Download to read offline











![Translate Cascading
• DAG is usually simple
• Most Cascading pipe has one-to-one mapping to Spark transformation
// val processedInput: RDD[(String, Token)]
// val tokenFreq: RDD[(String, Double)]
val tokenFreqVar = spark.sparkContext.broadcast(tokenFreq.collectAsMap())
val joined = processedInput.map {
t => (t._1, (t._2, tokenFreqVar.value.get(t._1)))
}
Cascading Pipe Spark RDD Operator Note
Each Map side UDF
Every Reduce side UDF
Merge union
CoGroup join/leftOuterJoin/right
OuterJoin/fullOuterJoin
GroupBy GroupBy/GroupByKey secondary sort might be needed
HashJoin Broadcast join no native support in RDD, simulate via broadcast variable
• Complexity is in UDF](https://image.slidesharecdn.com/690daili-210608224358/75/Migrating-ETL-Workflow-to-Apache-Spark-at-Scale-in-Pinterest-16-2048.jpg)





























![Translate Cascading
• DAG is usually simple
• Most Cascading pipe has one-to-one mapping to Spark transformation
// val processedInput: RDD[(String, Token)]
// val tokenFreq: RDD[(String, Double)]
val tokenFreqVar = spark.sparkContext.broadcast(tokenFreq.collectAsMap())
val joined = processedInput.map {
t => (t._1, (t._2, tokenFreqVar.value.get(t._1)))
}
Cascading Pipe Spark RDD Operator Note
Each Map side UDF
Every Reduce side UDF
Merge union
CoGroup join/leftOuterJoin/right
OuterJoin/fullOuterJoin
GroupBy GroupBy/GroupByKey secondary sort might be needed
HashJoin Broadcast join no native support in RDD, simulate via broadcast variable
• Complexity is in UDF](https://crownmelresort.com/image.slidesharecdn.com/690daili-210608224358/75/Migrating-ETL-Workflow-to-Apache-Spark-at-Scale-in-Pinterest-16-2048.jpg)





















The document summarizes Pinterest's migration of ETL workflows from Cascading and Scalding to Spark. Key points: - Pinterest runs Spark on AWS but manages its own clusters to avoid vendor lock-in. They have multiple Spark clusters with hundreds to thousands of nodes. - The migration plan is to move remaining workloads from Hive, Cascading/Scalding, and Hadoop streaming to SparkSQL, PySpark, and native Spark over time. An automatic migration service helps with the process. - Technical challenges included secondary sorting, accumulators behaving differently between frameworks, and output committer issues. Performance profiling and tuning was also important. - Results of migrating so far include
Presentation on migrating ETL workflow to Spark at Pinterest led by Daniel Dai and Zirui Li, covering the agenda for the event.
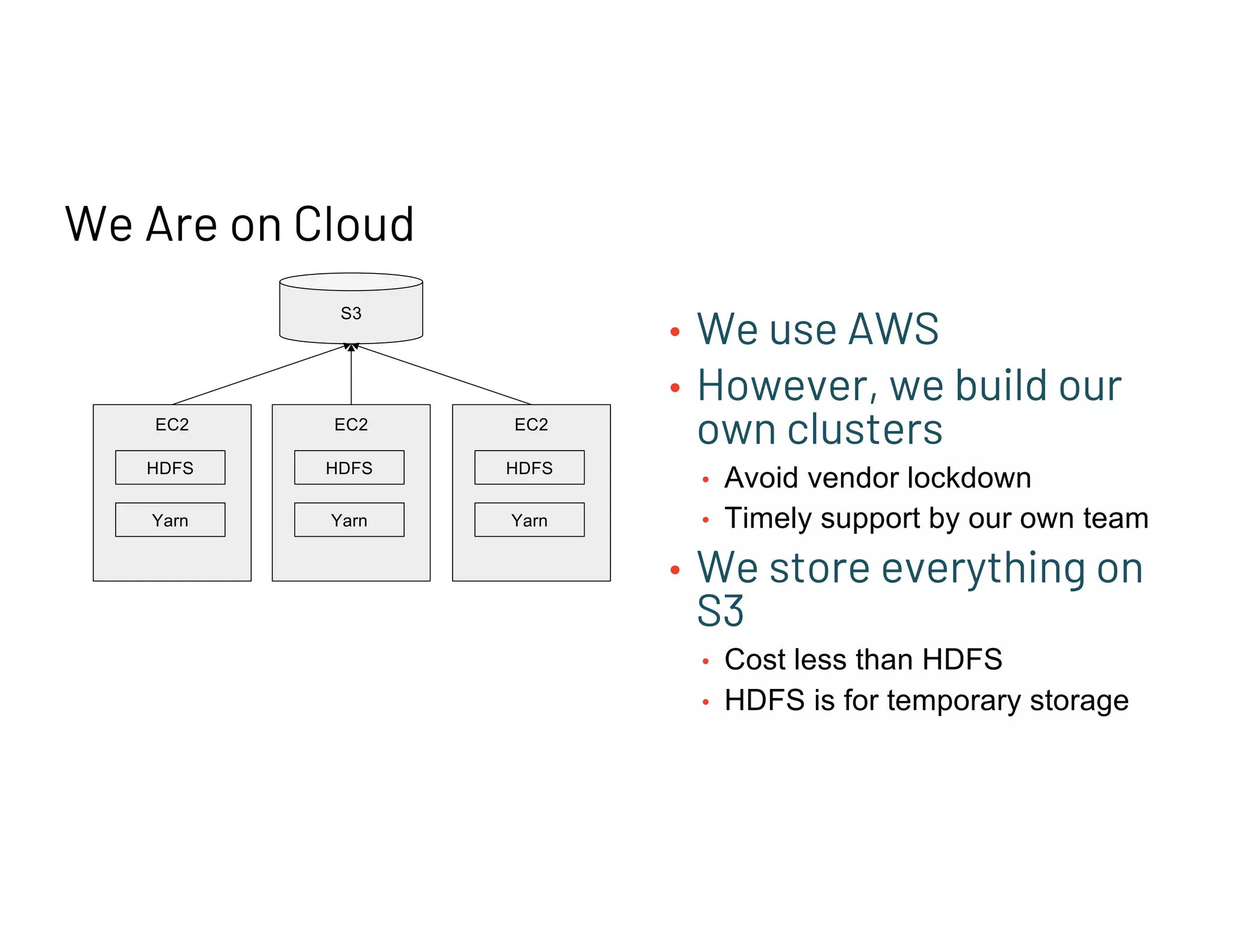
Pinterest uses AWS with custom clusters, avoiding vendor lock-in. They have Spark clusters, 1000+ nodes for efficient processing.
Currently running Spark 2.4, migrating to 3.1, with increasing workloads on Spark, transitioning from Hive and Cascading.
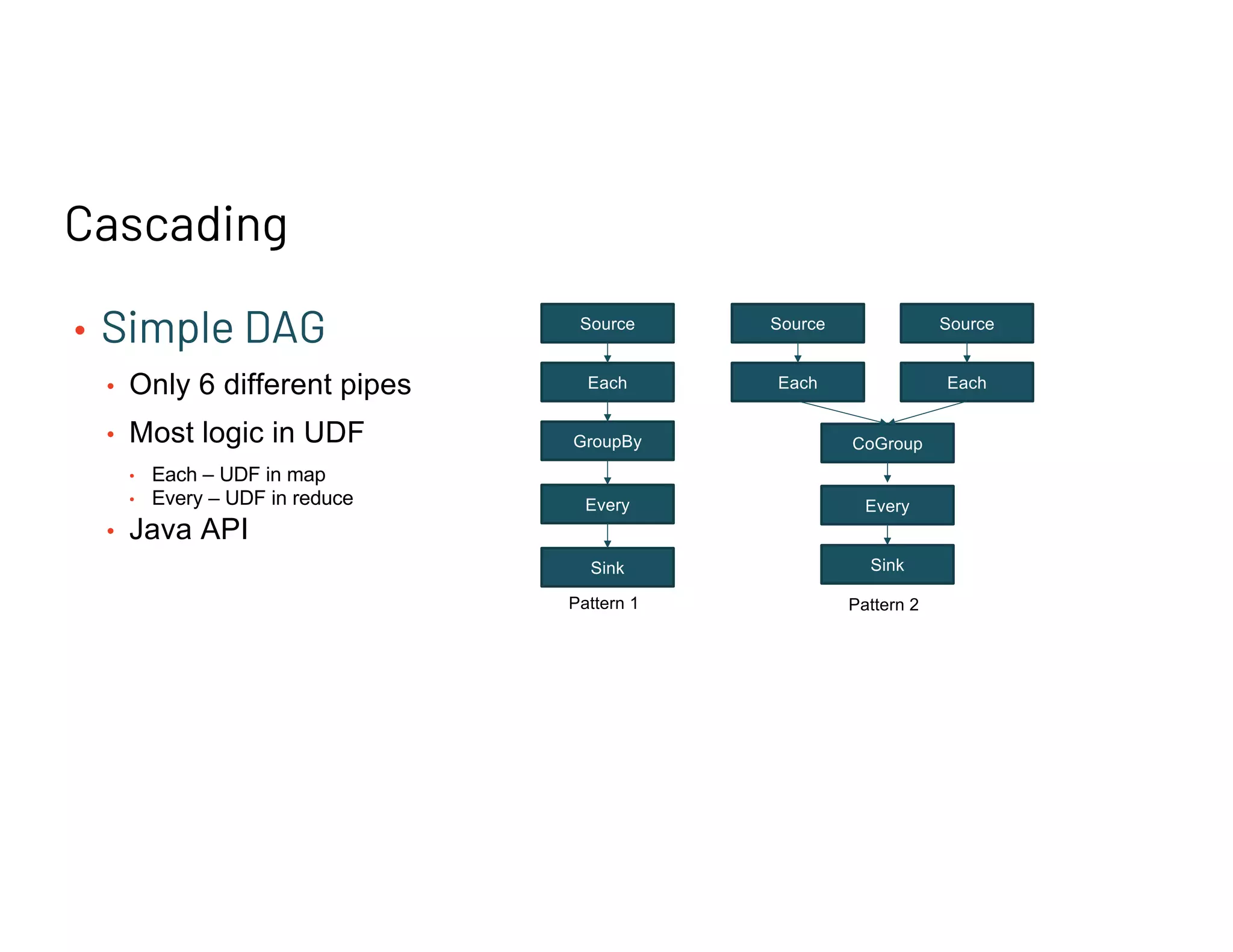
Describes Cascading's simple DAG structure and Scalding's advanced operators, both essential for Spark migration.
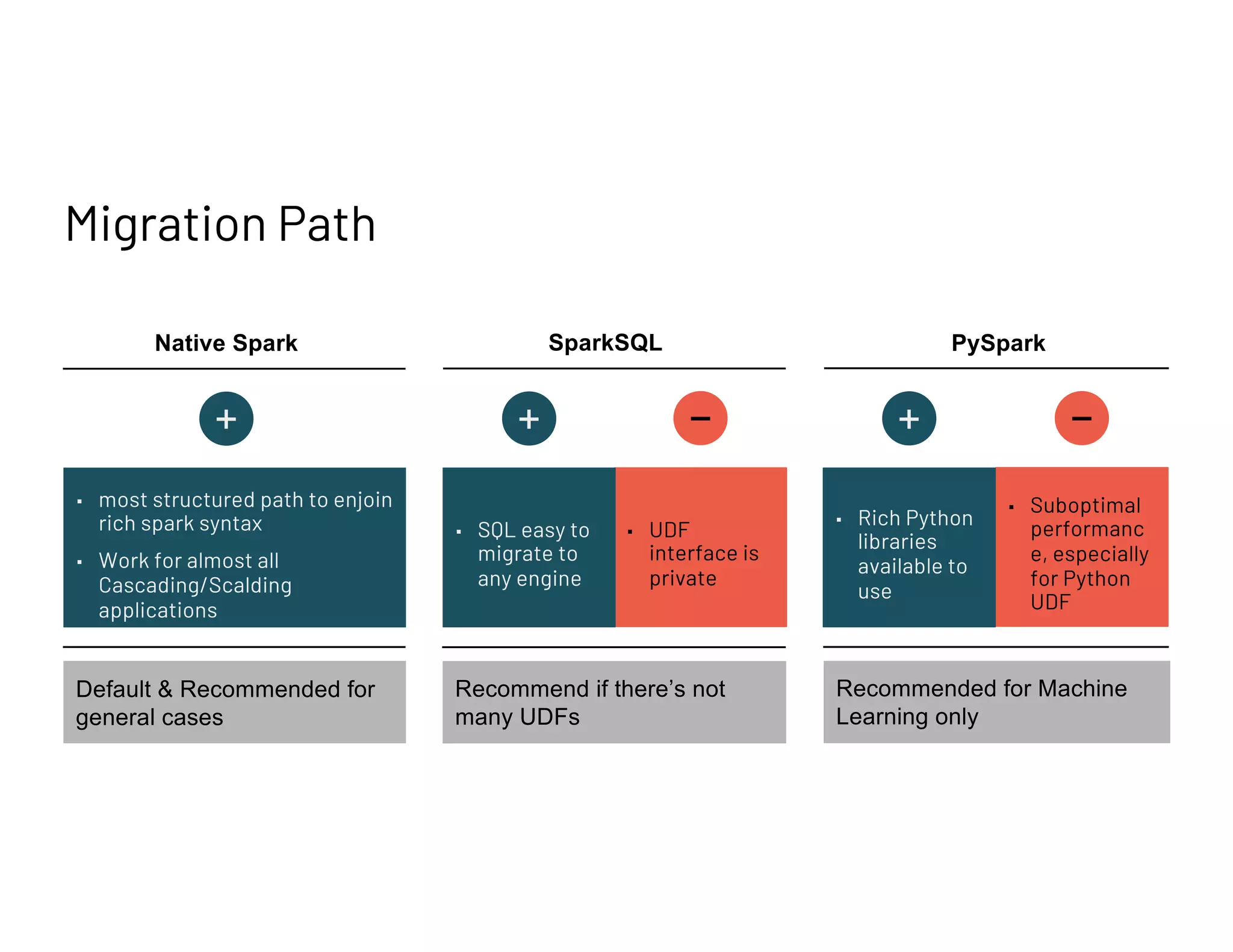
Outlines recommended migration path from Cascading to Spark, emphasizing the use of SparkSQL and DataFrames for optimal performance.
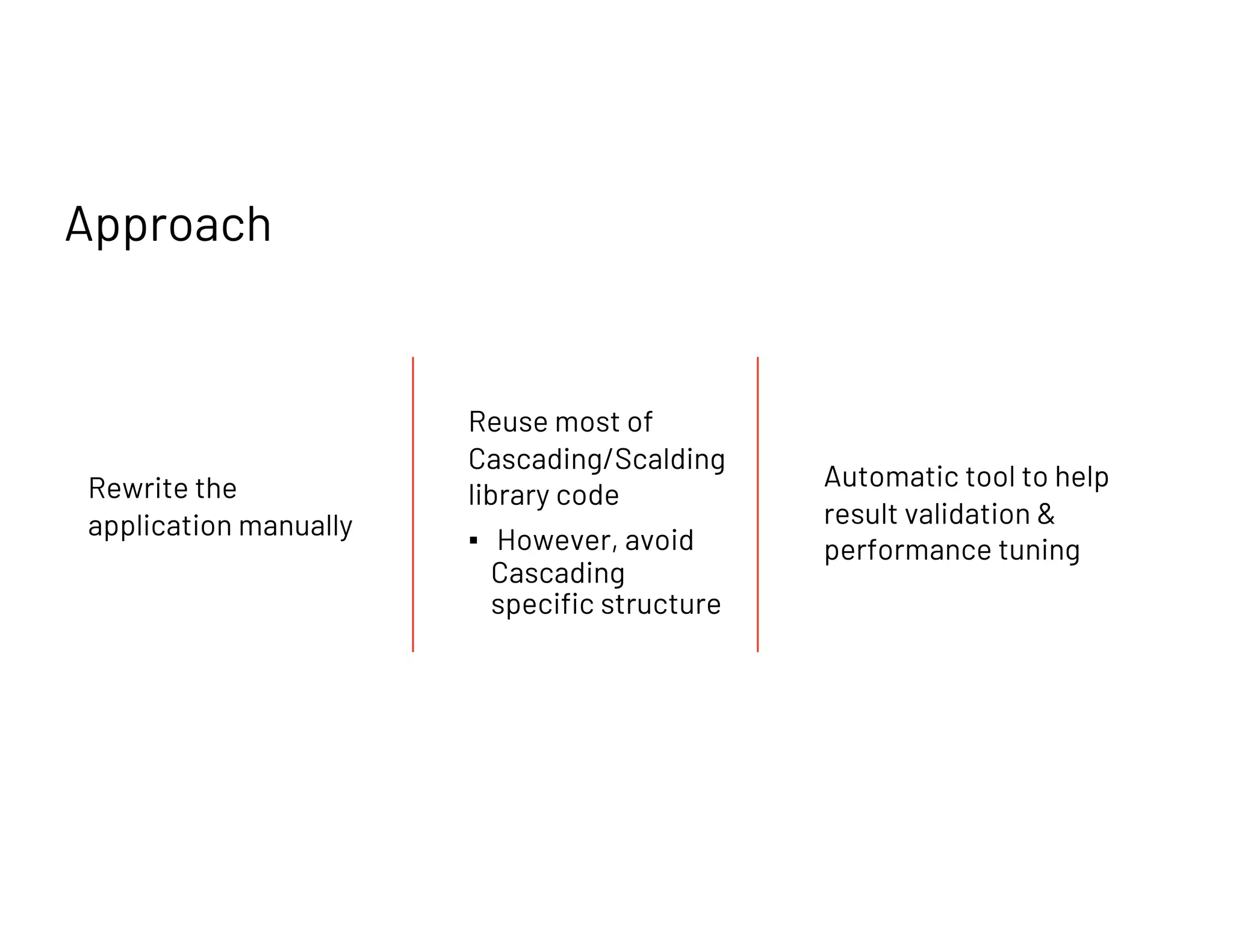
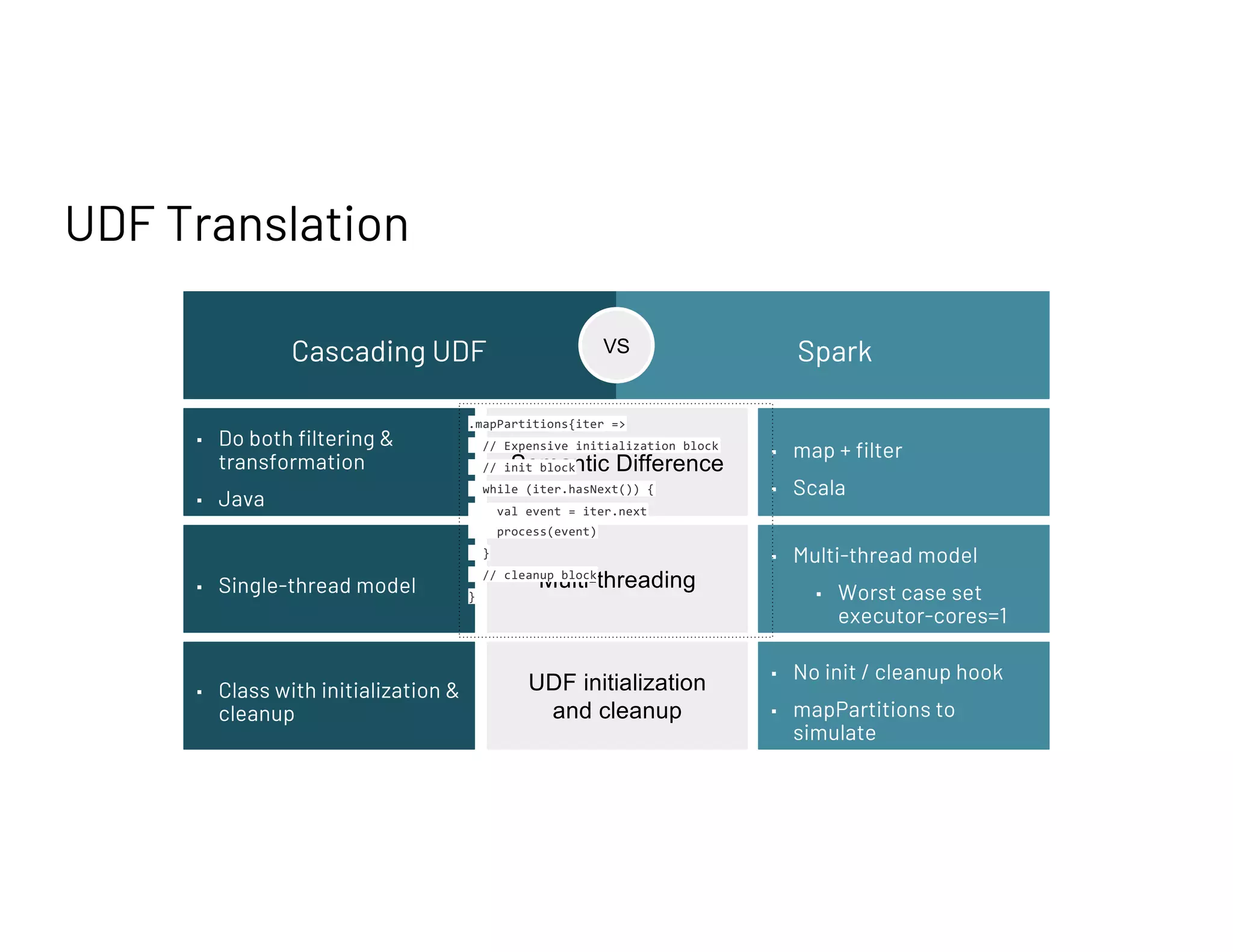
Discusses manual rewriting of applications versus using automated tools for mapping Cascading to Spark, focusing on UDF translation.
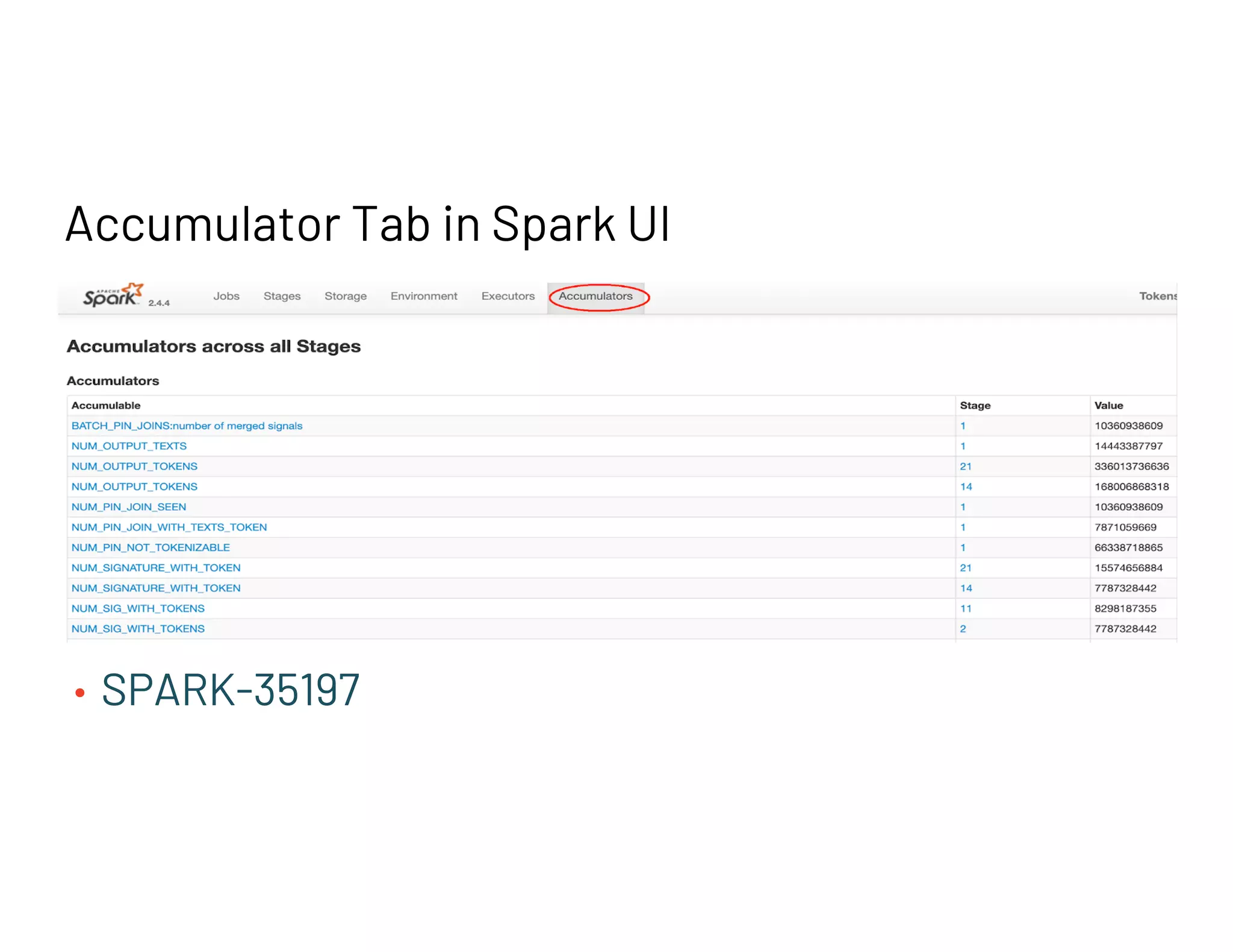
Challenges with implementing secondary sort in Spark, as well as accurate accumulator behavior across stages.
Tools for visualizing performance, identifying issues with OutputCommitter, and methods to improve metadata operations.
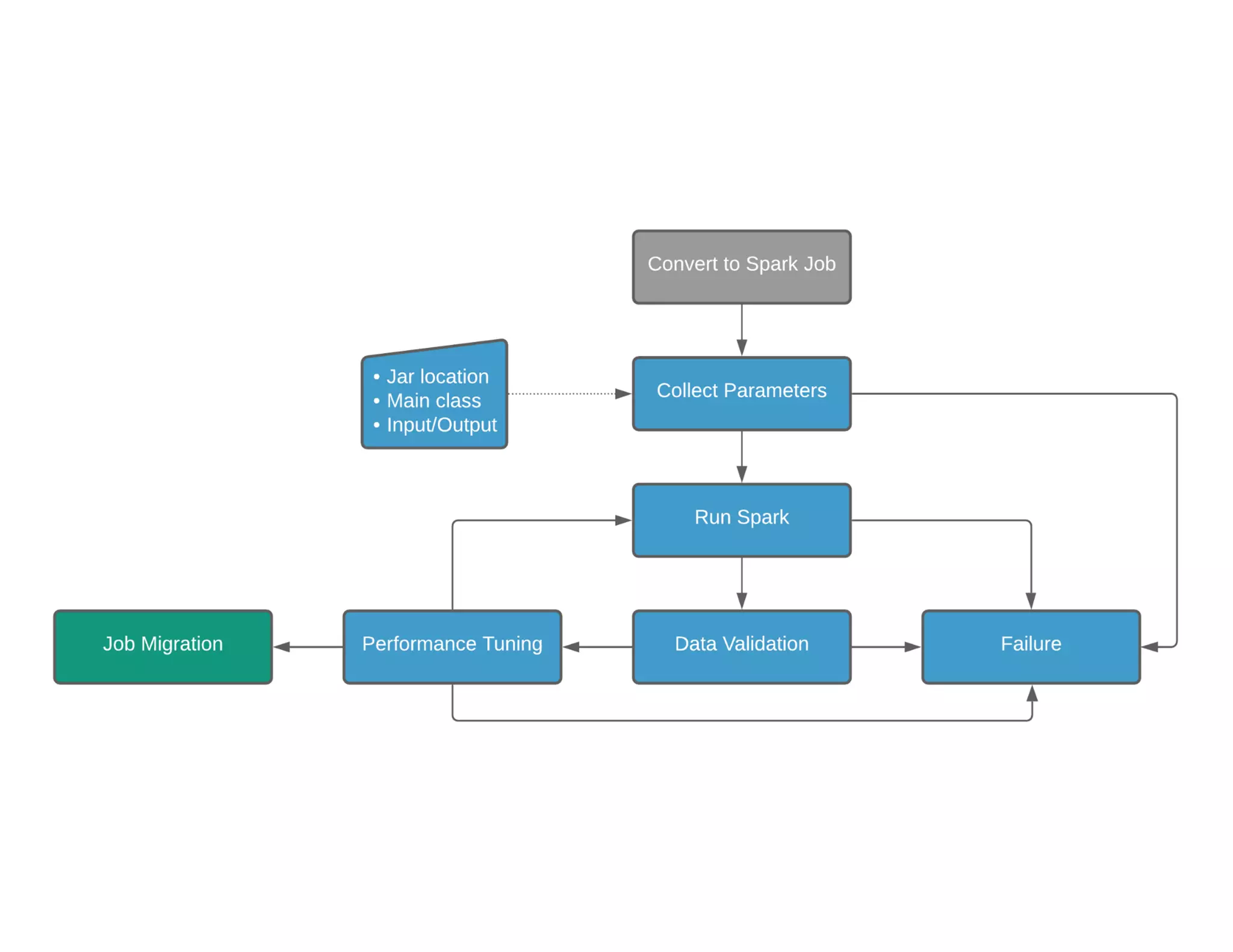
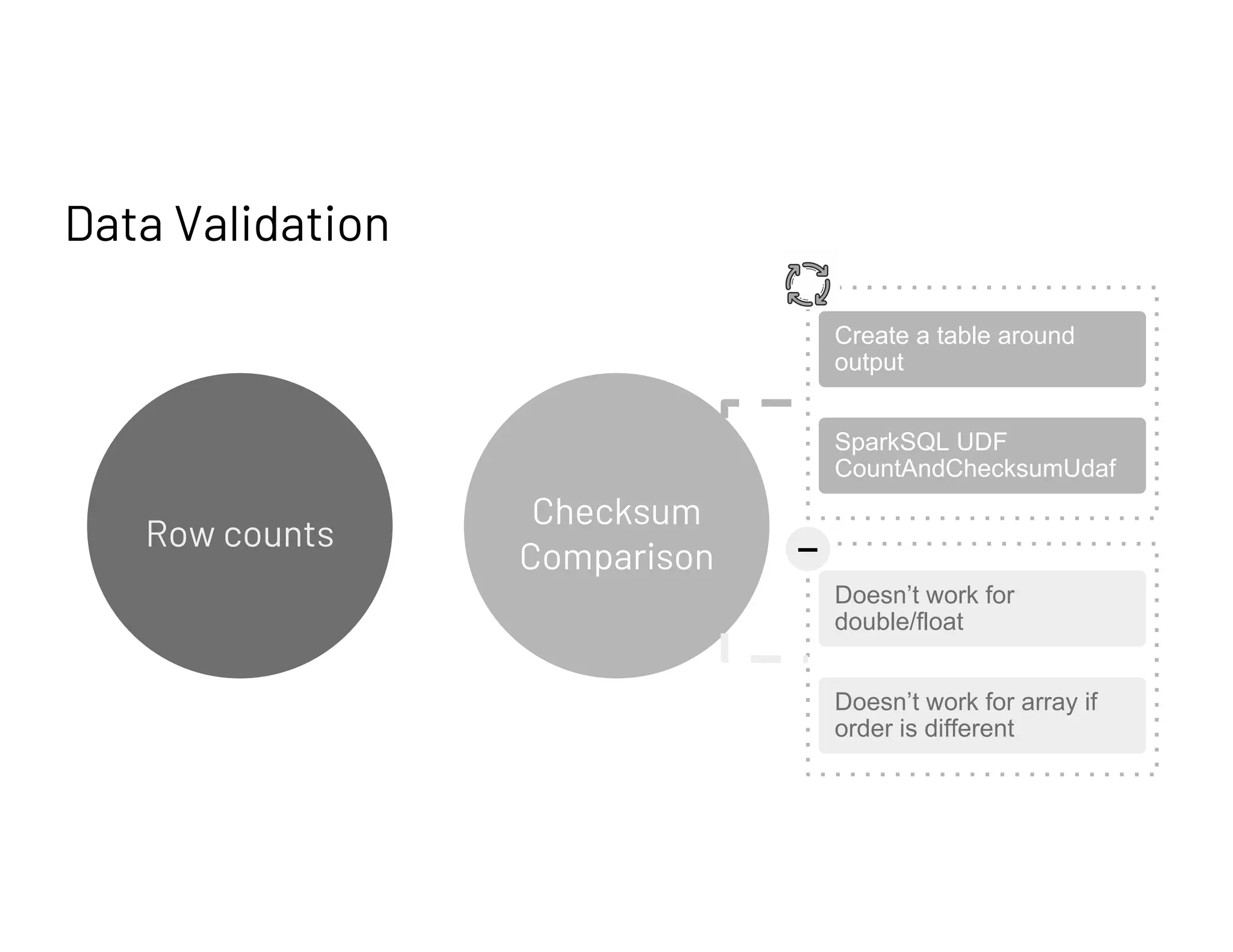
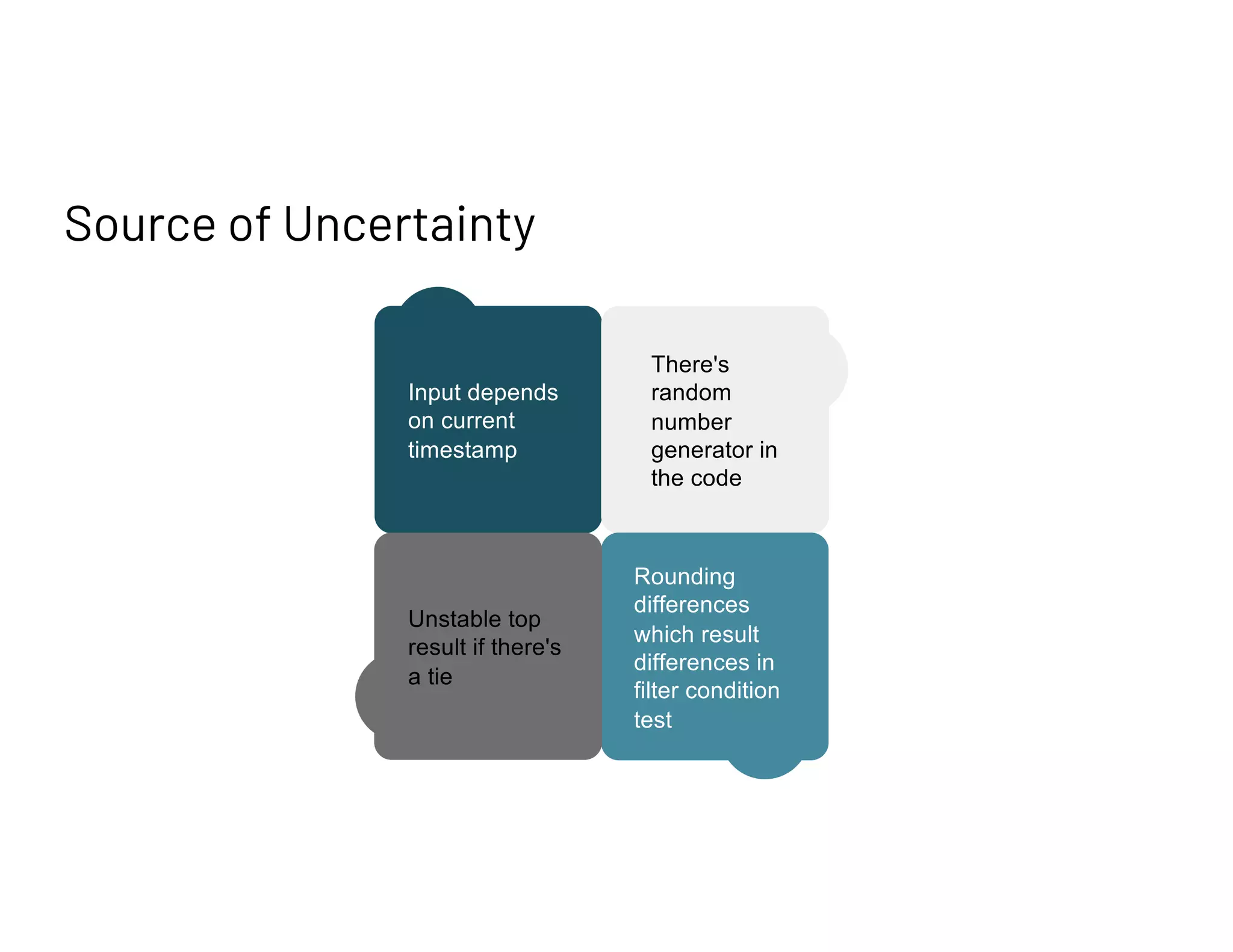
Describes an Automatic Migration Service for bulk migration processes and challenges in data validation due to dynamic factors.
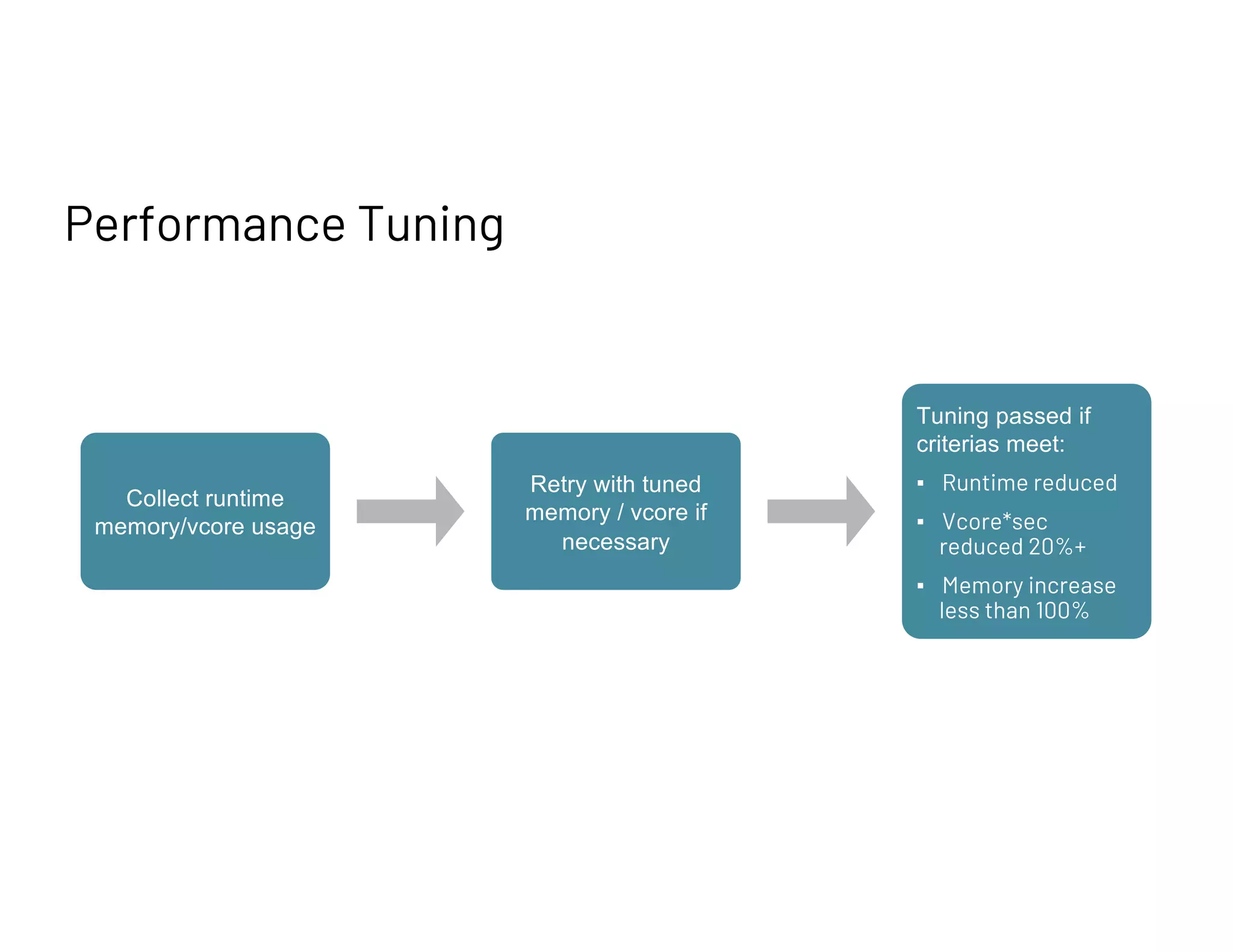
Guidelines for runtime optimization, criteria for passing performance tuning, and balancing executor usage for cost efficiency.
Automatic migration handling of errors and performance assessment results, forecasting future evolution for ongoing applications.























































































