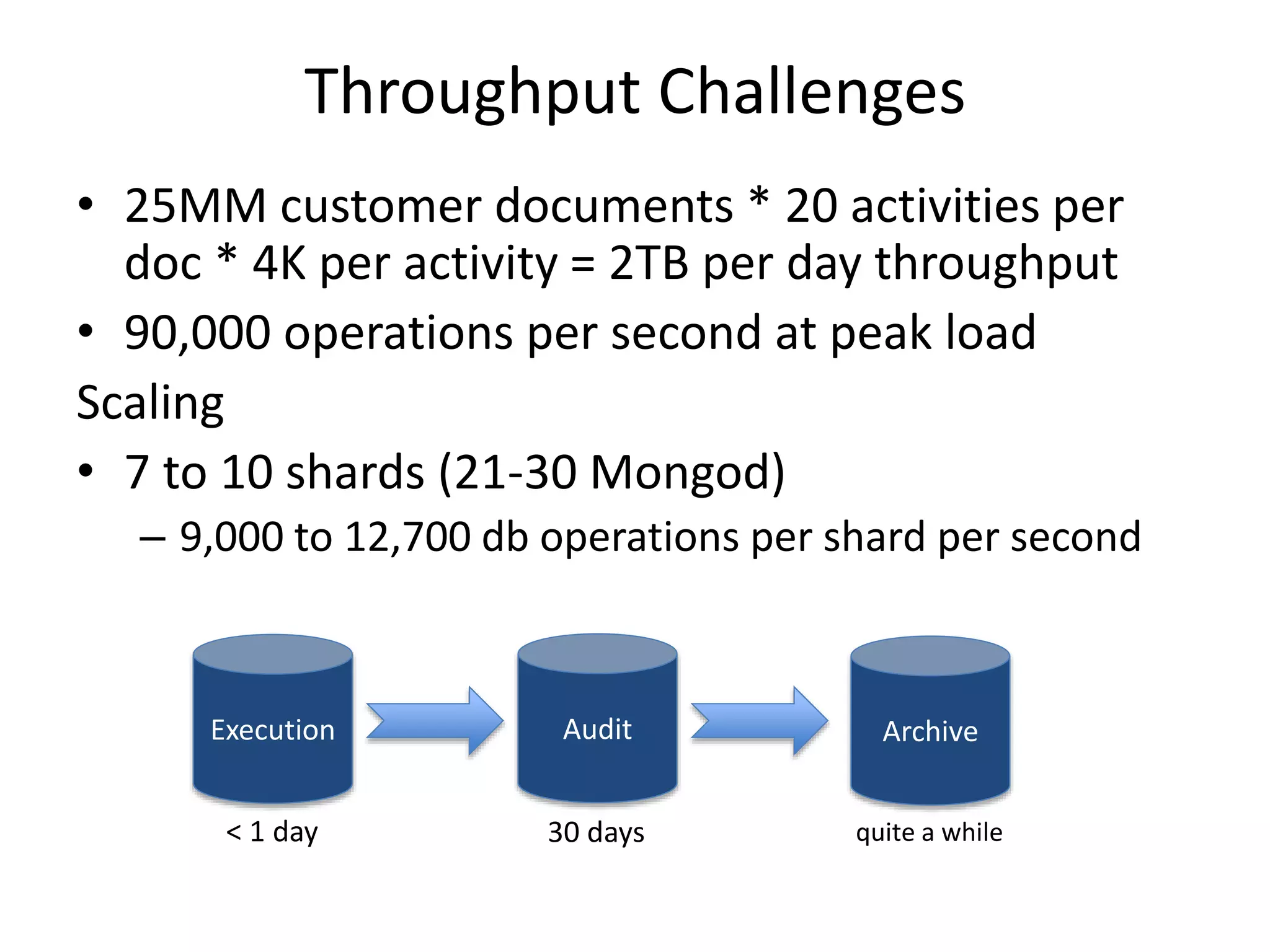

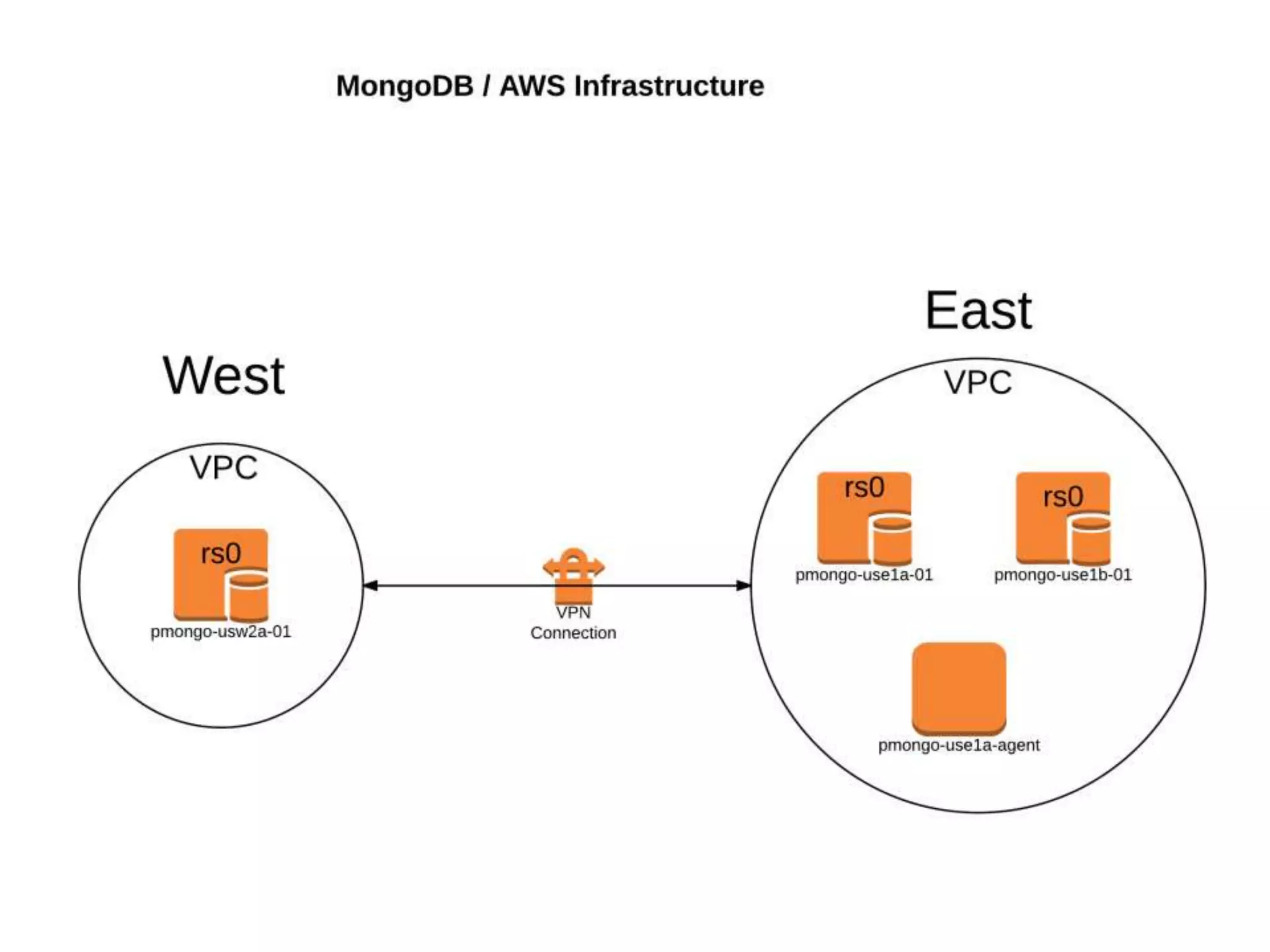
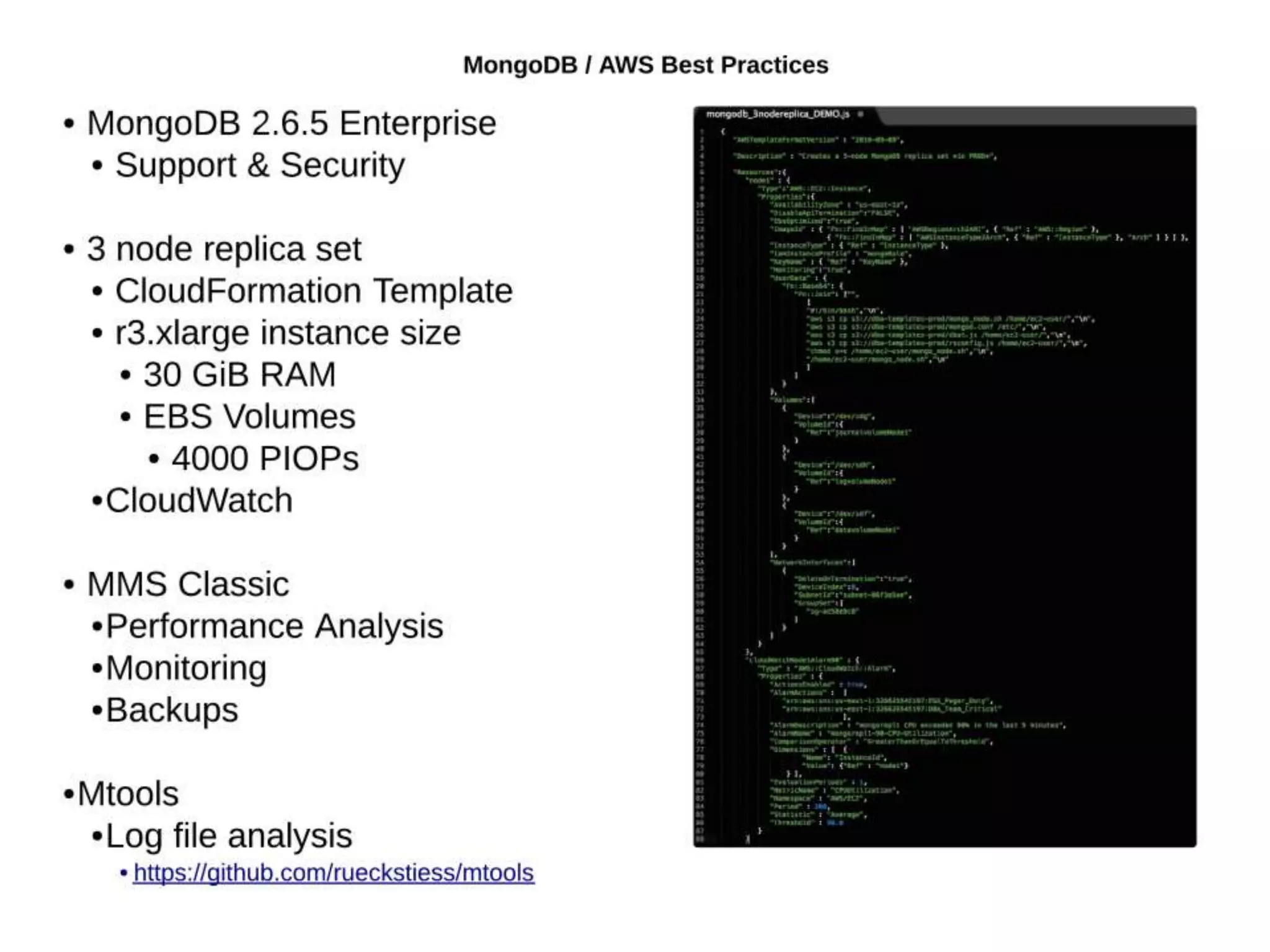



































GHX uses MongoDB to store over 500,000 documents per day relating to healthcare transactions. They evaluated NoSQL databases and selected MongoDB due to its scalability, flexible data model, and developer friendliness. Their data model involves storing events that are assigned to workers by a distributed event broker. After 9 months in production, MongoDB has supported throughput of over 90,000 operations per second through sharding and indexing, meeting GHX's requirements.




























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)
































