Download as ODP, PPTX


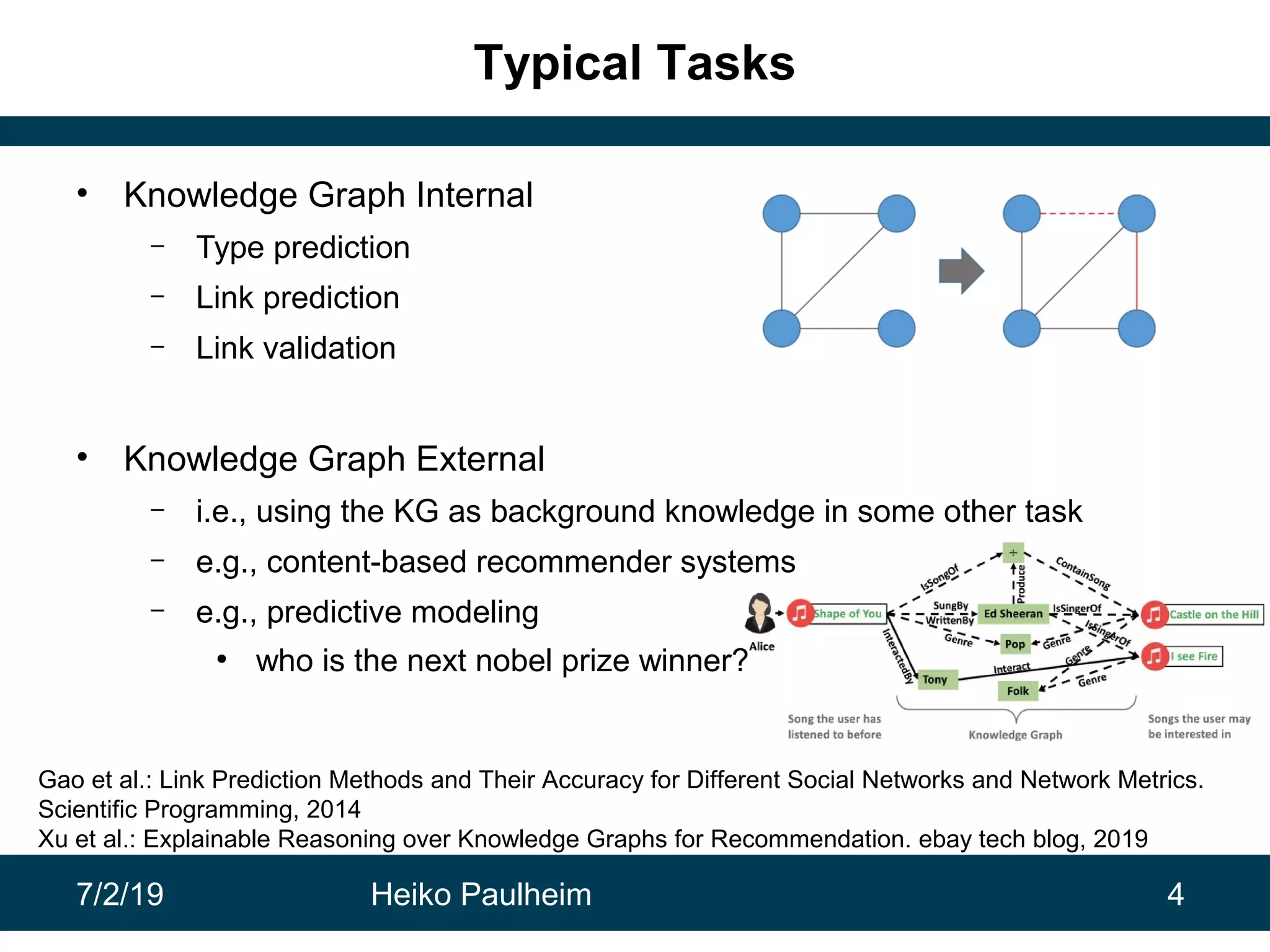
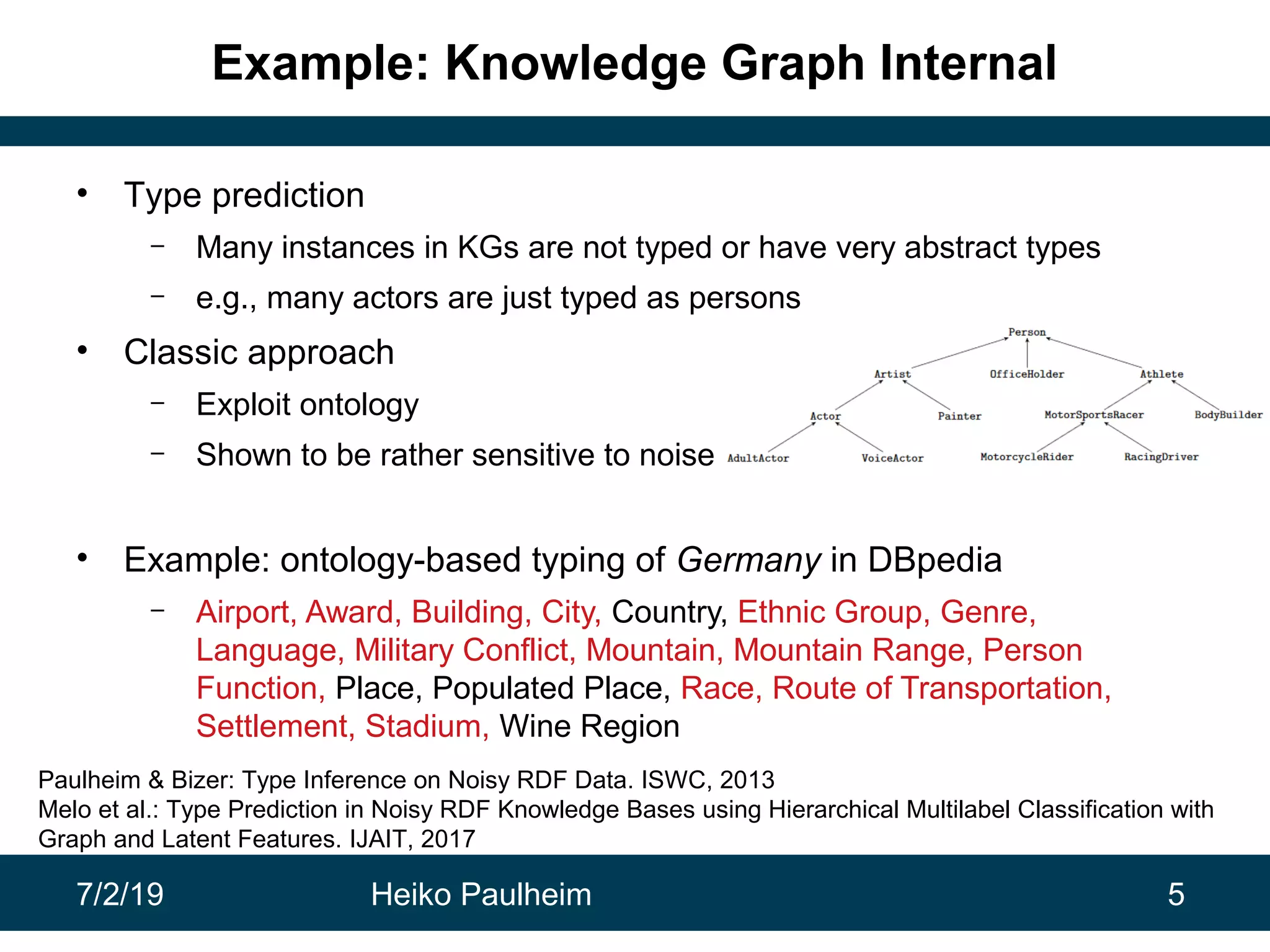

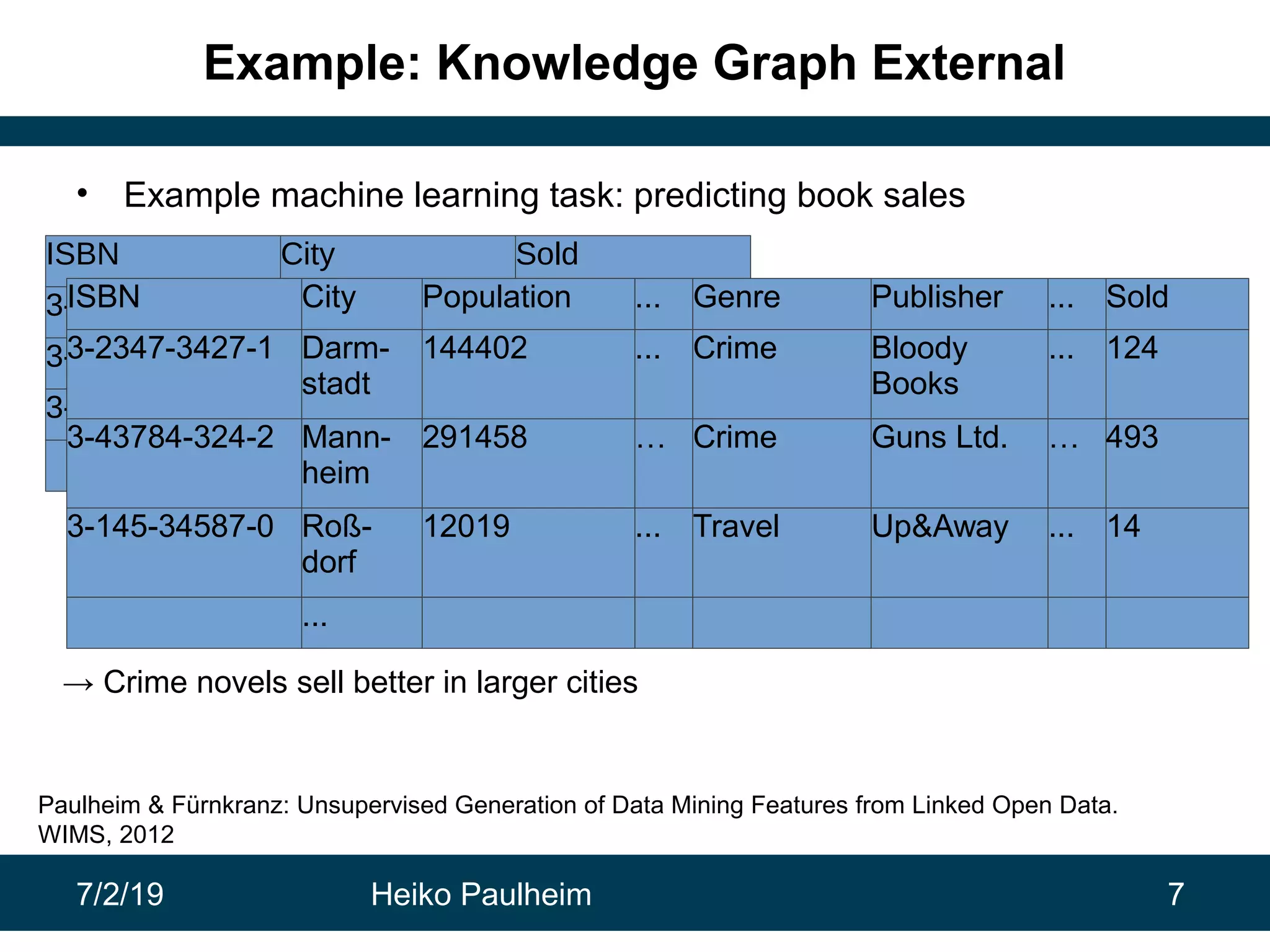
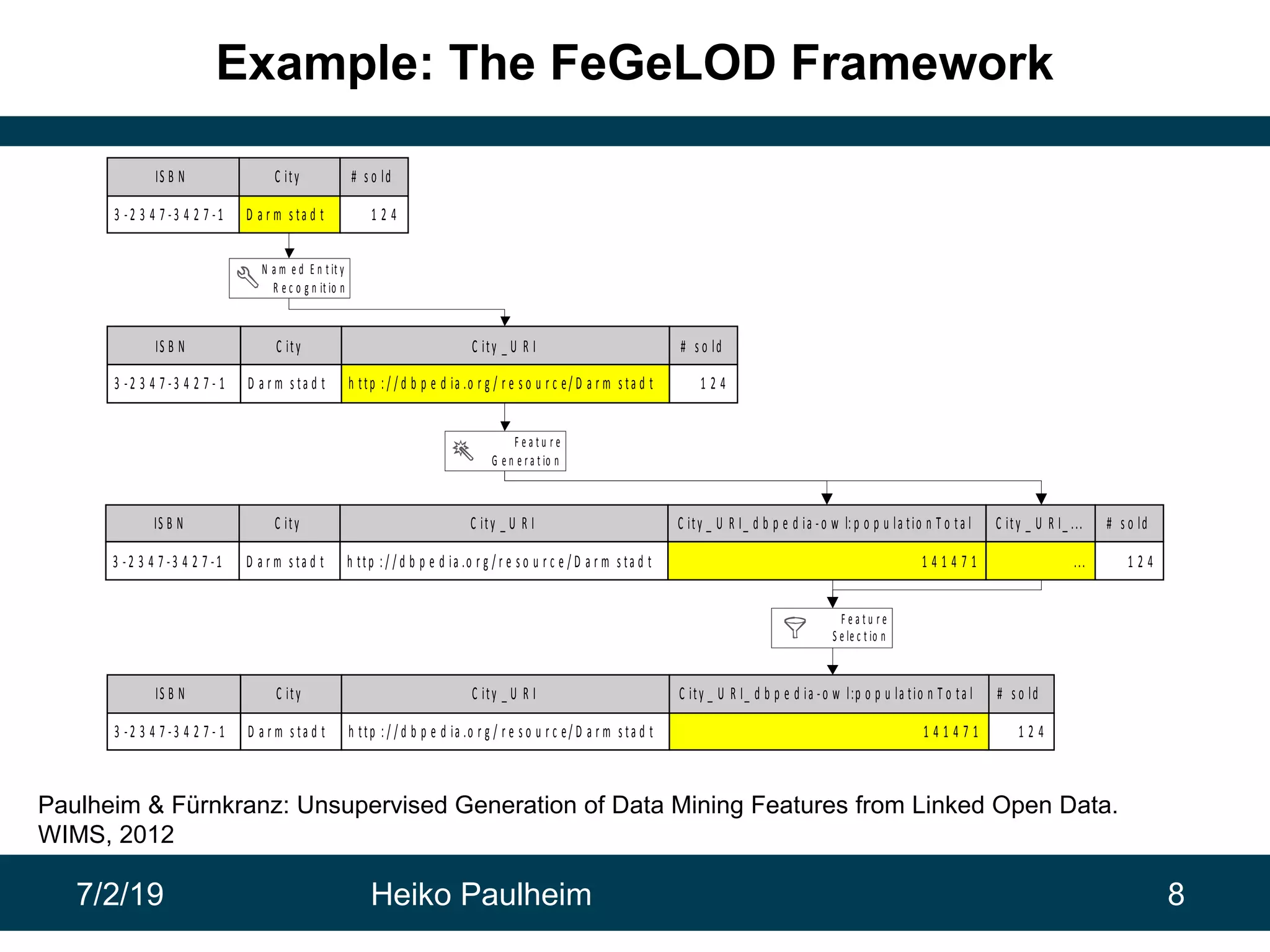

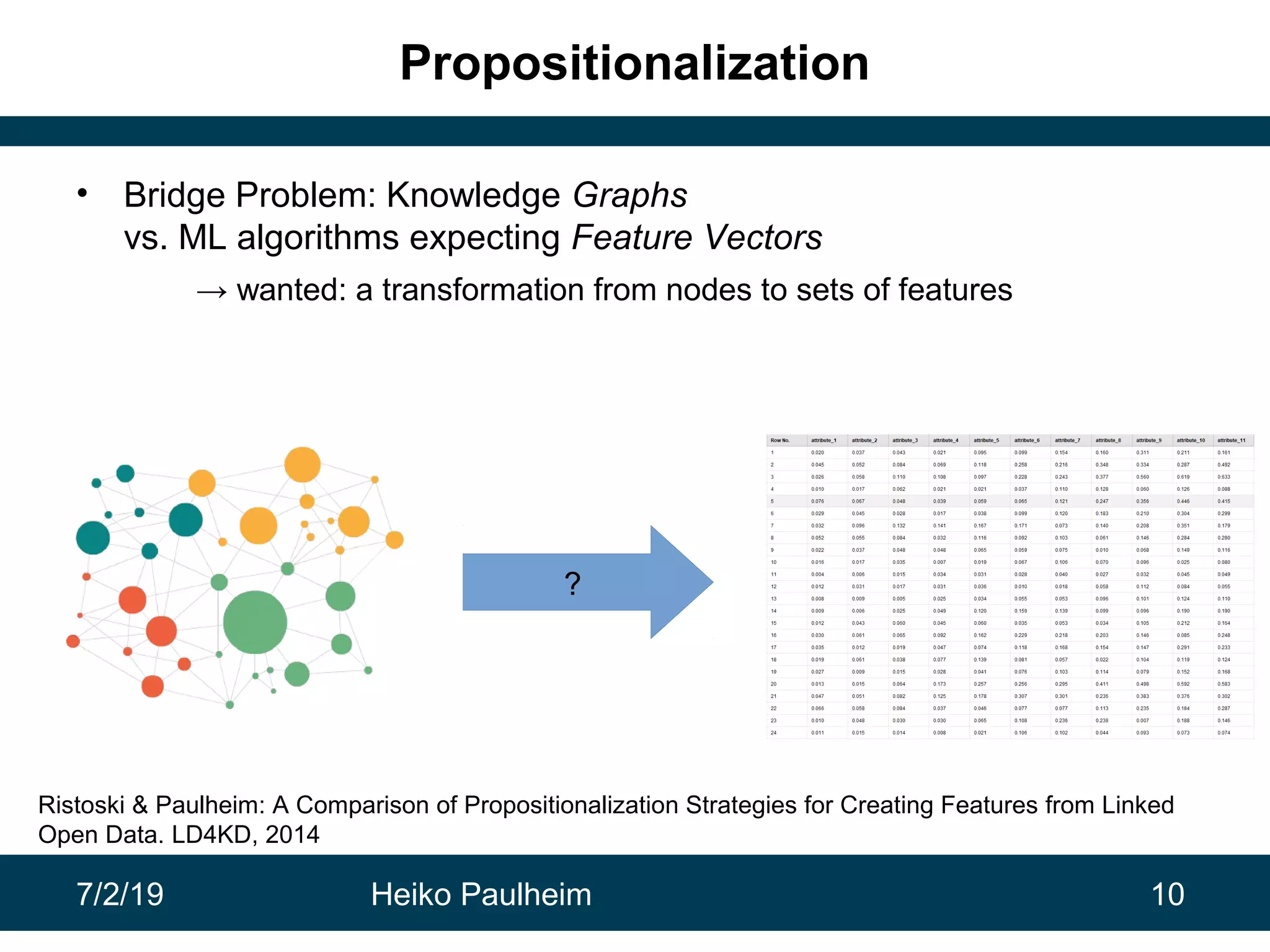



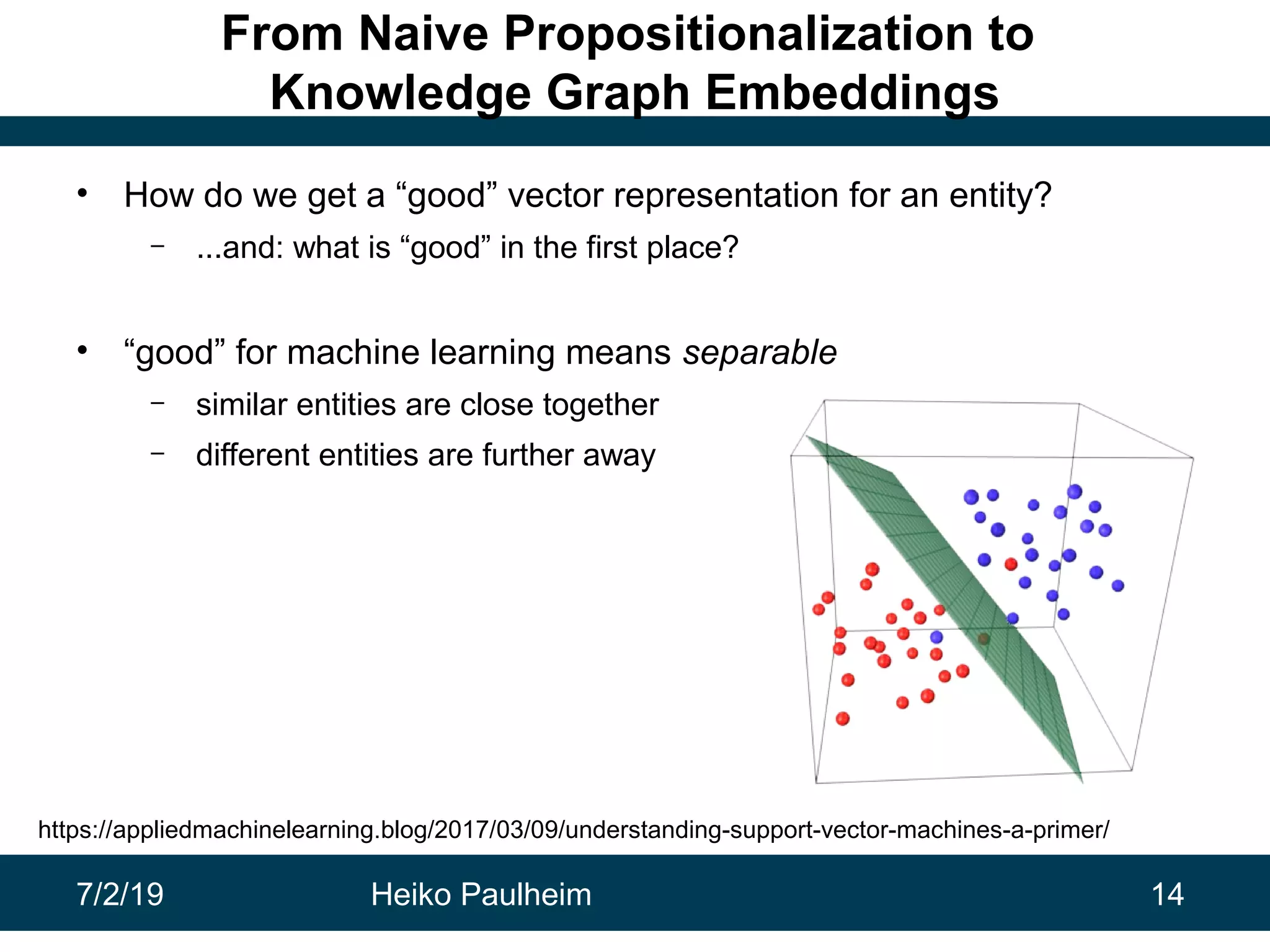




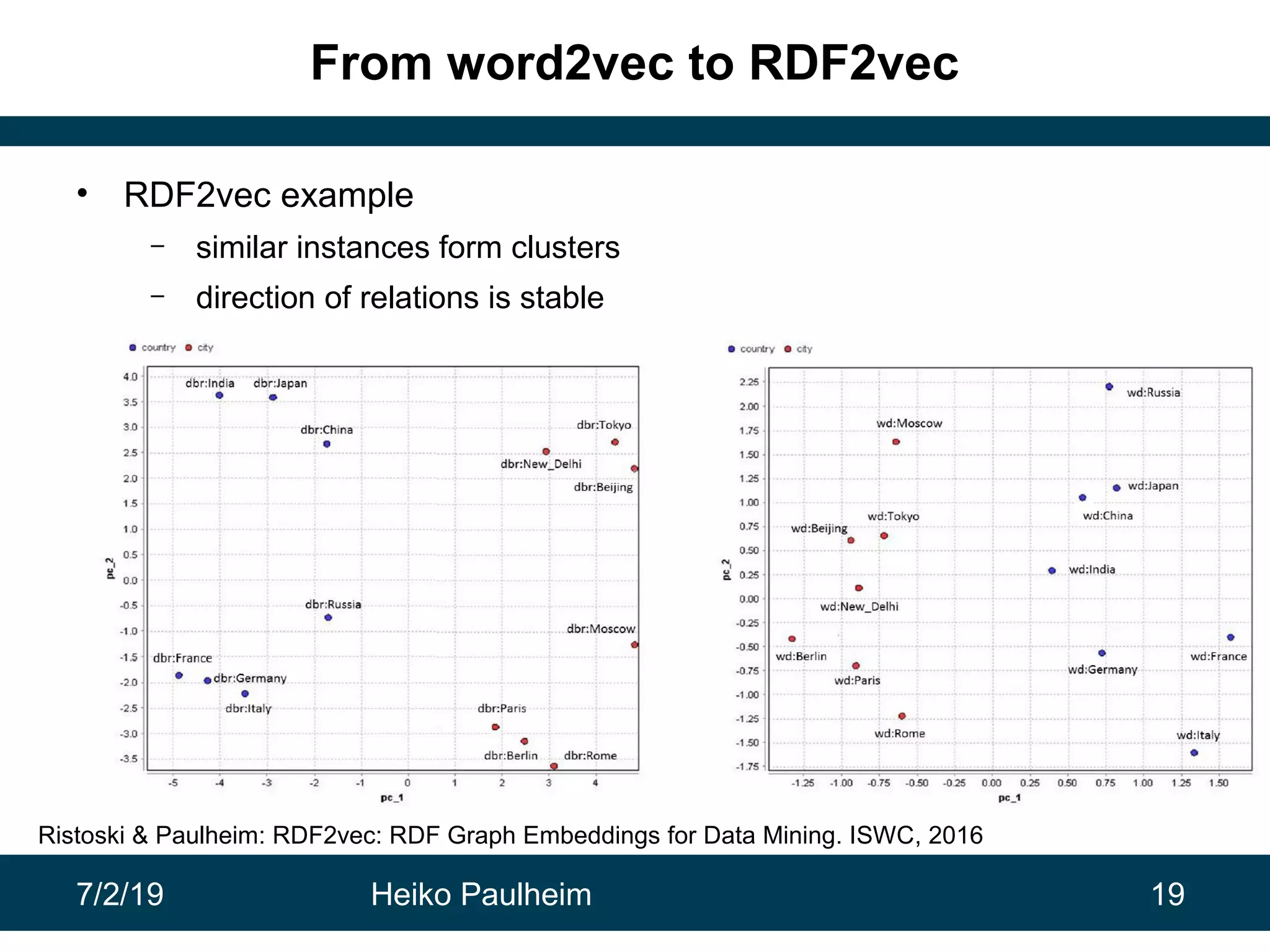


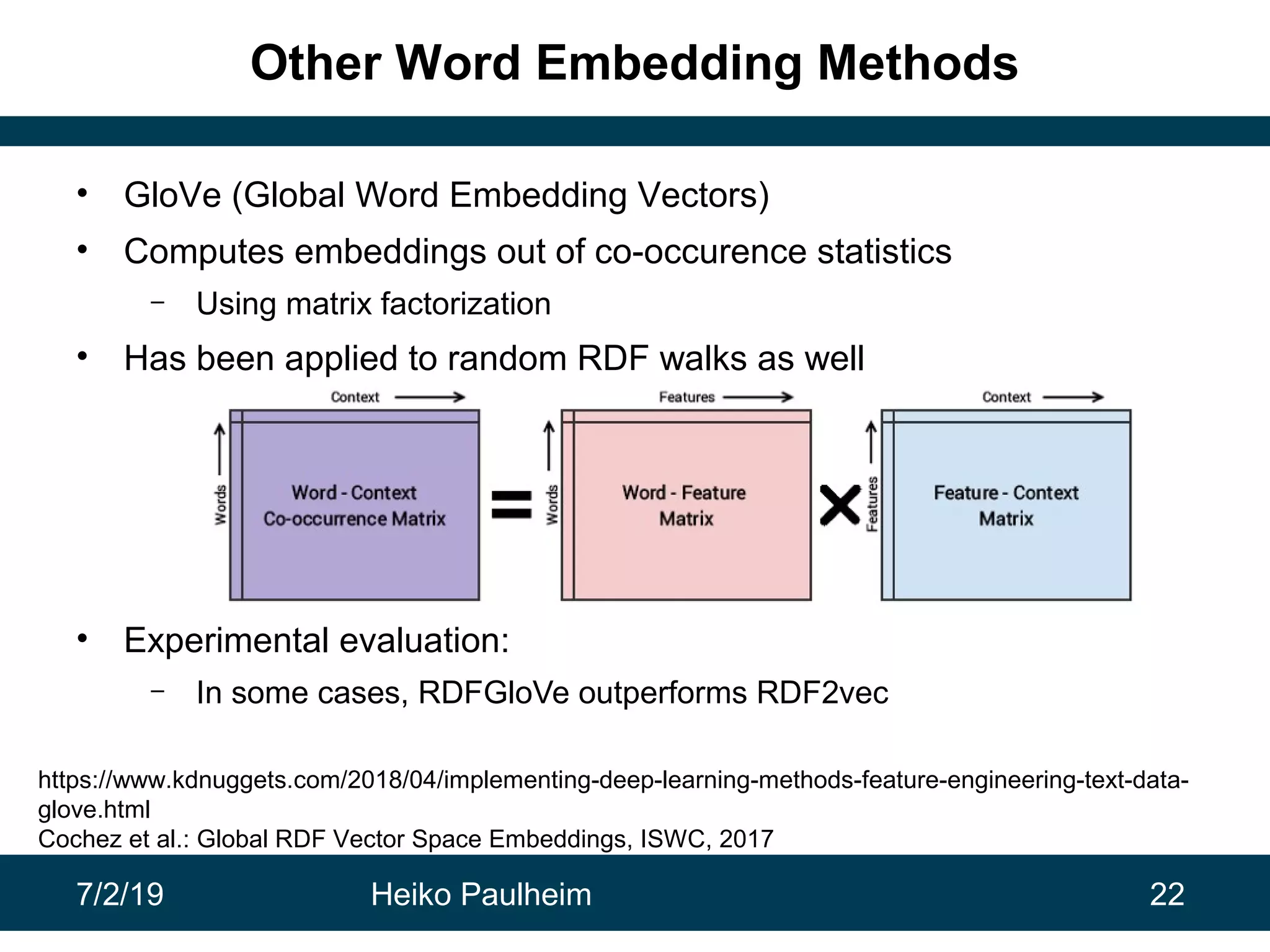


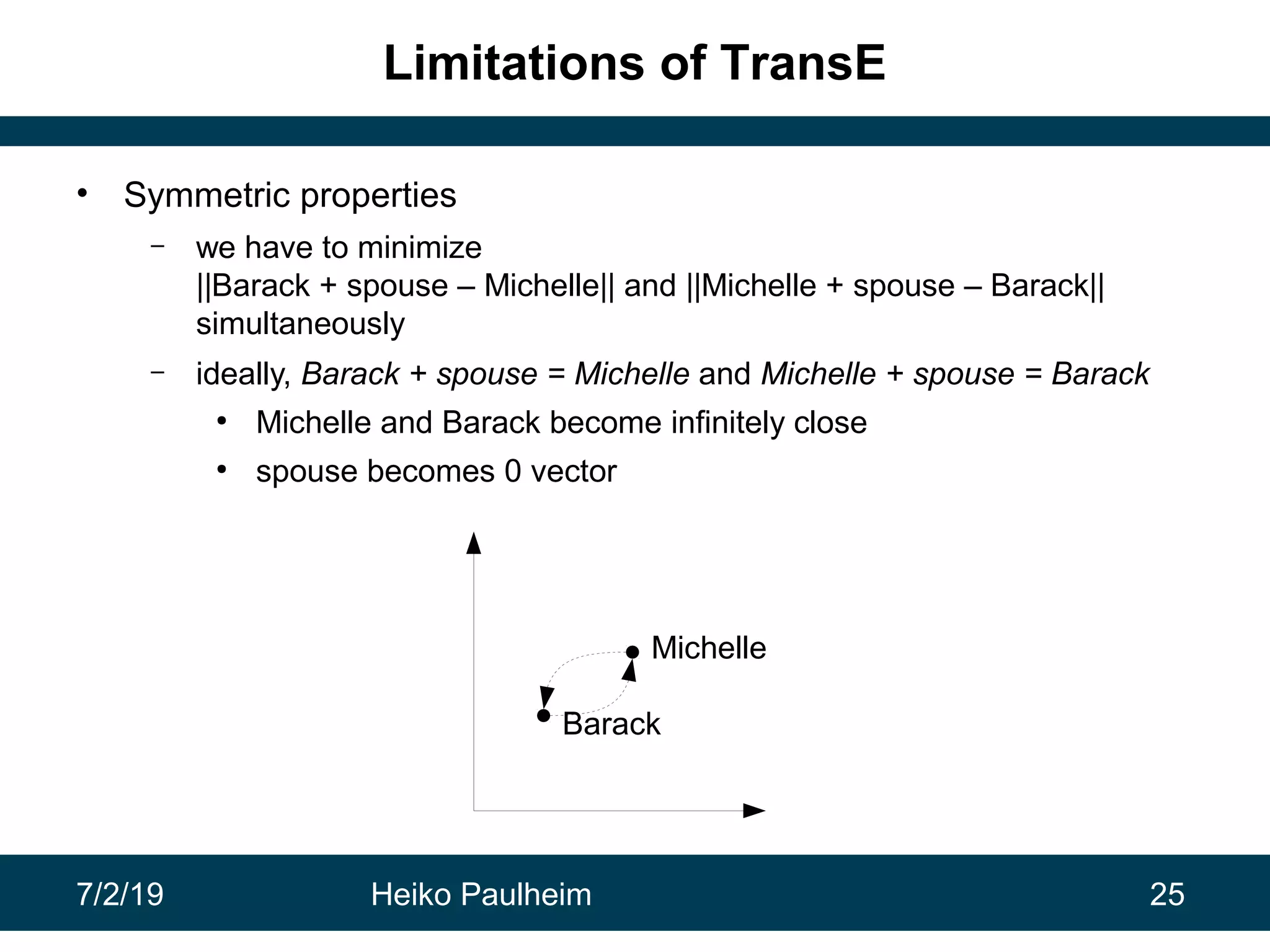

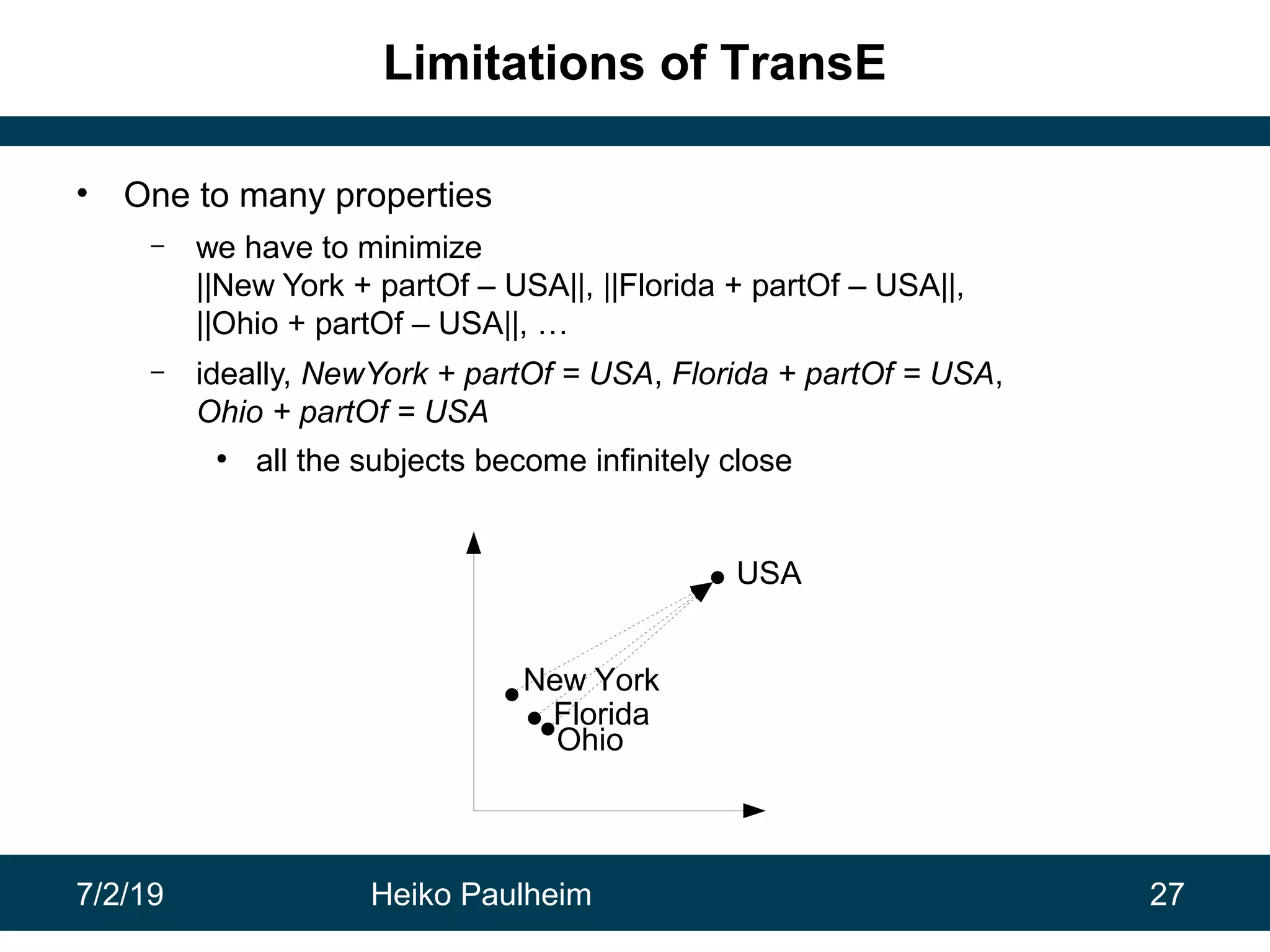



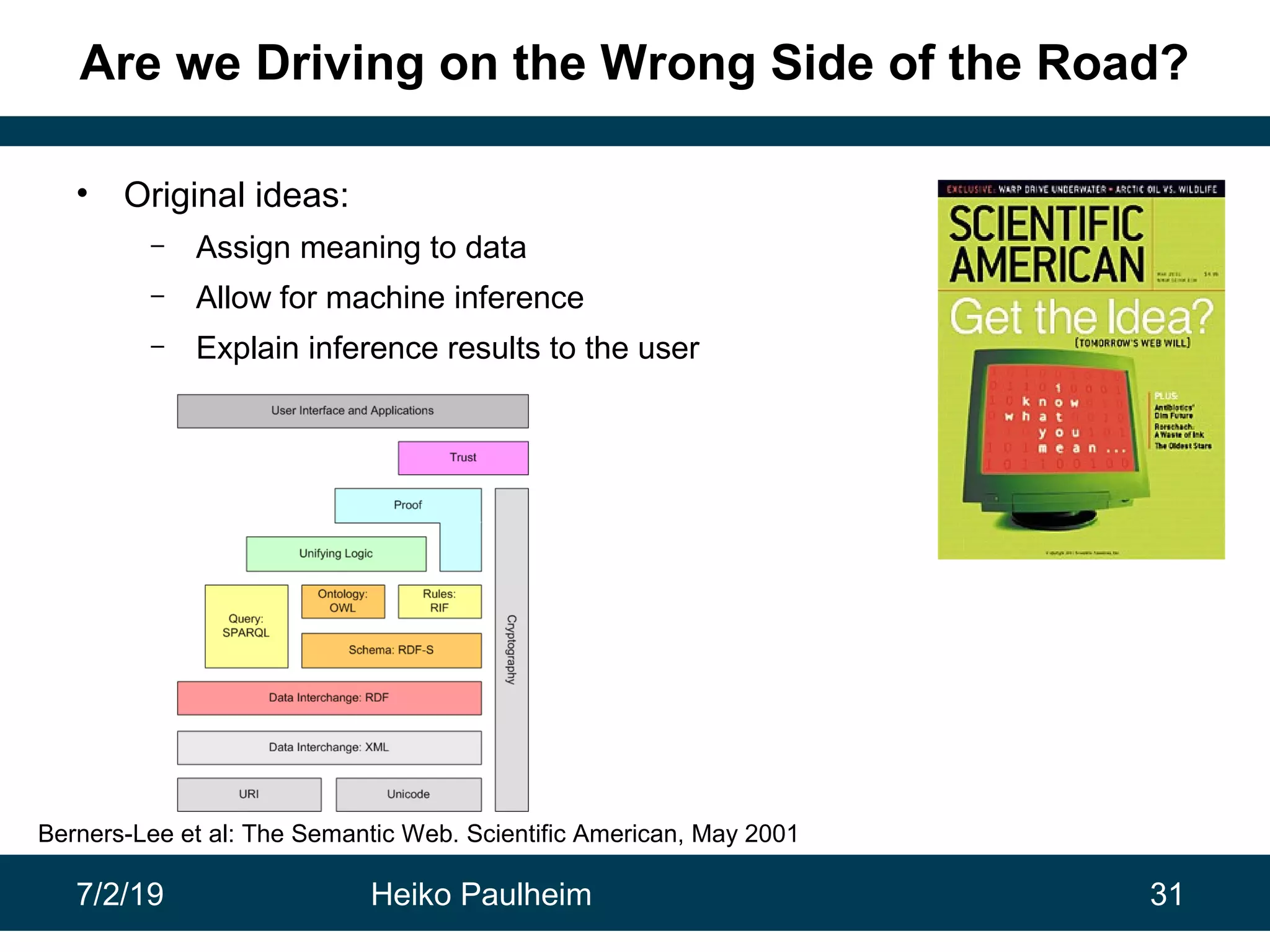
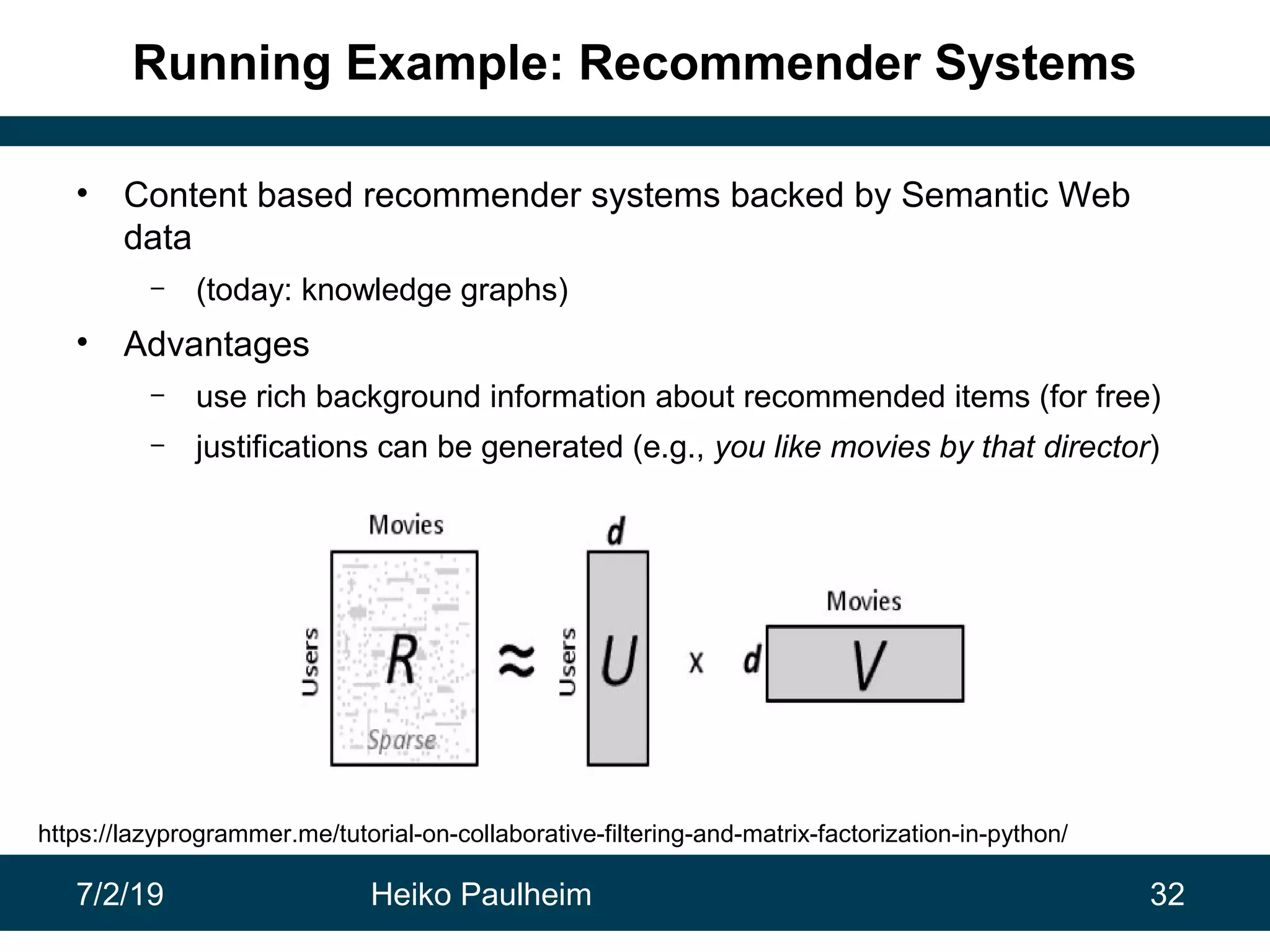
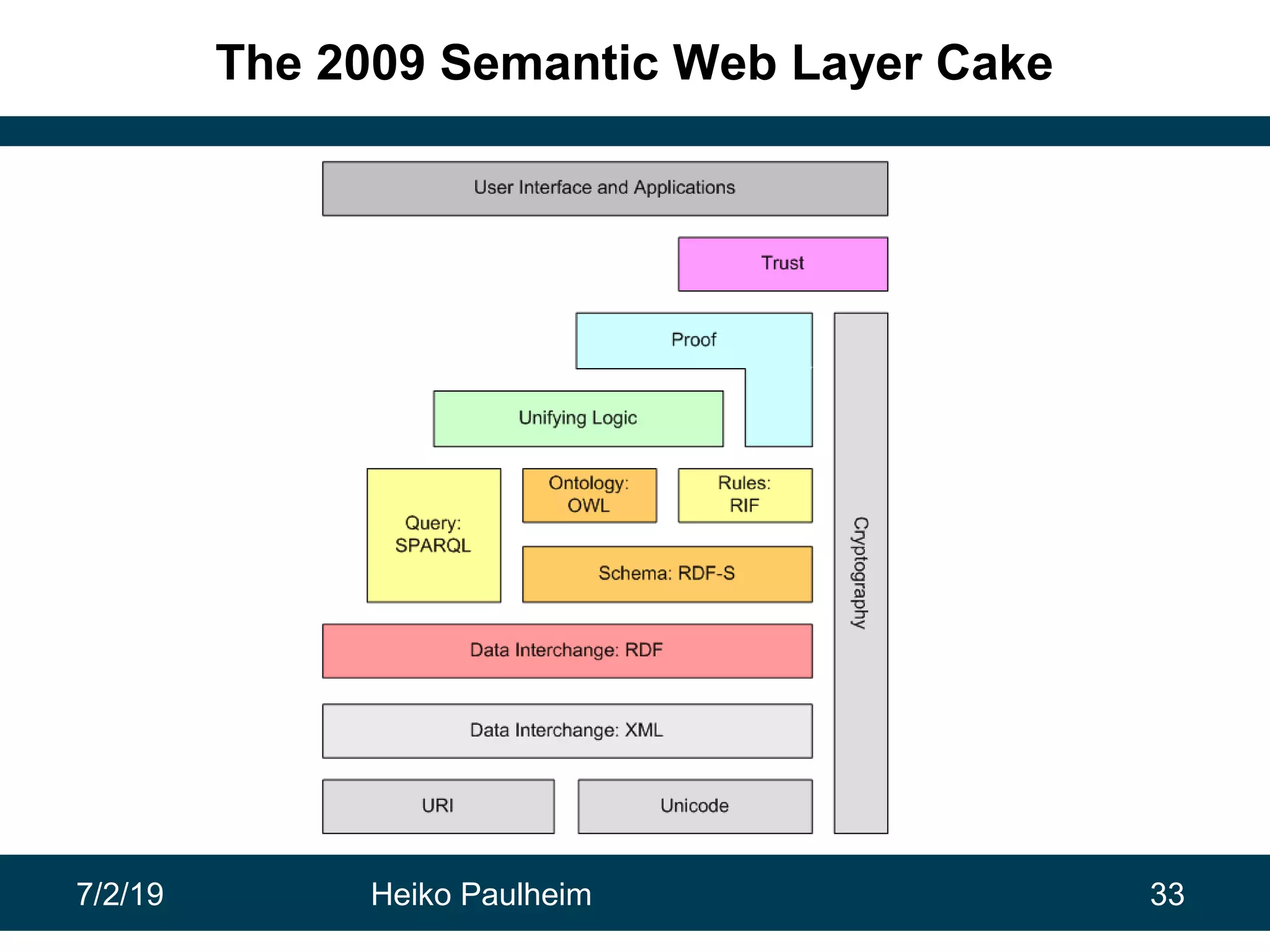

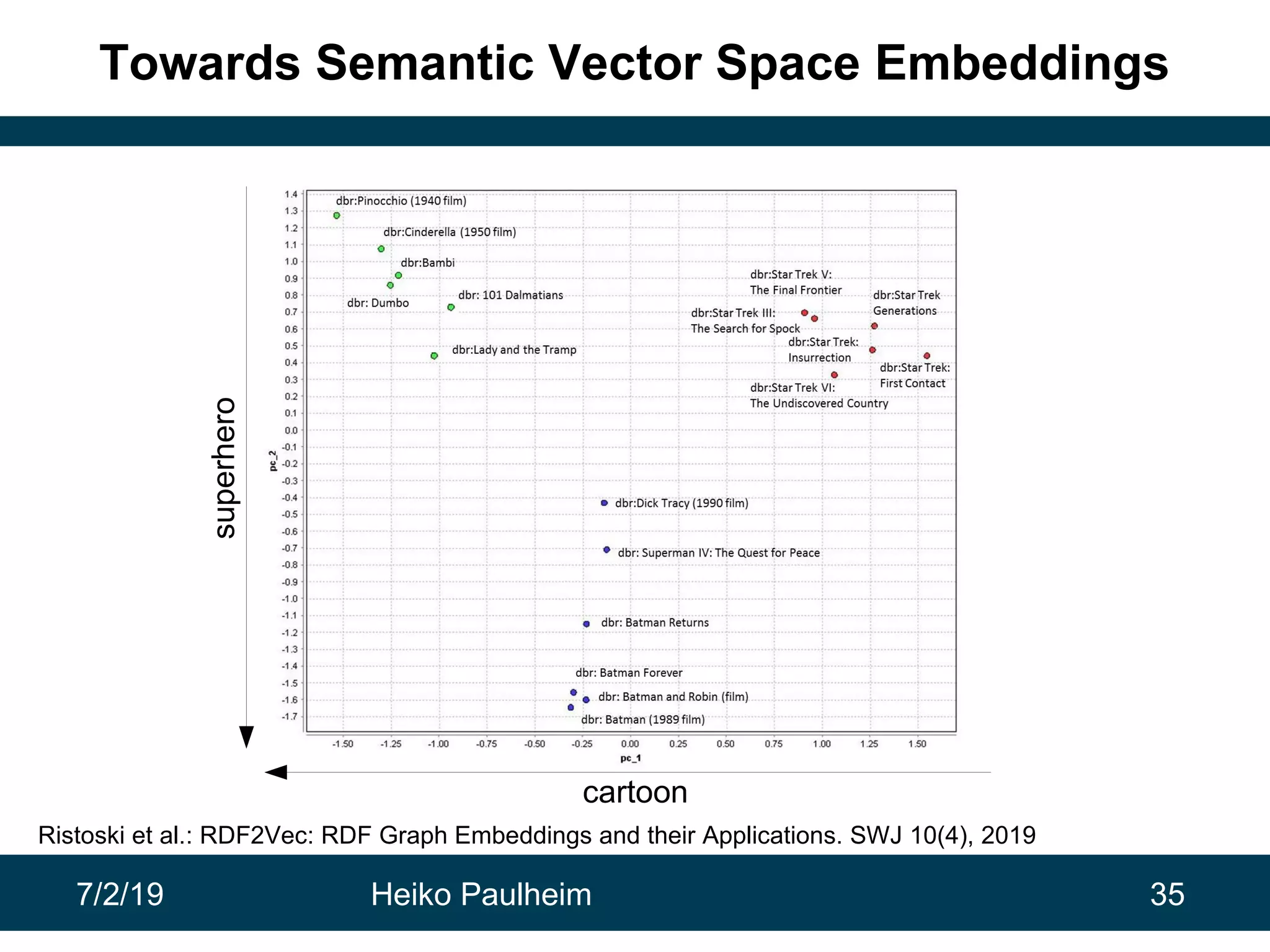
















































This document discusses machine learning techniques for knowledge graphs. It begins with an overview of typical machine learning tasks involving knowledge graphs, such as type prediction and link prediction. It then discusses challenges in applying traditional machine learning algorithms to knowledge graphs due to their graph-based structure rather than feature vectors. Several techniques are presented to address this, including propositionalization to transform graphs into feature vectors, and knowledge graph embeddings which learn vector representations of entities that preserve structural relationships. Word2vec and its adaptation RDF2vec for knowledge graphs are explained as early embedding techniques, along with subsequent extensions and related methods like TransE.















































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)







